Nesta página
Exemplo: Configuração de rotas BGP IPv6 pelo transporte IPv4
Entendendo a redistribuição de rotas IPv4 com o próximo salto IPv6 no BGP
Configuração do BGP para redistribuir rotas IPv4 com endereços IPv6 next-hop
Exemplo: Permitindo que o BGP carregue rotas de especificação de fluxo
Exemplo: Configuração do BGP para transportar rotas de especificação de fluxo IPv6
Encaminhamento de tráfego usando especificação de fluxo BGP Ação DSCP
BGP multiprotocolo
Entendendo o BGP multiprotocol
O BGP multiprotocol (MP-BGP) é uma extensão ao BGP que permite que o BGP carregue informações de roteamento para várias camadas de rede e atenda às famílias. O MP-BGP pode transportar as rotas unicast usadas para roteamento multicast separadamente das rotas usadas para encaminhamento ip unicast.
Para habilitar o MP-BGP, você configura o BGP para transportar informações de alcance da camada de rede (NLRI) para famílias de endereços que não sejam IPv4 unicast, incluindo a family inet declaração:
family inet { (any | flow | labeled-unicast | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; topology name { community { target identifier; } } } }
Para permitir que o MP-BGP carregue o NLRI para a família de endereços IPv6, inclua a family inet6 declaração:
family inet6 { (any | labeled-unicast | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; } }
Apenas em roteadores, para permitir que o MP-BGP carregue a NLRI de rede virtual privada (VPN) de Camada 3 para a família de endereços IPv4, inclua a family inet-vpn declaração:
family inet-vpn { (any | flow | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; } }
Somente nos roteadores, para permitir que o MP-BGP carregue a VPN NLRI de Camada 3 para a família de endereços IPv6, inclua a family inet6-vpn declaração:
family inet6-vpn { (any | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;}} rib-group group-name; } }
Apenas em roteadores, para permitir que o MP-BGP carregue VPN MULTICAST NLRI para a família de endereços IPv4 e habilitar a sinalização de VPN, inclua a family inet-mvpn declaração:
family inet-mvpn {
signaling {
accepted-prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
<loops number>;
prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
}
}
Para permitir que o MP-BGP carregue VPN NLRI multicast para a família de endereços IPv6 e habilitar a sinalização de VPN, inclua a family inet6-mvpn declaração:
family inet6-mvpn {
signaling {
accepted-prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
<loops number>;
prefix-limit {
maximum number;
teardown <percentage> <idle-timeout <forever | minutes>;
drop-excess <percentage>;
hide-excess <percentage>;}}
}
}
Para obter mais informações sobre VPNs multiprotocol multicast baseadas em BGP, consulte o Guia de usuário de protocolos multicast do Junos OS.
Para obter uma lista de níveis de hierarquia nos quais você pode incluir essas declarações, veja as seções de resumo da declaração para essas declarações.
Se você alterar a família de endereços especificada no nível de [edit protocols bgp family] hierarquia, todas as sessões BGP atuais no dispositivo de roteamento serão descartadas e depois restabelecidas.
No Junos OS Release 9.6 e posterior, você pode especificar um valor de loops para uma família de endereços BGP específica.
Por padrão, os pares BGP transportam apenas rotas unicast usadas para fins de encaminhamento unicast. Para configurar os pares BGP para transportar apenas rotas multicast, especifique a opção multicast . Para configurar os pares BGP para transportar rotas unicast e multicast, especifique a opção any .
Quando o MP-BGP é configurado, o BGP instala as rotas MP-BGP em diferentes tabelas de roteamento. Cada tabela de roteamento é identificada pela família de protocolo ou indicador familiar de endereço (AFI) e um identificador familiar de endereço (SAFI) subsequente.
A lista a seguir mostra todas as possíveis combinações de AFI e SAFI:
AFI=1, SAFI=1, IPv4 unicast
AFI=1, SAFI=2, IPv4 multicast
AFI=1, SAFI=128, L3VPN IPv4 unicast
AFI=1, SAFI=129, L3VPN IPv4 multicast
AFI=2, SAFI=1, IPv6 unicast
AFI=2, SAFI=2, IPv6 multicast
AFI=25, SAFI=65, BGP-VPLS/BGP-L2VPN
AFI=2, SAFI=128, L3VPN IPv6 unicast
AFI=2, SAFI=129, L3VPN IPv6 multicast
AFI=1, SAFI=132, RT-Constrain
AFI=1, SAFI=133, especificação de fluxo
AFI=1, SAFI=134, especificação de fluxo
AFI=3, SAFI=128, CLNS VPN
AFI=1, SAFI=5, NG-MVPN IPv4
AFI=2, SAFI=5, NG-MVPN IPv6
AFI=1, SAFI=66, MDT-SAFI
AFI=1, SAFI=4, IPv4 rotulado
AFI=2, SAFI=4, IPv6 rotulado (6PE)
As rotas instaladas na tabela de roteamento inet.2 só podem ser exportadas para pares MP-BGP porque usam o SAFI, identificando-os como rotas para fontes multicast. As rotas instaladas na tabela de roteamento inet.0 só podem ser exportadas para pares BGP padrão.
A tabela de roteamento inet.2 deve ser um subconjunto das rotas que você tem no inet.0, uma vez que é improvável que você tenha uma rota para uma fonte multicast para a qual você não poderia enviar tráfego unicast. A tabela de roteamento inet.2 armazena as rotas unicast que são usadas para verificações de encaminhamento de caminho reverso multicast e as informações adicionais de alcance aprendidas pelo MP-BGP a partir das atualizações multicast da NLRI. Uma tabela de roteamento inet.2 é criada automaticamente quando você configura MP-BGP (configurando NLRI para any).
Ao habilitar o MP-BGP, você pode fazer o seguinte:
- Limitando o número de prefixos recebidos em uma sessão de peer BGP
- Limitando o número de prefixos aceitos em uma sessão de peer BGP
- Configuração de grupos de tabela de roteamento BGP
- Resolução de rotas para dispositivos de roteamento de PE localizados em outras ASs
- Permitindo rotas rotuladas e sem rótulos
Limitando o número de prefixos recebidos em uma sessão de peer BGP
Você pode limitar o número de prefixos recebidos em uma sessão de peer BGP, e registrar mensagens limitadas por taxa de log quando o número de prefixos injetados excede um limite definido. Você também pode derrubar o peering quando o número de prefixos exceder o limite.
Para configurar um limite para o número de prefixos que podem ser recebidos em uma sessão BGP, inclua a prefix-limit declaração:
prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>; }
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Para maximum number, especifique um valor na faixa de 1 a 4.294.967.295. Quando o número máximo de prefixos especificado é excedido, uma mensagem de log do sistema é enviada.
Se você incluir a teardown declaração, a sessão será demolida quando o número máximo de prefixos for excedido. Se você especificar uma porcentagem, as mensagens são registradas quando o número de prefixos excede essa porcentagem do limite máximo especificado. Após a demolição da sessão, ela é restabelecida em pouco tempo (a menos que você inclua a idle-timeout declaração). Se você incluir a idle-timeout declaração, a sessão pode ser mantida baixa por um período especificado de tempo ou para sempre. Se você especificar forever, a sessão só será restabelecida após a emissão de um clear bgp neighbor comando. Se você incluir a opção drop-excess <percentage> , as rotas em excesso são perdidas quando o número máximo de prefixos é alcançado. Se você especificar uma porcentagem, as rotas são registradas quando o número de prefixos excede esse valor percentual do número máximo. Se você incluir a opção hide-excess <percentage> , as rotas em excesso ficam ocultas quando o número máximo de prefixos é alcançado. Se você especificar uma porcentagem, as rotas são registradas quando o número de prefixos excede esse valor percentual do número máximo. Se a porcentagem for modificada, as rotas serão reavaliadas automaticamente. Se as rotas ativas caírem abaixo da porcentagem especificada, essas rotas serão mantidas ocultas.
No Junos OS Release 9.2 e posterior, você pode configurar alternativamente um limite para o número de prefixos que podem ser aceitos em uma sessão de peer BGP. Para obter mais informações, veja Limitando o número de prefixos aceitos em uma sessão de peer BGP.
Limitando o número de prefixos aceitos em uma sessão de peer BGP
No Junos OS Release 9.2 e posterior, você pode limitar o número de prefixos que podem ser aceitos em uma sessão de peer BGP. Quando esse limite especificado é excedido, uma mensagem de log do sistema é enviada. Você também pode especificar para redefinir a sessão BGP se o limite para o número de prefixos especificados for excedido.
Para configurar um limite para o número de prefixos que podem ser aceitos em uma sessão de peer BGP, inclua a accepted-prefix-limit declaração:
accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop <percentage>; hide <percentage>; }
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Para maximum number, especifique um valor na faixa de 1 a 4.294.967.295.
Inclua a teardown declaração para redefinir a sessão de peer BGP quando o número de prefixos aceitos exceder o limite configurado. Você também pode incluir um valor percentual de 1 a 100 para ter uma mensagem de log do sistema enviada quando o número de prefixos aceitos excede essa porcentagem do limite máximo. Por padrão, uma sessão BGP que é reiniciada é restabelecida em um curto espaço de tempo. Inclua a idle-timeout declaração para evitar que a sessão BGP seja restabelecida por um determinado período de tempo. Você pode configurar um valor de tempo limite de 1 a 2400 minutos. Inclua a opção forever de evitar que a sessão BGP seja restabelecida até que você emita o clear bgp neighbor comando. Se você incluir a drop-excess <percentage> declaração e especificar uma porcentagem, as rotas em excesso são perdidas quando o número de prefixos excede a porcentagem. Se você incluir a hide-excess <percentage> declaração e especificar uma porcentagem, as rotas em excesso ficam ocultas quando o número de prefixos excede a porcentagem. Se a porcentagem for modificada, as rotas serão reavaliadas automaticamente.
Quando o roteamento ativo (NSR) ininterrupto é habilitado e ocorre uma transferência para um mecanismo de roteamento de backup, os pares BGP que estão desativados são reiniciados automaticamente. Os pares são reiniciados mesmo se a idle-timeout forever declaração estiver configurada.
Como alternativa, você pode configurar um limite para o número de prefixos que podem ser recebidos (em vez de aceitos) em uma sessão de peer BGP. Para obter mais informações, veja Limitando o número de prefixos recebidos em uma sessão de peer BGP.
Configuração de grupos de tabela de roteamento BGP
Quando uma sessão BGP recebe um NLRI unicast ou multicast, ele instala a rota na tabela apropriada (inet.0 ou inet6.0 para unicast, e inet.2 ou inet6.2 para multicast). Para adicionar prefixos unicast às tabelas unicast e multicast, você pode configurar grupos de tabela de roteamento BGP. Isso é útil se você não puder realizar negociações de NLRI multicast.
Para configurar grupos de tabela de roteamento BGP, inclua a rib-group declaração:
rib-group group-name;
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Resolução de rotas para dispositivos de roteamento de PE localizados em outras ASs
Você pode permitir que rotas rotuladas sejam colocadas na inet.3 tabela de roteamento para resolução de rotas. Essas rotas são então resolvidas para conexões de dispositivos de roteamento de borda de provedor (PE), onde o PE remoto está localizado em outro sistema autônomo (AS). Para que um dispositivo de roteamento de PE instale uma rota na instância de roteamento de roteamento e encaminhamento VPN (VRF), o próximo salto deve ser resolvido para uma rota armazenada dentro da inet.3 tabela.
Para resolver rotas na inet.3 tabela de roteamento, inclua a resolve-vpn declaração:
resolve-vpn group-name;
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Permitindo rotas rotuladas e sem rótulos
Você pode permitir que rotas rotuladas e não rotuladas sejam trocadas em uma única sessão. As rotas rotuladas são colocadas na tabela de roteamento inet.3 ou inet6.3, e rotas unicast rotuladas e não rotuladas podem ser enviadas ou recebidas pelo dispositivo de roteamento.
Para permitir que rotas rotuladas e não rotuladas sejam trocadas, inclua a rib declaração:
rib (inet.3 | inet6.3);
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
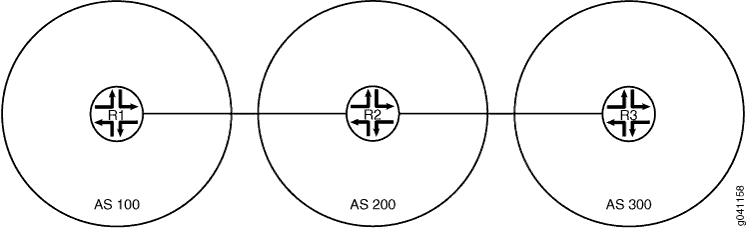
Exemplo: Configuração de rotas BGP IPv6 pelo transporte IPv4
Este exemplo demonstra como exportar prefixos IPv6 e IPv4 em uma conexão IPv4 onde ambos os lados estão configurados com uma interface IPv4.
Requisitos
Nenhuma configuração especial além da inicialização do dispositivo é necessária antes de configurar este exemplo.
Visão geral
Tenha em mente o seguinte quando exportar prefixos IPv6 BGP:
O BGP deriva prefixos de próximo salto usando o prefixo IPv4 mapeado IPv6. Por exemplo, o prefixo
10.19.1.1de próximo salto IPv4 se traduz no prefixo de próximo salto IPv6 ::ffff:10.19.1.1.1.Nota:Deve haver uma rota ativa para o IPv4 mapeado IPv6 próximo salto para exportar prefixos IPv6 BGP.
Uma conexão IPv6 deve ser configurada pelo link. A conexão deve ser um túnel IPv6 ou uma configuração de pilha dupla. O empilhamento duplo é usado neste exemplo.
Ao configurar prefixos IPv4 mapeados com IPv6, use uma máscara com mais de 96 bits.
Configure uma rota estática se quiser usar prefixos IPv6 normais. Este exemplo usa rotas estáticas.
Figura 1 mostra a topologia da amostra.
Configuração
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
Dispositivo R1
set interfaces fe-1/2/0 unit 1 family inet address 192.168.10.1/24 set interfaces fe-1/2/0 unit 1 family inet6 address ::ffff:192.168.10.1/120 set interfaces lo0 unit 1 family inet address 10.10.10.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext peer-as 200 set protocols bgp group ext neighbor 192.168.10.10 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options rib inet6.0 static route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10 set routing-options static route 192.168.20.0/24 next-hop 192.168.10.10 set routing-options autonomous-system 100
Dispositivo R2
set interfaces fe-1/2/0 unit 2 family inet address 192.168.10.10/24 set interfaces fe-1/2/0 unit 2 family inet6 address ::ffff:192.168.10.10/120 set interfaces fe-1/2/1 unit 3 family inet address 192.168.20.21/24 set interfaces fe-1/2/1 unit 3 family inet6 address ::ffff:192.168.20.21/120 set interfaces lo0 unit 2 family inet address 10.10.0.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext neighbor 192.168.10.1 peer-as 100 set protocols bgp group ext neighbor 192.168.20.1 peer-as 300 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options autonomous-system 200
Dispositivo R3
set interfaces fe-1/2/0 unit 4 family inet address 192.168.20.1/24 set interfaces fe-1/2/0 unit 4 family inet6 address ::ffff:192.168.20.1/120 set interfaces lo0 unit 3 family inet address 10.10.20.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext peer-as 200 set protocols bgp group ext neighbor 192.168.20.21 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options rib inet6.0 static route ::ffff:192.168.10.0/120 next-hop ::ffff:192.168.20.21 set routing-options static route 192.168.10.0/24 next-hop 192.168.20.21 set routing-options autonomous-system 300
Configuração do dispositivo R1
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Para configurar o dispositivo R1:
Configure as interfaces, incluindo um endereço IPv4 e um endereço IPv6.
