EVPN/VXLAN GPU 백엔드 패브릭 – GPU 멀티테넌시
GPU 멀티테넌시(GPU as a Service – GPUaaS)
GPUaaS(GPU as a Service)는 다른 유틸리티 스타일 컴퓨팅 서비스와 유사하게 GPU 컴퓨팅 리소스가 사용자 또는 애플리케이션에 온디맨드 방식으로 제공되는 모델입니다. GPUaaS를 사용하면 전체 서버나 클러스터를 단일 팀이나 목적에 전념하는 대신 현재 워크로드 요구 사항에 따라 리소스를 동적으로 할당할 수 있습니다. 테넌트는 종종 여러 서버에 걸쳐 특정 수의 GPU를 요청하고 이를 AI 교육, 데이터 분석 또는 시각화와 같은 작업에 사용할 수 있습니다. 이 서비스는 기본 인프라를 추상화하여 사용자에게 원활하고 확장 가능한 경험을 제공하는 동시에 안전하고 효율적인 리소스 격리를 유지합니다. GPUaaS는 유연성과 중앙 집중식 관리를 결합하여 여러 팀이나 프로젝트가 동일한 데이터센터를 공유하는 환경에서 리소스 활용도를 높이고 운영을 단순화합니다.
GPU 멀티테넌시는 여러 테넌트가 공유 인프라 내에서 GPU 리소스를 독립적으로 사용할 수 있도록 하는 리소스 관리 접근 방식입니다. 서버의 모든 GPU를 단일 테넌트에 할당하는 대신 GPU 멀티테넌시를 사용하면 서버의 하나 이상의 GPU를 다른 테넌트에 예약할 수 있는 보다 유연한 할당이 가능합니다. 이 모델은 조직이 전체 서버를 과도하게 프로비저닝하는 대신 GPU 리소스를 각 워크로드의 특정 요구 사항에 맞출 수 있도록 하여 효율성을 향상시킵니다. 각 테넌트는 논리적으로 격리된 환경에서 운영되며, 컴퓨팅 리소스, 네트워크 경로 및 관련 구성이 명확하게 분리되어 있습니다. 이러한 격리를 통해 테넌트는 간섭 없이 애플리케이션을 실행할 수 있고 관리자는 GPU 배포 및 액세스에 대한 중앙 집중식 제어를 유지할 수 있습니다.
GPU 멀티테넌시와 GPUaaS(GPU as a Service)는 밀접하게 관련된 개념으로, 결합하면 멀티 테넌트 환경에서 GPU 인프라를 효율적이고 확장 가능한 방식으로 사용할 수 있습니다. GPU 멀티테넌시는 GPU 리소스를 하나의 GPU, 여러 GPU 또는 서로 다른 서버의 특정 GPU에 관계없이 세분화된 수준에서 서로 다른 테넌트에 유연하게 할당할 수 있도록 하여 기반을 제공합니다. 이 접근 방식을 통해 각 테넌트가 논리적으로 격리된 환경에서 작동하여 물리적 인프라가 공유되는 경우에도 보안 및 성능 일관성을 유지할 수 있습니다.
이를 기반으로 GPUaaS는 이러한 기능을 온디맨드 서비스 모델로 추상화합니다. 사용자가 물리적 서버나 하드웨어 구성을 관리할 필요 없이 GPUaaS는 필요에 따라 GPU 리소스를 동적으로 제공합니다. 기본 멀티테넌시 프레임워크를 활용하여 사용자 요청에 따라 GPU를 할당하고, 격리를 적용하고, 다양한 워크로드 세트에서 사용을 최적화합니다. 이를 통해 데이터센터는 전체 서버를 각각에 할당하지 않고도 다양한 팀이나 애플리케이션을 동시에 지원할 수 있습니다.
GPU 멀티테넌시와 GPUaaS를 함께 사용하면 고효율, 리소스 활용도 향상, 운영 간소화가 가능합니다. 멀티테넌시가 GPU 리소스의 안전하고 유연한 슬라이싱을 처리하는 동안 GPUaaS는 이러한 슬라이스를 소모형 서비스로 제공하여 필요에 따라 컴퓨팅 용량을 확장 또는 축소하고 다양한 사용 사례에서 GPU 기반 컴퓨팅에 보다 접근성과 비용 효율적으로 만듭니다.
GPU 멀티테넌시 유형
서버 격리:
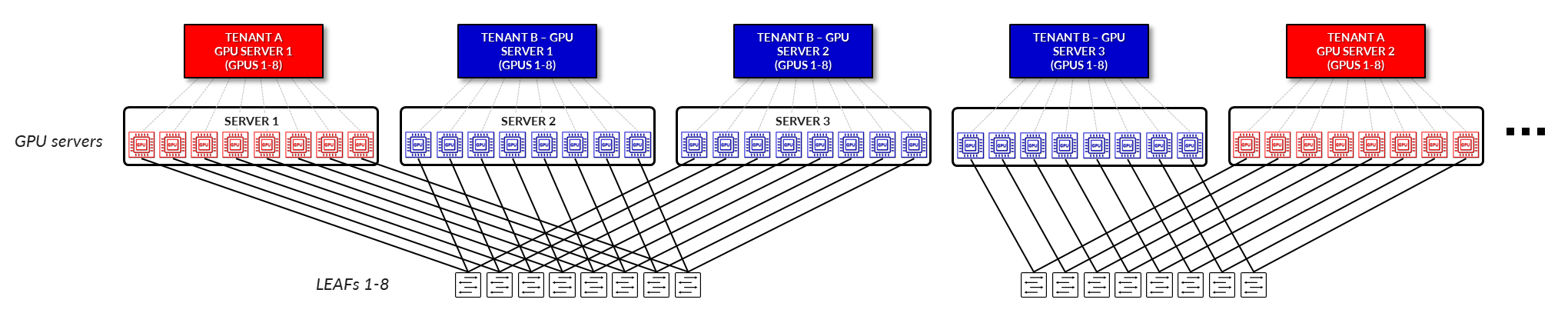
서버 격리 모델에서 각 테넌트에는 하나 이상의 전체 서버가 할당됩니다. 이러한 서버 내의 모든 GPU는 단일 테넌트 전용이므로 다른 테넌트와 물리적, 논리적으로 완전히 분리됩니다. 이 모델은 리소스 할당을 단순화하고 테넌트 간 간섭의 위험을 최소화하므로 예측 가능한 성능과 엄격한 격리가 필요한 워크로드에 매우 적합합니다. (그림 4).
그림 4: GPU as a Service - 서버 격리
GPU 격리:
GPU 격리 모델에서는 서버 내의 개별 GPU가 서로 다른 테넌트에 할당됩니다. 이를 통해 여러 테넌트가 동일한 물리적 서버를 안전하게 공유할 수 있으며 각 테넌트는 할당된 GPU에만 액세스할 수 있습니다. 기본 패브릭은 논리적 분리를 제공하고 GPU 수준에서 격리를 보장하여 보안이나 성능을 손상시키지 않으면서 유연성을 높이고 리소스 활용도를 높일 수 있습니다. (그림 5).
그림 5: GPU as a Service – GPU 격리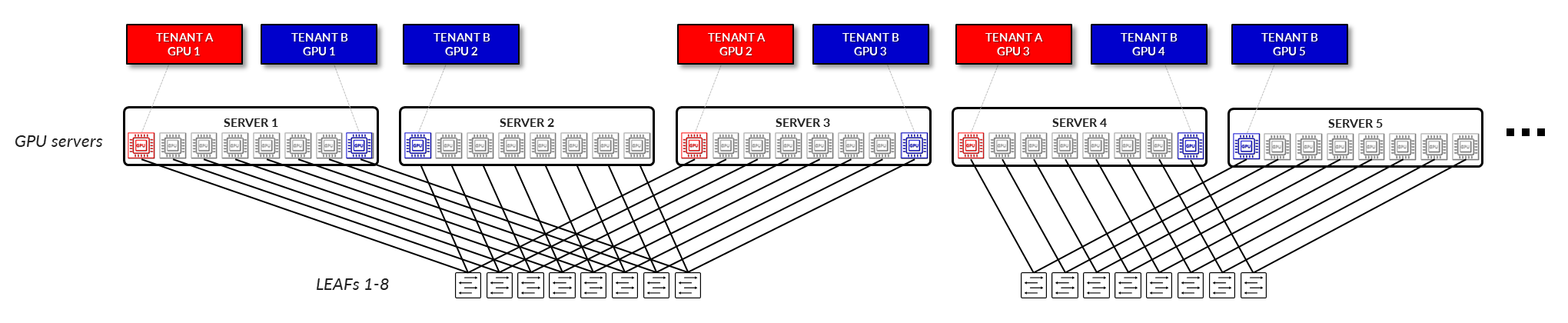
멀티테넌시 아키텍처를 위한 GPU 백엔드 패브릭
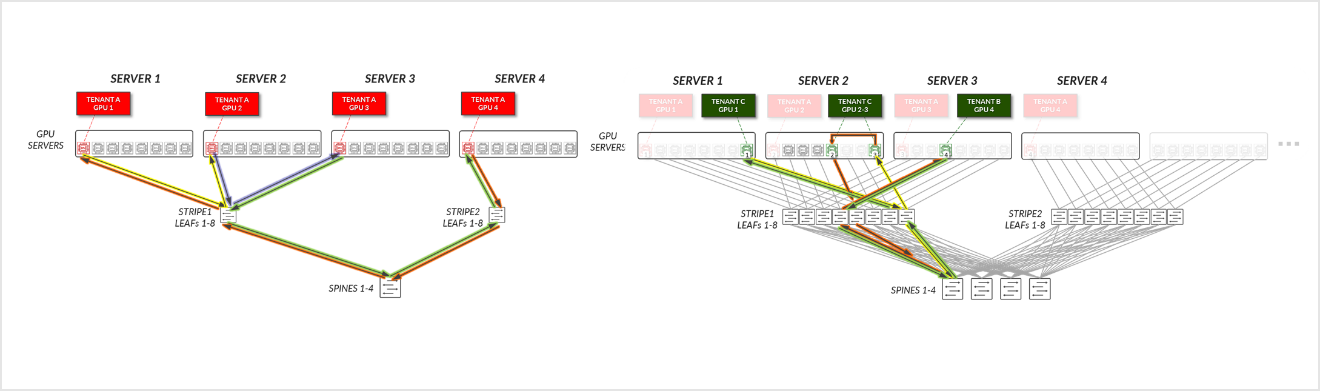
멀티테넌시를 위한 GPU 백엔드 패브릭의 설계는 EVPN/VXLAN을 사용하는 3단계 Clos 레일 최적화 스트라이프 아키텍처를 따릅니다. 이 접근 방식을 사용하면 동일한 테넌트에 할당된 GPU 간에 고성능 통신이 가능해지면서 서버 격리 및 GPU 격리 모두에 대해 테넌트 간의 트래픽 격리가 보장됩니다. 서버 격리 및 GPU 격리에 대한 자세한 내용은 GPU 멀티테넌시를 사용한 레일 정렬 및 로컬 최적화 고려 사항 단원을 참조하십시오.
그림 6: GPU 백엔드 패브릭 아키텍처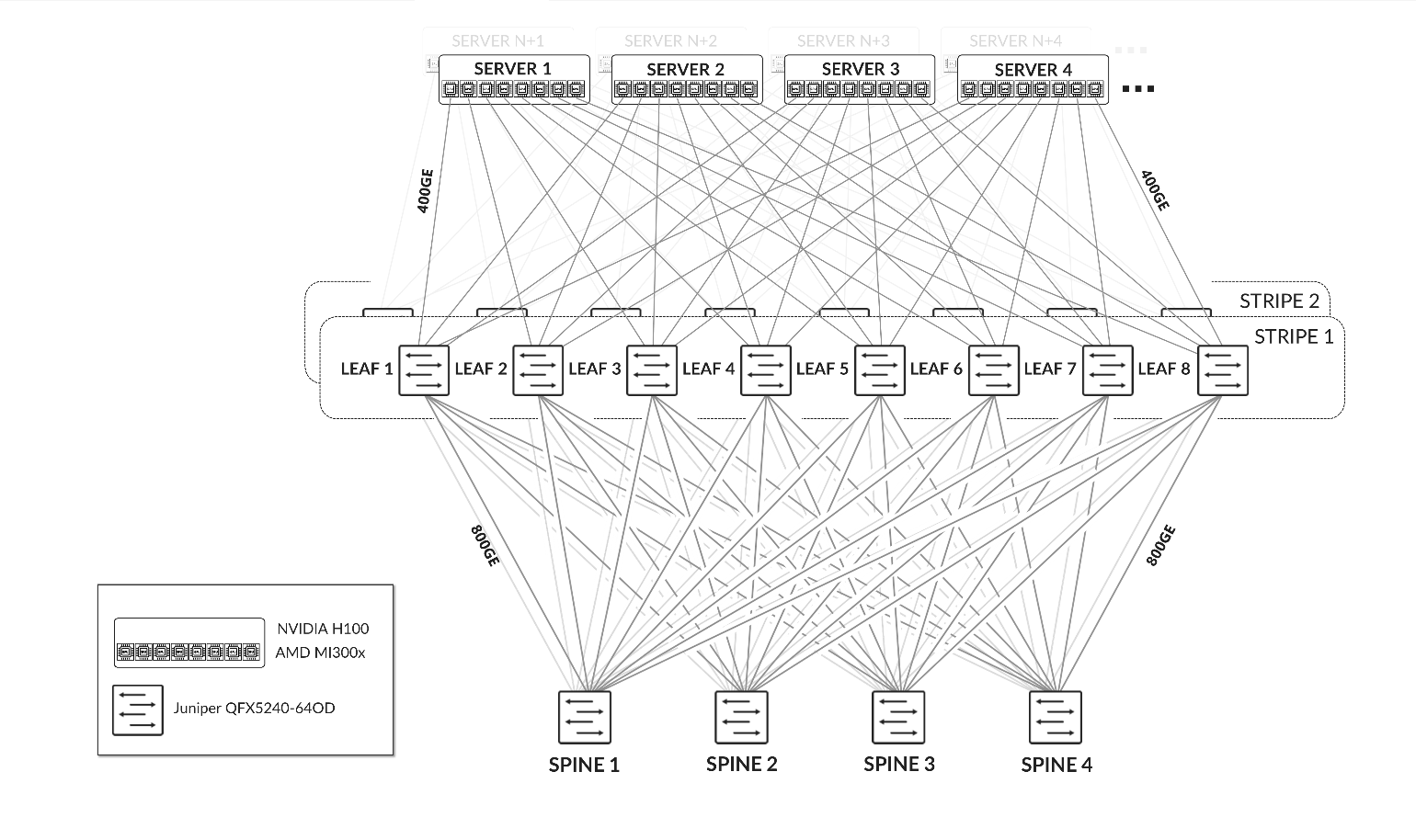
그림 7: GPU 백엔드 패브릭 EVPN/VXLAN 연결 – 서버 격리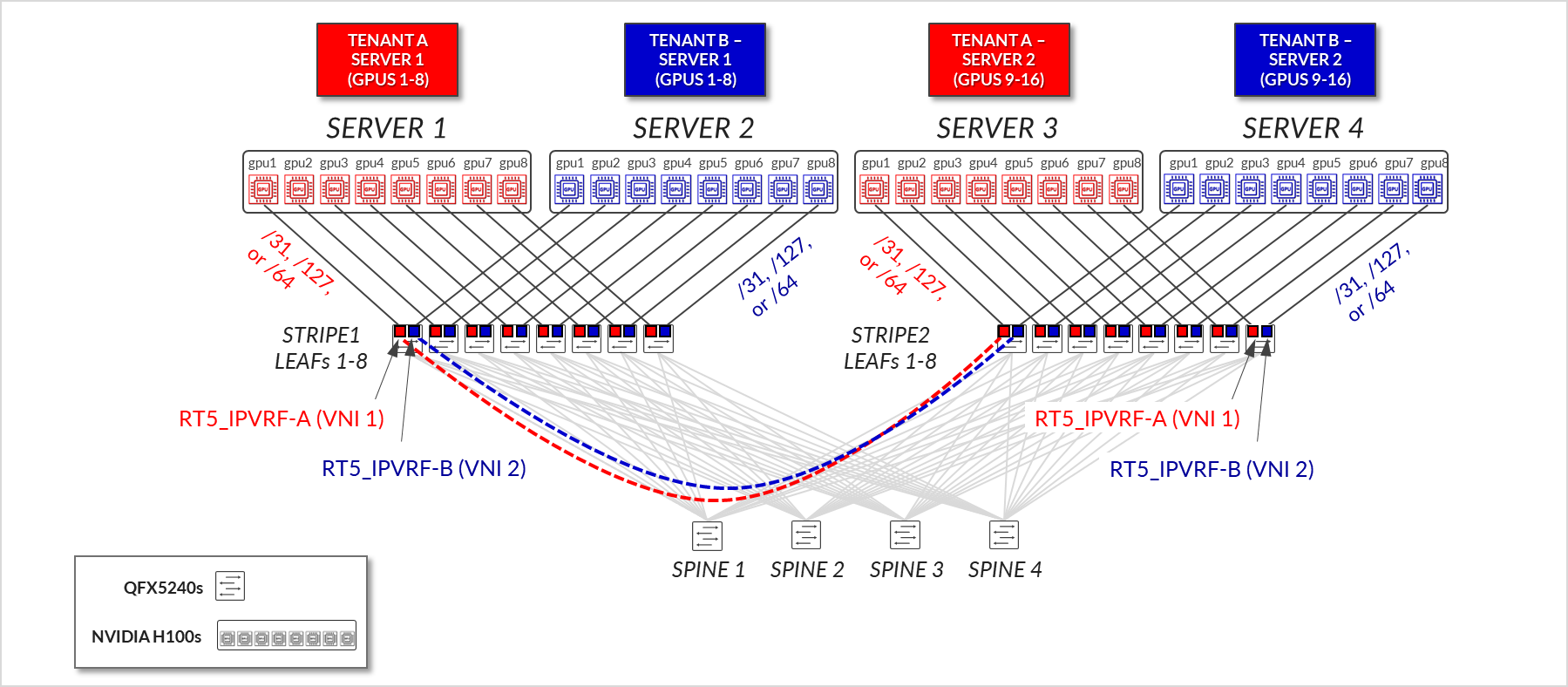
그림 8: GPU 백엔드 패브릭 EVPN/VXLAN 연결 – GPU 격리
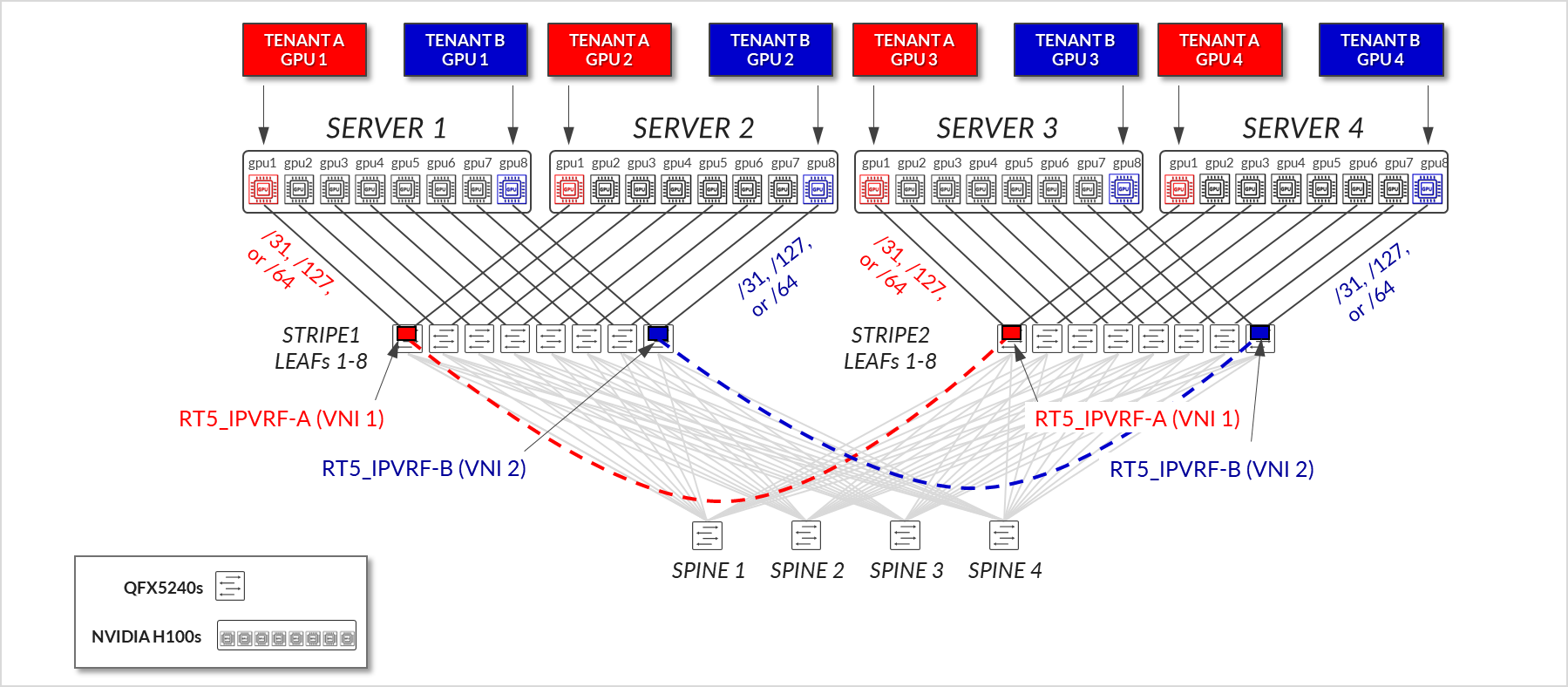
