Estructura de backend de GPU
La estructura de backend de GPU proporciona la infraestructura para que las GPU se comuniquen entre sí dentro de un clúster mediante RDMA sobre Ethernet convergente (RoCEv2). ROCEv2 aumenta la eficiencia del centro de datos, reduce la complejidad general y aumenta el rendimiento de la entrega de datos al permitir que las GPU se comuniquen como lo harían con el protocolo InfiniBand.
La pérdida de paquetes puede afectar los tiempos de finalización del trabajo y debe evitarse. Por lo tanto, cuando se diseña la infraestructura de red para admitir RoCEv2 para un grupo de IA, uno de los objetivos clave es proporcionar una estructura sin pérdidas y, al mismo tiempo, lograr la máxima transferencia de datos, latencia mínima e interferencia de red mínima para los flujos de tráfico de IA. ROCEv2 es más eficiente en redes sin pérdida, lo que resulta en tiempos óptimos de finalización del trabajo.
La estructura de backend de GPU en este JVD se diseñó con estos objetivos en mente y sigue una arquitectura de IP clos de 3 etapas combinada con la arquitectura de bandas optimizadas para rieles de NVIDIA (que se describe en la siguiente sección), como se muestra en la Figura 5.
Figura 5: Arquitectura de la estructura de backend de GPU
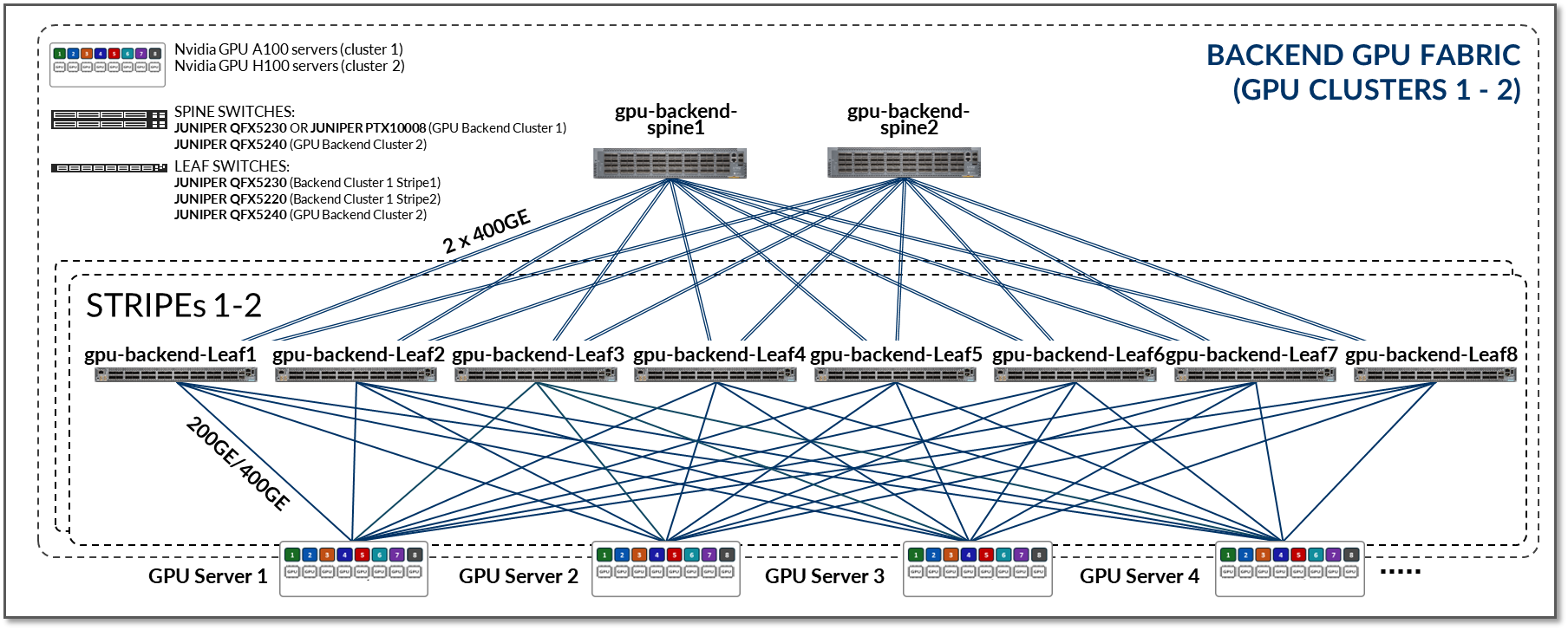
Los dispositivos backend de GPU incluidos en esta estructura, y las conexiones entre ellos, se resumen en la siguiente tabla:
Tabla 3: Dispositivos de backend de GPU por clúster y franja
| Clúster | Raya | Servidores de GPU Nvidia DGX | Modelo de conmutador de nodos leaf de backend de GPU (gpu-backend-leaf#) |
Modelo de conmutador de nodos spine de backend de GPU (gpu-backend-spine#) |
| 1 | 1 | A100-01 a A100-04 | QFX5230-64CD x 8 | QFX5230-64CD x 2 O BIEN PTX10008 con JNP10K-LC1201 |
