EN ESTA PÁGINA
Descripción general de la recuperación ante desastres
Un clúster de Junos Space le permite mantener una alta disponibilidad y escalabilidad en su solución de administración de red. Sin embargo, dado que todos los nodos de un clúster deben estar dentro de la misma subred, normalmente se implementan en el mismo centro de datos o dentro del mismo campus. Sin embargo, puede recuperar fácilmente un clúster de un desastre en una ubicación reflejando la instalación original de Junos Space en un clúster a otro clúster en una ubicación geográficamente diferente. Por lo tanto, si el sitio principal de Junos Space falla debido a un desastre como un terremoto, el otro sitio puede tomar el control. Por lo tanto, la instalación física de la configuración de recuperación ante desastres suele ser un conjunto de dos clústeres geográficamente independientes: el sitio activo o principal (es decir, el sitio local) y el sitio en espera o de copia de seguridad (es decir, el sitio remoto).
Cuando se cumplen los requisitos y requisitos previos básicos de conectividad (consulte Requisitos previos para configurar la recuperación ante desastres y Requisitos de conectividad para configurar la recuperación ante desastres), los datos del clúster en el sitio activo se replican en el clúster en el sitio en espera casi en tiempo real.
Los datos de las bases de datos MySQL y PgSQL se replican de forma asincrónica desde el sitio activo al sitio en espera a través de una conexión SSL. Los datos MySQL y PgSQL entre los sitios de recuperación ante desastres se cifran mediante certificados SSL autofirmados que se generan cuando se inicializa la recuperación ante desastres. El certificado raíz de CA, las CRL, los certificados de usuario, los scripts, las imágenes de dispositivo, los registros de auditoría archivados y la información sobre los trabajos programados se replican en el sitio en espera durante la replicación de datos en tiempo real en el sitio en espera. Los archivos de configuración y de base de datos por turnos (RRD) se sincronizan periódicamente mediante el protocolo de copia segura (SCP) del sitio activo al sitio en espera.
El organismo de control de recuperación ante desastres, un mecanismo integrado de Junos Space, supervisa la integridad de la replicación de bases de datos en todos los sitios. Todos los demás servicios (como JBoss, OpenNMS, Apache, etc.) no se ejecutan en el sitio en espera hasta que el sitio activo conmuta por error al sitio en espera. Una conmutación por error al sitio en espera se inicia automáticamente cuando el sitio activo está inactivo. Se utiliza un algoritmo de arbitraje de dispositivos para determinar qué sitio debe ser el sitio activo para evitar un escenario de cerebro dividido en el que ambos sitios intenten estar activos. Para obtener información acerca del algoritmo de arbitraje de dispositivos, consulte Detección de errores mediante el algoritmo de arbitraje de dispositivos.
En las secciones siguientes se describen los requisitos de conectividad para el proceso de recuperación ante desastres, los mecanismos de detección de errores y los comandos de recuperación ante desastres:
Solución de recuperación ante desastres
Después de configurar e iniciar el proceso de recuperación ante desastres entre un sitio activo y un sitio en espera, se inicia la replicación asincrónica de bases de datos MySQL y PgSQL entre los sitios. Se realiza una copia de seguridad de los archivos de configuración y RRD en el sitio de espera a través de SCP en intervalos de tiempo definidos.
El proceso de recuperación ante desastres no realiza la replicación en tiempo real de la base de datos de Cassandra en el sitio en espera ni supervisa el servicio de Cassandra que se ejecuta en los nodos de Junos Space.
Durante el funcionamiento normal de la solución de recuperación ante desastres, los usuarios de la GUI y la API y los dispositivos administrados se conectan al sitio activo para todos los servicios de administración de red. La conectividad entre el sitio en espera y los dispositivos administrados está deshabilitada mientras el sitio activo sea funcional. Cuando el sitio activo deja de estar disponible debido a un desastre, el sitio en espera pasa a estar operativo. En este momento, se inician todos los servicios del sitio en espera y se establece la conectividad entre el sitio en espera y los dispositivos administrados.
La figura 1 muestra la solución de recuperación ante desastres.
