그래프
그래프 개요
Apstra는 그래프 모델을 사용하여 인프라, 정책, 제약 조건 등과 관련된 단일 정보 소스를 나타냅니다. 이 그래프 모델은 지속적으로 변경될 수 있으며 다양한 이유로 쿼리할 수 있습니다. 그래프로 표시됩니다. 네트워크에 대한 모든 정보는 노드 및 노드 간의 관계로 모델링됩니다.
그래프의 모든 개체에는 고유한 ID가 있습니다. 노드에는 형식(문자열)과 특정 형식을 기반으로 하는 추가 속성 집합이 있습니다. 예를 들어, 시스템의 모든 스위치는 system 유형의 노드로 표시되며 네트워크에서 할당된 역할(스파인/리프/서버)을 결정하는 속성 역할을 가질 수 있습니다. 물리적 및 논리적 스위치 포트는 인터페이스 노드로 표시되며, 인터페이스 노드에는 if_type라는 속성도 있습니다.
서로 다른 노드 간의 관계는 그래프 에지로 표시되며 이를 관계라고 합니다. 관계는 지시되며, 이는 각 관계에는 소스 노드와 대상 노드가 있음을 의미합니다. 관계에는 특정 관계가 가질 수 있는 추가 속성을 결정하는 형식도 있습니다. 예를 들어, 시스템 노드는 인터페이스 노드에 대한 유형 hosted_interfaces 관계를 갖습니다.
가능한 노드 및 관계 유형 집합은 그래프 스키마에 의해 결정됩니다. 스키마는 특정 유형의 속성, 노드 및 관계와 함께 해당 속성의 유형(문자열/정수/부울/등) 및 제약 조건을 정의합니다. 우리는 가치 유형의 유연한 사용자 정의를 허용하는 오픈 소스 스키마 라이브러리인 Lollipop을 사용하고 유지 관리합니다.
단일 정보 소스(SSOT)를 나타내는 그래프로 돌아가서, 가장 어려운 측면 중 하나는 운영자와 관리 시스템 모두에서 발생하는 변경 사항이 있는 상황에서 이를 추론하는 방법이었습니다. 이를 지원하기 위해 세 가지 필수 구성 요소가 있는 Live Query 메커니즘을 개발했습니다.
- 쿼리 사양
- 변경 통지
- 통지 처리
도메인 모델을 그래프로 모델링하면 그래프 쿼리로 지정된 그래프에서 검색을 실행하여 그래프에서 특정 패턴(하위 그래프)을 찾을 수 있습니다. 쿼리를 표현하는 언어는 개념적으로 오픈 소스 그래프 순회 언어인 Gremlin을 기반으로 합니다. 또한 인기 있는 그래프 데이터베이스 neo4j에서 사용하는 쿼리 언어인 Cypher라는 다른 언어로 표현된 쿼리에 대한 파서도 있습니다.
쿼리 사양
node()로 시작한 다음 일치하는 관계와 노드를 번갈아 가며 메서드 호출을 계속 연결합니다.
node('system', name='system').out().node('interface', name='interface').out().node('link', name='link')
영어로 번역 된 위의 쿼리는 다음과 같습니다 : type system 의 노드에서 시작하여 interface 유형의 노드에 도달하는 모든 나가는 관계를 트래버스하고 해당 노드에서 'link 유형의 노드로 이어지는 모든 나가는 관계를 트래버스합니다.
언제든지 제약 조건을 추가할 수 있습니다.
node('system', role='spine', name='system').out().node('interface', if_type='ip', name='interface')
role='spine' 인수를 사용하면 role 속성이 spine으로 설정된 시스템 노드만 선택합니다.
인터페이스 노드if_type 속성과 동일합니다.
node('system', role=is_in(['spine', 'leaf']), name='system')
.out()
.node('interface', if_type=ne('ip'), name='interface')
이 쿼리는 스파인 또는 리프 역할이 있는 모든 시스템 노드와 ip 이외의 if_type 있는 인터페이스 노드를 모두 선택합니다(ne는 같지 않음을 의미).
