이 페이지 내용
QBA Exporatory Interface
주니퍼 Apstra 릴리스 5.0에는 쿼리 기반 분석(QBA) 언어를 사용하여 데이터 세트를 탐색하고 시각화할 수 있는 탐색적 분석 인터페이스가 도입되었습니다. 이 기능을 사용하면 대규모 데이터 세트를 분석하고 네트워크 인프라의 주요 측면에 대한 상관 관계 또는 이전에 알려지지 않은 데이터 패턴을 발견할 수 있습니다.
이 기능은 주니퍼 Apstra 기술 프리뷰 기능으로 분류되었습니다. 이러한 기능은 "있는 그대로" 자발적으로 사용됩니다. 주니퍼 지원 부서는 고객이 이러한 기능을 사용할 때 경험하는 모든 문제를 해결하려고 시도하고 지원 사례를 대신하여 버그 보고서를 작성합니다. 그러나 주니퍼는 기술 프리뷰 기능에 대한 포괄적인 지원 서비스를 제공하지 않을 수 있습니다.
자세한 정보는 주니퍼 Apstra 기술 프리뷰 페이지를 참조하거나 주니퍼 지원에 문의하십시오.
쿼리 기반 분석 개요
주니퍼 Apstra 릴리스 5.0은 쿼리 기반 분석(QBA) 인터페이스를 도입하여 IBA를 향상시킵니다. QBA는 Apstra 내의 다양한 데이터 소스와 상호 작용하기 위한 통합 쿼리 인터페이스입니다. Apstra는 데이터센터(DC)에 대한 다양한 종류의 데이터를 생성합니다. 이 데이터는 메모리 내 또는 디스크의 다른 데이터베이스에 저장됩니다. 이 인터페이스를 통해 문제 해결 또는 데이터 분석을 위해 다양한 소스의 데이터를 쿼리하고 연결할 수 있습니다.
QBA Exploratory Interface는 QBA를 사용하여 강력한 쿼리 및 데이터 시각화 옵션으로 자체 데이터 분석을 수행할 수 있는 GUI 도구입니다. 탐색적 인터페이스를 사용하여 쿼리를 체계적으로 작성한 다음 직관적인 시각화 옵션을 선택할 수 있습니다. Apstra가 데이터를 시각화한 후 데이터에 대한 다양한 변환(통계 연산자)을 실험하여 적절하다고 판단되는 대로 데이터를 형성하고 조작할 수 있습니다.
예를 들어 스위치의 평균 TX 사용률에 관심이 있다고 가정해 보겠습니다. 인터페이스를 사용하여 최대 30일에서 분 단위까지 다양한 집계 간격으로 이 지표를 시각화할 수 있습니다. 쿼리를 특정 인터페이스 및 시스템 ID(system_id)로 제한할 수 있습니다. 쿼리를 제출하면 페이지 오른쪽에 있는 쿼리 시각화 탭이 채워집니다. 다음 시각화 옵션 중에서 선택할 수 있습니다.
-
꺾은선형 차트: 시간 간격에 따른 숫자 값의 변화를 시각화합니다. 데이터 포인트는 직선으로 연결됩니다.
-
영역 차트: 시간 간격에 따른 숫자 값의 변화를 시각화합니다. 꺾은선형 차트와 비슷하지만 x축과 플로팅된 선 사이의 공간이 채워집니다.
-
누적 영역 차트: 시간 간격에 따른 데이터 그룹의 변경 사항을 시각화합니다. 영역 차트와 비슷하지만 각 그룹의 데이터가 서로 겹쳐서 표시되거나 누적된다는 점이 다릅니다.
-
산점도: 두 숫자 값 간의 관계를 시각화합니다. x축은 첫 번째 데이터 포인트의 값을 나타내고 y축은 두 번째 데이터 포인트의 값을 나타냅니다.
-
파이 차트: 전체 값(100%)과 관련된 데이터의 백분율(부분)을 시각화합니다.
-
도넛형 차트: 전체와 관련하여 데이터의 여러 부분의 값을 시각화합니다.
또한 다음과 같은 출력 옵션을 사용하여 데이터를 볼 수 있습니다.