[edit interfaces] user@R1# set fe-1/2/0 unit 1 family inet address 192.168.10.1/24 user@R1# set fe-1/2/0 unit 1 family inet6 address ::ffff:192.168.10.1/120 user@R1# set lo0 unit 1 family inet address 10.10.10.1/32
Configure EBGP.
[edit protocols bgp group ext] user@R1# set type external user@R1# set export send-direct user@R1# set export send-static user@R1# set peer-as 200 user@R1# set neighbor 192.168.10.10
-
Habilite o BGP para transportar rotas unicast IPv4 e IPv6 unicast.
[edit protocols bgp group ext] user@R1# set family inet unicast user@R1# set family inet6 unicast
As rotas unicast IPv4 são habilitadas por padrão. No entanto, quando você configura outras famílias de endereços NLRI, o unicast IPv4 deve ser configurado explicitamente.
-
Configure a política de roteamento.
[edit policy-options] user@R1# set policy-statement send-direct term 1 from protocol direct user@R1# set policy-statement send-direct term 1 then accept user@R1# set policy-statement send-static term 1 from protocol static user@R1# set policy-statement send-static term 1 then accept
Configure algumas rotas estáticas.
[edit routing-options] user@R1# set rib inet6.0 static route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10 user@R1# set static route 192.168.20.0/24 next-hop 192.168.10.10
Configure o número do sistema autônomo (AS).
[edit routing-options] user@R1# set autonomous-system 100
Resultados
A partir do modo de configuração, confirme sua configuração entrando noshow interfaces, show policy-optionsshow protocolse show routing-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
user@R1# show interfaces
fe-1/2/0 {
unit 1 {
family inet {
address 192.168.10.1/24;
}
family inet6 {
address ::ffff:192.168.10.1/120;
}
}
}
lo0 {
unit 1 {
family inet {
address 10.10.10.1/32;
}
}
}
user@R1# show policy-options
policy-statement send-direct {
term 1 {
from protocol direct;
then accept;
}
}
policy-statement send-static {
term 1 {
from protocol static;
then accept;
}
}
user@R1# show protocols
bgp {
group ext {
type external;
family inet {
unicast;
}
family inet6 {
unicast;
}
export [ send-direct send-static ];
peer-as 200;
neighbor 192.168.10.10;
}
}
user@R1# show routing-options
rib inet6.0 {
static {
route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10;
}
}
static {
route 192.168.20.0/24 next-hop 192.168.10.10;
}
autonomous-system 100;
Se você terminar de configurar o dispositivo, entre no commit modo de configuração. Repita a configuração no dispositivo R2 e no dispositivo R3, alterando os nomes da interface e endereços IP, conforme necessário.
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando o estado do vizinho
Propósito
Certifique-se de que o BGP esteja habilitado para transportar rotas unicast IPv6.
Ação
A partir do modo operacional, entre no show bgp neighbor comando.
user@R2> show bgp neighbor
Peer: 192.168.10.1+179 AS 100 Local: 192.168.10.10+54226 AS 200
Type: External State: Established Flags: <Sync>
Last State: OpenConfirm Last Event: RecvKeepAlive
Last Error: None
Export: [ send-direct send-static ]
Options: <Preference AddressFamily PeerAS Refresh>
Address families configured: inet-unicast inet6-unicast
Holdtime: 90 Preference: 170
Number of flaps: 0
Peer ID: 10.10.10.1 Local ID: 10.10.0.1 Active Holdtime: 90
Keepalive Interval: 30 Peer index: 0
BFD: disabled, down
Local Interface: fe-1/2/0.2
NLRI for restart configured on peer: inet-unicast inet6-unicast
NLRI advertised by peer: inet-unicast inet6-unicast
NLRI for this session: inet-unicast inet6-unicast
Peer supports Refresh capability (2)
Stale routes from peer are kept for: 300
Peer does not support Restarter functionality
NLRI that restart is negotiated for: inet-unicast inet6-unicast
NLRI of received end-of-rib markers: inet-unicast inet6-unicast
NLRI of all end-of-rib markers sent: inet-unicast inet6-unicast
Peer supports 4 byte AS extension (peer-as 100)
Peer does not support Addpath
Table inet.0 Bit: 10000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 1
Received prefixes: 3
Accepted prefixes: 2
Suppressed due to damping: 0
Advertised prefixes: 4
Table inet6.0 Bit: 20000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 0
Received prefixes: 1
Accepted prefixes: 1
Suppressed due to damping: 0
Advertised prefixes: 2
Last traffic (seconds): Received 24 Sent 12 Checked 60
Input messages: Total 132 Updates 6 Refreshes 0 Octets 2700
Output messages: Total 133 Updates 3 Refreshes 0 Octets 2772
Output Queue[0]: 0
Output Queue[1]: 0
Peer: 192.168.20.1+179 AS 300 Local: 192.168.20.21+54706 AS 200
Type: External State: Established Flags: <Sync>
Last State: OpenConfirm Last Event: RecvKeepAlive
Last Error: None
Export: [ send-direct send-static ]
Options: <Preference AddressFamily PeerAS Refresh>
Address families configured: inet-unicast inet6-unicast
Holdtime: 90 Preference: 170
Number of flaps: 0
Peer ID: 10.10.20.1 Local ID: 10.10.0.1 Active Holdtime: 90
Keepalive Interval: 30 Peer index: 1
BFD: disabled, down
Local Interface: fe-1/2/1.3
NLRI for restart configured on peer: inet-unicast inet6-unicast
NLRI advertised by peer: inet-unicast inet6-unicast
NLRI for this session: inet-unicast inet6-unicast
Peer supports Refresh capability (2)
Stale routes from peer are kept for: 300
Peer does not support Restarter functionality
NLRI that restart is negotiated for: inet-unicast inet6-unicast
NLRI of received end-of-rib markers: inet-unicast inet6-unicast
NLRI of all end-of-rib markers sent: inet-unicast inet6-unicast
Peer supports 4 byte AS extension (peer-as 300)
Peer does not support Addpath
Table inet.0 Bit: 10000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 1
Received prefixes: 3
Accepted prefixes: 2
Suppressed due to damping: 0
Advertised prefixes: 4
Table inet6.0 Bit: 20000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 0
Received prefixes: 1
Accepted prefixes: 1
Suppressed due to damping: 0
Advertised prefixes: 2
Last traffic (seconds): Received 1 Sent 15 Checked 75
Input messages: Total 133 Updates 6 Refreshes 0 Octets 2719
Output messages: Total 131 Updates 3 Refreshes 0 Octets 2734
Output Queue[0]: 0
Output Queue[1]: 0Significado
As várias ocorrências da inet6-unicast saída mostram que o BGP está habilitado a transportar rotas unicast IPv6.
Verificando a tabela de roteamento
Propósito
Certifique-se de que o dispositivo R2 tenha rotas BGP em sua tabela de roteamento inet6.0.
Ação
A partir do modo operacional, entre no show route protocol bgp inet6.0 comando.
user@R2> show route protocol bgp table inet6.0
inet6.0: 7 destinations, 10 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
::ffff:192.168.10.0/120 [BGP/170] 01:03:49, localpref 100, from 192.168.20.1
AS path: 300 I
> to ::ffff:192.168.20.21 via fe-1/2/1.3
::ffff:192.168.20.0/120 [BGP/170] 01:03:53, localpref 100, from 192.168.10.1
AS path: 100 I
> to ::ffff:192.168.10.10 via fe-1/2/0.2Publicidade Rotas IPv4 em visão geral do BGP IPv6 Sessions
Em uma rede IPv6, o BGP normalmente anuncia informações de acessibilidade da camada de rede IPv6 em uma sessão de IPv6 entre pares BGP. Em lançamentos anteriores, o Junos OS apoiava a troca de famílias de endereços unicast inet6, inet6 multicast ou inet6 rotuladas. Esse recurso permite a troca de todas as famílias de endereços BGP. Em um ambiente de pilha dupla que tem o IPv6 em seu núcleo. este recurso permite que o BGP anuncie a acessibilidade unicast IPv4 com iPv4 próximo salto em uma sessão BGP IPv6.
Este recurso é apenas para sessões BGP IPv6, onde o IPv4 está configurado em ambos os endpoints. Pode local-ipv4-address ser um endereço de loopback ou qualquer endereço ipv4 para uma sessão de EBGP de IBGP ou de múltiplos saltos. Para alto-falantes BGP externos de salto único que não fazem parte das confederações BGP, se o endereço IPv4 local configurado não estiver conectado diretamente, a sessão BGP é fechada e permanece ociosa e um erro é gerado, que é exibido na saída do show bgp neighbor comando.
Para habilitar a publicidade de rotas IPv4 na sessão IPv6, configure local-ipv4-address da seguinte forma:
[edit protocols bgp family inet unicast] local-ipv4-address local ipv4 address;
Você não pode configurar esse recurso para as famílias de endereços unicast inet6, inet6 multicast ou inet6 de endereços unicast rotulados porque o BGP já tem a capacidade de anunciar essas famílias de endereços em uma sessão BGP IPv6.
A configuração local-ipv4-address só é usada quando o BGP anuncia rotas com auto-próximo salto. Quando o IBGP anuncia rotas aprendidas com pares de EBGP ou o refletor de rota anuncia rotas BGP para seus clientes, o BGP não muda a rota do próximo salto, ignora a configuração local-ipv4-addresse usa o próximo salto IPv4 original.
Consulte também
Exemplo: Publicidade Rotas IPv4 em sessões BGP IPv6
Este exemplo mostra como anunciar rotas IPv4 na sessão BGP do IPv6. Em um ambiente de pilha dupla que tenha o IPv6 em seu núcleo, há a necessidade de alcançar hosts IPv4 remotos. Portanto, o BGP anuncia rotas IPv4 com próximo salto IPv4 para peers BGP em sessões BGP usando endereços de origem e destino IPv6. Esse recurso permite que o BGP anuncie a acessibilidade unicast IPv4 com o próximo salto IPv4 em sessões BGP IPv6.
Requisitos
Este exemplo usa os seguintes componentes de hardware e software:
Três roteadores com capacidade de empilhamento duplo
Junos OS Release 16.1 ou posterior em todos os dispositivos
Antes de habilitar anúncios IPv4 em sessões BGP IPv6, certifique-se de:
Configure as interfaces do dispositivo.
Configure o empilhamento duplo em todos os dispositivos.
Visão geral
Começando com o lançamento de 16.1, o Junos OS permite que o BGP anuncie a acessibilidade unicast IPv4 com o próximo salto IPv4 em uma sessão BGP IPv6. Em lançamentos anteriores do Junos OS, o BGP poderia anunciar apenas inet6 unicast, inet6 multicast e inet6 famílias de endereços unicast rotulados em sessões BGP IPv6. Esse recurso permite que o BGP troque todas as famílias de endereços BGP em uma sessão IPv6. Você pode habilitar o BGP a anunciar rotas IPv4 com o próximo salto IPv4 para peers BGP durante a sessão IPv6. A configuração local-ipv4-address só é usada quando o BGP anuncia rotas com auto-próximo salto.
Você não pode configurar esse recurso para as famílias de endereços unicast inet6, inet6 multicast ou inet6 de endereços unicast rotulados porque o BGP já tem a capacidade de anunciar essas famílias de endereços em uma sessão BGP IPv6.
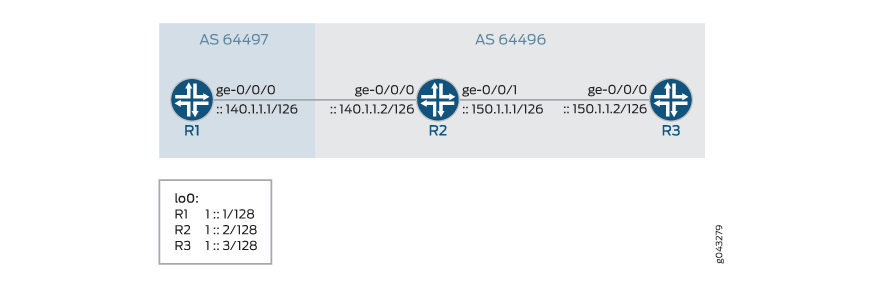
Topologia
Em Figura 2, uma sessão BGP externa do IPv6 está sendo executada entre os roteadores R1 e R2. Uma sessão IPv6 IBGP é estabelecida entre o Roteador R2 e o Roteador R3. As rotas estáticas IPv4 são redistribuídas para o BGP no R1. Para redistribuir as rotas IPv4 na sessão BGP IPv6, o novo recurso deve ser habilitado em todos os roteadores no nível de [edit protocols bgp address family] hierarquia.
Configuração
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos na CLI no nível de [edit] hierarquia e, em seguida, entrar no commit modo de configuração.
Roteador R1
set interfaces ge-0/0/0 unit 0 description R1->R2 set interfaces ge-0/0/0 unit 0 family inet address 140.1.1.1/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::140.1.1.1/126 set interfaces lo0 unit 0 family inet6 address 1::1/128 set routing-options static route 11.1.1.1/32 discard set routing-options static route 11.1.1.2/32 discard set routing-options autonomous-system 64497 set protocols bgp group ebgp-v6 type external set protocols bgp group ebgp-v6 export p1 set protocols bgp group ebgp-v6 peer-as 64496 set protocols bgp group ebgp-v6 neighbor ::140.1.1.2 description R2 set protocols bgp group ebgp-v6 neighbor ::140.1.1.2 family inet unicast local-ipv4-address 140.1.1.1 set policy-options policy-statement p1 from protocol static set policy-options policy-statement p1 then accept
Roteador R2
set interfaces ge-0/0/0 unit 0 description R2->R1 set interfaces ge-0/0/0 unit 0 family inet address 140.1.1.2/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::140.1.1.2/126 set interfaces ge-0/0/1 unit 0 description R2->R3 set interfaces ge-0/0/1 unit 0 family inet address 150.1.1.1/24 set interfaces ge-0/0/1 unit 0 family inet6 address ::150.1.1.1/126 set interfaces lo0 unit 0 family inet6 address 1::2/128 set routing-options autonomous-system 64496 set protocols bgp group ibgp-v6 type internal set protocols bgp group ibgp-v6 export change-nh set protocols bgp group ibgp-v6 neighbor ::150.1.1.2 description R3 set protocols bgp group ibgp-v6 neighbor ::150.1.1.2 family inet unicast local-ipv4-address 150.1.1.1 set protocols bgp group ebgp-v6 type external set protocols bgp group ebgp-v6 peer-as 64497 set protocols bgp group ebgp-v6 neighbor ::140.1.1.1 description R1 set protocols bgp group ebgp-v6 neighbor ::140.1.1.1 family inet unicast local-ipv4-address 140.1.1.2 set policy-options policy-statement change-nh from protocol bgp set policy-options policy-statement change-nh then next-hop self set policy-options policy-statement change-nh then accept
Roteador R3
set interfaces ge-0/0/0 unit 0 description R3->R2 set interfaces ge-0/0/0 unit 0 family inet address 150.1.1.2/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::150.1.1.2/126 set interfaces lo0 unit 0 family inet6 address 1::3/128 set routing-options autonomous-system 64496 set protocols bgp group ibgp-v6 type internal set protocols bgp group ibgp-v6 neighbor ::150.1.1.1 description R2 set protocols bgp group ibgp-v6 neighbor ::150.1.1.1 family inet unicast local-ipv4-address 150.1.1.2
Configuração do roteador R1
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia do usuário da CLI.