임의의 Python 함수가 될 수 있는 교차 객체 조건을 추가할 수도 있습니다.
node('system', name='system')
.out().node('interface', name='if1')
.out().node('link')
.in_().node('interface', name='if2')
.in_().node('system', name='remote_system')
.where(lambda if1, if2: if1.if_type != if2.if_type)
Name 객체를 참조하고 그 이름을 제약 조건 함수의 인자 이름으로 사용합니다 (물론 재정의 할 수 있지만 편리한 기본 동작을 만듭니다). 따라서 위의 예에서 if1 과 if2 라는 두 개의 인터페이스 노드를 가져 와서 주어진 where 함수에 전달하고 함수가 False를 반환하는 경로를 필터링합니다. 제약 조건을 어디에 두는지 걱정하지 마십시오: 제약 조건에 의해 참조되는 모든 개체를 사용할 수 있게 되자마자 검색 중에 적용됩니다.
이제 단일 경로가 있으므로 이를 사용하여 검색을 수행할 수 있습니다. 그러나 단일 경로보다 더 복잡한 쿼리를 원할 수도 있습니다. 이를 지원하기 위해 쿼리 DSL을 사용하면 동일한 쿼리에서 쉼표로 구분된 여러 경로를 정의할 수 있습니다.
match(
node('a').out().node('b', name='b').out().node('c'),
node(name='b').out().node('d'),
)
이 match() 함수는 경로 그룹을 만듭니다. 서로 다른 경로에서 같은 이름을 공유하는 모든 개체는 실제로 동일한 개체를 참조합니다. match() 또한 를 사용하여 개체에 더 많은 제약 조건을 추가할 수 있습니다 where(). 특정 개체에 대해 고유한 검색을 수행할 수 있으며 각 값 조합이 결과에 한 번만 표시되도록 합니다.
match(
node('a', name='a').out().node('b').out().node('c', name='c')
).distinct(['a', 'c'])
이는 a -> b -> c 노드의 체인과 일치합니다. 두 개의 노드 a와 c가 유형 b의 둘 이상의 노드를 통해 연결된 경우 결과에는 여전히 하나의 (a, c) 쌍만 포함됩니다.
쿼리를 작성할 때 사용할 수 있는 또 다른 편리한 패턴이 있습니다: 구조와 조건을 분리하는 것입니다.
match(
node('a', name='a').out().node('b').out().node('c', name='c'),
node('a', foo='bar'),
node('c', bar=123),
)
쿼리 엔진은 해당 쿼리를 다음과 같이 최적화합니다.
match(
node('a', name='a', foo='bar')
.out().node('b')
.out().node('c', name='c', bar=123)
)
데카르트 곱이 없으며 불필요한 단계가 없습니다.
변경 통지
자, 이제 그래프 쿼리가 정의되었습니다. 알림 결과는 어떻게 표시되나요? 각 결과는 쿼리 개체에 대해 정의한 이름을 찾은 개체에 매핑하는 사전이 됩니다. 예를 들어 다음 쿼리의 경우
node('a', name='a').out().node('b').out().node('c', name='c')
결과는 와 같습니다 {'a': <node type='a'>, 'c': <node type='c'>}. 명명 된 객체 만 있습니다 (해당 노드는 이름이 없기 때문에 쿼리에 있지만 결과에는 없음 <node type='b'> ).
모니터링할 쿼리와 변경 사항이 있을 경우 실행할 콜백을 등록합니다. 나중에 누군가 모니터링 중인 그래프를 수정하면 새 그래프 업데이트로 인해 새 쿼리 결과가 나타나거나 이전 결과가 사라지거나 업데이트되는 것을 감지합니다. 응답은 쿼리와 연결된 콜백을 실행합니다. 콜백은 쿼리의 전체 경로를 응답으로 수신하고 실행할 특정 작업(추가/업데이트/제거)을 수신합니다.
통지 처리
결과가 처리(콜백) 함수로 전달되면 거기에서 추론 논리를 지정할 수 있습니다. 로그 생성, 오류 생성부터 구성 렌더링 또는 의미 체계 유효성 검사 실행에 이르기까지 무엇이든 될 수 있습니다. 그래프 API를 사용하여 그래프 자체를 수정할 수도 있으며 일부 다른 논리는 변경 사항에 반응할 수 있습니다. 이렇게 하면 그래프를 단일 정보 소스로 적용하는 동시에 애플리케이션 논리 요소 간의 논리적 통신 채널 역할도 할 수 있습니다. Graph API는 다음 세 부분으로 구성됩니다.
