NESTA PÁGINA
Configuração da engenharia de tráfego MPLS
MPLS e engenharia de tráfego
A engenharia de tráfego permite controlar o caminho que os pacotes de dados seguem, ignorando o modelo de roteamento padrão, que usa tabelas de roteamento. A engenharia de tráfego move fluxos de links congestionados para links alternativos que não seriam selecionados pelo caminho mais curto baseado em destino calculado automaticamente. Com a engenharia de tráfego, você pode:
Faça uso mais eficiente de fibras caras de longa distância.
Controle como o tráfego é redirecionado em face de falhas únicas ou múltiplas.
Classifique o tráfego crítico e regular por percurso.
O núcleo do projeto de engenharia de tráfego é baseado na construção de caminhos comutados por rótulos (LSPs) entre roteadores. Um LSP é orientado à conexão, como um circuito virtual no Frame Relay ou ATM. Os LSPs não são confiáveis: Os pacotes que entram em um LSP não têm garantias de entrega, embora o tratamento preferencial seja possível. Os LSPs também são semelhantes aos túneis unidirecionais, pois os pacotes que entram em um caminho são encapsulados em um envelope e comutados em todo o caminho sem serem tocados por nós intermediários. Os LSPs fornecem controle refinado sobre como os pacotes são encaminhados em uma rede. Para fornecer confiabilidade, um LSP pode usar um conjunto de caminhos primários e secundários.
Os LSPs podem ser configurados apenas para tráfego BGP (tráfego cujo destino está fora de um sistema autônomo [AS]). Nesse caso, o tráfego dentro do AS não é afetado pela presença de LSPs. Os LSPs também podem ser configurados para tráfego BGP e IGP (Interior Gateway Protocol); portanto, tanto o tráfego intra-AS quanto o inter-AS são afetados pelos LSPs.
Visão geral dos protocolos de sinalização e engenharia de tráfego MPLS
A engenharia de tráfego facilita operações de rede eficientes e confiáveis, otimizando simultaneamente os recursos de rede e o desempenho do tráfego. A engenharia de tráfego oferece a capacidade de mover o fluxo de tráfego do caminho mais curto selecionado pelo Interior Gateway Protocol (IGP) para um caminho físico potencialmente menos congestionado em uma rede. Para oferecer suporte à engenharia de tráfego, além do roteamento de origem, a rede deve fazer o seguinte:
Calcule um caminho na origem levando em conta todas as restrições, como largura de banda e requisitos administrativos.
Distribua as informações sobre a topologia da rede e os atributos do link por toda a rede assim que o caminho for calculado.
Reserve recursos de rede e modifique os atributos do link.
Quando o tráfego de trânsito é roteado por uma rede IP, o MPLS é frequentemente usado para projetar sua passagem. Embora o caminho exato pela rede de trânsito seja de pouca importância para o remetente ou destinatário do tráfego, os administradores de rede geralmente desejam rotear o tráfego de forma mais eficiente entre determinados pares de endereços de origem e destino. Ao adicionar um pequeno rótulo com instruções de roteamento específicas a cada pacote, o MPLS comuta pacotes de roteador para roteador pela rede, em vez de encaminhar pacotes com base em pesquisas de próximo salto. As rotas resultantes são chamadas de caminhos comutados por rótulos (LSPs). Os LSPs controlam a passagem de tráfego pela rede e aceleram o encaminhamento de tráfego.
Você pode criar LSPs manualmente ou por meio do uso de protocolos de sinalização. Os protocolos de sinalização são usados em um ambiente MPLS para estabelecer LSPs para o tráfego em uma rede de trânsito. O Junos OS oferece suporte a dois protocolos de sinalização: LDP e Resource Reservation Protocol (RSVP).
A engenharia de tráfego de MPLS usa os seguintes componentes:
LSPs MPLS para encaminhamento de pacotes
Extensões IGP para distribuir informações sobre a topologia de rede e atributos de link
CSPF (Constrained Shortest Path First, Caminho mais curto restrito) primeiro para computação e seleção de caminhos
Extensões RSVP para estabelecer o estado de encaminhamento ao longo do caminho e reservar recursos ao longo do caminho
O Junos OS também oferece suporte à engenharia de tráfego em diferentes regiões OSPF.
Recursos de engenharia de tráfego
A tarefa de mapear fluxos de tráfego em uma topologia física existente é chamada de engenharia de tráfego. A engenharia de tráfego oferece a capacidade de mover o fluxo de tráfego do caminho mais curto selecionado pelo protocolo de gateway interior (IGP) para um caminho físico potencialmente menos congestionado em uma rede.
A engenharia de tráfego fornece os recursos para fazer o seguinte:
Encaminhe caminhos primários em torno de gargalos conhecidos ou pontos de congestionamento na rede.
Forneça controle preciso sobre como o tráfego é redirecionado quando o caminho principal se depara com falhas únicas ou múltiplas.
Fornecer um uso mais eficiente da largura de banda agregada disponível e da fibra de longa distância, garantindo que os subconjuntos da rede não sejam superutilizados enquanto outros subconjuntos da rede ao longo de possíveis caminhos alternativos são subutilizados.
Maximize a eficiência operacional.
Melhore as características de desempenho orientadas ao tráfego da rede, minimizando a perda de pacotes, minimizando períodos prolongados de congestionamento e maximizando a taxa de transferência.
Aprimorar as características de desempenho estatisticamente vinculadas da rede (como taxa de perda, variação de atraso e atraso de transferência) necessárias para suportar uma Internet multisserviços.
Componentes da engenharia de tráfego
No sistema operacional (OS) Junos®, a engenharia de tráfego é implementada com MPLS e RSVP. A engenharia de tráfego é composta por quatro componentes funcionais:
Configuração da engenharia de tráfego para LSPs
Quando você configura um LSP, uma rota de host (uma máscara de 32 bits) é instalada no roteador de entrada em direção ao roteador de saída; o endereço da rota do host é o endereço de destino do LSP. A bgp opção para a declaração no nível de [edit protocols mpls] hierarquia é habilitada por padrão (você também pode configurar explicitamente a opção), permitindo que apenas o traffic engineering bgp BGP use LSPs em seus cálculos de rota. As outras traffic-engineering opções de instrução permitem que você altere esse comportamento na instância de roteamento mestre. Essa funcionalidade não está disponível para instâncias de roteamento específicas. Além disso, você pode habilitar apenas uma das traffic-engineering opções de instrução (bgp, bgp-igp, bgp-igp-both-ribsou mpls-forwarding) por vez.
Habilitar ou desabilitar qualquer uma das traffic-engineering opções de declaração faz com que todas as rotas MPLS sejam removidas e, em seguida, reinseridas nas tabelas de roteamento.
Você pode configurar o OSPF e a engenharia de tráfego para anunciar a métrica LSP em anúncios resumidos de estado de enlace (LSAs), conforme descrito na seção Anunciando a métrica LSP em LSAs resumidos.
As seções a seguir descrevem como configurar a engenharia de tráfego para LSPs:
- Uso de LSPs para encaminhamento de tráfego BGP e IGP
- Uso de LSPs para encaminhamento em redes privadas virtuais
- Uso de rotas RSVP e LDP para encaminhamento, mas não seleção de rota
- Anunciando a métrica LSP em LSAs resumidos
Uso de LSPs para encaminhamento de tráfego BGP e IGP
Você pode configurar o BGP e os IGPs para usar LSPs para encaminhar o tráfego destinado a roteadores de saída, incluindo a bgp-igp opção para a traffic-engineering declaração. A bgp-igp opção faz com que todas as rotas inet.3 sejam movidas para a tabela de roteamento inet.0.
No roteador de entrada, inclua bgp-igp a opção para a traffic-engineering declaração:
traffic-engineering bgp-igp;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]Observação:A
bgp-igpopção para a instrução não pode ser configuradatraffic-engineeringpara VPN). As VPNs exigem que as rotas estejam na tabela de roteamento inet.3.
Uso de LSPs para encaminhamento em redes privadas virtuais
As VPNs exigem que as rotas permaneçam na tabela de roteamento inet.3 para funcionar corretamente. Para VPNs, configure a bgp-igp-both-ribs opção da declaração para fazer com que o traffic-engineering BGP e os IGPs usem LSPs para encaminhar o tráfego destinado a roteadores de saída. A bgp-igp-both-ribs opção instala as rotas de entrada na tabela de roteamento inet.0 (para rotas unicast IPv4) e na tabela de roteamento inet.3 (para informações de caminho MPLS).
No roteador de entrada, inclua a traffic-engineering bgp-igp-both-ribs declaração:
traffic-engineering bgp-igp-both-ribs;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]
Quando você usa a bgp-igp-both-ribs instrução, as rotas da tabela inet.3 são copiadas para a tabela inet.0. As rotas copiadas são sinalizadas por LDP ou RSVP e provavelmente terão uma preferência inferior às outras rotas em inet.0. Rotas com preferência inferior têm maior probabilidade de serem escolhidas como rotas ativas. Isso pode ser um problema porque as políticas de roteamento agem apenas em rotas ativas. Para evitar esse problema, use a mpls-forwarding opção.
Os LSPs com o valor de preferência numericamente mais baixo são escolhidos como a rota preferida.
Por exemplo:
user@host# show protocols mpls
label-switched-path lsp1 {
to 192.168.4.4;
preference 1000;
}
label-switched-path lsp2 {
to 192.168.4.4;
preference 1001;
}
user@host# run show route table inet.3
inet.3: 2 destinations, 3 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
198.168.4.4/32 *[RSVP/1000/1] 00:17:23, metric 30
> to 192.168.2.18 via ge-0/0/1.0, label-switched-path lsp1
to 192.168.5.5 via ge-0/0/2.0, label-switched-path Bypass->192.168.2.18->192.168.3.3
[RSVP/1001/1] 00:17:23, metric 30
> to 192.168.2.18 via ge-0/0/1.0, label-switched-path lsp2
to 192.168.5.5 via ge-0/0/2.0, label-switched-path Bypass->192.168.2.18->192.168.3.3
O LSP com um valor de preferência de 1000 é superior e, portanto, é preferido ao LSP com um valor de preferência de 1001.
Uso de rotas RSVP e LDP para encaminhamento, mas não seleção de rota
Se você configurar as opções or bgp-igp-both-ribs para a declaração, os bgp-igp traffic-engineering LSPs de alta prioridade podem substituir as rotas IGP na tabela de roteamento inet.0. As rotas IGP podem não ser mais redistribuídas, pois não são mais as rotas ativas.
Se você configurar a mpls-forwarding opção para a declaração, os traffic-engineering LSPs serão usados para encaminhamento, mas serão excluídos da seleção de rota. Essas rotas são adicionadas às tabelas de roteamento inet.0 e inet.3. Os LSPs na tabela de roteamento inet.0 recebem uma preferência inferior quando a rota ativa é selecionada. No entanto, os LSPs na tabela de roteamento inet.3 recebem uma preferência normal e, portanto, são usados para selecionar o encaminhamento dos próximos hops.
Quando você ativa a opção, as mpls-forwarding rotas cujo estado é ForwardingOnly são preferidas para encaminhamento, mesmo que sua preferência seja inferior à da rota ativa no momento. Para examinar o estado de uma rota, execute um show route detail comando.
Para usar LSPs para encaminhamento, mas excluí-los da seleção de rota, inclua a mpls-forwarding opção para a traffic-engineering declaração:
traffic-engineering mpls-forwarding;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]
Quando você configura a opção, as mpls-forwarding rotas de atalho do IGP são copiadas apenas para a tabela de roteamento inet.0.
Ao contrário da bgp-igp-both-ribs opção, a mpls-forwarding opção permite que você use as rotas sinalizadas por LDP e RSVP para encaminhamento e mantenha as rotas BGP e IGP ativas para fins de roteamento para que as políticas de roteamento possam agir sobre elas.
Por exemplo, suponha que um roteador esteja executando o BGP e tenha uma rota BGP de 10.10.10.1/32 que precisa enviar para outro roteador BGP. Se você usar a bgp-igp-both-ribs opção e seu roteador também tiver um caminho comutado por rótulos (LSP) para 10.10.10.1, a rota MPLS para 10.10.10.1 se tornará ativa na tabela de roteamento inet.0. Isso impede que o roteador anuncie a rota 10.10.10.1 para o outro roteador BGP. Por outro lado, se você usar a mpls-forwarding opção em vez da bgp-igp-both-ribs opção, a rota BGP 10.10.10.1/32 será anunciada para o outro roteador BGP, e o LSP ainda será usado para encaminhar o tráfego para o destino 10.10.10.1.
Anunciando a métrica LSP em LSAs resumidos
Você pode configurar o MPLS e o OSPF para tratar um LSP como um link. Essa configuração permite que outros roteadores na rede usem esse LSP. Para atingir esse objetivo, você precisa configurar a engenharia de tráfego MPLS e OSPF para anunciar a métrica LSP em LSAs resumidos.
Para MPLS, inclua as traffic-engineering bgp-igp instruções and label-switched-path :
traffic-engineering bgp-igp; label-switched-path lsp-name { to address; }
Você pode incluir essas instruções nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]
Para OSPF, inclua a lsp-metric-into-summary declaração:
lsp-metric-into-summary;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols ospf traffic-engineering shortcuts][edit logical-systems logical-system-name protocols ospf traffic-engineering shortcuts]
Para obter mais informações sobre a engenharia de tráfego OSPF, consulte a Biblioteca de protocolos de roteamento do Junos OS para dispositivos de roteamento.
Habilitação da engenharia de tráfego entre áreas
O Junos OS pode sinalizar um LSP de engenharia de tráfego contíguo em várias áreas de OSPF. A sinalização LSP deve ser feita usando aninhamento ou sinalização contígua, conforme descrito em RFC 4206, Label-Switched Paths (LSP) Hierarchy with Generalized Multi-Protocol Label Switching (GMPLS) Traffic Engineering (TE). No entanto, o suporte à sinalização contígua é limitado apenas à sinalização básica. A reotimização não é suportada com sinalização contígua.
A seguir, são descritos alguns dos recursos de engenharia de tráfego entre áreas:
A engenharia de tráfego entre áreas pode ser habilitada quando os roteadores de borda de área de salto solto (ABRs) são configurados no roteador de entrada usando CSPF para o cálculo do Objeto de Rota Explícito (ERO) dentro de uma área OSPF. A expansão do ERO é concluída nos ABRs.
A engenharia de tráfego entre áreas pode ser habilitada quando o CSPF está habilitado, mas sem ABRs especificados na configuração do LSP no roteador de entrada (ABRs podem ser designados automaticamente).
Há suporte para a engenharia de tráfego de serviços diferenciados (DiffServ), desde que os mapeamentos de tipo de classe sejam uniformes em várias áreas.
Para habilitar a engenharia de tráfego entre áreas, inclua a expand-loose-hop declaração na configuração de cada roteador de trânsito LSP:
expand-loose-hop;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]
Habilitação da engenharia de tráfego Inter-AS para LSPs
Geralmente, a engenharia de tráfego é possível para LSPs que atendem às seguintes condições:
Ambas as extremidades do LSP estão na mesma área OSPF ou no mesmo nível IS-IS.
