Contrail 网络分析
概述:分析
分析是瞻博网络云原生 Contrail® 网络™版本 22.1 中的可选功能集。它与 Contrail 网络核心 CNI 组件单独打包,并具有自己的安装过程。该软件包由开源软件与瞻博网络开发的软件组合组成。
分析功能分为以下高级功能领域:
- 指标 — 从 Contrail 网络组件和基本 Kubernetes 系统收集的统计时间系列数据。
- 流和会话记录 — 从 Contrail 网络 vRouter 收集的网络流量信息。
- Sandesh 用户可见实体 (UVE)— 代表从 Contrail 网络 vRouter 和控制节点组件收集的外部可见对象的系统范围状态的记录。
- 日志 — 记录从 Kubernetes pod 收集的消息。
- 内省 — 提供浏览 Contrail 网络组件内部状态的诊断实用程序。
指标
数据模型
指标信息基于数字时间系列数据模型。一个系列中的每个数据点都是定期收集的某些系统状态的示例。记录取样值以及收集发生的时间戳。示例记录还可包含一组称为标签的可选密钥值对。标签为指标提供了一个尺寸功能,其中相同度量名称的既定标签组合可识别该指标的特定维度实例化。例如,命名 api_http_requests_total 的指标可以利用标签,以便在 URL 和方法类型级别上提供对请求计数的可见性。在以下示例中,示例值 10 的度量记录将包括一组指示请求类型的标签。
api_http_requests_total{method="POST", handler="/messages"} 10
指标数据类型
尽管所有度量样本值都只是数字,但此数字数据模型中有一个类型概念。指标被视为以下类型之一:
- 计数器 — 表示单个单调增加计数器的累积指标,其值只能在重新启动时增加或重置为零。
- 规格 — 表示单个数字值的指标,可任意上下推。
- Histogram — 一个直图样本观察结果(通常如请求持续时间或响应大小),并将其计数在可配置的桶中。他的图还提供了所有观察到的值的总和。
- 摘要 — 类似于语法,摘要取样观察(通常为请求持续时间和响应大小等)。该摘要还提供了总共的观察结果和所有观察值的总和,但是汇总计算滑动时间窗口上的可配置量化值。
Contrail 网络中的指标功能由 Prometheus 实施。有关指标数据模型的更多详细信息,请参阅 Prometheus 上的文档。
