Monitor Network Service Quality by using RMON
RMON for Monitoring Service Quality
Health and performance monitoring can benefit from the remote monitoring of SNMP variables by the local SNMP agents running on each router. The SNMP agents compare MIB values against predefined thresholds and generate exception alarms without the need for polling by a central SNMP management platform. This is an effective mechanism for proactive management, as long as the thresholds have baselines determined and set correctly. For more information, see RFC 2819, Remote Network Monitoring MIB.
This topic includes the following sections:
Setting Thresholds
By setting a rising and a falling threshold for a monitored variable, you can be alerted whenever the value of the variable falls outside of the allowable operational range. (See Figure 1.)
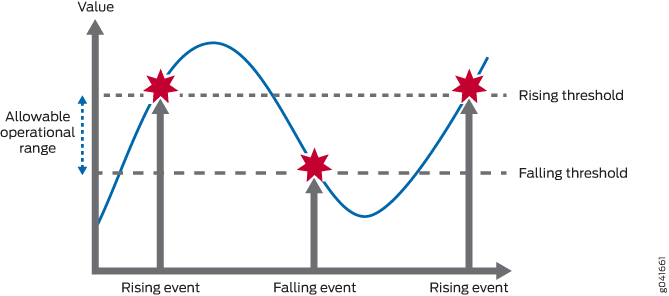
Events are only generated when the threshold is first crossed in any one direction rather than after each sample period. For example, if a rising threshold crossing event is raised, no more threshold crossing events will occur until a corresponding falling event. This considerably reduces the quantity of alarms that are produced by the system, making it easier for operations staff to react when alarms do occur.
To configure remote monitoring, specify the following pieces of information:
-
The variable to be monitored (by its SNMP object identifier)
-
The length of time between each inspection
-
A rising threshold
-
A falling threshold
-
A rising event
-
A falling event
Before you can successfully configure remote monitoring, you should identify what variables need to be monitored and their allowable operational range. This requires some period of baselining to determine the allowable operational ranges. An initial baseline period of at least three months is not unusual when first identifying the operational ranges and defining thresholds, but baseline monitoring should continue over the life span of each monitored variable.
RMON Command-Line Interface
Junos OS provides two mechanisms that you use to control the Remote Monitoring agent on the
router: command-line interface (CLI) and SNMP. To configure an RMON entry using the
CLI, include the following statements at the [edit snmp] hierarchy
level:
rmon {
alarm index {
description;
falling-event-index;
falling-threshold;
intervals;
rising-event-index;
rising-threshold;
sample-type (absolute-value | delta-value);
startup-alarm (falling | rising | rising-or-falling);
variable;
}
event index {
community;
description;
type (log | trap | log-and-trap | none);
}
}
If you do not have CLI access, you can configure remote monitoring
using the SNMP Manager or management application, assuming SNMP access
has been granted. (See Table 1.) To configure
RMON using SNMP, perform SNMP Set requests to the RMON
event and alarm tables.
RMON Event Table
Set up an event for each type that you want to generate. For example, you could have two generic events, rising and falling, or many different events for each variable that is being monitored (for example, temperature rising event, temperature falling event, firewall hit event, interface utilization event, and so on). Once the events have been configured, you do not need to update them.
|
Field |
Description |
|---|---|
|
|
Text description of this event |
|
|
Type of event (for example, |
|
|
Trap group to which to send this event (as defined in the Junos OS configuration, which is not the same as the community) |
|
|
Entity (for example, |
|
|
Status of this row (for example, |
RMON Alarm Table
The RMON alarm table stores the SNMP object identifiers (including their instances) of the variables that are being monitored, together with any rising and falling thresholds and their corresponding event indexes. To create an RMON request, specify the fields shown in Table 2.
|
Field |
Description |
|---|---|
|
|
Status of this row (for example, |
|
|
Sampling period (in seconds) of the monitored variable |
|
|
OID (and instance) of the variable to be monitored |
|
|
Actual value of the sampled variable |
|
|
Sample type ( |
|
|
Initial alarm ( |
|
|
Rising threshold against which to compare the value |
|
|
Falling threshold against which to compare the value |
|
|
Index (row) of the rising event in the event table |
|
|
Index (row) of the falling event in the event table |
Both the alarmStatus and eventStatus fields
are entryStatus primitives, as defined in RFC 2579, Textual Conventions for SMIv2.