AI 실험실에서 GPU 백엔드 패브릭의 일부인 디바이스와 이들 간의 연결은 표 1과 표 2에 요약되어 있습니다.
표 1: 스트라이프당 GPU 백엔드 디바이스 수
| Stripe | GPU 서버 | GPU 백엔드 리프 노드 스위치 모델 |
GPU 백엔드 스파인 노드 스위치 모델 |
|---|---|---|---|
| 1 | MI300X x 2 (MI300X-01 및 MI300X-02) H100 x 2 (H100-01 및 H100-02) |
QFX5240-64OD x 8 (GPU 백엔드-001_leaf#; #=1-8) |
QFX5240-64OD x 4 (GPU-백엔드-스파인#; #=1-4) |
| 2 | MI300X x 2 (MI300X-03 및 MI300X-04) H100 x 2 (H100-01 및 H100-02) |
QFX5240-64OD x 8 (GPU 백엔드-002_leaf#; #=1-8) |
모든 Nvidia H100 및 AMD MI300X GPU 서버는 400GE 인터페이스를 사용하여 GPU 백엔드 패브릭에 연결됩니다.
표 2: 서버, 리프 노드 및 스파스파인 노드 간의 GPU 백엔드 연결.
| 스트라이프 | GPU 서버 <=> GPU 백엔드 리프 노드 |
GPU 백엔드 리프 노드 <=> GPU 백엔드 스파인 노드 |
|---|---|---|
| 1 | 총 400GE 링크 수 서버와 리프 노드 간 = 8(서버당 GPU 수) x 1(400GE 서버-리프 링크 수) x 4(서버 수) = 32 |
총 400GE 링크 수 GPU 백엔드 리프 노드와 스파스파인 노드 간 = 8(리프 노드 수) x 2(리프-스파인 연결당 400GE 링크 수) x 4(스파인 노드 수) = 64 |
| 2 | 총 400GE 링크 수 서버와 리프 노드 간 = 8(서버당 GPU 수) x 1(400GE 서버-리프 링크 수) x 4(서버 수) = 32 |
총 400GE 링크 수 GPU 백엔드 리프 노드와 스파스파인 노드 간 = 8(리프 노드 수) x 2(리프-스파인 연결당 400GE 링크 수) x 4(스파인 노드 수) = 64 |
GPU 서버와 리프 노드 간, 리프와 스파스파인 노드 간의 링크 속도와 수에 따라 초과 구독 요인이 결정됩니다. 예를 들어, 랩에서 사용할 수 있는 GPU 서버의 수와 위에서 설명한 대로 GPU 백엔드 패브릭에 연결된 방법을 고려하십시오.
서버와 리프 노드 간의 대역폭은 25.6Tbps(표 3)이며, 리프와 스파스파인 노드 간에 사용 가능한 대역폭도 51.2Tbps(표 4)입니다. 즉, 패브릭은 이 트래픽이 100% 스트라이프 간 트래픽인 경우에도 GPU 간의 모든 트래픽을 처리할 수 있는 충분한 용량을 가지고 있으며 4대의 서버를 더 수용할 수 있는 추가 용량을 가지고 있습니다. 4개의 추가 서버를 사용하면 구독 비율은 1:1(초과 구독 없음)이 됩니다.
표 3: 스트라이프당 서버에서 리프 대역폭까지
| 스트라이프당 서버-리프 대역폭 | ||||
|---|---|---|---|---|
| 스트라이프 | 서버 수 스트라이프당 |
400GE 수 서버 Ó 리프 링크 서버당 (리프 노드 수와 동일 & 서버당 GPU 수) |
서버 <=> 리프 링크 대역폭 [Gbps] |
총 서버 <=리프 링크 >개 스트라이프당 대역폭 [Tbps] |
| 1 | 4 | 8 | 400Gbps | 4 x 8 x 400Gbps = 12.8Tbps |
| 2 | 4 | 8 | 400Gbps | 4 x 8 x 400Gbps = 12.8Tbps |
| 합계 서버 <=> 리프 대역폭 |
25.6Tbps | |||
표 4: 스트라이프당 리프-스파인 대역폭
| 리프 노드 - 스파인 노드 스트라이프당 대역폭 | |||||
|---|---|---|---|---|---|
| 스트라이프 | 수 리프 노드 |
스파인 노드 수 | 800GE 수 리프 Ó 스파인 링크 리프 노드당 |
서버 <=> 리프 링크 대역폭 [Gbps] |
대역폭 리프 <=> 스파인 스트라이프당 [Tbps] |
| 1 | 8 | 4 | 1 | 800Gbps | 8 x 4 x 1 x 800Gbps = 25.6Tbps |
| 2 | 8 | 4 | 1 | 800Gbps | 8 x 4 x 1 x 400Gbps = 25.6Tbps |
| 합계 리프 <=> 스파인 대역폭 |
51.2Tbps | ||||
GPU에서 리프 노드로의 연결은 백엔드 GPU 레일 최적화 스트라이프 아키텍처에 설명된 레일 최적화 아키텍처를 따릅니다.
백엔드 GPU 레일 최적화 스트라이프 아키텍처
레일 최적화 스트라이프 아키텍처는 GPU 간의 효율적인 데이터 전송을 제공하며, 특히 합리적인 시간 내에 작업을 완료하기 위해 원활한 데이터 전송이 필요한 AI 대규모 언어 모델(LLM) 학습 워크로드와 같이 계산 집약적인 작업 중에 더욱 그렇습니다. 레일 최적화 토폴로지는 대역폭 경합, 지연 시간, 네트워크 간섭을 최소화하여 성능을 극대화하고 효율적인 데이터 전송을 제공하는 것을 목표로 합니다.
레일 최적화 스트라이프 아키텍처에는 레일과 스트라이프라는 두 가지 중요한 개념이 있습니다.
서버의 GPU는 1-8로 번호가 매겨지며, 숫자는 그림 9와 같이 서버에서 GPU의 위치를 나타냅니다.
레일은 패브릭의 리프 노드 중 하나에서 동일한 순서의 GPU를 연결합니다. 즉, 레일 N은 모든 서버의 위치 N에 있는 GPU를 리프 노드 N에 연결합니다.
그림 9: 레일 최적화 아키텍처 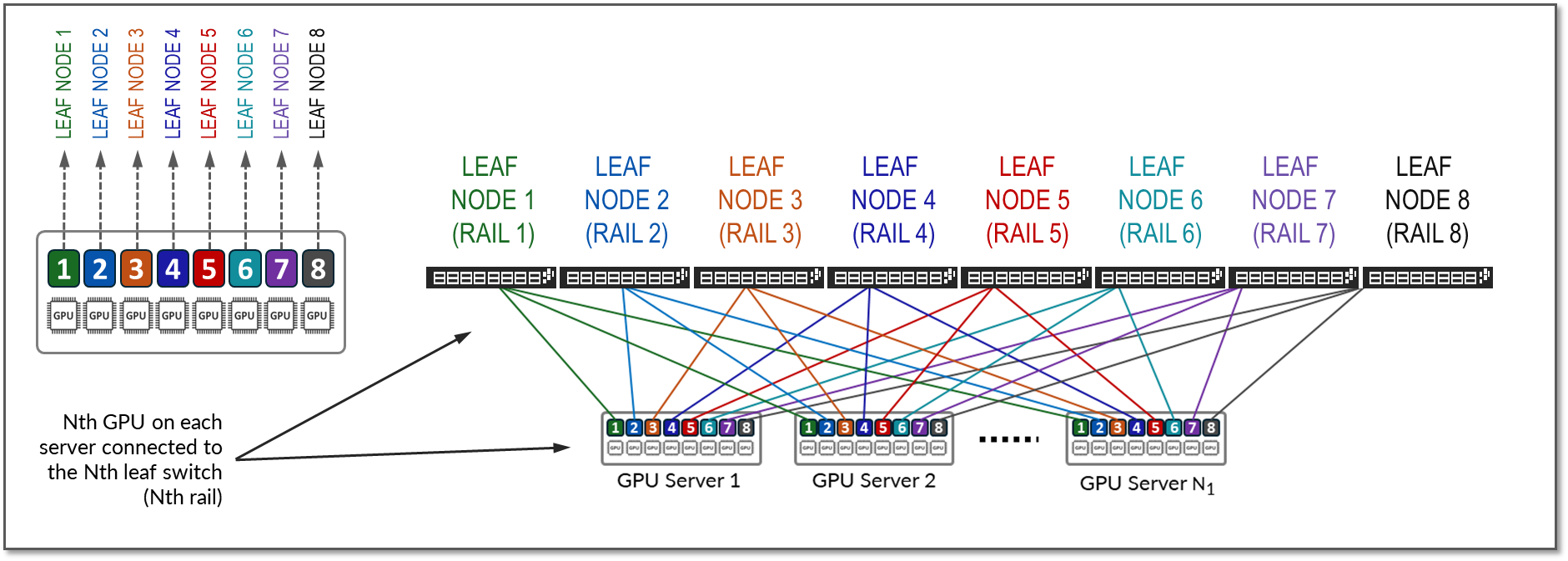 의 레일
의 레일
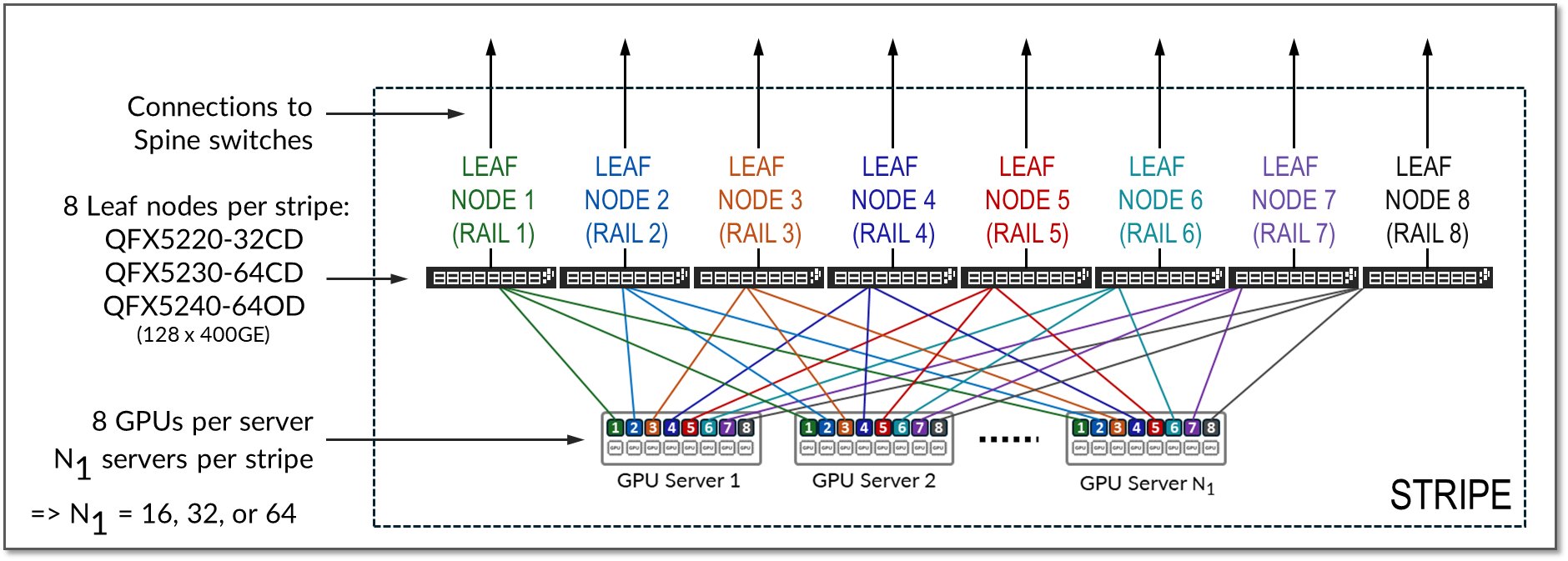
스트라이프는 그림 10과 같이 리프 노드와 GPU 서버 그룹으로 구성된 설계 모듈 또는 빌딩 블록을 의미합니다. 이 모듈을 복제하여 AI 클러스터를 확장할 수 있습니다.
