Supervisión de la calidad del servicio de red mediante RMON
RMON para monitorear la calidad del servicio
La supervisión del estado y el rendimiento puede beneficiarse de la supervisión remota de variables SNMP por parte de los agentes SNMP locales que se ejecutan en cada enrutador. Los agentes SNMP comparan los valores MIB con umbrales predefinidos y generan alarmas de excepción sin necesidad de sondeo por parte de una plataforma de administración SNMP central. Este es un mecanismo eficaz para la gestión proactiva, siempre que los umbrales tengan líneas de base determinadas y establecidas correctamente. Para obtener más información, consulte RFC 2819, MIB de supervisión remota de red.
En este tema, se incluyen las siguientes secciones:
- Configuración de umbrales
- Interfaz de línea de comandos RMON
- Tabla de eventos RMON
- Tabla de alarma RMON
- Solución de problemas de RMON
Configuración de umbrales
Al establecer un umbral ascendente y descendente para una variable supervisada, se le puede alertar cada vez que el valor de la variable caiga fuera del rango operativo permitido. (Consulte Figura 1.)
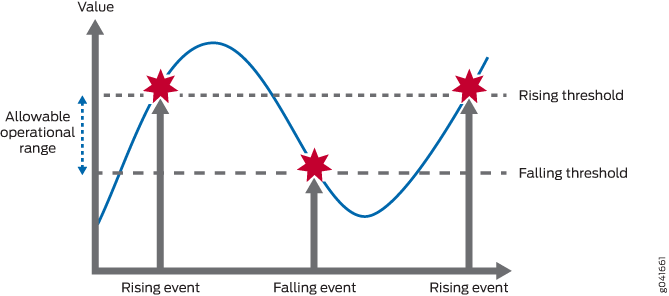
Los eventos solo se generan cuando el umbral se cruza por primera vez en una dirección en lugar de después de cada período de muestreo. Por ejemplo, si se eleva un evento de cruce de umbral ascendente, no se producirán más eventos de cruce de umbral hasta un evento de caída correspondiente. Esto reduce considerablemente la cantidad de alarmas que produce el sistema, lo que facilita que el personal de operaciones reaccione cuando se producen alarmas.
Para configurar la supervisión remota, especifique los siguientes datos:
La variable que se va a supervisar (por su identificador de objeto SNMP)
El tiempo transcurrido entre cada inspección
Un umbral ascendente
Un umbral descendente
Un evento en alza
Un evento de caída
Antes de poder configurar correctamente la supervisión remota, debe identificar qué variables deben supervisarse y su rango operativo permitido. Esto requiere un período de referencia para determinar los rangos operativos permitidos. Un período inicial de referencia de al menos tres meses no es inusual cuando se identifican por primera vez los rangos operativos y se definen los umbrales, pero el monitoreo de línea de base debe continuar durante la vida útil de cada variable monitoreada.
Interfaz de línea de comandos RMON
Junos OS proporciona dos mecanismos que se utilizan para controlar el agente de supervisión remota en el enrutador: interfaz de línea de comandos (CLI) y SNMP. Para configurar una entrada de RMON mediante la CLI, incluya las siguientes instrucciones en el nivel de [edit snmp] jerarquía:
rmon {
alarm index {
description;
falling-event-index;
falling-threshold;
intervals;
rising-event-index;
rising-threshold;
sample-type (absolute-value | delta-value);
startup-alarm (falling | rising | rising-or-falling);
variable;
}
event index {
community;
description;
type (log | trap | log-and-trap | none);
}
}
Si no tiene acceso a la CLI, puede configurar la supervisión remota mediante SNMP Manager o la aplicación de administración, suponiendo que se haya concedido acceso SNMP. (Véase Tabla 1.) Para configurar RMON mediante SNMP, realice solicitudes SNMP Set a las tablas de eventos y alarmas de RMON.
Tabla de eventos RMON
Configure un evento para cada tipo que desee generar. Por ejemplo, podría tener dos eventos genéricos, subida y bajada, o muchos eventos diferentes para cada variable que se está supervisando (por ejemplo, evento de aumento de temperatura , evento de caída de temperatura , evento de golpe de firewall , evento de utilización de interfaz , etc.). Una vez configurados los eventos, no es necesario actualizarlos.
Campo |
Description |
|---|---|
|
Descripción textual de este evento |
|
Tipo de evento (por ejemplo, |
|
Grupo de captura al que enviar este evento (como se define en la configuración de Junos OS, que no es lo mismo que la comunidad) |
|
Entidad (por ejemplo, |
|
Estado de esta fila (por ejemplo, |
Tabla de alarma RMON
La tabla de alarmas RMON almacena los identificadores de objeto SNMP (incluidas sus instancias) de las variables que se supervisan, junto con los umbrales ascendentes y descendentes y sus índices de eventos correspondientes. Para crear una solicitud RMON, especifique los campos que se muestran en Tabla 2.