Troubleshoot RMON
You troubleshoot the RMON agent, rmopd, that runs
on the router by inspecting the contents of the Juniper Networks enterprise
RMON MIB, jnxRmon, which provides the extensions listed
in Table 3 to the RFC 2819 alarmTable.
|
Field |
Description |
|---|---|
|
|
Number of times the internal |
|
|
Value of |
|
|
Reason why the |
|
|
Value of |
|
|
Status of this alarm entry |
Monitoring the extensions in this table provides clues as to why remote alarms may not behave as expected.
Understand Measurement Points, Key Performance Indicators, and Baseline Values
This chapter topic provides guidelines for monitoring the service quality of an IP network. It describes how service providers and network administrators can use information provided by Juniper Networks routers to monitor network performance and capacity. You should have a thorough understanding of the SNMP and the associated MIB supported by Junos OS.
For a good introduction to the process of monitoring an IP network, see RFC 2330, Framework for IP Performance Metrics.
This topic contains the following sections:
Measurement Points
Defining the measurement points where metrics are measured is equally as important as defining the metrics themselves. This section describes measurement points within the context of this chapter and helps identify where measurements can be taken from a service provider network. It is important to understand exactly where a measurement point is. Measurement points are vital to understanding the implication of what the actual measurement means.
An IP network consists of a collection of routers connected by physical links that are all running the Internet Protocol. You can view the network as a collection of routers with an ingress (entry) point and an egress (exit) point. See Figure 2.
-
Network-centric measurements are taken at measurement points that most closely map to the ingress and egress points for the network itself. For example, to measure delay across the provider network from Site A to Site B, the measurement points should be the ingress point to the provider network at Site A and the egress point at Site B.
-
Router-centric measurements are taken directly from the routers themselves, but be careful to ensure that the correct router subcomponents have been identified in advance.
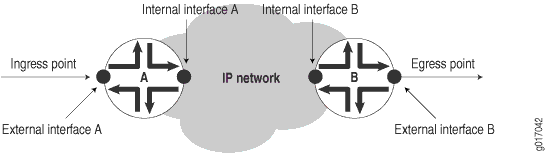
Figure 2 does not show the client networks at customer premises, but they would be located on either side of the ingress and egress points. Although this chapter does not discuss how to measure network services as perceived by these client networks, you can use measurements taken for the service provider network as input into such calculations.
Basic Key Performance Indicators
For example, you could monitor a service provider network for three basic key performance indicators (KPIs):
-
measures the “reachability” of one measurement point from another measurement point at the network layer (for example, using ICMP ping). The underlying routing and transport infrastructure of the provider network will support the availability measurements, with failures highlighted as unavailability.
-
measures the number and type of errors that are occurring on the provider network, and can consist of both router-centric and network-centric measurements, such as hardware failures or packet loss.
-
of the provider network measures how well it can support IP services (for example, in terms of delay or utilization).
Setting Baselines
How well is the provider network performing? We recommend an initial three-month period of monitoring to identify a network’s normal operational parameters. With this information, you can recognize exceptions and identify abnormal behavior. You should continue baseline monitoring for the lifetime of each measured metric. Over time, you must be able to recognize performance trends and growth patterns.
Within the context of this chapter, many of the metrics identified do not have an allowable operational range associated with them. In most cases, you cannot identify the allowable operational range until you have determined a baseline for the actual variable on a specific network.
Define and Measure Network Availability
This topic includes the following sections:
Define Network Availability
Availability of a service provider’s IP network can be thought of as the reachability between the regional points of presence (POP), as shown in Figure 3.
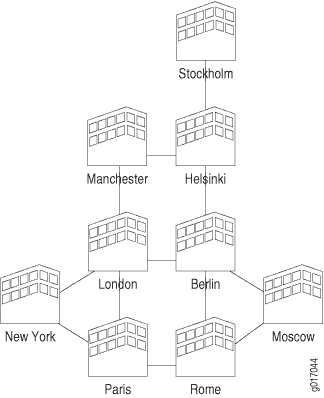
With the example above, when you use a full mesh of measurement points, where every POP measures the availability to every other POP, you can calculate the total availability of the service provider’s network. This KPI can also be used to help monitor the service level of the network, and can be used by the service provider and its customers to determine if they are operating within the terms of their service-level agreement (SLA).
