NESTA PÁGINA
Exemplo: limitação do número de prefixos exportados para OSPF
Exemplo: controle do custo de segmentos de rede OSPF individuais
Entenda a distribuição ponderada de tráfego ECMP nos vizinhos do OSPFv2 de um salto
Exemplo: Distribuição ponderada de tráfego ECMP em vizinhos osPFv2 de um salto
Exemplo: Ajustando dinamicamente as métricas da interface dos OSPF com base na largura de banda
Exemplo: configuração do OSPF para fazer os dispositivos de roteamento aparecerem sobrecarregados
Exemplo: Configuração de opções de algoritmo de SPF para OSPF
Configuração da atualização do OSPF e redução de inundações em topologias estáveis
Exemplo: Desativação da compatibilidade do OSPFv2 com RFC 1583
Configuração do controle de rota OSPF
Entendendo a resumo da rota OSPF
Os roteadores de borda de área (ABRs) enviam anúncios de link sumário para descrever as rotas para outras áreas. Dependendo do número de destinos, uma área pode ser inundada com um grande número de registros de estado de enlace, que podem utilizar recursos de dispositivos de roteamento. Para minimizar o número de anúncios que estão inundados em uma área, você pode configurar a ABR para unir, ou resumir, uma variedade de endereços IP e enviar informações de acessibilidade sobre esses endereços em um único anúncio de estado de link (LSA). Você pode resumir uma ou mais faixas de endereços IP, onde todas as rotas que correspondem à faixa de área especificada são filtradas no limite da área, e o resumo é anunciado em seu lugar.
Para uma área de OSPF, você pode resumir e filtrar prefixos intraáreas. Todas as rotas que correspondem à faixa de área especificada são filtradas no limite da área, e o resumo é anunciado em seu lugar. Para uma área não tão stubby (NSSA), você só pode unir ou filtrar LSAs externos (Tipo 7) NSSA antes que eles sejam traduzidos em LSAs externos (Tipo 5) e entrar na área do backbone. Todas as rotas externas aprendidas na área que não caem na faixa de um dos prefixos são anunciadas individualmente para outras áreas.
Além disso, você também pode limitar o número de prefixos (rotas) que são exportados para OSPF. Ao definir um número máximo de prefixos definido pelo usuário, você impede que o dispositivo de roteamento invada um número excessivo de rotas em uma área.
Exemplo: Resumindo as faixas de rotas em anúncios de estado de enlace OSPF enviados para a área de backbone
Este exemplo mostra como resumir as rotas enviadas para a área de backbone.
Requisitos
Antes de começar:
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rota estática. Veja exemplos: Configuração de rotas estáticas na biblioteca de protocolos de roteamento do Junos OS para dispositivos de roteamento.
Visão geral
Você pode resumir uma variedade de endereços IP para minimizar o tamanho do banco de dados de estado de enlace do roteador de backbone. Todas as rotas que correspondem à faixa de área especificada são filtradas no limite da área, e o resumo é anunciado em seu lugar.
A Figura 1 mostra a topologia usada neste exemplo. R5 é a ABR entre a área 0.0.0.4 e o backbone. As redes na área 0.0.0.4 são 10.0.8.4/30, 10.0.8.0/30 e 10.0.8.8/30, que podem ser resumidas como 10.0.8.0/28. R3 é a ABR entre a área NSSA 0.0.0.3 e o backbone. As redes na área 0.0.0.3 são 10.0.4.4/30, 10.0.4.0/30 e 10.0.4.12/30, que podem ser resumidas como 10.0.4.0/28. A área 0.0.0.3 também contém a rota estática externa 3.0.0.8, que será inundada por toda a rede.
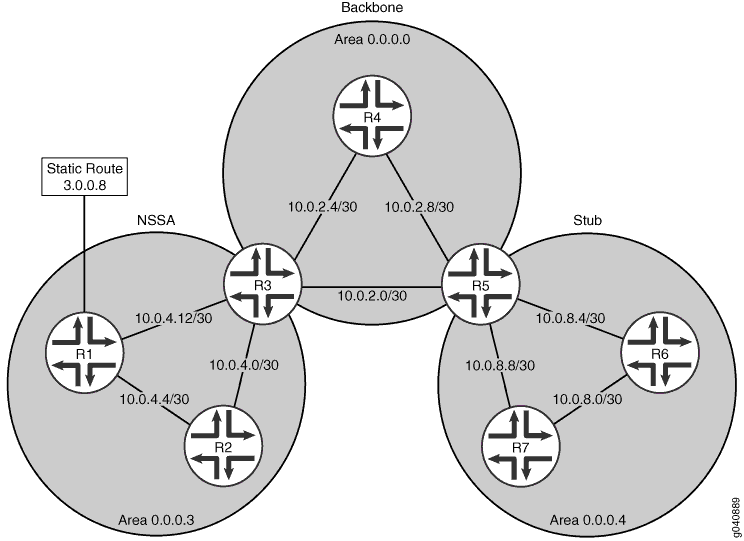
Neste exemplo, você configura os ABRs para resumo de rotas, incluindo as seguintes configurações:
intervalo de área — Para uma área, resume uma variedade de endereços IP ao enviar anúncios de link intraárea sumários. Para um NSSA, resume uma variedade de endereços IP ao enviar anúncios de estado de link NSSA (Type 7 LSAs). Os prefixos especificados são usados para agregar rotas externas aprendidas na área quando as rotas são anunciadas para outras áreas.
rede/comprimento de máscara — indica a faixa de endereço IP resumida e o número de bits significativos na máscara de rede.
Topologia
Configuração
Configuração rápida da CLI
Para configurar rapidamente a resumição de rota para uma área de OSPF, copie os seguintes comandos e cole-os na CLI. A seguir, a configuração no ABR R5:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30 set protocols ospf area 0.0.0.4 stub set protocols ospf area 0.0.0.4 interface fe-0/0/1 set protocols ospf area 0.0.0.4 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
Para configurar rapidamente a resumição de rota para um NSSA OSPF, copie os seguintes comandos e cole-os na CLI. A seguir, a configuração no ABR R3:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30 set protocols ospf area 0.0.0.3 interface fe-0/0/1 set protocols ospf area 0.0.0.3 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28 set protocols ospf area 0.0.0.3 nssa set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
Procedimento
Procedimento passo a passo
Para resumir as rotas enviadas para a área de backbone:
Configure as interfaces.
Nota:Para o OSPFv3, inclua endereços IPv6.
[edit] user@R5#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30user@R5#set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30user@R5#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30user@R5#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30[edit] user@R3#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30user@R3#set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30user@R3#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30user@R3#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30Configure o tipo de área de OSPF.
Nota:Para o OSPFv3, inclua a
ospf3declaração no nível de[edit protocols]hierarquia.[edit] user@R5# set protocols ospf area 0.0.0.4 stub
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa
Atribua as interfaces às áreas de OSPF.
user@R5#
set protocols ospf area 0.0.0.4 interface fe-0/0/1user@R5#set protocols ospf area 0.0.0.4 interface fe-0/0/2user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/4user@R3#
set protocols ospf area 0.0.0.3 interface fe-0/0/1user@R3#set protocols ospf area 0.0.0.3 interface fe-0/0/2user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/4Resumir as rotas que estão inundadas no backbone.
[edit] user@R5# set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
[edit] user@R3# set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28
Na ABR R3, restrinja a rota estática externa de deixar a área 0,0.0.3.
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
Se você terminar de configurar os dispositivos, confirme a configuração.
[edit] user@host# commit
Resultados
Confirme sua configuração inserindo os comandos e a show interfaces show protocols ospf configuração. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
Configuração no ABR R5:
user@R5# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.3/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.8.3/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.8.4/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.5/32;
}
}
}
user@R5# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.4 {
stub;
area-range 10.0.8.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
Configuração no ABR R3:
user@R3# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.1/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.4.10/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.4.1/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.7/32;
}
}
}
user@R3t# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.3 {
nssa {
area-range 3.0.0.0/8 ;
}
area-range 10.0.4.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
Para confirmar sua configuração OSPFv3, digite e show interfaces show protocols ospf3 comandos.
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando a rota resumida
Propósito
Verifique se as rotas configuradas para a resumo da rota estão sendo agregadas pelos ABRs antes que as rotas entrem na área do backbone. Confirme a resumo da rota verificando as entradas do banco de dados de estado do enlace OSPF para os dispositivos de roteamento no backbone.
Ação
A partir do modo operacional, insira o show ospf database comando para o OSPFv2 e insira o show ospf3 database comando para o OSPFv3.
Exemplo: limitação do número de prefixos exportados para OSPF
Este exemplo mostra como limitar o número de prefixos exportados para OSPF.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte a biblioteca de interfaces de rede do Junos OS para dispositivos de roteamento.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Configure uma rede OSPF multiárea. Veja exemplo: Configuração de uma rede OSPF multiárea.
