Solución de problemas de instalación de Paragon Automation
RESUMEN Lea los temas siguientes para obtener información sobre cómo solucionar problemas típicos que pueden surgir durante y después de la instalación.
Resolver conflictos de combinación del archivo de configuración
El init script crea los archivos de configuración de la plantilla. Si actualiza una instalación existente utilizando el mismo config-dir directorio que se utilizó para la instalación, los archivos de plantilla que crea la init secuencia de comandos se combinan con los archivos de configuración existentes. A veces, esta acción de fusión crea un conflicto de combinación que debe resolver. El script le preguntará cómo resolver el conflicto. Cuando se le solicite, seleccione una de las siguientes opciones:
-
C: puede conservar el archivo de configuración existente y descartar el nuevo archivo de plantilla. Esta es la opción predeterminada.
-
n: puede descartar el archivo de configuración existente y reinicializar el archivo de plantilla.
-
m: puede combinar los archivos manualmente. Las secciones conflictivas se marcan con líneas que comienzan por
<<<<<<<<,||||||||,========y>>>>>>>>. Debe editar el archivo y quitar los marcadores de combinación antes de continuar con la actualización. -
d: puede ver las diferencias entre los archivos antes de decidir cómo resolver el conflicto.
Resolver problemas comunes de copia de seguridad y restauración
Supongamos que destruye un clúster existente y vuelve a implementar una imagen de software en los mismos nodos del clúster. En tal escenario, si intenta restaurar una configuración desde una carpeta de configuración de la que se realizó una copia de seguridad anteriormente, es posible que se produzca un error en la operación de restauración. Se produce un error en la operación de restauración porque ahora se ha cambiado la ruta de montaje para la configuración de la copia de seguridad. Cuando se destruye un clúster existente, se elimina el volumen persistente. Cuando se vuelve a implementar la nueva imagen, el volumen persistente se vuelve a crear en uno de los nodos del clúster siempre que haya espacio disponible, pero no necesariamente en el mismo nodo en el que estaba presente anteriormente. Como resultado, se produce un error en la operación de restauración.
Para evitar estos problemas de copia de seguridad y restauración:
-
Determine la ruta de montaje del nuevo volumen persistente.
-
Copie el contenido de la ruta de montaje del volumen persistente anterior en la nueva ruta.
-
Vuelva a intentar la operación de restauración.
Ver archivos de registro de instalación
Si se produce un error en la secuencia de deploy comandos, debe comprobar los archivos de registro de instalación en el config-dir directorio. De forma predeterminada, el config-dir directorio almacena seis archivos de registro comprimidos. El archivo de registro actual se guarda como registro y los archivos de registro anteriores se guardan como archivos log.1 a log.5 . Cada vez que ejecuta el deploy script, se guarda el registro actual y se descarta el más antiguo.
Normalmente, encontrará mensajes de error al final de un archivo de registro. Vea el mensaje de error y corrija la configuración.
Solución de problemas mediante la interfaz kubectl
kubectl (Kube Control) es una utilidad de línea de comandos que interactúa con la API de Kubernetes, y la línea de comandos más común tomada para controlar los clústeres de Kubernetes.
Puede emitir comandos kubectl en el nodo principal justo después de la instalación. Para emitir comandos kubectl en los nodos de trabajo, debe copiar el archivo admin.conf y establecer la variable de kubeconfig entorno o usar el comando export KUBECONFIG=config-dir /admin.conf . El archivo admin.conf se copia en el directorio config-dir del host de control como parte del proceso de instalación.
Utilice la herramienta de línea de comandos kubectl para comunicarse con la API de Kubernetes y obtener información sobre los recursos de la API, como nodos, pods y servicios, mostrar archivos de registro, así como crear, eliminar o modificar esos recursos.
La sintaxis de los comandos kubectl es la siguiente:
kubectl [command] [TYPE] [NAME] [flags]
[command] es simplemente la acción que desea ejecutar.
Puede utilizar el siguiente comando para ver una lista de comandos kubectl:
root@primary-node:/# kubectl [enter]
Puede pedir ayuda, para obtener detalles y enumerar todas las banderas y opciones asociadas con un comando en particular. Por ejemplo:
root@primary-node:/# kubectl get -h
Para comprobar y solucionar problemas de las operaciones en Paragon Automation, deberá usar los siguientes comandos:
| [comando] | Descripción |
|---|---|
| Obtener | Mostrar uno o varios recursos. El resultado muestra una tabla con la información más importante sobre los recursos especificados. |
| describir | Muestra detalles de un recurso específico o un grupo de recursos. |
| explicar | Documentación de recursos. |
| trozas | Muestra los registros de un contenedor en un pod. |
| reinicio de la implementación | Administrar la implementación de un recurso. |
| editar | Editar un recurso. |
[TYPE] representa el tipo de recurso que desea ver. Los tipos de recursos no distinguen entre mayúsculas y minúsculas y puede usar formas singulares, plurales o abreviadas.
Por ejemplo, pod, nodo, servicio o implementación. Para obtener una lista completa de recursos y abreviaturas permitidas (ejemplo, pod = po), emita este comando:
kubectl api-resources
Para obtener más información acerca de un recurso, emita este comando:
kubectl explain [TYPE]
Por ejemplo:
root@primary-node:/# kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
---more---
[NAME] es el nombre de un recurso específico, por ejemplo, el nombre de un servicio o pod. Los nombres distinguen entre mayúsculas y minúsculas.
root@primary-node:/# kubectl get pod pod_name
[flags] Proporcionar opciones adicionales para un comando. Por ejemplo, -o enumera más atributos para un recurso. Utilice la ayuda (-h) para obtener información sobre los indicadores disponibles.
