本页内容
配置 OSPF 路由控制
了解 OSPF 路由汇总
区域边界路由器 (ABR) 发送汇总链路通告,以描述到其他区域的路由。根据目的地的数量,一个区域可能会充斥着大量链路状态记录,而这些记录可以利用路由设备资源。为了最大程度地减少涌入某个区域的播发数量,可以将 ABR 配置为合并或汇总一系列 IP 地址,并在单个链路状态播发 (LSA) 中发送有关这些地址的可访问性信息。您可以汇总一个或多个 IP 地址范围,其中与指定区域范围匹配的所有路由都将在区域边界进行过滤,并在其位置公布摘要。
对于 OSPF 区域,您可以汇总和过滤区域内的前缀。与指定区域范围匹配的所有路径都将在区域边界进行过滤,并在其位置播发摘要。对于 OSPF 不完全剩余区域 (NSSA),您只能合并或过滤 NSSA 外部(7 类)LSA,然后再将其转换为 AS 外部(5 类)LSA 并进入主干区域。在区域内学习的所有不属于某个前缀范围的外部路由都将单独播发到其他区域。
此外,您还可以限制导出到 OSPF 的前缀(路由)的数量。通过设置用户定义的最大前缀数,可以防止路由设备将过多的路由泛滥到某个区域。
示例:汇总发送到骨干区域的 OSPF 链路状态通告中的路由范围
此示例说明如何汇总发送到主干网区域的路由。
要求
开始之前:
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置静态路由。请参阅 Junos OS 路由协议库中的示例:为路由设备配置静态路由。
概述
您可以汇总一系列 IP 地址,以减小骨干路由器的链路状态数据库的大小。与指定区域范围匹配的所有路径都将在区域边界进行过滤,并在其位置播发摘要。
图 1 显示了此示例中使用的拓扑。R5 是区域 0.0.0.4 和主干网之间的 ABR。区域0.0.0.4中的网络分别为10.0.8.4/30、10.0.8.0/30和10.0.8.8/30,可以汇总为10.0.8.0/28。R3 是 NSSA 区域 0.0.0.3 和主干网之间的 ABR。0.0.0.3区域中的网络分别为10.0.4.4/30、10.0.4.0/30和10.0.4.12/30,可以归纳为10.0.4.0/28。Area 0.0.0.3 还包含外部静态路由 3.0.0.8,它将在整个网络中泛洪。
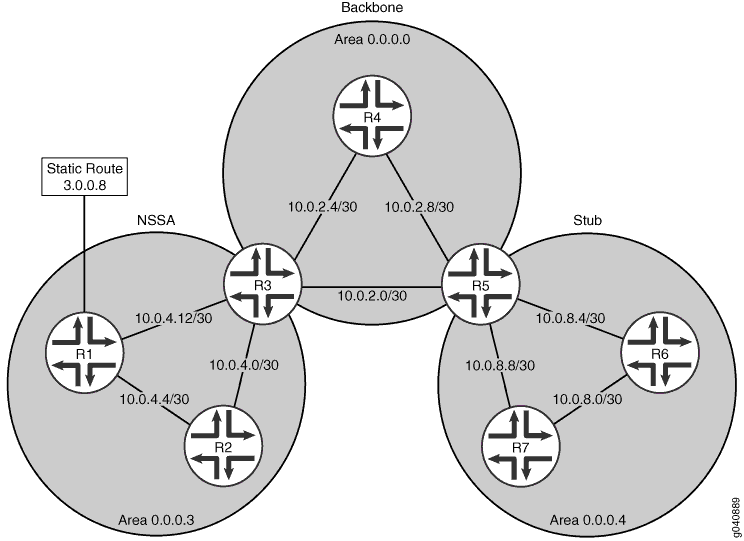 中的路由范围
中的路由范围
在此示例中,您通过包括以下设置来配置用于路由汇总的 ABR:
area-range — 对于某个区域,在发送汇总区域内链路通告时汇总一系列 IP 地址。对于 NSSA,汇总发送 NSSA 链路状态播发(类型 7 LSA)时的 IP 地址范围。指定的前缀用于聚合在将路由播发至其他区域时在该区域内获知的外部路由。
network/mask length—指示汇总的 IP 地址范围和网络掩码中的有效位数。
拓扑学
配置
CLI 快速配置
要为 OSPF 区域快速配置路由汇总,请复制以下命令并将其粘贴到 CLI 中。以下是 ABR R5 上的配置:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30 set protocols ospf area 0.0.0.4 stub set protocols ospf area 0.0.0.4 interface fe-0/0/1 set protocols ospf area 0.0.0.4 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
要为 OSPF NSSA 快速配置路由汇总,请将以下命令复制粘贴到 CLI 中。以下是 ABR R3 上的配置:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30 set protocols ospf area 0.0.0.3 interface fe-0/0/1 set protocols ospf area 0.0.0.3 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28 set protocols ospf area 0.0.0.3 nssa set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
程序
分步过程
要汇总发送到主干区的路由:
配置接口。
注意:对于 OSPFv3,请包括 IPv6 地址。
[edit] user@R5#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30user@R5#set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30user@R5#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30user@R5#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30[edit] user@R3#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30user@R3#set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30user@R3#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30user@R3#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30配置 OSPF 区域的类型。
注意:对于 OSPFv3,请在
[edit protocols]层次结构级别包含ospf3语句。[edit] user@R5# set protocols ospf area 0.0.0.4 stub
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa
将接口分配给 OSPF 区域。
user@R5#
set protocols ospf area 0.0.0.4 interface fe-0/0/1user@R5#set protocols ospf area 0.0.0.4 interface fe-0/0/2user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/4user@R3#
set protocols ospf area 0.0.0.3 interface fe-0/0/1user@R3#set protocols ospf area 0.0.0.3 interface fe-0/0/2user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/4汇总涌入主干网的路由。
[edit] user@R5# set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
[edit] user@R3# set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28
在 ABR R3 上,限制外部静态路由离开区域 0.0.0.3。
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
如果完成设备配置,请提交配置。
[edit] user@host# commit
结果
输入 show interfaces 和 命令 show protocols ospf ,以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
ABR R5 上的配置:
user@R5# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.3/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.8.3/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.8.4/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.5/32;
}
}
}
user@R5# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.4 {