As duas extremidades do LSP estão em diferentes áreas de OSPF dentro do mesmo sistema autônomo (AS). Os LSPs que terminam em diferentes níveis de IS-IS não são suportados.
As duas extremidades de um LSP de caminho explícito estão em ASs OSPF diferentes e os roteadores de borda de sistema autônomo (ASBRs) são configurados estaticamente como os saltos soltos suportados no LSP de caminho explícito. Para obter mais informações, consulte Configuração de LSPs de caminho explícito.
Sem ASBRs definidos estaticamente em LSPs, a engenharia de tráfego não é possível entre um domínio de roteamento, ou AS, e outro. No entanto, quando os ASs estão sob o controle de um único provedor de serviços, é possível, em alguns casos, que os LSPs projetados de tráfego abranjam os ASs e descubram dinamicamente os ASBRs OSPF que os vinculam (o IS-IS não é suportado com esse recurso).
Os LSPs projetados para tráfego inter-AS são possíveis desde que certos requisitos de rede sejam atendidos, nenhuma das condições limitantes se aplique e o modo passivo OSPF esteja configurado com EBGP. Os detalhes são fornecidos nas seções a seguir:
- Requisitos da engenharia de tráfego Inter-AS
- Limitações da engenharia de tráfego Inter-AS
- Configurando o modo TE passivo OSPF
Requisitos da engenharia de tráfego Inter-AS
O estabelecimento e o funcionamento adequados dos LSPs de engenharia de tráfego inter-AS dependem dos seguintes requisitos de rede, todos os quais devem ser atendidos:
Todos os ASs estão sob o controle de um único provedor de serviços.
O OSPF é usado como o protocolo de roteamento em cada AS, e o EBGP é usado como o protocolo de roteamento entre os ASs.
As informações do ASBR estão disponíveis dentro de cada AS.
As informações de roteamento EBGP são distribuídas pelo OSPF, e uma malha completa do IBGP está em vigor em cada AS.
Os LSPs de trânsito não são configurados nos links inter-AS, mas são configurados entre ASBRs de ponto de entrada e saída em cada AS.
O enlace EBGP entre ASBRs em diferentes ASs é um enlace direto e deve ser configurado como um enlace passivo de engenharia de tráfego no OSPF. O endereço de link remoto em si, não o loopback ou qualquer outro endereço de link, é usado como o identificador de nó remoto para esse link passivo. Para obter mais informações sobre a configuração do modo de engenharia de tráfego passivo OSPF, consulte Configurando o modo TE passivo do OSPF.
Além disso, o endereço usado para o nó remoto do enlace de engenharia de tráfego passivo do OSPF deve ser o mesmo que o endereço usado para o enlace EBGP. Para obter mais informações sobre OSPF e BGP em geral, consulte a Biblioteca de protocolos de roteamento do Junos OS para dispositivos de roteamento.
Limitações da engenharia de tráfego Inter-AS
Somente a sinalização hierárquica LSP ou aninhada é suportada para LSPs projetados de tráfego inter-AS. Somente LSPs ponto a ponto são suportados (não há suporte ponto a multiponto).
Além disso, as seguintes limitações se aplicam. Qualquer uma dessas condições é suficiente para impossibilitar os LSPs de engenharia de tráfego inter-AS, mesmo que os requisitos acima sejam atendidos.
O uso de BGP multihop não é suportado.
Não há suporte para o uso de policiais ou topologias que impedem que as rotas BGP sejam conhecidas dentro do AS.
Vários ASBRs em uma LAN entre pares EBGP não são suportados. Apenas um ASBR em uma LAN entre pares EBGP é suportado (outros ASBRs podem existir na LAN, mas não podem ser anunciados).
Não há suporte para refletores de rota ou políticas que ocultam informações ASBR ou impedem que informações ASBR sejam distribuídas dentro dos ASs.
Os LSPs bidirecionais não são suportados (os LSPs são unidirecionais da perspectiva da engenharia de tráfego).
Não há suporte para topologias com caminhos inter-AS e intra-AS para o mesmo destino.
Além disso, vários recursos que são rotineiros com todos os LSPs não são suportados com a engenharia de tráfego inter-AS:
Não há suporte para cores de link do grupo de administradores.
Não há suporte para o modo de espera secundário.
A reotimização não é suportada.
O crankback em roteadores de trânsito não é suportado.
Não há suporte para cálculos de caminhos diversos.
A reinicialização graciosa não é suportada.
Essas listas de limitações ou recursos não suportados com LSPs de engenharia de tráfego inter-AS não são exaustivas.
Configurando o modo TE passivo OSPF
Normalmente, os protocolos de roteamento interno, como o OSPF, não são executados em links entre ASs. No entanto, para que a engenharia de tráfego inter-AS funcione corretamente, as informações sobre o link inter-AS, em particular, o endereço na interface remota, devem ser disponibilizadas dentro do AS. Essas informações normalmente não são incluídas em mensagens de alcance EBGP ou em anúncios de roteamento OSPF.
Para inundar essas informações de endereço de link dentro do AS e disponibilizá-las para cálculos de engenharia de tráfego, você deve configurar o modo passivo OSPF para engenharia de tráfego em cada interface inter-AS. Você também deve fornecer o endereço remoto para o OSPF distribuir e incluir no banco de dados de engenharia de tráfego.
Para configurar o modo passivo OSPF para engenharia de tráfego em uma interface inter-AS, inclua a passive declaração para o enlace no nível de [edit protocols ospf area area-id interface interface-name] hierarquia:
passive {
traffic-engineering {
remote-node-id ip-address; /* IP address at far end of inter-AS link */
}
}
O OSPF deve ser configurado corretamente no roteador. O exemplo a seguir configura o enlace so-1/1/0 inter-AS para distribuir informações de engenharia de tráfego com OSPF dentro do AS. O endereço IP remoto é 192.168.207.2.
[edit protocols ospf area 0.0.0.0]
interface so-1/1/0 {
unit 0 {
passive {
traffic-engineering {
remote-node-id 192.168.207.2;
}
}
}
}
Componente de Encaminhamento de Pacotes
O componente de encaminhamento de pacotes da arquitetura de engenharia de tráfego do Junos é o MPLS, que é responsável por direcionar um fluxo de pacotes IP ao longo de um caminho predeterminado em uma rede. Esse caminho é chamado de caminho comutado por rótulos (LSP). LSPs são simplex; ou seja, o tráfego flui em uma direção do roteador head-end (entrada) para um roteador tail-end (saída). O tráfego duplex requer dois LSPs: um LSP para transportar o tráfego em cada direção. Um LSP é criado pela concatenação de um ou mais saltos comutados por rótulos, permitindo que um pacote seja encaminhado de um roteador para outro através do domínio MPLS.
Quando um roteador de entrada recebe um pacote IP, ele adiciona um cabeçalho MPLS ao pacote e o encaminha para o próximo roteador no LSP. O pacote rotulado é encaminhado ao longo do LSP por cada roteador até atingir a extremidade final do LSP, o roteador de saída. Nesse ponto, o cabeçalho MPLS é removido e o pacote é encaminhado com base em informações da Camada 3, como o endereço de destino IP. O valor desse esquema é que o caminho físico do LSP não se limita ao que o IGP escolheria como o caminho mais curto para chegar ao endereço IP de destino.
- Encaminhamento de pacotes com base na troca de rótulos
- Como um pacote atravessa um backbone MPLS
- Componente de distribuição de informações
- Componente de seleção de caminho
- Componente de sinalização
Encaminhamento de pacotes com base na troca de rótulos
O processo de encaminhamento de pacotes em cada roteador é baseado no conceito de troca de rótulos. Esse conceito é semelhante ao que ocorre em cada switch de modo de transferência assíncrona (ATM) em um circuito virtual permanente (PVC). Cada pacote MPLS carrega um cabeçalho de encapsulamento de 4 bytes que contém um campo de rótulo de comprimento fixo de 20 bits. Quando um pacote contendo um rótulo chega a um roteador, o roteador examina o rótulo e o copia como um índice para sua tabela de encaminhamento MPLS. Cada entrada na tabela de encaminhamento contém um par de rótulos de entrada de interface mapeado para um conjunto de informações de encaminhamento que é aplicado a todos os pacotes que chegam na interface específica com o mesmo rótulo de entrada.
Como um pacote atravessa um backbone MPLS
Esta seção descreve como um pacote IP é processado à medida que atravessa uma rede de backbone MPLS.
Na borda de entrada do backbone MPLS, o cabeçalho IP é examinado pelo roteador de entrada. Com base nessa análise, o pacote é classificado, atribuído a um rótulo, encapsulado em um cabeçalho MPLS e encaminhado para o próximo salto no LSP. O MPLS oferece um alto grau de flexibilidade na maneira como um pacote IP pode ser atribuído a um LSP. Por exemplo, na implementação de engenharia de tráfego do Junos, todos os pacotes que chegam ao roteador de entrada que são destinados a sair do domínio MPLS no mesmo roteador de saída são encaminhados ao longo do mesmo LSP.
Quando o pacote começa a atravessar o LSP, cada roteador usa o rótulo para tomar a decisão de encaminhamento. A decisão de encaminhamento MPLS é tomada independentemente do cabeçalho IP original: a interface de entrada e o rótulo são usados como chaves de pesquisa na tabela de encaminhamento MPLS. O rótulo antigo é substituído por um novo rótulo e o pacote é encaminhado para o próximo salto ao longo do LSP. Esse processo é repetido em cada roteador no LSP até que o pacote chegue ao roteador de saída.
Quando o pacote chega ao roteador de saída, o rótulo é removido e o pacote sai do domínio MPLS. O pacote é então encaminhado com base no endereço IP de destino contido no cabeçalho IP original do pacote de acordo com o caminho mais curto tradicional calculado pelo protocolo de roteamento IP.
Componente de distribuição de informações
A engenharia de tráfego requer conhecimento detalhado sobre a topologia da rede, bem como informações dinâmicas sobre o carregamento da rede. Para implementar o componente de distribuição de informações, são definidas extensões simples para os IGPs. Os atributos de enlace são incluídos como parte do anúncio de estado de enlace de cada roteador. As extensões IS-IS incluem a definição de novos valores de comprimento de tipo (TLVs), enquanto as extensões OSPF são implementadas com anúncios de estado de enlace (LSAs) opacos. O algoritmo de flooding padrão usado pelos IGPs de estado de enlace garante que os atributos do enlace sejam distribuídos a todos os roteadores no domínio de roteamento. Algumas das extensões de engenharia de tráfego a serem adicionadas ao anúncio de estado do enlace do IGP incluem largura de banda máxima do enlace, largura de banda máxima do enlace reservada, reserva de largura de banda atual e coloração do enlace.
Cada roteador mantém atributos de link de rede e informações de topologia em um banco de dados especializado em engenharia de tráfego. O banco de dados de engenharia de tráfego é usado exclusivamente para calcular caminhos explícitos para a colocação de LSPs na topologia física. Um banco de dados separado é mantido para que o cálculo de engenharia de tráfego subsequente seja independente do IGP e do banco de dados de estado de enlace do IGP. Enquanto isso, o IGP continua sua operação sem modificações, realizando o cálculo tradicional do caminho mais curto com base nas informações contidas no banco de dados de estado do enlace do roteador.
Componente de seleção de caminho
Depois que os atributos do link de rede e as informações de topologia são inundados pelo IGP e colocados no banco de dados de engenharia de tráfego, cada roteador de entrada usa o banco de dados de engenharia de tráfego para calcular os caminhos para seu próprio conjunto de LSPs em todo o domínio de roteamento. O caminho para cada LSP pode ser representado por uma rota explícita estrita ou solta. Uma rota explícita é uma sequência pré-configurada de roteadores que deve fazer parte do caminho físico do LSP. Se o roteador de entrada especificar todos os roteadores no LSP, o LSP será identificado por uma rota explícita estrita. Se o roteador de entrada especificar apenas alguns dos roteadores no LSP, o LSP será descrito como uma rota explícita solta. O suporte para rotas explícitas estritas e soltas permite que o processo de seleção de caminho tenha ampla latitude sempre que possível, mas seja restrito quando necessário.
O roteador de entrada determina o caminho físico para cada LSP aplicando um algoritmo CSPF (Constrained Shortest Path First, Caminho mais curto restrito primeiro) às informações no banco de dados de engenharia de tráfego. O CSPF é um algoritmo de caminho mais curto que foi modificado para levar em conta restrições específicas quando o caminho mais curto na rede é calculado. A entrada no algoritmo CSPF inclui:
Informações de estado do enlace de topologia aprendidas com o IGP e mantidas no banco de dados de engenharia de tráfego
Atributos associados ao estado dos recursos de rede (como largura de banda total do link, largura de banda reservada do link, largura de banda disponível do link e cor do link) que são transportados por extensões IGP e armazenados no banco de dados de engenharia de tráfego
Atributos administrativos necessários para suportar o tráfego que atravessa o LSP proposto (como requisitos de largura de banda, contagem máxima de saltos e requisitos de políticas administrativas) que são obtidos da configuração do usuário
Como o CSPF considera cada nó e link candidato para um novo LSP, ele aceita ou rejeita um componente de caminho específico com base na disponibilidade de recursos ou se a seleção do componente viola as restrições da política do usuário. A saída do cálculo do CSPF é uma rota explícita que consiste em uma sequência de endereços de roteador que fornece o caminho mais curto pela rede que atende às restrições. Essa rota explícita é então passada para o componente de sinalização, que estabelece o estado de encaminhamento nos roteadores ao longo do LSP.
Componente de sinalização
Um LSP não é conhecido por ser viável até que seja realmente estabelecido pelo componente de sinalização. O componente de sinalização, que é responsável por estabelecer o estado do LSP e distribuir rótulos, depende de várias extensões para RSVP:
O objeto Explicit Route permite que uma mensagem de caminho RSVP atravesse uma sequência explícita de roteadores que é independente do roteamento IP convencional de caminho mais curto. A rota explícita pode ser estrita ou flexível.
O objeto Label Request permite que a mensagem de caminho RSVP solicite que os roteadores intermediários forneçam uma ligação de rótulos para o LSP que está estabelecendo.
O objeto Label permite que o RSVP dê suporte à distribuição de rótulos sem alterar seus mecanismos existentes. Como a mensagem RSVP Resv segue o caminho inverso da mensagem de caminho RSVP, o objeto Label dá suporte à distribuição de rótulos de nós downstream para nós upstream.
