このページの内容
NorthStar Controllerトラブルシューティングガイド
このドキュメントには、明らかな問題が NorthStar Controller またはルーターのどちらに起因するかを特定するための戦略が含まれており、NorthStar Controller に起因すると特定された問題のトラブルシューティング手法を提供します。
トラブルシューティングの調査を開始する前に、すべてのシステム プロセスが稼働していることを確認します。プロセスのサンプルリストを以下に示します。実際のプロセスリストは異なる場合があります。
[root@node-1 ~]# supervisorctl status bmp:bmpMonitor RUNNING pid 2957, uptime 0:58:02 collector:worker1 RUNNING pid 19921, uptime 0:01:42 collector:worker2 RUNNING pid 19923, uptime 0:01:42 collector:worker3 RUNNING pid 19922, uptime 0:01:42 collector:worker4 RUNNING pid 19924, uptime 0:01:42 collector_main:beat_scheduler RUNNING pid 19770, uptime 0:01:53 collector_main:es_publisher RUNNING pid 19771, uptime 0:01:53 collector_main:task_scheduler RUNNING pid 19772, uptime 0:01:53 config:cmgd RUNNING pid 22087, uptime 0:01:53 config:cmgd-rest RUNNING pid 22088, uptime 0:01:53 docker:dockerd RUNNING pid 4368, uptime 0:57:34 epe:epeplanner RUNNING pid 9047, uptime 0:50:34 infra:cassandra RUNNING pid 2971, uptime 0:58:02 infra:ha_agent RUNNING pid 9009, uptime 0:50:45 infra:healthmonitor RUNNING pid 9172, uptime 0:49:40 infra:license_monitor RUNNING pid 2968, uptime 0:58:02 infra:prunedb RUNNING pid 19770, uptime 0:01:53 infra:rabbitmq RUNNING pid 7712, uptime 0:52:03 infra:redis_server RUNNING pid 2970, uptime 0:58:02 infra:zookeeper RUNNING pid 2965, uptime 0:58:02 ipe:ipe_app RUNNING pid 2956, uptime 0:58:02 listener1:listener1_00 RUNNING pid 9212, uptime 0:49:29 netconf:netconfd_00 RUNNING pid 19768, uptime 0:01:53 northstar:anycastGrouper RUNNING pid 19762, uptime 0:01:53 northstar:configServer RUNNING pid 19767, uptime 0:01:53 northstar:mladapter RUNNING pid 19765, uptime 0:01:53 northstar:npat RUNNING pid 19766, uptime 0:01:53 northstar:pceserver RUNNING pid 19441, uptime 0:02:59 northstar:privatet1vproxy RUNNING pid 19432, uptime 0:02:59 northstar:prpdclient RUNNING pid 19763, uptime 0:01:53 northstar:scheduler RUNNING pid 