Visão geral
Por padrão, não há limite para o número de prefixos (rotas) que podem ser exportados para OSPF. Ao permitir que qualquer número de rotas seja exportada para o OSPF, o dispositivo de roteamento pode ficar sobrecarregado e potencialmente inundar um número excessivo de rotas para uma área.
Você pode limitar o número de rotas exportadas para OSPF para minimizar a carga no dispositivo de roteamento e evitar esse problema em potencial. Se o dispositivo de roteamento exceder o valor de exportação de prefixo configurado, o dispositivo de roteamento elimina os prefixos externos e entra em um estado de sobrecarga. Esse estado garante que o dispositivo de roteamento não esteja sobrecarregado enquanto tenta processar informações de roteamento. O número limite de exportação do prefixo pode ser um valor de 0 a 4.294.967.295.
Neste exemplo, você configura um limite de exportação de prefixo de 100.000, incluindo a prefix-export-limit declaração.
Topologia
Configuração
Configuração rápida da CLI
Para limitar rapidamente o número de prefixos exportados para OSPF, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e então entrar no commit modo de configuração.
[edit] set protocols ospf prefix-export-limit 100000
Procedimento
Procedimento passo a passo
Para limitar o número de prefixos exportados para OSPF:
Configure o valor limite de exportação do prefixo.
Nota:Para o OSPFv3, inclua a
ospf3declaração no nível de[edit protocols]hierarquia.[edit] user@host# set protocols ospf prefix-export-limit 100000
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit] user@host# commit
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf prefix-export-limit 100000;
Para confirmar sua configuração OSPFv3, entre no show protocols ospf3 comando.
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando o limite de exportação de prefixo
Propósito
Verifique o contador de exportação de prefixo que exibe o número ou as rotas exportadas para OSPF.
Ação
A partir do modo operacional, insira o show ospf overview comando para o OSPFv2 e insira o show ospf3 overview comando para o OSPFv3.
Entendendo o controle de tráfego OSPF
Uma vez que uma topologia é compartilhada em toda a rede, o OSPF usa a topologia para rotear pacotes entre nós de rede. Cada caminho entre os vizinhos recebe um custo baseado na taxa de transferência da interface. O algoritmo padrão computa a métrica da interface com base em uma largura de banda de referência de 100 Mbps usando a fórmula cost = reference-bandwidth / interface bandwidth. O resultado é que qualquer interface que opera a 100 Mbps ou mais rápido recebe o mesmo valor métrica de 1. Você pode atribuir manualmente a métrica da interface OSPF para substituir o valor padrão. Como alternativa, dadas as interfaces de suporte atuais da Juniper que operam a 400 Gbps, muitas vezes é uma boa ideia configurar um valor maior reference-bandwidth . Configurar um valor de largura de banda de referência baseado em uma várias das interfaces de maior velocidade da sua rede otimiza automaticamente caminhos de rede com base na velocidade da interface e oferece espaço para o crescimento nas velocidades da rede.
A soma dos custos em um caminho específico entre hosts determina o custo global do caminho. Os pacotes são então roteados ao longo do caminho mais curto usando o algoritmo de caminho mais curto primeiro (SPF). Se existirem vários caminhos de igual custo entre um endereço de origem e destino, o OSPF roteia pacotes em cada caminho de forma alternativa, de forma redonda. Rotas com métricas totais de caminho menores são preferidas em relação àqueles com métricas de caminho mais altas.
Você pode usar os seguintes métodos para controlar o tráfego OSPF:
-
Controle o custo de segmentos de rede OSPF individuais
-
Ajuste dinamicamente as métricas da interface OSPF com base na largura de banda
-
Seleção de rotas de OSPF de controle
- Controle do custo de segmentos de rede OSPF individuais
- Ajustando dinamicamente as métricas da interface dos OSPF com base na largura de banda
- Controle das preferências de rota OSPF
Controle do custo de segmentos de rede OSPF individuais
O OSPF usa a seguinte fórmula para determinar o custo de uma rota:
cost = reference-bandwidth / interface bandwidth
Você pode modificar o valor de largura de banda de referência, que é usado para calcular o custo padrão da interface. O valor da largura de banda da interface não é configurável pelo usuário e refere-se à largura de banda real da interface física.
Por padrão, o OSPF atribui uma métrica de custo padrão de 1 a qualquer link mais rápido que 100 Mbps, e uma métrica de custo padrão de 0 para a interface de loopback (lo0). Nenhuma largura de banda está associada à interface de loopback.
Para controlar o fluxo de pacotes por toda a rede, o OSPF permite que você atribua manualmente um custo (ou métrica) a um segmento de caminho específico. Quando você especifica uma métrica para uma interface OSPF específica, esse valor é usado para determinar o custo das rotas anunciadas por essa interface. Por exemplo, se todos os roteadores da rede OSPF usarem valores métricas padrão e aumentarem a métrica em uma interface para 5, todos os caminhos por essa interface têm uma métrica calculada superior à padrão e não são preferidas.
Qualquer valor que você configure para a métrica substitui o comportamento padrão de usar o valor de largura de banda de referência para calcular o custo de rota para essa interface.
Quando existem várias rotas de igual custo para o mesmo destino em uma tabela de roteamento, um conjunto multicaminho de igual custo (ECMP) é formado. Se houver um conjunto de ECMP para a rota ativa, o software Junos OS usa um algoritmo de hash para escolher um dos endereços de próximo salto no conjunto ECMP para instalar na tabela de encaminhamento.
Você pode configurar o Junos OS para que várias entradas de próximo salto em um conjunto de ECMP sejam instaladas na tabela de encaminhamento. Defina uma política de roteamento de balanceamento de carga incluindo uma ou mais declarações de configuração de declaração de política no nível hierárquico [editar opções de política], com o equilíbrio de carga por pacote de ação. Em seguida, aplique a política de roteamento às rotas exportadas da tabela de roteamento para a tabela de encaminhamento.
Ajustando dinamicamente as métricas da interface dos OSPF com base na largura de banda
Você pode especificar um conjunto de valores limiares de largura de banda e valores métricas associados para uma interface OSPF ou para uma topologia em uma interface OSPF. Quando a largura de banda de uma interface muda (por exemplo, se o lag perder um membro da interface ou se a velocidade da interface for alterada administrativamente), o Junos OS define automaticamente a métrica da interface para o valor associado ao valor limite de largura de banda apropriado. O Junos OS usa o menor valor de limite de largura de banda configurado igual ou maior do que a largura de banda da interface real para determinar o valor métrica. Se a largura de banda da interface for maior do que qualquer um dos valores de limiar de largura de banda configurados, o valor métrica configurado para a interface é usado em vez de qualquer um dos valores métricas baseados em largura de banda configurados. A capacidade de recalcular a métrica para uma interface quando sua largura de banda muda é especialmente útil para interfaces agregadas.
Você também deve configurar uma métrica para a interface quando habilitar métricas baseadas em largura de banda.
Controle das preferências de rota OSPF
Você pode controlar o fluxo de pacotes pela rede usando preferências de rota. As preferências de rota são usadas para selecionar qual rota está instalada na tabela de encaminhamento quando vários protocolos calculam rotas para o mesmo destino. A rota com o menor valor de preferência é selecionada.
Por padrão, as rotas internas de OSPF têm um valor de preferência de 10, e as rotas OSPF externas têm um valor de preferência de 150. Embora as configurações padrão sejam apropriadas para a maioria dos ambientes, você pode querer modificar as configurações padrão se todos os dispositivos de roteamento em sua rede OSPF usarem os valores de preferência padrão, ou se você estiver planejando migrar do OSPF para um protocolo de gateway interior diferente (IGP). Se todos os dispositivos usarem os valores de preferência de rota padrão, você pode alterar as preferências de rota para garantir que o caminho por um determinado dispositivo seja selecionado para a tabela de encaminhamento sempre que existirem vários caminhos de igual custo para um destino. Ao migrar do OSPF para um IGP diferente, modificar as preferências de rota permite que você realize a migração de maneira controlada.
Veja também
Exemplo: controle do custo de segmentos de rede OSPF individuais
Este exemplo mostra como controlar o custo de segmentos de rede OSPF individuais.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte o guia de usuário de interfaces para dispositivos de segurança.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Visão geral
Todas as interfaces OSPF têm um custo, que é uma métrica de roteamento que é usada no cálculo do estado do enlace. Rotas com métricas totais de caminho menores são preferidas para aqueles com métricas de caminho mais altas. Neste exemplo, exploramos como controlar o custo dos segmentos de rede OSPF.
