Gráfico
Descripción general del gráfico
Apstra utiliza el modelo Graph para representar una única fuente de información sobre infraestructura, políticas, restricciones, etc. Este modelo de Graph está sujeto a cambios constantes y podemos consultarlo por varias razones. Se representa como un gráfico. Toda la información sobre la red se modela como nodos y relaciones entre ellos.
Cada objeto en un gráfico tiene un ID único. Los nodos tienen un tipo (una cadena) y un conjunto de propiedades adicionales basadas en un tipo particular. Por ejemplo, todos los conmutadores de nuestro sistema están representados por nodos de tipo sistema y pueden tener un rol de propiedad que determina qué rol en la red se le asigna (spine/leaf/server). Los puertos de conmutación físicos y lógicos están representados por un nodo de interfaz, que también tiene una propiedad denominada if_type.
Las relaciones entre diferentes nodos se representan como bordes de grafo que llamamos relaciones. Las relaciones son dirigidas, lo que significa que cada relación tiene un nodo de origen y un nodo de destino. Las relaciones también tienen un tipo que determina qué propiedades adicionales puede tener una relación particular. Por ejemplo, los nodos del sistema tienen relaciones de tipo hosted_interfaces hacia los nodos de interfaz.
Un conjunto de posibles tipos de nodo y relación está determinado por un esquema de gráfico. El esquema define qué propiedades pueden tener los nodos y las relaciones de tipo particular junto con los tipos de esas propiedades (cadena / entero / booleano / etc.) y restricciones. Usamos y mantenemos una biblioteca de esquemas de código abierto, Lollipop, que permite una personalización flexible de los tipos de valor.
Volviendo al gráfico que representa una única fuente de verdad, uno de los aspectos más desafiantes fue cómo razonar sobre ella en presencia de un cambio, proveniente tanto del operador como del sistema administrado. Para apoyar esto, desarrollamos lo que llamamos mecanismo de consulta en vivo que tiene tres componentes esenciales:
- Especificación de consulta
- Notificación de cambio
- Procesamiento de notificaciones
Después de modelar nuestro modelo de dominio como un gráfico, puede ejecutar búsquedas en el gráfico especificado por las consultas de gráficos para encontrar patrones particulares (subgráficos) en un gráfico. El lenguaje para expresar la consulta se basa conceptualmente en Gremlin, un lenguaje transversal de grafos de código abierto. También tenemos analizadores para consultas expresadas en otro idioma: Cypher, que es un lenguaje de consulta utilizado por la popular base de datos de grafos neo4j.
Especificación de consulta
Comienzas con un node() y luego sigues encadenando llamadas a métodos, alternando entre relaciones y nodos coincidentes:
node('system', name='system').out().node('interface', name='interface').out().node('link', name='link')
La consulta anterior traducida al inglés dice algo así como: comenzando desde un nodo de sistema de tipos, recorre cualquier relación saliente que llegue al nodo de la interfaz de tipo, y desde ese nodo atraviesa toda la relación saliente que conduce al nodo de tipo 'enlace.
En cualquier momento puede agregar restricciones adicionales:
node('system', role='spine', name='system').out().node('interface', if_type='ip', name='interface')
Observe el argumento role='spine', seleccionará solo los nodos del sistema que tengan la propiedad role establecida en spine.
Lo mismo ocurre con if_type propiedad para los nodos de interfaz.
node('system', role=is_in(['spine', 'leaf']), name='system')
.out()
.node('interface', if_type=ne('ip'), name='interface')
Esa consulta seleccionará todos los nodos del sistema que tienen rol spine u leaf y nodos de interfaz que tienen if_type cualquier cosa que no sea ip (ne significa no igual).
