GPU Backend Fabric
The GPU Backend fabric provides the infrastructure for GPUs to communicate with each other within a cluster, using RDMA over Converged Ethernet (RoCEv2). ROCEv2 boosts data center efficiency, reduces overall complexity, and increases data delivery performance by enabling the GPUs to communicate as they would with the InfiniBand protocol.
Packet loss can impact job completion times and should be avoided. Therefore, when designing the network infrastructure to support RoCEv2 for an AI cluster, one of the key objectives is to provide a lossless fabric, while also achieving maximum throughput, minimal latency, and minimal network interference for the AI traffic flows. ROCEv2 is more efficient over lossless networks, resulting in optimum job completion times.
The GPU Backend fabric in this JVD was designed with these goals in mind and follows a 3-stage IP clos architecture combined with NVIDIA’s Rail Optimized Stripe Architecture (discussed in the next section), as shown in Figure 5.
Figure 5: GPU Backend Fabric Architecture
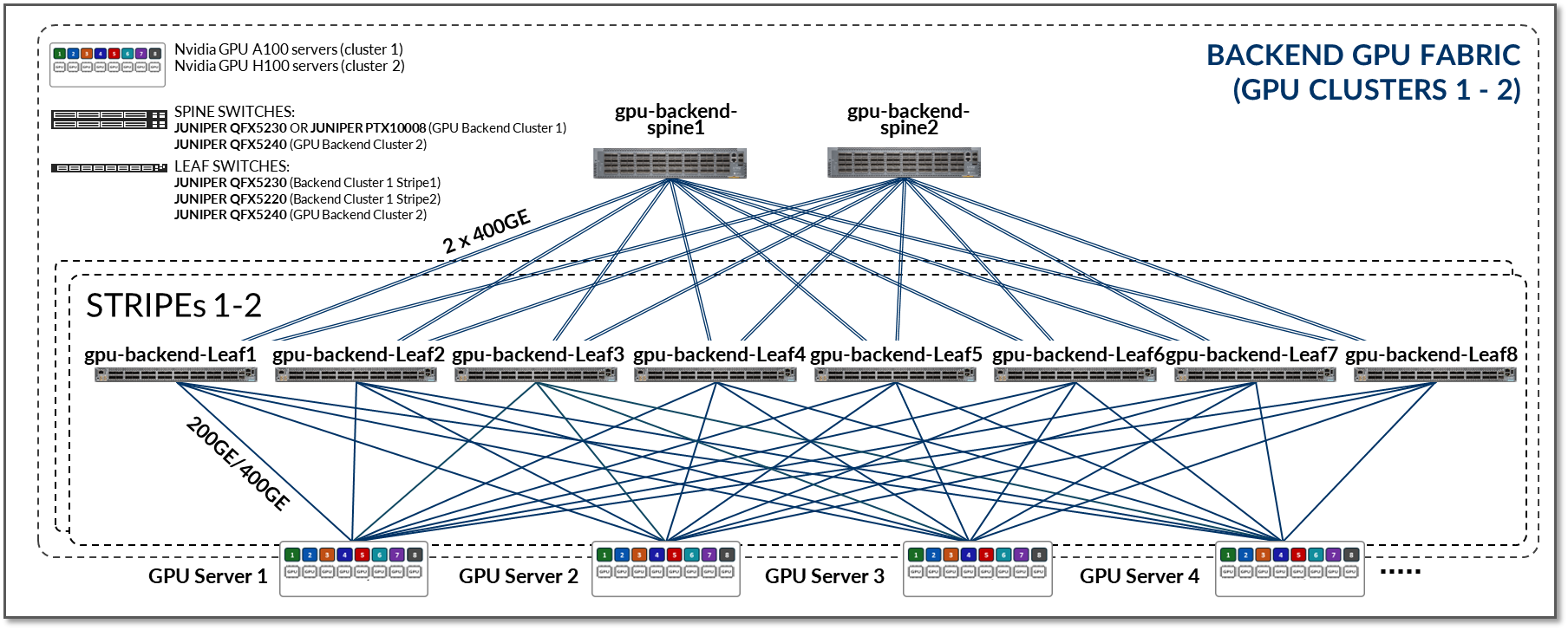
The GPU Backend devices included in this fabric, and the connections between them, are summarized in the following table:
Table 3: GPU Backend devices per cluster and stripe
| Cluster | Stripe | Nvidia DGX GPU Servers |
GPU Backend Leaf Nodes switch model (gpu-backend-leaf#) |
GPU Backend Spine Nodes switch model (gpu-backend-spine#) |
| 1 | 1 | A100-01 to A100-04 | QFX5230-64CD x 8 |
QFX5230-64CD x 2 OR PTX10008 w/ JNP10K-LC1201 |
| 1 | 2 | A100-05 to A100-08 | QFX5220-32CD x 8 | |
| 2 | 1 | H100-01 to H100-02 | QFX5240-64OD x 8 | QFX5230-64OD x 4 |
| 2 | 2 | H100-03 to H100-04 | QFX5240-64OD x 8 |
Table 4: Connections between servers, leaf and spine nodes per cluster and stripe in the GPU Backend
| Cluster | Stripe |
GPU Servers <=> GPU Backend Leaf Nodes |
GPU Backend Spine Nodes <=> GPU Backend Leaf Nodes |
| 1 | 1 |
1 x 200GE links between each A100 server and each leaf node (200GE x 8 links per server) |
2 x 400GE links between each leaf node and each spines node (2 x 400GE x 2 links per leaf node) |
| 1 | 2 |
1 x 200GE links between each A100 server and each leaf nodes (200GE x 8 links per server) |
2 x 400GE links between each leaf node and each spines node (2 x 400GE x 2 links per leaf node) |
| 2 | 1 |
1 x 400GE links between each H100 server and each leaf nodes (400GE x 8 links per server) |
2 x 400GE links between each leaf node and each spines node (2 x 400GE x 4 links per leaf node) |
| 2 | 2 |
1 x 400GE links between each H100 server and each leaf nodes (400GE x 8 links per server) |
2 x 400GE links between each leaf node and each spines node (2 x 400GE x 4 links per leaf node) |
- All the Nvidia A100 servers in the lab are connected to the QFX5220 and QFX5230 leaf nodes in cluster 1 using 200GE interfaces, while the H100 servers are connected to the QFX5240 leaf nodes in cluster 2 using 400GE interfaces.