19764, uptime 0:01:53 northstar:topologyfilter RUNNING pid 19760, uptime 0:01:53 northstar:toposerver RUNNING pid 19762, uptime 0:01:53 northstar_pcs:PCServer RUNNING pid 19487, uptime 0:02:49 northstar_pcs:PCViewer RUNNING pid 19486, uptime 0:02:49 web:app RUNNING pid 19273, uptime 0:03:18 web:gui RUNNING pid 19280, uptime 0:03:18 web:notification RUNNING pid 19272, uptime 0:03:18 web:proxy RUNNING pid 19275, uptime 0:03:18 web:restconf RUNNING pid 19271, uptime 0:03:18 web:resthandler RUNNING pid 19275, uptime 0:03:18
RUNNING ではなく STOPPED と表示されているプロセスをすべて再始動します。
すべてのプロセスを停止、開始、または再起動するには、 service northstar stop、 service northstar start、および service northstar restart コマンドを使用します。
NorthStar Controller Web UIからシステムプロセスのステータス情報にアクセスするには、 More Options>Administration に移動し、 System Healthを選択します。
各システムプロセスの現在のCPU%、メモリ使用率、仮想メモリ使用率、およびその他の統計情報が表示されます。 図1 に例を示します。
この表示には、実行中のプロセスのみが含まれます。
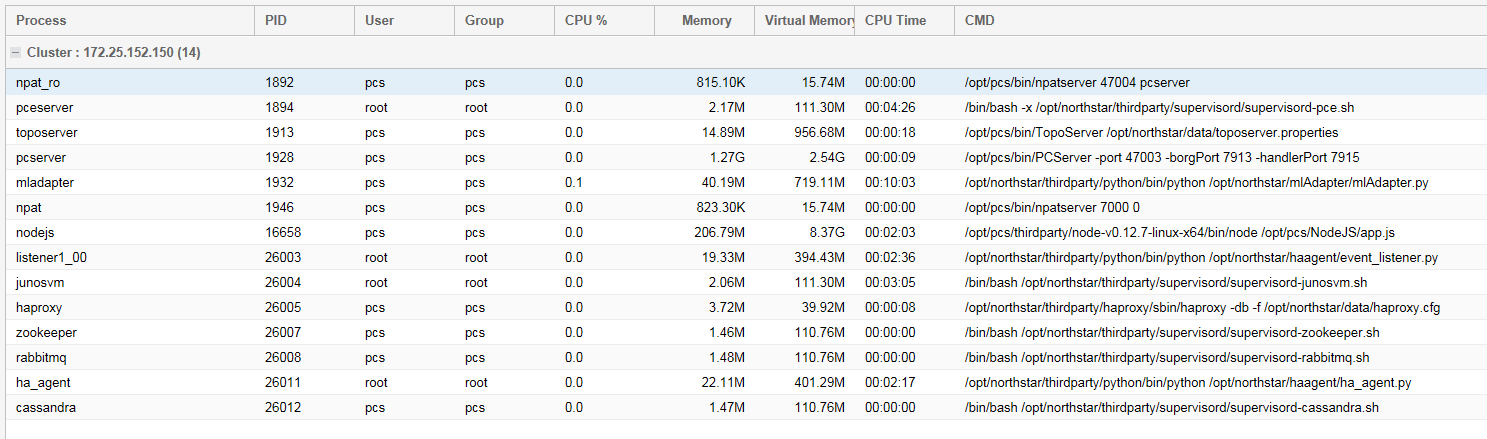
表1は、プロセスステータステーブルに表示される各フィールドについて説明しています。
| フィールド | 説明 |
|---|---|
| プロセス |
NorthStar Controllerプロセスの名前。 |
| PID |
プロセスID番号。 |
| ユーザー |
このプロセスに関する情報にアクセスするために必要なNorthStar Controllerユーザーの権限。 |
| グループ |
このプロセスに関する情報にアクセスするために必要なNorthStar Controllerユーザーグループの権限。 |
| CPU% |
このプロセスで現在使用されているCPUの現在の割合を表示します。 |
| メモリ |
このプロセスで現在使用されているメモリの現在の割合を表示します。 |
| 仮想メモリ |
このプロセスで使用中の現在の仮想メモリを表示します。 |
| CPU時間 |
プロセスの命令を処理するためにCPUが使用された時間 |
| CMD |
システムプロセスに対する特定のコマンドオプションを表示します。 |
トラブルシューティング情報は、次のセクションで説明します。
NorthStar Controllerログファイル
トラブルシューティング作業中は、さまざまな NorthStar Controller ログファイルを表示すると役立ちます。ログファイルにアクセスするには:
-
NorthStar Controller Web UIにログインします。
-
More Options > Administrationに移動し、Logsを選択します。
NorthStarシステムログファイルとメッセージファイルのリストが表示され、その切り捨てられた例を 図2に示します。
図2:システムログおよびメッセージファイルのサンプル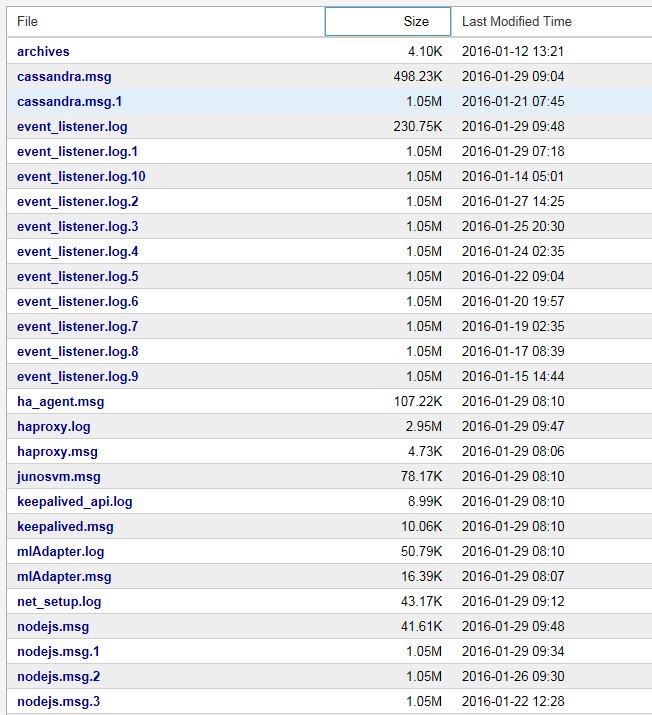
-
表示するログファイルまたはメッセージファイルをクリックします。
ログファイルの内容がポップアップウィンドウに表示されます。
-
別のブラウザー ウィンドウまたはタブでファイルを開くには、ポップアップ ウィンドウで View Raw Log をクリックします。
-
ポップアップウィンドウを閉じてログファイルとメッセージファイルのリストに戻るには、ポップアップウィンドウの右上隅にある X をクリックします。