Para configurar o roteador R1:
Repita este procedimento para outros roteadores após modificar os nomes, endereços e outros parâmetros de interface apropriados.
Configure as interfaces com endereços IPv4 e IPv6.
[edit interfaces] user@R1# set ge-0/0/0 unit 0 description R1->R2 user@R1# set ge-0/0/0 unit 0 family inet address 140.1.1.1/24 user@R1# set ge-0/0/0 unit 0 family inet6 address ::140.1.1.1/126
Configure o endereço de loopback.
[edit interfaces] user@R1# set lo0 unit 0 family inet6 address 1::1/128
Configure uma rota estática IPv4 que precisa ser anunciada.
[edit routing-options] user@R1# set static route 11.1.1.1/32 discard user@R1# set static route 11.1.1.2/32 discard
Configure o sistema autônomo para hosts BGP.
[edit routing-options] user@R1# set autonomous-system 64497
Configure o EBGP nos roteadores de borda externos.
[edit protocols] user@R1# set bgp group ebgp-v6 type external user@R1# set bgp group ebgp-v6 peer-as 64496 user@R1# set bgp group ebgp-v6 neighbor ::140.1.1.2 description R2
Habilite o recurso para anunciar o adddress IPv4 140.1.1.1 em sessões BGP IPv6.
[edit protocols] user@R1# set bgp group ebgp-v6 neighbor ::140.1.1.2 family inet unicast local-ipv4-address 140.1.1.1
Definir uma política p1 para aceitar todas as rotas estáticas.
[edit policy-options] user@R1# set policy-statement p1 from protocol static user@R1# set policy-statement p1 then accept
Aplique a política p1 no grupo EBGP ebgp-v6.
[edit protocols] user@R1# set bgp group ebgp-v6 export p1
Resultados
A partir do modo de configuração, confirme sua configuração entrando noshow interfaces, show protocolsshow routing-optionse show policy-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@R1# show interfaces
ge-0/0/0 {
unit 0 {
description R1->R2;
family inet {
address 140.1.1.1/24;
}
family inet6 {
address ::140.1.1.1/126;
}
}
lo0 {
unit 0 {
family inet {
address 1::1/128;
}
}
}
}
[edit]
user@R1# show protocols
bgp {
group ebgp-v6 {
type external;
export p1;
peer-as 64496;
neighbor ::140.1.1.2 {
description R2;
family inet {
unicast {
local-ipv4-address 140.1.1.1;
}
}
}
}
}
[edit]
user@R1# show routing-options
static {
route 11.1.1.1/32 discard;
route 11.1.1.2/32 discard;
}
autonomous-system 64497;
[edit]
user@R1# show policy-options
policy-statement p1 {
from {
protocol static;
}
then accept;
}
Se você terminar de configurar o dispositivo, confirme a configuração.
user@R1# commit
Verificação
Confirme se a configuração está funcionando corretamente.
- Verificando se a sessão bgp está ativa
- Verificando se o endereço IPv4 está sendo anunciado
- Verificando se o roteador vizinho BGP R2 recebe o endereço IPv4 anunciado
Verificando se a sessão bgp está ativa
Propósito
Verifique se o BGP está sendo executado nas interfaces configuradas e se a sessão BGP está ativa para cada endereço vizinho.
Ação
A partir do modo operacional, execute o show bgp summary comando no Roteador R1.
user@R1> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
::140.1.1.2 64496 4140 4158 0 0 1d 7:10:36 0/0/0/0 0/0/0/0
Significado
A sessão bgp está em funcionamento, e o peering BGP está estabelecido.
Verificando se o endereço IPv4 está sendo anunciado
Propósito
Verifique se o endereço IPv4 configurado está sendo anunciado pelo Roteador R1 para os vizinhos BGP configurados.
Ação
A partir do modo operacional, execute o show route advertising-protocol bgp ::150.1.1.2 comando no Roteador R1.
user@R1> show route advertising-protocol bgp ::150.1.1.2 inet.0: 48 destinations, 48 routes (48 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 11.1.1.1/32 Self 64497 64497 I * 11.1.1.2/32 Self 64497 64497 I
Significado
A rota estática IPv4 está sendo anunciada para o roteador vizinho BGP R2.
Verificando se o roteador vizinho BGP R2 recebe o endereço IPv4 anunciado
Propósito
Verifique se o Roteador R2 recebe o endereço IPv4 que o Roteador R1 está anunciando para o vizinho BGP por IPv6.
Ação
user@R2> show route receive-protocol bgp ::140.1.1.1 inet.0: 48 destinations, 48 routes (48 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 11.1.1.1/32 140.1.1.1 64497 I * 11.1.1.2/32 140.1.1.1 64497 I iso.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden) inet6.0: 9 destinations, 10 routes (9 active, 0 holddown, 0 hidden)
Significado
A presença da rota IPv4 estática na tabela de roteamento do Roteador R2 indica que ele está recebendo as rotas IPv4 anunciadas do Roteador R1.
Entendendo a redistribuição de rotas IPv4 com o próximo salto IPv6 no BGP
Em uma rede que transporta predominantemente o tráfego IPv6, há a necessidade de rotear rotas IPv4 quando necessário. Por exemplo, um provedor de serviços de Internet que tem uma rede exclusiva para IPv6, mas tem clientes que ainda roteam o tráfego IPv4. Neste caso, é necessário atender a esses clientes e encaminhar o tráfego IPv4 por uma rede IPv6. Como descrito no RFC 5549, as informações de acessibilidade da camada de rede IPv4 com um tráfego IPv6 Next Hop IPv4 são tuneladas de dispositivos de equipamentos nas instalações do cliente (CPE) para gateways IPv4-over-IPv6. Esses gateways são anunciados para dispositivos CPE por meio de endereçoscast. Os dispositivos de gateway então criam túneis IPv4-over-IPv6 dinâmicos para dispositivos CPE remotos e anunciam rotas agregadas IPv4 para direcionar o tráfego.
O recurso dinâmico de túnel IPv4-over-IPv6 não oferece suporte a ISSU unificado no Junos OS Release 17.3R1.
Os refletores de rota (RRs) com uma interface programável são conectados pelo IBGP aos roteadores de gateway e rotas de host com endereço IPv6 como próximo salto. Esses RRs anunciam os endereços IPv4/32 para injetar as informações do túnel na rede. Os roteadores de gateway criam túneis IPv4-over-IPv6 dinâmicos para a borda remota do provedor de clientes. O roteador de gateway também anuncia as rotas agregadas IPv4 para direcionar o tráfego. A RR então anuncia as rotas de origem do túnel para o ISP. Quando o RR remove a rota do túnel, o BGP também retira a rota fazendo com que o túnel seja demolido e o CPE seja inalcançável. O roteador de gateway também retira as rotas agregadas IPv4 e as rotas de origem do túnel IPv6 quando todas as rotas agregadas contribuintes são removidas. O roteador de gateway envia retirada de rota quando a placa de linha âncora do Mecanismo de encaminhamento de pacotes cai, para que ele redirecione o tráfego para outros roteadores de gateway.
As seguintes extensões são introduzidas para oferecer suporte a rotas IPv4 com um próximo salto IPv6:
- Codificação de próximo salto BGP
- Localização de túneis
- Manuseio de túneis
- Balanceamento de carga de túnel e manuseio de falhas no mecanismo de encaminhamento de pacotes âncora
- Estatísticas do fluxo de loopback de túnel
Codificação de próximo salto BGP
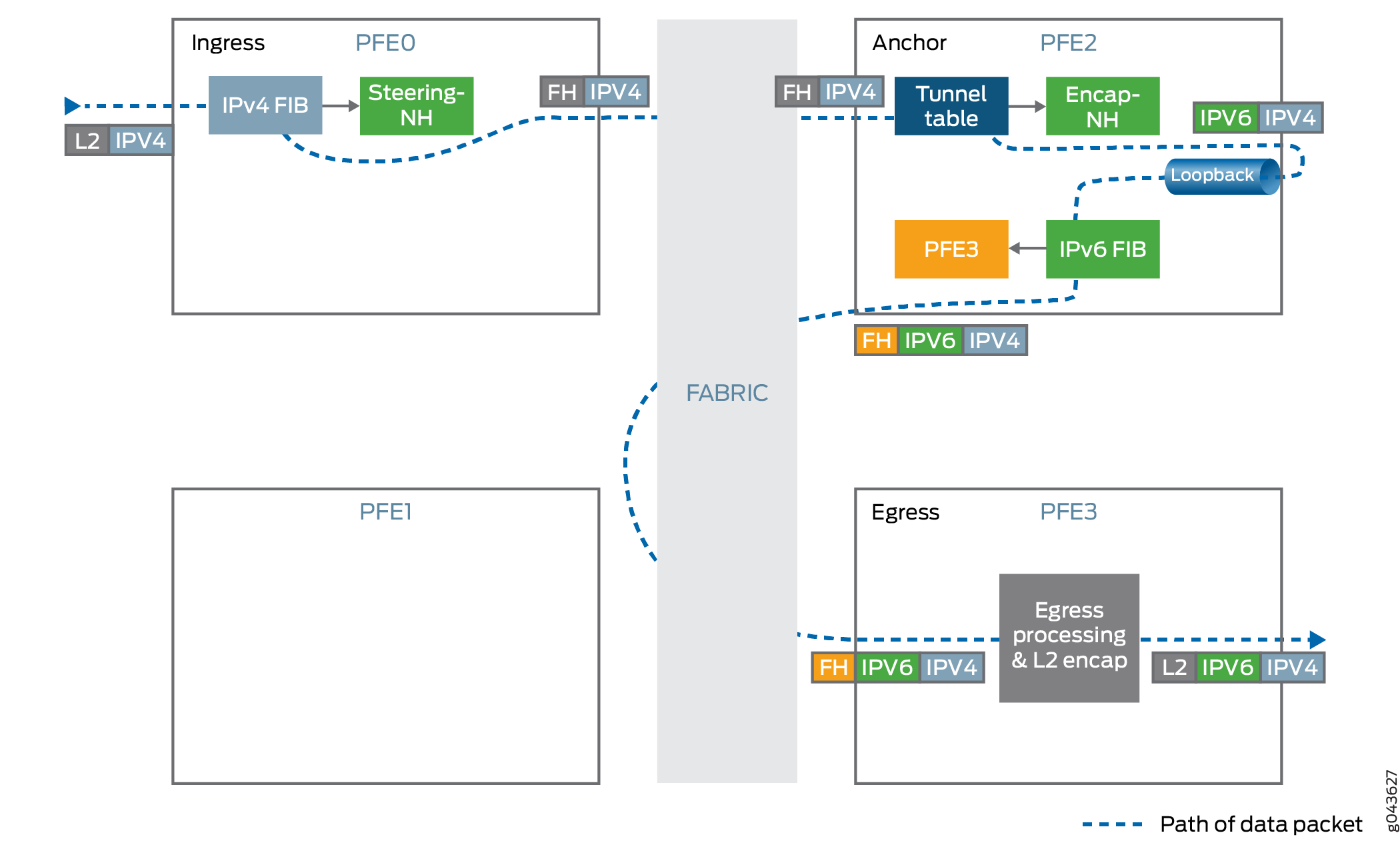
O BGP é estendido com recursos de codificação de próximo salto usados para enviar rotas IPv4 com saltos próximos IPv6. Se esse recurso não estiver disponível no peer remoto, o BGP agrupa os pares com base nesse recurso de codificação e remove a família BGP sem codificar recursos da lista de informações de alcance da camada de rede (NLRI) negociadas. O Junos OS permite apenas uma tabela de resolução, como o inet.0. Para permitir rotas BGP IPv4 com o próximo salto IPv6, o BGP cria uma nova árvore de resolução. Esse recurso permite que uma tabela de roteamento do Junos OS tenha várias árvores de resolução.
Além do RFC 5549, as informações de acessibilidade da camada de rede IPv4 com um IPv6 Next Hop uma nova comunidade de encapsulamento especificada no RFC 5512, o BGP Encapsulation Subsequent Address Family Identifier (SAFI) e o Atributo de encapsulamento de túnel BGP são introduzidos para determinar a família de endereços do endereço próximo. A comunidade de encapsulamento indica o tipo de túneis que o nó de entrada precisa criar. Quando o BGP recebe rotas IPv4 com endereço IPv6 de próximo salto e a comunidade de encapsulamento V4oV6, o BGP cria túneis dinâmicos IPv4-over-IPv6. Quando o BGP recebe rotas sem a comunidade de encapsulamento, as rotas BGP são resolvidas sem criar o túnel V4oV6.
Uma nova ação dynamic-tunnel-attributes dyan-attribute de política está disponível no nível de [edit policy-statement policy name term then] hierarquia para oferecer suporte ao novo encapsulamento estendido.
Localização de túneis
A infraestrutura dinâmica de túneis é aprimorada com a localização de túneis para oferecer suporte a um número maior de túneis. Há necessidade de localização de túneis para fornecer resiliência para lidar com o tráfego quando a âncora falha. Um ou mais chassis se respaldam e permitem que o processo de protocolo de roteamento (rpd) afaste o tráfego do ponto de falha para o chassi de backup. O chassi anuncia apenas esses prefixos agregados em vez dos endereços de loopback individuais na rede.
Manuseio de túneis
Os túneis IPv4 sobre IPv6 usam a infraestrutura dinâmica de túneis, juntamente com a ancoragem de túneis para oferecer suporte ao chassi necessário em grande escala. O estado do túnel é localizado em um mecanismo de encaminhamento de pacotes e os outros Mecanismos de encaminhamento de pacotes direcionam o tráfego para a âncora do túnel.