stub;
area-range 10.0.8.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
ABR R3 上的配置:
user@R3# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.1/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.4.10/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.4.1/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.7/32;
}
}
}
user@R3t# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.3 {
nssa {
area-range 3.0.0.0/8 ;
}
area-range 10.0.4.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
要确认您的 OSPFv3 配置,请输入 show interfaces 和 show protocols ospf3 命令。
示例:限制导出到 OSPF 的前缀数量
此示例说明如何限制导出到 OSPF 的前缀数。
要求
开始之前:
配置设备接口。请参阅 路由设备 Junos OS 网络接口库。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
配置多区域 OSPF 网络。请参阅 示例:配置多区域 OSPF 网络。
概述
默认情况下,可导出到 OSPF 的前缀(路由)数量没有限制。如果允许将任意数量的路由导出到 OSPF 中,路由设备可能会不堪重负,并可能使过多的路由涌入某个区域。
您可以限制导出到 OSPF 的路由数量,以最大程度地减少路由设备上的负载并防止此潜在问题。如果路由设备超过配置的前缀导出值,路由设备将清除外部前缀并进入过载状态。此状态可确保路由设备在尝试处理路由信息时不会不堪重负。前缀导出限制编号可以是介于 0 到 4,294,967,295 之间的值。
在此示例中,通过包含 prefix-export-limit 语句来配置 100,000 的前缀导出限制。
拓扑学
配置
CLI 快速配置
要快速限制导出到 OSPF 的前缀数量,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到 [编辑] 层次结构级别的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf prefix-export-limit 100000
程序
分步过程
要限制导出到 OSPF 的前缀数,请执行以下作:
配置前缀导出限制值。
注意:对于 OSPFv3,请在
[edit protocols]层次结构级别包含ospf3语句。[edit] user@host# set protocols ospf prefix-export-limit 100000
如果完成设备配置,请提交配置。
[edit] user@host# commit
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf prefix-export-limit 100000;
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
了解 OSPF 流量控制
在网络中共享拓扑结构后,OSPF 将使用拓扑结构在网络节点之间路由数据包。系统会根据接口吞吐量为邻接方之间的每条路径分配成本。默认算法使用公式 cost = reference-bandwidth / interface bandwidth100 Mbps 的参考带宽计算接口指标。结果是,任何以 100 Mbps 或更快速度运行的接口都会被分配相同的指标值 1。您可以手动分配 OSPF 接口指标来覆盖默认值。另外,鉴于当前瞻博网络平台支持以 400 Gbps 运行的接口,通常最好配置一个 reference-bandwidth 更大的值。配置基于网络中最高速度接口倍数的参考带宽值,将根据接口速度自动优化网络路径,并为网络速度的增长留出空间。
主机之间特定路径上的成本总和决定了该路径的总成本。然后,使用最短路径优先 (SPF) 算法沿最短路径路由数据包。如果源地址和目标地址之间存在多个等价路径,则 OSPF 会以循环方式沿每条路径交替路由数据包。总路径指标较低的路由优先于路径指标较高的路由。
您可以使用以下方法控制 OSPF 流量:
-
控制单个 OSPF 网段的成本
-
根据带宽动态调整 OSPF 接口指标
-
控制 OSPF 路由选择
控制单个 OSPF 网段的成本
OSPF 使用以下公式确定路由成本:
cost = reference-bandwidth / interface bandwidth
您可以修改 reference-bandwidth 值,该值用于计算默认接口成本。接口带宽值不可用户配置,它指的是物理接口的实际带宽。
默认情况下,OSPF 会为任何速度超过 100 Mbps 的链路分配默认成本指标 1,为环路接口 (lo0) 分配默认成本指标 0。没有带宽与环路接口相关联。
为了控制网络中的数据包流,OSPF 允许您手动为特定路径分段分配成本(或指标)。当您为特定 OSPF 接口指定指标时,该值将用于确定从该接口播发的路由的成本。例如,如果 OSPF 网络中的所有路由器都使用默认指标值,而您将一个接口上的指标增加到 5,则通过该接口的所有路径的计算指标都高于默认指标,因此不是首选指标。
您为指标配置的任何值都会覆盖使用引用带宽值计算该接口的路由成本的默认行为。
当路由表中有多个到同一目标的等价路由时,将形成等价多路径 (ECMP) 集。如果为活动路由设置了 ECMP,则 Junos OS 软件将使用散列算法选择 ECMP 集中的下一跃点地址之一,以安装在转转发表中。
您可以对 Junos OS 进行配置,以便在转转发表中安装 ECMP 集中的多个下一跃点条目。通过在 [edit policy-options] 层次结构级别包含一个或多个策略语句配置语句来定义负载平衡路由策略,并按数据包执行负载平衡作。然后将路由策略应用于从路由表导出到转发表的路由。
根据带宽动态调整 OSPF 接口指标
您可以为 OSPF 接口或 OSPF 接口上的拓扑指定一组带宽阈值和关联的衡量指标值。当接口的带宽发生变化时(例如,如果 LAG 丢失了接口成员,或者接口速度发生了管理性更改),Junos OS 会自动将接口指标设置为与相应带宽阈值关联的值。Junos OS 使用等于或大于实际接口带宽的最小配置带宽阈值来确定衡量指标值。如果接口带宽大于任何配置的带宽阈值,则将使用为接口配置的指标值,而不是配置的任何基于带宽的指标值。当接口的带宽发生变化时,重新计算其指标的功能对于聚合接口特别有用。
启用基于带宽的指标时,还必须为接口配置指标。
控制 OSPF 路由优先级
您可以使用路由优先级控制数据包在网络中的流动。当多个协议计算到同一目标的路由时,路由优先级用于选择在转转发表中安装的路由。选择优先级值最低的路由。
默认情况下,内部 OSPF 路由的首选值为 10,外部 OSPF 路由的首选值为 150。尽管默认设置适用于大多数环境,但如果 OSPF 网络中的所有路由设备都使用默认首选项值,或者您计划从 OSPF 迁移到其他内部网关协议 (IGP),则可能需要修改默认设置。如果所有设备都使用默认 路由优先级 值,则可以更改路由优先级,以确保在存在到目标的多个等价路径时,为转转发表选择通过特定设备的路径。从 OSPF 迁移到其他 IGP 时,修改路由优先级允许您以受控方式执行迁移。
另见
示例:控制单个 OSPF 网段的成本
此示例说明如何控制各个 OSPF 网段的成本。
要求
开始之前:
配置设备接口。请参阅 安全设备接口用户指南。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
概述
所有 OSPF 接口都有成本,这是链路状态计算中使用的路由指标。总路径指标较低的路由优先于路径指标较高的路由。在此示例中,我们将探讨如何控制 OSPF 网段的成本。
默认情况下,OSPF 会为任何速度超过 100 Mbps 的链路分配默认成本指标 1,为环路接口 (lo0) 分配默认成本指标 0。没有带宽与环路接口相关联。这意味着,所有速度超过 100 Mbps 的接口都具有相同的默认成本指标 1。如果源地址和目标地址之间存在多个等价路径,则 OSPF 会以循环方式沿每条路径交替路由数据包。
