Software Architecture Overview
Juniper Apstra has the following two major components in its system architecture:
-
Apstra Server
-
Apstra Device Agents
Every device managed by Apstra will require an Apstra agent installed on it. Apstra server and all the Apstra agents act as a distributed operating system.
TCP connectivity is the only requirement between nodes.
Apstra translates high-level business requirements, referred to as “intent,” and translates that into a fully operational data center network environment.
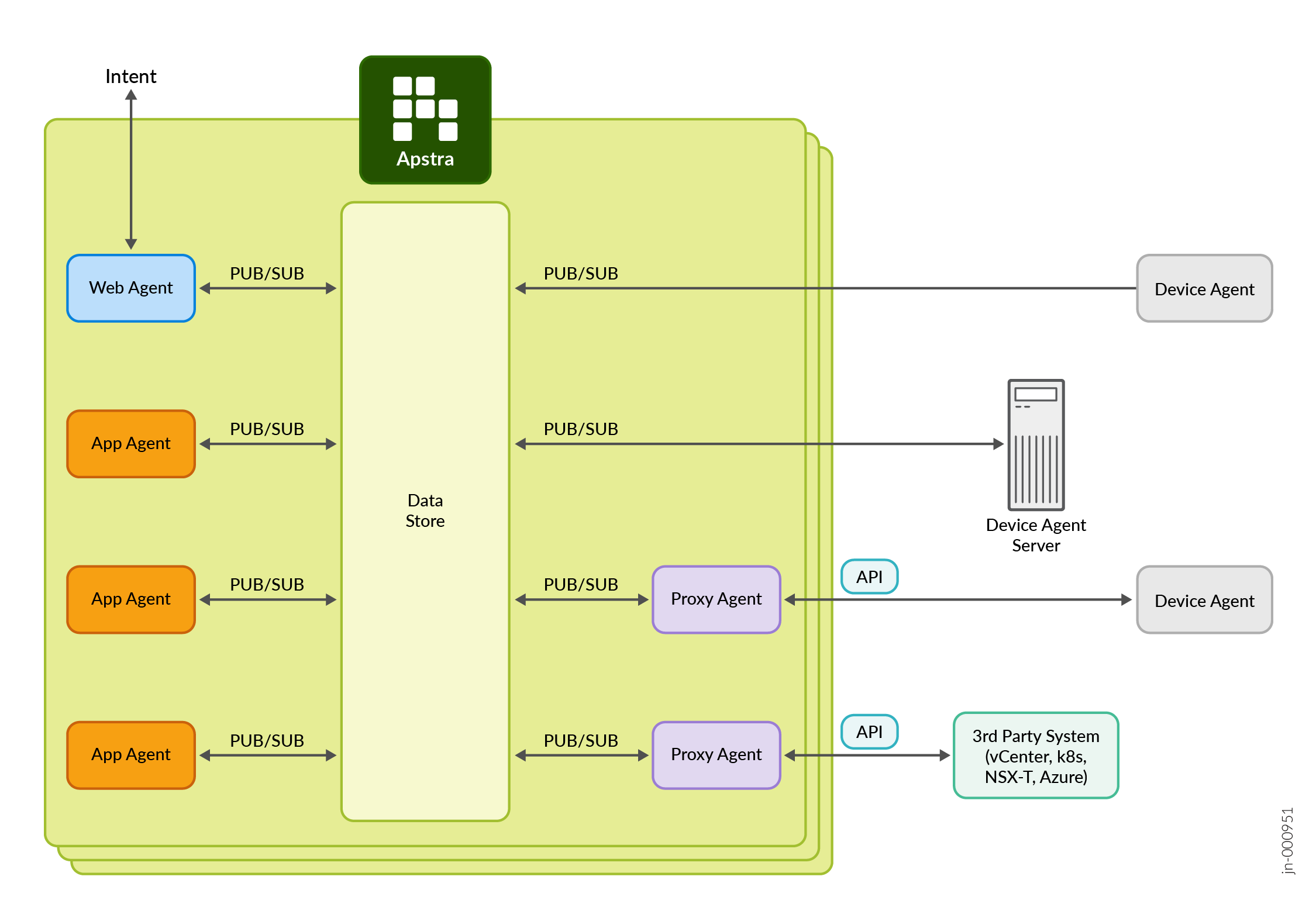
Juniper Apstra architecture is based on distributed state-management infrastructure, which can be described as a data-centric communication fabric with horizontally scalable and fault-tolerant in-memory datastore. All the functionalities of the specific reference design application are implemented via a set of stateless agents. Agents communicate with each other via a logical publish-subscribe-based communication channel and essentially implement the application’s logic.
