Data Redundancy and Recovery in JSA Deployments
To safeguard from data loss, configure your deployments to include data redundancy and recovery functionality. Data Synchronization is possible when you have two identical JSA systems in separate geographic environments that are a mirror of each other, and data is synchronized at both sites. Forwarding data uses off-site forwarding, which is set up on both the primary and secondary deployments. You can set up data synchronization with deployments that are in different geographical locations.
Data Synchronization App
Implement the Data Synchronization app to safeguard your JSA configurations and data by mirroring your data to another identical JSA. Recovery from a data loss is possible when you have two identical JSA systems in separate geographic environments that are a mirror of each other, and data is collected at both sites.
If you do not meet the requirements for the Data Synchronization app, the following are some alternative solutions. Recovery from data loss is possible when you forward live data, for example, flows and events from a primary JSA, to a parallel system at another site.
Primary JSA Console and backup console
A hardware failure solution, where the backup console is a copy of the primary server, with the same configuration but stays powered off. Only one console is operational at any one time. If the primary console fails, you manually turn the power on the backup console, apply the primary configuration backup, and use the IP address from the primary console. After you restore the primary server and before you turn it on, you manually turn off the backup server. If the system is down for a long time, apply the backup console configuration backup to the primary server.
Event and flow forwarding
Events and flows are forwarded from a primary site to a secondary site. Identical architectures in two separate data centers are required.
Distributing the same events and flows to the primary and secondary sites
Distribute the same event and flow data to two live sites by using a load balancer or other method to deliver the same data to mirrored appliances. Each site has a record of the log data that is sent.
Primary JSA Console and backup JSA Console
When the primary JSA Console fails and you want the backup JSA Console to take up the role of the primary, you manually turn the power on the backup console, apply the configuration backup and the IP address from the primary. Use a similar switchover method for other appliances such as a JSA Flow Processor or an Event Collector, where each appliance has a cold backup or spare that is an identical appliance.
The backup console takes over the primary JSA Console role from the time of activation, and does not store past events, flow, or offenses from the original primary JSA Console. Use this type of deployment for your appliances, to minimize downtime, when there is a hardware failure.
A backup console requires its own dedicated license key (matching the EPS and FPM values of the primary console).
The license configuration of the backup console needs to match the values of the primary JSA Console; this includes the EPS and FPS values of the primary JSA Console.
Example: If the primary JSA Event Processor was licensed for 15K EPS, the redundant backup console should also be licensed for 15K EPS.
There are special failover upgrade parts that need to be purchased for the backup console.
From a technical perspective, the license for both primary and backup consoles are identical, however for compliance reasons the backup console (and associated license) cannot not be processing live data unless a failure has occurred with the primary JSA Console.
Data collected by the backup console will need to be copied back to the Primary console when the Primary console once again becomes functional.
If the primary fails, take the following steps to set up the backup console as the primary JSA Console:
Power on the backup console.
Add the IP address from the primary console.
Restore configuration backup data from the primary console to the backup console.
The backup console functions as the primary console until the primary console is brought back online. Ensure that both servers are not online at the same time.
Configuring the IP Address on the Backup Console
When the primary JSA Console fails, you configure the secondary backup console to take on the primary console role. Add the IP address of the failed JSA Console to the backup console so that your JSA system continues to function.
Power on the backup console.
Use SSH to log in to as the root user.
To configure the IP address on the backup console, follow these steps:
-
Type the following command:
qchange_netsetupNote:Verify all external storage which is not /store/ariel or /store is not mounted.
Follow the instructions in the wizard to enter the configuration parameters.
After the requested changes are processed, the JSA automatically shuts down and restarts.
-
Backup and Recovery
Back up your JSA configuration information and data so that you can recover from a system failure or data loss.
Use the backup and recovery that is built-in to JSA to back up your data. However, you must restore the data manually. By default, JSA creates a daily backup archive of your configuration information at midnight. The backup archive includes configuration information, generated data, or both from the previous day.
You can create the following types of backup:
Configuration backups, which include system configuration data, for example, assets and log sources in your JSA deployment.
Data backups, which include information that is generated by a working JSA deployment such as log information or event dates.
Event and Flow Forwarding from a Primary Data Center to Another Data Center
To ensure that there is a redundant data store for events, flows, offenses, and that there is an identical architecture in two separate data centers, forward event and flow data from site 1 to site 2.
The following information is provided only for general guidance and is not intended or designed as a how-to guide.