| 1 | 2 | A100-05 a A100-08 | QFX5220-32CD x 8 | |
| 2 | 1 | De H100-01 a H100-02 | QFX5240-64OD x 8 | QFX5230-64OD x 4 |
| 2 | 2 | De H100-03 a H100-04 | QFX5240-64OD x 8 |
Tabla 4: Conexiones entre servidores, nodos leaf y nodos spine por clúster y franja en el backend de GPU
| Clúster | Raya | Servidores de GPU <=> Nodos de hoja de backend de GPU |
Nodos spine de backend de GPU <=> Nodos de hoja de backend de GPU |
| 1 | 1 | 1 x enlaces de 200GE entre cada servidor A100 y cada nodo leaf (200GE x 8 enlaces por servidor) |
2 enlaces de 400GE entre cada nodo leaf y cada nodo spines (2 x 400GE x 2 enlaces por nodo leaf) |
| 1 | 2 | 1 x enlaces de 200GE entre cada servidor A100 y cada nodo leaf (200GE x 8 enlaces por servidor) |
2 enlaces de 400GE entre cada nodo leaf y cada nodo spines (2 x 400GE x 2 enlaces por nodo leaf) |
| 2 | 1 | 1 x enlaces 400GE entre cada servidor H100 y cada nodo leaf (400GE x 8 enlaces por servidor) |
2 enlaces de 400GE entre cada nodo leaf y cada nodo spines (2 x 400GE x 4 enlaces por nodo leaf) |
| 2 | 2 | 1 x enlaces 400GE entre cada servidor H100 y cada nodo leaf (400GE x 8 enlaces por servidor) |
2 enlaces de 400GE entre cada nodo leaf y cada nodo spines (2 x 400GE x 4 enlaces por nodo leaf) |
- Todos los servidores Nvidia A100 del laboratorio están conectados a los nodos leaf QFX5220 y QFX5230 del clúster 1 mediante interfaces 200GE, mientras que los servidores H100 están conectados a los nodos leaf QFX5240 del clúster 2 mediante interfaces 400GE.
- Esta estructura es una estructura IP L3 pura (IPv4 o IPV6) que utiliza EBGP para el anuncio de rutas (descrita en la sección de redes).
- La conectividad entre los servidores y los nodos leaf se basa en VLAN L2, con una IRB en los nodos leaf que actúa como puerta de enlace predeterminada para los servidores (descrita en la sección Redes).