Entrada de túnel
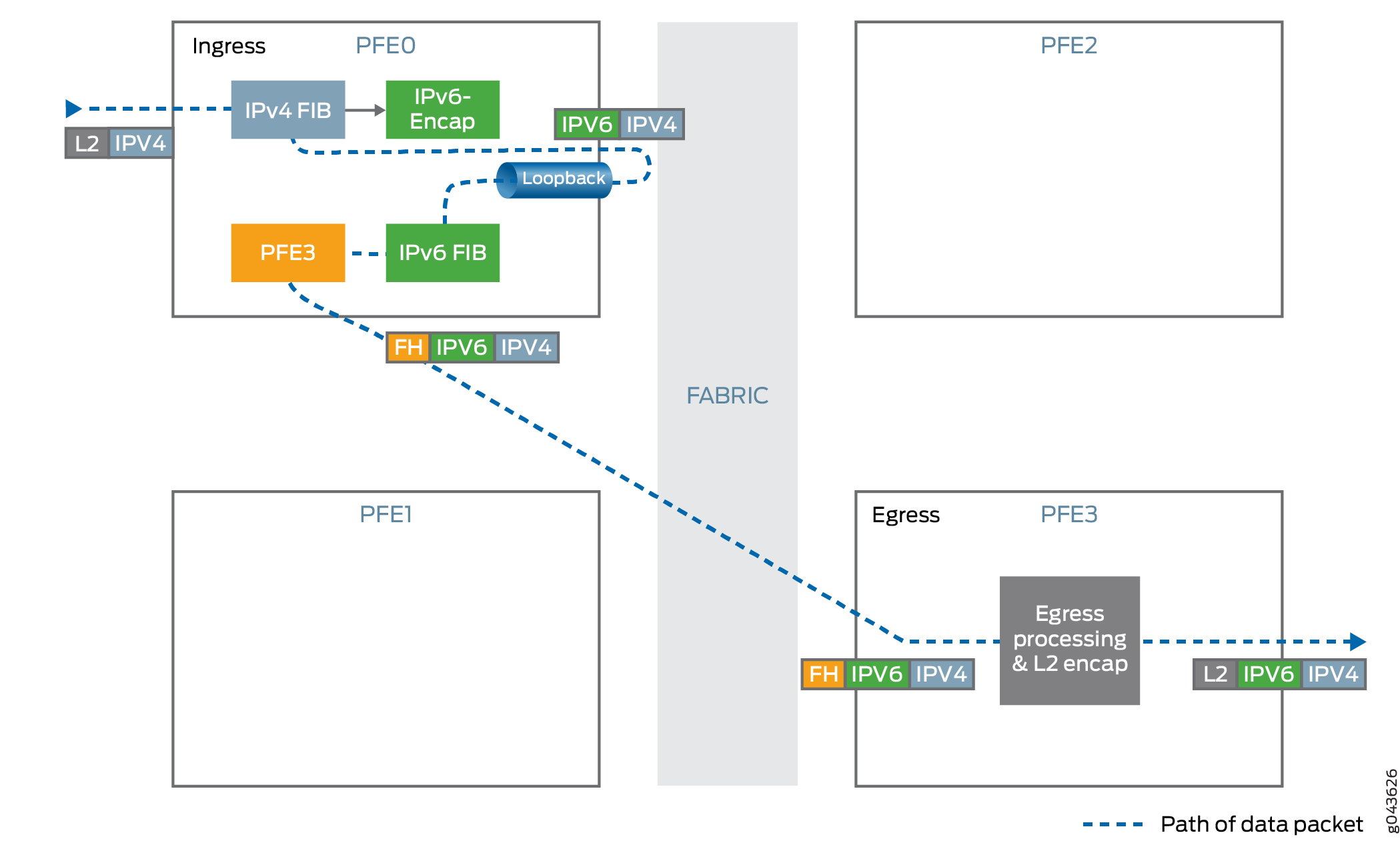
Encapsula o tráfego IPv4 dentro do cabeçalho IPv6.
A aplicação da unidade de transmissão máxima (MTU) é realizada antes do encapsulamento. Se o tamanho do pacote encapsulado exceder o MTU do
DF-bittúnel e o pacote IPv4 não for definido, então o pacote é fragmentado e esses fragmentos são encapsulados.Usa balanceamento de carga de tráfego baseado em hash em cabeçalhos internos de pacotes.
Encaminha o tráfego para o endereço IPv6 de destino. O endereço IPv6 é retirado do cabeçalho IPv6.
Saída de túnel
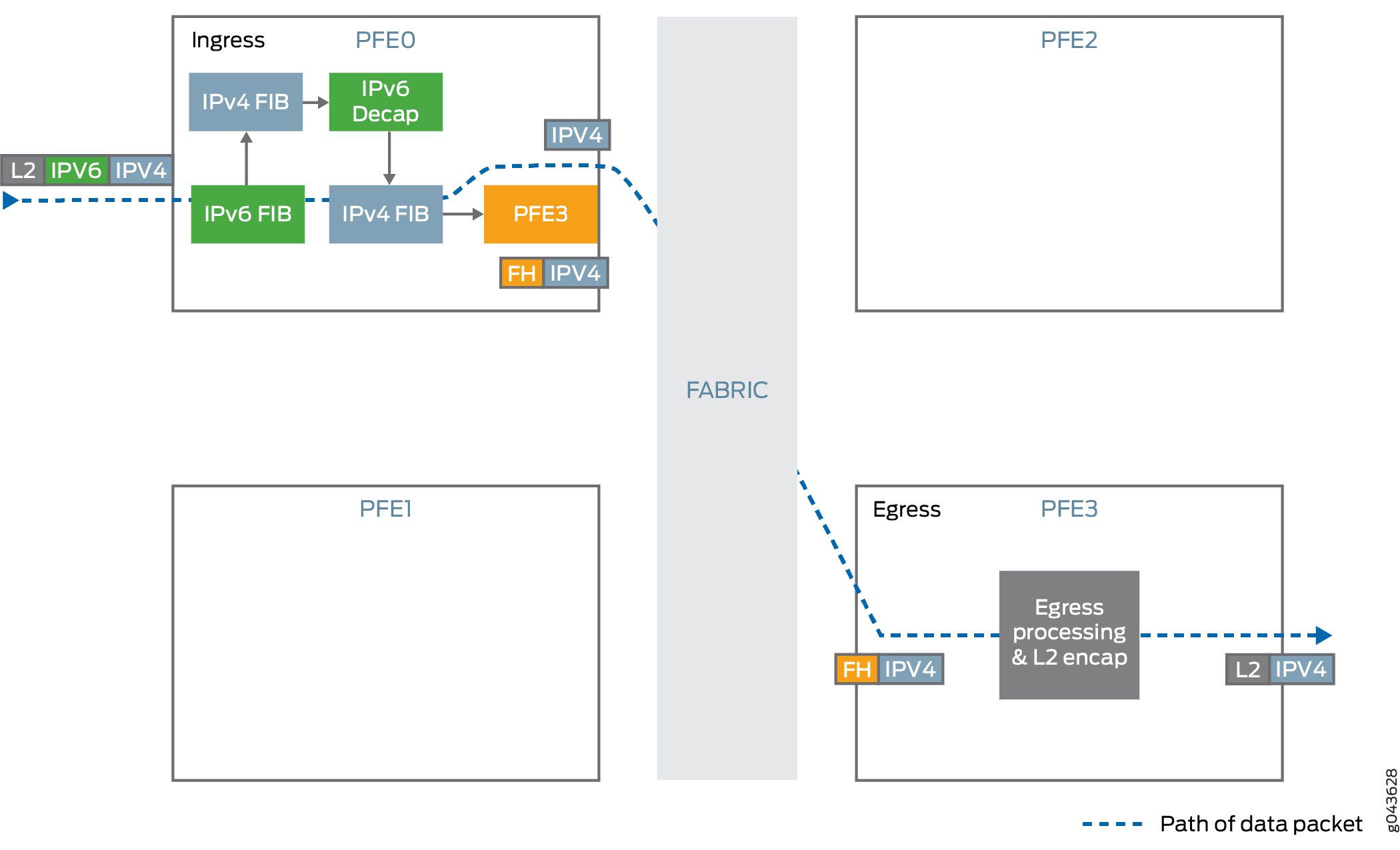
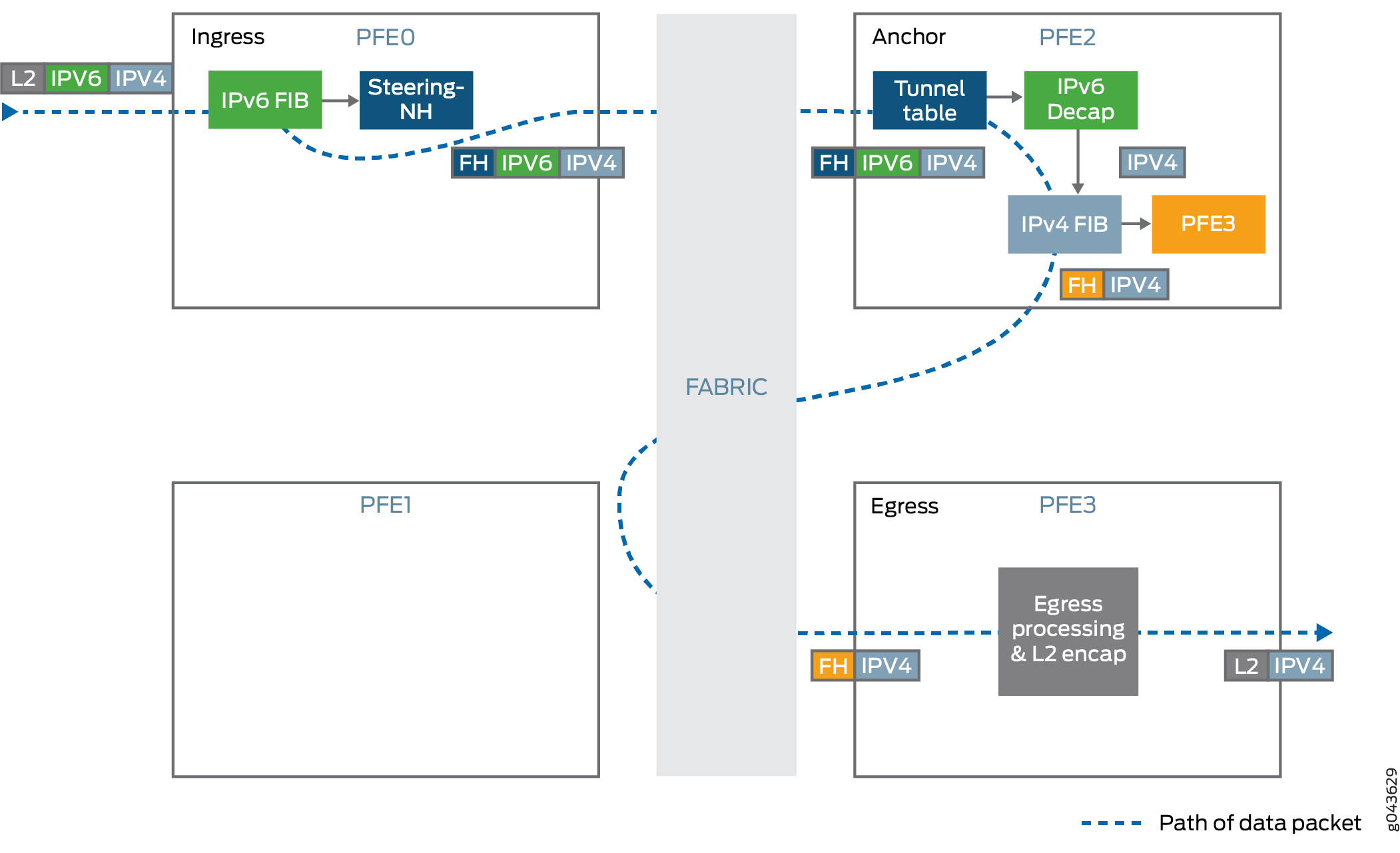
Descapsula o pacote IPv4 presente dentro do pacote IPv6.
Realiza verificações anti-spoof para garantir que o par IPv6 e IPv4 combine com as informações usadas para configurar o túnel.
Procure o endereço de destino IPv4 a partir do cabeçalho IPv4 do pacote descapsulado e encaminhe o pacote para o endereço IPv4 especificado.
Balanceamento de carga de túnel e manuseio de falhas no mecanismo de encaminhamento de pacotes âncora
A falha do mecanismo de encaminhamento de pacotes precisa ser tratada prontamente para evitar a filtragem de rotas nulas do tráfego de túneis ancorado no Mecanismo de encaminhamento de pacotes. A localização de túneis envolve o uso de anúncios BGP para reparar a falha globalmente. O tráfego do túnel é desviado do ponto de falha para outro chassi de backup que contém o estado de túnel idêntico. Para balanceamento de carga de tráfego, o chassi está configurado para anunciar diferentes valores discriminatórios de múltiplas saídas (MED) para cada um dos conjuntos de prefixo, de modo que apenas o tráfego de um quarto dos túneis passe por cada chassi. O tráfego de CPE também é tratado de maneira semelhante, configurando o mesmo conjunto de endereços anycast em cada chassi e direcionando apenas um quarto do tráfego em direção a cada chassi.
O Anchor Packet Forwarding Engine é a entidade única que faz todo o processamento para um túnel. A seleção âncora do Mecanismo de encaminhamento de pacotes é por provisionamento estático e vinculada às interfaces físicas do Mecanismo de encaminhamento de pacotes. Quando um dos mecanismos de encaminhamento de pacotes cai, o daemon marca todos os Mecanismos de encaminhamento de pacotes na placa de linha e comunica essas informações ao processo de protocolo de roteamento de protocolo de roteamento e outros daemons. O processo de protocolo de roteamento envia retiradas BGP para os prefixos ancorados no mecanismo de encaminhamento de pacotes com falha e nos endereços IPv6 atribuídos ao Mecanismo de encaminhamento de pacotes que está desativado. Esses anúncios redirecionam o tráfego para outro chassi de backup. Quando o mecanismo de encaminhamento de pacotes falha novamente, o chassi marca o Mecanismo up de encaminhamento de pacotes e atualiza o processo de protocolo de roteamento. O processo de protocolo de roteamento desencadeia atualizações BGP para seus pares de que os túneis ancorados no mecanismo de encaminhamento de pacotes específico estão agora disponíveis para tráfego de roteamento. Esse processo pode levar minutos para a configuração de túneis em grande escala. Portanto, o Ack mecanismo é integrado ao sistema para garantir uma perda mínima de tráfego ao mudar o tráfego de volta para o chassi original.
Estatísticas do fluxo de loopback de túnel
A infraestrutura dinâmica de túneis usa fluxos de loopback no Packet Forwarding Engine para looping do pacote após o encapsulamento. Como a largura de banda desse fluxo de loopback é limitada, há a necessidade de monitorar o desempenho de fluxos de loopback de túnel.
Para monitorar as estatísticas do fluxo de loopback, use o comando show pfe statistics traffic detail operacional que exibe as estatísticas agregadas de fluxo de loopback, incluindo taxa de encaminhamento, taxa de pacotes de queda e taxa de byte.
Consulte também
Configuração do BGP para redistribuir rotas IPv4 com endereços IPv6 next-hop
A partir do lançamento do 17.3R1, os dispositivos Junos OS podem encaminhar o tráfego IPv4 em uma rede somente IPv6, que geralmente não pode encaminhar o tráfego IPv4. Como descrito no RFC 5549, o tráfego IPv4 é tunelado de dispositivos CPE para gateways IPv4-over-IPv6. Esses gateways são anunciados para dispositivos CPE por meio de endereçoscast. Os dispositivos de gateway então criam túneis IPv4-over-IPv6 dinâmicos para equipamentos remotos nas instalações do cliente e anunciam rotas agregadas IPv4 para direcionar o tráfego. Refletores de roteamento com interfaces programáveis injetam as informações do túnel na rede. Os refletores de rota são conectados através do IBGP aos roteadores de gateway, que anunciam os endereços IPv4 de rotas de host com endereços IPv6 como próximo salto.
O recurso dinâmico de túnel IPv4-over-IPv6 não oferece suporte a ISSU unificado no Junos OS Release 17.3R1.
Antes de começar a configurar o BGP para distribuir rotas IPv4 com endereços IPv6 de próximo salto, faça o seguinte:
Configure as interfaces do dispositivo.
Configure o OSPF ou qualquer outro protocolo IGP.
Configure MPLS e LDP.
Configure BGP.