- This fabric is a pure L3 IP fabric (either IPv4 or IPV6) that uses EBGP for route advertisement (described in the networking section).
- Connectivity between the servers and the leaf nodes is L2 vlan-based with an IRB on the leaf nodes acting as default gateway for the servers (described in the networking section).
Table 5: Per cluster, per stripe Server to Leaf Bandwidth
| Server to Leaf Bandwidth per Stripe (per Cluster) | |||||
| Cluster | AI Systems (server type) | Servers per Stripe | Server <=> Leaf Links per Server | Bandwidth of Server <=> Leaf Links [Gbps] |
Total Bandwidth Servers <=> Leaf per stripe [Tbps} |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6.4 |
| 2 | H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6.4 |
Table 6: Per cluster, per stripe Leaf to Spine Bandwidth
| Leaf to Spine Bandwidth per Stripe | |||
| Leaf <=> Spine Links Per Spine Node & Per Stripe |
Speed Of Leaf <=> Spine Links [Gbps] |
Number of Spine Nodes |
Total Bandwidth Leaf <=> Spine Per Stripe [Tbps] |
| 8 | 2 x 400 | 2 | 12.8 |
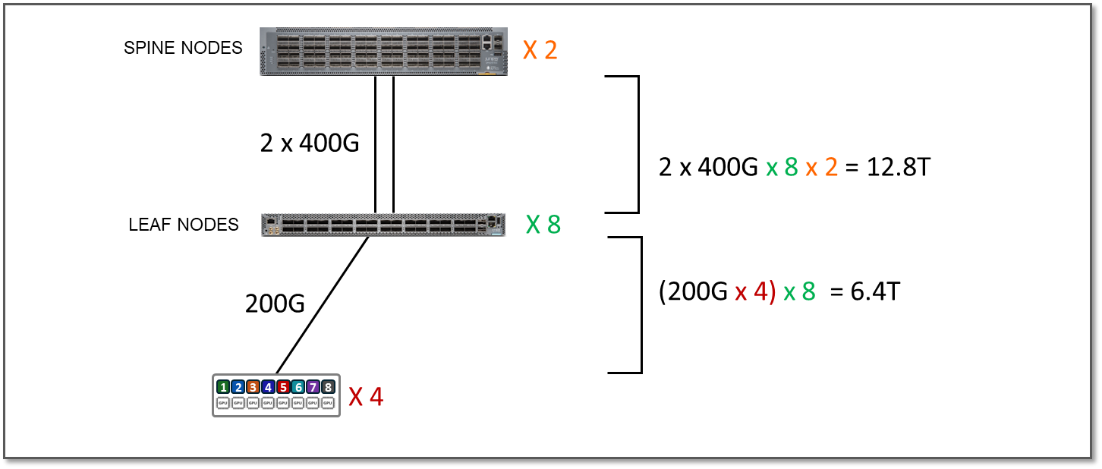
The (over)subscription rate is simply calculated by comparing the numbers from the two tables above:
In cluster 1, the bandwidth between the servers and the leaf nodes is 6.4 Tbps per stripe, while the bandwidth available between the leaf and spine nodes is 12.8 Tbps per stripe. This means that the fabric has enough capacity to process all traffic between the GPUs even when this traffic was 100% inter-stripe, while still having extra capacity to accommodate additional servers without becoming oversubscribed.
