EN ESTA PÁGINA
Ejemplo: Configuración de pares de EBGP de un solo salto para aceptar próximos saltos remotos
Ejemplo: Equilibrio de carga de tráfico de BGP con ancho de banda desigual asignado a las rutas
Descripción del anuncio de varias rutas a un solo destino en BGP
Ejemplo: Configuración de publicidad selectiva de varias rutas de BGP para equilibrio de carga
Configuración de la resolución recursiva a través de múltiples rutas de BGP
Configuración de los próximos saltos de ECMP para RSVP y LSP de LDP para equilibrio de carga
Configuración del equilibrio de carga coherente para grupos ECMP
Mejore la resistencia de red mediante varios pares de BGP ECMP
Descripción de la etiqueta de entropía para LSP de unidifusión etiquetado con BGP
Configurar una etiqueta de entropía para un LSP de unidifusión etiquetado con BGP
Ejemplo: Configuración de una etiqueta de entropía para un LSP de unidifusión etiquetado con BGP
Configuración de la convergencia independiente del prefijo del BGP para inet
Ejemplo: Configuración de la convergencia independiente del prefijo del BGP para inet
Descripción general de Conservar la jerarquía de salto siguiente
Descripción general del borde de la PIC del BGP con la etiqueta de unidifusión del BGP
Descripción general de la compatibilidad con el pseudocable FAT para BGP, L2VPN y VPLS
Equilibrio de carga para una sesión de BGP
Descripción de la multiruta de BGP
La multirruta de BGP le permite instalar varias rutas de BGP internas y varias rutas de BGP externas en la tabla de reenvío. La selección de varias rutas permite al BGP equilibrar la carga de tráfico entre varios vínculos.
Una ruta se considera una ruta de BGP de igual costo (y se usa para el reenvío) si el proceso de selección de ruta de BGP realiza un desempate después de comparar el costo de IGP con el siguiente salto. De forma predeterminada, todas las rutas con el mismo AS vecino aprendidas por un BGP vecino habilitado para multirruta se consideran dentro del proceso de selección de multirruta.
Normalmente, el BGP selecciona solo una mejor ruta para cada prefijo e instala esa ruta en la tabla de reenvío. Cuando se habilita la multirruta de BGP, el dispositivo selecciona varias rutas de BGP de igual costo para llegar a un destino determinado y todas estas rutas se instalan en la tabla de reenvío. BGP anuncia solo la ruta activa a sus vecinos, a menos que add-path esté en uso.
La función de multirruta BGP de Junos OS es compatible con las siguientes aplicaciones:
Equilibrio de carga en varios vínculos entre dos dispositivos de enrutamiento que pertenecen a sistemas autónomos (AS) diferentes
Equilibrio de carga en una o varias subredes a distintos dispositivos de enrutamiento que pertenecen al mismo par de AS
Equilibrio de carga en varios vínculos entre dos dispositivos de enrutamiento que pertenecen a diferentes pares de confederación externa
Equilibrio de carga en una o varias subredes a distintos dispositivos de enrutamiento que pertenecen a pares de confederación externos
En un escenario común para el equilibrio de carga, un cliente es multiconexión a múltiples enrutadores o conmutadores en un punto de presencia (POP). El comportamiento predeterminado es enviar todo el tráfico a través de solo uno de los vínculos disponibles. El equilibrio de carga hace que el tráfico use dos o más de los vínculos.
La multirruta BGP no se aplica a rutas que comparten el mismo costo de MED más IGP, pero difieren en el costo de IGP. La selección de rutas múltiples se basa en la métrica de costo IGP, incluso si dos rutas tienen el mismo costo MED más IGP.
A partir de la versión 18.1R1 de Junos OS, la multirruta BGP se admite globalmente en [edit protocols bgp] el nivel de jerarquía. Puede deshabilitar selectivamente la multirruta en algunos grupos de BGP y vecinos. Incluir disable en el [edit protocols bgp group group-name multipath] nivel de jerarquía para deshabilitar la opción de multirruta para un grupo o un vecino de BGP específico.
A partir de Junos OS versión 18.1R1, puede aplazar el cálculo de multirruta hasta que se reciban todas las rutas de BGP. Cuando se habilita la multirruta, el BGP inserta la ruta en la cola de multirruta cada vez que se agrega una nueva ruta o cada vez que cambia una ruta existente. Cuando se reciben varias rutas mediante la función de adición de ruta del BGP, el BGP puede calcular una ruta de multirruta varias veces. El cálculo de múltiples rutas ralentiza la velocidad de aprendizaje de RIB (también conocida como tabla de enrutamiento). Para acelerar el aprendizaje de RIB, el cálculo de multirruta se puede diferir hasta que se reciban las rutas BGP o puede reducir la prioridad del trabajo de compilación de multirruta según sus requisitos hasta que se resuelvan las rutas BGP. Para aplazar el cálculo de la multirruta, configure defer-initial-multipath-build a [edit protocols bgp] nivel de jerarquía. Como alternativa, puede reducir la prioridad del trabajo de compilación de multirruta del BGP utilizando multipath-build-priority la instrucción de configuración en el [edit protocols bgp] nivel de jerarquía para acelerar el aprendizaje de RIB.
Ver también
Ejemplo: Equilibrio de carga de tráfico de BGP
En este ejemplo, se muestra cómo configurar el BGP para seleccionar varias rutas de BGP externas (EBGP) o internas (IBGP) de igual costo como rutas activas.
Requisitos
Antes de empezar:
Configure las interfaces de los dispositivos.
Configure un protocolo de puerta de enlace interior (IGP).
Configure BGP.
Configure una política de enrutamiento que exporte rutas (como rutas directas o rutas IGP) de la tabla de enrutamiento al BGP.
Descripción general
En los siguientes pasos, se muestra cómo configurar el equilibrio de carga por paquete:
Defina una política de enrutamiento de equilibrio de carga incluyendo una o más
policy-statementinstrucciones en el[edit policy-options]nivel de jerarquía, definiendo una acción deload-balance per-packet:policy-statement policy-name { from { match-conditions; route-filter destination-prefix match-type <actions>; prefix-list name; } then { load-balance per-packet; } }Nota:Para habilitar el equilibrio de carga entre varias rutas de EBGP y varias rutas de IBGP, incluya la
multipathinstrucción globalmente en el[edit protocols bgp]nivel de jerarquía. No puede habilitar el equilibrio de carga del tráfico del BGP sin incluir lamultipathinstrucción globalmente, ni para un grupo de BGP en el[edit protocols bgp group group-namenivel jerárquico, ni para vecinos de BGP específicos en el nivel jerárquico[edit protocols bgp group group-name neighbor address].Aplique la política a las rutas exportadas desde la tabla de enrutamiento a la tabla de reenvío. Para ello, incluya las
forwarding-tableinstrucciones yexport:forwarding-table { export policy-name; }
No puede aplicar la política de exportación a instancias de enrutamiento VRF.
Especifique todos los próximos saltos de esa ruta, si existe más de uno, al asignar una etiqueta correspondiente a una ruta que se anuncia.
Configure la clave hash de opciones de reenvío para que MPLS incluya la carga IP.
En algunas plataformas, puede aumentar el número de rutas con equilibrio de carga mediante la instrucción chassis maximum-ecmp .
Con esta instrucción, puede cambiar el número máximo de rutas con equilibrio de carga de igual costo a 32, 64, 128, 256 o 512 (el número máximo varía según la plataforma; consulte maximum-ecmp).
La función de multirruta se admite en todas las plataformas que admiten BGP. Se han realizado algunas mejoras en las plataformas QFX:
-
- A partir de Junos OS versión 19.1R1, puede especificar un número máximo de 128 rutas de igual costo en conmutadores QFX10000.
-
- A partir de Junos OS versión 19.2R1, puede especificar un número máximo de 512 rutas de igual costo en conmutadores QFX10000 (consulte Descripción de la configuración de hasta 512 rutas de igual costo con equilibrio de carga coherente opcional).
En este ejemplo, el dispositivo R1 está en el AS 64500 y está conectado a los dispositivos R2 y R3, que están en el AS 64501. En este ejemplo, se muestra la configuración en el dispositivo R1.
Topología
En la figura 1 , se muestra la topología utilizada en este ejemplo.
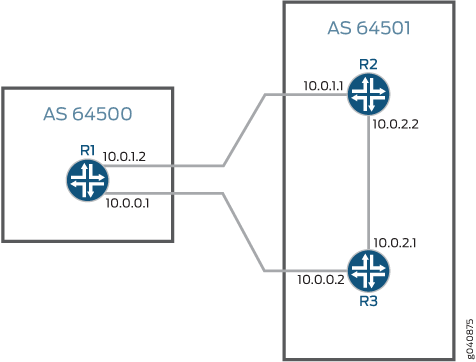 BGP
BGP
Configuración
Procedimiento
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red y, luego, copie y pegue los comandos en la CLI en el nivel jerárquico [edit] .
set protocols bgp group external type external set protocols bgp group external peer-as 64501 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.1.1 set protocols bgp group external neighbor 10.0.0.2 set policy-options policy-statement loadbal from route-filter 10.0.0.0/16 orlonger set policy-options policy-statement loadbal then load-balance per-packet set routing-options forwarding-table export loadbal set routing-options autonomous-system 64500
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar las sesiones de par BGP:
Configure el grupo BGP.
[edit protocols bgp group external] user@R1# set type external user@R1# set peer-as 64501 user@R1# set neighbor 10.0.1.1 user@R1# set neighbor 10.0.0.2
Habilite el grupo BGP para utilizar varias rutas.
Nota:Para deshabilitar la comprobación predeterminada que requiere que las rutas aceptadas por la multirruta BGP tengan el mismo sistema autónomo vecino (AS), incluya la
multiple-asopción.[edit protocols bgp group external] user@R1# set multipath
Configure la política de equilibrio de carga.
[edit policy-options policy-statement loadbal] user@R1# set from route-filter 10.0.0.0/16 orlonger user@R1# set then load-balance per-packet
Aplique la política de equilibrio de carga.
[edit routing-options] user@R1# set forwarding-table export loadbal
Configure el número de sistema autónomo local (AS).
[edit routing-options] user@R1# set autonomous-system 64500
Resultados
Desde el modo de configuración, ingrese los comandos , y show routing-options para confirmar la show protocolsshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
[edit]
user@R1# show protocols
bgp {
group external {
type external;
peer-as 64501;
multipath;
neighbor 10.0.1.1;
neighbor 10.0.0.2;
}
}
[edit]
user@R1# show policy-options
policy-statement loadbal {
from {
route-filter 10.0.0.0/16 orlonger;
}
then {
load-balance per-packet;
}
}
[edit]
user@R1# show routing-options
autonomous-system 64500;
forwarding-table {
export loadbal;
}
Cuando termine de configurar el dispositivo, ingrese commit desde el modo de configuración.
Verificación
Confirme que la configuración funcione correctamente:
Verificación de rutas
Propósito
Compruebe que las rutas se aprendieron desde ambos enrutadores del AS vecino.
Acción
Desde el modo operativo, ejecute el show route comando.
user@R1> show route 10.0.2.0
inet.0: 12 destinations, 15 routes (12 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.0.2.0/30 *[BGP/170] 03:12:32, localpref 100
AS path: 64501 I
to 10.0.1.1 via ge-1/2/0.0
> to 10.0.0.2 via ge-1/2/1.0
[BGP/170] 03:12:32, localpref 100
AS path: 64501 I
> to 10.0.1.1 via ge-1/2/0.0
user@R1> show route 10.0.2.0 detail
inet.0: 12 destinations, 15 routes (12 active, 0 holddown, 0 hidden)
10.0.2.0/30 (2 entries, 1 announced)
*BGP Preference: 170/-101
Next hop type: Router, Next hop index: 262142
Next-hop reference count: 3
Source: 10.0.0.2
Next hop: 10.0.1.1 via ge-1/2/0.0
Next hop: 10.0.0.2 via ge-1/2/1.0, selected
State: <Active Ext>
Local AS: 64500 Peer AS: 64501
Age: 3:18:30
Task: BGP_64501.10.0.0.2+55402
Announcement bits (1): 2-KRT
AS path: 64501 I
Accepted Multipath
Localpref: 100
Router ID: 192.168.2.1
BGP Preference: 170/-101
Next hop type: Router, Next hop index: 602
Next-hop reference count: 5
Source: 10.0.1.1
Next hop: 10.0.1.1 via ge-1/2/0.0, selected
State: <NotBest Ext>
Inactive reason: Not Best in its group - Active preferred
Local AS: 64500 Peer AS: 64501
Age: 3:18:30
Task: BGP_64501.10.0.1.1+53135
AS path: 64501 I
Accepted
Localpref: 100
Router ID: 192.168.3.1
Significado
La ruta activa, indicada con un asterisco (*), tiene dos saltos siguientes: 10.0.1.1 y 10.0.0.2 al destino 10.0.2.0. El siguiente salto 10.0.1.1 se copia de la ruta inactiva a la ruta activa.
El show route detail resultado del comando designa una puerta de enlace como selected. Este resultado es potencialmente confuso en el contexto del equilibrio de carga. La puerta de enlace seleccionada se utiliza para muchos propósitos, además de decidir qué puerta de enlace instalar en el kernel cuando Junos OS no está realizando equilibrio de carga por paquete. Por ejemplo, el ping mpls comando utiliza la puerta de enlace seleccionada al enviar paquetes. Los protocolos de multidifusión utilizan la puerta de enlace seleccionada en algunos casos para determinar la interfaz ascendente. Por lo tanto, aun cuando Junos OS esté realizando el equilibrio de carga por paquete mediante una política de tabla de reenvío, la información de puerta de enlace seleccionada sigue siendo necesaria para otros fines. Es útil mostrar la puerta de enlace seleccionada para fines de resolución de problemas. Además, es posible usar la política de tabla de reenvío para anular lo que está instalado en el kernel (por ejemplo, usando la install-nexthop acción). En este caso, la puerta de enlace de salto siguiente instalada en la tabla de reenvío puede ser un subconjunto del total de puertas de enlace que se muestran en el show route comando.
Verificar el reenvío
Propósito
Compruebe que los dos saltos siguientes están instalados en la tabla de reenvío.
Acción
Desde el modo operativo, ejecute el show route forwarding-table comando.
user@R1> show route forwarding-table destination 10.0.2.0
Routing table: default.inet
Internet:
Destination Type RtRef Next hop Type Index NhRef Netif
10.0.2.0/30 user 0 ulst 262142 2
10.0.1.1 ucst 602 5 ge-1/2/0.0
10.0.0.2 ucst 522 6 ge-1/2/1.0
Descripción de la configuración de hasta 512 rutas de igual costo con equilibrio de carga consistente opcional
Puede configurar la función de multirruta de igual costo (ECMP) con hasta 512 rutas para pares de BGP externos. Tener la capacidad de configurar hasta 512 próximos saltos ECMP le permite aumentar la cantidad de conexiones directas de par BGP con su dispositivo de enrutamiento especificado, lo que mejora la latencia y optimiza el flujo de datos. Opcionalmente, puede incluir un equilibrio de carga coherente en esa configuración de ECMP. El equilibrio de carga coherente garantiza que si se produce un error en un miembro del ECMP (es decir, una ruta de acceso), solo los flujos que fluyen a través del miembro con errores se redistribuyan a otros miembros activos del ECMP. El equilibrio de carga coherente también garantiza que, si se agrega un miembro ECMP, la redistribución de los flujos desde los miembros EMCP existentes al nuevo miembro ECMP sea mínima.
- Directrices y limitaciones para configurar de 256 a 512 rutas de igual costo, opcionalmente con equilibrio de carga consistente
- Instrucciones para configurar hasta 512 próximos saltos ECMP y, opcionalmente, configurar un equilibrio de carga coherente
Directrices y limitaciones para configurar de 256 a 512 rutas de igual costo, opcionalmente con equilibrio de carga consistente
La función solo se aplica a pares de BGP externos de un solo salto. (Esta función no se aplica a las rutas MPLS).
El proceso de enrutamiento del dispositivo (RPD) debe ser compatible con el modo de 64 bits; No se admite RPD de 32 bits.
Esta función solo se aplica al tráfico de unidifusión.
Es posible que la distribución del tráfico no sea uniforme entre todos los miembros del grupo: depende del patrón de tráfico y de la organización de la tabla de conjuntos de flujo hash en el hardware. El hash coherente minimiza la reasignación de flujos a vínculos de destino cuando se agregan o eliminan miembros del grupo.
Si configura
set forwarding-options enhanced-hash-keycon una de las opcioneshash-mode, ,inet,inet6olayer2, algunos flujos pueden cambiar los vínculos de destino, ya que los nuevos parámetros hash pueden generar nuevos índices hash para los flujos, lo que da como resultado nuevos vínculos de destino.Para lograr la mejor precisión de hash posible, esta característica usa una topología en cascada para implementar la estructura de salto siguiente para configuraciones de más de 128 saltos siguientes. Por lo tanto, la precisión del hash es algo menor que para las configuraciones de próximo salto ECMP de menos de 128, que no requieren una topología en cascada.
Los flujos existentes en las rutas ECMP afectadas y los nuevos flujos que fluyen sobre esas rutas ECMP afectadas pueden cambiar de ruta durante la reparación de la ruta local y se puede notar un sesgo del tráfico. Sin embargo, cualquier sesgo de este tipo se corrige durante la reparación posterior de la ruta global.
Cuando aumenta el
maximum-ecmpvalor, el hash de coherencia se pierde durante el siguiente evento de cambio de salto para el prefijo de ruta.Si agrega una nueva ruta a un grupo ECMP existente, es posible que algunos flujos sobre rutas no afectadas se muevan a la ruta recién agregada.
Es posible que el reenrutamiento rápido (FRR) no funcione con un hash coherente.
No se puede lograr una distribución perfecta del tráfico similar a ECMP. Las rutas que tienen más "depósitos" que otras rutas tienen más flujos de tráfico que las rutas con menos depósitos (un depósito es una entrada en la lista de distribución de la tabla de equilibrio de carga que se asigna a un índice miembro del ECMP).
Durante los eventos de cambio de topología de red, en algunos casos se pierde un hash coherente para los prefijos de red, ya que esos prefijos apuntan a un nuevo salto siguiente de ECMP que no tiene todas las propiedades de los próximos saltos de ECMP anteriores de los prefijos.
Si varios prefijos de red apuntan al mismo próximo salto ECMP y uno o más de esos prefijos están habilitados con la
consistent-hashinstrucción, todos los prefijos de red que apuntan a ese mismo próximo salto ECMP muestran un comportamiento hash coherente.El hash coherente solo se admite en el grupo ECMP basado en rutas de BGP de igual costo. Cuando se configuran otros protocolos o rutas estáticas que tienen prioridad sobre las rutas del BGP, no se admite el hash coherente.
El hash coherente puede tener limitaciones cuando la configuración se combina con configuraciones para las siguientes funciones, ya que estas funciones tienen terminaciones de túnel o ingeniería de tráfico que no utiliza hash para seleccionar rutas (túnel GRE; tráfico BUM; EVPN-VXLAN; y MPLS TE, ancho de banda automático.
Instrucciones para configurar hasta 512 próximos saltos ECMP y, opcionalmente, configurar un equilibrio de carga coherente
Cuando esté listo para configurar hasta 512 próximos saltos, siga las siguientes instrucciones de configuración:
Configure el número máximo de próximos saltos ECMP, por ejemplo, configure 512 próximos saltos ECMP:
[edit] user@host# set chassis maximum-ecmp 512
Crear una política de enrutamiento y habilitar el equilibrio de carga por paquete, habilitando así el ECMP globalmente en el sistema:
[edit] user@host# set routing-options forwarding-table export load-balancing-policy user@host# set policy-options policy-statement load-balancing-policy then load-balance per-packet
Habilite la resistencia en los prefijos seleccionados mediante la creación de una política de enrutamiento independiente para hacer coincidir las rutas entrantes con uno o más prefijos de destino, por ejemplo:
[edit] user@host# set policy-options policy-statement c-hash from route-filter 20.0.0.0/24 orlonger user@host# set policy-options policy-statement c-hash then load-balance consistent-hash
Aplique una política de importación de eBGP (por ejemplo, "c-hash") al grupo BGP de pares externos:
[edit] user@host# set protocols bgp import c-hash
Para obtener más información sobre cómo configurar rutas de igual costo, consulte Ejemplo: Equilibrio de carga de tráfico de BGP, que aparece anteriormente en este documento.
(Opcional) Para obtener más información sobre cómo configurar el equilibrio de carga coherente (también conocido como hash coherente), consulte Configurar el equilibrio de carga coherente para grupos ECMP
Ver también
Ejemplo: Configuración de pares de EBGP de un solo salto para aceptar próximos saltos remotos
En este ejemplo, se muestra cómo configurar un par BGP externo (EBGP) de un solo salto para aceptar un próximo salto remoto con el que no comparte una subred común.
Requisitos
No se necesita ninguna configuración especial más allá de la inicialización del dispositivo antes de configurar este ejemplo.
Descripción general
En algunas situaciones, es necesario configurar un par EBGP de un solo salto para aceptar un próximo salto remoto con el que no comparta una subred común. El comportamiento predeterminado es que se descarte cualquier dirección de salto siguiente recibida de un par EBGP de un solo salto que no se reconozca como compartiendo una subred común. La capacidad de hacer que un par de EBGP de un solo salto acepte un próximo salto remoto al que no está conectado directamente también evita que tenga que configurar el vecino de EBGP de un solo salto como una sesión de varios saltos. Cuando se configura una sesión de varios saltos en esta situación, todas las rutas de próximo salto aprendidas a través de este par EBGP se etiquetan como indirectas, incluso cuando comparten una subred común. Esta situación interrumpe la funcionalidad de multirruta para rutas que se resuelven recursivamente en rutas que incluyen estas direcciones de salto siguiente. La configuración de la instrucción permite que un par de EBGP de un solo salto acepte un próximo salto remoto, lo que restaura la accept-remote-nexthop funcionalidad de multirruta para las rutas que se resuelven en estas direcciones de salto siguiente. Puede configurar esta instrucción en los niveles de jerarquía global, de grupo y de vecino para BGP. La instrucción también se admite en sistemas lógicos y en el tipo de instancia de enrutamiento y reenvío VPN (VRF). Tanto el próximo salto remoto como el par EBGP deben admitir la actualización de ruta del BGP, tal y como se define en el RFC 2918, Capacidad de Actualizar de ruta en BGP-4. Si el par remoto no admite la actualización de ruta del BGP, la sesión se restablece.
Un par de EBGP de un solo salto anuncia su propia dirección como el siguiente salto de forma predeterminada. Si desea anunciar un próximo salto diferente, debe definir una política de enrutamiento de importación en el par EBGP. Cuando habilita un par de EBGP de un solo salto para aceptar un próximo salto remoto, también puede configurar una política de enrutamiento de importación en el par EBGP. Sin embargo, no se requiere una política de enrutamiento si configuró un próximo salto remoto.
Este ejemplo incluye una política de enrutamiento de importación, agg_route, que permite que un par de par BGP externo de un solo salto (dispositivo R1) acepte el próximo salto remoto 10.1.10.10 para la ruta a la red 10.1.230.0/23. En el nivel jerárquico [edit protocols bgp] , el ejemplo incluye la import agg_route instrucción para aplicar la política al par BGP externo e incluye la accept-remote-nexthop instrucción para permitir que el par EBGP de un solo salto acepte el próximo salto remoto.
La Figura 2 muestra la topología de ejemplo.
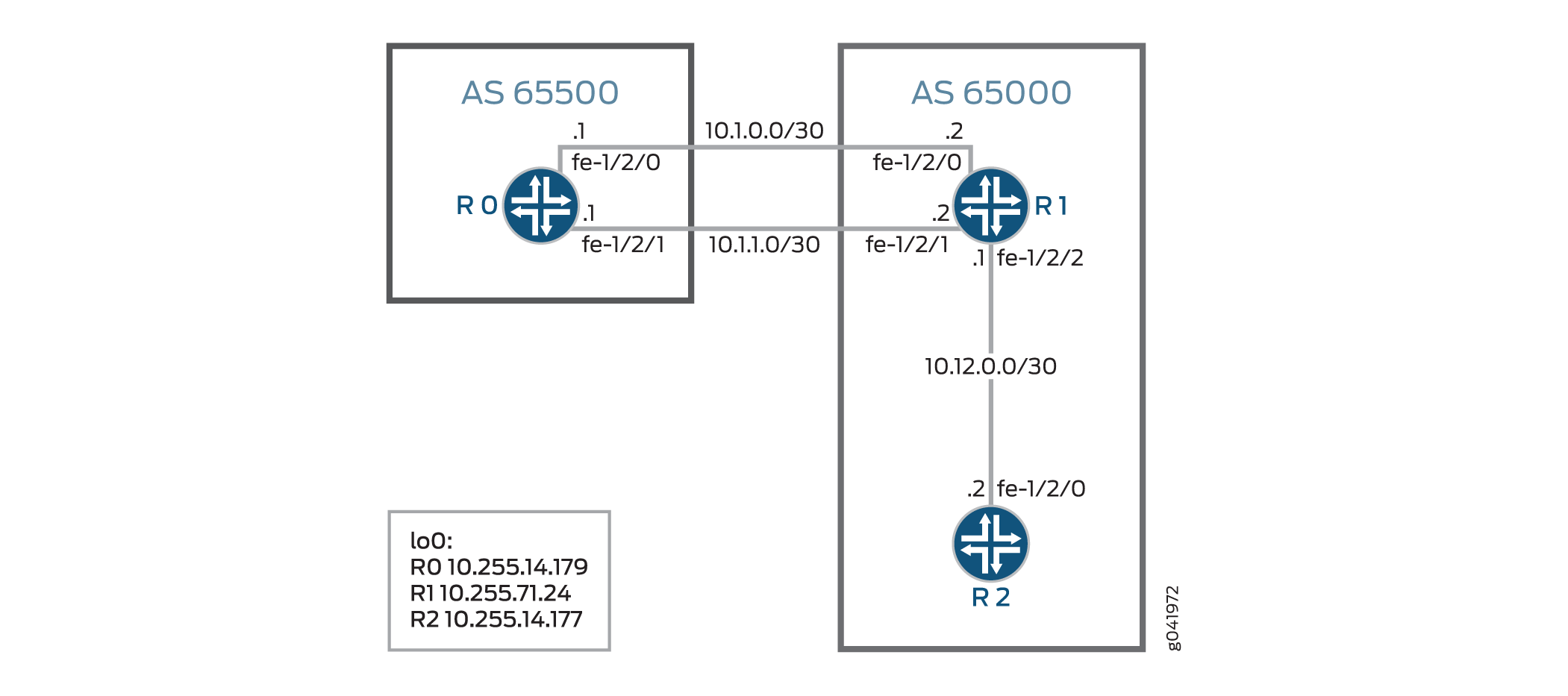 remoto
remoto
Configuración
- Configuración rápida de CLI
- Dispositivo R0
- Configuración del dispositivo R1
- Configuración del dispositivo R2
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red y, luego, copie y pegue los comandos en la CLI en el nivel jerárquico [edit] .
Dispositivo R0
set interfaces fe-1/2/0 unit 0 family inet address 10.1.0.1/30 set interfaces fe-1/2/1 unit 0 family inet address 10.1.1.1/30 set interfaces lo0 unit 0 family inet address 10.255.14.179/32 set protocols bgp group ext type external set protocols bgp group ext export test_route set protocols bgp group ext export agg_route set protocols bgp group ext peer-as 65000 set protocols bgp group ext multipath set protocols bgp group ext neighbor 10.1.0.2 set protocols bgp group ext neighbor 10.1.1.2 set policy-options policy-statement agg_route term 1 from protocol static set policy-options policy-statement agg_route term 1 from route-filter 10.1.230.0/23 exact set policy-options policy-statement agg_route term 1 then accept set policy-options policy-statement test_route term 1 from protocol static set policy-options policy-statement test_route term 1 from route-filter 10.1.10.10/32 exact set policy-options policy-statement test_route term 1 then accept set routing-options static route 10.1.10.10/32 reject set routing-options static route 10.1.230.0/23 reject set routing-options autonomous-system 65500
Dispositivo R1
set interfaces fe-1/2/0 unit 0 family inet address 10.1.0.2/30 set interfaces fe-1/2/1 unit 0 family inet address 10.1.1.2/30 set interfaces fe-1/2/2 unit 0 family inet address 10.12.0.1/30 set interfaces lo0 unit 2 family inet address 10.255.71.24/32 set protocols bgp accept-remote-nexthop set protocols bgp group ext type external set protocols bgp group ext import agg_route set protocols bgp group ext peer-as 65500 set protocols bgp group ext multipath set protocols bgp group ext neighbor 10.1.0.1 set protocols bgp group ext neighbor 10.1.1.1 set protocols bgp group int type internal set protocols bgp group int local-address 10.255.71.24 set protocols bgp group int neighbor 10.255.14.177 set protocols ospf area 0.0.0.0 interface fe-1/2/1.4 set protocols ospf area 0.0.0.0 interface 10.255.71.24 set policy-options policy-statement agg_route term 1 from protocol bgp set policy-options policy-statement agg_route term 1 from route-filter 10.1.230.0/23 exact set policy-options policy-statement agg_route term 1 then next-hop 10.1.10.10 set policy-options policy-statement agg_route term 1 then accept set routing-options autonomous-system 65000
Dispositivo R2
set interfaces fe-1/2/0 unit 0 family inet address 10.12.0.2/30 set interfaces lo0 unit 0 family inet address 10.255.14.177/32 set protocols bgp group int type internal set protocols bgp group int local-address 10.255.14.177 set protocols bgp group int neighbor 10.255.71.24 set protocols ospf area 0.0.0.0 interface fe-1/2/0.6 set protocols ospf area 0.0.0.0 interface 10.255.14.177 set routing-options autonomous-system 65000
Dispositivo R0
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo R0:
-
Configure las interfaces.
[edit interfaces fe-1/2/0 unit 0] user@R0# set family inet address 10.1.0.1/30 [edit interfaces fe-1/2/1 unit 0] user@R0# set family inet address 10.1.1.1/30 [edit interfaces lo0 unit 0] user@R0# set family inet address 10.255.14.179/32
-
Configure EBGP.
[edit protocols bgp group ext] user@R0# set type external user@R0# set peer-as 65000 user@R0# set neighbor 10.1.0.2 user@R0# set neighbor 10.1.1.2
-
Habilite el BGP de multirruta entre los dispositivos R0 y R1.
[edit protocols bgp group ext] user@R0# set multipath
-
Configure rutas estáticas a redes remotas. Estas rutas no forman parte de la topología. El propósito de estas rutas es demostrar la funcionalidad de este ejemplo.
[edit routing-options] user@R0# set static route 10.1.10.10/32 reject user@R0# set static route 10.1.230.0/23 reject
-
Configure políticas de enrutamiento que acepten las rutas estáticas.
[edit policy-options policy-statement agg_route term 1] user@R0# set from protocol static user@R0# set from route-filter 10.1.230.0/23 exact user@R0# set then accept [edit policy-options policy-statement test_route term 1] user@R0# set from protocol static user@R0# set from route-filter 10.1.10.10/32 exact user@R0# set then accept
-
Exporte las
agg_routepolíticas ytest_routede la tabla de enrutamiento al BGP.[edit protocols bgp group ext] user@R0# set export test_route user@R0# set export agg_route
-
Configure el número de sistema autónomo (AS).
[edit routing-options] user@R0# set autonomous-system 65500
Resultados
Desde el modo de configuración, ingrese los comandos , show policy-optionsy show protocolsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R0# show interfaces
fe-1/2/0 {
unit 0 {
family inet {
address 10.1.0.1/30;
}
}
}
fe-1/2/1 {
unit 0 {
family inet {
address 10.1.1.1/30;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.255.14.179/32;
}
}
}
user@R0# show policy-options
policy-statement agg_route {
term 0 {
from {
protocol static;
route-filter 10.1.230.0/23 exact;
}
then accept;
}
}
policy-statement test_route {
term 1 {
from {
protocol static;
route-filter 10.1.10.10/32 exact;
}
then accept;
}
}
user@R0# show protocols
bgp {
group ext {
type external;
export [ test_route agg_route ];
peer-as 65000;
multipath;
neighbor 10.1.0.2;
neighbor 10.1.1.2;
}
}
user@R0# show routing-options
static {
route 10.1.10.10/32 reject;
route 10.1.230.0/23 reject;
}
autonomous-system 65500;
Cuando termine de configurar el dispositivo, ingrese commit desde el modo de configuración.
Configuración del dispositivo R1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo R1:
-
Configure las interfaces.
[edit interfaces fe-1/2/0 unit 0] user@R1# set family inet address 10.1.0.2/30 [edit interfaces fe-1/2/1 unit 0] user@R1# set family inet address 10.1.1.2/30 [edit interfaces fe-1/2/2 unit 0] user@R1# set family inet address 10.12.0.1/30 [edit interfaces lo0 unit 0] user@R1# set family inet address 10.255.71.24/32
-
Configure OSPF.
[edit protocols ospf area 0.0.0.0] user@R1# set interface fe-1/2/1.0 user@R1# set interface 10.255.71.24
-
Habilite el dispositivo R1 para aceptar el próximo salto remoto.
[edit protocols bgp] user@R1# set accept-remote-nexthop
-
Configure IBGP.
[edit protocols bgp group int] user@R1# set type internal user@R1# set local-address 10.255.71.24 user@R1# set neighbor 10.255.14.177
-
Configure EBGP.
[edit protocols bgp group ext] user@R1# set type external user@R1# set peer-as 65500 user@R1# set neighbor 10.1.0.1 user@R1# set neighbor 10.1.1.1
-
Habilite el BGP de multirruta entre los dispositivos R0 y R1.
[edit protocols bgp group ext] user@R1# set multipath
-
Configure una política de enrutamiento que permita a un par BGP externo de un solo salto (dispositivo R1) aceptar el próximo salto remoto 10.1.10.10 para la ruta a la red 10.1.230.0/23.
[edit policy-options policy-statement agg_route term 1] user@R1# set from protocol bgp user@R1# set from route-filter 10.1.230.0/23 exact user@R1# set then next-hop 10.1.10.10 user@R1# set then accept
-
Importe la
agg_routepolítica a la tabla de enrutamiento en el dispositivo R1.[edit protocols bgp group ext] user@R1# set import agg_route
-
Configure el número de sistema autónomo (AS).
[edit routing-options] user@R1# set autonomous-system 65000
Resultados
Desde el modo de configuración, ingrese los comandos , show policy-optionsy show protocolsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R1# show interfaces
fe-1/2/0 {
unit 0 {
family inet {
address 10.1.0.2/30;
}
}
}
fe-1/2/1 {
unit 0 {
family inet {
address 10.1.1.2/30;
}
}
}
fe-1/2/2 {
unit 0 {
family inet {
address 10.12.0.1/30;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.255.71.24/32;
}
}
}
user@R1# show policy-options
policy-statement agg_route {
term 1 {
from {
protocol bgp;
route-filter 10.1.230.0/23 exact;
}
then {
next-hop 10.1.10.10;
accept;
}
}
}
user@R1# show protocols
bgp {
accept-remote-nexthop;
group ext {
type external;
import agg_route;
peer-as 65500;
multipath;
neighbor 10.1.0.1;
neighbor 10.1.1.1;
}
group int {
type internal;
local-address 10.255.71.24;
neighbor 10.255.14.177;
}
}
ospf {
area 0.0.0.0 {
interface fe-1/2/1.0;
interface 10.255.71.24;
}
}
user@R1# show routing-options autonomous-system 65000;
Cuando termine de configurar el dispositivo, ingrese commit desde el modo de configuración.
Configuración del dispositivo R2
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo R2:
-
Configure las interfaces.
[edit interfaces fe-1/2/0 unit 0] user@R2# set family inet address 10.12.0.2/30 [edit interfaces lo0 unit 0] user@R2# set family inet address 10.255.14.177/32
-
Configure OSPF.
[edit protocols ospf area 0.0.0.0] user@R2# set interface fe-1/2/0.0 user@R2# set interface 10.255.14.177
-
Configure IBGP.
[edit protocols bgp group int] user@R2# set type internal user@R2# set local-address 10.255.14.177 user@R2# set neighbor 10.255.71.24
-
Configure el número de sistema autónomo (AS).
[edit routing-options] user@R1# set autonomous-system 65000
Resultados
Desde el modo de configuración, ingrese los comandos , y show routing-options para confirmar la show interfacesshow protocolsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R2# show interfaces
fe-1/2/0 {
unit 0 {
family inet {
address 10.12.0.2/30;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.255.14.177/32;
}
}
}
user@R2# show protocols
bgp {
group int {
type internal;
local-address 10.255.14.177;
neighbor 10.255.71.24;
}
}
ospf {
area 0.0.0.0 {
interface fe-1/2/0.0;
interface 10.255.14.177;
}
}
user@R2# show routing-options autonomous-system 65000;
Cuando termine de configurar el dispositivo, ingrese commit desde el modo de configuración.
Verificación
Confirme que la configuración funcione correctamente.
- Verificar que la ruta de múltiples rutas con el siguiente salto indirecto está en la tabla de enrutamiento
- Desactivación y reactivación de la instrucción accept-remote-nexthop
Verificar que la ruta de múltiples rutas con el siguiente salto indirecto está en la tabla de enrutamiento
Propósito
Verifique que el dispositivo R1 tenga una ruta a la red 10.1.230.0/23.
Acción
Desde el modo operativo, introduzca el show route 10.1.230.0 extensive comando.
user@R1> show route 10.1.230.0 extensive
inet.0: 11 destinations, 13 routes (11 active, 0 holddown, 0 hidden)
Restart Complete
10.1.230.0/23 (2 entries, 1 announced)
TSI:
KRT in-kernel 10.1.230.0/23 -> {indirect(262142)}
Page 0 idx 1 Type 1 val 9168f6c
Nexthop: 10.1.10.10
Localpref: 100
AS path: [65000] 65500 I
Communities:
Path 10.1.230.0 from 10.1.0.1 Vector len 4. Val: 1
*BGP Preference: 170/-101
Next hop type: Indirect
Address: 0x90c44d8
Next-hop reference count: 4
Source: 10.1.0.1
Next hop type: Router, Next hop index: 262143
Next hop: 10.1.0.1 via fe-1/2/0.0, selected
Next hop: 10.1.1.1 via fe-1/2/2.0
Protocol next hop: 10.1.10.10
Indirect next hop: 91c0000 262142
State: <Active Ext>
Local AS: 65000 Peer AS: 65500
Age: 2:55:31 Metric2: 0
Task: BGP_65500.10.1.0.1+64631
Announcement bits (3): 2-KRT 3-BGP_RT_Background 4-Resolve tree 1
AS path: 65500 I
Accepted Multipath
Localpref: 100
Router ID: 10.255.14.179
Indirect next hops: 1
Protocol next hop: 10.1.10.10
Indirect next hop: 91c0000 262142
Indirect path forwarding next hops: 2
Next hop type: Router
Next hop: 10.1.0.1 via fe-1/2/0.0
Next hop: 10.1.1.1 via fe-1/2/2.0
10.1.10.10/32 Originating RIB: inet.0
Node path count: 1
Forwarding nexthops: 2
Nexthop: 10.1.0.1 via fe-1/2/0.0
Nexthop: 10.1.1.1 via fe-1/2/2.0
BGP Preference: 170/-101
Next hop type: Indirect
Address: 0x90c44d8
Next-hop reference count: 4
Source: 10.1.1.1
Next hop type: Router, Next hop index: 262143
Next hop: 10.1.0.1 via fe-1/2/0.0, selected
Next hop: 10.1.1.1 via fe-1/2/2.0
Protocol next hop: 10.1.10.10
Indirect next hop: 91c0000 262142
State: <NotBest Ext>
Inactive reason: Not Best in its group - Update source
Local AS: 65000 Peer AS: 65500
Age: 2:55:27 Metric2: 0
Task: BGP_65500.10.1.1.1+53260
AS path: 65500 I
Accepted
Localpref: 100
Router ID: 10.255.14.179
Indirect next hops: 1
Protocol next hop: 10.1.10.10
Indirect next hop: 91c0000 262142
Indirect path forwarding next hops: 2
Next hop type: Router
Next hop: 10.1.0.1 via fe-1/2/0.0
Next hop: 10.1.1.1 via fe-1/2/2.0
10.1.10.10/32 Originating RIB: inet.0
Node path count: 1
Forwarding nexthops: 2
Nexthop: 10.1.0.1 via fe-1/2/0.0
Nexthop: 10.1.1.1 via fe-1/2/2.0
Significado
El resultado muestra que el dispositivo R1 tiene una ruta a la red 10.1.230.0 con la función multirruta habilitada (Accepted Multipath). La salida también muestra que la ruta tiene un siguiente salto indirecto de 10.1.10.10.
Desactivación y reactivación de la instrucción accept-remote-nexthop
Propósito
Asegúrese de que la ruta multirruta con el siguiente salto indirecto se elimina de la tabla de enrutamiento cuando desactive la accept-remote-nexthop instrucción.
Acción
-
En el modo de configuración, escriba el
deactivate protocols bgp accept-remote-nexthopcomando.user@R1# deactivate protocols bgp accept-remote-nexthop user@R1# commit
-
Desde el modo operativo, introduzca el
show route 10.1.230.0comando.user@R1> show route 10.1.230.0
-
Desde el modo de configuración, reactive la instrucción ingresando el
activate protocols bgp accept-remote-nexthopcomando.user@R1# activate protocols bgp accept-remote-nexthop user@R1# commit
-
Desde el modo operativo, vuelva a introducir el
show route 10.1.230.0comando.user@R1> show route 10.1.230.0 inet.0: 11 destinations, 13 routes (11 active, 0 holddown, 0 hidden) Restart Complete + = Active Route, - = Last Active, * = Both 10.1.230.0/23 *[BGP/170] 03:13:19, localpref 100 AS path: 65500 I > to 10.1.0.1 via fe-1/2/0.0 to 10.1.1.1 via fe-1/2/2.0 [BGP/170] 03:13:15, localpref 100, from 10.1.1.1 AS path: 65500 I > to 10.1.0.1 via fe-1/2/0.0 to 10.1.1.1 via fe-1/2/2.0
Significado
Cuando se desactiva la accept-remote-nexthop instrucción, la ruta de multirruta a la red 10.1.230.0 se elimina de la tabla de enrutamiento.
Descripción del equilibrio de carga para el tráfico de BGP con ancho de banda desigual asignado a las rutas
La opción multirruta elimina los criterios de desempate del proceso de decisión de ruta activo, lo que permite que las rutas de BGP de igual costo aprendidas de varias fuentes se instalen en la tabla de reenvío. Sin embargo, cuando las rutas disponibles no tienen el mismo costo, es posible que desee equilibrar la carga del tráfico de forma asimétrica.
Una vez que se instalan varios saltos siguientes en la tabla de reenvío, el algoritmo de equilibrio de carga por prefijo de Junos OS selecciona un próximo salto de reenvío específico. Este proceso aplica un hash a las direcciones de origen y destino de un paquete para asignar de forma determinística el emparejamiento de prefijos a uno de los próximos saltos disponibles. La asignación por prefijo funciona mejor cuando a la función hash se le presenta un gran número de prefijos, como podría ocurrir en un intercambio de emparejamiento por Internet, y sirve para evitar el reordenamiento de paquetes entre pares de nodos que se comunican.
Una red empresarial normalmente desea alterar el comportamiento predeterminado para evocar un algoritmo de equilibrio de carga por paquete . Cada paquete se enfatiza aquí porque su uso es un nombre inapropiado que se deriva del comportamiento histórico del procesador ASIC de Internet original. En realidad, los enrutadores actuales de Juniper Networks admiten el equilibrio de carga por prefijo (predeterminado) y por flujo. Esto último implica hash en varios encabezados de capa 3 y capa 4, incluidas partes de la dirección de origen, la dirección de destino, el protocolo de transporte, la interfaz entrante y los puertos de aplicación. El efecto es que ahora los flujos individuales se cifran en un siguiente salto específico, lo que da como resultado una distribución más uniforme entre los próximos saltos disponibles, especialmente cuando se enruta entre menos pares de origen y destino.
Con el equilibrio de carga por paquete, los paquetes que comprenden una corriente de comunicación entre dos puntos de conexión pueden volver a secuenciarse, pero los paquetes dentro de flujos individuales mantienen una secuencia correcta. Ya sea que opte por un equilibrio de carga por prefijo o por paquete, la asimetría de los vínculos de acceso puede presentar un desafío técnico. En cualquier caso, los prefijos o flujos que se asignan, por ejemplo, a un vínculo T1 mostrarán un rendimiento degradado en comparación con los flujos que se asignan, por ejemplo, a un vínculo de acceso Ethernet de alta velocidad. Peor aún, con cargas de tráfico pesadas, es probable que cualquier intento de equilibrio de carga equitativo resulte en la saturación total del vínculo T1 y la interrupción de la sesión derivada de la pérdida de paquetes.
Afortunadamente, la implementación de BGP de Juniper Networks admite la noción de una comunidad de ancho de banda. Esta comunidad extendida codifica el ancho de banda de un próximo salto dado y, cuando se combina con multirruta, el algoritmo de equilibrio de carga distribuye los flujos a través del conjunto de los siguientes saltos proporcionalmente a sus anchos de banda relativos. Dicho de otra manera, si tiene un próximo salto de 10 Mbps y uno de 1 Mbps, en promedio nueve flujos se asignarán al próximo salto de alta velocidad por cada uno que use la velocidad baja.
El uso de la comunidad de ancho de banda del BGP solo se admite con el equilibrio de carga por paquete.
La tarea de configuración tiene dos partes:
Configure las sesiones de emparejamiento de BGP externo (EBGP), habilite la multirruta y defina una política de importación para etiquetar rutas con una comunidad de ancho de banda que refleje la velocidad del enlace.
Habilite el equilibrio de carga por paquete (en realidad por flujo) para una distribución óptima del tráfico.
Ver también
Comunidad de ancho de banda de vínculo BGP
Descripción general
Dentro de una implementación de BGP, una comunidad extendida de ancho de banda de vínculo codifica el ancho de banda de un próximo salto determinado. El BGP ayuda a equilibrar la carga del tráfico mediante la comunicación de las velocidades de los vínculos del BGP a los pares remotos. Cuando usted (el administrador de red) combina una comunidad de ancho de banda de vínculo con multirruta, el algoritmo de equilibrio de carga de su elección distribuye los flujos de tráfico entre el conjunto de saltos siguientes proporcionalmente a sus anchos de banda relativos.
Cuando la comunidad extendida de ancho de banda de vínculo del BGP es un atributo transitivo en sistemas autónomos (AS), el grupo BGP anuncia la comunidad extendida de ancho de banda de vínculo a los AS vecinos. Puede optar por usar la comunidad de ancho de banda de vínculo del BGP como un atributo no transitivo para que los enrutadores eliminen la comunidad de ancho de banda de vínculo en el límite del AS. El grupo BGP no anuncia comunidades de ancho de banda de vínculo no transitivo a vecinos de BGP externos (EBGP).
También puede configurar el BGP para que detecte automáticamente el ancho de banda e importe la comunidad a nivel de grupo o vecino. Con esta función de detección automática de ancho de banda de vínculo, la red puede establecer automáticamente el valor de ancho de banda de vínculo en la velocidad de la interfaz mediante la cual el dispositivo recibió la ruta BGP.
Solo el equilibrio de carga por paquete admite la comunidad de ancho de banda de vínculo BGP.
Beneficios
-
Con la multirruta habilitada, el ancho de banda de vínculo proporciona una multirruta ponderada de igual costo (WECMP) para un equilibrio de carga desigual.
-
Garantiza que los vínculos de ancho de banda alto transporten más flujos que los vínculos de ancho de banda bajo.
-
Reduce la probabilidad de congestión del tráfico.
Configuración
Ancho de banda
De forma predeterminada, la comunidad de ancho de banda de vínculo es transitiva. Puede usar cualquiera de estas instrucciones para configurar la comunidad de ancho de banda de vínculo como transitiva:
set policy-options community name members bandwidth:value
set policy-options community name members bandwidth-transitive:value
Para que no sea transitivo, use la siguiente configuración:
set policy-options community policy-name members bandwidth-non-transitive:value
Anulación no transitiva
Puede anular una configuración no transitiva para que un grupo de BGP envíe la comunidad extendida de ancho de banda de vínculo a través de una sesión de EBGP, incluso cuando el ancho de banda de vínculo no sea transitivo. Para enviar la comunidad de ancho de banda de vínculo no transitivo a través de un vecino de EBGP, incluya la siguiente configuración:
set protocols bgp group group-name send-non-transitive-link-bandwidth
La send-non-transitive-link-bandwidth instrucción no diferencia entre la comunidad de ancho de banda de vínculo originada y la que se ha recibido y vuelto a anunciar. Cuando habilita esta opción, el BGP anuncia todas las comunidades de ancho de banda de vínculo no transitivo al vecino del EBGP.
Ancho de banda agregado
De forma predeterminada, la comunidad agregada de ancho de banda de vínculo es transitiva. Puede usar cualquiera de estas instrucciones para configurar la comunidad de ancho de banda de vínculo como transitiva:
set policy-options policy-statement name then aggregate-bandwidth
set policy-options policy-statement name then aggregate-bandwidth transitive
Para que no sea transitivo, use la siguiente configuración:
set policy-options policy-statement policy-name then aggregate-bandwidth non-transitive
Para dividir el ancho de banda total del vínculo por el número de pares del grupo de publicidad, habilite la divide-equal instrucción:
set policy-options policy-statement policy-name then aggregate-bandwidth divide-equal
Detección automática
Solo puede habilitar la detección automática para sesiones de EBGP de un solo salto.
Configure la detección automática para el grupo BGP.
Configure la
auto-senseinstrucción en laneighborjerarquía para detectar y almacenar el ancho de banda hacia ese vecino del BGP. Configúrelo en lagroupjerarquía para detectar y almacenar el ancho de banda de todos los vecinos de ese grupo de BGP:set protocols bgp group group-name link-bandwith auto-sense set protocols bgp group group-name neighbor link-bandwith auto-sense
Configure la política de importación con
auto-link-bandwidthset totransitiveonon-transitive. Si no especifica, de forma predeterminadaauto-link-bandwidthes transitivo:set protocols bgp group group-name import policy-name set policy-options policy-statement policy-name then auto-link-bandwidth non-transitive
(Opcional) Para suprimir cambios frecuentes en el valor de ancho de banda del vínculo cuando aumenta el ancho de banda, puede configurar el temporizador de espera de detección automática. El temporizador de espera solo se activa cuando aumenta el ancho de banda. De forma predeterminada, el temporizador se establece en 60 segundos:
set protocols bgp group group-name link-bandwith auto-sense hold-down time-in-seconds
Verificación
Compruebe que la configuración se ha realizado correctamente mediante los siguientes comandos:
-
show route receive-protocol bgp peer-ip-address extensive -
show route advertising-protocol bgp peer-ip-address extensive -
show route address extensive -
show bgp neighbor address
Ejemplo: Equilibrio de carga de tráfico de BGP con ancho de banda desigual asignado a las rutas
En este ejemplo, se muestra cómo configurar el BGP para seleccionar varias rutas de costo desigual como rutas activas.
