이 페이지의 내용
NVIDIA 구성
NVIDIA® ConnectX® 네트워크 인터페이스 카드(NIC) 제품군은 이더넷과 인피니밴드 프로토콜을 모두 지원하며 고급 하드웨어 오프로드 및 가속 기능과 최대 400G의 속도를 제공합니다.
변경할 때는 항상 공식 제조업체 설명서를 참조하세요. 이 섹션에서는 AI JVD 랩 테스트를 기반으로 한 몇 가지 지침을 제공합니다.
NVIDIA ConnectX NIC를 인피니밴드에서 이더넷으로 변환
기본적으로 NVIDIA ConnectX NIC는 Infiniband 인터페이스로 작동하도록 설정되어 있으며 mlxconfig 도구를 사용하여 이더넷으로 변환해야 합니다.
1) sudo mst status를 사용하여 ConnectX NIC의 상태를 확인합니다.
-
user@A100-01:/dev/mst$ sudo mst -h Usage: /usr/bin/mst {start|stop|status|remote|server|restart|save|load|rm|add|help|version|gearbox|cable} Type "/usr/bin/mst help" for detailed help user@A100-01:/dev/mst$ sudo mst status | egrep "module|load" MST modules: MST PCI module loaded MST PCI configuration module loaded
필요한 경우 mst 서비스를 시작하거나 mst 모듈을 로드합니다.
예:
-
user@H100-01:~$ sudo mst start Starting MST (Mellanox Software Tools) driver set Loading MST PCI module - Success [warn] mst_pciconf is already loaded, skipping Create devices Unloading MST PCI module (unused) - Success user@A100-01:~/scripts$ sudo mst status MST modules: ------------ MST PCI module is not loaded MST PCI configuration module loaded
modprobe mst_pci.
-
user@A100-01:/dev/mst$ sudo modprobe mst_pci user@A100-01:/dev/mst$ sudo mst status MST modules: ------------ MST PCI module loaded MST PCI configuration module loaded
2) 변환하려는 인터페이스를 식별하고,
이 sudo mst status -v 명령은 아래 예와 같이 유형, Mellanox 디바이스 이름, PCI 주소, RDMA 인터페이스 이름, NET 인터페이스 이름 및 NUMA ID와 함께 시스템에서 감지된 Mellanox 디바이스(ConnectX-6 및 ConnectX-7 NIC) 목록을 제공합니다.
-
user@A100-01:/dev/mst$ sudo mst status -v MST modules: ------------ MST PCI module loaded MST PCI configuration module loaded PCI devices: ------------ DEVICE_TYPE MST PCI RDMA NET NUMA ConnectX7(rev:0) /dev/mst/mt4129_pciconf7.1 cb:00.1 mlx5_13 net-eth13 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf7 cb:00.0 mlx5_12 net-gpu6_eth 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf6.1 c8:00.1 mlx5_11 net-enp200s0f1np1 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf6 c8:00.0 mlx5_10 net-gpu7_eth 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf5.1 8e:00.1 mlx5_19 net-eth19 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf5 8e:00.0 mlx5_18 net-gpu5_eth 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf4.1 8b:00.1 mlx5_17 net-enp139s0f1np1 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf4 8b:00.0 mlx5_1 net-gpu4_eth 1 ConnectX7(rev:0) /dev/mst/mt4129_pciconf3.1 52:00.1 mlx5_3 net-enp82s0f1np1 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf3 52:00.0 mlx5_2 net-gpu3_eth 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf2.1 51:00.1 mlx5_1 net-enp81s0f1np1 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf2 51:00.0 mlx5_0 net-gpu2_eth 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf1.1 11:00.1 mlx5_9 net-enp17s0f1np1 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf1 11:00.0 mlx5_8 net-gpu1_eth 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf0.1 0e:00.1 mlx5_7 net-enp14s0f1np1 0 ConnectX7(rev:0) /dev/mst/mt4129_pciconf0 0e:00.0 mlx5_6 net-gpu0_eth 0 ConnectX6DX(rev:0) /dev/mst/mt4125_pciconf0.1 2c:00.1 mlx5_5 net-enp44s0f1np1 0 ConnectX6DX(rev:0) /dev/mst/mt4125_pciconf0 2c:00.0 mlx5_4 net-mgmt_eth 0 ConnectX6(rev:0) /dev/mst/mt4123_pciconf0.1 a9:00.1 mlx5_15 net-eth15 1 ConnectX6(rev:0) /dev/mst/mt4123_pciconf0 a9:00.0 mlx5_14 net-weka_eth 1 Cable devices: --------------- mt4129_pciconf7_cable_0 mt4129_pciconf6_cable_0 mt4129_pciconf5_cable_0 mt4129_pciconf4_cable_0 mt4129_pciconf3_cable_0 mt4129_pciconf2_cable_0 mt4129_pciconf1_cable_0 mt4129_pciconf0_cable_0 mt4125_pciconf0_cable_0 mt4123_pciconf0_cable_0
목록의 첫 번째 인터페이스에서 다음을 식별할 수 있습니다.
- 유형 = ConnectX7(rev:0)
- Mellanox 디바이스 이름 = mt4129_pciconf7(/dev/mst/mt4129_pciconf7)
- PCI 주소 = cb:00.0
- RDMA 인터페이스 이름 = mlx5_12
- NET 인터페이스 이름 = net-gpu6_eth
- NUMA = 1
일부 인터페이스의 경우 이름이 표준 Linux 인터페이스 명명 체계(예: net-enp14s0f1np1)를 따르는 반면 다른 인터페이스(예: net-gpu0_eth)는 그렇지 않습니다. 표준을 따르지 않는 인터페이스 이름은 쉽게 식별할 수 있도록 사용자 정의 이름입니다. 이는 /etc/netplan/에서 기본 이름이 변경되었음을 의미합니다. 이 섹션의 뒷부분에서 이를 수행하는 방법의 예를 보여 드리겠습니다.
3) 다음을 사용하여 주어진 인터페이스가 실행 중인 모드를 식별합니다.
mlxconfig -d <디바이스> 쿼리
예:
-
user@A100-01:~/scripts$ sudo mlxconfig -d /dev/mst/mt4129_pciconf7query | grep LINK_TYPE LINK_TYPE_P1 IB(1) LINK_TYPE_P2 IB(1) <= indicates link is operating in Infiniband mode
경로(/dev/mst/mt4129_pciconf7)를 포함하여 Mellanox 디바이스 이름을 사용해야 합니다.
또한 LINK_TYPE_P1 및 LINK_TYPE_P2는 듀얼 포트 Mellanox 어댑터의 물리적 포트 두 개를 나타냅니다.
4) 인터페이스가 Infiniband 모드에서 작동하는 경우, 다음을 사용하여 이더넷 모드의 모드를 변경할 수 있습니다.
mlxconfig -d <디바이스> 설정 [LINK_TYPE_P1=<link_type>] [LINK_TYPE_P2=<link_type>]
예문
-
user@A100-01:~/scripts$ sudo mlxconfig -d /dev/mst/mt4129_pciconf7 set LINK_TYPE_P1=2 LINK_TYPE_P2=2 Device #1: ---------- Device type: ConnectX7 Name: MCX755106AS-HEA_Ax Description: NVIDIA ConnectX-7 HHHL Adapter Card; 200GbE (default mode) / NDR200 IB; Dual-port QSFP112; PCIe 5.0 x16 with x16 PCIe extension option; Crypto Disabled; Secure Boot Enabled Device: /dev/mst/mt4129_pciconf7 Configurations: Next Boot New LINK_TYPE_P1 ETH(2) ETH(2) LINK_TYPE_P2 ETH(2) ETH(2) Apply new Configuration? (y/n) [n] : y Applying... Done! -I- Please reboot machine to load new configurations. user@A100-01:~/scripts$ sudo mlxconfig -d /dev/mst/mt4129_pciconf7query | grep LINK_TYPE LINK_TYPE_P1 ETH(2) LINK_TYPE_P2 ETH(2) <= indicates link is operating in Ethernet mode
다시 말하지만, 경로(/dev/mst/mt4129_pciconf7)를 포함하여 Mellanox 디바이스 이름을 사용해야 합니다.
