Descripción de los clústeres lógicos dentro de un clúster de Junos Space
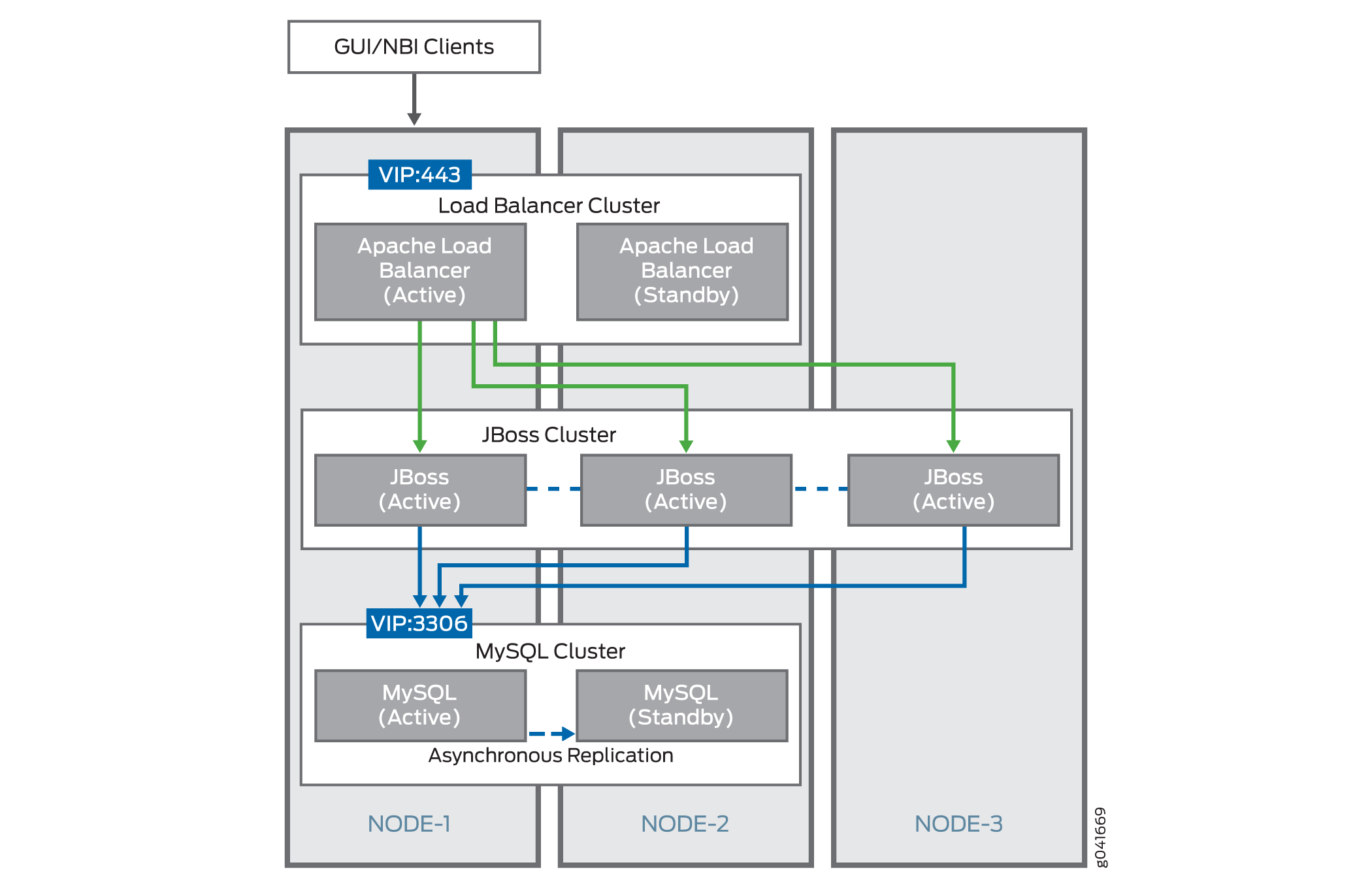
Puede conectar varios dispositivos virtuales Junos Space para formar un clúster de Junos Space. La figura 1 muestra los clústeres lógicos (clúster de Apache Load Balancer, clúster de JBoss y clúster de MySQL) que se forman dentro de cada clúster de Junos Space.