Planejamento e análise de caminhos offline
Apesar do esforço de gerenciamento reduzido resultante do cálculo de caminho online, uma ferramenta de planejamento e análise offline ainda é necessária para otimizar a engenharia de tráfego globalmente. O cálculo online leva em consideração as restrições de recursos e calcula um LSP por vez. O desafio dessa abordagem é que ela não é determinística. A ordem na qual os LSPs são calculados desempenha um papel crítico na determinação do caminho físico de cada LSP na rede. Os LSPs calculados no início do processo têm mais recursos disponíveis do que os LSPs calculados posteriormente no processo, porque os LSPs calculados anteriormente consomem recursos de rede. Se a ordem na qual os LSPs são calculados for alterada, o conjunto resultante de caminhos físicos para os LSPs também poderá mudar.
Uma ferramenta de planejamento e análise offline examina simultaneamente as restrições de recursos de cada link e os requisitos de cada LSP. Embora a abordagem off-line possa levar várias horas para ser concluída, ela realiza cálculos globais, compara os resultados de cada cálculo e, em seguida, seleciona a melhor solução para a rede como um todo. A saída do cálculo offline é um conjunto de LSPs que otimiza a utilização dos recursos da rede. Após a conclusão do cálculo offline, os LSPs podem ser estabelecidos em qualquer ordem, pois cada um é instalado de acordo com as regras da solução otimizada globalmente.
Cálculo e configuração flexíveis de LSP
A engenharia de tráfego envolve o mapeamento do fluxo de tráfego em uma topologia física. Você pode determinar os caminhos on-line usando o roteamento baseado em restrições. Independentemente de como o caminho físico é calculado, o estado de encaminhamento é instalado em toda a rede por meio do RSVP.
O Junos OS oferece suporte às seguintes maneiras de rotear e configurar um LSP:
Você pode calcular o caminho completo para o LSP offline e configurar individualmente cada roteador no LSP com o estado de encaminhamento estático necessário. Isso é análogo à maneira como alguns provedores de serviços de Internet (ISPs) configuram seus núcleos IP sobre ATM.
Você pode calcular o caminho completo para o LSP offline e configurar estaticamente o roteador de entrada com o caminho completo. O roteador de entrada usa o RSVP como um protocolo de sinalização dinâmica para instalar um estado de encaminhamento em cada roteador ao longo do LSP.
Você pode contar com o roteamento baseado em restrições para realizar o cálculo dinâmico de LSP on-line. Você configura as restrições para cada LSP; Em seguida, a própria rede determina o caminho que melhor atende a essas restrições. Especificamente, o roteador de entrada calcula todo o LSP com base nas restrições e então inicia a sinalização em toda a rede.
Você pode calcular um caminho parcial para um LSP offline e configurar estaticamente o roteador de entrada com um subconjunto dos roteadores no caminho; Em seguida, você pode permitir o cálculo on-line para determinar o caminho completo.
Por exemplo, considere uma topologia que inclui dois caminhos leste-oeste nos Estados Unidos: um no norte através de Chicago e outro no sul através de Dallas. Se você quiser estabelecer um LSP entre um roteador em Nova York e outro em San Francisco, você pode configurar o caminho parcial para o LSP incluir um único salto com roteamento solto de um roteador em Dallas. O resultado é um LSP roteado ao longo do caminho do sul. O roteador de entrada usa CSPF para calcular o caminho completo e RSVP para instalar o estado de encaminhamento ao longo do LSP.
Você pode configurar o roteador de entrada sem nenhuma restrição. Nesse caso, o roteamento de caminho mais curto normal do IGP é usado para determinar o caminho do LSP. Essa configuração não fornece nenhum valor em termos de engenharia de tráfego. No entanto, é fácil e pode ser útil em situações em que serviços como redes privadas virtuais (VPNs) são necessários.
Em todos esses casos, você pode especificar qualquer número de LSPs como backups para o LSP principal, permitindo assim combinar mais de uma abordagem de configuração. Por exemplo, você pode calcular explicitamente o caminho primário offline, definir o caminho secundário como baseado em restrições e fazer com que o caminho terciário seja irrestrito. Se um circuito no qual o LSP primário é roteado falhar, o roteador de entrada percebe a interrupção das notificações de erro recebidas de um roteador downstream ou pela expiração das informações de estado suave do RSVP. Em seguida, o roteador encaminha dinamicamente o tráfego para um LSP em espera ativa ou chama o RSVP para criar um estado de encaminhamento para um novo LSP de backup.
Distribuição de estado de enlace usando a visão geral do BGP
- Função de um protocolo de gateway interior
- Limitações de um protocolo de gateway interior
- Necessidade de distribuição de estado de enlace abrangente
- Usando o BGP como uma solução
- Recursos com e sem suporte
- Extensões de estado de enlace BGP para roteamento de pacotes de origem em redes (SPRING)
- Verificando o nó NLRI aprendido por meio do BGP com OSPF como IGP
- Verificando o prefixo NLRI aprendido por meio de BGP com OSPF como IGP
Função de um protocolo de gateway interior
Um interior gateway protocol (IGP) é um tipo de protocolo usado para trocar informações de roteamento entre dispositivos dentro de um sistema autônomo (AS). Com base no método de cálculo do melhor caminho para um destino, os IGPs são divididos em duas categorias:
Protocolos de estado do enlace — Anunciam informações sobre a topologia da rede (links conectados diretamente e o estado desses enlaces) para todos os roteadores usando endereços multicast e atualizações de roteamento acionadas até que todos os roteadores que executam o protocolo de estado do enlace tenham informações idênticas sobre o conjunto de redes. O melhor caminho para um destino é calculado com base em restrições como atraso máximo, largura de banda mínima disponível e afinidade de classe de recurso.
OSPF e IS-IS são exemplos de protocolos de estado de enlace.
Protocolos de vetor de distância — anuncie informações completas da tabela de roteamento para vizinhos conectados diretamente usando um endereço de broadcast. O melhor caminho é calculado com base no número de saltos para a rede de destino.
RIP é um exemplo de protocolo de vetor de distância.
Como o nome indica, a função de um IGP é fornecer conectividade de roteamento dentro ou dentro de um determinado domínio de roteamento. Um domínio de roteamento é um conjunto de roteadores sob controle administrativo comum que compartilham um protocolo de roteamento comum. Um AS pode consistir em vários domínios de roteamento, onde o IGP funciona para anunciar e aprender prefixos de rede (rotas) de roteadores vizinhos para construir uma tabela de rotas que, em última análise, contém entradas para todas as fontes que anunciam a acessibilidade de um determinado prefixo. O IGP executa um algoritmo de seleção de rota para selecionar o melhor caminho entre o roteador local e cada destino, e fornece conectividade total entre os roteadores que compõem um domínio de roteamento.
Além de anunciar a acessibilidade da rede interna, os IGPs são frequentemente usados para anunciar informações de roteamento externas ao domínio de roteamento desse IGP por meio de um processo conhecido como redistribuição de rotas. A redistribuição de rotas é o processo de troca de informações de roteamento entre protocolos de roteamento distintos para unir vários domínios de roteamento quando a conectividade intra-AS é desejada.
Limitações de um protocolo de gateway interior
Embora cada IGP individual tenha suas próprias vantagens e limitações, as maiores limitações do IGP em geral são desempenho e escalabilidade.
Os IGPs são projetados para lidar com a tarefa de adquirir e distribuir informações de topologia de rede para fins de engenharia de tráfego. Embora esse modelo tenha funcionado bem, os IGPs têm limitações de escalabilidade inerentes quando se trata de distribuir grandes bancos de dados. Os IGPs podem detectar automaticamente vizinhos, com os quais adquirem informações de topologia de rede intra-área. No entanto, o banco de dados de estado de enlace ou um banco de dados de engenharia de tráfego tem o escopo de uma única área ou AS, limitando assim as aplicações, como a engenharia de tráfego de ponta a ponta, o benefício de ter visibilidade externa para tomar melhores decisões.
Para redes com comutação de rótulos, como MPLS e MPLS generalizada (GMPLS), a maioria das soluções de engenharia de tráfego existentes funciona em um único domínio de roteamento. Essas soluções não funcionam quando uma rota do nó de entrada para o nó de saída deixa a área de roteamento ou AS do nó de entrada. Nesses casos, o problema de computação de caminho torna-se complicado devido à indisponibilidade das informações completas de roteamento em toda a rede. Isso ocorre porque os provedores de serviços geralmente optam por não vazar informações de roteamento além da área de roteamento ou AS para restrições de escalabilidade e questões de confidencialidade.
Necessidade de distribuição de estado de enlace abrangente
Uma das limitações do IGP é sua incapacidade de abranger a distribuição de estado do enlace fora de uma única área ou AS. No entanto, a abrangência de informações de estado do enlace adquiridas por um IGP em várias áreas ou ASs tem as seguintes necessidades:
Computação de caminho LSP — Essas informações são usadas para calcular o caminho para LSPs MPLS em vários domínios de roteamento, por exemplo, um LSP TE inter-área.
Entidades de computação de caminho externo — entidades de computação de caminho externas, como ALTO (Otimização de Tráfego de Camada de Aplicativo) e Elementos de Computação de Caminho (PCE), executam cálculos de caminho com base na topologia da rede e no estado atual das conexões dentro da rede, incluindo informações de engenharia de tráfego. Essas informações são normalmente distribuídas por IGPs dentro da rede.
No entanto, como as entidades de computação de caminhos externas não podem extrair essas informações dos IGPs, elas realizam o monitoramento da rede para otimizar os serviços de rede.
Usando o BGP como uma solução
Visão geral
Para atender às necessidades de abranger a distribuição de estado de enlace em vários domínios, um protocolo de gateway exterior (EGP) é necessário para coletar informações de estado de enlace e engenharia de tráfego de uma área de IGP, compartilhá-las com componentes externos e usá-las para caminhos de computação para LSPs MPLS entre domínios.
O BGP é um EGP padronizado projetado para trocar informações de roteamento e acessibilidade entre sistemas autônomos (ASs). O BGP é um protocolo comprovado que tem melhores propriedades de escalabilidade porque pode distribuir milhões de entradas (por exemplo, prefixos VPN) de forma escalável. O BGP é o único protocolo de roteamento em uso hoje que é adequado para transportar todas as rotas na Internet. Isso ocorre principalmente porque o BGP é executado sobre o TCP e pode fazer uso do controle de fluxo TCP. Por outro lado, os protocolos de gateway interno (IGPs) não têm controle de fluxo. Quando os IGPs têm muitas informações de rota, eles começam a se agitar. Quando o BGP tem um alto-falante vizinho que está enviando informações muito rapidamente, o BGP pode limitar o vizinho atrasando as confirmações de TCP.
Outro benefício do BGP é que ele usa tuplas de tipo, comprimento, valor (TLV) e informações de alcance de camada de rede (NLRI) que fornecem extensibilidade aparentemente infinita sem a necessidade de alterar o protocolo subjacente.
A distribuição de informações de estado do enlace entre domínios é regulada por políticas para proteger os interesses do provedor de serviços. Isso requer um controle sobre a distribuição de topologia usando políticas. O BGP, com sua estrutura de políticas implementada, atua bem na distribuição de rotas entre domínios. No Junos OS, o BGP é totalmente orientado por políticas. O operador deve configurar explicitamente os vizinhos para emparelhar e aceitar explicitamente as rotas no BGP. Além disso, a política de roteamento é usada para filtrar e modificar as informações de roteamento. Assim, as políticas de roteamento fornecem controle administrativo completo sobre as tabelas de roteamento.
Embora, dentro de um AS, tanto o IGP-TE quanto o BGP-TE forneçam o mesmo conjunto de informações, o BGP-TE tem melhores características de escalabilidade herdadas do protocolo BGP padrão. Isso torna o BGP-TE uma opção mais escalável para adquirir informações de topologia multiárea/multias.
Ao usar o BGP como solução, as informações adquiridas pelo IGP são usadas para distribuição no BGP. Os ISPs podem expor seletivamente essas informações com outros ISPs, provedores de serviços e redes de distribuição de conteúdo (CDNs) por meio de peering BGP normal. Isso permite a agregação das informações adquiridas pelo IGP em várias áreas e ASs, de modo que uma entidade de computação de caminho externa possa acessar as informações ouvindo passivamente um refletor de rota.
Implementação
No Junos OS, os IGPs instalam informações de topologia em um banco de dados chamado banco de dados de engenharia de tráfego. O banco de dados de engenharia de tráfego contém as informações agregadas de topologia. Para instalar informações de topologia de IGP no banco de dados de engenharia de tráfego, use a set igp-topology declaração de configuração nos [edit protocols isis traffic-engineering] níveis de hierarquia e [edit protocols ospf traffic-engineering] . O mecanismo para distribuir informações de estado do enlace usando o BGP inclui o processo de anunciar o banco de dados de engenharia de tráfego no BGP-TE (importação) e instalar entradas do BGP-TE no banco de dados de engenharia de tráfego (exportação).
Você pode configurar a engenharia de tráfego IS-IS para armazenar informações IPv6 no banco de dados de engenharia de tráfego (TED), além dos endereços IPv4. BGP-LS distribui essas informações como rotas do banco de dados de engenharia de tráfego para o lsdist.0 tabela de roteamento usando as políticas de importação do banco de dados de engenharia de tráfego. Essas rotas são anunciadas aos pares BGP-TE como informações de alcance de camada de rede (NLRI) com tipo, comprimento e valor de ID de roteador IPv6 (TLV). Com a adição das informações IPv6, você pode se beneficiar da obtenção da topologia de rede completa no banco de dados de engenharia de tráfego.
 de estado de enlace BGP
de estado de enlace BGP
BGP-LS NLRI e ID da confederação
O Junos OS permite que as informações de alcance da camada de rede (NLRI) do estado do enlace BGP (BGP-LS) carreguem o ID de confederação no TLV 512 quando a confederação BGP está habilitada. O NLRI carrega o ID da confederação junto com o número do sistema autônomo do membro (número AS) no TLV 517, conforme definido no RFC 9086. O módulo de banco de dados de engenharia de tráfego do Junos OS faz as mudanças necessárias para codificar o ID da confederação e o número AS do membro em TLV 512 e TLV 517, respectivamente, enquanto origina o NLRI BGP-LS (que é injetado na tabela de roteamento lsdist.0). Em versões anteriores ao Junos OS Release 23.1R1, o BGP-LS NLRI transporta apenas o número AS do membro no TLV 512 e o ID da confederação não é codificado na tabela de roteamento lsdist.0.