Las comunidades de BGP pueden ayudarlo a controlar la política de enrutamiento. Un ejemplo de un buen uso para las comunidades de BGP es el equilibrio de carga desigual. Cuando un enrutador de borde del sistema autónomo (ASBR) recibe rutas de vecinos de BGP externos (EBGP) conectados directamente, el ASBR anuncia esas rutas a vecinos internos mediante anuncios de IBGP. En las versiones de IBGP, puede asociar la comunidad de ancho de banda de vínculo para comunicar el ancho de banda del vínculo externo anunciado. Esto resulta útil cuando hay varios vínculos externos disponibles y desea realizar un equilibrio de carga desigual en los vínculos. Configure la comunidad extendida de ancho de banda de vínculo en todos los vínculos de entrada del AS. La información de ancho de banda de la comunidad extendida link-bandwidth se basa en el ancho de banda configurado del vínculo EBGP. No se basa en la cantidad de tráfico del vínculo. Junos OS admite el ancho de banda de vínculo BGP y el equilibrio de carga de multirutas, como se describe en el borrador de Internet draft-ietf-idr-link-bandwidth-06, Comunidad extendida de ancho de banda de vínculo BGP.
Requisitos
Antes de empezar:
Configure las interfaces de los dispositivos.
Configure un protocolo de puerta de enlace interior (IGP).
Configure BGP.
Configure una política de enrutamiento que exporte rutas (como rutas directas o rutas IGP) de la tabla de enrutamiento al BGP.
Descripción general
En este ejemplo, el dispositivo R1 está en el AS 64500 y está conectado a los dispositivos R2 y R3, que están en el AS 64501.
En el ejemplo se utiliza la comunidad extendida de ancho de banda.
De forma predeterminada, cuando se utiliza la multirruta BGP, el tráfico se distribuye equitativamente entre las distintas rutas calculadas. La comunidad extendida de ancho de banda permite agregar un atributo adicional a las rutas de BGP, lo que permite que el tráfico se distribuya de manera desigual. La aplicación principal es un escenario en el que existen múltiples rutas externas para una red dada con capacidades de ancho de banda asimétrico. En tal escenario, puede etiquetar las rutas recibidas con la comunidad extendida de ancho de banda. Cuando la multirruta BGP (interna o externa) funciona entre rutas que contienen el atributo bandwidth, el motor de reenvío puede distribuir el tráfico de manera desigual según el ancho de banda correspondiente a cada ruta.
Cuando el BGP tiene varias rutas candidatas disponibles para fines de multirruta, el BGP no realiza un equilibrio de carga de costos desigual según la comunidad de ancho de banda, a menos que todas las rutas candidatas tengan este atributo.
La aplicabilidad de la comunidad extendida de ancho de banda está limitada por las restricciones bajo las cuales la multirruta de BGP acepta múltiples rutas para su consideración. Explícitamente, la distancia del IGP, en lo que respecta al BGP, entre el enrutador que realiza el equilibrio de carga y los múltiples puntos de salida debe ser la misma. Esto se puede lograr mediante el uso de una malla completa de rutas conmutadas por etiquetas (LSP) que no rastrean la métrica de IGP correspondiente. Sin embargo, en una red en la que el retardo de propagación de los circuitos es significativo (por ejemplo, si hay circuitos de larga distancia), a menudo es valioso tener en cuenta las características de retardo de los diferentes trayectos.
Configure la comunidad de ancho de banda de la siguiente manera:
[edit policy-options] user@host# set community members bandwidth:[1-65535]:[0-4294967295]
El primer número de 16 bits representa el sistema autónomo local. El segundo número de 32 bits representa el ancho de banda del vínculo en bytes por segundo.
Por ejemplo:
[edit policy-options] user@host# show community bw-t1 members bandwidth:10458:193000; community bw-t3 members bandwidth:10458:5592000; community bw-oc3 members bandwidth:10458:19440000;
Cuando 10458 es el número de AS local. Los valores corresponden al ancho de banda de las rutas T1, T3 y OC-3 en bytes por segundo. No es necesario que el valor especificado como valor de ancho de banda coincida con el ancho de banda real de una interfaz específica. Los factores de balance utilizados se calculan en función del ancho de banda total especificado. Para etiquetar una ruta con esta comunidad extendida, defina una instrucción de política de la siguiente manera:
[edit policy-options]
user@host# show
policy-statement link-bw-t1 {
then {
community set bw-t1;
}
accept;
}
Aplique esto como una política de importación en las sesiones de emparejamiento del BGP que se enfrentan a los vínculos de ancho de banda asimétricos. Aunque en teoría el atributo de comunidad se puede agregar o eliminar en cualquier punto de la red, en el escenario descrito anteriormente, aplicar la comunidad como una política de importación en la sesión de emparejamiento de EBGP frente al vínculo externo permite que ese atributo influya en la decisión de multirruta local y es potencialmente más fácil de administrar.
Topología
En la figura 3 se muestra la topología utilizada en este ejemplo.
BGP
Configuración rápida de la CLI muestra la configuración de todos los dispositivos de la Figura 3. En la sección #d15e120__d15e383 se describen los pasos del dispositivo R1.
Configuración
Procedimiento
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red y, luego, copie y pegue los comandos en la CLI en el nivel jerárquico [edit] .
Dispositivo R1
set interfaces ge-1/2/0 unit 0 description R1->R3 set interfaces ge-1/2/0 unit 0 family inet address 10.0.0.1/30 set interfaces ge-1/2/1 unit 0 description R1->R2 set interfaces ge-1/2/1 unit 0 family inet address 10.0.1.2/30 set interfaces lo0 unit 0 family inet address 192.168.0.1/32 set protocols bgp group external type external set protocols bgp group external import bw-dis set protocols bgp group external peer-as 64501 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.1.1 set protocols bgp group external neighbor 10.0.0.2 set policy-options policy-statement bw-dis term a from protocol bgp set policy-options policy-statement bw-dis term a from neighbor 10.0.1.1 set policy-options policy-statement bw-dis term a then community add bw-high set policy-options policy-statement bw-dis term a then accept set policy-options policy-statement bw-dis term b from protocol bgp set policy-options policy-statement bw-dis term b from neighbor 10.0.0.2 set policy-options policy-statement bw-dis term b then community add bw-low set policy-options policy-statement bw-dis term b then accept set policy-options policy-statement loadbal from route-filter 10.0.0.0/16 orlonger set policy-options policy-statement loadbal then load-balance per-packet set policy-options community bw-high members bandwidth:65000:60000000 set policy-options community bw-low members bandwidth:65000:40000000 set routing-options autonomous-system 64500 set routing-options forwarding-table export loadbal
Dispositivo R2
set interfaces ge-1/2/0 unit 0 description R2->R1 set interfaces ge-1/2/0 unit 0 family inet address 10.0.1.1/30 set interfaces ge-1/2/1 unit 0 description R2->R3 set interfaces ge-1/2/1 unit 0 family inet address 10.0.2.2/30 set interfaces ge-1/2/1 unit 0 family iso set interfaces lo0 unit 0 family inet address 192.168.0.2/32 set interfaces lo0 unit 0 family iso address 49.0001.1921.6800.0002.00 set protocols bgp group external type external set protocols bgp group external export bgp-default set protocols bgp group external export send-direct set protocols bgp group external peer-as 64500 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.1.2 set protocols isis interface ge-1/2/1.0 set protocols isis interface lo0.0 set policy-options policy-statement bgp-default from protocol static set policy-options policy-statement bgp-default from route-filter 172.16.0.0/16 exact set policy-options policy-statement bgp-default then accept set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set routing-options static route 172.16.0.0/16 discard set routing-options static route 172.16.0.0/16 no-install set routing-options autonomous-system 64501
Dispositivo R3
set interfaces ge-1/2/0 unit 0 description R3->R2 set interfaces ge-1/2/0 unit 0 family inet address 10.0.2.1/30 set interfaces ge-1/2/0 unit 0 family iso set interfaces ge-1/2/1 unit 0 description R3->R1 set interfaces ge-1/2/1 unit 0 family inet address 10.0.0.2/30 set interfaces lo0 unit 0 family inet address 192.168.0.3/32 set interfaces lo0 unit 0 family iso address 49.0001.1921.6800.0003.00 set protocols bgp group external type external set protocols bgp group external export send-direct set protocols bgp group external export bgp-default set protocols bgp group external peer-as 64500 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.0.1 set protocols isis interface ge-1/2/0.0 set protocols isis interface lo0.0 set policy-options policy-statement bgp-default from protocol static set policy-options policy-statement bgp-default from route-filter 172.16.0.0/16 exact set policy-options policy-statement bgp-default then accept set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set routing-options static route 172.16.0.0/16 discard set routing-options static route 172.16.0.0/16 no-install set routing-options autonomous-system 64501
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar las sesiones de par BGP:
Configure las interfaces.
user@R1# set ge-1/2/0 unit 0 description R1->R3 user@R1# set ge-1/2/0 unit 0 family inet address 10.0.0.1/30 user@R1# set ge-1/2/1 unit 0 description R1->R2 user@R1# set ge-1/2/1 unit 0 family inet address 10.0.1.2/30 user@R1# set lo0 unit 0 family inet address 192.168.0.1/32
Configure el grupo BGP.
[edit protocols bgp group external] user@R1# set type external user@R1# set import bw-dis user@R1# set peer-as 64501 user@R1# set neighbor 10.0.1.1 user@R1# set neighbor 10.0.0.2
Habilite el grupo BGP para utilizar varias rutas.
Nota:Para deshabilitar la comprobación predeterminada que requiere que las rutas aceptadas por la multirruta BGP tengan el mismo sistema autónomo vecino (AS), incluya la
multiple-asopción. Utilice estamultiple-asopción si los vecinos están en diferentes AS.[edit protocols bgp group external] user@R1# set multipath
Configure la política de equilibrio de carga.
[edit policy-options policy-statement loadbal] user@R1# set from route-filter 10.0.0.0/16 orlonger user@R1# set then load-balance per-packet
Aplique la política de equilibrio de carga.
[edit routing-options] user@R1# set forwarding-table export loadbal
Configure los miembros de la comunidad del BGP.
En este ejemplo, se supone un ancho de banda de 1 Gbps y asigna el 60 por ciento a bw-high y el 40 % a bw-low. No es necesario que el ancho de banda de referencia sea el mismo que el ancho de banda del vínculo.
[edit policy-options] user@R1# set community bw-high members bandwidth:65000:60000000 user@R1# set community bw-low members bandwidth:65000:40000000
Configure la política de distribución del ancho de banda.
[edit policy-options bw-dis] user@R1# set term a from protocol bgp user@R1# set term a from neighbor 10.0.1.1 user@R1# set term a then community add bw-high user@R1# set term a then accept user@R1# set term b from protocol bgp user@R1# set term b from neighbor 10.0.0.2 user@R1# set term b then community add bw-low user@R1# set term b then accept
Configure el número de sistema autónomo local (AS).
[edit routing-options] user@R1# set autonomous-system 64500
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R1# show interfaces
ge-1/2/0 {
unit 0 {
description R1->R3;
family inet {
address 10.0.0.1/30;
}
}
}
ge-1/2/1 {
unit 0 {
description R1->R2;
family inet {
address 10.0.1.2/30;
}
}
}
lo0 {
unit 0 {
family inet {
address 192.168.0.1/32;
}
}
}
user@R1# show protocols
bgp {
group external {
type external;
import bw-dis;
peer-as 64501;
multipath;
neighbor 10.0.1.1;
neighbor 10.0.0.2;
}
}
user@R1# show policy-options
policy-statement bw-dis {
term a {
from {
protocol bgp;
neighbor 10.0.1.1;
}
then {
community add bw-high;
accept;
}
}
term b {
from {
protocol bgp;
neighbor 10.0.0.2;
}
then {
community add bw-low;
accept;
}
}
}
policy-statement loadbal {
from {
route-filter 10.0.0.0/16 orlonger;
}
then {
load-balance per-packet;
}
}
community bw-high members bandwidth:65000:60000000;
community bw-low members bandwidth:65000:40000000;
user@R1# show routing-options
autonomous-system 64500;
forwarding-table {
export loadbal;
}
Cuando termine de configurar el dispositivo, ingrese commit desde el modo de configuración.
Verificación
Confirme que la configuración funcione correctamente:
Verificación de rutas
Propósito
Verifique que ambas rutas estén seleccionadas y que los siguientes saltos en las rutas muestren un saldo del 60 %/40 %.
Acción
Desde el modo operativo, ejecute el show route protocol bgp detail comando.
user@R1> show route 172.16/16 protocol bgp detail
inet.0: 9 destinations, 13 routes (9 active, 0 holddown, 0 hidden)
172.16.0.0/16 (2 entries, 1 announced)
*BGP Preference: 170/-101
Next hop type: Router, Next hop index: 262143
Address: 0x93fc078
Next-hop reference count: 3
Source: 10.0.0.2
Next hop: 10.0.0.2 via ge-1/2/0.0 balance 40%
Next hop: 10.0.1.1 via ge-1/2/1.0 balance 60%, selected
State: **Active Ext>
Local AS: 64500 Peer AS: 64501
Age: 3:22:55
Task: BGP_64501.10.0.0.2+55344
Announcement bits (1): 0-KRT
AS path: 64501 I
Communities: bandwidth:65000:40000000
Accepted Multipath
Localpref: 100
Router ID: 192.168.0.3
BGP Preference: 170/-101
Next hop type: Router, Next hop index: 658
Address: 0x9260520
Next-hop reference count: 4
Source: 10.0.1.1
Next hop: 10.0.1.1 via ge-1/2/1.0, selected
State: <NotBest Ext>
Inactive reason: Not Best in its group - Active preferred
Local AS: 64500 Peer AS: 64501
Age: 3:22:55
Task: BGP_65001.10.0.1.1+62586
AS path: 64501 I
Communities: bandwidth:65000:60000000
Accepted MultipathContrib
Localpref: 100
Router ID: 192.168.0.2
user@R1> show route 10.0.2.0 protocol bgp detail
inet.0: 9 destinations, 13 routes (9 active, 0 holddown, 0 hidden)
10.0.2.0/30 (2 entries, 1 announced)
*BGP Preference: 170/-101
Next hop type: Router, Next hop index: 262143
Address: 0x93fc078
Next-hop reference count: 3
Source: 10.0.1.1
Next hop: 10.0.0.2 via ge-1/2/0.0 balance 40%
Next hop: 10.0.1.1 via ge-1/2/1.0 balance 60%, selected
State: <Active Ext>
Local AS: 64500 Peer AS: 64501
Age: 3:36:37
Task: BGP_65001.10.0.1.1+62586
Announcement bits (1): 0-KRT
AS path: 64501 I
Communities: bandwidth:65000:60000000
Accepted Multipath
Localpref: 100
Router ID: 192.168.0.2
BGP Preference: 170/-101
Next hop type: Router, Next hop index: 657
Address: 0x92604d8
Next-hop reference count: 4
Source: 10.0.0.2
Next hop: 10.0.0.2 via ge-1/2/0.0, selected
State: <NotBest Ext>
Inactive reason: Not Best in its group - Active preferred
Local AS: 64500 Peer AS: 65001
Age: 3:36:36
Task: BGP_65001.10.0.0.2+55344
AS path: 64501 I
Communities: bandwidth:65000:40000000
Accepted MultipathContrib
Localpref: 100
Router ID: 192.168.0.3
Significado
La ruta activa, indicada con un asterisco (*), tiene dos saltos siguientes: 10.0.1.1 y 10.0.0.2 al destino 172.16/16.
Del mismo modo, la ruta activa, indicada con un asterisco (*), tiene dos saltos siguientes: 10.0.1.1 y 10.0.0.2 al destino 10.0.2.0.
En ambos casos, el siguiente salto 10.0.1.1 se copia de la ruta inactiva a la ruta activa.
El equilibrio del 40 por ciento y el 60 por ciento se muestra en la show route salida. Esto indica que el tráfico se distribuye entre los dos saltos siguientes y que el 60 % del tráfico sigue la primera ruta, mientras que el 40 % sigue la segunda ruta.
Anuncio del ancho de banda agregado en vínculos de BGP externos para la descripción general del equilibrio de carga
Un par de par BGP que recibe varias rutas de sus pares internos equilibra la carga del tráfico entre estas rutas. En versiones anteriores a Junos OS versión 17.4, un anunciador BGP que recibía varias rutas de sus pares internos anunciaba solo el ancho de banda del vínculo asociado con la ruta activa. El BGP utiliza la comunidad extendida de ancho de banda de vínculos para anunciar el ancho de banda agregado de varias rutas a través de vínculos externos. El BGP calcula el ancho de banda agregado de las múltiples rutas que tienen una asignación de ancho de banda desigual y anuncia el ancho de banda agregado a los pares de BGP externos. Se puede configurar un umbral para el ancho de banda agregado para restringir el uso de ancho de banda de un grupo BGP. Las rutas IPv4 e IPv6, incluidas las direcciones de difusión ancha, admiten ancho de banda agregado.
Para anunciar el ancho de banda agregado de rutas multirruta y establecer un umbral máximo, configure una política con aggregate-bandwidth y limit-bandwidth actions en el nivel de jerarquía [edit policy-options policy-statement name then].
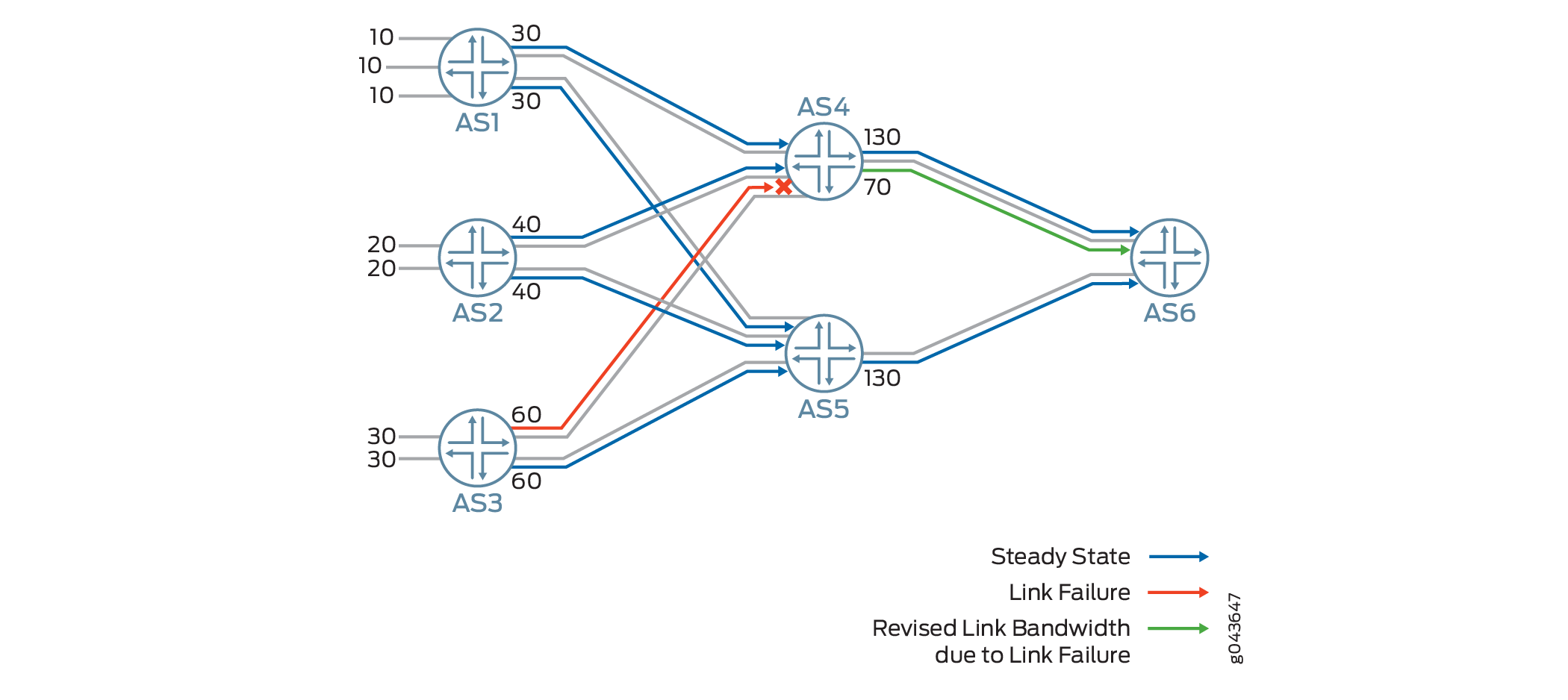 carga
carga
En la figura 4, el sistema autónomo 1 (AS1) agrega el ancho de banda de sus 3 rutas multirruta a un prefijo remoto y lo anuncia al sistema autónomo 4 (AS4) con un ancho de banda de 30 mediante la comunidad extendida de ancho de banda de vínculo. En caso de que se produzca un error en un vínculo entre el AS3 y AS4, el AS4 restará el 60 del ancho de banda que anuncia a AS6 y modifica el ancho de banda que anuncia de 130 a 70.
Cuando se produce un error en uno de los vínculos multirruta, el BGP vuelve a anunciar la ruta con el ancho de banda del vínculo con error restado de la comunidad de ancho de banda del vínculo de salida. Si se descubre que el ancho de banda del vínculo agregado supera el límite configurado, el ancho de banda agregado anunciado se trunca al límite de ancho de banda del vínculo configurado entre los dos pares.
Cuando un par BGP propaga rutas de multirruta configuradas con una comunidad de ancho de banda agregada, se agrega una nueva comunidad de ancho de banda de vínculo con la suma del ancho de banda de las comunidades de ancho de banda entrantes o ese prefijo. El ancho de banda de vínculo disponible se deriva dinámicamente de la velocidad de la interfaz. El ancho de banda del vínculo se envía como una comunidad extendida transitiva.
BGP puede comunicar velocidades de vínculo a pares remotos, lo que permite una mejor optimización de la distribución del tráfico para el equilibrio de carga. Un grupo BGP puede enviar la comunidad extendida no transitiva de ancho de banda de vínculo a través de una sesión de EBGP para comunidades extendidas de ancho de banda de vínculo originadas o recibidas y anunciadas. Para configurar la comunidad extendida de ancho de banda de vínculo no transitivo:
-
Incluya el
bandwidth-non-transitive:valueen la política de exportación en el[edit policy-options community name members community-ids]nivel jerárquico. -
Incluya la
send-non-transitive-link-bandwidthopción en el[edit protocols bgp group (Protocols BGP) group-name]nivel de jerarquía de enviar una comunidad extendida de ancho de banda de vínculo no transitivo a los vecinos del EBGP solo para comunidades de ancho de banda de vínculo.
Para permitir que el dispositivo detecte y adjunte automáticamente la comunidad de ancho de banda de vínculo en una ruta en el momento de la importación, incluya la instrucción auto-sense en el [edit protocols bgp group link-bandwidth] nivel de jerarquía. Esta característica facilita la integración de dispositivos con diferentes velocidades de transmisión dentro de la red, lo que permite una distribución eficiente del tráfico basada en la velocidad del enlace.
Ver también
Ejemplo: Configurar una política para anunciar el ancho de banda agregado en vínculos de BGP externos para equilibrar la carga
En este ejemplo, se muestra cómo configurar una política para anunciar el ancho de banda agregado en vínculos de BGP externos para el equilibrio de carga y para especificar un umbral para el ancho de banda agregado configurado. El BGP suma el ancho de banda de vínculo disponible de varias rutas y calcula el ancho de banda agregado. En caso de que se produzca un error en un vínculo, el ancho de banda agregado se ajusta para reflejar el estado actual del ancho de banda disponible.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Cuatro enrutadores con capacidad de equilibrio de carga
-
Junos OS versión 17.4 o posterior ejecutándose en todos los dispositivos
Descripción general
A partir de la versión 17.4R1 de Junos OS, un anunciador BGP que recibe varias rutas de sus pares internos equilibra la carga del tráfico entre estas rutas. En versiones anteriores de Junos OS, un anunciador BGP que recibía varias rutas de sus pares internos anunciaba solo el ancho de banda del vínculo asociado con la ruta activa. El BGP usa una nueva comunidad extendida de ancho de banda de vínculo con el ancho de banda agregado para etiquetar varias rutas y anuncia el ancho de banda agregado para estas varias rutas en su vínculo ZDM. Para anunciar varias rutas agregadas, configure una política con aggregate-bandwidth y limit bandwidth actions en el nivel de jerarquía [edit policy-options policy-statement name then].
Topología
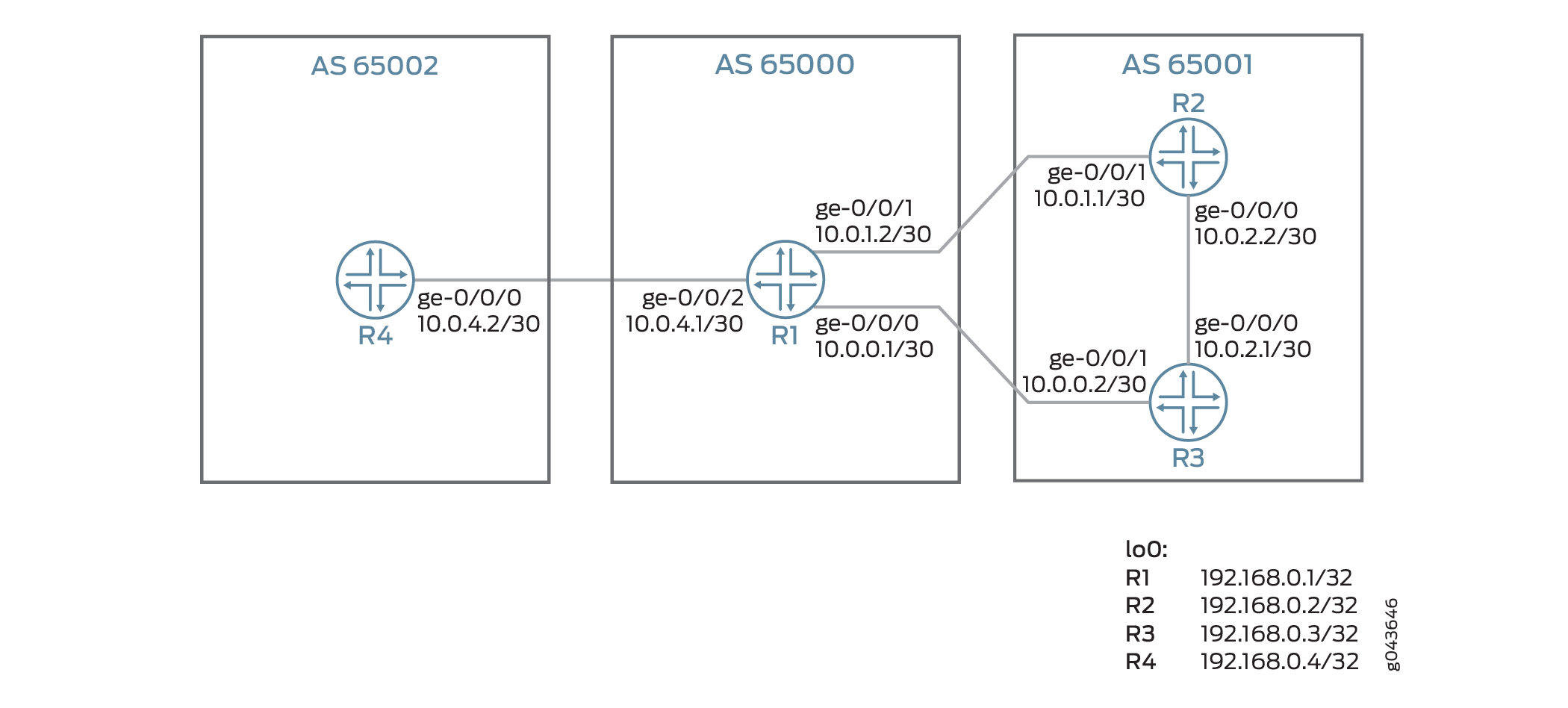 carga
carga
En la Figura 5, el enrutador R1 equilibra la carga del tráfico a un destino remoto a través del siguiente salto 10.0.1.1 en el enrutador R2 a 60 000 000 bytes por segundo y a través del 10.0.0.2 en el enrutador R3 a 40 000 000 bytes por segundo. El enrutador R1 anuncia el destino 10.0.2.0 al enrutador R4. El enrutador R1 calcula el agregado del ancho de banda disponible, que es de 100000000 bytes por segundo. Sin embargo, una política configurada en el enrutador R1 establece el umbral para el ancho de banda agregado en 80 000 000 bytes por segundo. Por lo tanto, R1 anuncia 80 000 000 bytes por segundo en lugar de los 10 000 000 bytes por segundo.
Si uno de los vínculos multirruta deja de funcionar, el ancho de banda del vínculo con errores no se agrega al ancho de banda agregado que se anuncia a los vecinos del BGP.
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese commit desde el [edit] modo de configuración.
Enrutador R1
set interfaces ge-0/0/0 unit 0 description R1->R3 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.1/30 set interfaces ge-0/0/1 unit 0 description R1->R2 set interfaces ge-0/0/1 unit 0 family inet address 10.0.1.2/30 set interfaces ge-0/0/2 unit 0 description R1->R4 set interfaces ge-0/0/2 unit 0 family inet address 10.0.4.1/30 set interfaces lo0 unit 0 family inet address 192.168.0.1/32 set routing-options autonomous-system 65000 set protocols bgp group external type external set protocols bgp group external import bw-dis set protocols bgp group external peer-as 65001 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.1.1 set protocols bgp group external neighbor 10.0.0.2 set protocols bgp group external2 type external set protocols bgp group external2 peer-as 65002 set policy-options policy-statement bw-dis term a from protocol bgp set policy-options policy-statement bw-dis term a from neighbor 10.0.1.1 set policy-options policy-statement bw-dis term a then community add bw-high set policy-options policy-statement bw-dis term a then accept set policy-options policy-statement bw-dis term b from protocol bgp set policy-options policy-statement bw-dis term b from neighbor 10.0.0.2 set policy-options policy-statement bw-dis term b then community add bw-low set policy-options policy-statement bw-dis term b then accept set policy-options policy-statement aggregate_bw_and_limit_capacity then aggregate-bandwidth set policy-options policy-statement aggregate_bw_and_limit_capacity then limit-bandwidth 80000000 set policy-options policy-statement aggregate_bw_and_limit_capacity then accept set protocols bgp group external2 neighbor 10.0.4.2 export aggregate_bw_and_limit_capacity set policy-options policy-statement loadbal from route-filter 10.0.0.0/16 orlonger set policy-options policy-statement loadbal then load-balance per-packet set routing-options forwarding-table export loadbal set policy-options community bw-high members bandwidth:65000:60000000 set policy-options community bw-low members bandwidth:65000:40000000
Enrutador R2
set interfaces ge-0/0/0 unit 0 description R2->R3 set interfaces ge-0/0/0 unit 0 family inet address 10.0.2.2/30 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/1 unit 0 description R2->R1 set interfaces ge-0/0/1 unit 0 family inet address 10.0.1.1/30 set interfaces lo0 unit 0 family inet address 192.168.0.2/32 set interfaces lo0 unit 0 family iso address 49.0001.1921.6800.0002.00 set routing-options static route 172.16.0.0/16 discard set routing-options static route 172.16.0.0/16 no-install set routing-options autonomous-system 65001 set protocols bgp group external type external set protocols bgp group external export bgp-default set protocols bgp group external export send-direct set protocols bgp group external peer-as 65000 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.1.2 set protocols isis interface ge-0/0/0.0 set protocols isis interface lo0.0 set policy-options policy-statement bgp-default from protocol static set policy-options policy-statement bgp-default from route-filter 172.16.0.0/16 exact set policy-options policy-statement bgp-default then accept set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept
Enrutador R3
set interfaces ge-0/0/0 description R3->R2 set interfaces ge-0/0/0 unit 0 family inet address 10.0.2.1/30 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/1 unit 0 description R3->R1 set interfaces ge-0/0/1 unit 0 family inet address 10.0.0.2/30 set interfaces lo0 unit 0 family inet address 192.168.0.3/32 set interfaces lo0 unit 0 family iso address 49.0001.1921.6800.0003.00 set routing-options static route 172.16.0.0/16 discard set routing-options static route 172.16.0.0/16 no-install set routing-options autonomous-system 65001 set protocols bgp group external type external set protocols bgp group external export bgp-default set protocols bgp group external export send-direct set protocols bgp group external peer-as 65000 set protocols bgp group external multipath set protocols bgp group external neighbor 10.0.0.1 set protocols isis interface ge-0/0/0.0 set protocols isis interface lo0.0 set policy-options policy-statement bgp-default from protocol static set policy-options policy-statement bgp-default from route-filter 172.16.0.0/16 exact set policy-options policy-statement bgp-default then accept set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept
Enrutador R4
set interfaces ge-0/0/0 unit 0 description R4->R1 set interfaces ge-0/0/0 unit 0 family inet address 10.0.4.2/30 set interfaces lo0 unit 0 family inet address 192.168.0.4/32 set routing-options autonomous-system 65002 set protocols bgp group external type external set protocols bgp group external peer-as 65000 set protocols bgp group external neighbor 10.0.4.1
Configuración de enrutadores, empezando por R1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar una política a fin de anunciar un ancho de banda agregado a los pares del BGP (a partir del enrutador R1):
Repita este procedimiento en los enrutadores R2, R3 y R4 después de modificar los nombres de interfaz, las direcciones y otros parámetros adecuados.
-
Configure las interfaces con direcciones IPv4.
>[edit interfaces] user@R1# set ge-0/0/0 unit 0 description R1->R3 user@R1# set ge-0/0/0 unit 0 family inet address 10.0.0.1/30 user@R1# set ge-0/0/1 unit 0 description R1->R2 user@R1# set ge-0/0/1 unit 0 family inet address 10.0.1.2/30 user@R1# set ge-0/0/2 unit 0 description R1->R4 user@R1# set ge-0/0/2 unit 0 family inet address 10.0.4.1/30
-
Configure la dirección de circuito cerrado.
[edit interfaces] user@R1# set lo0 unit 0 family inet address 192.168.0.1/32
-
Configure el sistema autónomo para los hosts BGP.
[edit routing-options] user@R1# set autonomous-system 65000
-
Configure EBGP en los enrutadores de borde externos.
[edit protocols] user@R1# set bgp group external type external user@R1# set bgp group external import bw-dis user@R1# set bgp group external peer-as 65001 user@R1# set bgp group external multipath user@R1# set bgp group external neighbor 10.0.1.1 user@R1# set bgp group external neighbor 10.0.0.2 user@R1# set bgp group external2 type external user@R1# set bgp group external2 peer-as 65002
-
Defina una política de distribución de ancho de banda para asignar una comunidad de ancho de banda alto al tráfico destinado al enrutador R3.
[edit policy-options] user@R1# set policy-statement bw-dis term a from protocol bgp user@R1# set policy-statement bw-dis term a from neighbor 10.0.1.1 user@R1# set policy-statement bw-dis term a then community add bw-high user@R1# set policy-statement bw-dis term a then accept
-
Defina una política de distribución de ancho de banda para asignar una comunidad de ancho de banda bajo al tráfico destinado al enrutador R2.
[edit policy-options] user@R1# set policy-statement bw-dis term b from protocol bgp user@R1# set policy-statement bw-dis term b from neighbor 10.0.0.2 user@R1# set policy-statement bw-dis term b then community add bw-low user@R1# set policy-statement bw-dis term b then accept
-
Active la función para anunciar un ancho de banda agregado de 80 000 000 bytes al enrutador par del EBGP R4 a través de sesiones de BGP.
[edit policy-options] user@R1# set policy-statement aggregate_bw_and_limit_capacity then aggregate-bandwidth user@R1# set policy-statement aggregate_bw_and_limit_capacity then limit-bandwidth 80000000 user@R1# set policy-statement aggregate_bw_and_limit_capacity then accept
-
Aplique la política de aggregate_bw_and limit_capacity al grupo
external2EBGP.[edit protocols] user@R1# set bgp group external2 neighbor 10.0.4.2 export aggregate_bw_and_limit_capacity
-
Defina una política de equilibrio de carga.
[edit policy-options] user@R1# set policy-statement loadbal from route-filter 10.0.0.0/16 orlonger user@R1# set policy-statement loadbal then load-balance per-packet
-
Aplique la política de equilibrio de carga.
[edit routing-options] user@R1# set forwarding-table export loadbal
-
Configure los miembros de la comunidad del BGP. El primer número de 16 bits representa el sistema autónomo local. El segundo número de 32 bits representa el ancho de banda del vínculo en bytes por segundo. Configure una
bw-highcomunidad con el 60 % de un enlace de 1 Gbps y otra comunidadbw-lowcon el 40 % de un enlace de 1 Gbps.Configure el 60 por ciento de un vínculo de 1 Gbps a la comunidad bw-high y el 40 % a la comunidad bw-low.
[edit policy-options] user@R1# set community bw-high members bandwidth:65000:60000000 user@R1# set community bw-low members bandwidth:65000:40000000
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show routing-optionsshow policy-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
[edit]
user@R1# show interfaces
interfaces {
ge-0/0/0 {
unit 0 {
description R1->R3;
family inet {
address 10.0.0.1/30;
}
}
}
ge-0/0/1 {
unit 0 {
description R1->R2;
family inet {
address 10.0.1.2/30;
}
}
}
ge-0/0/2 {
unit 0 {
description R1->R4;
family inet {
address 10.0.4.1/30;
}
}
}
lo0 {
unit 0 {
family inet {
address 192.168.0.1/32;
}
}
}
}
[edit]
user@R1# show protocols
protocols {
bgp {
group external {
type external;
import bw-dis;
peer-as 65001;
multipath;
neighbor 10.0.1.1;
neighbor 10.0.0.2;
}
group external2 {
type external;
peer-as 65002;
neighbor 10.0.4.2 {
export aggregate_bw_and_limit_capacity;
}
}
}
}
[edit]
user@R1# show routing-options
routing-options {
autonomous-system 65000;
forwarding-table {
export loadbal;
}
}
[edit]
user@R1# show policy-options
policy-options {
policy-statement bw-dis {
term a {
from {
protocol bgp;
neighbor 10.0.1.1;
}
then {
community add bw-high;
accept;
}
}
term b {
from {
protocol bgp;
neighbor 10.0.0.2;
}
then {
community add bw-low;
accept;
}
}
}
policy-statement aggregate_bw_and_limit_capacity {
then {
aggregate-bandwidth;
limit-bandwidth 80000000;
accept;
}
}
policy-statement loadbal {
from {
route-filter 10.0.0.0/16 orlonger;
}
then {
load-balance per-packet;
}
}
community bw-high members bandwidth:65000:60000000;
community bw-low members bandwidth:65000:40000000;
}
Verificación
- Verificar que la sesión BGP esté establecida
- Verificar que el ancho de banda agregado esté presente en cada ruta
- Verificar que el enrutador R1 anuncia el ancho de banda agregado a su enrutador vecino R4
Verificar que la sesión BGP esté establecida
Propósito
Para comprobar que el emparejamiento de BGP se completó y que se estableció una sesión de BGP entre los enrutadores,
Acción
user@R1> show bgp summary
Groups: 2 Peers: 3 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
12 8 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.0.0.2 65001 153 149 0 0 1:07:23 4/6/6/0 0/0/0/0
10.0.1.1 65001 229 226 0 0 1:41:44 4/6/6/0 0/0/0/0
10.0.4.2 65002 1227 1227 0 0 9:10:27 0/0/0/0 0/0/0/0
Significado
El enrutador R1 completó el emparejamiento con los enrutadores R2, R3 y R4.
Verificar que el ancho de banda agregado esté presente en cada ruta
Propósito
Para comprobar que la comunidad extendida está presente para cada ruta de ruta.
Acción
Desde el modo operativo, ejecute el show route protocol bgp detail comando.
user@R1> show route 10.0.2.0 protocol bgp detail
inet.0: 20 destinations, 26 routes (20 active, 0 holddown, 0 hidden)
10.0.2.0/30 (2 entries, 1 announced)
*BGP Preference: 170/-101
Next hop type: Router, Next hop index: 0
Address: 0xb618990
Next-hop reference count: 3
Source: 10.0.1.1
Next hop: 10.0.0.2 via ge-0/0/0.0 balance 40%
Session Id: 0x0
Next hop: 10.0.1.1 via ge-0/0/1.0 balance 60%, selected
Session Id: 0x0
State: <Active Ext>
Local AS: 65000 Peer AS: 65001
Age: 20:33
Validation State: unverified
Task: BGP_65001.10.0.1.1
Announcement bits (3): 0-KRT 2-BGP_Listen.0.0.0.0+179 3-BGP_RT_Background
AS path: 65001 I
Communities: bandwidth:65000:60000000
Accepted Multipath
Localpref: 100
Router ID: 128.49.121.137
BGP Preference: 170/-101
Next hop type: Router, Next hop index: 595
Address: 0xb7a1330
Next-hop reference count: 9
Source: 10.0.0.2
Next hop: 10.0.0.2 via ge-0/0/0.0, selected
Session Id: 0x141
State: <NotBest Ext>
Inactive reason: Not Best in its group - Active preferred
Local AS: 65000 Peer AS: 65001
Age: 20:33
Validation State: unverified
Task: BGP_65001.10.0.0.2
AS path: 65001 I
Communities: bandwidth:65000:40000000
Accepted MultipathContrib
Localpref: 100
Router ID: 128.49.121.132
Significado
Verificar que el enrutador R1 anuncia el ancho de banda agregado a su enrutador vecino R4
Propósito
Para comprobar que el enrutador R1 anuncia el ancho de banda agregado a sus vecinos externos.
Acción
user@R1> show route advertising-protocol bgp 10.0.4.2 10.0.2.0/30 detail
inet.0: 20 destinations, 26 routes (20 active, 0 holddown, 0 hidden)
* 10.0.2.0/30 (2 entries, 1 announced)
BGP group external2 type External
Nexthop: Self
AS path: [65000] 65001 I
Communities: bandwidth:65000:80000000
Significado
El enrutador R1 anuncia el ancho de banda agregado de 80 000 000 bytes a sus vecinos.
Descripción del anuncio de varias rutas a un solo destino en BGP
Los pares del BGP anuncian rutas entre sí en los mensajes de actualización. El BGP almacena sus rutas en la tabla de enrutamiento de Junos OS (inet.0). Para cada prefijo de la tabla de enrutamiento, el proceso de protocolo de enrutamiento selecciona una única mejor ruta, denominada ruta activa. A menos que configure el BGP para anunciar varias rutas al mismo destino, el BGP anuncia solo la ruta activa.
En lugar de anunciar solo la ruta activa a un destino, puede configurar el BGP para que anuncie varias rutas al destino. Dentro de un sistema autónomo (AS), la disponibilidad de múltiples puntos de salida para llegar a un destino proporciona los siguientes beneficios:
Tolerancia a errores: la diversidad de rutas conduce a una reducción del tiempo de restauración después de la falla. Por ejemplo, un borde después de recibir varias rutas al mismo destino puede precalcular una ruta de respaldo y tenerla lista para que, cuando la ruta principal deje de ser válida, el dispositivo de enrutamiento de borde pueda usar la copia de seguridad para restaurar rápidamente la conectividad. Sin una ruta de respaldo, el tiempo de restauración depende de la reconvergencia del BGP, que incluye mensajes de retiro y anuncio en la red antes de que se pueda aprender una nueva mejor ruta.
Equilibrio de carga: la disponibilidad de varias rutas para llegar al mismo destino permite el equilibrio de carga del tráfico si la ruta dentro del AS cumple con ciertas restricciones.
Mantenimiento: la disponibilidad de puntos de salida alternativos permite una operación de mantenimiento elegante de los enrutadores.
Se aplican las siguientes limitaciones al anuncio de varias rutas en BGP:
-
Familias de direcciones apoyadas:
-
IPv4 de unidifusión (
family inet unicast) -
IPv6 de unidifusión (
family inet6 unicast) -
IPv4 etiquetado como unidifusión (
family inet labeled-unicast) -
IPv6 etiquetado como unidifusión (
family inet6 labeled-unicast) -
VPN IPv4 de unidifusión (
family inet-vpn unicast) -
VPN IPv6 de unidifusión (
family inet6-vpn unicast)
En el siguiente ejemplo, se muestra la configuración de las familias de unidifusión VPN IPv4 y de unidifusión VPN IPv6:
bgp { group <group-name> { family inet-vpn unicast { add-path { send { include-backup-path include-backup-path; multipath; path-count path-count; path-selection-mode { (all-paths | equal-cost-paths); } prefix-policy [ policy-names ... ]; } receive; } family inet6-vpn unicast { add-path { send { include-backup-path include-backup-path; multipath; path-count path-count; path-selection-mode { (all-paths | equal-cost-paths); } prefix-policy [ policy-names ... ]; } receive; } } } -
-
Admitimos
add-pathpares BGP internos (IBGP) y BGP externos (EBGP).Nota:-
Se admite la recepción de ruta de adición para los pares IBGP y EBGP.
-
Solo se admite el envío de ruta de adición para pares de IBGP.
-
No se admite el envío de ruta de adición para pares de EBGP. Cuando intenta confirmar la configuración para el envío de ruta de adición para los pares EBGP, la CLI arroja un error de confirmación.
-
-
Solo instancia maestra. No admite instancias de enrutamiento.
-
Se admiten el reinicio elegante y el enrutamiento activo sin detención (NSR).
-
No es compatible con el protocolo de monitoreo BGP (BMP).
-
Las políticas de prefijo le permiten filtrar rutas en un enrutador configurado para anunciar varias rutas a un destino. Las políticas de prefijo solo pueden coincidir con prefijos. No pueden coincidir con atributos de ruta y no pueden cambiar los atributos de las rutas.
A partir de la versión 18.4R1 de Junos OS, el BGP puede anunciar un máximo de 2 rutas de adición de rutas, además de las varias rutas ECMP.
Para anunciar todas las rutas de adición hasta 64 rutas de adición o solo rutas de igual costo, inclúyalas path-selection-mode en el [edit protocols bgp group group-name family name addpath send] nivel de jerarquía. No puede habilitar ambos multipath y path-selection-mode al mismo tiempo.
Ver también
Ejemplo: Anuncio de varias rutas en BGP
En este ejemplo, los enrutadores BGP están configurados para anunciar varias rutas en lugar de anunciar solo la ruta activa. El anuncio de varias rutas en BGP se especifica en RFC 7911, Anuncio de varias rutas en BGP.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
Ocho dispositivos habilitados para BGP.
Cinco de los dispositivos habilitados para BGP no tienen que ser necesariamente enrutadores. Por ejemplo, pueden ser conmutadores Ethernet de la serie EX.
Tres de los dispositivos habilitados para BGP están configurados para enviar varias rutas o recibir varias rutas (o ambos enviar y recibir múltiples rutas). Estos tres dispositivos habilitados para BGP deben ser enrutadores de borde multiservicio de la serie M, plataformas de enrutamiento universal 5G de la serie MX o enrutadores de núcleo de la serie T.
Los tres enrutadores deben ejecutar la versión 11.4 o posterior de Junos OS.
Descripción general
Las siguientes instrucciones se utilizan para configurar varias rutas a un destino:
[edit protocols bgp group group-name family family] add-path { receive; send { include-backup-path include-backup-path; multipath; path-count path-count; path-selection-mode { (all-paths | equal-cost-paths); } prefix-policy [ policy-names ... ]; } }
En este ejemplo, el enrutador R5, R6 y R7 redistribuyen rutas estáticas en BGP. Los enrutadores R1 y R4 son reflectores de ruta. Los enrutadores R2 y R3 son clientes de Route Reflector R1. El enrutador R8 es un cliente para Route Reflector R4.
La reflexión de ruta es opcional cuando el anuncio de varias rutas está habilitado en BGP.
Con esta configuración, el add-path send path-count 6 enrutador R1 está configurado para enviar hasta seis rutas (por destino) al enrutador R4.
Con esta configuración, el add-path receive enrutador R4 está configurado para recibir varias rutas del enrutador R1.
Con esta configuración, el add-path send path-count 6 enrutador R4 está configurado para enviar hasta seis rutas al enrutador R8.
Con esta configuración, el add-path receive enrutador R8 se configura para recibir varias rutas del enrutador R4.
La add-path send prefix-policy allow_199 configuración de política (junto con el filtro de ruta correspondiente) limita al enrutador R4 a enviar varias rutas solo para la ruta 172.16.199.1/32.
Diagrama de topología
En la Figura 6 se muestra la topología utilizada en este ejemplo.
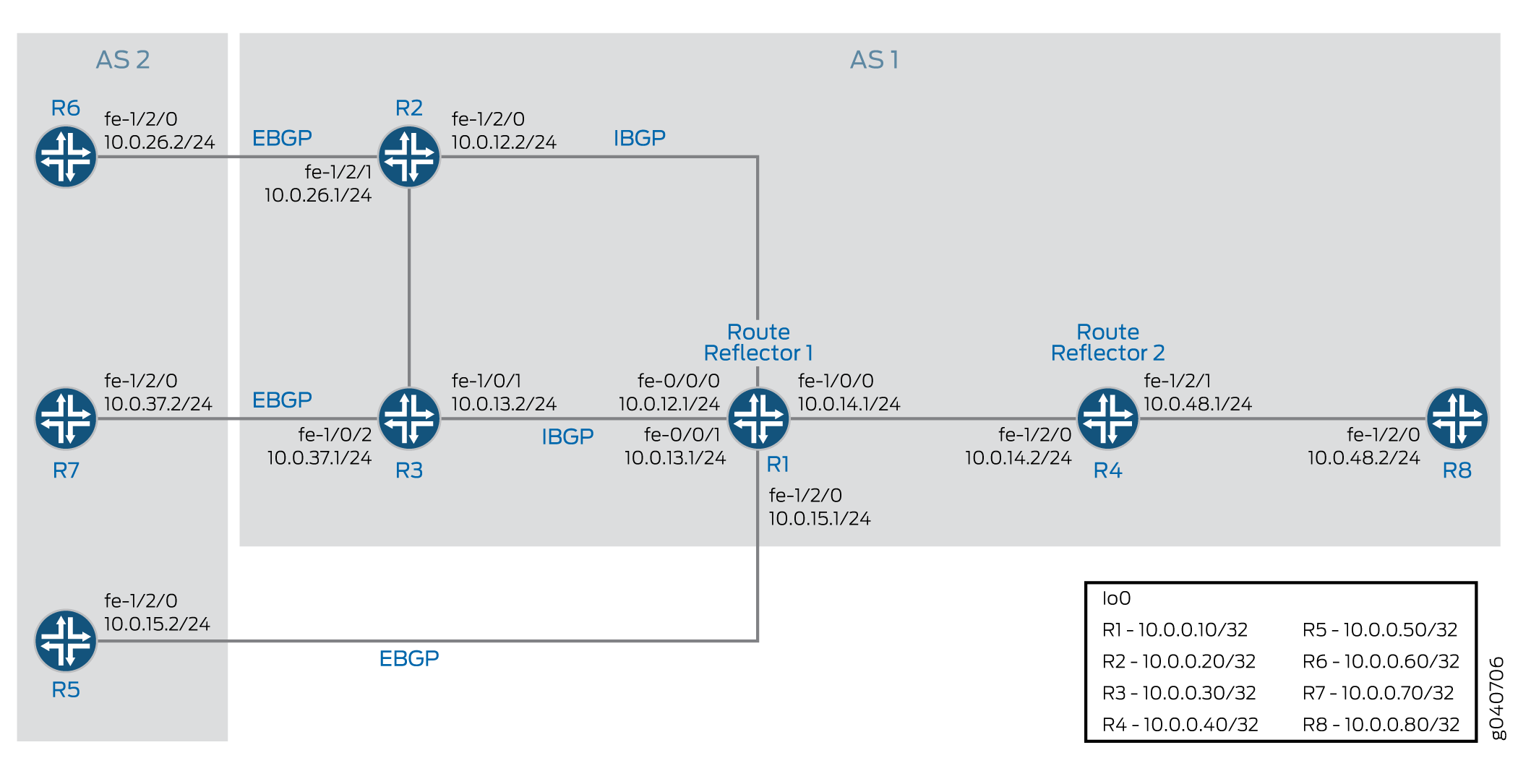
Configuración
- Configuración rápida de CLI
- Configuración del enrutador R1
- Configuración del enrutador R2
- Configuración del enrutador R3
- Configuración del enrutador R4
- Configuración del enrutador R5
- Configuración del enrutador R6
- Configuración del enrutador R7
- Configuración del enrutador R8
- Resultados
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red y, luego, copie y pegue los comandos en la CLI en el nivel jerárquico [edit] .