Campo |
Description |
|---|---|
|
Estado de esta fila (por ejemplo, |
|
Período de muestreo (en segundos) de la variable monitoreada |
|
OID (e instancia) de la variable a monitorear |
|
Valor real de la variable muestreada |
|
Tipo de muestra ( |
|
Alarma inicial ( |
|
Umbral ascendente con el que comparar el valor |
|
Umbral descendente con el que comparar el valor |
|
Índice (fila) del evento ascendente en la tabla de eventos |
|
Índice (fila) del evento descendente en la tabla de eventos |
Tanto los campos como los son primitivos, como se define en RFC 2579, Convenciones textuales para SMIv2.entryStatusalarmStatuseventStatus
Solución de problemas de RMON
Para solucionar los problemas del agente RMON, rmopd, que se ejecuta en el enrutador, inspeccione el contenido de la MIB de RMON empresarial de Juniper Networks, jnxRmon, que proporciona las extensiones enumeradas en Tabla 3 el RFC 2819 alarmTable.
Campo |
Description |
|---|---|
|
Número de veces que se produjo un error en la solicitud interna |
|
Valor de |
|
Motivo por el que se produjo un error en la |
|
Valor de |
|
Estado de esta entrada de alarma |
La supervisión de las extensiones de esta tabla proporciona pistas sobre por qué las alarmas remotas pueden no comportarse como se esperaba.
Comprender los puntos de medición, los indicadores clave de rendimiento y los valores de referencia
En este tema del capítulo se proporcionan directrices para supervisar la calidad del servicio de una red IP. Describe cómo los proveedores de servicios y los administradores de red pueden usar la información proporcionada por los enrutadores de Juniper Networks para monitorear el rendimiento y la capacidad de la red. Debe tener un conocimiento profundo del SNMP y de la MIB asociada compatible con Junos OS.
Para obtener una buena introducción al proceso de supervisión de una red IP, consulte RFC 2330, Framework for IP Performance Metrics.
Este tema contiene las siguientes secciones:
Puntos de medición
Definir los puntos de medición donde se miden las métricas es tan importante como definir las métricas en sí. En esta sección se describen los puntos de medición en el contexto de este capítulo y se ayuda a identificar dónde se pueden realizar mediciones desde una red de proveedores de servicios. Es importante entender exactamente dónde está un punto de medición. Los puntos de medición son vitales para comprender la implicación de lo que significa la medición real.
Una red IP consiste en una colección de enrutadores conectados por vínculos físicos que ejecutan el protocolo de Internet. Puede ver la red como una colección de enrutadores con un punto de entrada y un punto de salida. Consulte Figura 2.
Las mediciones centradas en la red se toman en los puntos de medición que se corresponden más estrechamente con los puntos de entrada y salida de la propia red. Por ejemplo, para medir el retraso en toda la red del proveedor desde el sitio A hasta el sitio B, los puntos de medición deben ser el punto de entrada a la red del proveedor en el sitio A y el punto de salida en el sitio B.
Las mediciones centradas en el enrutador se toman directamente de los propios enrutadores, pero tenga cuidado de asegurarse de que los subcomponentes correctos del enrutador se hayan identificado de antemano.
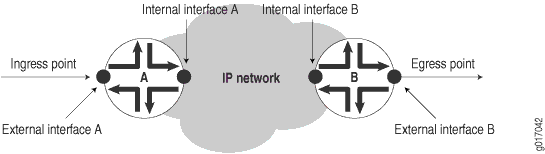
Figura 2 no muestra las redes del cliente en las instalaciones del cliente, pero estarían ubicadas a ambos lados de los puntos de entrada y salida. Aunque en este capítulo no se describe cómo medir los servicios de red tal como los perciben estas redes cliente, puede utilizar las mediciones tomadas para la red del proveedor de servicios como entrada en dichos cálculos.
Indicadores clave básicos de rendimiento
Por ejemplo, podría supervisar una red de proveedores de servicios en busca de tres indicadores clave de rendimiento (KPI) básicos:
mide la "accesibilidad" de un punto de medición desde otro punto de medición en la capa de red (por ejemplo, utilizando ping ICMP). La infraestructura subyacente de enrutamiento y transporte de la red de proveedores admitirá las mediciones de disponibilidad, y las fallas se destacarán como indisponibilidad.
Mide el número y el tipo de errores que se producen en la red del proveedor, y puede consistir en mediciones centradas tanto en el enrutador como en la red, como fallas de hardware o pérdida de paquetes.
de la red de proveedores mide en qué medida puede soportar los servicios de IP (por ejemplo, en términos de retraso o utilización).