También puede agregar condiciones entre objetos que pueden ser funciones arbitrarias de Python:
node('system', name='system')
.out().node('interface', name='if1')
.out().node('link')
.in_().node('interface', name='if2')
.in_().node('system', name='remote_system')
.where(lambda if1, if2: if1.if_type != if2.if_type)
Asigne un nombre a los objetos para hacer referencia a ellos y use esos nombres como nombres de argumento para su función de restricción (por supuesto, puede anular eso, pero es un comportamiento predeterminado conveniente). Entonces, en el ejemplo anterior, tomará dos nodos de interfaz llamados if1 e if2, los pasará a la función where dada y filtrará esas rutas, para las cuales la función devuelve False. No se preocupe por dónde coloca su restricción: se aplicará durante la búsqueda tan pronto como todos los objetos a los que hace referencia la restricción estén disponibles.
Ahora, tienes una sola ruta, puedes usarla para hacer búsquedas. Sin embargo, a veces es posible que desee tener una consulta más compleja que una sola ruta. Para apoyar esto, la consulta DSL le permite definir varias rutas en la misma consulta, separadas por comas:
match(
node('a').out().node('b', name='b').out().node('c'),
node(name='b').out().node('d'),
)
Esta match() función crea una agrupación de rutas. Todos los objetos que comparten el mismo nombre en diferentes rutas en realidad se referirán al mismo objeto. Además, match() permite agregar más restricciones en objetos con where(). Puede hacer una búsqueda distinta en objetos particulares y se asegurará de que cada combinación de valores se vea solo una vez en los resultados:
match(
node('a', name='a').out().node('b').out().node('c', name='c')
).distinct(['a', 'c'])
Esto coincide con una cadena de nodos a -> b -> c. Si dos nodos a y c están conectados a través de más de un nodo de tipo b, el resultado seguirá conteniendo solo un par (a, c).
Hay otro patrón conveniente para usar al escribir consultas: separa su estructura de sus criterios:
match(
node('a', name='a').out().node('b').out().node('c', name='c'),
node('a', foo='bar'),
node('c', bar=123),
)
El motor de consultas optimizará esa consulta en:
match(
node('a', name='a', foo='bar')
.out().node('b')
.out().node('c', name='c', bar=123)
)
Sin producto cartesiano, sin pasos innecesarios.
Notificación de cambio
Ok, ahora tienes una consulta de gráfico definida. ¿Qué aspecto tiene el resultado de una notificación? Cada resultado será un diccionario que asigna un nombre que ha definido para un objeto de consulta a objeto encontrado. Por ejemplo, para la siguiente consulta
node('a', name='a').out().node('b').out().node('c', name='c')
Los resultados se verán como {'a': <node type='a'>, 'c': <node type='c'>}. Tenga en cuenta que solo están presentes los objetos con nombre (no <node type='b'> hay resultados incluidos, aunque ese nodo está presente en la consulta porque no tiene nombre).
Registre una consulta para ser monitoreada y una devolución de llamada para ejecutar si algo cambia. Más tarde, si alguien modifica el gráfico que se está monitoreando, detectará que las nuevas actualizaciones del gráfico causaron que aparecieran nuevos resultados de consulta, o que los resultados antiguos desaparecieran o se actualizaran. La respuesta ejecuta la devolución de llamada asociada a la consulta. La devolución de llamada recibe toda la ruta de acceso de la consulta como respuesta y una acción específica (agregada/actualizada/eliminada) para ejecutar.
Procesamiento de notificaciones
Cuando el resultado se pasa a la función de procesamiento (devolución de llamada), desde allí puede especificar la lógica de razonamiento. Esto realmente podría ser cualquier cosa, desde generar registros, errores hasta representar configuraciones o ejecutar validaciones semánticas. También puede modificar el gráfico en sí, utilizando API de gráficos y alguna otra pieza de lógica que puede reaccionar a los cambios realizados. De esta forma, puede aplicar el gráfico como una única fuente de verdad y, al mismo tiempo, servir como canal de comunicación lógico entre partes de la lógica de la aplicación. La API Graph consta de tres partes:
Gestión de gráficos: métodos para agregar/actualizar/eliminar cosas en un gráfico. add_node(), set_node(), del_node(), get_node()add_relationship(), set_relationship(), del_relationship(), get_relationship()Consulta commit() get_nodes()get_relationships() Interfaz observable add_observer(),remove_observer()
Las API de administración de gráficos se explican por sí mismas. add_node() Crea un nuevo nodo, set_node() actualiza las propiedades del nodo existente y del_node() elimina un nodo.
commit() se utiliza para indicar que todas las actualizaciones del gráfico están completas y que se pueden propagar a todos los oyentes.