Tabla 5: Por clúster, por franja Ancho de banda de servidor a leaf
| Ancho de banda de servidor a leaf por franja (por clúster) | |||||
| Clúster | Sistemas de IA (tipo de servidor) | Servidores por banda | < servidor = > enlaces leaf por servidor | Ancho de banda del servidor <=> enlaces leaf [Gbps] | Ancho de banda total Servidores <=> Leaf por franja [Tbps} |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6,4 |
| 2 | H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6,4 |
Tabla 6: Por clúster, por franja Ancho de banda de leaf a spine
| Ancho de banda de leaf a spine por franja | |||
| leaf <=> enlaces spine por nodo spine y por franja | Velocidad de Leaf <=> enlaces spine [Gbps] |
Número de nodos spine | Ancho de banda total < de la hoja = > espina por franja [Tbps] |
| 8 | 2 x 400 | 2 | 12.8 |
La tasa de (sobre)suscripción se calcula simplemente comparando los números de las dos tablas anteriores:
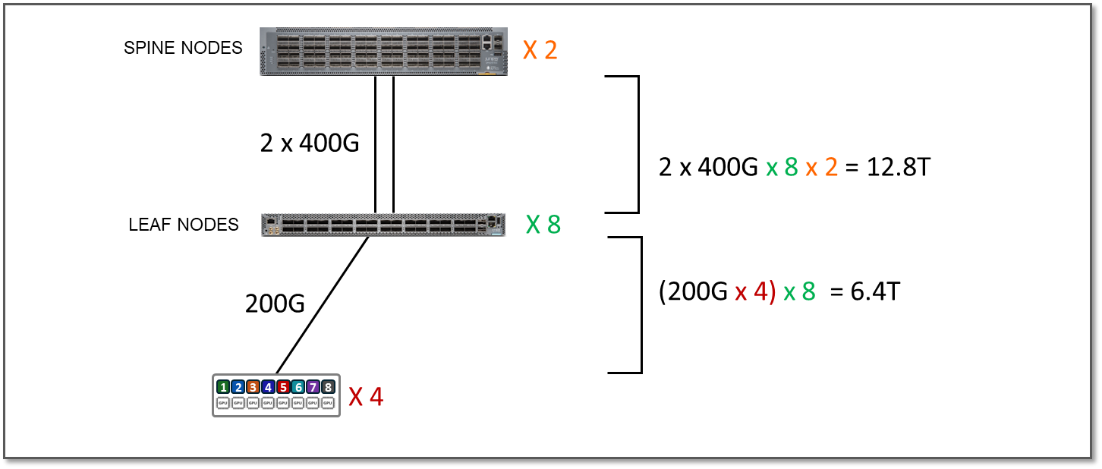
En el clúster 1, el ancho de banda entre los servidores y los nodos leaf es de 6,4 Tbps por banda, mientras que el ancho de banda disponible entre los nodos leaf y nodos spine es de 12,8 Tbps por banda. Esto significa que la estructura tiene suficiente capacidad para procesar todo el tráfico entre las GPU, incluso cuando este tráfico era 100 % entre franjas, a la vez que sigue teniendo capacidad adicional para acomodar servidores adicionales sin tener que sobresuscribirse.
Figura 6: Ejemplo de capacidad adicional
También probamos la conexión de los servidores de GPU H100 a lo largo de los servidores A100 a las franjas del clúster 1 de la siguiente manera:
Figura 7: Ejemplo de suscripción 1:1
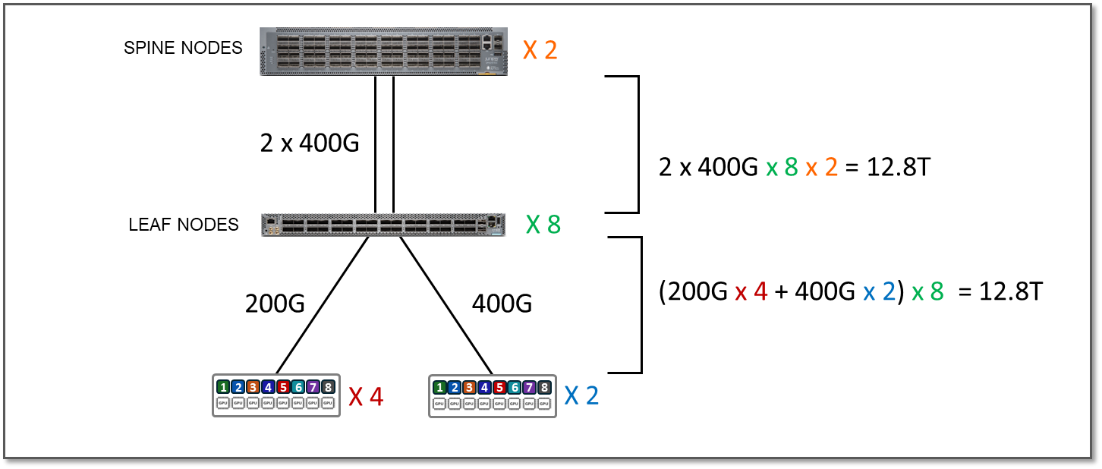
Tabla 7: Por clúster, por franja De servidor a leaf Ancho de banda con todos los servidores conectados al mismo clúster
| De servidor a leaf de ancho de banda por banda por banda | |||||
| Clúster | Al Systems | Servidores por banda | < servidor = > enlaces leaf por servidor | < del servidor = > ancho de banda de vínculos leaf [Gbps] |
Total de servidores <=> enlaces leaf Ancho de banda por franja [Tbps] |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6,4 |
| H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6,4 | |
| Ancho de banda total del servidor <=> enlaces leaf | 12.8 | ||||
El ancho de banda entre los servidores y los nodos leaf es ahora de 12,8 Tbps por banda, mientras que el ancho de banda disponible entre los nodos leaf y nodos spine también es de 12,8 Tbps por banda (como se muestra en la tabla anterior). Esto significa que la estructura tiene suficiente capacidad para procesar todo el tráfico entre las GPU, incluso cuando este tráfico era 100 % entre franjas, pero ahora no hay capacidad adicional para acomodar servidores adicionales. El factor de suscripción en este caso es 1:1 (sin suscripción).