Tenga en cuenta que la mayoría de los recursos de Kubernetes (como pods y servicios) se encuentran en algunos espacios de nombres, mientras que otros no lo están (como los nodos).
Los espacios de nombres proporcionan un mecanismo para aislar grupos de recursos dentro de un único clúster. Los nombres de los recursos deben ser únicos dentro de un espacio de nombres, pero no en todos los espacios de nombres.
Cuando utilice un comando en un recurso que se encuentra en un espacio de nombres, debe incluir el espacio de nombres como parte del comando. Los espacios de nombres distinguen entre mayúsculas y minúsculas. Sin el espacio de nombres adecuado, es posible que no se muestre el recurso específico que le interesa.
root@primary-node:/# kubectl get services mgd Error from server (NotFound): services "mgd" not found root@primary-node:/# kubectl get services mgd -n healthbot NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE mgd ClusterIP 10.102.xx.12 <none> 22/TCP,6500/TCP,8082/TCP 18h
Puede obtener una lista de todos los espacios de nombres emitiendo el kubectl get namespace comando.
Si desea mostrar recursos para todos los espacios de nombres, o no está seguro de a qué espacios de nombres pertenece el recurso específico que le interesa, puede escribir --all-namespaces o - A.
Para obtener más información acerca de Kubernetes, consulte:
- https://kubernetes.io/docs/reference/kubectl/overview/
- https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
Utilice los temas siguientes para solucionar problemas y ver los detalles de la instalación mediante la interfaz kubectl.
- Ver estado del nodo
- Ver el estado del pod
- Ver información detallada sobre un pod
- Ver los registros de un contenedor en un pod
- Ejecutar un comando en un contenedor de un pod
- Ver Servicios
- Comandos kubectl de uso frecuente
Ver estado del nodo
Utilice el kubectl get nodes comando, abreviado como kubectl get no comando, para ver el estado de los nodos del clúster. El estado de los nodos debe ser Ready, y los roles deben ser o nonecontrol-plane . Por ejemplo:
root@primary-node:~# kubectl get no NAME STATUS ROLES AGE VERSION 10.49.xx.x1 Ready control-plane,master 5d5h v1.20.4 10.49.xx.x6 Ready <none> 5d5h v1.20.4 10.49.xx.x7 Ready <none> 5d5h v1.20.4 10.49.xx.x8 Ready <none> 5d5h v1.20.4
Si un nodo no Readyes , compruebe si el proceso kubelet se está ejecutando. También puede utilizar el registro del sistema del nodo para investigar el problema.
Para verificar kubelet: root@primary-node:/# kubelet
Ver el estado del pod
Use el kubectl get po –n namespace comando o kubectl get po -A para ver el estado de un pod. Puede especificar un espacio de nombres individual (como healthbot, northstary common) o puede utilizar el -A parámetro para ver el estado de todos los espacios de nombres. Por ejemplo:
root@primary-node:~# kubectl get po -n northstar NAME READY STATUS RESTARTS AGE bmp-854f8d4b58-4hwx4 3/3 Running 1 30h dcscheduler-55d69d9645-m9ncf 1/1 Running 1 7h13m
El estado de las cápsulas en buen estado debe ser Running o Completed, y el número de contenedores listos debe coincidir con el total. Si el estado de un pod no Running es o si el número de contenedores no coincide, use el kubectl describe po comando o kubectl log (POD | TYPE/NAME) [-c CONTAINER] para solucionar el problema.
Ver información detallada sobre un pod
Use el kubectl describe po -n namespace pod-name comando para ver información detallada sobre un pod específico. Por ejemplo:
root@primary-node:~# kubectl describe po -n northstar bmp-854f8d4b58-4hwx4
Name: bmp-854f8d4b58-4hwx4
Namespace: northstar
Priority: 0
Node: 10.49.xx.x1/10.49.xx.x1
Start Time: Mon, 10 May 2021 07:11:17 -0700
Labels: app=bmp
northstar=bmp
pod-template-hash=854f8d4b58
…
Ver los registros de un contenedor en un pod
Use el kubectl logs -n namespace pod-name [-c container-name] comando para ver los registros de un pod en particular. Si un pod tiene varios contenedores, debe especificar el contenedor cuyo contenedor desea ver los registros. Por ejemplo:
root@primary-node:~# kubectl logs -n common atom-db-0 | tail -3
2021-05-31 17:39:21.708 36 LOG {ticks: 0, maint: 0, retry: 0}
2021-05-31 17:39:26,292 INFO: Lock owner: atom-db-0; I am atom-db-0
2021-05-31 17:39:26,350 INFO: no action. i am the leader with the lock
Ejecutar un comando en un contenedor de un pod
Use el kubectl exec –ti –n namespacepod-name [-c container-name] -- command-line comando para ejecutar comandos en un contenedor dentro de un pod. Por ejemplo:
root@primary-node:~# kubectl exec -ti -n common atom-db-0 -- bash
____ _ _
/ ___| _ __ (_) | ___
\___ \| '_ \| | |/ _ \
___) | |_) | | | (_) |
|____/| .__/|_|_|\___/
|_|
This container is managed by runit, when stopping/starting services use sv
Examples:
sv stop cron
sv restart patroni
Current status: (sv status /etc/service/*)
run: /etc/service/cron: (pid 29) 26948s
run: /etc/service/patroni: (pid 27) 26948s
run: /etc/service/pgqd: (pid 28) 26948s
root@atom-db-0:/home/postgres#
Después de ejecutar exec el comando, obtiene un shell bash en el servidor de base de datos Postgres. Puede acceder al shell bash dentro del contenedor y ejecutar comandos para conectarse a la base de datos. No todos los contenedores proporcionan un shell bash. Algunos contenedores solo proporcionan SSH y algunos contenedores no tienen cáscaras.
