Use Juniper BNG CUPS with Multiple Geographical Redundancy
In a disaggregated BNG model, the control plane provides services to many user planes and their associated subscribers. The control plane’s role in the disaggregated model enables new use cases, services, and levels of network redundancy. The use cases require that the control plane has new levels of redundancy. Moving the control plane into a cloud backed by a Kubernetes cluster enables these redundancies.
Kubernetes brings scalability, operational efficiency, and reliability to the solution. The modularity of a Kubernetes cloud enables cluster architectures to have unparalleled redundancy. But, even the most redundant cluster architectures are susceptible to events such as natural disasters or cyberattacks which might target a specific location or geography. A multiple geographic, multiple cluster setup mitigates these susceptibilities.
Figure 1 shows an example of a multiple geographic, multiple cluster setup.
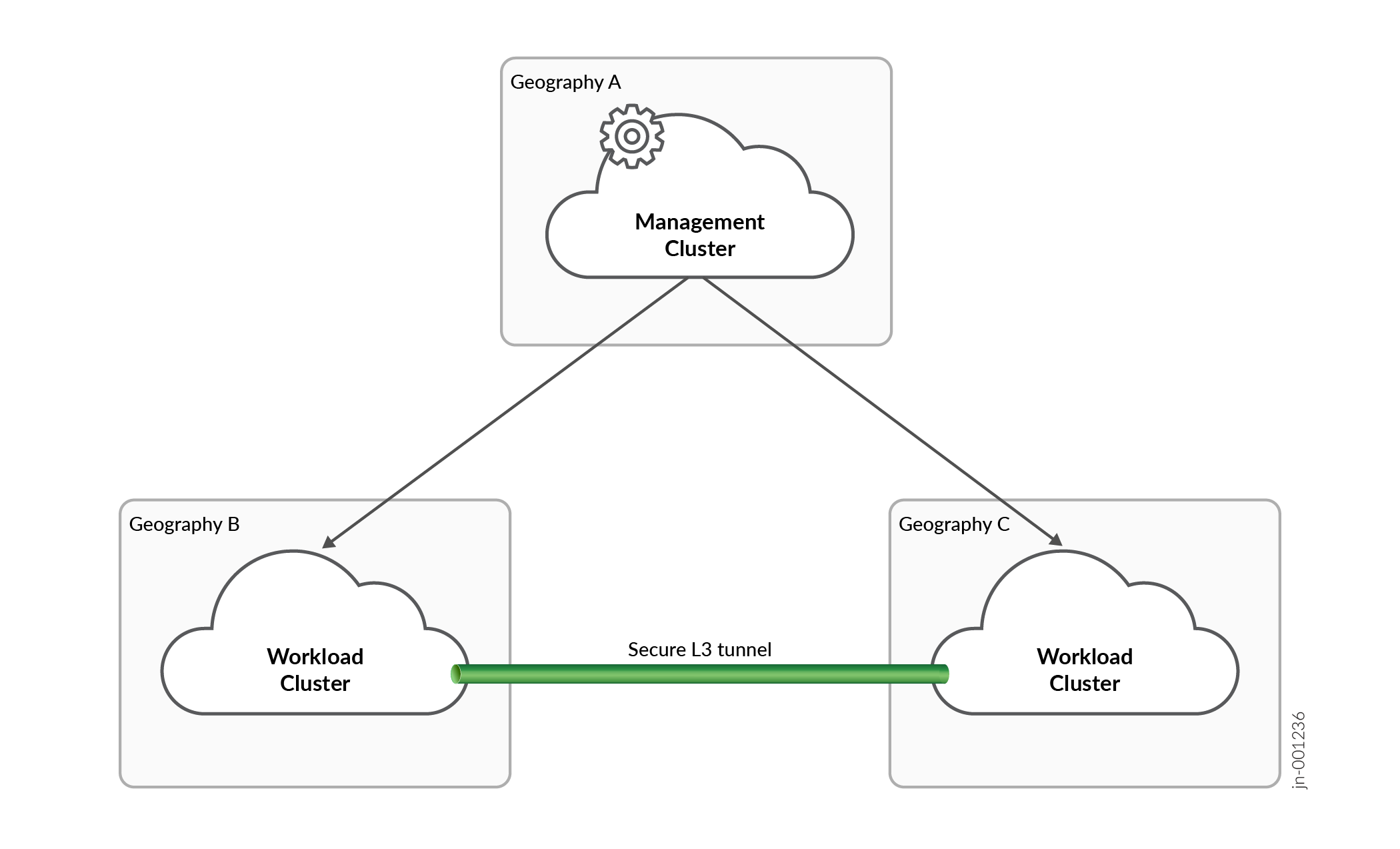
In a multiple geographic, multiple cluster setup, the management cluster maintains a separate context for running multiple cluster scheduling and monitoring functions and is connected to both workload clusters. The multiple cluster context is driven by a policy engine that informs the scheduler how to distribute the application across the workload clusters. Applications that use the multiple cluster setup for multiple geographical redundancy, have policy rules that distribute application microservices involved in state replication to both workload clusters. Other application microservices are distributed to one workload cluster that is chosen as the primary workload cluster.
