Receiving DHCP Options From a RADIUS Server
Centrally Configure DHCP Options on a RADIUS Server
DHCP management on Junos OS devices support central configuration of DHCP options directly on the RADIUS server (RADIUS-sourced options) and traditional client-sourced options configuration. Read the following sections for information on central configuration of DHCP options on the RADIUS server.
- RADIUS-Sourced Options
- Client-Sourced Options Configuration
- Data Flow for RADIUS-Sourced DHCP Options
- Multiple VSA 26-55 Instances Configuration
- DHCP Options That Cannot Be Centrally Configured
RADIUS-Sourced Options
Subscriber management (on the routers) or DHCP management (on the switches) enables you to centrally configure DHCP options on a RADIUS server and then distribute the options on a per-subscriber or per DHCP-client basis. This method results in RADIUS-sourced DHCP options—the DHCP options originate at the RADIUS server and are sent to the subscriber (or DHCP client). This differs from the traditional client-sourced method (also called DHCP-sourced) of configuring DHCP options, in which the options originate at the client and are sent to the RADIUS server. The subscriber management (DHCP management) RADIUS-sourced DHCP options are also considered to be opaque, because DHCP local server performs minimal processing and error checking for the DHCP options string before passing the options to the subscriber (DHCP client).
Subscriber management (or DHCP management) uses Juniper Networks VSA 26-55 (DHCP-Options) to distribute the RADIUS-sourced DHCP options. The RADIUS server includes VSA 26-55 in the Access-Accept message that the server returns during subscriber authentication or DHCP client authentication. The RADIUS server sends the Access-Accept message to the RADIUS client, and then on to DHCP local server for return to the DHCP subscriber. The RADIUS server can include multiple instances of VSA 26-55 in a single Access-Accept message. The RADIUS client concatenates the multiple instances and uses the result as a single instance.
There is no CLI configuration required to enable subscriber management (DHCP management) to use the centrally configured DHCP options—the procedure is triggered by the presence of VSA 26-55 in the RADIUS Access-Accept message.
When building the offer packet for the DHCP client, DHCP local server uses the following sequence:
Processes any RADIUS-configured parameters that are passed as separate RADIUS attributes; for example, RADIUS attribute 27 (Session Timeout).
Processes any client-sourced parameters; for example, RADIUS attributes 53 (DHCP Message Type) and 54 (Server Identifier).
Appends (without performing any processing) the opaque DHCP options string contained in the VSA 26-55 received from the RADIUS server.
Client-Sourced Options Configuration
In addition to supporting central configuration of DHCP options directly on the RADIUS server (RADIUS-sourced options), subscriber management (DHCP management) also supports the traditional client-sourced options configuration, in which the router’s (switch’s) DHCP component sends the options to the RADIUS server. The client-sourced DHCP options method is supported for both DHCP local server and DHCP relay agent; however, the RADIUS-sourced central configuration method is supported on DHCP local server only. Both the RADIUS-sourced and client-sourced methods support DHCPv4 and DHCPv6 subscribers (clients).
You can use the RADIUS-sourced and client-sourced methods simultaneously on DHCP local server. However, you must ensure that the central configuration method does not include options that override client-sourced DHCP options, because this can create unpredictable results.
Data Flow for RADIUS-Sourced DHCP Options
Figure 1 shows the procedure subscriber management (DHCP management) uses when configuring DHCP options for subscribers (DHCP clients).
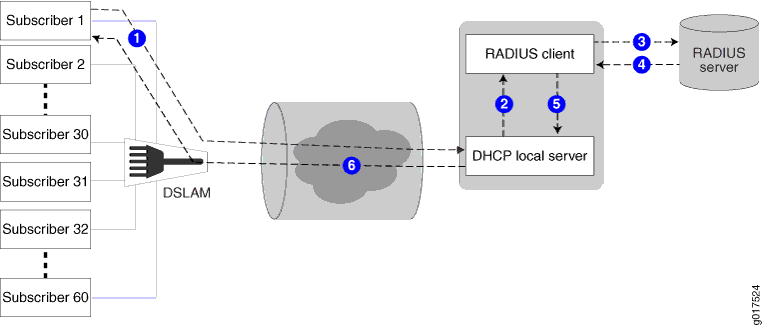
The following general sequence describes the data flow when subscriber management (DHCP management) uses RADIUS-sourced DHCP options and VSA 26-55 to configure a DHCP subscriber (client):
The subscriber (DHCP client) sends a DHCP discover message (or DHCPv6 solicit message) to the DHCP local server. The message includes client-sourced DHCP options.
