보안 디바이스 문제 해결
논리적 시스템 보안 정책에서 DNS 이름 확인 문제 해결(기본 관리자만 해당)
문제
설명
보안 정책에 사용되는 주소록 항목의 호스트 이름 주소가 올바르게 확인되지 않을 수 있습니다.
원인
일반적으로 동적 호스트 이름이 포함된 주소록 항목은 SRX 시리즈 방화벽에 대해 자동으로 새로 고쳐집니다. DNS 항목과 연결된 TTL 필드는 정책 캐시에서 항목을 새로 고쳐야 하는 시간을 나타냅니다. TTL 값이 만료되면 SRX 시리즈 방화벽은 주소록 항목의 DNS 항목을 자동으로 새로 고칩니다.
그러나 SRX 시리즈 방화벽이 DNS 서버로부터 응답을 얻을 수 없는 경우(예: 네트워크에서 DNS 요청 또는 응답 패킷이 손실되거나 DNS 서버가 응답을 보낼 수 없는 경우) 주소록 항목의 호스트 이름 주소가 올바르게 확인되지 않을 수 있습니다. 이로 인해 보안 정책 또는 세션 일치가 발견되지 않아 트래픽이 손실될 수 있습니다.
솔루션
주 관리자는 명령을 사용하여 show security dns-cache SRX 시리즈 방화벽에 DNS 캐시 정보를 표시할 수 있습니다. DNS 캐시 정보를 새로 고쳐야 하는 경우 기본 관리자가 명령을 사용할 수 있습니다 clear security dns-cache .
이러한 명령은 논리적 시스템에 대해 구성된 디바이스의 기본 관리자만 사용할 수 있습니다. 이 명령은 사용자 논리적 시스템 또는 논리적 시스템에 대해 구성되지 않은 디바이스에서는 사용할 수 없습니다.
참조
링크 서비스 인터페이스 문제 해결
링크 서비스 인터페이스에서 구성 문제를 해결하려면:
- 구성 링크에 적용되는 CoS 구성 요소 결정
- 멀티링크 번들에서 지터 및 지연의 원인 파악
- LFI 및 로드 밸런싱이 올바르게 작동하는지 확인
- 주니퍼 네트웍스 디바이스와 타사 디바이스 간의 PVC에서 패킷이 손실되는 이유 확인
구성 링크에 적용되는 CoS 구성 요소 결정
문제
설명
멀티링크 번들을 구성하고 있지만, MLPPP 캡슐화가 없는 트래픽이 멀티링크 번들의 구성 링크를 통과합니다. 모든 CoS 구성 요소를 구성 링크에 적용합니까, 아니면 멀티링크 번들에 충분히 적용하고 있습니까?
솔루션
스케줄러 맵을 멀티링크 번들 및 해당 구성 링크에 적용할 수 있습니다. 스케줄러 맵을 사용하여 여러 CoS 구성 요소를 적용할 수 있지만 필요한 것만 구성합니다. 불필요한 전송 지연을 방지하기 위해 구성 링크의 구성을 단순하게 유지하는 것이 좋습니다.
표 1 에는 멀티링크 번들 및 해당 구성 링크에 적용될 CoS 구성 요소가 나와 있습니다.
CoS 구성 요소 |
멀티링크 번들 |
구성 링크 |
설명 |
|---|---|---|---|
분류자 |
예 |
아니요 |
CoS 분류는 전송 측이 아닌 인터페이스의 수신 측에서 이루어지므로 구성 링크에 분류자가 필요하지 않습니다. |
포워딩 클래스 |
예 |
아니요 |
포워딩 클래스는 대기열과 연결되며, 대기열은 스케줄러 맵에 의해 인터페이스에 적용됩니다. 대기열 할당은 구성 링크에서 미리 결정됩니다. 멀티링크 번들의 Q2에 있는 모든 패킷은 구성 링크의 Q2에 할당되고 다른 모든 대기열의 패킷은 구성 링크의 Q0에 대기됩니다. |
스케줄러 맵 |
예 |
예 |
다음과 같이 멀티링크 번들 및 구성 링크에 스케줄러 맵을 적용합니다.
