Carregando arquivos de configuração
O carregamento de arquivos de configuração no dispositivo é útil para carregar partes dos arquivos de configuração que podem ser comuns em muitos dispositivos em uma rede.
Exemplos para carregar uma configuração de um arquivo ou do terminal
Você pode criar um arquivo contendo dados de configuração para um dispositivo da Juniper Networks, copiar o arquivo para o dispositivo local e, em seguida, carregá-lo na CLI. Depois de carregar o arquivo, você pode confirmá-lo para ativar a configuração no dispositivo ou editar a configuração interativamente usando a CLI e confirmar a configuração posteriormente.
Você também pode criar uma configuração enquanto digita no terminal e, em seguida, carregar a configuração. Carregar uma configuração do terminal é útil quando você está cortando partes existentes da configuração e colando-as em outro lugar na configuração.
Para carregar um arquivo de configuração existente localizado no dispositivo, use o load comando configuration mode:
[edit] user@host# load (factory-default | merge | override | patch | replace | set | update) filename <relative> <json>
Para carregar uma configuração do terminal, use a seguinte versão do load comando configuration mode. Pressione Ctrl-d para encerrar a entrada.
[edit] user@host# load (factory-default | merge | override | patch | replace | set | update) terminal <relative> <json>
Para substituir uma configuração inteira, você especifica a override opção em qualquer nível da hierarquia. Uma load override operação substitui completamente a configuração candidata atual pelo arquivo que você está carregando. Assim, se você salvou uma configuração completa, use esta opção.
Uma override operação descarta a configuração candidata atual e carrega a configuração ou filename a configuração que você digita no terminal. Quando você usa a override opção e confirma a configuração, todos os processos do sistema analisam a configuração.
Para substituir partes de uma configuração, especifique a replace opção. A load replace operação procura replace: marcas que você adicionou ao arquivo carregado. Em seguida, a operação substitui essas partes da configuração candidata pelo que for especificado após a marca. Isso é útil quando você deseja mais controle sobre exatamente o que está sendo alterado. Para que essa operação funcione, você deve incluir replace: tags no arquivo ou configuração digitada no terminal. O software procura as replace: tags, exclui as instruções existentes com o mesmo nome, se houver, e as substitui pela configuração de entrada. Se não houver nenhuma instrução com o mesmo nome, a replace operação adicionará à configuração as instruções marcadas com a replace: tag.
Se, em uma override operação ou merge , você especificar um texto de arquivo ou tipo que contenha replace: tags, as replace: tags serão ignoradas. Nesse cenário, a override operação or merge tem precedência e é executada.
Se você estiver executando uma replace operação e se o arquivo especificado não tiver replace: tags, a operação será executada replace como uma merge operação. A replace operação também será executada como uma merge operação se o texto digitado não tiver replace: marcas. Essas informações podem ser úteis se você estiver executando scripts automatizados e não puder saber com antecedência se os scripts precisam executar uma replace operação ou uma merge operação. Os scripts podem usar a replace operação para cobrir qualquer um dos casos.
A load merge operação mescla a configuração do arquivo ou terminal salvo com a configuração candidata existente. Essas informações serão úteis se você estiver adicionando novas seções de configuração. Por exemplo, suponha que você esteja adicionando uma configuração BGP ao [edit protocols] nível de hierarquia, onde não havia nenhuma configuração BGP antes. Você pode usar a load merge operação para combinar a configuração de entrada com a configuração candidata existente. Se a configuração existente e a configuração de entrada contiverem declarações conflitantes, as instruções na configuração de entrada substituirão as da configuração existente.
Para substituir apenas as partes da configuração que foram alteradas, especifique a update opção em qualquer nível da hierarquia. A load update operação compara a configuração candidata e os novos dados de configuração. Essa operação altera apenas as partes da configuração candidata que são diferentes da nova configuração. Você usaria essa operação, por exemplo, se houver uma configuração de BGP existente e o arquivo que você está carregando a alterar de alguma forma.
As mergeopções , overridee update dão suporte ao carregamento de dados de configuração no formato JSON (JavaScript Object Notation). Ao carregar dados de configuração que usam o formato JSON, você deve especificar a json opção no comando. Para carregar dados de configuração JSON que contêm entradas de lista não ordenadas, ou seja, entradas de lista em que a chave de lista não é necessariamente o primeiro elemento na entrada de lista, consulte Carregar dados de configuração JSON com entradas de lista não ordenadas.