如果所有接口都以相同的速度运行,则具有相同的默认指标可能不是问题。如果接口以不同的速度运行,您可能会注意到流量不会通过最快的接口路由,因为 OSPF 在不同接口之间同样路由数据包。例如,如果您的路由设备具有运行 OSPF 的快速以太网和千兆以太网接口,则每个接口的默认成本指标为 1。
在第一个示例中,通过包含 reference-bandwidth 语句,将参考带宽设置为 10g(10 Gbps,用 10,000,000,000 位表示)。使用此配置时,OSPF 会为快速以太网接口分配默认指标 100,为千兆以太网接口分配指标 10。由于千兆以太网接口的指标最低,OSPF 在路由数据包时会选择该接口。范围为 9600 到 1,000,000,000,000 位。
图 2 显示了区域 0.0.0.0 中的三个路由设备,并假定设备 R2 和设备 R3 之间的链路被其他流量拥塞。您还可以通过将指标手动分配给特定路径分段来控制数据包在网络中的流动。您为指标配置的任何值都会覆盖使用引用带宽值计算该接口的路由成本的默认行为。要防止来自设备 R3 的流量直接流向设备 R2,请调整设备 R3 上与设备 R1 连接的接口上的指标,以便所有流量都通过设备 R1。
在第二个示例中,通过包含 metric 语句在与设备 R1 连接的设备 R3 上的接口 fe-1/0/1 上将指标设置为 5。范围是 1 到 65,535。
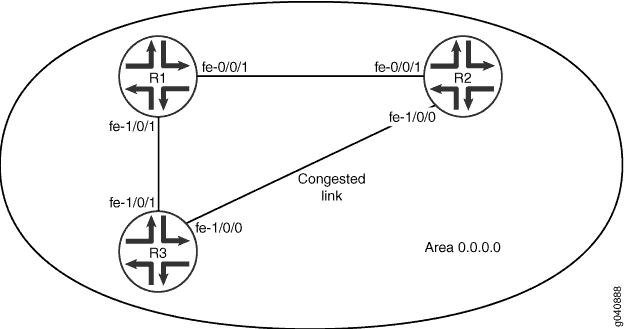
拓扑学
配置
配置参考带宽
CLI 快速配置
要快速配置参考带宽,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到层级的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf reference-bandwidth 10g
分步过程
要配置参考带宽,请执行以下作:
配置参考带宽以计算默认接口开销。
注意:要指定 OSPFv3,请在 [edit protocols] 层次结构级别包含 ospf3 语句。
[edit] user@host# set protocols ospf reference-bandwidth 10g
提示:在此示例中,作为快捷方式,输入 10g 以指定 10 Gbps 参考带宽。无论输入 10g 还是 1000000000,show protocols ospf 命令的输出都会将 10 Gbps 显示为 10g,而不是 10000000000。
如果完成设备配置,请提交配置。
[edit] user@host# commit
注意:在共享网络中的所有路由设备上重复此整个配置。
结果
输入 show protocols ospf 命令,以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf reference-bandwidth 10g;
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
为特定 OSPF 接口配置指标
CLI 快速配置
要为特定 OSPF 接口快速配置指标,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到 [edit] 层次结构级别的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf area 0.0.0.0 interface fe-1/0/1 metric 5
分步过程
要为特定 OSPF 接口配置指标,请执行以下作:
创建 OSPF 区域。
注意:要指定 OSPFv3,请在 [edit protocols] 层次结构级别包含 ospf3 语句。
[edit] user@host# edit protocols ospf area 0.0.0.0
配置OSPF网段的指标。
[edit protocols ospf area 0.0.0.0 ] user@host# set interface fe-1/0/1 metric 5
如果完成设备配置,请提交配置。
[edit protocols ospf area 0.0.0.0 ] user@host# commit
结果
输入 show protocols ospf 命令,以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf
area 0.0.0.0 {
interface fe-1/0/1.0 {
metric 5;
}
}
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
了解单跃点 OSPFv2 邻接方上的加权 ECMP 流量分布
等价多路径 (ECMP) 是一种用于在多条路径上均衡流量负载的常用技术。启用 ECMP 后,如果到远程目标的路径具有相同的成本,则流量将在它们之间按相等比例分配。如果到通往最终目的地的相邻路由器的本地链路的容量不相等,则不希望在多个路径上均等分配流量。通常,两个链路之间的流量分布相等,链路利用率也相同。但是,如果聚合以太网捆绑包的容量发生变化,均等的流量分配会导致链路利用率的不平衡。在这种情况下,加权 ECMP 能够实现与本地链路容量成比例的等价路径之间的流量负载平衡。
举例来说,有两台设备与具有四个链路和一个相同成本链路的聚合以太网捆绑包互连。在正常情况下,AE 束和单链路都会被均匀地利用来分配流量。但是,如果 AE 捆绑包中的链路出现故障,则链路容量会发生变化,从而导致链路利用率参差不齐。加权 ECMP 按本地链路的容量比例在等价路径之间对流量进行负载平衡。在这种情况量在 AE 捆绑包和单个链路之间以 30/40 的比例分配。
此功能为相隔一个跃点的 OSPFv2 邻接方提供加权 ECMP 路由。作系统仅在立即连接的路由器上支持此功能,在多跃点路由器(即距离超过一个跃点的路由器)上不支持加权 ECMP。
要在直接连接的 OSPFv2 邻接方上启用加权 ECMP 流量分配,请在[edit protocols ospf spf-options multipath]层次结构级别上配置weighted one-hop语句。
在配置此功能之前,您必须配置按数据包负载平衡策略。如果制定了按数据包的负载平衡策略,WECMP 将正常运行。
对于逻辑接口,您必须配置接口带宽,以便根据底层物理接口带宽在等价多路径上分配流量。如果不为每个逻辑接口配置逻辑带宽,作系统将假定物理接口的全部带宽都可用于每个逻辑接口。
示例:单跃点 OSPFv2 邻接方上的加权 ECMP 流量分布
使用此示例配置加权等价多路径 (ECMP) 路由,以便将流量分发到相隔一个跃点的 OSPFv2 邻接方,以确保最佳的负载平衡。
我们的内容测试团队已经验证并更新了此示例。
| 阅读时间 |
30 分钟 |
| 配置时间 |
20 分钟 |
先决条件示例
| 硬件要求 |
两台 MX 系列路由器。 |
| 软件要求 |
在所有设备上运行 Junos OS 24.2R1 或更高版本。 |
准备工作
| 好处 |
加权 ECMP 路由会在多个路径上不均衡地分配流量,从而实现更好的负载平衡。在按数据包负载平衡期间,它比平均分配流量更有效。 |
| 了解更多 |
功能概述
| 使用的技术 |
|
| 主要验证任务 |
|
拓扑概览
此配置示例描述了三个聚合以太网捆绑包 ae0、ae1 和 ae2,在路由器 R0 和路由器 R1 之间各配置两个链路。当其中一个链路出现故障时,数据包转发引擎会在三个以太网捆绑包之间不均衡地分配流量,具体取决于可用带宽。
| 主机名 |
角色 |
功能 |
|---|---|---|
| R0 |
配置了 WECMP 的设备。 |
R0 向 R1 发送流量。 |
| R1 |
直接连接到 R0 的设备。 |
R1 接收来自 R0 的流量。 |
拓扑图示
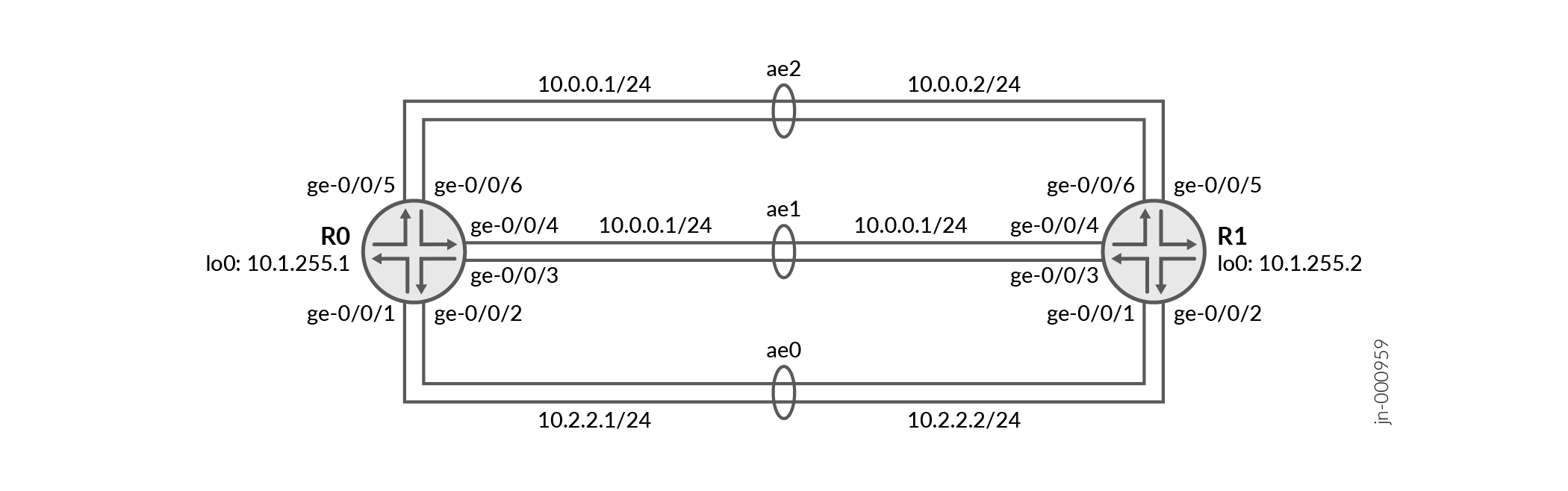 方上的加权 ECMP 流量分布
方上的加权 ECMP 流量分布
R0 配置步骤
有关 R0 上的完整示例配置,请参阅: 附录 1:在所有设备上设置命令
本节重点介绍在此示例中配置 R0 设备所需的主要配置任务。第一步是配置聚合以太网接口的通用步骤。以下一组步骤特定于在 AE 捆绑包上配置 OSPF 和配置加权 ECMP。
-
配置 ae0、ae1 和 ae2 聚合以太网捆绑包的两个成员链路。