支持的指标
分析解决方案支持的一组指标分类如下所示:
- Contrail 网络指标列表 — 从 vRouter 和控制节点组件收集的指标。
- Kubernetes 指标列表 — 从各种 Kubernetes 组件(如
apiserveretcdkubelet、 等)收集的指标。 - 群集节点指标 — 从 Kubernetes 群集节点收集的主机级指标。
警报
警报根据收集的度量数据分析生成。支持的每种警报类型均基于包含以下信息的规则定义:
- 警报名称 — 警报类型的唯一字符串标识符。
- 条件表达式 — Prometheus 查询语言表达式,根据收集的度量值进行评估,以确定是否存在警报情况。
- 条件持续时间 — 问题情况必须存在的时间量才能生成警报。
- 严重性 — 警报级别(严重、主要、警告、信息)。
- 摘要 — 有问题情况的简短描述。
- 说明 — 有问题情况的详细说明。
Contrail 网络分析解决方案会安装一组 预定义的警报规则。您还可以定义自己的自定义警报规则。在部署分析掌舵图的名称空间中创建 PrometheusRule Kubernetes 资源支持这一点。如下所示自定义警报规则的示例。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: acme-corp-rules
spec:
groups:
- name: acme-corp.rules
rules:
- alert: HostUnusualNetworkThroughputOut
expr: "sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100"
labels:
severity: warning
annotations:
summary: "Host unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are sending too much data (> 100 MB/s)\n VALUE = {{ $value }}"
生成的警报作为记录存储在 Prometheus 中,可在 Grafana UI 中查看。AlertManager 组件还支持与外部系统(如 PagerDuty、OpsGenie、电子邮件等)集成以获取警报通知。
建筑