|
유닛당 스케줄러 또는 인터페이스 수준 스케줄러의 셰이핑 속도 |
아니요 |
예 |
단위당 스케줄링은 엔드포인트에서만 적용되므로, 이 셰이핑 속도를 구성 링크에만 적용합니다. 앞서 적용된 모든 구성은 구성 링크 구성으로 덮어씁니다. |
정확한 전송 속도 또는 대기열 수준 셰이핑 |
예 |
아니요 |
구성 링크에 적용된 인터페이스 수준 셰이핑은 대기열의 모든 셰이핑보다 우선합니다. 따라서 멀티링크 번들에만 전송 속도 정확한 쉐이핑을 적용합니다. |
규칙 재작성 |
예 |
아니요 |
재작성 비트는 단편화 중에 패킷에서 단편으로 자동으로 복사됩니다. 따라서 멀티링크 번들에서 구성한 내용은 단편에서 구성 링크로 전달됩니다. |
가상 채널 그룹 |
예 |
아니요 |
가상 채널 그룹은 멀티링크 번들 이전의 패킷에만 적용되는 방화벽 필터 규칙을 통해 식별됩니다. 따라서 구성 링크에 가상 채널 그룹 구성을 적용할 필요가 없습니다. |
참조
멀티링크 번들에서 지터 및 지연의 원인 파악
문제
설명
지터와 지연 시간을 테스트하려면 IP 패킷 스트림 3개를 보냅니다. 모든 패킷의 IP 우선 순위 설정은 동일합니다. LFI 및 CRTP를 구성한 후에는 혼잡하지 않은 링크에서도 지연 시간이 증가했습니다. 지터와 지연 시간을 줄이려면 어떻게 해야 할까요?
솔루션
지터와 지연 시간을 줄이려면 다음을 수행합니다.
각 구성 링크에서 셰이핑 속도를 구성했는지 확인합니다.
링크 서비스 인터페이스에서 셰이핑 속도를 구성하지 않았는지 확인합니다.
구성된 셰이핑 속도 값이 물리적 인터페이스 대역폭과 동일한지 확인합니다.
셰이핑 속도가 올바르게 구성되었는데도 지터가 지속되면 주니퍼 네트웍스 기술 지원 센터(JTAC)에 문의하십시오.
LFI 및 로드 밸런싱이 올바르게 작동하는지 확인
문제
설명
이 경우 여러 서비스를 지원하는 단일 네트워크가 있습니다. 네트워크는 데이터 및 지연에 민감한 음성 트래픽을 전송합니다. MLPPP 및 LFI를 구성한 후, 지연과 지터가 거의 없이 음성 패킷이 네트워크를 통해 전송되는지 확인합니다. 음성 패킷이 LFI 패킷으로 처리되고 로드 밸런싱이 올바르게 수행되는지 어떻게 알 수 있습니까?
솔루션
LFI가 활성화되면 데이터(비 LFI) 패킷이 MLPPP 헤더로 캡슐화되고 지정된 크기의 패킷으로 단편화됩니다. LFI(Delay-Sensitive, Voice) 패킷은 PPP로 캡슐화되어 데이터 패킷 조각 사이에 인터리브됩니다. 대기열 및 로드 밸런싱은 LFI 패킷과 비 LFI 패킷에 대해 다르게 수행됩니다.
LFI가 올바르게 수행되는지 확인하려면 패킷이 구성된 대로 단편화되고 캡슐화되는지 확인합니다. 패킷이 LFI 패킷으로 처리되는지 또는 비 LFI 패킷으로 처리되는지 확인한 후 로드 밸런싱이 올바르게 수행되는지 확인할 수 있습니다.
Solution Scenario—두 개의 주니퍼 네트웍스 디바이스 R0 및 R1이 두 개의 시리얼 링크 se-1/0/0 및 se-1/0/1를 통합하는 멀티링크 번들 lsq-0/0/0.0 로 연결되어 있다고 가정해 보겠습니다. R0 및 R1에서 MLPPP 및 LFI는 링크 서비스 인터페이스에서 활성화되고 단편화 임계값은 128바이트로 설정됩니다.