Enrutador R1
set interfaces fe-0/0/0 unit 12 family inet address 10.0.12.1/24 set interfaces fe-0/0/1 unit 13 family inet address 10.0.13.1/24 set interfaces fe-1/0/0 unit 14 family inet address 10.0.14.1/24 set interfaces fe-1/2/0 unit 15 family inet address 10.0.15.1/24 set interfaces lo0 unit 10 family inet address 10.0.0.10/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.10 set protocols bgp group rr cluster 10.0.0.10 set protocols bgp group rr neighbor 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.30 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.2 local-address 10.0.15.1 set protocols bgp group e1 neighbor 10.0.15.2 peer-as 2 set protocols bgp group rr_rr type internal set protocols bgp group rr_rr local-address 10.0.0.10 set protocols bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send path-count 6 set protocols ospf area 0.0.0.0 interface lo0.10 passive set protocols ospf area 0.0.0.0 interface fe-0/0/0.12 set protocols ospf area 0.0.0.0 interface fe-0/0/1.13 set protocols ospf area 0.0.0.0 interface fe-1/0/0.14 set protocols ospf area 0.0.0.0 interface fe-1/2/0.15 set routing-options router-id 10.0.0.10 set routing-options autonomous-system 1
Enrutador R2
set interfaces fe-1/2/0 unit 21 family inet address 10.0.12.2/24 set interfaces fe-1/2/1 unit 26 family inet address 10.0.26.1/24 set interfaces lo0 unit 20 family inet address 10.0.0.20/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.2 peer-as 2 set protocols ospf area 0.0.0.0 interface lo0.20 passive set protocols ospf area 0.0.0.0 interface fe-1/2/0.21 set protocols ospf area 0.0.0.0 interface fe-1/2/1.28 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 1
Enrutador R3
set interfaces fe-1/0/1 unit 31 family inet address 10.0.13.2/24 set interfaces fe-1/0/2 unit 37 family inet address 10.0.37.1/24 set interfaces lo0 unit 30 family inet address 10.0.0.30/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.30 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.2 peer-as 2 set protocols ospf area 0.0.0.0 interface lo0.30 passive set protocols ospf area 0.0.0.0 interface fe-1/0/1.31 set protocols ospf area 0.0.0.0 interface fe-1/0/2.37 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 1
Enrutador R4
set interfaces fe-1/2/0 unit 41 family inet address 10.0.14.2/24 set interfaces fe-1/2/1 unit 48 family inet address 10.0.48.1/24 set interfaces lo0 unit 40 family inet address 10.0.0.40/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.40 set protocols bgp group rr family inet unicast add-path receive set protocols bgp group rr neighbor 10.0.0.10 set protocols bgp group rr_client type internal set protocols bgp group rr_client local-address 10.0.0.40 set protocols bgp group rr_client cluster 10.0.0.40 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send path-count 6 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send prefix-policy allow_199 set protocols ospf area 0.0.0.0 interface fe-1/2/0.41 set protocols ospf area 0.0.0.0 interface lo0.40 passive set protocols ospf area 0.0.0.0 interface fe-1/2/1.48 set policy-options policy-statement allow_199 from route-filter 172.16.199.1/32 exact set policy-options policy-statement allow_199 term match_199 from prefix-list match_199 set policy-options policy-statement allow_199 then add-path send-count 20 set policy-options policy-statement allow_199 then accept set routing-options autonomous-system 1
Enrutador R5
set interfaces fe-1/2/0 unit 51 family inet address 10.0.15.2/24 set interfaces lo0 unit 50 family inet address 10.0.0.50/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.1 export s2b set protocols bgp group e1 neighbor 10.0.15.1 peer-as 1 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then as-path-expand 2 set policy-options policy-statement s2b then accept set routing-options autonomous-system 2 set routing-options static route 172.16.199.1/32 reject set routing-options static route 172.16.198.1/32 reject
Enrutador R6
set interfaces fe-1/2/0 unit 62 family inet address 10.0.26.2/24 set interfaces lo0 unit 60 family inet address 10.0.0.60/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.1 export s2b set protocols bgp group e1 neighbor 10.0.26.1 peer-as 1 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then accept set routing-options autonomous-system 2 set routing-options static route 172.16.199.1/32 reject set routing-options static route 172.16.198.1/32 reject
Enrutador R7
set interfaces fe-1/2/0 unit 73 family inet address 10.0.37.2/24 set interfaces lo0 unit 70 family inet address 10.0.0.70/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.1 export s2b set protocols bgp group e1 neighbor 10.0.37.1 peer-as 1 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then accept set routing-options autonomous-system 2 set routing-options static route 172.16.199.1/32 reject
Enrutador R8
set interfaces fe-1/2/0 unit 84 family inet address 10.0.48.2/24 set interfaces lo0 unit 80 family inet address 10.0.0.80/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.80 set protocols bgp group rr neighbor 10.0.0.40 family inet unicast add-path receive set protocols ospf area 0.0.0.0 interface lo0.80 passive set protocols ospf area 0.0.0.0 interface fe-1/2/0.84 set routing-options autonomous-system 1
Configuración del enrutador R1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el enrutador R1:
Configure las interfaces para el enrutador R2, R3, R4 y R5, y configure la interfaz de circuito cerrado (lo0).
[edit interfaces] user@R1# set fe-0/0/0 unit 12 family inet address 10.0.12.1/24 user@R1# set fe-0/0/1 unit 13 family inet address 10.0.13.1/24 user@R1# set fe-1/0/0 unit 14 family inet address 10.0.14.1/24 user@R1# set fe-1/2/0 unit 15 family inet address 10.0.15.1/24 user@R1#set lo0 unit 10 family inet address 10.0.0.10/32
Configure el BGP en las interfaces y configure la reflexión de la ruta del IBGP.
[edit protocols bgp] user@R1# set group rr type internal user@R1# set group rr local-address 10.0.0.10 user@R1# set group rr cluster 10.0.0.10 user@R1# set group rr neighbor 10.0.0.20 user@R1# set group rr neighbor 10.0.0.30 user@R1# set group rr_rr type internal user@R1# set group rr_rr local-address 10.0.0.10 user@R1# set group e1 type external user@R1# set group e1 neighbor 10.0.15.2 local-address 10.0.15.1 user@R1# set group e1 neighbor 10.0.15.2 peer-as 2
Configure el enrutador R1 para enviar hasta seis rutas a su vecino, el enrutador R4.
El destino de las rutas puede ser cualquier destino al que el enrutador R1 pueda llegar a través de varias rutas.
[edit protocols bgp] user@R1# set group rr_rr neighbor 10.0.0.40 family inet unicast add-path send path-count 6
Configure OSPF en las interfaces.
[edit protocols ospf] user@R1# set area 0.0.0.0 interface lo0.10 passive user@R1# set area 0.0.0.0 interface fe-0/0/0.12 user@R1# set area 0.0.0.0 interface fe-0/0/1.13 user@R1# set area 0.0.0.0 interface fe-1/0/0.14 user@R1# set area 0.0.0.0 interface fe-1/2/0.15
Configure el ID del enrutador y el número de sistema autónomo.
[edit routing-options] user@R1# set router-id 10.0.0.10 user@R1# set autonomous-system 1
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R1# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R1# show interfaces
fe-0/0/0 {
unit 12 {
family inet {
address 10.0.12.1/24;
}
}
}
fe-0/0/1 {
unit 13 {
family inet {
address 10.0.13.1/24;
}
}
}
fe-1/0/0 {
unit 14 {
family inet {
address 10.0.14.1/24;
}
}
}
fe-1/2/0 {
unit 15 {
family inet {
address 10.0.15.1/24;
}
}
}
lo0 {
unit 10 {
family inet {
address 10.0.0.10/32;
}
}
}
user@R1# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.10;
cluster 10.0.0.10;
neighbor 10.0.0.20;
neighbor 10.0.0.30;
}
group e1 {
type external;
neighbor 10.0.15.2 {
local-address 10.0.15.1;
peer-as 2;
}
}
group rr_rr {
type internal;
local-address 10.0.0.10;
neighbor 10.0.0.40 {
family inet {
unicast {
add-path {
send {
path-count 6;
}
}
}
}
}
}
}
ospf {
area 0.0.0.0 {
interface lo0.10 {
passive;
}
interface fe-0/0/0.12;
interface fe-0/0/1.13;
interface fe-1/0/0.14;
interface fe-1/2/0.15;
}
}
user@R1# show routing-options router-id 10.0.0.10; autonomous-system 1;
Configuración del enrutador R2
Procedimiento paso a paso
Para configurar el enrutador R2:
Configure la interfaz de circuito cerrado (lo0) y las interfaces para el enrutador R6 y el enrutador R1.
[edit interfaces] user@R2# set fe-1/2/0 unit 21 family inet address 10.0.12.2/24 user@R2# set fe-1/2/1 unit 26 family inet address 10.0.26.1/24 user@R2# set lo0 unit 20 family inet address 10.0.0.20/32
Configure BGP y OSPF en las interfaces del enrutador R2.
[edit protocols] user@R2# set bgp group rr type internal user@R2# set bgp group rr local-address 10.0.0.20 user@R2# set bgp group e1 type external user@R2# set bgp group e1 neighbor 10.0.26.2 peer-as 2 user@R2# set ospf area 0.0.0.0 interface lo0.20 passive user@R2# set ospf area 0.0.0.0 interface fe-1/2/0.21 user@R2# set ospf area 0.0.0.0 interface fe-1/2/1.28
Para las rutas enviadas del enrutador R2 al R1, anuncie el enrutador R2 como el siguiente salto, ya que el enrutador R1 no tiene una ruta a la dirección del enrutador R6 en la red 10.0.26.0/24.
[edit] user@R2# set policy-options policy-statement set_nh_self then next-hop self user@R2# set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self
Configure el número de sistema autónomo.
[edit] user@R2# set routing-options autonomous-system 1
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R2# commit
Resultados
En el modo de configuración, escriba los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R2# show interfaces
fe-1/2/0 {
unit 21 {
family inet {
address 10.0.12.2/24;
}
}
}
fe-1/2/1 {
unit 26 {
family inet {
address 10.0.26.1/24;
}
}
}
lo0 {
unit 20 {
family inet {
address 10.0.0.20/32;
}
}
}
user@R2# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.20;
neighbor 10.0.0.10 {
export set_nh_self;
}
}
group e1 {
type external;
neighbor 10.0.26.2 {
peer-as 2;
}
}
}
ospf {
area 0.0.0.0 {
interface lo0.20 {
passive;
}
interface fe-1/2/0.21;
interface fe-1/2/1.28;
}
}
user@R2# show policy-options
policy-statement set_nh_self {
then {
next-hop self;
}
}
user@R2# show routing-options autonomous-system 1;
Configuración del enrutador R3
Procedimiento paso a paso
Para configurar el enrutador R3:
Configure la interfaz de circuito cerrado (lo0) y las interfaces para el enrutador R7 y el enrutador R1.
[edit interfaces] user@R3# set fe-1/0/1 unit 31 family inet address 10.0.13.2/24 user@R3# set fe-1/0/2 unit 37 family inet address 10.0.37.1/24 user@R3# set lo0 unit 30 family inet address 10.0.0.30/32
Configure BGP y OSPF en las interfaces del enrutador R3.
[edit protocols] user@R3# set bgp group rr type internal user@R3# set bgp group rr local-address 10.0.0.30 user@R3# set bgp group e1 type external user@R3# set bgp group e1 neighbor 10.0.37.2 peer-as 2 user@R3# set ospf area 0.0.0.0 interface lo0.30 passive user@R3# set ospf area 0.0.0.0 interface fe-1/0/1.31 user@R3# set ospf area 0.0.0.0 interface fe-1/0/2.37
Para las rutas enviadas del enrutador R3 al R1, anuncie el enrutador R3 como el siguiente salto, ya que el enrutador R1 no tiene una ruta a la dirección del enrutador R7 en la red 10.0.37.0/24.
[edit] user@R3# set policy-options policy-statement set_nh_self then next-hop self user@R3# set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self
Configure el número de sistema autónomo.
[edit] user@R3# set routing-options autonomous-system 1
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R3# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R3# show interfaces
fe-1/0/1 {
unit 31 {
family inet {
address 10.0.13.2/24;
}
}
}
fe-1/0/2 {
unit 37 {
family inet {
address 10.0.37.1/24;
}
}
}
lo0 {
unit 30 {
family inet {
address 10.0.0.30/32;
}
}
}
user@R3# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.30;
neighbor 10.0.0.10 {
export set_nh_self;
}
}
group e1 {
type external;
neighbor 10.0.37.2 {
peer-as 2;
}
}
}
ospf {
area 0.0.0.0 {
interface lo0.30 {
passive;
}
interface fe-1/0/1.31;
interface fe-1/0/2.37;
}
}
user@R3# show policy-options
policy-statement set_nh_self {
then {
next-hop self;
}
}
user@R3# show routing-options autonomous-system 1;
Configuración del enrutador R4
Procedimiento paso a paso
Para configurar el enrutador R4:
Configure las interfaces para los enrutadores R1 y R8 y configure la interfaz de circuito cerrado (lo0).
[edit interfaces] user@R4# set fe-1/2/0 unit 41 family inet address 10.0.14.2/24 user@R4# set fe-1/2/1 unit 48 family inet address 10.0.48.1/24 user@R4# set lo0 unit 40 family inet address 10.0.0.40/32
Configure el BGP en las interfaces y configure la reflexión de la ruta del IBGP.
[edit protocols bgp] user@R4# set group rr type internal user@R4# set group rr local-address 10.0.0.40 user@R4# set group rr neighbor 10.0.0.10 user@R4# set group rr_client type internal user@R4# set group rr_client local-address 10.0.0.40 user@R4# set group rr_client cluster 10.0.0.40
Configure el enrutador R4 para enviar hasta seis rutas a su vecino, el enrutador R8.
El destino de las rutas puede ser cualquier destino al que el enrutador R4 pueda llegar a través de múltiples rutas.
[edit protocols bgp] user@R4# set group rr_client neighbor 10.0.0.80 family inet unicast add-path send path-count 6
Configure el enrutador R4 para recibir varias rutas de su vecino, el enrutador R1.
El destino de las rutas puede ser cualquier destino al que el enrutador R1 pueda llegar a través de varias rutas.
[edit protocols bgp group rr family inet unicast] user@R4# set add-path receive
Configure OSPF en las interfaces.
[edit protocols ospf area 0.0.0.0] user@R4# set interface fe-1/2/0.41 user@R4# set interface lo0.40 passive user@R4# set interface fe-1/2/1.48
Configure una política que permita que el enrutador R4 envíe al enrutador R8 varias rutas a la ruta 172.16.199.1/32.
El enrutador R4 recibe varias rutas para la ruta 172.16.198.1/32 y la ruta 172.16.199.1/32. Sin embargo, debido a esta política, el enrutador R4 solo envía varias rutas para la ruta 172.16.199.1/32.
[edit protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast] user@R4# set add-path send prefix-policy allow_199 [edit policy-options policy-statement allow_199] user@R4# set from route-filter 172.16.199.1/32 exact user@R4# set then accept
El enrutador R4 también se puede configurar para enviar hasta 20 rutas de BGP
add-pathpara un subconjunto de prefijos anunciados de adición de ruta.[edit policy-options policy-statement allow_199] user@R4# set term match_199 from prefix-list match_199 user@R4# set then add-path send-count 20
Configure el número de sistema autónomo.
[edit routing-options] user@R4# set autonomous-system 1
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R4# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R4# show interfaces
fe-1/2/0 {
unit 41 {
family inet {
address 10.0.14.2/24;
}
}
}
fe-1/2/1 {
unit 48 {
family inet {
address 10.0.48.1/24;
}
}
}
lo0 {
unit 40 {
family inet {
address 10.0.0.40/32;
}
}
}
user@R4# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.40;
family inet {
unicast {
add-path {
receive;
}
}
}
neighbor 10.0.0.10;
}
group rr_client {
type internal;
local-address 10.0.0.40;
cluster 10.0.0.40;
neighbor 10.0.0.80 {
family inet {
unicast {
add-path {
send {
path-count 6;
prefix-policy allow_199;
}
}
}
}
}
}
}
ospf {
area 0.0.0.0 {
interface lo0.40 {
passive;
}
interface fe-1/2/0.41;
interface fe-1/2/1.48;
}
}
user@R4# show policy-options
policy-statement allow_199 {
from {
route-filter 172.16.199.1/32 exact;
}
from term match_199 {
prefix-list match_199;
}
then add-path send-count 20;
then accept;
}
user@R4# show routing-options autonomous-system 1;
Configuración del enrutador R5
Procedimiento paso a paso
Para configurar el enrutador R5:
Configure la interfaz de circuito cerrado (lo0) y la interfaz con el enrutador R1.
[edit interfaces] user@R5# set fe-1/2/0 unit 51 family inet address 10.0.15.2/24 user@R5# set lo0 unit 50 family inet address 10.0.0.50/32
Configure el BGP en la interfaz del enrutador R5.
[edit protocols bgp group e1] user@R5# set type external user@R5# set neighbor 10.0.15.1 peer-as 1
Cree rutas estáticas para su redistribución en BGP.
[edit routing-options] user@R5# set static route 172.16.199.1/32 reject user@R5# set static route 172.16.198.1/32 reject
Redistribuya rutas estáticas y directas en BGP.
[edit protocols bgp group e1 neighbor 10.0.15.1] user@R5# set export s2b [edit policy-options policy-statement s2b] user@R5# set from protocol static user@R5# set from protocol direct user@R5# set then as-path-expand 2 user@R5# set then accept
Configure el número de sistema autónomo.
[edit routing-options] user@R5# set autonomous-system 2
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R5# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R5# show interfaces
fe-1/2/0 {
unit 51 {
family inet {
address 10.0.15.2/24;
}
}
}
lo0 {
unit 50 {
family inet {
address 10.0.0.50/32;
}
}
}
user@R5# show protocols
bgp {
group e1 {
type external;
neighbor 10.0.15.1 {
export s2b;
peer-as 1;
}
}
}
user@R5# show policy-options
policy-statement s2b {
from protocol [ static direct ];
then {
as-path-expand 2;
accept;
}
}
user@R5# show routing-options
static {
route 172.16.198.1/32 reject;
route 172.16.199.1/32 reject;
}
autonomous-system 2;
Configuración del enrutador R6
Procedimiento paso a paso
Para configurar el enrutador R6:
Configure la interfaz de circuito cerrado (lo0) y la interfaz al enrutador R2.
[edit interfaces] user@R6# set fe-1/2/0 unit 62 family inet address 10.0.26.2/24 user@R6# set lo0 unit 60 family inet address 10.0.0.60/32
Configure el BGP en la interfaz del enrutador R6.
[edit protocols] user@R6# set bgp group e1 type external user@R6# set bgp group e1 neighbor 10.0.26.1 peer-as 1
Cree rutas estáticas para su redistribución en BGP.
[edit] user@R6# set routing-options static route 172.16.199.1/32 reject user@R6# set routing-options static route 172.16.198.1/32 reject
Redistribuya rutas estáticas y directas desde la tabla de enrutamiento del enrutador R6 al BGP.
[edit protocols bgp group e1 neighbor 10.0.26.1] user@R6# set export s2b [edit policy-options policy-statement s2b] user@R6# set from protocol static user@R6# set from protocol direct user@R6# set then accept
Configure el número de sistema autónomo.
[edit routing-options] user@R6# set autonomous-system 2
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R6# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R6# show interfaces
fe-1/2/0 {
unit 62 {
family inet {
address 10.0.26.2/24;
}
}
}
lo0 {
unit 60 {
family inet {
address 10.0.0.60/32;
}
}
}
user@R6# show protocols
bgp {
group e1 {
type external;
neighbor 10.0.26.1 {
export s2b;
peer-as 1;
}
}
}
user@R6# show policy-options
policy-statement s2b {
from protocol [ static direct ];
then accept;
}
user@R6# show routing-options
static {
route 172.16.198.1/32 reject;
route 172.16.199.1/32 reject;
}
autonomous-system 2;
Configuración del enrutador R7
Procedimiento paso a paso
Para configurar el enrutador R7:
Configure la interfaz de circuito cerrado (lo0) y la interfaz al enrutador R3.
[edit interfaces] user@R7# set fe-1/2/0 unit 73 family inet address 10.0.37.2/24 user@R7# set lo0 unit 70 family inet address 10.0.0.70/32
Configure el BGP en la interfaz del enrutador R7.
[edit protocols bgp group e1] user@R7# set type external user@R7# set neighbor 10.0.37.1 peer-as 1
Cree una ruta estática para la redistribución en BGP.
[edit] user@R7# set routing-options static route 172.16.199.1/32 reject
Redistribuya rutas estáticas y directas desde la tabla de enrutamiento del enrutador R7 al BGP.
[edit protocols bgp group e1 neighbor 10.0.37.1] user@R7# set export s2b [edit policy-options policy-statement s2b] user@R7# set from protocol static user@R7# set from protocol direct user@R7# set then accept
Configure el número de sistema autónomo.
[edit routing-options] user@R7# set autonomous-system 2
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R7# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R7# show interfaces
fe-1/2/0 {
unit 73 {
family inet {
address 10.0.37.2/24;
}
}
}
lo0 {
unit 70 {
family inet {
address 10.0.0.70/32;
}
}
}
user@R7# show protocols
bgp {
group e1 {
type external;
neighbor 10.0.37.1 {
export s2b;
peer-as 1;
}
}
}
user@R7# show policy-options
policy-statement s2b {
from protocol [ static direct ];
then accept;
}
user@R7# show routing-options
static {
route 172.16.199.1/32 reject;
}
autonomous-system 2;
Configuración del enrutador R8
Procedimiento paso a paso
Para configurar el enrutador R8:
Configure la interfaz de circuito cerrado (lo0) y la interfaz con el enrutador R4.
[edit interfaces] user@R8# set fe-1/2/0 unit 84 family inet address 10.0.48.2/24 user@R8# set lo0 unit 80 family inet address 10.0.0.80/32
Configure BGP y OSPF en la interfaz del enrutador R8.
[edit protocols] user@R8# set bgp group rr type internal user@R8# set bgp group rr local-address 10.0.0.80 user@R8# set ospf area 0.0.0.0 interface lo0.80 passive user@R8# set ospf area 0.0.0.0 interface fe-1/2/0.84
Configure el enrutador R8 para recibir varias rutas de su vecino, el enrutador R4.
El destino de las rutas puede ser cualquier destino al que el enrutador R4 pueda llegar a través de múltiples rutas.
[edit protocols] user@R8# set bgp group rr neighbor 10.0.0.40 family inet unicast add-path receive
Configure el número de sistema autónomo.
[edit] user@R8# set routing-options autonomous-system 1
Cuando termine de configurar el dispositivo, confirme la configuración.
user@R8# commit
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show policy-optionsshow routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@R8# show interfaces
fe-1/2/0 {
unit 84 {
family inet {
address 10.0.48.2/24;
}
}
}
lo0 {
unit 80 {
family inet {
address 10.0.0.80/32;
}
}
}
user@R8# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.80;
neighbor 10.0.0.40 {
family inet {
unicast {
add-path {
receive;
}
}
}
}
}
}
ospf {
area 0.0.0.0 {
interface lo0.80 {
passive;
}
interface fe-1/2/0.84;
}
}
user@R8# show routing-options autonomous-system 1;
Verificación
Confirme que la configuración funcione correctamente.
- Verificar que los pares del BGP tengan la capacidad de enviar y recibir varias rutas
- Verificar que el enrutador R1 anuncia varias rutas
- Verificar que el enrutador R4 recibe y anuncia varias rutas
- Verificar que el enrutador R8 recibe varias rutas
- Comprobación del ID de ruta
Verificar que los pares del BGP tengan la capacidad de enviar y recibir varias rutas
Propósito
Asegúrese de que una o ambas de las siguientes cadenas aparecen en la salida del show bgp neighbor comando:
NLRI's for which peer can receive multiple paths: inet-unicastNLRI's for which peer can send multiple paths: inet-unicast
Acción
user@R1> show bgp neighbor 10.0.0.40 Peer: 10.0.0.40+179 AS 1 Local: 10.0.0.10+64227 AS 1 Type: Internal State: Established Flags: <Sync> ... NLRI's for which peer can receive multiple paths: inet-unicast ...
user@R4> show bgp neighbor 10.0.0.10 Peer: 10.0.0.10+64227 AS 1 Local: 10.0.0.40+179 AS 1 Type: Internal State: Established Flags: <Sync> ... NLRI's for which peer can send multiple paths: inet-unicast ...
user@R4> show bgp neighbor 10.0.0.80 Peer: 10.0.0.80+55416 AS 1 Local: 10.0.0.40+179 AS 1 Type: Internal State: Established (route reflector client)Flags: <Sync> ,,, NLRI's for which peer can receive multiple paths: inet-unicast ...
user@R8> show bgp neighbor 10.0.0.40 Peer: 10.0.0.40+179 AS 1 Local: 10.0.0.80+55416 AS 1 Type: Internal State: Established Flags: <Sync> ... NLRI's for which peer can send multiple paths: inet-unicast ...
Verificar que el enrutador R1 anuncia varias rutas
Propósito
Asegúrese de que se anuncien varias rutas al destino 172.16.198.1/32 y varias rutas al destino 172.16.199.1/32 en el enrutador R4.
Acción
user@R1> show route advertising-protocol bgp 10.0.0.40
inet.0: 21 destinations, 25 routes (21 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 172.16.198.1/32 10.0.0.20 100 2 I
10.0.15.2 100 2 2 I
* 172.16.199.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
* 172.16.200.0/30 10.0.0.20 100 2 I
Significado
Cuando vea un prefijo y más de un próximo salto, significa que se anuncian varias rutas al enrutador R4.
Verificar que el enrutador R4 recibe y anuncia varias rutas
Propósito
Asegúrese de que se reciban varias rutas al destino 172.16.199.1/32 del enrutador R1 y se anuncien al enrutador R8. Asegúrese de que se reciban varias rutas al destino 172.16.198.1/32 del enrutador R1, pero que solo se anuncie una ruta a este destino al enrutador R8.
Acción
user@R4> show route receive-protocol bgp 10.0.0.10
inet.0: 19 destinations, 22 routes (19 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 172.16.198.1/32 10.0.0.20 100 2 I
10.0.15.2 100 2 2 I
* 172.16.199.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
* 172.16.200.0/30 10.0.0.20 100 2 I
user@R4> show route advertising-protocol bgp 10.0.0.80
inet.0: 19 destinations, 22 routes (19 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 172.16.198.1/32 10.0.0.20 100 2 I
* 172.16.199.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
* 172.16.200.0/30 10.0.0.20 100 2 I
Significado
El show route receive-protocol comando muestra que el enrutador R4 recibe dos rutas al destino 172.16.198.1/32 y tres rutas al destino 172.16.199.1/32. El show route advertising-protocol comando muestra que el enrutador R4 anuncia solo una ruta al destino 172.16.198.1/32 y anuncia las tres rutas al destino 172.16.199.1/32.
Debido a la política de prefijo que se aplica al enrutador R4, este no anuncia varias rutas al destino 172.16.198.1/32. El enrutador R4 anuncia solo una ruta al destino 172.16.198.1/32, aunque reciba varias rutas a este destino.
Verificar que el enrutador R8 recibe varias rutas
Propósito
Asegúrese de que el enrutador R8 reciba varias rutas al destino 172.16.199.1/32 a través del enrutador R4. Asegúrese de que el enrutador R8 reciba solo una ruta al destino 172.16.198.1/32 a través del enrutador R4.
Acción
user@R8> show route receive-protocol bgp 10.0.0.40
inet.0: 18 destinations, 20 routes (18 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 172.16.198.1/32 10.0.0.20 100 2 I
* 172.16.199.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
* 200.1.1.0/30 10.0.0.20 100 2 I
Comprobación del ID de ruta
Propósito
En los dispositivos descendentes, los enrutadores R4 y R8, compruebe que el ID de ruta la identifica de forma exclusiva. Busca la Addpath Path ID: cuerda.
Acción
user@R4> show route 172.16.199.1/32 detail
inet.0: 18 destinations, 20 routes (18 active, 0 holddown, 0 hidden)
172.16.199.1/32 (3 entries, 3 announced)
*BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 9
Source: 10.0.0.10
Next hop type: Router, Next hop index: 676
Next hop: 10.0.14.1 via lt-1/2/0.41, selected
Protocol next hop: 10.0.0.20
Indirect next hop: 92041c8 262146
State: <Active Int Ext>
Local AS: 1 Peer AS: 1
Age: 1:44:37 Metric2: 2
Task: BGP_1.10.0.0.10+64227
Announcement bits (3): 2-KRT 3-BGP RT Background 4-Resolve tree 1
AS path: 2 I (Originator) Cluster list: 10.0.0.10
AS path: Originator ID: 10.0.0.20
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 1
BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 4
Source: 10.0.0.10
Next hop type: Router, Next hop index: 676
Next hop: 10.0.14.1 via lt-1/2/0.41, selected
Protocol next hop: 10.0.0.30
Indirect next hop: 92042ac 262151
State: <NotBest Int Ext>
Inactive reason: Not Best in its group - Router ID
Local AS: 1 Peer AS: 1
Age: 1:44:37 Metric2: 2
Task: BGP_1.10.0.0.10+64227
Announcement bits (1): 3-BGP RT Background
AS path: 2 I (Originator) Cluster list: 10.0.0.10
AS path: Originator ID: 10.0.0.30
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 2
BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 4
Source: 10.0.0.10
Next hop type: Router, Next hop index: 676
Next hop: 10.0.14.1 via lt-1/2/0.41, selected
Protocol next hop: 10.0.15.2
Indirect next hop: 92040e4 262150
State: <Int Ext>
Inactive reason: AS path
Local AS: 1 Peer AS: 1
Age: 1:44:37 Metric2: 2
Task: BGP_1.10.0.0.10+64227
Announcement bits (1): 3-BGP RT Background
AS path: 2 2 I
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 3
user@R8> show route 172.16.199.1/32 detail
inet.0: 17 destinations, 19 routes (17 active, 0 holddown, 0 hidden)
172.16.199.1/32 (3 entries, 1 announced)
*BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 9
Source: 10.0.0.40
Next hop type: Router, Next hop index: 1045
Next hop: 10.0.48.1 via lt-1/2/0.84, selected
Protocol next hop: 10.0.0.20
Indirect next hop: 91fc0e4 262148
State: <Active Int Ext>
Local AS: 1 Peer AS: 1
Age: 1:56:51 Metric2: 3
Task: BGP_1.10.0.0.40+179
Announcement bits (2): 2-KRT 4-Resolve tree 1
AS path: 2 I (Originator) Cluster list: 10.0.0.40 10.0.0.10
AS path: Originator ID: 10.0.0.20
Accepted
Localpref: 100
Router ID: 10.0.0.40
Addpath Path ID: 1
BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 4
Source: 10.0.0.40
Next hop type: Router, Next hop index: 1045
Next hop: 10.0.48.1 via lt-1/2/0.84, selected
Protocol next hop: 10.0.0.30
Indirect next hop: 91fc1c8 262152
State: <NotBest Int Ext>
Inactive reason: Not Best in its group - Router ID
Local AS: 1 Peer AS: 1
Age: 1:56:51 Metric2: 3
Task: BGP_1.10.0.0.40+179
AS path: 2 I (Originator) Cluster list: 10.0.0.40 10.0.0.10
AS path: Originator ID: 10.0.0.30
Accepted
Localpref: 100
Router ID: 10.0.0.40
Addpath Path ID: 2
BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 4
Source: 10.0.0.40
Next hop type: Router, Next hop index: 1045
Next hop: 10.0.48.1 via lt-1/2/0.84, selected
Protocol next hop: 10.0.15.2
Indirect next hop: 91fc2ac 262153
State: <Int Ext>
Inactive reason: AS path
Local AS: 1 Peer AS: 1
Age: 1:56:51 Metric2: 3
Task: BGP_1.10.0.0.40+179
AS path: 2 2 I (Originator) Cluster list: 10.0.0.40
AS path: Originator ID: 10.0.0.10
Accepted
Localpref: 100
Router ID: 10.0.0.40
Addpath Path ID: 3
Ejemplo: Configuración de publicidad selectiva de varias rutas de BGP para equilibrio de carga
En este ejemplo, se muestra cómo configurar la publicidad selectiva de varias rutas de BGP. Anunciar todas las rutas múltiples disponibles puede generar una gran sobrecarga de procesamiento en la memoria del dispositivo y también es una consideración de escalabilidad. Puede configurar un reflector de ruta de BGP para anunciar solo las múltiples rutas de colaborador para el equilibrio de carga.
Requisitos
No se necesita ninguna configuración especial más allá de la inicialización del dispositivo antes de configurar este ejemplo.
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Ocho enrutadores que pueden ser una combinación de enrutadores serie M, serie MX o serie T
-
Junos OS versión 16.1R2 o posterior en el dispositivo
Descripción general
A partir de Junos OS versión 16.1R2, puede restringir el BGP add-path para anunciar solo varias rutas de acceso del colaborador. Puede limitar y configurar hasta seis prefijos que seleccione el algoritmo del BGP multipath . La publicidad selectiva de múltiples rutas facilita a los proveedores de servicios de Internet y a los centros de datos que usan reflector de rutas para crear diversidad en las rutas en el IBGP. Puede habilitar un reflector de ruta de BGP para anunciar varias rutas que son rutas de contribución para el equilibrio de carga.
Topología
En la Figura 7, RR1 y RR4 son reflectores de ruta. Los enrutadores R2 y R3 son clientes del reflector de ruta RR1. El enrutador R8 es un reflector de cliente a enrutamiento RR4. El grupo RR1 con los vecinos R2 y R3 está configurado para multirruta. Los enrutadores R5, R6 y R7 redistribuyen las rutas estáticas 199.1.1.1/32 y 198.1.1.1/32 en BGP.
En el enrutador RR1 se configura una política de equilibrio de carga de manera tal que las rutas 199.1.1.1/32 tengan calculada la multirruta. La función multirruta se configura en add-path for neighbor RR4. Sin embargo, el enrutador RR4 no tiene configurada una multirruta de equilibrio de carga. El enrutador RR1 está configurado para enviar al enrutador RR4 hasta seis rutas de adición de ruta a 199.1.1.1/32 elegidas de rutas candidatas de multirruta.
 de carga
de carga
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese confirmar desde el [edit] modo de configuración.
Enrutador RR1
set interfaces ge-1/0/10 unit 0 description RR1->R2 set interfaces ge-1/0/10 unit 0 family inet address 10.0.12.1/24 set interfaces ge-1/0/11 unit 0 description RR1->RR4 set interfaces ge-1/0/11 unit 0 family inet address 10.0.14.1/24 set interfaces ge-1/0/12 unit 0 description RR1->R5 set interfaces ge-1/0/12 unit 0 family inet address 10.0.15.1/24 set interfaces ge-1/0/13 unit 0 description RR1->R3 set interfaces ge-1/0/13 unit 0 family inet address 10.0.13.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.10/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.10 set protocols bgp group rr cluster 10.0.0.10 set protocols bgp group rr multipath set protocols bgp group rr neighbor 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.30 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.2 local-address 10.0.15.1 set protocols bgp group e1 neighbor 10.0.15.2 peer-as 64502 set protocols bgp group rr_rr type internal set protocols bgp group rr_rr local-address 10.0.0.10 set protocols bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send path-count 6 set protocols bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send multipath set protocols ospf area 0.0.0.0 interface lo0.10 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/13 set protocols ospf area 0.0.0.0 interface ge-1/0/11 set protocols ospf area 0.0.0.0 interface ge-1/0/12 set policy-options prefix-list match_199 199.1.1.1/32 set policy-options policy-statement loadbal_199 term match_100 from prefix-list match_199 set policy-options policy-statement loadbal_199 from route-filter 199.1.1.1/32 exact set policy-options policy-statement loadbal_199 then load-balance per-packet set routing-options router-id 10.0.0.10 set routing-options autonomous-system 64501 set routing-options forwarding-table export loadbal_199
Enrutador R2
set interfaces ge-1/0/10 unit 0 description R2->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.12.2/24 set interfaces ge-1/0/11 unit 0 description R2->R6 set interfaces ge-1/0/11 unit 0 family inet address 10.0.26.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.20/32 set protocols bgp group rr local-address 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.2 peer-as 64502 set protocols ospf area 0.0.0.0 interface lo0.20 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/11 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 64501
Enrutador R3
set interfaces ge-1/0/10 unit 0 description R3->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.13.2/24 set interfaces ge-1/0/11 unit 0 description R3->R7 set interfaces ge-1/0/11 unit 0 family inet address 10.0.37.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.30/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.30 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.2 peer-as 64502 set protocols ospf area 0.0.0.0 interface lo0.30 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/13 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 64501
Enrutador RR4
set interfaces ge-1/0/10 unit 0 description RR4->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.14.2/24 set interfaces ge-1/0/11 unit 0 description RR4->R8 set interfaces ge-1/0/11 unit 0 family inet address 10.0.48.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.40/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.40 set protocols bgp group rr family inet unicast add-path receive set protocols bgp group rr neighbor 10.0.0.10 set protocols bgp group rr_client type internal set protocols bgp group rr_client local-address 10.0.0.40 set protocols bgp group rr_client cluster 10.0.0.40 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send prefix-policy addpath-communities-send-4713-100 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send path-count 2 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send multipath set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface lo0.40 passive set protocols ospf area 0.0.0.0 interface ge-1/0/11 set policy-options prefix-list match_199 199.1.1.1/32 set routing-options autonomous-system 64501
Enrutador R5
set interfaces ge-1/0/10 unit 0 description R5->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.15.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.50/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.1 export s2b set protocols bgp group e1 neighbor 10.0.15.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then as-path-expand 2 set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options static route 198.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R6
set interfaces ge-1/0/10 unit 0 description R6->R2 set interfaces ge-1/0/10 unit 0 family inet address 10.0.26.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.60/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.1 export s2b set protocols bgp group e1 neighbor 10.0.26.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options static route 198.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R7
set interfaces ge-1/0/10 unit 0 description R7->R3 set interfaces ge-1/0/10 unit 0 family inet address 10.0.37.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.70/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.1 export s2b set protocols bgp group e1 neighbor 10.0.37.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R8
set interfaces ge-1/0/10 unit 0 description R8->RR4 set interfaces ge-1/0/10 unit 0 family inet address 10.0.48.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.80/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.80 set protocols bgp group rr neighbor 10.0.0.40 family inet unicast add-path receive set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10.8 set routing-options autonomous-system 64501 set chassis fpc 1 pic 0 tunnel-services bandwidth 1g
Configuración del enrutador RR1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador RR1:
Repita este procedimiento para otros enrutadores después de modificar los nombres de interfaz, las direcciones y otros parámetros adecuados.
-
Configure las interfaces con direcciones IPv4.
[edit interfaces] user@RR1# set ge-1/0/10 unit 0 description RR1->R2 user@RR1# set ge-1/0/10 unit 0 family inet address 10.0.12.1/24 user@RR1# set ge-1/0/11 unit 0 description RR1->RR4 user@RR1# set ge-1/0/11 unit 0 family inet address 10.0.14.1/24 user@RR1# set ge-1/0/12 unit 0 description RR1->R5 user@RR1# set ge-1/0/12 unit 0 family inet address 10.0.15.1/24 user@RR1# set ge-1/0/13 unit 0 description RR1->R3 user@RR1# set ge-1/0/13 unit 0 family inet address 10.0.13.1/24
-
Configure la dirección de circuito cerrado.
[edit interfaces] user@RR1# set lo0 unit 0 family inet address 10.0.0.10/32
-
Configure el protocolo de puerta de enlace interior (IGP), como OSPF o SI-SI.
[edit protocols] user@RR1# set ospf area 0.0.0.0 interface lo0.10 passive user@RR1# set ospf area 0.0.0.0 interface ge-1/0/10 user@RR1# set ospf area 0.0.0.0 interface ge-1/0/13 user@RR1# set ospf area 0.0.0.0 interface ge-1/0/11 user@RR1# set ospf area 0.0.0.0 interface ge-1/0/12
-
Configure el RR del grupo interno para las interfaces que se conectan a los enrutadores internos R2 y R3.
[edit protocols] user@RR1# set bgp group rr type internal user@RR1# set bgp group rr local-address 10.0.0.10 user@RR1# set bgp group rr cluster 10.0.0.10 user@RR1# set bgp group rr neighbor 10.0.0.20 user@RR1# set bgp group rr neighbor 10.0.0.30
-
Configure el equilibrio de carga para el RR del grupo interno del BGP.
[edit protocols] user@RR1# set bgp group rr multipath
-
Configure rr_rr de grupo interno para reflectores de ruta.
[edit protocols] user@RR1# set bgp group rr_rr type internal user@RR1# set bgp group rr_rr local-address 10.0.0.10
-
Configure la función addpath multirruta para anunciar solo varias rutas de colaborador y limite el número de multirutas anunciadas a 6.
[edit protocols] user@RR1# set bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send multipath user@RR1# set bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send path-count 6
-
Configure el EBGP en las interfaces que se conecten a los enrutadores perimetrales externos.
[edit protocols] user@RR1# set bgp group e1 type external user@RR1# set bgp group e1 neighbor 10.0.15.2 local-address 10.0.15.1 user@RR1# set bgp group e1 neighbor 10.0.15.2 peer-as 64502
-
Defina una loadbal_199 de política para cada equilibrio de carga de paquete.
[edit policy-options] user@RR1# set prefix-list match_199 199.1.1.1/32 user@RR1# set policy-statement loadbal_199 term match_100 from prefix-list match_199 user@RR1# set policy-statement loadbal_199 from route-filter 199.1.1.1/32 exact user@RR1# set policy-statement loadbal_199 then load-balance per-packet
-
Aplique la política de exportación definida loadbal_199.
[edit routing-options] user@RR1# set forwarding-table export loadbal_199
-
Configure el ID del enrutador y el sistema autónomo para los hosts del BGP.
[edit routing-options] user@RR1# set router-id 10.0.0.10 user@RR1# set autonomous-system 64501
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show routing-optionsshow policy-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
[edit]
user@RR1# show interfaces
ge-1/0/10 {
unit 0 {
description RR1->R2;
family inet {
address 10.0.12.1/24;
}
}
}
ge-1/0/11 {
unit 0 {
description RR1->RR4;
family inet {
address 10.0.14.1/24;
}
}
}
ge-1/0/12 {
unit 0 {
description RR1->R5;
family inet {
address 10.0.15.1/24;
}
}
}
ge-1/0/13 {
unit 0 {
description RR1->R3;
family inet {
address 10.0.13.1/24;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.0.0.10/32;
}
}
}
[edit]
user@RR1# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.10;
cluster 10.0.0.10;
multipath;
neighbor 10.0.0.20;
neighbor 10.0.0.30;
}
group e1 {
type external;
neighbor 10.0.15.2 {
local-address 10.0.15.1;
peer-as 64502;
}
}
group rr_rr {
type internal;
local-address 10.0.0.10;
neighbor 10.0.0.40 {
family inet {
unicast {
add-path {
send {
path-count 6;
multipath;
}
}
}
}
}
}
}
ospf {
area 0.0.0.0 {
interface all;
interface fxp0.0 {
disable;
}
interface lo0.10 {
passive;
}
interface ge-1/0/10;
interface ge-1/0/13;
interface ge-1/0/11;
interface ge-1/0/12;
}
}
[edit]
user@RR1# show routing-options
router-id 10.0.0.10;
autonomous-system 64501;
forwarding-table {
export load-bal_199;
}
[edit]
user@RR1# show policy-options
prefix-list match_199 {
199.1.1.1/32;
}
policy-statement loadbal_199 {
term match_100 {
from {
prefix-list match_199;
}
}
from {
route-filter 199.1.1.1/32 exact;
}
then {
load-balance per-packet;
}
}
Cuando termine de configurar el dispositivo, confirme la configuración.
user@RR1# commit
Verificación
Confirme que la configuración funcione correctamente.
- Verificación de las rutas multiruta para la ruta estática 199.1.1.1/32
- Verificar que las rutas de múltiples rutas se anuncian desde el enrutador RR1 al enrutador RR4
- Verificar que el enrutador RR4 anuncia una ruta para 199.1.1.1/32 al enrutador R8
Verificación de las rutas multiruta para la ruta estática 199.1.1.1/32
Propósito
Compruebe las rutas multirruta disponibles para el destino 199.1.1.1/32.
Acción
Desde el modo operativo, ejecute el comando en el show route 199.1.1.1/32 detail enrutador RR1.
user@RR1> show route 199.1.1.1/32 detail
inet.0: 22 destinations, 26 routes (22 active, 0 holddown, 0 hidden)
199.1.1.1/32 (3 entries, 2 announced)
*BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xae5cc90
Next-hop reference count: 1
Source: 10.0.0.20
Next hop type: Router, Next hop index: 1118
Next hop: 10.0.12.2 via lt-1/0/10.1, selected
Session Id: 0x0
Next hop type: Router, Next hop index: 1115
Next hop: 10.0.13.2 via lt-1/0/10.9
Session Id: 0x0
Protocol next hop: 10.0.0.20
Indirect next hop: 0xc409410 1048574 INH Session ID: 0x0
Protocol next hop: 10.0.0.30
Indirect next hop: 0xc409520 1048575 INH Session ID: 0x0
State: <Active Int Ext>
Local AS: 1 Peer AS: 1
Age: 4:03:29 Metric2: 1
Validation State: unverified
Task: BGP_1.10.0.0.20
Announcement bits (3): 2-KRT 3-BGP_RT_Background 4-Resolve tree 2
AS path: 2 I
Communities: 4713:100
Accepted Multipath
Localpref: 100
Router ID: 10.0.0.20
BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xae0ec10
Next-hop reference count: 4
Source: 10.0.0.30
Next hop type: Router, Next hop index: 1115
Next hop: 10.0.13.2 via lt-1/0/10.9, selected
Session Id: 0x0
Protocol next hop: 10.0.0.30
Indirect next hop: 0xc409520 1048575 INH Session ID: 0x0
State: <NotBest Int Ext>
Inactive reason: Not Best in its group - Router ID
Local AS: 64501 Peer AS: 64501
Age: 4:03:29 Metric2: 1
Validation State: unverified
Task: BGP_1.10.0.0.30
Announcement bits (1): 3-BGP_RT_Background
AS path: 2 I
Communities: 4713:100
Accepted MultipathContrib
Localpref: 100
Router ID: 10.0.0.30
BGP Preference: 170/-101
Next hop type: Router, Next hop index: 1105
Address: 0xae0e970
Next-hop reference count: 5
Source: 10.0.15.2
Next hop: 10.0.15.2 via lt-1/0/10.6, selected
Session Id: 0x0
State: <Ext>
Inactive reason: AS path
Local AS: 1 Peer AS: 2
Age: 4:05:01
Validation State: unverified
Task: BGP_2.10.0.15.2
AS path: 2 2 I
Communities: 4713:100
Accepted
Localpref: 100
Router ID: 10.0.0.50
Significado
La función de multirruta de publicidad selectiva está habilitada en el enrutador RR1 y hay más de un próximo salto disponible para la ruta 199.1.1.1/32. Los dos próximos saltos disponibles para la ruta 199.1.1.1/32 son 10.0.0.20 y 10.0.0.30.
Verificar que las rutas de múltiples rutas se anuncian desde el enrutador RR1 al enrutador RR4
Propósito
Compruebe que el enrutador RR1 anuncia las rutas de multirruta.
Acción
Desde el modo operativo, ejecute el comando en el show route advertising-protocol bgp 10.0.0.40 enrutador RR1.
user@RR1> show route advertising-protocol bgp 10.0.0.40
inet.0: 22 destinations, 26 routes (22 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 198.1.1.1/32 10.0.0.20 100 2 I
* 199.1.1.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
user@RR1> show route advertising-protocol bgp 10.0.0.40 detail
inet.0: 22 destinations, 26 routes (22 active, 0 holddown, 0 hidden)
* 10.0.0.50/32 (1 entry, 1 announced)
BGP group rr_rr type Internal
Nexthop: 10.0.15.2
Localpref: 100
AS path: [1] 2 2 I
Communities: 4713:100
Addpath Path ID: 1
….* 199.1.1.1/32 (3 entries, 2 announced)
BGP group rr_rr type Internal
Nexthop: 10.0.0.20
Localpref: 100
AS path: [1] 2 I
Communities: 4713:100
Cluster ID: 10.0.0.10
Originator ID: 10.0.0.20
Addpath Path ID: 1
BGP group rr_rr type Internal
Nexthop: 10.0.0.30
Localpref: 100
AS path: [1] 2 I
Communities: 4713:100
Cluster ID: 10.0.0.10
Originator ID: 10.0.0.30
Addpath Path ID: 2
Significado
El enrutador RR1 anuncia dos próximos saltos, 10.0.0.20 y 10.0.0.30, para la ruta 199.1.1.1/32 al enrutador RR4.
Verificar que el enrutador RR4 anuncia una ruta para 199.1.1.1/32 al enrutador R8
Propósito
La ruta múltiple no está configurada en el enrutador RR4, por lo que la ruta 199.1.1.1/32 no es elegible para agregar ruta. Compruebe que el enrutador RR4 anuncia solo una ruta para 199.1.1.1/32 al enrutador R8.
Acción
Desde el modo operativo, ejecute el comando en el show route advertising-protocol bgp 10.0.0.80 enrutador RR4.
user@RR4> show route advertising-protocol bgp 10.0.0.80 detail
inet.0: 20 destinations, 21 routes (20 active, 0 holddown, 0 hidden)
* 10.0.0.50/32 (1 entry, 1 announced)
BGP group rr_client type Internal
Nexthop: 10.0.15.2
Localpref: 100
AS path: [1] 2 2 I
Communities: 4713:100
Cluster ID: 10.0.0.40
Originator ID: 10.0.0.10
Addpath Path ID: 1
…
* 198.1.1.1/32 (1 entry, 1 announced)
BGP group rr_client type Internal
Nexthop: 10.0.0.20
Localpref: 100
AS path: [1] 2 I (Originator)
Cluster list: 10.0.0.10
Originator ID: 10.0.0.20
Communities: 4713:100
Cluster ID: 10.0.0.40
Addpath Path ID: 1
* 199.1.1.1/32 (2 entries, 1 announced)
BGP group rr_client type Internal
Nexthop: 10.0.0.20
Localpref: 100
AS path: [1] 2 I (Originator)
Cluster list: 10.0.0.10
Originator ID: 10.0.0.20
Communities: 4713:100
Cluster ID: 10.0.0.40
Addpath Path ID: 1
Significado
Dado que la multirruta no está habilitada en el enrutador RR4, solo se anuncia una ruta 10.0.0.20 al enrutador R8.