Por padrão, o OSPF atribui uma métrica de custo padrão de 1 a qualquer link mais rápido que 100 Mbps, e uma métrica de custo padrão de 0 para a interface de loopback (lo0). Nenhuma largura de banda está associada à interface de loopback. Isso significa que todas as interfaces com mais rapidez que 100 Mbps têm a mesma métrica de custo padrão de 1. Se existirem vários caminhos de igual custo entre um endereço de origem e destino, o OSPF roteia pacotes em cada caminho de forma alternativa, de forma redonda.
Ter a mesma métrica padrão pode não ser um problema se todas as interfaces estiverem sendo executadas na mesma velocidade. Se as interfaces funcionarem em velocidades diferentes, você pode notar que o tráfego não é roteado pela interface mais rápida, pois o OSPF também roteia pacotes pelas diferentes interfaces. Por exemplo, se o seu dispositivo de roteamento tiver interfaces Ethernet rápidas e Gigabit Ethernet executando OSPF, cada uma dessas interfaces terá uma métrica de custo padrão de 1.
No primeiro exemplo, você define a largura de banda de referência para 10g (10 Gbps, como denotado por 10.000.000.000 bits) incluindo a declaração de largura de banda de referência . Com essa configuração, o OSPF atribui à interface Fast Ethernet uma métrica padrão de 100, e a interface Gigabit Ethernet uma métrica de 10. Como a interface Gigabit Ethernet tem a métrica mais baixa, o OSPF a seleciona ao rotear pacotes. A faixa é de 9600 a 1.000.000.000.000 bits.
A Figura 2 mostra três dispositivos de roteamento na área 0.0.0.0 e assume que a ligação entre o Dispositivo R2 e o Dispositivo R3 está congestionada com outro tráfego. Você também pode controlar o fluxo de pacotes por toda a rede atribuindo manualmente uma métrica a um segmento de caminho específico. Qualquer valor que você configure para a métrica substitui o comportamento padrão de usar o valor de largura de banda de referência para calcular o custo de rota para essa interface. Para evitar que o tráfego do dispositivo R3 vá diretamente para o Dispositivo R2, você ajusta a métrica na interface no dispositivo R3 que se conecta ao dispositivo R1 para que todo o tráfego passe pelo Dispositivo R1.
No segundo exemplo, você define a métrica para 5 na interface fe-1/0/1 no dispositivo R3 que se conecta com o dispositivo R1, incluindo a declaração métrica . O intervalo é de 1 a 65.535.
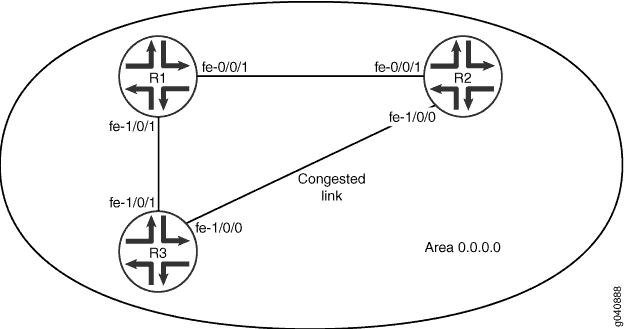 métrica do OSPF
métrica do OSPF
Topologia
Configuração
- Configurando a largura de banda de referência
- Configuração de uma métrica para uma interface OSPF específica
Configurando a largura de banda de referência
Configuração rápida da CLI
Para configurar rapidamente a largura de banda de referência, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e então entrar no commit modo de configuração.
[edit] set protocols ospf reference-bandwidth 10g
Procedimento passo a passo
Para configurar a largura de banda de referência:
Configure a largura de banda de referência para calcular o custo padrão da interface.
Nota:Para especificar o OSPFv3, inclua a declaração ospf3 no nível de hierarquia [editar protocolos] .
[edit] user@host# set protocols ospf reference-bandwidth 10g
Ponta:Como um atalho neste exemplo, você digita 10g para especificar largura de banda de referência de 10 Gbps. Quer você insira 10g ou 10000000000, a saída de protocolos de exibição do comando ospf exibe 10 Gbps como 10g, não 10000000000.
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit] user@host# commit
Nota:Repita toda essa configuração em todos os dispositivos de roteamento em uma rede compartilhada.
Resultados
Confirme sua configuração inserindo o comando ospf de protocolos de exibição . Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf reference-bandwidth 10g;
Para confirmar sua configuração OSPFv3, insira o comando ospf3 dos protocolos de exibição .
Configuração de uma métrica para uma interface OSPF específica
Configuração rápida da CLI
Para configurar rapidamente uma métrica para uma interface OSPF específica, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e então entrar no commit modo de configuração.
[edit] set protocols ospf area 0.0.0.0 interface fe-1/0/1 metric 5
Procedimento passo a passo
Para configurar a métrica para uma interface OSPF específica:
Crie uma área de OSPF.
Nota:Para especificar o OSPFv3, inclua a declaração ospf3 no nível de hierarquia [editar protocolos] .
[edit] user@host# edit protocols ospf area 0.0.0.0
Configure a métrica do segmento de rede OSPF.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface fe-1/0/1 metric 5
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Resultados
Confirme sua configuração inserindo o comando ospf de protocolos de exibição . Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf
area 0.0.0.0 {
interface fe-1/0/1.0 {
metric 5;
}
}
Para confirmar sua configuração OSPFv3, insira o comando ospf3 dos protocolos de exibição .
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando a métrica configurada
Propósito
Verifique a configuração métrica na interface. Confirme que o campo Custo exibe a métrica configurada (custo) da interface. Ao escolher caminhos para um destino, o OSPF usa o caminho com o menor custo.
Ação
A partir do modo operacional, insira o comando de detalhe da interface show ospf para OSPFv2 e insira o comando de detalhe da interface show ospf3 para OSPFv3.
Entenda a distribuição ponderada de tráfego ECMP nos vizinhos do OSPFv2 de um salto
Multicaminho de custo igual (ECMP) é uma técnica popular para carregar o tráfego de equilíbrio em vários caminhos. Com o ECMP habilitado, se os caminhos para um destino remoto tiverem o mesmo custo, o tráfego será distribuído entre eles em igual proporção. A distribuição igual de tráfego em vários caminhos não é desejável se as ligações locais com roteadores adjacentes em direção ao destino final tiverem capacidade desigual. Normalmente, a distribuição de tráfego entre dois links é igual e a utilização do link é a mesma. No entanto, se a capacidade de um pacote Ethernet agregado mudar, a distribuição de tráfego igual resulta em um descasamento da utilização do enlace. Neste caso, o ECMP ponderado permite o balanceamento de carga do tráfego entre caminhos de custo iguais em proporção à capacidade dos links locais.
Considerando como exemplo, existem dois dispositivos interconectados com um pacote Ethernet agregado com quatro links e um único link do mesmo custo. Em condições normais, tanto os pacotes AE quanto o link único são usados uniformemente para distribuir tráfego. No entanto, se um link no pacote AE cair, há uma mudança na capacidade de enlace que resulta em utilização inigualável de enlaces. A carga ponderada de ECMP equilibra o tráfego entre os caminhos de custo igual em proporção à capacidade dos links locais. Neste caso, o tráfego é distribuído em proporção 30/40 entre o pacote AE e o link único.
Esse recurso oferece roteamento ECMP ponderado para vizinhos OSPFv2 que estão a um salto de distância. O sistema operacional oferece suporte a esse recurso apenas em roteadores conectados imediatamente e não oferece suporte a ECMP ponderado em roteadores multihop, ou seja, em roteadores que estão a mais de um salto de distância.
Para permitir a distribuição ponderada de tráfego ECMP em vizinhos OSPFv2 conectados diretamente, configure weighted one-hop a declaração no nível de [edit protocols ospf spf-options multipath] hierarquia.
Você deve configurar a política de balanceamento de carga por pacote antes de configurar este recurso. O WECMP estará operacional se a política de balanceamento de carga por pacote estiver em vigor.
Para interfaces lógicas, você deve configurar a largura de banda da interface para distribuir tráfego em multicaminhos de custo igual com base na largura de banda da interface física subjacente. Se você não configurar a largura de banda lógica para cada interface lógica, o sistema operacional assume que toda a largura de banda da interface física está disponível para cada interface lógica.
Exemplo: Distribuição ponderada de tráfego ECMP em vizinhos osPFv2 de um salto
Use este exemplo para configurar o roteamento multicaminho de custo igual ponderado (ECMP) para distribuir tráfego para vizinhos OSPFv2 que estão a um salto de distância para garantir o balanceamento de carga ideal.