 Junos Space
Junos Space
Clúster de balanceador de carga de Apache
El servidor HTTP Apache, con el módulo de equilibrador de carga mod_proxy habilitado, se ejecuta en dos nodos del clúster en un momento dado. Estos servidores forman un clúster lógico de espera activa. Ambos escuchan en el puerto TCP 443 las solicitudes HTTP de los clientes GUI y NBI. Todos los clientes utilizan la dirección IP virtual (VIP) del clúster para acceder a sus servicios. En cualquier momento, la dirección VIP es propiedad de un solo nodo del clúster. Por lo tanto, el servidor HTTP Apache en el nodo que posee la dirección VIP recibe todas las solicitudes HTTP de los clientes GUI y NBI y actúa como el servidor activo del equilibrador de carga, mientras que el otro servidor actúa como el modo de espera. Se utiliza un algoritmo de equilibrio de carga por turnos para distribuir las solicitudes a los servidores JBoss que se ejecutan en todos los nodos del clúster. El equilibrador de carga también emplea adherencia a la sesión para garantizar que todas las solicitudes HTTP de una sesión de usuario se envíen al mismo nodo del clúster. Para lograr esto, el servidor establece una cookie llamada JSESSIONID. El valor de esta cookie identifica el nodo específico del clúster que atiende las solicitudes que pertenecen a esta sesión de usuario. Todas las solicitudes adicionales contienen esta cookie y el equilibrador de carga reenvía la solicitud al servidor de JBoss que se ejecuta en el nodo que identifica esta cookie.
Si el servidor HTTP Apache en un nodo deja de funcionar, el servicio de vigilancia de ese nodo lo reinicia automáticamente. Si este nodo posee la dirección VIP, los clientes GUI y NBI pueden experimentar una breve interrupción del servicio hasta que se reinicie el servidor HTTP Apache. Sin embargo, esta interrupción dura solo unos segundos (por lo general, dos segundos) y los clientes apenas la notan. Por otro lado, si el servidor HTTP Apache deja de funcionar en el nodo que actualmente no posee la dirección VIP, ningún cliente ni ningún otro componente notará efectos secundarios. El servicio de vigilancia reinicia el servidor y el servidor vuelve a funcionar en unos dos segundos.
Clúster de JBoss
El servidor de aplicaciones JBoss se ejecuta en todos los nodos excepto en los nodos de base de datos dedicados del clúster de Junos Space. Los nodos forman un único clúster lógico totalmente activo y el servidor equilibrador de carga (descrito anteriormente) distribuye la carga entre todos los nodos. Incluso si uno o más de los servidores JBoss del clúster fallan, la lógica de la aplicación sigue siendo accesible desde los nodos supervivientes. Los servidores JBoss de todos los nodos se inician con la misma configuración y utilizan multidifusión UDP para detectarse entre sí y formar un único clúster. JBoss también utiliza la multidifusión UDP para la replicación de sesiones y los servicios de almacenamiento en caché en todos los nodos.
El servidor JBoss no se ejecuta en nodos de supervisión de errores y rendimiento (FMPM) ni en máquinas virtuales alojadas.