Where a POP may consist of multiple routers, take measurements to each router as shown in Figure 4.
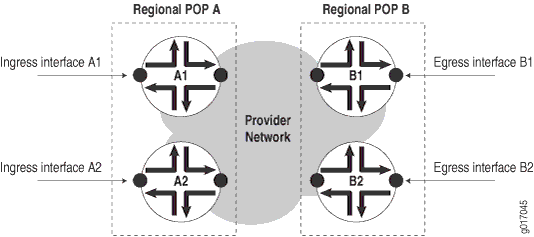
Measurements include:
Path availability—Availability of an egress interface B1 as seen from an ingress interface A1.
Router availability—Percentage of path availability of all measured paths terminating on the router.
POP availability—Percentage of router availability between any two regional POPs, A and B.
Network availability—Percentage of POP availability for all regional POPs in the service provider’s network.
To measure POP availability of POP A to POP B in Figure 4, you must measure the following four paths:
Path A1 => B1 Path A1 => B2 Path A2 => B1 Path A2 => B2
Measuring availability from POP B to POP A would require a further four measurements, and so on.
A full mesh of availability measurements can generate significant management traffic. From the sample diagram above:
Each POP has two co-located provider edge (PE) routers, each with 2xSTM1 interfaces, for a total of 18 PE routers and 36xSTM1 interfaces.
There are six core provider (P) routers, four with 2xSTM4 and 3xSTM1 interfaces each, and two with 3xSTM4 and 3xSTM1 interfaces each.
This makes a total of 68 interfaces. A full mesh of paths between every interface is:
[n x (n–l)] / 2 gives
[68 x (68–1)] / 2=2278 paths
To reduce management traffic on the service provider’s network, instead of generating a full mesh of interface availability tests (for example, from each interface to every other interface), you can measure from each router’s loopback address. This reduces the number of availability measurements required to a total of one for each router, or:
[n x (n–1)] / 2 gives [24 x (24–1)] / 2=276 measurements
This measures availability from each router to every other router.
Monitoring the SLA and the Required Bandwidth
A typical SLA between a service provider and a customer might state:
A Point of Presence is the connection of two back-to-back provider edge routers to separate core provider routers using different links for resilience. The system is considered to be unavailable when either an entire POP becomes unavailable or for the duration of a Priority 1 fault.
An SLA availability figure of 99.999 percent for a provider’s network would relate to a down time of approximately 5 minutes per year. Therefore, to measure this proactively, you would have to take availability measurements at a granularity of less than one every five minutes. With a standard size of 64 bytes per ICMP ping request, one ping test per minute would generate 7680 bytes of traffic per hour per destination, including ping responses. A full mesh of ping tests to 276 destinations would generate 2,119,680 bytes per hour, which represents the following:
On an OC3/STM1 link of 155.52 Mbps, a utilization of 1.362 percent
On an OC12/STM4 link of 622.08 Mbps, a utilization of 0.340 percent
With a size of 1500 bytes per ICMP ping request, one ping test per minute would generate 180,000 bytes per hour per destination, including ping responses. A full mesh of ping tests to 276 destinations would generate 49,680,000 bytes per hour, which represents the following:
On an OC3/STM1 link, 31.94 percent utilization
On an OC12/STM4 link, 7.986 percent utilization
Each router can record the results for every destination tested.
With one test per minute to each destination, a total of 1 x 60 x
24 x 276 = 397,440 tests per day would be performed and recorded by
each router. All ping results are stored in the pingProbeHistoryTable (see RFC 2925) and can be retrieved by an SNMP performance reporting
application (for example, service performance management software
from InfoVista, Inc., or Concord Communications, Inc.) for post processing.
This table has a maximum size of 4,294,967,295 rows, which is more
than adequate.
Measure Availability
There are two methods you can use to measure availability:
Proactive—Availability is automatically measured as often as possible by an operational support system.
Reactive—Availability is recorded by a Help desk when a fault is first reported by a user or a fault monitoring system.
This section discusses real-time performance monitoring as a proactive monitoring solution.
Real-Time Performance Monitoring
Juniper Networks provides a real-time performance monitoring (RPM) service to monitor real-time network performance. Use the J-Web Quick Configuration feature to configure real-time performance monitoring parameters used in real-time performance monitoring tests. (J-Web Quick Configuration is a browser-based GUI that runs on Juniper Networks routers. For more information, see the J-Web Interface User Guide.)