그래프 관리 - 그래프에서 항목을 추가/업데이트/제거하는 방법. add_node(), , set_node(), del_node(), set_relationship()get_node()add_relationship(), , del_relationship(), , get_relationship()쿼리 commit() get_nodes()get_relationships() 관찰 가능한 인터페이스add_observer(),remove_observer()
그래프 관리 API는 따로 설명이 필요 없습니다. add_node() 새 노드를 만들고, set_node() 기존 노드의 속성을 업데이트하고 del_node() , 노드를 삭제합니다.
commit() 는 그래프에 대한 모든 업데이트가 완료되었으며 모든 리스너에 전파될 수 있음을 알리는 데 사용됩니다.
관계에는 유사한 API가 있습니다.
관찰 가능한 인터페이스를 사용하면 콜백 인터페이스 알림을 구현하는 객체인 관찰자를 추가/제거할 수 있습니다. 알림 콜백은 세 가지 메서드로 구성됩니다.
on_node()- 노드/관계가 추가, 제거 또는 업데이트될 때 호출됩니다.on_relationship()- 노드/관계가 추가, 제거 또는 업데이트될 때 호출됩니다.on_graph()- 그래프가 커밋될 때 호출됩니다.
쿼리 API는 그래프 API의 핵심이며 모든 검색을 지원합니다. 둘 다 get_nodes() 및 get_relationships() 그래프에서 해당 개체를 검색할 수 있습니다. 이러한 함수에 대한 인수는 검색된 개체에 대한 제약 조건입니다.
예를 들어 get_nodes() 그래프의 모든 노드를 반환하고, get_nodes(type='system') 모든 시스템 노드를 반환하고, get_nodes(type='system', role='spine') 반환 된 노드를 특정 속성 값을 가진 노드로 제한 할 수 있습니다. 각 인수의 값은 일반 값 또는 특수 속성 일치자 개체일 수 있습니다. 값이 일반 값인 경우 해당 결과 개체는 지정된 일반 값과 동일한 속성을 가져야 합니다. 속성 일치자를 사용하면 더 복잡한 기준(예: 같지 않음, 보다 작음, 주어진 값 중 하나 등)을 표현할 수 있습니다.
아래 예제는 Graph python을 직접 사용하는 예제입니다. 데모를 위해 그래프 탐색기에서 graph.get_nodes를 노드로 바꿀 수 있습니다. 이 특정 예제는 Apstra GUI에서 작동하지 않습니다.
graph.get_nodes(
type='system',
role=is_in(['spine', 'leaf']),
system_id=not_none(),
)
그래프 스키마에서 특정 노드/관계 유형 및 메서드 get_nodes() 에 대한 사용자 지정 인덱스를 정의하고 get_relationships() 검색 시간을 최소화하기 위해 전달된 제약 조건의 각 특정 조합에 가장 적합한 인덱스를 선택할 수 있습니다.
/get_relationships()의 get_nodes()결과는 특수 이터레이터 객체입니다. 그것들을 반복 할 수 있으며 발견 된 모든 그래프 객체를 생성합니다. 이러한 반복기가 제공하는 API를 사용하여 이러한 결과 집합을 탐색할 수도 있습니다. 예를 들어 get_nodes() 메서드out(가있는 NodeIterator 객체를 반환합니다 ) 및 in_(). 이를 사용하여 원래 결과 집합의 각 노드에서 나가거나 들어오는 모든 관계에 대한 반복자를 가져올 수 있습니다. 그런 다음 이를 사용하여 해당 관계의 다른 쪽 끝에 노드를 가져오고 계속 진행할 수 있습니다. 또한 속성 제약 조건을 for get_nodes() 및 get_relationships()와 같은 방식으로 이러한 메서드에 전달할 수 있습니다.
graph.get_nodes('system', role='spine') \
.out('interface').node('interface', if_type='loopback')
위 예제의 코드는 유형이 system 및 role spine인 모든 노드를 찾은 다음 해당 모든 루프백 인터페이스를 찾습니다.
모두 합치기
아래 쿼리는 Apstra가 텔레메트리 기대치(예: 링크 및 인터페이스 상태)를 도출하는 데 사용할 수 있는 내부 규칙의 예입니다. @rule는 process_spine_leaf_link에 콜백을 삽입하며, 이 경우 원격 분석 기대치에 씁니다.