Ejemplo: Configuración de una política de enrutamiento para seleccionar y anunciar varias rutas según el valor de la comunidad del BGP
Anunciar todas las rutas múltiples disponibles puede generar una gran sobrecarga de procesamiento en la memoria del dispositivo. Si desea anunciar un subconjunto limitado de prefijos sin conocer realmente los prefijos de antemano, puede usar el valor de comunidad del BGP para identificar las rutas de prefijo que se deben anunciar a los vecinos del BGP. En este ejemplo, se muestra cómo definir una política de enrutamiento para filtrar y anunciar varias rutas en función de un valor de comunidad de BGP conocido.
Requisitos
No se necesita ninguna configuración especial más allá de la inicialización del dispositivo antes de configurar este ejemplo.
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Ocho enrutadores que pueden ser una combinación de enrutadores serie M, serie MX o serie T
-
Junos OS versión 16.1R2 o posterior en el dispositivo
Descripción general
A partir de Junos OS 16.1R2, puede definir una política para identificar varios prefijos de ruta aptos en función de los valores de la comunidad. El BGP anuncia estas rutas etiquetadas por la comunidad, además de la ruta activa a un destino determinado. Si el valor de comunidad de una ruta no coincide con el valor de comunidad definido en la política, el BGP no anuncia esa ruta. Esta función permite que el BGP anuncie no más de 20 rutas a un destino determinado. Puede limitar y configurar la cantidad de prefijos que BGP considera para varias rutas sin conocer realmente los prefijos de antemano. En su lugar, un valor de comunidad de BGP conocido determina si se anuncia o no un prefijo.
Topología
En la Figura 8, RR1 y RR4 son reflectores de ruta. Los enrutadores R2 y R3 son clientes del reflector de ruta RR1. El enrutador R8 es un reflector de cliente a enrutamiento RR4. Los enrutadores R5, R6 y R7 redistribuyen rutas estáticas en BGP. El enrutador R5 anuncia las rutas estáticas 199.1.1.1/32 y 198.1.1.1/32 con el valor comunitario 4713:100.
El enrutador RR1 está configurado para enviar hasta seis rutas (por destino) al enrutador RR4. El enrutador RR4 está configurado para enviar hasta seis rutas al enrutador R8. El enrutador R8 está configurado para recibir varias rutas del enrutador RR4. La configuración de comunidad add-path restringe que el enrutador RR4 envíe varias rutas para rutas que contengan solo el valor de comunidad 4713:100. El enrutador RR4 filtra y anuncia múltiples rutas que contienen solo el valor de comunidad 4714:100.
de la comunidad
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese confirmar desde el [edit] modo de configuración.
Enrutador RR1
set interfaces ge-1/0/10 unit 0 description RR1->R2 set interfaces ge-1/0/10 unit 0 family inet address 10.0.12.1/24 set interfaces ge-1/0/11 unit 0 description RR1->RR4 set interfaces ge-1/0/11 unit 0 family inet address 10.0.14.1/24 set interfaces ge-1/0/12 unit 0 description RR1->R5 set interfaces ge-1/0/12 unit 0 family inet address 10.0.15.1/24 set interfaces ge-1/0/13 unit 0 description RR1->R3 set interfaces ge-1/0/13 unit 0 family inet address 10.0.13.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.10/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.10 set protocols bgp group rr cluster 10.0.0.10 set protocols bgp group rr multipath set protocols bgp group rr neighbor 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.30 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.2 local-address 10.0.15.1 set protocols bgp group e1 neighbor 10.0.15.2 peer-as 64502 set protocols bgp group rr_rr type internal set protocols bgp group rr_rr local-address 10.0.0.10 set protocols bgp group rr_rr neighbor 10.0.0.40 family inet unicast add-path send path-count 6 set protocols ospf area 0.0.0.0 interface lo0.10 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/13 set protocols ospf area 0.0.0.0 interface ge-1/0/11 set protocols ospf area 0.0.0.0 interface ge-1/0/12 set routing-options router-id 10.0.0.10 set routing-options autonomous-system 64501
Enrutador R2
set interfaces ge-1/0/10 unit 0 description R2->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.12.2/24 set interfaces ge-1/0/11 unit 0 description R2->R6 set interfaces ge-1/0/11 unit 0 family inet address 10.0.26.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.20/32 set protocols bgp group rr local-address 10.0.0.20 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.2 peer-as 64502 set protocols ospf area 0.0.0.0 interface lo0.20 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/11 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 64501
Enrutador R3
set interfaces ge-1/0/10 unit 0 description R3->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.13.2/24 set interfaces ge-1/0/11 unit 0 description R3->R7 set interfaces ge-1/0/11 unit 0 family inet address 10.0.37.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.30/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.30 set protocols bgp group rr neighbor 10.0.0.10 export set_nh_self set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.2 peer-as 64502 set protocols ospf area 0.0.0.0 interface lo0.30 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface ge-1/0/13 set policy-options policy-statement set_nh_self then next-hop self set routing-options autonomous-system 64501
Enrutador RR4
set interfaces ge-1/0/10 unit 0 description RR4->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.14.2/24 set interfaces ge-1/0/11 unit 0 description RR4->R8 set interfaces ge-1/0/11 unit 0 family inet address 10.0.48.1/24 set interfaces lo0 unit 0 family inet address 10.0.0.40/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.40 set protocols bgp group rr family inet unicast add-path receive set protocols bgp group rr neighbor 10.0.0.10 set protocols bgp group rr_client type internal set protocols bgp group rr_client local-address 10.0.0.40 set protocols bgp group rr_client cluster 10.0.0.40 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send prefix-policy addpath-communities-send-4713-100 set protocols bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send path-count 6 set protocols ospf area 0.0.0.0 interface ge-1/0/10 set protocols ospf area 0.0.0.0 interface lo0.40 passive set protocols ospf area 0.0.0.0 interface ge-1/0/11 set policy-options community addpath-communities-send members 4713:100 set policy-options policy-statement addpath-communities-send-4713-100 term term1 from protocol bgp set policy-options policy-statement addpath-communities-send-4713-100 term term1 from community addpath-communities-send set policy-options policy-statement addpath-communities-send-4713-100 term term1 then add-path send-count 16 set policy-options policy-statement addpath-communities-send-4713-100 term term1 then accept set routing-options autonomous-system 64501
Enrutador R5
set interfaces ge-1/0/10 unit 0 description R5->RR1 set interfaces ge-1/0/10 unit 0 family inet address 10.0.15.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.50/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.15.1 export s2b set protocols bgp group e1 neighbor 10.0.15.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then as-path-expand 2 set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options static route 198.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R6
set interfaces ge-1/0/10 unit 0 description R6->R2 set interfaces ge-1/0/10 unit 0 family inet address 10.0.26.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.60/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.26.1 export s2b set protocols bgp group e1 neighbor 10.0.26.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options static route 198.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R7
set interfaces ge-1/0/10 unit 0 description R7->R3 set interfaces ge-1/0/10 unit 0 family inet address 10.0.37.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.70/32 set protocols bgp group e1 type external set protocols bgp group e1 neighbor 10.0.37.1 export s2b set protocols bgp group e1 neighbor 10.0.37.1 peer-as 64501 set policy-options policy-statement s2b from protocol static set policy-options policy-statement s2b from protocol direct set policy-options policy-statement s2b then community add addpath-community set policy-options policy-statement s2b then accept set policy-options community addpath-community members 4713:100 set routing-options static route 199.1.1.1/32 reject set routing-options autonomous-system 64502
Enrutador R8
set interfaces ge-1/0/10 unit 0 description R8->RR4 set interfaces ge-1/0/10 unit 0 family inet address 10.0.48.2/24 set interfaces lo0 unit 0 family inet address 10.0.0.80/32 set protocols bgp group rr type internal set protocols bgp group rr local-address 10.0.0.80 set protocols bgp group rr neighbor 10.0.0.40 family inet unicast add-path receive set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-1/0/10.8 set routing-options autonomous-system 64501 set chassis fpc 1 pic 0 tunnel-services bandwidth 1g
Configuración del enrutador RR4
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador RR4:
Repita este procedimiento para otros enrutadores después de modificar los nombres de interfaz, las direcciones y otros parámetros adecuados.
-
Configure las interfaces con direcciones IPv4.
[edit interfaces] user@RR4# set ge-1/0/10 unit 0 description RR4->RR1 user@RR4# set ge-1/0/10 unit 0 family inet address 10.0.14.2/24 user@RR4# set ge-1/0/11 unit 0 description RR4->R8 user@RR4# set ge-1/0/11 unit 0 family inet address 10.0.48.1/24
-
Configure la dirección de circuito cerrado.
[edit interfaces] user@RR4# set lo0 unit 0 family inet address 10.0.0.40/32
-
Configure OSPF o cualquier otro protocolo de puerta de enlace interior (IGP).
[edit protocols] user@RR4# set ospf area 0.0.0.0 interface lo0.40 passive user@RR4# set ospf area 0.0.0.0 interface ge-1/0/10 user@RR4# set ospf area 0.0.0.0 interface ge-1/0/11
-
Configure dos grupos de IBGP, rr para reflectores de ruta y rr_client para clientes de reflectores de ruta.
[edit protocols] user@RR4# set bgp group rr type internal user@RR4# set bgp group rr local-address 10.0.0.40 user@RR4# set bgp group rr family inet unicast add-path receive user@RR4# set bgp group rr neighbor 10.0.0.10 user@RR4# set bgp group rr_client type internal user@RR4# set bgp group rr_client local-address 10.0.0.40 user@RR4# set bgp group rr_client cluster 10.0.0.40
-
Configure la función para enviar varias rutas que contengan solo el valor de comunidad 4713:100 y limite el número de rutas múltiples anunciadas a 6.
[edit protocols] user@RR4# set bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send prefix-policy addpath-communities-send-4713-100 user@RR4# set bgp group rr_client neighbor 10.0.0.80 family inet unicast add-path send path-count 6
-
Defina una política
addpath-community-members 4713:100para filtrar los prefijos con el valor de comunidad 4713:100 y restringir el dispositivo para enviar hasta 16 rutas al enrutador R8. Este límite anula el recuento de rutas de envío de ruta de adición configurado previamente de 6 en el nivel de jerarquía de grupo BGP.[edit policy-options] user@RR4# set community addpath-communities-send members 4713:100 user@RR4# set policy-statement addpath-communities-send-4713-100 term term1 from protocol bgp user@RR4# set policy-statement addpath-communities-send-4713-100 term term1 from community addpath-communities-send user@RR4# set policy-statement addpath-communities-send-4713-100 term term1 then add-path send-count 16 user@RR4# set policy-statement addpath-communities-send-4713-100 term term1 then accept
-
Configure el ID del enrutador y el sistema autónomo para los hosts del BGP.
[edit routing-options] user@RR4# set router-id 10.0.0.40 user@RR4# set autonomous-system 64501
Resultados
Desde el modo de configuración, ingrese los comandos , show protocolsy show routing-optionsshow policy-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
[edit]
user@RR4# show interfaces
ge-1/0/10 {
unit 0 {
description RR4->RR1;
family inet {
address 10.0.14.2/24;
}
}
}
ge-1/0/11 {
unit 0 {
description RR4->R8;
family inet {
address 10.0.48.1/24;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.0.0.10/32;
}
}
}
[edit]
user@RR4# show protocols
bgp {
group rr {
type internal;
local-address 10.0.0.40;
family inet {
unicast {
add-path {
receive;
}
}
}
neighbor 10.0.0.10;
}
group rr_client {
type internal;
local-address 10.0.0.40;
cluster 10.0.0.40;
neighbor 10.0.0.80 {
family inet {
unicast {
add-path {
send {
prefix-policy addpath-communities-send-4713-100;
path-count 6;
}
}
}
}
}
}
}
ospf {
area 0.0.0.0 {
interface ge-1/0/10.0;
interface lo0.40 {
passive;
}
interface ge-1/0/11.0;
}
}
[edit]
user@RR4# show policy-options
policy-statement addpath-communities-send-4713-100 {
term term1 {
from {
protocol bgp;
community addpath-communities-send;
}
then {
add-path send-count 16;
accept;
}
}
}
community addpath-communities-send members 4713:100;
[edit] user@RR4# show routing-options router-id 10.0.0.40; autonomous-system 64501;
Cuando termine de configurar el dispositivo, confirme la configuración.
user@RR4# commit
Verificación
Confirme que la configuración funcione correctamente.
- Verificar que las rutas de múltiples rutas se anuncian desde el enrutador RR4 al enrutador R8
- Verificar que el enrutador R8 recibe las rutas de múltiples rutas que anuncia el enrutador RR4
- Verificar que el enrutador RR4 solo anuncia rutas múltiples con valor de comunidad 4713:100 al enrutador R8
Verificar que las rutas de múltiples rutas se anuncian desde el enrutador RR4 al enrutador R8
Propósito
Compruebe que el enrutador RR4 puede enviar varias rutas al enrutador R8.
Acción
Desde el modo operativo, ejecute el comando en el show route advertising-protocol bgp neighbor-address enrutador RR4.
user@RR4> show route advertising-protocol bgp 10.0.0.80
inet.0: 20 destinations, 23 routes (20 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 198.1.1.1/32 10.0.0.20 100 2 I
10.0.15.2 100 2 2 I
* 199.1.1.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
Significado
El enrutador RR4 anuncia varias rutas 10.0.0.20, 10.0.0.30 y 10.0.15.2 al enrutador R8.
Verificar que el enrutador R8 recibe las rutas de múltiples rutas que anuncia el enrutador RR4
Propósito
Compruebe que el enrutador R8 recibe las rutas de multirruta del enrutador RR4.
Acción
Desde el modo operativo, ejecute el comando en el show route receive-protocol bgp neighbor-address enrutador R8.
user@R8> show route receive-protocol bgp 10.0.0.40
inet.0: 19 destinations, 22 routes (19 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.0.0.50/32 10.0.15.2 100 2 2 I
* 10.0.0.60/32 10.0.0.20 100 2 I
* 10.0.0.70/32 10.0.0.30 100 2 I
* 198.1.1.1/32 10.0.0.20 100 2 I
10.0.15.2 100 2 2 I
* 199.1.1.1/32 10.0.0.20 100 2 I
10.0.0.30 100 2 I
10.0.15.2 100 2 2 I
Significado
El enrutador R8 recibe varios saltos siguientes 10.0.0.20, 10.0.0.30 y 10.0.15.2 para la ruta 199.1.1.1/32 del enrutador RR4.
Verificar que el enrutador RR4 solo anuncia rutas múltiples con valor de comunidad 4713:100 al enrutador R8
Propósito
El enrutador RR4 debe anunciar rutas de multirruta con un valor de comunidad de 4713:100 solo al enrutador R8.
Acción
Desde el modo operativo, ejecute el comando en el show route 199.1.1.1/32 detail enrutador RR4.
user@RR4> show route 199.1.1.1/32 detail
inet.0: 20 destinations, 23 routes (20 active, 0 holddown, 0 hidden)
199.1.1.1/32 (3 entries, 3 announced)
*BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xae0ea90
Next-hop reference count: 6
Source: 10.0.0.10
Next hop type: Router, Next hop index: 1115
Next hop: 10.0.14.1 via ge-1/0/10.4, selected
Session Id: 0x0
Protocol next hop: 10.0.0.20
Indirect next hop: 0xc4091f0 1048581 INH Session ID: 0x0
State: <Active Int Ext>
Local AS: 1 Peer AS: 1
Age: 4d 20:56:53 Metric2: 2
Validation State: unverified
Task: BGP_1.10.0.0.10
Announcement bits (3): 2-KRT 3-BGP_RT_Background 4-Resolve tree 2
AS path: 2 I (Originator)
Cluster list: 10.0.0.10
Originator ID: 10.0.0.20
Communities: 4713:100
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 1
BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xae0eb50
Next-hop reference count: 3
Source: 10.0.0.10
Next hop type: Router, Next hop index: 1115
Next hop: 10.0.14.1 via lt-1/0/10.4, selected
Session Id: 0x0
Protocol next hop: 10.0.0.30
Indirect next hop: 0xc409300 1048582 INH Session ID: 0x0
State: <NotBest Int Ext>
Inactive reason: Not Best in its group - Router ID
Local AS: 1 Peer AS: 1
Age: 4d 20:56:53 Metric2: 2
Validation State: unverified
Task: BGP_1.10.0.0.10
Announcement bits (1): 3-BGP_RT_Background
AS path: 2 I (Originator)
Cluster list: 10.0.0.10
Originator ID: 10.0.0.30
Communities: 4713:100
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 2
BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xae0e9d0
Next-hop reference count: 4
Source: 10.0.0.10
Next hop type: Router, Next hop index: 1115
Next hop: 10.0.14.1 via lt-1/0/10.4, selected
Session Id: 0x0
Protocol next hop: 10.0.15.2
Indirect next hop: 0xc4090e0 1048580 INH Session ID: 0x0
State: <Int Ext>
Inactive reason: AS path
Local AS: 1 Peer AS: 1
Age: 4d 20:56:53 Metric2: 2
Validation State: unverified
Task: BGP_1.10.0.0.10
Announcement bits (1): 3-BGP_RT_Background
AS path: 2 2 I
Communities: 4713:100
Accepted
Localpref: 100
Router ID: 10.0.0.10
Addpath Path ID: 3
Significado
El enrutador RR4 anuncia tres rutas con un valor de comunidad de 4713:100 al enrutador R8.
Configuración de la resolución recursiva a través de múltiples rutas de BGP
A partir de la versión 17.3R1 de Junos OS, cuando un prefijo de BGP que tiene un único salto siguiente de protocolo se resuelve sobre otro prefijo de BGP que tiene varias rutas resueltas (unilist), se seleccionan todas las rutas para la resolución del próximo salto de protocolo. En versiones anteriores de Junos OS, solo se elige una de las rutas para la resolución del protocolo de siguiente salto porque el solucionador no admitía el equilibrio de carga en todas las rutas de la ruta de multirruta del IBGP. El solucionador en el proceso de protocolo de enrutamiento (RPD) resuelve la dirección del protocolo del próximo salto (PNH) en los siguientes saltos de reenvío inmediato. La función de resolución recursiva de BGP mejora el solucionador para resolver rutas a través de una ruta multirruta de IBGP y usar todas las rutas factibles como próximos saltos. Esta característica beneficia a las redes densamente conectadas en las que se utiliza BGP para establecer la conectividad de la infraestructura, como las redes de WAN con multirruta de alto costo y topología MPLS sin interrupciones.
Antes de empezar a configurar la resolución recursiva de la multirruta BGP, debe hacer lo siguiente:
Configure las interfaces de los dispositivos.
Configure OSPF o cualquier otro protocolo IGP.
Configure MPLS y LDP.
Configure BGP.
Para configurar la resolución recursiva por multirruta,
Ver también
Configuración de los próximos saltos de ECMP para RSVP y LSP de LDP para equilibrio de carga
Junos OS admite configuraciones de 16, 32, 64 o 128 próximos saltos de multirruta de igual costo (ECMP) para LSP de RSVP y LDP. Para redes con tráfico de alto volumen, esto proporciona más flexibilidad para equilibrar la carga del tráfico en hasta 128 LSP.
Para configurar el límite máximo de los próximos saltos de ECMP, incluya la maximum-ecmp next-hops instrucción en el nivel de [edit chassis] jerarquía:
[edit chassis] maximum-ecmp next-hops;
Puede configurar un límite máximo de ECMP de próximo salto de 16, 32, 64 o 128 con esta instrucción. El límite predeterminado es 16.
Los enrutadores de la serie MX con una o más tarjetas de concentrador de puerto modular (MPC) y con Junos OS 11.4 o anterior instalado, admiten la configuración de la maximum-ecmp instrucción con solo 16 saltos siguientes. No debe configurar la maximum-ecmp instrucción con 32 o 64 próximos saltos. Cuando confirme la configuración con 32 o 64 saltos siguientes, aparecerá el siguiente mensaje de advertencia:
Error: Number of members in Unilist NH exceeds the maximum supported 16 on Trio.
Los siguientes tipos de rutas admiten la configuración del próximo salto máximo de ECMP para hasta 128 puertas de enlace ECMP:
-
Rutas IPv4 e IPv6 estáticas con ECMP de próximo salto directo e indirecto
-
Rutas de entrada y tránsito de LDP aprendidas a través de rutas IGP asociadas
-
Próximos saltos de ECMP de RSVP creados para LSP
-
ECMP de ruta IPv4 e IPv6 de OSPF
-
ECMP de ruta IPv4 e IPv6 SI-SI
-
ECMP de ruta IPv4 e IPv6 del EBGP
-
IBGP (resolución mediante rutas IGP) ECMP de rutas IPv4 e IPv6
El límite de ECMP mejorado de hasta 128 próximos saltos ECMP también se aplica a las VPN de capa 3, VPN de capa 2, circuitos de capa 2 y servicios VPLS que se resuelven a través de una ruta MPLS, ya que dicho tráfico también puede utilizar las rutas ECMP disponibles en la ruta MPLS.
Si los LSP de RSVP están configurados con asignación de ancho de banda, para los próximos saltos de ECMP con más de 16 LSP, el tráfico no se distribuye de forma óptima según los anchos de banda configurados. Algunos LSP con anchos de banda asignados más pequeños reciben más tráfico que los configurados con anchos de banda más altos. La distribución del tráfico no cumple estrictamente con la asignación de ancho de banda configurada. Esta advertencia se aplica a los siguientes enrutadores:
-
Enrutadores de la serie MX con todos los tipos de FPC y DPC, excluyendo las MPC. Esta advertencia no se aplica a los enrutadores de la serie MX con tarjetas de línea basadas en el conjunto de chips de Junos Trio.
Para ver los detalles de los siguientes saltos de ECMP, ejecute el show route comando. También show route summary command muestra la configuración actual del límite máximo de ECMP. Para ver detalles de las rutas de LDP de ECMP, ejecute el traceroute mpls ldp comando.
Ver también
Configuración del equilibrio de carga coherente para grupos ECMP
El equilibrio de carga por paquete le permite distribuir el tráfico en varias rutas de igual costo. De forma predeterminada, cuando se produce un error en una o más rutas, el algoritmo hash vuelve a calcular el siguiente salto para todas las rutas, lo que normalmente da como resultado la redistribución de todos los flujos. El equilibrio de carga coherente permite invalidar este comportamiento para que solo se redirijan los flujos de vínculos que están inactivos. Todos los flujos activos existentes se mantienen sin interrupciones. En un entorno de centro de datos, la redistribución de todos los flujos cuando un vínculo falla puede dar como resultado una pérdida significativa de tráfico o una pérdida del servicio a los servidores cuyos vínculos permanecen activos. El equilibrio de carga coherente mantiene todos los vínculos activos y, en su lugar, reasigna solo los flujos afectados por uno o más errores de vínculo. Esta característica garantiza que los flujos conectados a los vínculos que permanecen activos continúen sin interrupciones.
Esta característica se aplica a topologías en las que los miembros de un grupo de multirrutas de igual costo (ECMP) son vecinos de BGP externos en una sesión de BGP de un solo salto. El equilibrio de carga coherente no se aplica cuando se agrega una nueva ruta ECMP ni se modifica una ruta existente de alguna manera. Para agregar una nueva ruta con una interrupción mínima, defina un nuevo grupo ECMP sin modificar las rutas existentes. De esta manera, los clientes se pueden mover al nuevo grupo gradualmente sin terminar las conexiones existentes.
(En la serie MX) Solo se admiten concentradores de puerto modulares (MPC).
Se admiten rutas IPv4 e IPv6.
También se admiten grupos ECMP que forman parte de una instancia de enrutamiento y reenvío virtual (VRF) u otra instancia de enrutamiento.
No se admite el tráfico de multidifusión.
Se admiten interfaces agregadas, pero no se admite el equilibrio de carga coherente entre los miembros del paquete de agregación de vínculos (LAG). El tráfico de los miembros activos del grupo de LAG se puede mover a otro miembro activo cuando se produce un error en uno o más vínculos de miembro. Los flujos se repiten cuando se produce un error en uno o varios vínculos de miembro del LAG.
Recomendamos encarecidamente que aplique un equilibrio de carga consistente a no más de un máximo de 1000 prefijos IP por enrutador o conmutador.
Se admite la adyacencia de capa 3 en interfaces de enrutamiento y puente integrados (IRB).
Puede configurar la función de agregar ruta del BGP para habilitar el reemplazo de una ruta fallida por una nueva ruta activa cuando fallen una o más rutas del grupo ECMP. La configuración del reemplazo de rutas fallidas garantiza que se redirija el flujo de tráfico solo en las rutas fallidas. El flujo de tráfico en las rutas activas permanecerá inalterado.
Cuando configure un equilibrio de carga coherente en interfaces de túnel de encapsulación de enrutamiento genérico (GRE), debe especificar la dirección inet de la interfaz GRE del extremo final para que las adyacencias de capa 3 sobre las interfaces de túnel GRE se instalen correctamente en la tabla de reenvío. Sin embargo, el reenrutamiento rápido ECMP (FRR) a través de interfaces de túnel GRE no se admite durante el equilibrio de carga coherente. Puede especificar la dirección de destino en el enrutador configurado con un equilibrio de carga coherente en el
[edit interfaces interface name unit unit name family inet address address]nivel jerárquico. Por ejemplo:[edit interfaces] user@host# set interfaces gr-4/0/0 unit 21 family inet address 10.10.31.2/32 destination 10.10.31.1
Para obtener más información acerca de la encapsulación de enrutamiento genérico, consulte Configurar la tunelización de encapsulación de enrutamiento genérico.
El equilibrio de carga coherente no admite el multisalto de BGP para vecinos de EBGP. Por lo tanto, no habilite la
multihopopción en dispositivos configurados con un equilibrio de carga coherente.
Para configurar un equilibrio de carga coherente para grupos ECMP:
Mejore la resistencia de red mediante varios pares de BGP ECMP
Descripción general
La multirruta de igual costo (ECMP) es una estrategia de enrutamiento de red que permite que el tráfico de la misma sesión, o flujo, se transmita a través de múltiples rutas de igual costo. Un flujo es tráfico con el mismo origen y destino. El proceso ECMP identifica los enrutadores que son legítimos y próximos saltos de igual costo hacia el destino del flujo. Luego, el dispositivo utiliza el equilibrio de carga para distribuir uniformemente el tráfico entre estos próximos saltos múltiples y de igual costo. ECMP es un mecanismo que le permite a usted (el administrador de red) equilibrar la carga de tráfico y aumentar el ancho de banda mediante la utilización completa del ancho de banda que de otro modo no se utilizaría en los vínculos al mismo destino.
A menudo usa ECMP con BGP. Cada ruta de BGP puede tener varios siguientes saltos ECMP. La política de exportación del BGP determina si se anuncia la ruta del BGP a estos próximos saltos. Como administrador de red, puede controlar el anuncio y la retirada de prefijos de BGP hacia y desde estos pares ECMP. La política de exportación de BGP determina si se anuncia un prefijo de BGP en función del número de pares de BGP ECMP de los que la política recibe el prefijo.
Puede configurar la política de exportación de BGP para retirar una ruta de BGP, a menos que reciba el prefijo de ruta de BGP de un número mínimo de pares de BGP ECMP. Requerir que la ruta del BGP tenga varios pares de BGP ECMP crea una mejor resistencia en caso de fallas de vínculos.
Beneficios
-
Mejora la resistencia de su red
-
Evita la sobrecarga accidental de enlaces
-
Ayuda con el equilibrio de carga
Configuración
La política de exportación del BGP compara el número de próximos saltos de ECMP para la ruta del BGP con el valor que configure con la from nexthop-ecmp instrucción en cualquiera de estas jerarquías: [edit policy-options policy-statement policy-name] o [edit policy-options policy-statement policy-name term term-name].
Las opciones para esta declaración son:
-
value: El número exacto de puertas de enlace ECMP (de 1 a 512) necesarias para cumplir la condición. -
equal: El número de puertas de enlace debe ser igual al valor configurado. -
greater-than: El número de puertas de enlace debe ser mayor que el valor configurado. -
greater-than-equal: El número de puertas de enlace debe ser mayor o igual que el valor configurado. -
less-than: El número de puertas de enlace debe ser inferior al valor configurado. -
less-than-equal: El número de puertas de enlace debe ser menor o igual que el valor configurado.
Descripción de la etiqueta de entropía para LSP de unidifusión etiquetado con BGP
- ¿Qué es una etiqueta de entropía?
- Etiqueta de entropía para BGP etiquetada con unidifusión
- Funciones compatibles y no compatibles
¿Qué es una etiqueta de entropía?
Una etiqueta de entropía es una etiqueta especial de equilibrio de carga que mejora la capacidad del enrutador para equilibrar la carga del tráfico a través de rutas multirrutas de igual costo (ECMP) o grupos de agregación de vínculos (LAG). La etiqueta de entropía permite a los enrutadores equilibrar la carga de tráfico de manera eficiente utilizando solo la pila de etiquetas en lugar de la inspección profunda de paquetes (DPI). DPI requiere más potencia de procesamiento del enrutador y no es una capacidad compartida por todos los enrutadores.
Cuando un paquete IP tiene varias rutas para llegar a su destino, Junos OS utiliza ciertos campos de los encabezados de paquete para aplicar hash al paquete a una ruta determinista. Las direcciones de origen o destino y los números de puerto del paquete se usan para aplicar hash, a fin de evitar el reordenamiento de paquetes de un flujo determinado. Si un enrutador de conmutación de etiquetas (LSR) de núcleo no es capaz de realizar un PPP para identificar el flujo o no puede hacerlo a velocidad de línea, la pila de etiquetas sola se utiliza para el hash ECMP. Esto requiere una etiqueta de entropía, una etiqueta especial de equilibrio de carga que pueda transportar la información del flujo. El LSR de entrada tiene más contexto e información sobre los paquetes entrantes que los LSR de tránsito. Por lo tanto, el enrutador de borde de etiquetas de entrada (LER) puede inspeccionar la información de flujo de un paquete, asignarla a una etiqueta de entropía e insertarla en la pila de etiquetas. Los LSR en el núcleo simplemente usan la etiqueta de entropía como clave para hash del paquete a la ruta correcta.
Una etiqueta de entropía puede ser cualquier valor de etiqueta entre 16 y 1048575 (intervalo de etiqueta normal de 20 bits). Dado que este intervalo se superpone con el intervalo de etiquetas regulares existente, se inserta una etiqueta especial denominada indicador de etiqueta de entropía (ELI) antes de la etiqueta de entropía. ELI es una etiqueta especial asignada por la AANI con el valor de 7.
La Figura 9 ilustra la etiqueta de entropía en una pila de etiquetas de paquete de ruta conmutada por etiqueta (LSP) RSVP. La pila de etiquetas está formada por el indicador de etiqueta de entropía (ELI), la etiqueta de entropía y el paquete IP.
 RSVP
RSVP
Etiqueta de entropía para BGP etiquetada con unidifusión
El BGP etiquetado con unidifusión concatena el RSVP o el LSP de LDP en varias áreas del protocolo de pasarela interior (IGP) o varios sistemas autónomos (inter-AS LSP). Los LSP de unidifusión etiquetados con BGP entre áreas suelen transportar tráfico de VPN e IP cuando los PE de entrada y salida se encuentran en distintas áreas del IGP. Cuando el BGP etiquetado con unidifusión concatena el RSVP o el LSP de LDP, Junos OS inserta las etiquetas de entropía en la entrada del LSP de unidifusión etiquetado con BGP para lograr el equilibrio de carga de la etiqueta de entropía de extremo a extremo. Esto se debe a que las etiquetas de entropía RSVP o LDP generalmente se extraen en el penúltimo nodo de salto, junto con la etiqueta RSVP o LDP, y no hay etiquetas de entropía en los puntos de unión, es decir, los enrutadores entre dos áreas o dos AS. Por lo tanto, en ausencia de etiquetas de entropía, el enrutador en el punto de unión utiliza las etiquetas del BGP para reenviar paquetes. La figura 10 ilustra la pila de etiquetas de paquete de unidifusión etiquetado con BGP con la etiqueta de entropía en una pila de etiquetas RSVP. La pila de etiquetas RSVP consta del indicador de etiqueta de entropía (ELI), la etiqueta de entropía, la etiqueta BGP y el paquete IP. Las etiquetas de entropía de RSVP se extraen en el penúltimo nodo de salto.
 de entropía RSVP
de entropía RSVP
El nodo de unión de unidifusión etiquetado con BGP no puede usar las etiquetas de entropía para el equilibrio de carga a menos que el nodo de unión señale la capacidad de la etiqueta de entropía en la salida del BGP. Si el nodo de unión de unidifusión etiquetado con BGP señala la capacidad de etiqueta de entropía (ELC) del BGP a los enrutadores perimetrales del proveedor, la entrada del LSP de unidifusión etiquetada con BGP es consciente de que la salida del LSP de unidifusión etiquetada con BGP puede manejar etiquetas de entropía e inserta un indicador de etiqueta de entropía y una etiqueta de entropía debajo de la etiqueta BGP. Todos los LSR pueden usar la etiqueta de entropía para el equilibrio de carga. Aunque el LSP de unidifusión etiquetado con BGP puede cruzar varios enrutadores en distintas áreas y AS, es posible que algunos segmentos admitan etiquetas de entropía, mientras que otras no. La figura 11 ilustra la etiqueta de entropía en la pila de etiquetas del BGP. La pila de etiquetas en el nodo de unión consta del ELI, la etiqueta de entropía y el paquete IP.
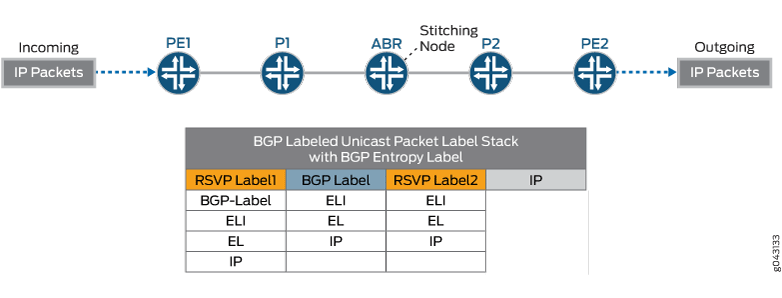 de unión
de unión
Para deshabilitar la capacidad de etiqueta de entropía para el BGP etiquetado como unidifusión en el nodo de salida, defina una política con la opción no-entropy-label-capability en el nivel de [edit policy-options policy-statement policy-name then] jerarquía.
[edit policy-options policy-statement policy-name then]user@PE#no-entropy-label-capability
De forma predeterminada, los enrutadores que admiten etiquetas de entropía se configuran con la instrucción load-balance-label-capability en el [edit forwarding-options] nivel de jerarquía para señalar las etiquetas por LSP. Si el enrutador par no está equipado para manejar etiquetas de equilibrio de carga, puede impedir la señalización de la capacidad de etiqueta de entropía configurando la no-load-balance-label-capability instrucción en el [edit forwarding-options] nivel de jerarquía.
[edit forwarding-options]user@PE#no-load-balance-label-capability
De forma predeterminada, un anunciador BGP usa el atributo de capacidad de etiqueta de entropía (ELCv3) definido en el atributo de capacidad de enrutador BGP (RCA) de GTI-I para el equilibrio de carga. Envía y recibe solo el atributo ELCv3. Si necesita usar el atributo ELCv2 interoperable con el borrador de RCA, configure explícitamente el elc-v2-compatible potenciómetro en la jerarquía labeled-unidifusión entropy-label. En tal escenario, tanto ELCv3 como ELCv2 se envían y reciben.
Funciones compatibles y no compatibles
Junos OS admite una etiqueta de entropía para BGP etiquetada como unidifusión en los siguientes escenarios:
-
Todos los nodos de los LSP tienen capacidad de etiqueta de entropía.
-
Algunos de los nodos de los LSP tienen capacidad de etiqueta de entropía.
-
Los LSP hacen un túnel a través de la VPN de otro operador.
-
Defina una política de entrada para seleccionar un subconjunto de LSP de unidifusión etiquetados con BGP para insertar una etiqueta de entropía en la entrada.
-
Defina una política de salida para deshabilitar el anuncio de capacidad de etiqueta de entropía.
Junos OS no admite las siguientes características para una etiqueta de entropía para BGP etiquetada como unidifusión:
-
Cuando los LSP de unidifusión etiquetados con BGP tunelizan a través de la VPN de otro operador, no existe una verdadera etiqueta de entropía de extremo a extremo, ya que Junos OS no inserta un indicador de etiqueta de entropía o una etiqueta de entropía debajo de las etiquetas VPN en la red de carrier de operadores.
-
Actualmente, Junos OS no admite LSP de unidifusión etiquetados con BGP IPv6 con sus propias etiquetas de entropía. Sin embargo, los LSP de unidifusión etiquetados con BGP IPv6 pueden usar las etiquetas de entropía de los LSP RSVP, LDP o BGP subyacentes.
Ver también
Configurar una etiqueta de entropía para un LSP de unidifusión etiquetado con BGP
Configure una etiqueta de entropía para el LSP de unidifusión etiquetado con BGP para lograr el equilibrio de carga de la etiqueta de entropía de extremo a extremo. Una etiqueta de entropía es una etiqueta especial de equilibrio de carga que puede transportar la información de flujo de los paquetes. El BGP etiquetado con unidifusión concatena el RSVP o el LSP de LDP en varias áreas del IGP o varios sistemas autónomos (AS). Las etiquetas de entropía RSVP o LDP se extraen en el penúltimo nodo de salto, junto con la etiqueta RSVP o LDP. Esta característica permite el uso de una etiqueta de entropía en el punto de unión, es decir, los enrutadores entre dos áreas o AS, para lograr el equilibrio de carga de la etiqueta de entropía de extremo a extremo para el tráfico del BGP. Esta característica permite la inserción de etiquetas de entropía en la entrada del LSP de unidifusión etiquetada con el BGP.
Una etiqueta de entropía puede ser cualquier valor de etiqueta entre 16 y 1048575 (intervalo de etiqueta normal de 20 bits). Dado que este intervalo se superpone con el intervalo de etiquetas regulares existente, se inserta una etiqueta especial denominada indicador de etiqueta de entropía (ELI) antes de la etiqueta de entropía. ELI es una etiqueta especial asignada por la AANI con el valor de 7.
Antes de configurar una etiqueta de entropía para BGP etiquetada como unidifusión, asegúrese de:
Configure las interfaces de los dispositivos.
Configure OSPF o cualquier otro protocolo IGP.
Configure BGP.
Configure LDP.
Configure RSVP.
Configure MPLS.
Para configurar una etiqueta de entropía para el LSP de unidifusión etiquetado con el BGP:
Ver también
Ejemplo: Configuración de una etiqueta de entropía para un LSP de unidifusión etiquetado con BGP
En este ejemplo, se muestra cómo configurar una etiqueta de entropía para un BGP etiquetado con unidifusión a fin de lograr el equilibrio de carga de extremo a extremo mediante etiquetas de entropía. Cuando un paquete IP tiene varias rutas para llegar a su destino, Junos OS utiliza ciertos campos de los encabezados de paquete para aplicar hash al paquete a una ruta determinista. Esto requiere una etiqueta de entropía, una etiqueta especial de equilibrio de carga que pueda transportar la información del flujo. Los LSR en el núcleo simplemente usan la etiqueta de entropía como clave para aplicar hash al paquete a la ruta correcta. Una etiqueta de entropía puede ser cualquier valor de etiqueta entre 16 y 1048575 (intervalo de etiqueta normal de 20 bits). Dado que este intervalo se superpone con el intervalo de etiquetas regulares existente, se inserta una etiqueta especial denominada indicador de etiqueta de entropía (ELI) antes de la etiqueta de entropía. ELI es una etiqueta especial asignada por la AANI con el valor de 7.
El BGP etiquetado con unidifusión concatena el RSVP o el LSP de LDP en varias áreas del IGP o varios sistemas autónomos. Las etiquetas de entropía RSVP o LDP se extraen en el penúltimo nodo de salto, junto con la etiqueta RSVP o LDP. Esta característica permite el uso de etiquetas de entropía en los puntos de unión para salvar la brecha entre el penúltimo nodo de salto y el punto de unión, con el fin de lograr un equilibrio de carga de la etiqueta de entropía de extremo a extremo para el tráfico del BGP.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Siete enrutadores de la serie MX con MPC
-
Junos OS versión 15.1 o posterior ejecutándose en todos los dispositivos
-
Revalidado mediante Junos OS Resase 22.4
-
Antes de configurar una etiqueta de entropía para BGP etiquetada como unidifusión, asegúrese de:
-
Configure las interfaces de los dispositivos.
-
Configure OSPF o cualquier otro protocolo IGP.
-
Configure BGP.
-
Configure RSVP.
-
Configure MPLS.
Descripción general
Cuando el BGP etiquetado con unidifusión concatena el RSVP o el LSP de LDP en varias áreas del IGP o varios sistemas autónomos, las etiquetas de entropía de RSVP o LDP se extraen en el penúltimo nodo del salto, junto con la etiqueta RSVP o LDP. Sin embargo, no hay etiquetas de entropía en los puntos de unión, es decir, los enrutadores entre dos áreas. Por lo tanto, los enrutadores en los puntos de unión usaron las etiquetas BGP para reenviar paquetes.
A partir de Junos OS versión 15.1, puede configurar una etiqueta de entropía para BGP etiquetada con unidifusión a fin de lograr un equilibrio de carga de etiqueta de entropía de extremo a extremo. Esta característica permite el uso de una etiqueta de entropía en los puntos de unión para lograr el equilibrio de carga de la etiqueta de entropía de extremo a extremo para el tráfico del BGP. Junos OS permite la inserción de etiquetas de entropía en la entrada del LSP de unidifusión etiquetada con el BGP.
De forma predeterminada, los enrutadores que admiten etiquetas de entropía se configuran con la load-balance-label-capability instrucción en el [edit forwarding-options] nivel de jerarquía para señalar las etiquetas por LSP. Si el enrutador par no está equipado para manejar etiquetas de equilibrio de carga, puede impedir la señalización de la capacidad de etiqueta de entropía configurando la no-load-balance-label-capability en el [edit forwarding-options] nivel jerárquico.
[edit forwarding-options]user@PE#no-load-balance-label-capability
Puede deshabilitar explícitamente la capacidad de la etiqueta de entropía de publicidad en la salida para las rutas especificadas en la política con la no-entropy-label-capability opción en el [edit policy-options policy-statement policy name then] nivel de jerarquía.
[edit policy-options policy-statement policy-name then]user@PE#no-entropy-label-capability
Topología
En la Figura 12 , el enrutador PE1 es el enrutador de entrada y el enrutador PE2 es el enrutador de salida. Los enrutadores P1 y P2 son los enrutadores de tránsito. El enrutador ABR es el enrutador de puente de área entre el Área 0 y el Área 1. Se configuran dos LSP en ABR a PE2 para equilibrar la equilibrio de carga del tráfico. La capacidad de la etiqueta de entropía para la etiqueta de unidifusión del BGP está habilitada en el enrutador de entrada PE1. El host 1 está conectado a P1 para las capturas de paquetes para que podamos mostrar la etiqueta de entropía.
Configuración
- Configuración rápida de CLI
- Configuración del enrutador PE1
- Configuración del enrutador P1
- Configuración del enrutador ABR
- (Opcional) Configuración de imitación de puerto
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese commit desde el [edit] modo de configuración.
Enrutador CE1
set interfaces ge-0/0/0 unit 0 family inet address 172.16.12.1/30 set interfaces lo0 unit 0 family inet address 172.16.255.1/32 primary set interfaces lo0 unit 0 family inet address 192.168.255.1/32 set routing-options router-id 172.16.255.1 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface lo0.0 passive
Enrutador PE1
set interfaces ge-0/0/0 unit 0 family inet address 172.16.12.2/30 set interfaces ge-0/0/2 unit 0 family inet address 10.1.23.1/30 set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.255.2/32 primary set interfaces lo0 unit 1 family inet address 10.1.255.22/32 set policy-options policy-statement bgp-to-ospf from protocol bgp set policy-options policy-statement bgp-to-ospf then accept set policy-options policy-statement pplb then load-balance per-packet set routing-instances VPN-l3vpn instance-type vrf set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface lo0.1 passive set routing-instances VPN-l3vpn protocols ospf export bgp-to-ospf set routing-instances VPN-l3vpn interface ge-0/0/0.0 set routing-instances VPN-l3vpn interface lo0.1 set routing-instances VPN-l3vpn route-distinguisher 10.1.255.2:1 set routing-instances VPN-l3vpn vrf-target target:65000:1 set routing-options router-id 10.1.255.2 set routing-options autonomous-system 65000 set routing-options forwarding-table export pplb set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.1.255.2 set protocols bgp group ibgp family inet labeled-unicast entropy-label set protocols bgp group ibgp neighbor 10.1.255.4 family inet labeled-unicast rib inet.3 set protocols bgp group ibgp neighbor 10.1.255.6 family inet-vpn unicast set protocols mpls icmp-tunneling set protocols mpls label-switched-path pe1-abr to 10.1.255.4 set protocols mpls label-switched-path pe1-abr entropy-label set protocols mpls interface ge-0/0/2.0 set protocols mpls interface lo0.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface ge-0/0/2.0 set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols rsvp interface ge-0/0/2.0 set protocols rsvp interface lo0.0
Enrutador P1
set interfaces ge-0/0/0 unit 0 family inet address 10.1.23.2/30 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/2 unit 0 family inet address 10.1.34.1/30 set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.255.3/32 primary set routing-options router-id 10.1.255.3 set protocols mpls icmp-tunneling set protocols mpls interface ge-0/0/0.0 set protocols mpls interface lo0.0 set protocols mpls interface ge-0/0/2.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/2.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface lo0.0 set protocols rsvp interface ge-0/0/2.0
Enrutador ABR
set interfaces ge-0/0/0 unit 0 family inet address 10.1.34.2/30 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/2 unit 0 family inet address 10.1.45.1/30 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 unit 0 family inet address 10.1.45.5/30 set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.255.4/32 primary set forwarding-options hash-key family mpls label-1 set forwarding-options hash-key family mpls label-2 set forwarding-options hash-key family mpls label-3 set forwarding-options enhanced-hash-key family mpls no-payload set policy-options policy-statement pplb then load-balance per-packet set policy-options policy-statement send-inet3-pe1 from route-filter 10.1.255.2/32 exact set policy-options policy-statement send-inet3-pe1 then accept set policy-options policy-statement send-inet3-pe2 from route-filter 10.1.255.6/32 exact set policy-options policy-statement send-inet3-pe2 then accept set routing-options router-id 10.1.255.4 set routing-options autonomous-system 65000 set routing-options forwarding-table export pplb set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.1.255.4 set protocols bgp group ibgp family inet labeled-unicast rib inet.3 set protocols bgp group ibgp neighbor 10.1.255.2 export send-inet3-pe2 set protocols bgp group ibgp neighbor 10.1.255.6 export send-inet3-pe1 set protocols mpls icmp-tunneling set protocols mpls label-switched-path abr-pe1 to 10.1.255.2 set protocols mpls label-switched-path abr-pe1 entropy-label set protocols mpls label-switched-path abr-pe2 to 10.1.255.6 set protocols mpls label-switched-path abr-pe2 entropy-label set protocols mpls label-switched-path abr-pe2 primary to-r6-1 set protocols mpls label-switched-path abr-pe2-2 to 10.1.255.6 set protocols mpls label-switched-path abr-pe2-2 entropy-label set protocols mpls label-switched-path abr-pe2-2 primary to-r6-2 set protocols mpls path to-r6-1 10.1.45.2 strict set protocols mpls path to-r6-1 10.1.56.2 strict set protocols mpls path to-r6-2 10.1.45.6 strict set protocols mpls path to-r6-2 10.1.56.6 strict set protocols mpls interface lo0.0 set protocols mpls interface ge-0/0/0.0 set protocols mpls interface ge-0/0/2.0 set protocols mpls interface ge-0/0/3.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.1 interface ge-0/0/2.0 set protocols ospf area 0.0.0.1 interface ge-0/0/3.0 set protocols rsvp interface lo0.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface ge-0/0/2.0 set protocols rsvp interface ge-0/0/3.0
Enrutador P2
set interfaces ge-0/0/0 unit 0 family inet address 10.1.45.2/30 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 10.1.45.6/30 set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 unit 0 family inet address 10.1.56.1/30 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 unit 0 family inet address 10.1.56.5/30 set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.255.5/32 primary set forwarding-options hash-key family mpls label-1 set forwarding-options hash-key family mpls label-2 set forwarding-options hash-key family mpls label-3 set forwarding-options enhanced-hash-key family mpls no-payload set policy-options policy-statement pplb then load-balance per-packet set routing-options router-id 10.1.255.5 set routing-options forwarding-table export pplb set protocols mpls icmp-tunneling set protocols mpls interface ge-0/0/2.0 set protocols mpls interface lo0.0 set protocols mpls interface ge-0/0/0.0 set protocols mpls interface ge-0/0/1.0 set protocols mpls interface ge-0/0/3.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.1 interface lo0.0 passive set protocols ospf area 0.0.0.1 interface ge-0/0/2.0 set protocols ospf area 0.0.0.1 interface ge-0/0/0.0 set protocols ospf area 0.0.0.1 interface ge-0/0/1.0 set protocols ospf area 0.0.0.1 interface ge-0/0/3.0 set protocols rsvp interface ge-0/0/2.0 set protocols rsvp interface lo0.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface ge-0/0/3.0
Enrutador PE2
set interfaces ge-0/0/0 unit 0 family inet address 10.1.56.2/30 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 10.1.56.6/30 set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 unit 0 family inet address 172.16.67.2/30 set interfaces lo0 unit 0 family inet address 10.1.255.6/32 primary set interfaces lo0 unit 1 family inet address 10.1.255.66/32 set forwarding-options hash-key family mpls label-1 set forwarding-options hash-key family mpls label-2 set forwarding-options hash-key family mpls label-3 set forwarding-options enhanced-hash-key family mpls no-payload set policy-options policy-statement bgp-to-ospf from protocol bgp set policy-options policy-statement bgp-to-ospf then accept set policy-options policy-statement pplb then load-balance per-packet set routing-instances VPN-l3vpn instance-type vrf set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface ge-0/0/2.0 set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface lo0.1 passive set routing-instances VPN-l3vpn protocols ospf export bgp-to-ospf set routing-instances VPN-l3vpn interface ge-0/0/2.0 set routing-instances VPN-l3vpn interface lo0.1 set routing-instances VPN-l3vpn route-distinguisher 10.1.255.6:1 set routing-instances VPN-l3vpn vrf-target target:65000:1 set routing-options router-id 10.1.255.6 set routing-options autonomous-system 65000 set routing-options forwarding-table export pplb set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 10.1.255.6 set protocols bgp group ibgp family inet labeled-unicast entropy-label set protocols bgp group ibgp neighbor 10.1.255.4 family inet labeled-unicast rib inet.3 set protocols bgp group ibgp neighbor 10.1.255.2 family inet-vpn unicast set protocols mpls icmp-tunneling set protocols mpls label-switched-path pe2-abr to 10.1.255.4 set protocols mpls label-switched-path pe2-abr entropy-label set protocols mpls interface ge-0/0/0.0 set protocols mpls interface lo0.0 set protocols mpls interface ge-0/0/1.0 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.1 interface ge-0/0/0.0 set protocols ospf area 0.0.0.1 interface lo0.0 passive set protocols ospf area 0.0.0.1 interface ge-0/0/1.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface lo0.0 set protocols rsvp interface ge-0/0/1.0
Enrutador CE2
set interfaces ge-0/0/0 unit 0 family inet address 172.16.67.1/30 set interfaces lo0 unit 0 family inet address 172.16.255.7/32 primary set interfaces lo0 unit 0 family inet address 192.168.255.7/32 set routing-options router-id 172.16.255.7 set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface lo0.0 passive
Configuración del enrutador PE1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador PE1:
Repita este procedimiento para el enrutador PE2 después de modificar los nombres de interfaz, las direcciones y otros parámetros adecuados.