Configuring Real-Time Performance Monitoring
Some of the most common options you can configure for real-time performance monitoring tests are shown in Table 4.
Field |
Description |
|---|---|
| Request Information | |
|
Type of probe to send as part of the test. Probe types can be:
|
|
Wait time (in seconds) between each probe transmission. The range is 1 to 255 seconds. |
|
Wait time (in seconds) between tests. The range is 0 to 86400 seconds. |
|
Total number of probes sent for each test. The range is 1 to 15 probes. |
|
TCP or UDP port to which probes are sent. Use number 7—a standard TCP or UDP port number—or select a port number from 49152 through 65535. |
|
Differentiated Services code point (DSCP) bits. This value must be a valid 6-bit pattern. The default is 000000. |
|
Size (in bytes) of the data portion of the ICMP probes. The range is 0 to 65507 bytes. |
|
Contents of the data portion of the ICMP probes. Contents must be a hexadecimal value. The range is 1 to 800h. |
| Maximum Probe Thresholds | |
|
Total number of probes that must be lost successively to trigger a probe failure and generate a system log message. The range is 0 to 15 probes. |
|
Total number of probes that must be lost to trigger a probe failure and generate a system log message. The range is 0 to 15 probes. |
|
Total round-trip time (in microseconds) from the Services Router to the remote server, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Total jitter (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Maximum allowable standard deviation (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Total one-way time (in microseconds) from the router to the remote server, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Total one-way time (in microseconds) from the remote server to the router, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Total outbound-time jitter (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Total inbound-time jitter (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Maximum allowable standard deviation of outbound times (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
|
Maximum allowable standard deviation of inbound times (in microseconds) for a test, which, if exceeded, triggers a probe failure and generates a system log message. The range is 0 to 60,000,000 microseconds. |
Displaying Real-Time Performance Monitoring Information
For each real-time performance monitoring test configured on
the router, monitoring information includes the round-trip time, jitter,
and standard deviation. To view this information, select Monitor
> RPM in the J-Web interface, or enter the show services
rpm command-line interface (CLI) command.
To display the results of the most recent real-time performance
monitoring probes, enter the show services rpm probe-results CLI command:
user@host> show services rpm probe-results
Owner: p1, Test: t1
Target address: 10.8.4.1, Source address: 10.8.4.2, Probe type: icmp-ping
Destination interface name: lt-0/0/0.0
Test size: 10 probes
Probe results:
Response received, Sun Jul 10 19:07:34 2005
Rtt: 50302 usec
Results over current test:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Results over all tests:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Measure Health
You can monitor health metrics reactively by using fault management software such as SMARTS InCharge, Micromuse Netcool Omnibus, or Concord Live Exceptions. We recommend that you monitor the health metrics shown in Table 5.
Metric |
Description |
Parameters |
|
|---|---|---|---|
Name |
Value |
||
Errors in |
Number of inbound packets that contained errors, preventing them from being delivered |
MIB name | IF-MIB (RFC 2233) |
| Variable name | ifInErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.14 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | Logical interfaces |
||
Errors out |
Number of outbound packets that contained errors, preventing them from being transmitted |
MIB name | IF-MIB (RFC 2233) |
| Variable name | ifOutErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.20 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | Logical interfaces |
||
Discards in |
Number of inbound packets discarded, even though no errors were detected |
MIB name | IF-MIB (RFC 2233) |
| Variable name | ifInDiscards |
||
| Variable OID | .1.3.6.1.31.2.2.1.13 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | Logical interfaces |
||
Unknown protocols |
Number of inbound packets discarded because they were of an unknown protocol |
MIB name | IF-MIB (RFC 2233) |
| Variable name | ifInUnknownProtos |
||