그림 10: 레일 최적화 아키텍처의 스트라이프
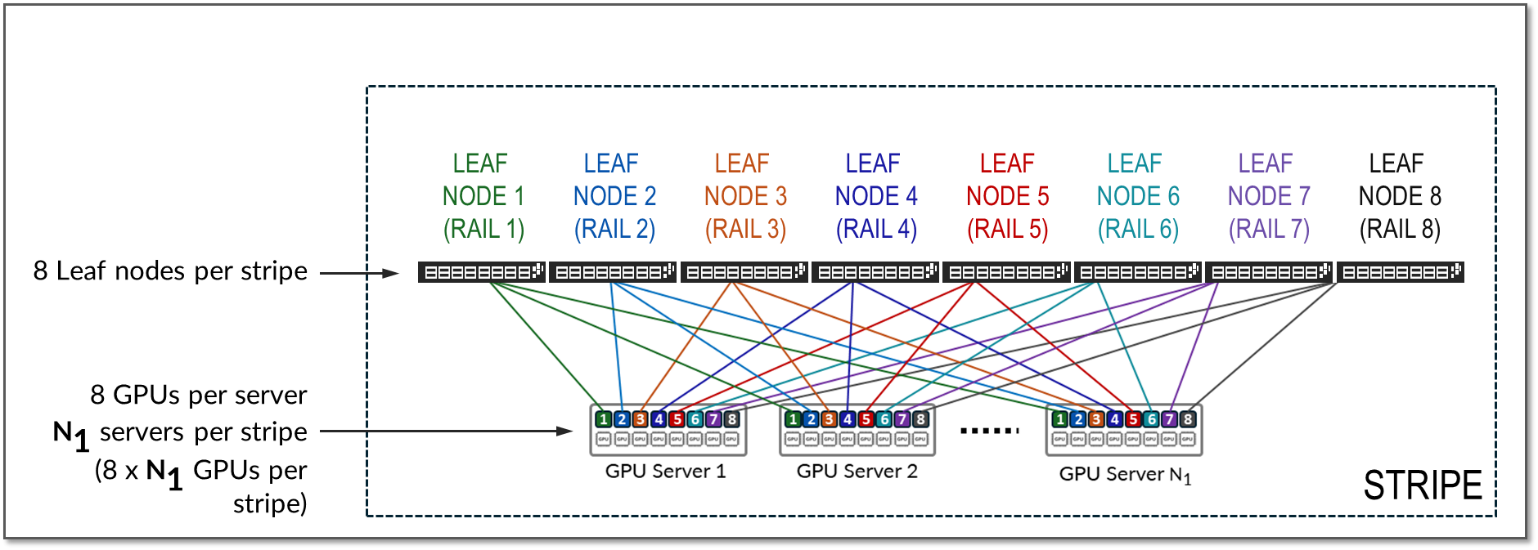
단일 스트라이프의 리프 노드 수 및 단일 스트라이프의 레일 수는 항상 서버당 GPU 수로 정의됩니다. 각 GPU 서버에는 일반적으로 8개의 GPU가 포함됩니다. 따라서 단일 스트라이프에는 일반적으로 8개의 리프 노드(8개의 레일)가 포함됩니다.
레일 최적화 아키텍처에서 단일 스트라이프(그림 7의 N1)에서 지원되는 최대 서버 수는 리프 노드 스위치 모델에서 지원하는 인터페이스의 수와 속도에 따라 제한됩니다. GPU 서버와 리프 노드 간의 총 대역폭이 리프와 스파인 노드 간의 총 대역폭과 일치해야 1:1의 구독 비율을 유지할 수 있기 때문입니다.
리프 노드의 모든 인터페이스가 동일한 속도로 작동한다고 가정하면 인터페이스의 절반은 GPU 서버에 연결하는 데 사용되고 나머지 절반은 스파인 연결에 사용됩니다. 따라서 스트라이프의 최대 서버 수는 각 리프 노드에 있는 전체 인터페이스의 절반으로 계산됩니다. 몇 가지 예가 표 5에 나와 있습니다.
표 5: 스트라이프당 지원되는 최대 GPU 수
| 리프 노드 QFX 스위치 모델 |
최대 400GE 인터페이스 수 스위치당 |
스트라이프당 지원되는 최대 서버 수(1:1 구독) | 서버당 GPU 스트 | 라이프당 지원되는 최대 GPU 수 |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 서버 16개 x 서버당 GPU 8개 = GPU 128개 |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 서버 32개 x GPU 8개/서버 = GPU 256개 |
| QFX5240-64OD | 128 | 128 ÷ 2 = 64 | 8 | 서버 64개 x GPU 8개/서버 = GPU 512개 |
- QFX5220-32CD 스위치는 32개의 400GE 포트를 제공합니다(16개는 서버 연결에 사용되고 16개는 스파인 스파인 노드 연결에 사용됨)
- QFX5230-64CD 스위치는 최대 64개의 400GE 포트를 제공합니다(32개는 서버 연결에 사용되고 32개는 스파인 노드 연결에 사용됨).
- QFX5240-64OD 스위치는 최대 128개의 400GE 포트를 제공합니다(64개는 서버 연결에 사용되고 64개는 스파인 노드 연결에 사용됨). 그림 11을 참조하십시오.
QFX5240-64OD 스위치에는 최대 128 400GE 인터페이스를 위해 2x400GE 포트로 분리할 수 있는 64개의 800GE 포트가 함께 제공됩니다.
그림 11: 레일 최적화 아키텍처에서 스트라이프당 최대 서버 수
지원되는 서버 수를 계산하고 레일과 스트라이프의 개념을 강화하는 방법에 대한 예로, 그림 12와 같이 동일한 속도의 포트가 8개뿐인 가상의 스위치와 각각 8개의 GPU가 있는 GPU 서버를 생각해 보겠습니다.
그림 12. 리프 노드로 8포트 스위치가 지원하는 서버 수의 예입니다. 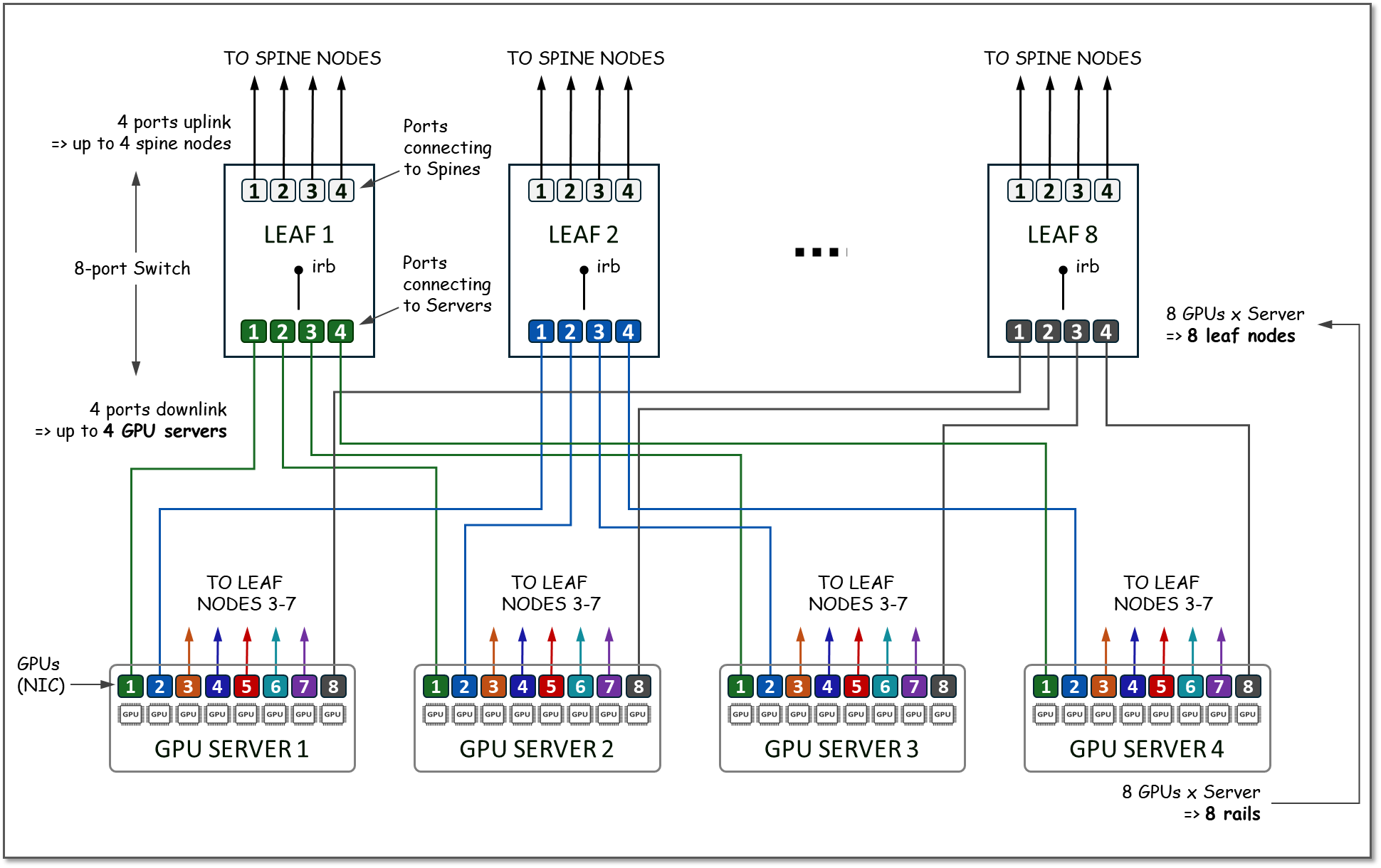
GPU 서버에는 8개의 GPU가 있으므로 리프 노드의 수는 8개가 됩니다. 각 리프 노드에서 4개의 포트는 스파인 노드에 연결하는 데 사용되며(다음 섹션에서 설명하는 대로 확장 목적으로) 4개의 포트는 GPU 서버에 연결하는 데 사용됩니다. 1로 번호가 매겨진 모든 GPU는 리프 노드 1에 연결되고, 2로 번호가 매겨진 모든 GPU는 리프 노드 2에 연결되는 식으로, 각 그룹은 RAIL(총 8개의 RAILS)을 나타내고, 4개의 서버 및 8개의 스위치 그룹은 함께 STRIPE(총 32개의 GPU 포함)를 나타냅니다. 그림 13에 나온 것과 같습니다.
그림 13. 8개의 리프(8포트 스위치) 노드가 있는 스트라이프 및 레일 예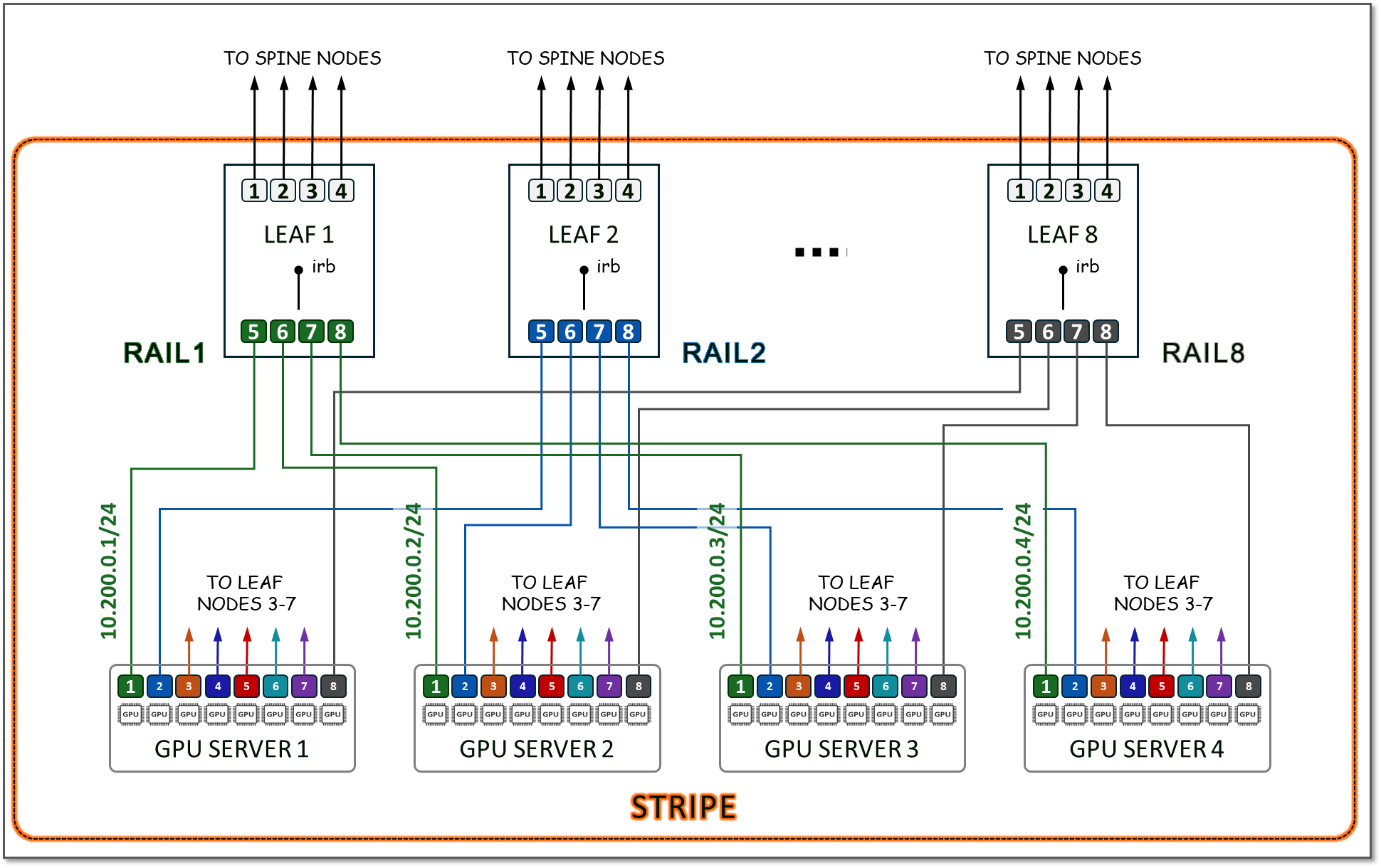
더 큰 규모를 달성하기 위해 여러 줄무늬를 구현할 수 있습니다. 스트라이프는 그림 14와 같이 스트라이프 간 연결을 제공하는 스파인 스위치를 사용하여 연결됩니다.