-
테이블
-
시계열 테이블
-
JSON (영문)
시각화 방법을 선택한 후 관심 있는 장치의 시스템 ID를 선택하여 차트를 조작할 수 있습니다. 다른 x축 및 y축 옵션을 선택할 수도 있습니다. 추세선 표시 옵션을 선택하면 더 나은 추세 시각화를 위해 차트의 포인트가 선으로 그려집니다.
쿼리 소스
탐색 인터페이스를 사용하면 관리되는 디바이스 전반에 걸쳐 다양한 소스의 다양한 유형의 데이터를 쿼리할 수 있습니다.
메트릭DB
MetricDb는 주니퍼 Apstra 독점 시계열 데이터베이스입니다. IBA, 감사, 이상 징후 및 시스템 리소스 모니터링과 같은 Apstra 구성 요소는 MetricDb를 사용하여 DC의 다양한 측면에 대한 시계열/기록 데이터를 저장합니다. 이 데이터에는 네트워크 트래픽 기능(예: 인터페이스 카운터, ecmp 불균형 등), 장치 상태 기능(예: CPU 사용량), 메모리 사용량, 온도, 전력, 트랜시버 통계, 컨트롤러 기능(예: 감사, 이상 등)이 포함됩니다. MetricDb를 쿼리할 때 'locator' 속성은 이전에 언급한 그래프 소스 중 사용할 소스를 지정합니다. QBA 쿼리에는 '연산' 그래프를 사용하는 것이 좋습니다.
그래프
Apstra 그래프 데이터베이스(블루프린트)는 DC의 실행 상태에 대한 기술 자료입니다. 그래프는 인프라, 정책, 제약 조건 등과 관련된 단일 정보 소스를 나타냅니다. Apstra는 다음과 같은 그래프 사본을 유지합니다.
-
구성: 보안 정책, 선호 경로, 네트워크 요구 사항 등의 형태로 사용자 인텐트를 캡처합니다.
-
스테이징: 구성 그래프와 의도를 DC 전체에서 자동화된 관리 작업으로 변환하는 것을 나타냅니다.
-
작동: DC의 현재 실행 상태를 캡처합니다.
다음은 그래프 쿼리의 예입니다.
graph_query = {
"name": "graph",
"from": {
"source": "persisted_sysdb_files",
"locator": ["{}/{}".format(base_dir, sysdb_stem),
blueprint_id,
"operation"]
},
"filter": "node('system', name='system', role=is_in(['leaf', 'spine']), deploy_mode='deploy').out('part_of_pod').node('pod', name='pod')",
"select": {
"keys": {
"system_id": ["system", "system_id"],
},
"data": {
"label": ["system", "label"],
"role": ["system", "role"],
"deploy_mode": ["system", "deploy_mode"],
"pod_label": ["pod", "label"],
}
}
}
'locator' 매개 변수는 일반적으로 "작동" 그래프를 나타냅니다. 그래프에 대한 자세한 내용은 그래프를 참조하십시오.
예를 들어 이 두 데이터 원본에서 데이터를 가져오는 쿼리를 작성해 보겠습니다. 옵티컬 트랜시버의 현재 DC 인벤토리를 개선하고 옵티컬 트랜시버의 가장 효율적인 유지 관리 기간에 대한 통찰력을 얻고 싶다고 가정해 보겠습니다. 트랜시버의 온도 추세를 시각화함으로써 더 많은 정보를 얻고 이 지식을 활용하여 장애를 예측하거나 공급업체를 비교할 수 있을 것으로 생각합니다.
우리는 우리가 찾고 있는 것이 무엇인지 명확하게 알지 못하지만 데이터를 탐색하기를 원합니다. Apstra IBA "옵티컬 트랜시버" 프로브는 DC의 모든 옵티컬 트랜시버에서 온도, 전력 등과 같은 다양한 통계를 모니터링합니다. 이 프로브의 단계 내에서 metricDb가 활성화되고 기록 데이터를 수집합니다. '2min-avg' 단계 메트릭을 사용하여 '모델', '공급업체' 및 '온도' 데이터를 수집할 수 있습니다. 또한 Graph의 시스템에 대한 'hostname', 'role', 'label' 및 'ipv4_addr' 정보를 사용하여 필요에 따라 이 데이터를 사용자 지정할 수 있습니다.