인터페이스의 상태를 확인하려면 mlxlink를 사용할 수 있습니다.
-
user@A100-01:/dev/mst$ sudo mlxlink -d /dev/mst/mt4129_pciconf4 Operational Info ---------------- State : Active Physical state : LinkUp Speed : 200G Width : 4x FEC : Standard_RS-FEC - (544,514) Loopback Mode : No Loopback Auto Negotiation : ON Supported Info -------------- Enabled Link Speed (Ext.) : 0x00003ff2 (200G_2X,200G_4X,100G_1X,100G_2X,100G_4X,50G_1X,50G_2X,40G,25G,10G,1G) Supported Cable Speed (Ext.) : 0x000017f2 (200G_4X,100G_2X,100G_4X,50G_1X,50G_2X,40G,25G,10G,1G) Troubleshooting Info -------------------- Status Opcode : 0 Group Opcode : N/A Recommendation : No issue was observed Tool Information ---------------- Firmware Version : 28.39.2048 amBER Version : 2.22 MFT Version : mft 4.26.0-93
자세한 내용은 다음을 참조하세요.
NIC 및 GPU 매핑 식별 및 적절한 인터페이스 이름 할당
NIC는 언제든지 모든 GPU에서 사용할 수 있습니다. 주어진 GPU가 특정 NIC 카드를 사용하여 외부 세계와만 통신할 수 있다는 것은 하드 코딩되어 있지 않습니다. 그러나 GPU와 NIC 사이에는 선호되는 통신 경로가 있으며, 경우에 따라 이들 간의 1:1 대응으로 볼 수 있습니다. 이는 아래 단계에 표시됩니다.
NCCL(NVIDIA Collective Communications Library) 은 지정된 GPU에서 NIC 중 하나로의 연결이 가장 좋은 경로를 선택합니다.
NCCL이 선택한 경로와 GPU와 NIC 간의 최적 경로를 식별하려면 다음 단계를 따르십시오.
시스템에 대한 토폴로지 정보를 표시하는 nvidia-smi topo -m 명령을 사용하여 GPU와 NIC 간의 연결 유형을 식별합니다.
예:
- DGX H100:
그림 92. Nvidia H100 시스템 관리 인터페이스(SMI) 시스템 토폴로지 정보 
저희 연구 기반:
표 26: 연결 유형별 성능
| 연결 유형 | 설명 | 성능 |
| 픽스 | 동일한 스위치의 PCIe | 좋음 |
| PXB | 여러 스위치를 통한 PCIe, 호스트 브리지는 아님 | 좋음 |
| PHB | PCIe 스위치 및 동일한 NUMA의 호스트 브리지를 통해 - CPU 사용 | 확인 |
| 노드 | PCIe 스위치 및 동일한 NUMA의 여러 호스트 브리지에서 | 나쁨 |
| 시스템 | PCIe 스위치 및 NUMA 노드 간 QPI/UPI 버스 - CPU 사용 | 매우 나쁨 |
| 네바다# | NVLink | 최고에요! |
- HGX A100:
그림 93. Nvidia A100 시스템 관리 인터페이스(SMI) 시스템 토폴로지 정보
PBX 연결 식별
nvidia-smi 출력의 강조 표시된 섹션에 초점을 맞추면 각 GPU에 대해 하나 이상의 PXB 유형의 NIC 연결이 있음을 알 수 있습니다. 이는 각 GPU에서 지정된 NIC로의 기본 "직접" 경로입니다. 즉, GPU가 원격 디바이스와 통신해야 할 때 이러한 특정 NIC 중 하나를 첫 번째 옵션으로 사용합니다.
- DGX H100:
그림 94. Nvidia H100 시스템 관리 인터페이스(SMI) 시스템 토폴로지 PBX 연결
그림 95. Nvidia H100 시스템 아키텍처
- HGX A100:
그림 96. Nvidia A100 시스템 관리 인터페이스(SMI) 시스템 토폴로지 PBX 연결 
그림 97. Nvidia A100 시스템 아키텍처
이러한 매핑은 Nvidia의 A100 또는 H100 사용자 가이드에서도 찾을 수 있습니다.
예를 들어, DGX H100/H200 시스템에서 NVIDIA의 DGX H100/H200 시스템 사용자 가이드 표 5 및 표 6 에 따른 포트 매핑은 다음과 같습니다.
표 27: GPU에서 NIC로의 매핑
| 포트 | 커넥트X | GPU | 기본값 | RDMA | NIC |
| OSFP4P2 | CX1 | 0 | IBP24S0 | mlx5_0 | NIC0 |
| OSFP3P2 | CX3 | 1 | IBP64S0 | mlx5_3 | NIC3 |
| OSFP3P1 | CX2 | 2 | IBP79S0 | mlx5_4 | NIC4 |
| OSFP4P1 | CX0 | 3 | IBP94S0 | mlx5_5 | NIC5 |
| OSFP1P2 | CX1 | 4 | IBP154S0 | mlx5_6 | NIC6 |
| OSFP2P2 | CX3 | 5 | IBP192S0 | mlx5_9 | NIC9 |
| OSFP2P1 | CX2 | 6 | IBP206S0 | mlx5_10 | NIC10 |
| OSFP1P1 | CX0 | 7 | IBP220S0 | mlx5_11 | NIC11 |
표 28: GPU-NIC 연결
| NIC | GPU0 | GPU1 | GPU2 | GPU3 | GPU4 | GPU5 | GPU6 | GPU7 |
| NIC0 | PXB | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 |
| NIC3 | 시스템 | PXB | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 |
| NIC4 | 시스템 | 시스템 | PXB | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 |
| NIC5 | 시스템 | 시스템 | 시스템 | PXB | 시스템 | 시스템 | 시스템 | 시스템 |
| NIC6 | 시스템 | 시스템 | 시스템 | 시스템 | PXB | 시스템 | 시스템 | 시스템 |
| NIC9 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | PXB | 시스템 | 시스템 |
| NIC10 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | PXB | 시스템 |
| NIC11 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | 시스템 | PXB |
그림 98. Nvidia H100 전면 패널
자세한 정보 및 A100 시스템에 대한 매핑은 다음을 확인하십시오.
NVIDIA HGX A100 시스템 소개 — NVIDIA HGX A100 사용자 가이드 1 문서
NVIDIA DGX H100/H200 시스템 소개 — NVIDIA DGX H100/H200 사용자 가이드 1 문서
NIC의 인터페이스 이름 변경 및 IP 주소 및 경로 할당
IP 주소 또는 인터페이스 이름과 같은 NIC 속성은 넷플랜을 편집하고 다시 적용하여 만들 수 있습니다.
네트워크 구성은 아래 예제 표와 같이 /etc/netplan/01-netcfg.yaml 파일에 설명되어 있습니다. 모든 속성 변경에는 이 파일을 편집하고 이 섹션의 뒷부분에 나와 있는 예제에 나와 있는 대로 네트워크 계획을 다시 적용하는 작업이 포함됩니다.