-
Configure las interfaces físicas. Asegúrese de configurar
family mplsen la interfaz frontal del núcleo.[edit] user@PE1# set interfaces ge-0/0/0 unit 0 family inet address 172.16.12.2/30 user@PE1# set interfaces ge-0/0/2 unit 0 family inet address 10.1.23.1/30 user@PE1# set interfaces ge-0/0/2 unit 0 family mpls
-
Configure las interfaces circuito cerrado. El circuito cerrado secundario es opcional y se aplica en la instancia de enrutamiento en un paso posterior.
[edit] user@PE1# set interfaces lo0 unit 0 family inet address 10.1.255.2/32 primary user@PE1# set interfaces lo0 unit 1 family inet address 10.1.255.22/32
-
Configure el ID del enrutador y el número de sistema autónomo.
[edit] user@PE1# set routing-options router-id 10.1.255.2 user@PE1# set routing-options autonomous-system 65000
-
Configure el protocolo OSPF.
[edit] user@PE1# set protocols ospf traffic-engineering user@PE1# set protocols ospf area 0.0.0.0 interface ge-0/0/2.0 user@PE1# set protocols ospf area 0.0.0.0 interface lo0.0 passive
-
Configure el protocolo RSVP.
[edit] user@PE1# set protocols rsvp interface ge-0/0/2.0 user@PE1# set protocols rsvp interface lo0.0
-
Configure el protocolo MPLS y un LSP para el ABR. Incluye la
entropy-labelopción de agregar la etiqueta de entropía a la pila de etiquetas de MPLS.[edit protocols] user@PE1# set protocols mpls icmp-tunneling user@PE1# set protocols mpls label-switched-path pe1-abr to 10.1.255.4 user@PE1# set protocols mpls label-switched-path pe1-abr entropy-label user@PE1# set protocols mpls interface ge-0/0/2.0 user@PE1# set protocols mpls interface lo0.0
-
Configure el IBGP utilizando
family inet labeled-unicastpara el emparejamiento ABR yfamily inet-vpnpara el emparejamiento PE2. Habilite la capacidad de etiqueta de entropía para BGP etiquetado con unidifusión.[edit] user@PE1# set protocols bgp group ibgp type internal user@PE1# set protocols bgp group ibgp local-address 10.1.255.2 user@PE1# set protocols bgp group ibgp family inet labeled-unicast entropy-label user@PE1# set protocols bgp group ibgp neighbor 10.1.255.4 family inet labeled-unicast rib inet.3 user@PE1# set protocols bgp group ibgp neighbor 10.1.255.6 family inet-vpn unicast
-
Defina una política para exportar rutas VPN de BGP a OSPF. La política se aplica en OSPF en la instancia de enrutamiento.
[edit] user@PE1# set policy-options policy-statement bgp-to-ospf from protocol bgp user@PE1# set policy-options policy-statement bgp-to-ospf then accept
-
Defina una política de equilibrio de carga y aplíquela en la opción
routing-options forwarding-table. PE1 solo tiene una ruta en el ejemplo, por lo tanto, este paso no es necesario, pero para este ejemplo estamos aplicando la misma política de equilibrio de carga en todos los dispositivos.[edit] user@PE1# set policy-options policy-statement pplb then load-balance per-packet user@PE1# set routing-options forwarding-table export pplb
-
Configure la instancia de enrutamiento VPN de capa 3.
[edit] user@PE1# set routing-instances VPN-l3vpn instance-type vrf
-
Asigne las interfaces a la instancia de enrutamiento.
[edit] user@PE1# set routing-instances VPN-l3vpn interface ge-0/0/0.0 user@PE1# set routing-instances VPN-l3vpn interface lo0.1
-
Configure el distinguidor de ruta para la instancia de enrutamiento.
[edit] user@PE1# set routing-instances VPN-l3vpn route-distinguisher 10.1.255.2:1
-
Configure un destino de enrutamiento y reenvío VPN (VRF) para la instancia de enrutamiento.
[edit] user@PE1# set routing-instances VPN-l3vpn vrf-target target:65000:1
-
Configure el protocolo OSPF en la instancia de enrutamiento y aplique la política configurada
bgp-to-ospfanteriormente.[edit] user@PE1# set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface ge-0/0/0.0 user@PE1# set routing-instances VPN-l3vpn protocols ospf area 0.0.0.0 interface lo0.1 passive user@PE1# set routing-instances VPN-l3vpn protocols ospf export bgp-to-ospf
Configuración del enrutador P1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador P1:
Repita este procedimiento para el enrutador P2 después de modificar los nombres de interfaz, las direcciones y otros parámetros adecuados.
-
Configure las interfaces físicas.
[edit] user@P1# set interfaces ge-0/0/0 unit 0 family inet address 10.1.23.2/30 user@P1# set interfaces ge-0/0/0 unit 0 family mpls user@P1# set interfaces ge-0/0/2 unit 0 family inet address 10.1.34.1/30 user@P1# set interfaces ge-0/0/2 unit 0 family mpls
-
Configure la interfaz de circuito cerrado.
[edit] user@P1# set interfaces lo0 unit 0 family inet address 10.1.255.3/32 primary
-
Configure el ID del enrutador.
[edit] user@P1# set routing-options router-id 10.1.255.3
-
Configure el protocolo OSPF.
[edit] user@P1# set protocols ospf traffic-engineering user@P1# set protocols ospf area 0.0.0.0 interface lo0.0 passive user@P1# set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 user@P1# set protocols ospf area 0.0.0.0 interface ge-0/0/2.0
-
Configure el protocolo RSVP.
[edit] user@P1# set protocols rsvp interface ge-0/0/0.0 user@P1# set protocols rsvp interface lo0.0 user@P1# set protocols rsvp interface ge-0/0/2.0
-
Configure el protocolo MPLS.
[edit] user@P1# set protocols mpls icmp-tunneling user@P1# set protocols mpls interface ge-0/0/0.0 user@P1# set protocols mpls interface lo0.0 user@P1# set protocols mpls interface ge-0/0/2.0
Configuración del enrutador ABR
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador ABR:
-
Configure las interfaces físicas.
[edit] user@ABR# set interfaces ge-0/0/0 unit 0 family inet address 10.1.34.2/30 user@ABR# set interfaces ge-0/0/0 unit 0 family mpls user@ABR# set interfaces ge-0/0/2 unit 0 family inet address 10.1.45.1/30 user@ABR# set interfaces ge-0/0/2 unit 0 family mpls user@ABR# set interfaces ge-0/0/3 unit 0 family inet address 10.1.45.5/30 user@ABR# set interfaces ge-0/0/3 unit 0 family mpls
-
Configure la interfaz de circuito cerrado.
[edit] user@ABR# set interfaces lo0 unit 0 family inet address 10.1.255.4/32 primary
-
Configure las etiquetas MPLS que el enrutador utiliza para aplicar hash de los paquetes a su destino para el equilibrio de carga.
[edit] user@ABR# set forwarding-options hash-key family mpls label-1 user@ABR# set forwarding-options hash-key family mpls label-2 user@ABR# set forwarding-options hash-key family mpls label-3 user@ABR# set forwarding-options enhanced-hash-key family mpls no-payload
-
Configure el ID del enrutador y el número de sistema autónomo.
[edit] user@ABR# set routing-options router-id 10.1.255.4 user@ABR# set routing-options autonomous-system 65000
-
Configure el protocolo OSPF.
[edit] user@ABR# set protocols ospf traffic-engineering user@ABR# set protocols ospf area 0.0.0.0 interface lo0.0 passive user@ABR# set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 user@ABR# set protocols ospf area 0.0.0.1 interface ge-0/0/2.0 user@ABR# set protocols ospf area 0.0.0.1 interface ge-0/0/3.0
-
Configure el protocolo RSVP.
[edit] user@ABR# set protocols rsvp interface lo0.0 user@ABR# set protocols rsvp interface ge-0/0/0.0 user@ABR# set protocols rsvp interface ge-0/0/2.0 user@ABR# set protocols rsvp interface ge-0/0/3.0
-
Configure el protocolo MPLS y especifique los LSP para PE1 y PE2. Se crean dos LSP hacia PE2 con el fin de equilibrar la equilibrio de carga del tráfico para mostrar que se utilizan diferentes LSP e interfaces.
[edit] user@ABR# set protocols mpls icmp-tunneling user@ABR# set protocols mpls label-switched-path abr-pe1 to 10.1.255.2 user@ABR# set protocols mpls label-switched-path abr-pe1 entropy-label user@ABR# set protocols mpls label-switched-path abr-pe2 to 10.1.255.6 user@ABR# set protocols mpls label-switched-path abr-pe2 entropy-label user@ABR# set protocols mpls label-switched-path abr-pe2 primary to-r6-1 user@ABR# set protocols mpls label-switched-path abr-pe2-2 to 10.1.255.6 user@ABR# set protocols mpls label-switched-path abr-pe2-2 entropy-label user@ABR# set protocols mpls label-switched-path abr-pe2-2 primary to-r6-2 user@ABR# set protocols mpls path to-r6-1 10.1.45.2 strict user@ABR# set protocols mpls path to-r6-1 10.1.56.2 strict user@ABR# set protocols mpls path to-r6-2 10.1.45.6 strict user@ABR# set protocols mpls path to-r6-2 10.1.56.6 strict user@ABR# set protocols mpls interface lo0.0 user@ABR# set protocols mpls interface ge-0/0/0.0 user@ABR# set protocols mpls interface ge-0/0/2.0 user@ABR# set protocols mpls interface ge-0/0/3.0
-
Configure el IBGP para PE1 y PE2 utilizando
family inet labeled-unicast. Aplique la política para anunciar la ruta de circuito cerrado inet.3 desde PE1 y PE2. Mostramos la política en el siguiente paso.[edit] user@ABR# set protocols bgp group ibgp type internal user@ABR# set protocols bgp group ibgp local-address 10.1.255.4 user@ABR# set protocols bgp group ibgp family inet labeled-unicast rib inet.3 user@ABR# set protocols bgp group ibgp neighbor 10.1.255.2 export send-inet3-pe2 user@ABR# set protocols bgp group ibgp neighbor 10.1.255.6 export send-inet3-pe1
-
Defina una política que coincida en las direcciones de circuito cerrado para PE1 y PE2.
[edit] user@ABR# set policy-options policy-statement send-inet3-pe1 from route-filter 10.1.255.2/32 exact user@ABR# set policy-options policy-statement send-inet3-pe1 then accept user@ABR# set policy-options policy-statement send-inet3-pe2 from route-filter 10.1.255.6/32 exact user@ABR# set policy-options policy-statement send-inet3-pe2 then accept
-
Defina una política para el equilibrio de carga y aplíquela en el
routing-options forwarding-table.[edit] user@ABR# set policy-options policy-statement pplb then load-balance per-packet user@ABR# set routing-options forwarding-table export pplb
(Opcional) Configuración de imitación de puerto
Para ver la etiqueta de entropía que se aplica, puede capturar el tráfico. En este ejemplo, se aplica un filtro en la interfaz orientada a PE1 en P1 para capturar el tráfico de CE1 a CE2. El tráfico se envía al host 1 para su visualización. Hay diferentes formas de capturar tráfico que las que usamos en este ejemplo. Para obtener más información, consulte Imitación y analizadores de puertos.
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el enrutador P1:
-
Configure las interfaces. En este ejemplo, colocamos la interfaz conectada a Host1 en un dominio de puente y creamos una interfaz IRB para comprobar la conectividad con Host1.
[edit] user@P1# set interfaces ge-0/0/4 unit 0 family bridge interface-mode access user@P1# set interfaces ge-0/0/4 unit 0 family bridge vlan-id 100 user@P1# set interfaces irb unit 0 family inet address 10.1.31.1/30
-
Configure el dominio del puente.
[edit] user@P1# set bridge-domains v100 vlan-id 100 user@P1# set bridge-domains v100 routing-interface irb.0
-
Configure un filtro para capturar el tráfico. En este ejemplo, capturamos todo el tráfico.
[edit] user@P1# set firewall family any filter test term 1 then count test user@P1# set firewall family any filter test term 1 then port-mirror user@P1# set firewall family any filter test term 1 then accept
-
Aplique el filtro a la interfaz frontal PE1.
[edit] user@P1# set interfaces ge-0/0/0 unit 0 filter input test
-
Configure las opciones de duplicación de puertos. En este ejemplo, duplicamos todo el tráfico y lo enviamos al host1 conectado a la interfaz ge-0/0/4.
[edit] user@P1# set forwarding-options port-mirroring input rate 1 user@P1# set forwarding-options port-mirroring family any output interface ge-0/0/4.0
Verificación
Confirme que la configuración funcione correctamente.
- Comprobación de que se está anunciando la capacidad de la etiqueta de entropía
- Comprobación de que el enrutador PE1 recibe el anuncio de la etiqueta de entropía
- Verificación de ECMP en ABR a PE2
- Mostrar rutas a CE2 en PE1
- Haga ping a CE2 desde CE1
- Verificar el equilibrio de carga
- Verificar la etiqueta de entropía
Comprobación de que se está anunciando la capacidad de la etiqueta de entropía
Propósito
Compruebe que el atributo de ruta de capacidad de la etiqueta de entropía se anuncia desde la ABR a PE1 para la ruta a PE2.
Acción
Desde el modo operativo, ejecute el comando en el show route advertising-protocol bgp 10.1.255.2 detail enrutador ABR.
user@ABR> show route advertising-protocol bgp 10.1.255.2 detail
inet.3: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
* 10.1.255.6/32 (1 entry, 1 announced)
BGP group ibgp type Internal
Route Label: 299952
Nexthop: Self
Flags: Nexthop Change
MED: 2
Localpref: 4294967294
AS path: [65000] I
Entropy label capable
Significado
El resultado muestra que el host PE2 con la dirección IP de 10.1.255.6 tiene la capacidad de etiqueta de entropía y la etiqueta de ruta que se usa. El host anuncia la capacidad de etiqueta de entropía a sus vecinos del BGP.
Comprobación de que el enrutador PE1 recibe el anuncio de la etiqueta de entropía
Propósito
Compruebe que el enrutador PE1 recibe el anuncio de la etiqueta de entropía para el enrutador PE2.
Acción
Desde el modo operativo, ejecute el comando en el show route protocol bgp 10.1.255.6 extensive enrutador PE1.
user@PE1> show route protocol bgp 10.1.255.6 extensive
inet.0: 19 destinations, 19 routes (19 active, 0 holddown, 0 hidden)
inet.3: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
10.1.255.6/32 (1 entry, 1 announced)
*BGP Preference: 170/1
Next hop type: Indirect, Next hop index: 0
Address: 0x7b3ffd4
Next-hop reference count: 2, key opaque handle: 0x0, non-key opaque handle: 0x0
Source: 10.1.255.4
Next hop type: Router, Next hop index: 0
Next hop: 10.1.23.2 via ge-0/0/2.0, selected
Label-switched-path pe1-abr
Label operation: Push 299952, Push 299808(top)
Label TTL action: prop-ttl, prop-ttl(top)
Load balance label: Label 299952: Entropy label; Label 299808: None;
Label element ptr: 0x93d6bf8
Label parent element ptr: 0x93d6c20
Label element references: 3
Label element child references: 2
Label element lsp id: 0
Session Id: 0
Protocol next hop: 10.1.255.4
Label operation: Push 299952
Label TTL action: prop-ttl
Load balance label: Label 299952: Entropy label;
Indirect next hop: 0x758c05c - INH Session ID: 0
State: <Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 1:33:11 Metric: 2 Metric2: 2
Validation State: unverified
Task: BGP_65000.10.1.255.4
Announcement bits (2): 3-Resolve tree 1 4-Resolve_IGP_FRR task
AS path: I
Accepted
Route Label: 299952
Localpref: 4294967294
Router ID: 10.1.255.4
Session-IDs associated:
Session-id: 324 Version: 3
Thread: junos-main
Indirect next hops: 1
Protocol next hop: 10.1.255.4 Metric: 2 ResolvState: Resolved
Label operation: Push 299952
Label TTL action: prop-ttl
Load balance label: Label 299952: Entropy label;
Indirect next hop: 0x758c05c - INH Session ID: 0
Indirect path forwarding next hops: 1
Next hop type: Router
Next hop: 10.1.23.2 via ge-0/0/2.0
Session Id: 0
10.1.255.4/32 Originating RIB: inet.3
Metric: 2 Node path count: 1
Forwarding nexthops: 1
Next hop type: Router
Next hop: 10.1.23.2 via ge-0/0/2.0
Session Id: 0
Significado
El enrutador PE1 recibe el anuncio de capacidad de etiqueta de entropía de su vecino BGP.
Verificación de ECMP en ABR a PE2
Propósito
Compruebe la multirruta de coste igual (ECMP) a PE2.
Acción
Desde el modo operativo, ejecute los comandos y show route forwarding-table label <label>en el show route table mpls.0 enrutador ABR.
user@ABR> show route table mpls.0
mpls.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0 *[MPLS/0] 2w1d 23:02:11, metric 1
Receive
1 *[MPLS/0] 2w1d 23:02:11, metric 1
Receive
2 *[MPLS/0] 2w1d 23:02:11, metric 1
Receive
13 *[MPLS/0] 2w1d 23:02:11, metric 1
Receive
299936 *[VPN/170] 2d 21:47:02
> to 10.1.34.1 via ge-0/0/0.0, label-switched-path abr-pe1
299952 *[VPN/170] 2d 21:47:02
> to 10.1.45.2 via ge-0/0/2.0, label-switched-path abr-pe2
to 10.1.45.6 via ge-0/0/3.0, label-switched-path abr-pe2-2
ruser@ABR> show route forwarding-table label 299952
Routing table: default.mpls
MPLS:
Destination Type RtRef Next hop Type Index NhRef Netif
299952 user 0 ulst 1048575 2
10.1.45.2 Swap 299824 516 2 ge-0/0/2.0
10.1.45.6 Swap 299840 572 2 ge-0/0/3.0
...
Significado
El resultado muestra un ECMP para la etiqueta utilizada para la ruta de unidifusión etiquetada con BGP.
Mostrar rutas a CE2 en PE1
Propósito
Verifique las rutas a CE2.
Acción
Desde el modo operativo, ejecute los comandos y show route table VPN-l3vpn.inet.0 192.168.255.7 extensiveen el show route table VPN-l3vpn.inet.0 172.16.255.7 extensive enrutador PE1.
user@PE1> show route table VPN-l3vpn.inet.0 172.16.255.7 extensive
VPN-l3vpn.inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
172.16.255.7/32 (1 entry, 1 announced)
TSI:
OSPF area : 0.0.0.0, LSA ID : 172.16.255.7, LSA type : Summary
KRT in-kernel 172.16.255.7/32 -> {indirect(1048574)}
*BGP Preference: 170/-101
Route Distinguisher: 10.1.255.6:1
Next hop type: Indirect, Next hop index: 0
Address: 0x7b40434
Next-hop reference count: 9, key opaque handle: 0x0, non-key opaque handle: 0x0
Source: 10.1.255.6
Next hop type: Router, Next hop index: 515
Next hop: 10.1.23.2 via ge-0/0/2.0, selected
Label-switched-path pe1-abr
Label operation: Push 299824, Push 299952, Push 299808(top)
Label TTL action: prop-ttl, prop-ttl, prop-ttl(top)
Load balance label: Label 299824: None; Label 299952: Entropy label; Label 299808: None;
Label element ptr: 0x93d6c98
Label parent element ptr: 0x93d6bf8
Label element references: 1
Label element child references: 0
Label element lsp id: 0
Session Id: 140
Protocol next hop: 10.1.255.6
Label operation: Push 299824
Label TTL action: prop-ttl
Load balance label: Label 299824: None;
...
user@PE1> show route table VPN-l3vpn.inet.0 192.168.255.7 extensive
VPN-l3vpn.inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
192.168.255.7/32 (1 entry, 1 announced)
TSI:
OSPF area : 0.0.0.0, LSA ID : 192.168.255.7, LSA type : Summary
KRT in-kernel 192.168.255.7/32 -> {indirect(1048574)}
*BGP Preference: 170/-101
Route Distinguisher: 10.1.255.6:1
Next hop type: Indirect, Next hop index: 0
Address: 0x7b40434
Next-hop reference count: 9, key opaque handle: 0x0, non-key opaque handle: 0x0
Source: 10.1.255.6
Next hop type: Router, Next hop index: 515
Next hop: 10.1.23.2 via ge-0/0/2.0, selected
Label-switched-path pe1-abr
Label operation: Push 299824, Push 299952, Push 299808(top)
Label TTL action: prop-ttl, prop-ttl, prop-ttl(top)
Load balance label: Label 299824: None; Label 299952: Entropy label; Label 299808: None;
Label element ptr: 0x93d6c98
Label parent element ptr: 0x93d6bf8
Label element references: 1
Label element child references: 0
Label element lsp id: 0
Session Id: 140
Protocol next hop: 10.1.255.6
Label operation: Push 299824
Label TTL action: prop-ttl
Load balance label: Label 299824: None;
...
Significado
El resultado muestra que se utilizan las mismas etiquetas para ambas rutas.
Haga ping a CE2 desde CE1
Propósito
Compruebe la conectividad y utilícelo para verificar el equilibrio de carga.
Acción
Desde el modo operativo, ejecute los comandos y ping 192.168.255.7 source 192.168.255.1 rapid count 200en el ping 172.16.255.7 source 172.16.12.1 rapid count 100 enrutador PE1.
user@CE1> ping 172.16.255.7 source 172.16.12.1 rapid count 100 PING 172.16.255.7 (172.16.255.7): 56 data bytes !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! --- 172.16.255.7 ping statistics --- 100 packets transmitted, 100 packets received, 0% packet loss round-trip min/avg/max/stddev = 5.369/6.070/8.828/0.612 ms user@CE1> ping 192.168.255.7 source 192.168.255.1 rapid count 200 PING 192.168.255.7 (192.168.255.7): 56 data bytes !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! --- 192.168.255.7 ping statistics --- 200 packets transmitted, 200 packets received, 0% packet loss round-trip min/avg/max/stddev = 5.086/5.994/10.665/0.649 ms
Significado
El resultado muestra que los pings se han realizado correctamente.
Verificar el equilibrio de carga
Propósito
Compruebe el equilibrio de carga.
Acción
Desde el modo operativo, ejecute el show mpls lsp ingress statistics comando en el ABR.
user@ABR> show mpls lsp ingress statistics Ingress LSP: 3 sessions To From State Packets Bytes LSPname 10.1.255.2 10.1.255.4 Up 300 30000 abr-pe1 10.1.255.6 10.1.255.4 Up 200 20000 abr-pe2 10.1.255.6 10.1.255.4 Up 100 10000 abr-pe2-2 Total 3 displayed, Up 3, Down 0
Significado
El resultado muestra el primer ping del comando anterior utilizado LSP abr-pe2-2 y el segundo ping utilizado LSP abr-pe2.
Verificar la etiqueta de entropía
Propósito
Compruebe que la etiqueta de entropía es diferente entre los pings que se usaron.
Acción
En el host 1, ejecute el tcpdump -i eth1 -narchivo .
user@Host1# tcpdump -i eth1 -n ... 13:42:31.993274 MPLS (label 299808, exp 0, ttl 63) (label 299952, exp 0, ttl 63) (label 7, exp 0, ttl 63) (label 1012776, exp 0, ttl 0) (label 299824, exp 0, [S], ttl 63) IP 172.16.12.1 > 172.16.255.7: ICMP echo request, id 32813, seq 9, length 64 ... 13:43:19.570260 MPLS (label 299808, exp 0, ttl 63) (label 299952, exp 0, ttl 63) (label 7, exp 0, ttl 63) (label 691092, exp 0, ttl 0) (label 299824, exp 0, [S], ttl 63) IP 192.168.255.1 > 192.168.255.7: ICMP echo request, id 46381, seq 9, length 64
Significado
El resultado muestra el valor diferente de la etiqueta de entropía para los dos comandos ping diferentes.
Caso de uso de convergencia independiente de prefijo de BGP para inet, inet6 o unidifusión etiquetada
En el caso de una falla del enrutador, una red BGP puede tardar desde unos segundos hasta minutos en recuperarse, dependiendo de parámetros como el tamaño de la red o el rendimiento del enrutador. Cuando la característica Convergencia independiente del prefijo (PIC) del BGP está habilitada en un enrutador, el BGP instala en el motor de reenvío de paquetes la segunda mejor ruta además de la mejor ruta calculada a un destino. El enrutador utiliza esta ruta de respaldo cuando un enrutador de salida falla en una red y reduce drásticamente el tiempo de interrupción. Puede habilitar esta función para reducir el tiempo de inactividad de la red si falla el enrutador de salida.
Cuando falla la accesibilidad a un enrutador de salida en una red, el IGP detecta esta interrupción y el estado del vínculo propaga esta información por toda la red y anuncia el próximo salto del BGP para ese prefijo como inaccesible. El BGP reevalúa las rutas alternativas y, si hay una ruta alternativa disponible, reinstala este próximo salto alternativo en el motor de reenvío de paquetes. Este tipo de error de salida generalmente afecta a varios prefijos al mismo tiempo, y BGP tiene que actualizar todos estos prefijos uno a la vez. En los enrutadores de entrada, el IGP completa primero la ruta más corta (SPF) y actualiza los saltos siguientes. A continuación, Junos OS determina los prefijos que se han vuelto inalcanzables y envía señales al protocolo para indicarles que deben actualizarse. BGP recibe la notificación y actualiza el siguiente salto para cada prefijo que ahora no es válido. Este proceso podría afectar la conectividad y podría tardar unos minutos en recuperarse de la interrupción. La PIC del BGP puede reducir este tiempo de inactividad, ya que la ruta de respaldo ya está instalada en el motor de reenvío de paquetes.
A partir de Junos OS versión 15.1, la función BGP PIC, que inicialmente se admitía para enrutadores VPN de capa 3, se extiende al BGP con varias rutas en las tablas globales, como inet e inet6 unidifusión, e inet e inet6 etiquetadas como unidifusión. En un enrutador habilitado para PIC del BGP, Junos OS instala la ruta de respaldo para el próximo salto indirecto en el motor de enrutamiento y también proporciona esta ruta al motor de reenvío de paquetes y al IGP. Cuando un IGP pierde accesibilidad a un prefijo con una o más rutas, envía una señal al motor de enrutamiento con un único mensaje antes de actualizar las tablas de enrutamiento. El motor de enrutamiento indica al motor de reenvío de paquetes que se produjo un error en un próximo salto indirecto y que el tráfico debe reenrutarse mediante la ruta de respaldo. El enrutamiento al prefijo de destino afectado continúa utilizando la ruta de respaldo incluso antes de que el BGP comience a recalcular los nuevos saltos siguientes para los prefijos del BGP. El enrutador utiliza esta ruta de reserva para reducir la pérdida de tráfico hasta que se resuelva la convergencia global mediante el BGP.
El tiempo en que ocurre la interrupción hasta el tiempo hasta que se señala la pérdida de accesibilidad en realidad depende del tiempo de detección de fallas del enrutador más cercano y del tiempo de convergencia de IGP. Una vez que el enrutador local detecta la interrupción, la convergencia de rutas sin la función de PIC de BGP habilitada depende en gran medida del número de prefijos afectados y del rendimiento del enrutador debido al recálculo de cada prefijo afectado. Sin embargo, con la característica de PIC del BGP habilitada, incluso antes de que el BGP vuelva a calcular la mejor ruta para esos prefijos afectados, el motor de enrutamiento envía una señal al plano de datos para que cambie a la siguiente mejor ruta en espera. Por lo tanto, la pérdida de tráfico es mínima. Las nuevas rutas se calculan incluso mientras se reenvía el tráfico, y estas nuevas rutas se empujan hacia abajo hasta el plano de datos. Por lo tanto, la cantidad de prefijos de BGP afectados no afecta el tiempo transcurrido desde el momento en que se produce la interrupción del tráfico hasta el punto en el que el BGP señala la pérdida de accesibilidad.
Ver también
Configuración de la convergencia independiente del prefijo del BGP para inet
En un enrutador habilitado para la convergencia independiente del prefijo (PIC) del BGP, Junos OS instala la ruta de respaldo para el próximo salto indirecto en el motor de enrutamiento y también proporciona esta ruta al motor de reenvío de paquetes y al IGP. Cuando un IGP pierde accesibilidad a un prefijo con una o más rutas, envía una señal al motor de enrutamiento con un único mensaje antes de actualizar las tablas de enrutamiento. El motor de enrutamiento indica al motor de reenvío de paquetes que se produjo un error en un próximo salto indirecto y que el tráfico debe reenrutarse mediante la ruta de respaldo. El enrutamiento al prefijo de destino afectado continúa utilizando la ruta de respaldo incluso antes de que el BGP comience a recalcular los nuevos saltos siguientes para los prefijos del BGP. El enrutador utiliza esta ruta de reserva para reducir la pérdida de tráfico hasta que se resuelva la convergencia global mediante el BGP. La característica PIC del BGP, que inicialmente se admitía para enrutadores VPN de capa 3, se extiende al BGP con varias rutas en las tablas globales, como inet e inet6 de unidifusión, e inet e inet6 etiquetados como unidifusión.
Antes de empezar:
Configure las interfaces de los dispositivos.
Configure OSPF o cualquier otro protocolo IGP.
Configure MPLS y LDP.
Configure BGP.
La función de PIC del BGP solo se admite en enrutadores con interfaces MPC.
En enrutadores con concentradores de puerto modulares (MPC), habilite servicios de red IP mejorados como se muestra a continuación:
[edit chassis network-services] user@host# set enhanced-ip
Para configurar la PIC del BGP para inet:
Ver también
Ejemplo: Configuración de la convergencia independiente del prefijo del BGP para inet
En este ejemplo, se muestra cómo configurar la PIC del BGP para inet. En el caso de una falla del enrutador, una red BGP puede tardar desde unos segundos hasta minutos en recuperarse, dependiendo de parámetros como el tamaño de la red o el rendimiento del enrutador. Cuando la característica Convergencia independiente del prefijo (PIC) del BGP está habilitada en un enrutador, el BGP con varias rutas en las tablas globales, como inet e inet6 de unidifusión, e inet e inet6 etiquetados como unidifusión, instala en el motor de reenvío de paquetes la segunda mejor ruta además de la mejor ruta calculada a un destino. El enrutador utiliza esta ruta de respaldo cuando un enrutador de salida falla en una red y reduce drásticamente el tiempo de interrupción.
Requisitos
No se necesita ninguna configuración especial más allá de la inicialización del dispositivo antes de configurar este ejemplo.
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Un enrutador de la serie MX con MPC para configurar la función de PIC del BGP
-
Siete enrutadores que pueden ser una combinación de enrutadores de la serie M, la serie MX, la serie T o la serie PTX
-
Junos OS versión 15.1 o posterior en el dispositivo con la PIC del BGP configurada
Descripción general
A partir de Junos OS versión 15.1, la PIC del BGP, que inicialmente se admitía para enrutadores VPN de capa 3, se extiende al BGP con varias rutas en las tablas globales, como inet e inet6 de unidifusión, e inet e inet6 etiquetadas como unidifusión. El BGP instala en el motor de reenvío de paquetes la segunda mejor ruta además de la mejor ruta calculada a un destino. Cuando un IGP pierde accesibilidad a un prefijo, el enrutador utiliza esta ruta de respaldo para reducir la pérdida de tráfico hasta que se resuelva la convergencia global a través del BGP, lo cual reduce la duración de la interrupción.
La función de PIC del BGP solo se admite en enrutadores con MPC.
Topología
En este ejemplo, se muestran tres enrutadores de borde de cliente (CE), el dispositivo CE0, CE1 y CE2. Los enrutadores PE0, PE1 y PE2 son enrutadores de borde del proveedor (PE). Los enrutadores P0 y P1 son los enrutadores centrales del proveedor. La PIC del BGP está configurada en el enrutador PE0. Para las pruebas, la dirección 192.168.1.5 se agrega como una segunda dirección de interfaz de circuito cerrado en el dispositivo CE1. La dirección se anuncia a los enrutadores PE1 y PE2, y el BGP interno (IBGP) la retransmite al enrutador PE0. En el enrutador PE0, hay dos rutas a la red 192.168.1.5. Estas son la ruta principal y una ruta de respaldo. En la Fig. 13 se muestra la red de ejemplo.
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese confirmar desde el [edit] modo de configuración.
Enrutador PE0
set chassis network-services enhanced-ip set interfaces ge-0/0/0 unit 0 description PE0->P0 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.5/24 set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8::1/32 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 description PE0->P1 set interfaces ge-0/0/1 unit 0 family inet address 10.0.0.1/24 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8::2/32 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.0.1/32 set interfaces ge-0/0/2 unit 0 description PE0->CE0 set interfaces ge-0/0/2 unit 0 family inet address 172.16.0.1/30 set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8::10/32 set interfaces ge-0/0/2 unit 0 family mpls set protocols mpls ipv6-tunneling set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local-address 192.168.0.1 set protocols bgp group ibgp family inet labeled-unicast per-prefix-label set protocols bgp group ibgp family inet6 labeled-unicast explicit-null set protocols bgp group ibgp export nhself set protocols bgp group ibgp neighbor 192.168.0.4 description PE1 set protocols bgp group ibgp neighbor 192.168.0.5 description PE2 set protocols bgp group ebgp type external set protocols bgp group ebgp local address 192.168.0.1 set protocols bgp group ebgp family inet labeled-unicast set protocols bgp group ebgp family inet6 labeled-unicast set protocols bgp group ebgp peer-as 64497 set protocols bgp group ebgp neighbor 172.16.0.2 description CE0 set protocols ospf area 0.0.0.0 interface all set protocols ospf area 0.0.0.0 interface fxp0.0 disable set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 metric 1000 set protocols ospf3 area 0.0.0.0 interface all set protocols ospf3 area 0.0.0.0 interface fxp0.0 disable set protocols ospf3 area 0.0.0.0 interface lo0.0 passive set protocols ospf3 area 0.0.0.0 interface ge-0/0/1.0 metric 1000 set protocols ldp track-igp-metric set protocols ldp interface all set protocols ldp interface fxp0.0 disable set policy-options policy-statement lb then load-balance per-packet set policy-options policy-statement nhself then next-hop self set routing-options protect core set routing-options forwarding-table export lb set routing-options router-id 192.168.0.1 set routing-options autonomous-system 64496
Enrutador P0
set chassis network-services enhanced-ip set interfaces ge-0/0/0 unit 0 description P0->PE0 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.6/24 set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8::3/32 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 description P0->PE1 set interfaces ge-0/0/1 unit 0 family inet address 10.0.0.9/24 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8::4/32 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.0.2/32 set protocols ospf area 0.0.0.0 interface all set protocols ospf area 0.0.0.0 interface fxp0.0 disable set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols bgp group ibgp type internal set protocols bgp group ibgp local address 192.168.0.1 set protocols bgp group ibgp neighbor 192.168.0.4 description PE1 set protocols bgp group ibgp neighbor 192.168.0.5 description PE2 set routing-options router-id 192.168.0.2 set routing-options autonomous-system 64496
Enrutador P1
set chassis network-services enhanced-ip set interfaces ge-0/0/1 unit 0 description P1->PE0 set interfaces ge-0/0/1 unit 0 family inet address 10.0.0.2/24 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8::5/32 set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/0 unit 0 description P1->PE2 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.13/24 set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8::6/32 set interfaces ge-0/0/0 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.0.3/32 set protocols ospf area 0.0.0.0 interface all set protocols ospf area 0.0.0.0 interface fxp0.0 disable set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols bgp group ibgp type internal set protocols bgp group ibgp local address 192.168.0.3 set protocols bgp group ibgp neighbor 192.168.0.1 description PE0 set protocols bgp group ibgp neighbor 192.168.0.5 description PE2 set routing-options router-id 192.168.0.3 set routing-options autonomous-system 64496
Enrutador PE1
set chassis network-services enhanced-ip set interfaces ge-0/0/0 unit 0 description PE1->P0 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.10/24 set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8::7/32 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/1 unit 0 description PE1->CE1 set interfaces ge-0/0/1 unit 0 family inet address 172.16.1.1/30 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8::12/32 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.0.4/32 set protocols bgp group ibgp type internal set protocols bgp group ibgp local address 192.168.0.4 set protocols bgp group ibgp family inet labeled-unicast per-prefix-label set protocols bgp group ibgp family inet6 labeled-unicast explicit-null set protocols bgp group ibgp export nhself set protocols bgp group ibgp neighbor 192.168.0.1 description PE0 set protocols bgp group ibgp neighbor 192.168.0.5 description PE2 set protocols bgp group ebgp type external set protocols bgp group ebgp local address 192.168.0.4 set protocols bgp group ebgp peer-as 64497 set protocols bgp group ebgp neighbor 172.16.1.2 description CE1 set protocols ospf area 0.0.0.0 interface all set protocols ospf area 0.0.0.0 interface fxp0.0 disable set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 metric 1000 set protocols ospf3 area 0.0.0.0 interface all set protocols ospf3 area 0.0.0.0 interface fxp0.0 disable set protocols ospf3 area 0.0.0.0 interface lo0.0 passive set protocols ospf3 area 0.0.0.0 interface ge-0/0/0.0 metric 1000 set protocols ldp track-igp-metric set protocols ldp interface all set protocols ldp interface fxp0.0 disable set policy-options policy-statement PE1-v6-nh_CE1 from family inet6 set policy-options policy-statement PE1-v6-nh_CE1 then next-hop 2001:DB8::13 set policy-options policy-statement nhself then next-hop self set routing-options router-id 192.168.0.4 set routing-options autonomous-system 64496 set routing-options static route 192.168.1.2 next-hop 172.16.1.2
Enrutador PE2
set chassis network-services enhanced-ip set interfaces ge-0/0/0 unit 0 description PE2->P1 set interfaces ge-0/0/0 unit 0 family inet address 10.0.0.14/24 set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8::8/32 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/0 unit 0 family iso set interfaces ge-0/0/1 unit 0 description PE2->CE2 set interfaces ge-0/0/1 unit 0 family inet address 172.16.2.1/30 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8::14/32 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.0.5/32 set protocols mpls ipv6-tunneling set protocols mpls interface all set protocols mpls interface fxp0.0 disable set protocols bgp group ibgp type internal set protocols bgp group ibgp local address 192.168.0.5 set protocols bgp group ibgp family inet labeled-unicast per-prefix-label set protocols bgp group ibgp family inet6 labeled-unicast explicit-null set protocols bgp group ibgp export nhself set protocols bgp group ibgp neighbor 192.168.0.4 description PE1 set protocols bgp group ibgp neighbor 192.168.0.1 description PE0 set protocols bgp group ebgp type external set protocols bgp group ebgp local address 192.168.0.5 set protocols bgp group ebgp peer-as 64497 set protocols bgp group ebgp family inet labeled-unicast set protocols bgp group ebgp family inet6 labeled-unicast set protocols bgp group ebgp neighbor 172.16.2.2 description CE2 set protocols ospf area 0.0.0.0 interface all set protocols ospf area 0.0.0.0 interface fxp0.0 disable set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 metric 1000 set protocols ospf3 area 0.0.0.0 interface all set protocols ospf3 area 0.0.0.0 interface fxp0.0 disable set protocols ospf3 area 0.0.0.0 interface lo0.0 passive set protocols ospf3 area 0.0.0.0 interface ge-0/0/0.0 metric 1000 set protocols ldp track-igp-metric set protocols ldp interface all set protocols ldp interface fxp0.0 disable set policy-options policy-statement nhself then next-hop self set routing-options router-id 192.168.0.5 set routing-options autonomous-system 64496 set routing-options static route 192.168.1.3 next-hop 172.16.2.2
Dispositivo CE0
set chassis network-services enhanced-ip set interfaces ge-0/0/2 unit 0 description CE0->PE0 set interfaces ge-0/0/2 unit 0 family inet address 172.16.0.2/30 set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8::11/32 set interfaces lo0 unit 0 family inet address 192.168.1.1/32 set protocols mpls interface all set protocols bgp group ebgp type external set protocols bgp group ebgp peer-as 64496 set protocols bgp group ebgp family inet labeled-unicast set protocols bgp group ebgp family inet6 labeled-unicast set protocols bgp group ebgp neighbor 172.16.0.1 description PE0 set protocols bgp group ebgp local-address 192.168.1.1 set routing-options autonomous-system 64497 set routing-options router-id 192.168.1.1
Dispositivo CE1
set chassis network-services enhanced-ip set interfaces ge-0/0/2 unit 0 description CE1->PE1 set interfaces ge-0/0/2 unit 0 family inet address 172.16.1.2/30 set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8::13/32 set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.1.2/32 set interfaces lo0 unit 0 family inet address 192.168.1.5/24 set protocols mpls interface all set protocols bgp group ebgp type external set protocols bgp group ebgp peer-as 64496 set protocols bgp group ebgp family inet labeled-unicast set protocols bgp group ebgp family inet6 labeled-unicast set protocols bgp group ebgp export send-direct set protocols bgp group ebgp neighbor 172.16.1.1 description PE1 set policy-options policy statement send-direct from protocol direct then accept set routing-options autonomous-system 64497 set routing-options router-id 192.168.1.2
Dispositivo CE2
set chassis network-services enhanced-ip set interfaces ge-0/0/2 unit 0 description CE2->PE2 set interfaces ge-0/0/2 unit 0 family inet address 172.16.2.2/30 set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8::15/32 set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 0 family inet address 192.168.1.3/32 set protocols mpls interface all set protocols bgp group ebgp type external set protocols bgp group ebgp peer-as 64496 set protocols bgp group ebgp family inet labeled-unicast set protocols bgp group ebgp family inet6 labeled-unicast set protocols bgp group ebgp export send-direct set protocols bgp group ebgp neighbor 172.16.2.1 description PE2 set policy-options policy statement send-direct from protocol direct then accept set routing-options autonomous-system 64497 set routing-options router-id 192.168.1.3
Configuración del dispositivo PE0
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo PE0:
-
En enrutadores con concentradores de puerto modulares (MPC), habilite servicios de red IP mejorados.
[edit chassis] usr@PE0# set network-services enhanced-ip -
Configure las interfaces de los dispositivos.
[edit interfaces] user@PE0# set ge-0/0/0 unit 0 description PE0->P0 user@PE0# set ge-0/0/0 unit 0 family inet address 10.0.0.5/24 user@PE0# set ge-0/0/0 unit 0 family iso user@PE0# set ge-0/0/0 unit 0 family inet6 address 2001:db8::1/32 user@PE0# set ge-0/0/0 unit 0 family mpls user@PE0# set ge-0/0/1 unit 0 description PE0->P1 user@PE0# set ge-0/0/1 unit 0 family inet address 10.0.0.1/24 user@PE0# set ge-0/0/1 unit 0 family iso user@PE0# set ge-0/0/1 unit 0 family inet6 address 2001:db8::2/32 user@PE0# set ge-0/0/1 unit 0 family mpls user@PE0# set ge-0/0/2 unit 0 description PE0->CE0 user@PE0# set ge-0/0/2 unit 0 family inet address 172.16.0.1/30 user@PE0# set ge-0/0/2 unit 0 family inet6 address 2001:db8::10/32 user@PE0# set ge-0/0/2 unit 0 family mpls
-
Configure la interfaz de circuito cerrado.
[edit interfaces] user@PE0# set lo0 unit 0 family inet address 192.168.0.1/32
-
Configure MPLS y LDP en todas las interfaces, excepto en la interfaz de administración.
[edit protocols] user@PE0# set mpls ipv6-tunneling user@PE0# set mpls interface all user@PE0# set mpls interface fxp0.0 disable user@PE0# set ldp track-igp-metric user@PE0# set ldp interface all user@PE0# set ldp interface fxp0.0 disable
-
Configure un IGP en las interfaces que mira el núcleo.
[edit protocols] user@PE0# set ospf area 0.0.0.0 interface all user@PE0# set ospf area 0.0.0.0 interface fxp0.0 disable user@PE0# set ospf area 0.0.0.0 interface lo0.0 passive user@PE0# set ospf area 0.0.0.0 interface ge-0/0/1.0 metric 1000 user@PE0# set ospf3 area 0.0.0.0 interface all user@PE0# set ospf3 area 0.0.0.0 interface fxp0.0 disable user@PE0# set ospf3 area 0.0.0.0 interface lo0.0 passive user@PE0# set ospf3 area 0.0.0.0 interface ge-0/0/1.0 metric 1000
-
Configure las conexiones de IBGP con los otros dispositivos PE.
[edit protocols] user@PE0# set bgp group ibgp type internal user@PE0# set bgp group ibgp local-address 192.168.0.1 user@PE0# set bgp group ibgp family inet labeled-unicast per-prefix-label user@PE0# set bgp group ibgp family inet6 labeled-unicast explicit-null user@PE0# set bgp group ibgp export nhself user@PE0# set bgp group ibgp neighbor 192.168.0.4 description PE1 user@PE0# set bgp group ibgp neighbor 192.168.0.5 description PE2
-
Configure las conexiones del EBGP con los dispositivos del cliente.
[edit protocols] user@PE0# set bgp group ebgp type external user@PE0# set bgp group ebgp local address 192.168.0.1 user@PE0# set bgp group ebgp family inet labeled-unicast user@PE0# set bgp group ebgp family inet6 labeled-unicast user@PE0# set bgp group ebgp peer-as 64497 user@PE0# set bgp group ebgp neighbor 172.16.0.2 description CE0
-
Configure la política de equilibrio de carga.
[edit policy-options] user@PE0# set policy-statement lb then load-balance per-packet
-
Configure una política propia de próximo salto.
[edit policy-options] user@PE0# set policy-statement nhself then next-hop self
-
Habilite la función de borde de PIC del BGP.
[edit routing-options] user@PE0# set protect core
-
Aplique la política de equilibrio de carga.
[edit routing-options] user@PE0# set forwarding-table export lb
-
Asignar el ID del enrutador y el número de sistema autónomo (AS).
[edit routing-options] user@PE0# set router-id 192.168.0.2 user@PE0# set autonomous-system 64496
Resultados
Desde el modo de configuración, escriba los comandos , show interfaces, show protocolsshow policy-optionsy show routing-options para confirmar la show chassisconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
[edit] user@PE0# show chassis network-services enhanced-ip;
[edit]
user@PE0# show interfaces
ge-0/0/0 {
unit 0 {
description PE0->P0;
family inet {
address 10.0.0.5/24;
}
family iso;
family inet6 {
address 2001:db8::1/32;
}
family mpls;
}
}
ge-0/0/1 {
unit 0 {
description PE0->P1;
family inet {
address 10.0.0.1/24;
}
family iso;
family inet6 {
address 2001:db8::2/32;
}
family mpls;
}
}
ge-0/0/2 {
unit 0 {
description PE0->CE0;
family inet {
address 172.16.0.1/30;
}
family inet6 {
address 2001:db8::10/32;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 192.168.0.1/32;
}
}
}
[edit]
user@PE0# show protocols
mpls {
ipv6-tunneling;
interface all;
interface fxp0.0 {
disable;
}
}
bgp {
group ibgp {
type internal;
local-address 192.168.0.1;
family inet {
labeled-unicast {
per-prefix-label;
}
}
family inet6 {
labeled-unicast {
explicit-null;
}
}
export nhself;
neighbor 192.168.0.4 {
description PE1;
}
neighbor 192.168.0.5 {
description PE2;
}
}
group ebgp {
type external;
local-address 192.168.0.1;
family inet {
labeled-unicast;
}
family inet6 {
labeled-unicast;
}
peer-as 64497;
neighbor 172.16.0.2 {
description CE0;
}
}
}
ospf {
area 0.0.0.0 {
interface all;
interface lo0.0 {
passive;
}
interface ge-0/0/1.0 {
metric 1000;
}
interface fxp0.0 {
disable;
}
}
}
ospf3 {
area 0.0.0.0 {
interface all;
interface lo0.0 {
passive;
}
interface ge-0/0/1.0 {
metric 1000;
}
interface fxp0.0 {
disable;
}
}
}
ldp {
track-igp-metric;
interface all;
interface fxp0.0 {
disable;
}
}
[edit]
user@PE1# show policy-options
policy-statement lb {
then {
load-balance per-packet;
}
}
policy-statement nhself {
then {
next-hop self;
}
}
[edit]
user@PE0# show routing-options
protect core;
router-id 192.168.0.1;
autonomous system 64496
forwarding-table {
export lb;
}
Verificación
Confirme que la configuración funcione correctamente.
Visualización de amplia información de rutas
Propósito
Confirme que el borde de la PIC del BGP funciona.
Acción
Desde el dispositivo PE0, ejecute el show route extensive comando.
user@PE0>
show route 192.168.1.5 extensive
inet.0: 236941 destinations, 630411 routes (236940 active, 0 holddown, 1 hidden)
20.1.1.1/32 (3 entries, 2 announced)
State: <CalcForwarding>
TSI:
KRT in-kernel 192.168.1.5/24 -> {indirect(1048574), indirect(1048575)}
@BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xafd09d0
Next-hop reference count: 236886
Source: 192.168.0.4
Next hop type: Router, Next hop index: 623
Next hop: 10.0.0.2 via ge-0/0/1.0, selected
Session Id: 0x140
Protocol next hop: 192.168.0.4
Indirect next hop: 0xab3b980 1048574 INH Session ID: 0x144
State: <Active Int Ext ProtectionPath ProtectionCand>
Local AS: 64496 Peer AS: 64496
Age: 1:11 Metric2: 2
Validation State: unverified
Task: BGP_100.192.168.0.5
Announcement bits (1): 6-Resolve tree 2
AS path: 64497 I
Accepted MultipathUnequal
Localpref: 100
Router ID: 192.168.0.5
Indirect next hops: 1
Protocol next hop: 192.168.0.5 Metric: 2
Indirect next hop: 0xab3b980 1048574 INH Session ID: 0x144
Indirect path forwarding next hops: 1
Next hop type: Router
Next hop: 10.0.0.2 via ge-0/0/1.0
Session Id: 0x140
192.168.0.5/32 Originating RIB: inet.0
Metric: 2 Node path count: 1
Forwarding nexthops: 1
Nexthop: 10.0.0.2 via ge-0/0/1.0
BGP Preference: 170/-101
Next hop type: Indirect, Next hop index: 0
Address: 0xafd0970
Next-hop reference count: 196735
Source: 192.168.0.4
Next hop type: Router, Next hop index: 624
Next hop: 10.0.0.6 via ge-0/0/0.0, selected
Session Id: 0x141
Protocol next hop: 192.168.0.4
Indirect next hop: 0xab3c240 1048575 INH Session ID: 0x145
State: <NotBest Int Ext ProtectionCand>
Inactive reason: Not Best in its group - IGP metric
Local AS: 100 Peer AS: 100
Age: 1:05 Metric2: 1001
Validation State: unverified
Task: BGP_100.192.168.0.4
AS path: 200 400 I
Accepted
Localpref: 100
Router ID: 192.168.0.4
Indirect next hops: 1
Protocol next hop: 192.168.0.4 Metric: 1001
Indirect next hop: 0xab3c240 1048575 INH Session ID: 0x145
Indirect path forwarding next hops: 1
Next hop type: Router
Next hop: 10.0.0.6 via ge-0/0/0.0
Session Id: 0x141
192.168.0.4/32 Originating RIB: inet.0
Metric: 1001 Node path count: 1
Forwarding nexthops: 1
Nexthop: 10.0.0.6 via ge-0/0/0.0
#Multipath Preference: 255
Next hop type: Indirect, Next hop index: 0
Address: 0xd330f90
Next-hop reference count: 304062
Next hop type: Router, Next hop index: 623
Next hop: 10.0.0.6 via ge-0/0/0.0, selected
Session Id: 0x140
Next hop type: Router, Next hop index: 624
Next hop: 10.0.0.2 via ge-0/0/1.0
Session Id: 0x141
Protocol next hop: 192.168.0.4
Indirect next hop: 0xab3b980 1048574 INH Session ID: 0x144 Weight 0x1
Protocol next hop: 192.168.0.5
Indirect next hop: 0xab3c240 1048575 INH Session ID: 0x145 Weight 0x4000
State: <ForwardinOnly Int Ext>
Inactive reason: Forwarding use only
Local AS: 64496
Age: 1:05 Metric2: 2
Validation State: unverified
Task: RT
Announcement bits (1): 0-KRT
AS path: 64497 I
Significado
Junos OS utiliza los siguientes saltos y los valores para seleccionar una ruta de respaldo cuando se produce un error en un weight vínculo. El peso del siguiente salto tiene uno de los siguientes valores:
-
0x1 indica la ruta principal con los siguientes saltos activos.