Importação de banco de dados de engenharia de tráfego
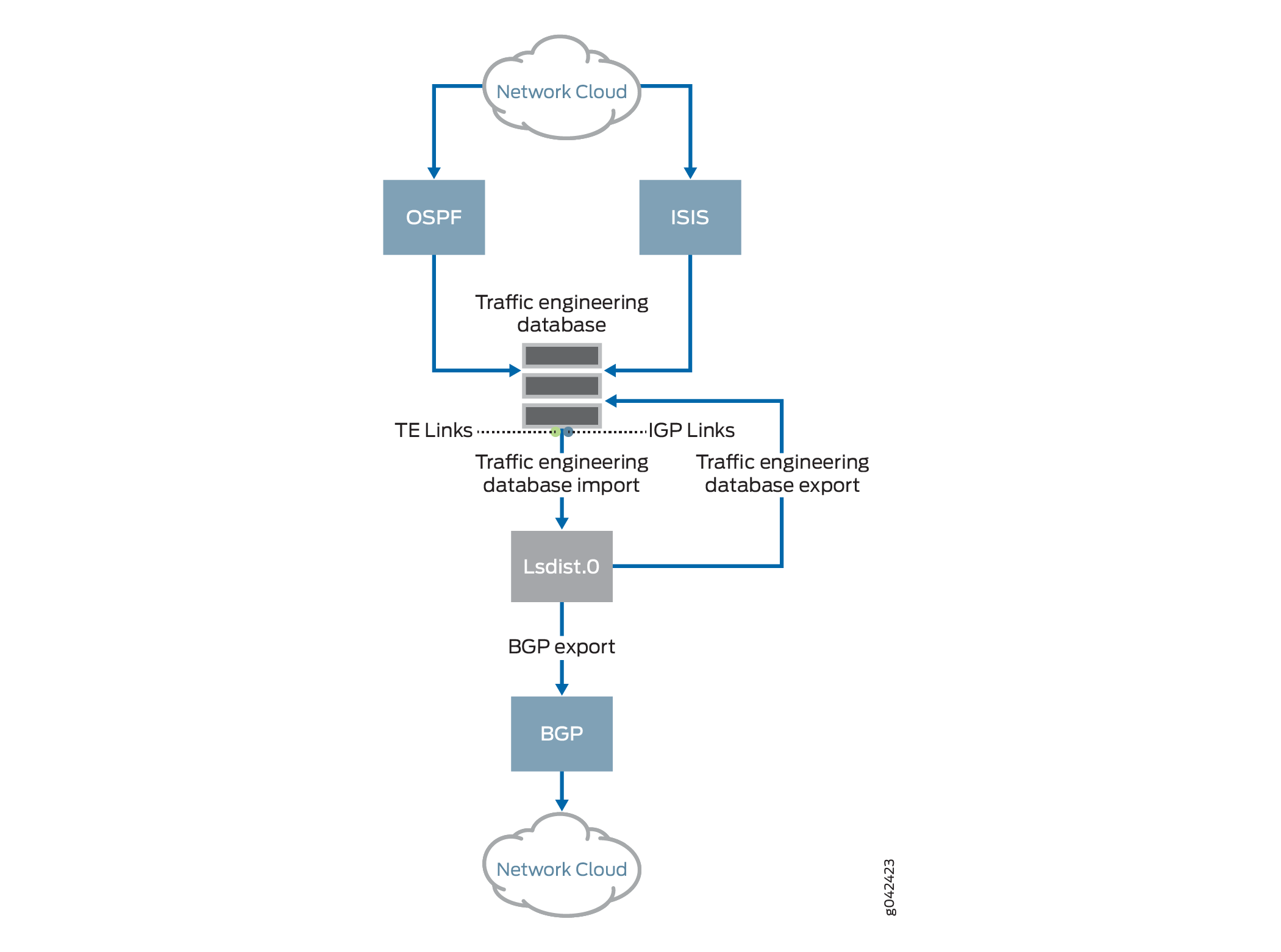
Para anunciar o banco de dados de engenharia de tráfego no BGP-TE, as entradas de link e nó no banco de dados de engenharia de tráfego são convertidas na forma de rotas. Essas rotas convertidas são então instaladas pelo banco de dados de engenharia de tráfego em nome do IGP correspondente, em uma tabela de roteamento visível ao usuário chamada lsdist.0, em condições sujeitas a políticas de rota. O procedimento de vazamento de entradas do banco de dados de engenharia de tráfego é lsdist.0 chamado de importação de banco de dados de engenharia de tráfego, conforme ilustrado na Figura 1.
Há políticas para governar o processo de importação do banco de dados de engenharia de tráfego. Por padrão, nenhuma entrada é vazada do banco de dados de engenharia de tráfego para a lsdist.0 tabela.
O banco de dados de engenharia de tráfego instala informações de topologia do interior gateway protocol (IGP), além das informações de topologia RSVP-TE na tabela de roteamento lsdist.0, conforme ilustrado na Figura 1. Você pode monitorar as informações de topologia de engenharia de tráfego e IGP. O BGP-LS lê IGP entradas de lsdist.0 e anuncia essas entradas para os pares BGP. Para importar informações de topologia de IGP para o [edit protocols mpls traffic-engineering database import igp-topology] BGP-LS de lsdist.0, use a set bgp-ls declaração de configuração no nível de hierarquia.
Exportação de banco de dados de engenharia de tráfego
O BGP pode ser configurado para exportar ou anunciar rotas da lsdist.0 tabela, sujeito à política. Isso é comum para qualquer tipo de origem de rota no BGP. Para anunciar o BGP-TE no banco de dados de engenharia de tráfego, o BGP precisa ser configurado com a família de endereços BGP-TE e uma política de exportação que selecione rotas para redistribuição no BGP.
O BGP então propaga essas rotas como qualquer outro NLRI. Os peers BGP que têm a família BGP-TE configurada e negociada recebem NLRIs BGP-TE. O BGP armazena os NLRIs BGP-TE recebidos na forma de rotas na lsdist.0 tabela, que é a mesma tabela que armazena as rotas BGP-TE originadas localmente. As rotas instaladas no lsdist.0 BGP são então distribuídas para outros peers como qualquer outra rota. Assim, o procedimento de seleção de rota padrão se aplica a NLRIs BGP-TE recebidos de vários alto-falantes.
Para alcançar o TE entre domínios, as rotas lsdist.0 são vazadas para o banco de dados de engenharia de tráfego por meio de uma política. Esse processo é chamado de exportação de banco de dados de engenharia de tráfego, conforme ilustrado na Figura 1.
Há políticas para controlar o processo de exportação do banco de dados de engenharia de tráfego. Por padrão, nenhuma entrada é vazada da lsdist.0 tabela para o banco de dados de engenharia de tráfego.
Você pode distribuir as políticas de engenharia de tráfego (TE) que se originam do protocolo de roteamento por segmentos para o banco de dados de engenharia de tráfego (TED) e para o estado de enlace BGP como rotas. O estado do enlace BGP coleta as informações relacionadas às políticas de TE, para que os controladores externos possam executar ações como computação de caminho, re-otimização e visualização de rede dentro e entre domínios.
Configure set protocols source-packet-routing traffic-engineering database para permitir que as políticas de roteamento por segmentos (SR) sejam armazenadas no TED.
Para aplicativos SDN, como PCE e ALTO, as informações anunciadas pelo BGP-TE não podem vazar para o banco de dados de engenharia de tráfego de um roteador. Nesses casos, um servidor externo que emparelha com os roteadores usando BGP-TE é usado para mover as informações de topologia para o sistema de céu/orquestração que abrange a rede. Esses servidores externos podem ser considerados consumidores BGP-TE, onde recebem rotas BGP-TE, mas não as anunciam.
Atribuindo valores de credibilidade
Depois que as entradas são instaladas no banco de dados de engenharia de tráfego, as informações aprendidas do BGP-TE são disponibilizadas para o cálculo do caminho CSPF. O banco de dados de engenharia de tráfego usa um esquema de preferência de protocolo baseado em valores de credibilidade. Um protocolo com um valor de credibilidade mais alto é preferível a um protocolo com um valor de credibilidade mais baixo. O BGP-TE tem a capacidade de anunciar informações aprendidas de vários protocolos ao mesmo tempo e, portanto, além das entradas instaladas pelo IGP no banco de dados de engenharia de tráfego, pode haver entradas instaladas no BGP-TE que correspondem a mais de um protocolo. O componente de exportação de banco de dados de engenharia de tráfego cria um protocolo de banco de dados de engenharia de tráfego e um nível de credibilidade para cada protocolo compatível com o BGP-TE. Esses valores de credibilidade são configuráveis na CLI.
A ordem de credibilidade para os protocolos BGP-TE é a seguinte:
-
Desconhecido - 80
-
OSPF — 81
-
IS-IS Nível 1 — 82
-
IS-IS Nível 2 — 83
-
Estático - 84
-
Direto - 85
Computação de caminho de credibilidade cruzada
Depois de atribuir valores de credibilidade, cada nível de credibilidade é tratado como um plano individual. O algoritmo Constrained Shorted Path First começa com a credibilidade atribuída mais alta para a mais baixa, encontrando um caminho dentro desse nível de credibilidade.
Com o BGP-TE, é essencial calcular caminhos entre níveis de credibilidade para calcular caminhos inter-AS. Por exemplo, diferentes configurações de credibilidade são vistas em um dispositivo da área 0 que calcula o caminho pela área 1, porque as entradas da área 0 são instaladas pelo OSPF e as entradas da área 1 são instaladas pelo BGP-TE.
Para habilitar a computação de caminho entre níveis de credibilidade, inclua a cross-credibility-cspf edit protocols mplsinstrução nos níveis , [edit protocols mpls label-switched-path lsp-name]e [edit protocols rsvp] hierarquia. No nível da hierarquia, os [edit protocols rsvp] impactos de habilitação cross-credibility-cspf ignoram LSPs e soltam a expansão de saltos em trânsito.
A configuração cross-credibility-cspf permite a computação de caminho em níveis de credibilidade usando o algoritmo Constrained Shortest Path First, em que a restrição não é executada em uma base de credibilidade por credibilidade, mas como uma única restrição ignorando os valores de credibilidade atribuídos.
BGP-TE, NLRIs e TLVs
Como outras rotas BGP, os NLRIs BGP-TE também podem ser distribuídos por meio de um refletor de rota que fala BGP-TE NLRI. O Junos OS implementa o suporte à reflexão de rota para a família BGP-TE.
Veja a seguir uma lista de NLRIs compatíveis:
-
Link NLRI
-
NLRI do nó
-
Prefixo IPv4 NLRI (receber e propagar)
-
Prefixo IPv6 NLRI (receber e propagar)
-
Política de TE NLRI
O Junos OS não oferece suporte para a forma de distinção de rota dos NRLIs acima.
Veja a seguir uma lista de campos compatíveis em NLRIs de link e nó:
-
Protocol-ID — o NLRI se origina com os seguintes valores de protocolo:
-
IS-IS-L1
-
IS-IS-L2
-
OSPF
-
PRIMAVERA-TE
-
-
Identificador — Este valor é configurável. Por padrão, o valor do identificador é definido como
0. -
Descritor de nó local/remoto — incluem:
-
Sistema autônomo
-
Identificador BGP-LS — esse valor é configurável. Por padrão, o valor do identificador BGP-LS é definido como
0 -
ID de área
-
ID do roteador IGP
-
-
Descritores de link (somente para NLRI de link) — Isso inclui:
-
Vincular identificadores locais/remotos
-
Endereço da interface IPv4
-
Endereço de vizinho IPv4
-
Endereço de vizinho/interface IPv6 — Os endereços de vizinho e interface IPv6 não são originados, mas apenas armazenados e propagados quando recebidos.
-
ID de multitopologia — esse valor não é originado, mas armazenado e propagado quando recebido.
-
Veja a seguir uma lista de TLVs de atributo LINK_STATE compatíveis:
-
Atributos de link:
-
Grupo administrativo
-
Largura de banda máxima do link
-
Largura de banda máxima reservável
-
Largura de banda não reservada
-
Métrica padrão do TE
-
SRLG
-
Os seguintes TLVs, que não são originados, mas apenas armazenados e propagados quando recebidos:
-
Atributos de link opacos
-
Máscara de protocolo MPLS
-
Métrica
-
Tipo de proteção de link
-
Atributo de nome do link
-
-
-
Atributos de nó:
-
ID do roteador IPv4
-
Bits de sinalizador de nó — Somente o bit de sobrecarga é definido.
-
Os seguintes TLVs, que não são originados, mas apenas armazenados e propagados quando recebidos:
-
Multitopologia
-
Propriedades do nó específicas do OSPF
-
Propriedades do nó opaco
-
Nome do nó
-
Identificador de área IS-IS
-
ID do roteador IPv6
-
-
Atributos de prefixo — esses TLVs são armazenados e propagados como quaisquer outros TLVs desconhecidos.
-
Recursos com e sem suporte
O Junos OS oferece suporte aos seguintes recursos com distribuição de estado de enlace usando BGP:
Anúncio de capacidade de encaminhamento garantido multiprotocolo
Transmissão e recepção de NLRIs BGP e BGP-TE de nó e estado de enlace
Roteamento ativo ininterrupto para NLRIs BGP-TE
Políticas
O Junos OS oferece not suporte à seguinte funcionalidade para distribuição de estado de enlace usando BGP:
Topologias, links ou nós agregados
Suporte a diferenciador de rota para NLRIs BGP-TE
Identificadores de várias topologias
Identificadores de várias instâncias (excluindo o ID de instância padrão 0)
Anúncio do link e da área do nó TLV
Anúncio de protocolos de sinalização MPLS
Importação de informações de nó e link com endereço sobreposto
Extensões de estado de enlace BGP para roteamento de pacotes de origem em redes (SPRING)
A família de endereços de estado de enlace BGP é estendida para distribuir as informações de topologia de roteamento de pacotes de origem em redes (SPRING) para controladores de redes definidas por software (SDN). O BGP normalmente aprende as informações de estado do enlace do IGP e as distribui para os pares do BGP. Além do BGP, o controlador SDN pode obter informações de estado do enlace diretamente do IGP se o controlador fizer parte de um domínio IGP. No entanto, a distribuição de estado do enlace BGP fornece um mecanismo escalável para exportar as informações de topologia. As extensões de estado de enlace BGP para SPRING são suportadas em redes entre domínios.
- Roteamento de pacotes de origem em redes (SPRING)
- Fluxo de dados SPRING de estado do enlace BGP
- Atributos de estado de enlace BGP e TLVs suportados e recursos não suportados para estado de enlace BGP com SPRING
Roteamento de pacotes de origem em redes (SPRING)
O SPRING é uma arquitetura de plano de controle que permite que um roteador de entrada direcione um pacote por um conjunto específico de nós e links na rede sem depender dos nós intermediários na rede para decidir o caminho real que ele deve seguir. A SPRING contrata IGPs, como IS-IS e OSPF, para anunciar segmentos de rede. Os segmentos de rede podem representar qualquer instrução, topológica ou baseada em serviço. Dentro das topologias de IGP, os segmentos de IGP são anunciados pelos protocolos de roteamento de estado de enlace. Existem dois tipos de segmentos de IGP:
| Adjacency segment | Um caminho de um salto sobre uma adjacência específica entre dois nós no IGP |
| Prefix segment | Um caminho mais curto multi-hop, de custo igual, com reconhecimento de multipath para um prefixo, de acordo com o estado da topologia do IGP |
Quando o SPRING é habilitado em uma rede BGP, a família de endereços de estado de enlace BGP aprende as informações de SPRING dos protocolos de roteamento de estado de enlace do IGP e anuncia segmentos na forma de identificadores de segmento (SIDs). A família de endereços de estado do enlace BGP foi estendida para transportar SIDs e outras informações relacionadas ao SPRING para pares BGP. O refletor de rota pode direcionar um pacote através de um conjunto desejado de nós e links, precedendo o pacote com uma combinação apropriada de túneis. Esse recurso permite que a família de endereços de estado de enlace BGP também anuncie as informações SPRING para pares BGP.