为 ae0、ae1 和 ae2 聚合以太网接口配置 IP 地址和链路聚合控制协议 (LACP)。
配置用于 VLAN 标记的聚合以太网接口(ae0、ae1 和 ae2)。
配置环路接口地址。
输入 [router-id] 配置值,配置 OSPF 路由器标识符。
根据底层物理带宽配置具有适当带宽的逻辑接口。
注意:对于逻辑接口,请配置接口带宽,以便根据底层作接口带宽在等价多路径之间分配流量。在单个接口上配置多个逻辑接口时,请为每个逻辑接口配置适当的逻辑带宽,以便查看逻辑接口上的所需流量分布。
配置隧道接口,并指定为 R0 的每个数据包转发引擎上的隧道流量预留的带宽量。
[edit] set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 gigether-options 802.3ad ae2
[edit] set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae2 aggregated-ether-options minimum-links 1 set interfaces ae2 aggregated-ether-options lacp active
[edit] set interfaces ae0 vlan-tagging set interfaces ae1 vlan-tagging set interfaces ae2 vlan-tagging
[edit] set interfaces lo0 unit 0 family inet address 10.1.255.1/32
[edit] set routing-options router-id 10.1.255.1
[edit] set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24
指定要配置的最大加权 ECMP 接口数。启用平滑切换并指定要创建的聚合以太网接口数量。
[edit] set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3
在所有接口和 AE 捆绑包上配置 OSPF。
[edit]set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0配置按数据包的负载平衡。
[edit] set policy-options policy-statement pplb then load-balance per-packet
应用按数据包负载平衡策略。
[edit] set routing-options forwarding-table export ppl
在直接连接的 OSPFv2 邻接方上启用加权 ECMP 流量分配。
[edit] set protocols ospf spf-options multipath weighted one-hop
验证
| 命令 | 验证任务 |
|---|---|
| 显示路线广泛 | 验证流量在等价多路径上的均匀分配。 |
| 显示路线广泛 | 验证可用带宽上的流量分布不均。 |
| show interfaces extensive | 验证可用带宽上的流量分布不均。 |
验证流量在等价多路径上的是否均匀分配
目的
验证流量是否均匀分布在聚合以太网捆绑包上。
行动
在作模式下,输入 show route 10.1.255.2 extensive 命令。
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819a814
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 33%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 33%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 33%
Session Id: 0
State: <Active Int>
Age: 4d 17:55:37 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
user@R0> show interfaces ae0.0 extensive
Logical interface ae0.0 (Index 337) (SNMP ifIndex 578) (Generation 173)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.6 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89241 0 7140674 0
Output: 89244 0 8731668 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/1.0
Input : 47583 0 3807058 0
Output: 0 0 0 0
ge-0/0/2.0
Input : 41632 0 3331512 0
Output: 89243 0 8731574 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/1.0 0 0 0 0
ge-0/0/2.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 177, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.0/24, Local: 10.0.0.1, Broadcast: 10.0.0.255, Generation: 157
Protocol multiservice, MTU: Unlimited, Generation: 178, Route table: 0
Flags: Is-Primary, 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae1.0 extensive
Logical interface ae1.0 (Index 362) (SNMP ifIndex 593) (Generation 175)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.16 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89631 0 7194074 312
Output: 89626 1 8793864 784
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/3.0
Input : 89631 0 7194074 312
Output: 89626 0 8793864 0
ge-0/0/4.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/3.0 0 0 0 0
ge-0/0/4.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 180, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.1/24, Local: 10.0.1.1, Broadcast: 10.0.1.255, Generation: 159
Protocol multiservice, MTU: Unlimited, Generation: 181, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae2.0 extensive
Logical interface ae2.0 (Index 364) (SNMP ifIndex 592) (Generation 177)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.26 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/5.0
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
ge-0/0/6.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/5.0 0 0 0 0