이 예에서는 패킷 생성기를 사용하여 음성 및 데이터 스트림을 생성했습니다. 패킷 캡처 기능을 사용하여 수신 인터페이스에서 패킷을 캡처하고 분석할 수 있습니다.
다음 두 데이터 스트림이 멀티링크 번들로 전송되었습니다.
200바이트의 데이터 패킷 100개(단편화 임계값보다 큼)
60바이트의 데이터 패킷 500개(단편화 임계값보다 작음)
다음 두 개의 음성 스트림이 멀티링크 번들로 전송되었습니다.
소스 포트 100에서 200바이트의 음성 패킷 100개
소스 포트 200에서 200바이트의 음성 패킷 300개
LFI 및 로드 밸런싱이 올바르게 수행되는지 확인하려면,
이 예에서는 명령 출력의 중요한 부분만 표시되고 설명됩니다.
패킷 단편화를 확인합니다. 운영 모드에서 명령을 입력하여
show interfaces lsq-0/0/0큰 패킷이 올바르게 조각화되었는지 확인합니다.user@R0#> show interfaces lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Link-level type: LinkService, MTU: 1504 Device flags : Present Running Interface flags: Point-To-Point SNMP-Traps Last flapped : 2006-08-01 10:45:13 PDT (2w0d 06:06 ago) Input rate : 0 bps (0 pps) Output rate : 0 bps (0 pps) Logical interface lsq-0/0/0.0 (Index 69) (SNMP ifIndex 42) Flags: Point-To-Point SNMP-Traps 0x4000 Encapsulation: Multilink-PPP Bandwidth: 16mbps Statistics Frames fps Bytes bps Bundle: Fragments: Input : 0 0 0 0 Output: 1100 0 118800 0 Packets: Input : 0 0 0 0 Output: 1000 0 112000 0 ... Protocol inet, MTU: 1500 Flags: None Addresses, Flags: Is-Preferred Is-Primary Destination: 9.9.9/24, Local: 9.9.9.10Meaning- 출력은 멀티링크 번들에서 디바이스를 전송하는 패킷의 요약을 보여줍니다. 멀티링크 번들에 대한 다음 정보를 확인합니다.총 전송 패킷 수 = 1000
총 통과 조각 수=1100
단편화된 데이터 패킷 수 = 100
멀티링크 번들에서 전송된 총 패킷 수(600 + 400)는 전송 패킷 수(1000)와 일치하여 손실된 패킷이 없음을 나타냅니다.
전송 프래그먼트 수는 전송 패킷 수를 100배 초과하여 100개의 대용량 데이터 패킷이 올바르게 프래그먼트화되었음을 나타냅니다.
Corrective Action- 패킷이 올바르게 단편화되지 않은 경우, 단편화 임계값 구성을 확인합니다. 지정된 단편화 임계값보다 작은 패킷은 단편화되지 않습니다.패킷 캡슐화를 확인합니다. 패킷이 LFI 또는 비 LFI 패킷으로 취급되는지 확인하려면 캡슐화 유형을 결정합니다. LFI 패킷은 PPP로 캡슐화되며, 비 LFI 패킷은 PPP와 MLPPP로 캡슐화됩니다. PPP 및 MLPPP 캡슐화는 서로 다른 오버헤드를 가지므로 패킷 크기가 다릅니다. 패킷 크기를 비교하여 캡슐화 유형을 결정할 수 있습니다.
단편화되지 않은 작은 데이터 패킷에는 PPP 헤더와 단일 MLPPP 헤더가 포함됩니다. 큰 단편화된 데이터 패킷에서 첫 번째 단편에는 PPP 헤더와 MLPPP 헤더가 포함되지만 연속된 단편에는 MLPPP 헤더만 포함됩니다.
PPP 및 MLPPP 캡슐화는 패킷에 다음과 같은 바이트 수를 추가합니다.
PPP 캡슐화는 7바이트를 추가합니다.