이 두 데이터 소스를 결합하여 (시스템, 인터페이스) 쌍별로 데이터를 분류하고 데이터 가용성을 기반으로 지난 주, 월 또는 연간 동안 온도 변수의 추세를 그릴 수 있습니다. 예비 인터페이스 도구는 이와 같은 쿼리를 위한 GUI 기반 빌더입니다. 아래 예제에서는 이 쿼리를 JSON 형식으로 보여 줍니다.
고급 사용자는 예비 인터페이스를 무시하고 대신 쿼리를 직접 업데이트하도록 선택할 수 있습니다. 이러한 경우 '/api/qba/query' rest-api 엔드포인트를 사용하여 수동으로 쿼리를 실행할 수 있습니다. 이 쿼리는 세 개의 하위 쿼리로 구성됩니다.
-
MetricDb 메트릭 'Optical probe, 2min-avg' 단계에 대한 하위 쿼리
-
그래프 하위 쿼리
-
이전 두 개의 하위 쿼리 결과를 결합하여 집계된 최종 결과를 형성하는 최종 하위 쿼리
이 쿼리 출력은 추세를 시각화하기 위해 선 그래프로 그릴 수 있습니다. 데이터를 시각화한 후 적절하다고 판단되는 정보를 탐색할 수 있습니다. 공급업체 또는 원하는 수의 옵티컬 트랜시버 통계를 기반으로 데이터를 비교할 수 있습니다.
query = [
# metric db query
{
# sub query can be referenced by name
"name": "xcvr_metricdb",
"from": {
"source": "metricdb",
"locator": ["iba", "sf-pod", "xcvr_probe", "2min-avg"],
"between": {
"begin": "2022-08-20T05:00:00",
"end": "2022-08-27T05:00:00",
"aggregation_interval": 3600
}
},
"select" : {
"keys": {
"system": "system",
"interface": "interface",
},
"data": {
"model": "model",
"vendor": "vendor",
"temp": "temperature"
}
},
"filter": [
"or",
["=", "vendor", "juniper"],
["=", "vendor", "arista"]
],
},
# graph query
{
# sub query can be referenced by name
"name": "graph",
"from": {
"source": "graph",
"locator": ["sf-pod", "operational"]
},
"select" : {
"keys": {
"system_id": ["@", "system", "system_id"],
"ifc_name": ["@", "interface", "if_name"]
},
"data": {
"hostname": ["@", "system", "hostanme"],
"role": ["@", "system", "role"],
"label": ["@", "interface", "label"],
"ipv4_addr": ["@", "interface", "ipv4_addr"]
}
},
"filter": "node('system', name='system', system_id=not_none())."
"out('hosted_interfaces')."
"node('interface', name='interface')",
"ordered": [
{"system_id": "ascending"},
{"ifc_name": "ascending"}
]
},
# To combine the above two query results, and show how
# each interface’s temperature is trending using simple
# linear regression. And sort the result in descending
# order, i.e. the one with faster rising temperature
# is placed in the front.
{
"from": [
{ # result of xcvr metricdb probe query
"source": "query",
"name": "xcvr_metricdb"
},
{ # result of graph query
"source": "query",
"name": "graph",
"join": {
"system_id": "system",
"ifc_name": "interface"
}
}
],
"select" : {
"keys": {
"system_id": ["@", "xcvr_metricdb", "system"],
"ifc_name": ["@", "xcvr_metricdb", "interface"]
},
"data": {
"temp_trend": ["slr", ["@", "xcvr_metricdb", "temp"]],
"Hostname": ["@", "graph", "hostname"],
"Ipv4_addr": ["@", "graph", "ipv4_addr"]
}
},
"ordered": [{"temp_trend|coef": "descending"}]
}
]
탐색적 인터페이스 사용
다음 단계에 따라 QBA 예비 인터페이스로 쿼리를 작성하고 시각화할 수 있습니다. 인터페이스는 쿼리를 단계별로 작성하는 GUI 도구입니다. 각 단계에서 하위 쿼리를 작성하고, 실행하고, 중간 데이터를 시각화할 수 있습니다. 데이터 모양과 크기를 변환하는 하위 쿼리 체인을 만들어 최종 데이터 시각화를 요약하는 최종 하위 쿼리에 도달할 수 있습니다. 다음 단계에서는 '트래픽 데이터 추세 분석' 사용 사례를 사용하여 GUI 구성 요소를 시연합니다.