The workload clusters accept work from the management cluster through the Kubernetes REST API. The workload clusters are standard Kubernetes clusters. A secure L3 tunnel is maintained between the workload clusters. The tunnel facilitates the exchange of application state and general communication between the two workload clusters. As a standard Kubernetes cluster, a workload cluster monitors pods and deployments and performs scheduling tasks for the worker nodes in the cluster, maintaining the deployed application components. The workload cluster does not require the presence of the management cluster to maintain its application workloads. When applications are deployed, it is the workload cluster's responsibility to maintain the application deployment.
If the management cluster detects that a workload cluster has failed or that an application's microservice cannot be satisfactorily scheduled on a workload cluster, the management cluster drives a switchover event. The switchover action is controlled by the policies that are defined for the application. In a switchover event, any application's microservices that exist only on the failed workload cluster are redeployed to the other workload cluster.
The BNG CUPS Controller can be deployed in a multiple geographic, multiple cluster environment. The BNG Controller’s Helm charts include propagation policy rules that instruct the management cluster’s multiple cluster context to deploy an instance of the state cache microservice on both workload clusters. The two state cache instances communicate over the secure tunnel to mirror the subscriber state between the two geographies. The control plane instance is deployed only on one workload cluster. The control plane instance mirrors its state to its local state cache instance, which is then replicated to its state cache peer in the other workload cluster.
Figure 2 Shows a BNG CUPS Controller in a multiple geographic, multiple cluster setup.
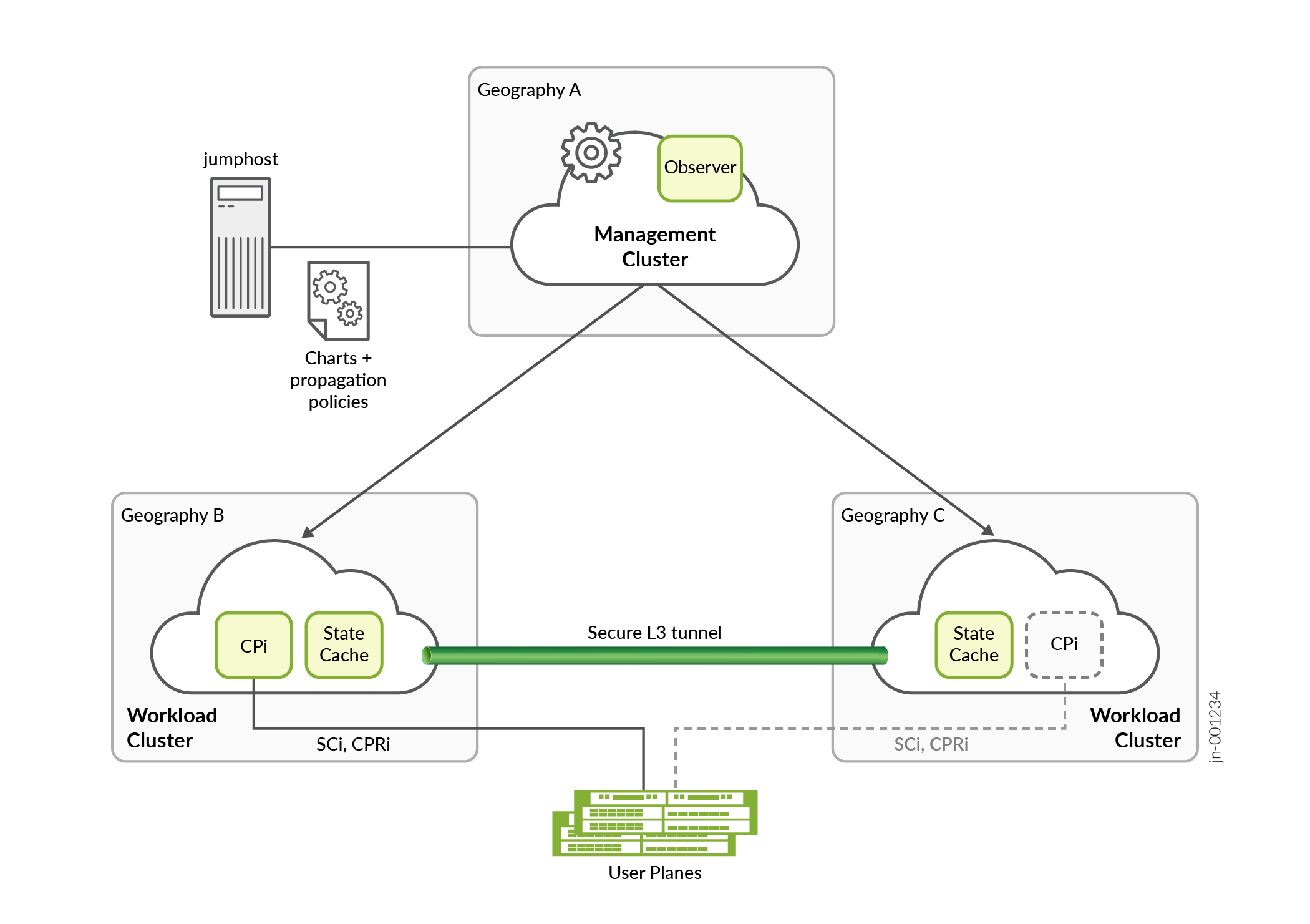
If the workload cluster, where the control plane instance is deployed fails, the management cluster reschedules the control plane instance on the other workload cluster. When the control plane instance initializes on the second workload cluster, it recovers its configuration from a replicated configuration cache (not shown). The control plane instance also recovers its subscriber state from the local state cache instance just as it would on any microservice restart. Since the local state cache received replication state information from the previous workload cluster, all stable states are recovered. Once the state is recovered, the control plane instance establishes its associations with the BNG User Planes. The BNG User Plane association logic detects that the new association is originating from the same BNG CUPS Controller (but in a different geography).