-
0x4000 indica la ruta de respaldo con los siguientes saltos pasivos.
Visualización de la tabla de reenvío
Propósito
Compruebe el estado de la tabla de enrutamiento de kernel y reenvío mediante el show route forwarding-table comando.
Acción
Desde el dispositivo PE0, ejecute el show route forwarding-table destination 192.168.1.5 extensive comando.
user@PE0>
show route forwarding-table destination 192.168.1.5 extensive
Routing table: default.inet [Index 0]
Internet:
Destination: 192.168.1.5/24
Route type: user
Route reference: 0 Route interface-index: 0
Multicast RPF nh index: 0
Flags: sent to PFE
Next-hop type: unilist Index: 1048576 Reference: 7401
Next-hop type: indirect Index: 1048574 Reference: 2 Weight: 0x1
Nexthop: 10.0.0.6
Next-hop type: unicast Index: 623 Reference: 8
Next-hop interface: ge-0/0/0.0 Weight: 0x1
Next-hop type: indirect Index: 1048575 Reference: 2 Weight: 0x4000
Nexthop: 10.0.0.2
Next-hop type: unicast Index: 624 Reference: 8
Next-hop interface: ge-0/0/1.0 Weight: 0x4000
Significado
Junos OS utiliza los siguientes saltos y los valores para seleccionar una ruta de respaldo cuando se produce un error en un weight vínculo. El peso del siguiente salto tiene uno de los siguientes valores:
-
0x1 indica la ruta principal con los siguientes saltos activos.
-
0x4000 indica la ruta de respaldo con los siguientes saltos pasivos.
Descripción general de Conservar la jerarquía de salto siguiente
En la jerarquía comprimida tradicional, las etiquetas de servicio se fusionan en un único próximo salto de transporte (FNH), lo que puede dar lugar a una explosión de próximos saltos en la PFE. La jerarquía comprimida tradicional también puede causar problemas como el truncamiento de ECMP y la pérdida de pesos jerárquicos.
Conservar la jerarquía de salto siguiente (también conocida como jerarquía expandida) mantiene cada etiqueta de servicio en su propio compuesto de cadena, conservando la jerarquía original en lugar de fusionar todo en una única estructura de salto siguiente.
- Beneficios de conservar la jerarquía del siguiente salto
- Configurar, conservar la jerarquía de salto siguiente
Beneficios de conservar la jerarquía del siguiente salto
Esta característica ofrece los siguientes beneficios:
- Reducción de los recursos de reenvío de próximos saltos: Proporciona una reducción significativa en el reenvío de recursos / recuento de próximos saltos.
- PIC de BGP en todos los niveles: es compatible con la PIC de BGP en todos los niveles jerárquicos (transporte, servicio, cadenas compuestas), lo que garantiza una rápida tolerancia a fallos y convergencia local para las rutas de BGP.
- Preservación de pesos jerárquicos: Mantiene la distribución de peso y ancho de banda para escenarios de enrutamiento jerárquico y ECMP.
- Evite el truncamiento de ECMP: garantiza que todas las patas de ECMP estén instaladas en PFE, lo que mejora el equilibrio de carga y la resistencia.
Servicios como servicios de capa 2 (circuito de capa 2, VPN de capa 2), VPN de capa 3 (IPv4 e IPv6), VPLS, túneles IPIP, servicios de Internet (IPv4, IPv6, 6PE), compatibilidad con EVPN y PRPD Conservar la jerarquía de salto siguiente.
Protocolos de transporte como unidifusión etiquetada con BGP, TRANSPORTE CON CLASE BGP (BGP-CT), RSVP-TE, SR-MPLS, SR-FlexAlgo, SR-TE, SRv6 TE, compatibilidad con MPLS-over-UDP Conservar la jerarquía de salto siguiente con la infraestructura de clase de transporte.
Consulte la herramienta Explorador de características para obtener la lista de plataformas que admiten conservar la jerarquía de salto siguiente.
Configurar, conservar la jerarquía de salto siguiente
Para configurar la característica Conservar jerarquía de salto siguiente, incluya la preserve-nexthop-hierarchy instrucción en el nivel de jerarquía [edit routing-options resolution]. Esto garantiza que todos los procesos de enrutamiento relacionados respeten la jerarquía de salto siguiente establecida. Esto facilita la resolución eficiente de rutas y una adaptación más rápida en caso de fallas de rutas, lo que contribuye a un rendimiento mejorado de la red.
La función Conservar la jerarquía del siguiente salto beneficia a las redes que requieren alta disponibilidad e integración fluida con tecnologías avanzadas como el enrutamiento por segmentos con MPLS y el enrutamiento por segmentos con IPv6. Ofrecen una distribución del tráfico mejorada, redundancia y un comportamiento de enrutamiento consistente en arquitecturas de red complejas.
preserve-nexthop-hierarchy instrucción, ya sea a nivel global o de protocolo, el siguiente salto al que apuntan las rutas afectadas se vuelve a calcular y se descarga en PFE y kernel. Esto da como resultado picos de CPU más altos en el dispositivo en un entorno de mayor escala, lo que lleva a la pérdida de paquetes hasta que las rutas se reprograman en la PFE.
Descripción general del borde de la PIC del BGP con la etiqueta de unidifusión del BGP
En esta sección, se tratan los beneficios y la descripción general de BGP PIC Edge mediante el uso de BGP etiquetado como unidifusión como protocolo de transporte.
- Beneficios del borde de la PIC del BGP mediante el uso de unidifusión etiquetada con BGP
- ¿Cómo funciona la convergencia independiente del prefijo BGP?
- Borde de la PIC del BGP que usa la unidifusión etiquetada con el BGP como protocolo de transporte
Beneficios del borde de la PIC del BGP mediante el uso de unidifusión etiquetada con BGP
Esta característica ofrece los siguientes beneficios:
Brinda protección de tráfico en caso de fallas en nodos de borde (ABR y ASBR) en redes de dominios múltiples.
Proporciona una restauración más rápida de la conectividad de red y reduce la pérdida de tráfico si la ruta principal deja de estar disponible.
¿Cómo funciona la convergencia independiente del prefijo BGP?
La convergencia independiente del prefijo (PIC) del BGP mejora la convergencia del BGP en errores de nodos de red. La PIC del BGP crea y almacena rutas principales y de respaldo para el próximo salto indirecto en el motor de enrutamiento y también proporciona la información de la ruta del próximo salto indirecto al motor de reenvío de paquetes. Cuando se produce un error en un nodo de red, el motor de enrutamiento indica al motor de reenvío de paquetes que se produjo un error en un próximo salto indirecto y que el tráfico se redirige a una ruta de respaldo o de igual costo calculada previamente sin modificar los prefijos del BGP. El enrutamiento del tráfico al prefijo de destino continúa mediante el uso de la ruta de respaldo para reducir la pérdida de tráfico hasta que se resuelva la convergencia global a través del BGP.
La convergencia del BGP se aplica a los errores de los nodos de red principal y de borde. En el caso del núcleo de PIC del BGP, se realizan ajustes en las cadenas de reenvío como resultado de fallas en el nodo o en el vínculo principal. En el caso de la PIC perimetral del BGP, se realizan ajustes en las cadenas de reenvío como resultado de fallas en el nodo de borde o en el vínculo de Edge.
Borde de la PIC del BGP que usa la unidifusión etiquetada con el BGP como protocolo de transporte
El borde de la PIC del BGP usa el protocolo de transporte de unidifusión etiquetado con BGP para ayudar a proteger y redireccionar el tráfico cuando se producen errores en los nodos de borde (ABR y ASBR) en redes con varios dominios. Las redes de múltiples dominios se utilizan normalmente en diseños de red de agregación y retorno móvil de Metro Ethernet.
En los dispositivos de la serie MX, la serie EX y la serie PTX de Juniper Networks, el borde de la PIC del BGP admite servicios de capa 3 con la etiqueta de unidifusión del BGP como protocolo de transporte. Además, en los dispositivos de la serie MX, EX9204, EX9204, EX9208, EX9214, EX9251 y EX9253 de Juniper Networks, el borde de la PIC del BGP admite servicios de circuito de capa 2, VPN de capa 2 y VPLS (BGP VPLS, LDP VPLS y FEC 129 VPLS) con BGP etiquetado como unidifusión como protocolo de transporte. Estos servicios de BGP son de multirruta (aprendidos de varios PE) y se resuelven a través de rutas de unidifusión etiquetadas con BGP, que nuevamente podrían ser una multirruta aprendida de otros ABR. Los protocolos de transporte admitidos a través del borde de PIC del BGP son RSVP, LDP, OSPF e ISIS. A partir de la versión 20.2R1 de Junos OS, la serie MX, EX9204, EX9208, EX9214, EX9251 y EX9253 admiten la protección de borde de PIC de BGP para circuitos de capa 2, VPN de capa 2 y servicios VPLS (BGP VPLS, LDP VPLS y FEC 129 VPLS) con BGP etiquetado como unidifusión como protocolo de transporte.
En Juniper Networks dispositivos serie MX, serie EX y serie PTX, la protección del borde de la PIC del BGP con el BGP etiquetado como unidifusión como transporte es compatible con los siguientes servicios:
Servicios IPv4 a través de BGP IPv4 etiquetados como unidifusión
IPv6 BGP etiquetado como servicio de unidifusión a través de IPv4 BGP etiquetado como unidifusión
Servicios VPN de capa 3 IPv4 a través de IPv4 BGP etiquetados como unidifusión
Servicios VPN de capa 3 IPv6 a través de IPv4 BGP etiquetados como unidifusión
En Juniper Networks dispositivos serie MX y serie EX, la protección del borde de la PIC del BGP con el BGP etiquetado como unidifusión como transporte es compatible con los siguientes servicios:
Servicios de circuito de capa 2 a través de IPv4 BGP etiquetados como unidifusión
Servicios VPN de capa 2 a través de IPv4 BGP etiquetados como unidifusión
Servicios VPLS (BGP VPLS, LDP VPLS y FEC 129 VPLS) a través de IPv4 BGP etiquetado como unidifusión
Configuración del borde de la PIC del BGP mediante la etiqueta de unidifusión del BGP para servicios de capa 2
Los dispositivos de la serie MX, EX9204, EX9208, EX9214, EX9251 y EX9253 admiten la protección de borde de PIC de BGP para circuitos de capa 2, VPN de capa 2 y servicios VPLS (BGP VPLS, LDP VPLS y FEC 129 VPLS) con BGP etiquetado como unidifusión como protocolo de transporte. El borde de la PIC del BGP usa el protocolo de transporte de unidifusión etiquetado con BGP para ayudar a proteger los errores de tráfico en los nodos de borde (ABR y ASBR) en redes con varios dominios. Las redes de múltiples dominios se utilizan típicamente en diseños de redes de retorno móvil y agregación metropolitana.
Un requisito previo para la protección de borde de PIC del BGP es programar el motor de reenvío de paquetes (PFE) con una jerarquía de salto siguiente expandida.
Para habilitar la jerarquía de próximo salto expandida para la familia de unidifusión etiquetada con BGP, debe configurar la siguiente instrucción de configuración de CLI en el nivel de jerarquía [edit protocols]:
[edit protocols] user@host#set bgp group group-name family inet labeled-unicast nexthop-resolution preserve-nexthop-hierarchy;
Para habilitar la PIC del BGP para los próximos saltos de equilibrio de carga de MPLS, debe configurar la siguiente instrucción de configuración de la CLI en el nivel de jerarquía [edit routing-options]:
[edit routing-options] user@host#set rib routing-table-name protect core;
Para habilitar una convergencia rápida para los servicios de capa 2, debe configurar las siguientes instrucciones de configuración de CLI en el nivel de jerarquía [edit protocols]:
Para circuito de capa 2 y LDP VPLS:
[edit protocols] user@host#set l2circuit resolution preserve-nexthop-heirarchy;
Para VPN de capa 2, BGP VPLS y FEC129:
[edit protocols] user@host#set l2vpn resolution preserve-nexthop-heirarchy;
Ejemplo: Protección del tráfico IPv4 mediante VPN de capa 3 que ejecuta BGP etiquetado como unidifusión
En este ejemplo, se muestra cómo configurar el borde de la convergencia independiente del prefijo (PIC) del BGP etiquetado como unidifusión y proteger el tráfico IPv4 mediante VPN de capa 3. Cuando se envía un tráfico IPv4 desde un enrutador CE a un enrutador PE, el tráfico IPv4 se enruta a través de una VPN de capa 3, donde el BGP etiquetado como unidifusión está configurado como el protocolo de transporte.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
enrutadores de la serie MX.
-
Junos OS versión 19.4R1 o posterior ejecutándose en todos los dispositivos.
Descripción general
La siguiente topología proporciona protección ABR y ASBR al cambiar el tráfico a rutas de respaldo cuando la ruta principal deja de estar disponible.
Topología
La figura 14 ilustra una VPN de capa 3 que ejecuta BGP etiquetada como unidifusión como protocolo de transporte entre dominios.
En la siguiente tabla se describen los componentes utilizados en la topología:
| Componentes principales |
Tipo de dispositivo |
Posición |
|---|---|---|
| CE1 |
serie MX |
Conectado a la red del cliente. |
| PE1 |
serie MX |
Configurado con rutas de enrutamiento principal y de respaldo para proteger y redireccionar el tráfico de CE1 a CE2. |
| P1-P3 |
serie MX |
Enrutadores centrales para transportar el tráfico. |
| ABR1-ABR2 |
serie MX |
Enrutadores de borde de área |
| ABSR1-ABSR4 |
serie MX |
enrutador de límite del sistema autónomo |
| RR1-RR3 |
serie MX |
Reflector de ruta |
| PE2-PE3 |
serie MX |
Enrutadores de PE conectados al enrutador de borde del cliente (CE2). |
| CE2 |
serie MX |
Conectado a la red del cliente. |
Las direcciones de dispositivos PE2 y PE3 se aprenden desde ABR1 y ABR2 como rutas de unidifusión etiquetadas. Estas rutas se resuelven mediante protocolos IGP/LDP. PE1 aprende rutas CE2 de dispositivos PE2 y PE3.
Configuración
Para configurar el borde de la PIC del BGP con la unidifusión de la etiqueta de BGP con LDP como protocolo de transporte, realice estas tareas:
- Configuración rápida de CLI
- Configuración de CE1
- Configuración de PE1
- Configuración del dispositivo P1
- Configuración del dispositivo RR1
- Configuración del dispositivo ABR1
- Configuración del dispositivo ABR2
- Configuración del dispositivo P2
- Configuración del dispositivo RR2
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese commit desde el [edit] modo de configuración.
Dispositivo CE1
set interfaces ge-0/0/1 description CE1-to-PE1-Link1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.0/31 set interfaces ge-0/0/2 description CE1-to-PE1-Link2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.2/31 set interfaces lo0 unit 0 family inet address 10.4.4.4/32 set policy-options policy-statement nhs term 1 from interface lo0.0 set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set routing-options router-id 10.4.4.4 set routing-options autonomous-system 65004 set protocols bgp path-selection external-router-id set protocols bgp group toAs2 export nhs set protocols bgp group toAs2 peer-as 65002 set protocols bgp group toAs2 neighbor 192.168.0.1 set protocols bgp group toAs2 neighbor 192.168.0.3
Dispositivo PE1
set interfaces ge-0/0/1 description PE1-to-CE1-Link1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.1/31 set interfaces ge-0/0/2 description PE1-to-CE1-Link2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.3/31 set interfaces ge-0/0/3 description PE1-to-P1 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.4/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.2.2.5/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0005.00 set policy-options policy-statement add-noexport term 1 then community add noexport set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement mp-resolv term 1 from route-filter 10.1.1.0/24 orlonger set policy-options policy-statement mp-resolv term 1 then accept set policy-options policy-statement mp-resolv term 1 then multipath-resolve set policy-options policy-statement mp-resolv term 2 from route-filter 10.2.2.0/24 orlonger set policy-options policy-statement mp-resolv term 2 then accept set policy-options policy-statement mp-resolv term 2 then multipath-resolve set policy-options policy-statement mp-resolv term def then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then local-preference 65200 set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set policy-options policy-statement vrf-export-red term 1 then community add leak2red set policy-options policy-statement vrf-export-red term 1 then accept set policy-options policy-statement vrf-import-red term 1 from community leak2red set policy-options policy-statement vrf-import-red term 1 then accept set policy-options community leak2red members target:100:100 set policy-options community noexport members no-export set policy-options community noexport members no-advertise set routing-instances red routing-options multipath preserve-nexthop-hierarchy set routing-instances red routing-options protect core set routing-instances red protocols bgp group toCE1 peer-as 4 set routing-instances red protocols bgp group toCE1 neighbor 192.168.0.2 set routing-instances red instance-type vrf set routing-instances red interface ge-0/0/2.0 set routing-instances red vrf-import vrf-import-red set routing-instances red vrf-export vrf-export-red set routing-options rib inet.3 protect core set routing-options route-distinguisher-id 10.2.2.5 set routing-options forwarding-table export pplb set routing-options resolution preserve-nexthop-hierarchy set routing-options resolution rib inet.0 import mp-resolv set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.2.2.5 set routing-options autonomous-system 2 set routing-options protect core set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set routing-options rib-groups inet3to0 import-rib inet.3 set routing-options rib-groups inet3to0 import-rib inet.0 set routing-options rib-groups inet3to0 import-policy add-noexport set protocols isis level 1 disable set protocols isis interface ge-0/0/3.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/3.0 set protocols ldp interface ge-0/0/3.0 set protocols mpls label-switched-path toABR1-gold to 10.2.2.3 set protocols mpls label-switched-path toABR1-bronze to 10.2.2.3 set protocols mpls label-switched-path toABR2-gold to 10.2.2.4 set protocols bgp path-selection external-router-id set protocols bgp group toAs2RR type internal set protocols bgp group toAs2RR local-address 10.2.2.5 set protocols bgp group toAs2RR family inet labeled-unicast rib-group inet3to0 set protocols bgp group toAs2RR family inet labeled-unicast add-path receive set protocols bgp group toAs2RR family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs2RR family inet labeled-unicast nexthop-resolution preserve-nexthop-hierarchy set protocols bgp group toAs2RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs2RR export nhs set protocols bgp group toAs2RR export export-inet3 set protocols bgp group toAs2RR neighbor 10.2.2.6 set protocols bgp group toAs4 peer-as 65004 set protocols bgp group toAs4 neighbor 192.168.0.0 set protocols bgp group toAs1PEs multihop no-nexthop-change set protocols bgp group toAs1PEs local-address 10.2.2.5 set protocols bgp group toAs1PEs family inet unicast set protocols bgp group toAs1PEs family inet-vpn unicast set protocols bgp group toAs1PEs family inet6 unicast set protocols bgp group toAs1PEs family inet6-vpn unicast set protocols bgp group toAs1PEs export nhs set protocols bgp group toAs1PEs peer-as 65001 set protocols bgp group toAs1PEs neighbor 10.1.1.1 set protocols bgp group toAs1PEs neighbor 10.1.1.2 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy set protocols bgp multipath
Dispositivo P1
set interfaces ge-0/0/1 description P1-to-RR1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.6/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description P1-to-ABR1 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.8/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 description P1-to-PE1 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.5/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces ge-0/0/4 description P1-to-ABR2 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.10/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.8/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0008.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set routing-options router-id 10.2.2.8 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all
Dispositivo RR1
set interfaces ge-0/0/1 description RR1-to-P1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.7/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.2.2.6/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0006.00 set policy-options policy-statement add-noexport term 1 then community add noexport set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement pplb then load-balance per-packet set policy-options community noexport members no-export set policy-options community noexport members no-advertise set routing-options forwarding-table export pplb set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.2.2.6 set routing-options autonomous-system 2 set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set routing-options rib-groups inet3to0 import-rib inet.3 set routing-options rib-groups inet3to0 import-rib inet.0 set routing-options rib-groups inet3to0 import-rib inet6.3 set routing-options rib-groups inet3to0 import-policy add-noexport set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all set protocols bgp path-selection external-router-id set protocols bgp group toAs2Reg2BNs type internal set protocols bgp group toAs2Reg2BNs family inet labeled-unicast rib-group inet3to0 set protocols bgp group toAs2Reg2BNs family inet labeled-unicast add-path receive set protocols bgp group toAs2Reg2BNs family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs2Reg2BNs family inet labeled-unicast rib inet.3 set protocols bgp group toAs2Reg2BNs export export-inet3 set protocols bgp group toAs2Reg2BNs neighbor 10.2.2.3 set protocols bgp group toAs2Reg2BNs neighbor 10.2.2.4 set protocols bgp group toAs2Reg2BNs neighbor 10.2.2.5 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy set protocols bgp local-address 10.2.2.6 set protocols bgp cluster 10.2.2.6
Dispositivo ABR1
set interfaces ge-0/0/1 description ABR1-to-P2 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.12/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description ABR1-to-P1 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.9/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.3/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0003.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.2.2.3 set routing-options autonomous-system 65002 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls label-switched-path toASBR2-gold to 10.2.2.2 set protocols mpls label-switched-path toASBR1-bronze to 10.2.2.1 set protocols mpls label-switched-path toASBR2-bronze to 10.2.2.2 set protocols mpls interface all set protocols bgp group toAs2RR type internal set protocols bgp group toAs2RR local-address 10.2.2.3 set protocols bgp group toAs2RR advertise-inactive set protocols bgp group toAs2RR family inet labeled-unicast add-path receive set protocols bgp group toAs2RR family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs2RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs2RR export nhs set protocols bgp group toAs2RR cluster 10.2.2.3 set protocols bgp group toAs2RR neighbor 10.2.2.6 set protocols bgp group toAs2RR neighbor 10.2.2.7 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo ABR2
set interfaces ge-0/0/2 description ABR2-to-P2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.14/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/4 description ABR2-to-P1 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.11/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.4/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0004.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.2.2.4 set routing-options autonomous-system 65002 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls label-switched-path toASBR1-bronze to 10.2.2.1 set protocols mpls interface all set protocols bgp group toAs2RR type internal set protocols bgp group toAs2RR local-address 10.2.2.4 set protocols bgp group toAs2RR advertise-inactive set protocols bgp group toAs2RR family inet labeled-unicast add-path receive set protocols bgp group toAs2RR family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs2RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs2RR export nhs set protocols bgp group toAs2RR cluster 10.2.2.4 set protocols bgp group toAs2RR neighbor 10.2.2.6 set protocols bgp group toAs2RR neighbor 10.2.2.7 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo P2
set interfaces ge-0/0/1 description P2-to-ABR1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.13/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description P2-to-ABR2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.15/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 description P2-to-RR2 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.16/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces ge-0/0/4 description P2-to-ASBR1 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.18/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces ge-0/0/5 description P2-to-ASBR2 set interfaces ge-0/0/5 vlan-tagging set interfaces ge-0/0/5 unit 0 vlan-id 100 set interfaces ge-0/0/5 unit 0 family inet address 192.168.0.20/31 set interfaces ge-0/0/5 unit 0 family iso set interfaces ge-0/0/5 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.9/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0009.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set routing-options router-id 10.2.2.9 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all
Dispositivo RR2
set interfaces ge-0/0/3 description RR2-to-P2 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.17/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.2.2.7/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0007.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.2.2.7 set routing-options autonomous-system 65002 set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all set protocols bgp path-selection external-router-id set protocols bgp group toAs2Reg1BNs type internal set protocols bgp group toAs2Reg1BNs family inet labeled-unicast add-path receive set protocols bgp group toAs2Reg1BNs family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs2Reg1BNs family inet labeled-unicast rib inet.3 set protocols bgp group toAs2Reg1BNs neighbor 10.2.2.1 set protocols bgp group toAs2Reg1BNs neighbor 10.2.2.2 set protocols bgp group toAs2Reg1BNs neighbor 10.2.2.3 set protocols bgp group toAs2Reg1BNs neighbor 10.2.2.4 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy set protocols bgp local-address 10.2.2.7 set protocols bgp cluster 10.2.2.7
Dispositivo ASBR1
set interfaces ge-0/0/2 description ASBR1-to-ASBR3 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.22/31 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 description ASBR1-to-ASBR4 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.24/31 set interfaces ge-0/0/3 unit 0 family mpls set interfaces ge-0/0/4 description ASBR1-to-P2 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.19/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.1/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0001.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.2.2.1 set routing-options autonomous-system 65002 set protocols isis level 1 disable set protocols isis interface ge-0/0/4.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/4.0 set protocols ldp interface ge-0/0/4.0 set protocols mpls interface ge-0/0/4.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs1-T family inet labeled-unicast rib inet.3 set protocols bgp group toAs1-T peer-as 1 set protocols bgp group toAs1-T neighbor 192.168.0.23 set protocols bgp group toAs1-T neighbor 192.168.0.27 set protocols bgp group toAs2RR type internal set protocols bgp group toAs2RR local-address 10.2.2.1 set protocols bgp group toAs2RR advertise-external set protocols bgp group toAs2RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs2RR export nhs set protocols bgp group toAs2RR neighbor 10.2.2.7 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo ASBR2
set interfaces ge-0/0/1 description ASBR2-to-ASBR3 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.28/31 set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description ASBR2-to-ASBR4 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.26/31 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/5 description ASBR2-to-P2 set interfaces ge-0/0/5 vlan-tagging set interfaces ge-0/0/5 unit 0 vlan-id 100 set interfaces ge-0/0/5 unit 0 family inet address 192.168.0.21/31 set interfaces ge-0/0/5 unit 0 family iso set interfaces ge-0/0/5 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.2.2.2/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0002.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.2.2.2 set routing-options autonomous-system 65002 set protocols isis level 1 disable set protocols isis interface ge-0/0/5.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/5.0 set protocols ldp interface ge-0/0/5.0 set protocols mpls interface ge-0/0/5.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs1-T family inet labeled-unicast rib inet.3 set protocols bgp group toAs1-T peer-as 1 set protocols bgp group toAs1-T neighbor 192.168.0.29 set protocols bgp group toAs1-T neighbor 192.168.0.25 set protocols bgp group toAs2RR type internal set protocols bgp group toAs2RR local-address 10.2.2.2 set protocols bgp group toAs2RR advertise-external set protocols bgp group toAs2RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs2RR export nhs set protocols bgp group toAs2RR neighbor 10.2.2.7 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo ASBR3
set interfaces ge-0/0/1 description ASBR3-to-ASBR2 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.29/31 set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description ASBR3-to-ASBR1 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.23/31 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/4 description ASBR3-to-P3 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.30/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.1.3/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0003.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.1.1.3 set routing-options autonomous-system 65001 set protocols isis level 1 disable set protocols isis interface ge-0/0/4.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/4.0 set protocols ldp interface ge-0/0/4.0 set protocols mpls label-switched-path toPE2-gold to 10.1.1.1 set protocols mpls interface ge-0/0/4.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs2-T family inet labeled-unicast rib inet.3 set protocols bgp group toAs2-T peer-as 65002 set protocols bgp group toAs2-T neighbor 192.168.0.22 set protocols bgp group toAs2-T neighbor 192.168.0.28 set protocols bgp group toAs1RR type internal set protocols bgp group toAs1RR local-address 10.1.1.3 set protocols bgp group toAs1RR advertise-external set protocols bgp group toAs1RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs1RR export nhs set protocols bgp group toAs1RR neighbor 10.1.1.6 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo ASBR4
set interfaces ge-0/0/1 description ASBR4-to-P3 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.32/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description ASBR4-to-ASBR2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.27/31 set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 description ASBR4-to-ASBR1 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.25/31 set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.1.4/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0004.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set routing-options forwarding-table export pplb set routing-options router-id 10.1.1.4 set routing-options autonomous-system 65001 set protocols isis level 1 disable set protocols isis interface ge-0/0/1.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/1.0 set protocols ldp interface ge-0/0/1.0 set protocols mpls label-switched-path toPE2-bronze to 10.1.1.1 set protocols mpls label-switched-path toPE3-bronze to 10.1.1.2 set protocols mpls interface ge-0/0/1.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs2-T family inet labeled-unicast rib inet.3 set protocols bgp group toAs2-T peer-as 2 set protocols bgp group toAs2-T neighbor 192.168.0.26 set protocols bgp group toAs2-T neighbor 192.168.0.24 set protocols bgp group toAs1RR type internal set protocols bgp group toAs1RR local-address 10.1.1.4 set protocols bgp group toAs1RR advertise-external set protocols bgp group toAs1RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs1RR export nhs set protocols bgp group toAs1RR neighbor 10.1.1.6 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo RR3
set interfaces ge-0/0/2 description RR3-to-P3 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.35/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.1.1.6/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0006.00 set policy-options policy-statement add-noexport term 1 then community add noexport set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement pplb then load-balance per-packet set policy-options community noexport members no-export set policy-options community noexport members no-advertise set routing-options forwarding-table export pplb set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.1.1.6 set routing-options autonomous-system 1 set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set routing-options rib-groups inet3to0 import-rib inet.3 set routing-options rib-groups inet3to0 import-rib inet.0 set routing-options rib-groups inet3to0 import-policy add-noexport set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all set protocols bgp path-selection external-router-id set protocols bgp group toAs1BNs type internal set protocols bgp group toAs1BNs family inet labeled-unicast rib-group inet3to0 set protocols bgp group toAs1BNs family inet labeled-unicast add-path receive set protocols bgp group toAs1BNs family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs1BNs family inet labeled-unicast rib inet.3 set protocols bgp group toAs1BNs export export-inet3 set protocols bgp group toAs1BNs neighbor 10.1.1.3 set protocols bgp group toAs1BNs neighbor 10.1.1.4 set protocols bgp group toAs1BNs neighbor 10.1.1.2 set protocols bgp group toAs1BNs neighbor 10.1.1.1 set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy set protocols bgp local-address 10.1.1.6 set protocols bgp cluster 10.1.1.6
Dispositivo P3
set interfaces ge-0/0/1 description P3-to-ASBR4 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.33/31 set interfaces ge-0/0/1 unit 0 family iso set interfaces ge-0/0/1 unit 0 family mpls set interfaces ge-0/0/2 description P3-to-RR3 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.34/31 set interfaces ge-0/0/2 unit 0 family iso set interfaces ge-0/0/2 unit 0 family mpls set interfaces ge-0/0/3 description P3-to-PE2 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.36/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces ge-0/0/4 description P3-to-ASBR3 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.31/31 set interfaces ge-0/0/4 unit 0 family iso set interfaces ge-0/0/4 unit 0 family mpls set interfaces ge-0/0/5 description P3-to-PE3 set interfaces ge-0/0/5 vlan-tagging set interfaces ge-0/0/5 unit 0 vlan-id 100 set interfaces ge-0/0/5 unit 0 family inet address 192.168.0.38/31 set interfaces ge-0/0/5 unit 0 family iso set interfaces ge-0/0/5 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.1.1.5/32 set interfaces lo0 unit 0 family iso address 49.0000.0000.aaaa.0005.00 set policy-options policy-statement allow-lo0 term 1 from interface lo0.0 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set routing-options router-id 10.1.1.5 set protocols isis level 1 disable set protocols isis interface all set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface all set protocols ldp interface all set protocols mpls interface all
Dispositivo PE2
set interfaces ge-0/0/1 description PE2-to-CE2-Link1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.40/31 set interfaces ge-0/0/2 description PE2-to-CE2-Link2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.42/31 set interfaces ge-0/0/3 description PE2-to-P3 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.37/31 set interfaces ge-0/0/3 unit 0 family iso set interfaces ge-0/0/3 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.1.1.1/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0001.00 set policy-options policy-statement add-noexport term 1 then community add noexport set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then metric add 0 set policy-options policy-statement nhs term 1 then local-preference 200 set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set policy-options policy-statement vrf-export-red term 1 then community add leak2red set policy-options policy-statement vrf-export-red term 1 then accept set policy-options policy-statement vrf-import-red term 1 from community leak2red set policy-options policy-statement vrf-import-red term 1 then accept set policy-options community leak2red members target:100:100 set policy-options community noexport members no-export set policy-options community noexport members no-advertise set routing-instances red protocols bgp group toCE2 peer-as 65003 set routing-instances red protocols bgp group toCE2 neighbor 192.168.0.43 set routing-instances red instance-type vrf set routing-instances red interface ge-0/0/2.0 set routing-instances red vrf-import vrf-import-red set routing-instances red vrf-export vrf-export-red set routing-options route-distinguisher-id 10.1.1.1 set routing-options forwarding-table export pplb set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.1.1.1 set routing-options autonomous-system 1 set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set routing-options rib-groups inet3to0 import-rib inet.3 set routing-options rib-groups inet3to0 import-rib inet.0 set routing-options rib-groups inet3to0 import-policy add-noexport set protocols isis level 1 disable set protocols isis interface ge-0/0/3.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/3.0 set protocols ldp interface ge-0/0/3.0 set protocols mpls interface ge-0/0/3.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs3-1 peer-as 65003 set protocols bgp group toAs3-1 neighbor 192.168.0.41 set protocols bgp group toAs1RR type internal set protocols bgp group toAs1RR local-address 10.1.1.1 set protocols bgp group toAs1RR advertise-external set protocols bgp group toAs1RR family inet labeled-unicast rib-group inet3to0 set protocols bgp group toAs1RR family inet labeled-unicast add-path receive set protocols bgp group toAs1RR family inet labeled-unicast add-path send path-count 4 set protocols bgp group toAs1RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs1RR family inet6-vpn unicast set protocols bgp group toAs1RR export nhs set protocols bgp group toAs1RR export export-inet3 set protocols bgp group toAs1RR neighbor 10.1.1.6 set protocols bgp group toAs2PEs multihop no-nexthop-change set protocols bgp group toAs2PEs local-address 10.1.1.1 set protocols bgp group toAs2PEs family inet unicast set protocols bgp group toAs2PEs family inet-vpn unicast set protocols bgp group toAs2PEs family inet6 unicast set protocols bgp group toAs2PEs family inet6-vpn unicast set protocols bgp group toAs2PEs export nhs set protocols bgp group toAs2PEs peer-as 65002 set protocols bgp group toAs2PEs neighbor 10.2.2.5 set protocols bgp group toAs2PEs vpn-apply-export set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo PE3
set interfaces ge-0/0/3 description PE3-to-CE2-Link1 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.44/31 set interfaces ge-0/0/4 description PE3-to-CE2-Link2 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.46/31 set interfaces ge-0/0/5 description PE3-to-P3 set interfaces ge-0/0/5 vlan-tagging set interfaces ge-0/0/5 unit 0 vlan-id 100 set interfaces ge-0/0/5 unit 0 family inet address 192.168.0.39/31 set interfaces ge-0/0/5 unit 0 family iso set interfaces ge-0/0/5 unit 0 family mpls set interfaces lo0 unit 1 family inet address 10.1.1.2/32 set interfaces lo0 unit 1 family iso address 49.0000.0000.aaaa.0002.00 set policy-options policy-statement add-noexport term 1 then community add noexport set policy-options policy-statement allow-lo0 term 1 from interface lo0.1 set policy-options policy-statement allow-lo0 term 1 then accept set policy-options policy-statement allow-lo0 term 2 then reject set policy-options policy-statement export-inet3 term 1 from rib inet.3 set policy-options policy-statement export-inet3 term 1 then accept set policy-options policy-statement export-inet3 term 2 then reject set policy-options policy-statement nhs term 1 from protocol bgp set policy-options policy-statement nhs term 1 then metric add 0 set policy-options policy-statement nhs term 1 then local-preference 200 set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement pplb then load-balance per-packet set policy-options policy-statement vrf-export-red term 1 then community add leak2red set policy-options policy-statement vrf-export-red term 1 then accept set policy-options policy-statement vrf-import-red term 1 from community leak2red set policy-options policy-statement vrf-import-red term 1 then accept set policy-options community leak2red members target:100:100 set policy-options community noexport members no-export set policy-options community noexport members no-advertise set routing-instances red protocols bgp group toCE2 peer-as 65003 set routing-instances red protocols bgp group toCE2 neighbor 192.168.0.47 set routing-instances red instance-type vrf set routing-instances red interface ge-0/0/4.0 set routing-instances red vrf-import vrf-import-red set routing-instances red vrf-export vrf-export-red set routing-options route-distinguisher-id 10.1.1.2 set routing-options forwarding-table export pplb set routing-options interface-routes rib-group inet inet0to3 set routing-options router-id 10.1.1.2 set routing-options autonomous-system 1 set routing-options rib-groups inet0to3 import-rib inet.0 set routing-options rib-groups inet0to3 import-rib inet.3 set routing-options rib-groups inet0to3 import-policy allow-lo0 set routing-options rib-groups inet3to0 import-rib inet.3 set routing-options rib-groups inet3to0 import-rib inet.0 set routing-options rib-groups inet3to0 import-policy add-noexport set protocols isis level 1 disable set protocols isis interface ge-0/0/5.0 set protocols isis export allow-lo0 set protocols isis topologies ipv6-unicast set protocols rsvp interface ge-0/0/5.0 set protocols ldp interface ge-0/0/5.0 set protocols mpls interface ge-0/0/5.0 set protocols bgp path-selection external-router-id set protocols bgp group toAs3 peer-as 65003 set protocols bgp group toAs3 neighbor 192.168.0.45 set protocols bgp group toAs1RR type internal set protocols bgp group toAs1RR local-address 10.1.1.2 set protocols bgp group toAs1RR advertise-external set protocols bgp group toAs1RR family inet labeled-unicast rib-group inet3to0 set protocols bgp group toAs1RR family inet labeled-unicast rib inet.3 set protocols bgp group toAs1RR export nhs set protocols bgp group toAs1RR export export-inet3 set protocols bgp group toAs1RR neighbor 10.1.1.6 set protocols bgp group toAs2PEs multihop no-nexthop-change set protocols bgp group toAs2PEs local-address 10.1.1.2 set protocols bgp group toAs2PEs family inet unicast set protocols bgp group toAs2PEs family inet-vpn unicast set protocols bgp group toAs2PEs family inet6 unicast set protocols bgp group toAs2PEs family inet6-vpn unicast set protocols bgp group toAs2PEs export nhs set protocols bgp group toAs2PEs peer-as 65002 set protocols bgp group toAs2PEs neighbor 10.2.2.5 set protocols bgp group toAs2PEs vpn-apply-export set protocols bgp traceoptions file bgp.log set protocols bgp traceoptions file size 100m set protocols bgp traceoptions flag state detail set protocols bgp traceoptions flag policy
Dispositivo CE2
set interfaces ge-0/0/1 description CE2-to-PE2-Link1 set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 unit 0 vlan-id 100 set interfaces ge-0/0/1 unit 0 family inet address 192.168.0.41/31 set interfaces ge-0/0/2 description CE2-to-PE2-Link2 set interfaces ge-0/0/2 vlan-tagging set interfaces ge-0/0/2 unit 0 vlan-id 100 set interfaces ge-0/0/2 unit 0 family inet address 192.168.0.43/31 set interfaces ge-0/0/3 description CE2-to-PE3-Link1 set interfaces ge-0/0/3 vlan-tagging set interfaces ge-0/0/3 unit 0 vlan-id 100 set interfaces ge-0/0/3 unit 0 family inet address 192.168.0.45/31 set interfaces ge-0/0/4 description CE2-to-PE3-Link2 set interfaces ge-0/0/4 vlan-tagging set interfaces ge-0/0/4 unit 0 vlan-id 100 set interfaces ge-0/0/4 unit 0 family inet address 192.168.0.47/31 set interfaces lo0 unit 0 family inet address 10.3.3.3/32 set policy-options policy-statement nhs term 1 from interface lo0.0 set policy-options policy-statement nhs term 1 then metric 50 set policy-options policy-statement nhs term 1 then next-hop self set policy-options policy-statement nhs term 1 then accept set policy-options policy-statement nhsMED100 term 1 from interface lo0.0 set policy-options policy-statement nhsMED100 term 1 then metric 100 set policy-options policy-statement nhsMED100 term 1 then next-hop self set policy-options policy-statement nhsMED100 term 1 then accept set policy-options community map2bronze members 100:200 set policy-options community map2gold members 100:100 set policy-options community map2gold_bronze_plain members 300:400 set routing-options router-id 10.3.3.3 set routing-options autonomous-system 65003 set protocols bgp path-selection external-router-id set protocols bgp group toAs1Internet export nhs set protocols bgp group toAs1Internet peer-as 65001 set protocols bgp group toAs1Internet neighbor 192.168.0.40 set protocols bgp group toAs1Internet neighbor 192.168.0.44 export nhsMED100 set protocols bgp group toAs1L3VPN export nhs set protocols bgp group toAs1L3VPN peer-as 65001 set protocols bgp group toAs1L3VPN neighbor 192.168.0.46 set protocols bgp group toAs1L3VPN neighbor 192.168.0.42 export nhsMED100
Configuración de CE1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo CE1:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@CE1#set ge-0/0/1 description CE1-to-PE1-Link1 user@CE1#set ge-0/0/1 vlan-tagging user@CE1#set ge-0/0/1 unit 0 vlan-id 100 user@CE1#set ge-0/0/1 unit 0 family inet address 192.168.0.0/31 user@CE1#set ge-0/0/2 description CE1-to-PE1-Link2 user@CE1#set ge-0/0/2 vlan-tagging user@CE1#set ge-0/0/2 unit 0 vlan-id 100 user@CE1#set ge-0/0/2 unit 0 family inet address 192.168.0.2/31
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@CE1#set lo0 unit 0 family inet address 10.4.4.4/32
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@CE1#set policy-statement nhs term 1 from interface lo0.0 user@CE1#set policy-statement nhs term 1 then next-hop self user@CE1#set policy-statement nhs term 1 then accept
-
Configure las opciones de enrutamiento.
[edit routing-options] user@CE1#set router-id 10.4.4.4 user@CE1#set autonomous-system 65004
-
Configure el BGP etiquetado como unidifusión a ABR para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols bgp] user@CE1#set path-selection external-router-id user@CE1#set group toAs2 export nhs user@CE1#set group toAs2 peer-as 65002 user@CE1#set group toAs2 neighbor 192.168.0.1 user@CE1#set group toAs2 neighbor 192.168.0.3
Resultados
Desde el modo de configuración, ingrese los comandos , show policy-optionsy show routing-optionsshow protocols para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description CE1-to-PE1-Link1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.0/31;
}
}
}
ge-0/0/2 {
description CE1-to-PE1-Link2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.2/31;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.4.4.4/32;
}
}
}
}
policy-options {
policy-statement nhs {
term 1 {
from interface lo0.0;
then {
next-hop self;
accept;
}
}
}
}
routing-options {
router-id 10.4.4.4;
autonomous-system 65004;
}
protocols {
bgp {
path-selection external-router-id;
group toAs2 {
export nhs;
peer-as 65002;
neighbor 192.168.0.1;
neighbor 192.168.0.3;
}
}
}
Configuración de PE1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo PE1:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@PE1#set ge-0/0/1 description PE1-to-CE1-Link1 user@PE1#set ge-0/0/1 vlan-tagging user@PE1#set ge-0/0/1 unit 0 vlan-id 100 user@PE1#set ge-0/0/1 unit 0 family inet address 192.168.0.1/31 user@PE1#set ge-0/0/2 description PE1-to-CE1-Link2 user@PE1#set ge-0/0/2 vlan-tagging user@PE1#set ge-0/0/2 unit 0 vlan-id 100 user@PE1#set ge-0/0/2 unit 0 family inet address 192.168.0.3/31 user@PE1#set ge-0/0/3 description PE1-to-P1 user@PE1#set ge-0/0/3 vlan-tagging user@PE1#set ge-0/0/3 unit 0 vlan-id 100 user@PE1#set ge-0/0/3 unit 0 family inet address 192.168.0.4/31 user@PE1#set ge-0/0/3 unit 0 family iso user@PE1#set ge-0/0/3 unit 0 family mpls
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@PE1#set lo0 unit 1 family inet address 10.2.2.5/32 user@PE1#set lo0 unit 1 family iso address 49.0000.0000.aaaa.0005.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@PE1#set policy-statement add-noexport term 1 then community add noexport user@PE1#set policy-statement allow-lo0 term 1 from interface lo0.1 user@PE1#set policy-statement allow-lo0 term 1 then accept user@PE1#set policy-statement allow-lo0 term 2 then reject user@PE1#set policy-statement export-inet3 term 1 from rib inet.3 user@PE1#set policy-statement export-inet3 term 1 then accept user@PE1#set policy-statement export-inet3 term 2 then reject user@PE1#set policy-statement mp-resolv term 1 from route-filter 10.1.1.0/24 orlonger user@PE1#set policy-statement mp-resolv term 1 then accept user@PE1#set policy-statement mp-resolv term 1 then multipath-resolve user@PE1#set policy-statement mp-resolv term 2 from route-filter 10.2.2.0/24 orlonger user@PE1#set policy-statement mp-resolv term 2 then accept user@PE1#set policy-statement mp-resolv term 2 then multipath-resolve user@PE1#set policy-statement mp-resolv term def then reject user@PE1#set policy-statement nhs term 1 from protocol bgp user@PE1#set policy-statement nhs term 1 then local-preference 200 user@PE1#set policy-statement nhs term 1 then next-hop self user@PE1#set policy-statement nhs term 1 then accept user@PE1#set policy-statement pplb then load-balance per-packet user@PE1#set policy-statement vrf-export-red term 1 then community add leak2red user@PE1#set policy-statement vrf-export-red term 1 then accept user@PE1#set policy-statement vrf-import-red term 1 from community leak2red user@PE1#set policy-statement vrf-import-red term 1 then accept user@PE1#set community leak2red members target:100:100 user@PE1#set community noexport members no-export user@PE1#set community noexport members no-advertise
-
Configure la instancia de enrutamiento VPN de capa 3 para proporcionar servicios al cliente.
[edit routing-instances] user@PE1#set red routing-options multipath preserve-nexthop-hierarchy user@PE1#set red routing-options protect core user@PE1#set red protocols bgp group toCE1 peer-as 65004 user@PE1#set red protocols bgp group toCE1 neighbor 192.168.0.2 user@PE1#set red instance-type vrf user@PE1#set red interface ge-0/0/2.0 user@PE1#set red vrf-import vrf-import-red user@PE1#set red vrf-export vrf-export-red
-
Configure las políticas de importación de RIB del solucionador y las RIB de resolución para habilitar una estructura de próximo salto jerárquica expandida para los prefijos VPN de capa 3 seleccionados especificados en la política.
[edit routing-options] user@PE1#set rib inet.3 protect core user@PE1#set route-distinguisher-id 10.2.2.5 user@PE1#set forwarding-table export pplb user@PE1#set resolution preserve-nexthop-hierarchy user@PE1#set resolution rib inet.0 import mp-resolv user@PE1#set interface-routes rib-group inet inet0to3 user@PE1#set router-id 10.2.2.5 user@PE1#set autonomous-system 65002 user@PE1#set protect core user@PE1#set rib-groups inet0to3 import-rib inet.0 user@PE1#set rib-groups inet0to3 import-rib inet.3 user@PE1#set rib-groups inet0to3 import-policy allow-lo0 user@PE1#set rib-groups inet3to0 import-rib inet.3 user@PE1#set rib-groups inet3to0 import-rib inet.0 user@PE1#set rib-groups inet3to0 import-policy add-noexport
-
Configure el protocolo OSPF.
[edit protocols ospf] user@PE1#set protocols ospf area 0.0.0.0 interface all link-protection; user@PE1#set protocols ospf area 0.0.0.0 interface fxp0.0 disable; user@PE1#set protocols ospf area 0.0.0.0 interface lo0.0 passive;
-
Configure los protocolos de enrutamiento para establecer la conectividad IP y MPLS en todo el dominio.