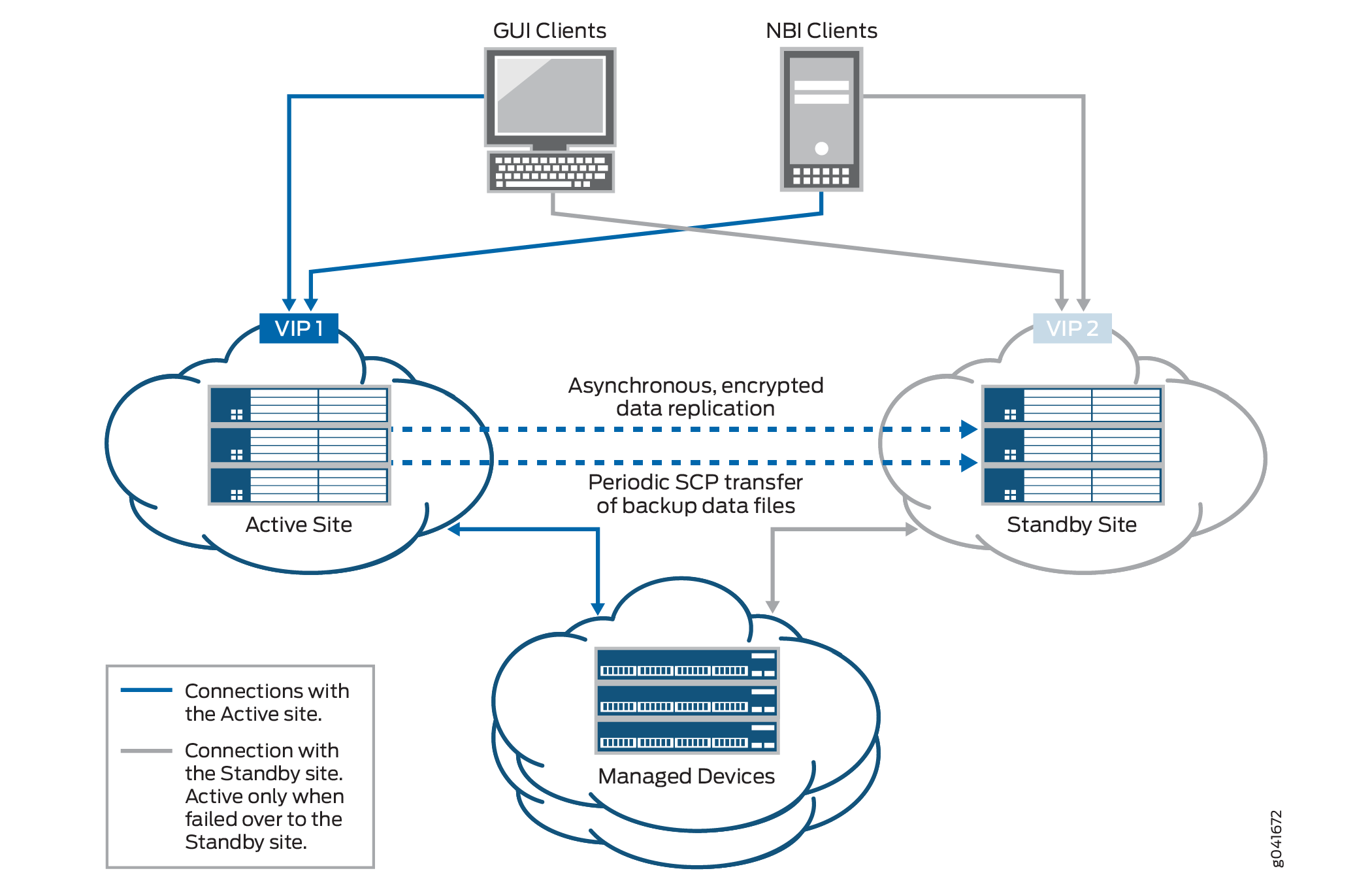 de recuperación ante desastres
de recuperación ante desastres
El proceso de vigilancia de recuperación ante desastres se inicia en el nodo VIP de los sitios activos y en espera para supervisar el estado del proceso de replicación y detectar cuándo el sitio remoto deja de funcionar. El organismo de control de recuperación ante desastres del sitio local comprueba si hay problemas de conectividad entre ambos sitios (haciendo ping a los nodos del sitio remoto) y si los sitios están conectados a dispositivos de árbitro (si utiliza el algoritmo de arbitraje de dispositivos).
El vigilante de recuperación ante desastres de un sitio realiza las siguientes tareas para confirmar la conectividad con el sitio remoto y los dispositivos del árbitro:
Haga ping a la dirección VIP del sitio remoto en un intervalo configurable regular. El valor predeterminado para el intervalo es 30 segundos.
Para cada ping, espere una respuesta dentro de un intervalo de tiempo de espera configurable. El valor predeterminado para el intervalo de tiempo de espera es de 5 segundos.
Si el sitio local no recibe una respuesta dentro del intervalo de tiempo de espera, el vigilante de recuperación ante desastres vuelve a intentar el ping durante un número configurable de veces. De forma predeterminada, el número de reintentos es 4.
Si se produce un error en todos los reintentos, el organismo de control de recuperación ante desastres del sitio local concluye que no se puede acceder a la dirección VIP del sitio remoto.
Sin embargo, el organismo de control de recuperación ante desastres no concluye que el sitio remoto esté inactivo porque el sitio remoto puede estar cambiando la dirección VIP a un nodo en espera debido a un cambio local.
Para considerar la posibilidad de un cambio de dirección VIP, el organismo de control de recuperación ante desastres hace ping a las direcciones IP de los otros nodos del equilibrador de carga en el sitio remoto. Si el ping a cualquiera de los nodos recibe una respuesta, el organismo de control de recuperación ante desastres concluye que el sitio remoto sigue activo.