Nossa equipe de testes de conteúdo validou e atualizou este exemplo.
| Tempo de leitura |
30 minutos |
| Tempo de configuração |
20 minutos |
- Pré-requisitos de exemplo
- Antes de começar
- Visão geral funcional
- Visão geral da topologia
- Ilustração de topologia
- Etapas de configuração do R0
- Verificação
- Apêndice 1: definir comandos em todos os dispositivos
Pré-requisitos de exemplo
| Requisitos de hardware |
Dois roteadores da Série MX. |
| Requisitos de software |
Junos OS Release 24.2R1 ou posterior em todos os dispositivos. |
Antes de começar
| Benefícios |
O roteamento ECMP ponderado distribui tráfego de forma desigual em vários caminhos para um melhor balanceamento de carga. É mais eficiente do que a distribuição igual de tráfego durante o balanceamento de carga por pacote. |
| Saiba mais |
Entendendo a distribuição ponderada de tráfego ECMP em vizinhos OSPF de um salto |
Visão geral funcional
| Tecnologias usadas |
|
| Tarefas primárias de verificação |
|
Visão geral da topologia
Este exemplo de configuração mostra três pacotes Ethernet agregados ae0, ae1 e ae2 com dois links cada um configurados entre o Roteador R0 e o Roteador R1. O Mecanismo de encaminhamento de pacotes distribui tráfego de forma desigual entre os três pacotes Ethernet quando um dos links cai, dependendo da largura de banda disponível.
| Nome de host |
Papel |
Função |
|---|---|---|
| R0 |
O dispositivo no qual o WECMP está configurado. |
O R0 envia tráfego para o R1. |
| R1 |
O dispositivo que está conectado diretamente ao R0. |
A R1 recebe tráfego do R0. |
Ilustração de topologia
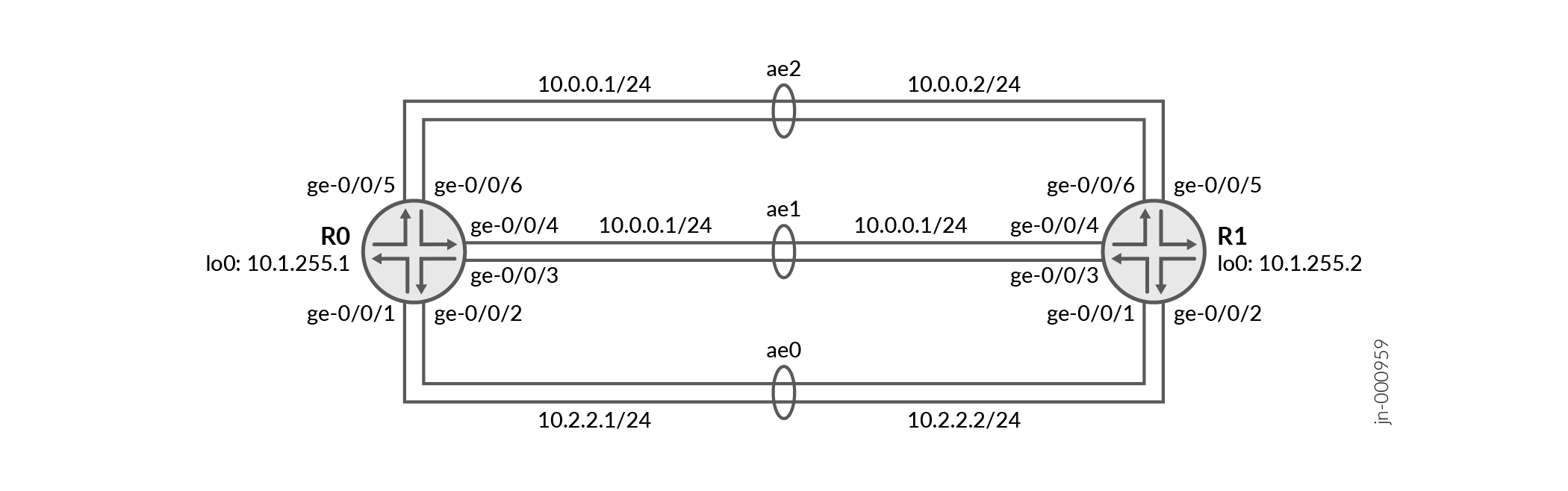 osPFv2 de um salto
osPFv2 de um salto
Etapas de configuração do R0
Para obter configurações de amostra completas no R0, veja: Apêndice 1: Definir comandos em todos os dispositivos
Esta seção destaca as principais tarefas de configuração necessárias para configurar o dispositivo R0 para este exemplo. A primeira etapa é comum configurar as interfaces Ethernet agregadas. O conjunto de etapas a seguir é específico para configurar o OSPF nos pacotes AE e configurar eCMP ponderado.
-
Configure os dois links de membros dos pacotes Ethernet agregados ae0, ae1 e ae2.
Configure o endereço IP e o Link Aggregation Control Protocol (LACP) para as interfaces Ethernet agregadas ae0, ae1 e ae2.
Configure as interfaces Ethernet agregadas (ae0, ae1 e ae2) para tags vlan.
Configure o endereço da interface de loopback.
Configure o identificador de roteador OSPF inserindo o valor de configuração [do roteador-id].
Configure interfaces lógicas com largura de banda apropriada com base na largura de banda física subjacente.
Nota:Para interfaces lógicas, configure a largura de banda da interface para distribuir tráfego em multicaminhos de igual custo com base na largura de banda da interface operacional subjacente. Quando você configura várias interfaces lógicas em uma única interface, configure a largura de banda lógica apropriada para cada interface lógica para ver a distribuição de tráfego desejada nas interfaces lógicas.
Configure uma interface de túnel e especifique a quantidade de largura de banda para reservar para tráfego de túnel em cada mecanismo de encaminhamento de pacotes do R0.
[edit] set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 gigether-options 802.3ad ae2
[edit] set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae2 aggregated-ether-options minimum-links 1 set interfaces ae2 aggregated-ether-options lacp active
[edit] set interfaces ae0 vlan-tagging set interfaces ae1 vlan-tagging set interfaces ae2 vlan-tagging
[edit] set interfaces lo0 unit 0 family inet address 10.1.255.1/32
[edit] set routing-options router-id 10.1.255.1
[edit] set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24
Especifique o número máximo de interfaces ECMP ponderadas que deseja configurar. Habilite o switchover gracioso e especifique o número de interfaces Ethernet agregadas a serem criadas.
[edit] set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3
Configure o OSPF em todas as interfaces e nos pacotes AE.
[edit]set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0Configure o balanceamento de carga por pacote.
[edit] set policy-options policy-statement pplb then load-balance per-packet
Aplicar política de balanceamento de carga por pacote.
[edit] set routing-options forwarding-table export ppl
Habilite a distribuição ponderada de tráfego ECMP em vizinhos OSPFv2 conectados diretamente.
[edit] set protocols ospf spf-options multipath weighted one-hop
Verificação
| Tarefa de verificação | de comandos |
|---|---|
| rota de exibição extensa | Verifique a distribuição igual de tráfego em vários caminhos de igual custo. |
| rota de exibição extensa | Verifique a distribuição de tráfego desigual na largura de banda disponível. |
| interfaces de exibição extensas | Verifique a distribuição de tráfego desigual na largura de banda disponível. |
- Verificando a distribuição igual do tráfego em vários caminhos de igual custo
- Verificando a distribuição de tráfego desigual na largura de banda disponível
Verificando a distribuição igual do tráfego em vários caminhos de igual custo
Propósito
Para verificar se o tráfego é igualmente distribuído pelos pacotes Ethernet agregados.
Ação
A partir do modo operacional, entre no show route 10.1.255.2 extensive comando.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819a814
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 33%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 33%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 33%
Session Id: 0
State: <Active Int>
Age: 4d 17:55:37 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
user@R0> show interfaces ae0.0 extensive
Logical interface ae0.0 (Index 337) (SNMP ifIndex 578) (Generation 173)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.6 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89241 0 7140674 0
Output: 89244 0 8731668 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/1.0
Input : 47583 0 3807058 0
Output: 0 0 0 0
ge-0/0/2.0
Input : 41632 0 3331512 0
Output: 89243 0 8731574 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/1.0 0 0 0 0
ge-0/0/2.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 177, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.0/24, Local: 10.0.0.1, Broadcast: 10.0.0.255, Generation: 157
Protocol multiservice, MTU: Unlimited, Generation: 178, Route table: 0
Flags: Is-Primary, 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae1.0 extensive
Logical interface ae1.0 (Index 362) (SNMP ifIndex 593) (Generation 175)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.16 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89631 0 7194074 312
Output: 89626 1 8793864 784
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/3.0
Input : 89631 0 7194074 312
Output: 89626 0 8793864 0
ge-0/0/4.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/3.0 0 0 0 0
ge-0/0/4.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 180, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.1/24, Local: 10.0.1.1, Broadcast: 10.0.1.255, Generation: 159
Protocol multiservice, MTU: Unlimited, Generation: 181, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae2.0 extensive
Logical interface ae2.0 (Index 364) (SNMP ifIndex 592) (Generation 177)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.26 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/5.0
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
ge-0/0/6.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/5.0 0 0 0 0
ge-0/0/6.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 183, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.2.2/24, Local: 10.2.2.1, Broadcast: 10.2.2.255, Generation: 161
Protocol multiservice, MTU: Unlimited, Generation: 184, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
Significado
O OSPF distribui tráfego igualmente quando os três pacotes Ethernet agregados têm a mesma largura de banda disponível.