Para alterar parte da configuração com um arquivo de patch, especifique a patch opção. A load patch operação carrega um arquivo ou entrada de terminal que contém alterações de configuração. Primeiro, em um dispositivo que já tem as alterações de configuração, você digita o show | compare comando para gerar as diferenças entre duas configurações. Em seguida, você pode carregar as diferenças em outro dispositivo. A vantagem do load patch comando é que ele evita que você tenha que copiar trechos de diferentes níveis de hierarquia em um arquivo de texto antes de carregá-los no dispositivo de destino. Isso pode ser uma economia de tempo útil se você estiver configurando vários dispositivos com as mesmas opções. Por exemplo, suponha que você configure uma política de roteamento no roteador1 e queira replicar a configuração de política no roteador2, roteador3 e roteador4. Você pode usar a load patch operação.
Neste exemplo, você primeiro executa o show | compare comando.
Exemplo:
user@router1# show | compare rollback 3
[edit protocols ospf]
+ export default-static;
- export static-default
[edit policy-options]
+ policy-statement default-static {
+ from protocol static;
+ then accept;
+ }
Continuando com este exemplo, você copia a show | compare saída do comando para a área de transferência, certificando-se de incluir os níveis de hierarquia. No roteador2, roteador3 e roteador4, você digita load patch terminal e cola a saída. Em seguida, pressione Enter e pressione Ctrl-d para encerrar a operação. Se a entrada de patch especificar valores diferentes para uma instrução existente, a entrada de patch substituirá a instrução existente.
Para usar a mergeopção , replace, set, ou update sem especificar o nível de hierarquia completo, especifique a relative opção. Essa opção carrega a configuração de entrada relativa ao seu ponto de edição atual na hierarquia de configuração.
Exemplo:
[edit system]
user@host# show static-host-mapping
bob sysid 987.654.321ab
[edit system]
user@host# load replace terminal relative
[Type ^D at a new line to end input]
replace: static-host-mapping {
bob sysid 0123.456.789bc;
}
load complete
[edit system]
user@host# show static-host-mapping
bob sysid 0123.456.789bc;
Para carregar uma configuração que contém set comandos do modo de configuração, especifique a set opção. Esta opção executa as instruções de configuração linha por linha à medida que são armazenadas em um arquivo ou de um terminal. As instruções podem conter qualquer comando de modo de configuração, como set, edit, exit, e top.
Para copiar um arquivo de configuração de outro sistema de rede para o roteador local, você pode usar os utilitários SSH e Telnet, conforme descrito no CLI Explorer.
Se você estiver trabalhando em um ambiente Common Criteria, as mensagens de log do sistema serão criadas sempre que um secret atributo for alterado (por exemplo, alterações de senha ou alterações no segredo compartilhado RADIUS). Essas alterações são registradas durante as seguintes operações de carregamento de configuração:
load merge load replace load override load update
Como a codificação de caracteres funciona em dispositivos da Juniper Networks
Os dados de configuração do Junos OS e a saída do comando operacional podem conter caracteres não ASCII, que estão fora do conjunto de caracteres ASCII de 7 bits. Ao exibir dados operacionais ou de configuração em determinados formatos ou em um determinado tipo de sessão, o software escapa e codifica esses caracteres. O software escapa ou codifica os caracteres usando a referência de caractere decimal UTF-8 equivalente.
A CLI tenta exibir quaisquer caracteres não ASCII em dados de configuração produzidos no formato de texto, conjunto ou JSON. A CLI também tenta exibir esses caracteres na saída do comando que é produzida em formato de texto. Nos casos de exceção, a CLI exibe a referência de caractere decimal UTF-8. (Os casos de exceção incluem dados de configuração no formato XML e saída de comando no formato XML ou JSON) Nas sessões do protocolo NETCONF e Junos XML, você verá um resultado semelhante se solicitar dados de configuração ou saída de comando que contenha caracteres não ASCII. Nesse caso, o servidor retorna a referência de caractere decimal UTF-8 equivalente para esses caracteres para todos os formatos.
Por exemplo, suponha que a conta de usuário a seguir, que contém a letra minúscula latina n com um til (ñ), esteja configurada no dispositivo.
[edit] user@host# set system login user mariap class super-user uid 2007 full-name "Maria Peña"
Quando você exibe a configuração resultante em formato de texto, a CLI imprime o caractere correspondente.