Si se produce un error en el ping a los nodos, el organismo de control de recuperación ante desastres no concluye que el sitio remoto esté inactivo. En cambio, el organismo de control de recuperación de desastres considera la posibilidad de problemas de conectividad entre los sitios. Ambos sitios intentarán activarse.
Para evitar que ambos sitios intenten activarse, el organismo de control de recuperación ante desastres inicia el algoritmo de arbitraje de dispositivos y determina si se requiere una conmutación por error.
Una conmutación por error solo se inicia si el porcentaje de dispositivos de árbitro administrados por el sitio activo cae por debajo del umbral de conmutación por error. A continuación, el sitio activo se convierte en el sitio en espera y el sitio en espera se convierte en el sitio activo.
Si el porcentaje de dispositivos de árbitro está por encima del umbral de conmutación por error, el sitio en espera permanece en espera y el sitio activo permanece activo. El porcentaje de dispositivos árbitros administrados por el sitio activo es configurable y su valor predeterminado es 50%.
La conmutación por error se inicia si se cumplen las condiciones siguientes:
El sitio en espera no puede alcanzar la dirección VIP del sitio activo ni las direcciones IP de nodo de otros nodos del equilibrador de carga del sitio activo.
El porcentaje de dispositivos de árbitro administrados por el sitio activo está por debajo del umbral de conmutación por error.
Para obtener más información acerca del algoritmo de arbitraje de dispositivos, consulte Detección de errores mediante el algoritmo de arbitraje de dispositivos.
Requisitos previos para configurar la recuperación ante desastres
Debe asegurarse de que la instalación de Junos Space cumple los siguientes requisitos previos antes de configurar la recuperación ante desastres:
El clúster de Junos Space en el sitio principal o activo (que puede ser un solo nodo o varios nodos) y el clúster en el sitio remoto o en espera (que puede ser un solo nodo o varios nodos) deben configurarse exactamente de la misma manera, con las mismas aplicaciones, adaptadores de dispositivo, mismas configuraciones de familia IP, y así sucesivamente.
Ambos clústeres deben configurarse con información del servidor SMTP de la interfaz de usuario de Junos Space. Para obtener más información, consulte Administración de servidores SMTP. Esta configuración permite que los clústeres tanto del sitio activo como del sitio en espera notifiquen al administrador por correo electrónico si se produce un error en las replicaciones.
El número de nodos en el sitio activo y en el sitio en espera debe ser el mismo.
Requisitos de conectividad para configurar la recuperación ante desastres
Debe asegurarse de que la solución de recuperación ante desastres cumple los siguientes requisitos de conectividad antes de configurar la recuperación ante desastres:
Conectividad de capa 3 entre los clústeres de Junos Space en los sitios activo y en espera. Esto significa:
Cada nodo de un clúster puede hacer ping correctamente a la dirección VIP del otro clúster
Cada nodo de un clúster puede utilizar SCP para transferir archivos entre los sitios activos y en espera
La replicación de bases de datos en los dos clústeres es posible a través de los puertos TCP 3306 (replicación de bases de datos MySQL) y 5432 (replicación de bases de datos PostgreSQL)
El ancho de banda y la latencia de la conexión entre los dos clústeres son tales que la replicación de la base de datos en tiempo real se realiza correctamente. Aunque el ancho de banda exacto requerido depende de la cantidad de datos transferidos, recomendamos un mínimo de una conexión de ancho de banda de 100 Mbps con una latencia de menos de 150 milisegundos.
Conectividad independiente de capa 3 entre cada clúster y los dispositivos administrados
Conectividad independiente de capa 3 entre cada clúster y los clientes GUI o NBI
Para configurar el proceso de recuperación ante desastres, consulte Configuración del proceso de recuperación ante desastres entre un sitio activo y uno en espera.
Organismo de Control de Recuperación de Desastres
El guardián de recuperación ante desastres, también conocido como perro guardián de recuperación ante desastres, es un mecanismo integrado de Junos Space para supervisar la integridad de la replicación de datos (base de datos MySQL, base de datos PgSQL, archivos de configuración y archivos RRD) en todos los sitios. El organismo de control de recuperación ante desastres también supervisa el estado general de la configuración de recuperación ante desastres, inicia una conmutación por error desde el sitio activo al sitio en espera cuando se produce un error en el sitio activo, y permite que el sitio en espera reanude los servicios de administración de red con una interrupción mínima del servicio. Se inicia una instancia del vigilante de recuperación ante desastres en el nodo VIP de ambos sitios cuando se inicia el proceso de recuperación ante desastres.
El organismo de control de recuperación ante desastres proporciona los siguientes servicios:
- Latido
- mysqlMonitor
- pgsqlMonitor
- fileMonitor
- arbiterMonitor
- configMonitor
- serviceMonitor
- Notificación
Latido
El servicio de latido entre los sitios activos y en espera usa ping para comprobar la conectividad entre los sitios. Ambos sitios se envían mensajes de latido entre sí. El servicio de latidos realiza las siguientes tareas:
Detecte un error en el sitio remoto haciendo ping al sitio remoto a intervalos regulares.