| Variable OID | .1.3.6.1.31.2.2.1.15 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | Logical interfaces |
||
Interface operating status |
Operational status of an interface |
MIB name | IF-MIB (RFC 2233) |
| Variable name | ifOperStatus |
||
| Variable OID | .1.3.6.1.31.2.2.1.8 |
||
| Frequency (mins) | 15 |
||
| Allowable range | 1 (up) |
||
| Managed objects | Logical interfaces |
||
Label Switched Path (LSP) state |
Operational state of an MPLS label-switched path |
MIB name | MPLS-MIB |
| Variable name | mplsLspState |
||
| Variable OID | mplsLspEntry.2 |
||
| Frequency (mins) | 60 |
||
| Allowable range | 2 (up) |
||
| Managed objects | All label-switched paths in the network |
||
Component operating status |
Operational status of a router hardware component |
MIB name | JUNIPER-MIB |
| Variable name | jnxOperatingState |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.6 |
||
| Frequency (mins) | 60 |
||
| Allowable range | 2 (running) or 3 (ready) |
||
| Managed objects | All components in each Juniper Networks router |
||
Component operating temperature |
Operational temperature of a hardware component, in Celsius |
MIB name | JUNIPER-MIB |
| Variable name | jnxOperatingTemp |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.7 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | All components in a chassis |
||
System up time |
Time, in milliseconds, that the system has been operational. |
MIB name | MIB-2 (RFC 1213) |
| Variable name | sysUpTime |
||
| Variable OID | .1.3.6.1.1.3 |
||
| Frequency (mins) | 60 |
||
| Allowable range | Increasing only (decrement indicates a restart) |
||
| Managed objects | All routers |
||
No IP route errors |
Number of packets that could not be delivered because there was no IP route to their destination. |
MIB name | MIB-2 (RFC 1213) |
| Variable name | ipOutNoRoutes |
||
| Variable OID | ip.12 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | Each router |
||
Wrong SNMP community names |
Number of incorrect SNMP community names received |
MIB name | MIB-2 (RFC 1213) |
| Variable name | snmpInBadCommunityNames |
||
| Variable OID | snmp.4 |
||
| Frequency (mins) | 24 |
||
| Allowable range | To be baselined |
||
| Managed objects | Each router |
||
SNMP community violations |
Number of valid SNMP communities used to attempt invalid operations (for example, attempting to perform SNMP Set requests) |
MIB name | MIB-2 (RFC 1213) |
| Variable name | snmpInBadCommunityUses |
||
| Variable OID | snmp.5 |
||
| Frequency (mins) | 24 |
||
| Allowable range | To be baselined |
||
| Managed objects | Each router |
||
Redundancy switchover |
Total number of redundancy switchovers reported by this entity |
MIB name | JUNIPER-MIB |
| Variable name | jnxRedundancySwitchoverCount |
||
| Variable OID | jnxRedundancyEntry.8 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | All Juniper Networks routers with redundant Routing Engines |
||
FRU state |
Operational status of each field-replaceable unit (FRU) |
MIB name | JUNIPER-MIB |
| Variable name | jnxFruState |
||
| Variable OID | jnxFruEntry.8 |
||
| Frequency (mins) | 15 |
||
| Allowable range | 2 through 6 for ready/online states. See jnxFruOfflineReason in the event of a FRU failure. |
||
| Managed objects | All FRUs in all Juniper Networks routers. |
||
Rate of tail-dropped packets |
Rate of tail-dropped packets per output queue, per forwarding class, per interface. |
MIB name | JUNIPER-COS-MIB |
| Variable name | jnxCosIfqTailDropPktRate |
||
| Variable OID | jnxCosIfqStatsEntry.12 |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | For each forwarding class per interface in the provider network, when CoS is enabled. |
||
Interface utilization: octets received |
Total number of octets received on the interface, including framing characters. |
MIB name | IF-MIB |
| Variable name | ifInOctets |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.10.x |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | All operational interfaces in the network |
||
Interface utilization: octets transmitted |
Total number of octets transmitted out of the interface, including framing characters. |
MIB name | IF-MIB |
| Variable name | ifOutOctets |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.16.x |
||
| Frequency (mins) | 60 |
||
| Allowable range | To be baselined |
||
| Managed objects | All operational interfaces in the network |
||
Byte counts vary depending on interface type, encapsulation used and PIC supported. For example, with vlan-ccc encapsulation on a 4xFE, GE, or GE 1Q PIC, the byte count includes framing and control word overhead. (See Table 6.)