4바이트의 헤더+2바이트의 FCS(Frame Check Sequence)+유휴 상태이거나 플래그를 포함하는 1바이트
MLPPP 캡슐화는 6바이트에서 8바이트 사이를 추가합니다.
4바이트의 PPP 헤더+2 - 4바이트의 멀티링크 헤더
그림 1 은(는) PPP 및 MLPPP 헤더에 추가된 오버헤드를 보여줍니다.
그림 1: PPP 및 MLPPP 헤더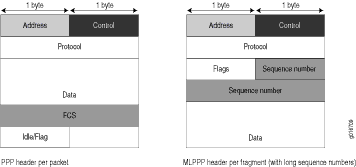
CRTP 패킷의 경우, 캡슐화 오버헤드와 패킷 크기는 LFI 패킷보다 훨씬 작습니다. 자세한 내용은 예: 압축된 실시간 전송 프로토콜 구성.
표 2 은(는) 데이터 패킷과 음성 패킷에 대한 캡슐화 오버헤드를 각각 70바이트로 보여줍니다. 캡슐화 후 데이터 패킷의 크기는 음성 패킷의 크기보다 큽니다.
표 2: PPP 및 MLPPP 캡슐화 오버헤드 패킷 유형
캡슐화
초기 패킷 크기
캡슐화 오버헤드
캡슐화 후의 패킷 크기
음성 패킷(LFI)
PPP
70바이트
4 + 2 + 1 = 7바이트
77 바이트
짧은 시퀀스의 데이터 조각(비 LFI)
메이저리그PPP
70바이트
4 + 2 + 1 + 4 + 2 = 13바이트
83바이트
긴 시퀀스의 데이터 조각(비 LFI)
메이저리그PPP
70바이트
4 + 2 + 1 + 4 + 4 = 15바이트
85바이트
운영 모드에서 명령을 입력하여
show interfaces queue각 대기열에서 전송된 패킷의 크기를 표시합니다. 전송된 바이트 수를 패킷 수로 나누어 패킷 크기를 구하고 캡슐화 유형을 결정합니다.로드 밸런싱을 확인합니다. 운영 모드에서 멀티링크 번들 및 해당 구성 링크에 명령을 입력하여
show interfaces queue패킷에 대해 로드 밸런싱이 적절하게 수행되는지 확인합니다.user@R0> show interfaces queue lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 600 0 pps Bytes : 44800 0 bps Transmitted: Packets : 600 0 pps Bytes : 44800 0 bps Tail-dropped packets : 0 0 pps RED-dropped packets : 0 0 pps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 400 0 pps Bytes : 61344 0 bps Transmitted: Packets : 400 0 pps Bytes : 61344 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 0 0 pps Bytes : 0 0 bps …user@R0> show interfaces queue se-1/0/0 Physical interface: se-1/0/0, Enabled, Physical link is Up Interface index: 141, SNMP ifIndex: 35 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps ... Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 100 0 pps Bytes : 15272 0 bps Transmitted: Packets : 100 0 pps Bytes : 15272 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 19 0 pps Bytes : 247 0 bps Transmitted: Packets : 19 0 pps Bytes : 247 0 bps …user@R0> show interfaces queue se-1/0/1 Physical interface: se-1/0/1, Enabled, Physical link is Up Interface index: 142, SNMP ifIndex: 38 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 300 0 pps Bytes : 45672 0 bps Transmitted: Packets : 300 0 pps Bytes : 45672 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 18 0 pps Bytes : 234 0 bps Transmitted: Packets : 18 0 pps Bytes : 234 0 bpsMeaning- 이러한 명령의 출력은 링크 서비스 인터페이스 및 해당 구성 링크의 각 대기열에서 전송 및 대기열에 있는 패킷을 보여줍니다. 표 3 에는 이러한 값의 요약이 나와 있습니다. (전송된 패킷 수가 모든 링크의 대기열 패킷 수와 같기 때문에 이 테이블에는 대기열에 있는 패킷만 표시됩니다.)표 3: 대기열에서 전송된 패킷 수 대기열에 있는 패킷
번들 lsq-0/0/0.0
구성 링크 se-1/0/0
구성 링크 se-1/0/1
설명
Q0의 패킷
600
350
350
구성 링크를 통과하는 총 패킷 수(350+350 = 700)가 멀티링크 번들에서 대기 중인 패킷 수(600)를 초과했습니다.