表2は、PCSとPCEに関する問題の特定とトラブルシューティングに最も一般的に使用されるNorthStar Controllerログファイルの一覧です。
| ログファイル |
説明 |
場所 |
|---|---|---|
| pcep_server.log |
PCEPサーバーに関連するログエントリー。PCEPサーバーは、PCEPセッションを維持します。ログには、双方向のPCCとPCE間の通信に関する情報が含まれています。 詳細なPCEPサーバーロギングを設定するには:
|
/var/log/jnc |
| pcs.log |
PCSに関連するログエントリー。PCS は、パスの計算を担当します。このログには、プロビジョニングオーダーなど、PCSがトポサーバーから受信したイベントが含まれます。また、PCS の正常な起動を妨げる通信エラーや問題の通知も含まれています。 |
/opt/northstar/logs |
| toposerver.log |
トポロジーサーバーに関連するログエントリー。トポロジーサーバーは、トポロジーの維持管理を担当します。これらのログには、PCSとトポサーバー、トポサーバーとNTAD、およびトポサーバーとPCEサーバー間のイベントの記録が含まれています |
/opt/northstar/logs |
表3は、トラブルシューティングにも役立つその他のログファイルを示しています。表3のすべてのログファイルは、/opt/northstar/logsディレクトリにあります。
| ログファイル | 説明 |
| cassandra.msg |
Cassandra データベースに関連するログイベント。 |
| ha_agent.msg |
HAコーディネーターログ |
| mlAdaptor.log |
トランスポートコントローラーログへのインターフェイス。 |
| net_setup.log |
設定スクリプトログ |
| nodejs.msg |
nodejsに関連するイベントをログに記録します。 |
| pcep_server.log |
PCCとPCE間の双方向の通信に関連するログファイル。 |
| pcs.log |
PCSに関連するログファイル。PCSがToposerverから受信したイベント、およびプロビジョニング注文を含むToposerverからPCSへのイベントが含まれます。このログには、通信エラーやPCSの正常な起動を妨げる問題も含まれています。 |
| rest_api.log |
REST APIリクエストのファイルをログに記録します。 |
| toposerver.log |
トポロジーサーバーに関連するログファイル。 PCSとトポロジーサーバー、トポロジーサーバーとNTAD、およびトポロジーサーバーとPCEサーバー間のイベントのレコードが含まれます
注:
pcshandler.logファイルに転送されたメッセージは、pcs.logファイルにも転送されます。 |
Junos VM に関連するログを表示するには、ルーターへの telnet セッションを確立する必要があります。Junos VMのデフォルトのIPアドレスは172.16.16.2です。Junos VM は、必要な BGP、IS-IS、または OSPF セッションを維持する責任があります。
空のトポロジー
図3は、ルーターからトポサーバーへの情報の流れを、NorthStar Controller UIにトポロジーを表示する結果を示しています。トポロジー表示が空の場合、このフローが中断されている可能性があります。フローが中断された場所を特定することで、問題解決プロセスの指針となります。
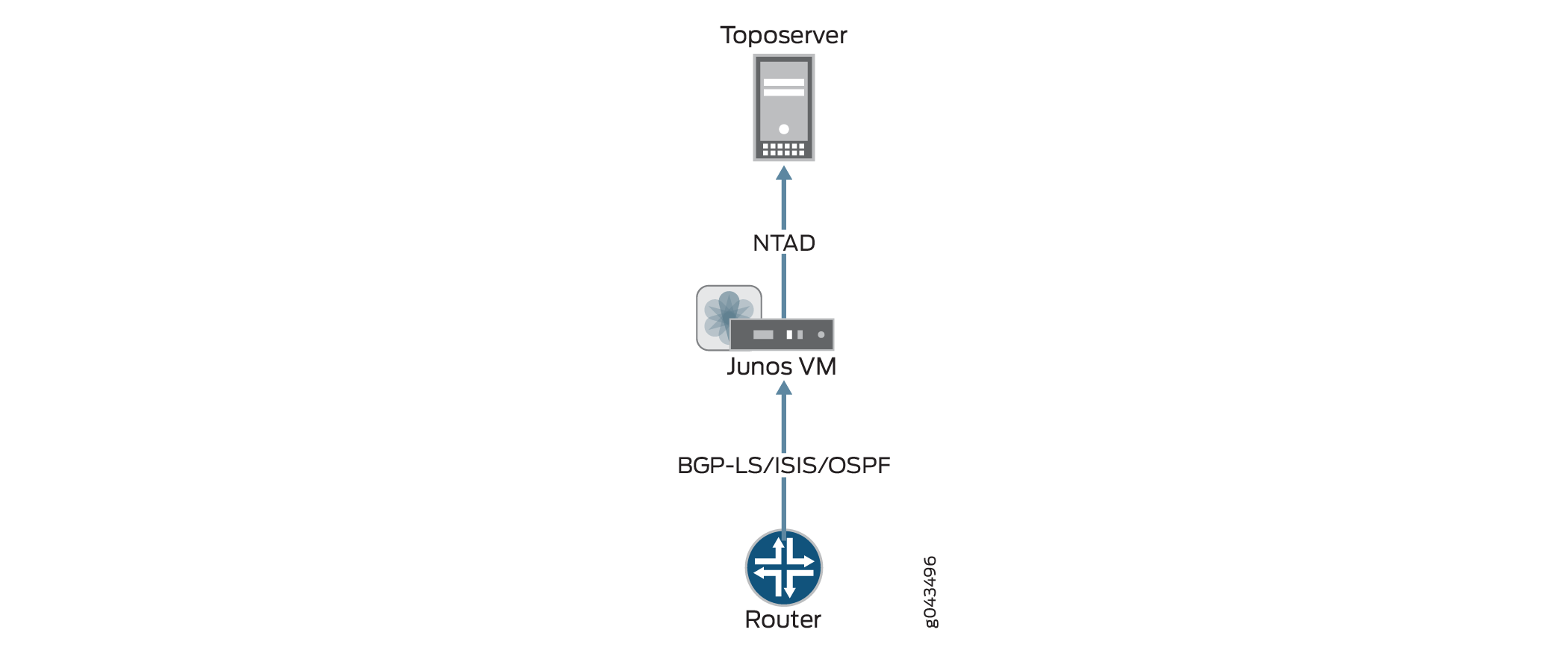
トポロジーはルーターを起点としています。NorthStar Controllerがトポロジーを受信するには、ネットワーク内のルーターの1つからJunos VMへのBGP-LS、IS-IS、またはOSPFセッションが必要です。また、Junos VMとトポサーバーの間には、確立されたネットワークトポロジーアブストラクタデーモン(NTAD)セッションも必要です。
これらの接続を確認するには:
-
次の例に示すように、NorthStar Controller CLIを使用して、トポサーバーとJunos VM間のNTAD接続が正常に確立されたことを確認します。