그림 14: 스파인 노드를 통해 연결된 여러 스트라이프
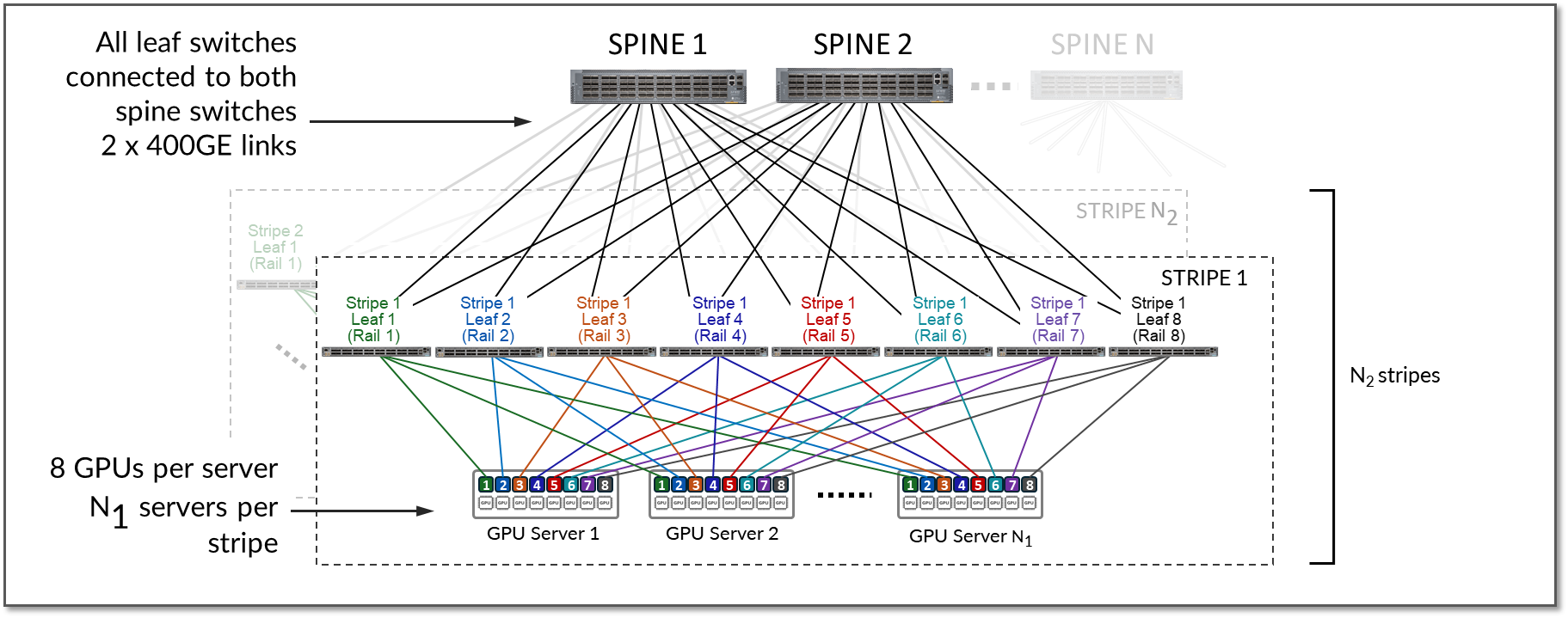
예를 들어, 원하는 GPU 수가 16,000이고 패브릭이 리프 노드로 QFX5230-64CD 또는 QFX5240-64OD를 사용한다고 가정해보겠습니다.
- QFX5240-64OD 리프 노드는 최대 128개의 400Gbps 포트를 지원합니다
- 스트라이프당 최대 서버 수(N1)는 리프 노드가 지원하는 포트 수를 나누어 계산됩니다.
N1 = 128 ÷ 2 = 64
- 스트라이프당 지원되는 최대 GPU 수는 스트라이프당 최대 서버 수(N1)에 각 서버의 GPU 수를 곱하여 계산됩니다.
N1 x 8 = 64 x 8 = 512
- 필요한 스트라이프 수(N2)는 필요한 GPU 수를 스트라이프당 지원되는 최대 GPU 수로 나누어 계산합니다.
N2 = 16000/512 ≈ 31.25개의 줄무늬(32로 반올림)
N2 = 64개의 스트라이프 & N1 개의 서버 = 32인 경우 클러스터는 16,384개의 GPU를 제공할 수 있습니다. N2 가 72 & N1 개의 서버 = 32로 증가하면 클러스터는 18,432개의 GPU를 제공할 수 있습니다.
표 6에 요약된 바와 같이 AI JVD 설정의 스트라이프 는 클러스터 및 스트라이프에 따라 위더 8주니퍼 QFX5220-32CD, QFX5230-64CD 또는 QFX5240-64OD 스위치로 구성됩니다.
표 6. JVD 랩에서 클러스터당 지원되는 최대 GPU 수
| 클러스터 | 스트라이프 | 리프 노드 QFX 모델 | 스트라이프당 지원되는 최대 GPU 수 |
|---|---|---|---|
| 1 | 1 | QFX5230-64CD | 서버 32개 x GPU 8개/서버 = GPU 256개 |
| 1 | 2 | QFX5220-32CD | 서버 16개 x 서버당 GPU 8개 = GPU 128개 |
| 클러스터에서 지원하는 총 GPU 수 = 384개 GPU | |||
| 2 | 1 | QFX5240-64OD | 서버 64개 x GPU 8개/서버 = GPU 512개 |
| 2 | 2 | QFX5240-64OD | 서버 64개 x GPU 8개/서버 = GPU 512개 |
| 클러스터에서 지원하는 총 GPU 수 = 1024개 GPU | |||
로컬 최적화
레일 최적화 토폴로지의 최적화는 GPU 통신을 관리하여 혼잡과 지연을 최소화하고 처리량을 최대화하는 방법을 나타냅니다. 이 최적화 전략의 핵심은 가능하면 트래픽을 로컬로 유지하는 것입니다. GPU 통신이 동일한 레일이나 스트라이프 내, 또는 가능한 경우 동일한 서버 내에서 유지되도록 함으로써 스파인 또는 외부 링크를 트래버스할 필요성이 줄어듭니다. 이는 대기 시간을 줄이고 혼잡을 최소화하며 전반적인 효율성을 향상시킵니다.
트래픽 현지화가 우선시되지만 대규모 GPU 클러스터에서는 스트라이프 간 통신이 필요합니다. 스트라이프 간 통신은 병목 현상과 패킷 손실을 방지하기 위해 사용 가능한 링크에 대한 적절한 라우팅 및 밸런싱 기술을 통해 최적화됩니다. 최적화의 핵심은 토폴로지를 활용하여 트래픽을 가장 짧고 혼잡도가 가장 적은 경로를 따라 전달함으로써 네트워크가 확장되더라도 일관된 성능을 보장하는 데 있습니다.
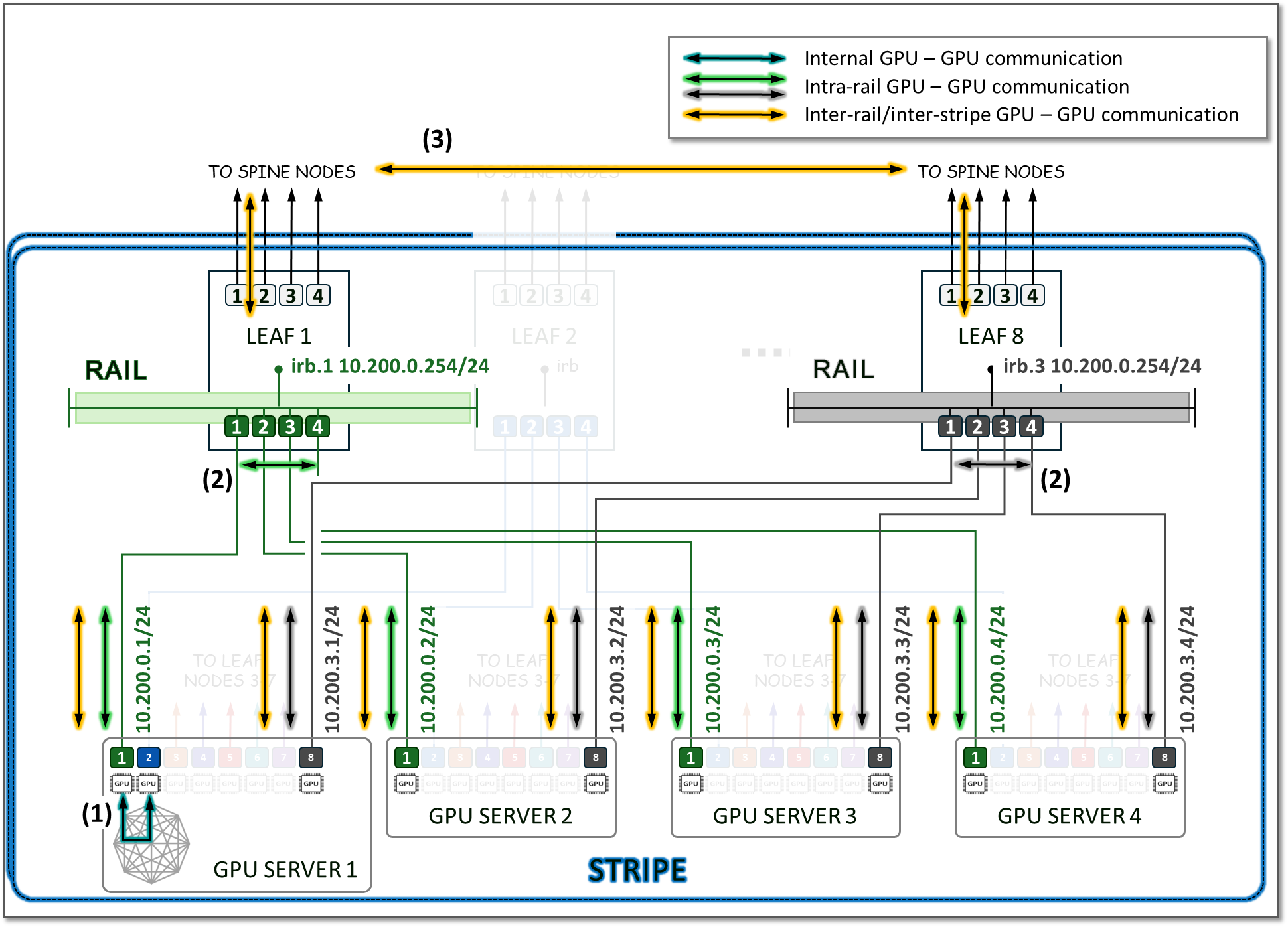
동일한 서버에 있는 GPU 간의 트래픽은 내부 서버 패브릭을 통해 로컬로 전달될 수 있습니다(서버 아키텍처에 따라 다름). 서로 다른 서버에 있는 GPU 간의 트래픽은 GPU 백엔드 인프라 전체에서 동일한 레일(인트라레일) 또는 서로 다른 레일(인터레일/인터스트라이프)에서 발생합니다.
레일 내 트래픽은 로컬 리프 노드에서 처리됩니다. 이러한 설계에 따라 서로 다른 서버(그러나 동일한 스트라이프에 있음)에 있는 GPU 간의 데이터는 항상 동일한 레일과 하나의 단일 스위치에서 이동되는 반면, 서로 다른 레일에 있는 GPU 간 데이터는 스파인을 통해 전달되어야 합니다.
이전 섹션에서 제공한 스트라이프당 서버 수를 계산하는 예제를 사용하여 다음 방법을 확인할 수 있습니다.
- 서버 1의 GPU 1과 GPU 2 간의 통신은 서버의 내부 패브릭(1)에서 발생합니다.
- 서버 1-4의 GPU 1 간의 통신과 서버 1-4의 GPU 8 간의 통신은 각각 리프 1과 리프 8에서 발생합니다(2).
- GPU 1과 GPU 8(서버 1-4) 간의 통신은 리프1, 스파인 노드 및 리프8(3)에서 발생합니다
이것은 그림 15에 설명되어 있습니다.
그림 15: 레일 간 vs. 레일 내 GPU-GPU 통신
대부분의 벤더는 로컬 최적화 를 구현하여 GPU 간 트래픽의 지연 시간을 최소화합니다. 동일한 수의 GPU 간 트래픽은 레일 내부로 유지됩니다. 그림 16은 서버 1의 GPU1이 서버 2의 GPU1과 통신하는 예를 보여줍니다. 트래픽은 리프 노드 1에 의해 전달되며 레일 1 내에 유지됩니다.
또한 PXN으로 알려진 NCCL 기능을 활성화하여 서버 내 GPU 간의 내부 패브릭 연결을 활용할 수 있습니다. 여기서 데이터는 먼저 대상과 동일한 레일에 있는 GPU로 이동한 다음 레일을 넘지 않고 대상으로 전송됩니다. 예를 들어 서버 1의 GPU4가 서버 2의 GPU5와 통신하려고 하고 서버 1의 GPU5가 내부 패브릭에서 사용할 수 있는 경우 트래픽은 자연스럽게 이 경로를 선호하여 성능을 최적화하고 GPU 간 통신을 레일 내부로 유지합니다.
그림 16: PXN을 사용하는 두 서버 간의 GPU 간 레일 간 통신.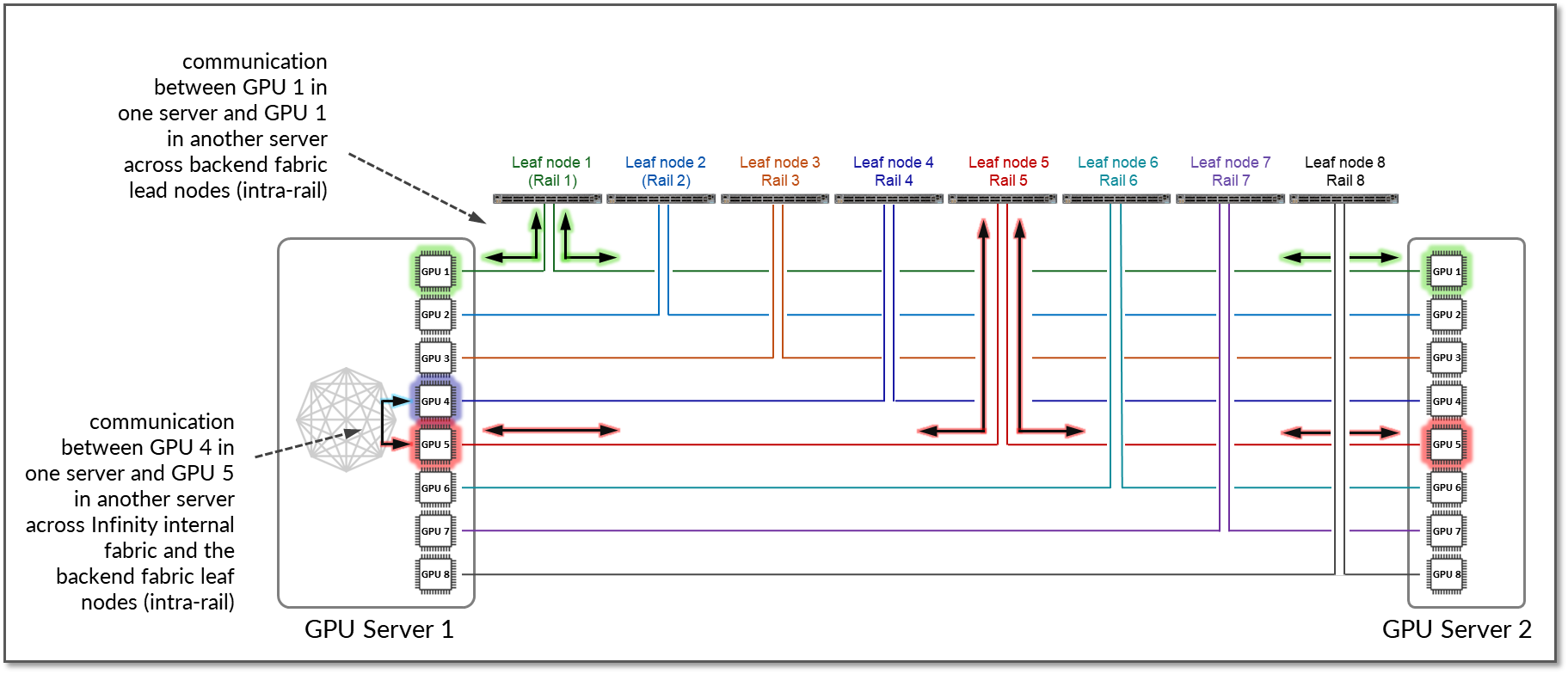
워크로드나 서비스 제약 때문에 또는 PXN이 비활성화되어 이 경로를 사용할 수 없는 경우 트래픽은 RDMA(오프노드 NIC 기반 통신)를 사용합니다. 이러한 경우 그림 17과 같이 서버 1의 GPU4는 RDMA를 사용하여 NIC를 통해 직접 데이터를 전송하여 서버 2의 GPU5와 통신하고, 이 데이터는 패브릭을 통해 전달됩니다.