Verificando a distribuição de tráfego desigual na largura de banda disponível
Propósito
Para verificar se o OSPF distribui tráfego de maneira desigual quando um dos enlaces agregados está desativado durante o balanceamento de carga por pacote, dependendo da largura de banda disponível.
Ação
Desativar um dos links do pacote ae0. A partir do modo operacional, entre no show route 10.1.255.2 extensive comando.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819ba14
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 20%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 40%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 40%
Session Id: 0
State: <Active Int>
Age: 23 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
Significado
O OSPF infere que o pacote ae0 tem menos largura de banda disponível. Portanto, modifica o balanceamento de carga por pacote de acordo com a largura de banda disponível. De acordo com a saída, apenas 20 por cento da largura de banda está disponível na ae0 porque um dos links Ethernet agregados está desativado. Assim, o OSPF distribui tráfego de forma desigual dependendo da largura de banda disponível.
Apêndice 1: definir comandos em todos os dispositivos
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de hierarquia [editar].
R0
set system host-name R0 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24 set interfaces lo0 unit 0 family inet address 10.1.255.1/32 set policy-options policy-statement pplb then load-balance per-packet set routing-options router-id 10.1.255.1 set routing-options forwarding-table export pplb set protocols ospf spf-options multipath weighted one-hop set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
R1
set system host-name R1 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.2/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.2/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.2/24 set interfaces lo0 unit 0 family inet address 10.1.255.2/32 set routing-options router-id 10.1.255.2 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
Exemplo: Ajustando dinamicamente as métricas da interface dos OSPF com base na largura de banda
Este exemplo mostra como ajustar dinamicamente as métricas da interface dos OSPF com base na largura de banda.
Configuração
Configuração rápida da CLI
Para configurar rapidamente os valores de limiar de largura de banda e os valores métricas associados para uma interface OSPF, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e, em seguida, entrar no commit modo de configuração.
[edit] set protocols ospf area 0.0.0.0 interface ae0.0 metric 5 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
Procedimento passo a passo
Para configurar a métrica para uma interface OSPF específica:
-
Crie uma área de OSPF.
Nota:Para especificar o OSPFv3, inclua a declaração ospf3 no nível de hierarquia [editar protocolos] .
[edit] user@host# edit protocols ospf area 0.0.0.0
-
Configure a métrica do segmento de rede OSPF.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0 metric 5
-
Configure os valores limiares de largura de banda e os valores métricas associados. Com essa configuração quando a largura de banda da interface Ethernet agregada é de 1g, a OSPF considera a métrica 60 para esta interface. Quando a largura de banda da interface Ethernet agregada é de 10g, a OSPF considera a métrica 50 para esta interface.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
-
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Resultados
Confirme sua configuração inserindo o comando ospf de protocolos de exibição . Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf
area 0.0.0.0 {
interface ae0.0 {
bandwidth-based-metrics {
bandwidth 1g metric 60;
bandwidth 10g metric 50;
}
metric 5;
}
}
Para confirmar sua configuração OSPFv3, insira o comando ospf3 dos protocolos de exibição .
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte o guia de usuário de interfaces para dispositivos de segurança.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Visão geral
Você pode especificar um conjunto de valores limiares de largura de banda e valores métricas associados para uma interface OSPF. Quando a largura de banda de uma interface muda, o Junos OS define automaticamente a métrica da interface para o valor associado ao valor limiar de largura de banda apropriado. Quando você configura valores métricas baseados em largura de banda, você normalmente configura várias largura de banda e valores métricas.
Neste exemplo, você configura a interface OSPF ae0 para métricas baseadas em largura de banda, incluindo a declaração de métricas baseadas em largura de banda e as seguintes configurações:
largura de banda — especifica o limiar de largura de banda em bits por segundo. A faixa é de 9.600 a 1.000.000.000.000.
métrica — especifica o valor métrica para associar a um valor de largura de banda específico. O intervalo é de 1 a 65.535.
Topologia
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando a métrica configurada
Propósito
Verifique a configuração métrica na interface. Confirme que o campo Custo exibe a métrica configurada (custo) da interface. Ao escolher caminhos para um destino, o OSPF usa o caminho com o menor custo.
Ação
A partir do modo operacional, insira o comando de detalhe da interface show ospf para OSPFv2 e insira o comando de detalhe da interface show ospf3 para OSPFv3.
Exemplo: Controle das preferências de rota dos OSPF
Este exemplo mostra como controlar a seleção de rota OSPF na tabela de encaminhamento. Este exemplo também mostra como você pode controlar a seleção de rotas se estiver migrando do OSPF para outro IGP.
Configuração
Configuração rápida da CLI
Para configurar rapidamente os valores de preferência de rota OSPF, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e, em seguida, entrar no commit modo de configuração.
[edit] set protocols ospf preference 168 external-preference 169
Procedimento passo a passo
Para configurar a seleção de rotas:
Insira o modo de configuração de OSPF e defina as preferências de roteamento externo e interno.
Nota:Para especificar o OSPFv3, inclua a
ospf3declaração no nível de[edit protocols]hierarquia.[edit] user@host# set protocols ospf preference 168 external-preference 169
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit] user@host# commit
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf preference 168; external-preference 169;
Para confirmar sua configuração OSPFv3, entre no show protocols ospf3 comando.
Requisitos
Este exemplo pressupõe que o OSPF esteja configurado e em execução corretamente em sua rede, e você deseja controlar a seleção de rotas porque está planejando migrar do OSPF para um IGP diferente.
Configure as interfaces do dispositivo. Consulte o guia de usuário de interfaces para dispositivos de segurança.
Configure o IGP para o que você deseja migrar.
Visão geral
As preferências de rota são usadas para selecionar qual rota está instalada na tabela de encaminhamento quando vários protocolos calculam rotas para o mesmo destino. A rota com o menor valor de preferência é selecionada.
Por padrão, as rotas internas de OSPF têm um valor de preferência de 10, e as rotas OSPF externas têm um valor de preferência de 150. Você pode querer modificar essa configuração se estiver planejando migrar do OSPF para um IGP diferente. Modificar as preferências de rota permite que você realize a migração de maneira controlada.
Este exemplo faz as seguintes suposições:
O OSPF já está sendo executado em sua rede.
Você deseja migrar do OSPF para o IS-IS.
Você configurou o IS-IS de acordo com seus requisitos de rede e confirmou que está funcionando corretamente.
Neste exemplo, você aumenta os valores de preferência de rota OSPF para torná-los menos preferidos do que as rotas IS-IS, especificando 168 para rotas internas de OSPF e 169 para rotas OSPF externas. As rotas internas IS-IS têm uma preferência de 15 (para Nível 1) ou 18 (para o Nível 2), e as rotas externas têm uma preferência de 160 (para o Nível 1) ou 165 (para o Nível 2). Em geral, é preferível deixar o novo protocolo em suas configurações padrão para minimizar as complexidades e simplificar qualquer adição futura de dispositivos de roteamento à rede. Para modificar os valores de preferência de rota OSPF, configure as seguintes configurações:
preference— especifica a preferência de rota por rotas internas de OSPF. Por padrão, as rotas internas de OSPF têm um valor de 10. A faixa é de 0 a 4.294967.295 (232 – 1).external-preference— especifica a preferência de rota por rotas OSPF externas. Por padrão, as rotas OSPF externas têm um valor de 150. A faixa é de 0 a 4.294967.295 (232 – 1).
Topologia
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando a rota
Propósito
Verifique se o IGP está usando a rota apropriada. Após o novo IGP se tornar o protocolo preferido (neste exemplo, IS-IS), você deve monitorar a rede para quaisquer problemas. Depois de confirmar que o novo IGP está funcionando corretamente, você pode remover a configuração de OSPF do dispositivo de roteamento entrando delete ospf no comando no nível de [edit protocols] hierarquia.
Ação
A partir do modo operacional, entre no show route comando.
Entender a função de sobrecarga do OSPF
Se o tempo decorrido após a instância OSPF for habilitado for menor do que o tempo limite especificado, o modo de sobrecarga será definido.