Fluxo de dados SPRING de estado do enlace BGP
A Figura 2 mostra o fluxo de dados dos dados SPRING de estado do enlace BGP que o IS-IS envia para o banco de dados de engenharia de tráfego.
-
O IGP envia os atributos SPRING para o banco de dados de engenharia de tráfego.
-
Os recursos do SPRING e as informações do algoritmo são transportados como atributos de nó para o banco de dados de engenharia de tráfego.
-
As informações de SID adjacentes e SID adjacentes de LAN são transportadas como atributos de link.
-
As informações de SID de prefixo ou SID de nó são transportadas como atributos de prefixo.
-
Um novo conjunto ou uma alteração nos atributos existentes aciona atualizações de IGP no banco de dados de engenharia de tráfego com novos dados.
ATENÇÃO:Se a engenharia de tráfego estiver desabilitada no nível do IGP, nenhum dos atributos será enviado para o banco de dados de engenharia de tráfego.
-
Todos os parâmetros no NLRI de engenharia de tráfego BGP, incluindo os descritores de link, nó e prefixo, são derivados de entradas no banco de dados de engenharia de tráfego.
-
O banco de dados de engenharia de tráfego importa entradas de rota para a
lsdist.0tabela de roteamento do IGP sujeitas à política. -
A política padrão do BGP é exportar rotas, que são conhecidas apenas pelo BGP. Você configura uma política de exportação para rotas não BGP na
lsdis.0tabela de roteamento. Essa política anuncia uma entrada aprendida com o banco de dados de engenharia de tráfego.
Atributos de estado de enlace BGP e TLVs suportados e recursos não suportados para estado de enlace BGP com SPRING
O estado de enlace BGP com SPRING suporta os seguintes atributos e tipo, comprimento e valores (TLVs) que são originados, recebidos e propagados na rede:
Node attributes
-
Recursos de roteamento por segmentos
-
Algoritmo de roteamento por segmentos
Link attributes
-
SID adjacente
-
LAN adjacente-SID
Prefix descriptors
-
Informações de acessibilidade de IP
Prefix attributes
-
SID de prefixo
A lista a seguir oferece suporte a TLVs que não são originados, mas apenas recebidos e propagados na rede:
Prefix descriptors
-
ID de multitopologia
-
Tipo de rota OSPF
Prefix attributes
-
Variação
-
SID de associação
O Junos OS não oferece suporte aos seguintes recursos com o estado de enlace BGP com extensões SPRING:
-
Origem de prefixo IPv6
-
Identificadores de multitopologia
-
Exportação de banco de dados de engenharia de tráfego para parâmetros SPRING
-
Novos TLVs com tcpdump (TLVs existentes também não são suportados).
-
SPRING sobre IPv6
Verificando o nó NLRI aprendido por meio do BGP com OSPF como IGP
Veja a seguir um exemplo de saída para verificar o nó NLRI aprendido por meio do BGP com OSPF como IGP:
Finalidade
Verifique as entradas da tabela de roteamento lsdist.0.
Ação
Do modo operacional, execute o show route table lsdist.0 comando.
user@host> show route table lsdist.0 te-node-ip 10.7.7.7 extensive
lsdist.0: 216 destinations, 216 routes (216 active, 0 holddown, 0 hidden)
NODE { AS:65100 Area:0.0.0.1 IPv4:10.7.7.7 OSPF:0 }/1536 (1 entry, 1 announced)
TSI:
LINK-STATE attribute handle 0x61d5da0
*BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0x61b07cc
Next-hop reference count: 216
Source: 10.2.2.2
Protocol next hop: 10.2.2.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State:<Active Int Ext>
Local AS: 65100 Peer AS: 65100
Age: 30:22 Metric2: 2
Validation State: unverified
Task: BGP_65100.10.2.2.2
Announcement bits (1): 0-TED Export
AS path: I
Accepted
Area border router: No
External router: No
Attached: No
Overload: No
SPRING-Capabilities:
- SRGB block [Start: 900000, Range: 90000, Flags: 0x00]
SPRING-Algorithms:
- Algo: 0
Localpref: 100
Router ID: 10.2.2.2
Indirect next hops: 1
Protocol next hop: 10.2.2.2 Metric: 2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
Indirect path forwarding next hops: 1
Next hop type: Router
Next hop: 10.11.1.2 via et-0/0/0.1 weight 0x1
Session Id: 0x143
10.2.2.2/32 Originating RIB: inet.0
Metric: 2 Node path count: 1
Forwarding nexthops: 1
Nexthop: 10.11.1.2 via et-0/0/0.1
Session Id: 143
Significado
As rotas estão aparecendo na tabela de roteamento lsdist.0.
Verificando o prefixo NLRI aprendido por meio de BGP com OSPF como IGP
Veja a seguir um exemplo de saída para verificar o prefixo NLRI aprendido por meio do BGP com OSPF como IGP:
Finalidade
Verifique as entradas da tabela de roteamento lsdist.0.
Ação
Do modo operacional, execute o show route table lsdist.0 comando.
user@host> show route table lsdist.0 te-ipv4-prefix-node-ip 10.7.7.7 extensive
lsdist.0: 216 destinations, 216 routes (216 active, 0 holddown, 0 hidden)
PREFIX { Node { AS:65100 Area:0.0.0.1 IPv4:10.7.7.7 } { IPv4:10.7.7.7/32 } OSPF:0 }/1536 (1 entry, 0 announced)
*BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0x61b07cc
Next-hop reference count: 216
Source: 10.2.2.2
Protocol next hop: 10.2.2.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State: <Active Int Ext>
Local AS: 65100 Peer AS: 65100
Age: 30:51 Metric2: 2
Validation State: unverified
Task: BGP_65100.10.2.2.2
AS path: I
Accepted
Prefix Flags: 0x00, Prefix SID: 1007, Flags: 0x50, Algo: 0
Localpref: 65100
Router ID: 10.2.2.2
Indirect next hops: 1
Protocol next hop: 10.2.2.2 Metric: 2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
Indirect path forwarding next hops: 1
Next hop type: Router
Next hop: 10.11.1.2 via et-0/0/0.1 weight 0x1
Session Id: 0x143
10.2.2.2/32 Originating RIB: inet.0
Metric: 2 Node path count: 1
Forwarding nexthops: 1
Nexthop: 10.11.1.2 via et-0/0/0.1
Session Id: 143
Significado
As rotas estão aparecendo na tabela de roteamento lsdist.0.
Exemplo: configurar a distribuição de estado do enlace usando o BGP
Este exemplo mostra como configurar o BGP para transportar informações de estado do enlace em vários domínios, que são usadas para caminhos de computação para LSPs MPLS abrangendo vários domínios, como TE LSP inter-área, e fornecendo um meio escalável e controlado por políticas para entidades externas de computação de caminhos, como ALTO e PCE, adquirirem topologia de rede.
Requerimentos
Este exemplo usa os seguintes componentes de hardware e software:
-
Quatro roteadores da Série MX
-
Junos OS versão 14.2 ou posterior em execução em todos os roteadores
Antes de começar:
-
Configure as interfaces do dispositivo.
-
Configure os números do sistema autônomo e os IDs do roteador para os dispositivos.
-
Configure os seguintes protocolos:
-
RSVP
-
MPLS
-
BGP
-
IS-IS
-
OSPF
-
Visão geral
Um novo mecanismo para distribuir informações de topologia em várias áreas e sistemas autônomos (ASs) é introduzido pela extensão do protocolo BGP para transportar informações de estado do link, que foram inicialmente adquiridas usando o IGP. Os protocolos IGP têm limitações de escala quando se trata de distribuir grandes bancos de dados. O BGP não é apenas um veículo mais escalável para transportar informações de topologia multiárea e multiAS, mas também fornece os controles de política que podem ser úteis para a distribuição de topologia multiAS. As informações de topologia de estado de enlace BGP são usadas para computar caminhos para caminhos comutados por rótulos (LSPs) MPLS abrangendo vários domínios, como TE LSP inter-área, e fornecer um meio escalável e controlado por políticas para entidades de computação de caminhos externos, como ALTO e PCE, adquirirem topologia de rede.
A distribuição de estado do enlace usando BGP é suportada em switches QFX10000.
Topologia
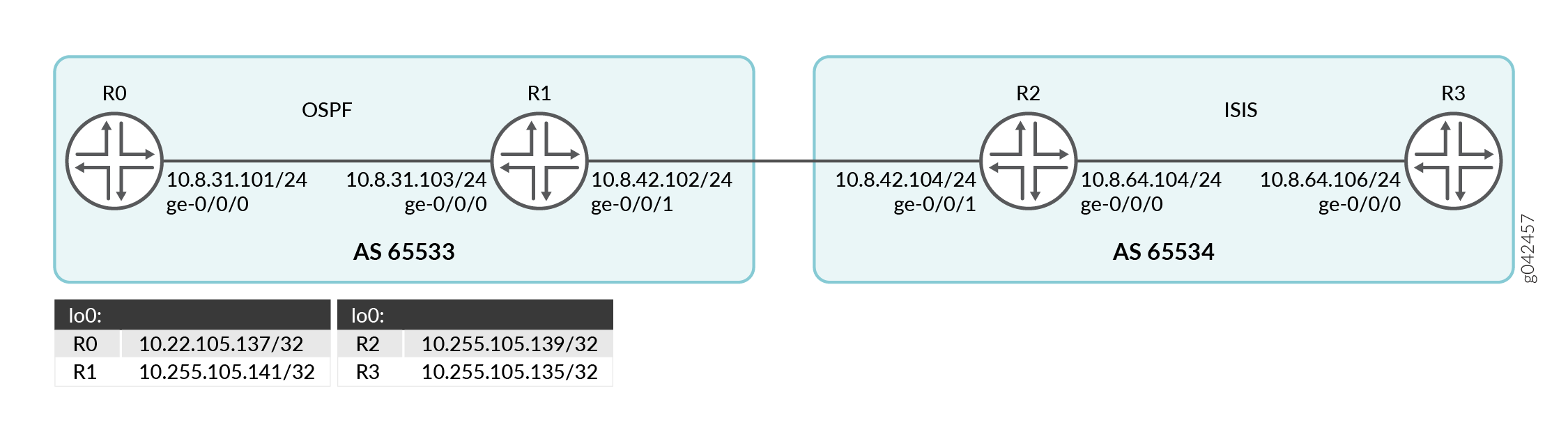
Na Figura 3, os Roteadores R0 e R1 e os Roteadores R2 e R3 pertencem a sistemas autônomos diferentes. Os roteadores R0 e R1 executam OSPF e os roteadores R2 e R3 executam IS-IS.
Configuração
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os comandos a seguir, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para corresponder à sua configuração de rede, copie e cole os comandos na CLI no nível de [edit] hierarquia e, em seguida, entre commit no modo de configuração.
R0
set interfaces ge-0/0/0 unit 0 family inet address 10.8.31.101/24 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/0 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.105.137/32 set routing-options router-id 10.255.105.137 set routing-options autonomous-system 65533 set protocols rsvp interface all set protocols rsvp interface fxp0.0 disable set protocols mpls traffic-engineering database export policy accept-all set protocols mpls cross-credibility-cspf set protocols mpls label-switched-path to-R3-inter-as to 10.255.105.135 set protocols mpls label-switched-path to-R3-inter-as bandwidth 40m set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.255.105.137 set protocols bgp group ibgp family traffic-engineering unicast set protocols bgp group ibgp neighbor 10.255.105.141 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set policy-options policy-statement accept-all from family traffic-engineering set policy-options policy-statement accept-all then accept
R1
set interfaces ge-0/0/0 unit 0 family inet address 10.8.31.103/24 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 10.8.42.102/24 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.105.141/32 set interfaces lo0 unit 0 family iso address 47.0005.0102.5501.8181 set routing-options router-id 10.255.105.141 set routing-options autonomous-system 65533 set protocols rsvp interface all set protocols rsvp interface fxp0.0 disable set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.255.105.141 set protocols bgp group ibgp family traffic-engineering unicast set protocols bgp group ibgp export nlri2bgp set protocols bgp group ibgp neighbor 10.255.105.137 set protocols bgp group ebgp type external set protocols bgp group ebgp family traffic-engineering unicast set protocols bgp group ebgp neighbor 10.8.42.104 local-address 10.8.42.102 set protocols bgp group ebgp neighbor 10.8.42.104 peer-as 65534 set protocols isis interface ge-0/0/1.0 passive remote-node-iso 0102.5502.4211 set protocols isis interface ge-0/0/1.0 passive remote-node-id 10.8.42.104 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-id 10.8.42.104 set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-router-id 10.255.105.139 set policy-options policy-statement accept-all from family traffic-engineering set policy-options policy-statement accept-all then accept set policy-options policy-statement nlri2bgp term 1 from family traffic-engineering set policy-options policy-statement nlri2bgp term 1 then accept
R2
set interfaces ge-0/0/0 unit 0 family inet address 10.8.64.104/24 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 10.8.42.104/24 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.105.139/32 set interfaces lo0 unit 0 family iso address 47.0005.0102.5502.4211.00 set routing-options router-id 10.255.105.139 set routing-options autonomous-system 65534 set protocols rsvp interface all set protocols rsvp interface fxp0.0 disable set protocols mpls traffic-engineering database import policy ted2nlri set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.255.105.139 set protocols bgp group ibgp family traffic-engineering unicast set protocols bgp group ibgp export nlri2bgp set protocols bgp group ibgp neighbor 10.255.105.135 set protocols bgp group ebgp type external set protocols bgp group ebgp family traffic-engineering unicast set protocols bgp group ebgp export nlri2bgp set protocols bgp group ebgp peer-as 65533 set protocols bgp group ebgp neighbor 10.8.42.102 set protocols isis level 1 disable set protocols isis interface ge-0/0/0.0 set protocols isis interface ge-0/0/1.0 passive remote-node-iso 0102.5501.8181 set protocols isis interface ge-0/0/1.0 passive remote-node-id 10.8.42.102 set protocols isis interface lo0.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-id 10.8.42.102 set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-router-id 10.255.105.141 set policy-options policy-statement accept-all from family traffic-engineering set policy-options policy-statement accept-all then accept set policy-options policy-statement nlri2bgp term 1 from family traffic-engineering set policy-options policy-statement nlri2bgp term 1 then accept set policy-options policy-statement ted2nlri term 1 from protocol isis set policy-options policy-statement ted2nlri term 1 from protocol ospf set policy-options policy-statement ted2nlri term 1 then accept set policy-options policy-statement ted2nlri term 2 then reject
R3
set interfaces ge-0/0/0 unit 0 family inet address 10.8.64.106/24 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/0 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.105.135/32 set interfaces lo0 unit 0 family iso address 47.0005.0102.5502.4250 set routing-options router-id 10.255.105.135 set routing-options autonomous-system 65534 set protocols rsvp interface all set protocols rsvp interface fxp0.0 disable set protocols mpls traffic-engineering database export policy accept-all set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.255.105.135 set protocols bgp group ibgp family traffic-engineering unicast set protocols bgp group ibgp neighbor 10.255.105.139 set protocols isis interface ge-0/0/0.0 level 1 disable set protocols isis interface lo0.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set policy-options policy-statement accept-all from family traffic-engineering set policy-options policy-statement accept-all then accept
Tramitação processual
Procedimento passo a passo
O exemplo a seguir requer que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no Modo de Configuração.