ge-0/0/6.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 183, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.2.2/24, Local: 10.2.2.1, Broadcast: 10.2.2.255, Generation: 161
Protocol multiservice, MTU: Unlimited, Generation: 184, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
意义
当三个聚合以太网捆绑包具有相同的可用带宽时,OSPF 会平均分配流量。
验证可用带宽上的流量分布不均
目的
验证当其中一个聚合链路关闭时,OSPF 是否分配流量不均匀,按数据包进行负载平衡,具体取决于可用带宽。
行动
禁用 ae0 捆绑包上的某个链路。在作模式下,输入 show route 10.1.255.2 extensive 命令。
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819ba14
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 20%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 40%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 40%
Session Id: 0
State: <Active Int>
Age: 23 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
意义
OSPF 推断 ae0 捆绑包的可用带宽较少。因此,会根据可用带宽修改每个数据包的负载平衡。根据输出,ae0 上只有 20% 的带宽可用,因为其中一个聚合以太网链路已关闭。因此,OSPF 会根据可用带宽不均衡地分配流量。
附录 1:在所有设备上设置命令
要快速配置此示例,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,然后将命令复制并粘贴到 [编辑] 层次结构级别的 CLI 中。
R0
set system host-name R0 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24 set interfaces lo0 unit 0 family inet address 10.1.255.1/32 set policy-options policy-statement pplb then load-balance per-packet set routing-options router-id 10.1.255.1 set routing-options forwarding-table export pplb set protocols ospf spf-options multipath weighted one-hop set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
R1
set system host-name R1 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.2/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.2/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.2/24 set interfaces lo0 unit 0 family inet address 10.1.255.2/32 set routing-options router-id 10.1.255.2 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
示例:根据带宽动态调整 OSPF 接口指标
此示例说明如何根据带宽动态调整 OSPF 接口指标。
配置
CLI 快速配置
要为 OSPF 接口快速配置带宽阈值和关联指标值,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到 [编辑] 层次结构级别的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf area 0.0.0.0 interface ae0.0 metric 5 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
分步过程
要为特定 OSPF 接口配置指标,请执行以下作:
-
创建 OSPF 区域。
注意:要指定 OSPFv3,请在 [edit protocols] 层次结构级别包含 ospf3 语句。
[edit] user@host# edit protocols ospf area 0.0.0.0
-
配置OSPF网段的指标。
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0 metric 5
-
配置带宽阈值和关联的指标值。使用此配置时,当聚合以太网接口的带宽为 1g 时,OSPF 会认为此接口的指标 60。当聚合以太网接口的带宽为 10g 时,OSPF 会认为此接口的度量标准为 50。
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
-
如果完成设备配置,请提交配置。
[edit protocols ospf area 0.0.0.0 ] user@host# commit
结果
输入 show protocols ospf 命令,以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf
area 0.0.0.0 {
interface ae0.0 {
bandwidth-based-metrics {
bandwidth 1g metric 60;
bandwidth 10g metric 50;
}
metric 5;
}
}
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
要求
开始之前:
配置设备接口。请参阅 安全设备接口用户指南。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
概述
您可以为 OSPF 接口指定一组带宽阈值和关联的指标值。当接口的带宽发生变化时,Junos OS 会自动将接口指标设置为与相应带宽阈值关联的值。配置基于带宽的指标值时,通常会配置多个带宽和指标值。
在此示例中,您可以通过包含 bandwidth-based-metrics 语句和以下设置,为基于带宽的指标配置 OSPF 接口 ae0:
bandwidth — 指定带宽阈值,以位/秒为单位。范围是 9600 到 1,000,000,000,000,000。
公制 — 指定要与特定带宽值关联的度量值。范围是 1 到 65,535。
拓扑学
示例:控制 OSPF 路由优先级
此示例说明如何控制转转发表中的 OSPF 路由选择。此示例还说明在从 OSPF 迁移到另一个 IGP 时如何控制路由选择。
配置
CLI 快速配置
要快速配置 OSPF 路由优先级值,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到 [编辑] 层次结构级别的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf preference 168 external-preference 169
分步过程
要配置路由选择:
进入 OSPF 配置模式并设置外部和内部路由优先级。
注意:要指定 OSPFv3,请在
[edit protocols]层次结构级别包含语ospf3句。[edit] user@host# set protocols ospf preference 168 external-preference 169
如果完成设备配置,请提交配置。
[edit] user@host# commit
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf preference 168; external-preference 169;