표 29: Nvidia HGX A100 인터페이스 구성 예:
| netcfg.yaml 출력 | ||
| jvd@A100-01:/etc/netplan$ 더 보기 01-netcfg.yaml | ||
| # 'subiquity'가 작성한 네트워크 구성입니다. | gpu0_eth: | gpu4_eth: |
| 네트워크: | 일치: | 일치: |
| 버전: 2 | MAC주소: 94:6D:AE:54:72:22 | macaddress: 94:6d:ae:5b:28:70 |
| 이더넷: | dhcp4: 거짓 | dhcp4: 거짓 |
| mgmt_eth: | 최대 전송 단위(MTU): 9000 | 최대 전송 단위(MTU): 9000 |
| 일치: | 주소: | 주소: |
| macaddress: 7c:c2:55:42:b2:28 | - 10.200.0.8/24 | - 10.200.4.8/24 |
| dhcp4: 거짓 | 경로: | 경로: |
| 주소: | - 받는 사람: 10.200.0.0/16 | - 받는 사람: 10.200.0.0/16 |
| - 10.10.1.0/31 | 경유: 10.200.0.254 | 경유: 10.200.4.254 |
| 네임서버: | 보낸 사람: 10.200.0.8 | 보낸 사람: 10.200.4.8 |
| 주소: | 세트 이름: gpu0_eth | 세트 이름: gpu4_eth |
| - 8.8.8.8 | gpu1_eth: | gpu5_eth: |
| 경로: | 일치: | 일치: |
| - to: 기본값 | macaddress: 94:6d:ae:5b:01:d0 | macaddress: 94:6d:ae:5b:27:f0 |
| 경유: 10.10.1.1 | dhcp4: 거짓 | dhcp4: 거짓 |
| 세트 이름: mgmt_eth | 최대 전송 단위(MTU): 9000 | 최대 전송 단위(MTU): 9000 |
| weka_eth: | 주소: | 주소: |
| 일치: | - 10.200.1.8/24 | - 10.200.5.8/24 |
| macaddress: b8:3f:d2:8b:68:e0 | 경로: | 경로: |
| dhcp4: 거짓 | - 받는 사람: 10.200.0.0/16 | - 받는 사람: 10.200.0.0/16 |
| 최대 전송 단위(MTU): 9000 | 경유: 10.200.1.254 | 경유: 10.200.5.254 |
| 주소: | 보낸 사람: 10.200.1.8 | 보낸 사람: 10.200.5.8 |
| - 10.100.1.0/31 | 세트 이름: gpu1_eth | 세트 이름: gpu5_eth |
| 경로: | gpu2_eth: | gpu6_eth: |
| - 받는 사람: 10.100.0.0/22 | 일치: | 일치: |
| 경유: 10.100.1.1 | macaddress: 94:6d:ae:5b:28:60 | macaddress: 94:6d:ae:54:78:e2 |
| 세트 이름: weka_eth | dhcp4: 거짓 | dhcp4: 거짓 |
| 최대 전송 단위(MTU): 9000 | 최대 전송 단위(MTU): 9000 | |
| 주소: | 주소: | |
| - 10.200.2.8/24 | - 10.200.6.8/24 | |
| 경로: | 경로: | |
| - 받는 사람: 10.200.0.0/16 | - 받는 사람: 10.200.0.0/16 | |
| 경유: 10.200.2.254 | 경유: 10.200.6.254 | |
| 보낸 사람: 10.200.2.8 | 보낸 사람: 10.200.6.8 | |
| 세트 이름: gpu2_eth | 세트 이름: gpu6_eth | |
| gpu3_eth: | gpu7_eth: | |
| 일치: | 일치: | |
| macaddress: 94:6d:ae:5b:01:e0 | macaddress: 94:6d:ae:54:72:12 | |
| dhcp4: 거짓 | dhcp4: 거짓 | |
| 최대 전송 단위(MTU): 9000 | 최대 전송 단위(MTU): 9000 | |
| 주소: | 주소: | |
| - 10.200.3.8/24 | - 10.200.7.8/24 | |
| 경로: | 경로: | |
| - 받는 사람: 10.200.0.0/16 | - 받는 사람: 10.200.0.0/16 | |
| 비아: 10.200.3.254 | 경유: 10.200.7.254 | |
| 보낸 사람: 10.200.3.8 | 보낸 사람: 10.200.7.8 | |
| 집합 이름: gpu3_eth | 세트 이름: gpu7_eth | |
특정 NIC(물리적 인터페이스)에 인터페이스 이름 매핑
인터페이스 이름을 구성 파일에서 물리적 인터페이스의 MAC에 매핑합니다.
그림 99. Nvidia A100 물리적 인터페이스 식별 예 시
시
여기서:
en = 이더넷 네트워크 인터페이스.
P203S0 = 네트워크 인터페이스의 물리적 위치.
203번 버스 번호.
s0 = 버스의 슬롯 번호 0.
f1 = 네트워크 인터페이스에 대한 기능 번호 1.
np1 = 네트워크 포트 1
기능 0: 기본 이더넷 인터페이스일 수 있습니다.
기능 1: 두 번째 이더넷 인터페이스일 수 있습니다.
기능 2: 관리 또는 진단 인터페이스일 수 있습니다.
그림 100. Nvidia A100 netplan 파일 수정 예제
devnames 파일에서 모든 논리적 인터페이스의 이름을 찾을 수 있습니다.
-
user@A100-01:/etc/network$ more devnames enp139s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp139s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp142s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp142s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp14s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp14s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp17s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp17s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp200s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp200s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp203s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp203s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp44s0f0:Intel Corporation Ethernet Controller X710 for 10GBASE-T enp44s0f1:Intel Corporation Ethernet Controller X710 for 10GBASE-T enp44s0f2:Intel Corporation Ethernet Controller X710 for 10 Gigabit SFP+ enp44s0f3:Intel Corporation Ethernet Controller X710 for 10 Gigabit SFP+ enp81s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp81s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enp82s0f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] enp82s0f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] ibp169s0f0:Mellanox Technologies MT28908 Family [ConnectX-6] ibp169s0f1:Mellanox Technologies MT28908 Family [ConnectX-6]
netplan apply 명령을 사용하여 변경 사항을 적용합니다
그림 101. Nvidia A100 netplan 애플리케이션 예제
NIC 이름 변경
구성 파일에서 set-name의 값을 변경하고 변경 사항을 저장합니다.
그림 102. Nvidia A100 넷플래시 인터페이스 이름 변경 예

netplan apply 명령을 사용하여 변경 사항 적용
그림 103. Nvidia A100 넷플랜 인터페이스 이름 변경 애플리케이션 및 검증 예시
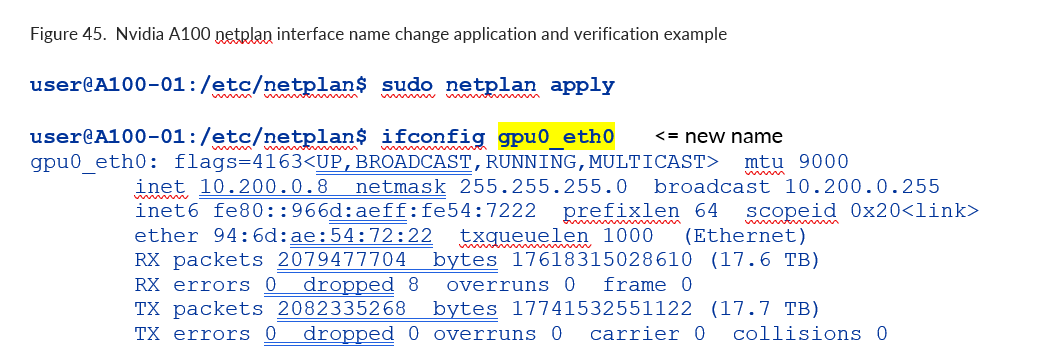
현재 IP 주소를 변경하거나 NIC에 IP 주소를 할당하려면
구성 파일의 적절한 인터페이스 아래에 주소를 변경하거나 추가하고 변경 사항을 저장합니다.