Si el sitio remoto no responde, descarte la posibilidad de un problema temporal debido a una conmutación por error local en el sitio remoto.
Habilite o deshabilite la conmutación por error automática en función de las opciones de configuración de recuperación ante desastres.
Evite escenarios de cerebro dividido ejecutando el algoritmo de arbitraje de dispositivos (predeterminado) o la lógica configurada en el script personalizado.
Compruebe la configuración de recuperación ante desastres después de reiniciar un sitio.
mysqlMonitor
El servicio mysqlMonitor realiza las siguientes tareas:
Supervise el estado de la replicación de la base de datos MySQL dentro del sitio y entre los sitios activos y en espera.
Corregir errores de replicación de bases de datos MySQL.
Notifique al administrador por correo electrónico si alguno de los errores de replicación de la base de datos MySQL no se puede corregir automáticamente.
pgsqlMonitor
El servicio pgsqlMonitor realiza las siguientes tareas:
Supervise el estado de la replicación de la base de datos PgSQL dentro del sitio y entre los sitios activos y en espera.
Corregir errores de replicación de bases de datos PgSQL.
Notifique al administrador por correo electrónico si alguno de los errores de replicación de la base de datos PgSQL no se puede corregir automáticamente.
fileMonitor
El servicio fileMonitor realiza las siguientes tareas:
Supervise el estado de los archivos de configuración y RRD replicados dentro de los sitios y entre los sitios activos y en espera.
Corregir errores encontrados durante la replicación de archivos de configuración y archivos RRD.
Notifique al administrador por correo electrónico si alguno de los errores de replicación no se puede corregir automáticamente. También puede ver los errores de replicación en la salida del trabajo cron.
arbiterMonitor
El servicio arbiterMonitor comprueba periódicamente si el sitio local puede hacer ping a todos los dispositivos árbitros. Si el porcentaje de dispositivos árbitros accesibles cae por debajo de un umbral de advertencia configurado (70%, de forma predeterminada), se envía una notificación por correo electrónico al administrador.
configMonitor
El servicio configMonitor realiza las siguientes tareas:
Supervise los archivos de configuración de recuperación ante desastres en todos los nodos de ambos sitios.
Transfiera los archivos de configuración entre nodos dentro de un sitio si los archivos no están sincronizados.
serviceMonitor
El servicio serviceMonitor realiza las siguientes tareas:
Supervise el estado de los servicios seleccionados (como jboss, jboss-dc, httpd y dr-watchdog) dentro de un sitio específico.
Inicie o detenga los servicios seleccionados si muestran un estado incorrecto.
Notificación
El servicio de notificación notifica al administrador sobre condiciones de error, advertencias o cambios de estado de recuperación ante desastres detectados por el organismo de control de recuperación ante desastres a través del correo electrónico. Los correos electrónicos de notificación se envían si:
La conmutación por error automática se deshabilita debido a problemas de conectividad entre un sitio y los dispositivos del árbitro.
El porcentaje de dispositivos árbitros a los que se puede acceder es inferior al umbral de advertencia.
Un sitio se convierte en modo de espera o activo.
El sitio en espera no puede realizar copias de seguridad de los archivos del sitio activo a través de SCP.
Un sitio no puede establecer una conexión SSH con el sitio remoto.
El sitio local no puede obtener el nombre de host del nodo principal de MySQL.
Un sitio no puede corregir errores de replicación de bases de datos MySQL y PgSQL.
El servicio de notificación no envía correos electrónicos para informar de los mismos errores dentro de un período de tiempo configurable (de forma predeterminada, 3600 segundos).
Detección de errores mediante el algoritmo de arbitraje de dispositivos
Se utiliza un algoritmo de arbitraje de dispositivos para detectar fallas en un sitio. Se selecciona una lista de dispositivos altamente accesibles que ejecutan Junos OS y que son administrados por Junos Space Platform como dispositivos árbitros. Le recomendamos que seleccione los dispositivos de árbitro en función de los siguientes criterios:
Debe poder llegar a los dispositivos árbitros a través de conexiones SSH iniciadas por Junos Space desde ambos sitios. No seleccione dispositivos que utilicen conexiones iniciadas por dispositivos a la plataforma Junos Space.
Debe poder hacer ping a los dispositivos de árbitro desde ambos sitios de recuperación ante desastres.
Debe elegir dispositivos de árbitro que permanezcan conectados a la plataforma Junos Space o que se reinicien o apaguen con menos frecuencia, ya que esto puede afectar a los resultados del algoritmo de arbitraje del dispositivo. Si prevé que ciertos dispositivos arbitrales estarán fuera de línea durante alguna parte de sus vidas, evite elegir esos dispositivos.
Debe elegir dispositivos de árbitro de diferentes ubicaciones geográficas para asegurarse de que un problema en la red de administración en una ubicación no haga que todos los dispositivos de árbitro sean inaccesibles desde sus sitios.