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
要求
此示例假定 OSPF 已正确配置并在您的网络中运行,并且您希望控制路由选择,因为您计划从 OSPF 迁移到其他 IGP。
配置设备接口。请参阅 安全设备接口用户指南。
配置要迁移到的 IGP。
概述
当多个协议计算到同一目标的路由时,路由优先级用于选择在转转发表中安装的路由。选择优先级值最低的路由。
默认情况下,内部 OSPF 路由的首选值为 10,外部 OSPF 路由的首选值为 150。如果您计划从 OSPF 迁移到其他 IGP,则可能需要修改此设置。通过修改路由首选项,您可以以受控方式执行迁移。
此示例做出以下假设:
OSPF 已在您的网络中运行。
您想要从 OSPF 迁移到 IS-IS。
您根据网络要求配置了 IS-IS,并确认其工作正常。
在此示例中,通过为内部 OSPF 路由指定 168,为外部 OSPF 路由指定 169,增加 OSPF 路由优先级值,使其优先级低于 IS-IS 路由。IS-IS 内部路由的优先级为 15(对于级别 1)或 18(对于级别 2),外部路由的首选优先级为 160(对于级别 1)或 165(对于级别 2)。通常,最好将新协议保留为默认设置,以最大程度地减少复杂性并简化未来向网络添加路由设备的过程。要修改 OSPF 路由优先级值,请配置以下设置:
preference- 指定内部 OSPF 路由的路由优先级。默认情况下,内部 OSPF 路由的值为 10。范围是从 0 到 4,294967,295 (232 – 1)。external-preference- 指定外部 OSPF 路由的路由优先级。默认情况下,外部 OSPF 路由的值为 150。范围是从 0 到 4,294967,295 (232 – 1)。
拓扑学
了解 OSPF 重载功能
如果OSPF实例开通后经过的时间小于规定的超时时间,则设置过载模式。
您可以对本地路由设备进行配置,使其看起来处于过载状态。过载的路由设备确定无法再处理任何 OSPF 传输流量,这会导致将 OSPF 传输流量发送到其他路由设备。到直连接口的 OSPF 流量继续到达路由设备。配置重载模式的原因可能有很多,包括:
如果您希望路由设备参与 OSPF 路由,但不希望它用于传输流量。这可能包括出于分析目的而连接到网络但不被视为生产网络一部分的路由设备,如网络管理路由设备。
如果要对生产网络中的路由设备执行维护。您可以将流量移离该路由设备,这样网络服务就不会在维护时段内中断。
您可以在 OSPF 中配置或禁用过载模式,无论是否有超时。如果不设置超时,将设置过载模式,直到将其从配置中显式删除。使用超时时,如果自OSPF实例启动以来经过的时间小于指定的超时时间,则设置过载模式。
将启动一个计时器,用于计算超时与实例启动后经过的时间之间的差值。当计时器到期时,过载模式将被清除。在过载模式下,路由器链路状态通告 (LSA) 是在将所有中转路由器链路(存根除外)设置为指标 0xFFFF 的情况下发出的。剩余路由器链路将使用与剩余节点对应的接口的实际成本进行播发。这会导致传输流量避开过载的路由设备,并在路由设备周围走路径。但是,仍可访问过载路由设备自身的链路。
无论将设备配置为何显示为过载,路由设备都可以动态进入过载状态。例如,如果路由设备超过配置的 OSPF 前缀限制,路由设备将清除外部前缀并进入过载状态。
如果配置不正确,大量路由可能会进入 OSPF,从而影响网络性能。为了防止这种情况, prefix-export-limit 应进行配置,以清除外部并防止网络受到不良影响。
如果允许将任意数量的路由导出到 OSPF 中,路由设备可能会不堪重负,并可能使过多的路由涌入某个区域。您可以限制导出到 OSPF 的路由数量,以最大程度地减少路由设备上的负载并防止此潜在问题。
默认情况下,可导出到 OSPF 的前缀(路由)数量没有限制。为了防止这种情况, prefix-export-limit 应配置以清除外部并阻止网络。
从 Junos OS 18.2 版开始,当 OSPF 过载时,OSPF 网络中的存根路由器支持以下功能:
允许路由泄漏 — 在 OSPF 过载期间,外部前缀将重新分配,并且前缀以正常成本产生。
使用最大指标播发剩余网络 — OSPF 过载期间,以最大指标播发剩余网络。
使用最大度量播发区域内前缀 — 在 OSPF 过载期间,以最大度量播发区域内前缀。
使用最大可能指标播发外部前缀 — OSPF AS 外部前缀将在 OSPF 过载期间重新分配,并以最大成本播发前缀。
您现在可以在 OSPF 过载时进行以下配置:
allow-route-leaking[edit protocols <ospf | ospf3> overload]在层次结构级别以正常成本播发外部前缀。stub-network[edit protocols ospf overload]在层次结构级别上,以使用最大指标通告剩余网络。intra-area-prefix[edit protocols ospf3 overload]在层次结构级别上,以使用最大指标播发区域内前缀。as-external[edit protocols <ospf | ospf3> overload]在层次结构级别上播发具有最大指标的外部前缀。
要限制导出到 OSPF 的前缀数,请执行以下作:
[edit] set protocols ospf prefix-export-limit number
前缀导出限制编号可以是介于 0 到 4,294,967,295 之间的值。
另见
示例:配置 OSPF 以使路由设备显示为过载
此示例说明如何将运行 OSPF 的路由设备配置为看起来负载过大。
要求
开始之前:
配置设备接口。请参阅 安全设备接口用户指南。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
配置多区域 OSPF 网络。请参阅 示例:配置多区域 OSPF 网络。
概述
您可以将运行 OSPF 的本地路由设备配置为看起来过载,这允许本地路由设备参与 OSPF 路由,但不能参与传输流量。配置后,传输接口指标将设置为最大值 65535。
此示例包含以下设置:
overload — 配置本地路由设备,使其看起来处于过载状态。如果您希望路由设备参与 OSPF 路由,但不希望将其用于传输流量,或者您正在对生产网络中的路由设备执行维护,则可以配置此配置。
超时 seconds—(可选)指定重置过载的秒数。如果未指定超时间隔,路由设备将保持过载状态,直到删除过载语句或设置超时。在此示例中,您将 60 秒配置为路由设备保持过载状态的时间量。默认情况下,超时间隔为 0 秒(未配置此值)。范围为 60 到 1800 秒。
拓扑学
配置
程序
CLI 快速配置
要快速将本地路由设备配置为显示为过载,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改详细信息,以便与网络配置匹配,将命令复制并粘贴到层级的 CLI 中,然后从配置模式进入 commit 。
[edit] set protocols ospf overload timeout 60
分步过程
要将本地路由设备配置为显示过载:
进入 OSPF 配置模式。
注意:要指定 OSPFv3,请在
[edit protocols]层次结构级别包含语ospf3句。[edit] user@host# edit protocols ospf将本地路由设备配置为过载。
[edit protocols ospf] user@host# set overload(选答)配置重置重载的秒数。
[edit protocols ospf] user@host#
set overload timeout 60(选答)配置导出到 OSPF 的前缀数量限制,以最大程度地减少路由设备上的负载并防止设备进入过载模式。
[edit protocols ospf] user@host# set prefix-export-limit 50
如果完成设备配置,请提交配置。
[edit protocols ospf] user@host# commit
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。输出包括可选的 timeout 和 prefix-export-limit 语句。
user@host# show protocols ospf prefix-export-limit 50; overload timeout 60;
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