The DHCP local server initiates authentication with the Junos OS RADIUS client.
The RADIUS client sends an Access-Request message on behalf of the subscriber (DHCP client) to the external RADIUS server. The message includes the subscriber’s (DHCP client’s) client-sourced DHCP options.
The external RADIUS server responds by sending an Access-Accept message to the RADIUS client. The Access-Accept message includes the RADIUS-sourced opaque DHCP options in VSA 26-55.
The RADIUS client sends the DHCP options string to DHCP local server. If there are multiple VSA 26-55 instances, the RADIUS client first assembles them into a single options string.
DHCP local server processes all options into the DHCP offer (or DHCPv6 reply) message, except for the RADIUS-sourced VSA 26-55 DHCP options. After processing all other options, DHCP local server then appends the unmodified VSA 26-55 DHCP options to the message and sends the message to the subscriber (DHCP client).
The subscriber (DHCP client) is configured with the DHCP options.
The following operations occur after the subscriber (DHCP client) receives the DHCP options:
Accounting—The RADIUS client sends Acct-Start and Interim-Accounting requests to the RADIUS server, including the RADIUS-sourced DHCP options in VSA 26-55. By default, the DHCP options are included in accounting requests.
Renewal—When the subscriber (DHCP client) renews, the cached DHCP options value is returned in the DHCP renew (or DHCPv6 ACK) message. The originally assigned DHCP options cannot be modified during a renew cycle.
Logout—When the subscriber (DHCP client) logs out, the RADIUS client sends an Acct-Stop message to the RADIUS server, including the RADIUS-sourced VSA 26-55.
Multiple VSA 26-55 Instances Configuration
VSA 26-55 supports a maximum size of 247 bytes. If your RADIUS-sourced DHCP options field is greater than 247 bytes, you must break the field up and manually configure multiple instances of VSA 26-55 for the RADIUS server to return. When using multiple instances for an options field, you must place the instances in the packet in the order in which the fragments are to by reassembled by the RADIUS client. The fragments can be of any size of 247 bytes or less.
For ease of configuration and management of your DHCP options, you might want to have one DHCP option per VSA 26-55 instance, regardless of the size of the option field.
When the RADIUS client returns a reassembled opaque options field in an accounting request to the RADIUS server, the client uses 247-byte fragments. If you had originally created instances of fewer than 247 bytes, the returned fragments might not be the same as you originally configured on the RADIUS server.
If you are configuring Steel-Belted Radius (SBR) to support
multiple VSA 26-55 instances, ensure that you specify VSA 26-55 with
the RO flags in the Subscriber Management RADIUS dictionary
file. The R value indicates a multivalued reply attribute
and the O value indicates an ordered attribute.
DHCP Options That Cannot Be Centrally Configured
Table 1 shows the DHCP options that you must not centrally configure on the RADIUS server.