Ver Servicios
Utilice el kubectl get svc -n namespace comando o kubectl get svc -A para ver los servicios de clúster. Puede especificar un espacio de nombres individual (como healthbot, northstary common), o puede usar el -A parámetro para ver los servicios de todos los espacios de nombres. Por ejemplo:
root@primary-node:~# kubectl get svc -A --sort-by spec.type NAMESPACE NAME TYPE EXTERNAL-IP PORT(S) … healthbot tsdb-shim LoadBalancer 10.54.xxx.x3 8086:32081/TCP healthbot ingest-snmp-proxy-udp LoadBalancer 10.54.xxx.x3 162:32685/UDP healthbot hb-proxy-syslog-udp LoadBalancer 10.54.xxx.x3 514:31535/UDP ems ztpservicedhcp LoadBalancer 10.54.xxx.x3 67:30336/UDP ambassador ambassador LoadBalancer 10.54.xxx.x2 80:32214/TCP,443:31315/TCP,7804:32529/TCP,7000:30571/TCP northstar ns-pceserver LoadBalancer 10.54.xxx.x4 4189:32629/TCP …
En este ejemplo, los servicios se ordenan por tipo y solo se muestran los servicios de tipo LoadBalancer . Puede ver los servicios proporcionados por el clúster y las direcciones IP externas seleccionadas por el equilibrador de carga para acceder a esos servicios.
Puede acceder a estos servicios desde fuera del clúster. La dirección IP externa está expuesta y accesible desde dispositivos fuera del clúster.
Comandos kubectl de uso frecuente
-
Enumere los controladores de replicación:
# kubectl get –n namespace deploy
# kubectl get –n namespace statefulset
-
Reinicie un componente:
kubectl rollout restart –n namespace deploy deployment-name
-
Editar un recurso de Kubernetes: puede editar una implementación o cualquier objeto de API de Kubernetes, y estos cambios se guardan en el clúster. Sin embargo, si vuelve a instalar el clúster, estos cambios no se conservan.
# kubectl edit –ti –n namespace deploy deployment-name
Solución de problemas mediante la utilidad paragon CLI
paragon utilidad CLI de comandos para ejecutar comandos en pods que se ejecutan en el sistema. Los
paragon comandos son un conjunto de comandos intuitivos que le permiten analizar, consultar y solucionar problemas del clúster. Para ejecutar los comandos, inicie sesión en cualquiera de los nodos principales. El resultado de algunos de los comandos está codificado por colores porque, para algunos comandos, la
paragon utilidad de comandos ejecuta los comandos kubecolor en lugar de kubectl, kubecolor color codifica la salida del comando kubectl. Consulte
la figura 1 para ver un ejemplo de salida. Debe ser un usuario raíz o no root con disposiciones de superusuario (sudo) para ejecutar los comandos de
paragon la utilidad de CLI.
Para ver todo el conjunto de opciones de ayuda de comandos disponibles, utilice uno de los siguientes comandos:
root@primary-node:~# paragon ? root@primary-node:~# paragon --help root@primary-node:~# paragon -h
Puede ver las opciones de ayuda en cualquier nivel de comando (no solo en el nivel superior). Por ejemplo:
root@primary-node:~# paragon insights cli ? paragon insights cli alerta => Gets into the CLI of paragon insights alerta pod. paragon insights cli byoi => Gets into the CLI of byoi plugin.Usage : --byoi <BYOI plugin name>. paragon insights cli configserver => Gets into the CLI of paragon insights config-server pod. paragon insights cli grafana => Gets into the CLI of paragon insights grafana pod. paragon insights cli influxdb => Gets into the CLI of paragon insights InfluxDB pod.Use Argument: --influx <influxdb-nodeip> to specify the node ip ,else the command will use first influx node as default.Eg: --influx influxdb-172-16-18-21 paragon insights cli mgd => Gets into the CLI of paragon insights mgd pod.