Você pode configurar o dispositivo de roteamento local para que pareça estar sobrecarregado. Um dispositivo de roteamento sobrecarregado determina que ele é incapaz de lidar com mais tráfego de trânsito OSPF, o que resulta no envio de tráfego de trânsito OSPF para outros dispositivos de roteamento. O tráfego OSPF para interfaces diretamente anexadas continua a chegar ao dispositivo de roteamento. Você pode configurar o modo de sobrecarga por muitos motivos, incluindo:
Se você quiser que o dispositivo de roteamento participe do roteamento OSPF, mas não queira que ele seja usado para tráfego de trânsito. Isso poderia incluir um dispositivo de roteamento conectado à rede para fins de análise, mas não é considerado parte da rede de produção, como dispositivos de roteamento de gerenciamento de rede.
Se você estiver realizando manutenção em um dispositivo de roteamento em uma rede de produção. Você pode mover o tráfego para fora desse dispositivo de roteamento para que os serviços de rede não sejam interrompidos durante a janela de manutenção.
Você configura ou desativa o modo de sobrecarga no OSPF com ou sem um tempo limite. Sem um tempo limite, o modo de sobrecarga é definido até que seja excluído explicitamente da configuração. Com um tempo limite, o modo de sobrecarga é definido se o tempo decorrido desde o início da instância OSPF for menor do que o tempo limite especificado.
Um temporizador é iniciado para a diferença entre o tempo limite e o tempo decorrido desde o início da instância. Quando o temporizador expira, o modo de sobrecarga é liberado. No modo de sobrecarga, o anúncio de estado do link do roteador (LSA) é originado com todos os links de roteador de trânsito (exceto stub) definidos para uma métrica de 0xFFFF. Os links de roteador stub são anunciados com o custo real das interfaces correspondentes ao stub. Isso faz com que o tráfego de trânsito evite o dispositivo de roteamento sobrecarregado e tome caminhos ao redor do dispositivo de roteamento. No entanto, os próprios links do dispositivo de roteamento sobrecarregado ainda estão acessíveis.
O dispositivo de roteamento também pode entrar dinamicamente no estado de sobrecarga, independentemente de configurar o dispositivo para parecer sobrecarregado. Por exemplo, se o dispositivo de roteamento exceder o limite de prefixo OSPF configurado, o dispositivo de roteamento elimina os prefixos externos e entra em um estado de sobrecarga.
Em casos de configurações incorretas, o enorme número de rotas pode entrar no OSPF, o que pode dificultar o desempenho da rede. Para evitar isso, prefix-export-limit deve ser configurado o que expurgará os externos e evitará que a rede tenha um impacto ruim.
Ao permitir que qualquer número de rotas seja exportada para o OSPF, o dispositivo de roteamento pode ficar sobrecarregado e potencialmente inundar um número excessivo de rotas para uma área. Você pode limitar o número de rotas exportadas para OSPF para minimizar a carga no dispositivo de roteamento e evitar esse problema em potencial.
Por padrão, não há limite para o número de prefixos (rotas) que podem ser exportados para OSPF. Para evitar isso, prefix-export-limit deve ser configurado o que expurgará os externos e impedirá a rede.
A partir do Junos OS Release 18.2 em diante, as seguintes funcionalidades são suportadas pelo Roteador Stub em sua rede OSPF, quando o OSPF está sobrecarregado:
Permita o vazamento da rota — prefixos externos são redistribuídos durante a sobrecarga de OSPF e os prefixos são originados com custo normal.
Anuncie a rede de stub com a métrica máxima — as redes stub são anunciadas com a métrica máxima durante a sobrecarga do OSPF.
Anuncie o prefixo intraárea com a métrica máxima — prefixos intraáreas são anunciados com a métrica máxima durante a sobrecarga de OSPF.
Anuncie o prefixo externo com a métrica máxima possível — OSPF AS prefixos externos são redistribuídos durante a sobrecarga do OSPF e os prefixos são anunciados com custo máximo.
Agora você pode configurar o seguinte quando o OSPF estiver sobrecarregado:
allow-route-leakingno nível hierárquicos[edit protocols <ospf | ospf3> overload]para anunciar os prefixos externos com custo normal.stub-networkno nível hierárquicos[edit protocols ospf overload]para anunciar a rede stub com a métrica máxima.intra-area-prefixno nível de hierarquia para anunciar o[edit protocols ospf3 overload]prefixo intraárea com a métrica máxima.as-externalno nível de[edit protocols <ospf | ospf3> overload]hierarquia para anunciar prefixo externo com a métrica máxima.
Para limitar o número de prefixos exportados para OSPF:
[edit] set protocols ospf prefix-export-limit number
O número limite de exportação do prefixo pode ser um valor de 0 a 4.294.967.295.
Veja também
Exemplo: configuração do OSPF para fazer os dispositivos de roteamento aparecerem sobrecarregados
Este exemplo mostra como configurar um dispositivo de roteamento que executa o OSPF para parecer estar sobrecarregado.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte o guia de usuário de interfaces para dispositivos de segurança.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Configure uma rede OSPF multiárea. Veja exemplo: Configuração de uma rede OSPF multiárea.
Visão geral
Você pode configurar um dispositivo de roteamento local que executa o OSPF para parecer estar sobrecarregado, o que permite que o dispositivo de roteamento local participe do roteamento OSPF, mas não para tráfego de trânsito. Quando configuradas, as métricas da interface de trânsito são definidas para o valor máximo de 65535.
Este exemplo inclui as seguintes configurações:
sobrecarga — configura o dispositivo de roteamento local para que pareça estar sobrecarregado. Você pode configurar isso se quiser que o dispositivo de roteamento participe do roteamento OSPF, mas não queira que ele seja usado para tráfego de trânsito ou esteja realizando manutenção em um dispositivo de roteamento em uma rede de produção.
timeout seconds— (Opcional) Especifica o número de segundos em que a sobrecarga é reiniciada. Se nenhum intervalo de tempo limite for especificado, o dispositivo de roteamento permanecerá no estado de sobrecarga até que a declaração de sobrecarga seja excluída ou um tempo limite seja definido. Neste exemplo, você configura 60 segundos conforme o tempo que o dispositivo de roteamento permanece no estado de sobrecarga. Por padrão, o intervalo de tempo limite é de 0 segundos (esse valor não está configurado). O intervalo é de 60 a 1800 segundos.
Topologia
Configuração
Procedimento
Configuração rápida da CLI
Para configurar rapidamente um dispositivo de roteamento local para aparecer sobrecarregado, copiar os seguintes comandos, cole-os em um arquivo de texto, remover quaisquer quebras de linha, alterar quaisquer detalhes necessários para combinar com sua configuração de rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e depois entrar no commit modo de configuração.
[edit] set protocols ospf overload timeout 60
Procedimento passo a passo
Para configurar um dispositivo de roteamento local a aparecer sobrecarregado:
Insira o modo de configuração dos OSPF.
Nota:Para especificar o OSPFv3, inclua a
ospf3declaração no nível de[edit protocols]hierarquia.[edit] user@host# edit protocols ospfConfigure o dispositivo de roteamento local a ser sobrecarregado.
[edit protocols ospf] user@host# set overload(Opcional) Configure o número de segundos em que a sobrecarga é reiniciada.
[edit protocols ospf] user@host#
set overload timeout 60(Opcional) Configure o limite do número de prefixos exportados para OSPF, para minimizar a carga no dispositivo de roteamento e impedir que o dispositivo entre no modo de sobrecarga.
[edit protocols ospf] user@host# set prefix-export-limit 50
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit protocols ospf] user@host# commit
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração. A saída inclui os opcionais timeout e prefix-export-limit as declarações.
user@host# show protocols ospf prefix-export-limit 50; overload timeout 60;
Para confirmar sua configuração OSPFv3, entre no show protocols ospf3 comando.
Verificação
Confirme se a configuração está funcionando corretamente.
- Verificar se o tráfego se moveu para fora dos dispositivos
- Verificação das métricas da interface de trânsito
- Verificando a configuração de sobrecarga
- Verificando o próximo salto viável
Verificar se o tráfego se moveu para fora dos dispositivos
Propósito
Verifique se o tráfego se moveu para fora dos dispositivos upstream.
Ação
A partir do modo operacional, entre no show interfaces detail comando.
Verificação das métricas da interface de trânsito
Propósito
Verifique se as métricas da interface de trânsito estão definidas para o valor máximo de 65535 no dispositivo vizinho downstream.
Ação
A partir do modo operacional, insira o show ospf database router detail advertising-router address comando para o OSPFv2 e insira o show ospf3 database router detail advertising-router address comando para o OSPFv3.
Verificando a configuração de sobrecarga
Propósito
Verifique se a sobrecarga está configurada ao revisar o campo de sobrecarga configurado. Se o temporizador de sobrecarga também estiver configurado, este campo também exibe o tempo que permanece antes de expirar.