DHCP Option |
Option Name |
Comments |
|---|---|---|
Option 0 |
Pad Option |
Not supported. |
Option 51 |
IP Address Lease Time |
Value is provided by RADIUS attribute 27 (Session-Timeout). |
Option 52 |
Option Overload |
Not supported. |
Option 53 |
DHCP Message Type |
Value is provided by DHCP local server. |
Option 54 |
Server Identifier |
Value is provided by DHCP local server. |
Option 55 |
Parameter Request List |
Value is provided by DHCP local server. |
Option 255 |
End |
Value is provided by DHCP local server. |
– |
DHCP magic cookie |
Not supported. |
See Also
Exchange of DHCPv4 and DHCPv6 Parameters with the RADIUS Server Overview
The RADIUS server, which is configured independently of DHCPv4 and DHCPv6, authenticates clients and supplies the IPv4 or IPv6 prefix and client configuration parameters. To establish the client sessions on the network, the DHCPv4 and DHCPv6 parameters are sent from the client device through the DHCP (either DHCPv4 or DHCPv6) server to the RADIUS server and vice versa. Starting in Junos OS Release 17.4R1, the exchange of parameters is enhanced with the introduction of several new vendor-specific attributes (VSAs) and changes to the existing DHCP-Options VSA (26-55).
An immediate interim accounting report is sent to the RADIUS server when configurable events occur, such as a change in family state. When these events occur, the RADIUS server has no direct way to determine the reason for the report. You can use the Acct-Request-Reason VSA (26-210) to send the reason in the start accounting report as well as in the immediate interim accounting report.
The broadband network gateway (BNG) sends an interim accounting
report to the RADIUS server whenever the second family (either IPv4
or IPv6) of a dual-stack session (DHCPv4, DHCPv6, or PPPoE) is activated
or the first family (either IPv4 or IPv6) of a dual-stack session
(DHCPv4, DHCPv6, or PPPoE) is deactivated. For the immediate interim
accounting report to be sent, configure the family-state-change-immediate-update statement on the BNG at the [edit access profile profile-name accounting] hierarchy level.
The following VSAs are used for exchanging the client parameters with the RADIUS server:
DHCPv6-Options VSA (26-207):
The DHCPv6-Options VSA (26-207) is used to exchange DHCPv6 options with the RADIUS server. In releases earlier than Junos OS Release 17.4R1, the DHCPv6 options are included with DHCPv4 options in the DHCP-Options VSA (26-55).
The option values sent from the DHCPv6 client to the DHCPv6 server are saved in the session database separately from the values sent from the DHCPv6 server to the DHCPv6 client.
If the DHCPv6 options are too large to fit in one VSA, then they are split into multiple, sequential VSAs in the RADIUS packet. In this case, the options are split at the VSA size limit rather than at the type-length-value (TLV) boundary.
If multiple instances of the VSA are included in the RADIUS Access-Accept message, then they are concatenated into a single block and stored in the session database without checking the TLV for validity.
DHCP-Options VSA (26-55):
The DHCP-Options VSA (26-55) is used to exchange DHCPv4 options with the RADIUS server.
With the introduction of VSA 26-207, VSA 26-55 includes only DHCPv4 options.
If the DHCPv4 options are too large to fit in one VSA, then they are split into multiple, sequential VSAs in the RADIUS packet. In this case, the options are split at the VSA size limit rather than at the TLV boundary.
If multiple instances of the VSA are included in the RADIUS Access-Accept message, then they are concatenated into a single block and stored in the session database without checking the TLV for validity.
DHCP-Header VSA (26-208):
The DHCP-Header VSA (26-208) conveys the DHCPv4 packet header to the RADIUS server. The header information is used for instantiating dynamic subscriber interfaces.
The VSA is allowed only in RADIUS Access-Request messages and is stored in the session database.
DHCPv6-Header VSA (26-209):
The DHCPv6-Header VSA (26-209) conveys the DHCPv6 packet header to the RADIUS server. The header information is used for instantiating dynamic subscriber interfaces.
The VSA is allowed only in RADIUS Access-Request messages and is stored in the session database.
Acct-Request-Reason VSA (26-210):
The Acct-Request-Reason VSA (26-210) conveys the reason for sending an accounting request. The VSA is included only in RADIUS Acct-Start and Interim-Update messages. The VSA is present only for subscriber accounting reports; it is not present for service session or Extensible Subscriber Services Manager (ESSM) reports.