Las relaciones tienen una API similar.
La interfaz observable le permite agregar / eliminar observadores, objetos que implementan una interfaz de notificación y devolución de llamada. La devolución de llamada de notificación consta de tres métodos:
on_node()- llamado cuando se agrega, elimina o actualiza cualquier nodo / relaciónon_relationship()- llamado cuando se agrega, elimina o actualiza cualquier nodo / relaciónon_graph()- llamado cuando se confirma el gráfico
La API de consulta es el corazón de nuestra API de gráficos y es lo que impulsa todas las búsquedas. Ambos get_nodes() y get_relationships() le permiten buscar objetos correspondientes en un gráfico. Los argumentos para esas funciones son restricciones en los objetos buscados.
Por ejemplo get_nodes() , le devuelve todos los nodos en un gráfico, get_nodes(type='system') le devuelve todos los nodos del sistema, get_nodes(type='system', role='spine') le permite restringir los nodos devueltos a aquellos que tienen valores de propiedad particulares. Los valores de cada argumento pueden ser un valor sin formato o un objeto especial de coincidencia de propiedades. Si el valor es un valor plano, el objeto de resultado correspondiente debe tener su propiedad igual al valor sin formato dado. Los emparejadores de propiedades le permiten expresar criterios más complejos, por ejemplo, no igual, menor que, uno de los valores dados, etc.:
El siguiente ejemplo es para usar directamente Graph python. Para fines de demostración, puede reemplazar graph.get_nodes por nodo en el explorador de grafos. Este ejemplo específico no funcionará en la GUI de Apstra.
graph.get_nodes(
type='system',
role=is_in(['spine', 'leaf']),
system_id=not_none(),
)
En el esquema del gráfico puede definir índices personalizados para determinados tipos de nodos o relaciones y los métodos get_nodes() , y get_relationships() elegir el mejor índice para cada combinación particular de restricciones pasadas para minimizar el tiempo de búsqueda.
Los resultados de get_nodes()/get_relationships() son objetos iteradores especiales. Puede iterar sobre ellos y producirán todos los objetos de grafo encontrados. También puede usar las API que proporcionan esos iteradores para navegar por esos conjuntos de resultados. Por ejemplo, get_nodes() devuelve un objeto NodeIterator que tiene métodos out() y in_(). Puede usarlos para obtener un iterador sobre todas las relaciones salientes o entrantes de cada nodo en el conjunto de resultados original. Luego, puede usarlos para obtener nodos en el otro extremo de esas relaciones y continuar desde ellos. También puede pasar restricciones de propiedad a esos métodos de la misma manera que puede hacer para get_nodes() y get_relationships().
graph.get_nodes('system', role='spine') \
.out('interface').node('interface', if_type='loopback')
El código del ejemplo anterior busca todos los nodos con sistema de tipos y spine de rol y, a continuación, encuentra todas sus interfaces de circuito cerrado.
Poniendo todo junto
La consulta siguiente es un ejemplo de una regla interna que Apstra puede usar para derivar expectativas de telemetría, por ejemplo, el estado del vínculo y la interfaz. El @rule insertará una devolución de llamada a process_spine_leaf_link, en cuyo caso escribiremos a las expectativas de telemetría.