@rule(match(
node('system', name='spine_device', role='spine')
.out('hosted_interfaces')
.node('interface', name='spine_if')
.out('link')
.node('link', name='link')
.in_('link')
.node('interface', name='leaf_if')
.in_('hosted_interfaces')
.node('system', name='leaf_device', role='leaf')
))
def process_spine_leaf_link(self, path, action):
"""
Process link between spine and leaf
"""
spine = path['spine_device']
leaf = path['leaf_device']
if action in ['added', 'updated']:
# do something with added/updated link
pass
else:
# do something about removed link
pass
편의 기능
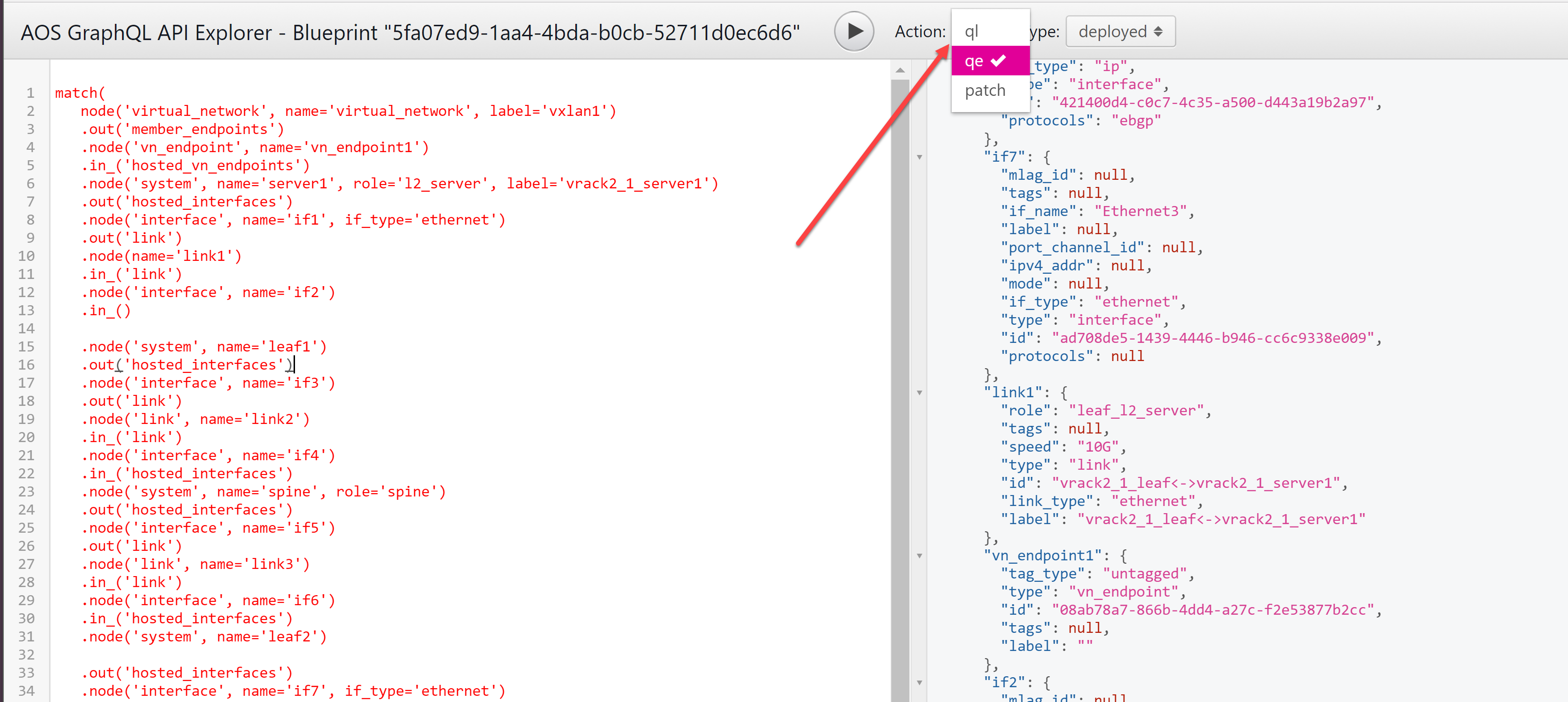
그래프 쿼리를 작성할 때 복잡한 where() 절이 생성되지 않도록 하려면 Apstra GUI에서 제공되는 편의 기능을 사용하십시오.
