NorthStar Controller Fail-Safe Mode
The Cassandra database is a key component of NorthStar Controller operation, with or without HA. Loss of connectivity to the Cassandra database results in service disruption for NorthStar northbound interface users because the web UI and REST API become unavailable. In that event, NorthStar enters into a fail-safe mode that allows users to retain visibility of the network through NorthStar and enables basic NorthStar functions until the Cassandra database problem can be corrected.
Because Apache Cassandra is an open source software, Cassandra troubleshooting strategies are well documented elsewhere. These are some sample web sites:
Main: Cassandra Documentation
Supplemental: Cassandra Wiki
DataStax Enterprise
In the case of simple loss of connectivity to the Cassandra database, the NorthStar processes are actually still running, and there is no service disruption for LSPs controlled by NorthStar or for newly delegated LSPs created on the routers. However, when you attempt to access the NorthStar web UI, you see an error message such as:
{"error":"All host(s) tried for query failed. First host tried, 172.25.152.169:9042: Host considered as DOWN. See innerErrors."}When this error is detected by the web server (nodejs), it switches to fail-safe mode so users can have view-only access.
Loss of connectivity to Cassandra can be compounded by restarting processes in an attempt to resolve the problem. Restarting NorthStar processes might seem like a natural troubleshooting step to take when you cannot access the web UI or the REST API. But if the web UI and REST API are unavailable because connectivity to Cassandra has been lost, restarting Toposerver and the web server cannot succeed. This results in service disruption for LSPs controlled by NorthStar. Also, restarting the NorthStar processes does not correct the Cassandra connectivity problem.
In this case, the web server and Toposerver switch to fail-safe mode, providing view-only access. Toposerver loads the network topology from the latest network snapshot saved in the file system.
Fail-Safe Mode Functionality
The trigger for fail-safe mode is that the Cassandra database is unavailable. In the absence of Cassandra, fail-safe mode cannot emulate full NorthStar functionality, but it does provide the following:
The PCEP server and Path Computation Server (PCS) remain running. The web server (nodejs), Toposerver, and task_scheduler remain running, but in fail-safe mode.
Even if the Cassandra database has been corrupted, fail-safe mode works.
Even if only one server in a NorthStar cluster is up and running, fail-safe mode works.
A fail-safe mode landing page is provided in the NorthStar web UI. Admin user login is required to access the landing page. Figure 1 shows the fail-safe mode landing page. Note the change in color of the top menu bar and the notation, (Safe Mode), in the upper right corner.
Figure 1: Fail-Safe Mode Landing Page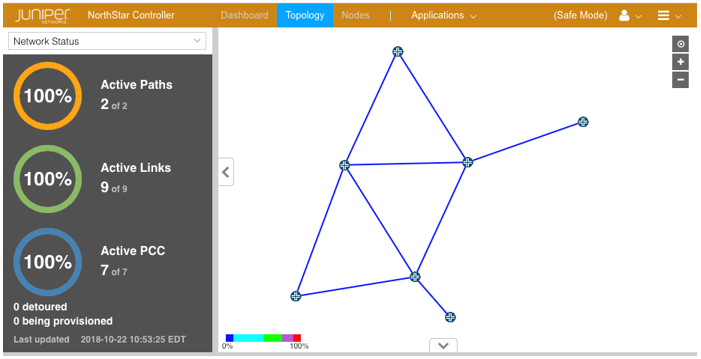
In fail-safe mode, existing delegated or PCE-initiated LSPs can be rerouted by the PCS in the event of network outages.
Toposerver does not use the Cassandra database to load the network model. Instead, it loads the network model based on the latest network snapshot collected by the NorthStar file system. During normal NorthStar operation, the file system collects and stores network snapshots hourly (by default).
If HA switchover occurs while Cassandra is inaccessible, the HA agent is still able to elect an active node as part of fail-safe mode. The NorthStar processes from the new active node start in fail-safe mode when they discover that Cassandra is not available.
While in fail-safe mode, the status of the NorthStar cluster is displayed for all users via a banner in the web UI. The NorthStar health reporting function also reports the status of nodes, even when they are down.
Limitations of Fail-Safe Mode
Fail-safe mode is intended for temporary use until the Cassandra database can be restored, and therefore has the following limitations:
You cannot provision, add, or delete new LSPs.
There is no guarantee that a network snapshot is available. If a snapshot is not available (possibly due to the timing of hourly snapshot creation and HA switchover activities), only live data can be visualized in NorthStar Controller. No user-defined properties can be loaded and considered by NorthStar.
Once you have restored the cluster to normal operation, you must manually exit fail-safe mode by restarting nodejs (infra:web), Toposerver, and task_scheduler:
# supervisorctl restart infra:web collector_main:task_scheduler northstar:toposerver