Para ejecutar pruebas de sobresuscripción, deshabilitamos algunas de las interfaces entre la hoja y los spines para reducir el ancho de banda disponible, como se muestra en el ejemplo de la Figura 8:
Figura 8: Ejemplo de sobresuscripción 2:1
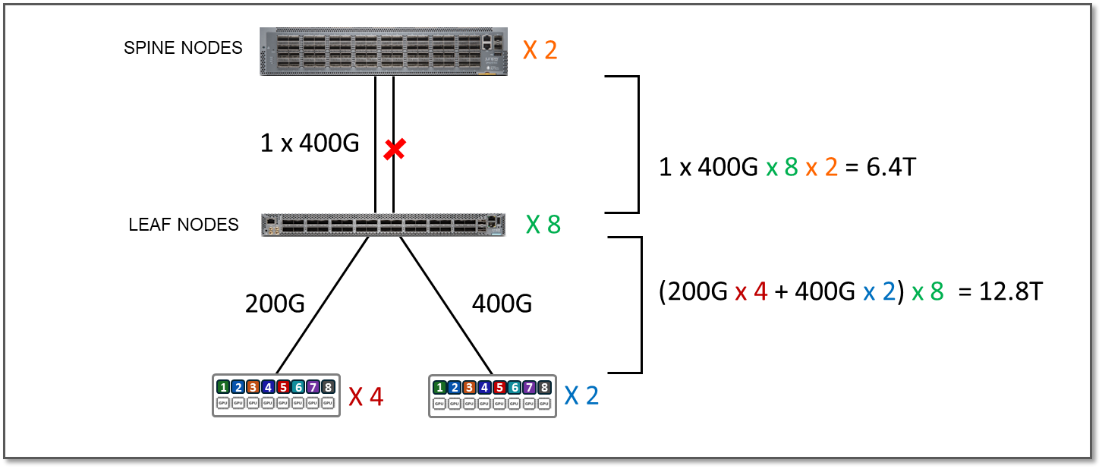
El ancho de banda total de servidores a enlaces leaf por banda no ha cambiado. Sigue siendo de 12,8 Tbps, como se muestra en la tabla 3 del escenario anterior.
Sin embargo, el ancho de banda disponible entre los nodos spine y leaf ahora es de solo 6,4 Tbps por banda.
Tabla 8: Ancho de banda de leaf a spine por franja
| Ancho de banda de leaf a spine por franja | |||
| leaf <=> enlaces spine por nodo spine y por franja | Velocidad de Leaf <=> enlaces spine [Gbps] |
Número de nodos spine | Ancho de banda total < de la hoja = > espina por franja [Tbps] |
| 8 | 1 x 400 | 2 | 6.4 |
Esto significa que la estructura ya no tiene suficiente capacidad para procesar todo el tráfico entre las GPU, incluso si este tráfico fuera 100 % entre franjas, lo que podría causar congestión y pérdida de tráfico. El factor de sobresuscripción en este caso es de 2:1.