@rule(match(
node('system', name='spine_device', role='spine')
.out('hosted_interfaces')
.node('interface', name='spine_if')
.out('link')
.node('link', name='link')
.in_('link')
.node('interface', name='leaf_if')
.in_('hosted_interfaces')
.node('system', name='leaf_device', role='leaf')
))
def process_spine_leaf_link(self, path, action):
"""
Process link between spine and leaf
"""
spine = path['spine_device']
leaf = path['leaf_device']
if action in ['added', 'updated']:
# do something with added/updated link
pass
else:
# do something about removed link
pass
Funciones de conveniencia
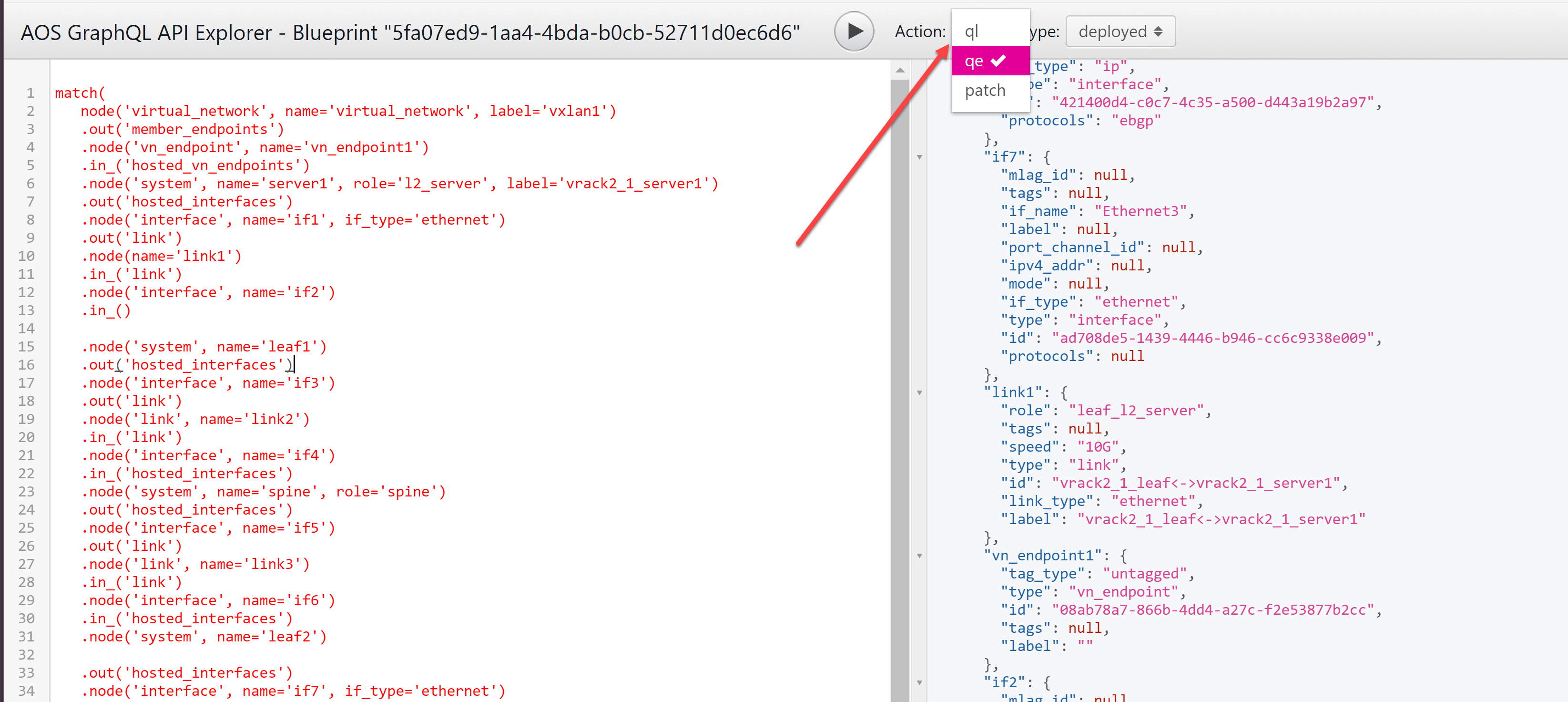
Para evitar la creación de cláusulas complejas where() al crear una consulta de gráfico, utilice las funciones de conveniencia, disponibles en la GUI de Apstra.