Q2의 패킷
400
100
300개
구성 링크를 통과하는 총 패킷 수는 번들의 패킷 수와 같습니다.
Q3의 패킷
0
19
18
구성 링크의 Q3을 통과하는 패킷은 구성 링크 간에 교환되는 keepalive 메시지를 위한 것입니다. 따라서 번들의 Q3에는 패킷이 계산되지 않았습니다.
멀티링크 번들에서 다음을 확인합니다.
대기열에 있는 패킷 수는 전송된 패킷 수와 일치합니다. 숫자가 일치하면 패킷이 삭제되지 않은 것입니다. 전송된 패킷보다 대기열에 더 많은 패킷이 있는 경우 버퍼가 너무 작기 때문에 패킷이 손실되었습니다. 구성 링크의 버퍼 크기는 출력 단계에서 혼잡을 제어합니다. 이 문제를 해결하려면 구성 링크의 버퍼 크기를 늘려야 합니다.
Q0(600)을 전송하는 패킷 수는 멀티링크 번들에서 수신된 크고 작은 데이터 패킷 수(100+500)와 일치합니다. 숫자가 일치하면 모든 데이터 패킷이 Q0을 올바르게 전송한 것입니다.
멀티링크 번들(400)에서 Q2를 전송하는 패킷 수는 멀티링크 번들에서 수신된 음성 패킷의 수와 일치합니다. 숫자가 일치하면 모든 음성 LFI 패킷이 Q2를 올바르게 전송합니다.
구성 링크에서 다음을 확인합니다.
Q0을 전송하는 총 패킷 수(350+350)는 데이터 패킷 및 데이터 조각 수(500+200)와 일치합니다. 숫자가 일치하면 단편화 후의 모든 데이터 패킷이 구성 링크의 Q0을 올바르게 전송합니다.
패킷이 두 구성 링크를 모두 전송하여 비 LFI 패킷에서 로드 밸런싱이 올바르게 수행되었음을 나타냅니다.
구성 링크에서 Q2(300+100)를 전송하는 총 패킷 수는 멀티링크 번들에서 수신된 음성 패킷 수(400)와 일치합니다. 숫자가 일치하면 모든 음성 LFI 패킷이 Q2를 올바르게 전송합니다.
전송된
se-1/0/0소스 포트100의 LFI 패킷 및 전송된 소스 포트200se-1/0/1의 LFI 패킷 . 따라서 모든 LFI(Q2) 패킷은 소스 포트를 기반으로 해시되었으며 두 구성 링크를 모두 올바르게 전송했습니다.
Corrective Action- 패킷이 하나의 링크만 전송한 경우 다음 단계를 수행하여 문제를 해결합니다.물리적 링크가 (작동) 또는
down(사용할 수 없음)인지up확인합니다. 사용할 수 없는 링크는 PIM, 인터페이스 포트 또는 물리적 연결에 문제가 있음을 나타냅니다(링크 레이어 오류). 링크가 작동하면 다음 단계로 이동합니다.비 LFI 패킷에 대해 분류자가 올바르게 정의되어 있는지 확인합니다. 비 LFI 패킷이 Q2까지 대기열에 추가되도록 구성되지 않았는지 확인합니다. Q2까지 대기열에 있는 모든 패킷은 LFI 패킷으로 처리됩니다.
LFI 패킷에서 다음 값 중 하나 이상이 다른지 확인합니다. 원본 주소, 대상 주소, IP 프로토콜, 원본 포트 또는 대상 포트. 모든 LFI 패킷에 대해 동일한 값이 구성된 경우, 패킷은 모두 동일한 플로우로 해시되고 동일한 링크를 전송합니다.
결과를 사용하여 부하 분산을 확인합니다.