Ação
A partir do modo operacional, insira o show ospf overview comando para o OSPFv2 e o show ospf3 overview comando para o OSPFv3.
Verificando o próximo salto viável
Propósito
Verifique a configuração de próximo salto viável no dispositivo vizinho upstream. Se o dispositivo vizinho estiver sobrecarregado, ele não será usado para tráfego de trânsito e não será exibido na saída.
Ação
A partir do modo operacional, entre no show route address comando.
Entendendo as opções de algoritmo SPF para OSPF
O OSPF usa o algoritmo de caminho mais curto em primeiro lugar (SPF), também conhecido como algoritmo Dijkstra, para determinar a rota para chegar a cada destino. O algoritmo SPF descreve como o OSPF determina a rota para chegar a cada destino, e as opções de SPF controlam os temporizantes que ditam quando o algoritmo SPF é executado. Dependendo do seu ambiente e requisitos de rede, você pode querer modificar as opções de SPF. Por exemplo, considere um ambiente de grande escala com um grande número de dispositivos inundando anúncios de estado de enlace (LSAs) por toda a área. Nesse ambiente, é possível receber um grande número de LSAs para processar, o que pode consumir recursos de memória. Ao configurar as opções de SPF, você continua a se adaptar à topologia de rede em mudança, mas pode minimizar a quantidade de recursos de memória que estão sendo usados pelos dispositivos para executar o algoritmo SPF.
Você pode configurar as seguintes opções de SPF:
O atraso no tempo entre a detecção de uma mudança de topologia e quando o algoritmo SPF realmente funciona.
O número máximo de vezes que o algoritmo SPF pode ser executado em sucessão antes que o temporizante de espera comece.
O tempo para segurar ou esperar antes de executar outro cálculo SPF após o algoritmo SPF ter sido executado em sucessão o número configurado de vezes. Se a rede se estabiliza durante o período de repressão e o algoritmo SPF não precisar ser executado novamente, o sistema reverterá para os valores configurados para o atraso e
rapid-runsas declarações.
Exemplo: Configuração de opções de algoritmo de SPF para OSPF
Este exemplo mostra como configurar as opções de algoritmo SPF. As opções de SPF controlam os temporizantes que ditam quando o algoritmo SPF é executado.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte a biblioteca de interfaces de rede do Junos OS para dispositivos de roteamento.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Configure uma rede OSPF multiárea. Veja exemplo: Configuração de uma rede OSPF multiárea.
Visão geral
O OSPF usa o algoritmo SPF para determinar a rota para chegar a cada destino. Todos os dispositivos de roteamento em uma área executam esse algoritmo em paralelo, armazenando os resultados em seus bancos de dados de topologia individuais. Dispositivos de roteamento com interfaces para várias áreas executam várias cópias do algoritmo. As opções de SPF controlam os temporizantes usados pelo algoritmo SPF.
Antes de modificar qualquer uma das configurações padrão, você deve ter uma boa compreensão do seu ambiente e requisitos de rede.
Este exemplo mostra como configurar as opções para executar o algoritmo SPF. Você inclui a spf-options declaração e as seguintes opções:
atraso — configura a quantidade de tempo (em milissegundos) entre a detecção de uma topologia e quando o SPF realmente é executado. Ao modificar o timer de atraso, considere seus requisitos para reconvergência de rede. Por exemplo, você deseja especificar um valor de temporizantes que possa ajudá-lo a identificar anormalidades na rede, mas permitir que uma rede estável se reconverge rapidamente. Por padrão, o algoritmo SPF executa 200 milissegundos após a detecção de uma topologia. A faixa é de 50 a 8000 milissegundos.
execuções rápidas — configura o número máximo de vezes que o algoritmo SPF pode ser executado em sucessão antes que o temporizante suspenso comece. Por padrão, o número de cálculos de SPF que podem ocorrer em sucessão é 3. A faixa é de 1 a 10. Cada algoritmo SPF é executado após o atraso configurado do SPF. Quando o número máximo de cálculos de SPF ocorre, o temporizante de retenção começa. Qualquer cálculo SPF subseqüente não é executado até que o temporizante de espera expira.
holddown — configura o tempo para segurar ou esperar antes de executar outro cálculo de SPF após o algoritmo SPF ter executado sucessão o número máximo configurado de vezes. Por padrão, o tempo de inatividade é de 5000 milissegundos. A faixa é de 2000 a 20.000 milissegundos. Se a rede se estabiliza durante o período de repressão e o algoritmo SPF não precisar ser executado novamente, o sistema reverterá para os valores configurados para o atraso e
rapid-runsas declarações.
Topologia
Configuração
Configuração rápida da CLI
Para configurar rapidamente as opções de SPF, copie os seguintes comandos e cole-os na CLI.
[edit] set protocols ospf spf-options delay 210 set protocols ospf spf-options rapid-runs 4 set protocols ospf spf-options holddown 5050
Procedimento
Procedimento passo a passo
Para configurar as opções de SPF:
Insira o modo de configuração dos OSPF.
Nota:Para especificar o OSPFv3, inclua a
ospf3declaração no nível de[edit protocols]hierarquia.[edit] user@host# edit protocols ospf
Configure o tempo de atraso do SPF.
[edit protocols ospf] user@host# set spf-options delay 210
Configure o número máximo de vezes que o algoritmo SPF pode ser executado em sucessão.
[edit protocols ospf] user@host# set spf-options rapid-runs 4
Configure o temporizar o hold-down SPF.
[edit protocols ospf] user@host# set spf-options holddown 5050
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit protocols ospf] user@host# commit
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf
spf-options {
delay 210;
holddown 5050;
rapid-runs 4;
}
Para confirmar sua configuração OSPFv3, entre no show protocols ospf3 comando.
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando opções de SPF
Propósito
Verifique se o SPF está operando de acordo com os requisitos da sua rede. Analise o campo de atraso SPF, o campo de repressão SPF e os campos de correção rápida SPF.
Ação
A partir do modo operacional, insira o show ospf overview comando para o OSPFv2 e insira o show ospf3 overview comando para o OSPFv3.
Configuração da atualização do OSPF e redução de inundações em topologias estáveis
O padrão OSPF exige que todos os anúncios de estado de link (LSA) sejam atualizados a cada 30 minutos. A implementação da Juniper Networks atualiza LSAs a cada 50 minutos. Por padrão, qualquer LSA que não for atualizado expira após 60 minutos. Esse requisito pode resultar em sobrecarga de tráfego que dificulta a escala das redes OSPF. Você pode substituir o comportamento padrão especificando que o bit DoNotAge será definido em LSAs auto-originados quando eles são enviados inicialmente pelo roteador ou switch. Qualquer LSA com o conjunto de bits DoNotAge é reprovado apenas quando uma mudança ocorre no LSA. Esse recurso reduz assim as sobrecargas de tráfego de protocolo, permitindo que quaisquer LSAs alterados sejam inundados imediatamente. Roteadores ou switches habilitados para a redução de inundações continuam a enviar pacotes de olá para seus vizinhos e envelhecer LSAs auto-originados em seus bancos de dados.
A implementação da OSPF pela Juniper é atualizada e a redução de inundações é baseada no RFC 4136, atualização de OSPF e redução de inundações em topologias estáveis. No entanto, a implementação da Juniper não inclui o intervalo de inundação forçada definido na RFC. Não implementar o intervalo de inundação forçada garante que os LSAs com o conjunto de bits DoNotAge sejam reprovados apenas quando uma mudança ocorre.
Este recurso é compatível com o seguinte:
Interfaces OSPFv2 e OSPFv3
Reinos OSPFv3
Links virtuais OSPFv2 e OSPFv3
Links falsos do OSPFv2
Interfaces peer OSPFv2
Todas as instâncias de roteamento apoiadas pelo OSPF
Sistemas lógicos
Para configurar a redução de inundação para uma interface OSPF, inclua a flood-reduction declaração no nível de [edit protocols (ospf | ospf3) area area-id interface interface-id] hierarquia.
Se você configurar a redução de inundação para uma interface configurada como um circuito de demanda, os LSAs não serão inicialmente inundados, mas enviados apenas quando o conteúdo deles tiver mudado. Olá pacotes e LSAs são enviados e recebidos em uma interface de circuito de demanda somente quando uma mudança ocorre na topologia da rede.
No exemplo a seguir, a interface OSPF so-0/0/1.0 está configurada para redução de inundações. Como resultado, todos os LSAs gerados pelas rotas que atravessam a interface especificada têm o conjunto de bits DoNotAge quando são inicialmente inundados, e os LSAs são atualizados apenas quando ocorre uma mudança.