Para configurar o Roteador R1:
-
Configure as interfaces do roteador R1.
[edit interfaces] user@R1# set ge-0/0/0 unit 0 family inet address 10.8.31.103/24 user@R1# set ge-0/0/0 unit 0 family iso user@R1# set ge-0/0/0 unit 0 family mpls user@R1# set ge-0/0/1 unit 0 family inet address 10.8.42.102/24 user@R1# set ge-0/0/1 unit 0 family iso user@R1# set ge-0/0/1 unit 0 family mpls user@R1# set lo0 unit 0 family inet address 10.255.105.141/32 user@R1# set lo0 unit 0 family iso address 47.0005.0102.5501.8181
-
Configure o ID do roteador e o sistema autônomo do Roteador R1.
[edit routing-options]user@R1# set router-id 10.255.105.141 user@R1# set autonomous-system 65533 -
Habilite o RSVP em todas as interfaces do Roteador R1 (excluindo a interface de gerenciamento).
[edit protocols]user@R1# set rsvp interface all user@R1# set rsvp interface fxp0.0 disable -
Habilite o MPLS em todas as interfaces do Roteador R1 (excluindo a interface de gerenciamento).
[edit protocols]user@R1# set mpls interface all user@R1# set mpls interface fxp0.0 disable -
Configure o grupo BGP para o Roteador R1 emparelhar com o Roteador R0 e atribua o endereço local e o endereço vizinho.
[edit protocols]user@R1# set bgp group ibgp type internal user@R1# set bgp group ibgp local-address 10.255.105.141 user@R1# set bgp group ibgp neighbor 10.255.105.137 -
Inclua as informações de alcance da camada de rede (NLRI) de sinalização BGP-TE para o grupo BGP do IBGP.
[edit protocols]user@R1# set bgp group ibgp family traffic-engineering unicast -
Habilite a exportação da política nlri2bgp no Roteador R1.
[edit protocols]user@R1# set bgp group ibgp export nlri2bgp -
Configure o grupo BGP para o Roteador R1 emparelhar com o Roteador R2 e atribua o endereço local e o sistema autônomo vizinho ao grupo BGP ebgp.
[edit protocols]user@R1# set bgp group ebgp type external user@R1# set bgp group ebgp neighbor 10.8.42.104 local-address 10.8.42.102 user@R1# set bgp group ebgp neighbor 10.8.42.104 peer-as 65534 -
Inclua o NLRI de sinalização BGP-TE para o grupo BGP ebgp.
[edit protocols]user@R1# set bgp group ebgp family traffic-engineering unicast -
Habilite a engenharia de tráfego passiva no enlace inter-AS.
[edit protocols]user@R1# set isis interface ge-0/0/1.0 passive remote-node-iso 0102.5502.4211 user@R1# set isis interface ge-0/0/1.0 passive remote-node-id 10.8.42.104 -
Habilite o OSPF na interface que conecta o Roteador R1 ao Roteador R0 e na interface de loopback do Roteador R1 e habilite os recursos de engenharia de tráfego.
[edit protocols]user@R1# set ospf traffic-engineering user@R1# set ospf area 0.0.0.0 interface lo0.0 user@R1# set ospf area 0.0.0.0 interface ge-0/0/0.0 -
Habilite a engenharia de tráfego passiva no enlace inter-AS.
[edit protocols]user@R1# set ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-id 10.8.42.104 user@R1# set ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-router-id 10.255.105.139 -
Configure políticas para aceitar tráfego do BGP-TE NLRI.
[edit policy-options]user@R1# set policy-statement accept-all from family traffic-engineering user@R1# set policy-statement accept-all then accept user@R1# set policy-statement nlri2bgp term 1 from family traffic-engineering user@R1# set policy-statement nlri2bgp term 1 then accept
Resultados
No modo de configuração, confirme sua configuração inserindo os show interfacescomandos , show routing-options, , show protocolse show policy-options . Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@R1# show interfaces
ge-0/0/0 {
unit 0 {
family inet {
address 10.8.31.103/24;
}
family iso;
family mpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 10.8.42.102/24;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.105.141/32;
family iso {
address 47.0005.0102.5501.8181:00;
}
}
}
user@R1# show routing-options router-id 10.255.105.141; autonomous-system 65533;
user@R1# show protocols
rsvp {
interface all;
interface fxp0.0 {
disable;
}
}
mpls {
interface all;
interface fxp0.0 {
disable;
}
}
bgp {
group ibgp {
type internal;
local-address 10.255.105.141;
family traffic-engineering {
unicast;
}
export nlri2bgp;
neighbor 10.255.105.137;
}
group ebgp {
type external;
family traffic-engineering {
unicast;
}
neighbor 10.8.42.104 {
local-address 10.8.42.102;
peer-as 65534;
}
}
}
isis {
interface ge-0/0/1.0 {
passive {
remote-node-iso 0102.5502.4211;
remote-node-id 10.8.42.104;
}
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface lo0.0;
interface ge-0/0/0.0;
interface ge-0/0/1.0 {
passive {
traffic-engineering {
remote-node-id 10.8.42.104;
remote-node-router-id 10.255.105.139;
}
}
}
}
}
user@R1# show policy-options
policy-statement accept-all {
from family traffic-engineering;
then accept;
}
policy-statement nlri2bgp {
term 1 {
from family traffic-engineering;
then {
accept;
}
}
}
Tramitação processual
Procedimento passo a passo
O exemplo a seguir requer que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no Modo de Configuração.
Para configurar o Roteador R2:
-
Configure as interfaces do roteador R2.
[edit interfaces] user@R2# set ge-0/0/0 unit 0 family inet address 10.8.64.104/24 user@R2# set ge-0/0/0 unit 0 family iso user@R2# set ge-0/0/0 unit 0 family mpls user@R2# set ge-0/0/1 unit 0 family inet address 10.8.42.104/24 user@R2# set ge-0/0/1 unit 0 family iso user@R2# set ge-0/0/1 unit 0 family mpls user@R2# set lo0 unit 0 family inet address 10.255.105.139/32 user@R2# set lo0 unit 0 family iso address 47.0005.0102.5502.4211.00
-
Configure o ID do roteador e o sistema autônomo do Roteador R2.
[edit routing-options]user@R2# set router-id 10.255.105.139 user@R2# set autonomous-system 65534 -
Habilite o RSVP em todas as interfaces do Roteador R2 (excluindo a interface de gerenciamento).
[edit routing-options]user@R2# set rsvp interface all user@R2# set rsvp interface fxp0.0 disable -
Habilite o MPLS em todas as interfaces do Roteador R2 (excluindo a interface de gerenciamento).
[edit routing-options]user@R2# set mpls interface all user@R2# set mpls interface fxp0.0 disable -
Habilite a importação de parâmetros de banco de dados de engenharia de tráfego usando a política ted2nlri.
[edit protocols]user@R2# set mpls traffic-engineering database import policy ted2nlri -
Configure o grupo BGP para o Roteador R2 emparelhar com o Roteador R3 e atribua o endereço local e o endereço vizinho.
[edit protocols]user@R2# set bgp group ibgp type internal user@R2# set bgp group ibgp local-address 10.255.105.139 user@R2# set bgp group ibgp neighbor 10.255.105.135 -
Inclua as informações de alcance da camada de rede (NLRI) de sinalização BGP-TE para o grupo BGP do IBGP.
[edit protocols]user@R2# set bgp group ibgp family traffic-engineering unicast -
Habilite a exportação da política nlri2bgp no Roteador R2.
[edit protocols]user@R2# set bgp group ibgp export nlri2bgp -
Configure o grupo BGP para o Roteador R2 emparelhar com o Roteador R1.
[edit protocols]user@R2# set bgp group ebgp type external -
Inclua o NLRI de sinalização BGP-TE para o grupo BGP ebgp.
[edit protocols]user@R2# set bgp group ebgp family traffic-engineering unicast -
Atribua o endereço local e o sistema autônomo vizinho ao grupo BGP ebgp.
[edit protocols]user@R2# set bgp group ebgp peer-as 65533 user@R2# set bgp group ebgp neighbor 10.8.42.102 -
Habilite a exportação da política nlri2bgp no Roteador R2.
[edit protocols]user@R2# set bgp group ebgp export nlri2bgp -
Habilite o IS-IS na interface que conecta o Roteador R2 ao Roteador R3 e à interface de loopback do Roteador R2.
[edit protocols]user@R2# set isis level 1 disable user@R2# set isis interface ge-0/0/0.0 user@R2# set isis interface lo0.0 -
Habilite apenas a publicidade IS-IS na interface que conecta o Roteador R2 ao Roteador R1.
[edit protocols]user@R2# set isis interface ge-0/0/1.0 passive remote-node-iso 0102.5501.8181 user@R2# set isis interface ge-0/0/1.0 passive remote-node-id 10.8.42.102 -
Configure a capacidade de engenharia de tráfego no Roteador R2.
[edit protocols]user@R2# set ospf traffic-engineering -
Habilite apenas anúncios OSPF na interface que conecta o Roteador R2 ao Roteador R1.
[edit protocols]user@R2# set ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-id 10.8.42.102 user@R2# set ospf area 0.0.0.0 interface ge-0/0/1.0 passive traffic-engineering remote-node-router-id 10.255.105.141 -
Configure políticas para aceitar o tráfego do NLRI do BGP-TE.
[edit policy-options]user@R2# set policy-statement accept-all from family traffic-engineering user@R2# set policy-statement accept-all then accept user@R2# set policy-statement nlri2bgp term 1 from family traffic-engineering user@R2# set policy-statement nlri2bgp term 1 then accept user@R2# set policy-statement ted2nlri term 1 from protocol isis user@R2# set policy-statement ted2nlri term 1 from protocol ospf user@R2# set policy-statement ted2nlri term 1 then accept user@R2# set policy-statement ted2nlri term 2 then reject
Resultados
No modo de configuração, confirme sua configuração inserindo os show interfacescomandos , show routing-options, , show protocolse show policy-options . Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@R2# show interfaces
ge-0/0/0 {
unit 0 {
family inet {
address 10.8.64.104/24;
}
family iso;
family mpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 10.8.42.104/24;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.105.139/32;
family iso {
address 47.0005.0102.5502.4211.00;
}
family iso;
}
}
user@R2# show routing-options router-id 10.255.105.139; autonomous-system 65534;
user@R2# show protocols
rsvp {
interface all;
interface fxp0.0 {
disable;
}
}
mpls {
traffic-engineering {
database {
import {
policy ted2nlri;
}
}
}
interface all;
interface fxp0.0 {
disable;
}
}
bgp {
group ibgp {
type internal;
local-address 10.255.105.139;
family traffic-engineering {
unicast;
}
export nlri2bgp;
neighbor 10.255.105.135;
}
group ebgp {
type external;
family traffic-engineering {
unicast;
}
export nlri2bgp;
peer-as 65533;
neighbor 10.8.42.102;
}
}
isis {
level 1 disable;
interface ge-0/0/0.0;
interface ge-0/0/1.0 {
passive {
remote-node-iso 0102.5501.8181;
remote-node-id 10.8.42.102;
}
}
interface lo0.0;
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface ge-0/0/1.0 {
passive {
traffic-engineering {
remote-node-id 10.8.42.102;
remote-node-router-id 10.255.105.141;
}
}
}
}
}
user@R2# show policy-options
policy-statement accept-all {
from family traffic-engineering;
then accept;
}
policy-statement nlri2bgp {
term 1 {
from family traffic-engineering;
then {
accept;
}
}
}
policy-statement ted2nlri {
term 1 {
from protocol [ isis ospf ];
then accept;
}
term 2 {
then reject;
}
}
Verificação
Verifique se a configuração está funcionando corretamente.
- Verificando o status do resumo do BGP
- Verificando o status do MPLS LSP
- Verificando as entradas da tabela de roteamento lsdist.0
- Verificando as entradas do banco de dados de engenharia de tráfego
Verificando o status do resumo do BGP
Finalidade
Verifique se o BGP está ativo e em execução nos roteadores R0 e R1.
Ação
Do modo operacional, execute o show bgp summary comando.
user@R0> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
lsdist.0
10 10 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.255.105.141 65533 20 14 0 79 5:18 Establ
lsdist.0: 10/10/10/0
Do modo operacional, execute o show bgp summary comando.
user@R1> show bgp summary
Groups: 2 Peers: 2 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
lsdist.0
10 10 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.8.42.104 65534 24 17 0 70 6:43 Establ
lsdist.0: 10/10/10/0
10.255.105.137 65533 15 23 0 79 6:19 Establ
lsdist.0: 0/0/0/0
Significado
O roteador R0 é emparelhado com o roteador R1.
Verificando o status do MPLS LSP
Finalidade
Verifique o status do LSP MPLS no roteador R0.
Ação
Do modo operacional, execute o show mpls lsp comando.
user@R0> show mpls lsp Ingress LSP: 1 sessions To From State Rt P ActivePath LSPname 10.255.105.135 10.255.105.137 Up 0 * to-R3-inter-as Total 1 displayed, Up 1, Down 0 Egress LSP: 0 sessions Total 0 displayed, Up 0, Down 0 Transit LSP: 0 sessions Total 0 displayed, Up 0, Down 0
Significado
O LSP MPLS do Roteador R0 ao Roteador R3 é estabelecido.
Verificando as entradas da tabela de roteamento lsdist.0
Finalidade
Verifique as entradas da tabela de roteamento lsdist.0 nos roteadores R0, R1 e R2.