[edit] user@host# show system login user mariap full-name "Maria Peña"; uid 2007; class super-user;
Quando você exibe a configuração resultante no formato XML na CLI, o caractere ñ é mapeado para sua referência ñde caractere decimal UTF-8 equivalente. O mesmo resultado ocorrerá se você exibir a configuração em qualquer formato em uma sessão do protocolo NETCONF ou Junos XML.
[edit]
user@host# show system login user mariap | display xml
<rpc-reply xmlns:junos="http://xml.juniper.net/junos/17.2R1/junos">
<configuration junos:changed-seconds="1494033077" junos:changed-localtime="2017-05-05 18:11:17 PDT">
<system>
<login>
<user>
<name>mariap</name>
<full-name>Maria Peña</full-name>
<uid>2007</uid>
<class>super-user</class>
</user>
</login>
</system>
</configuration>
<cli>
<banner>[edit]</banner>
</cli>
</rpc-reply>
Ao carregar dados de configuração em um dispositivo, você pode carregar caracteres não ASCII usando suas referências de caracteres decimais UTF-8 equivalentes.
Sobre a especificação de instruções e identificadores
Este tópico fornece detalhes sobre as instruções de contêiner da CLI e as instruções leaf para que você saiba como especificá-las ao criar arquivos de configuração ASCII. Este tópico também descreve como a CLI executa a verificação de tipo para verificar se os dados inseridos estão no formato correto.
Especificando instruções
As instruções são mostradas de duas maneiras, com chaves ({ }) ou sem:
-
Nome e identificador da instrução, com uma ou mais instruções de nível inferior entre chaves:
statement-name1 identifier-name { statement-name2; additional-statements; } -
Nome da instrução, identificador e um único identificador:
statement-name identifier-name1 identifier-name2;
O statement-name é o nome da declaração. O identifier-name é um nome ou outra cadeia de caracteres que identifica exclusivamente uma instância de uma instrução. Você usa um identificador quando uma instrução pode ser especificada mais de uma vez em uma configuração.
Ao especificar uma instrução, você deve especificar um nome de instrução, um nome de identificador ou ambos, dependendo da hierarquia da instrução.
Você especifica identificadores de uma das seguintes maneiras:
-
identifier-name— A identifier-name é uma palavra-chave usada para identificar exclusivamente uma declaração quando uma declaração pode ser especificada mais de uma vez em uma instrução.
-
identifier-name value— O identifier-name é uma palavra-chave e o value é uma variável de opção obrigatória.
-
identifier-name [value1 value2 value3
...]—A identifier-name é uma palavra-chave que aceita vários valores. Os colchetes são necessários quando você especifica um conjunto de valores; no entanto, eles são opcionais quando você especifica apenas um valor.
Os exemplos a seguir ilustram como as instruções e os identificadores são especificados na configuração:
protocol { # Top-level statement (statement-name).
ospf { # Statement under "protocol" (statement-name).
area 0.0.0.0 { # OSPF area "0.0.0.0" (statement-name identifier-name),
interface so-0/0/0 { # which contains an interface named "so-0/0/0."
hello-interval 25; # Identifier and value (identifier-name value).
priority 2; # Identifier and value (identifier-name value).
disable; # Flag identifier (identifier-name).
}
interface so-0/0/1; # Another instance of "interface," named so-0/0/1,
} # this instance contains no data, so no braces
} # are displayed.
}
policy-options { # Top-level statement (statement-name).
term term1 { # Statement under "policy-options"
# (statement-name value).
from { # Statement under "term" (statement-name).
route-filter 10.0.0.0/8 orlonger reject; # One identifier ("route-filter") with
route-filter 127.0.0.0/8 orlonger reject; # multiple values.
route-filter 128.0.0.0/16 orlonger reject;
route-filter 149.20.64.0/24 orlonger reject;
route-filter 172.16.0.0/12 orlonger reject;
route-filter 191.255.0.0/16 orlonger reject;
}
then { # Statement under "term" (statement-name).
next term; # Identifier (identifier-name).
