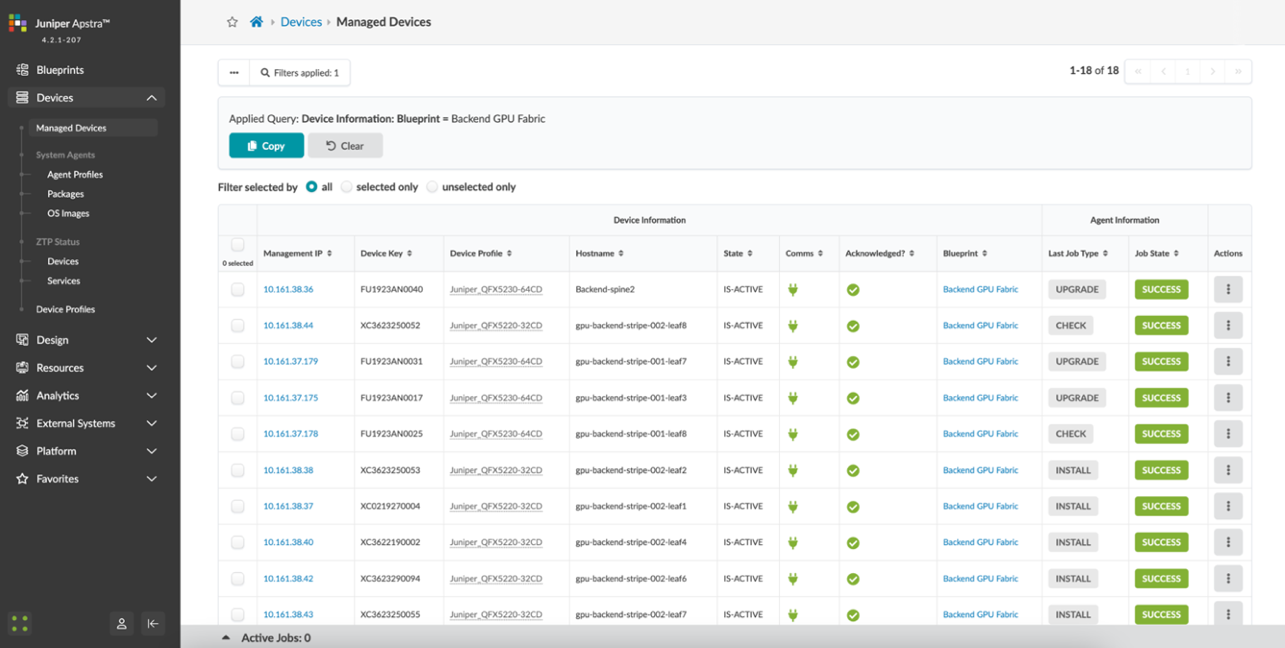
AI Fabric IP Services
In the next few sections, we describe the various strategies that can be employed to handle traffic congestion and traffic load distribution in the Backend GPU fabric.
Congestion Management
AI clusters pose unique demands on network infrastructure due to their high-density, and low-entropy traffic patterns, characterized by frequent elephant flows with minimal flow variation. Additionally, most AI modes require uninterrupted packet flow with no packet loss for training jobs to be completed.
For these reasons, when designing a network infrastructure for AI traffic flows, the key objectives include maximum throughput, minimal latency, and minimal network interference over a lossless fabric, resulting in the need to configure effective congestion control methods.
Data Center Quantized Congestion Notification (DCQCN) has become the industry-standard for end-to-end congestion control for RDMA over Converged Ethernet (RoCEv2) traffic. DCQCN congestion control methods offer techniques to strike a balance between reducing traffic rates and stopping traffic all together to alleviate congestion, without resorting to packet drops.
It is important to note that DCQCN is primarily required in the GPU backend fabric, where the majority of AI workload traffic resides, while it is generally unnecessary in the frontend or storage backend."
DCQCN combines two different mechanisms for flow and congestion control:
- Priority-Based Flow Control (PFC), and
- Explicit Congestion Notification (ECN).
Priority-Based Flow Control (PFC)
Priority-Based Flow Control (PFC) is a standard (IEEE 802.1Qbb) backpressure mechanism for Ethernet network devices that signals congestion and causes traffic on a particular priority to temporarily stop packet drops. PFC helps relieve congestion by halting traffic flow for individual traffic priorities (IEEE 802.1p or DSCP markings) mapped to specific queues or ports.