Ação
Do modo operacional, execute o show route table lsdist.0 comando.
user@R0> show route table lsdist.0
lsdist.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
NODE { AS:65534 ISO:0102.5502.4211.00 ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
NODE { AS:65534 ISO:0102.5502.4250.00 ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
NODE { AS:65534 ISO:0102.5502.4250.02 ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
NODE { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 OSPF:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:8.42.1.104 } Remote { AS:65534 ISO:0102.5501.8181.00 }.{ IPv4:10.8.42.102 } ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:10.8.64.104 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:02:03, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 ISO:0102.5502.4250.00 }.{ IPv4:10.8.64.106 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4211.00 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4250.00 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
LINK { Local { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 }.{ IPv4:10. 8.42.104 } Remote { AS:65534 Area:0.0.0.0 IPv4:10.255.105.141 }.{ IPv4:10.8.42.102 } OSPF:0 }/1152
*[BGP/170] 00:17:32, localpref 100, from 10.255.105.141
AS path: 65534 I, validation-state: unverified
> to 10.8.31.103 via ge-0/0/0.0
Do modo operacional, execute o show route table lsdist.0 comando.
user@R1> show route table lsdist.0
lsdist.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
NODE { AS:65534 ISO:0102.5502.4211.00 ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
NODE { AS:65534 ISO:0102.5502.4250.00 ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
NODE { AS:65534 ISO:0102.5502.4250.02 ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
NODE { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 OSPF:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:10.8.42.104 } Remote { AS:65534 ISO:0102.5501.8181.00 }.{ IPv4:10.8.42.102 } ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:10.8.64.104 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:02:19, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 ISO:0102.5502.4250.00 }.{ IPv4:10.8.64.106 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4211.00 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4250.00 }.{ } ISIS-L2:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
LINK { Local { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 }.{ IPv4:10.8.42.104 } Remote { AS:65534 Area:0.0.0.0 IPv4:10.255.105.141 }.{ IPv4:10.8.42.102 } OSPF:0 }/1152
*[BGP/170] 00:18:00, localpref 100
AS path: 65534 I, validation-state: unverified
> to 10.8.42.104 via ge-0/0/1.0
Do modo operacional, execute o show route table lsdist.0 comando.
user@R2> show route table lsdist.0
lsdist.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
NODE { AS:65534 ISO:0102.5502.4211.00 ISIS-L2:0 }/1152
*[IS-IS/18] 1d 00:24:39
Fictitious
NODE { AS:65534 ISO:0102.5502.4250.00 ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:45
Fictitious
NODE { AS:65534 ISO:0102.5502.4250.02 ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:45
Fictitious
NODE { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 OSPF:0 }/1152
*[OSPF/10] 1d 00:24:39
Fictitious
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:10.8.42.104 } Remote { AS:65534 ISO:0102.5501.8181.00 }.{ IPv4:10.8.42.102 } ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:58
Fictitious
LINK { Local { AS:65534 ISO:0102.5502.4211.00 }.{ IPv4:10.8.64.104 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[IS-IS/18] 00:02:34
Fictitious
LINK { Local { AS:65534 ISO:0102.5502.4250.00 }.{ IPv4:10.8.64.106 } Remote { AS:65534 ISO:0102.5502.4250.02 }.{ } ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:45
Fictitious
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4211.00 }.{ } ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:45
Fictitious
LINK { Local { AS:65534 ISO:0102.5502.4250.02 }.{ } Remote { AS:65534 ISO:0102.5502.4250.00 }.{ } ISIS-L2:0 }/1152
*[IS-IS/18] 00:20:45
Fictitious
LINK { Local { AS:65534 Area:0.0.0.0 IPv4:10.255.105.139 }.{ IPv4:10.8.42.104 } Remote { AS:65534 Area:0.0.0.0 IPv4:10.255.105.141 }.{ IPv4:10.8.42.102 } OSPF:0 }/1152
*[OSPF/10] 00:20:57
Fictitious
Significado
As rotas estão aparecendo na tabela de roteamento lsdist.0.
Verificando as entradas do banco de dados de engenharia de tráfego
Finalidade
Verifique as entradas do banco de dados de engenharia de tráfego no Roteador R0.
Ação
Do modo operacional, execute o show ted database comando.
user@R0> show ted database
TED database: 5 ISIS nodes 5 INET nodes
ID Type Age(s) LnkIn LnkOut Protocol
0102.5501.8168.00(10.255.105.137) Rtr 1046 1 1 OSPF(0.0.0.0)
To: 10.8.31.101-1, Local: 10.8.31.101, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
0102.5501.8181.00 --- 1033 1 0
0102.5502.4211.00(10.255.105.139) Rtr 3519 2 3 Exported ISIS-L2(1)
To: 0102.5502.4250.02, Local: 10.8.64.104, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
To: 0102.5501.8181.00, Local: 10.8.42.104, Remote: 10.8.42.102
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
Exported OSPF(2)
To: 10.255.105.141, Local: 10.8.42.104, Remote: 10.8.42.102
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
0102.5502.4250.00(10.255.105.135) Rtr 1033 1 1 Exported ISIS-L2(1)
To: 0102.5502.4250.02, Local: 10.8.64.106, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
0102.5502.4250.02 Net 1033 2 2 Exported ISIS-L2(1)
To: 0102.5502.4211.00(10.255.105.139), Local: 0.0.0.0, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
To: 0102.5502.4250.00(10.255.105.135), Local: 0.0.0.0, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
10.8.31.101-1 Net 1046 2 2 OSPF(0.0.0.0)
To: 0102.5501.8168.00(10.255.105.137), Local: 0.0.0.0, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
To: 10.255.105.141, Local: 0.0.0.0, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
ID Type Age(s) LnkIn LnkOut Protocol
10.255.105.141 Rtr 1045 2 2 OSPF(0.0.0.0)
To: 0102.5502.4211.00(10.255.105.139), Local: 10.8.42.102, Remote: 10.8.42.104
Local interface index: 0, Remote interface index: 0
To: 10.8.31.101-1, Local: 10.8.31.103, Remote: 0.0.0.0
Local interface index: 0, Remote interface index: 0
Significado
As rotas estão aparecendo no banco de dados de engenharia de tráfego.
Configuração da distribuição de estado do enlace usando BGP
Você pode habilitar a distribuição de informações de topologia em várias áreas e sistemas autônomos (ASs) estendendo o protocolo BGP para transportar informações de estado do enlace, que foram inicialmente adquiridas usando o IGP. Os protocolos IGP têm limitações de escala quando se trata de distribuir grandes bancos de dados. O BGP não é apenas um veículo mais escalável para transportar informações de topologia multiárea e multiAS, mas também fornece os controles de política que podem ser úteis para a distribuição de topologia multiAS. As informações de topologia de estado de enlace BGP são usadas para computar caminhos para LSPs MPLS abrangendo vários domínios, como TE LSP inter-área, e fornecendo um meio escalável e controlado por políticas para entidades de computação de caminhos externos, como ALTO e PCE, para adquirir topologia de rede.
Antes de começar:
Configure as interfaces do dispositivo.
Configure o ID do roteador e o número do sistema autônomo para o dispositivo.
Configure os seguintes protocolos:
RSVP
MPLS
IS-IS
OSPF
Para habilitar a distribuição de estado de enlace usando BGP:
Visão geral dos planos de transporte com classe BGP
- Benefícios dos planos de transporte com classe BGP
- Terminologia dos planos de transporte com classe BGP
- Entender os planos de transporte com classe BGP
- Implementação intra-AS de planos de transporte com classe BGP
- Implementação Inter-AS de planos de transporte com classe BGP
Benefícios dos planos de transporte com classe BGP
-
Fatiamento de rede — As camadas de serviço e transporte são desacopladas umas das outras, estabelecendo as bases para o fatiamento de rede e a virtualização com o fatiamento de ponta a ponta em vários domínios, reduzindo significativamente o CAPEX.
- Interoperabilidade entre domínios — estende a implantação da classe de transporte em domínios cooperativos para que os diferentes protocolos de sinalização de transporte em cada domínio interoperem. Reconcilia quaisquer diferenças entre namespaces de comunidade estendidos que possam estar em uso em cada domínio.
-
Resolução colorida com fallback — Permite a resolução em túneis coloridos (RSVP, algoritmo flexível IS-IS) com opções flexíveis de fallback em túneis de melhor esforço ou qualquer outro túnel colorido.
- Qualidade de serviço — Personaliza e otimiza a rede para atender aos requisitos do SLA de ponta a ponta.
- Aproveitando as implantações existentes — oferece suporte a protocolos de tunelamento bem implantados, como RSVP, juntamente com novos protocolos, como o algoritmo flexível IS-IS, preservando o ROI e reduzindo as despesas operacionais.
Terminologia dos planos de transporte com classe BGP
Esta seção fornece um resumo dos termos comumente usados para entender o plano de transporte com classe BGP.
-
Nó de serviço — dispositivos de borda do provedor de entrada (PE) que enviam e recebem rotas de serviço (Internet e VPN de camada 3).
-
Nó de borda — dispositivo no ponto de conexão de diferentes domínios (áreas de IGP ou ASs).
-
Nó de transporte — dispositivo que envia e recebe rotas Unicast (LU) rotuladas de BGP.
-
BGP-VPN — VPNs criadas usando mecanismos RFC4364.
-
Destino de rota (RT) — Tipo de comunidade estendida usada para definir a associação de VPN.
-
Route Distinguisher (RD)— Identificador usado para distinguir a qual VPN ou serviço de LAN privada virtual (VPLS) uma rota pertence. Cada instância de roteamento deve ter um diferenciador de rota exclusivo associado a ela.
- Esquema de resolução — usado para resolver o endereço de próximo salto (PNH) do protocolo em RIBs de resolução que fornecem fallback.
Eles mapeiam as rotas para os diferentes RIBs de transporte no sistema com base no mapeamento da comunidade.
-
Família de serviços — família de endereços BGP usada para anunciar rotas para tráfego de dados, em oposição a túneis.
-
Família de transporte – família de endereços BGP usada para anunciar túneis, que por sua vez são usados por rotas de serviço para resolução.
-
Túnel de transporte — Um túnel sobre o qual um serviço pode colocar tráfego, por exemplo, GRE, UDP, LDP, RSVP, SR-TE, BGP-LU.
-
Domínio de túnel — Um domínio da rede que contém nós de serviço e nós de borda sob um único controle administrativo que tem um túnel entre eles. Um túnel de ponta a ponta abrangendo vários domínios de túnel adjacentes pode ser criado unindo os nós usando rótulos.
-
Classe de transporte — Um grupo de túneis de transporte que oferecem o mesmo tipo de serviço.
Classe de transporte RT — Um novo formato de destino de rota usado para identificar uma classe de transporte específica.
Um novo formato de Route Target usado para identificar uma classe de transporte específica.-
RIB de transporte — No nó de serviço e no nó de borda, uma classe de transporte tem um RIB de transporte associado que mantém suas rotas de túnel.
-
Instância de roteamento RTI de transporte — A; contêiner de transporte RIB e classe de transporte associada Route Target e Route Distinguisher.
-
Plano de transporte — Conjunto de RTIs de transporte que importam a mesma classe de transporte RT. Estes, por sua vez, são costurados para abranger os limites do domínio do túnel usando um mecanismo semelhante ao Inter-AS option-b para trocar rótulos nos nós de borda (nexthop-self), formando um plano de transporte de ponta a ponta.
-
Comunidade de mapeamento — Comunidade em uma rota de serviço que mapeia para resolver em uma classe de transporte.
Entender os planos de transporte com classe BGP
Você pode usar planos de transporte com classe BGP para configurar classes de transporte para classificar um conjunto de túneis de transporte em uma rede intra-AS com base nas características de engenharia de tráfego e usar esses túneis de transporte para mapear rotas de serviço com o SLA desejado e o fallback pretendido.
Os planos de transporte com classe BGP podem estender esses túneis para redes entre domínios que se estendem por vários domínios (ASs ou áreas IGP), preservando a classe de transporte. Para fazer isso, você deve configurar a família BGP de camada de transporte com classe BGP entre a borda e os nós de serviço.
Em implementações inter-AS e intra-AS, pode haver muitos túneis de transporte (LSPs MPLS, algoritmo flexível IS-IS, SR-TE) criados a partir dos nós de serviço e borda. Os LSPs podem ser sinalizados usando diferentes protocolos de sinalização em diferentes domínios e podem ser configurados com diferentes características de engenharia de tráfego (classe ou cor). O endpoint do túnel de transporte também atua como o endpoint de serviço e pode estar presente no mesmo domínio de túnel que o nó de entrada de serviço ou em um domínio adjacente ou não adjacente. Você pode usar planos de transporte com classe BGP para resolver serviços sobre LSPs com certas características de engenharia de tráfego dentro de um único domínio ou em vários domínios.
Os planos de transporte com classe BGP reutilizam a tecnologia BGP-VPN, mantendo os domínios de tunelamento fracamente acoplados e coordenados.
- As informações de alcance da camada de rede (NLRI) são RD:TunnelEndpoint usadas para ocultar caminhos.
- O destino da rota indica a classe de transporte dos LSPs e vaza rotas para o RIB de transporte correspondente no dispositivo de destino.
- Cada protocolo de tunelamento de transporte instala uma rota de entrada na tabela de roteamento transport-class.inet.3, modela a classe de transporte do túnel como um alvo de rota VPN e coleta os LSPs da mesma classe de transporte na tabela de roteamento transport-class.inet.3 transport-rib.
-
As rotas nessa instância de roteamento são anunciadas no plano de transporte com classe BGP (transporte inet) AFI-SAFI seguindo procedimentos semelhantes ao RFC-4364.
-
Ao cruzar o limite do link inter-AS, você deve seguir os procedimentos da Opção-b para costurar os túneis de transporte nesses domínios adjacentes.
Da mesma forma, ao cruzar regiões intra-AS, você deve seguir os procedimentos da Opção-b para costurar os túneis de transporte nos diferentes domínios TE.
-
Você pode definir esquemas de resolução para especificar a intenção na variedade de classes de transporte em uma ordem de fallback.
- Você pode resolver rotas de serviço e rotas de transporte com classe BGP sobre essas classes de transporte, transportando a comunidade de mapeamento nelas.
A família de transporte com classe BGP corre ao lado da família de camadas de transporte BGP-LU. Em uma rede MPLS perfeita que executa BGP-LU, atender aos requisitos SLAs rigorosos do 5G é um desafio, pois as características de engenharia de tráfego dos túneis não são conhecidas ou preservadas além dos limites do domínio. Os planos de transporte com classe BGP fornecem meios operacionalmente fáceis e escaláveis para anunciar vários caminhos para loopbacks remotos junto com as informações de classe de transporte na arquitetura MPLS perfeita. Nas rotas da família de transporte com classe BGP, diferentes caminhos SLA são representados usando a comunidade estendida Transport Route-Target, que carrega a cor da classe de transporte. Esse destino de rota de transporte é usado pelos roteadores BGP receptores para associar a rota de transporte com classe BGP à classe de transporte apropriada. Ao anunciar novamente as rotas de transporte com classe BGP, o MPLS troca de rotas, interconecta os túneis intra-AS da mesma classe de transporte, formando assim um túnel de ponta a ponta que preserva a classe de transporte.
Implementação intra-AS de planos de transporte com classe BGP
A Figura 4 ilustra uma topologia de rede com cenários de antes e depois da implementação de planos de transporte com classe BGP em um domínio intra-AS. Os dispositivos PE11 e PE12 usam LSPs RSVP como o túnel de transporte e todas as rotas do túnel de transporte são instaladas no inet.3 RIB. A implementação de planos de classificação com classe BGP permite que os túneis de transporte RSVP tenham reconhecimento de cores, semelhante aos túneis de roteamento por segmentos.