This scenario is dependent upon site 1 remaining active. If site 1 fails, data is not transmitted to Site 2, but the data is current up to the time of failure. In the case of failure at site 1, you implement recovery of your data, by manually changing IP addresses and use a backup and restore to fail over from site 1 to site 2, and to switch to site 2 for all JSA hosts.
The following list describes the setup for event and flow forwarding from the primary site to the secondary site:
There is an identical distributed architecture in two separate data centers, which includes a primary data center and a secondary data center.
The primary JSA Console is active and collecting all events and flows from log sources and is generating correlated offenses.
You configure off-site targets on the primary JSA Console to enable forwarding of event and flow data from the primary data center to the event and flow processors in another data center.
Fast path: Use routing rules instead of off-site targets because the setup is easier.
Periodically, use the content management tool to update content from the primary JSA Console to the secondary JSA Console.
In the case of a failure at site 1, you can use a high-availability (HA) deployment to trigger an automatic failover to site 2. The secondary HA host on site 2 takes over the role of the primary HA host on site 1. Site 2 continues to collect, store, and process event and flow data. Secondary HA hosts that are in a standby state don't have services that are running but data is synchronized if disk replication is enabled.
You can use a load balancer to divide events, and split flows such as NetFlow, J-Flow, and sFlow but you can't use a load balancer to split Flow Processors. Use external technologies such as a regenerative tap to divide Flow Processor and send to the backup site.
The following diagram shows how site 2 is used as a redundant data store for site 1. Event and flow data are forwarded from site 1 to site 2.
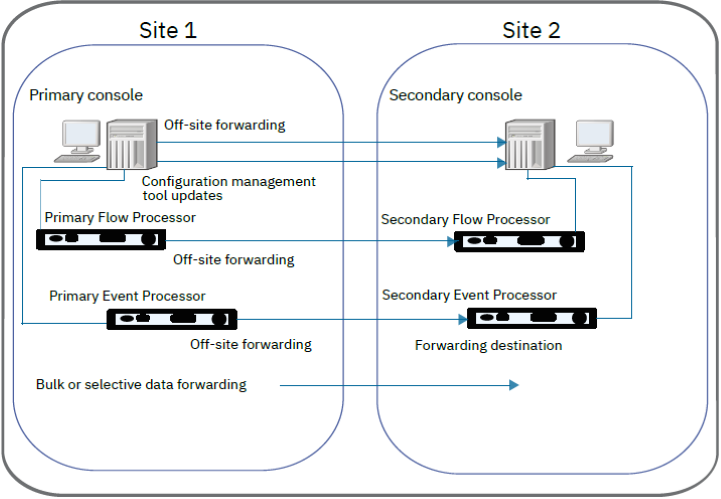
Event and Flow Forwarding Configuration
For data redundancy, configure JSA to forward data from one site to a backup site.
The target system that receives the data from JSA is known as a forwarding destination. JSA ensure that all forwarded data is unaltered. Newer releases of JSA can receive data from earlier releases of JSA. However, earlier releases cannot receive data from later releases. To avoid compatibility issues, upgrade all receivers before you upgrade JSA systems that send data. Follow these steps to set up forwarding:
Configure one or more forwarding destinations.
A forwarding destination is the target system that receives the event and flow data from the JSA primary console. You must add forwarding destinations before you can configure bulk or selective data forwarding.
Configure routing rules, custom rules, or both.
After you add one or more forwarding destinations for your event and flow data, you can create filterbased routing rules to forward large quantities of data.
Configure data exports, imports, and updates.
You use the content management tool to move data from your primary JSA Console to the JSA secondary console. Export security and configuration content from JSA into an external, portable format.
Load Balancing of Events and Flows Between Two Sites
When you are running two live JSA deployments at both a primary and secondary site, you send event and flow data to both sites. Each site has a record of the log data that is sent. Use the content management tool to keep the data synchronized between the deployments
The following diagram shows two live sites, where data from each site is replicated to the other site.