Cuando el servidor de JBoss en un nodo deja de funcionar, otros nodos del clúster de JBoss detectan este cambio y se reconfiguran automáticamente para eliminar el nodo fallido del clúster. El tiempo que tardan otros miembros del clúster en detectar un servidor JBoss fallido depende de si el proceso del servidor JBoss se bloqueó de forma anormal o no responde. En el primer caso, los miembros del clúster detectan el fallo inmediatamente (alrededor de dos segundos) porque el sistema operativo cierra sus conexiones TCP con el servidor JBoss bloqueado. En este último caso, los miembros del clúster detectan el error en unos 52 segundos. Si un servidor JBoss se bloquea, el servidor JBoss se reinicia automáticamente mediante el servicio de vigilancia (jmp-watchdog) que se ejecuta en el nodo. Cuando el servidor JBoss vuelve a funcionar, el servidor JBoss es descubierto automáticamente por otros miembros del clúster y añadido al clúster. A continuación, el servidor JBoss sincroniza su caché desde los demás nodos del clúster. El tiempo de reinicio típico para el servidor JBoss es de dos a cinco minutos, pero puede tardar más tiempo dependiendo de la cantidad de aplicaciones instaladas, la cantidad de dispositivos que se administran, la cantidad de versiones de esquema DMI instaladas, etc.
Un servidor JBoss en el clúster siempre actúa como el principal del clúster. El objetivo principal de la designación principal es hospedar servicios que se implementan como singletons de todo el clúster (singletons de alta disponibilidad), por ejemplo, servicios que deben implementarse en un solo servidor del clúster en cualquier momento. Junos Space utiliza varios servicios de este tipo, incluido el servicio Sondeador de trabajos, que proporciona un temporizador único para programar trabajos en todo el clúster, y el servicio Administrador de recursos distribuidos (DRM), que supervisa y administra los nodos del clúster. Estos servicios solo se despliegan en el servidor JBoss designado como principal.
Esto no significa que el principal no aloje otros servicios. Los servicios singleton que no son de clúster también se alojan en el servidor principal. Junos Space está configurado de tal manera que el primer servidor JBoss que aparece en el clúster se convierte en el principal. Si el servidor principal deja de funcionar, otros miembros del clúster de JBoss lo detectan y eligen un nuevo principal.