-
Desde el plano, vaya a la vista por etapas o la vista activa y, a continuación, haga clic en el botón GraphQL API Explorer (arriba a la derecha >_). El explorador de gráficos se abre en una nueva pestaña.
-
Escriba una consulta de gráfico a la izquierda. Consulte las descripciones de las funciones a continuación.
-
En la lista desplegable Acción , seleccione qe.
-
Haga clic en el botón Ejecutar consulta (parece un botón de reproducción) para ver los resultados.
Funciones
El motor de consultas describe una serie de funciones útiles:
partido(*path_queries)
Esta función devuelve un QueryBuilder objeto que contiene cada resultado de una consulta coincidente. Este suele ser un atajo útil para agrupar varias consultas coincidentes.
Estas dos consultas no son una "ruta" juntas (sin relación intencionada). Observe la coma para separar los argumentos. Esta consulta devolverá todos los dispositivos leaf y spine devices juntos.
match(
node('system', name='leaf', role='leaf'),
node('system', name='spine', role='spine'),
)
node(self, type=None, name=None, id=None, **properties)
- Parámetros
- type (str o None): tipo de nodo que se va a buscar
- name (str o None): establece el nombre del emparejador de propiedades en los resultados.
- id (str o None): hace coincidir un nodo específico por ID de nodo en el gráfico
- properties (dict o None): cualquier argumento de palabra clave adicional o funciones adicionales de conveniencia de coincidencia de propiedades que se vayan a utilizar
- Devoluciones : objeto del generador de consultas para encadenar consultas
- Tipo de retorno : QueryBuilder
Si bien ambas son una función, este es un alias para los nodos PathQueryBuilder -- ver más abajo.
iterar()
- Devoluciones - generador
- Tipo de retorno: generador
Iterate le ofrece una función generadora que puede usar para iterar en consultas de ruta individuales como si fuera una lista. Por ejemplo:
def find_router_facing_systems_and_intfs(graph):
return q.iterate(graph, q.match(
q.node('link', role='to_external_router')
.in_('link')
.node('interface', name='interface')
.in_('hosted_interfaces')
.node('system', name='system')
))
Nodos PathQueryBuilder
node(self, type=None, name=None, id=None, **properties)
Esta función describe un nodo de grafo específico, pero también es un acceso directo para iniciar una consulta de ruta desde un nodo específico. El resultado de una `node() llamada devuelve un objeto de consulta de ruta de acceso. Al consultar una ruta, normalmente desea especificar un 'tipo' de nodo: por ejemplo node('system') , devolvería un nodo del sistema.
- Parámetros
- type (str o None): tipo de nodo que se va a buscar
- name (str o None): establece el nombre del emparejador de propiedades en los resultados.
- id (str o None): hace coincidir un nodo específico por ID de nodo en el gráfico
- properties (dict o None): cualquier argumento de palabra clave adicional o funciones adicionales de conveniencia de coincidencia de propiedades que se vayan a utilizar
- Devoluciones : objeto del generador de consultas para encadenar consultas
- Tipo de retorno : QueryBuilder
Si desea utilizar el nodo en los resultados de la consulta, debe asignarle un nombre --node('system', name='device'). Además, si desea coincidir con propiedades específicas de kwarg, puede especificar directamente los requisitos de coincidencia:
node('system', name='device', role='leaf')
node('system', name='device', role='leaf')
out(type=None, id=None, name=None, **properties)
Recorre una relación en la dirección "hacia afuera" de acuerdo con un esquema de gráfico. Los parámetros aceptables son el tipo de relación (por ejemplo, interfaces), el nombre específico de una relación, el identificador de una relación u otras coincidencias de propiedad que deben coincidir exactamente como argumentos de palabras clave.