Puede usar la opción de ficha para ver posibles opciones de autocompletado para los comandos. Para ver el autocompletado de comandos de nivel superior, escriba paragon y presione la tecla TAB. Por ejemplo:
root@primary-node:~# paragon ambassador describe get pathfinder set common ems insights rookceph
Para ver el comando subyacente que ejecuta un comando de parangón, utilice el eco o -e la opción. Por ejemplo:
root@primary-node:~# paragon -e get nodes all >>>> command: kubecolor --force-colors get nodes
Para ejecutar un comando de paragon y ver el comando subyacente que ejecuta, utilice la opción depurar o -d . Por ejemplo:
root@primary-node:~# paragon -d get nodes all >>>> command: kubecolor --force-colors get nodes NAME STATUS ROLES AGE VERSION ix-pgn-pr-01 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-pr-02 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-pr-03 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-wo-01 Ready <none> 17d v1.26.6+rke2r1
Para ver la lista completa de paragon comandos y los comandos subyacentes correspondientes que ejecutan, use:
root@primary-node:~# paragon --mapped
paragon de salida
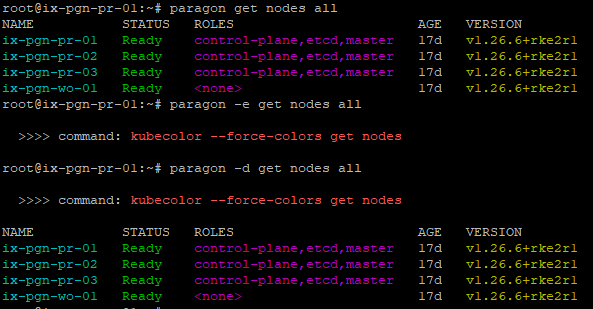 de comando
de comando
Siga las instrucciones con respecto a criterios de uso específicos, como argumentos o requisitos previos, si los hay, en la sección de ayuda de cada comando. Algunos comandos necesitan argumentos obligatorios. Por ejemplo, el paragon insights logs devicegroup analytical comando necesita el argumento --dg devicegroup-name-with subgroup. Por ejemplo:
paragon insights logs devicegroup analytical --dg controller-0
Algunos comandos tienen requisitos previos. Por ejemplo, antes de usar el paragon insights get playbooks comando, debe establecer el nombre de usuario y la contraseña mediante los paragon set username --cred username comandos y paragon set password --cred password .
El conjunto completo de comandos junto con sus criterios de uso se enumeran en la Tabla 1.
| Mandar |
Descripción |
|---|---|
|
|
Muestra las cápsulas del emisario del embajador Paragon. |
|
|
Muestra todos los pods de embajadores de Paragon. |
|
|
Muestra todos los servicios de embajador de Paragon. |
|
|
Ayuda a encontrar los roles de Postgres. |
|
|
Muestra la descripción de un nodo concreto del clúster. Utilice el Ejemplo: Puede usar el |
|
|
Muestra los pods del administrador de dispositivos Paragon ems. |
|
|
Muestra los pods del administrador de trabajos de Paragon EMS. |
|
|
Muestra todos los pods de Paragon EMS. |
|
|
Muestra todos los servicios de Paragon EMS. |
|
|
Muestra los registros de los pods del administrador de dispositivos de Paragon EMS. Use el argumento para obtener registros de |
|
|
Muestra los registros del pod del administrador de trabajos de paragon ems. Use el argumento para obtener registros de |
|
|
Muestra todos los espacios de nombres disponibles en Paragon. |
|
|
Muestra una lista de todos los nodos del clúster. |
|
|
Valida si kubelet tiene alguna presión de disco. Utilice el Ejemplo: |
|
|
Valida si kubelet tiene suficiente memoria. Utilice el Ejemplo: |
|
|
Comprueba si hay problemas con calico y la red. Utilice el Ejemplo: |
|
|
Muestra una lista de todos los nodos que no están listos en el clúster. |
|
|
Valida si kubelet tiene suficiente PID disponible. Utilice el Ejemplo: |
|
|
Muestra una lista de todos los nodos que están listos en el clúster. |
|
|
Muestra una lista de todas las manchas en los nodos. |
|
|
Muestra todas las vainas saludables de Paragon. |
|
|
Muestra todas las vainas poco saludables de Paragon. |
|
|
Muestra todos los servicios de Paragon que están expuestos. |
|
|
Inicia sesión en la CLI del pod de alerta de Paragon Insights. |
|
|
Inicia sesión en la CLI del complemento BYOI. Utilice el |
|
|
Inicia sesión en la CLI del pod config-server de Paragon Insights. |
|
|
Inicia sesión en la CLI del pod de grafana de Paragon Insights. |
|
|
Inicia sesión en la CLI del pod influxdb de Paragon Insights. Utilice el Ejemplo: |
|
|
Inicia sesión en la CLI del pod mgd de Paragon Insights. |
|
|
Describe el pod de alerta de Paragon Insights. |
|
|
Describe el pod de la API de REST de Paragon Insights. |
|
|
Describe el pod config-server de Paragon Insights. |
|
|
Describe el pod de grafana de Paragon Insights. |
|
|
Describe el pod de influxdb de Paragon Insights. Utilice el Ejemplo: |
|
|
Describe el pod mgd de Paragon Insights. |
|
|
Muestra el pod de alerta de Paragon Insights. |
|
|
Muestra el pod de la API de REST de Paragon Insights. |
|
|
Muestra el pod config-server de Paragon Insights. |
|
|
Muestra todos los grupos de dispositivos de Paragon Insights. El nombre de usuario predeterminado es Como requisito previo, ejecute el |
|
|
Muestra todos los dispositivos de Paragon Insights. El nombre de usuario predeterminado es Como requisito previo, ejecute el |
|
|
Muestra el pod de grafana de Paragon Insights. |
|
|
Muestra el pod influxdb de Paragon Insights. |
|
|
Muestra los pods de ingesta de telemetría de red de Paragon Insights. |
|
|
Muestra el pod mgd de Paragon Insights. |
|
|
Muestra todos los manuales de estrategia de Paragon Insights. El nombre de usuario predeterminado es Como requisito previo, ejecute el |
|
|
Muestra todos los pods de Paragon Insights. |
|
|
Muestra todos los servicios de Paragon Insights. |
|
|
Muestra los registros del pod de alerta de Paragon Insights. |
|
|
Muestra los registros del pod de la API REST de Paragon Insights. |
|
|
Muestra los registros del complemento BYOI de Paragon Insights. Utilice el |