[root@northstar ~]# netstat -na | grep :450 tcp 0 0 172.16.16.1:55752 172.16.16.2:450 ESTABLISHED
注:ポート450は、Junos VMからToposerverへの接続に使用するポートです。
次の例では、NTAD接続は確立されていません。
[root@northstar ~]# netstat -na | grep :450 tcp 0 0 172.16.16.1:55752 172.16.16.2:450 LISTENING
-
Junos VMにログインして、NTADがトポロジーエクスポートを有効にするように設定されているかどうかを確認します。以下の grep コマンドは、Junos VM の IP アドレスを提供します。
[root@northstar ~]# grep "ntad_host" /opt/northstar/data/northstar.cfg ntad_host=172.16.16.2 [root@northstar ~]# telnet 172.16.16.2 Trying 172.16.16.2... Connected to 172.16.16.2. Escape character is '^]'. northstar_junosvm (ttyp0) login: northstar Password: --- JUNOS 14.2R4.9 built 2015-08-25 21:01:39 UTC This JunOS VM is running in non-persistent mode. If you make any changes on this JunOS VM, Please make sure you save to the Host using net_setup.py utility, otherwise the config will be lost if this VM is restarted. northstar@northstar_junosvm> show configuration protocols | display set set protocols topology-exporttopology-exportステートメントが欠落している場合、Junos VM はデータをトポサーバーにエクスポートできません。 -
Junos OS
showコマンドを使用して、Junos VM と ルーター の間のBGP、IS-IS、またはOSPF関係がアクティブかどうかを確認します。セッションがアクティブでない場合、トポロジー情報を Junos VM に送信することはできません。 -
Junos VMで、lsdist.0ルーティングテーブルに以下のエントリーがあるかどうかを確認します。
northstar@northstar_junosvm> show route table lsdist.0 terse | match lsdist.0 lsdist.0: 54 destinations, 54 routes (54 active, 0 holddown, 0 hidden)
lsdist.0 のルーティングテーブルにゼロしか表示されない場合は、送信できるトポロジーはありません。トポロジー取得の設定については、 『NorthStar Controller 入門ガイド 』のセクションを参照してください。
-
lsdist.0 のルーティングテーブルに少なくとも 1 つのリンクがあることを確認します。トポサーバーは、少なくとも1つのNTADリンクイベントを受信した場合にのみ、初期トポロジーを生成できます。他のノードとのIGP隣接関係のない単一のノードで構成されるネットワーク(ラボ環境など)では、トポサーバーはトポロジーを生成できません。 図4 は、初期トポロジーを作成するためのToposerverのロジック・プロセスを示しています。
図4:トポロジーの初期作成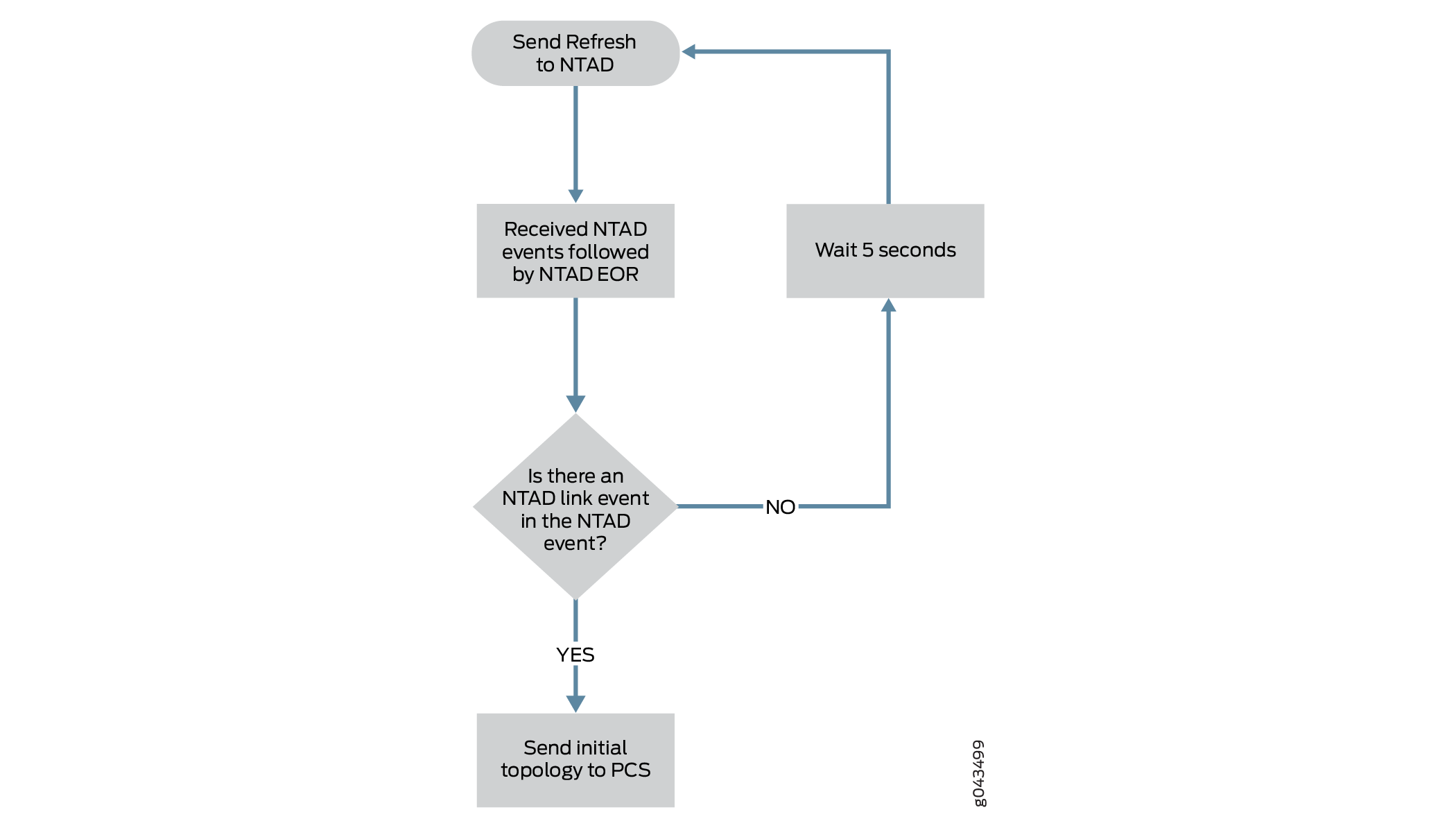 のロジックプロセス
のロジックプロセス
この理由で初期トポロジーを作成できない場合、toposerver.logは次の例のようなエントリーを生成します。
Dec 9 16:03:57.788514 fe-cluster-03 TopoServer Did not send the topology because no links were found.