[edit]
protocols ospf {
area 0.0.0.0 {
interface so-0/0/1.0 {
flood-reduction;
}
interface lo0.0;
interface so-0/0/0.0;
}
}
Começando com o Junos OS Release 12.2, você pode configurar um intervalo global de inundação de anúncio de estado de link (LSA) padrão no OSPF para LSAs auto-gerados, incluindo a lsa-refresh-interval minutes declaração no nível de [edit protocols (ospf | ospf3)] hierarquia. A implementação da Juniper Networks atualiza LSAs a cada 50 minutos. O intervalo é de 25 a 50 minutos. Por padrão, qualquer LSA que não for atualizado expira após 60 minutos.
Se você tiver o intervalo de atualização de LSA global configurado para redução de inundação de OSPF e OSPF configurado para uma interface específica em uma área de OSPF, a configuração de redução de inundação do OSPF tem precedência para essa interface específica.
Entendendo a sincronização entre LDP e IGPs
LDP é um protocolo para distribuir rótulos em aplicativos não projetados para tráfego. As etiquetas são distribuídas ao longo do melhor caminho determinado pelo protocolo de gateway interior (IGP). Se a sincronização entre LDP e IGP não for mantida, o caminho de switch de rótulo (LSP) cairá. Quando o LDP não está totalmente operacional em um determinado link (uma sessão não está estabelecida e os rótulos não são trocados), o IGP anuncia o link com a métrica de custo máximo. O link não é preferido, mas permanece na topologia da rede.
A sincronização de LDP é suportada apenas em interfaces ativas de ponto a ponto e interfaces LAN configuradas como ponto a ponto sob o IGP. A sincronização do LDP não é suportada durante a reinicialização graciosa.
Veja também
Exemplo: configuração da sincronização entre LDP e OSPF
Este exemplo mostra como configurar a sincronização entre LDP e OSPFv2.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo. Consulte a biblioteca de interfaces de rede do Junos OS para dispositivos de roteamento.
Configure os identificadores do roteador para os dispositivos em sua rede OSPF. Veja exemplo: configuração de um identificador de roteador OSPF.
Controle OSPF designado para eleição de roteador. Veja exemplo: Controle da eleição de roteador designado pelo OSPF
Configure uma rede OSPF de área única. Veja exemplo: configuração de uma rede OSPF de área única.
Configure uma rede OSPF multiárea. Veja exemplo: Configuração de uma rede OSPF multiárea.
Visão geral
Neste exemplo, configure a sincronização entre LDP e OSPFv2 realizando as seguintes tarefas:
Habilite o LDP na interface so-1/0/3, que é um membro da área de OSPF 0.0.0.0, incluindo a
ldpdeclaração no nível de[edit protocols]hierarquia. Você pode configurar uma ou mais interfaces. Por padrão, o LDP é desativado no dispositivo de roteamento.Habilite a sincronização do LDP incluindo a
ldp-synchronizationdeclaração no nível de[edit protocols ospf area area-id interface interface-name]hierarquia. Essa declaração permite a sincronização do LDP anunciando a métrica de custo máximo até que o LDP esteja operacional no link.Configure a quantidade de tempo (em segundos) que o dispositivo de roteamento anuncia a métrica de custo máximo para um link que não está totalmente operacional, incluindo a
hold-timedeclaração no nível de[edit protocols ospf area area-id interface interface-name ldp-synchronization]hierarquia. Se você não configurar ahold-timedeclaração, o valor de tempo de espera é padrão para o infinito. O intervalo é de 1 a 65.535 segundos. Neste exemplo, configure 10 segundos para o intervalo de tempo de espera.
Este exemplo também mostra como desabilitar a sincronização entre LDP e OSPFv2, incluindo a disable declaração no nível de [edit protocols ospf area area-id interface interface-name ldp-synchronization] hierarquia.
Topologia
Configuração
Habilitando a sincronização entre LDP e OSPFv2
Configuração rápida da CLI
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Modificar a configuração do Junos OS no Guia de usuário da CLI.
Para habilitar a sincronização rapidamente entre LDP e OSPFv2, copie os seguintes comandos, remova qualquer quebra de linha e depois cole-os no CLI.
[edit] set protocols ldp interface so-1/0/3 set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-syncrhonization hold-time 10
Procedimento passo a passo
Para permitir a sincronização entre LDP e OSPFv2:
Habilite o LDP na interface.
[edit] user@host# set protocols ldp interface so-1/0/3
Configure a sincronização do LDP e configure opcionalmente um período de tempo de 10 segundos para anunciar a métrica de custo máximo para um link que não esteja totalmente operacional.
[edit ] user@host# edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization
Configure um período de tempo de 10 segundos para anunciar a métrica de custo máximo para um link que não esteja totalmente operacional.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization ] user@host# set hold-time 10
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization] user@host# commit
Resultados
Confirme sua configuração inserindo os comandos e show protocols ospf a show protocols ldp configuração. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ldp interface so-1/0/3.0;
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
hold-time 10;
}
}
}
Desativar a sincronização entre LDP e OSPFv2
Configuração rápida da CLI
Para desabilitar rapidamente a sincronização entre LDP e OSPFv2, copie o comando a seguir e cole-o no CLI.
[edit] set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
Procedimento passo a passo
Para desabilitar a sincronização entre LDP e OSPF:
Sincronização desabilitar ao incluir a
disabledeclaração.[edit ] user@host# set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit] user@host# commit
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
disable;
}
}
}
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando o estado de sincronização do LDP da interface
Propósito
Verifique o estado atual da sincronização do LDP na interface. O estado de sincronização do LDP exibe informações relacionadas ao estado atual, e o campo de tempo de espera da configuração exibe o intervalo de tempo de espera configurado.
Ação
A partir do modo operacional, entre no show ospf interface extensive comando.
Compatibilidade do OSPFv2 com visão geral do RFC 1583
Por padrão, a implementação do JUNOS OS do OSPFv2 é compatível com RFC 1583, OSPF Versão 2. Isso significa que o Junos OS mantém uma única rota melhor para um roteador de fronteira autônomo (AS) na tabela de roteamento OSPF, em vez de vários caminhos intra-AS, se estiverem disponíveis. Agora você pode desabilitar a compatibilidade com a RFC 1583. É preferível fazê-lo quando o mesmo destino externo é anunciado por roteadores de fronteira AS que pertencem a diferentes áreas de OSPF. Quando você desativa a compatibilidade com RFC 1583, a tabela de roteamento OSPF mantém os múltiplos caminhos intra-AS disponíveis, que o roteador usa para calcular as rotas externas conforme definido no RFC 2328, OSPF Versão 2. Ser capaz de usar vários caminhos disponíveis para calcular uma rota externa AS pode evitar loops de roteamento.
Veja também
Exemplo: Desativação da compatibilidade do OSPFv2 com RFC 1583
Este exemplo mostra como desativar a compatibilidade do OSPFv2 com o RFC 1583 no dispositivo de roteamento.
Requisitos
Nenhuma configuração especial além da inicialização do dispositivo é necessária antes de desativar a compatibilidade do OSPFv2 com o RFC 1583.
Visão geral
Por padrão, a implementação do OSPF pelo Junos OS é compatível com o RFC 1583. Isso significa que o Junos OS mantém uma única rota melhor para um roteador de fronteira autônomo (AS) na tabela de roteamento OSPF, em vez de vários caminhos intra-AS, se estiverem disponíveis. Você pode desativar a compatibilidade com a RFC 1583. É preferível fazê-lo quando o mesmo destino externo é anunciado por roteadores de fronteira AS que pertencem a diferentes áreas de OSPF. Quando você desativa a compatibilidade com RFC 1583, a tabela de roteamento OSPF mantém os múltiplos caminhos intra-AS disponíveis, que o roteador usa para calcular as rotas externas conforme definido na RFC 2328. Ser capaz de usar vários caminhos disponíveis para calcular uma rota externa AS pode evitar loops de roteamento. Para minimizar o potencial de loops de roteamento, configure a mesma compatibilidade de RFC em todos os dispositivos OSPF em um domínio OSPF.
Topologia
Configuração
Procedimento
Configuração rápida da CLI
Para desativar rapidamente a compatibilidade do OSPFv2 com o RFC 1583, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos no CLI no nível de hierarquia [editar] e então entrar no commit modo de configuração. Você configura essa configuração em todos os dispositivos que fazem parte do domínio OSPF.
[edit] set protocols ospf no-rfc-1583
Procedimento passo a passo
Para desativar a compatibilidade do OSPFv2 com o RFC 1583:
Desativar a RFC 1583.
[edit] user@host# set protocols ospf no-rfc-1583
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit] user@host# commit
Nota:Repita essa configuração em cada dispositivo de roteamento que participa de um domínio de roteamento OSPF.
Resultados
Confirme sua configuração inserindo o show protocols ospf comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@host# show protocols ospf no-rfc-1583;
Verificação
Confirme se a configuração está funcionando corretamente.