Every Apstra reference design application is simply a collection of stateless agents described above. Broadly speaking, there are three classes of agents in Apstra:
- Interaction (web) agents are responsible for interacting with users, i.e., taking user input and feeding users with relevant context from the data store.
- Application agents are responsible for performing application domain-specific data transformations, by subscribing to input entities and producing output entities.
- Device agents reside on (or are proxies for) a managed physical or virtual system such as a switch, server, firewall, load balancer, or even controller and are used for writing configuration and gathering telemetry using native (device-specific) interfaces, often vendor’s APIs.
This interaction can be illustrated with an example that describes a portion of the Apstra data center networking reference design application.
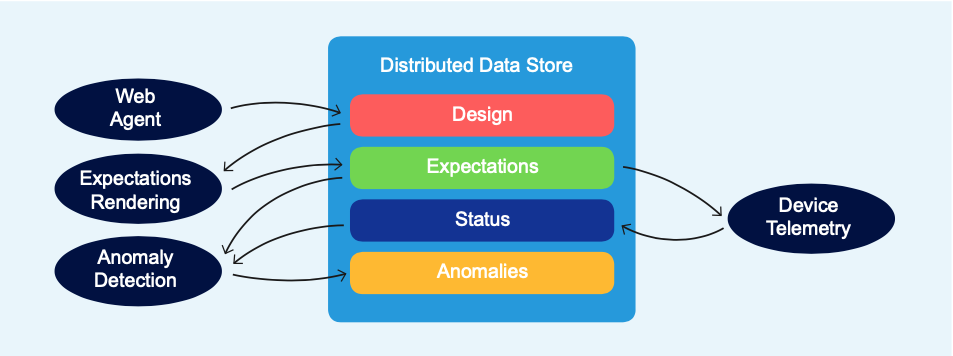
The web agent takes user input — in this case, a design for an L3 Clos Fabric that contains the number of spines, leafs, and links between them, and the resource pools to use for fabric IPs and ASN numbers. The web agent publishes this intent into the data store as a set of graph nodes and relationships and their respective properties.
The build agent subscribes to this intent and:
- Performs correctness and completeness validations
- Allocates resources from resource pools
Assuming the validations pass, the build agent publishes that intent along with resource allocations into the data store.
The config rendering agent subscribes to the output of the build agent. For each node, the config agent fetches the relevant data, including resources, and merges it with configuration templates.
The expectations agent also subscribes to the output of the build agent and generates expectations that need to be met in order to validate the outcome.
The device telemetry agent subscribes to the output of the expectations agent and starts collecting relevant telemetry. IBA probes process the raw telemetry and compare it against expectations and publish anomalies.
The Root Cause Identification (RCI) agent analyzes the anomalies and classifies them into symptoms, impacts, and identified root causes.
Agents communicate via attribute-based interfaces (hence the term data-centric) by publishing entities and subscribing to changes in entities. Data-centric also implies that data definition is part of the framework and is implemented by defining the entities, as opposed to message-based systems, for example.
The data-centric publish-subscribe system does not suffer from the problems of message-based systems. In a message-based system, sooner or later the number of messages exceeds the capacity of the system to store or consume them; dealing with this is hard as one must replay the history of messages to get to a consistent state. The data-centric system is resilient to surges in state changes as it is fundamentally dependent only on the last state. This state captures the important context and abstracts away all the possible (and irrelevant) event sequences that lead to it.
The difficult problems (e.g., elasticity, fault tolerance) are solved once, and on behalf of all agents. Typical architecture then consists of several stateless agents that can be restarted in case of failure and pick up where they left off by simply re-reading the state they subscribe to from the database.