验证
确认配置工作正常。
验证传输接口指标
目的
验证是否将传输接口指标设置为下游相邻设备上的最大值 65535。
行动
在作模式下, show ospf database router detail advertising-router address 输入适用于 OSPFv2 的命令,然后 show ospf3 database router detail advertising-router address 输入适用于 OSPFv3 的命令。
验证重载配置
目的
通过查看“配置的重载”字段来验证是否配置了重载。如果还配置了过载计时器,则此字段还会显示设置为过期之前的剩余时间。
行动
在作模式下,为 OSPFv2 输入命令,show ospf3 overview为 OSPFv3 输入show ospf overview命令。
了解 OSPF 的 SPF 算法选项
OSPF 使用最短路径优先 (SPF) 算法(也称为 Dijkstra 算法)来确定到达每个目的地的路由。SPF 算法描述 OSPF 如何确定到达每个目的地的路线,SPF 选项控制指示 SPF 算法何时运行的计时器。根据您的网络环境和要求,您可能需要修改 SPF 选项。例如,考虑一个大型环境,其中有大量设备在整个区域内进行泛滥的链路状态通告 (LSA)。在此环境中,可能会接收大量 LSA 进行处理,这可能会消耗内存资源。通过配置 SPF 选项,您可以继续适应不断变化的网络拓扑,但可以最大限度地减少设备用于运行 SPF 算法的内存资源量。
您可以配置以下 SPF 选项:
从检测到拓扑变化到SPF算法实际运行之间的时间延迟。
在抑制计时器开始之前,SPF 算法可以连续运行的最大次数。
在 SPF 算法连续运行配置的次数后,在运行另一个 SPF 计算之前按住或等待的时间。如果网络在抑制期间稳定下来,并且 SPF 算法不需要再次运行,系统将恢复到 延迟 和
rapid-runs语句的配置值。
示例:为 OSPF 配置 SPF 算法选项
此示例说明如何配置 SPF 算法选项。SPF 选项控制指示 SPF 算法何时运行的计时器。
要求
开始之前:
配置设备接口。请参阅 路由设备 Junos OS 网络接口库。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
配置多区域 OSPF 网络。请参阅 示例:配置多区域 OSPF 网络。
概述
OSPF 使用 SPF 算法来确定到达每个目的地的路线。一个区域中的所有路由设备并行运行此算法,并将结果存储在各自的拓扑数据库中。具有多个区域接口的路由设备运行该算法的多个副本。SPF 选项控制 SPF 算法使用的计时器。
在修改任何默认设置之前,应充分了解网络环境和要求。
此示例说明如何配置用于运行 SPF 算法的选项。包括 spf-options 语句和以下选项:
延迟 - 配置检测拓扑与 SPF 实际运行之间的时间量(以毫秒为单位)。修改延迟计时器时,请考虑网络重新融合的要求。例如,您希望指定一个计时器值,该值可以帮助您识别网络中的异常,同时允许稳定的网络快速重新融合。默认情况下,SPF 算法在检测到拓扑后 200 毫秒运行。范围为 50 到 8000 毫秒。
rapid-runs - 配置 SPF 算法在抑制计时器开始之前可以连续运行的最大次数。默认情况下,可以连续进行的 SPF 计算次数为 3。范围是从 1 到 10。每个 SPF 算法都在配置的 SPF 延迟后运行。当发生最大 SPF 计算次数时,抑制计时器开始。在抑制计时器到期之前,不会运行任何后续的 SPF 计算。
抑制 - 在 SPF 算法连续运行配置的最大次数后,配置在运行另一个 SPF 计算之前抑制或等待的时间。默认情况下,抑制时间为 5000 毫秒。范围为 2000 到 20,000 毫秒。如果网络在抑制期间稳定下来,并且 SPF 算法不需要再次运行,系统将恢复到 延迟 和
rapid-runs语句的配置值。
拓扑学
配置
CLI 快速配置
要快速配置 SPF 选项,请复制以下命令并将其粘贴到 CLI 中。
[edit] set protocols ospf spf-options delay 210 set protocols ospf spf-options rapid-runs 4 set protocols ospf spf-options holddown 5050
程序
分步过程
要配置 SPF 选项:
进入 OSPF 配置模式。
注意:要指定 OSPFv3,请在
[edit protocols]层次结构级别包含语ospf3句。[edit] user@host# edit protocols ospf
配置 SPF 延迟时间。
[edit protocols ospf] user@host# set spf-options delay 210
配置 SPF 算法可以连续运行的最大次数。
[edit protocols ospf] user@host# set spf-options rapid-runs 4
配置 SPF 抑制计时器。
[edit protocols ospf] user@host# set spf-options holddown 5050
如果完成设备配置,请提交配置。
[edit protocols ospf] user@host# commit
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf
spf-options {
delay 210;
holddown 5050;
rapid-runs 4;
}
要确认您的 OSPFv3 配置,请输入 show protocols ospf3 命令。
配置 OSPF 刷新和泛洪 稳定拓扑中的减少
OSPF 标准要求每 30 分钟刷新一次链路状态通告 (LSA)。瞻博网络实施每 50 分钟刷新一次 LSA。默认情况下,任何未刷新的 LSA 都会在 60 分钟后过期。此要求可能会导致流量开销,从而难以扩展 OSPF 网络。可以通过指定在路由器或交换机最初发送自发起 LSA 时在自生成 LSA 中设置 DoNotAge 位来覆盖默认行为。仅当 LSA 中发生更改时,才会重新泛洪任何具有 DoNotAge 位集的 LSA。因此,此功能减少了协议流量开销,同时允许任何更改的 LSA 立即泛洪。启用了泛洪减少功能的路由器或交换机会继续向其邻居发送hello数据包,并在其数据库中对自发LSA进行老化。
瞻博网络实施的 OSPF 刷新和泛洪减少基于 RFC 4136, 稳定拓扑中的 OSPF 刷新和泛洪减少。但是,瞻博网络的实施不包括 RFC 中定义的强制泛洪间隔。不实现强制泛洪间隔可确保仅在发生更改时才重新泛洪设置了 DoNotAge 位的 LSA。
以下情况支持此功能:
OSPFv2 和 OSPFv3 接口
OSPFv3 领域
OSPFv2 和 OSPFv3 虚拟链路
OSPFv2 假链接
OSPFv2 对等接口
OSPF 支持的所有路由实例
逻辑系统
要为 OSPF 接口配置泛洪减少,请在[edit protocols (ospf | ospf3) area area-id interface interface-id]层次结构级别包含flood-reduction语句。
如果为配置为按需电路的接口配置泛洪减少,则 LSA 最初不会泛洪,而仅在其内容发生更改时才会发送。仅当网络拓扑发生变化时,才会在需求电路接口上发送和接收 hello 数据包和 LSA。
在以下示例中,OSPF 接口 so-0/0/1.0 配置为泛洪减少。因此,遍历指定接口的路由生成的所有 LSA 在最初泛洪时都会设置 DoNotAge 位,并且仅当发生更改时才会刷新 LSA。
[edit]
protocols ospf {
area 0.0.0.0 {
interface so-0/0/1.0 {
flood-reduction;
}
interface lo0.0;
interface so-0/0/0.0;
}
}
从 Junos OS 12.2 版开始,您可以通过在[edit protocols (ospf | ospf3)]层次结构级别包含lsa-refresh-interval minutes语句,在 OSPF 中为自生成的 LSA 配置全局默认链路状态通告 (LSA) 泛洪间隔。瞻博网络实施每 50 分钟刷新一次 LSA。范围是 25 到 50 分钟。默认情况下,任何未刷新的 LSA 都会在 60 分钟后过期。
如果同时为 OSPF 区域中的特定接口配置了全局 LSA 刷新间隔和减少泛洪的 OSPF,则该特定接口的 OSPF 泛洪减少配置优先。