|
|
Muestra los registros del pod del servidor de configuración de Paragon Insights. |
|
|
Muestra los registros del grupo de dispositivos Paragon Insights para el motor analítico de servicios. Utilice el Ejemplo: En el ejemplo, es el nombre del grupodispositivo controller y 0 es el subgrupo. |
|
|
Muestra los registros del grupo de dispositivos de Paragon Insights para el servicio itsdb. Utilice el
Ejemplo: En el ejemplo, es el nombre del grupodispositivo controller y 0 es el subgrupo. |
|
|
Muestra los registros del grupo de dispositivos de Paragon Insights para jtimon de servicio. Utilice el Ejemplo: En el ejemplo, es el nombre del grupodispositivo controller y 0 es el subgrupo. |
|
|
Muestra los registros del grupo de dispositivos de Paragon Insights para el servicio jti nativo. Utilice el Ejemplo: En el ejemplo, es el nombre del grupodispositivo controller y 0 es el subgrupo. |
|
|
Muestra los registros del grupo de dispositivos Paragon Insights para syslog de servicio. Utilice el Ejemplo: En el ejemplo, es el nombre del grupodispositivo controller y 0 es el subgrupo. |
|
|
Muestra los registros del pod de Grafana de Paragon Insights. |
|
|
Muestra los registros del pod influxdb de Paragon Insights. Utilice el Ejemplo: |
|
|
Muestra los registros del pod mgd de Paragon Insights. |
|
|
Inicia sesión en la CLI del contenedor BMP de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor ns-configserver de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor cRPD de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor debugutils de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor netconf de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI de los servicios de contenedor ns-pceserver (PCEP) de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor ns-pcserver (PCS) de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor ns-pcsviewer (Aplicación de escritorio Paragon Pathfinder). |
|
|
Entra en la CLI del contenedor del programador de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor ns-toposerver (servicio de topología) de Paragon Pathfinder. |
|
|
Inicia sesión en la CLI del contenedor ns-web de Paragon Pathfinder. |
|
|
Depura la configuración de las opciones de enrutamiento de cRPD de Paragon Pathfinder relacionada con BGP-LS. |
|
|
Depura las rutas cRPD de Paragon Pathfinder relacionadas con BGP-LS. |
|
|
Muestra la ayuda de Paragon Pathfinder debugutils genjvisiondata. |
|
|
Muestra Paragon Pathfinder debugutils genjvisiondata params. |
|
|
Inicia sesión en la CLI de PCEP de Paragon Pathfinder para realizar la depuración. |
|
|
Muestra el estado de Postgres del clúster de Kubernetes. |
|
|
Muestra el estado del clúster de rabbitmqctl. |
|
|
Ejecuta el pod debugutils de Paragon Pathfinder para espiar y decodificar datos intercambiados entre AMQP. |
|
|
Muestra Paragon Pathfinder debugutils snoop help. |
|
|
Ejecuta Paragon Pathfinder debugutils pod para espiar y decodificar datos intercambiados entre Postgres. |
|
|
Ejecuta el pod debugutils de Paragon Pathfinder para espiar y decodificar los datos intercambiados entre el enlace de Redis. |
|
|
Ejecuta el pod debugutils de Paragon Pathfinder para espiar y decodificar los datos intercambiados entre Redis lsp. |
|
|
Ejecuta el pod debugutils de Paragon Pathfinder para espiar y decodificar los datos intercambiados entre los nodos de redis. |
|
|
Muestra las depuraciones de Paragon Pathfinder topo_util ayuda. |
|
|
Muestra Paragon Pathfinder debugutils topo_util herramienta para desactivar el modo seguro. |
|
|
Ejecuta Paragon Pathfinder debugutils topo_util herramienta para actualizar la topología actual. |
|
|
Ejecuta la herramienta topo_util debugutils de Paragon Pathfinder para guardar la instantánea de la topología actual. |
|
|
Describe el pod de Paragon Pathfinder, incluidos los contenedores cRPD y BMP. |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor config-server. |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor debugutils. |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor ns-netconfd. |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor ns-pceserver (servicios PCEP). |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor ns-pcserver (PCS). |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor ns-pcsviewer (Aplicación de escritorio Paragon Planner). |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor del programador. |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor ns-toposerver (servicio de topología). |
|
|
Describe el pod de Paragon Pathfinder, incluido el contenedor web. |
|
|
Muestra el pod de Paragon Pathfinder, incluidos los contenedores cRPD y BMP. |
|
|
Muestra el pod de Paragon Pathfinder, incluidos los contenedores ns-configserver y syslog. |
|
|
Muestra el pod de Paragon Pathfinder, incluido el contenedor debugutils. |
|
|
Muestra el pod de Paragon Pathfinder asociado con el proceso netconf. |
|
|
Muestra el pod de Paragon Pathfinder, incluido el contenedor ns-pceserver (servicios PCEP). |
|
|
Muestra el pod de Paragon Pathfinder, incluido el contenedor ns-pcserver (PCS). |
|
|
Muestra el pod de Paragon Pathfinder, incluido el contenedor ns-pcsviewer (aplicación de escritorio Paragon Planner). |
|
|
Muestra todos los pods de Paragon Pathfinder. |
|
|
Muestra el pod de Paragon Pathfinder asociado con el proceso del programador. |
|
|
Muestra todos los servicios de Paragon Pathfinder. |
|
|
Muestra el pod de Paragon Pathfinder, incluido el contenedor ns-toposerver (servicio de topología). |
|
|