[edit protocols] user@PE1#set isis level 1 disable user@PE1#set isis interface ge-0/0/3.0 user@PE1#set isis export allow-lo0 user@PE1#set isis topologies ipv6-unicast user@PE1#set rsvp interface ge-0/0/3.0 user@PE1#set ldp interface ge-0/0/3.0 user@PE1#set mpls label-switched-path toABR1-gold to 10.2.2.3 user@PE1#set mpls label-switched-path toABR1-bronze to 10.2.2.3 user@PE1#set mpls label-switched-path toABR2-gold to 10.2.2.4
-
Configure el BGP etiquetado como unidifusión a ABR para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols bgp] user@PE1#set path-selection external-router-id user@PE1#set group toAs2RR type internal user@PE1#set group toAs2RR local-address 10.2.2.5 user@PE1#set group toAs2RR family inet labeled-unicast rib-group inet3to0 user@PE1#set group toAs2RR family inet labeled-unicast add-path receive user@PE1#set group toAs2RR family inet labeled-unicast add-path send path-count 4 user@PE1#set group toAs2RR family inet labeled-unicast nexthop-resolution preserve-nexthop-hierarchy user@PE1#set group toAs2RR family inet labeled-unicast rib inet.3 user@PE1#set group toAs2RR export nhs user@PE1#set group toAs2RR export export-inet3 user@PE1#set group toAs2RR neighbor 10.2.2.6 user@PE1#set group toAs4 peer-as 65004 user@PE1#set group toAs4 neighbor 192.168.0.0 user@PE1#set group toAs1PEs multihop no-nexthop-change user@PE1#set group toAs1PEs local-address 10.2.2.5 user@PE1#set group toAs1PEs family inet unicast user@PE1#set group toAs1PEs family inet-vpn unicast user@PE1#set group toAs1PEs family inet6 unicast user@PE1#set group toAs1PEs family inet6-vpn unicast user@PE1#set group toAs1PEs export nhs user@PE1#set group toAs1PEs peer-as 65001 user@PE1#set group toAs1PEs neighbor 10.1.1.1 user@PE1#set group toAs1PEs neighbor 10 .1.1.2 user@PE1#set traceoptions file bgp.log user@PE1#set traceoptions file size 100m user@PE1#set traceoptions flag state detail user@PE1#set traceoptions flag policy user@PE1#set multipath
Resultados
En el modo de configuración, escriba los comandos , show interfaces, show policy-options,show routing-optionsshow routing-instances y show protocols para confirmar la show chassisconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description PE1-to-CE1-Link1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.1/31;
}
}
}
ge-0/0/2 {
description PE1-to-CE1-Link2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.3/31;
}
}
}
ge-0/0/3 {
description PE1-to-P1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.4/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 1 {
family inet {
address 10.2.2.5/32;
}
family iso {
address 49.0000.0000.aaaa.0005.00;
}
}
}
}
policy-options {
policy-statement add-noexport {
term 1 {
then {
community add noexport;
}
}
}
policy-statement allow-lo0 {
term 1 {
from interface lo0.1;
then accept;
}
term 2 {
then reject;
}
}
policy-statement export-inet3 {
term 1 {
from rib inet.3;
then accept;
}
term 2 {
then reject;
}
}
policy-statement mp-resolv {
term 1 {
from {
route-filter 10.1.1.0/24 orlonger;
}
then {
accept;
multipath-resolve;
}
}
term 2 {
from {
route-filter 10.2.2.0/24 orlonger;
}
then {
accept;
multipath-resolve;
}
}
term def {
then reject;
}
}
policy-statement nhs {
term 1 {
from protocol bgp;
then {
local-preference 200;
next-hop self;
accept;
}
}
}
policy-statement pplb {
then {
load-balance per-packet;
}
}
policy-statement vrf-export-red {
term 1 {
then {
community add leak2red;
accept;
}
}
}
policy-statement vrf-import-red {
term 1 {
from community leak2red;
then accept;
}
}
community leak2red members target:100:100;
community noexport members [ no-export no-advertise ];
}
routing-instances {
red {
routing-options {
multipath preserve-nexthop-hierarchy;
protect core;
}
protocols {
bgp {
group toCE1 {
peer-as 65004;
neighbor 192.168.0.2;
}
}
}
instance-type vrf;
interface ge-0/0/2.0;
vrf-import vrf-import-red;
vrf-export vrf-export-red;
}
}
routing-options {
rib inet.3 {
protect core;
}
route-distinguisher-id 10.2.2.5;
forwarding-table {
export pplb;
}
resolution {
preserve-nexthop-hierarchy;
rib inet.0 {
import mp-resolv;
}
}
interface-routes {
rib-group inet inet0to3;
}
router-id 10.2.2.5;
autonomous-system 65002;
protect core;
rib-groups {
inet0to3 {
import-rib [ inet.0 inet.3 ];
import-policy allow-lo0;
}
inet3to0 {
import-rib [ inet.3 inet.0 ];
import-policy add-noexport;
}
}
}
protocols {
isis {
level 1 disable;
interface ge-0/0/3.0;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface ge-0/0/3.0;
}
bgp {
path-selection external-router-id;
group toAs2RR {
type internal;
local-address 10.2.2.5;
family inet {
labeled-unicast {
rib-group inet3to0;
add-path {
receive;
send {
path-count 4;
}
}
nexthop-resolution {
preserve-nexthop-hierarchy;
}
rib {
inet.3;
}
}
}
export [ nhs export-inet3 ];
neighbor 10.2.2.6;
}
group toAs4 {
peer-as 65004;
neighbor 192.168.0.0;
}
group toAs1PEs {
multihop {
no-nexthop-change;
}
local-address 10.2.2.5;
family inet {
unicast;
}
family inet-vpn {
unicast;
}
family inet6 {
unicast;
}
family inet6-vpn {
unicast;
}
export nhs;
peer-as 65001;
neighbor 10.1.1.1;
neighbor 10.1.1.2;
}
traceoptions {
file bgp.log size 100m;
flag state detail;
flag policy;
}
multipath;
}
ldp {
interface ge-0/0/3.0;
}
mpls {
label-switched-path toABR1-gold {
to 10.2.2.3;
}
label-switched-path toABR1-bronze {
to 10.2.2.3;
}
label-switched-path toABR2-gold {
to 10.2.2.4;
}
}
}
Configuración del dispositivo P1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo P1:
-
Configure las interfaces.
[edit interfaces] user@P1#set ge-0/0/1 description P1-to-RR1 user@P1#set ge-0/0/1 vlan-tagging user@P1#set ge-0/0/1 unit 0 vlan-id 100 user@P1#set ge-0/0/1 unit 0 family inet address 192.168.0.6/31 user@P1#set ge-0/0/1 unit 0 family iso user@P1#set ge-0/0/1 unit 0 family mpls user@P1#set ge-0/0/2 description P1-to-ABR1 user@P1#set ge-0/0/2 vlan-tagging user@P1#set ge-0/0/2 unit 0 vlan-id 100 user@P1#set ge-0/0/2 unit 0 family inet address 192.168.0.8/31 user@P1#set ge-0/0/2 unit 0 family iso user@P1#set ge-0/0/2 unit 0 family mpls user@P1#set ge-0/0/3 description P1-to-PE1 user@P1#set ge-0/0/3 vlan-tagging user@P1#set ge-0/0/3 unit 0 vlan-id 100 user@P1#set ge-0/0/3 unit 0 family inet address 192.168.0.5/31 user@P1#set ge-0/0/3 unit 0 family iso user@P1#set ge-0/0/3 unit 0 family mpls user@P1#set ge-0/0/4 description P1-to-ABR2 user@P1#set ge-0/0/4 vlan-tagging user@P1#set ge-0/0/4 unit 0 vlan-id 100 user@P1#set ge-0/0/4 unit 0 family inet address 192.168.0.10/31 user@P1#set ge-0/0/4 unit 0 family iso user@P1#set ge-0/0/4 unit 0 family mpls
-
Configure la interfaz de circuito cerrado.
[edit interfaces] user@P1#set lo0 unit 0 family inet address 10.2.2.8/32 user@P1#set lo0 unit 0 family iso address 49.0000.0000.aaaa.0008.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@P1#set policy-statement allow-lo0 term 1 from interface lo0.0 user@P1#set policy-statement allow-lo0 term 1 then accept user@P1#set policy-statement allow-lo0 term 2 then reject
-
Configure las opciones de enrutamiento.
[edit routing-options] user@P1#set router-id 10.2.2.8
-
Configure los protocolos ISIS, RSVP, LDP y MPLS en la interfaz.
[edit protocols] user@P1#set isis level 1 disable user@P1#set isis interface all user@P1#set isis export allow-lo0 user@P1#set isis topologies ipv6-unicast user@P1#set rsvp interface all user@P1#set ldp interface all user@P1#set mpls interface all
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description P1-to-RR1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.6/31;
}
family iso;
family mpls;
}
}
ge-0/0/2 {
description P1-to-ABR1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.8/31;
}
family iso;
family mpls;
}
}
ge-0/0/3 {
description P1-to-PE1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.5/31;
}
family iso;
family mpls;
}
}
ge-0/0/4 {
description P1-to-ABR2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.10/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.2.2.8/32;
}
family iso {
address 49.0000.0000.aaaa.0008.00;
}
}
}
}
policy-options {
policy-statement allow-lo0 {
term 1 {
from interface lo0.0;
then accept;
}
term 2 {
then reject;
}
}
}
routing-options {
router-id 10.2.2.8;
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
ldp {
interface all;
}
mpls {
interface all;
}
}
Configuración del dispositivo RR1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo RR1:
-
Configure las interfaces.
[edit interfaces] user@RR1#set ge-0/0/1 description RR1-to-P1 user@RR1#set ge-0/0/1 vlan-tagging user@RR1#set ge-0/0/1 unit 0 vlan-id 100 user@RR1#set ge-0/0/1 unit 0 family inet address 192.168.0.7/31 user@RR1#set ge-0/0/1 unit 0 family iso user@RR1#set ge-0/0/1 unit 0 family mpls
-
Configure la interfaz de circuito cerrado.
[edit interfaces] user@RR1#set lo0 unit 1 family inet address 10.2.2.6/32 user@RR1#set lo0 unit 1 family iso address 49.0000.0000.aaaa.0006.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@RR1#set policy-statement add-noexport term 1 then community add noexport user@RR1#set policy-statement allow-lo0 term 1 from interface lo0.1 user@RR1#set policy-statement allow-lo0 term 1 then accept user@RR1#set policy-statement allow-lo0 term 2 then reject user@RR1#set policy-statement export-inet3 term 1 from rib inet.3 user@RR1#set policy-statement export-inet3 term 1 then accept user@RR1#set policy-statement export-inet3 term 2 then reject user@RR1#set policy-statement pplb then load-balance per-packet user@RR1#set community noexport members no-export user@RR1#set community noexport members no-advertise
-
Configure las opciones de enrutamiento.
[edit routing-options] user@RR1#set forwarding-table export pplb user@RR1#set interface-routes rib-group inet inet0to3 user@RR1#set router-id 10.2.2.6 user@RR1#set autonomous-system 2 user@RR1#set rib-groups inet0to3 import-rib inet.0 user@RR1#set rib-groups inet0to3 import-rib inet.3 user@RR1#set rib-groups inet0to3 import-policy allow-lo0 user@RR1#set rib-groups inet3to0 import-rib inet.3 user@RR1#set rib-groups inet3to0 import-rib inet.0 user@RR1#set rib-groups inet3to0 import-rib inet6.3 user@RR1#set rib-groups inet3to0 import-policy add-noexport
-
Configure los protocolos ISIS, RSVP, LDP y MPLS en la interfaz.
[edit protocols] user@RR1#set isis level 1 disable user@RR1#set isis interface all user@RR1#set isis export allow-lo0 user@RR1#set isis topologies ipv6-unicast user@RR1#set rsvp interface all user@RR1#set ldp interface all user@RR1#set mpls interface all
-
Configure el BGP etiquetado como unidifusión para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols bgp] user@RR1#set path-selection external-router-id user@RR1#set group toAs2Reg2BNs type internal user@RR1#set group toAs2Reg2BNs family inet labeled-unicast rib-group inet3to0 user@RR1#set group toAs2Reg2BNs family inet labeled-unicast add-path receive user@RR1#set group toAs2Reg2BNs family inet labeled-unicast add-path send path-count 4 user@RR1#set group toAs2Reg2BNs family inet labeled-unicast rib inet.3 user@RR1#set group toAs2Reg2BNs export export-inet3 user@RR1#set group toAs2Reg2BNs neighbor 10.2.2.3 user@RR1#set group toAs2Reg2BNs neighbor 10.2.2.4 user@RR1#set group toAs2Reg2BNs neighbor 10.2.2.5 user@RR1#set traceoptions file bgp.log user@RR1#set traceoptions file size 100m user@RR1#set traceoptions flag state detail user@RR1#set traceoptions flag policy user@RR1#set local-address 10.2.2.6 user@RR1#set cluster 10.2.2.6
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show routing-optionsshow interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description RR1-to-P1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.7/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 1 {
family inet {
address 10.2.2.6/32;
}
family iso {
address 49.0000.0000.aaaa.0006.00;
}
}
}
}
policy-options {
policy-statement add-noexport {
term 1 {
then {
community add noexport;
}
}
}
policy-statement allow-lo0 {
term 1 {
from interface lo0.1;
then accept;
}
term 2 {
then reject;
}
}
policy-statement export-inet3 {
term 1 {
from rib inet.3;
then accept;
}
term 2 {
then reject;
}
}
policy-statement pplb {
then {
load-balance per-packet;
}
}
community noexport members [ no-export no-advertise ];
}
routing-options {
forwarding-table {
export pplb;
}
interface-routes {
rib-group inet inet0to3;
}
router-id 10.2.2.6;
autonomous-system 2;
rib-groups {
inet0to3 {
import-rib [ inet.0 inet.3 ];
import-policy allow-lo0;
}
inet3to0 {
import-rib [ inet.3 inet.0 inet6.3 ];
import-policy add-noexport;
}
}
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
bgp {
path-selection external-router-id;
group toAs2Reg2BNs {
type internal;
family inet {
labeled-unicast {
rib-group inet3to0;
add-path {
receive;
send {
path-count 4;
}
}
rib {
inet.3;
}
}
}
export export-inet3;
neighbor 10.2.2.3;
neighbor 10.2.2.4;
neighbor 10.2.2.5;
}
traceoptions {
file bgp.log size 100m;
flag state detail;
flag policy;
}
local-address 10.2.2.6;
cluster 10.2.2.6;
}
ldp {
interface all;
}
mpls {
interface all;
}
}
Configuración del dispositivo ABR1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo ABR1:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@ABR1#set ge-0/0/1 description ABR1-to-P2 user@ABR1#set ge-0/0/1 vlan-tagging user@ABR1#set ge-0/0/1 unit 0 vlan-id 100 user@ABR1#set ge-0/0/1 unit 0 family inet address 192.168.0.12/31 user@ABR1#set ge-0/0/1 unit 0 family iso user@ABR1#set ge-0/0/1 unit 0 family mpls user@ABR1#set ge-0/0/2 description ABR1-to-P1 user@ABR1#set ge-0/0/2 vlan-tagging user@ABR1#set ge-0/0/2 unit 0 vlan-id 100 user@ABR1#set ge-0/0/2 unit 0 family inet address 192.168.0.9/31 user@ABR1#set ge-0/0/2 unit 0 family iso user@ABR1#set ge-0/0/2 unit 0 family mpls
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@ABR1#set lo0 unit 0 family inet address 10.2.2.3/32 user@ABR1#set lo0 unit 0 family iso address 49.0000.0000.aaaa.0003.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@ABR1#set policy-statement allow-lo0 term 1 from interface lo0.0 user@ABR1#set policy-statement allow-lo0 term 1 then accept user@ABR1#set policy-statement allow-lo0 term 2 then reject user@ABR1#set policy-statement nhs term 1 from protocol bgp user@ABR1#set policy-statement nhs term 1 then next-hop self user@ABR1#set policy-statement nhs term 1 then accept user@ABR1#set policy-statement pplb then load-balance per-packet
-
Aplique una política de equilibrio de carga por flujo para habilitar la protección del tráfico.
[edit routing-options] user@ABR1#set forwarding-table export pplb user@ABR1#set router-id 10.2.2.3 user@ABR1#set autonomous-system 65002
-
Configure los protocolos ISIS, RSVP, MPLS y LDP en la interfaz.
[edit protocols] user@ABR1#set isis level 1 disable user@ABR1#set isis interface all user@ABR1#set isis export allow-lo0 user@ABR1#set isis topologies ipv6-unicast user@ABR1#set rsvp interface all user@ABR1#set ldp interface all user@ABR1#set mpls label-switched-path toASBR2-gold to 10.2.2.2 user@ABR1#set mpls label-switched-path toASBR1-bronze to 10.2.2.1 user@ABR1#set mpls label-switched-path toASBR2-bronze to 10.2.2.2 user@ABR1#set mpls interface all
-
Configure el BGP etiquetado como unidifusión para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols] user@ABR1#set bgp group toAs2RR type internal user@ABR1#set bgp group toAs2RR local-address 10.2.2.3 user@ABR1#set bgp group toAs2RR advertise-inactive user@ABR1#set bgp group toAs2RR family inet labeled-unicast add-path receive user@ABR1#set bgp group toAs2RR family inet labeled-unicast add-path send path-count 4 user@ABR1#set bgp group toAs2RR family inet labeled-unicast rib inet.3 user@ABR1#set bgp group toAs2RR export nhs user@ABR1#set bgp group toAs2RR cluster 10.2.2.3 user@ABR1#set bgp group toAs2RR neighbor 10.2.2.6 user@ABR1#set bgp group toAs2RR neighbor 10.2.2.7 user@ABR1#set bgp traceoptions file bgp.log user@ABR1#set bgp traceoptions file size 100m user@ABR1#set bgp traceoptions flag state detail user@ABR1#set bgp traceoptions flag policy
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show routing-optionsshow interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description ABR1-to-P2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.12/31;
}
family iso;
family mpls;
}
}
ge-0/0/2 {
description ABR1-to-P1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.9/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.2.2.3/32;
}
family iso {
address 49.0000.0000.aaaa.0003.00;
}
}
}
}
policy-options {
policy-statement allow-lo0 {
term 1 {
from interface lo0.0;
then accept;
}
term 2 {
then reject;
}
}
policy-statement nhs {
term 1 {
from protocol bgp;
then {
next-hop self;
accept;
}
}
}
policy-statement pplb {
then {
load-balance per-packet;
}
}
}
routing-options {
forwarding-table {
export pplb;
}
router-id 10.2.2.3;
autonomous-system 65002;
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
bgp {
group toAs2RR {
type internal;
local-address 10.2.2.3;
advertise-inactive;
family inet {
labeled-unicast {
add-path {
receive;
send {
path-count 4;
}
}
rib {
inet.3;
}
}
}
export nhs;
cluster 10.2.2.3;
neighbor 10.2.2.6;
neighbor 10.2.2.7;
}
traceoptions {
file bgp.log size 100m;
flag state detail;
flag policy;
}
}
ldp {
interface all;
}
mpls {
label-switched-path toASBR2-gold {
to 10.2.2.2;
}
label-switched-path toASBR1-bronze {
to 10.2.2.1;
}
label-switched-path toASBR2-bronze {
to 10.2.2.2;
}
interface all;
}
}
Configuración del dispositivo ABR2
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo ABR2:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@ABR2#set ge-0/0/2 description ABR2-to-P2 user@ABR2#set ge-0/0/2 vlan-tagging user@ABR2#set ge-0/0/2 unit 0 vlan-id 100 user@ABR2#set ge-0/0/2 unit 0 family inet address 192.168.0.14/31 user@ABR2#set ge-0/0/2 unit 0 family iso user@ABR2#set ge-0/0/2 unit 0 family mpls user@ABR2#set ge-0/0/4 description ABR2-to-P1 user@ABR2#set ge-0/0/4 vlan-tagging user@ABR2#set ge-0/0/4 unit 0 vlan-id 100 user@ABR2#set ge-0/0/4 unit 0 family inet address 192.168.0.11/31 user@ABR2#set ge-0/0/4 unit 0 family iso user@ABR2#set ge-0/0/4 unit 0 family mpls
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@ABR2#set lo0 unit 0 family inet address 2.2.2.4/32 user@ABR2#set lo0 unit 0 family iso address 49.0000.0000.aaaa.0004.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@ABR2#set policy-statement allow-lo0 term 1 from interface lo0.0 user@ABR2#set policy-statement allow-lo0 term 1 then accept user@ABR2#set policy-statement allow-lo0 term 2 then reject user@ABR2#set policy-statement nhs term 1 from protocol bgp user@ABR2#set policy-statement nhs term 1 then next-hop self user@ABR2#set policy-statement nhs term 1 then accept user@ABR2#set policy-statement pplb then load-balance per-packet
-
Aplique una política de equilibrio de carga por flujo para habilitar la protección del tráfico.
[edit routing-options] user@ABR2#set forwarding-table export pplb user@ABR2#set router-id 2.2.2.4 user@ABR2#set autonomous-system 2
-
Configure los protocolos ISIS, RSVP, MPLS y LDP en la interfaz.
[edit protocols] user@ABR2#set isis level 1 disable user@ABR2#set isis interface all user@ABR2#set isis export allow-lo0 user@ABR2#set isis topologies ipv6-unicast user@ABR2#set rsvp interface all user@ABR2#set ldp interface all user@ABR2#set mpls label-switched-path toASBR1-bronze to 2.2.2.1 user@ABR2#set mpls interface all
-
Configure el BGP etiquetado como unidifusión para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols] user@ABR2#set bgp group toAs2RR type internal user@ABR2#set bgp group toAs2RR local-address 2.2.2.4 user@ABR2#set bgp group toAs2RR advertise-inactive user@ABR2#set bgp group toAs2RR family inet labeled-unicast add-path receive user@ABR2#set bgp group toAs2RR family inet labeled-unicast add-path send path-count 4 user@ABR2#set bgp group toAs2RR family inet labeled-unicast rib inet.3 user@ABR2#set bgp group toAs2RR export nhs user@ABR2#set bgp group toAs2RR cluster 2.2.2.4 user@ABR2#set bgp group toAs2RR neighbor 2.2.2.6 user@ABR2#set bgp group toAs2RR neighbor 2.2.2.7 user@ABR2#set bgp traceoptions file bgp.log user@ABR2#set bgp traceoptions file size 100m user@ABR2#set bgp traceoptions flag state detail user@ABR2#set bgp traceoptions flag policy
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show routing-optionsshow interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/2 {
description ABR2-to-P2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.14/31;
}
family iso;
family mpls;
}
}
ge-0/0/4 {
description ABR2-to-P1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.11/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 2.2.2.4/32;
}
family iso {
address 49.0000.0000.aaaa.0004.00;
}
}
}
}
policy-options {
policy-statement allow-lo0 {
term 1 {
from interface lo0.0;
then accept;
}
term 2 {
then reject;
}
}
policy-statement nhs {
term 1 {
from protocol bgp;
then {
next-hop self;
accept;
}
}
}
policy-statement pplb {
then {
load-balance per-packet;
}
}
}
routing-options {
forwarding-table {
export pplb;
}
router-id 2.2.2.4;
autonomous-system 2;
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
bgp {
group toAs2RR {
type internal;
local-address 2.2.2.4;
advertise-inactive;
family inet {
labeled-unicast {
add-path {
receive;
send {
path-count 4;
}
}
rib {
inet.3;
}
}
}
export nhs;
cluster 2.2.2.4;
neighbor 2.2.2.6;
neighbor 2.2.2.7;
}
traceoptions {
file bgp.log size 100m;
flag state detail;
flag policy;
}
}
ldp {
interface all;
}
mpls {
label-switched-path toASBR1-bronze {
to 2.2.2.1;
}
interface all;
}
}
Configuración del dispositivo P2
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo P2:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@P2#set ge-0/0/1 description P2-to-ABR1 user@P2#set ge-0/0/1 vlan-tagging user@P2#set ge-0/0/1 unit 0 vlan-id 100 user@P2#set ge-0/0/1 unit 0 family inet address 192.168.0.13/31 user@P2#set ge-0/0/1 unit 0 family iso user@P2#set ge-0/0/1 unit 0 family mpls user@P2#set ge-0/0/2 description P2-to-ABR2 user@P2#set ge-0/0/2 vlan-tagging user@P2#set ge-0/0/2 unit 0 vlan-id 100 user@P2#set ge-0/0/2 unit 0 family inet address 192.168.0.15/31 user@P2#set ge-0/0/2 unit 0 family iso user@P2#set ge-0/0/2 unit 0 family mpls user@P2#set ge-0/0/3 description P2-to-RR2 user@P2#set ge-0/0/3 vlan-tagging user@P2#set ge-0/0/3 unit 0 vlan-id 100 user@P2#set ge-0/0/3 unit 0 family inet address 192.168.0.16/31 user@P2#set ge-0/0/3 unit 0 family iso user@P2#set ge-0/0/3 unit 0 family mpls user@P2#set ge-0/0/4 description P2-to-ASBR1 user@P2#set ge-0/0/4 vlan-tagging user@P2#set ge-0/0/4 unit 0 vlan-id 100 user@P2#set ge-0/0/4 unit 0 family inet address 192.168.0.18/31 user@P2#set ge-0/0/4 unit 0 family iso user@P2#set ge-0/0/4 unit 0 family mpls user@P2#set ge-0/0/5 description P2-to-ASBR2 user@P2#set ge-0/0/5 vlan-tagging user@P2#set ge-0/0/5 unit 0 vlan-id 100 user@P2#set ge-0/0/5 unit 0 family inet address 192.168.0.20/31 user@P2#set ge-0/0/5 unit 0 family iso user@P2#set ge-0/0/5 unit 0 family mpls
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@P2#set lo0 unit 0 family inet address 2.2.2.9/32 user@P2#set lo0 unit 0 family iso address 49.0000.0000.aaaa.0009.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@P2#set policy-statement allow-lo0 term 1 from interface lo0.0 user@P2#set policy-statement allow-lo0 term 1 then accept user@P2#set policy-statement allow-lo0 term 2 then reject
-
Configure las opciones de enrutamiento.
[edit routing-options] user@P2#set router-id 2.2.2.9
-
Configure los protocolos ISIS, RSVP, MPLS y LDP en la interfaz.
[edit protocols] user@P2#set isis level 1 disable user@P2#set isis interface all user@P2#set isis export allow-lo0 user@P2#set isis topologies ipv6-unicast user@P2#set rsvp interface all user@P2#set ldp interface all user@P2#set mpls interface all
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show routing-optionsshow interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/1 {
description P2-to-ABR1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.13/31;
}
family iso;
family mpls;
}
}
ge-0/0/2 {
description P2-to-ABR2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.15/31;
}
family iso;
family mpls;
}
}
ge-0/0/3 {
description P2-to-RR2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.16/31;
}
family iso;
family mpls;
}
}
ge-0/0/4 {
description P2-to-ASBR1;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.18/31;
}
family iso;
family mpls;
}
}
ge-0/0/5 {
description P2-to-ASBR2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.20/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 2.2.2.9/32;
}
family iso {
address 49.0000.0000.aaaa.0009.00;
}
}
}
}
policy-options {
policy-statement allow-lo0 {
term 1 {
from interface lo0.0;
then accept;
}
term 2 {
then reject;
}
}
}
routing-options {
router-id 2.2.2.9;
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
ldp {
interface all;
}
mpls {
interface all;
}
}
Configuración del dispositivo RR2
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de CLI.
Para configurar el dispositivo RR2:
-
Configure las interfaces para habilitar el transporte IP y MPLS.
[edit interfaces] user@RR2#set ge-0/0/3 description RR2-to-P2 user@RR2#set ge-0/0/3 vlan-tagging user@RR2#set ge-0/0/3 unit 0 vlan-id 100 user@RR2#set ge-0/0/3 unit 0 family inet address 192.168.0.17/31 user@RR2#set ge-0/0/3 unit 0 family iso user@RR2#set ge-0/0/3 unit 0 family mpls
-
Configure la interfaz de circuito cerrado que se utilizará como ID de enrutador e interfaz de terminación para las sesiones LDP y BGP.
[edit interfaces] user@RR2#set lo0 unit 1 family inet address 2.2.2.7/32 user@RR2#set lo0 unit 1 family iso address 49.0000.0000.aaaa.0007.00
-
Configure políticas de resolución de multirrutas para instalar múltiples rutas jerárquicas en PFE.
[edit policy-options] user@RR2#set policy-statement allow-lo0 term 1 from interface lo0.1 user@RR2#set policy-statement allow-lo0 term 1 then accept user@RR2#set policy-statement allow-lo0 term 2 then reject user@RR2#set policy-statement export-inet3 term 1 from rib inet.3 user@RR2#set policy-statement export-inet3 term 1 then accept user@RR2#set policy-statement export-inet3 term 2 then reject user@RR2#set policy-statement pplb then load-balance per-packet
-
Aplique una política de equilibrio de carga por flujo para habilitar la protección del tráfico.
[edit routing-options] user@RR2#set forwarding-table export pplb user@RR2#set interface-routes rib-group inet inet0to3 user@RR2#set router-id 2.2.2.7 user@RR2#set autonomous-system 2 user@RR2#set rib-groups inet0to3 import-rib inet.0 user@RR2#set rib-groups inet0to3 import-rib inet.3 user@RR2#set rib-groups inet0to3 import-policy allow-lo0
-
Configure los protocolos ISIS, RSVP, MPLS y LDP en la interfaz.
[edit protocols] user@RR2#set isis level 1 disable user@RR2#set isis interface all user@RR2#set isis export allow-lo0 user@RR2#set isis topologies ipv6-unicast user@RR2#set rsvp interface all user@RR2#set ldp interface all user@RR2#set mpls interface all
-
Configure el BGP etiquetado como unidifusión para intercambiar direcciones IP de circuito cerrado como prefijos de unidifusión etiquetados con BGP.
[edit protocols] user@RR2#set bgp path-selection external-router-id user@RR2#set bgp group toAs2Reg1BNs type internal user@RR2#set bgp group toAs2Reg1BNs family inet labeled-unicast add-path receive user@RR2#set bgp group toAs2Reg1BNs family inet labeled-unicast add-path send path-count 4 user@RR2#set bgp group toAs2Reg1BNs family inet labeled-unicast rib inet.3 user@RR2#set bgp group toAs2Reg1BNs neighbor 2.2.2.1 user@RR2#set bgp group toAs2Reg1BNs neighbor 2.2.2.2 user@RR2#set bgp group toAs2Reg1BNs neighbor 2.2.2.3 user@RR2#set bgp group toAs2Reg1BNs neighbor 2.2.2.4 user@RR2#set bgp traceoptions file bgp.log user@RR2#set bgp traceoptions file size 100m user@RR2#set bgp traceoptions flag state detail user@RR2#set bgp traceoptions flag policy user@RR2#set bgp local-address 2.2.2.7 user@RR2#set bgp cluster 2.2.2.7
Resultados
Desde el modo de configuración, ingrese los comandos , y show protocols para confirmar la show routing-optionsshow interfacesshow policy-optionsconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
interfaces {
ge-0/0/3 {
description RR2-to-P2;
vlan-tagging;
unit 0 {
vlan-id 100;
family inet {
address 192.168.0.17/31;
}
family iso;
family mpls;
}
}
lo0 {
unit 1 {
family inet {
address 2.2.2.7/32;
}
family iso {
address 49.0000.0000.aaaa.0007.00;
}
}
}
}
policy-options {
policy-statement allow-lo0 {
term 1 {
from interface lo0.1;
then accept;
}
term 2 {
then reject;
}
}
policy-statement export-inet3 {
term 1 {
from rib inet.3;
then accept;
}
term 2 {
then reject;
}
}
policy-statement pplb {
then {
load-balance per-packet;
}
}
}
routing-options {
forwarding-table {
export pplb;
}
interface-routes {
rib-group inet inet0to3;
}
router-id 2.2.2.7;
autonomous-system 2;
rib-groups {
inet0to3 {
import-rib [ inet.0 inet.3 ];
import-policy allow-lo0;
}
}
}
protocols {
isis {
level 1 disable;
interface all;
export allow-lo0;
topologies ipv6-unicast;
}
rsvp {
interface all;
}
bgp {
path-selection external-router-id;
group toAs2Reg1BNs {
type internal;
family inet {
labeled-unicast {
add-path {
receive;
send {
path-count 4;
}
}
rib {
inet.3;
}
}
}
neighbor 2.2.2.1;
neighbor 2.2.2.2;
neighbor 2.2.2.3;
neighbor 2.2.2.4;
}
traceoptions {
file bgp.log size 100m;
flag state detail;
flag policy;
}
local-address 2.2.2.7;
cluster 2.2.2.7;
}
ldp {
interface all;
}
mpls {
interface all;
}
}
Verificación
Confirme que la configuración funcione correctamente.
- Verificar que los próximos saltos estén resueltos
- Comprobación de las entradas de próximo salto en la tabla de enrutamiento
Verificar que los próximos saltos estén resueltos
Propósito
Compruebe que los próximos saltos de PE2 y PE3 se resuelven en PE1.
Acción
Desde el modo operativo, ejecute el show route forwarding-table destination comando.
user@PE1> show route forwarding-table destination 10.3.3.3 extensive table default | match Weight
Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x4000
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
user@PE1> show route forwarding-table destination 10.3.3.3 extensive table red | match Weight
Weight: 0x1
Weight: 0x1
Next-hop interface: ge-0/0/3.0 Weight: 0x1
Weight: 0x4000
Weight: 0x4000
Next-hop interface: ge-0/0/3.0 Weight: 0x4000
Significado
Puede ver los pesos y 0x4000 los próximos saltos primarios 0x1 y de respaldo.
Comprobación de las entradas de próximo salto en la tabla de enrutamiento
Propósito
Compruebe las entradas activas de enrutamiento del próximo salto en PE1.
Acción
Desde el modo operativo, ejecute el show route extensive expanded-nh comando.
user@PE1> show route 10.3.3.3 extensive expanded-nh
inet.0: 36 destinations, 65 routes (36 active, 0 holddown, 0 hidden)
10.3.3.3/32 (2 entries, 1 announced)
Installed-nexthop:
List (0xd6ba4b8) Index:1048626
Indr (0xc593cac) 10.1.1.1
Krt_inh (0xcc14684) Index:1048614
List (0xc4cf7b4) Index:1048613
Frr_inh (0xc592730) Index:1048608
Chain (0xc59334c) Index:651 Push 300368
Router (0xc58ea40) Index:628 192.168.0.5 Push 299808
Frr_inh (0xc592604) Index:1048609
Chain (0xc5924d8) Index:649 Push 300384
Router (0xc58ea40) Index:628 192.168.0.5 Push 299808
Frr_inh (0xc592154) Index:1048611
Chain (0xc591bdc) Index:654 Push 300368
Router (0xc58ebd0) Index:629 192.168.0.5 Push 299824
Frr_inh (0xc5921b8) Index:1048612
Chain (0xc591a4c) Index:655 Push 300384
Router (0xc58ebd0) Index:629 192.168.0.5 Push 299824
Indr (0xc593ab8) 10.1.1.2
Krt_inh (0xcc14f84) Index:1048624
List (0xc4d0074) Index:1048623
Frr_inh (0xc5939f0) Index:1048619
Chain (0xc592ab4) Index:638 Push 300144
Router (0xc58ea40) Index:628 192.168.0.5 Push 299808
Frr_inh (0xc593a54) Index:1048620
Chain (0xc591efc) Index:637 Push 300160
Router (0xc58ea40) Index:628 192.168.0.5 Push 299808
Frr_inh (0xc59172c) Index:1048589
Chain (0xc5903a4) Index:640 Push 300144
Router (0xc58ebd0) Index:629 192.168.0.5 Push 299824
Frr_inh (0xc59159c) Index:1048590
Chain (0xc58fa44) Index:639 Push 300160
Router (0xc58ebd0) Index:629 192.168.0.5 Push 299824
TSI:
<SNIP>
Protocol next hop: 10.1.1.1
Indirect next hop: 0xcc14684 1048614 INH Session ID: 0x146 Weight 0x1
Protocol next hop: 10.1.1.2
Indirect next hop: 0xcc14f84 1048624 INH Session ID: 0x145 Weight 0x4000
State: >Active Ext>
Local AS: 65002 Peer AS: 65001
<SNIP>
Indirect next hops: 2
Protocol next hop: 10.1.1.1 Metric: 1
Indirect next hop: 0xcc14684 1048614 INH Session ID: 0x146 Weight 0x1
Indirect path forwarding next hops (Merged): 4
<SNIP>
Protocol next hop: 10.1.1.2 Metric: 1
Indirect next hop: 0xcc14f84 1048624 INH Session ID: 0x145 Weight 0x4000
Indirect path forwarding next hops (Merged): 4
Significado
Puede ver los pesos y 0x4000 los próximos saltos primarios 0x1 y de respaldo.
Descripción general de la compatibilidad con el pseudocable FAT para BGP, L2VPN y VPLS
Un pseudocable es un circuito o servicio de capa 2 que emula los atributos esenciales de un servicio de telecomunicaciones, como una línea T1, a través de una red conmutada por paquetes (PSN) MPLS. El seudocable está diseñado para proporcionar solo la funcionalidad mínima necesaria para emular el cable con los requisitos de resistencia necesarios para la definición de servicio dada.
En una red MPLS, el transporte consciente de flujo (FAT) de la etiqueta de flujo de pseudocables, como se describe en draft-keyupdate-l2vpn-fat-pw-bgp, se utiliza para equilibrar la carga del tráfico a través de pseudocables señalizados por BGP para la red privada virtual de capa 2 (L2VPN) y el servicio de LAN privada virtual (VPLS).
La etiqueta de flujo FAT solo se configura en los enrutadores de borde (LER) de la etiqueta. Esto hace que los enrutadores de tránsito o los enrutadores de conmutación de etiquetas (LSR) realicen el equilibrio de carga de los paquetes MPLS en rutas multirruta de igual costo (ECMP) o grupos de agregación de vínculos (LAG) sin la necesidad de una inspección profunda de paquetes de la carga útil.
La etiqueta de flujo FAT se puede usar para pseudocables de clase de equivalencia de reenvío señalizada con LDP (FEC 128 y FEC 129) para pseudocables VPWS y VPLS. El parámetro de interfaz (Sub-TLV) se utiliza para los pseudocables FEC 128 y FEC 129. El sub-TLV definido para LDP contiene los bits de transmisión (T) y recepción (R). El bit T anuncia la capacidad de insertar la etiqueta de flujo. El bit R anuncia la capacidad de extraer la etiqueta de flujo. De forma predeterminada, el comportamiento de señalización del enrutador perimetral del proveedor (PE) para cualquiera de estos pseudocables es anunciar los bits T y R de la etiqueta establecida en 0.
Las flow-label-transmit instrucciones de configuración and flow-label-receive proporcionan la capacidad de establecer el bit T y el anuncio del bit R en 1 en el campo Sub-TLV, que forma parte de los parámetros de interfaz de la FEC para el mensaje de asignación de etiquetas de LDP. Puede usar estas instrucciones para controlar la inserción de la etiqueta de equilibrio de carga y el anuncio de la etiqueta a los pares de enrutamiento en el plano de control para pseudocables señalizados por BGP como L2VPN y VPLS.
Ver también
Configuración de la compatibilidad con FAT Pseudowire para BGP L2VPN para equilibrar la carga del tráfico MPLS
El transporte consciente de flujo (FAT) o la etiqueta de flujo se admiten para pseudocables señalizados por BGP, como L2VPN, para configurarse solo en los enrutadores de borde de etiqueta (LER). Esto permite que los enrutadores de tránsito o los enrutadores de conmutación de etiquetas (LSR) realicen el equilibrio de carga de paquetes MPLS en rutas multirruta de igual costo (ECMP) o grupos de agregación de vínculos (LAG) sin la necesidad de una inspección profunda de paquetes de la carga útil. Los pseudocables FAT o la etiqueta de flujo se pueden usar con L2VPN con señalización LDP con clase de equivalencia de reenvío (FEC128 y FEC129), y la compatibilidad con la etiqueta de flujo se extiende para pseudocables con señalización BGP para servicios de capa 2 punto a punto o punto a multipunto.
Antes de configurar la compatibilidad con pseudocables FAT para BGP L2VPN para equilibrar la carga del tráfico MPLS:
Configure las interfaces de dispositivo y habilite MPLS en todas las interfaces.
Configure RSVP.
Configure MPLS y un LSP para el enrutador de PE remoto.
Configure BGP y OSPF.
Para configurar la compatibilidad con pseudocable FAT para BGP L2VPN a fin de equilibrar la carga del tráfico MPLS, debe hacer lo siguiente:
Ver también
Ejemplo: Configuración de la compatibilidad con FAT Pseudowire para BGP L2VPN para equilibrar la carga de tráfico MPLS
En este ejemplo, se muestra cómo implementar la compatibilidad con pseudocables FAT para BGP L2VPN para ayudar a equilibrar la carga del tráfico MPLS.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Cinco enrutadores de la serie MX
-
Junos OS versión 16.1 o posterior ejecutándose en todos los dispositivos
Antes de configurar la compatibilidad con pseudocables FAT para BGP L2VPN, asegúrese de configurar los protocolos de enrutamiento y señalización.
Descripción general
Junos OS permite que la etiqueta de flujo de transporte consciente de flujo (FAT) compatible con pseudocables señalizados por BGP, como L2VPN, se configure solo en los enrutadores de borde de etiqueta (LER). Esto hace que los enrutadores de tránsito o los enrutadores de conmutación de etiquetas (LSR) realicen el equilibrio de carga de paquetes MPLS en rutas multirruta de igual costo (ECMP) o grupos de agregación de vínculos (LAG) sin la necesidad de una inspección profunda de paquetes de la carga útil. La etiqueta de flujo FAT se puede usar para pseudocables de clase de equivalencia de reenvío señalizada con LDP (FEC 128 y FEC 129) para pseudocables VPWS y VPLS.
Topología
En la figura 15, se muestra la compatibilidad con el pseudocable FAT para BGP L2VPN configurado en los dispositivos PE1 y PE2.
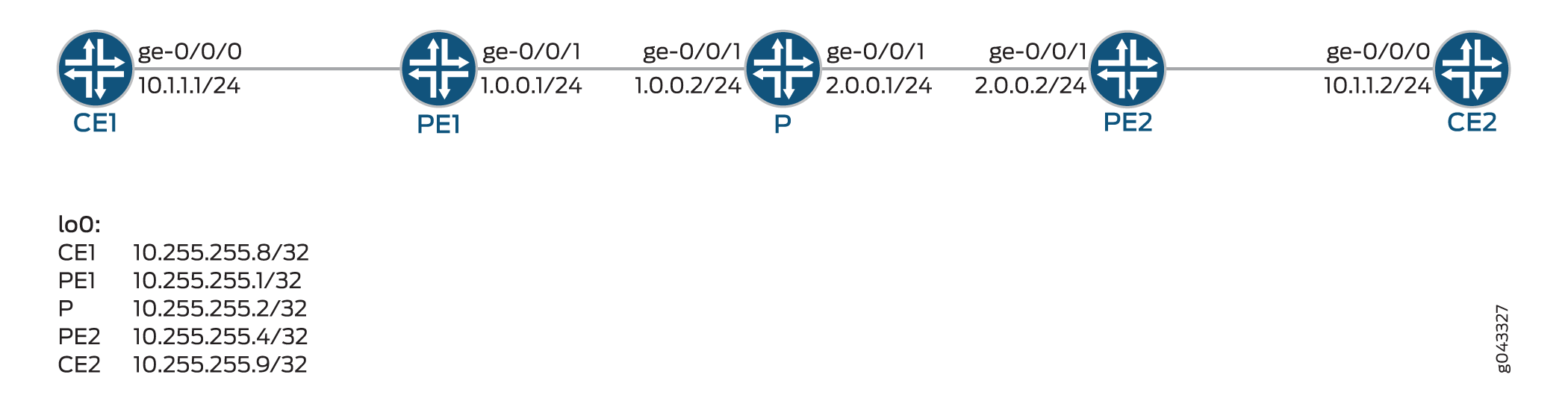
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese commit desde el [edit] modo de configuración.
CE1
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family inet address 10.1.1.1/24 set interfaces lo0 unit 0 family inet address 10.255.255.8/32
PE1
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 mtu 1600 set interfaces ge-0/0/0 encapsulation vlan-ccc set interfaces ge-0/0/0 unit 300 encapsulation vlan-ccc set interfaces ge-0/0/0 unit 300 vlan-id 600 set interfaces ge-0/0/0 unit 600 encapsulation vlan-vpls set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family vpls set interfaces ge-0/0/1 unit 0 family inet address 1.0.0.1/24 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.255.1/32 set routing-options nonstop-routing set routing-options router-id 10.255.255.1 set routing-options autonomous-system 100 set routing-options forwarding-table export exp-to-frwd set protocols rsvp interface all set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface lo0.0 set protocols mpls label-switched-path to-pe2 to 10.255.255.4 set protocols mpls interface ge-0/0/1.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.1 set protocols bgp group vpls-pe family l2vpn auto-discovery-only set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.4 set protocols bgp group vpls-pe neighbor 10.255.255.2 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 set policy-options policy-statement exp-to-frwd term 0 from community vpls-com set policy-options policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe2 set policy-options policy-statement exp-to-frwd term 0 then accept set policy-options community vpls-com members target:100:100 set routing-instances l2vpn-inst instance-type l2vpn set routing-instances l2vpn-inst interface ge-0/0/0.300 set routing-instances l2vpn-inst route-distinguisher 10.255.255.1:200 set routing-instances l2vpn-inst vrf-target target:100:100 set routing-instances l2vpn-inst protocols l2vpn encapsulation-type ethernet-vlan set routing-instances l2vpn-inst protocols l2vpn site pe1 site-identifier 1 set routing-instances l2vpn-inst protocols l2vpn site pe1 interface ge-0/0/0.300 remote-site-id 2 set routing-instances l2vpn-inst protocols l2vpn flow-label-transmit set routing-instances l2vpn-inst protocols l2vpn flow-label-receive set routing-instances vpl1 instance-type vpls set routing-instances vpl1 interface ge-0/0/0.600 set routing-instances vpl1 route-distinguisher 10.255.255.1:100 set routing-instances vpl1 vrf-target target:100:100 set routing-instances vpl1 protocols vpls site-range 10 set routing-instances vpl1 protocols vpls no-tunnel-services set routing-instances vpl1 protocols vpls site vpl1PE1 site-identifier 1 set routing-instances vpl1 protocols vpls flow-label-transmit set routing-instances vpl1 protocols vpls flow-label-receive
P
set interfaces ge-0/0/0 unit 0 family inet address 1.0.0.2/24 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 2.0.0.1/24 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.255.2/32 set routing-options router-id 10.255.255.2 set routing-options autonomous-system 100 set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface lo0.0 set protocols mpls interface ge-0/0/0.0 set protocols mpls interface ge-0/0/1.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.2 set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.1 set protocols bgp group vpls-pe neighbor 10.255.255.4 deactivate protocols bgp set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/1.0
PE2
set interfaces ge-0/0/0 unit 0 family inet address 2.0.0.2/24 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 mtu 1600 set interfaces ge-0/0/1 encapsulation vlan-ccc set interfaces ge-0/0/1 unit 300 encapsulation vlan-ccc set interfaces ge-0/0/1 unit 300 vlan-id 600 set interfaces ge-0/0/1 unit 600 encapsulation vlan-vpls set interfaces ge-0/0/1 unit 600 vlan-id 600 set interfaces ge-0/0/1 unit 600 family vpls set interfaces lo0 unit 0 family inet address 10.255.255.4/32 set routing-options router-id 10.255.255.4 set routing-options autonomous-system 100 set routing-options forwarding-table export exp-to-frwd set protocols rsvp interface all set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface lo0.0 set protocols mpls label-switched-path to-pe1 to 10.255.255.1 set protocols mpls interface ge-0/0/0.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.4 set protocols bgp group vpls-pe family l2vpn auto-discovery-only set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.1 set protocols bgp group vpls-pe neighbor 10.255.255.2 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set policy-options policy-statement exp-to-frwd term 0 from community vpls-com set policy-options policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe1 set policy-options policy-statement exp-to-frwd term 0 then accept set policy-options community vpls-com members target:100:100 set routing-instances l2vpn-inst instance-type l2vpn set routing-instances l2vpn-inst interface ge-0/0/1.300 set routing-instances l2vpn-inst route-distinguisher 10.255.255.4:200 set routing-instances l2vpn-inst vrf-target target:100:100 set routing-instances l2vpn-inst protocols l2vpn encapsulation-type ethernet-vlan set routing-instances l2vpn-inst protocols l2vpn site pe2 site-identifier 2 set routing-instances l2vpn-inst protocols l2vpn site pe2 interface ge-0/0/1.300 remote-site-id 1 set routing-instances l2vpn-inst protocols l2vpn flow-label-transmit set routing-instances l2vpn-inst protocols l2vpn flow-label-receive set routing-instances vpl1 instance-type vpls set routing-instances vpl1 interface ge-0/0/1.600 set routing-instances vpl1 route-distinguisher 10.255.255.4:100 set routing-instances vpl1 vrf-target target:100:100 set routing-instances vpl1 protocols vpls site-range 10 set routing-instances vpl1 protocols vpls no-tunnel-services set routing-instances vpl1 protocols vpls site vpl1PE2 site-identifier 2 set routing-instances vpl1 protocols vpls flow-label-transmit set routing-instances vpl1 protocols vpls flow-label-receive deactivate routing-instances vpl1
CE2
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family inet address 10.1.1.2/24 set interfaces lo0 unit 0 family inet address 10.255.255.9/32
Configuración de PE1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo PE1:
-
Configure las interfaces.
[edit interfaces] user@PE1# set ge-0/0/0 vlan-tagging user@PE1# set ge-0/0/0 mtu 1600 user@PE1# set ge-0/0/0 encapsulation vlan-ccc user@PE1# set ge-0/0/0 unit 300 encapsulation vlan-ccc user@PE1# set ge-0/0/0 unit 300 vlan-id 600 user@PE1# set ge-0/0/0 unit 600 encapsulation vlan-vpls user@PE1# set ge-0/0/0 unit 600 vlan-id 600 user@PE1# set ge-0/0/0 unit 600 family vpls deactivate interfaces ge-0/0/0 unit 600 user@PE1# set ge-0/0/1 unit 0 family inet address 1.0.0.1/24 user@PE1# set ge-0/0/1 unit 0 family mpls user@PE1# set lo0 unit 0 family inet address 10.255.255.1/32
-
Configure el enrutamiento sin paradas y configure el ID del enrutador.
[edit routing-options] user@PE1# set nonstop-routing user@PE1# set router-id 10.255.255.1
-
Configure el número del sistema autónomo (AS) y aplique la política a la tabla de reenvío del enrutador local con la instrucción exportar.
[edit routing-options] user@PE1# set autonomous-system 100 user@PE1# set forwarding-table export exp-to-frwd
-
Configure el protocolo RSVP en las interfaces.
[edit protocols rsvp] user@PE1# set interface all user@PE1# set interface ge-0/0/1.0 user@PE1# set interface lo0.0
-
Aplique los atributos de ruta conmutada por etiqueta al protocolo MPLS y configure la interfaz.
[edit protocols mpls] user@PE1# set label-switched-path to-pe2 to 10.255.255.4 user@PE1# set interface ge-0/0/1.0
-
Defina un grupo par y configure la dirección de la dirección del extremo local de la sesión del BGP para el grupo
vpls-pepar.[edit protocols bgp group vpls-pe] user@PE1# set type internal user@PE1# set local-address 10.255.255.1
-
Configure los atributos de la familia de protocolos para NLRI en las actualizaciones.
[edit protocols bgp group vpls-pe] user@PE1# set family l2vpn auto-discovery-only user@PE1# set family l2vpn signaling
-
Configure vecinos para el grupo
vpls-pepar .[edit protocols bgp group vpls-pe] user@PE1# set neighbor 10.255.255.4 user@PE1# set neighbor 10.255.255.2
-
Configure la ingeniería de tráfico y configure las interfaces del área OSPF 0.0.0.0.
[edit protocols ospf] user@PE1# set traffic-engineering user@PE1# set area 0.0.0.0 interface lo0.0 passive user@PE1# set area 0.0.0.0 interface ge-0/0/1.0
-
Configure la política de enrutamiento y la información de la comunidad del BGP.
[edit policy-options] user@PE1# set policy-statement exp-to-fwd term 0 from community vpls-com user@PE1# set policy-statement exp-to-fwd term 0 then install-nexthop lsp to-pe2 user@PE1# set policy-statement exp-to-fwd term 0 then accept user@PE1# set community vpls-com members target:100:100
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances l2vpn-inst] user@PE1# set instance-type l2vpn user@PE1# set interface ge-0/0/0.300
-
Configure el distinguidor de ruta, por ejemplo
l2vpn-inst, y configure la comunidad de destino de VRF.[edit routing-instances l2vpn-inst] user@PE1# set route-distinguisher 10.255.255.1:200 user@PE1# set vrf-target target:100:100
-
Configure el tipo de encapsulación necesaria para el protocolo L2VPN.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE1# set encapsulation-type ethernet-vlan
-
Configure los sitios conectados al equipo del proveedor.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE1# set site pe1 site-identifier 1 user@PE1# set site pe1 interface ge-0/0/0.300 remote-site-id 2
-
Configure el protocolo L2VPN para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para extraer la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad para insertar la etiqueta de flujo en la dirección de transmisión al PE remoto.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE1# set flow-label-transmit user@PE1# set flow-label-receive
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances vpl1] user@PE1# set instance-type vpls user@PE1# set interface ge-0/0/0.600
-
Configure el distinguidor de ruta, por ejemplo
vp1, y configure la comunidad de destino de VRF.[edit routing-instances vpl1] user@PE1# set route-distinguisher 10.255.255.1:100 user@PE1# set vrf-target target:100:100
-
Asigne el identificador de sitio máximo para el dominio VPLS.