The typical value for the VSA in Acct-Start messages is IP active (0x0004) or IPv6 active (0x0010), indicating that the IPv4 or IPv6 address family has been activated. For Layer 2 wholesale VLAN networks, the value is Session active (0x0040), because there is no IPv4 or IPv6 family. The value for MLPPP is also Session active, because accounting messages are sent for the link session rather than the bundle session. ESSM sessions are child sessions of a parent subscriber session and are treated as ESSM service sessions. The VSA is sent only for the parent subscriber session.
- Differentiating Subscriber Classes with DHCPv6 Option 17 and VSA 26-207
- Excluding the VSAs from RADIUS Messages
Differentiating Subscriber Classes with DHCPv6 Option 17 and VSA 26-207
Starting in Junos OS Release 18.3R1, you can use the DHCPv6-Options VSA (26-207) to differentiate between different classes of subscribers during DHCPv6 relay authentication. For example, you may want to assign different IPv6 prefixes to different subscriber classes.
You must configure your RADIUS server to include the following information in the VSA:
Juniper Networks enterprise number, 2636
Suboption 5, JDHCPD_VS_OPT_CODE_KT_SUBSCRIBER_CLASS
To configure this information, refer to the documentation for your RADIUS server. You must encode the information in the DHCPv6 options format in RFC 3315, Dynamic Host Configuration Protocol for IPv6 (DHCPv6).
You set a different value for suboption 5 for each class you want to differentiate. You develop your own scheme to determine the mapping between value and class.
VSA 26-207 conveys the subscriber class information in the Access-Accept message returned by the RADIUS server during DHCPv6 subscriber authentication. The contents of the VSA are passed from the AAA process to the DHCP process in the session database attribute, SDB_SERVER_DHCPV6_OPTIONS. The DHCPv6 relay agent extracts the information from the SDB attribute and places it in DHCPv6 option 17. The relay agent subsequently passes option 17 to the DHCPv6 local server in the Relay-Forward header. The local server can then return the relay agent configuration and service information specific to the relevant subscriber classes.
In releases earlier than Junos OS 18.3R1, only the DHCP local server supports VSA 26-207. Only suboption 1 (JDHCPD_VS_OPT_CODE_HOST_NAME) and suboption 4 (JDHCPD_VS_OPT_CODE_LOCATION_NAME) are supported. The DHCP relay agent also discards the SDB_SERVER_DHCPV6_OPTIONS attribute if it is received.
Suboptions received from RADIUS have a higher precedence than
the information configured locally. For example, if the host name
and the location are configured with the host-name statement
at the [edit forwarding-options dhcp-relay dhcpv6 relay-option-vendor-specific] hierarchy level and they are received in suboptions 1 and 4 from
RADIUS, the RADIUS values are used.
Excluding the VSAs from RADIUS Messages
You can exclude any of these VSAs from being sent by using the exclude statement as shown in the following example:
[edit access profile profile-name radius attributes] user@host# set exclude acct-request-reason [accounting-start | accounting-stop] user@host# set exclude dhcp-header [access-request] user@host# set exclude dhcpv6-header [access-request] user@host# set exclude dhcpv6-options [access-request | accounting-start | accounting-stop]
Dedicated Session Database and Vendor-Specific Attributes for DHCPv4 and DHCPv6 Subscribers
The Dynamic Host Configuration Protocol (DHCP) server can serve as a DHCP local server, a DHCP client, or a DHCP relay agent, for both DHCPv4 and DHCPv6 subscribers.
Currently, some of the client parameters—for example, the DHCPv4 and DHCPv6 packet header—cannot be passed to and from the RADIUS server. From Junos OS Release 17.4 onward, enhancements are made to facilitate better communication between the DHCP servers (both DHCPv4 and DHCPv6) and the RADIUS server. The client parameters are saved in a session database and sent to the RADIUS server; and the RADIUS server, in turn, authenticates the client and also responds with the options to be sent back to that client.