Para configurar o BGP para distribuir rotas IPv4 com endereços de próximo salto IPv6:
Consulte também
Habilitando a vpn de camada 2 e a sinalização VPLS
Você pode habilitar o BGP a transportar mensagens VPLS NLRI e VPN de Camada 2.
Para habilitar a sinalização VPN e VPLS, inclua a family declaração:
family { l2vpn { signaling { prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>; } } } }
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Para configurar um número máximo de prefixos, inclua a prefix-limit declaração:
prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;}
Para obter uma lista de níveis de hierarquia em que você possa incluir esta declaração, veja a seção de resumo da declaração para esta declaração.
Quando você define o número máximo de prefixos, uma mensagem é registrada quando esse número é atingido. Se você incluir a teardown declaração, a sessão será dividida quando o número máximo de prefixos é alcançado. Se você especificar uma porcentagem, as mensagens são registradas quando o número de prefixos atinge essa porcentagem. Uma vez que a sessão é demolida, ela é restabelecida em pouco tempo. Inclua a idle-timeout declaração para manter a sessão baixa por um período especificado de tempo ou para sempre. Se você especificar forever, a sessão só será restabelecida após o uso do clear bgp neighbor comando. Se você incluir a drop-excess <percentage> declaração e especificar uma porcentagem, as rotas em excesso são perdidas quando o número de prefixos excede a porcentagem. Se você incluir a hide-excess <percentage> declaração e especificar uma porcentagem, as rotas em excesso ficam ocultas quando o número de prefixos excede a porcentagem. Se a porcentagem for modificada, as rotas serão reavaliadas automaticamente.
Consulte também
Entenda as rotas de fluxo BGP para filtragem de tráfego
Uma rota de fluxo é uma agregação de condições de correspondência para pacotes IP. As rotas de fluxo são instaladas como filtros de tabela de encaminhamento de entrada (implícitos) e são propagadas pela rede usando mensagens de informações de alcance da camada de rede (NLRI) de especificação de fluxo e instaladas na tabela instance-name.inetflow.0de roteamento de fluxo. Os pacotes só podem viajar por rotas de fluxo se as condições específicas de correspondência forem atendidas.
Rotas de fluxo e filtros de firewall são semelhantes na medida em que filtram pacotes com base em seus componentes e executam uma ação nos pacotes compatíveis. As rotas de fluxo oferecem recursos de filtragem de tráfego e limitação de taxa, assim como filtros de firewall. Além disso, você pode propagar rotas de fluxo em diferentes sistemas autônomos.
As rotas de fluxo são propagadas pelo BGP por meio de mensagens NLRI de especificação de fluxo. Você deve habilitar o BGP a propagar essas NLRIs.
Começando com o Junos OS Release 15.1, mudanças são implementadas para estender o suporte ininterrupto de roteamento ativo (NSR) para famílias existentes de fluxo de inetvpn e fluxo de inetvpn e estender a validação de rota para fluxos BGP por draft-ietf-idr-bgp-flowspec-oid-01. Duas novas declarações são introduzidas como parte desse aprimoramento. Veja enforce-first-as e no-install.
Começando pelo Junos OS Release 16.1, o suporte para IPv6 é estendido à especificação de fluxo BGP que permite a propagação de regras de especificação de fluxo de tráfego para pacotes IPv6 e VPN-IPv6. A especificação de fluxo BGP automatiza a coordenação das regras de filtragem de tráfego, a fim de mitigar ataques distribuídos de negação de serviço durante o roteamento ativo (NSR) sem parar.
Começando pelo Junos OS Release 16.1R1, a especificação de fluxo BGP oferece suporte a ação de filtragem de marcação extended-community de tráfego. Para tráfego IPv4, o Junos OS modifica os bits de ponto de código DiffServ (DSCP) de um pacote IPv4 em trânsito para o valor correspondente da comunidade estendida. Para pacotes IPv6, o Junos OS modifica os primeiros seis bits do traffic class campo do pacote IPv6 transmissor para o valor correspondente da comunidade estendida.
A partir do Junos OS Release 17.1R1, o BGP pode transportar mensagens de alcance de camada de rede (NLRI) de especificação de fluxo em roteadores da Série PTX que têm FPCs de terceira geração (FPC3-PTX-U2 e FPC3-PTX-U3 no PTX5000 e FPC3-SFF-PTX-U0 e FPC3-SFF-PTX-U1 no PTX3000) instalados. A propagação de informações de filtro de firewall como parte do BGP permite que você propagar filtros de firewall contra ataques de negação de serviço (DOS) dinamicamente em sistemas autônomos.
A partir do Junos OS Release 17.2R1, o BGP pode transportar mensagens de informações de acessibilidade de camada de rede (NLRI) de especificação de fluxo em PTX1000 roteadores que têm FPCs de terceira geração instalados. A propagação de informações de filtro de firewall como parte do BGP permite que você propagar filtros de firewall contra ataques de negação de serviço (DOS) dinamicamente em sistemas autônomos.
A partir do lançamento do cRPD 20.3R1, as rotas de fluxo e as regras de policiamento propagadas pela especificação de fluxo BGP NLRI são baixadas no kernel linux por meio da estrutura do netfilter Linux em ambientes cRPD.
- Condições de correspondência para rotas de fluxo
- Ações para rotas de fluxo
- Validação de rotas de fluxo
- Suporte para o algoritmo de especificação de fluxo BGP Versão 7 e posterior
Condições de correspondência para rotas de fluxo
Você especifica as condições que o pacote deve combinar antes que a ação na then declaração seja tomada para uma rota de fluxo. Todas as condições na from declaração devem corresponder à ação a ser tomada. A ordem na qual você especifica as condições de correspondência não é importante, porque um pacote deve corresponder a todas as condições em um termo para que uma correspondência ocorra.
Para configurar uma condição de correspondência, inclua a match declaração no nível de [edit routing-options flow] hierarquia.
Tabela 1 descreve as condições de correspondência da rota de fluxo.
|
Condição da partida |
Descrição |
|---|---|
|
|
Campo de endereços de destino IP. Você pode usar o |
|
|
Campo de porta de destino do TCP ou do protocolo de datagrama do usuário (UDP). Você não pode especificar as No lugar do valor numérico, você pode especificar um dos seguintes sinônimos de texto (os números de porta também estão listados): |
|
|
Ponto de código de serviços diferenciados (DSCP). O protocolo DiffServ usa o byte de tipo de serviço (ToS) no cabeçalho IP. Os seis bits mais significativos desse byte formam o DSCP. Você pode especificar DSCP em forma hexadima ou decima. |
|
|
Combine com o valor do rótulo de fluxo. O valor deste campo varia de 0 a 1048575. Essa condição de correspondência é suportada apenas em dispositivos Junos com MPCs aprimorados que estão configurados para |
|
|
Campo do tipo de fragmento. As palavras-chave são agrupadas pelo tipo de fragmento com o qual estão associadas:
Essa condição de correspondência é suportada apenas em dispositivos Junos OS com MPCs aprimorados que estão configurados para |
|
|
Campo de código ICMP. Esse valor ou palavra-chave fornece informações mais específicas do que No lugar do valor numérico, você pode especificar um dos seguintes sinônimos de texto (os valores de campo também estão listados). As palavras-chave são agrupadas pelo tipo ICMP com as quais estão associadas:
|
|
|
Campo do tipo de pacote ICMP. Normalmente, você especifica esta correspondência em conjunto com a declaração de No lugar do valor numérico, você pode especificar um dos seguintes sinônimos de texto (os valores de campo também estão listados): |
|
|
Comprimento total do pacote IP. |
|
|
Campo de porta de origem ou destino TCP ou UDP. Você não pode especificar tanto a No lugar do valor numérico, você pode especificar um dos sinônimos de texto listados em |
|
|
Campo de protocolo IP. No lugar do valor numérico, você pode especificar um dos seguintes sinônimos de texto (os valores de campo também estão listados): Essa condição de correspondência é suportada apenas para IPv6 em dispositivos Junos com MPCs aprimorados que estão configurados para |
|
|
Campo de endereços de origem IP. Você pode usar o |
|
|
Campo de porta de origem TCP ou UDP. Você não pode especificar as No lugar do campo numérico, você pode especificar um dos sinônimos de texto listados em |
|
|
Formato de cabeçalho de TCP. |
Ações para rotas de fluxo
Você pode especificar a ação a ser tomada se o pacote corresponde às condições que você configurou na rota de fluxo. Para configurar uma ação, inclua a then declaração no nível de [edit routing-options flow] hierarquia.
Tabela 2 descreve as ações de rota de fluxo.
|
Modificador de ação ou ação |
Descrição |
|---|---|
| Ações | |
|
|
Aceite um pacote. Esse é o padrão. |
|
|
Descarte um pacote silenciosamente, sem enviar uma mensagem de Protocolo de Mensagem de Controle de Internet (ICMP). |
|
|
Substitua todas as comunidades da rota pelas comunidades especificadas. |
|
assinalar value |
Defina um valor de DSCP para o tráfego que corresponda a esse fluxo. Especifique um valor de 0 a 63. Essa ação é suportada apenas em dispositivos Junos com MPCs aprimorados que estão configurados para |
|
|
Continue a próxima condição de jogo para avaliação. |
|
|
Especifique uma instância de roteamento para a qual os pacotes são encaminhados. |
|
|
Limite a largura de banda na rota de fluxo. Expresse o limite em bits por segundo (bps). Começando com o Junos OS Release 16.1R4, a faixa de limite de taxa é [0 a 100000000000]. |
|
|
Experimente o tráfego na rota de fluxo. |
Validação de rotas de fluxo
O Junos OS instala rotas de fluxo na tabela de roteamento de fluxo apenas se tiverem sido validadas usando o procedimento de validação. O mecanismo de roteamento faz a validação antes da instalação de rotas na tabela de roteamento de fluxo.
As rotas de fluxo recebidas usando as mensagens de informações de alcance da camada de rede BGP (NLRI) são validadas antes de serem instaladas na tabela instance.inetflow.0de roteamento de instâncias primárias de fluxo. O procedimento de validação é descrito na draft-ietf-idr-flow-spec-09.txt, disseminação de regras de especificação de fluxo. Você pode ignorar o processo de validação para rotas de fluxo usando mensagens BGP NLRI e usar sua própria política de importação específica.
Para rastrear as operações de validação, inclua a validation declaração no nível de [edit routing-options flow] hierarquia.
Suporte para o algoritmo de especificação de fluxo BGP Versão 7 e posterior
Por padrão, o Junos OS usa o algoritmo de pedidos de termo definido na versão 6 do rascunho da especificação de fluxo BGP. No Junos OS Release 10.0 e posterior, você pode configurar o roteador para cumprir com o algoritmo de pedidos de termo definido pela primeira vez na versão 7 da especificação de fluxo BGP e suportado por RFC 5575, disseminação de rotas de especificação de fluxo.
Recomendamos que você configure o Junos OS para usar o algoritmo de pedido de termo definido pela primeira vez na versão 7 do rascunho da especificação de fluxo BGP. Também recomendamos que você configure o Junos OS para usar o mesmo algoritmo de pedido de termo em todas as instâncias de roteamento configuradas em um roteador.
Para configurar o BGP para usar o algoritmo de especificação de fluxo definido pela primeira vez na versão 7 do rascunho da Internet, inclua a standard declaração no nível de [edit routing-options flow term-order] hierarquia.
Para reverter ao uso do algoritmo de ordenação de termo definido na versão 6, inclua a legacy declaração no nível hierárquico [edit routing-options flow term-order] .
A ordem de termo configurada tem apenas significado local. Ou seja, o termo ordem não se propaga com rotas de fluxo enviadas para os pares BGP remotos, cuja ordem de termo é completamente determinada por sua própria configuração de ordem de termo. Portanto, você deve ter cuidado ao configurar a ação next term dependente de pedidos quando não estiver ciente da configuração de ordem de termo dos pares remotos. O local next term pode diferir da next term configuração no peer remoto.
No Junos OS Evolved, next term não pode aparecer como o último termo da ação. Um termo de filtro em que next term é especificado como uma ação, mas sem qualquer condição de correspondência configurada não é suportado.
A partir do Junos OS Release 16.1, você tem a opção de não aplicar o flowspec filtro ao tráfego recebido em interfaces específicas. Um novo termo é adicionado no início do flowspec filtro que aceita qualquer pacote recebido nessas interfaces específicas. O novo termo é uma variável que cria uma lista de exclusão de termos anexados ao filtro da tabela de encaminhamento como parte do filtro de especificação de fluxo.
Para excluir o flowspec filtro de ser aplicado ao tráfego recebido em interfaces específicas, você deve primeiro configurar uma group-id nessas interfaces, incluindo a declaração do grupo group-id do filtro da família inet no nível de hierarquia e, em [edit interfaces] seguida, anexar o flowspec filtro com o grupo de interface, incluindo a flow interface-group group-id exclude declaração no [edit routing-options] nível de hierarquia. Você pode configurar apenas uma group-id por instância de roteamento com a set routing-options flow interface-group group-id declaração.
Consulte também
Exemplo: Permitindo que o BGP carregue rotas de especificação de fluxo
Este exemplo mostra como permitir que o BGP carregue mensagens de informações de alcance de camada de rede (NLRI) de especificação de fluxo.
Requisitos
Antes de começar:
Configure as interfaces do dispositivo.
Configure um protocolo de gateway interior (IGP).
Configure BGP.
Configure uma política de roteamento que exporta rotas (como rotas diretas ou rotas de IGP) da tabela de roteamento para o BGP.
Visão geral
A propagação de informações de filtro de firewall como parte do BGP permite que você propagar filtros de firewall contra ataques de negação de serviço (DOS) dinamicamente em sistemas autônomos. As rotas de fluxo são encapsuladas na NLRI de especificação de fluxo e propagadas por uma rede ou redes privadas virtuais (VPNs), compartilhando informações semelhantes a filtros. As rotas de fluxo são uma agregação de condições de correspondência e ações resultantes para pacotes. Eles fornecem a você recursos de filtragem de tráfego e limitação de taxa, assim como filtros de firewall. As rotas de fluxo Unicast são suportadas para a instância padrão, instâncias de roteamento e encaminhamento de VPN (VRF) e instâncias de roteador virtual.
As políticas de importação e exportação podem ser aplicadas ao NLRI familiar inet flow ou familiar inet-vpn flow , afetando as rotas de fluxo aceitas ou anunciadas, semelhante à forma como as políticas de importação e exportação são aplicadas a outras famílias BGP. A única diferença é que a configuração da política de fluxo deve incluir a declaração.rib inetflow.0 Essa declaração faz com que a política seja aplicada às rotas de fluxo. Uma exceção a essa regra ocorre se a política tiver apenas a then reject declaração ou a then accept declaração e nenhuma from declaração. Em seguida, a política afeta todas as rotas, incluindo ip unicast e fluxo IP.
Os filtros de rota de fluxo são configurados primeiro em um roteador estaticamente, com um conjunto de critérios de correspondência seguidos pelas ações a serem tomadas. Em seguida, além family inet unicastde , family inet flow (ou family inet-vpn flow) está configurado entre este dispositivo habilitado para BGP e seus pares.
Por padrão, as rotas de fluxo configuradas estaticamente (filtros de firewall) são anunciadas em outros dispositivos habilitados para BGP que oferecem suporte ao family inet flow NLRI.family inet-vpn flow
O dispositivo habilitado para BGP receptor realiza um processo de validação antes de instalar o filtro de firewall na tabela instance-name.inetflow.0de roteamento de fluxo. O procedimento de validação é descrito na RFC 5575, Disseminação de regras de especificação de fluxo.