그림 17: PXN이 없는 두 서버 간의 GPU 간 레일 간 통신. 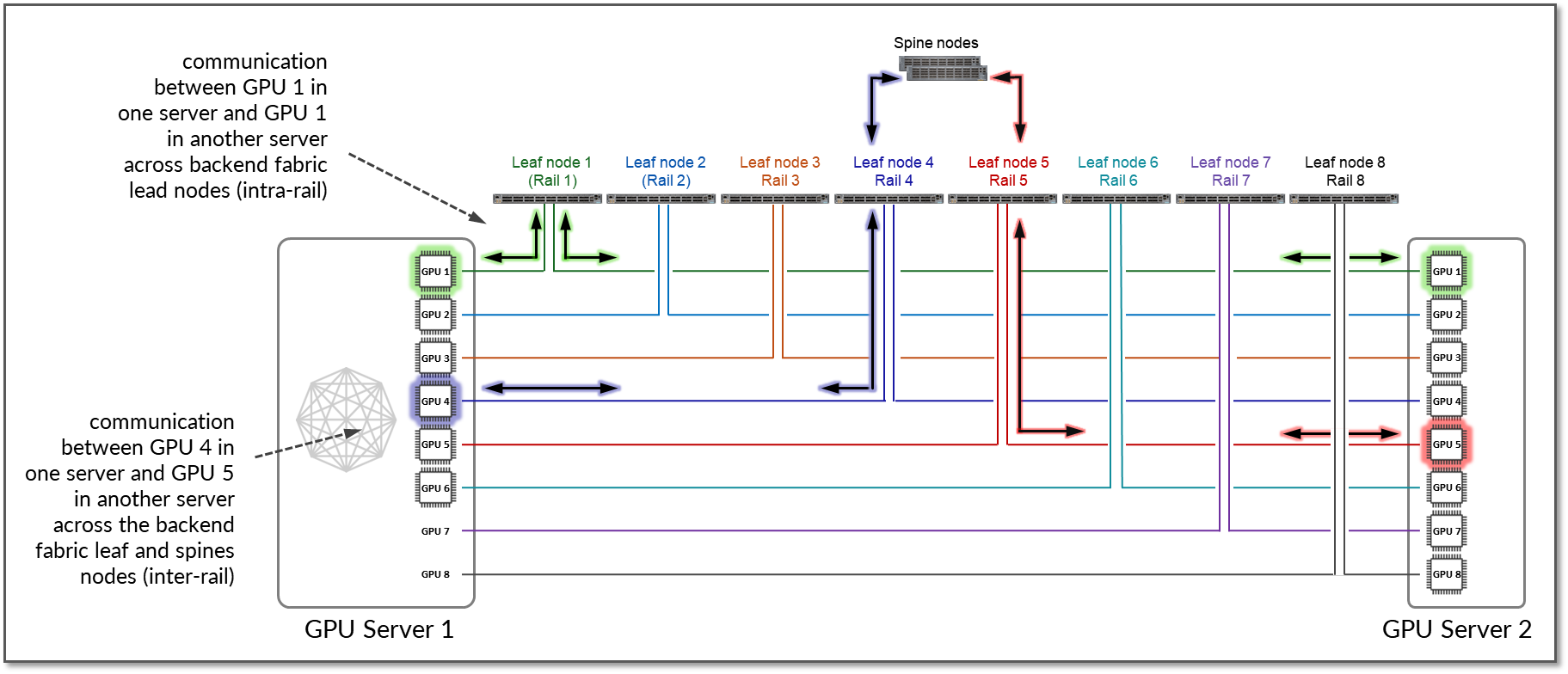
PXN은 NCCL(NVIDIA Collective Communication Library)이지만 AMD ROCm Communication Collectives Library에서도 지원합니다. PXN을 활성화 또는 비활성화하려면 변수 NCCL_PXN_DISABLE를 사용합니다.
GPU 멀티테넌시를 통한 레일 정렬 및 로컬 최적화 고려 사항
GPU 패브릭에서 멀티테넌시를 구현할 때 GPU가 할당되는 방법과 GPU 간의 통신이 처리되는 방식과 관련하여 추가적인 고려 사항이 적용됩니다.
서버 격리 모델
서버 격리 모델에서 서버의 모든 GPU는 단일 테넌트 전용입니다. 이 모델에서는 동일한 서버 내의 GPU 간의 직접 통신이 적절하고 바람직합니다. 서로 다른 테넌트에 할당된 서버를 연결하는 네트워크 인터페이스를 리프 노드의 서로 다른 VRF에 배치하는 것만으로도 네트워크 전체에서 테넌트를 분리하는 데 충분하지만 GPU 간 통신도 고려해야 합니다. 로컬 최적화는 GPU 간 통신이 최적의 내부 경로를 따르도록 보장합니다.
-
- 동일한 서버 내의 GPU는 서버의 내부 메커니즘을 사용하여 통신합니다.
- 서로 다른 서버에 있지만 동일한 스트라이프에 연결된 GPU는 리프 노드 간에 통신할 수 있습니다.
- 서로 다른 스트라이프에 연결하는 서버에 위치한 GPU는 스파인 레이어를 통해 통신하며, 여기서 트래픽은 VXLAN에 캡슐화되어 EVPN/VXLAN 패브릭을 통해 라우팅됩니다.
이 섹션의 예에서는 GPU 간의 가능한 데이터 경로를 보여 줍니다. 실제 경로는 선택한 집단(All-Gather, All-Reduce, All-To-All 등) 및 토폴로지 알고리즘(링, 트리 등)에 따라 달라집니다. 또한 작업이 실행될 때 효율성을 높이기 위해 구축된 서로 다른 경로를 따르는 동시에 여러 토폴로지(예: 여러 링)가 있을 수 있습니다. 실제 경로는 예에 표시된 것처럼 slurm 로그에서 찾을 수 있습니다.
-
jnpr@headend-svr-1:/mnt/nfsshare/logs/nccl/H100-RAILS-ALL/06102025_19_35_46$ cat slurm-25432.out | egrep Channel H100-01:3179628:3180857 [0] NCCL INFO Channel 00/16 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 H100-01:3179628:3180857 [0] NCCL INFO Channel 01/16 : 0 3 2 9 15 14 13 12 8 11 10 1 7 6 5 4 H100-01:3179628:3180857 [0] NCCL INFO Channel 02/16 : 0 3 10 15 14 13 12 9 8 11 2 7 6 5 4 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 03/16 : 0 11 15 14 13 12 10 9 8 3 7 6 5 4 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 04/16 : 0 7 6 5 12 11 10 9 8 15 14 13 4 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 05/16 : 0 4 7 6 13 11 10 9 8 12 15 14 5 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 06/16 : 0 5 4 7 14 11 10 9 8 13 12 15 6 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 07/16 : 0 6 5 4 15 11 10 9 8 14 13 12 7 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 08/16 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 H100-01:3179628:3180857 [0] NCCL INFO Channel 09/16 : 0 3 2 9 15 14 13 12 8 11 10 1 7 6 5 4 H100-01:3179628:3180857 [0] NCCL INFO Channel 10/16 : 0 3 10 15 14 13 12 9 8 11 2 7 6 5 4 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 11/16 : 0 11 15 14 13 12 10 9 8 3 7 6 5 4 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 12/16 : 0 7 6 5 12 11 10 9 8 15 14 13 4 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 13/16 : 0 4 7 6 13 11 10 9 8 12 15 14 5 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 14/16 : 0 5 4 7 14 11 10 9 8 13 12 15 6 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 15/16 : 0 6 5 4 15 11 10 9 8 14 13 12 7 3 2 1 H100-02:2723777:2725118 [2] NCCL INFO Channel 00/0 : 10[2] -> 11[3] via P2P/IPC H100-02:2723779:2725122 [4] NCCL INFO Channel 00/0 : 12[4] -> 13[5] via P2P/IPC H100-02:2723778:2725124 [3] NCCL INFO Channel 00/0 : 11[3] -> 12[4] via P2P/IPC H100-02:2723780:2725121 [5] NCCL INFO Channel 00/0 : 13[5] -> 14[6] via P2P/IPC H100-02:2723781:2725125 [6] NCCL INFO Channel 00/0 : 14[6] -> 15[7] via P2P/IPC H100-02:2723776:2725123 [1] NCCL INFO Channel 00/0 : 9[1] -> 10[2] via P2P/IPC H100-02:2723777:2725118 [2] NCCL INFO Channel 08/0 : 10[2] -> 11[3] via P2P/IPC H100-02:2723775:2725119 [0] NCCL INFO Channel 00/0 : 7[7] -> 8[0] [receive] via NET/IBext/0/GDRDMA H100-02:2723779:2725122 [4] NCCL INFO Channel 08/0 : 12[4] -> 13[5] via P2P/IPC H100-02:2723780:2725121 [5] NCCL INFO Channel 08/0 : 13[5] -> 14[6] via P2P/IPC H100-02:2723782:2725120 [7] NCCL INFO Channel 00/0 : 15[7] -> 0[0] [send] via NET/IBext/0(8)/GDRDMA H100-02:2723775:2725119 [0] NCCL INFO Channel 08/0 : 7[7] -> 8[0] [receive] via NET/IBext/0/GDRDMA H100-02:2723775:2725119 [0] NCCL INFO Channel 00/0 : 8[0] -> 9[1] via P2P/IPC --more---
여기서:
X[Y] -> A[B]:
- X 소스 GPU 글로벌 인덱스입니다.
- Y 로컬 GPU 인덱스(노드 내).
- 대상 GPU 글로벌 인덱스입니다.
- B 로컬 GPU 인덱스입니다.
[보내기] / [받기]: 로그를 쓰는 프로세스의 관점에서 바라본 방향입니다.
NET/IBext/N 또는 NET/IBext/N(P):
- N=InfiniBand 인터페이스 인덱스(N)
- P(괄호 안) = NIC 포트 또는 피어 순위.
GDRDMA: GPUDirect RDMA는 데이터가 CPU의 개입 없이 RDMA 지원 NIC를 통해 GPU의 메모리 간에 직접 이동한다는 것을 의미합니다. 이는 지연 시간과 대역폭에 최적입니다. PCI Express의 표준 기능을 사용하여 GPU와 타사 피어 디바이스 간의 직접 데이터 교환을 지원합니다. Mellanox 및 기타 RDMA 지원 NIC가 NIC RDMA 경로를 사용하여 CUDA 메모리를 직접 읽고 쓸 수 있도록 하는 nv_peer_mem라는 커널 모듈을 기반으로 합니다. NCCL은 PCIe, NVLink 및 NVIDIA Mellanox 네트워크를 통해 고대역폭 및 저지연에 최적화된 루틴을 제공합니다.
P2P/IPC: NVIDIA NCCL(Collective Communications Library)의 P2P(Point-to-Point) 전송입니다. 이를 통해 GPU는 호스트, CPU 또는 네트워크를 거치지 않고 서로 직접 통신할 수 있습니다. NCCL은 토폴로지를 인식하고 애플리케이션에 쉽게 통합할 수 있는 GPU 간 통신 프리미티브를 제공합니다.
예 1
그림 18에 설명된 예를 생각해 보겠습니다. 여기서 테넌트 A는 동일한 스트라이프에 서버 4와 서버 5가 할당되고 테넌트 B에게는 동일한 스트라이프에 서버 1, 서버 2 및 서버 3이 할당되었습니다.
그림 18: 서버 격리 모델 GPU 간 통신 예제 1
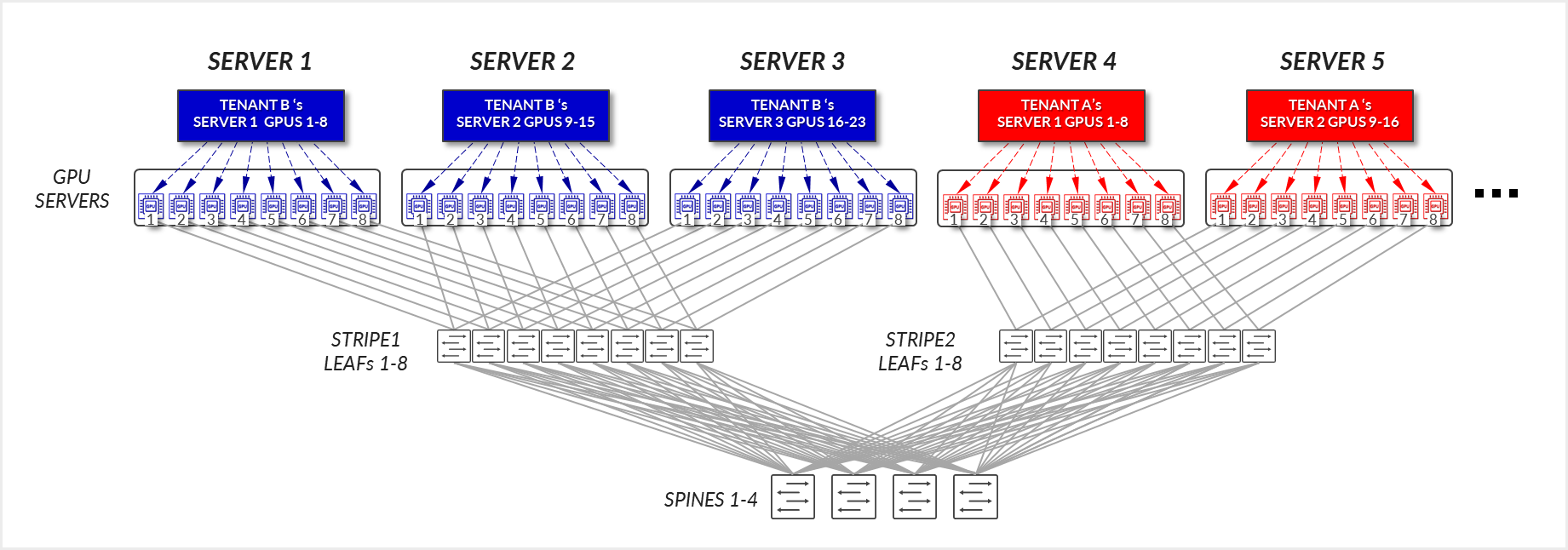
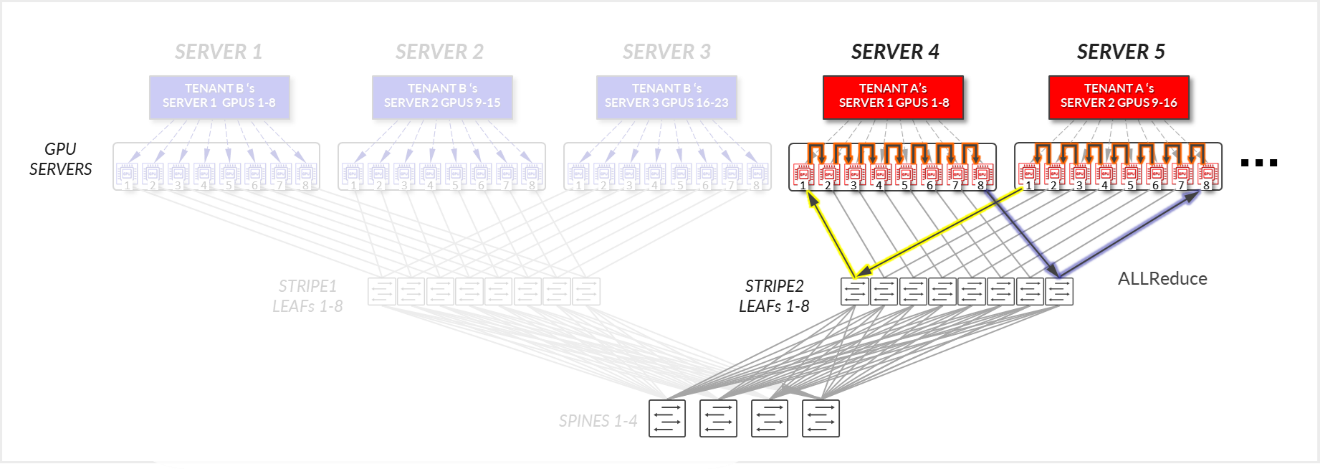
테넌트 A의 경우:
- SERVER 4의 GPU 1-8 및 SERVER 5의 GPU 1-8은 로컬 최적화 섹션에 설명된 대로 해당 서버 내에서 내부적으로 통신합니다.