No puede seleccionar dispositivos NAT y ww Junos OS como dispositivos árbitros.
El algoritmo de arbitraje de dispositivos en el sitio activo utiliza ping para conectarse a los dispositivos árbitros desde el sitio activo. El algoritmo de arbitraje de dispositivos en el sitio en espera inicia sesión en los dispositivos árbitros a través de conexiones SSH utilizando las credenciales de inicio de sesión de la base de datos de la plataforma Junos Space. A continuación, se muestran los flujos de trabajo del algoritmo de arbitraje de dispositivos en los sitios activos y en espera.
En el sitio activo:
Haga ping a todos los dispositivos árbitros seleccionados.
Calcule el porcentaje de dispositivos arbitrales a los que se puede hacer ping.
Compruebe si el porcentaje de dispositivos de árbitro a los que se puede hacer ping es superior o el mismo que el valor configurado del umbral de conmutación por error.
Si el porcentaje de dispositivos de árbitro conectados es superior o el mismo que el valor configurado del umbral de conmutación por error (parámetro failureDetection.threshold.failover en la sección de vigilancia de la API de recuperación ante desastres), la conmutación por error no se inicia porque el sitio activo administra la mayoría de los dispositivos del árbitro.
Si el porcentaje de dispositivos de árbitro está por debajo del valor configurado del umbral de conmutación por error, se inicia la conmutación por error (si la conmutación por error automática está habilitada) y el sitio activo pasa a estar en espera. Si la conmutación por error automática está deshabilitada, el sitio activo permanece activo.
En el lugar de espera:
Inicie sesión en los dispositivos de árbitro a través de conexiones SSH.
Ejecute un comando en cada dispositivo arbitral para recuperar la lista de conexiones SSH a cualquier nodo (administrado por el nodo) en el sitio activo.
Calcule el porcentaje de dispositivos árbitros administrados por el sitio activo.
Calcule el porcentaje de dispositivos árbitros a los que no se puede acceder a través de conexiones SSH.
Si el porcentaje de dispositivos de árbitro administrados por el sitio activo es superior o el mismo que el valor configurado del umbral de conmutación por error, no es necesaria la conmutación por error porque el sitio activo sigue administrando la mayoría de los dispositivos de árbitro.
Si el porcentaje de dispositivos de árbitro administrados por el sitio activo está por debajo del valor configurado del umbral de conmutación por error, el organismo de control de recuperación ante desastres concluye que puede ser necesaria una conmutación por error.
Sin embargo, dado que el sitio activo puede conectar y administrar los dispositivos a los que no se puede acceder desde el sitio en espera, el sitio en espera asume que el sitio activo administra todos los dispositivos árbitros a los que no se puede acceder y calcula el nuevo porcentaje de dispositivos administrados por el sitio activo.
Si el porcentaje de dispositivos administrados por el sitio activo está por debajo del porcentaje de umbral para ajustar los dispositivos administrados (parámetro failureDetection.threshold.adjustManaged en la sección de vigilancia de la API de recuperación ante desastres, el valor predeterminado es 50%), el sitio en espera permanece en espera. De forma predeterminada, el porcentaje de umbral para ajustar los dispositivos administrados debe estar por debajo del umbral de conmutación por error.
Si el nuevo porcentaje calculado sumando los dispositivos administrados por el sitio activo y los dispositivos árbitros a los que no se puede acceder está por debajo del umbral de conmutación por error, el organismo de control de recuperación ante desastres concluye que se debe iniciar una conmutación por error.
Si la conmutación por error automática está habilitada, el sitio en espera inicia el proceso de activación. Si la conmutación por error automática está deshabilitada, no se produce ninguna conmutación por error.
Si deshabilitó la conmutación por error automática o la característica se deshabilitó debido a problemas de conectividad, debe ejecutarla jmp-dr manualFailover en el sitio en espera para reanudar los servicios de administración de red desde el sitio en espera.
Detección de errores mediante scripts personalizados de detección de errores
Además de usar el algoritmo de arbitraje de dispositivos, puede crear scripts personalizados de detección de errores (sh, bash, Perl o Python) para decidir cuándo o si se debe conmutar por error al sitio en espera. Los scripts de error personalizados invocan el comando y obtienen la configuración de recuperación ante desastres y el jmp-dr api v1 config ––include estado de los servicios de vigilancia de recuperación ante desastres. La configuración de recuperación ante desastres y el estado de los servicios de vigilancia de recuperación ante desastres en un sitio se organizan en varias secciones. En el cuadro 1 se enumeran estas secciones.
Utilice la opción -- include <section-name> para ver los detalles de una sección o utilice los detalles de la sección en el script de detección de errores personalizado.