그림 104. Nvidia A100 넷플랜 인터페이스 IP 주소 변경 예
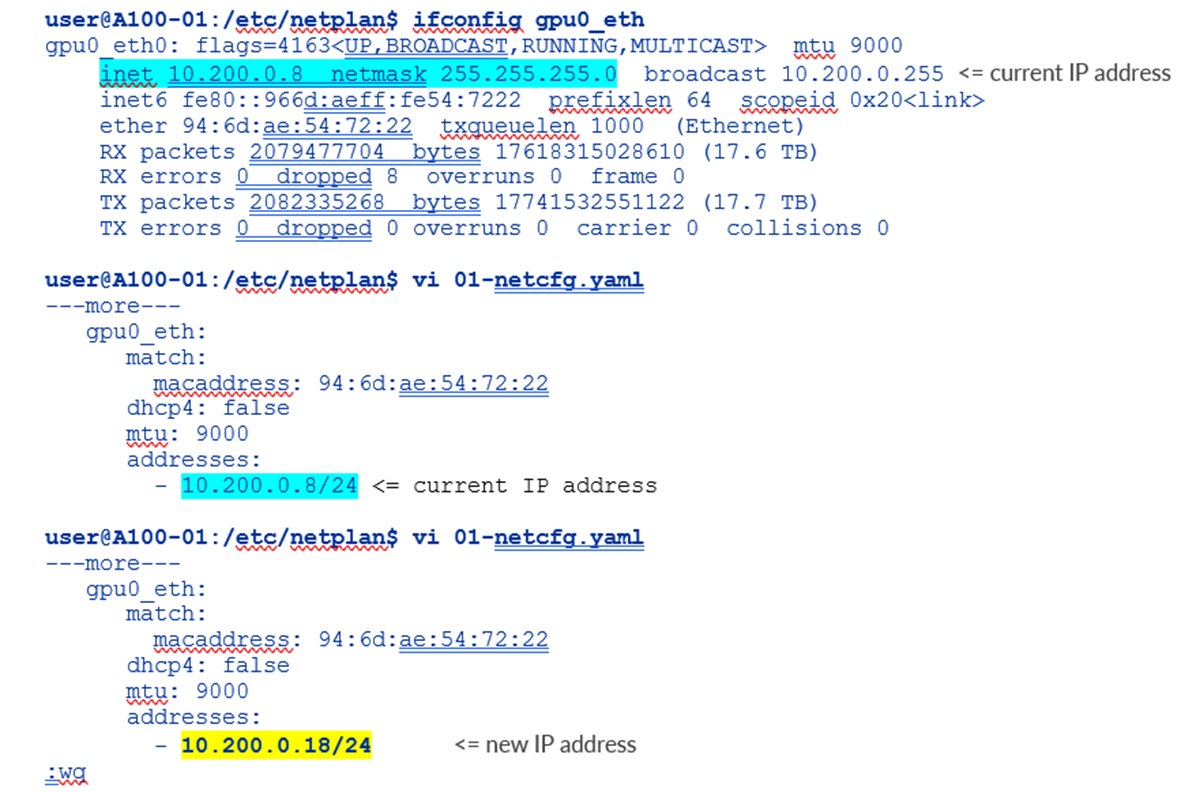
IP 주소를 하이픈과 들여쓰기로 앞에 입력합니다. 서브넷 마스크를 추가해야 합니다.
netplan apply 명령을 사용하여 변경 사항 적용
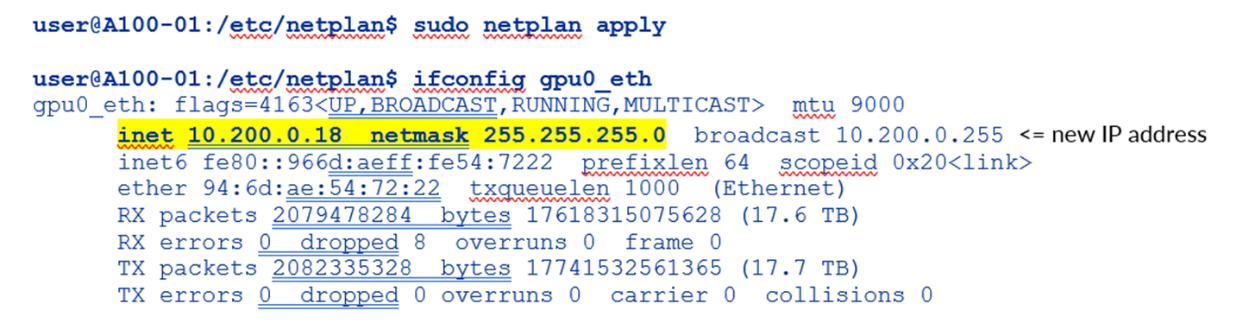
그림 105. Nvidia A100 netplan 인터페이스, 새로운 IP 주소 애플리케이션 및 검증 예제
NIC에 경로 변경 또는 추가
구성 파일의 적절한 인터페이스 아래에서 경로를 변경하거나 추가하고 변경 사항을 저장합니다.