O dispositivo habilitado para BGP receptor aceita uma rota de fluxo se passar pelos seguintes critérios:
O criador de uma rota de fluxo corresponde ao criador da melhor rota unicast compatível para o endereço de destino que está incorporado na rota.
Não há rotas unicast mais específicas, quando comparadas com o endereço de destino da rota de fluxo, para a qual a rota ativa foi recebida de um sistema autônomo de próximo salto diferente.
O primeiro critério garante que o filtro esteja sendo anunciado pelo próximo salto usado pelo encaminhamento unicast para o endereço de destino incorporado na rota de fluxo. Por exemplo, se uma rota de fluxo for dada como 10.1.1.1, proto=6, port=80, o dispositivo habilitado para BGP receptor seleciona a rota unicast mais específica na tabela de roteamento unicast que corresponde ao prefixo de destino 10.1.1.1/32. Em uma tabela de roteamento unicast contendo 10,1/16 e 10,1,1/24, esta última é escolhida como a rota unicast para comparação. Considera-se apenas a entrada ativa de rota unicast. Isso segue o conceito de que uma rota de fluxo é válida se anunciada pelo criador da melhor rota unicast.
O segundo critério atende a situações em que um determinado bloco de endereço é alocado para diferentes entidades. Os fluxos que resolvem a melhor rota unicast que é uma rota agregada só são aceitos se não cobrirem rotas mais específicas que estão sendo roteadas para diferentes sistemas autônomos de próximo salto.
Você pode ignorar o processo de validação para rotas de fluxo usando mensagens BGP NLRI e usar sua própria política de importação específica. Quando o BGP transporta mensagens NLRI de especificação de fluxo, a no-validate declaração no nível da [edit protocols bgp group group-name family inet flow] hierarquia omite o procedimento de validação da rota de fluxo após a aceitação de pacotes por uma política. Você pode configurar a política de importação para combinar em atributos de endereço de destino e caminho, como a comunidade, o próximo salto e o caminho AS. Você pode especificar a ação a ser tomada se o pacote corresponde às condições que você configurou na rota de fluxo. Para configurar uma ação, inclua a declaração no nível de [edit routing-options flow] hierarquia. A especificação de fluxo do tipo NLRI inclui componentes como prefixo de destino, prefixo de origem, protocolo e portas conforme definido no RFC 5575. A política de importação pode filtrar uma rota de entrada usando atributos de caminho e endereço de destino na especificação de fluxo NLRI. A política de importação não pode filtrar outros componentes no RFC 5575.
A especificação de fluxo define as extensões de protocolo necessárias para atender aos aplicativos mais comuns de filtragem unicast IPv4 e VPN unicast. O mesmo mecanismo pode ser reutilizado e novos critérios de correspondência adicionados para lidar com filtragem semelhante para outras famílias de endereços BGP (por exemplo, IPv6 unicast).
Depois que uma rota de fluxo é instalada na inetflow.0 tabela, ela também é adicionada à lista de filtros de firewall no kernel.
Apenas em roteadores, as mensagens NLRI com especificação de fluxo são suportadas em VPNs. A VPN compara a meta de rota estendida da comunidade na NLRI com a política de importação. Se houver correspondência, a VPN pode começar a usar as rotas de fluxo para filtrar e limitar o tráfego de pacotes. As rotas de fluxo recebidas são instaladas na tabela instance-name.inetflow.0de roteamento de fluxo. As rotas de fluxo também podem ser propagadas por toda a rede VPN e compartilhadas entre VPNs. Para permitir que o BGP multiprotocol (MP-BGP) carregue a NLRI de especificação de fluxo para a família de inet-vpn endereços, inclua a flow declaração no nível hierárquico [edit protocols bgp group group-name family inet-vpn] . As rotas de fluxo de VPN são suportadas apenas para a instância padrão. As rotas de fluxo configuradas para VPNs com família inet-vpn não são validadas automaticamente, de modo que a no-validate declaração não seja suportada no nível hierárquicos [edit protocols bgp group group-name family inet-vpn] . Nenhuma validação é necessária se as rotas de fluxo forem configuradas localmente entre dispositivos em um único AS.
As políticas de importação e exportação podem ser aplicadas ao family inet flow NLRI, family inet-vpn flow afetando as rotas de fluxo aceitas ou anunciadas, semelhante à forma como as políticas de importação e exportação são aplicadas a outras famílias BGP. A única diferença é que a configuração da política de fluxo deve incluir a from rib inetflow.0 declaração. Essa declaração faz com que a política seja aplicada às rotas de fluxo. Uma exceção a essa regra ocorre se a política tiver apenas a then reject declaração ou a then accept declaração e nenhuma from declaração. Em seguida, a política afeta todas as rotas, incluindo ip unicast e fluxo IP.
Este exemplo mostra como configurar as seguintes políticas de exportação:
Uma política que permite o anúncio de rotas de fluxo especificadas por um filtro de rota. Apenas as rotas de fluxo cobertas pelo bloco 10.13/16 são anunciadas. Essa política não afeta as rotas unicast.
Uma política que permite que todas as rotas unicast e de fluxo sejam anunciadas para o vizinho.
Uma política que não permite que todas as rotas (unicast ou fluxo) sejam anunciadas ao vizinho.
Topologia
Configuração
- Configurando uma rota de fluxo estático
- Rotas de fluxo de publicidade especificadas por um filtro de rota
- Publicidade Todas as rotas unicast e de fluxo
- Publicidade Sem unicast ou rotas de fluxo
- Limitando o número de rotas de fluxo instaladas em uma tabela de roteamento
- Limitando o número de prefixos recebidos em uma sessão de peering BGP
Configurando uma rota de fluxo estático
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set routing-options flow route block-10.131.1.1 match destination 10.131.1.1/32 set routing-options flow route block-10.131.1.1 match protocol icmp set routing-options flow route block-10.131.1.1 match icmp-type echo-request set routing-options flow route block-10.131.1.1 then discard set routing-options flow term-order standard
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Para configurar as sessões de peer BGP:
Configure as condições de correspondência.
[edit routing-options flow route block-10.131.1.1] user@host# set match destination 10.131.1.1/32 user@host# set match protocol icmp user@host# set match icmp-type echo-request
Configure a ação.
[edit routing-options flow route block-10.131.1.1] user@host# set then discard
(Recomendado) Para o algoritmo de especificação de fluxo, configure a ordem de termo baseada em padrão.
[edit routing-options flow] user@host# set term-order standard
No algoritmo de pedidos de termo padrão, conforme especificado no fluxospec RFC draft Versão 6, um termo com condições de correspondência menos específicas é sempre avaliado antes de um termo com condições de correspondência mais específicas. Isso faz com que o termo com condições de correspondência mais específicas nunca seja avaliado. A versão 7 da RFC 5575 fez uma revisão no algoritmo para que as condições de correspondência mais específicas sejam avaliadas antes das condições de correspondência menos específicas. Para uma compatibilidade retrógrada, o comportamento padrão não é alterado no Junos OS, embora o algoritmo mais novo faça mais sentido. Para usar o algoritmo mais novo, inclua a
term-order standarddeclaração na configuração. Esta declaração é apoiada no Junos OS Release 10.0 e posteriores.
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show routing-options comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show routing-options
flow {
term-order standard;
route block-10.131.1.1 {
match {
destination 10.131.1.1/32;
protocol icmp;
icmp-type echo-request;
}
then discard;
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Rotas de fluxo de publicidade especificadas por um filtro de rota
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a from rib inetflow.0 set policy-options policy-statement p1 term a from route-filter 10.13.0.0/16 orlonger set policy-options policy-statement p1 term a then accept set policy-options policy-statement p1 term b then reject set routing-options autonomous-system 65001
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Para configurar as sessões de peer BGP:
Configure o grupo BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configure a política de fluxo.
[edit policy-options policy-statement p1] user@host# set term a from rib inetflow.0 user@host# set term a from route-filter 10.13.0.0/16 orlonger user@host# set term a then accept user@host# set term b then reject
Configure o número do sistema autônomo local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show protocols, show policy-optionse show routing-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
from {
rib inetflow.0;
route-filter 10.13.0.0/16 orlonger;
}
then accept;
}
term b {
then reject;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Publicidade Todas as rotas unicast e de fluxo
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a then accept set routing-options autonomous-system 65001
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Para configurar as sessões de peer BGP:
Configure o grupo BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configure a política de fluxo.
[edit policy-options policy-statement p1] user@host# set term a then accept
Configure o número do sistema autônomo local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show protocols, show policy-optionse show routing-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
prefix-list inetflow;
}
then accept;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Publicidade Sem unicast ou rotas de fluxo
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a then reject set routing-options autonomous-system 65001
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Para configurar as sessões de peer BGP:
Configure o grupo BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configure a política de fluxo.
[edit policy-options policy-statement p1] user@host# set term a then reject
Configure o número do sistema autônomo local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show protocols, show policy-optionse show routing-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
then reject;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Limitando o número de rotas de fluxo instaladas em uma tabela de roteamento
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set routing-options rib inetflow.0 maximum-prefixes 1000 set routing-options rib inetflow.0 maximum-prefixes threshold 50
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
A aplicação de um limite de rota pode resultar em um comportamento imprevisível de protocolo de rota dinâmica. Por exemplo, uma vez que o limite é atingido e as rotas estão sendo recusadas, o BGP não necessariamente tenta reinstalar as rotas recusadas após o número de rotas cair abaixo do limite. As sessões de BGP podem precisar ser liberadas para resolver esse problema.
Para limitar as rotas de fluxo:
Definir um limite superior para o número de prefixos instalados na
inetflow.0tabela.[edit routing-options rib inetflow.0] user@host# set maximum-prefixes 1000
Definir um valor limite de 50%, onde quando 500 rotas são instaladas, um aviso é registrado no log do sistema.
[edit routing-options rib inetflow.0] user@host# set maximum-prefixes threshold 50
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show routing-options comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show routing-options
rib inetflow.0 {
maximum-prefixes 1000 threshold 50;
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Limitando o número de prefixos recebidos em uma sessão de peering BGP
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit maximum 1000 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit teardown 50 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit drop-excess 50 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit hide-excess 50
Você pode incluir a opção teardown <percentage>, drop-excess <percentage>ou hide-excess<percentage> a opção de declaração uma de cada vez.
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia de usuário do Junos OS CLI.
Configurar um limite de prefixo para um vizinho específico fornece controle mais previsível sobre quais peer podem anunciar quantas rotas de fluxo.
Para limitar o número de prefixos:
Definir um limite de 1000 rotas BGP do vizinho 10.12.99.2.
[edit protocols bgp group x1] user@host# set neighbor 10.12.99.2 family inet flow prefix-limit maximum 1000
-
Configure a sessão ou os prefixos vizinhos para executar,
teardown <percentage>drop-excess <percentage>ouhide-excess<percentage>a opção de declaração quando a sessão ou os prefixos atingirem seu limite.[edit routing-options rib inetflow.0] user@host# set neighbor 10.12.99.2 family inet flow prefix-limit teardown 50 set neighbor 10.12.99.2 family inet flow prefix-limit drop-excess 50 set neighbor 10.12.99.2 family inet flow prefix-limit hide-excess 50
Se você especificar a
teardown <percentage>declaração e especificar uma porcentagem, as mensagens serão registradas quando o número de prefixos atinge essa porcentagem. Após a sessão ser interrompida, a sessão se restabelecerá em pouco tempo, a menos que você inclua aidle-timeoutdeclaração.Se você especificar a
drop-excess <percentage>declaração e especificar uma porcentagem, as rotas em excesso são perdidas quando o número de prefixos excede esse percentualSe você especificar a
hide-excess <percentage>declaração e especificar uma porcentagem, as rotas em excesso ficam ocultas quando o número de prefixos excede essa porcentagem.
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show protocols comando. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@host# show protocols
bgp {
group x1 {
neighbor 10.12.99.2 {
flow {
prefix-limit {
maximum 1000;
teardown 50;
drop-excess <percentage>;
hide-excess <percentage>;
}
}
}
}
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Verificação
Confirme se a configuração está funcionando corretamente.
- Verificação da NLRI
- Verificação de rotas
- Verificação da validação do fluxo
- Verificação de filtros de firewall
- Verificação do registro do sistema ao exceder o número de rotas de fluxo permitidas
- Verificação do registro do sistema ao exceder o número de prefixos recebidos em uma sessão de peering BGP
Verificação da NLRI
Propósito
Veja o NLRI habilitado para o vizinho.
Ação
A partir do modo operacional, execute o show bgp neighbor 10.12.99.5 comando. Procure inet-flow na saída.
user@host> show bgp neighbor 10.12.99.5 Peer: 10.12.99.5+3792 AS 65000 Local: 10.12.99.6+179 AS 65002 Type: External State: Established Flags: <Sync> Last State: OpenConfirm Last Event: RecvKeepAlive Last Error: None Export: [ direct ] Options: <Preference HoldTime AddressFamily PeerAS Refresh> Address families configured: inet-unicast inet-multicast inet-flow Holdtime: 90 Preference: 170 Number of flaps: 1 Error: 'Cease' Sent: 0 Recv: 1 Peer ID: 10.255.71.161 Local ID: 10.255.124.107 Active Holdtime: 90 Keepalive Interval: 30 Peer index: 0 Local Interface: e1-3/0/0.0 NLRI advertised by peer: inet-unicast inet-multicast inet-flow NLRI for this session: inet-unicast inet-multicast inet-flow Peer supports Refresh capability (2) Table inet.0 Bit: 10000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 2 Received prefixes: 2 Suppressed due to damping: 0 Advertised prefixes: 3 Table inet.2 Bit: 20000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 0 Received prefixes: 0 Suppressed due to damping: 0 Advertised prefixes: 0 Table inetflow.0 Bit: 30000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 0 Received prefixes: 0 Suppressed due to damping: 0 Advertised prefixes: 0 Last traffic (seconds): Received 29 Sent 15 Checked 15 Input messages: Total 5549 Updates 2618 Refreshes 0 Octets 416486 Output messages: Total 2943 Updates 1 Refreshes 0 Octets 55995 Output Queue[0]: 0 Output Queue[1]: 0 Output Queue[2]: 0
Verificação de rotas
Propósito
Veja as rotas de fluxo. A saída de amostra mostra uma rota de fluxo aprendida com o BGP e uma rota de fluxo configurada estaticamente.
Para rotas de fluxo configuradas localmente (configuradas no nível de [edit routing-options flow] hierarquia), as rotas são instaladas pelo protocolo de fluxo. Portanto, você pode exibir as rotas de fluxo especificando a tabela, como em show route table inetflow.0 ou show route table instance-name.inetflow.0, onde instance-name está o nome da instância de roteamento. Ou, você pode exibir todas as rotas de fluxo configuradas localmente em várias instâncias de roteamento executando o show route protocol flow comando.
Se uma rota de fluxo não estiver configurada localmente, mas recebida do peer BGP do roteador, essa rota de fluxo será instalada na tabela de roteamento pelo BGP. Você pode exibir as rotas de fluxo especificando a tabela ou executando show route protocol bgp, que exibe todas as rotas BGP (fluxo e não fluxo).