Sección |
Descripción |
Detalles incluidos en la sección |
Salida de muestra |
|---|---|---|---|
Papel |
Función de recuperación ante desastres del sitio actual |
Los roles pueden ser activos, en espera o independientes. |
– |
Failover |
Tipo de conmutación por error que ocurrió por última vez |
El valor puede estar active_to_standby, standby_to_active o vacío si aún no se ha producido la conmutación por error. |
– |
Núcleo |
Configuración principal de recuperación ante desastres que incluye los detalles del nodo de sitio remoto |
peerVip–VIP del equilibrador de carga en el sitio remoto adminPass: contraseñas de administrador cifradas del sitio remoto. Varias entradas están separadas por comas. scpTimeout: valor de tiempo de espera utilizado para detectar errores de transferencia de SCP entre sitios peerLoadBalancerNodes: direcciones IP de nodo de los nodos del equilibrador de carga en el sitio remoto. Varias entradas están separadas por comas. peerBusinessLogicNodes: direcciones IP de nodo de los nodos de JBoss en el sitio remoto. Varias entradas están separadas por comas. peerDeviceMgtIps: direcciones IP de administración de dispositivos del sitio remoto. Varias entradas están separadas por comas. |
{
"core": {
"peerVip": "10.155.90.210",
"adminPass": "ABCDE12345",
"scpTimeout": 120,
"peerLoadBalancerNodes": "10.155.90.211",
"peerBusinessLogicNodes": "10.155.90.211",
"peerDeviceMgtIps": "10.155.90.211"}
}
|
Mysql |
Configuración de recuperación ante desastres relacionada con la base de datos MySQL en el sitio remoto |
hasDedicatedDb: si el sitio remoto incluye nodos de base de datos dedicados peerVip–VIP de los nodos MySQL en el sitio remoto (nodo normal o nodo de base de datos dedicado) peerNodes: direcciones IP de nodo de los nodos MySQL en el sitio remoto (nodo normal o nodo de base de datos dedicado). Varias entradas están separadas por comas. |
{ "mysql": {
"hasDedicatedDb": false,
"peerVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
Pgsql |
Configuración de recuperación ante desastres relacionada con la base de datos PgSQL en el sitio remoto |
hasFmpm: si el sitio remoto incluye nodos FMPM especializados peerFmpmVip–VIP de los nodos de PostgreSQL en el sitio remoto (nodo normal o nodo especializado FM/PM) peerNodes: direcciones IP de nodo de los nodos de PostgreSQL en el sitio remoto (nodo normal o nodo especializado FM/PM). Varias entradas están separadas por comas. |
{ "psql": {
"hasFmpm": false,
"peerFmpmVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
Archivo |
Configuración y configuración de recuperación ante desastres relacionada con archivos RRD en el sitio remoto |
backup.maxCount: número máximo de archivos de copia de seguridad que se conservarán backup.hoursOfDay–Horas del día para realizar copias de seguridad de archivos backup.daysOfWeek–Días de la semana para realizar copias de seguridad de archivos restore.hoursOfDay–Horas del día para sondear archivos del sitio activo restore.daysOfWeek–Días de la semana para sondear archivos del sitio activo |
{ "file": {
"backup": {
"maxCount": 3,
"hoursOfDay": "*",
"daysOfWeek": "*" },
"restore": {
"hoursOfDay": "*",
"daysOfWeek": "*" }
}
}
|
Perro guardián |
Configuración de recuperación ante desastres relacionada con el organismo de control de recuperación ante desastres en el sitio actual |
heartbeat.retries: número de veces que se debe volver a intentar el mensaje de latidos heartbeat.timeout: tiempo de espera de cada mensaje de latido en segundos heartbeat.interval: intervalo de mensajes de latidos entre sitios en segundos notification.email–Dirección de correo electrónico de contacto para informar problemas de servicio notification.interval: intervalo de amortiguación entre la recepción de correos electrónicos sobre los servicios afectados failureDetection.isCustom–Si el sitio remoto utiliza la detección de errores personalizada failureDetection.script–Ruta del script de detección de errores failureDetection.threshold.failover– Porcentaje de umbral para desencadenar una conmutación por error
failureDetection.threshold.adjustManaged– Porcentaje de umbral para ajustar el porcentaje de dispositivos administrados
failureDetection.threshold.warning– Porcentaje de umbral para enviar una advertencia para garantizar que un sitio de recuperación ante desastres pueda llegar a más dispositivos de árbitro para mejorar la precisión del algoritmo de arbitraje de dispositivos
failureDetection.waitDuration–Período de gracia para permitir que el sitio activo original vuelva a estar activo cuando ambos sitios estén en espera failureDetection.arbiters–Lista de dispositivos de árbitro |
{ "watchdog": {
"heartbeat": {
"retries": 4,
"timeout": 5,
"interval": 30 },
"notification": {
"email": "abc@example.com",
"interval": 3600 },
"failureDetection": {
"isCustom": false,
"script": "/var/cache/jmp-geo/watchdog/bin/arbitration",
"threshold": {
"failover": 0.5,
"adjustManaged": 0.5,
"warning": 0.7 },
"waitDuration": "8h",
"arbiters": [{
"username": "user1",
"password": "xxx",
"host": "10.155.69.114",