[edit routing-instances vpl1 protocols vpls] user@PE1# set site-range 10
-
Configure para no usar los servicios de túnel para la instancia de VPLS y asigne un identificador de sitio al sitio conectado al equipo del proveedor.
[edit routing-instances vpl1 protocols vpls] user@PE1# set no-tunnel-services user@PE1# set site vpl1PE1 site-identifier 1
-
Configure el protocolo VPLS para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para hacer pasar la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad para insertar la etiqueta de flujo en la dirección de transmisión al PE remoto.
[edit routing-instances vpl1 protocols vpls] user@PE1# set flow-label-transmit user@PE1# set flow-label-receive
Resultados
Desde el modo de configuración, escriba los comandos , show protocols, show policy-optionsshow routing-instancesy show routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@PE1# show interfaces
ge-0/0/0 {
vlan-tagging;
mtu 1600;
encapsulation vlan-ccc;
unit 300 {
encapsulation vlan-ccc;
vlan-id 600;
}
unit 600 {
encapsulation vlan-vpls;
vlan-id 600;
family vpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 1.0.0.1/24;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.255.1/32;
}
}
}
user@PE1# show protocols
rsvp {
interface all;
interface ge-0/0/1.0;
interface lo0.0;
}
mpls {
label-switched-path to-pe2 {
to 10.255.255.4;
}
interface ge-0/0/1.0;
}
bgp {
group vpls-pe {
type internal;
local-address 10.255.255.1;
family l2vpn {
auto-discovery-only;
signaling;
}
neighbor 10.255.255.4;
neighbor 10.255.255.2;
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface lo0.0 {
passive;
}
interface ge-0/0/1.0;
}
}
user@PE1# show policy-options
policy-statement exp-to-frwd {
term 0 {
from community vpls-com;
then {
install-nexthop lsp to-pe2;
accept;
}
}
}
community vpls-com members target:100:100;
user@PE1# show routing-instances
l2vpn-inst {
instance-type l2vpn;
interface ge-0/0/0.300;
route-distinguisher 10.255.255.1:200;
vrf-target target:100:100;
protocols {
l2vpn {
encapsulation-type ethernet-vlan;
site pe1 {
site-identifier 1;
interface ge-0/0/0.300 {
remote-site-id 2;
}
}
flow-label-transmit;
flow-label-receive;
}
}
}
vpl1 {
instance-type vpls;
interface ge-0/0/0.600;
route-distinguisher 10.255.255.1:100;
vrf-target target:100:100;
protocols {
vpls {
site-range 10;
no-tunnel-services;
site vpl1PE1 {
site-identifier 1;
}
flow-label-transmit;
flow-label-receive;
}
}
}
user@PE1# show routing-options
nonstop-routing;
router-id 10.255.255.1;
autonomous-system 100;
forwarding-table {
export exp-to-frwd;
}
Verificación
Confirme que la configuración funcione correctamente.
- Verificar la información del resumen del BGP
- Comprobación de la información de conexiones L2VPN
- Verificación de las rutas
Verificar la información del resumen del BGP
Propósito
Compruebe la información de resumen del BGP.
Acción
Desde el modo operativo, introduzca el show bgp summary comando.
user@PE1> show bgp summary
Groups: 1 Peers: 2 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
bgp.l2vpn.0
1 1 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.255.255.2 100 0 0 0 0 2d 12:54:28 Active
10.255.255.4 100 8121 8093 0 0 2d 12:53:56 Establ
bgp.l2vpn.0: 1/1/1/0
l2vpn-inst.l2vpn.0: 1/1/1/0
Significado
El resultado muestra la información de resumen del BGP.
Comprobación de la información de conexiones L2VPN
Propósito
Compruebe la información de conexiones VPN de capa 2.
Acción
Desde el modo operativo, ejecute el show l2vpn connections comando para mostrar la información de conexiones VPN de capa 2.
user@PE1> show l2vpn connections
Layer-2 VPN connections:
Legend for connection status (St)
EI -- encapsulation invalid NC -- interface encapsulation not CCC/TCC/VPLS
EM -- encapsulation mismatch WE -- interface and instance encaps not same
VC-Dn -- Virtual circuit down NP -- interface hardware not present
CM -- control-word mismatch -> -- only outbound connection is up
CN -- circuit not provisioned <- -- only inbound connection is up
OR -- out of range Up -- operational
OL -- no outgoing label Dn -- down
LD -- local site signaled down CF -- call admission control failure
RD -- remote site signaled down SC -- local and remote site ID collision
LN -- local site not designated LM -- local site ID not minimum designated
RN -- remote site not designated RM -- remote site ID not minimum designated
XX -- unknown connection status IL -- no incoming label
MM -- MTU mismatch MI -- Mesh-Group ID not available
BK -- Backup connection ST -- Standby connection
PF -- Profile parse failure PB -- Profile busy
RS -- remote site standby SN -- Static Neighbor
LB -- Local site not best-site RB -- Remote site not best-site
VM -- VLAN ID mismatch
Legend for interface status
Up -- operational
Dn -- down
Instance: l2vpn-inst
Edge protection: Not-Primary
Local site: pe1 (1)
connection-site Type St Time last up # Up trans
2 rmt Up Jun 22 14:46:50 2015 1
Remote PE: 10.255.255.4, Negotiated control-word: Yes (Null)
Incoming label: 800003, Outgoing label: 800002
Local interface: ge-0/0/0.300, Status: Up, Encapsulation: VLAN
Flow Label Transmit: Yes, Flow Label Receive: Yes
Significado
El resultado muestra la información de conexiones VPN de capa 2 junto con la información de transmisión de la etiqueta de flujo y la información de recepción de la etiqueta de flujo.
Verificación de las rutas
Propósito
Compruebe que se han aprendido las rutas esperadas.
Acción
Desde el modo operativo, ejecute el show route comando para mostrar las rutas en la tabla de enrutamiento.
user@PE1> show route
inet.0: 51 destinations, 51 routes (51 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
1.0.0.0/24 *[Direct/0] 2d 12:48:34
> via ge-0/0/1.0
1.0.0.1/32 *[Local/0] 2d 12:48:34
Local via ge-0/0/1.0
2.0.0.0/24 *[OSPF/10] 2d 12:48:24, metric 2
> to 1.0.0.2 via ge-0/0/1.0
10.4.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.5.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.6.128.0/17 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.9.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.10.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.13.4.0/23 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.13.10.0/23 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.82.0.0/15 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.84.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.85.12.0/22 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.92.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.94.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.99.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.102.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.102.160.0/19 *[Direct/0] 2d 12:48:34
> via fxp0.0
10.102.169.99/32 *[Local/0] 2d 12:48:34
Local via fxp0.0
10.150.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.155.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.157.64.0/19 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.160.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.204.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.205.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.206.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.207.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.209.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.212.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.213.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.214.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.215.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.216.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.218.13.0/24 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.218.14.0/24 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.218.16.0/20 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.218.32.0/20 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.227.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
10.255.255.1/32 *[Direct/0] 2d 12:48:34
> via lo0.0
10.255.255.2/32 *[OSPF/10] 2d 12:48:24, metric 1
> to 1.0.0.2 via ge-0/0/1.0
10.255.255.4/32 *[OSPF/10] 2d 12:48:24, metric 2
> to 1.0.0.2 via ge-0/0/1.0
128.102.161.191/32 *[OSPF/10] 2d 12:48:24, metric 1
> to 1.0.0.2 via ge-0/0/1.0
128.102.169.99/32 *[Direct/0] 2d 12:48:34
> via lo0.0
128.102.171.41/32 *[OSPF/10] 2d 12:48:24, metric 2
> to 1.0.0.2 via ge-0/0/1.0
172.16.0.0/12 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
192.168.0.0/16 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
192.168.102.0/23 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
207.17.136.0/24 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
207.17.136.192/32 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
207.17.137.0/24 *[Static/5] 2d 12:48:34
> to 10.102.191.254 via fxp0.0
224.0.0.5/32 *[OSPF/10] 2d 12:48:34, metric 1
MultiRecv
inet.3: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.4/32 *[RSVP/7/1] 2d 12:48:04, metric 2
> to 1.0.0.2 via ge-0/0/1.0, label-switched-path to-pe2
iso.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
47.0005.80ff.f800.0000.0108.0001.1281.0216.9099/152
*[Direct/0] 2d 12:48:34
> via lo0.0
mpls.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0 *[MPLS/0] 2d 12:48:34, metric 1
Receive
1 *[MPLS/0] 2d 12:48:34, metric 1
Receive
2 *[MPLS/0] 2d 12:48:34, metric 1
Receive
13 *[MPLS/0] 2d 12:48:34, metric 1
Receive
800003 *[L2VPN/7] 2d 12:41:29
> via ge-0/0/0.300, Pop Offset: 4
ge-0/0/0.300 *[L2VPN/7] 2d 12:41:29, metric2 2
> to 1.0.0.2 via ge-0/0/1.0, label-switched-path to-pe2
inet6.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
abcd::128:102:169:99/128
*[Direct/0] 2d 12:48:34
> via lo0.0
fe80::5668:a60f:fc6b:eb97/128
*[Direct/0] 2d 12:48:34
> via lo0.0
bgp.l2vpn.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.4:200:2:1/96
*[BGP/170] 2d 12:41:35, localpref 100, from 10.255.255.4
AS path: I, validation-state: unverified
> to 1.0.0.2 via ge-0/0/1.0, label-switched-path to-pe2
l2vpn-inst.l2vpn.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.1:200:1:1/96
*[L2VPN/170/-101] 2d 12:41:29, metric2 1
Indirect
10.255.255.4:200:2:1/96
*[BGP/170] 2d 12:41:35, localpref 100, from 10.255.255.4
AS path: I, validation-state: unverified
> to 1.0.0.2 via ge-0/0/1.0, label-switched-path to-pe2
l2vpn-inst.l2id.0: 2 destinations, 3 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
1 *[L2VPN/170/-101] 2d 12:41:29, metric2 1
Indirect
[L2VPN/175] 2d 12:41:29
> via ge-0/0/0.300, Pop Offset: 4
2 *[BGP/170] 2d 12:41:35, localpref 100, from 10.255.255.4
AS path: I, validation-state: unverified
> to 1.0.0.2 via ge-0/0/1.0, label-switched-path to-pe2
Significado
El resultado muestra todas las rutas de la tabla de enrutamiento.
Configuración de PE2
Procedimiento
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo PE2:
-
Configure las interfaces.
[edit interfaces] user@PE2# set ge-0/0/0 unit 0 family inet address 2.0.0.2/24 user@PE2# set ge-0/0/0 unit 0 family mpls user@PE2# set ge-0/0/1 vlan-tagging user@PE2# set ge-0/0/1 mtu 1600 user@PE2# set ge-0/0/1 encapsulation vlan-ccc user@PE2# set ge-0/0/1 unit 300 encapsulation vlan-ccc user@PE2# set ge-0/0/1 unit 300 vlan-id 600 user@PE2# set ge-0/0/1 unit 600 encapsulation vlan-vpls user@PE2# set ge-0/0/1 unit 600 vlan-id 600 user@PE2# set ge-0/0/1 unit 600 family vpls deactivate interfaces ge-0/0/1 unit 600 user@PE2# set lo0 unit 0 family inet address 10.255.255.4/32
-
Configure el ID del enrutador.
[edit routing-options] user@PE2# set router-id 10.255.255.4
-
Configure el número del sistema autónomo (AS) y aplique la política a la tabla de reenvío del enrutador local con la instrucción exportar.
[edit routing-options] user@PE2# set autonomous-system 100 user@PE2# set forwarding-table export exp-to-frwd
-
Configure el protocolo RSVP en las interfaces.
[edit protocols rsvp] user@PE2# set interface all user@PE2# set interface ge-0/0/1.0 user@PE2# set interface lo0.0
-
Aplique los atributos de ruta conmutada por etiqueta al protocolo MPLS y configure la interfaz.
[edit protocols mpls] user@PE2# set label-switched-path to-pe1 to 10.255.255.1 user@PE2# set interface ge-0/0/0.0
-
Defina un grupo par y configure la dirección final local de la sesión del BGP para el grupo
vpls-pepar.[edit protocols bgp group vpls-pe] user@PE2# set type internal user@PE2# set local-address 10.255.255.4
-
Configure los atributos de la familia de protocolos para NLRI en las actualizaciones.
[edit protocols bgp group vpls-pe] user@PE2# set family l2vpn auto-discovery-only user@PE2# set family l2vpn signaling
-
Configure los vecinos para el grupo
vpls-pepar .[edit protocols bgp group vpls-pe] user@PE2# set neighbor 10.255.255.1 user@PE2# set neighbor 10.255.255.2
-
Configure la ingeniería de tráfico y configure las interfaces del área OSPF 0.0.0.0.
[edit protocols ospf] user@PE2# set traffic-engineering user@PE2# set area 0.0.0.0 interface lo0.0 passive user@PE2# set area 0.0.0.0 interface ge-0/0/0.0
-
Configure la política de enrutamiento y la información de la comunidad del BGP.
[edit policy-options] user@PE2# set policy-statement exp-to-frwd term 0 from community vpls-com user@PE2# set policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe1 user@PE2# set policy-statement exp-to-frwd term 0 then accept user@PE2# set community vpls-com members target:100:100
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances l2vpn-inst] user@PE2# set instance-type l2vpn user@PE2# set interface ge-0/0/1.300
-
Configure el distinguidor de ruta, por ejemplo
l2vpn-inst, y configure la comunidad de destino de VRF.[edit routing-instances l2vpn-inst] user@PE2# set route-distinguisher 10.255.255.4:200 user@PE2# set vrf-target target:100:100
-
Configure el tipo de encapsulación necesaria para el protocolo L2VPN.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE2# set encapsulation-type ethernet-vlan
-
Configure los sitios conectados al equipo del proveedor.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE2# set site pe2 site-identifier 2 user@PE2# set site pe2 interface ge-0/0/1.300 remote-site-id 1
-
Configure el protocolo L2VPN para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para extraer la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad para insertar la etiqueta de flujo en la dirección de transmisión al PE remoto.
[edit routing-instances l2vpn-inst protocols l2vpn] user@PE2# set flow-label-transmit user@PE2# set flow-label-receive
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances vpl1] user@PE2# set instance-type vpls user@PE2# set interface ge-0/0/1.600
-
Configure el distinguidor de ruta, por ejemplo
vpl1, y configure la comunidad de destino de VRF.[edit routing-instances vpl1] user@PE2# set route-distinguisher 10.255.255.4:100 user@PE2# set vrf-target target:100:100
-
Asigne el identificador de sitio máximo para el dominio VPLS.
[edit routing-instances vpl1 protocols vpls] user@PE2# set site-range 10
-
Configure para no usar los servicios de túnel para la instancia de VPLS y asigne un identificador de sitio al sitio conectado al equipo del proveedor.
[edit routing-instances vpl1 protocols vpls] user@PE2# set no-tunnel-services user@PE2# set site vpl1PE2 site-identifier 2
-
Configure el protocolo VPLS para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para extraer la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad a la etiqueta de flujo de inserción en la dirección de transmisión al PE remoto.
[edit routing-instances vpl1 protocols vpls] user@PE2# set flow-label-transmit user@PE2# set flow-label-receive
Resultados
Desde el modo de configuración, escriba los comandos , show protocols, show policy-optionsshow routing-instancesy show routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@PE2# show interfaces
ge-0/0/0 {
unit 0 {
family inet {
address 2.0.0.2/24;
}
family mpls;
}
}
ge-0/0/1 {
vlan-tagging;
mtu 1600;
encapsulation vlan-ccc;
unit 300 {
encapsulation vlan-ccc;
vlan-id 600;
}
unit 600 {
encapsulation vlan-vpls;
vlan-id 600;
family vpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.255.4/32;
}
}
}
user@PE2# show protocols
rsvp {
interface all;
interface ge-0/0/1.0;
interface lo0.0;
}
mpls {
label-switched-path to-pe1 {
to 10.255.255.1;
}
interface ge-0/0/0.0;
}
bgp {
group vpls-pe {
type internal;
local-address 10.255.255.4;
family l2vpn {
auto-discovery-only;
signaling;
}
neighbor 10.255.255.1;
neighbor 10.255.255.2;
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface lo0.0 {
passive;
}
interface ge-0/0/0.0;
}
}
user@PE2# show policy-options
policy-statement exp-to-frwd {
term 0 {
from community vpls-com;
then {
install-nexthop lsp to-pe1;
accept;
}
}
}
community vpls-com members target:100:100;
user@PE2# show routing-instances
l2vpn-inst {
instance-type l2vpn;
interface ge-0/0/1.300;
route-distinguisher 10.255.255.4:200;
vrf-target target:100:100;
protocols {
l2vpn {
encapsulation-type ethernet-vlan;
site pe2 {
site-identifier 2;
interface ge-0/0/1.300 {
remote-site-id 1;
}
}
flow-label-transmit;
flow-label-receive;
}
}
}
vpl1 {
instance-type vpls;
interface ge-0/0/1.600;
route-distinguisher 10.255.255.4:100;
vrf-target target:100:100;
protocols {
vpls {
site-range 10;
no-tunnel-services;
site vpl1PE2 {
site-identifier 2;
}
flow-label-transmit;
flow-label-receive;
}
}
}
user@PE2# show routing-options
router-id 10.255.255.4;
autonomous-system 100;
forwarding-table {
export exp-to-frwd;
}
Verificación
Confirme que la configuración funcione correctamente.
- Verificar la información del resumen del BGP
- Comprobación de la información de conexiones L2VPN
- Verificación de las rutas
Verificar la información del resumen del BGP
Propósito
Compruebe la información de resumen del BGP.
Acción
Desde el modo operativo, introduzca el show bgp summary comando.
user@PE2> show bgp summary
Groups: 1 Peers: 2 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
bgp.l2vpn.0
1 1 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
10.255.255.1 100 8090 8119 0 1 2d 12:53:15 Establ
bgp.l2vpn.0: 1/1/1/0
l2vpn-inst.l2vpn.0: 1/1/1/0
10.255.255.2 100 0 0 0 0 2d 14:14:49 Active
Significado
El resultado muestra la información de resumen del BGP.
Comprobación de la información de conexiones L2VPN
Propósito
Compruebe la información de conexiones VPN de capa 2.
Acción
Desde el modo operativo, ejecute el show l2vpn connections comando para mostrar la información de conexiones VPN de capa 2.
user@PE2> show l2vpn connections
Layer-2 VPN connections:
Legend for connection status (St)
EI -- encapsulation invalid NC -- interface encapsulation not CCC/TCC/VPLS
EM -- encapsulation mismatch WE -- interface and instance encaps not same
VC-Dn -- Virtual circuit down NP -- interface hardware not present
CM -- control-word mismatch -> -- only outbound connection is up
CN -- circuit not provisioned <- -- only inbound connection is up
OR -- out of range Up -- operational
OL -- no outgoing label Dn -- down
LD -- local site signaled down CF -- call admission control failure
RD -- remote site signaled down SC -- local and remote site ID collision
LN -- local site not designated LM -- local site ID not minimum designated
RN -- remote site not designated RM -- remote site ID not minimum designated
XX -- unknown connection status IL -- no incoming label
MM -- MTU mismatch MI -- Mesh-Group ID not available
BK -- Backup connection ST -- Standby connection
PF -- Profile parse failure PB -- Profile busy
RS -- remote site standby SN -- Static Neighbor
LB -- Local site not best-site RB -- Remote site not best-site
VM -- VLAN ID mismatch
Legend for interface status
Up -- operational
Dn -- down
Instance: l2vpn-inst
Edge protection: Not-Primary
Local site: pe2 (2)
connection-site Type St Time last up # Up trans
1 rmt Up Jun 22 14:46:50 2015 1
Remote PE: 10.255.255.1, Negotiated control-word: Yes (Null)
Incoming label: 800002, Outgoing label: 800003
Local interface: ge-0/0/1.300, Status: Up, Encapsulation: VLAN
Flow Label Transmit: Yes, Flow Label Receive: Yes
Significado
El resultado muestra la información de conexiones VPN de capa 2 junto con la información de transmisión de la etiqueta de flujo y la información de recepción de la etiqueta de flujo.
Verificación de las rutas
Propósito
Compruebe que se han aprendido las rutas esperadas.
Acción
Desde el modo operativo, ejecute el show route comando para mostrar las rutas en la tabla de enrutamiento.
user@PE2> show route
inet.0: 51 destinations, 51 routes (51 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
1.0.0.0/24 *[OSPF/10] 2d 14:09:33, metric 2
> to 2.0.0.1 via ge-0/0/0.0
2.0.0.0/24 *[Direct/0] 2d 14:10:18
> via ge-0/0/0.0
2.0.0.2/32 *[Local/0] 2d 14:10:20
Local via ge-0/0/0.0
10.4.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.5.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.6.128.0/17 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.9.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.10.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.13.4.0/23 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.13.10.0/23 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.82.0.0/15 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.84.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.85.12.0/22 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.92.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.94.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.99.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.102.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.102.160.0/19 *[Direct/0] 2d 14:12:18
> via fxp0.0
10.102.171.41/32 *[Local/0] 2d 14:12:18
Local via fxp0.0
10.150.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.155.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.157.64.0/19 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.160.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.204.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.205.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.206.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.207.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.209.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.212.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.213.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.214.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.215.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.216.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.218.13.0/24 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.218.14.0/24 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.218.16.0/20 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.218.32.0/20 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.227.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
10.255.255.1/32 *[OSPF/10] 2d 12:50:36, metric 2
> to 2.0.0.1 via ge-0/0/0.0
10.255.255.2/32 *[OSPF/10] 2d 14:09:33, metric 1
> to 2.0.0.1 via ge-0/0/0.0
10.255.255.4/32 *[Direct/0] 2d 14:11:51
> via lo0.0
128.102.161.191/32 *[OSPF/10] 2d 14:09:33, metric 1
> to 2.0.0.1 via ge-0/0/0.0
128.102.169.99/32 *[OSPF/10] 2d 12:50:36, metric 2
> to 2.0.0.1 via ge-0/0/0.0
128.102.171.41/32 *[Direct/0] 2d 14:12:18
> via lo0.0
172.16.0.0/12 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
192.168.0.0/16 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
192.168.102.0/23 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
207.17.136.0/24 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
207.17.136.192/32 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
207.17.137.0/24 *[Static/5] 2d 14:12:18
> to 10.102.191.254 via fxp0.0
224.0.0.5/32 *[OSPF/10] 2d 14:11:51, metric 1
MultiRecv
inet.3: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.1/32 *[RSVP/7/1] 2d 12:50:24, metric 2
> to 2.0.0.1 via ge-0/0/0.0, label-switched-path to-pe1
iso.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
47.0005.80ff.f800.0000.0108.0001.1281.0217.1041/152
*[Direct/0] 2d 14:12:18
> via lo0.0
mpls.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0 *[MPLS/0] 2d 14:11:51, metric 1
Receive
1 *[MPLS/0] 2d 14:11:51, metric 1
Receive
2 *[MPLS/0] 2d 14:11:51, metric 1
Receive
13 *[MPLS/0] 2d 14:11:51, metric 1
Receive
800002 *[L2VPN/7] 2d 12:43:43
> via ge-0/0/1.300, Pop Offset: 4
ge-0/0/1.300 *[L2VPN/7] 2d 12:43:43, metric2 2
> to 2.0.0.1 via ge-0/0/0.0, label-switched-path to-pe1
inet6.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
abcd::128:102:171:41/128
*[Direct/0] 2d 14:12:18
> via lo0.0
fe80::5668:a60f:fc6b:ee28/128
*[Direct/0] 2d 14:12:18
> via lo0.0
bgp.l2vpn.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.1:200:1:1/96
*[BGP/170] 2d 12:43:43, localpref 100, from 10.255.255.1
AS path: I, validation-state: unverified
> to 2.0.0.1 via ge-0/0/0.0, label-switched-path to-pe1
l2vpn-inst.l2vpn.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.255.255.1:200:1:1/96
*[BGP/170] 2d 12:43:43, localpref 100, from 10.255.255.1
AS path: I, validation-state: unverified
> to 2.0.0.1 via ge-0/0/0.0, label-switched-path to-pe1
10.255.255.4:200:2:1/96
*[L2VPN/170/-101] 2d 12:43:50, metric2 1
Indirect
l2vpn-inst.l2id.0: 2 destinations, 3 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
1 *[BGP/170] 2d 12:43:43, localpref 100, from 10.255.255.1
AS path: I, validation-state: unverified
> to 2.0.0.1 via ge-0/0/0.0, label-switched-path to-pe1
2 *[L2VPN/170/-101] 2d 12:43:50, metric2 1
Indirect
[L2VPN/175] 2d 12:43:43
> via ge-0/0/1.300, Pop Offset: 4
Significado
El resultado muestra todas las rutas de la tabla de enrutamiento.
Configuración de la compatibilidad con FAT Pseudowire para BGP VPLS para equilibrar la carga del tráfico MPLS
El transporte consciente de flujo (FAT) o la etiqueta de flujo se admiten para pseudocables señalizados por BGP, como VPLS, y solo deben configurarse en los enrutadores de borde de etiqueta (LER). Esto permite que los enrutadores de tránsito o los enrutadores de conmutación de etiquetas (LSR) realicen el equilibrio de carga de paquetes MPLS en multirrutas de igual costo (ECMP) o grupos de agregación de vínculos (LAG) sin la necesidad de una inspección profunda de paquetes de la carga útil. Los pseudocables FAT o la etiqueta de flujo se pueden usar con VPLS señalizada por LDP con clase de equivalencia de reenvío (FEC128 y FEC129), y la compatibilidad con la etiqueta de flujo se extiende para pseudocables señalizados por BGP para servicios de capa 2 punto a punto o punto a multipunto.
Antes de configurar la compatibilidad con pseudocables FAT para BGP VPLS para equilibrar la carga del tráfico MPLS:
Configure las interfaces de dispositivo y habilite MPLS en todas las interfaces.
Configure RSVP.
Configure MPLS y un LSP para el enrutador de PE remoto.
Configure BGP y OSPF.
Para configurar la compatibilidad con pseudocables FAT para BGP VPLS a fin de equilibrar la carga del tráfico MPLS, debe hacer lo siguiente:
Ver también
Ejemplo: Configuración de la compatibilidad con FAT Pseudowire para BGP VPLS para equilibrar la carga de tráfico MPLS
En este ejemplo, se muestra cómo implementar la compatibilidad con pseudocables FAT para BGP VPLS para ayudar a equilibrar la carga del tráfico MPLS.
Requisitos
En este ejemplo, se utilizan los siguientes componentes de hardware y software:
-
Cinco enrutadores de la serie MX
-
Junos OS versión 16.1 o posterior ejecutándose en todos los dispositivos
Antes de configurar la compatibilidad con pseudocables FAT para BGP VPLS, asegúrese de configurar los protocolos de enrutamiento y señalización.
Descripción general
Junos OS permite que la etiqueta de flujo de transporte consciente de flujo (FAT) compatible con pseudocables señalizados por BGP, como VPLS, se configure solo en los enrutadores de borde de etiqueta (LER). Esto hace que los enrutadores de tránsito o los enrutadores de conmutación de etiquetas (LSR) realicen un equilibrio de carga de paquetes MPLS en rutas multirruta de igual costo (ECMP) o grupos de agregación de vínculos (LAG) sin la necesidad de una inspección profunda de paquetes de la carga. La etiqueta de flujo FAT se puede usar para pseudocables de clase de equivalencia de reenvío señalizada con LDP (FEC 128 y FEC 129) para pseudocables VPWS y VPLS.
Topología
En la figura 16, se muestra la compatibilidad con pseudocables FAT para BGP VPLS configurado en los dispositivos PE1 y PE2.
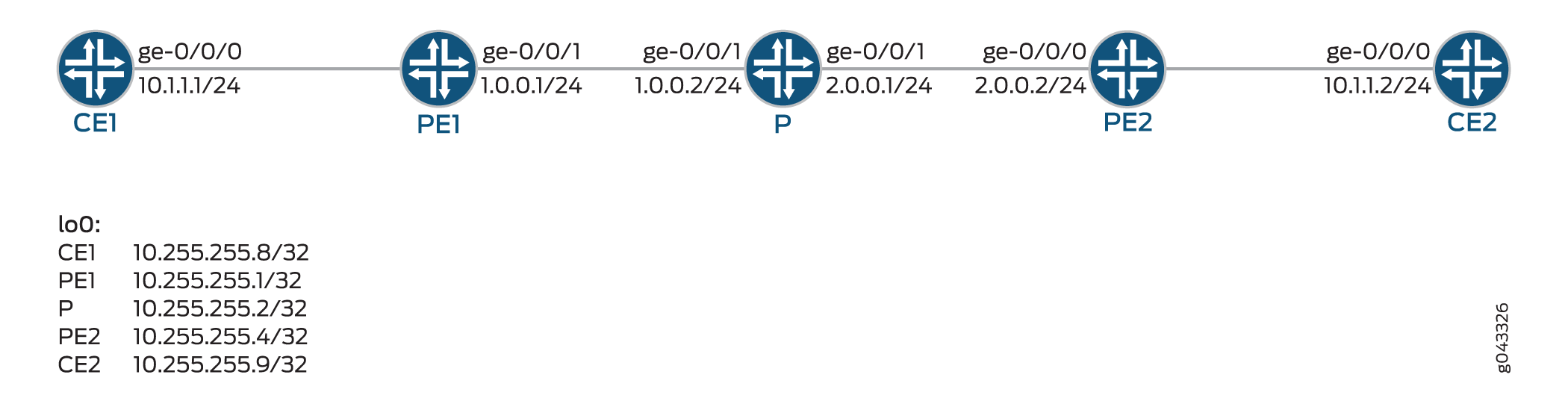
Configuración
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, luego, ingrese commit desde el [edit] modo de configuración.
CE1
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family inet address 10.1.1.1/24 set interfaces lo0 unit 0 family inet address 10.255.255.8/32
PE1
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 mtu 1600 set interfaces ge-0/0/0 encapsulation vlan-vpls set interfaces ge-0/0/0 unit 600 encapsulation vlan-vpls set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family vpls set interfaces ge-0/0/1 unit 0 family inet address 1.0.0.1/24 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.255.1/32 set routing-options nonstop-routing set routing-options router-id 10.255.255.1 set routing-options autonomous-system 100 set routing-options forwarding-table export exp-to-frwd set protocols rsvp interface all set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface lo0.0 set protocols mpls label-switched-path to-pe2 to 10.255.255.4 set protocols mpls interface ge-0/0/1.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.1 set protocols bgp group vpls-pe family l2vpn auto-discovery-only set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.4 set protocols bgp group vpls-pe neighbor 10.255.255.2 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/1.0 set policy-options policy-statement exp-to-frwd term 0 from community vpls-com set policy-options policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe2 set policy-options policy-statement exp-to-frwd term 0 then accept set policy-options community vpls-com members target:100:100 set routing-instances vpl1 instance-type vpls set routing-instances vpl1 interface ge-0/0/0.600 set routing-instances vpl1 route-distinguisher 10.255.255.1:100 set routing-instances vpl1 vrf-target target:100:100 set routing-instances vpl1 protocols vpls site-range 10 set routing-instances vpl1 protocols vpls no-tunnel-services set routing-instances vpl1 protocols vpls site vpl1PE1 site-identifier 1 set routing-instances vpl1 protocols vpls flow-label-transmit set routing-instances vpl1 protocols vpls flow-label-receive
P
set interfaces ge-0/0/0 unit 0 family inet address 1.0.0.2/24 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 unit 0 family inet address 2.0.0.1/24 set interfaces ge-0/0/1 unit 0 family mpls set interfaces lo0 unit 0 family inet address 10.255.255.2/32 set routing-options router-id 10.255.255.2 set routing-options autonomous-system 100 set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface ge-0/0/0.0 set protocols rsvp interface lo0.0 set protocols mpls interface ge-0/0/0.0 set protocols mpls interface ge-0/0/1.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.2 set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.1 set protocols bgp group vpls-pe neighbor 10.255.255.4 deactivate protocols bgp set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set protocols ospf area 0.0.0.0 interface ge-0/0/1.0
PE2
set interfaces ge-0/0/0 unit 0 family inet address 2.0.0.2/24 set interfaces ge-0/0/0 unit 0 family mpls set interfaces ge-0/0/1 vlan-tagging set interfaces ge-0/0/1 mtu 1600 set interfaces ge-0/0/1 encapsulation vlan-vpls set interfaces ge-0/0/1 unit 600 encapsulation vlan-vpls set interfaces ge-0/0/1 unit 600 vlan-id 600 set interfaces ge-0/0/1 unit 600 family vpls set interfaces lo0 unit 0 family inet address 10.255.255.4/32 set routing-options router-id 10.255.255.4 set routing-options autonomous-system 100 set routing-options forwarding-table export exp-to-frwd set protocols rsvp interface all set protocols rsvp interface ge-0/0/1.0 set protocols rsvp interface lo0.0 set protocols mpls label-switched-path to-pe1 to 10.255.255.1 set protocols mpls interface ge-0/0/0.0 set protocols bgp group vpls-pe type internal set protocols bgp group vpls-pe local-address 10.255.255.4 set protocols bgp group vpls-pe family l2vpn auto-discovery-only set protocols bgp group vpls-pe family l2vpn signaling set protocols bgp group vpls-pe neighbor 10.255.255.1 set protocols bgp group vpls-pe neighbor 10.255.255.2 set protocols ospf traffic-engineering set protocols ospf area 0.0.0.0 interface lo0.0 passive set protocols ospf area 0.0.0.0 interface ge-0/0/0.0 set policy-options policy-statement exp-to-frwd term 0 from community vpls-com set policy-options policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe1 set policy-options policy-statement exp-to-frwd term 0 then accept set policy-options community vpls-com members target:100:100 set routing-instances vpl1 instance-type vpls set routing-instances vpl1 interface ge-0/0/1.600 set routing-instances vpl1 route-distinguisher 10.255.255.4:100 set routing-instances vpl1 vrf-target target:100:100 set routing-instances vpl1 protocols vpls site-range 10 set routing-instances vpl1 protocols vpls no-tunnel-services set routing-instances vpl1 protocols vpls site vpl1PE2 site-identifier 2 set routing-instances vpl1 protocols vpls flow-label-transmit set routing-instances vpl1 protocols vpls flow-label-receive
CE2
set interfaces ge-0/0/0 vlan-tagging set interfaces ge-0/0/0 unit 600 vlan-id 600 set interfaces ge-0/0/0 unit 600 family inet address 10.1.1.2/24 set interfaces lo0 unit 0 family inet address 10.255.255.9/32
Configuración de PE1
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo PE1:
-
Configure las interfaces.
[edit interfaces] user@PE1# set ge-0/0/0 vlan-tagging user@PE1# set ge-0/0/0 mtu 1600 user@PE1# set ge-0/0/0 encapsulation vlan-vpls user@PE1# set ge-0/0/0 unit 600 encapsulation vlan-vpls user@PE1# set ge-0/0/0 unit 600 vlan-id 600 user@PE1# set ge-0/0/0 unit 600 family vpls user@PE1# set ge-0/0/1 unit 0 family inet address 1.0.0.1/24 user@PE1# set ge-0/0/1 unit 0 family mpls user@PE1# set lo0 unit 0 family inet address 10.255.255.1/32
-
Configure el enrutamiento sin paradas y configure el ID del enrutador.
[edit routing-options] user@PE1# set nonstop-routing user@PE1# set router-id 10.255.255.1
-
Configure el número del sistema autónomo (AS) y aplique la política a la tabla de reenvío del enrutador local con la instrucción exportar.
[edit routing-options] user@PE1# set autonomous-system 100 user@PE1# set forwarding-table export exp-to-frwd
-
Configure el protocolo RSVP en las interfaces.
[edit protocols rsvp] user@PE1# set interface all user@PE1# set interface ge-0/0/1.0 user@PE1# set interface lo0.0
-
Aplique los atributos de ruta conmutada por etiqueta al protocolo MPLS y configure la interfaz.
[edit protocols mpls] user@PE1# set label-switched-path to-pe2 to 10.255.255.4 user@PE1# set interface ge-0/0/1.0
-
Defina un grupo par y configure la dirección del extremo local de la sesión del BGP para el grupo
vpls-pepar.[edit protocols bgp group vpls-pe] user@PE1# set type internal user@PE1# set local-address 10.255.255.1
-
Configure los atributos de la familia de protocolos para NLRI en las actualizaciones.
[edit protocols bgp group vpls-pe family l2vpn] user@PE1# set auto-discovery-only user@PE1# set signaling
-
Configure vecinos para el grupo
vpls-pepar .[edit protocols bgp group vpls-pe] user@PE1# set neighbor 10.255.255.4 user@PE1# set neighbor 10.255.255.2
-
Configure la ingeniería de tráfico y configure las interfaces del área OSPF 0.0.0.0.
[edit protocols ospf] user@PE1# set traffic-engineering user@PE1# set area 0.0.0.0 interface lo0.0 passive user@PE1# set area 0.0.0.0 interface ge-0/0/1.0
-
Configure la política de enrutamiento y la información de la comunidad del BGP.
[edit policy-options ] user@PE1# set policy-statement exp-to-frwd term 0 from community vpls-com user@PE1# set policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe2 user@PE1# set policy-statement exp-to-frwd term 0 then accept user@PE1# set community vpls-com members target:100:100
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances vp1] user@PE1# set instance-type vpls user@PE1# set interface ge-0/0/0.600
-
Configure el distinguidor de ruta, por ejemplo
vpl1, y configure la comunidad de destino de VRF.[edit routing-instances vpl1] user@PE1# set route-distinguisher 10.255.255.1:100 user@PE1# set vrf-target target:100:100
-
Asigne el identificador de sitio máximo para el dominio VPLS.
[edit routing-instances vp1 protocols vpls] user@PE1# set site-range 10
-
Configure el protocolo VPLS para que no utilice los servicios de túnel para la instancia de VPLS y asigne el identificador de sitio al sitio conectado al equipo del proveedor.
[edit routing-instances vp1 protocols vpls] user@PE1# set no-tunnel-services user@PE1# set site vpl1PE1 site-identifier 1
-
Configure el protocolo VPLS para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para hacer pasar la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad para insertar la etiqueta de flujo en la dirección de transmisión al PE remoto.
[edit routing-instances vp1 protocols vpls] user@PE1# set flow-label-receive user@PE1# set flow-label-transmit
Resultados
Desde el modo de configuración, escriba los comandos , show protocols, show policy-optionsshow routing-instancesy show routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@PE1# show interfaces
ge-0/0/0 {
vlan-tagging;
mtu 1600;
encapsulation vlan-vpls;
unit 600 {
encapsulation vlan-vpls;
vlan-id 600;
family vpls;
}
}
ge-0/0/1 {
unit 0 {
family inet {
address 1.0.0.1/24;
}
family mpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.255.1/32;
}
}
}
user@PE1# show protocols
rsvp {
interface all;
interface ge-0/0/1.0;
interface lo0.0;
}
mpls {
label-switched-path to-pe2 {
to 10.255.255.4;
}
interface ge-0/0/1.0;
}
bgp {
group vpls-pe {
type internal;
local-address 10.255.255.1;
family l2vpn {
auto-discovery-only;
signaling;
}
neighbor 10.255.255.4;
neighbor 10.255.255.2;
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface lo0.0 {
passive;
}
interface ge-0/0/1.0;
}
}
user@PE1# show policy-options
policy-statement exp-to-frwd {
term 0 {
from community vpls-com;
then {
install-nexthop lsp to-pe2;
accept;
}
}
}
community vpls-com members target:100:100;
user@PE1# show routing-instances
vpl1 {
instance-type vpls;
interface ge-0/0/0.600;
route-distinguisher 10.255.255.1:100;
vrf-target target:100:100;
protocols {
vpls {
site-range 10;
no-tunnel-services;
site vpl1PE1 {
site-identifier 1;
}
flow-label-transmit;
flow-label-receive;
}
}
}
user@PE1# show routing-options
nonstop-routing;
router-id 10.255.255.1;
autonomous-system 100;
forwarding-table {
export exp-to-frwd;
}
Configuración de PE2
Procedimiento paso a paso
En el ejemplo siguiente, debe explorar por varios niveles en la jerarquía de configuración. Para obtener más información acerca de cómo navegar por la CLI, consulte Uso del editor de CLI en el modo de configuración de la Guía del usuario de la CLI de Junos OS.
Para configurar el dispositivo PE2:
-
Configure las interfaces.
[edit interfaces] user@PE2# set ge-0/0/0 unit 0 family inet address 2.0.0.2/24 user@PE2# set ge-0/0/0 unit 0 family mpls user@PE2# set ge-0/0/1 vlan-tagging user@PE2# set ge-0/0/1 mtu 1600 user@PE2# set ge-0/0/1 encapsulation vlan-vpls user@PE2# set ge-0/0/1 unit 600 encapsulation vlan-vpls user@PE2# set ge-0/0/1 unit 600 vlan-id 600 user@PE2# set ge-0/0/1 unit 600 family vpls user@PE2# set lo0 unit 0 family inet address 10.255.255.4/32
-
Configure el ID del enrutador.
[edit routing-options] user@PE2# set router-id 10.255.255.4
-
Configure el número del sistema autónomo (AS) y aplique la política a la tabla de reenvío del enrutador local con la instrucción exportar.
[edit routing-options] user@PE2# set autonomous-system 100 user@PE2# set forwarding-table export exp-to-frwd
-
Configure el protocolo RSVP en las interfaces.
[edit protocols rsvp] user@PE2# set interface all user@PE2# set interface ge-0/0/1.0 user@PE2# set interface lo0.0
-
Aplique los atributos de ruta conmutada por etiqueta al protocolo MPLS y configure la interfaz.
[edit protocols mpls] user@PE2# set label-switched-path to-pe1 to 10.255.255.1 user@PE2# set interface ge-0/0/0.0
-
Defina un grupo par y configure la dirección final local de la sesión del BGP para el grupo
vpls-pepar.[edit protocols bgp group vpls-pe] user@PE2# set type internal user@PE2# set local-address 10.255.255.4
-
Configure los atributos de la familia de protocolos para NLRI en las actualizaciones.
[edit protocols bgp group vpls-pe] user@PE2# set family l2vpn auto-discovery-only user@PE2# set family l2vpn signaling
-
Configure vecinos para el grupo
vpls-pepar .[edit protocols bgp group vpls-pe] user@PE2# set neighbor 10.255.255.1 user@PE2# set neighbor 10.255.255.2
-
Configure la ingeniería de tráfico y configure las interfaces del área OSPF 0.0.0.0.
[edit protocols ospf] user@PE2# set traffic-engineering user@PE2# set area 0.0.0.0 interface lo0.0 passive user@PE2# set area 0.0.0.0 interface ge-0/0/0.0
-
Configure la política de enrutamiento y la información de la comunidad del BGP.
[edit policy-options ] user@PE2# set policy-statement exp-to-frwd term 0 from community vpls-com user@PE2# set policy-statement exp-to-frwd term 0 then install-nexthop lsp to-pe1 user@PE2# set policy-statement exp-to-frwd term 0 then accept user@PE2# set community vpls-com members target:100:100
-
Configure el tipo de instancia de enrutamiento y configure la interfaz.
[edit routing-instances vpl1] user@PE2# set instance-type vpls user@PE2# set interface ge-0/0/1.600
-
Configure el distinguidor de ruta, por ejemplo
vp11, y configure la comunidad de destino de VRF.[edit routing-instances vpl1] user@PE2# set route-distinguisher 10.255.255.4:100 user@PE2# set vrf-target target:100:100
-
Asigne el identificador de sitio máximo para el dominio VPLS.
[edit routing-instances vpl1 protocols vpls] user@PE2# set site-range 10
-
Configure el protocolo VPLS para que no utilice los servicios de túnel para la instancia de VPLS y asigne el identificador de sitio al sitio conectado al equipo del proveedor.
[edit routing-instances vpl1 protocols vpls] user@PE2# set no-tunnel-services user@PE2# set site vpl1PE2 site-identifier 2
-
Configure el protocolo VPLS para la instancia de enrutamiento a fin de proporcionar capacidad de publicidad para hacer pasar la etiqueta de flujo en la dirección de recepción al PE remoto y para proporcionar capacidad de publicidad para insertar la etiqueta de flujo en la dirección de transmisión al PE remoto.
[edit routing-instances vpl1 protocols vpls] user@PE2# set flow-label-transmit user@PE2# set flow-label-receive
Resultados
Desde el modo de configuración, escriba los comandos , show protocols, show policy-optionsshow routing-instancesy show routing-options para confirmar la show interfacesconfiguración. Si el resultado no muestra la configuración deseada, repita las instrucciones de este ejemplo para corregirla.
user@PE2# show interfaces
ge-0/0/0 {
unit 0 {
family inet {
address 2.0.0.2/24;
}
family mpls;
}
}
ge-0/0/1 {
vlan-tagging;
mtu 1600;
encapsulation vlan-vpls;
unit 600 {
encapsulation vlan-vpls;
vlan-id 600;
family vpls;
}
}
lo0 {
unit 0 {
family inet {
address 10.255.255.4/32;
}
}
}
user@PE2# show protocols
rsvp {
interface all;
interface ge-0/0/1.0;
interface lo0.0;
}
mpls {
label-switched-path to-pe1 {
to 10.255.255.1;
}
interface ge-0/0/0.0;
}
bgp {
group vpls-pe {
type internal;
local-address 10.255.255.4;
family l2vpn {
auto-discovery-only;
signaling;
}
neighbor 10.255.255.1;
neighbor 10.255.255.2;
}
}
ospf {
traffic-engineering;
area 0.0.0.0 {
interface lo0.0 {
passive;
}
interface ge-0/0/0.0;
}
}
user@PE2# show policy-options
policy-statement exp-to-frwd {
term 0 {
from community vpls-com;
then {
install-nexthop lsp to-pe1;
accept;
}
}
}
community vpls-com members target:100:100;
user@PE2# show routing-instances
vpl1 {
instance-type vpls;
interface ge-0/0/1.600;
route-distinguisher 10.255.255.4:100;
vrf-target target:100:100;
protocols {
vpls {
site-range 10;
no-tunnel-services;
site vpl1PE2 {
site-identifier 2;
}
flow-label-transmit;
flow-label-receive;
}
}
}
user@PE2# show routing-options
router-id 10.255.255.4;
autonomous-system 100;
forwarding-table {
export exp-to-frwd;
}
Verificación
Confirme que la configuración funcione correctamente.
Verificación de la información de conexión VPLS
Propósito
Verifique la información de conexión VPLS.
Acción
Desde el modo operativo, ejecute el show vpls connections comando para mostrar la información de conexiones VPLS.
user@PE1> show vpls connections
Layer-2 VPN connections:
Legend for connection status (St)
EI -- encapsulation invalid NC -- interface encapsulation not CCC/TCC/VPLS
EM -- encapsulation mismatch WE -- interface and instance encaps not same
VC-Dn -- Virtual circuit down NP -- interface hardware not present
CM -- control-word mismatch -> -- only outbound connection is up
CN -- circuit not provisioned <- -- only inbound connection is up
OR -- out of range Up -- operational
OL -- no outgoing label Dn -- down
LD -- local site signaled down CF -- call admission control failure
RD -- remote site signaled down SC -- local and remote site ID collision
LN -- local site not designated LM -- local site ID not minimum designated
RN -- remote site not designated RM -- remote site ID not minimum designated
XX -- unknown connection status IL -- no incoming label
MM -- MTU mismatch MI -- Mesh-Group ID not available
BK -- Backup connection ST -- Standby connection
PF -- Profile parse failure PB -- Profile busy
RS -- remote site standby SN -- Static Neighbor
LB -- Local site not best-site RB -- Remote site not best-site
VM -- VLAN ID mismatch
Legend for interface status
Up -- operational
Dn -- down
Instance: vpl1
Edge protection: Not-Primary
Local site: vpl1PE1 (1)
connection-site Type St Time last up # Up trans
2 rmt Up Jun 17 11:38:14 2015 1
Remote PE: 10.255.255.4, Negotiated control-word: No
Incoming label: 262146, Outgoing label: 262145
Local interface: lsi.1048576, Status: Up, Encapsulation: VPLS
Description: Intf - vpls vpl1 local site 1 remote site 2
Flow Label Transmit: Yes, Flow Label Receive: Yes
Significado
El resultado muestra la información de conexión VPLS junto con la información de recepción de la etiqueta de flujo y la información de transmisión de la etiqueta de flujo.
Verificación
Confirme que la configuración funcione correctamente.
Verificación de la información de conexión VPLS
Propósito
Verifique la información de conexión VPLS.
Acción
Desde el modo operativo, ejecute el show vpls connections comando para mostrar la información de conexiones VPLS.
user@PE2> show vpls connections
Layer-2 VPN connections:
Legend for connection status (St)
EI -- encapsulation invalid NC -- interface encapsulation not CCC/TCC/VPLS
EM -- encapsulation mismatch WE -- interface and instance encaps not same
VC-Dn -- Virtual circuit down NP -- interface hardware not present
CM -- control-word mismatch -> -- only outbound connection is up
CN -- circuit not provisioned <- -- only inbound connection is up
OR -- out of range Up -- operational
OL -- no outgoing label Dn -- down
LD -- local site signaled down CF -- call admission control failure
RD -- remote site signaled down SC -- local and remote site ID collision
LN -- local site not designated LM -- local site ID not minimum designated
RN -- remote site not designated RM -- remote site ID not minimum designated
XX -- unknown connection status IL -- no incoming label
MM -- MTU mismatch MI -- Mesh-Group ID not available
BK -- Backup connection ST -- Standby connection
PF -- Profile parse failure PB -- Profile busy
RS -- remote site standby SN -- Static Neighbor
LB -- Local site not best-site RB -- Remote site not best-site
VM -- VLAN ID mismatch
Legend for interface status
Up -- operational
Dn -- down
Instance: vpl1
Edge protection: Not-Primary
Local site: vpl1PE2 (2)
connection-site Type St Time last up # Up trans
1 rmt Up Jun 17 11:38:14 2015 1
Remote PE: 10.255.255.1, Negotiated control-word: No
Incoming label: 262145, Outgoing label: 262146
Local interface: lsi.1048576, Status: Up, Encapsulation: VPLS
Description: Intf - vpls vpl1 local site 2 remote site 1
Flow Label Transmit: Yes, Flow Label Receive: Yes
Significado
El resultado muestra la información de conexión VPLS junto con la información de recepción de la etiqueta de flujo y la información de transmisión de la etiqueta de flujo.
Tabla de historial de cambios
La compatibilidad de la función depende de la plataforma y la versión que utilice. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.
[edit protocols bgp] el nivel de jerarquía. Puede deshabilitar selectivamente la multirruta en algunos grupos de BGP y vecinos. Incluir
disable en el
[edit protocols bgp group group-name multipath] nivel de jerarquía para deshabilitar la opción de multirruta para un grupo o un vecino de BGP específico.
defer-initial-multipath-build a
[edit protocols bgp] nivel de jerarquía. Como alternativa, puede reducir la prioridad del trabajo de compilación de multirruta del BGP utilizando
multipath-build-priority la instrucción de configuración en el
[edit protocols bgp] nivel de jerarquía para acelerar el aprendizaje de RIB.