Ação
A partir do modo operacional, execute o show route table inetflow.0 comando.
user@host> show route table inetflow.0
inetflow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
100.100.100.100,*,proto=1,icmp-type=8/term:1
*[BGP/170] 00:00:18, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
200.200.200.200,*,proto=6,port=80/term:2
*[BGP/170] 00:00:18, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
user@host> show route table inetflow.0 extensive
inetflow.0: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden)
7.7.7.7,8.8.8.8/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
*Flow Preference: 5
Next hop type: Fictitious
Address: 0x8d383a4
Next-hop reference count: 3
State: <Active>
Local AS: 65000
Age: 9:50
Task: RT Flow
Announcement bits (1): 0-Flow
AS path: I
user@host> show route hidden
inetflow.0: 2 destinations, 2 routes (0 active, 0 holddown, 2 hidden)
+ = Active Route, - = Last Active, * = Both
100.100.100.100,*,proto=1,icmp-type=8/term:N/A
[BGP ] 00:00:17, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
200.200.200.200,*,proto=6,port=80/term:N/A
[BGP ] 00:00:17, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
Significado
Uma rota de fluxo representa um termo de filtro de firewall. Ao configurar uma rota de fluxo, você especifica as condições de correspondência e as ações. Nos atributos da correspondência, você pode combinar um endereço de origem, um endereço de destino e outras qualificações, como a porta e o protocolo. Para uma única rota de fluxo que contenha várias condições de correspondência, todas as condições de correspondência são encapsuladas no campo de prefixo da rota. Quando você emite o show route comando em uma rota de fluxo, o campo de prefixo da rota é exibido com todas as condições da partida. 10.12.44.1,* Significa que a condição de correspondência é match destination 10.12.44.1/32. Se o prefixo na saída fosse *,10.12.44.1, isso significaria que a condição da correspondência era match source 10.12.44.1/32. Se as condições de correspondência conterem uma fonte e um destino, o asterisco será substituído pelo endereço.
Os números de ordem de termo indicam a sequência dos termos (rotas de fluxo) que estão sendo avaliados no filtro de firewall. O show route extensive comando exibe as ações para cada termo (rota).
Verificação da validação do fluxo
Propósito
Exibir informações de rota de fluxo.
Ação
A partir do modo operacional, execute o show route flow validation detail comando.
user@host> show route flow validation detail
inet.0:
0.0.0.0/0
Internal node: best match, inconsistent
10.0.0.0/8
Internal node: no match, inconsistent
10.12.42.0/24
Internal node: no match, consistent, next-as: 65003
Active unicast route
Dependent flow destinations: 1
Origin: 10.255.124.106, Neighbor AS: 65003
10.12.42.1/32
Flow destination (1 entries, 1 match origin)
Unicast best match: 10.12.42.0/24
Flags: Consistent
10.131.0.0/16
Internal node: no match, consistent, next-as: 65001
Active unicast route
Dependent flow destinations: 5000
Origin: 10.12.99.2, Neighbor AS: 65001
10.131.0.0/19
Internal node: best match
10.131.0.0/20
Internal node: best match
10.131.0.0/21
Verificação de filtros de firewall
Propósito
Exibir os filtros de firewall que estão instalados no kernel.
Ação
A partir do modo operacional, execute o show firewall comando.
user@host> show firewall Filter: __default_bpdu_filter__ Filter: __flowspec_default_inet__ Counters: Name Bytes Packets 10.12.42.1,* 0 0 196.1.28/23,* 0 0 196.1.30/24,* 0 0 196.1.31/24,* 0 0 196.1.32/24,* 0 0 196.1.56/21,* 0 0 196.1.68/24,* 0 0 196.1.69/24,* 0 0 196.1.70/24,* 0 0 196.1.75/24,* 0 0 196.1.76/24,* 0 0
Verificação do registro do sistema ao exceder o número de rotas de fluxo permitidas
Propósito
Se você configurar um limite no número de rotas de fluxo instaladas, conforme descrito Limitando o número de rotas de fluxo instaladas em uma tabela de roteamento, visualize a mensagem de log do sistema quando o limiar for atingido.
Ação
A partir do modo operacional, execute o show log <message> comando.
user@host> show log message Jul 12 08:19:01 host rpd[2748]: RPD_RT_MAXROUTES_WARN: Number of routes (1000) in table inetflow.0 exceeded warning threshold (50 percent of configured maximum 1000)
Verificação do registro do sistema ao exceder o número de prefixos recebidos em uma sessão de peering BGP
Propósito
Se você configurar um limite no número de rotas de fluxo instaladas, conforme descrito Limitando o número de prefixos recebidos em uma sessão de peering BGP, visualize a mensagem de log do sistema quando o limiar for atingido.
Ação
A partir do modo operacional, execute o show log message comando.
Se você especificar a opção de teradown <percentage> declaração:
user@host> show log message Jul 12 08:44:47 host rpd[2748]: 10.12.99.2 (External AS 65001): Shutting down peer due to exceeding configured maximum prefix-limit(1000) for inet-flow nlri: 1001
Se você especificar a opção de drop-excess <percentage> declaração:
user@host> show log message Jul 27 15:26:57 R1_re rpd[32443]: BGP_DROP_PREFIX_LIMIT_EXCEEDED: 1.1.1.2 (Internal AS 1): Exceeded drop-excess maximum prefix-limit(4) for inet-unicast nlri: 5 (instance master)
Se você especificar a opção de hide-excess <percentage> declaração:
user@host> show log message Jul 27 15:26:57 R1_re rpd[32443]: BGP_HIDE_PREFIX_LIMIT_EXCEEDED: 1.1.1.2 (Internal AS 1): Exceeded hide-excess maximum prefix-limit(4) for inet-unicast nlri: 5 (instance master)
Exemplo: Configuração do BGP para transportar rotas de especificação de fluxo IPv6
Este exemplo mostra como configurar a especificação de fluxo IPv6 para filtragem de tráfego. A especificação do fluxo BGP pode ser usada para automatizar a coordenação entre domínios e intra domínio das regras de filtragem de tráfego, a fim de mitigar ataques de negação de serviço.
Requisitos
Este exemplo usa os seguintes componentes de hardware e software:
Dois roteadores da Série MX
Versão do Junos OS 16.1 ou posterior
Antes de habilitar o BGP a transportar rotas de especificação de fluxo IPv6:
Configure endereços IP nas interfaces do dispositivo.
Configure BGP.
Configure uma política de roteamento que exporta rotas (como rotas estáticas, rotas diretas ou rotas IGP) da tabela de roteamento para o BGP.
Visão geral
A especificação de fluxo oferece proteção contra ataques de negação de serviço e restringe o tráfego ruim que consome a largura de banda e a impede de chegar perto da fonte. Em versões anteriores do Junos OS, as regras de especificação de fluxo foram propagadas para IPv4 em BGP como informações de acessibilidade da camada de rede. Começando pelo Junos OS Release 16.1, o recurso de especificação de fluxo é suportado na família IPv6 e permite a propagação de regras de especificação de fluxo de tráfego para VPN IPv6 e IPv6.
Topologia
Figura 7 mostra a topologia da amostra. O Roteador R1 e o Roteador R2 pertencem a diferentes sistemas autônomos. A especificação de fluxo IPv6 está configurada no Roteador R2. Todo tráfego de entrada é filtrado com base nas condições de especificação de fluxo, e o tráfego é tratado de forma diferente dependendo da ação especificada. Neste exemplo, todo o tráfego que vai para abcd:11:11:11:10/128 que corresponda às condições de especificação do fluxo é descartado; enquanto que o tráfego destinado a abcd:11:11:11:30/128 e correspondente às condições de especificação do fluxo é aceito.
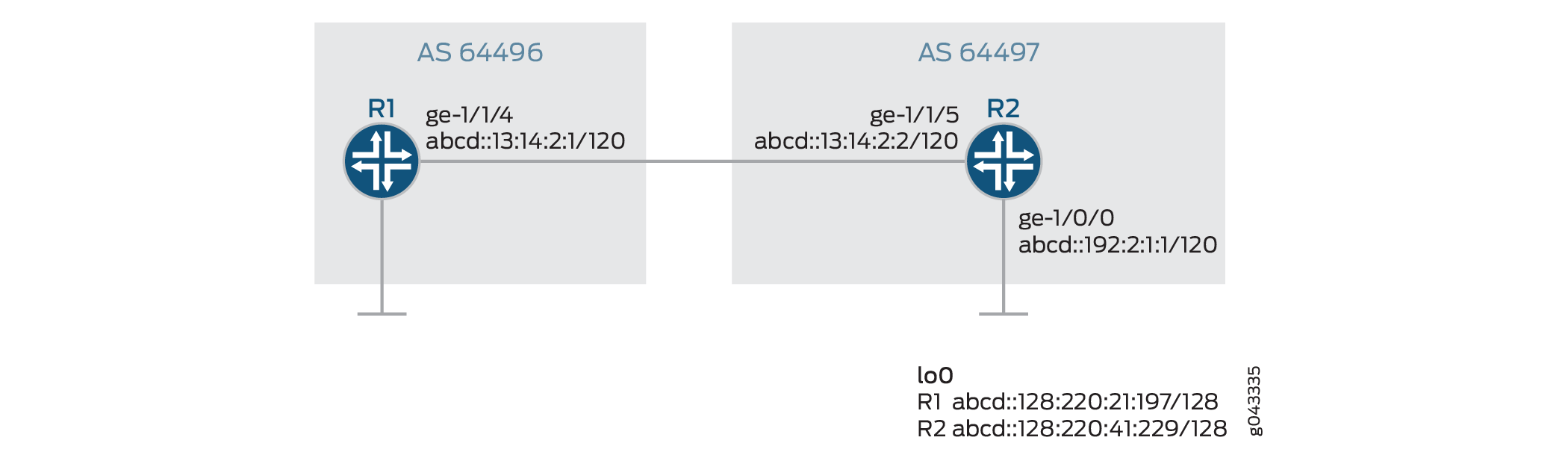
Configuração
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos na CLI no nível de [edit] hierarquia e, em seguida, entrar no commit modo de configuração.
Roteador R1
set interfaces ge-1/1/4 unit 0 family inet6 address abcd::13:14:2:1/120 set interfaces lo0 unit 0 family inet6 address abcd::128:220:21:197/128 set routing-options router-id 128.220.21.197 set routing-options autonomous-system 64496 set protocols bgp group ebgp type external set protocols bgp group ebgp family inet6 unicast set protocols bgp group ebgp family inet6 flow set protocols bgp group ebgp peer-as 64497 set protocols bgp group ebgp neighbor abcd::13:14:2:2
Roteador R2
set interfaces ge-1/0/0 unit 0 family inet6 address abcd::192:2:1:1/120 set interfaces ge-1/1/5 unit 0 family inet6 address abcd::13:14:2:2/120 set interfaces lo0 unit 0 family inet6 address abcd::128:220:41:229/128 set routing-options rib inet6.0 static route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2 set routing-options rib inet6.0 flow route route-1 match destination abcd::11:11:11:10/128 set routing-options rib inet6.0 flow route route-1 match protocol tcp set routing-options rib inet6.0 flow route route-1 match destination-port http set routing-options rib inet6.0 flow route route-1 match source-port 65535 set routing-options rib inet6.0 flow route route-1 then discard set routing-options rib inet6.0 flow route route-2 match destination abcd::11:11:11:30/128 set routing-options rib inet6.0 flow route route-2 match icmp6-type echo-request set routing-options rib inet6.0 flow route route-2 match packet-length 100 set routing-options rib inet6.0 flow route route-2 match dscp 10 set routing-options rib inet6.0 flow route route-2 then accept set routing-options router-id 128.220.41.229 set routing-options autonomous-system 64497 set protocols bgp group ebgp type external set protocols bgp group ebgp family inet6 unicast set protocols bgp group ebgp family inet6 flow set protocols bgp group ebgp export redis set protocols bgp group ebgp peer-as 64496 set protocols bgp group ebgp neighbor abcd::13:14:2:1 set policy-options policy-statement redis from protocol static set policy-options policy-statement redis then accept
Configuração do roteador R2
Procedimento passo a passo
O exemplo a seguir exige que você navegue por vários níveis na hierarquia de configuração. Para obter informações sobre como navegar na CLI, consulte Usando o Editor de CLI no modo de configuração no Guia do usuário da CLI.
Para configurar o roteador R2:
Repita este procedimento para o Roteador R1 depois de modificar os nomes, endereços e outros parâmetros de interface apropriados.
Configure as interfaces com endereços IPv6.
[edit interfaces] user@R2# set ge-1/0/0 unit 0 family inet6 address abcd::192:2:1:1/120 user@R2# set ge-1/1/5 unit 0 family inet6 address abcd::13:14:2:2/120
Configure o endereço de loopback IPv6.
[edit interfaces] user@R2# set lo0 unit 0 family inet6 address abcd::128:220:41:229/128
Configure a ID do roteador e o número do sistema autônomo (AS).
[edit routing-options] user@R2# set router-id 128.220.41.229 user@R2# set autonomous-system 64497
Configure uma sessão de peering EBGP entre o roteador R1 e o roteador R2.
[edit protocols] user@R2# set bgp group ebgp type external user@R2# set bgp group ebgp family inet6 unicast user@R2# set bgp group ebgp family inet6 flow user@R2# set bgp group ebgp export redis user@R2# set bgp group ebgp peer-as 64496 user@R2# set bgp group ebgp neighbor abcd::13:14:2:1
Configure uma rota estática e um próximo salto. Assim, uma rota é adicionada à tabela de roteamento para verificar o recurso neste exemplo.
[edit routing-options] user@R2# set rib inet6.0 static route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2
Especifique as condições de especificação do fluxo.
[edit routing-options] user@R2# set rib inet6.0 flow route route-1 match destination abcd::11:11:11:10/128 user@R2# set rib inet6.0 flow route route-1 match protocol tcp user@R2# set rib inet6.0 flow route route-1 match destination-port http user@R2# set rib inet6.0 flow route route-1 match source-port 65535
Configure uma discard ação para descartar pacotes que correspondam às condições de correspondência especificadas.
[edit routing-options] user@R2# set rib inet6.0 flow route route-1 then discard
Especifique as condições de especificação do fluxo.
[edit routing-options] user@R2# set rib inet6.0 flow route route-2 match destination abcd::11:11:11:30/128 user@R2# set rib inet6.0 flow route route-2 match icmp6-type echo-request user@R2# set rib inet6.0 flow route route-2 match packet-length 100 user@R2# set rib inet6.0 flow route route-2 match dscp 10
Configure uma accept ação para aceitar pacotes que correspondam às condições de correspondência especificadas
[edit routing-options] user@R2# set rib inet6.0 flow route route-2 then accept
Defina uma política que permite que o BGP aceite rotas estáticas.