PIC Type |
Encapsulation |
input (Unit Level) |
Output (Unit Level) |
SNMP |
|---|---|---|---|---|
4xFE |
vlan-ccc |
Frame (no frame check sequence [FCS]) |
Frame (including FCS and control word) |
ifInOctets, ifOutOctets |
GE |
vlan-ccc |
Frame (no FCS) |
Frame (including FCS and control word) |
ifInOctets, ifOutOctets |
GE IQ |
vlan-ccc |
Frame (no FCS) |
Frame (including FCS and control word) |
ifInOctets, ifOutOctets |
SNMP traps are also a good mechanism to use for health management. For more information, see “SNMP Traps Supported by Junos OS” and “Enterprise-Specific SNMP Traps Supported by Junos OS.”
Measure Performance
The performance of a service provider’s network is usually defined as how well it can support services, and is measured with metrics such as delay and utilization. We suggest that you monitor the following performance metrics using applications such as InfoVista Service Performance Management or Concord Network Health (see Table 7).
| Metric: |
Average delay |
|
Description |
Average round-trip time (in milliseconds) between two measurement points. |
|
MIB name |
DISMAN-PING-MIB (RFC 2925) |
|
Variable name |
|
|
Variable OID |
pingResultsEntry.6 |
|
Frequency (mins) |
15 (or depending upon ping test frequency) |
|
Allowable range |
To be baselined |
|
Managed objects |
Each measured path in the network |
| Metric: |
Interface utilization |
|
Description |
Utilization percentage of a logical connection. |
|
MIB name |
IF-MIB |
|
Variable name |
( |
|
Variable OID |
ifTable entries |
|
Frequency (mins) |
60 |
|
Allowable range |
To be baselined |
|
Managed objects |
All operational interfaces in the network |
| Metric: |
Disk utilization |
|
Description |
Utilization of disk space within the Juniper Networks router |
|
MIB name |
HOST-RESOURCES-MIB (RFC 2790) |
|
Variable name |
hrStorageSize – hrStorageUsed |
|
Variable OID |
hrStorageEntry.5 – hrStorageEntry.6 |
|
Frequency (mins) |
1440 |
|
Allowable range |
To be baselined |
|
Managed objects |
All Routing Engine hard disks |
| Metric: |
Memory utilization |
|
Description |
Utilization of memory on the Routing Engine and FPC. |
|
MIB name |
JUNIPER-MIB (Juniper Networks enterprise Chassis MIB) |
|
Variable name |
jnxOperatingHeap |
|
Variable OID |
Table for each component |
|
Frequency (mins) |
60 |
|
Allowable range |
To be baselined |
|
Managed objects |
All Juniper Networks routers |
| Metric: |
CPU load |
|
Description |
Average utilization over the past minute of a CPU. |
|
MIB name |
JUNIPER-MIB (Juniper Networks enterprise Chassis MIB) |
|
Variable name |
jnxOperatingCPU |
|
Variable OID |
Table for each component |
|
Frequency (mins) |
60 |
|
Allowable range |
To be baselined |
|
Managed objects |
All Juniper Networks routers |
| Metric: |
LSP utilization |
|
Description |
Utilization of the MPLS label-switched path. |
|
MIB name |
MPLS-MIB |
|
Variable name |
mplsPathBandwidth / (mplsLspOctets * 8) |
|
Variable OID |
mplsLspEntry.21 and mplsLspEntry.3 |
|
Frequency (mins) |
60 |
|
Allowable range |
To be baselined |
|
Managed objects |
All label-switched paths in the network |
| Metric: |
Output queue size |
|
Description |
Size, in packets, of each output queue per forwarding class, per interface. |
|
MIB name |
JUNIPER-COS-MIB |
|
Variable name |
jnxCosIfqQedPkts |
|
Variable OID |
jnxCosIfqStatsEntry.3 |
|
Frequency (mins) |
60 |
|
Allowable range |
To be baselined |
|
Managed objects |
For each forwarding class per interface in the network, once CoS is enabled. |
This section includes the following topics:
- Measure Class of Service
- Inbound Firewall Filter Counters per Class
- Monitor Output Bytes per Queue
- Calculate Dropped Traffic
Measure Class of Service
You can use class-of-service (CoS) mechanisms to regulate how certain classes of packets are handled within your network during times of peak congestion. Typically you must perform the following steps when implementing a CoS mechanism:
-
Identify the type of packets that is applied to this class. For example, include all customer traffic from a specific ingress edge interface within one class, or include all packets of a particular protocol such as voice over IP (VoIP).
-
Identify the required deterministic behavior for each class. For example, if VoIP is important, give VoIP traffic the highest priority during times of network congestion. Conversely, you can downgrade the importance of Web traffic during congestion, as it may not impact customers too much.