"port": 22,
"privateKey": ""
}]
}
}
}
|
Administración de dispositivos |
Direcciones IP de administración de dispositivos en el sitio remoto |
peerNodes: direcciones IP de administración de dispositivos del sitio remoto. Varias entradas están separadas por comas. nodos: direcciones IP de administración de dispositivos en el sitio actual. Varias entradas están separadas por comas. dirección IP de administración de dispositivos e interfaz en este nodo (nodo en el que se ejecuta el |
{ "deviceManagement": {
"peerNodes": "10.155.90.211",
"nodes": "10.155.90.222",
”ip”: “10.155.90.228,eth0”
}
}
|
Estados |
Información de tiempo de ejecución de los servicios de vigilancia de recuperación ante desastres en el sitio actual. Si el guardián de recuperación de desastres nunca se ha ejecutado en este sitio, esta sección no está disponible. Si el organismo de control de recuperación ante desastres se ha detenido, la información de esta sección no está actualizada. |
– |
{ "states": {
"arbiterMonitor": {
"progress": "idle",
"msg": {
"service": "arbiterMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:55+00:00"
},
"service": {}
}, |
"configMonitor": {
"progress": "idle",
"msg": {
"service": "configMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:15+00:00"
},"service": {}
},
|
|||
"fileMonitor": {
"progress": "idle",
"msg": {
"service": "fileMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:59+00:00"
},
"service": {}
},
|
|||
"heartbeat": {
"progress": "unknown",
"msg": {
"service": "heartbeat",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"localFailover": false
},
"time": "2015-07-18T22:17:49+00:00"
},
"service": {
"booting": false,
"bootEndTime": null,
"waitTime": null,
"automaticFailover": false,
"automaticFailoverEndTime": "2015-07-18T07:41:41+00:00"
}
},
|
|||
"mysqlMonitor": {
"progress": "idle",
"msg": {
"service": "mysqlMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:09+00:00"
},
"service": {}
},
|
|||
"pgsqlMonitor": {
"progress": "unknown",
"msg": {
"service": "pgsqlMonitor",
"description": "Master node pgsql in active or standby site maybe CRASHED. Pgsql replication is in bad status. Please manually check Postgresql-9.4 status.",
"state": false,
"force": false,
"progress": "unknown",
"payload": {
"code": 1098
},
"time": "2015-07-18T22:18:27+00:00"
},"service": {}
},
|
|||
"serviceMonitor": {
"progress": "running",
"msg": {
"service": "serviceMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:30+00:00"
},
"service": {}
}
}
} |
El resultado del script personalizado informa al vigilante de recuperación ante desastres si se requiere una conmutación por error al sitio en espera. El vigilante de recuperación ante desastres interpreta el resultado del script en formato JSON. El siguiente es un ejemplo:
{
"state": "active",
"action": "nothing",
"description": "",
"payload": {
"waitTime": "",
"details": {
"percentages": {
"connected": 1,
"arbiters": {
"10.155.69.114": "reachable"
}
}
}
}
}
En la tabla 2 se describen los detalles de la salida del script.
Propiedad |
Descripción |
Tipo de datos |
Valores o formato |
Otros detalles |
|---|---|---|---|---|
Estado |
Función actual de recuperación ante desastres de este sitio |
Cadena |
Activo Espera |
Obligatorio No se permite una cadena vacía. |
Acción |
Acción que debe realizar el organismo de control de recuperación ante desastres |
Cadena |
beActive: cambie el rol a activo. beStandby: cambie el rol a standby. nada: no cambiar de rol. wait: espera en el rol actual el tiempo especificado en la propiedad payload.waitTime. |
Obligatorio No se permite una cadena vacía. |
Descripción |
Descripción del campo de acción y del mensaje que se envía en la notificación por correo electrónico |
Cadena |
– |
Obligatorio Se permite una cadena vacía. |
payload.waitTime |
Hora de finalización del período de gracia cuando ambos sitios pasan a estar en espera |
Cadena (fecha) |
AAAA-MM-DD, hora UTC en formato HH:MM+00:00 |
Obligatorio Se permite una cadena vacía. Esta propiedad se utiliza cuando se especifica el valor de la acción como espera. |
payload.details |
Información personalizada del usuario que se puede usar para depurar el script |
– |
Objeto JSON |
Opcional No se permite una cadena vacía. |
Pasos para configurar la recuperación ante desastres
Para configurar la recuperación ante desastres entre un sitio activo y un sitio en espera:
Detenga el proceso de recuperación ante desastres configurado durante versiones anteriores antes de actualizar a la versión 15.2R1 de la plataforma de administración de red de Junos Space. Para obtener más información sobre el proceso de actualización, consulte la sección Instrucciones de actualización en las Notas de la versión 15.2R1 de la plataforma de administración de red de Junos Space.
Para obtener más información acerca de cómo detener el proceso de recuperación ante desastres configurado durante versiones anteriores, consulte Detención del proceso de recuperación ante desastres en la plataforma de administración de red de Junos Space versión 14.1R3 y anteriores.