- Apstra GUI에서 Analytics > Exploratory Analytics 아래의 인터페이스로 이동합니다.
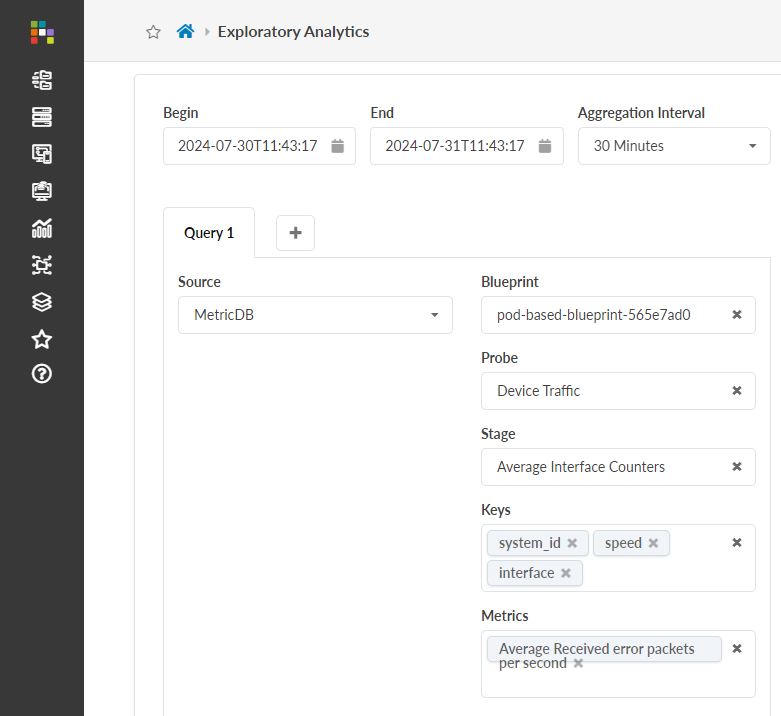
- 드롭다운에서 시각화할 메트릭을 하나 이상 선택합니다.
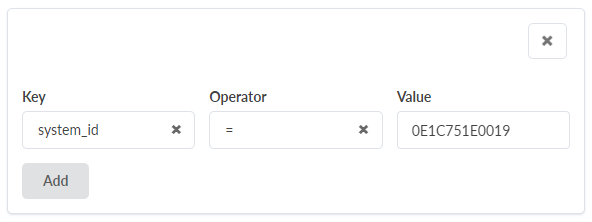
- (선택 사항) 필터를 추가하여 쿼리 결과의 범위를 좁힙니다.
사용 가능한 옵션은 다음과 같습니다.
-
키: 결과 차트에서 행을 식별하는 속성입니다.
-
연산자: 쿼리의 두 가지 조건을 정의하는 커넥터입니다.
-
값: 사용자 정의 문자열입니다.
예를 들어 필터
system_id = 0E1C751E0019는 쿼리 출력을 해당system_id값과 연결된 디바이스로 제한합니다.