- SERVER 4의 GPU 1 및 8은 리프 및 스파인 노드을 통해 SERVER 5의 GPU 1 및 8과 통신합니다. - 레일 내부(트래픽은 리프 노드 수준에서 유지됨).
그림 19: 서버 격리 모델 GPU 간 통신 예제 1 – 테넌트 A
-
- 스파인 노드를 통과하는 트래픽 없이 테넌트 A에 할당된 16개의 GPU를 상호 연결하는 링 논리적 토폴로지가 어떻게 설정되는지 확인할 수 있습니다.
그림 20: 서버 격리 모델 GPU 간 통신 예제 1 – 테넌트 A 링 토폴로지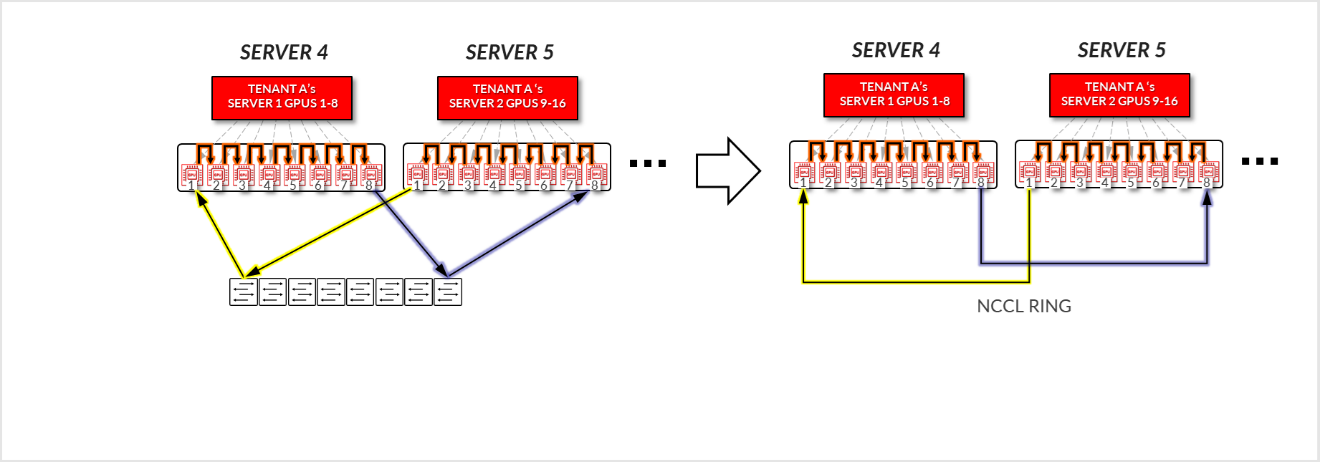
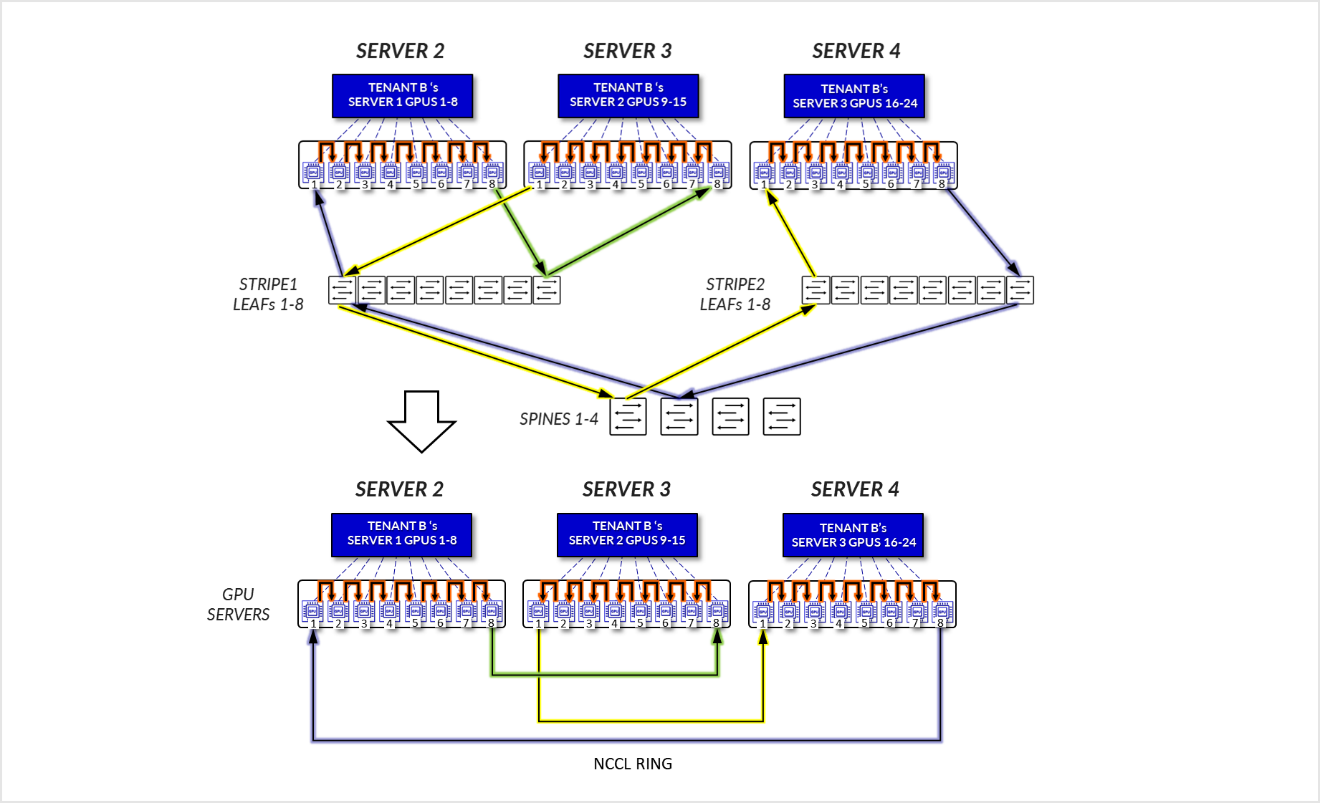
테넌트 B의 경우:
- GPU 1-8 SERVER 1, SERVER 2의 GPU 1-8 및 SERVER3의 GPU 1-8은 로컬 최적화 섹션에 설명된 대로 해당 서버 내에서 내부적으로 통신합니다.
- SERVER 1의 GPU 1은 통신하고, SERVER 3의 GPU 1은 리프 노드를 통해 서로 통신합니다. - 레일 내부(트래픽은 리프 노드 수준에 유지됨).
- SERVER 1의 GPU 8은 리프 노드를 통해 서로 통신합니다. SERVER 3의 GPU 8은 리프 노드를 통해 서로 통신합니다. - 레일 내부(트래픽은 리프 노드 수준에 유지됨).
- SERVER 1의 GPU 8 및 SERVER 2의 GPU 1은 리프 및 스파스파인 노드를 통해 통신합니다. - 레일 간. 이것은 반지를 완성하는 데 필요합니다.
그림 21: 서버 격리 모델 GPU 간 통신 예제 1 – 테넌트 B
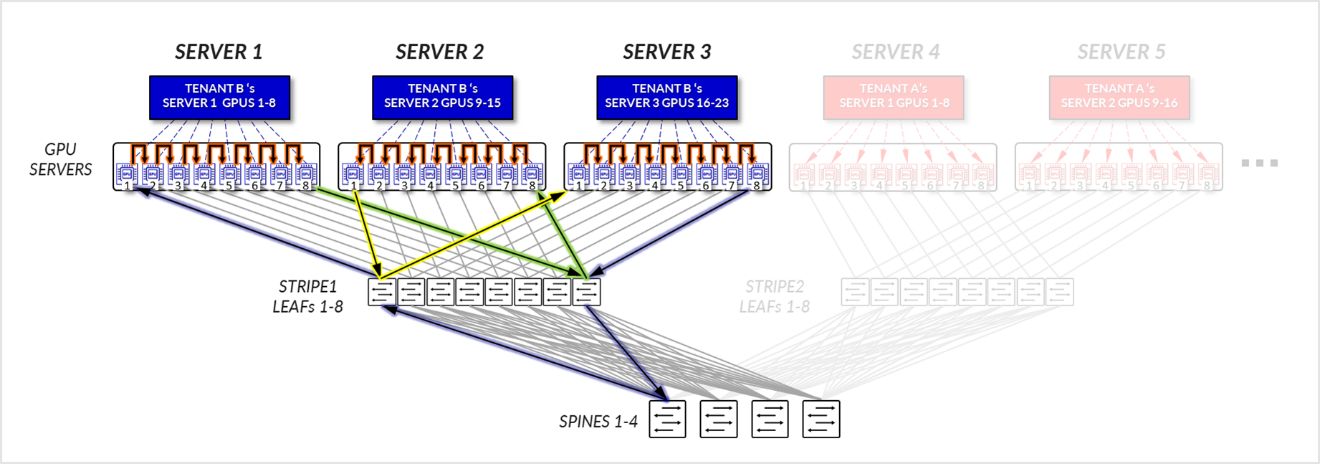
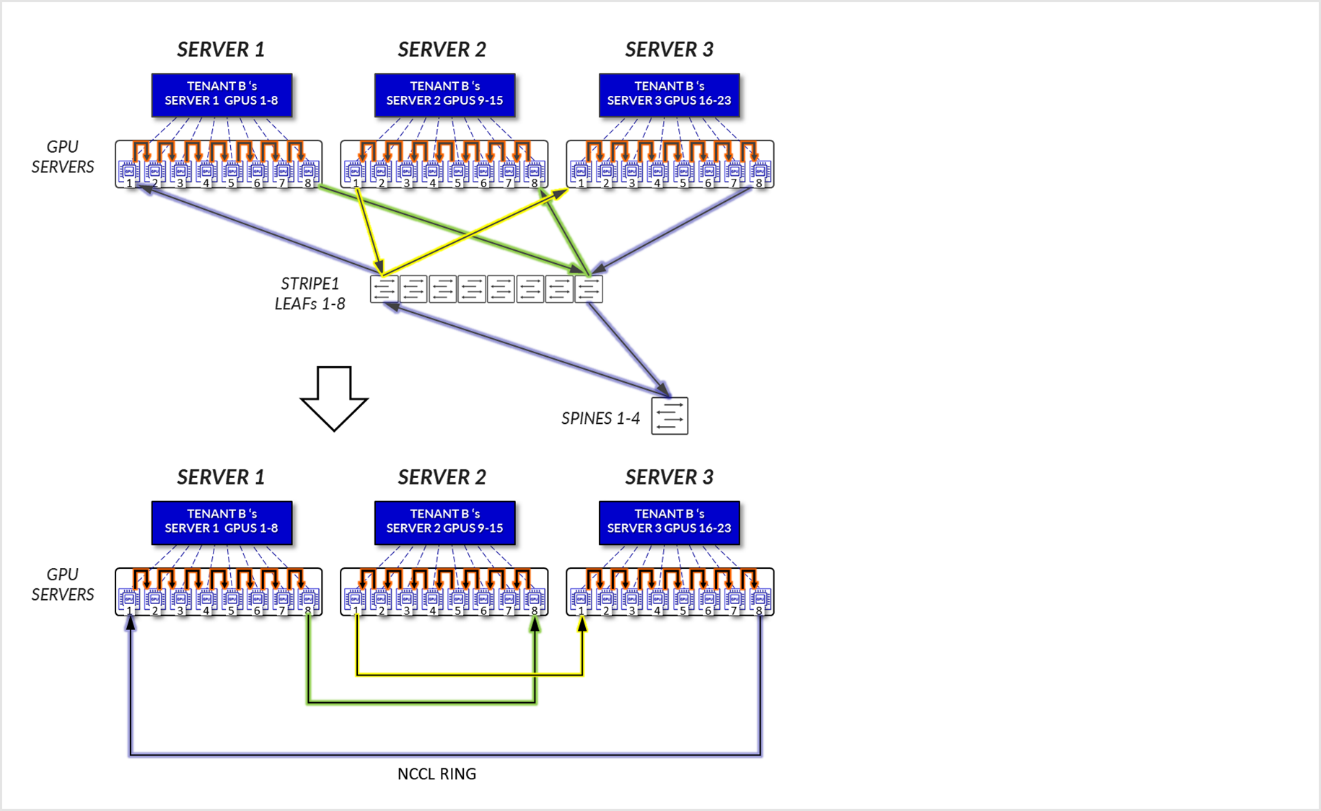
그림 22: 서버 격리 모델 GPU-GPU 통신 예제 1 – 테넌트 B 링 토폴로지
예 2
이제 그림 23에 설명된 예를 살펴보겠습니다. 여기서 테넌트 A는 두 개의 서로 다른 스트라이프에서 서버 1과 서버 5가 할당되었고, 테넌트 B는 동일한 스트라이프에 서버 2와 서버 3, 서버 4는 다른 스트라이프에 할당되었습니다.