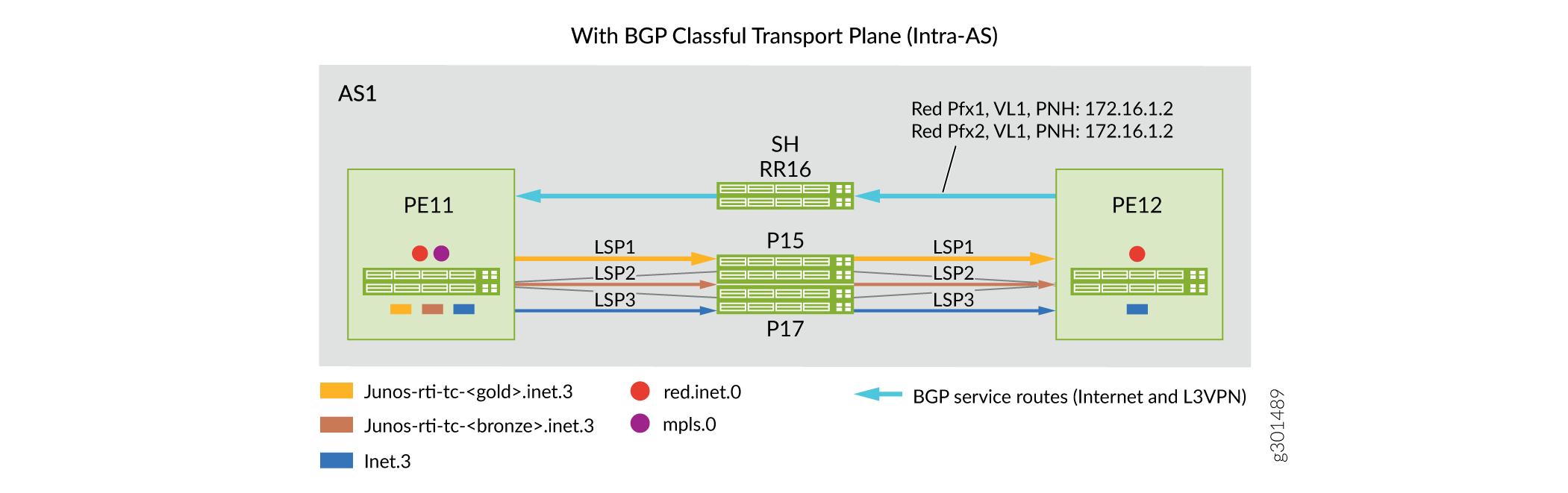
Para classificar túneis de transporte na classe de transporte BGP em uma configuração intra-AS:
- Defina a classe de transporte no nó de serviço (dispositivos PE de entrada), por exemplo, ouro e bronze, e atribua valores de comunidade de cores à classe de transporte definida.
Configuração de exemplo:
pe11# show routing-options route-distinguisher-id 172.16.1.1; transport-class { name gold { color 100; } name bronze { color 200; - Associe o túnel de transporte a uma classe de transporte específica no nó de entrada dos túneis.
Configuração de exemplo:
pe11# show protocols mpls label-switched-path toPE12-bronze { transport-class bronze; } label-switched-path toPE12-gold { transport-class gold; }
Funcionalidade do plano de transporte com classe BGP intra-AS:
- O transporte com classe BGP cria RIBs de transporte predefinidas por classe de transporte nomeada (ouro e bronze) e a comunidade de mapeamento deriva automaticamente de seu valor de cor (100 e 200).
- As rotas de transporte intra-AS são preenchidas em RIBs de transporte pelo protocolo de tunelamento quando ele está associado a uma classe de transporte.
Neste exemplo, as rotas RSVP LSP associadas à classe de transporte ouro (cor 100) e à classe de transporte bronze (cor 200) são instaladas nos RIBs de transporte junos-rti-tc-<100>.inet.3 e junos-rti-tc-<200>.inet.3, respectivamente.
- O nó de serviço (PEs de entrada) faz a correspondência da comunidade de cores estendida (cor:0:100 e cor:0:200) da rota de serviço com a comunidade de mapeamento em RIBs de resolução predefinida e resolve o próximo salto do protocolo (PNH) nas RIBs de transporte correspondentes (junos-rti-tc-<100>.inet.3 ou junos-rti-tc-<200>.inet.3).
- As rotas BGP se vinculam a um esquema de resolução carregando a comunidade de mapeamento assiocaited.
- Cada classe de transporte cria automaticamente dois esquemas de resolução predefinidos e deriva automaticamente a comunidade de mapeamento.
Um esquema de resolução é para resolver rotas de serviço que usam Color:0:<val> como a comunidade de mapeamento.
O outro esquema de resolução é para resolver rotas de transporte que usam Transport-Target:0:<val> como a comunidade de mapeamento.
- Se o PNH da rota de serviço não puder ser resolvido usando RIBs listados no esquema de resolução predefinido, ele poderá voltar para a tabela de roteamento inet.3.
- Você também pode configurar o fallback entre RIBs de transporte de cores diferentes usando esquemas de resolução definidos pelo usuário na [ edit routing-options resolution scheme] hierarquia de configuração.
Implementação Inter-AS de planos de transporte com classe BGP
Em uma rede inter-AS, o BGP-LU é convertido em uma rede de transporte com classe BGP após a configuração de um mínimo de duas classes de transporte (ouro e bronze) em todos os nós de serviço ou dispositivos PE e nós de borda (ABRs e ASBRs).
Para converter os túneis de transporte em transporte com classe BGP:
- Defina a classe de transporte nos nós de serviço (dispositivos PE de entrada) e nos nós de borda (ABRs e ASBRs), por exemplo, ouro e broze.
Configuração de exemplo:
pe11# show routing-options route-distinguisher-id 172.16.1.1; transport-class { name gold { color 100; } name bronze { color 200; - Associe os túneis de transporte a uma classe de transporte específica no nó de entrada dos túneis (PEs de entrada, ABRs e ASBRs).
Configuração de exemplo:
Para LSPs RSVP
abr23# show protocols mpls label-switched-path toASBR21-bronze { transport-class bronze; } label-switched-path toASBR22-gold { transport-class gold;Para o algoritmo flxible IS-IS
asbr13# show routing-options flex-algorithm 128 { … color 100; use-transport-class; } flex-algorithm 129 { … color 200; use-transport-class; } - Habilite uma nova família para o transporte com classe BGP (transporte inet) e BGP-LU (inet labeled-unicast) na rede.
Configuração de exemplo:
abr23# show protocols bgp group toAs2-RR27 { family inet { labeled-unicast { … } transport { … } cluster 172.16.2.3; neighbor 172.16.2.7; } - Anuncie rotas de serviço do dispositivo PE de saída com a comunidade de cores estendida apropriada.
Configuração de exemplo:
pe11# show policy-options policy-statement red term 1 { from { route-filter 192.168.3.3/32 exact; } then { community add map2gold; next-hop self; accept; } } term 2 { from { route-filter 192.168.33.33/32 exact; } then { community add map2bronze; next-hop self; accept; } } community map2bronze members color:0:200; community map2gold members color:0:100;
Funcionalidade do plano de transporte com classe Inter-AS BGP:
- Os planos de transporte com classe BGP criam RIBs de transporte predefinidos por classe de transporte nomeada (ouro e bronze) e derivam automaticamente a comunidade de mapeamento de seu valor de cor.
-
As rotas de transporte intra-AS são preenchidas em RIBs de transporte por protocolos de tunelamento quando associadas a uma classe de transporte.
Por exemplo, as rotas de túnel de transporte associadas à classe de transporte gold e bronze são instaladas nos RIBs de transporte junos-rti-tc-<100>.inet.3 e junos-rti-tc-<200>.inet.3, respectivamente.
- Os planos de transporte com classe BGP usam o Diferenciador de Rota e o Destino de Rota exclusivos quando copiam as rotas do túnel de transporte de cada RIB de transporte para a tabela de roteamento bgp.transport.3.
- Os nós de borda anunciam rotas da tabela de roteamento bgp.transport.3 para seus pares em outros domínios se o transporte inet familiar for negociado na sessão BGP.
- O nó de borda receptor instala essas rotas bgp-ct na tabela de roteamento bgp.transport.3 e copia essas rotas com base no destino da rota de transporte para os RIBs de transporte apropriados.
- O nó de serviço combina a comunidade de cores na rota de serviço com uma comunidade de mapeamento nos esquemas de resolução e resolve a PNH no RIB de transporte correspondente ( junos-rti-tc-<100>.inet.3 ou junos-rti-tc-<200>.inet.3).
- Os nós de borda usam esquemas de resolução predefinidos para resolução de PNH de rota de transporte.
- Predefinidos ou definidos pelo usuário, ambos os esquemas de resolução suportam a resolução PNH da rota de serviço. Predefinido usa inet.3 como fallback, e o esquema de resolução definido pelo usuário permite que a lista de RIBs de transporte seja usada na ordem especificada durante a resolução de HPN.
- Se o PNH da rota de serviço não puder ser resolvido usando RIBs listados no esquema de resolução definido pelo usuário, a rota será descartada.
Melhorando a precisão do banco de dados de engenharia de tráfego com mensagens RSVP PathErr
Um elemento essencial da engenharia de tráfego baseada em RSVP é o banco de dados de engenharia de tráfego. O banco de dados de engenharia de tráfego contém uma lista completa de todos os nós e links de rede que participam da engenharia de tráfego e um conjunto de atributos que cada um desses links pode conter. (Para obter mais informações sobre o banco de dados de engenharia de tráfego, consulte Computação LSP de caminho restrito.) Um dos atributos de link mais importantes é a largura de banda.
A disponibilidade de largura de banda nos links muda rapidamente à medida que os LSPs RSVP são estabelecidos e terminados. É provável que o banco de dados de engenharia de tráfego desenvolva inconsistências em relação à rede real. Essas inconsistências não podem ser corrigidas aumentando a taxa de atualizações do IGP.
A disponibilidade do link pode compartilhar o mesmo problema de inconsistência. Um enlace que se torna indisponível pode interromper todos os LSPs RSVP existentes. No entanto, sua indisponibilidade pode não ser prontamente conhecida pela rede.
Quando você configura a rsvp-error-hold-time declaração, um nó de origem (entrada de um LSP RSVP) aprende com as falhas de seu LSP monitorando as mensagens PathErr transmitidas dos nós downstream. As informações das mensagens do PathErr são incorporadas aos cálculos LSP subsequentes, o que pode melhorar a precisão e a velocidade da configuração do LSP. Algumas mensagens PathErr também são usadas para atualizar as informações de largura de banda do banco de dados de engenharia de tráfego, reduzindo as inconsistências entre o banco de dados de engenharia de tráfego e a rede.
Você pode controlar a frequência das atualizações do IGP usando a update-threshold instrução. Consulte Configurando o Limite de Atualização RSVP em uma Interface.
Esta seção discute os seguintes tópicos:
- Mensagens do PathErr
- Identificando o link do problema
- Configurando o roteador para melhorar a precisão do banco de dados de engenharia de tráfego
Mensagens do PathErr
As mensagens PathErr relatam uma ampla variedade de problemas por meio de diferentes números de código e subcódigo. Você pode encontrar uma lista completa dessas mensagens PathErr no RFC 2205, Resource Reservation Protocol (RSVP), Versão 1, Especificação Funcional e RFC 3209, RSVP-TE: Extensões para RSVP para túneis LSP.
Quando você configura a rsvp-error-hold-time declaração, duas categorias de mensagens PathErr, que representam especificamente falhas de link, são examinadas:
A largura de banda do enlace é baixa para este LSP: Largura de banda solicitada indisponível — código 1, subcódigo 2
Esse tipo de mensagem PathErr representa um problema global que afeta todos os LSPs que transitam pelo link. Eles indicam que a largura de banda real do link é menor do que a exigida pelo LSP e que é provável que as informações de largura de banda no banco de dados de engenharia de tráfego sejam superestimadas.
Quando esse tipo de erro é recebido, a largura de banda do link disponível é reduzida no banco de dados de engenharia de tráfego local, afetando todos os cálculos futuros de LSP.
Link indisponível para este LSP:
Falha no controle de admissão — código 1, qualquer subcódigo, exceto 2
Falhas de controle de política — código 2
Service Preempted — código 12
Problema de roteamento — nenhuma rota disponível para o destino — código 24, subcódigo 5
Esses tipos de mensagens PathErr geralmente são pertinentes ao LSP especificado. O fracasso deste LSP não implica necessariamente que outros LSPs também possam falhar. Esses erros podem indicar problemas de unidade de transferência máxima (MTU), preempção de serviço (iniciada manualmente pelo operador ou por outro LSP com prioridade mais alta), que um link de próximo salto está inativo, que um vizinho de próximo salto está inativo ou rejeição de serviço devido a considerações de política. É melhor direcionar esse LSP específico para longe do link.
Identificando o link do problema
Cada mensagem PathErr inclui o endereço IP do remetente. Essas informações são propagadas inalteradas em direção ao roteador de entrada. Uma pesquisa no banco de dados de engenharia de tráfego pode identificar o nó que originou a mensagem PathErr.
Cada mensagem PathErr carrega informações suficientes para identificar a sessão de RSVP que disparou a mensagem. Se este for um roteador de trânsito, ele simplesmente encaminha a mensagem. Se esse roteador for o roteador de entrada (para esta sessão de RSVP), ele terá a lista completa de todos os nós e links que a sessão deve atravessar. Juntamente com as informações do nó de origem, o link pode ser identificado de forma exclusiva.
Configurando o roteador para melhorar a precisão do banco de dados de engenharia de tráfego
Para melhorar a precisão do banco de dados de engenharia de tráfego, configure a rsvp-error-hold-time declaração. Quando essa declaração é configurada, um nó de origem (entrada de um LSP RSVP) aprende com as falhas de seu LSP monitorando mensagens PathErr transmitidas de nós downstream. As informações das mensagens do PathErr são incorporadas aos cálculos LSP subsequentes, o que pode melhorar a precisão e a velocidade da configuração do LSP. Algumas mensagens PathErr também são usadas para atualizar as informações de largura de banda do banco de dados de engenharia de tráfego, reduzindo as inconsistências entre o banco de dados de engenharia de tráfego e a rede.
Para configurar por quanto tempo o MPLS deve se lembrar das mensagens RSVP PathErr e considerá-las na computação CSPF, inclua a rsvp-error-hold-time declaração:
rsvp-error-hold-time seconds;
Você pode incluir essa instrução nos seguintes níveis de hierarquia:
[edit protocols mpls][edit logical-systems logical-system-name protocols mpls]
O tempo pode ser um valor de 1 a 240 segundos. O padrão é 25 segundos. A configuração de um valor de 0 desabilita o monitoramento de mensagens PathErr.
Tabela de histórico de alterações
A compatibilidade com recursos é determinada pela plataforma e versão utilizada. Use o Explorador de recursos para determinar se um recurso é compatível com sua plataforma.