Clúster de MySQL
El servidor MySQL se ejecuta en dos nodos del clúster de Junos Space en un momento dado. Estos nodos forman un clúster lógico de espera activa y ambos nodos escuchan en el puerto TCP 3306 las solicitudes de base de datos de los servidores JBoss. De forma predeterminada, los servidores de JBoss están configurados para utilizar la dirección IP virtual (VIP) del clúster para acceder a los servicios de base de datos. En cualquier momento, la dirección VIP es propiedad de un solo nodo del clúster. Por lo tanto, el servidor MySQL en el nodo que posee la dirección VIP recibe todas las solicitudes de base de datos del servidor JBoss, que actúa como el servidor de base de datos activo mientras que el otro servidor actúa como el modo de espera.
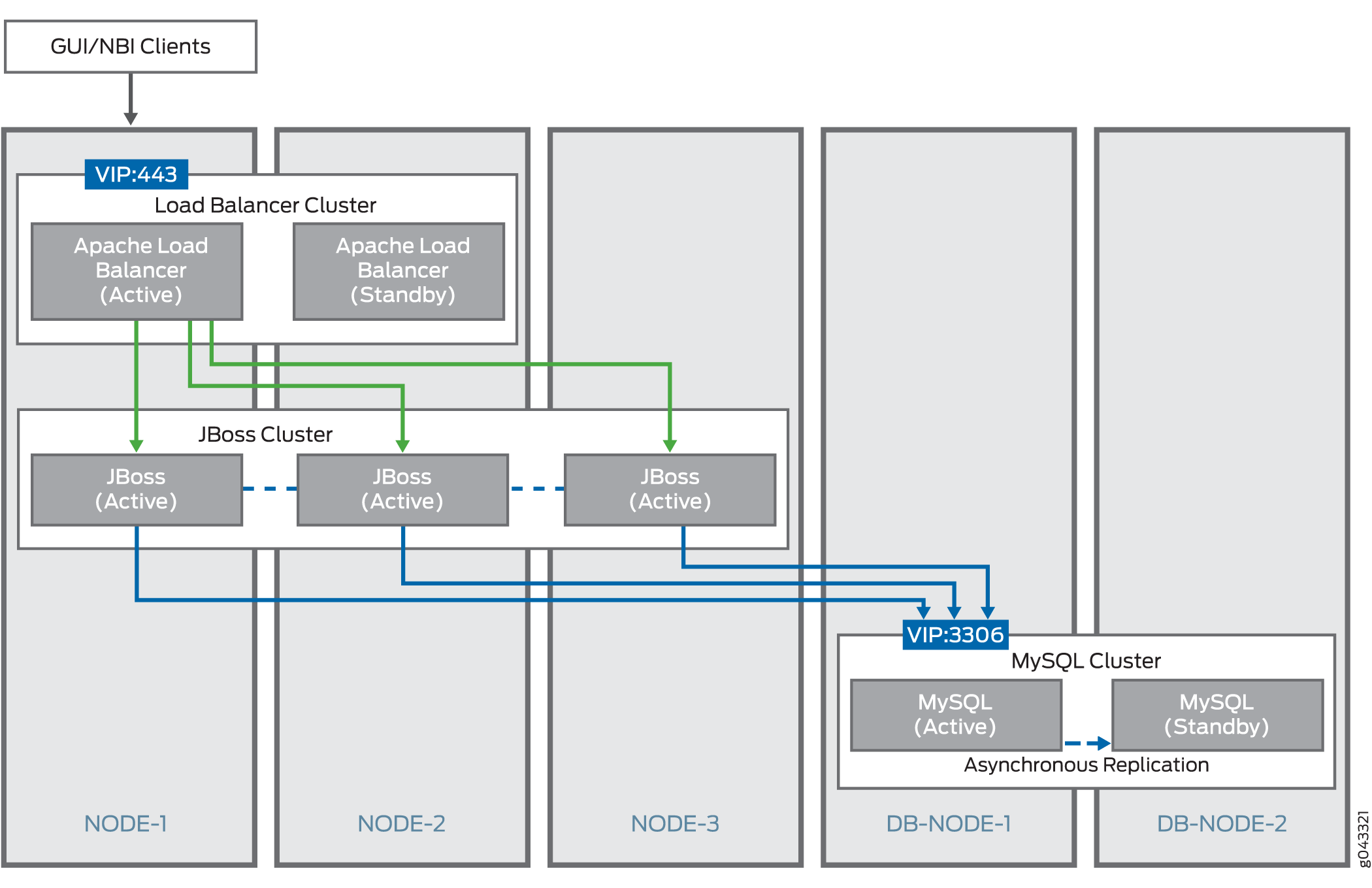
Si desea mejorar el rendimiento de la plataforma de administración de red de Junos Space y de las aplicaciones de Junos Space, puede agregar dos nodos de Junos Space para que se ejecuten como nodos de base de datos dedicados. Cuando se agregan dos nodos de Junos Space como nodos de base de datos principal y secundario, el servidor MySQL se mueve a los dos nodos de base de datos dedicados y se deshabilita en los dos primeros nodos del clúster de Junos Space. Esto libera recursos del sistema en el nodo VIP activo de Junos Space, lo que mejora el rendimiento del nodo.
Los servidores de JBoss utilizan una dirección IP virtual (VIP) de base de datos independiente para acceder a los servicios de base de datos en nodos de base de datos dedicados. La dirección VIP de la base de datos se especifica cuando se agregan nodos como nodos de base de datos dedicados al clúster de Junos Space. Esta dirección VIP es propiedad del nodo designado nodo principal de la base de datos. El servidor MySQL en el nodo de base de datos principal actúa como el servidor de base de datos activo, y el servidor en el nodo de base de datos secundario actúa como el modo de espera. La figura 2 muestra los clústeres lógicos (clúster de Apache Load Balancer, clúster de JBoss y clúster de MySQL) que se forman dentro de un clúster de Junos Space cuando se tienen nodos de base de datos dedicados como parte del clúster de Junos Space.