그림 23: 서버 격리 모델 GPU 간 통신 예제 2
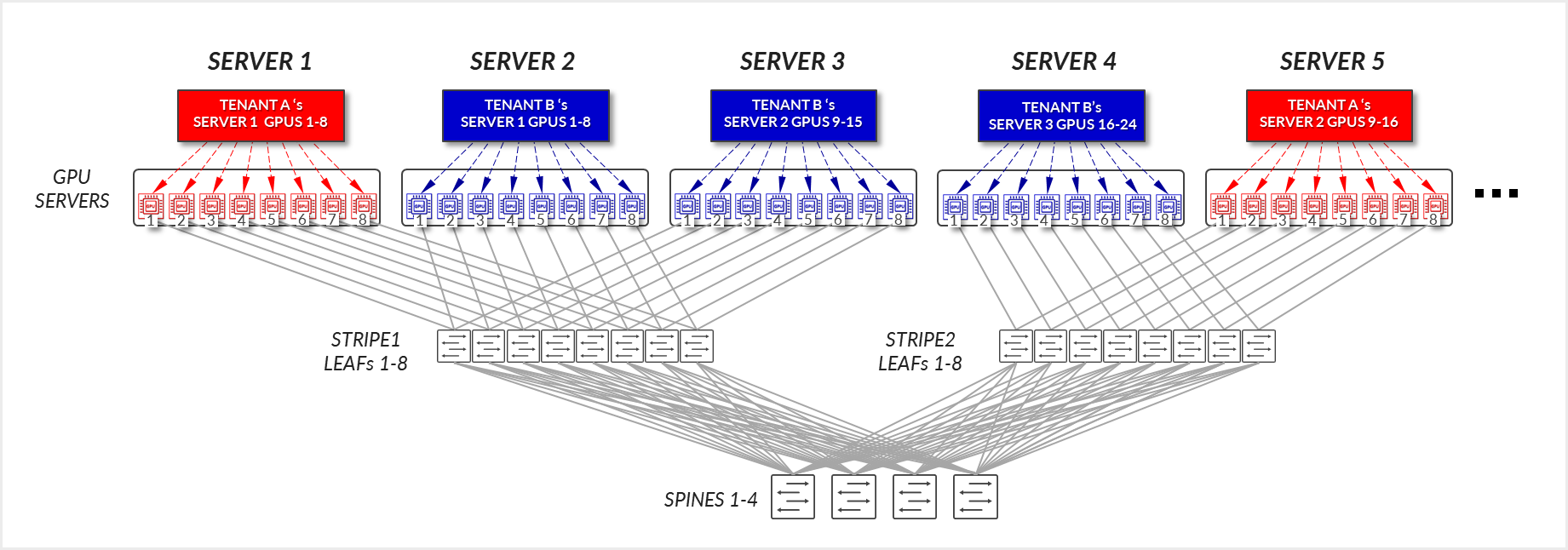
테넌트 A의 경우:
- SERVER 1의 GPU 1-8 및 SERVER 5의 GPU 1-8은 해당 서버 내에서 내부적으로 통신합니다.
- SERVER 1의 GPU 1 및 SERVER 5의 GPU 1은 리프 및 스파스파인 노드 - 스트라이프 간 트래픽을 통해 통신합니다.
- SERVER 1의 GPU 8 및 SERVER 5의 GPU 8은 리프 및 스파스파인 노드 - 스트라이프 간 트래픽을 통해 통신합니다. 이것은 반지를 완성하는 데 필요합니다.
그림 24: 서버 격리 모델 GPU 간 통신 예제 2 – 테넌트 A
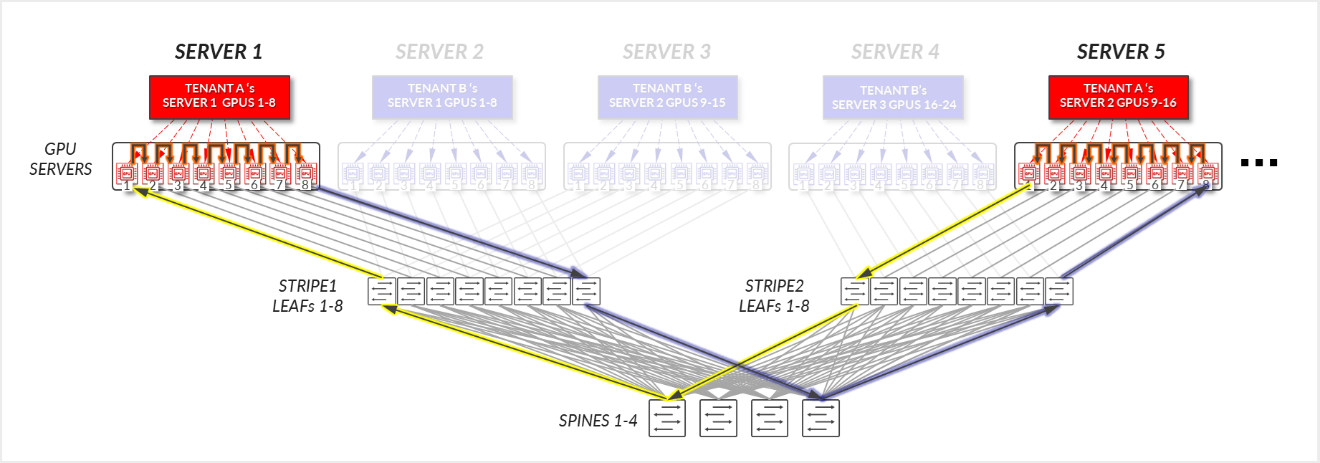
그림 25: 서버 격리 모델 GPU 간 통신 예제 2 – 테넌트 A 링 토폴로지
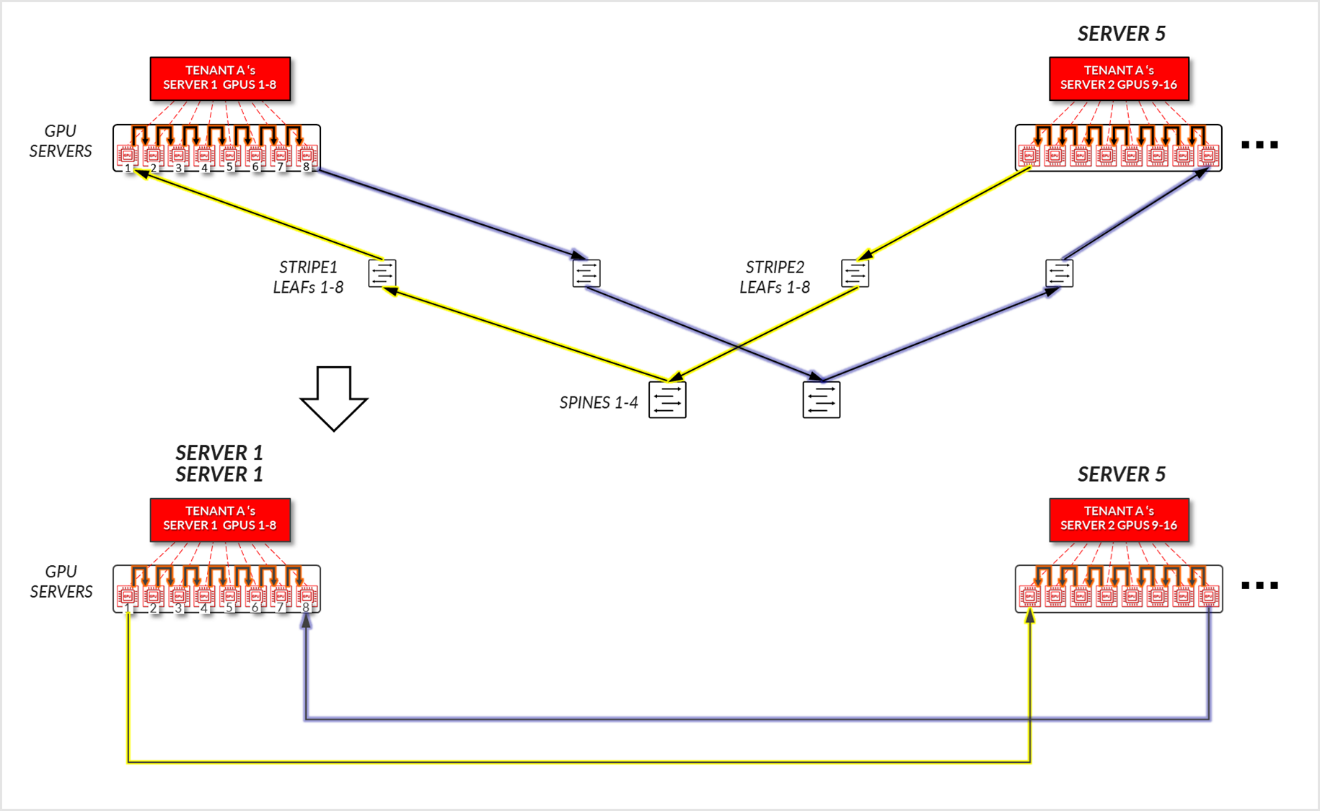
테넌트 B의 경우:
- GPU 1-8 SERVER 2, SERVER 3의 GPU 1-8 및 SERVER4의 GPU 1-8은 해당 서버 내에서 내부적으로 통신합니다.
- SERVER 2의 GPU 1과 SERVER 4의 GPU 1은 리프 및 스파스파인 노드 - 스트라이프 간 트래픽을 통해 통신합니다.
- SERVER 4의 GPU 8 및 SERVER 3의 GPU 8은 리프 및 스파스파인 노드 - 스트라이프 간 트래픽을 통해 통신합니다.
- SERVER 3의 GPU 1과 SERVER 2의 GPU 8은 리프와 스파스파인 노드(레일 간)에서 통신합니다. 이것은 반지를 완성하는 데 필요합니다.
그림 26: 서버 격리 모델 GPU 간 통신 예제 2 – 테넌트 B
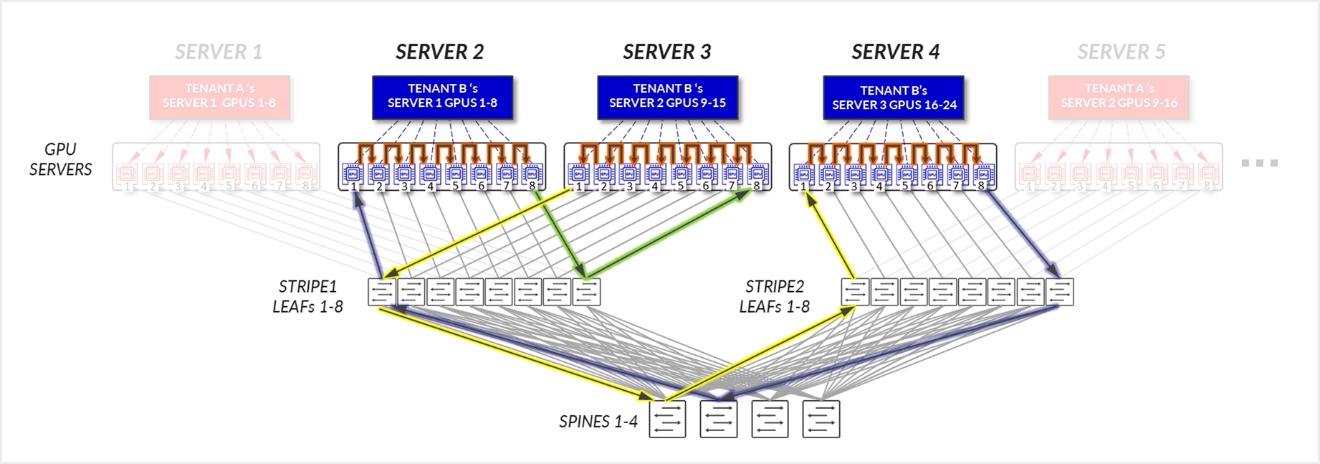
그림 27: 서버 격리 모델 GPU 간 통신 예제 2 – 테넌트 B 링 토폴로지
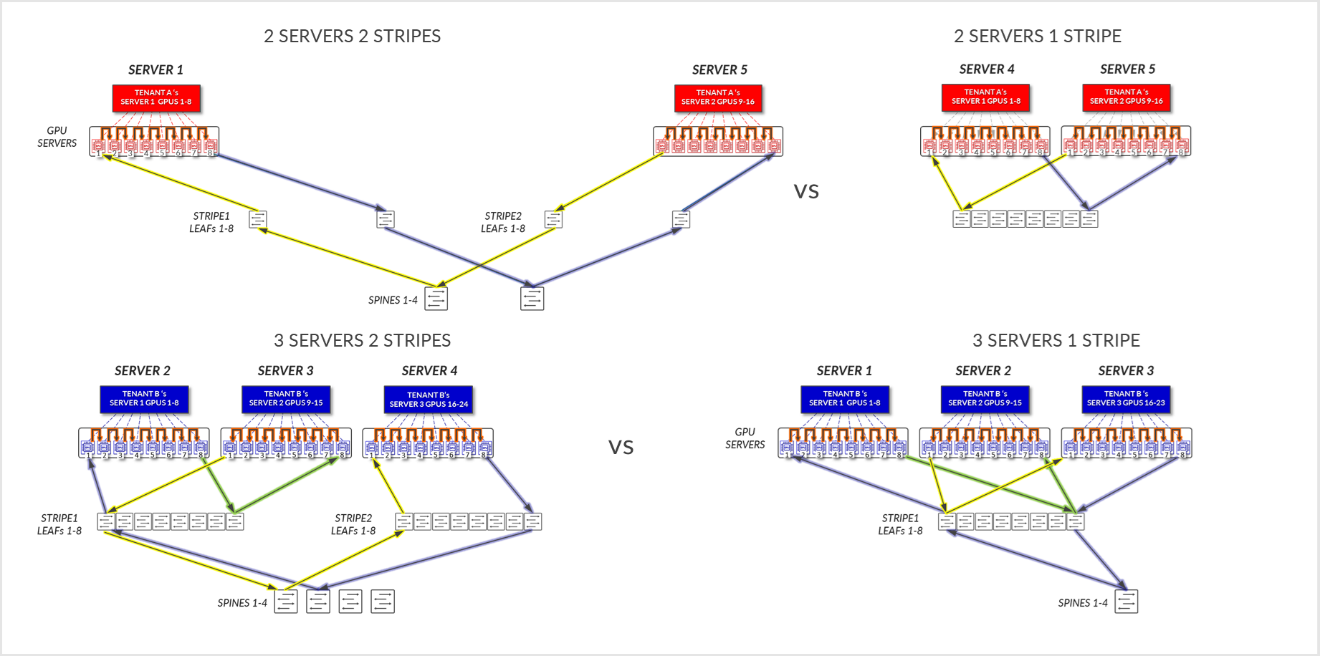
예제 1과 2의 데이터 흐름을 비교하면 테넌트에 서버를 할당하면 작업 성능에 어떻게 영향을 미칠 수 있는지 알 수 있습니다.
그림 28: 동일한 스트라이프의 서버와 다른 스트라이프의 서버를 사용한 서버 격리
GPU 격리 모델
GPU 격리 모델에서는 동일한 서버의 서로 다른 GPU를 서로 다른 테넌트에 할당할 수 있습니다. 또한 테넌트에는 여러 스트라이프에 걸쳐 여러 서버의 GPU가 할당될 수 있습니다. 서버 격리 모델의 경우 할당된 GPU가 있는 위치가 경로와 잠재적으로 성능에 영향을 미칩니다.