-
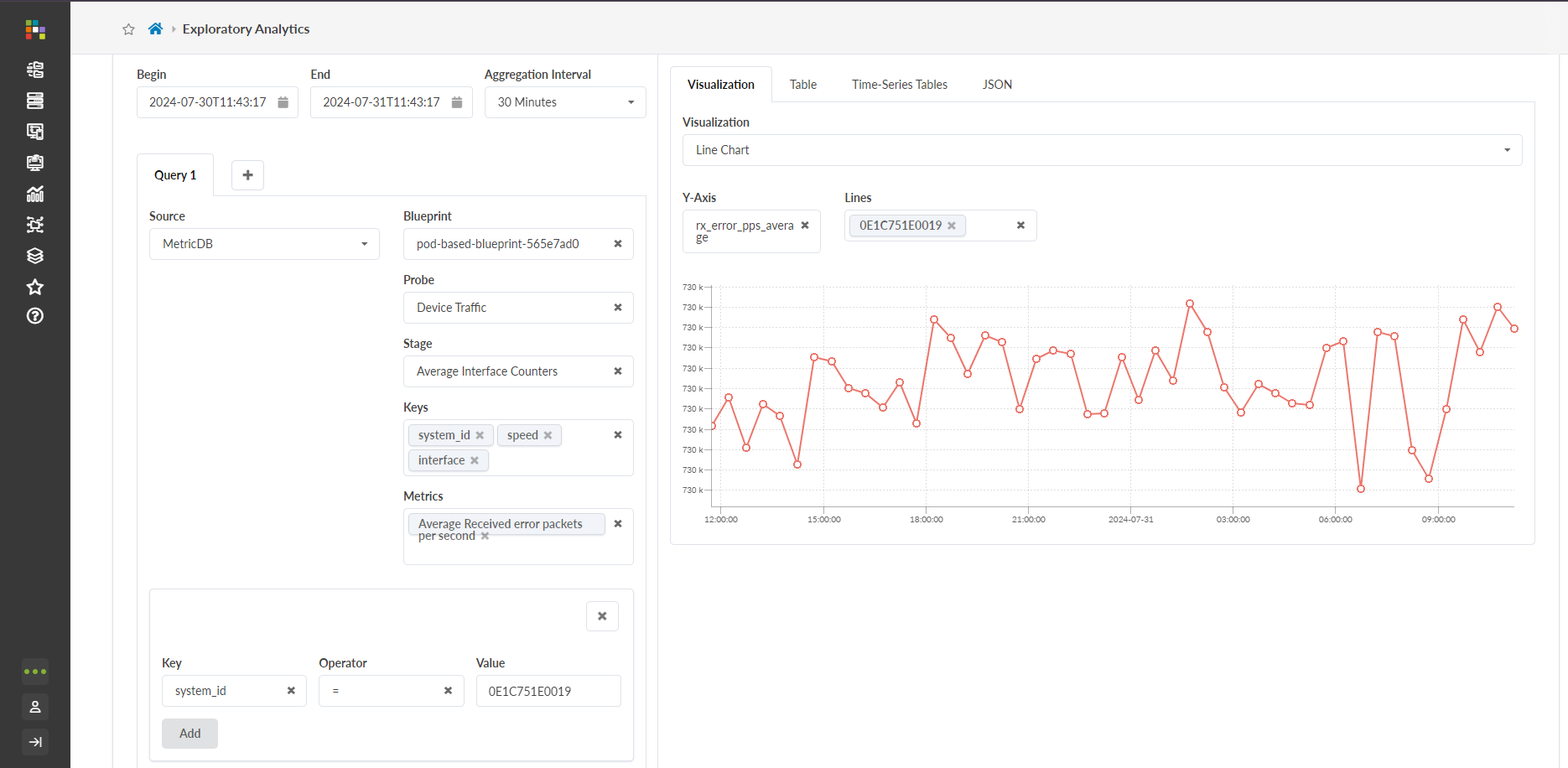
- 쿼리 제출을 클릭하고 시각화 창의 드롭다운에서 시각화 옵션을 선택합니다.
- (선택 사항) 쿼리 출력에 변환을 추가합니다.
변환은 데이터 처리 파이프라인의 중간에 수행되는 작업입니다. QBA에서 변환은 입력 테이블(초기 쿼리 출력)에서 그룹화 또는 집계 작업을 수행합니다. 새로 집계된 데이터가 출력 테이블에 표시됩니다.이전에 위에서 작성한 쿼리(테이블 보기에 표시됨)를 입력 테이블로 사용해 보겠습니다. 변환을 적용하지 않으면 입력 테이블에는 많은 행이 있는 5개의 열이 있습니다. 이 행은 지정된 타임스탬프에서 지정된
system_id와 연결된 각 인터페이스에 대한 "초당 평균 수신 오류 패킷(rx_error_pps_average)"을 나타냅니다.