Configuración de líneas base
¿Qué tan bien está funcionando la red de proveedores? Recomendamos un período inicial de monitoreo de tres meses para identificar los parámetros operativos normales de una red. Con esta información, puede reconocer excepciones e identificar comportamientos anormales. Debe continuar con el monitoreo de línea base durante la vida útil de cada métrica medida. Con el tiempo, debe ser capaz de reconocer las tendencias de rendimiento y los patrones de crecimiento.
En el contexto de este capítulo, muchas de las métricas identificadas no tienen un rango operativo permitido asociado. En la mayoría de los casos, no se puede identificar el rango operativo permitido hasta que se haya determinado una línea base para la variable real en una red específica.
Definir y medir la disponibilidad de la red
En este tema, se incluyen las siguientes secciones:
Definir la disponibilidad de la red
La disponibilidad de la red IP de un proveedor de servicios puede considerarse como la accesibilidad entre los puntos de presencia regionales (POP), como se muestra en Figura 3.
Con el ejemplo anterior, cuando se utiliza una malla completa de puntos de medición, donde cada POP mide la disponibilidad de cada otro POP, se puede calcular la disponibilidad total de la red del proveedor de servicios. Este KPI también se puede usar para ayudar a monitorear el nivel de servicio de la red, y puede ser utilizado por el proveedor de servicios y sus clientes para determinar si están operando dentro de los términos de su acuerdo de nivel de servicio (SLA).
Cuando un POP pueda constar de varios enrutadores, tome medidas en cada enrutador como se muestra en Figura 4.
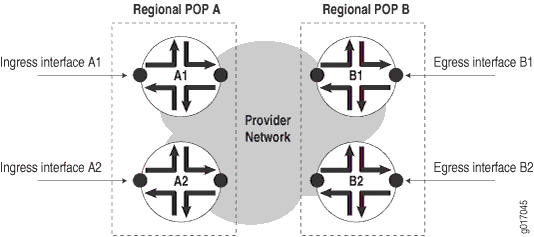
Las mediciones incluyen:
Disponibilidad de ruta: disponibilidad de una interfaz de salida B1 vista desde una interfaz de entrada A1.
Disponibilidad del enrutador: porcentaje de disponibilidad de rutas de todas las rutas medidas que terminan en el enrutador.
Disponibilidad de COP: porcentaje de disponibilidad del enrutador entre dos POP regionales, A y B.
Disponibilidad de red: porcentaje de disponibilidad de POP para todos los POP regionales de la red del proveedor de servicios.
Para medir la disponibilidad de POP de POP A a POP B en Figura 4, debe medir las cuatro rutas siguientes:
Path A1 => B1 Path A1 => B2 Path A2 => B1 Path A2 => B2
La medición de la disponibilidad de COP B a COP A requeriría otras cuatro mediciones, y así sucesivamente.
Una malla completa de mediciones de disponibilidad puede generar un tráfico de administración significativo. Del diagrama de ejemplo anterior:
Cada POP tiene dos enrutadores perimetrales de proveedor (PE) coubicados, cada uno con interfaces 2xSTM1, para un total de 18 enrutadores PE y 36xSTM1 interfaces.
Hay seis enrutadores de proveedor principal (P), cuatro con interfaces 2xSTM4 y 3xSTM1 cada uno, y dos con interfaces 3xSTM4 y 3xSTM1 cada uno.
Esto hace un total de 68 interfaces. Una malla completa de rutas entre cada interfaz es:
[n x (n–l)] / 2 da [68 x (68–1)] / 2=2278 rutas
Para reducir el tráfico de administración en la red del proveedor de servicios, en lugar de generar una malla completa de pruebas de disponibilidad de interfaz (por ejemplo, de cada interfaz a cualquier otra interfaz), puede medir a partir de la dirección de circuito cerrado de cada enrutador. Esto reduce el número de mediciones de disponibilidad necesarias a un total de una para cada enrutador o:
n[ x (n–1)] / 2 da [24 x (24–1)] / 2=276 mediciones
Esto mide la disponibilidad de cada enrutador a todos los demás.
Supervisión del SLA y del ancho de banda necesario
Un SLA típico entre un proveedor de servicios y un cliente podría indicar:
A Point of Presence is the connection of two back-to-back provider edge routers to separate core provider routers using different links for resilience. The system is considered to be unavailable when either an entire POP becomes unavailable or for the duration of a Priority 1 fault.