그림 106. Nvidia A100 netplan 추가 경로 예

netplan apply 명령을 사용하여 변경 사항을 적용합니다
그림 107. Nvidia A100 netplan 추가 경로 애플리케이션 및 검증 예:

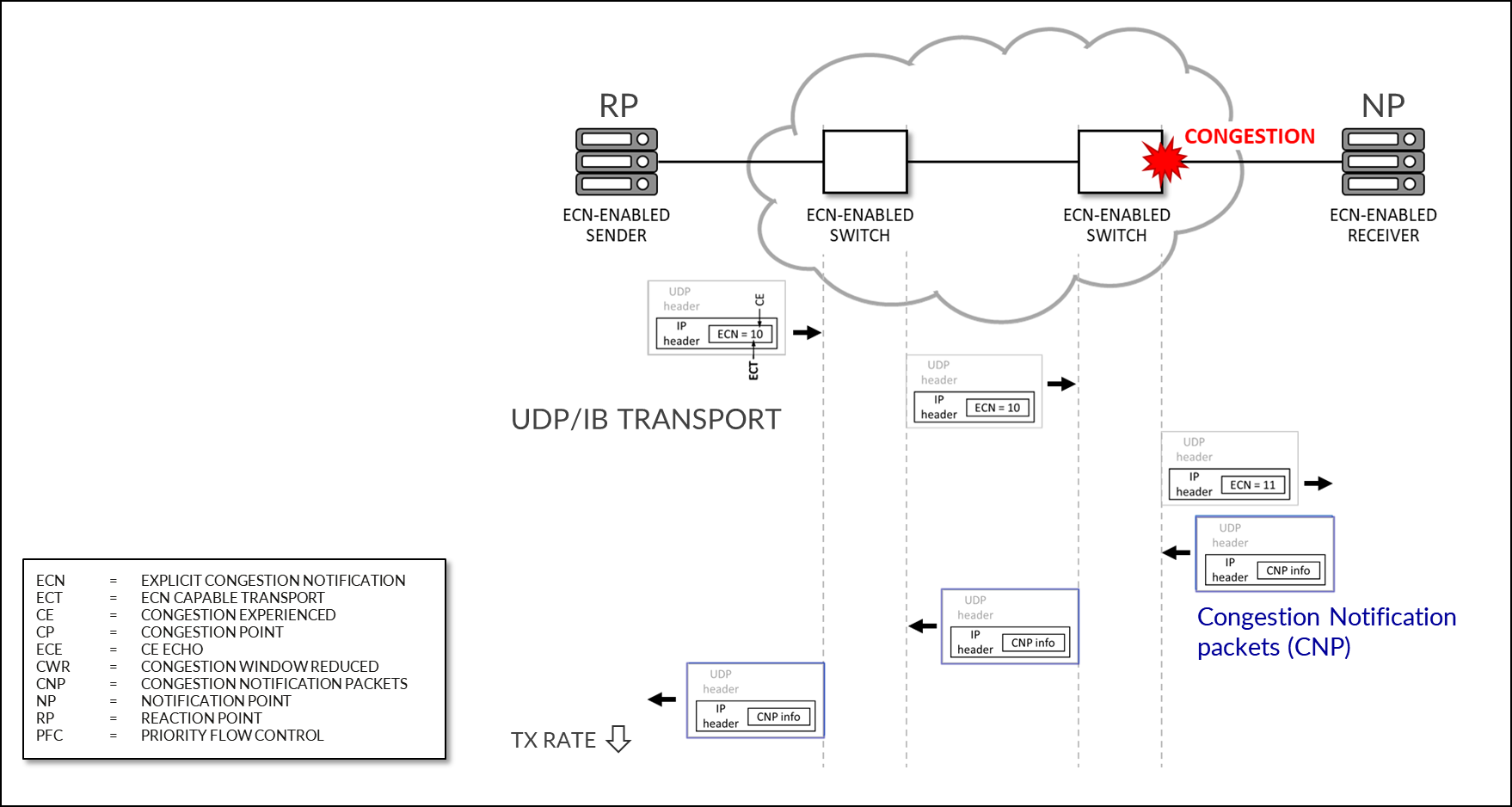
NVIDIA DCQCN – ECN 구성
그림 108: NVIDIA DCQCN – ECN
MLNX_OFED 4.1부터 ECN은 기본적으로 (펌웨어에서) 활성화됩니다.
ECN이 활성화되었는지 확인하려면 다음 명령을 사용합니다: mlxconfig -d <device> q | grep ROCE_CC
예:
-
root@A100-01:/home/ylara# mlxconfig -d mlx5_0 q | grep ROCE_CC ROCE_CC_PRIO_MASK_P1 255 ROCE_CC_PRIO_MASK_P2 255
마스크 255는 NIC에 구성된 모든 TC(트래픽 클래스)에 대해 DCQCN(ECN)이 활성화되었음을 의미합니다.
ECN을 비활성화하려면 mlxconfig -d <device> s ROCE_CC_PRIO_MASK_P1=<mask> 명령을 사용하여 마스크를 변경할 수 있습니다.
예:
-
root@A100-01:/home/ylara# sudo mlxconfig -d mlx5_0 s ROCE_CC_PRIO_MASK_P1=0 Device #1: ---------- Device type: ConnectX7 Name: MCX755106AS-HEA_Ax Description: NVIDIA ConnectX-7 HHHL Adapter Card; 200GbE (default mode) / NDR200 IB; Dual-port QSFP112; PCIe 5.0 x16 with x16 PCIe extension option; Crypto Disabled; Secure Boot Enabled Device: mlx5_0 Configurations: Next Boot New ROCE_CC_PRIO_MASK_P1 0 0 Apply new Configuration? (y/n) [n] :
새 구성을 적용할지 묻는 질문을 받지 않으려면 다음 예와 같이 -y 옵션을 포함하십시오.
-
root@A100-01:/home/ylara# sudo mlxconfig -d mlx5_0 -y s ROCE_CC_PRIO_MASK_P1=0 Device #1: ---------- Device type: ConnectX7 Name: MCX755106AS-HEA_Ax Description: NVIDIA ConnectX-7 HHHL Adapter Card; 200GbE (default mode) / NDR200 IB; Dual-port QSFP112; PCIe 5.0 x16 with x16 PCIe extension option; Crypto Disabled; Secure Boot Enabled Device: mlx5_0 Configurations: Next Boot New ROCE_CC_PRIO_MASK_P1 0 0 Apply new Configuration? (y/n) [n] : y Applying... Done! -I- Please reboot machine to load new configurations.
출력에는 서버 재부팅이 필요하다는 메시지가 표시됩니다. 대안으로, mlxfwreset -d <device> -l 3 -y r 명령을 사용하여 인터페이스를 재설정할 수 있습니다.
예:
-
root@A100-01:/home/ylara# mlxfwreset -d mlx5_0 -l 3 -y r Requested reset level for device, /dev/mst/mt4129_pciconf2: 3: Driver restart and PCI reset Continue with reset?[y/N] y -I- Sending Reset Command To Fw -Done -I- Stopping Driver -Done -I- Resetting PCI -Done -I- Starting Driver -Done -I- Restarting MST -Done -I- FW was loaded successfully.
ECN 작업 매개 변수는 다음 경로에 있습니다 /sys/class/net/<interface>/ecn
다음 명령을 사용하여 인터페이스를 찾습니다:
-
jvd@A100-01:~/$ ls /sys/class/net/ docker0 enp14s0f1np1 enp17s0f1np1 enp44s0f1np1 gpu0_eth gpu3_eth gpu6_eth mgmt_eth enp139s0f1np1 enp169s0f0np0 enp200s0f1np1 enp81s0f1np1 gpu1_eth gpu4_eth gpu7_eth usb0 enp142s0f1np1 enp169s0f1np1 enp203s0f1np1 enp82s0f1np1 gpu2_eth gpu5_eth lo jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ ls roce_np roce_rp
NP(알림 지점) 매개 변수
ECN 지원 수신기는 ECN으로 표시된 RoCE 패킷을 수신하면 CNP(혼잡 알림 패킷)를 전송하여 응답합니다.
다음 명령은 알림 매개 변수에 대해 설명합니다.
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ ls /roce_np/ cnp_802p_prio cnp_dscp enable min_time_between_cnps
예:
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_np/cnp_802p_prio 6
cnp_802p_prio = CNP 패킷의 PCP(우선순위 코드 포인트) 필드 값.
PCP는 IEEE 802.1Q에서 정의한 대로 VLAN 태그가 지정된 프레임을 사용할 때 이더넷 프레임 헤더 내의 3비트 필드입니다.
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_np/cnp_dscp 48
cnp_dscp = CNP 패킷의 DSCP(Differentiated Services Code Point) 필드 값.
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_np/min_time_between_cnps 4
min_time_between_cnps = 전송된 두 개의 연속 CNP 사이의 최소 시간. ECN으로 표시된 RoCE 패킷이 이전에 전송된 CNP 이후 min_time_between_cnps보다 짧은 기간에 도착하면 응답으로 CNP가 전송되지 않습니다. 이 값은 마이크로초 단위입니다. 기본값 = 0
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_np/enable/* 1 1 1 1 1 1 1 1
출력은 모든 우선 순위 값에 대해 roce_np가 활성화되어 있음을 보여줍니다.