The BNG CUPS Controller also deploys a microservice on the management cluster that is called the observer. The observer runs in the regular context of the management cluster and watches control plane instance scheduling events in the multiple cluster context (associated with the management cluster). In switchover situations where a control plane instance might exist temporarily in both workload clusters, the observer allows the BNG CUPS Controller to resolve any ambiguity over which control plane instance should be running.
For example, in the event that the management cluster can no longer reach or monitor a workload cluster, the management cluster declares that the workload cluster has failed. The management cluster initiates a switchover of workloads from the failed workload cluster to the other workload cluster.
A scenario where the failed workload cluster is operational, but not reachable from the management cluster creates an ambiguous deployment. Multiple instances of application workloads exist on both workload clusters. Since the management cluster is the final arbiter on where workloads run in a multiple cluster deployment, a mechanism is needed to force the duplicate workloads on the workload cluster that has perceived to have failed to enter an inactive or dormant state in deference to their switched over counterparts.
As previously mentioned, the observer microservice runs on the management cluster. The observer watches for scheduling events for application workloads. Each time an application workload is scheduled on a workload cluster, the observer assigns a unique generation number to that workload. When the same workload is switched over to the other workload cluster, the generation number is incremented. As the applications workloads initialize, they request their generation number from the observer. The generation number passes between the workload clusters. Application workloads on the failed workload cluster take note that the same workloads have a higher generation number on the other workload cluster and transition the application into a dormant state (all connections are dropped, no state is generated or consumed).
The generation number helps correct the ambiguous deployment caused by the management cluster's inability to view the true state of the failed workload cluster. When reachability is restored to the failed workload cluster, the management cluster removes the dormant application workloads.
When a cluster switchover occurs, the set of external IP addresses used to contact the BNG CUPS Controller change to the address space used in the new workload cluster. Some back-office applications are more sensitive to IP address changes. For instance, RADIUS wants the value of the NAS-IP-Address to remain constant across cluster switchovers.
The BNG CUPS Controller supports a consistent value for the NAS-IP-Address through a microservice called the Multi-geo IP Route Prioritization Operator (MIRP). The Multi-geo IP Route Prioritization Operator is a microservice that is deployed to each workload cluster.
When a CPi is added, you can provide a persistent external address to use for the CPi’s
RADIUS listener address by adding the ip-aaa
external-radius-address option to the cpi
add command.
When the CPi microservice is deployed, a custom resource is created for the MetalLB IP address pool containing the configured external address. A separate load balancer service is created for the RADIUS listener port with MetalLB annotations to reference the IP address pool. This ensures that the service is assigned the listed external address.
The Multi-geo IP Route Prioritization Operator in the workload cluster, where the CPi’s
RADIUS load balancer service is created, generates a BGP advertisement custom resource.
This resource contains a LOCAL_PREF value derived from the CPi’s
generation number as obtained by the observer (the generation number is incremented by
the observer when a cluster switchover event is observed). The BGP advertisement is
exchanged with the network load balancer’s IBGP peers. The back-office systems (RADIUS
in this case) sit behind the IBGP peers. When the CPi switches over to the other
workload cluster, its generation number increments. The associated
LOCAL_PREF value of the Multi-geo IP Route Prioritization
Operator-generated BGP advertisement is also incremented. Traffic bound for the
service’s external IP address is routed to the cluster with the higher
LOCAL_PREF value which is also the active workload cluster for the
CPi.