Una cifra de disponibilidad de SLA del 99,999 por ciento para la red de un proveedor se relacionaría con un tiempo de inactividad de aproximadamente 5 minutos por año. Por lo tanto, para medir esto de manera proactiva, tendría que tomar medidas de disponibilidad con una granularidad de menos de una cada cinco minutos. Con un tamaño estándar de 64 bytes por solicitud de ping ICMP, una prueba de ping por minuto generaría 7680 bytes de tráfico por hora por destino, incluidas las respuestas de ping. Una malla completa de pruebas de ping a 276 destinos generaría 2.119.680 bytes por hora, lo que representa lo siguiente:
En un vínculo OC3/STM1 de 155,52 Mbps, una utilización del 1,362 por ciento
En un vínculo OC12/STM4 de 622,08 Mbps, una utilización del 0,340 por ciento
Con un tamaño de 1500 bytes por solicitud de ping ICMP, una prueba de ping por minuto generaría 180.000 bytes por hora por destino, incluidas las respuestas de ping. Una malla completa de pruebas de ping a 276 destinos generaría 49.680.000 bytes por hora, lo que representa lo siguiente:
En un vínculo OC3/STM1, 31,94 por ciento de utilización
En un vínculo OC12/STM4, 7,986 por ciento de utilización
Cada enrutador puede registrar los resultados de cada destino probado. Con una prueba por minuto a cada destino, un total de 1 x 60 x 24 x 276 = 397.440 pruebas por día serían realizadas y registradas por cada router. Todos los resultados del ping se almacenan en el pingProbeHistoryTable (consulte RFC 2925) y pueden ser recuperados por una aplicación de informes de rendimiento SNMP (por ejemplo, software de gestión del rendimiento del servicio de InfoVista, Inc. o Concord Communications, Inc.) para el procesamiento posterior. Esta tabla tiene un tamaño máximo de 4.294.967.295 filas, que es más que adecuado.
Mida la disponibilidad
Hay dos métodos que puede utilizar para medir la disponibilidad:
Proactivo: la disponibilidad se mide automáticamente con la mayor frecuencia posible mediante un sistema de soporte operativo.
Reactivo: la disponibilidad es registrada por un servicio de asistencia cuando un usuario o un sistema de monitoreo de fallas reportan por primera vez una falla.
En esta sección se describe la supervisión del rendimiento en tiempo real como una solución de supervisión proactiva.
Monitoreo de desempeño en tiempo real
Juniper Networks ofrece un servicio de monitoreo de desempeño en tiempo real (RPM) para monitorear el desempeño de la red en tiempo real. Utilice la función de configuración rápida de J-Web para configurar los parámetros de supervisión del rendimiento en tiempo real utilizados en las pruebas de supervisión del rendimiento en tiempo real. (La configuración rápida de J-Web es una GUI basada en navegador que se ejecuta en los enrutadores de Juniper Networks. Para obtener más información, consulte la Guía del usuario de la interfaz J-Web.)
Configuración de la supervisión del rendimiento en tiempo real
Algunas de las opciones más comunes que puede configurar para las pruebas de supervisión del rendimiento en tiempo real se muestran en Tabla 4.
Campo |
Description |
|---|---|
| Solicitar información | |
|
Tipo de sonda que se va a enviar como parte de la prueba. Los tipos de sondeo pueden ser:
|
|
Tiempo de espera (en segundos) entre cada transmisión de sonda. El rango es de 1 a 255 segundos. |
|
Tiempo de espera (en segundos) entre pruebas. El rango es de 0 a 86400 segundos. |
|
Número total de sondas enviadas para cada prueba. El rango es de 1 a 15 sondas. |
|
Puerto TCP o UDP al que se envían las sondeos. Utilice el número 7, un número de puerto TCP o UDP estándar, o seleccione un número de puerto del 49152 al 65535. |
|
Bits de punto de código de servicios diferenciados (DSCP). Este valor debe ser un patrón de 6 bits válido. El valor predeterminado es 000000. |
|
Tamaño (en bytes) de la parte de datos de las sondas ICMP. El intervalo es de 0 a 65507 bytes. |
|
Contenido de la parte de datos de las sondas ICMP. El contenido debe ser un valor hexadecimal. El rango es de 1 a 800h. |
| Umbrales máximos de sonda | |
|
Número total de sondeos que deben perderse sucesivamente para desencadenar un error de sonda y generar un mensaje de registro del sistema. El rango es de 0 a 15 sondas. |
|
Número total de sondeos que deben perderse para desencadenar un error de sonda y generar un mensaje de registro del sistema. El rango es de 0 a 15 sondas. |
|
Tiempo total de ida y vuelta (en microsegundos) desde el enrutador de servicios hasta el servidor remoto, el cual, si se supera, desencadena un error de sondeo y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Fluctuación total (en microsegundos) de una prueba que, si se supera, desencadena un fallo de la sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Desviación estándar máxima permitida (en microsegundos) para una prueba que, si se supera, desencadena un fallo de la sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Tiempo unidireccional total (en microsegundos) desde el enrutador hasta el servidor remoto, que, si se supera, desencadena un error de sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Tiempo unidireccional total (en microsegundos) desde el servidor remoto hasta el enrutador que, si se supera, desencadena un error de sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Fluctuación total en tiempo de salida (en microsegundos) de una prueba que, si se supera, desencadena un error de la sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Fluctuación total en tiempo de entrada (en microsegundos) para una prueba que, si se supera, desencadena un error de la sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Desviación estándar máxima permitida de los tiempos de salida (en microsegundos) para una prueba que, si se supera, desencadena un error de sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
|
Desviación estándar máxima permitida de los tiempos de entrada (en microsegundos) para una prueba que, si se supera, desencadena un error de la sonda y genera un mensaje de registro del sistema. El rango es de 0 a 60,000,000 microsegundos. |
Visualización de información de supervisión del rendimiento en tiempo real
Para cada prueba de monitoreo de desempeño en tiempo real configurada en el enrutador, la información de monitoreo incluye el tiempo de ida y vuelta, la fluctuación y la desviación estándar. Para ver esta información, seleccione Monitor > RPM en la interfaz J-Web o escriba el comando de interfaz show services rpm de línea de comandos (CLI).