Figure 6: Extra Capacity Example
We also tested connecting the H100 GPU servers along the A100 servers to the stripes in Cluster 1 as follows:
Figure 7: 1:1 Subscription Example
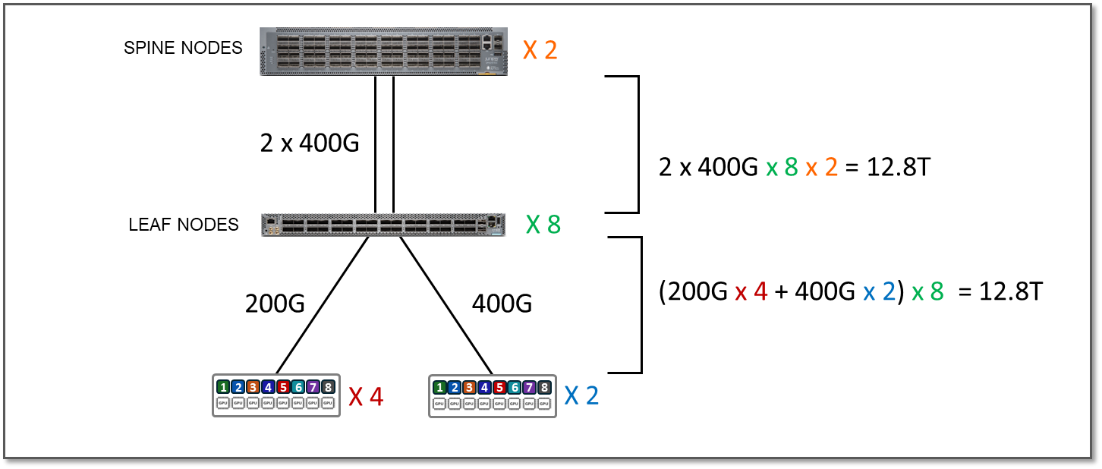
Table 7: Per cluster, per stripe Server to Leaf Bandwidth with all servers connected to same cluster
| Server to Leaf Bandwidth per Stripe | |||||
| Cluster | Al Systems | Servers per Stripe | Server <=> Leaf Links per Server |
Server <=> Leaf Links Bandwidth [Gbps] |
Total Servers <=> Leaf Links Bandwidth per stripe [Tbps] |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6.4 |
| H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6.4 | |
| Total Bandwidth of Server <=> Leaf Links | 12.8 | ||||
The bandwidth between the servers and the leaf nodes is now 12.8 Tbps per stripe, while the bandwidth available between the leaf and spine nodes is also 12.8 Tbps per stripe (as shown in table above). This means that the fabric has enough capacity to process all traffic between the GPUs even when this traffic was 100% inter-stripe, but now there is no extra capacity to accommodate additional servers. The subscription factor in this case is 1:1 (no subscription).
To run oversubscription testing, we disabled some of the interfaces between the leaf and spines to reduce the available bandwidth as shown in the example in Figure 8:
Figure 8: 2:1 Oversubscription Example
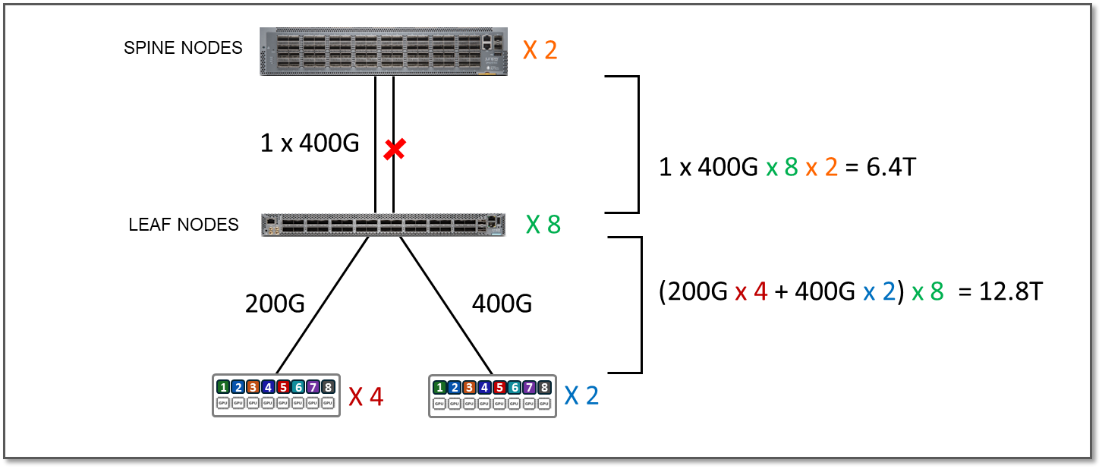
The total Servers to Leaf Links bandwidth per stripe has not changed. It is still 12.8 Tbps as shown in table 3 in the previous scenario.
However, the bandwidth available between the leaf and spine nodes is now only 6.4 Tbps per stripe.
Table 8: Per Stripe Leaf to Spine Bandwidth
| Leaf to Spine Bandwidth per Stripe | |||
| Leaf <=> Spine Links Per Spine Node & Per Stripe |
Speed Of Leaf <=> Spine Links [Gbps] |
Number of Spine Nodes |
Total Bandwidth Leaf <=> Spine Per Stripe [Tbps] |
| 8 | 1 x 400 | 2 | 6.4 |
This means that the fabric no longer has enough capacity to process all traffic between the GPUs even if this traffic was 100% inter-stripe, potentially causing congestion and traffic loss. The oversubscription factor in this case is 2:1.