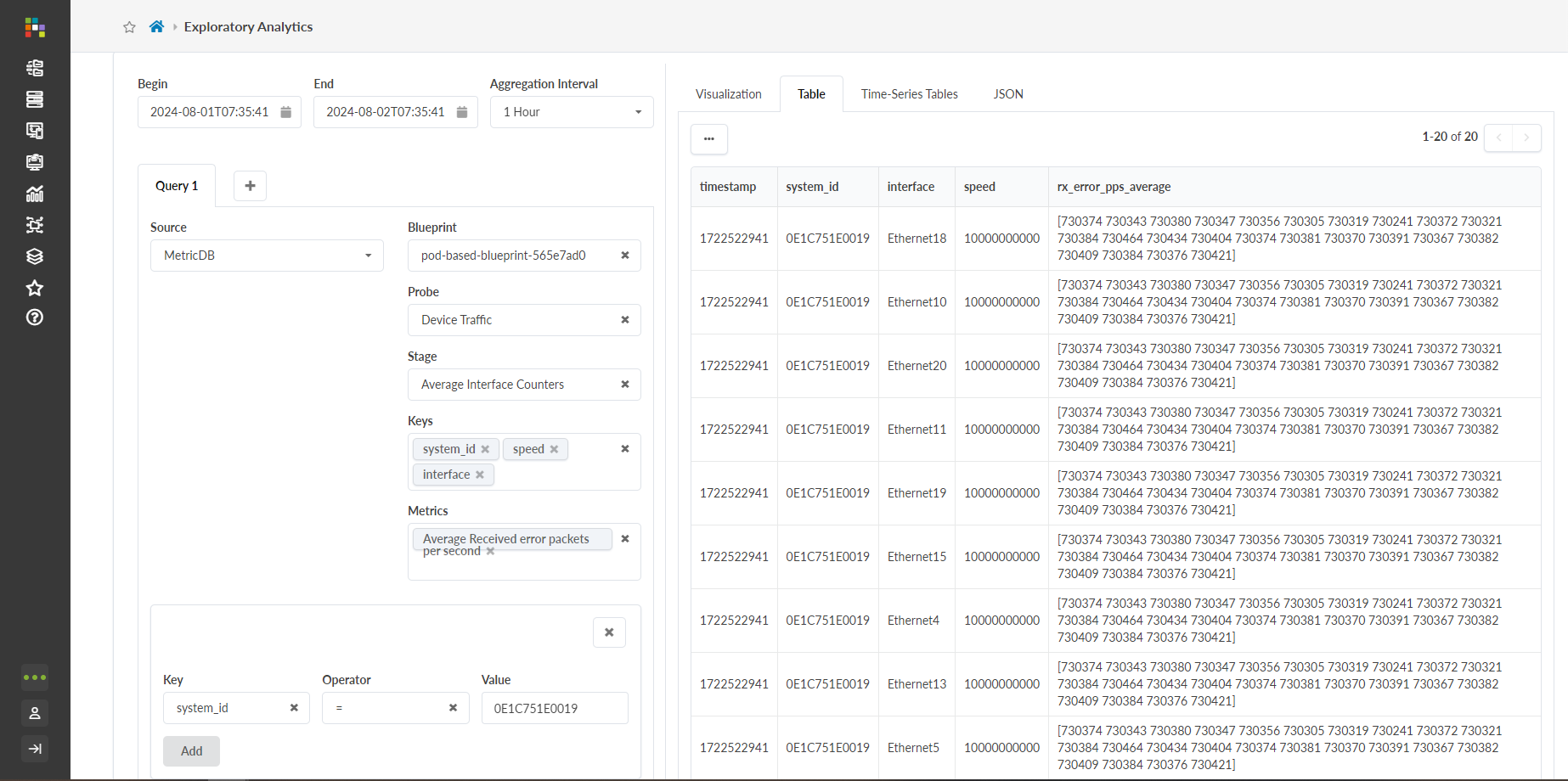
변환은 위 예제 입력 테이블의 데이터를 기반으로 출력 테이블의 셀을 압축하고 필터링합니다.-
단순 선형 회귀(SLR): 두 변수 간의 선형 관계를 모델링합니다. SLR을 사용하여 종속 변수의 값을 기반으로 독립 변수의 값을 예측합니다. 이 예에서 종속 변수(x축)는 초당 평균 수신 오류 패킷입니다. 독립 변수(y축)는 인터페이스 유형입니다. SLR 변환을 적용하면 다음과 같은 결과가 출력됩니다.