Para mostrar los resultados de las sondas de monitoreo de rendimiento en tiempo real más recientes, ingrese el comando de la show services rpm probe-results CLI:
user@host> show services rpm probe-results
Owner: p1, Test: t1
Target address: 10.8.4.1, Source address: 10.8.4.2, Probe type: icmp-ping
Destination interface name: lt-0/0/0.0
Test size: 10 probes
Probe results:
Response received, Sun Jul 10 19:07:34 2005
Rtt: 50302 usec
Results over current test:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Results over all tests:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Medir la salud
Puede supervisar las métricas de estado de forma reactiva mediante el uso de software de administración de errores como SMARTS InCharge, Micromuse Netcool Omnibus o Concord Live Exceptions. Le recomendamos que supervise las métricas de estado que se muestran en Tabla 5.
Métrico |
Description |
Parámetros |
|
|---|---|---|---|
Nombre |
valor |
||
Errores en |
Número de paquetes entrantes que contenían errores, lo que impedía que se entregaran |
Nombre MIB | IF-MIB (RFC 2233) |
| Nombre de la variable | ifInErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.14 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Interfaces lógicas |
||
Errores de salida |
Número de paquetes salientes que contenían errores, lo que impedía su transmisión |
Nombre MIB | IF-MIB (RFC 2233) |
| Nombre de la variable | ifOutErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.20 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Interfaces lógicas |
||
Descartes en |
Número de paquetes entrantes descartados, aunque no se detectaron errores |
Nombre MIB | IF-MIB (RFC 2233) |
| Nombre de la variable | ifInDiscards |
||
| Variable OID | .1.3.6.1.31.2.2.1.13 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Interfaces lógicas |
||
Protocolos desconocidos |
Número de paquetes entrantes descartados porque eran de un protocolo desconocido |
Nombre MIB | IF-MIB (RFC 2233) |
| Nombre de la variable | ifInUnknownProtos |
||
| Variable OID | .1.3.6.1.31.2.2.1.15 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Interfaces lógicas |
||
Estado operativo de la interfaz |
Estado operativo de una interfaz |
Nombre MIB | IF-MIB (RFC 2233) |
| Nombre de la variable | ifOperStatus |
||
| Variable OID | .1.3.6.1.31.2.2.1.8 |
||
| Frecuencia (minutos) | 15 |
||
| Rango permitido | 1 (arriba) |
||
| Objetos administrados | Interfaces lógicas |
||
Estado de ruta conmutada de etiquetas (LSP) |
Estado operativo de una ruta de conmutación de etiquetas MPLS |
Nombre MIB | MPLS-MIB |
| Nombre de la variable | mplsLspState |
||
| Variable OID | mplsLspEntry.2 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | 2 (arriba) |
||
| Objetos administrados | Todas las rutas de conmutación de etiquetas de la red |
||
Estado operativo de los componentes |
Estado operativo de un componente de hardware del enrutador |
Nombre MIB | JUNIPER-MIB |
| Nombre de la variable | jnxEstadooperativo |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.6 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | 2 (en ejecución) o 3 (listo) |
||
| Objetos administrados | Todos los componentes de cada enrutador de Juniper Networks |
||
Temperatura de funcionamiento de los componentes |
Temperatura de funcionamiento de un componente de hardware, en grados Celsius |
Nombre MIB | JUNIPER-MIB |
| Nombre de la variable | jnxOperatingTemp |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.7 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Todos los componentes de un chasis |
||
Tiempo de actividad del sistema |
Tiempo, en milisegundos, que el sistema ha estado operativo. |
Nombre MIB | MIB-2 (RFC 1213) |
| Nombre de la variable | sysUpTime |
||
| Variable OID | .1.3.6.1.1.3 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | Solo aumentando (disminución indica un reinicio) |
||
| Objetos administrados | Todos los enrutadores |
||
Sin errores de ruta IP |