-
청사진에서 스테이징 보기 또는 활성 보기로 이동한 다음 GraphQL API 탐색기 버튼(오른쪽 상단 >_)을 클릭합니다. 그래프 탐색기가 새 탭에서 열립니다.
-
왼쪽에 그래프 쿼리를 입력합니다. 아래의 기능 설명을 참조하십시오.
-
Action( 작업 ) 드롭다운 목록에서 qe를 선택합니다.
-
쿼리 실행 버튼(재생 버튼처럼 보임)을 클릭하여 결과를 확인합니다.
함수
쿼리 엔진은 다음과 같은 여러 가지 유용한 함수를 설명합니다.
성냥(*path_queries)
이 함수는 일치하는 쿼리의 QueryBuilder 각 결과를 포함하는 개체를 반환합니다. 이는 일반적으로 여러 일치 쿼리를 함께 그룹화하는 데 유용한 바로 가기입니다.
이 두 쿼리는 함께 '경로'가 아닙니다(의도된 관계 없음). 인수를 구분하기 위해 쉼표에 주의하십시오. 이 쿼리는 모든 리프 디바이스와 스파인 디바이스를 함께 반환합니다.
match(
node('system', name='leaf', role='leaf'),
node('system', name='spine', role='spine'),
)
node(self, type=None, name=None, id=None, **properties)
- 매개 변수
- type (str 또는 None) - 검색할 노드의 타입
- name (str 또는 None) - 결과에서 속성 일치자의 이름을 설정합니다.
- id (str 또는 None) - 그래프의 노드 ID로 특정 노드를 일치시킵니다.
- properties ( dict 또는 None) - 사용할 추가 키워드 인자 또는 추가 속성 일치자 편의 함수
- Returns - 쿼리 연결을 위한 쿼리 빌더 오브젝트
- 반환 형식 - QueryBuilder
둘 다 함수이지만 PathQueryBuilder 노드의 별칭입니다 (아래 참조).
반복()
- 반환 - 생성기
- 반환 유형: 생성기
Iterate는 개별 경로 쿼리를 목록처럼 반복하는 데 사용할 수 있는 생성기 함수를 제공합니다. 예를 들어:
def find_router_facing_systems_and_intfs(graph):
return q.iterate(graph, q.match(
q.node('link', role='to_external_router')
.in_('link')
.node('interface', name='interface')
.in_('hosted_interfaces')
.node('system', name='system')
))
PathQueryBuilder 노드
node(self, type=None, name=None, id=None, **properties)
이 함수는 특정 그래프 노드를 설명하지만 특정 노드에서 경로 쿼리를 시작하기 위한 바로 가기이기도 합니다. 호출 결과는 `node() 경로 쿼리 개체를 반환합니다. 경로를 쿼리 할 때 일반적으로 노드 'type'을 지정하려고합니다 : 예를 node('system') 들어 시스템 노드를 반환합니다.
- 매개 변수
- type (str 또는 None) - 검색할 노드의 타입
- name (str 또는 None) - 결과에서 속성 일치자의 이름을 설정합니다.
- id (str 또는 None) - 그래프의 노드 ID로 특정 노드를 일치시킵니다.
- properties ( dict 또는 None) - 사용할 추가 키워드 인자 또는 추가 속성 일치자 편의 함수
- Returns - 쿼리 연결을 위한 쿼리 빌더 오브젝트
- 반환 형식 - QueryBuilder
쿼리 결과에서 노드를 사용하려면 이름을 --로node('system', name='device') 지정해야 합니다. 또한 특정 kwarg 속성을 일치시키려면 일치 요구 사항을 직접 지정할 수 있습니다.
node('system', name='device', role='leaf')
node('system', name='device', role='leaf')
out(유형=없음, id=없음, 이름=없음, **속성)
그래프 스키마에 따라 'out' 방향으로 관계를 트래버스합니다. 허용되는 매개 변수는 관계 유형(예: 인터페이스), 관계의 특정 이름, 관계 ID 또는 키워드 인수로 지정된 정확히 일치해야 하는 기타 속성 일치입니다.