예 1
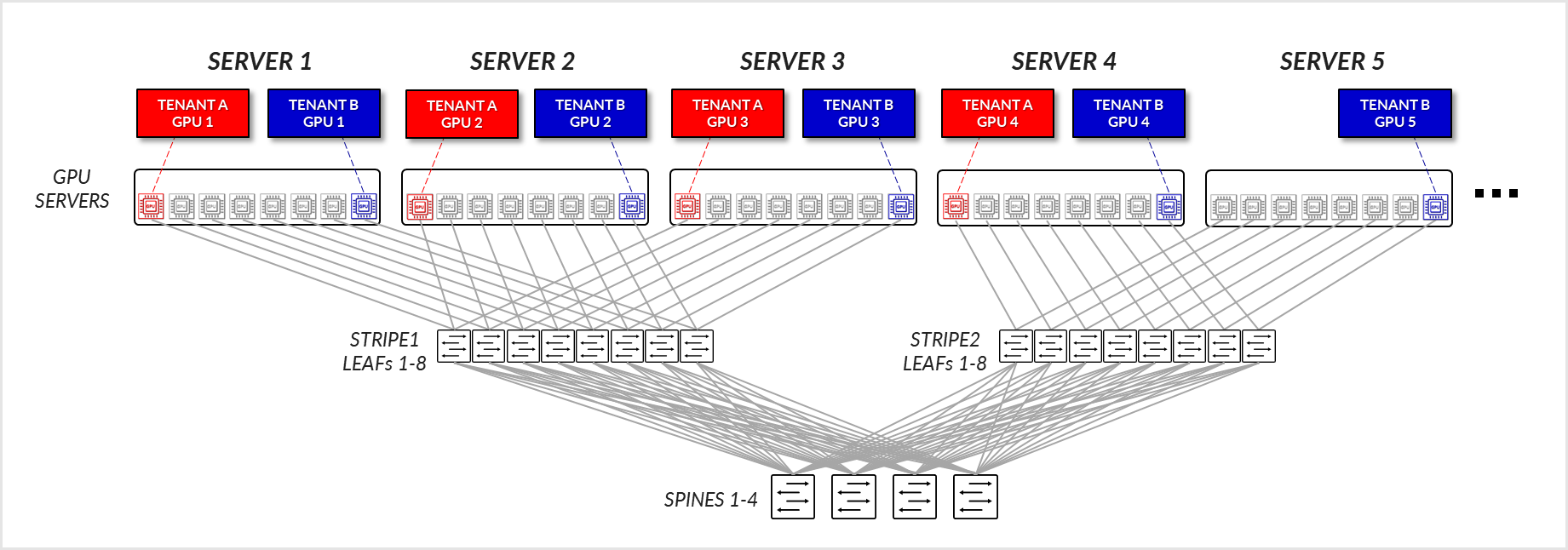
그림 29에 설명된 예를 생각해 보겠습니다. 여기서 테넌트 A는 서버 1-4에서 GPU1이 할당되고 테넌트 B는 서버 1-5에서 GPU8이 할당되었습니다.
그림 29: GPU 격리 모델 GPU 간 통신 예제 1
테넌트 A의 경우:
- 테넌트 A의 GPU 1, 2 및 3은 연결된 리프 노드에서 서로 통신합니다. (철도 내)
- 테넌트 A의 GPU 1, 2 및 3은 리프 및 스파스파인 노드를 통해 GPU 4와 통신합니다.
그림 30: GPU 격리 모델 GPU-GPU 통신 예제 1 – 테넌트 A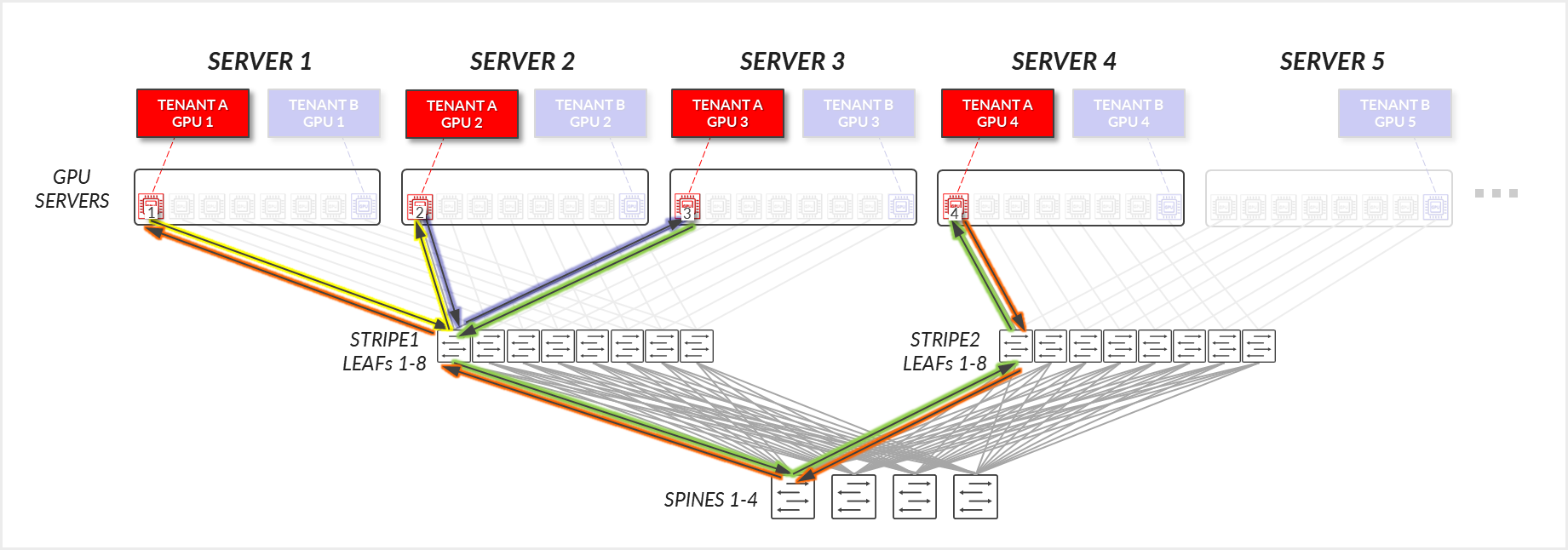
그림 31: GPU 격리 모델 GPU 간 통신 예제 1 – 테넌트 A 링 토폴로지
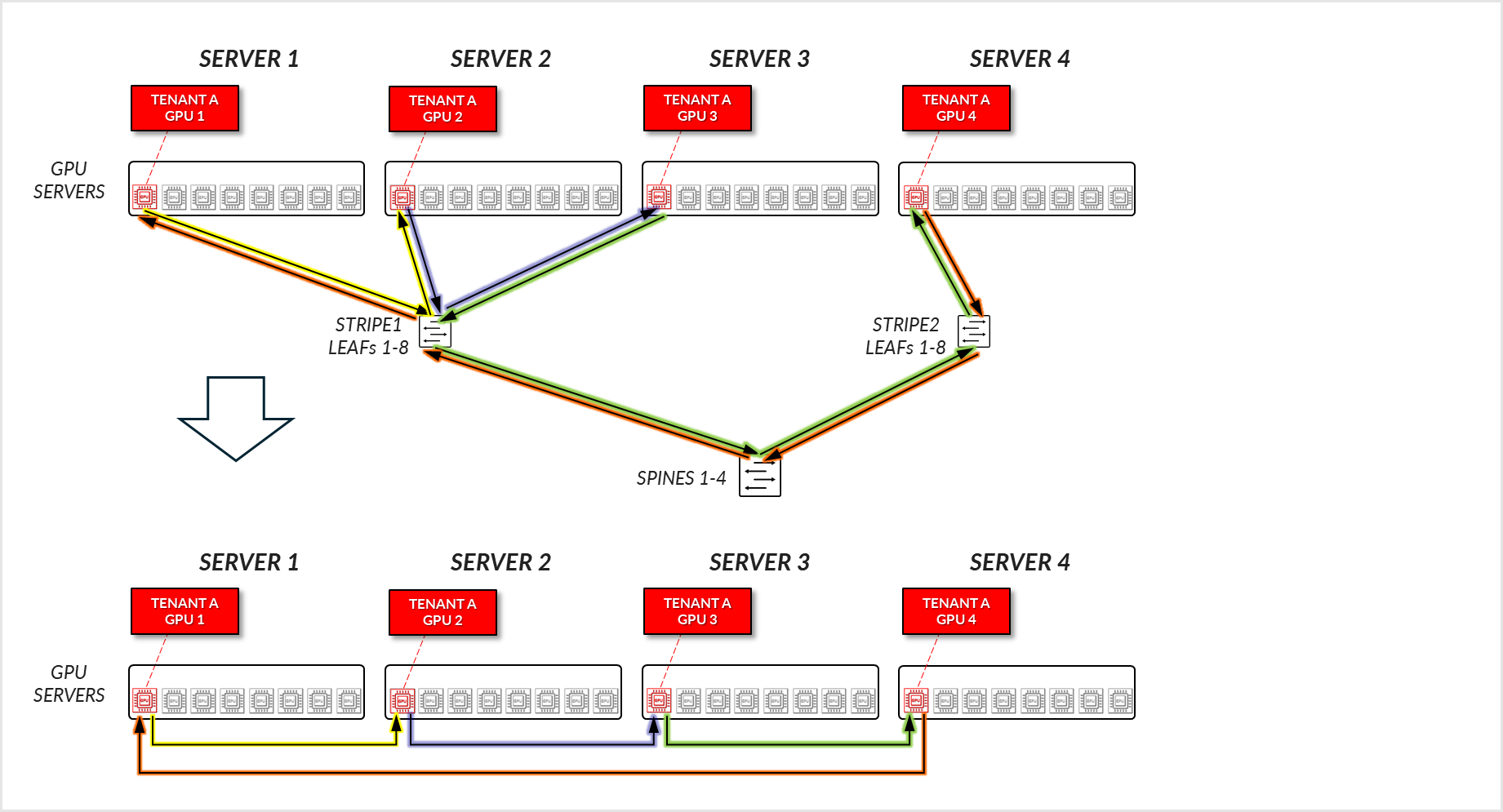
테넌트 B의 경우, 유사한 통신 경로가 설정됩니다.
예 2
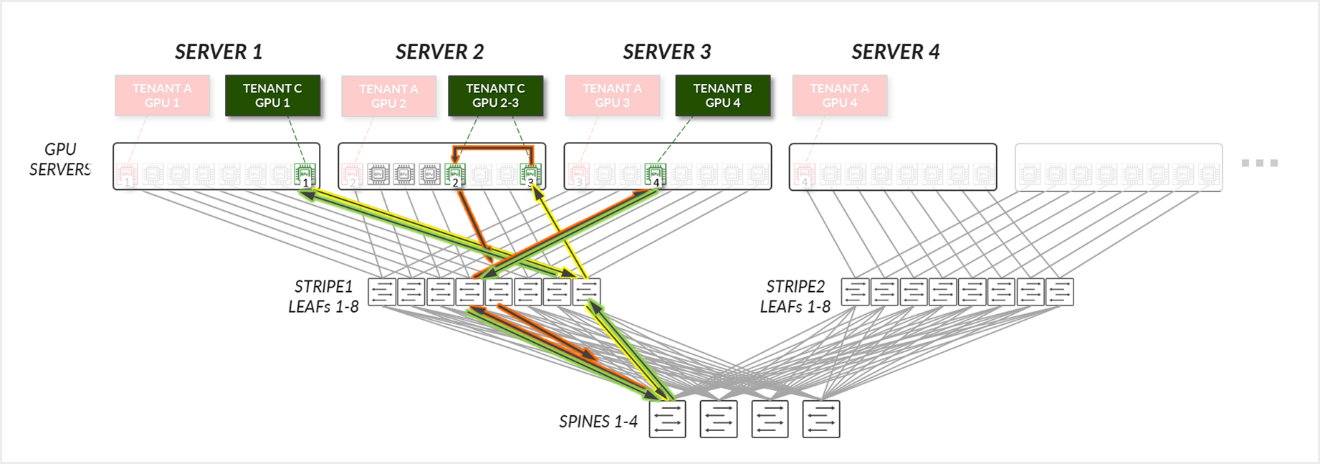
이제 그림 32에 설명된 예를 생각해 보겠습니다. 여기서 테넌트 C는 서버 1에서 GPU 8, 서버 2에서 GPU 5 및 8, 서버 3에서 GPU 4가 할당되었습니다(다이어그램의 테넌트 C의 GPU 1-4에 해당).
그림 32: GPU 격리 모델 GPU 간 통신 예제 2
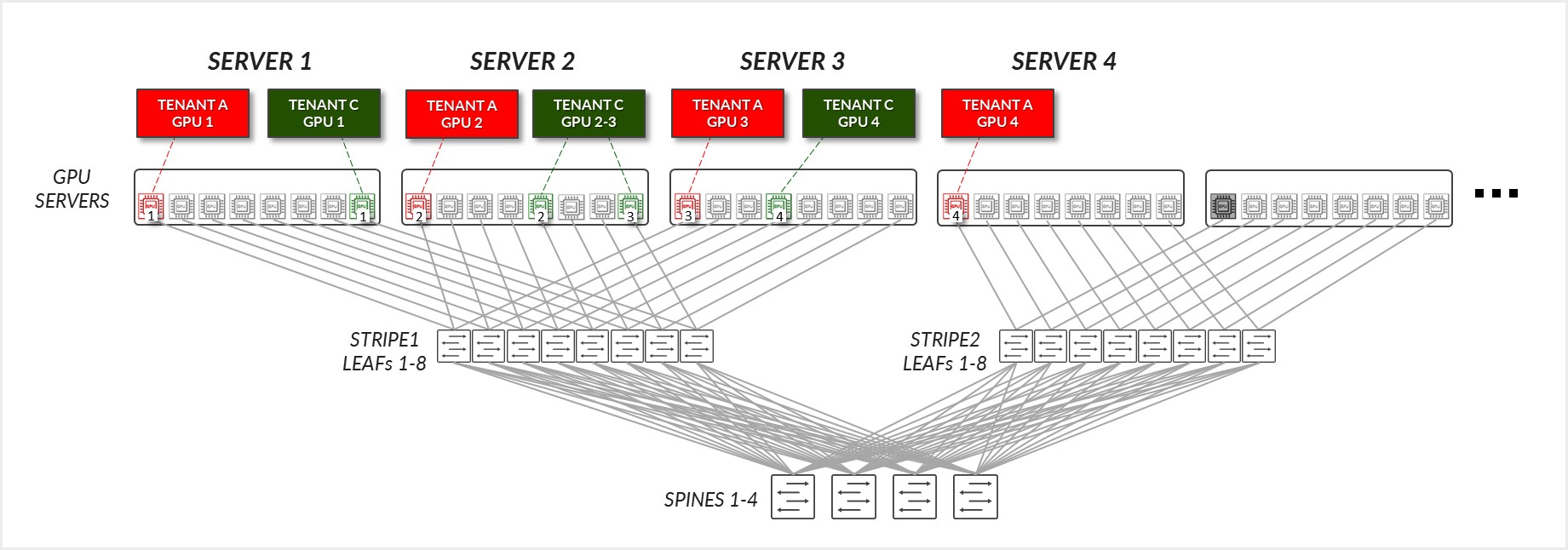
테넌트 C의 경우:
- 테넌트 C의 GPU 2 및 3(동일한 서버에 있음)은 서버 내에서 내부적으로 통신합니다.
- 테넌트 C의 GPU 3(서버 2) 및 GPU 4(서버 3)는 리프 및 스파스파인 노드를 통해 통신합니다.
- 테넌트 C의 GPU 4(서버 3) 및 GPU 1(서버 1)은 리프 및 스파스파인 노드를 통해 통신합니다.
- 테넌트 C의 GPU 1(서버 1) 및 GPU 2(서버 2)는 리프 및 스파스파인 노드를 통해 통신합니다.
그림 33: GPU 격리 모델 GPU 간 통신 예제 2 – 테넌트 C
예제 1과 2를 비교하면 레일 정렬과 적절한 서버 또는 GPU 할당 전략이 규모에서 최적의 GPU 간 통신 효율성을 달성하는 데 얼마나 중요한지 분명해집니다.
예제 1의 테넌트 A는 서버 1-4에서 GPU0이 할당되었으므로 통신은 대부분 리프 수준에 유지됩니다. 예제 2의 테넌트 C에는 SERVER 1에서 GPU 8, SERVER 2에서 GPU 5 및 8, SERVER 3에서 GPU 4가 할당되었으므로 통신은 스파인을 통해 전달되어야 하며 추가 대기 시간과 잠재적인 혼잡이 발생합니다. 테넌트 A와 테넌트 C 모두 동일한 수의 GPU가 할당되었지만 GPU 간의 통신은 서로 다른 경로를 따릅니다. 이로 인해 성능 수준이 달라질 수 있습니다.
그림 34: 동일한 스트라이프의 서버와 다른 스트라이프의 서버를 사용한 GPU 격리