The goal of PFC is to stop a neighbor from sending traffic for a defined amount of time (PAUSE time), or until congestion clears. This process consists of sending PAUSE control frames upstream, requesting the sender to halt transmission of all traffic for a specific class or priority while congestion is ongoing. The sender completely stops sending traffic to the receiving device for the specified priority.
For RoCE traffic, PFC relies on fabric switches detecting congestion and generating PFC Pause frames upstream, and devices that can respond to these frames, including the sending NIC, which receives the PFC Pause frames and reacts accordingly.
While PFC mitigates data loss and allows the receiver to catch up on processing packets already in the queue, it impacts the performance of applications using the affected queues during the congestion period. Additionally, resuming traffic transmission of post-congestion often triggers a surge, potentially exacerbating or reinstating the congestion scenario.
We recommend configuring PFC only on the QFX devices acting as leaf nodes.
Figure 20: DCQCN – PFC Operation
Explicit Congestion Notification (ECN)
Explicit Congestion Notification (ECN) is a standard (RFC 3168) backpressure mechanism for Ethernet network devices that signals congestion and causes traffic to temporarily slow down to avoid packet drops. ECN curtails transmit rates during congestion while enabling traffic to persist, albeit at reduced rates, until congestion subsides. The goal of ECN is to reduce packet loss and delay by making the traffic source decrease the transmission rate until the congestion clears.
This process entails marking packets with ECN bits at congestion points by setting the ECN bits to 11 in the IP header. The presence of this ECN marking prompts receivers to generate Congestion Notification Packets (CNPs) sent back to the source, which signals the source to throttle traffic rates.
ECN for RoCE traffic relies on fabric switches that can detect congestion and implement ECN marking for traffic downstream, and devices that can respond to these markings, as shown in Figure 21:
Figure 21: DCQCN – ECN Operation
- The receiving NIC, or Notification Point (NP), which transmits CNPs when receiving ECN-marked packets
- The sending NIC, or Reaction Point (RP), that receives the CNP packets and reacts accordingly
Combining PFC and ECN offers the most effective congestion relief in a lossless IP fabric supporting RoCEv2, while safeguarding against packet loss. To achieve this, when implementing PFC and ECN together, their parameters should be carefully selected so that ECN is triggered before PFC.
TOS/DSCP for RDMA Traffic
RDMA traffic must be properly marked to allow the switch to correctly classify it, and to place it in the lossless queue for proper treatment. Marking can be either DSCP within the IP header, or PCP in the ethernet frame vlan-tag field. Whether DSCP or PCP is used depends on whether the interface between the GPU server and the switch is doing vlan tagging (802.1q) or not. Figure 64 shows how RDMA and CNP are marked differently, and as a result, the fabric switch classified and schedules the two types of packets differently.
Figure 22: TOS/DSCP operation
For more information refer to Introduction to Congestion Control in Juniper AI Networks which explores how to build a lossless fabric for AI workloads using DCQCN (ECN and PFC) congestion control methods and DLB. The document was based on DLRM training model as a reference and demonstrates how different congestion parameters such as ECN and PFC counters, input drops and tail drops can be monitored to adjust configuration and build a lossless fabric infrastructure for RoCEv2 traffic.
NOTE: We provide general recommendations and describe the parameters validated in the lab. However, each language model has a unique traffic profile and characteristics. Class of Service and load balancing attributes must be tuned to meet your specific model requirements.
Load Balancing
The fabric architecture used in this JVD in all the fabrics follows the 2-stage clos design, with every leaf node connected to all the available spine nodes, and via multiple interfaces. As a result, multiple paths are available between the leaf and spine nodes to reach other devices.
Equal Cost Multiple Path (ECMP) can lead to suboptimal link utilization when distributing AI traffic. ECMP relies on hashing selected packet header fields to spread flows across available paths; however, AI workloads typically generate large, long-lived flows with highly similar header characteristics (for example, identical source and destination addresses, ports, and protocols). This limited flow diversity significantly reduces hashing entropy, causing multiple flows to be mapped onto the same link. As a result, certain links become overutilized while others remain underused, increasing the risk of congestion and packet loss. This is particularly critical in the GPU backend fabric, where GPU-to-GPU communication occurs.
To improve the distribution of traffic across all the available paths, either Dynamic Load Balancing (DLB), Adaptive load balancing (ALB) for ECMP, or Global Load Balancing (GLB) can be implemented instead of ECMP.
For this, JVD Dynamic Load Balancing flowlet-mode was validated on all the QFX leaf nodes and spines nodes, and Adaptive load balancing (ALB) on the PTX spine nodes. Global Load Balancing is also included as an alternative solution.