- 매개 변수
- type (str 또는 None) - 검색할 노드 관계의 유형
- id (str 또는 None) - 그래프의 관계 ID로 특정 관계를 일치시킵니다.
- name (str 또는 None) - 명명된 관계로 특정 관계를 일치시킵니다.
예를 들어:
node('system', name='system') \
.out('hosted_interfaces')
in_(유형=없음, id=없음, 이름=없음, **속성)
관계를 'in' 방향으로 트래버스합니다. 현재 노드를 관계 원본 노드로 설정합니다. 허용되는 매개 변수는 관계 유형(예: 인터페이스), 관계의 특정 이름, 관계 ID 또는 키워드 인수로 지정된 정확히 일치해야 하는 기타 속성 일치입니다.
- 매개 변수
- type (str 또는 None) - 검색할 노드 관계의 유형
- id (str 또는 None) - 그래프의 관계 ID로 특정 관계를 일치시킵니다.
- name (str 또는 None) - 명명된 관계로 특정 관계를 일치시킵니다.
- properties ( dict 또는 None ) - 추가 kwargs 또는 함수에 의한 관계와 일치합니다.
node('interface', name='interface') \
.in_('hosted_interfaces')
where(술어, names=None)
그래프 결과에 대한 콜백 함수를 필터 또는 제약 조건으로 지정할 수 있습니다. 조건자는 전체 쿼리 결과에 대해 실행되는 콜백(일반적으로 람다 함수)입니다. where() 경로 쿼리 결과에서 직접 사용할 수 있습니다.
- 매개 변수
- predicate (callback) - 그래프의 모든 노드에 대해 실행할 콜백 함수
- names (str 또는 None) - 이름이 주어지면 일치를 위해 콜백 함수로 전달됩니다.
node('system', name='system') \
.where(lambda system: system.role in ('leaf', 'spine'))
enure_different(*이름)
사용자가 그래프에서 두 개의 서로 다른 명명된 노드가 동일하지 않은지 확인할 수 있습니다. 이는 양방향일 수 있고 자체 소스 노드에서 일치할 수 있는 관계에 유용합니다. 다음 쿼리를 고려하십시오.
- 매개 변수
- names (tuple or list) - 그래프에서 다른 노드 또는 관계를 반환하도록 하는 이름 목록
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.ensure_different('interface', 'remote_interface')
마지막 줄은 람다 콜백 함수가 있는 함수와 기능적으로 동일 where() 할 수 있습니다
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.where(lambda interface, remote_interface: interface != remote_interface)
속성 일치자
속성 일치는 그래프 쿼리 개체에서 직접 실행할 수 있으며, 일반적으로 함수 내에서 node() 사용됩니다. 속성 일치를 통해 몇 가지 기능을 사용할 수 있습니다.
eq(값)
노드의 속성값이 함수의 eq(value) 결과와 정확히 일치하는지 확인합니다.
- 매개 변수
- value - 같음을 위해 일치시킬 특성
node('system', name='system', role=eq('leaf'))
이는 단순히 노드 객체에서 값을 kwarg로 설정하는 것과 유사합니다.
node('system', name='system', role='leaf')
node('system', name='system').where(lambda system: system.role == 'leaf')
반환:
{
"count": 4,
"items": [
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf1",
"label": "l2_virtual_mlag_2_leaf1",
"system_id": "000C29EE8EBE",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "391598de-c2c7-4cd7-acdd-7611cb097b5e"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf2",
"label": "l2_virtual_mlag_2_leaf2",
"system_id": "000C29D62A69",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "7f286634-fbd1-43b3-9aed-159f1e0e6abb"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf2",
"label": "l2_virtual_mlag_1_leaf2",
"system_id": "000C29CFDEAF",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "b9ad6921-6ce3-4d05-a5c7-c31d96785045"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf1",
"label": "l2_virtual_mlag_1_leaf1",
"system_id": "000C297823FD",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "71bbd11c-ed0f-4a38-842f-341781c01c24"
}
}
]
}
ne(값)
같지 않음. 노드의 속성 값이 함수의 결과와 일치하지 않는지 확인합니다.ne(value)
- 매개 변수
- value - 같지 않음 조건에 대해 보장할 값
node('system', name='system', role=ne('spine'))
유사 항목:
node('system', name='system').where(lambda system: system != 'spine')
gt(값)
보다 큼. 노드의 속성이 함수의 gt(value) 결과보다 큰지 확인합니다.