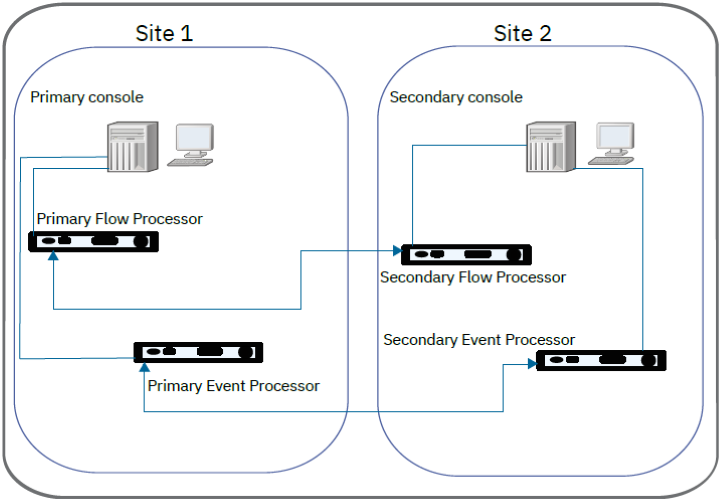
Send the same events and flows to separate data centers or geographically separate sites and enable data redundancy by using a load balancer or other method to deliver the same data to mirrored appliances.
Restoring Configuration Data from the Primary to the Secondary JSA Console
After you set up the secondary JSA Console as the destination for the logs, you either add or import a backup archive from the primary JSA Console. You can restore a backup archive that is created on another JSA host. Log in to the secondary JSA Console and do a full restore of the primary console backup archive to the secondary JSA Console.
You must have a data backup from your primary console to complete this task.
On the navigation menu, click Admin.
On the navigation menu, click System Configuration.
Click the Backup and Recovery icon.
In the Upload Archive field, click Browse.
Locate and select the archive file that you want to upload.
Tip:If the JSA backup archive file is in the /store/backupHost/inbound directory on the console server, the backup archive file is automatically imported.
The archive file must have a .tgz extension.
Click Open.
Click Upload.
Select the archive that you uploaded and click Restore.
When the restore is finished, the secondary JSA Console becomes the primary console.
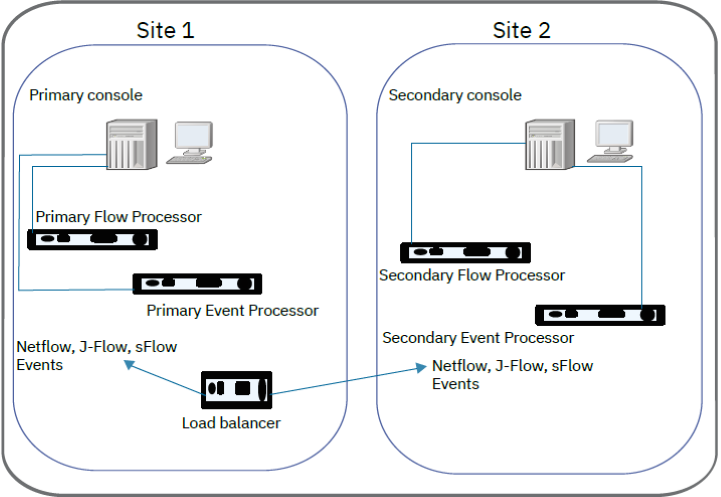
Event and Flow Data Redundancy
Send the same events and flows to separate data centers or geographically separate sites and enable data redundancy by using a load balancer or other method to deliver the same data to mirrored appliances.
Configure the distribution of log and flow sources for data redundancy:
Send log source data to the Event Processor on the second site.
Send flow source data to the Flow Processor on the second site.
For more information about configuring log sources, see the Juniper Secure Analytics Configuring DSMs Guide.
- Configure JSA to receive events
- Configure JSA to Receive Flows
- Use the Content Management Tool (CMT)
Configure JSA to receive events
JSA automatically discovers many log sources that send syslog messages in your deployment. Log sources that are automatically discovered by JSA appear in the Log Sources window.
You configure the automatic discovery of log sources for each Event Collector by using the Autodetection Enabled setting in the Event Collector configuration. If you want to keep the log source event IDs synchronized with the primary Event Collector, you disable the Autodetection setting. In this situation, use the content management tool to synchronize the log source configuration or restore a configuration backup to the site.
For more information about auto discovered log sources and configurations specific to your device or appliance, see the Juniper Secure Analytics Configuring DSMs Guide.
Configure JSA to Receive Flows
To enable data redundancy for flows, you need to send NetFlow, J-Flow, and sFlow to both sites for Flow Processor collection.
You can collect flows from a SPAN or tap and then send packets to your backup location, or you mirror the SPAN or tap in the backup location by using external technologies. A load balancer splits flows such as NetFlow, J-Flow, and sFlow but it can't split Flow Processor.
Use the Content Management Tool (CMT)
If you want to ensure that the primary JSA Console from site 1 and the secondary JSA Console from site 2 have identical configurations, use the content management tool to update site 2 with the configurations from site 1.