Muestra el pod de Paragon Pathfinder asociado con el proceso ns-web. |
|
|
Muestra los registros del contenedor bmp pods bmp de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor cRPD de los pods bmp de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods bmp de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-configserver pods ns-configserver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods del servidor configserver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-netconfd pods ns-netconfd de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods de red de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-pceserver pods ns-pceserver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods de pceserver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros procesados del contenedor syslog de Paragon Pathfinder pceserver pods que solo obtienen la marca de tiempo, el nivel y el mensaje. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-pcserver pods de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods de pcserver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros procesados del contenedor syslog de los pods de pceserver de Paragon Pathfinder que solo se obtienen con marca de tiempo, nivel y mensaje. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-pcviewer pods ns-pcviewer de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods de pcviewer de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-topo-dbinit de Paragon Pathfinder toposerver pods. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-topo-dbinit-cache de los pods del servidor toposerver de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-toposerver pods de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods del servidor topográfico de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros procesados del contenedor syslog de los pods de toposerver de Paragon Pathfinder que solo se obtienen con marca de tiempo, nivel y mensaje. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-web de los pods web de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor ns-web-dbinit de los pods web de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra los registros del contenedor syslog de los pods web de Paragon Pathfinder. Use el argumento para obtener registros de |
|
|
Muestra el estado de federación (de la instancia rabbitmq-0). El estado GeoHa solo está disponible para una configuración de clúster dual. |
|
|
Informa sobre el uso de espacio en disco del sistema de archivos Rook y Ceph OSD. |
|
|
Muestra estadísticas del grupo OSD de torre y Ceph. |
|
|
Muestra el estado de Torre y Ceph OSD. |
|
|
Muestra el árbol OSD de torre y Ceph. |
|
|
Muestra el uso de OSD de torre y Ceph. |
|
|
Muestra el estado de Torre y Ceph pg. |
|
|
Muestra el estado de Torre y Ceph. |
|
|
Inicia sesión en la CLI del pod de la caja de herramientas de Torre y Ceph. |
|
|
Muestra vainas Rook y Ceph. |
|
|
Muestra los servicios de Torre y Ceph. |
|
|
Esta es la utilidad de administración de usuarios de la puerta de enlace RADOS que obtiene la información del período. |
|
|
Esta es la utilidad de administración de usuarios de la puerta de enlace RADOS que obtiene el estado de sincronización de metadatos. |
|
|
Establece la contraseña de Paragon (host de interfaz de usuario) para la autenticación de llamadas REST. Utilice este comando obligatorio de establecer contraseña de una sola vez para establecer la contraseña mediante el Ejemplo: |
|
|
Establece el nombre de usuario de Paragon (host de la interfaz de usuario) para la autenticación de llamadas REST. El nombre de usuario predeterminado es Utilice el argumento para establecer un nombre de Ejemplo: |
Solucionar problemas de ceph y torre
Ceph requiere versiones de kernel relativamente nuevas. Si su kernel de Linux es muy antiguo, considere actualizar o reinstalar uno nuevo.
Utilice esta sección para solucionar problemas con Ceph y Rook.
Espacio en disco insuficiente
Una razón común de error de instalación es que no se crean los demonios de almacenamiento de objetos (OSD). Una OSD configura el almacenamiento en un nodo de clúster. Es posible que los OSD no se creen debido a la falta de disponibilidad de recursos de disco, ya sea en forma de recursos insuficientes o de espacio en disco particionado incorrectamente. Asegúrese de que los nodos tengan suficiente espacio disponible en disco sin particiones.
Volver a formatear un disco
Examine los registros de los trabajos "rook-ceph-osd-prepare-hostname-*". Los registros son descriptivos. Si necesita volver a formatear el disco o la partición y reiniciar la torre, realice los pasos siguientes:
- Utilice uno de los métodos siguientes para volver a formatear un disco o partición existente.
- Si tiene un dispositivo de almacenamiento en bloque que debería haberse utilizado para Ceph, pero no se usó porque estaba en un estado inutilizable, puede volver a formatear el disco por completo.
$ sgdisk -zap /dev/disk $ dd if=/dev/zero of=/dev/disk bs=1M count=100
- Si tiene una partición de disco que debería haberse utilizado para Ceph, puede borrar los datos de la partición por completo.
$ wipefs -a -f /dev/partition $ dd if=/dev/zero of=/dev/partition bs=1M count=100
Nota:Estos comandos reformatean completamente el disco o las particiones que está utilizando y perderá todos los datos en ellos.
- Si tiene un dispositivo de almacenamiento en bloque que debería haberse utilizado para Ceph, pero no se usó porque estaba en un estado inutilizable, puede volver a formatear el disco por completo.