- 매개 변수
- value - 속성 함수가 이 값보다 큰지 확인합니다.
node('vn_instance', name='vlan', vlan_id=gt(200))
ge(값)
보다 크거나 같음. 노드의 속성이 의 ge()결과보다 크거나 같은지 확인합니다.
- 매개 변수: value - 속성 함수가 이 값보다 크거나 같은지 확인합니다.
node('vn_instance', name='vlan', vlan_id=ge(200))
lt(값)
보다 작음. 노드의 속성이 의 lt(value)결과보다 작은지 확인합니다.
- 매개 변수
- value - 속성 함수가 이 값보다 작은지 확인합니다.
node('vn_instance', name='vlan', vlan_id=lt(200))
유사 항목:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id <= 200)
le(값)
보다 작거나 같음. 속성이 function의 le(value) 결과보다 작거나 같은지 확인합니다.
- 매개 변수
- value - 주어진 값이 속성 함수보다 작거나 같은지 확인합니다.
node('vn_instance', name='vlan', vlan_id=le(200))
유사 항목:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id < 200)
is_in(값)
(목록)에 있습니다. 속성이 지정된 목록 또는 항목이 is_in(value)포함된 집합에 있는지 확인합니다.
- 매개 변수
- value(list) - 지정된 속성이 이 목록에 있는지 확인합니다.
node('system', name='system', role=is_in(['leaf', 'spine']))
유사 항목:
node('system', name='system').where(lambda system: system.role in ['leaf', 'spine'])
not_in(값)
(목록)에 없습니다. 속성이 주어진 목록이나 항목을 not_in(value)포함하는 집합에 없는지 확인하십시오.
- 매개 변수
- value (list) - 속성 일치자가 없는지 확인하기 위한 목록 값
node('system', name='system', role=not_in(['leaf', 'spine']))
유사 항목:
node('system', name='system').where(lambda system: system.role not in ['leaf', 'spine'])
is_none()
is_none 예상하는 쿼리는 이 특정 속성이 구체적일 None것으로 예상합니다.
node('interface', name='interface', ipv4_addr=is_none()
유사 항목:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is None)
not_none()
이 속성에 값이 있을 것으로 예상하는 matcher입니다.
node('interface', name='interface', ipv4_addr=not_none()
유사 항목:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is not None)
Apstra 그래프 데이터스토어
Apstra 그래프 데이터저장소는 인메모리 그래프 데이터베이스입니다. 로그 파일 크기는 정기적으로 확인되며 블루프린트 변경 사항이 커밋될 때 확인됩니다. 그래프 데이터스토어가 100MB 이상에 도달하면 새 그래프 데이터스토어 체크포인트 파일이 생성됩니다. 데이터베이스 자체는 그래프 데이터스토어 지속성 로그 또는 체크포인트 파일을 제거하지 않습니다. Apstra는 메인 그래프 데이터스토어를 위한 정리 도구를 제공합니다.
유효한 그래프 데이터저장소 지속성 파일 그룹에는 , , , 및 의 네 개 파일이 log포함되어 있습니다checkpoint-valid. checkpointlog-valid 유효한 파일은 로그 및 검사점 파일에 대한 효과적인 표시기입니다. 각 지속성 파일의 이름은 basename, id 및 extension의 세 부분으로 구성됩니다.
# regex for sysdb persistence files. # e.g. # _Main-0000000059ba612e-00017938-checkpoint-valid # \--/ \-----------------------/ \--------------/ # basename id extension
- baseName - 기본 그래프 데이터 저장소 파티션 이름에서 파생됩니다.
- id - GetTimeOfDay에서 가져온 유닉스 타임스탬프입니다. 타임스탬프의 초와 마이크로초는 "-"로 구분됩니다. 지속성 파일 그룹은 id로 식별할 수 있습니다. 타임스탬프는 지속성 파일 그룹의 생성된 시간 시퀀스를 확인하는 데도 도움이 될 수 있습니다.
- 확장 -
log,log-valid,checkpoint, 또는checkpoint-valid.