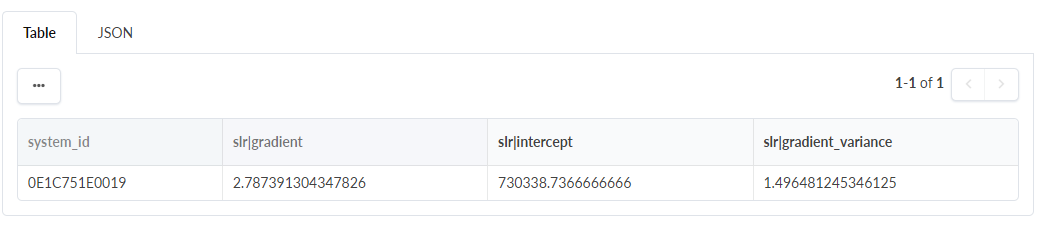
테이블 요소에 유의하십시오.
-
slr|gradient: 회귀선의 그라데이션입니다. 인터페이스 유형의 1단위 변경에 대해 초당 평균 수신 오류 패킷의 변화율을 나타냅니다.
-
slr|intercept: 회귀선이 y축을 가로채는 위치입니다. 독립 변수가 0인 경우 종속 변수의 값입니다.
-
slr|gradient_variance: 기울기의 분산 또는 기울기 추정값의 불확실성입니다.
-
-
사분위간 범위(IQR): 데이터 분포의 중간(50%)에 있는 산포의 양입니다. 지정된 열(Value)에서 IQR을 계산하고 5개의 숫자 열을 반환합니다.
-
분
-
25%
-
50%
-
75%
-
최대
-
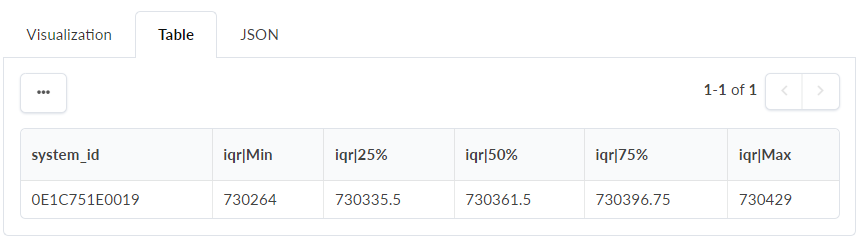
-
가장 최근: "rx_error_pps_average" 열의 마지막 값을 반환합니다.
-
통계 측정값: 입력 테이블의 각 행에 대한 "rx_error_pps_average" 열에 대한 통계("min", "max", "mean", "median", "mode", standard deviation("stddev"))를 계산합니다.
-
공분산: 지정된 두 열 간의 공분산을 계산하고 단일 숫자 열을 반환합니다.
-
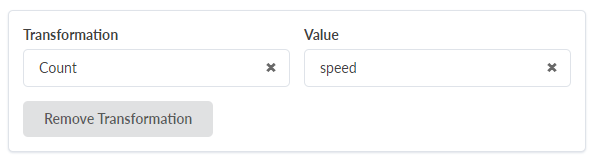
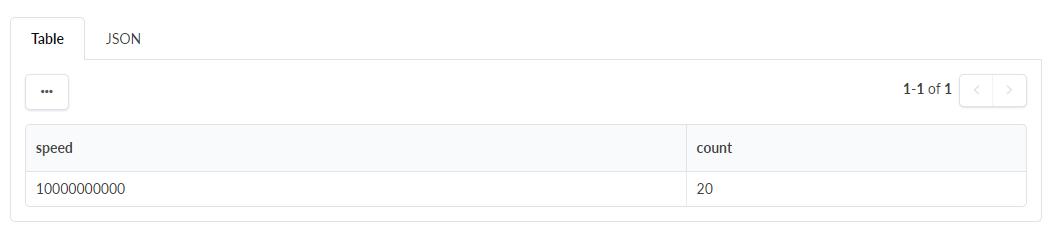
개수: 유사한 키를 가진 행 수를 계산하고 최종 개수를 단일 변수로 저장합니다.
카운트 변환을 추가하고 속도 열의 값을 선택하면 출력 테이블이 세로로 압축되어 지정된 속도의 인터페이스의 집계된 값이 있는 단일 행을 표시합니다.
-