Número de paquetes que no se pudieron entregar porque no había una ruta IP a su destino. |
Nombre MIB | MIB-2 (RFC 1213) |
| Nombre de la variable | ipOutNoRoutes |
||
| Variable OID | IP.12 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Cada enrutador |
||
Nombres de comunidad SNMP incorrectos |
Número de nombres de comunidad SNMP incorrectos recibidos |
Nombre MIB | MIB-2 (RFC 1213) |
| Nombre de la variable | snmpInBadCommunityNames |
||
| Variable OID | SNMP.4 |
||
| Frecuencia (minutos) | 24 |
||
| Rango permitido | A base |
||
| Objetos administrados | Cada enrutador |
||
Infracciones de la comunidad SNMP |
Número de comunidades SNMP válidas utilizadas para intentar operaciones no válidas (por ejemplo, intentar realizar solicitudes SNMP Set) |
Nombre MIB | MIB-2 (RFC 1213) |
| Nombre de la variable | snmpInBadCommunityUses |
||
| Variable OID | SNMP.5 |
||
| Frecuencia (minutos) | 24 |
||
| Rango permitido | A base |
||
| Objetos administrados | Cada enrutador |
||
Cambio de redundancia |
Número total de cambios de redundancia notificados por esta entidad |
Nombre MIB | JUNIPER-MIB |
| Nombre de la variable | jnxRedundancySwitchoverCount |
||
| Variable OID | jnxRedundancyEntry.8 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Todos los enrutadores de Juniper Networks con motores de enrutamiento redundantes |
||
Estado de FRU |
Estado operativo de cada unidad reemplazable en el campo (FRU) |
Nombre MIB | JUNIPER-MIB |
| Nombre de la variable | jnxFruState |
||
| Variable OID | jnxFruEntry.8 |
||
| Frecuencia (minutos) | 15 |
||
| Rango permitido | 2 a 6 para estados listos/en línea. Consulte jnxFruOfflineReason en caso de que se produzca un error en la FRU. |
||
| Objetos administrados | Todas las FRU en todos los enrutadores de Juniper Networks. |
||
Tasa de paquetes caídos de cola |
Tasa de paquetes caídos por cola de salida, por clase de reenvío y por interfaz. |
Nombre MIB | JUNIPER-COS-MIB |
| Nombre de la variable | jnxCosIfqTailDropPktRate |
||
| Variable OID | jnxCosIfqStatsEntry.12 |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Para cada clase de reenvío por interfaz en la red del proveedor, cuando CoS está habilitado. |
||
Utilización de la interfaz: Octetos recibidos |
Número total de octetos recibidos en la interfaz, incluidos los caracteres de trama. |
Nombre MIB | IF-MIB |
| Nombre de la variable | ifInOctets |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.10.x |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Todas las interfaces operativas de la red |
||
Utilización de la interfaz: Octetos transmitidos |
Número total de octetos transmitidos fuera de la interfaz, incluidos los caracteres de trama. |
Nombre MIB | IF-MIB |
| Nombre de la variable | ifOutOctets |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.16.x |
||
| Frecuencia (minutos) | 60 |
||
| Rango permitido | A base |
||
| Objetos administrados | Todas las interfaces operativas de la red |
||
El recuento de bytes varía según el tipo de interfaz, la encapsulación utilizada y la PIC admitida. Por ejemplo, con la encapsulación vlan-ccc en un PIC 4xFE, GE o GE 1Q, el recuento de bytes incluye la sobrecarga de palabras de encuadre y control. (Consulte Tabla 6.)
Tipo de PIC |
Encapsulación |
entrada (nivel de unidad) |
Resultado (nivel de unidad) |
SNMP |
|---|---|---|---|---|
4xFE |
VLAN-CCC |
Fotograma (sin secuencia de comprobación de fotogramas [FCS]) |
Marco (incluido FCS y palabra de control) |
ifInOctets, ifOutOctets |
GE |
VLAN-CCC |
Marco (sin FCS) |
Marco (incluido FCS y palabra de control) |
ifInOctets, ifOutOctets |
GE IQ |
VLAN-CCC |
Marco (sin FCS) |
Marco (incluido FCS y palabra de control) |
ifInOctets, ifOutOctets |
Las trampas SNMP también son un buen mecanismo para usar en la gestión de la salud. Para obtener más información, consulte "Capturas SNMP compatibles con Junos OS" y "Capturas SNMP específicas de la empresa compatibles con Junos OS".