[edit policy-options] user@R2# set policy-statement redis from protocol static user@R2# set policy-statement redis then accept
Resultados
A partir do modo de configuração, confirme sua configuração entrando noshow interfaces, show protocolsshow routing-optionse show policy-options comandos. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@R2# show interfaces
ge-1/0/0 {
unit 0 {
family inet6 {
address abcd::192:2:1:1/120;
}
}
}
ge-1/1/5 {
unit 0 {
family inet6 {
address abcd::13:14:2:2/120;
}
}
}
lo0 {
unit 0 {
family inet6 {
address abcd::128:220:41:229/128;
}
}
}
[edit]
user@R2# show protocols
bgp {
group ebgp {
type external;
family inet6 {
unicast;
flow;
}
export redis;
peer-as 64496;
neighbor abcd::13:14:2:1;
}
}
[edit]
user@R2# show routing-options
rib inet6.0 {
static {
route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2;
}
flow {
route route-1 {
match {
destination abcd::11:11:11:10/128;
protocol tcp;
destination-port http;
source-port 65535;
}
then discard;
}
route route-2 {
match {
destination abcd::11:11:11:30/128;
icmp6-type echo-request;
packet-length 100;
dscp 10;
}
then accept;
}
}
}
router-id 128.220.41.229;
autonomous-system 64497;
[edit]
user@R2# show policy-options
policy-statement redis {
from protocol static;
then accept;
}
Verificação
Confirme se a configuração está funcionando corretamente.
- Verificando a presença de rotas de especificação de fluxo IPv6 na tabela de fluxo de inet6
- Verificando as informações do resumo do BGP
- Verificação da validação do fluxo
- Verificando a especificação de fluxo das rotas IPv6
Verificando a presença de rotas de especificação de fluxo IPv6 na tabela de fluxo de inet6
Propósito
Exibir as rotas na tabela no inet6flow Roteador R1 e R2 e verificar se o BGP aprendeu as rotas de fluxo.
Ação
A partir do modo operacional, execute o show route table inet6flow.0 extensive comando no Roteador R1.
user@R1> show route table inet6flow.0 extensive
inet6flow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): discard,count
*BGP Preference: 170/-101
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 2
State:<Active Ext>
Local AS: 64496 Peer AS: 64497
Age: 20:55
Validation State: unverified
Task: BGP_64497.abcd::13:14:2:2
Announcement bits (1): 0-Flow
AS path: 64497 I
Communities: traffic-rate:64497:0
Accepted
Validation state: Accept, Originator: abcd::13:14:2:2, Nbr AS: 64497
Via: abcd::11:11:11:0/120, Active
Localpref: 100
Router ID: 128.220.41.229
abcd::11:11:11:30/128,*,icmp6-type=128,len=100,dscp=10/term:2 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
*BGP Preference: 170/-101
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 2
State: <Active Ext>
Local AS: 64496 Peer AS: 64497
Age: 12:51
Validation State: unverified
Task: BGP_64497.abcd::13:14:2:2
Announcement bits (1): 0-Flow
AS path: 64497 I
Accepted
Validation state: Accept, Originator: abcd::13:14:2:2, Nbr AS: 64497
Via: abcd::11:11:11:0/120, Active
Localpref: 100
Router ID: 128.220.41.229A partir do modo operacional, execute o show route table inet6flow.0 extensive comando no Roteador R2.
user@R2> show route table inet6flow.0 extensive
inet6flow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): discard,count
Page 0 idx 0, (group pe-v6 type External) Type 1 val 0xaec8850 (adv_entry)
Advertised metrics:
Nexthop: Self
AS path: [64497]
Communities: traffic-rate:64497:0
Path abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535 Vector len 4. Val: 0
*Flow Preference: 5
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 3
State: <Active>
Local AS: 64497
Age: 14:21
Validation State: unverified
Task: RT Flow
Announcement bits (2): 0-Flow 1-BGP_RT_Background
AS path: I
Communities: traffic-rate:64497:0
abcd::11:11:11:30/128,*,proto=17,port=65535/term:2 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
Page 0 idx 0, (group pe-v6 type External) Type 1 val 0xaec8930 (adv_entry)
Advertised metrics:
Nexthop: Self
AS path: [64497]
Communities:
Path abcd::11:11:11:30/128,*,proto=17,port=65535 Vector len 4. Val: 0
*Flow Preference: 5
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 3
State: <Active>
Local AS: 64497
Age: 14:21
Validation State: unverified
Task: RT Flow
Announcement bits (2): 0-Flow 1-BGP_RT_Background
AS path: I Significado
A presença de rotas abcd:11:11:11:11/128 e abcd::11:11:11:30/128 na tabela confirma que o inet6flow BGP aprendeu as rotas de fluxo.
Verificando as informações do resumo do BGP
Propósito
Verifique se a configuração do BGP está correta.
Ação
A partir do modo operacional, execute o show bgp summary comando no Roteador R1 e R2.
user@R1> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet6.0
1 1 0 0 0 0
inet6flow.0
2 2 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
abcd::13:14:2:2 2000 58 58 0 2 19:48 Establ
inet6.0: 1/1/1/0
inet6flow.0: 2/2/2/0
user@R2> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet6.0
0 0 0 0 0 0
inet6flow.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
abcd::13:14:2:1 64496 51 52 0 0 23:03 Establ
inet6.0: 0/0/0/0
inet6flow.0: 0/0/0/0Significado
Verifique se a inet6.0 tabela contém o endereço vizinho BGP e uma sessão de peering foi estabelecida com seu vizinho BGP.
Verificação da validação do fluxo
Propósito
Exibir informações de rota de fluxo.
Ação
A partir do modo operacional, execute o show route flow validation comando no Roteador R1.
user@R1> show route flow validation
inet6.0:
abcd::11:11:11:0/120
Active unicast route
Dependent flow destinations: 2
Origin: abcd::13:14:2:2, Neighbor AS: 64497
abcd::11:11:11:10/128
Flow destination (1 entries, 1 match origin, next-as)
Unicast best match: abcd::11:11:11:0/120
Flags: Consistent
abcd::11:11:11:30/128
Flow destination (1 entries, 1 match origin, next-as)
Unicast best match: abcd::11:11:11:0/120
Flags: ConsistentSignificado
A saída exibe as rotas de fluxo na inet6.0 tabela.
Verificando a especificação de fluxo das rotas IPv6
Propósito
Exibir o número de pacotes que são descartados e aceitos com base nas rotas especificadas de especificação de fluxo.
Ação
A partir do modo operacional, execute o show firewall filter_flowspec_default_inet6_ comando no Roteador R2.
user@R2> show firewall filter __flowspec_default_inet6__ Filter: __flowspec_default_inet6__ Counters: Name Bytes Packets abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535 0 0 abcd::11:11:11:30/128,*,proto=17,port=65535 6395472 88826
Significado
A saída indica que os pacotes destinados a abcd:11:11:11:10/128 são descartados e 88826 pacotes foram aceitos para a rota abcd::11:11:11:11:30/128.
Configuração da ação de especificação de fluxo BGP redirecionamento para IP para filtrar tráfego DDoS
A partir do Junos OS Release 18.4R1, a especificação de fluxo BGP conforme descrito no draft de Internet de fluxo BGP draft-ietf-idr-flowspec-redirect-ip-02.txt, o redirecionamento para o IP Action é suportado. Redirecionamento para a ação ip usa comunidade BGP estendida para fornecer opções de filtragem de tráfego para mitigação de DDoS em redes de provedores de serviços. O redirecionamento da especificação de fluxo legado para IP usa o atributo nexthop BGP. O Junos OS anuncia o redirecionamento para a ação de especificação de fluxo IP usando a comunidade estendida por padrão. Esse recurso é necessário para oferecer suporte ao encadeamento de serviços no gateway de controle de serviços virtuais (vSCG). Redirecionar para a ação ip permite desviar o tráfego de especificação de fluxo correspondente para um endereço globalmente acessível que poderia ser conectado a um dispositivo de filtragem que pode filtrar o tráfego DDoS e enviar o tráfego limpo para o dispositivo de saída.
O IPv6 é suportado apenas no modo de codificação de redirecionamento legado para Nexthop. Não oferecemos suporte ao novo formato de codificação de redirecionamento para IP para IPv6.
Antes de começar a redirecionar o tráfego para IP para rotas de especificação de fluxo BGP, faça o seguinte:
Configure as interfaces do dispositivo.
Configure o OSPF ou qualquer outro protocolo IGP.
Configure MPLS e LDP.
Configure BGP.
Configure o redirecionamento para o recurso IP usando a comunidade estendida BGP.
Configure o redirecionamento da especificação de fluxo legado para o recurso IP usando o atributo nexthop.
Você não pode configurar políticas para redirecionar o tráfego para um endereço IP usando a comunidade estendida BGP e o redirecionamento legado para um endereço IP de próximo salto em conjunto.
Configure o redirecionamento da especificação de fluxo legado para IP especificado no rascunho da internet draft-ietf-idr-flowspec-redirect-ip-00.txt, a comunidade estendida bgp flow-spec para redirecionamento de tráfego para IP Next Hop incluem no nível de hierarquia.
[edit group bgp-group neighbor bgp neighbor family inet flow] user@host# set legacy-redirect-ip-action
Defina uma política para combinar com o atributo do próximo salto.
[edit policy options] user@host#policy statement policy_name user@host#from community community-name user@host#from next-hop ip-address
Por exemplo, defina uma política p1 para redirecionar o tráfego para o endereço IP de próximo salto 10.1.1.1.
[edit policy options] user@host#policy statement p1 user@host#from community redirnh user@host#from next-hop 10.1.1.1
Defina uma política para definir, adicionar ou excluir a comunidade BGP usando a especificação de fluxo legado próximo atributo de salto redirecionado para a ação IP.
[edit policy-options] user@host# policy-statement policy_name user@host# then community set community-name user@host# then community add community-name user@host# then community delete community-name user@host# then next-hop next-hop-address
Por exemplo, defina uma política p1 e defina, adicione ou exclua um redirnh da comunidade BGP para redirecionar o tráfego DDoS para o endereço IP de próximo salto 10.1.1.1.1.
[edit policy-options policy-statement p1] user@host# then community set redirnh user@host# then community add redirnh user@host# then community delete redirnh user@host# then next-hop 10.1.1.1
Consulte também
Encaminhamento de tráfego usando especificação de fluxo BGP Ação DSCP
Configure a ação de DSCP da Especificação de Fluxo BGP (FlowSpec) para encaminhar pacotes usando as informações de prioridade de encaminhamento e perda em toda a rede de forma eficaz.
Benefícios da ação BGP FlowSpec DSCP para encaminhar pacotes
-
Encaminha o tráfego para as filas de COS pretendidas, onde as políticas de COS são aplicadas corretamente ao tráfego.
-
Influencia o comportamento de encaminhamento local (por exemplo, seleção do túnel) com base no valor de DSCP provisionado.
-
Ajuda a gerenciar o tráfego em sua rede de maneira eficaz.
Quando um pacote entra em um roteador, o pacote passa pelos recursos (como firewall, COS etc.) aplicados na interface de entrada. Quando você configura o filtro BGP FlowSpec na interface de entrada, o filtro é aplicado nos pacotes por instância de roteamento com base na ação DSCP. A ação do DSCP classifica e reescreve os pacotes, juntamente com a mudança de código DSCP através do filtro BGP FlowSpec. Com base nas informações de prioridade de encaminhamento e perda, os pacotes são colocados na fila de encaminhamento correta. Os pacotes viajam por rotas de fluxo apenas se as condições específicas de correspondência forem atendidas. As condições de correspondência podem ser endereço IP de origem e destino, porta de origem e destino, DSCP, número de protocolo etc. As informações de prioridade de encaminhamento e perda são atualizadas por meio da tabela de mapeamento reverso.
Aqui está uma topologia de uma sessão BGP estabelecida entre o provedor de serviços e as redes de clientes empresariais.
Nesta topologia, uma sessão BGP é configurada entre o provedor de serviços e a rede de clientes empresariais para o BGP FlowSpec. O filtro BGP FlowSpec é aplicado em roteadores PE1 e PE2. Os pacotes que entram nesses roteadores são reescritos com base no filtro BGP FlowSpec e na ação DSCP.
Para habilitar o filtro BGP FlowSpec em um dispositivo, você precisa adicionar a dscp-mapping-classifier declaração de configuração no nível [edit forwarding-options family (inet | inet6)] de hierarquia:
forwarding-options {
family inet {
dscp-mapping-classifier ipv4-classifer;
}
family inet6 {
dscp-mapping-classifier ipv6-classifer;
}
}
A classe amostra a seguir de configuração de serviço mapeia pontos de código DSCP para a classe de encaminhamento e prioridade de perda:
class-of-service {
classifiers {
dscp dscp1 {
forwarding-class best-effort {
loss-priority low code-points 000000;
}
}
}
}
Configuração de políticas para validação de rota de fluxo
Quando a especificação de fluxo é usada para distribuir filtros pela rede para os pontos de peering, o formato dos filtros de especificação de fluxo é validado na fonte. Se você deseja rotas de fluxo de sinal na sessão de EBGP para os pares, os filtros de especificação de fluxo devem ser validados nos roteadores de borda.
As políticas podem ser usadas para realizar essa validação adicional de rotas de fluxo. Uma política pode filtrar as condições de correspondência da rota de fluxo para evitar a admissão de rotas de fluxo malformadas, sem suporte ou indesejadas injetadas da fonte. Ele também pode impedir que as rotas de fluxo bloqueiem sessões de protocolo acidentalmente ou maliciosamente.
Políticas podem ser usadas para
-
Verifique se existe uma determinada condição de correspondência/ação de especificação de fluxo
-
Impeça a programação de condições inválidas ou indesejável de correspondência.
- Configuração de políticas para verificar se existe uma condição de correspondência/ação de especificação de fluxo
- Configuração de políticas para verificar atributos compatíveis com especificações de fluxo
Configuração de políticas para verificar se existe uma condição de correspondência/ação de especificação de fluxo
Você pode configurar políticas para verificar se uma determinada condição de correspondência/ação de fluxo é anunciada da fonte e tomar qualquer ação necessária. Cada rota de fluxo tem uma condição de correspondência e uma condição de ação. Configure as seguintes declarações especificando a condição da correspondência e a ação a ser tomada se ocorrer uma correspondência.
set policy-options flowspec-attribute <> match condition <>
set policy-options flowspec-attribute < Flow Route action >
Essas configurações de políticas buscam correspondências exatas ou parciais na rota de fluxo e, quando encontradas, a política corresponderá à rota de fluxo. Se você configurar várias condições de correspondência, a correspondência só ocorre quando todas as condições são atendidas.
Você pode usar a opção de correspondência "invertido" para excluir uma determinada condição de correspondência. Por exemplo; nas declarações de configuração abaixo, a política corresponde a rotas de fluxo "sem protocolo tcp e, em seguida, combina "com o valor dscp 'x'. Se ambas as correspondências forem encontradas, a política aceita as rotas de fluxo.
set policy-options flowspec-attribute fl1 invert-match protocol value tcp set policy-options flowspec-attribute fl1 match dscp value <x> set policy-options policy-statement pl1 term 1 from flowspec-attribute fl1 set policy-options policy-statement pl1 term 1 then accept
Configuração de políticas para verificar atributos compatíveis com especificações de fluxo
Você pode configurar políticas para verificar se a rota de fluxo corresponde ao valor específico de uma condição de correspondência de fluxo. Isso pode impedir que as rotas de fluxo bloqueiem sessões de protocolo acidentalmente ou maliciosamente.
Configure a declaração a seguir especificando o valor específico do atributo.
set policy-options flowspec-attribute < match value >
A política de especificação de fluxo corresponde a atributos específicos do IPv4 não afetam as rotas de fluxo IPv6 e vice-versa.
Tabela de histórico de alterações
A compatibillidadde com o recurso dependerá da platadorma e versão utilizada. Use o Feature Explorer para saber se o recurso é compatível com sua plataforma.
extended-community de tráfego.