With this information, you can configure mechanisms at the network ingress to monitor, mark, and police traffic classes. Marked traffic can then be handled in a more deterministic way at egress interfaces, typically by applying different queuing mechanisms for each class during times of network congestion. You can collect information from the network to provide customers with reports showing how the network is behaving during times of congestion. (See Figure 5.)
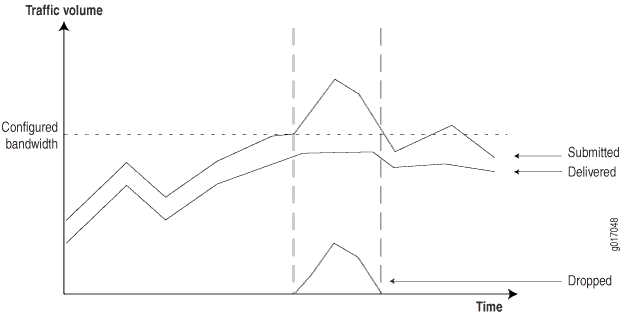
To generate these reports, routers must provide the following information:
-
Submitted traffic—Amount of traffic received per class.
-
Delivered traffic—Amount of traffic transmitted per class.
-
Dropped traffic—Amount of traffic dropped because of CoS limits.
The following section outlines how this information is provided by Juniper Networks routers.
Inbound Firewall Filter Counters per Class
Firewall filter counters are a very flexible mechanism you can use to match and count inbound traffic per class, per interface. For example:
firewall {
filter f1 {
term t1 {
from {
dscp af11;
}
then {
# Assured forwarding class 1 drop profile 1 count inbound-af11;
accept;
}
}
}
}
For example, Table 8 shows additional filters used to match the other classes.
|
DSCP Value |
Firewall Match Condition |
Description |
|---|---|---|
|
10 |
af11 |
Assured forwarding class 1 drop profile 1 |
|
12 |
af12 |
Assured forwarding class 1 drop profile 2 |
|
18 |
af21 |
Best effort class 2 drop profile 1 |
|
20 |
af22 |
Best effort class 2 drop profile 2 |
|
26 |
af31 |
Best effort class 3 drop profile 1 |
Any packet with a CoS DiffServ code point (DSCP) conforming to RFC 2474 can be counted in this way. The Juniper Networks enterprise-specific Firewall Filter MIB presents the counter information in the variables shown in Table 9.
|
Indicator Name |
Inbound Counters |
|---|---|
|
MIB |
|
|
Table |
|
|
Index |
|
|
Variables |
|
|
Description |
Number of bytes being counted pertaining to the specified firewall filter counter |
|
SNMP version |
SNMPv2 |
This information can be collected by any SNMP management application that supports SNMPv2. Products from vendors such as Concord Communications, Inc., and InfoVista, Inc., provide support for the Juniper Networks Firewall MIB with their native Juniper Networks device drivers.
Monitor Output Bytes per Queue
You can use the Juniper Networks enterprise ATM CoS MIB to monitor outbound traffic, per virtual circuit forwarding class, per interface. (See Table 10.)
|
Indicator Name |
Outbound Counters |
|---|---|
|
MIB |
|
|
Variable |
|
|
Index |
|
|
Description |
Number of bytes belonging to the specified forwarding class that were transmitted on the specified virtual circuit. |
|
SNMP version |
SNMPv2 |
Non-ATM interface counters are provided by the Juniper Networks enterprise-specific CoS MIB, which provides information shown in Table 11.
|
Indicator Name |
Outbound Counters |
|---|---|
|
MIB |
|
|
Table |
|
|
Index |
|
|
Variables |
|
|
Description |
Number of transmitted bytes or packets per interface per forwarding class |
|
SNMP version |
SNMPv2 |
Calculate Dropped Traffic
You can calculate the amount of dropped traffic by subtracting the outbound traffic from the incoming traffic:
Dropped = Inbound Counter – Outbound Counter
You can also select counters from the CoS MIB, as shown in Table 12.
|
Indicator Name |
Dropped Traffic |
|---|---|
|
MIB |
|
|
Table |
|
|
Index |
|
|
Variables |
|
|
Description |
The number of tail-dropped or RED-dropped packets per interface per forwarding class |
|
SNMP version |
SNMPv2 |