- Client Options
- Exchange of DHCPv4 Client, DHCPv4 Server, and RADIUS-Sourced Options
- Exchange of DHCPv6 Client, DHCPv6 Server, and RADIUS-Sourced Options
Client Options
The client options can be configured in multiple locations such as DHCPv4 or DHCPv6 servers, or in the RADIUS server. If the client configuration is available in multiple locations, a conflict can arise regarding the source of the configuration details. In case of such conflicts, the following order of preference is considered:
Options received from the RADIUS server through vendor-specific attributes (VSAs)
Options received from the RADIUS server through the respective session databases
Options from the DHCP local configuration, which are present on the DHCP server
As an example of the aforementioned preference, consider the
case of DHCPv4 lease time. If the AUTHD_ATTR_SESSION_TIMEOUT option, which is a VSA stored in the RADIUS server, is returned
from the RADIUS server, preference is given to it. If this option
is not returned, preference is given to option 51 in respective session
database for DHCPv4. If that option is also not returned, the option
is sourced from DHCP local configuration.
Similarly, for DHCPv6 lease time, the first preference is given
to the AUTHD_ATTR_SESSION_TIMEOUT VSA from the RADIUS server.
If AUTHD_ATTR_SESSION_TIMEOUT is not present, the RADIUS-sourced
option valid-lifetime or preferred-lifetime takes
the precedence. If that is also not available, then the option is
sourced from the DHCPv6 local configuration.
Exchange of DHCPv4 Client, DHCPv4 Server, and RADIUS-Sourced Options
The following steps illustrate the process of exchange of configuration options between a DHCPv4 client, a DHCPv4 server, and the RADIUS server:
A discover message from a DHCPv4 client is received by the DHCPv4 server.
The DHCP option is saved to the respective session database.
In Junos OS releases before 17.4R1, the same attribute is used to store both DHCPv4 and DHCPv6 options. However, with the support for single-session DHCP dual-stack, there are separate session database attributes for DHCPv4 and DHCPv6.
The DHCP header information is saved in the session database.
A new session database attribute is added to store the header information, and this information is sent to the RADIUS server for authentication.
An access request message is sent from the DHCPv4 server to the RADIUS server, and when an access accept message is received from the RADIUS server, the DHCPv4 options are saved to the respective session database attributes and sent to the client.
DHCPv4 server-specific options are added to the packet.
Note:The DHCPv4 server can source both solicited and unsolicited options from the local configuration. Thus, it is important to prevent duplication while the options are added.
DHCPv4 lease information is extracted from the RADIUS-sourced DHCP option 51.
The respective session database attribute is used to check whether option 51 (lease time) is sourced by RADIUS. If it is, then the attribute value is extracted and saved in the client data structure. If it is not sourced by RADIUS, the attribute value is taken from the local pool configuration or the DHCPv4 attribute configuration, which is an existing functionality. A similar check is performed for option 58 (renewal time (T1)) and option 59 (rebinding time (T2)).
An offer message is sent from the DHCPv4 server to DHCPv4 client.
Exchange of DHCPv6 Client, DHCPv6 Server, and RADIUS-Sourced Options
The following steps illustrate the process of exchange of configuration options between a DHCPv6 client, a DHCPv6 server, and the RADIUS server:
A solicit message from a DHCP client is received by the DHCPv6 server.
DHCPv6 options are saved in the session database of the DHCPv6 server.
In Junos OS releases before 17.4R1, DHCPv6 options are saved in the respective session database attribute. Because of the current single-session DHCP dual-stack support, there is need to have separate session database attributes for saving DHCPv4 and DHCPv6 options. If the client is part of a single-session dual-stack configuration, the respective DHCPv6 options session database attribute is used. The DHCPv6 options are directly copied to the session database without any changes and then sent to the RADIUS server.
Note:DHCPv6
auth-option(option 11) is also part of these options.A DHCPv6 message header is saved to the session database.
A new session database attribute is added to copy the DHCPv6 message header.
An access request message is sent from the DHCPv6 server, which in turn receives an access accept message from the RADIUS server. This message contains RADIUS-sourced DHCPv6 options that are stored in a new session database attribute.
DHCPv6 lease information is extracted from the RADIUS-sourced DHCPv6 option.