위에서 설명한 속성을 변경하려면 mlxconfig 유틸리티를 사용합니다.
-
mlxconfig -d /dev/mst/<mst_module> -y s CNP_DSCP_P1=<value> CNP_802P_PRIO_P1=<value>
예:
-
jvd@A100-01:/dev/mst$ sudo mst start Starting MST (Mellanox Software Tools) driver set Loading MST PCI module - Success [warn] mst_pciconf is already loaded, skipping Create devices Unloading MST PCI module (unused) – Success jvd@A100-01:~/scripts$ ./map_full_mellanox.sh Mellanox Device to mlx and Network Interface Mapping: /dev/mst/mt4123_pciconf0 => mlx5_14 => enp169s0f0np0 (0000:a9:00.0) /dev/mst/mt4125_pciconf0 => mlx5_4 => mgmt_eth (0000:2c:00.0) /dev/mst/ mt4129_pciconf0 => mlx5_6 => gpu0_eth (0000:0e:00.0) /dev/mst/mt4129_pciconf1 => mlx5_8 => gpu1_eth (0000:11:00.0) /dev/mst/mt4129_pciconf2 => mlx5_0 => gpu2_eth (0000:51:00.0) /dev/mst/mt4129_pciconf3 => mlx5_2 => gpu3_eth (0000:52:00.0) /dev/mst/mt4129_pciconf4 => mlx5_16 => gpu4_eth (0000:8b:00.0) /dev/mst/mt4129_pciconf5 => mlx5_18 => gpu5_eth (0000:8e:00.0) /dev/mst/mt4129_pciconf6 => mlx5_10 => gpu7_eth (0000:c8:00.0) /dev/mst/mt4129_pciconf7 => mlx5_12 => gpu6_eth (0000:cb:00.0) jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ sudo mlxconfig -d /dev/mst/ mt4129_pciconf0 -y set CNP_DSCP_P1=40 CNP_802P_PRIO_P1=7 Device #1: ---------- Device type: ConnectX7 Name: MCX755106AS-HEA_Ax Description: NVIDIA ConnectX-7 HHHL Adapter Card; 200GbE (default mode) / NDR200 IB; Dual-port QSFP112; PCIe 5.0 x16 with x16 PCIe extension option; Crypto Disabled; Secure Boot Enabled Device: /dev/mst/mt4129_pciconf0 Configurations: Next Boot New CNP_DSCP_P1 48 40 CNP_802P_PRIO_P1 6 7 Apply new Configuration? (y/n) [n] : y Applying... Done! -I- Please reboot machine to load new configurations.
반응점(RP) 매개 변수
ECN 활성화 발신자는 CNP 패킷을 수신하면 지정된 흐름(우선순위)에 대한 전송 속도를 늦추는 방식으로 응답합니다.
다음 매개 변수는 CNP 패킷이 도착한 후 트래픽 흐름이 속도를 제한하는 방법을 정의합니다.
-
jvd@A100-01:/sys/class/net$ ls gpu0_eth/ecn/roce_rp/ clamp_tgt_rate enable rpg_ai_rate rpg_max_rate rpg_time_reset clamp_tgt_rate_after_time_inc initial_alpha_value rpg_byte_reset rpg_min_dec_fac dce_tcp_g rate_reduce_monitor_period rpg_gd rpg_min_rate dce_tcp_rtt rate_to_set_on_first_cnp rpg_hai_rate rpg_threshold
예:
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_rp/enable/* 1 1 1 1 1 1 1 1 jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ cat roce_rp/rpg_max_rate 0
rpg_max_rate = 반응점 노드가 전송할 수 있는 최대 속도. 이 제한에 도달하면 RP는 더 이상 속도 제한이 되지 않습니다.
이 값은 Mbits/sec 단위로 구성됩니다. 기본값 = 0(최대 속도 – 최대 없음)
출력은 모든 우선 순위 값에 대해 roce_rp가 활성화되어 있음을 보여줍니다.
ECN 통계를 확인하려면 ethtool -S <인터페이스> | 그렙 ECN
예:
-
jvd@A100-01:~/scripts$ ethtool -S gpu0_eth | grep ecn rx_ecn_mark: 0 rx_xsk_ecn_mark: 0 rx0_ecn_mark: 0 rx1_ecn_mark: 0 rx2_ecn_mark: 0 rx3_ecn_mark: 0 rx4_ecn_mark: 0 rx5_ecn_mark: 0 rx6_ecn_mark: 0 rx7_ecn_mark: 0 rx8_ecn_mark: 0 ---more---
NVIDIA DCQCN – PFC 구성
IEEE 802.1Qbb는 이더넷 링크의 특정 등급의 트래픽에 일시 중지 기능을 적용합니다.
그림 109: NVIDIA DCQCN – PFC 구성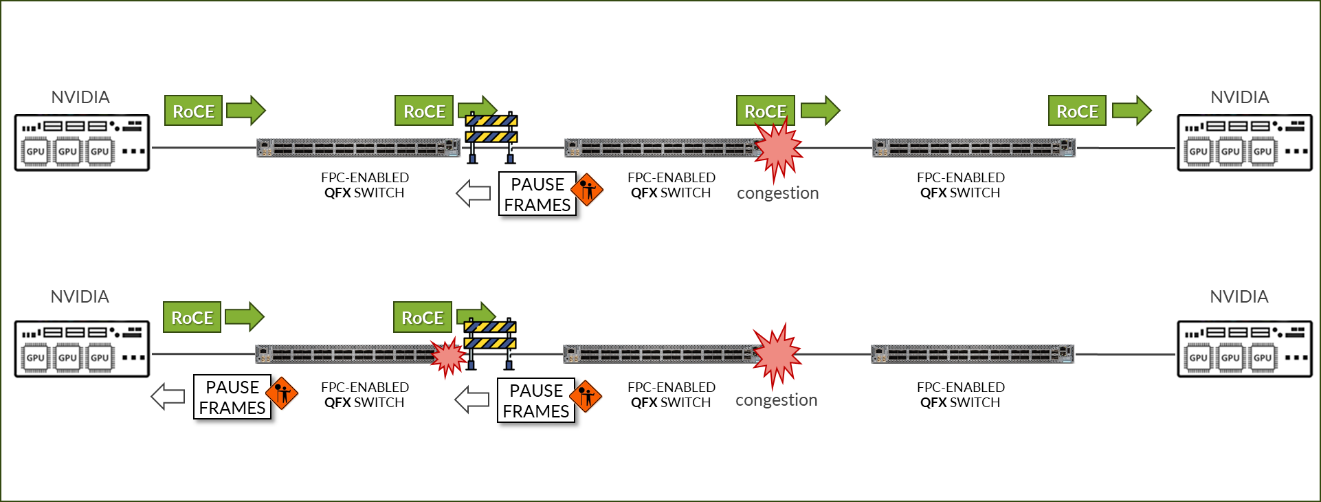
인터페이스에서 PFC가 활성화되었는지 확인하려면 다음을 사용합니다. mlnx_qos -i <인터페이스>
예:
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ sudo mlnx_qos -i gpu0_eth DCBX mode: OS controlled Priority trust state: dscp dscp2prio mapping: prio:0 dscp:07,06,05,04,03,02,01,00, prio:1 dscp:15,14,13,12,11,10,09,08, prio:2 dscp:23,22,21,20,19,18,17,16, prio:3 dscp:31,30,29,28,27,26,25,24, prio:4 dscp:39,38,37,36,35,34,33,32, prio:5 dscp:47,46,45,44,43,42,41,40, prio:6 dscp:55,54,53,52,51,50,49,48, prio:7 dscp:63,62,61,60,59,58,57,56, default priority: Receive buffer size (bytes): 19872,243072,0,0,0,0,0,0,max_buffer_size=2069280 Cable len: 7 PFC configuration : priority 0 1 2 3 4 5 6 7 enabled 0 0 0 1 0 0 0 0 buffer 0 0 0 1 0 0 0 0 tc: 0 ratelimit: unlimited, tsa: vendor priority: 1 tc: 1 ratelimit: unlimited, tsa: vendor priority: 0 tc: 2 ratelimit: unlimited, tsa: vendor priority: 2 tc: 3 ratelimit: unlimited, tsa: vendor priority: 3 tc: 4 ratelimit: unlimited, tsa: vendor priority: 4 tc: 5 ratelimit: unlimited, tsa: vendor priority: 5 tc: 6 ratelimit: unlimited, tsa: vendor priority: 6 tc: 7 ratelimit: unlimited, tsa: vendor priority: 7
PFC를 활성화/비활성화하려면 다음을 사용하십시오. mlnx_qos -i <인터페이스> --pfc <0/1>,<0/1>,<0/1>,<0/1>,<0/1>,<0/1>,<0/1>,<0/1>
예:
- 현재 구성을 확인합니다.