Mida el rendimiento
El rendimiento de la red de un proveedor de servicios generalmente se define como qué tan bien puede soportar los servicios, y se mide con métricas como el retraso y la utilización. Le sugerimos que supervise las siguientes métricas de rendimiento mediante aplicaciones como InfoVista Service Performance Management o Concord Network Health (consulte Tabla 7).
| Métrico: | Retraso medio |
Description |
Tiempo medio de ida y vuelta (en milisegundos) entre dos puntos de medición. |
Nombre MIB |
DISMAN-PING-MIB (RFC 2925) |
Nombre de la variable |
|
Variable OID |
pingResultsEntry.6 |
Frecuencia (minutos) |
15 (o dependiendo de la frecuencia de la prueba de ping) |
Rango permitido |
A base |
Objetos administrados |
Cada ruta medida en la red |
| Métrico: | Utilización de la interfaz |
Description |
Porcentaje de utilización de una conexión lógica. |
Nombre MIB |
IF-MIB |
Nombre de la variable |
|
Variable OID |
Entradas ifTable |
Frecuencia (minutos) |
60 |
Rango permitido |
A base |
Objetos administrados |
Todas las interfaces operativas de la red |
| Métrico: | Utilización del disco |
Description |
Utilización del espacio en disco dentro del enrutador de Juniper Networks |
Nombre MIB |
HOST-RESOURCES-MIB (RFC 2790) |
Nombre de la variable |
hrStorageSize – hrStorageUsed |
Variable OID |
hrStorageEntry.5 – hrStorageEntry.6 |
Frecuencia (minutos) |
1440 |
Rango permitido |
A base |
Objetos administrados |
Todos los discos duros del motor de enrutamiento |
| Métrico: | Utilización de memoria |
Description |
Utilización de memoria en el motor de enrutamiento y FPC. |
Nombre MIB |
JUNIPER-MIB (MIB de chasis empresarial de Juniper Networks) |
Nombre de la variable |
jnxOperatingHeap |
Variable OID |
Tabla para cada componente |
Frecuencia (minutos) |
60 |
Rango permitido |
A base |
Objetos administrados |
Todos los enrutadores de Juniper Networks |
| Métrico: | Carga de CPU |
Description |
Uso promedio durante el último minuto de una CPU. |
Nombre MIB |
JUNIPER-MIB (MIB de chasis empresarial de Juniper Networks) |
Nombre de la variable |
jnxOperatingCPU |
Variable OID |
Tabla para cada componente |
Frecuencia (minutos) |
60 |
Rango permitido |
A base |
Objetos administrados |
Todos los enrutadores de Juniper Networks |
| Métrico: | Utilización de LSP |
Description |
Utilización de la ruta de conmutación de etiquetas MPLS. |
Nombre MIB |
MPLS-MIB |
Nombre de la variable |
mplsPathBandwidth / (mplsLspOctets * 8) |
Variable OID |
mplsLspEntry.21 y mplsLspEntry.3 |
Frecuencia (minutos) |
60 |
Rango permitido |
A base |
Objetos administrados |
Todas las rutas de conmutación de etiquetas de la red |
| Métrico: | Tamaño de la cola de salida |
Description |
Tamaño, en paquetes, de cada cola de salida por clase de reenvío, por interfaz. |
Nombre MIB |
JUNIPER-COS-MIB |
Nombre de la variable |
jnxCosIfqQedPkts |
Variable OID |
jnxCosIfqStatsEntry.3 |
Frecuencia (minutos) |
60 |
Rango permitido |
A base |
Objetos administrados |
Para cada clase de reenvío por interfaz en la red, una vez que CoS esté habilitado. |
Esta sección incluye los siguientes temas:
- Medir la clase de servicio
- Contadores de filtro de firewall entrantes por clase
- Supervisar bytes de salida por cola
- Calcular el tráfico perdido
Medir la clase de servicio
Puede usar mecanismos de clase de servicio (CoS) para regular cómo se manejan ciertas clases de paquetes dentro de su red durante los momentos de máxima congestión. Normalmente, debe realizar los pasos siguientes al implementar un mecanismo de CoS:
Identifique el tipo de paquetes que se aplica a esta clase. Por ejemplo, incluya todo el tráfico del cliente desde una interfaz de borde de entrada específica dentro de una clase, o incluya todos los paquetes de un protocolo determinado, como voz sobre IP (VoIP).
Identificar el comportamiento determinista requerido para cada clase. Por ejemplo, si VoIP es importante, otorgue al tráfico VoIP la máxima prioridad durante los momentos de congestión de la red. Por el contrario, puede degradar la importancia del tráfico web durante la congestión, ya que puede no afectar demasiado a los clientes.
Con esta información, puede configurar mecanismos en la entrada de red para supervisar, marcar y controlar las clases de tráfico. El tráfico marcado se puede manejar de una manera más determinista en las interfaces de salida, normalmente aplicando diferentes mecanismos de cola para cada clase durante los momentos de congestión de la red. Puede recopilar información de la red para proporcionar a los clientes informes que muestren cómo se comporta la red en tiempos de congestión. (Consulte Figura 5.)