No es necesario realizar este paso para una instalación limpia de la versión 15.2R1 de la plataforma de administración de red de Junos Space.
Configure servidores SMTP en ambos sitios desde la interfaz de usuario de Junos Space para recibir notificaciones. Para obtener más información, consulte Administración de servidores SMTP en la Guía del usuario de las áreas de trabajo de la plataforma de administración de red de Junos Space.
Copie el archivo con la lista de dispositivos árbitros (si está utilizando el algoritmo de arbitraje de dispositivos) o el script de detección de errores personalizado en la ubicación adecuada del sitio activo. Asegúrese de que todos los dispositivos de árbitro se descubran en el sitio activo. Para obtener más información, consulte Descripción general de los perfiles de detección de dispositivos en la Guía del usuario de los espacios de trabajo de la plataforma de administración de red de Junos Space.
Configure el archivo de configuración de recuperación ante desastres en el sitio activo. La configuración de recuperación ante desastres incluye la configuración de SCP para sincronizar la configuración y los archivos RRD, la configuración de latidos, la configuración de notificaciones y el mecanismo de detección de errores.
Configure el archivo de configuración de recuperación ante desastres en el sitio en espera. La configuración de recuperación ante desastres incluye la configuración de SCP para sincronizar la configuración y los archivos RRD, la configuración de latidos y la configuración de notificaciones.
Inicie el proceso de recuperación ante desastres desde el sitio activo.
Para obtener más información, consulte Configuración del proceso de recuperación ante desastres entre un sitio activo y un sitio en espera.
Comandos de recuperación ante desastres
Utilice los comandos de recuperación ante desastres enumerados en la tabla 3 para configurar y administrar sitios de recuperación ante desastres. Debe ejecutar estos comandos en el nodo VIP del sitio. Puede usar la --help opción con estos comandos para ver más información.
Comando |
Descripción |
Opciones |
|---|---|---|
|
Inicialice los archivos de configuración de recuperación ante desastres en ambos sitios. Debe introducir valores para los parámetros indicados por el comando. Cree los usuarios y contraseñas de MySQL y PgSQL necesarios para replicar datos y supervisar la replicación en los sitios de recuperación ante desastres. Se crean los siguientes usuarios:
|
|
|
||
|
Inicie el proceso de recuperación ante desastres en ambos sitios. Debe ejecutar este comando en el nodo VIP del sitio activo. El sitio activo establece una conexión SSH con el sitio en espera y ejecuta el comando en el Al ejecutar este comando, se inicia la replicación y configuración de bases de datos MySQL y PgSQL y la copia de seguridad de archivos RRD en el sitio en espera. Ejecute este comando:
|
|
|
||
|
Cuando el comando se ejecuta sin opciones, el comando:
Debe ejecutar el comando en el orden siguiente:
Debe ejecutar este comando en el nodo VIP del sitio local para modificar la configuración y en el nodo VIP del sitio remoto para aceptar la configuración modificada. |
Use estas opciones para modificar la configuración de recuperación ante desastres en un sitio y actualizar el cambio en el sitio par: |
|
||
|
||
|
||
|
||
|
||
|
||
|
Compruebe el estado del proceso de recuperación ante desastres. El comando comprueba si las bases de datos MySQL y PgSQL están replicadas y si se realiza una copia de seguridad de la configuración y los archivos RRD, y comprueba el estado del vigilante de recuperación ante desastres e informa de errores. |
– |
|
Detenga el proceso de recuperación ante desastres entre sitios. Al ejecutar este comando, se detiene la replicación y configuración de bases de datos MySQL y PgSQL y la copia de seguridad de archivos RRD entre sitios. Los archivos de datos de recuperación ante desastres no se eliminan. El estado de servicios como JBoss, OpenNMS, Apache permanece sin cambios. |
– |
|
Detenga el proceso de recuperación ante desastres y elimine los archivos de datos de recuperación ante desastres de un sitio. El sitio inicia los servicios como un clúster independiente. Debe ejecutar este comando en el nodo VIP de ambos sitios para detener completamente el proceso de recuperación ante desastres y eliminar los archivos de datos de recuperación ante desastres de ambos sitios. |
– |
|
Conmutación por error manual al sitio en espera. Al ejecutar este comando, el sitio en espera se convierte en el nuevo sitio activo y el sitio activo se convierte en el nuevo sitio en espera. |
|
|
||
|
Habilite la conmutación por error automática en el sitio en espera o deshabilite la conmutación por error automática en el sitio en espera durante un período especificado.
Nota:
Solo puede ejecutar este comando si el organismo de control de recuperación ante desastres está activo en el sitio. |
|
|
||
|
Vea la configuración de recuperación ante desastres y la información de tiempo de ejecución en formato JSON. |
|
Cuando se incluye este comando en una secuencia de comandos personalizada de detección de errores, el comando recupera la configuración y el estado de recuperación ante desastres de los servicios de vigilancia de recuperación ante desastres y ejecuta la lógica en la secuencia de comandos. |