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ sudo mlnx_qos -i gpu0_eth DCBX mode: OS controlled Priority trust state: dscp dscp2prio mapping: prio:0 dscp:07,06,05,04,03,02,01,00, prio:1 dscp:15,14,13,12,11,10,09,08, prio:2 dscp:23,22,21,20,19,18,17,16, prio:3 dscp:31,30,29,28,27,26,25,24, prio:4 dscp:39,38,37,36,35,34,33,32, prio:5 dscp:47,46,45,44,43,42,41,40, prio:6 dscp:55,54,53,52,51,50,49,48, prio:7 dscp:63,62,61,60,59,58,57,56, default priority: Receive buffer size (bytes): 19872,243072,0,0,0,0,0,0,max_buffer_size=2069280 Cable len: 7 PFC configuration : priority 0 1 2 3 4 5 6 7 enabled 0 0 0 1 0 0 0 0 buffer 0 0 0 1 0 0 0 0 ---more---
예의 출력은 PFC가 우선순위 3에 대해 활성화되었음을 나타냅니다.
- 우선 순위 2에 대해 PFC를 활성화하고 우선 순위 3에 대해 PFC를 비활성화합니다.
-
jvd@A100-01:~/scripts$ sudo mlnx_qos -i gpu0_eth --pfc 0,0, 1 ,0,0,0,0,0 DCBX mode: OS controlled Priority trust state: dscp dscp2prio mapping: prio:0 dscp:07,06,05,04,03,02,01,00, prio:1 dscp:15,14,13,12,11,10,09,08, prio:2 dscp:23,22,21,20,19,18,17,16, prio:3 dscp:31,30,29,28,27,26,25,24, prio:4 dscp:39,38,37,36,35,34,33,32, prio:5 dscp:47,46,45,44,43,42,41,40, prio:6 dscp:55,54,53,52,51,50,49,48, prio:7 dscp:63,62,61,60,59,58,57,56, default priority: Receive buffer size (bytes): 19872,243072,0,0,0,0,0,0,max_buffer_size=2069280 Cable len: 7 PFC configuration: priority 0 1 2 3 4 5 6 7 enabled 0 0 1 0 0 0 0 0 buffer 0 0 1 0 0 0 0 0 ---more--- - PFC 통계 확인:
jvd@A100-01:~/scripts$ ethtool -S gpu0_eth | grep pause rx_pause_ctrl_phy: 8143294 tx_pause_ctrl_phy: 502 rx_prio3 _pause: 8143294 rx_prio3 _pause_duration: 10848932 tx_prio3 _pause: 502 tx_prio3 _pause_duration: 30445 rx_prio3 _pause_transition: 4071126 tx_pause_storm_warning_events: 0 tx_pause_storm_error_events: 0
RDMA-CM QPS(RDMA 트래픽)에 대한 NVIDIA TOS/DSCP 구성
그림 110: NVIDIA TOS/DSCP
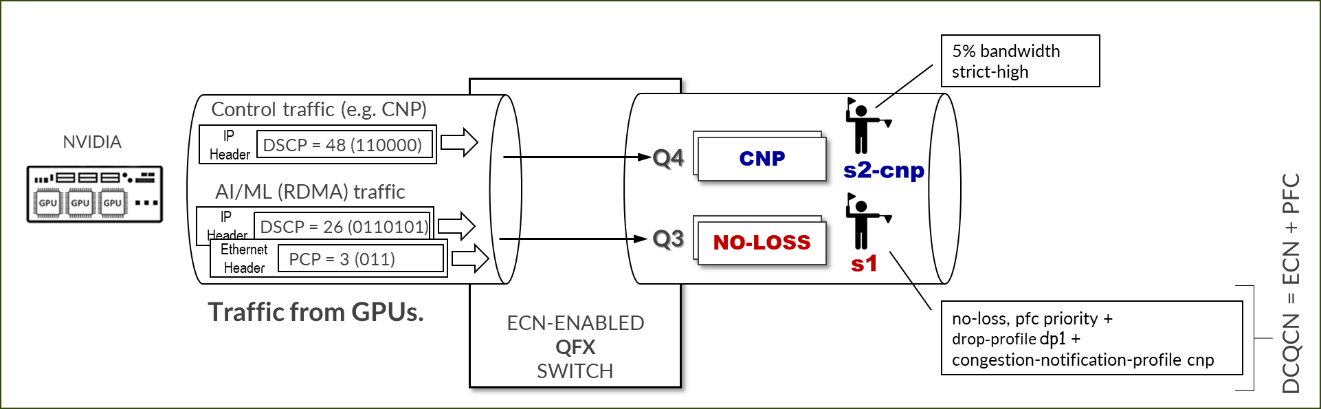
스위치가 RDMA 트래픽을 올바르게 분류하고 적절한 처리를 위해 무손실 대기열에 배치할 수 있도록 적절하게 표시해야 합니다. 마킹은 IP 헤더 내의 DSCP 또는 이더넷 프레임 vlan-tag 필드의 PCP일 수 있습니다. DSCP 또는 PCP의 사용 여부는 GPU 서버와 스위치 간의 인터페이스가 VLAN 태깅(802.1q)을 수행하는지 여부에 따라 달라집니다.
현재 구성을 확인하고 RDMA 아웃바운드 트래픽에 대한 TOS 값을 변경하려면 MLNX_OFED 4.0의 일부인 cma_roce_tos 스크립트를 사용합니다.
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ sudo cma_roce_tos -h Set/Show RoCE default TOS of RDMA_CM applications Usage: cma_roce_tos OPTIONS Options: -h show this help -d <dev> use IB device <dev> (default mlx5_0) -p <port> use port <port> of IB device (default 1) -t <TOS> set TOS of RoCE RDMA_CM applications (0)
TOS 필드의 현재 값을 확인하려면 옵션 없이 sudo cma_roce_tos를 입력합니다.
예:
-
jvd@A100-01:/sys/class/net/gpu0_eth/ecn$ sudo cma_roce_tos 106
이 예에서 현재 TOS 값 = 106은 DSCP 값 = 48을 의미하며 ECN 비트는 10으로 설정됩니다.