NTADバージョン
SR LSPがプロビジョニングされておらず、pcs.logに次の例のようなメッセージが表示されている場合は:
2020 Apr 27 15:05:36.430366 ns1-site1-q-pod07 PCServer [NorthStar][PCServer][Routing] msg=0x0000300b Provided path is not valid for SR for sean427@0110.0000.0101 path=sean427, node 0110.0000.0104 has no NodeIndex
NTADのバージョンが間違っている可能性があります。NTAD のバージョンについては、「 NorthStar Controller のインストール 」を参照してください。
誤ったトポロジー
トポサーバーの重要な機能の1つは、NTADリンクイベントからの送信元と宛先のIPv4 Link_Identifiersを照合することで、ルーターからの一方向リンク(インターフェイス)情報を双方向リンクに関連付けることです。NorthStar UIに表示されたトポロジーが正しくないように見える場合は、トポサーバーが双方向リンクの生成とメンテナンスをどのように処理するかを理解すると役立ちます。
双方向リンクの生成とメンテナンスは複雑なプロセスですが、重要なポイントをいくつか紹介します。
-
各双方向リンクを構成する 2 つのノードでは、最初に割り当てられた(したがってノード ID 番号が低い)ノード ID にノード A の指定が与えられ、もう一方のノードにはノード Z の指定が与えられます。
注:ノードIDは、トポサーバーが最初にNTADからノードイベントを受信したときに割り当てられます。
-
ノードIDがクリアされて再割り当てされるたびに(トポサーバーの再起動中やネットワークモデルのリセット中など)、ノードID、ひいてはAとZの指定が変更される可能性があります。
-
トポサーバーは、ネットワーク内のリンクが追加または変更されると、リンク更新メッセージを受信します。
-
リンクがネットワークから削除されると、トポサーバーはリンク取り消しメッセージを受け取ります。
-
リンク更新とリンク撤回メッセージは、ノードの運用ステータスに影響します。
-
ノードの動作状態とプロトコル(IGP 対 IGP と MPLS)によって、リンクを LSP のルーティングに使用できるかどうかが決定されます。リンクをLSPのルーティングに使用するには、そのリンクの運用ステータスがUPであり、MPLSプロトコルがアクティブである必要があります。
LSPの欠落
トポロジーは正しく表示されているが、LSPが欠落している場合は、 図5に示すように、PCCからToposerverへの情報の流れを見て、トンネルがNorthStar Controller UIに追加される結果を確認します。フローは、PCCでの設定から始まり、そこからLSPアップデートメッセージがPCEPセッションを介してPCEPサーバーに渡され、次にAMQP(Advanced Message Queuing Protocol)接続を介してトポサーバーに渡されます。
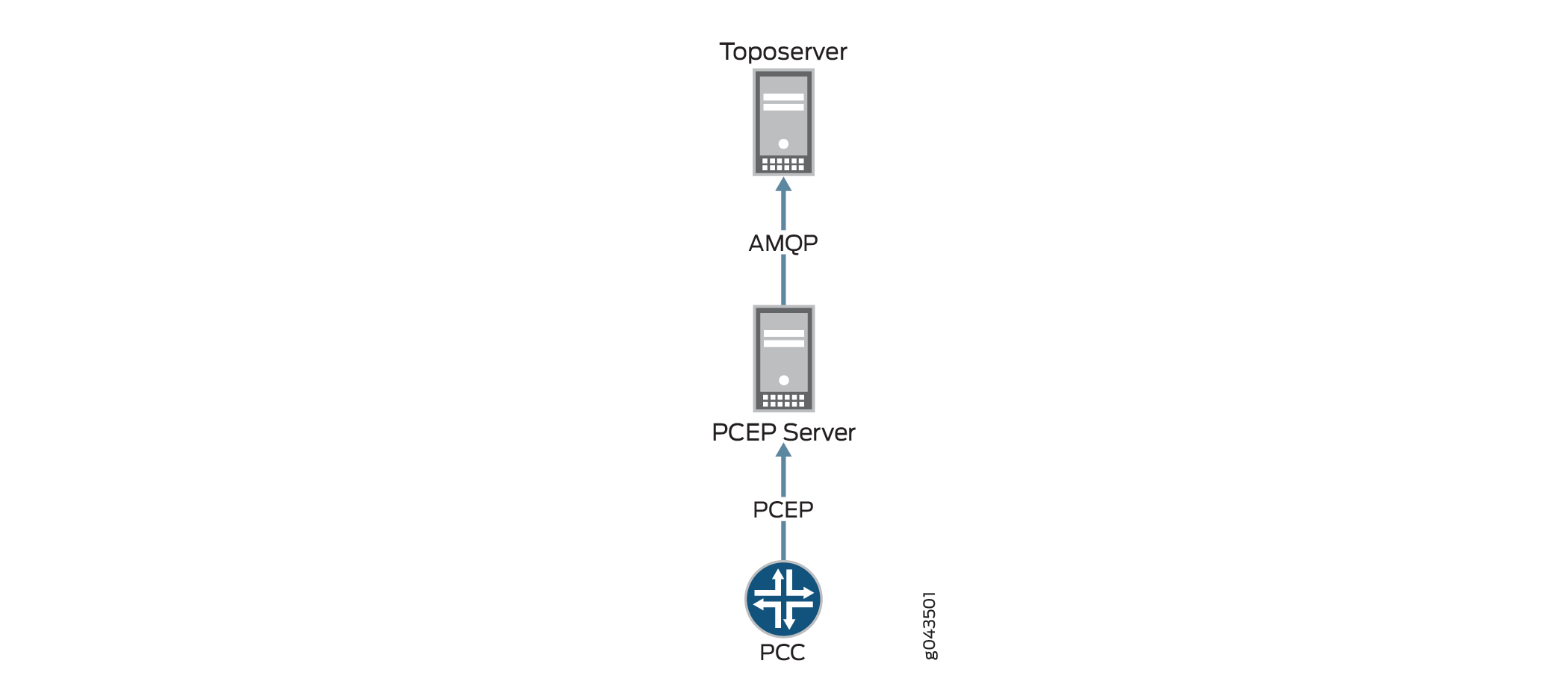
これらの接続を確認するには:
-
toposerver.logを見てください。ログは、PCEPサーバーとの接続が失われたか、正常に確立されていないことを検出すると、15秒ごとにメッセージを出力します。次の例では、トポサーバーとPCEPサーバー間の接続がダウンとしてマークされていることに注意してください。
Toposerver log: Apr 22 16:21:35.016721 user-PCS TopoServer Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:35.016901 user-PCS TopoServer [->PCS] PCE Down: Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:50.030592 user-PCS TopoServer Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:50.031268 user-PCS TopoServer [->PCS] PCE Down: Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016
-
次の例に示すように、NorthStar Controller CLIを使用して、PCCとPCEPサーバー間のPCEPセッションが正常に確立されたことを確認します。
[root@northstar ~]# netstat -na | grep :4189 tcp 0 0 0.0.0.0:4189 0.0.0.0:* LISTEN tcp 0 0 172.25.152.42:4189 172.25.155.50:59143 ESTABLISHED tcp 0 0 172.25.152.42:4189 172.25.155.48:65083 ESTABLISHED
注:ポート4189は、PCCからPCEPサーバーへの接続に使用するポートです。
セッションが確立されたことを知ることは便利ですが、必ずしもデータが転送されたことを意味するわけではありません。
-
PCEPサーバーがPCCからLSPについて学習したかどうかを確認します。
[root@user-PCS ~]# pcep_cli # show lsp all list 2016-04-22 17:09:39.696061(19661)[DEBUG]: pcc_lsp_table.begin: 2016-04-22 17:09:39.696101(19661)[DEBUG]: pcc-id:1033771436/172.25.158.61, state: 0 2016-04-22 17:09:39.696112(19661)[DEBUG]: START of LSP-NAME-TABLE … 2016-04-22 17:09:39.705358(19661)[DEBUG]: Summary pcc_lsp_table: 2016-04-22 17:09:39.705366(19661)[DEBUG]: Summary LSP name tabl: 2016-04-22 17:09:39.705375(19661)[DEBUG]: client_id:1033771436/172.25.158.61, state:0,num LSPs:13 2016-04-22 17:09:39.705388(19661)[DEBUG]: client_id:1100880300/172.25.158.65, state:0,num