주니퍼 네트웍스 디바이스와 타사 디바이스 간의 PVC에서 패킷이 손실되는 이유 확인
문제
설명
주니퍼 네트웍스 디바이스와 타사 디바이스의 T1, E1, T3 또는 E3 인터페이스 간에 영구 가상 회로(PVC)를 구성하고 있는데 패킷이 손실되고 ping이 실패합니다.
솔루션
타사 디바이스가 주니퍼 네트웍스 디바이스와 동일한 FRF.12를 지원하지 않거나 다른 방식으로 FRF.12를 지원하는 경우, PVC의 주니퍼 네트웍스 디바이스 인터페이스는 FRF.12 헤더가 포함된 단편화된 패킷을 폐기하고 이를 "폴리싱된 폐기"로 간주할 수 있습니다.
해결 방법으로, 두 피어 모두에서 멀티링크 번들을 구성하고 멀티링크 번들에서 단편화 임계값을 구성합니다.
보안 정책 문제 해결
라우팅 엔진과 패킷 포워딩 엔진 간의 정책 동기화
문제
설명
보안 정책은 라우팅 엔진과 패킷 전달 엔진에 저장됩니다. 구성을 커밋할 때 보안 정책이 라우팅 엔진에서 패킷 전달 엔진으로 푸시됩니다. 라우팅 엔진의 보안 정책이 패킷 전달 엔진과 동기화되지 않으면 구성 커밋이 실패합니다. 커밋을 반복적으로 시도하면 코어 덤프 파일이 생성될 수 있습니다. 동기화되지 않은 이유는 다음과 같습니다.
라우팅 엔진에서 패킷 전달 엔진으로의 정책 메시지는 전송 중에 손실됩니다.
재사용된 정책 UID와 같은 라우팅 엔진에 오류가 있습니다.
환경
구성을 커밋하려면 라우팅 엔진과 패킷 전달 엔진의 정책이 동기화되어야 합니다. 그러나 특정 상황에서는 라우팅 엔진과 패킷 전달 엔진의 정책이 동기화되지 않아 커밋이 실패할 수 있습니다.
증상
정책 구성이 수정되고 정책이 동기화되지 않으면 다음 오류 메시지가 표시됩니다. error: Warning: policy might be out of sync between RE and PFE <SPU-name(s)> Please request security policies check/resync.
솔루션
show security policies checksum 명령을 사용하여 보안 정책 체크섬 값을 표시하고, 보안 정책이 동기화되지 않은 경우 명령을 사용하여 request security policies resync 라우팅 엔진 및 패킷 전달 엔진의 보안 정책 구성을 동기화합니다.
보안 정책 커밋 실패 확인
보안 정책 커밋 확인
문제
설명
정책 구성 커밋을 수행할 때 시스템 동작이 올바르지 않은 경우 다음 단계를 사용하여 이 문제를 해결합니다.
솔루션
운영 show 명령 - 보안 정책에 대한 운영 명령을 실행하고 출력에 표시된 정보가 예상한 것과 일치하는지 확인합니다. 그렇지 않은 경우 구성을 적절하게 변경해야 합니다.
Traceoptions - 정책 구성에서 명령을 설정합니다
traceoptions. 이 계층 아래의 플래그는 명령 출력의 사용자 분석에 따라 선택할 수 있습니다show. 사용할 플래그를 결정할 수 없는 경우 flag 옵션을all사용하여 모든 추적 로그를 캡처할 수 있습니다.user@host#
set security policies traceoptions <flag all>
로그를 캡처하기 위해 선택적 파일 이름을 구성할 수도 있습니다.
user@host# set security policies traceoptions <filename>
추적 옵션에서 파일 이름을 지정한 경우 /var/log/<filename>에서 로그 파일을 확인하여 파일에 오류가 보고되었는지 확인할 수 있습니다. (파일 이름을 지정하지 않은 경우 기본 파일 이름이 이벤트됩니다.) 오류 메시지는 실패 위치와 적절한 이유를 나타냅니다.
추적 옵션을 구성한 후에는 잘못된 시스템 동작을 일으킨 구성 변경을 다시 커밋해야 합니다.