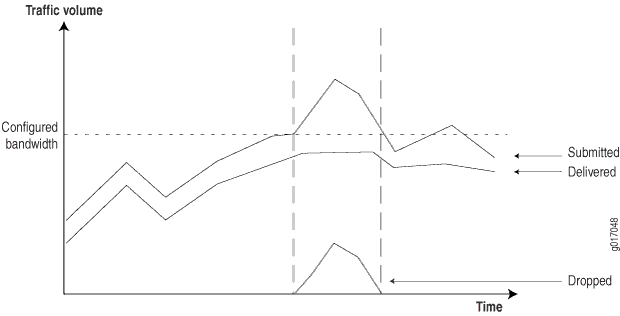
Para generar estos informes, los enrutadores deben proporcionar la siguiente información:
Tráfico enviado: cantidad de tráfico recibido por clase.
Tráfico entregado: cantidad de tráfico transmitido por clase.
Tráfico perdido: cantidad de tráfico eliminado debido a los límites de CoS.
La siguiente sección describe cómo los enrutadores de Juniper Networks proporcionan esta información.
Contadores de filtro de firewall entrantes por clase
Los contadores de filtros de firewall son un mecanismo muy flexible que puede usar para hacer coincidir y contar el tráfico entrante por clase e interfaz. Veamos algunos ejemplos:
firewall {
filter f1 {
term t1 {
from {
dscp af11;
}
then {
# Assured forwarding class 1 drop profile 1 count inbound-af11;
accept;
}
}
}
}
Por ejemplo, Tabla 8 muestra los filtros adicionales utilizados para que coincidan con las otras clases.
Valor DSCP |
Condición de coincidencia del firewall |
Description |
|---|---|---|
10 |
af11 |
Reenvío garantizado clase 1 perfil de caída 1 |
12 |
af12 |
Reenvío garantizado clase 1 perfil de caída 2 |
18 |
af21 |
Mejor esfuerzo clase 2 perfil de caída 1 |
20 |
af22 |
Mejor esfuerzo clase 2 perfil de caída 2 |
26 |
af31 |
Mejor esfuerzo clase 3 perfil de caída 1 |
Cualquier paquete con un punto de código CoS DiffServ (DSCP) conforme a RFC 2474 se puede contar de esta manera. La MIB del filtro de firewall específico para empresa de Juniper Networks presenta la información del contador en las variables que se muestran en Tabla 9.
Nombre del indicador |
Contadores entrantes |
|---|---|
base de información gestionada (MIB) |
|
Mesa |
|
Índice |
|
Variables |
|
Description |
Número de bytes que se cuentan en relación con el contador de filtros de firewall especificado |
Versión de SNMP |
SNMPv2 |
Esta información puede ser recopilada por cualquier aplicación de administración SNMP que admita SNMPv2. Los productos de proveedores como Concord Communications, Inc. e InfoVista, Inc., proporcionan compatibilidad con la MIB del firewall de Juniper Networks con sus controladores de dispositivo nativos de Juniper Networks.
Supervisar bytes de salida por cola
Puede usar la MIB CoS ATM empresarial de Juniper Networks para supervisar el tráfico saliente, por clase de reenvío de circuito virtual, por interfaz. (Consulte Tabla 10.)
Nombre del indicador |
Contadores de salida |
|---|---|
base de información gestionada (MIB) |
|
Variable |
|
Índice |
|
Description |
Número de bytes pertenecientes a la clase de reenvío especificada que se transmitieron en el circuito virtual especificado. |
Versión de SNMP |
SNMPv2 |
Los contadores de interfaz que no son ATM son proporcionados por la MIB de CoS específica para la empresa de Juniper Networks, que proporciona la información que se muestra en Tabla 11.
Nombre del indicador |
Contadores de salida |
|---|---|
base de información gestionada (MIB) |
|
Mesa |
|
Índice |
|
Variables |
|
Description |
Número de bytes o paquetes transmitidos por interfaz por clase de reenvío |
Versión de SNMP |
SNMPv2 |
Calcular el tráfico perdido
Puede calcular la cantidad de tráfico perdido restando el tráfico saliente del tráfico entrante:
Dropped = Inbound Counter – Outbound Counter
También puede seleccionar contadores de la MIB de CoS, como se muestra en Tabla 12.
Nombre del indicador |
Tráfico perdido |
|---|---|
base de información gestionada (MIB) |
|
Mesa |
|
Índice |
|
Variables |
|
Description |
El número de paquetes descartados o descartados en rojo por interfaz por clase de reenvío |
Versión de SNMP |
SNMPv2 |