- Reinicie Torre para guardar los cambios y volver a intentar el proceso de creación de OSD.
$ kubectl rollout restart deploy -n rook-ceph rook-ceph-operator
Ver el estado del pod
Para comprobar el estado de los pods Torre y Ceph instalados en el espacio de rook-ceph nombres, use el # kubectl get po -n rook-ceph comando. Los siguientes pods deben estar en el running estado.
rook-ceph-mon-*—Normalmente, se crean tres pods de monitor.rook-ceph-mgr-*—Un pod de administradorrook-ceph-osd-*—Tres o más pods OSDrook-ceph-mds-cephfs-*—Servidores de metadatosrook-ceph-rgw-object-store-*—Puerta de enlace de ObjectStorerook-ceph-tools*: para obtener opciones de depuración adicionales.Para conectarse a la caja de herramientas, use el comando:
$ kubectl exec -ti -n rook-ceph $(kubectl get po -n rook-ceph -l app=rook-ceph-tools \ -o jsonpath={..metadata.name}) -- bashAlgunos de los comandos comunes que puede utilizar en la caja de herramientas son:
# ceph status # ceph osd status, # ceph osd df, # ceph osd utilization, # ceph osd pool stats, # ceph osd tree, and # ceph pg stat
Solucionar problemas de falla de Ceph OSD
Compruebe el estado de los pods instalados en el rook-ceph espacio de nombres.
# kubectl get po -n rook-ceph
Si un rook-ceph-osd-* pod está en el Error estado o CrashLoopBackoff , debe reparar el disco.
-
Detenga el
rook-ceph-operatorarchivo .# kubectl scale deploy -n rook-ceph rook-ceph-operator --replicas=0 -
Elimine los procesos de OSD que fallan.
# kubectl delete deploy -n rook-ceph rook-ceph-osd-number -
Conéctese a la caja de herramientas.
$ kubectl exec -ti -n rook-ceph $(kubectl get po -n rook-ceph -l app=rook-ceph-tools -o jsonpath={..metadata.name}) -- bash -
Identifique la OSD que falla.
# ceph osd status -
Marque el OSD fallido.
[root@rook-ceph-tools-/]# ceph osd out 5 marked out osd.5. [root@rook-ceph-tools-/]# ceph osd status ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE 0 10.xx.xx.210 4856M 75.2G 0 0 0 0 exists,up 1 10.xx.xx.215 2986M 77.0G 0 0 1 89 exists,up 2 10.xx.xx.98 3243M 76.8G 0 0 1 15 exists,up 3 10.xx.xx.195 4945M 75.1G 0 0 0 0 exists,up 4 10.xx.xx.170 5053M 75.0G 0 0 0 0 exists,up 5 10.xx.xx.197 0 0 0 0 0 0 exists
-
Elimine el OSD fallido.
# ceph osd purge number --yes-i-really-mean-it - Conéctese al nodo que alojó el OSD con errores y realice una de las siguientes acciones:
- Reemplace el disco duro en caso de que se produzca un error de hardware.
- Vuelva a formatear el disco completamente.
$ sgdisk -zap /dev/disk $ dd if=/dev/zero of=/dev/disk bs=1M count=100
- Vuelva a formatear la partición completamente.
$ wipefs -a -f /dev/partition $ dd if=/dev/zero of=/dev/partition bs=1M count=100
-
Reinicie
rook-ceph-operator.# kubectl scale deploy -n rook-ceph rook-ceph-operator --replicas=1 -
Supervise los pods OSD.
# kubectl get po -n rook-cephSi la OSD no se recupera, utilice el mismo procedimiento para quitar la OSD y, a continuación, quite el disco o elimine la partición antes de reiniciar
rook-ceph-operator.
Solucionar problemas de falla de instalación de Air-Gap
La instalación de air-gap, así como el kube-apiserver falla con el siguiente error porque no tiene un archivo existente /etc/resolv.conf .
TASK [kubernetes/master : Activate etcd backup cronjob] ******************************************************************** fatal: [192.xx.xx.2]: FAILED! => changed=true cmd: - kubectl - apply - -f - /etc/kubernetes/etcd-backup.yaml delta: '0:00:00.197012' end: '2022-09-13 13:46:31.220256' msg: non-zero return code rc: 1 start: '2022-09-13 13:46:31.023244' stderr: The connection to the server 192.xx.xx.2:6443 was refused - did you specify the right host or port? stderr_lines: <omitted> stdout: '' stdout_lines: <omitted>
Para crear un archivo nuevo, debe ejecutar el #touch /etc/resolv.conf comando como usuario raíz y, a continuación, volver a implementar el clúster de Paragon Automation.
Recuperarse de un fallo de clúster de RabbitMQ
Para comprobar esta condición, ejecute el kubectl get po -n northstar -l app=rabbitmq comando. Este comando debe mostrar tres pods con su estado como Running. Por ejemplo:
$ kubectl get po -n northstar -l app=rabbitmq NAME READY STATUS RESTARTS AGE rabbitmq-0 1/1 Running 0 10m rabbitmq-1 1/1 Running 0 10m rabbitmq-2 1/1 Running 0 9m37s
Sin embargo, si el estado de uno o varios pods es Error, utilice el siguiente procedimiento de recuperación:
-
Eliminar RabbitMQ.
kubectl delete po -n northstar -l app=rabbitmq -
Compruebe el estado de los pods.
kubectl get po -n northstar -l app=rabbitmq.Repita
kubectl delete po -n northstar -l app=rabbitmqhasta que el estado de todos los pods seaRunning. -
Reinicie las aplicaciones de Paragon Pathfinder.
kubectl rollout restart deploy -n northstar
Deshabilitar udevd Daemon durante la creación de OSD
udevd demonio para administrar hardware nuevo, como discos, tarjetas de red y CD. Durante la creación de OSD, el
udevd demonio detecta los OSD y puede bloquearlos antes de que se inicialicen por completo. El instalador de Paragon Automation lo deshabilita
systemd-udevd durante la instalación y lo habilita después de que Rook haya inicializado los OSD.