如 图 1 所示,Prometheus 是指标架构的核心组件。Prometheus 实施以下功能:
- 集合 — 定期轮询机制,对其他组件(导出方)调用 API 调用以提取一组指标的值。
- 存储 — 为从导出方收集的指标提供持久性的时间系列数据库。
- 查询 — 支持名为 PromQL(Prometheus 查询语言)的表达式语言的 API,允许从数据库中检索历史指标信息。
- 警报 — 此框架能够定义在收集的度量数据中观察到某些情况时生成警报的规则。
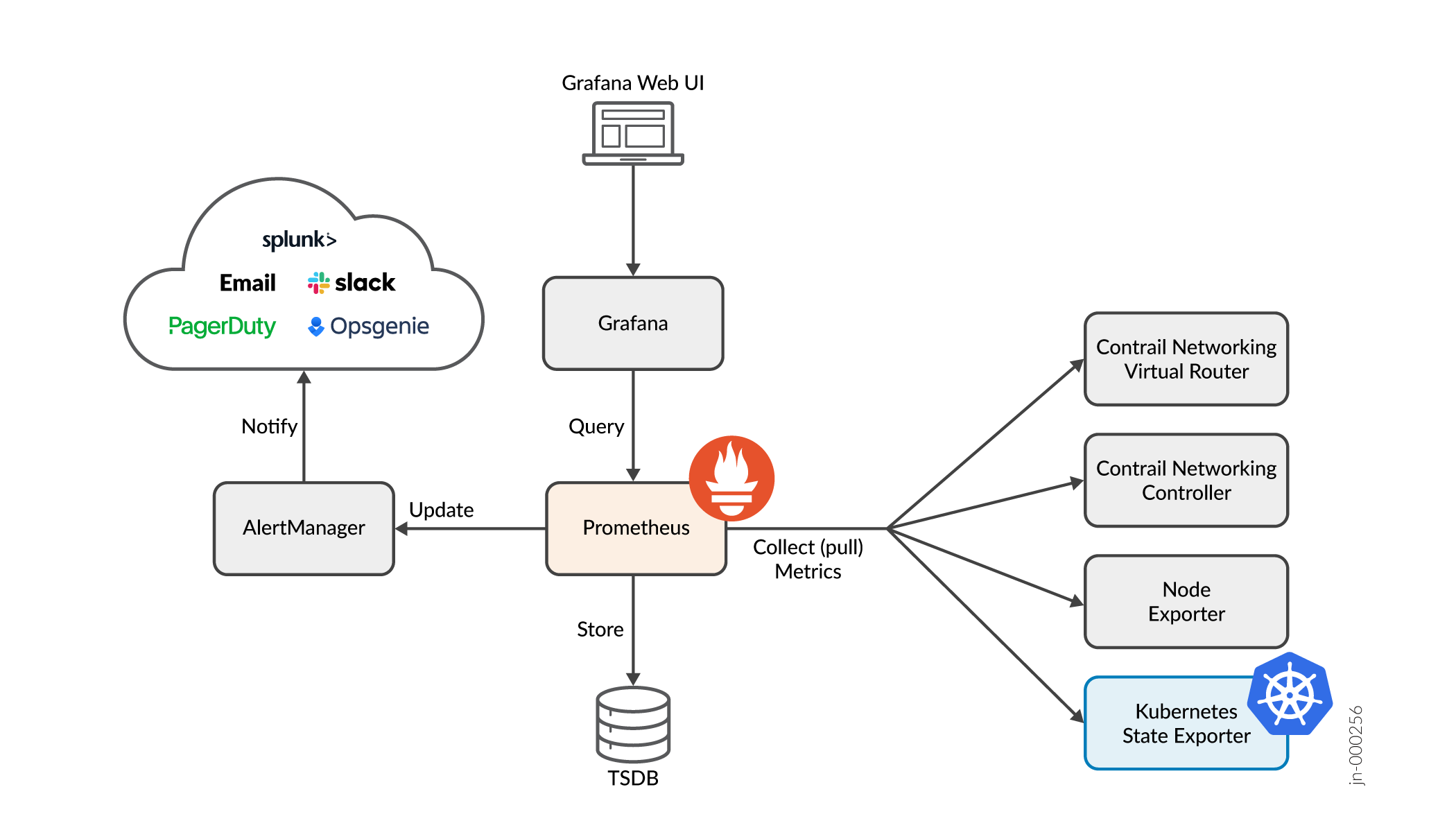
指标架构的其他组件包括:
- Grafana — 提供 Web UI 界面的服务,允许用户可视化图形中的度量数据。
- AlertManager — 一种集成服务,用于通知外部系统 Prometheus 生成的警报。
配置
指标功能不需要最终用户进行任何配置。分析的安装需要将 Prometheus 配置为从提供上述 受支持指标 部分中所述所有指标的导出方收集。作为安装的一部分,还会自动设置一组默认警报规则。但是,在安装之后,最终用户可以通过附加配置来扩展此基本功能。例如,可以定义客户特定的警报规则,并且可以配置 AlertManager,以便与环境中存在的任何受支持的外部系统集成。
Prometheus 和 AlertManager 的配置涉及一个名为 Prometheus 操作员的附加架构组件。如 图 2 所示,配置指定为 Kubernetes 自定义资源。操作人员负责将这些资源的内容转换为 Prometheus 组件理解的本机配置,并相应更新组件,然后在需要重新启动特定配置时注意重新启动组件。
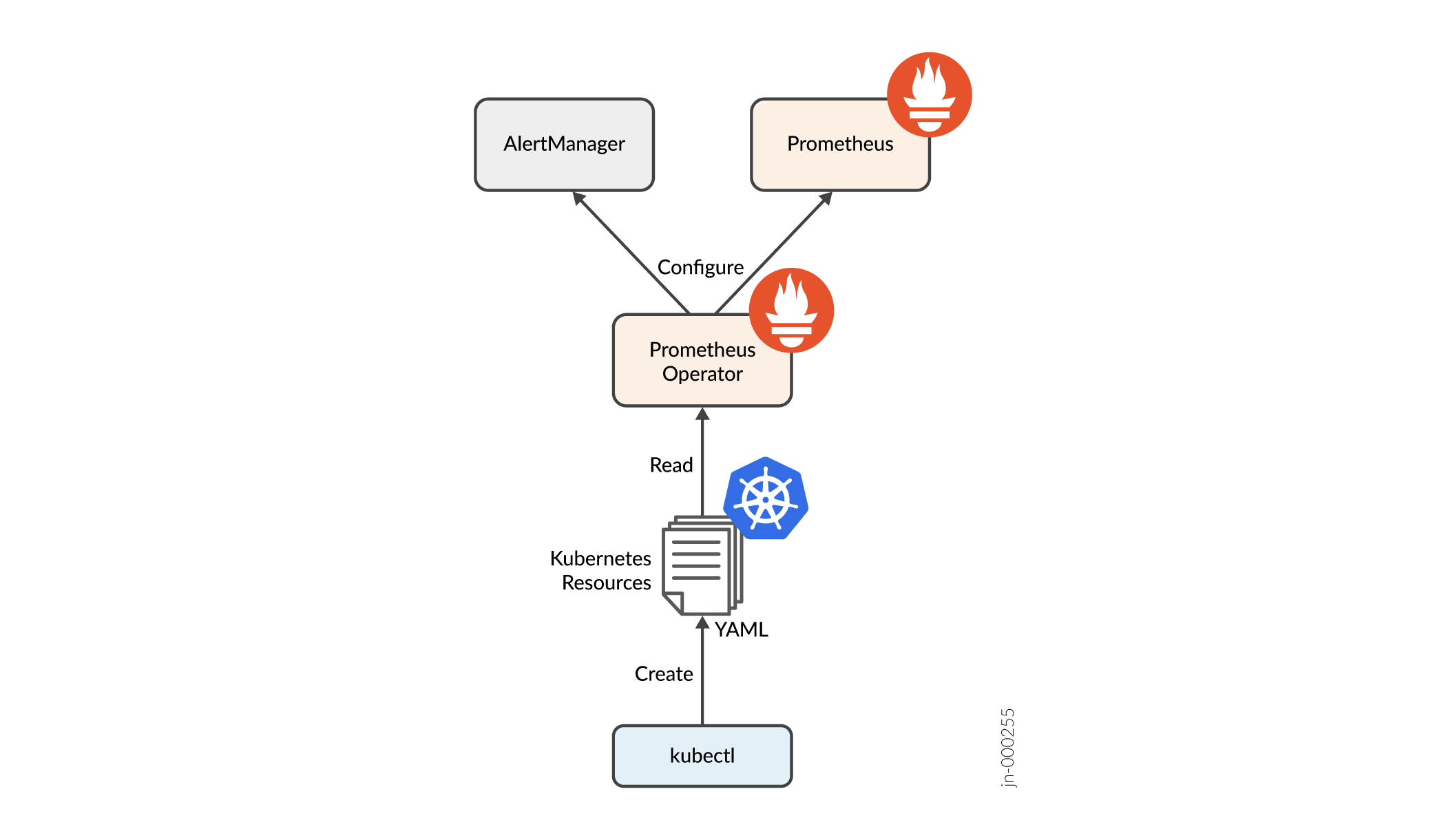
Prometheus 操作员 API 提供有关操作员支持的全套资源的文档。但是,建议客户将其配置限制在与警报规则定义和外部系统集成相关的资源类型子集中。
格拉法纳
查看指标数据和警报的主要 UI 是 Grafana。作为分析安装的一部分,Grafana 服务通过 Prometheus 作为数据源进行设置并自动配置。还会创建一组默认仪表板。
访问 Grafana Web UI,网速为: https://<k8sClusterIP>/grafana/login.默认登录凭据为用户 admin 和密码 prom-operator。