 de base de datos dedicados
de base de datos dedicados
Los servidores MySQL en cada uno de los nodos están configurados con ID de servidor únicos. La relación primario/copia de seguridad también se configura simétricamente en los nodos para que el servidor del primer nodo esté configurado con el segundo nodo como principal; y el servidor del segundo nodo está configurado con el primer nodo como principal. Por lo tanto, ambos nodos son capaces de actuar como una copia de seguridad para el otro, y el servidor que se ejecuta en el nodo que posee la dirección VIP actúa como principal en cualquier momento, lo que garantiza que la relación principal-copia de seguridad cambie dinámicamente a medida que la propiedad VIP cambia de un nodo a otro. Todas las transacciones confirmadas en el servidor activo (primario) se replican en el servidor en espera (copia de seguridad) casi en tiempo real, por medio de la solución de replicación asíncrona [2] proporcionada por MySQL, que se basa en el mecanismo de registro binario. El servidor MySQL que funciona como principal (el origen de los cambios en la base de datos) escribe actualizaciones y cambios como "eventos" en el registro binario. La información del registro binario se almacena en diferentes formatos de registro de acuerdo con los cambios de base de datos que se registran. El servidor de copia de seguridad está configurado para leer el registro binario del principal y ejecutar todos los eventos del registro binario en la base de datos local de la copia de seguridad.
Si el servidor MySQL en un nodo deja de funcionar, el servidor se reinicia automáticamente por el servicio de vigilancia en ese nodo. Cuando se reinicia, el servidor MySQL debe aparecer en 20 a 60 segundos. Si este nodo posee la dirección VIP, JBoss podría experimentar una breve interrupción de la base de datos durante estos 20 a 60 segundos de duración. Se produce un error en todas las solicitudes que requieren acceso a la base de datos durante este período. Por otro lado, si el servidor MySQL deja de funcionar en el nodo que actualmente no posee la dirección VIP, JBoss no observa efectos secundarios. El servicio de vigilancia reinicia el servidor y el servidor vuelve a funcionar en menos de un minuto. Después de realizar una copia de seguridad del servidor, se vuelve a sincronizar con el principal en segundo plano y el tiempo de resincronización depende del número de cambios que se produjeron durante la interrupción.