- Parámetros
- type (str o None): tipo de relación de nodo que se va a buscar
- id (str o None): hace coincidir una relación específica por ID de relación en el gráfico
- name (str o None): hace coincidir una relación específica por relación con nombre
Por ejemplo:
node('system', name='system') \
.out('hosted_interfaces')
in_(type=None, id=None, name=None, **properties)
Atraviesa una relación en la dirección "in". Establece el nodo actual en el nodo de origen de relación. Los parámetros aceptables son el tipo de relación (por ejemplo, interfaces), el nombre específico de una relación, el identificador de una relación u otras coincidencias de propiedad que deben coincidir exactamente como argumentos de palabras clave.
- Parámetros
- type (str o None): tipo de relación de nodo que se va a buscar
- id (str o None): hace coincidir una relación específica por ID de relación en el gráfico
- name (str o None): hace coincidir una relación específica por relación con nombre
- propiedades (dict o None) - Hace coincidir las relaciones por cualquier otra kwargs o función
node('interface', name='interface') \
.in_('hosted_interfaces')
where(predicate, names=None)
Permite especificar una función de devolución de llamada en los resultados del gráfico como filtro o restricción. El predicado es una devolución de llamada (normalmente una función lambda) que se ejecuta en todo el resultado de la consulta. where() Se puede usar directamente en un resultado de consulta de ruta A.
- Parámetros
- predicate (callback): función de devolución de llamada que se ejecuta en todos los nodos del gráfico
- nombres (str o ninguno): si se dan nombres, se pasan a la función de devolución de llamada para que coincida
node('system', name='system') \
.where(lambda system: system.role in ('leaf', 'spine'))
enure_different(*nombres)
Permite a un usuario asegurarse de que dos nodos con nombre diferentes en el gráfico no son iguales. Esto es útil para las relaciones que pueden ser bidireccionales y podrían coincidir en sus propios nodos de origen. Considere la consulta:
- Parámetros
- nombres (tupla o lista): una lista de nombres para garantizar que se devuelvan diferentes nodos o relaciones del gráfico.
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.ensure_different('interface', 'remote_interface')
La última línea podría ser funcionalmente equivalente a la where() función con una función de devolución de llamada lambda
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.where(lambda interface, remote_interface: interface != remote_interface)
Emparejadores de propiedades
Las coincidencias de propiedades se pueden ejecutar directamente en objetos de consulta de gráficos, generalmente se usan dentro de una node() función. Las coincidencias de propiedad permiten algunas funciones.
eq(valor)
Garantiza que el valor de propiedad del nodo coincida exactamente con los resultados de la eq(value) función.
- Parámetros
- value - Propiedad a la altura de la igualdad
node('system', name='system', role=eq('leaf'))
Lo cual es similar a simplemente establecer un valor como kwarg en un objeto de nodo:
node('system', name='system', role='leaf')
node('system', name='system').where(lambda system: system.role == 'leaf')
Devuelve:
{
"count": 4,
"items": [
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf1",
"label": "l2_virtual_mlag_2_leaf1",
"system_id": "000C29EE8EBE",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "391598de-c2c7-4cd7-acdd-7611cb097b5e"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf2",
"label": "l2_virtual_mlag_2_leaf2",
"system_id": "000C29D62A69",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "7f286634-fbd1-43b3-9aed-159f1e0e6abb"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf2",
"label": "l2_virtual_mlag_1_leaf2",
"system_id": "000C29CFDEAF",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "b9ad6921-6ce3-4d05-a5c7-c31d96785045"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf1",
"label": "l2_virtual_mlag_1_leaf1",
"system_id": "000C297823FD",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "71bbd11c-ed0f-4a38-842f-341781c01c24"
}
}
]
}
ne(valor)
No-iguales. Garantiza que el valor de propiedad del nodo NO coincida con los resultados de ne(value) la función
- Parámetros
- valor: valor para garantizar la condición de desigualdad
node('system', name='system', role=ne('spine'))
Similar a:
node('system', name='system').where(lambda system: system != 'spine')
gt(valor)
Mayor que. Garantiza que la propiedad del nodo sea mayor que los resultados de gt(value) la función.