}
}
}
Ao criar um arquivo de configuração ASCII, você especifica instruções e identificadores. Cada instrução tem um estilo preferencial, e a CLI usa esse estilo ao exibir a configuração em resposta a um comando do modo show de configuração. Você pode especificar instruções e identificadores de uma das seguintes maneiras:
-
Declaração seguida de identificadores:
statement-name identifier-name [...] identifier-name value [...];
-
Declaração seguida por identificadores entre chaves:
statement-name { identifier-name; [...] identifier-name value; [...] } -
Para alguns identificadores de repetição, você pode usar um conjunto de chaves para todas as instruções:
statement-name { identifier-name value1; identifier-name value2; }
Execução da verificação de tipo de CLI
Quando você especifica identificadores e valores, a CLI executa a verificação de tipo para verificar se os dados inseridos estão no formato correto. Por exemplo, para uma instrução na qual você deve especificar um endereço IP, a CLI exige que você insira um endereço em um formato válido. Caso contrário, uma mensagem de erro indicará o que você precisa digitar. lista os tipos de dados que a CLI verifica. A seguir estão os tipos de entrada de configuração da CLI:
| Tipo de dados |
Formato |
Exemplos |
|---|---|---|
| Nome da |
|
Correct: Incorrect: |
| Nome completo da interface |
|
Correct: Incorrect: |
| Nome completo ou abreviado da interface (usado em locais diferentes da |
|
Correct: |
| Endereço IP |
|
Correct: Sample translations:
|
| Endereço IP (prefixo de destino) e comprimento do prefixo |
|
Correct: Sample translations:
|
| Endereço da Organização Internacional de Normalização (ISO) |
|
Correct: Sample translations:
|
| Identificador de área (ID) OSPF |
|
Correct: Sample translations:
|
Sobre o carregamento de uma configuração de um arquivo
Os exemplos a seguir demonstram o processo de carregamento de uma configuração de um arquivo.
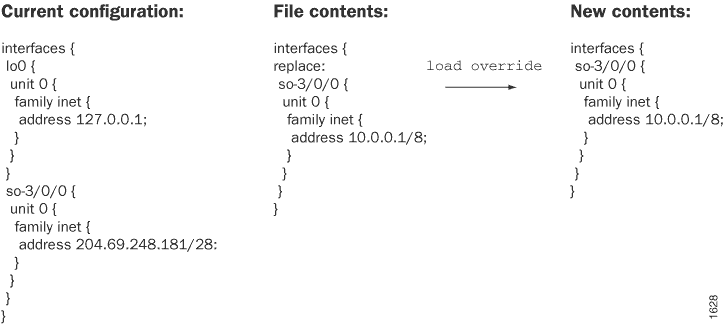 atual
atual
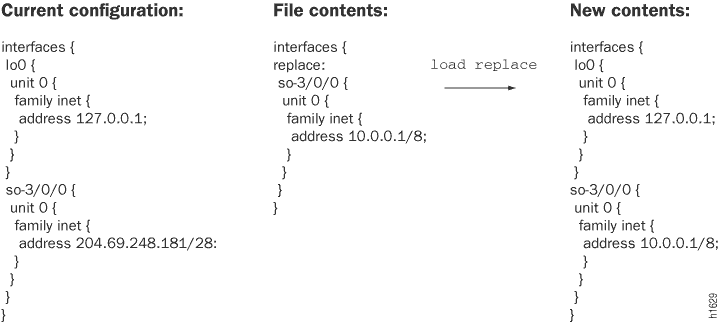 de substituição
de substituição
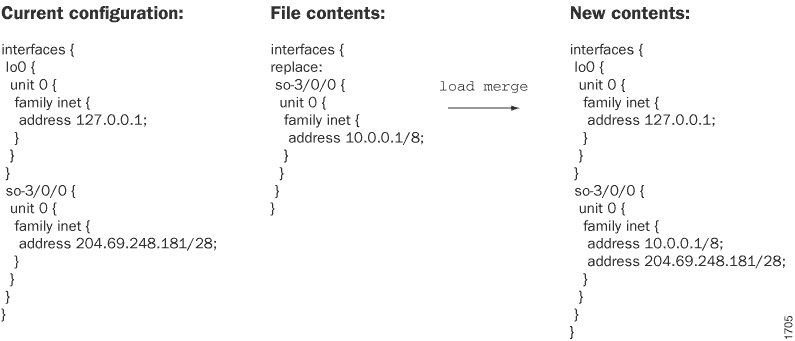 merge
merge
 de patch
de patch
 set
set
Carregar um arquivo de configuração
Você pode criar um arquivo de configuração em seu sistema local, copiar o arquivo para o dispositivo e, em seguida, carregar o arquivo na CLI. Depois de carregar o arquivo de configuração, você pode confirmá-lo para ativar a configuração no dispositivo. Você também pode editar a configuração interativamente usando a CLI e confirmá-la posteriormente.