LSPs:6 2016-04-22 17:09:39.705399(19661)[DEBUG]: client_id:1117657516/172.25.158.66, state:0,num LSPs:23 2016-04-22 17:09:39.705410(19661)[DEBUG]: client_id:1134434732/172.25.158.67, state:0,num LSPs:4 2016-04-22 17:09:39.705420(19661)[DEBUG]: Summary LSP id table: 2016-04-22 17:09:39.705429(19661)[DEBUG]: client_id:1033771436/172.25.158.61, state:0, num LSPs:13 2016-04-22 17:09:39.705440(19661)[DEBUG]: client_id:1100880300/172.25.158.65, state:0, num LSPs:6 2016-04-22 17:09:39.705451(19661)[DEBUG]: client_id:1117657516/172.25.158.66, state:0, num LSPs:23 2016-04-22 17:09:39.705461(19661)[DEBUG]: client_id:1134434732/172.25.158.67, state:0, num LSPs:4
出力の右端の列には、学習されたLSPの数が表示されます。この数値が0の場合、PCEPサーバーにLSP情報は送信されません。その場合は、 『NorthStar Controller Getting Started Guide』に記載されているとおりにPCC側の設定を確認してください。
LSP コントローラのステータス
LSPのコントローラステータスは、ネットワーク情報テーブル(NorthStar Controller GUI)のトンネルタブの Controller Status 列で確認できます。
表4は、さまざまなコントローラのステータスとその説明を示しています。
| コントローラのステータス |
次のことを示します。 |
|---|---|
| 失敗しました |
NorthStar ControllerがLSPのプロビジョニングに失敗しました。 |
| 保留中 |
PCSがPCEPサーバーにLSPプロビジョニング命令を送信しました。PCSはPCEPサーバーからの応答を待っています。 |
| PCC_PENDING |
PCEPサーバーがLSPプロビジョニング注文をPCCに送信しました。PCSはPCCからの応答を待っています。 |
| NETCONF_PENDING |
PCSがnetconfdにLSPプロビジョニング命令を送信しました。PCSはnetconfdからの応答を待っています。 |
| PRPD_PENDING |
PCSは、BGPルートをプロビジョニングするために、BGPプロビジョニングオーダーをPRPDクライアントに送信しました。PCS は、PRPD クライアントからの応答を待っています。 |
| SCHEDULED_DELETE |
PCSはLSPを削除するスケジュールを設定しています。PCSは、削除プロビジョニング命令をPCCに送信します。 |
| SCHEDULED_DISCONNECT |
PCSは、LSPを切断するスケジュールを設定しました。LSPはシャットダウンステータスに移動します。LSPは、Persist状態が関連付けられたNorthStarデータストアに保持され、CSPF計算では使用されません。 |
| NoRoute_Rescheduled |
PCSはLSPへのパスを見つけられませんでした。PCSは定期的にLSPをスキャンし、ルーティングされていないLSPのパスを見つけ、再プロビジョニングをスケジュールします。 |
| FRR_DETOUR_Rescheduled |
PCSはLSPを迂回し、LSPの再プロビジョニングのスケジュールを変更しました。 |
| Provision_Rescheduled |
PCSは、LSPのプロビジョニングをスケジュールしています。 |
| Maint_NotHandled |
LSPはNorthStarによって制御されていないため、LSPは進行中のメンテナンスイベントには含まれません。 |
| Maint_Rerouted |
PCSはメンテナンスのためLSPを再ルーティングしました。 |
| Callsetup_Scheduled |
PCSは、イベント開始時にLSPをプロビジョニングする必要があります。 |
| Disconnect_Scheduled |
PCSは、イベントが終了したらLSPを切断する必要があります。 |
| パスが見つかりません |
PCSはLSPへのパスを見つけることができませんでした。 |
| ダウンLSPでパスが見つかりました |
PCEPサーバーはLSPがダウンしていることを報告しましたが、PCSはLSPのパスを見つけました。 |
| パスインクルードループ |
SR-LSP には 1 つ以上のループがあります。 |
| Maint_NotReroute_DivPathUp |
スタンバイパスがすでに稼働しているため、メンテナンスイベントによってLSPが再ルーティングされることはありません。 |
| Maint_NotReroute_NodeDown |
メンテナンスイベントはLSPのエンドポイント向けであるため、LSPは再ルーティングされません。 |
| PLANNED_LSP |
LSPはプロビジョニングされている必要がありますが、まだプロビジョニングキューにはありません。 |
| PLANNED_DISCONNECT |
LSP は切断されている必要がありますが、まだプロビジョニング キューにはありません。 |
| PLANNED_DELETE |
LSP を削除する必要がありますが、まだプロビジョニング キューにはありません。 |
| Candidate_ReOptimization |
PCSは、このLSPを再最適化の候補として選択しました。 |
| アクティブ化(used_by_primary) |
LSPのセカンダリパスがアクティブになります。 |
| Time_Expired |
LSPのスケジュールされたウィンドウの有効期限が切れました。 |
| PCEP_Capability_not_supported |
PCEPがデバイスでサポートされていないか、サポートされている場合でも、PCEPがデバイス上で設定されていないか、無効になっているか、または誤って設定されている可能性があります。 |
| 非アクティブ化済み |