了解 LDP 和 IGP 之间的同步
LDP 是一种用于在非流量工程应用中分发标签的协议。标签沿着内部网关协议 (IGP) 确定的最佳路径分布。如果未保持 LDP 和 IGP 之间的同步,则标签交换机路径 (LSP) 将关闭。当 LDP 在给定链路上未完全运行(未建立会话且未交换标签)时,IGP 会以最高成本指标播发链路。该链路不是首选链路,而是保留在网络拓扑中。
LDP 同步仅在 IGP 下配置为点对点的活动点对点接口和 LAN 接口上受支持。平滑重启期间不支持 LDP 同步。
另见
示例:配置 LDP 和 OSPF 同步
此示例说明如何配置 LDP 和 OSPFv2 之间的同步。
要求
开始之前:
配置设备接口。请参阅 路由设备 Junos OS 网络接口库。
为 OSPF 网络中的设备配置路由器标识符。请参阅 示例:配置 OSPF 路由器标识符。
控制 OSPF 指定的路由器选择。请参阅 示例:控制 OSPF 指定路由器选择
配置单区域 OSPF 网络。请参阅 示例:配置单区域 OSPF 网络。
配置多区域 OSPF 网络。请参阅 示例:配置多区域 OSPF 网络。
概述
在此示例中,通过执行以下作来配置 LDP 和 OSPFv2 之间的同步:
通过在
[edit protocols]层次结构级别包含ldp语句,在接口 so-1/0/3(OSPF 区域 0.0.0.0 的成员)上启用 LDP。您可以配置一个或多个接口。默认情况下,路由设备上禁用 LDP。通过在
[edit protocols ospf area area-id interface interface-name]层次结构级别包含ldp-synchronization语句来启用 LDP 同步。此语句通过播发最大成本指标来实现 LDP 同步,直到 LDP 在链路上运行。配置路由设备通过在
[edit protocols ospf area area-id interface interface-name ldp-synchronization]层次结构级别包含hold-time语句,为未完全运行的链路通告最大成本指标的时间量(以秒为单位)。如果未配置语hold-time句,则保持时间值默认为无穷大。范围为 1 到 65,535 秒。在此示例中,配置 10 秒的等待时间间隔。
此示例还演示如何通过在[edit protocols ospf area area-id interface interface-name ldp-synchronization] 层次结构级别包含disable语句来禁用 LDP 和 OSPFv2 之间的同步。
拓扑学
配置
启用 LDP 和 OSPFv2 之间的同步
CLI 快速配置
下面的示例要求您在各个配置层级中进行导航。有关导航 CLI 的信息,请参阅在 CLI 用户指南中修改 Junos OS 配置。
要快速启用 LDP 和 OSPFv2 之间的同步,请复制以下命令,删除所有换行符,然后将其粘贴到 CLI 中。
[edit] set protocols ldp interface so-1/0/3 set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-syncrhonization hold-time 10
分步过程
要启用 LDP 和 OSPFv2 之间的同步,请执行以下作:
在接口上启用 LDP。
[edit] user@host# set protocols ldp interface so-1/0/3
配置 LDP 同步,并选择性地配置 10 秒的时间段,以便为未完全运行的链路播发最大成本指标。
[edit ] user@host# edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization
配置 10 秒的时间段,用于播发未完全运行的链路的最大成本指标。
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization ] user@host# set hold-time 10
如果完成设备配置,请提交配置。
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization] user@host# commit
结果
输入 show protocols ldp 和 show protocols ospf 命令,以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ldp interface so-1/0/3.0;
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
hold-time 10;
}
}
}
禁用 LDP 和 OSPFv2 之间的同步
CLI 快速配置
要快速禁用 LDP 和 OSPFv2 之间的同步,请复制以下命令并将其粘贴到 CLI 中。
[edit] set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
分步过程
要禁用 LDP 和 OSPF 之间的同步,请执行以下作:
通过包含
disable语句来禁用同步。[edit ] user@host# set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
如果完成设备配置,请提交配置。
[edit] user@host# commit
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
disable;
}
}
}
OSPFv2 与 RFC 1583 的兼容性概述
默认情况下,OSPFv2 的 Junos OS 实施与 RFC 1583 OSPF 版本 2 兼容。这意味着 Junos OS 会在 OSPF 路由表中维护一条到自治系统 (AS) 边界路由器的最佳路由,而不是多个 AS 内部路径(如果可用)。您现在可以禁用与 RFC 1583 的兼容性。当属于不同 OSPF 区域的 AS 边界路由器播发同一外部目标时,最好执行此作。禁用与 RFC 1583 的兼容性后,OSPF 路由表将保留多个可用的 AS 内部路径,路由器使用这些路径来计算 RFC 2328 OSPF 版本 2 中定义的 AS 外部路由。能够使用多个可用路径来计算 AS 外部路由可以防止路由环路。
另见
示例:禁用 OSPFv2 与 RFC 1583 的兼容性
此示例说明如何在路由设备上禁用 OSPFv2 与 RFC 1583 的兼容性。
要求
在禁用 OSPFv2 与 RFC 1583 的兼容性之前,不需要除设备初始化之外的特殊配置。
概述
默认情况下,OSPF 的 Junos OS 实现与 RFC 1583 兼容。这意味着 Junos OS 会在 OSPF 路由表中维护一条到自治系统 (AS) 边界路由器的最佳路由,而不是多个 AS 内部路径(如果可用)。您可以禁用与 RFC 1583 的兼容性。当属于不同 OSPF 区域的 AS 边界路由器播发同一外部目标时,最好执行此作。禁用与 RFC 1583 的兼容性后,OSPF 路由表将保留多个可用的 AS 内部路径,路由器使用这些路径来计算 RFC 2328 中定义的 AS 外部路由。能够使用多个可用路径来计算 AS 外部路由可以防止路由环路。要尽可能减少路由环路的可能性,请在 OSPF 域中的所有 OSPF 设备上配置相同的 RFC 兼容性。
拓扑学
配置
程序
CLI 快速配置
要快速禁用 OSPFv2 与 RFC 1583 的兼容性,请复制以下命令,将其粘贴到文本文件中,删除所有换行符,更改任何必要的详细信息以匹配您的网络配置,将命令复制并粘贴到 [编辑] 层次结构级别的 CLI 中,然后从配置模式进入 commit 。您可以在属于 OSPF 域的所有设备上配置此设置。
[edit] set protocols ospf no-rfc-1583
分步过程
要禁用 OSPFv2 与 RFC 1583 的兼容性,请执行以下作:
禁用 RFC 1583。
[edit] user@host# set protocols ospf no-rfc-1583
如果完成设备配置,请提交配置。
[edit] user@host# commit
注意:在加入 OSPF 路由域的每台路由设备上重复此配置。
结果
输入 show protocols ospf 命令以确认您的配置。如果输出未显示预期的配置,请重复此示例中的说明以更正配置。
user@host# show protocols ospf no-rfc-1583;