Additional testing was conducted on the QFX5240-64OD/QFX5241-64OD to evaluate Selective Dynamic Load Balancing, and Reactive path rebalancing. Notice that these load balancing mechanisms are only available on QFX devices.
Dynamic Load Balancing (DLB)
DLB ensures that all paths are utilized more fairly, by not only looking at the packet headers, but also considering real-time link quality based on port load (link utilization) and port queue depth, when selecting a path. This method provides better results when multiple long-lived flows moving large amounts of data need to be load balanced.
DLB can be configured in two different modes:
- Per packet mode: packets from the same flow are sprayed across link members of an IP ECMP group, which can cause packets to arrive out of order.
- Flowlet Mode: packets from the same flow are sent across a link member of an IP ECMP group. A flowlet is defined as bursts of the same flow separated by periods of inactivity. If a flow pauses for longer than the configured inactivity timer, it is possible to reevaluate the link members' quality, and for the flow to be reassigned to a different.
Adaptive load balancing (ALB):
Adaptive Load Balancing (ALB) is a feedback-driven mechanism designed to detect and correct traffic imbalances across equal-cost paths, improving link utilization beyond what is achievable with static hash-based forwarding. Rather than relying solely on fixed ECMP hashing, ALB continuously evaluates traffic distribution and dynamically adjusts forwarding behavior to mitigate overload conditions and promote fair use of available links.
ALB operates by monitoring packet and byte rates associated with hash buckets and their corresponding next-hop mappings. An adaptive monitoring process, running in the ukernel, periodically scans all next-hops for which ALB is enabled. The monitoring interval is user-configurable and can be as short as a few seconds.
During each scan cycle, ALB computes the aggregate traffic rate per next-hop by summing the traffic carried by all hash buckets mapped to that next-hop. This observed rate is compared against the ideal balanced rate. If the deviation exceeds a user-configurable tolerance threshold, the imbalance compensation algorithm is triggered.
When imbalance is detected, ALB takes corrective action by reprogramming the selector (hash bucket–to–next-hop mapping) to shift traffic away from heavily utilized next-hops toward less utilized ones. This redistribution process effectively addresses a bin-packing problem, as it seeks to reassign hash buckets in a way that minimizes load variance across links. Due to the computational complexity involved, ALB performs these adjustments incrementally at each monitoring interval.
By default, the monitoring interval is 30 seconds and can be configured from one to five 30-second intervals. During each interval, the control software reads packet and byte counters collected over the most recent two seconds to calculate current traffic rates and inform rebalancing decisions.
The tolerance threshold used to detect imbalance is defined as:
ALB is supported on the PTX10001-36MR, PTX10002-36QDD, PTX10003, PTX10004, PTX10008, and PTX10016 platforms, starting with Junos OS Evolved Release 24.4R1.
Global load balancing (GLB):
GLB is an improvement on DLB which only considers the local link bandwidth utilization. GLB, on the other hand, has visibility into the bandwidth utilization of links at the next-to-next-hop (NNH) level. As a result, GLB can reroute traffic flows to avoid traffic congestion farther out in the network than DLB can detect.
AI-ML data centers have less entropy, and larger data flows than other networks. Because hash-based load balancing does not always effectively load-balance large data flows of traffic with less entropy, dynamic load balancing (DLB) is often used instead. However, DLB considers only the local link bandwidth utilization. For this reason, DLB can effectively mitigate traffic congestion only on the immediate next hop. GLB more effectively load-balances large data flows by taking traffic congestion on remote links into account.
GLB is only supported for QFX-5240 (TH5) starting on 23.4R2 and 24.4R1, requires a full 3-tier CLOS architecture, and is limited to only one link between each spine and leaf. When there is more than one interface or a bundle between a pair of leaf and spine, GLB won’t work. Also, GLB supports 64 profiles in the table. This means there can be 64 leaves in the 3-stage Clos topology where GLB is running.
For additional details on the operation and configuration of GLB refer to Avoiding AI/ML traffic congestion with global load balancing | HPE Juniper Networking Blogs
Introduction to Congestion Control in Juniper AI Networks explores how to build a lossless fabric for AI workloads using DCQCN (ECN and PFC) congestion control methods and DLB. The document was based on DLRM training model as a reference and demonstrates how different congestion parameters such as ECN and PFC counters, input drops and tail drops can be monitored to adjust configuration and build a lossless fabric infrastructure for RoCEv2 traffic.
Load Balancing in the Data Center provides a comprehensive deep dive into the various load-balancing mechanisms and their evolution to suit the needs of the data center.