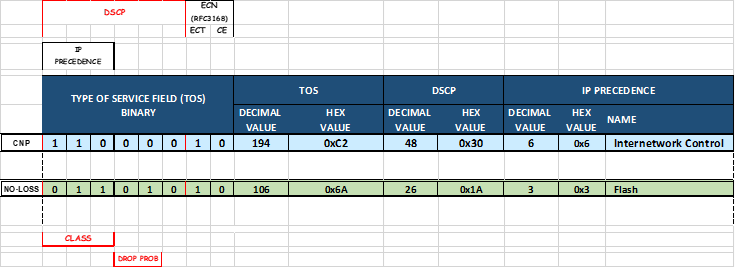
값을 변경하려면 cma_roce_tos –d <ib_device> -t<TOS>를 사용하십시오.
이 명령에 ib_device를 입력해야 합니다. 다음 스크립트는 물리적 인터페이스와 ib_device 간의 매핑을 자동으로 수행합니다.
-
map_full_mellanox.sh #!/bin/bash # Script to map Mellanox devices to mlx and network interfaces # Get Mellanox device PCI addresses mst_status=$(sudo mst status | awk ' //dev/mst/ { dev = $1 } /domain:bus:dev.fn/ { pci = $1 printf "%s: %s\n", dev, pci } ') # Get network interface PCI addresses iface_status=$(for iface in $(ls /sys/class/net/); do pci_addr=$(ethtool -i $iface 2>/dev/null | grep bus-info | awk '{print $2}') if [ ! -z "$pci_addr" ]; then echo "$iface: $pci_addr" fi done) # Get network interface to mlx interface mapping mlx_iface_status=$(for iface in $(ls /sys/class/net/); do if [ -d /sys/class/net/$iface/device/infiniband_verbs ]; then mlx_iface=$(cat /sys/class/net/$iface/device/infiniband_verbs/*/ibdev) echo "$iface: $mlx_iface" fi done) # Combine and print the mapping echo "Mellanox Device to mlx and Network Interface Mapping:" echo "$mst_status" | while read -r mst_line; do mst_dev=$(echo $mst_line | awk -F ': ' '{print $1}') mst_pci=$(echo $mst_line | awk -F '=| ' '{print $3}') iface=$(echo "$iface_status" | grep $mst_pci | awk -F ': ' '{print $1}') iface_pci=$(echo "$iface_status" | grep $mst_pci | awk -F ': ' '{print $2}') mlx_iface=$(echo "$mlx_iface_status" | grep $iface | awk -F ': ' '{print $2}') if [ ! -z "$iface" ] && [ ! -z "$mlx_iface" ]; then echo "$mst_dev => $mlx_iface => $iface ($iface_pci)" fi done
예:
그림 111. 스크립트 결과 예제
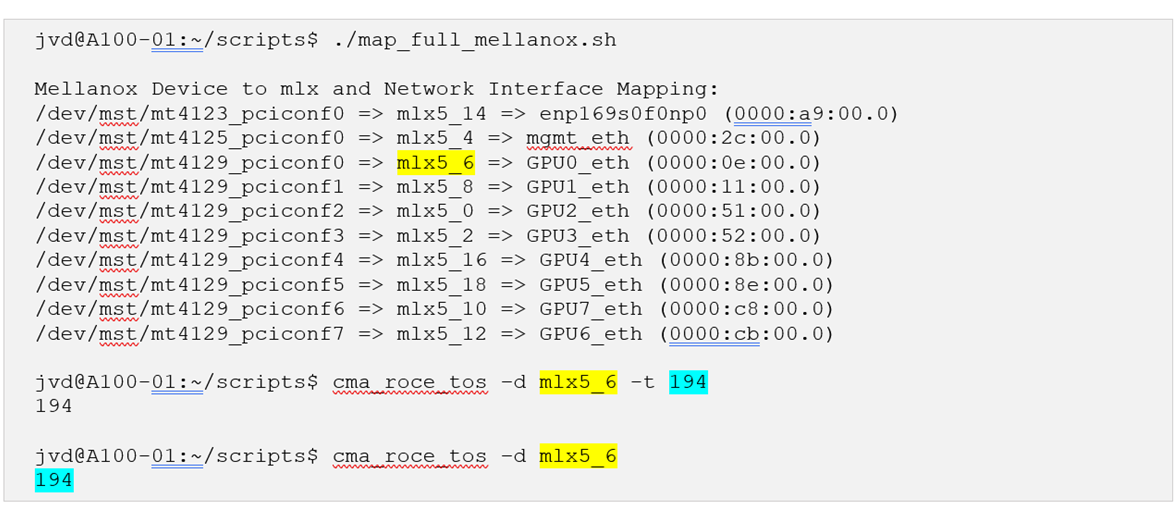
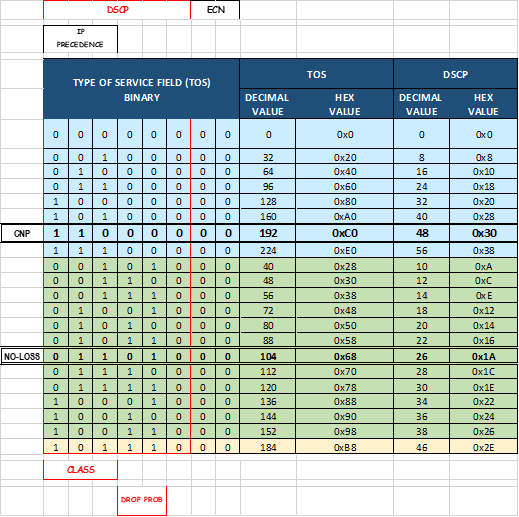
그림 112. 참조 TOS, DSCP 매핑:
NCCL 제어 트래픽에 관리 인터페이스를 사용하도록 NVIDIA 구성
NCCL은 TCP 세션을 사용하여 프로세스를 서로 연결하고 RoCE, GID(글로벌 ID), 로컬 및 원격 버퍼 주소, RDMA 키(메모리 액세스 권한의 RKEY)에 대한 QP 정보를 교환합니다
이러한 세션은 작업이 시작될 때 생성되며 기본적으로 GPU 인터페이스 중 하나(RoCEv2 트래픽에 사용되는 것과 동일한 인터페이스)를 사용합니다.
예:
-
ylara@A100-01:~$ netstat -atn | grep 10.200 | grep "ESTABLISHED" tcp 0 0 10.200.4.8:47932 10.200.4.2:43131 ESTABLISHED tcp 0 0 10.200.4.8:46699 10.200.4.2:37236 ESTABLISHED tcp 0 0 10.200.2.8:60502 10.200.13.2:35547 ESTABLISHED tcp 0 0 10.200.4.8:37330 10.200.4.2:55355 ESTABLISHED tcp 0 0 10.200.4.8:56438 10.200.4.2:53947 ESTABLISHED ---more---
작업을 시작할 때 다음 매개 변수를 포함하여 관리 인터페이스((프론트엔드 패브릭에 연결됨)로 이동하는 것이 좋습니다. export NCCL_SOCKET_IFNAME="mgmt_eth"
예:
-
ylara@A100-01:~$ netstat -atn | grep 10.10.1 | grep "ESTABLISHED" tcp 0 0 10.10.1.0:44926 10.10.1.2:33149 ESTABLISHED tcp 0 0 10.10.1.0:46705 10.10.1.0:40320 ESTABLISHED tcp 0 0 10.10.1.0:54661 10.10.1.10:52452 ESTABLISHED ---more---