NorthStar ControllerがセカンダリLSPを無効化しました。 |
| NS_ERR_NCC_NOT_FOUND |
NorthStar Controllerは、Netconf接続クライアント(NCC)を使用してデバイスへのNetconf接続を確立できません。回避策:NorthStarサーバーでNetconfを再起動します。 [root@pcs-1 templates]# supervisorctl restart netconf netconf:netconf: stopped netconf:netconf: started |
| SR LSPプロビジョニングには、LSPステートフルSR機能が必要です |
SR LSPをプロビジョニングするには、CLIを介してJunosデバイス上で以下のコマンドを設定する必要があります。 set protocols pcep pce <name> spring-capability |
PCEP非対応のPCC
トポサーバーは、ノードをPCEP対応にするために、PCEPセッションをTEDからのトポロジー内のノードに関連付けます。PCCがPCEPセッションを確立するために使用したIPアドレスが、トポサーバーがTEDから自動的に学習したIPアドレスでない場合、このトポサーバー機能は妨げられます。たとえば、管理IPアドレスを使用してPCEPセッションが確立されている場合、トポサーバーはTEDからそのIPアドレスを受信しません。
PCCがPCEPセッションを正常に確立すると、トポサーバーにPCC_SYNC_COMPLETEメッセージを送信します。このメッセージは、同期が完了したことを NorthStar に示します。以下は、対応するトポサーバーログエントリーのサンプルであり、NorthStarが認識する場合と認識できない可能性のあるPCC_SYNC_COMPLETEメッセージとPCEP IPアドレスの両方を示しています。
Dec 9 17:12:11.610225 fe-cluster-03 TopoServer NSTopo::updateNode (PCCNodeEvent) ip: 172.25.155.26 pcc_ip: 172.25.155.26 evt_type: PCC_SYNC_COMPLETE Dec 9 17:12:11.610230 fe-cluster-03 TopoServer Adding PCEP flag to pcep_ip: 172.25.155.26 node_id: 0880.0000.0026 router_ID: 10.0.0.26 protocols: 4 Dec 9 17:12:11.610232 fe-cluster-03 TopoServer Setting live pcep_ip: 172.25.155.26 for router_ID: 88.0.0.26
認識できないIPアドレスの問題を修正するためのいくつかのオプションは次のとおりです。
-
More Options > Administration > Device Profileに移動して、NorthStar Web UIのデバイスプロファイルに認識できないIPアドレスを手動で入力します。
-
ルーターから発信されているLSPが少なくとも1つあることを確認すると、ToposerverがPCEPセッションをTEDデータベース内のノードに関連付けることができます。
IPアドレスの問題が解決され、トポサーバーがPCEPセッションをトポロジー内のノードに正常に関連付けることができるようになると、PCSログに見られるように、PCEP IPアドレスがノード属性に追加されます。
Dec 9 17:12:11.611392 fe-cluster-03 PCServer [<-TopoServer] routing_key = ns_node_update_key Dec 9 17:12:11.611394 fe-cluster-03 PCServer [<-TopoServer] NODE UPDATE(Live): ID=0880.0000.0026 protocols=(20)ISIS2,PCEP status=UNKNOWN hostname=skynet_26 router_ID=88.0.0.26 iso=0880.0000.0026 isis_area=490001 AS=41 mgmt_ip=172.25.155.26 source=NTAD Hostname=skynet_26 pcep_ip=172.25.155.26
LSPが保留中またはPCC_PENDING状態でスタック
ノードがPCEP対応として正しく確立されたら、LSPのプロビジョニングを開始できます。Web UIネットワーク情報テーブル(コントローラステータス列)のトンネルタブに表示されるように、LSPコントローラのステータスに保留中またはPCC_PENDINGを示すことができます。このセクションでは、これらのステータスの解釈方法について説明します。
LSPがプロビジョニングされると、PCSサーバーはLSPのすべての要件を満たすパスを計算し、PCEPサーバーにプロビジョニング順序を送信します。このプロセスが実行されている間は、次の例のようなログメッセージがPCSログに表示されます。
Apr Apr 25 10:06:44.798336 user-PCS PCServer [->TopoServer] push lsp configlet, action=ADD
Apr 25 10:06:44.798341 user-PCS PCServer {#012"lsps":[#012{"request-id":928380025,"name":"JTAC","from":"10.0.0.102",
"to":"10.0.0.104","pcc":"172.25.158.66","bandwidth":"100000","metric":0,"local-protection":false,"type":"primary",
"association-group-id":0,"path-attributes":{"admin-group":{"exclude":0,"include-all":0, "include-any":0},"setup-priority":
7,"reservation-priority":7,"ero":[{"ipv4-address":"10.102.105.2"},{"ipv4-address":"10.105.107.2"}, {"ipv4-address":
"10.114.117.1"}]}}#012]#012}
Apr 25 10:06:44.802500 user-PCS PCServer provisioning order sent, status = SUCCESS