- Parámetros
- valor: asegúrese de que la función de propiedad es mayor que este valor
node('vn_instance', name='vlan', vlan_id=gt(200))
ge(valor)
Mayor o igual a. Garantiza que la propiedad del nodo sea mayor o igual que los resultados de ge().
- Parámetros: valor: asegúrese de que la función de propiedad es mayor o igual que este valor
node('vn_instance', name='vlan', vlan_id=ge(200))
lt(valor)
Menos que. Garantiza que la propiedad del nodo sea menor que los resultados de lt(value).
- Parámetros
- valor: asegúrese de que la función de propiedad sea menor que este valor
node('vn_instance', name='vlan', vlan_id=lt(200))
Similar a:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id <= 200)
le(valor)
Menor o igual que. Asegura que la propiedad sea menor o igual que los resultados de le(value) la función.
- Parámetros
- valor: garantiza que el valor dado sea menor o igual que la función de propiedad.
node('vn_instance', name='vlan', vlan_id=le(200))
Similar a:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id < 200)
is_in(valor)
Está en (lista). Compruebe si la propiedad está en una lista determinada o en un conjunto que contiene elementos is_in(value).
- Parámetros
- valor (lista): asegúrese de que la propiedad dada esté en esta lista
node('system', name='system', role=is_in(['leaf', 'spine']))
Similar a:
node('system', name='system').where(lambda system: system.role in ['leaf', 'spine'])
not_in(valor)
No está en (lista). Compruebe si la propiedad NO está en una lista determinada o en un conjunto que contenga elementos not_in(value).
- Parámetros
- value (list): valor de lista para garantizar que el coincidente de propiedades no esté en
node('system', name='system', role=not_in(['leaf', 'spine']))
Similar a:
node('system', name='system').where(lambda system: system.role not in ['leaf', 'spine'])
is_none()
Una consulta que espera is_none espera que este atributo en particular sea específicamente None.
node('interface', name='interface', ipv4_addr=is_none()
Similar a:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is None)
not_none()
Un emparejador que espera que este atributo tenga un valor.
node('interface', name='interface', ipv4_addr=not_none()
Similar a:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is not None)
Almacén de datos de Apstra Graph
El almacén de datos de gráficos de Apstra es una base de datos de gráficos en memoria. El tamaño del archivo de registro se comprueba periódicamente y cuando se confirma un cambio de plano. Si el almacén de datos del gráfico alcanza los 100 MB o más, se genera un nuevo archivo de punto de control del almacén de datos del gráfico. La base de datos en sí no quita ningún registro de persistencia del almacén de datos de gráficos ni archivos de puntos de control. Apstra proporciona herramientas de limpieza para el almacén de datos del gráfico principal.
Los grupos de archivos de persistencia del almacén de datos de gráficos válidos contienen cuatro archivos: log, log-valid, checkpointy checkpoint-valid. Los archivos válidos son los indicadores efectivos para los archivos de registro y punto de control. El nombre de cada archivo de persistencia tiene tres partes: nombre base, identificador y extensión.
# regex for sysdb persistence files. # e.g. # _Main-0000000059ba612e-00017938-checkpoint-valid # \--/ \-----------------------/ \--------------/ # basename id extension
- BaseName : derivado del nombre de la partición del almacén de datos del gráfico principal.
- id: una marca de tiempo de Unix obtenida de GetTimeofDay. Los segundos y microsegundos en la marca de tiempo están separados por un "-". Un grupo de archivos de persistencia se puede identificar por id. La marca de tiempo también puede ayudar a determinar la secuencia de tiempo generada de los grupos de archivos de persistencia.
- extensión -
log,log-valid,checkpoint, ocheckpoint-valid.