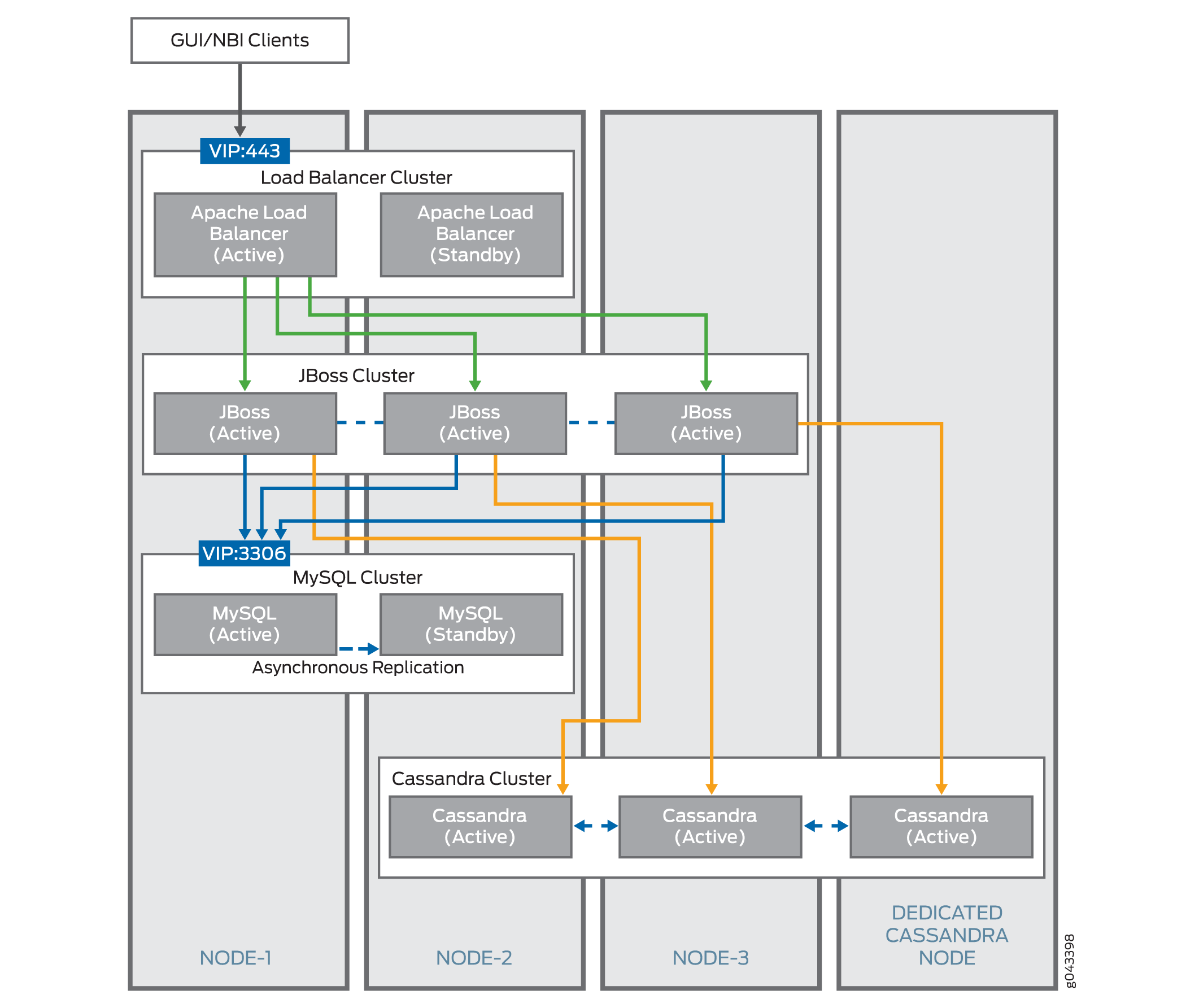
Clúster Cassandra
A partir de la versión 15.2R2, el clúster de Cassandra es un clúster lógico opcional que puede incluir en el clúster de Junos Space. El clúster de Cassandra se forma cuando hay dos o más nodos de Cassandra dedicados o dos o más nodos de JBoss con el servicio Cassandra en ejecución, o una combinación de ambos, dentro de la estructura de Junos Space. Puede optar por ejecutar el servicio Cassandra en ninguno o en todos los nodos de la estructura, excepto los nodos de base de datos dedicados y los nodos FMPM. El servicio Cassandra que se ejecuta en los nodos de Junos Space proporciona un sistema de archivos distribuido para almacenar imágenes de dispositivos y archivos de aplicaciones de Junos Space (como Juniper Message Bundle [JMB] generado por Service Now y archivos RRD generados por Network Director). Si no hay nodos de Cassandra en la estructura, los archivos de imagen de dispositivo y los archivos de aplicación de Junos Space se almacenan en la base de datos MySQL. La figura 3 muestra los clústeres lógicos (clúster de Apache Load Balancer, clúster de JBoss, clúster de MySQL y clúster de Cassandra) que se forman dentro de un clúster de Junos Space cuando se tienen nodos de Cassandra como parte del clúster de Junos Space.
 de Cassandra
de Cassandra
El servicio Cassandra se ejecuta en todos los nodos de Cassandra en una configuración activa-activa con replicación en tiempo real de la base de datos de Cassandra. Todos los archivos cargados en la base de datos de Cassandra se copian en todos los nodos del clúster de Cassandra. Los servidores de JBoss envían solicitudes a los nodos de Cassandra en el clúster de Cassandra de forma rotativa y acceden a los nodos utilizando la dirección IP (de la interfaz eth0) del nodo de Cassandra respectivo.
Si algún nodo de Cassandra deja de funcionar, Junos Space Platform no puede cargar ni eliminar archivos de la base de datos de Cassandra hasta que el nodo que está inactivo se elimine de la estructura. Si se eliminan todos los nodos de Cassandra existentes, los archivos almacenados en la base de datos de Cassandra se pierden.
Tabla de historial de cambios
La compatibilidad con las funciones viene determinada por la plataforma y la versión que esté utilizando. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.