Para carregar um arquivo de configuração do seu sistema local:
Para visualizar os resultados das etapas de configuração antes de confirmar a configuração, digite o show comando no prompt do usuário.
Para confirmar essas alterações na configuração ativa, digite o commit comando no prompt do usuário. Você também pode editar a configuração interativamente usando a CLI e confirmá-la posteriormente.
Carregar dados de configuração JSON com entradas de lista não ordenadas
O esquema do Junos define determinados objetos de configuração como listas. Nos dados de configuração JSON, uma instância de lista é codificada como um par de nome/matriz e os elementos da matriz são objetos JSON. Geralmente, a ordem dos membros em uma entrada de lista codificada em JSON é arbitrária porque os objetos JSON são fundamentalmente coleções não ordenadas de membros. No entanto, o esquema Junos requer que as chaves de lista precedam quaisquer outros irmãos em uma entrada de lista e apareçam na ordem especificada pelo esquema.
Por exemplo, o user objeto no nível de [edit system login] hierarquia é uma lista em name que está a chave de lista que identifica exclusivamente cada usuário.
list user {
key name;
description "Username";
uses login-user-object;
}
Nos dados de configuração de exemplo a seguir, a chave de lista (name) é o primeiro elemento para cada usuário. Por padrão, quando você carrega dados de configuração JSON, os dispositivos Junos exigem que as chaves de lista precedam quaisquer outros irmãos em uma entrada de lista e apareçam na ordem especificada pelo esquema.
{
"configuration" : {
"system" : {
"login" : {
"user" : [
{
"name" : "operator",
"class" : "operator",
"uid" : 3001
},
{
"name" : "security-admin",
"class" : "super-user",
"uid" : 3002
}
]
}
}
}
}
Os dispositivos Junos oferecem duas opções para carregar dados de configuração JSON que contêm entradas de lista não ordenadas, ou seja, entradas de lista em que a chave de lista não é necessariamente o primeiro elemento.
-
Use o
request system convert-json-configurationcomando de modo operacional para produzir dados de configuração JSON com entradas de lista ordenada antes de carregar os dados no dispositivo. -
Configure a
reorder-list-keysdeclaração no nível da[edit system configuration input format json]hierarquia. Depois de configurar a declaração, você pode carregar dados de configuração JSON com entradas de lista não ordenadas, e o dispositivo reordena as chaves de lista conforme exigido pelo esquema Junos durante a operação de carregamento.
Quando você configura a reorder-list-keys declaração, a operação de carregamento pode levar muito mais tempo para analisar a configuração, dependendo do tamanho da configuração e do número de listas. Assim, para configurações grandes ou configurações com muitas listas, recomendamos usar o request system convert-json-configuration comando em vez da reorder-list-keys instrução.
Por exemplo, suponha que o user-data.json arquivo contenha a seguinte configuração JSON. Se você tentasse carregar a configuração, o dispositivo emitiria um erro de carregamento porque admin2 a chave name de lista não é o primeiro elemento nessa entrada de lista.
user@host> file show /var/tmp/user-data.json
{
"configuration" : {
"system" : {
"login" : {
"user" : [
{
"name" : "admin1",
"class" : "super-user",
"uid" : 3003
},
{
"class" : "super-user",
"name" : "admin2",
"uid" : 3004
}
]
}
}
}
}
Se você usar o request system convert-json-configuration comando com o arquivo anterior como entrada, o comando gerará o arquivo de saída especificado com dados de configuração JSON que o dispositivo Junos pode analisar durante a operação de carregamento.
user@host> request system convert-json-configuration /var/tmp/user-data.json output-filename user-data-ordered.json
user@host> file show user-data-ordered.json
{
"configuration":{
"system":{
"login":{
"user":[
{
"name":"admin1",
"class":"super-user",
"uid":3003
},
{
"name":"admin2",
"class":"super-user",
"uid":3004
}
]
}
}
}
}
Como alternativa, você pode configurar a declaração de reorder-list-keys configuração.
user@host# set system configuration input format json reorder-list-keys user@host# commit
Depois de configurar a instrução, você pode carregar o arquivo de configuração JSON original com entradas de lista não ordenadas e o dispositivo manipula as entradas da lista quando analisa a configuração.
user@host# load merge json /var/tmp/user-data.json load complete