Al agregar o reemplazar nodos y reparar nodos con errores, debe deshabilitar manualmente el demonio para que la udevd creación de OSD no falle. Puede volver a habilitar el demonio después de crear los OSD.
Utilice estos comandos para deshabilitar y habilitar udevdmanualmente .
- Inicie sesión en el nodo que desea agregar o reparar.
- Desactive el
udevddemonio.- Compruebe si udevd se está ejecutando.
# systemctl is-active systemd-udevd - Si
udevdestá activo, desactívelo.# systemctl mask system-udevd --now
- Compruebe si udevd se está ejecutando.
-
Cuando repara o reemplaza un nodo, los sistemas de archivos distribuidos Ceph no se actualizan automáticamente. Si los discos de datos se destruyen como parte del proceso de reparación, debe recuperar los demonios de almacenamiento de objetos (OSD) alojados en esos discos de datos.
-
Conéctese a la caja de herramientas de Ceph y vea el estado de los OSD. El
ceph-toolsscript se instala en un nodo principal. Puede iniciar sesión en el nodo principal y utilizar la interfaz kubectl para accederceph-toolsa . Para utilizar un nodo distinto del nodo principal, debe copiar el archivo admin.conf (en el config-dir directorio del host de control) y establecer la variable dekubeconfigentorno o utilizar elexport KUBECONFIG=config-dir/admin.confcomando.$ ceph-tools# ceph osd status -
Compruebe que todas las OSD aparecen como
exists,up. Si los OSD están dañados, siga las instrucciones de solución de problemas que se explican en Solución de problemas de ceph y torre.
-
- Inicie sesión en el nodo que agregó o reparó después de verificar que se han creado todas las OSD.
-
Vuelva a habilitar
udevden el nodo.systemctl unmask system-udevd
disable_udevd: true el
config.yml y ejecutar el
./run -c config-dir deploy comando. No se recomienda volver a implementar el clúster solo para deshabilitar el
udevd demonio.
Secuencias de comandos contenedoras para comandos de utilidad comunes
| Descripción del comando | |
|---|---|
paragon-db [arguments] |
Conéctese al servidor de base de datos e inicie el shell SQL de Postgres con la cuenta de superusuario. Los argumentos opcionales se pasan al comando SQL de Postgres. |
pf-cmgd [arguments] |
Inicie la CLI en el pod CMGD de Paragon Pathfinder. La CLI ejecuta los argumentos opcionales. |
pf-crpd [arguments] |
Inicie la CLI en el pod cRPD de Paragon Pathfinder. La CLI ejecuta los argumentos opcionales. |
pf-redis [arguments] |
Inicie la redis-cli (autenticada) en el pod Redis de Paragon Pathfinder. El pod de Redis ejecuta los argumentos opcionales. |
pf-debugutils [arguments] |
Inicie el shell en el pod debugutils de Paragon Pathfinder. El shell ejecuta argumentos opcionales. Las utilidades debugutils de Pathfinder se instalan si install_northstar_debugutils: true están configuradas en el archivo config.yml . |
ceph-tools [arguments] |
Inicie el shell en la caja de herramientas Ceph. El shell ejecuta argumentos opcionales. |
Copia de seguridad del host de control
Como alternativa, también puede reconstruir el inventario y config.yml archivos descargando información del clúster mediante los siguientes comandos:
# kubectl get cm -n common metadata -o jsonpath={..inventory} > inventory
# kubectl get cm -n common metadata -o jsonpath={..config_yml} > config.yml
No puede recuperar claves SSH; Debe reemplazar las claves erróneas por claves nuevas.
Cuentas de servicio de usuario para depuración
Paragon Pathfinder, el administrador de telemetría y las aplicaciones de plataforma base usan Paragon Insights internamente para la recopilación de telemetría. Para depurar los problemas de configuración asociados con estas aplicaciones, se crean tres cuentas de servicio de usuario, de forma predeterminada, durante la instalación de Paragon Automation. El ámbito de estas cuentas de servicio se limita únicamente a depurar la aplicación correspondiente. Los detalles de las cuentas de servicio se enumeran en la tabla siguiente.
| Nombre de aplicación y ámbito | de la cuenta Nombre de usuario | Contraseña predeterminada de la cuenta |
|---|---|---|
| Paragon Pathfinder (estrella del norte) | hb-northstar-admin | Admin123! |
| Gestor de telemetría (tm) | hb-tm-admin | |
| Plataforma base (ems-dmon) | hb-ems-dmon |
Debe usar estas cuentas únicamente con fines de depuración. No utilice estas cuentas para las operaciones diarias ni para modificar ninguna configuración. Le recomendamos que cambie las credenciales de inicio de sesión por razones de seguridad.