In case of DHCPv6, the lease time is embedded within the options
OPTION_IA_NAandOPTION_IA_PD. Client lease time starts with these values from the RADIUS Server. If theIA_ADDRESS,IA_PREFIX,IA_NA, orIA_PDoption is not sourced from RADIUS, then these options are taken from the local pool and delegated pool configuration.DHCPV6 server-specific options are added to the packet.
Note:A DHCPv6 server can source both solicited and unsolicited options from the local configuration. Thus, it is important to prevent duplication while the options are added.
An advertise message is sent from the DHCPv6 server to the DHCPv6 client.
Monitoring DHCP Options Configured on RADIUS Servers
Purpose
View information for DHCP options that are centrally configured on a RADIUS server and that are distributed using Juniper Networks VSA 26-55 (DHCP-Options).
Action
To display information for opaque DHCP options:
user@host> show subscribers detailType: DHCP IP Address: 192.168.9.7 IP Netmask: 255.255.0.0 Logical System: default Routing Instance: default Interface: demux0.1073744127 Interface type: Dynamic Dynamic Profile Name: dhcp-prof-23 MAC Address: 00:00:5E:00:53:98 State: Active Radius Accounting ID: jnpr :2304 Session Timeout (seconds): 3600 Idle Timeout (seconds): 600 Login Time: 2011-08-25 14:43:52 PDT DHCP Options: len 52 35 01 01 39 02 02 40 3d 07 01 00 10 94 00 00 08 33 04 00 00 00 3c 0c 15 63 6c 69 65 6e 74 5f 50 6f 72 74 20 2f 2f 36 2f 33 2d 37 2d 30 37 05 01 06 0f 21 2c
Meaning
DHCP Options: len 52 35 01 01 39 02 02 40 3d 07 01 00 10 94 00 00 08 33 04 00 00 00 3c 0c 15 63 6c 69 65 6e 74 5f 50 6f 72 74 20 2f 2f 36 2f 33 2d 37 2d 30 37 05 01 06 0f 21 2c
The DHCP options output provides the following information:
The
lenfield is the total number of hex values in the message.The hex values specify the type, length, and value (TLV) of DHCP options, and are converted to decimal to identify the DHCP options, as defined in RFC 2132.
The number of hex values that make up a particular DHCP option
varies, depending on the length of the option. For example, the first
DHCP option specified in the output includes three sets of hex values
(35 01 01). The first hex value (35) identifies the option type, the second value (01) indicates
the length of the value entry, which is this case is one set of hex
values. The third hex value (01) specifies the value for
the DHCP option.
In the second DHCP option specification (39 02 02 40), the hex value 39 is the type, and the length of 02 specifies that two sets of hex entries make up the value
for the option. Therefore, this option specification uses four sets
of hex entries; one for the type (39), one to specify the
length (02), and two for the option value (02 40).
The third DHCP option is specified by the hex values 3d 07 01 00 10 94 00 00 08. The hex value 3d is the type, followed by the length
(07), which specifies that the next seven sets of hex entries
make up the value for the option. Therefore, this option specification
uses a total of nine sets of hex entries; one for the type (3d), one to specify the length (07), and seven for the value
of the DHCP option (01 00 10 94 00 00 08).
Table 2 describes the first two options in more detail.
Option |
Type |
Length |
Value |
|---|---|---|---|
35 01 01 |
35 = decimal 53 (Code 53 in RFC 2132 is the DHCP Message Type option) |
01 = the length of the option is one set of hex values (the next set in the list) |
01 = value of the message type that is described in RFC 2132. The code 01 specifies a message type of DHCPDISCOVER. |
39 02 02 40 |
39 = decimal 57 (Code 57 is the Maximum DHCP Message Size option) |
02 = the length of the option is two sets of hex values (the next two sets in the list) |
0240 = converted to a length of 576 octets |
Change History Table
Feature support is determined by the platform and release you are using. Use Feature Explorer to determine if a feature is supported on your platform.