Apr 25 10:06:44.802519 user-PCS PCServer [->TopoServer] Save LSP action, id=928380025 event=Provisioning Order(ADD) sent request_id=928380025
Apr 25 10:06:44.802534 user-PCS PCServer lsp action=ADD JTAC@10.0.0.102 path= controller_state=PENDING
この時点で LSP コントローラのステータスは PENDING です。これは、プロビジョニング注文が PCEP サーバーに送信されたものの、確認応答をまだ受信していないことを意味します。LSPがPENDINGでスタックしている場合は、PCEPサーバーに問題があることを示唆しています。PCEPサーバーにログインし、詳細なログメッセージを設定して、トラブルシューティングの価値の可能性に関する追加情報を提供できます。
pcep_cli
set log-level all
PCEPサーバーには、有用な情報を表示できるさまざまな show コマンドもあります。Junos OS構文と同様に、 show ? を入力して show コマンドオプションを確認できます。
PCEPサーバーがプロビジョニング注文を正常に受信すると、2つのアクションを実行します。
-
注文をPCCに転送します。
-
これは、確認応答をPCSに送り返します。
PCEPサーバーログには、次の例のようなエントリが表示されます。
2016-04-25 10:06:45.196263(27897)[EVENT]: 172.25.158.66:JTAC UPD RCVD FROM PCC, ack 928380025 2016-04-25 10:06:45.196517(27897)[EVENT]: 172.25.158.66:JTAC ADD SENT TO PCS 928380025, UP
LSP コントローラのステータスが PCC_PENDING に変わり、PCEP サーバーがプロビジョニング注文を受信し、それを PCC に転送したものの、PCC がまだ応答していないことを示します。LSPがPCC_PENDINGでスタックしている場合は、PCCに問題があることを示唆しています。
PCCがプロビジョニング注文を正常に受信すると、PCEPサーバーに応答を送信し、PCEPサーバーが応答をPCSに転送します。PCSがこの応答を受信すると、LSPコントローラのステータスが完全にクリアされ、LSPが完全にプロビジョニングされ、PCEPサーバーまたはPCCからのアクションを待機していないことを示します。運用ステータス(運用ステータス列)がトンネルの状態を示す指標になります。
PCSログには、次の例のようなエントリが表示されます。
Apr 25 10:06:45.203909 user-PCS PCServer [<-TopoServer] JTAC@10.0.0.102, LSP event=(0)CREATE request_id=928380025 tunnel_id=9513 lsp_id=1 report_type=ACK
アクティブでないLSP
LSPプロビジョニング注文が正常に送信および確認され、コントローラのステータスがクリアされている場合でも、LSPが稼働していない可能性があります。LSP の動作ステータスが DOWN の場合、PCC は LSP に信号を送受信できません。このセクションでは、LSPの運用ステータスがDOWNとなる考えられる理由について説明します。
使用率は、DOWN でスタックしている LSP に関連する重要な概念です。利用には 2 つのタイプがあり、特定の時点で互いに異なる場合があります。
-
ライブ利用—このタイプは、ネットワーク内のルーターがLSPパスをシグナリングするために使用します。このタイプの利用は、NTADを介してTEDから学習されます。次の例のようなPCSログエントリが表示される場合があります。特に、リンク上でRSVPの利用をアドバタイズする予約可能な帯域幅(reservable_bw)エントリーに注目してください。
Apr 25 10:10:11.475686 user-PCS PCServer [<-TopoServer] LINK UPDATE: ID=L10.105.107.1_10.105.107.2 status=UP nodeA=0110.0000.0105 nodeZ=0110.0000.0107 protocols=(260)ISIS2,MPLS Apr 25 10:10:11.475690 user-PCS PCServer [A->Z] ID=L10.105.107.1_10.105.107.2 IP address=10.105.107.1 bw=10000000000 max_rsvp_bw=10000000000 te_metric=10 color=0 reservable_bw={9599699968 8599699456 7599699456 7599699456 7599699456 7599699456 7599699456 7099599360 } Apr 25 10:10:11.475694 user-PCS PCServer [Z->A] ID=L10.105.107.1_10.105.107.2 IP address=10.105.107.2 bw=10000000000 max_rsvp_bw=10000000000 te_metric=10 color=0 reservable_bw={10000000000 10000000000 10000000000 8999999488 7899999232 7899999232 7899999232 7899999232 } -
計画利用—このタイプは、NorthStar Controller内でパス計算に使用されます。この利用率は、ルーターがLSPをアドバタイズし、LSP帯域幅とLSPが使用するパスをNorthStarに通信するときにPCEPから学習されます。次の例のようなPCSログエントリが表示される場合があります。特に、リンク上でRSVPの利用率をアドバタイズする帯域幅(bw)とレコードルートオブジェクト(RRO)エントリーに注目してください。
Apr 25 10:06:45.208021 ns-PCS PCServer [<-TopoServer] routing_key = ns_lsp_link_key Apr 25 10:06:45.208034 ns-PCS PCServer [<-TopoServer] JTAC@10.0.0.102, LSP event=(2)UPDATE request_id=0 tunnel_id=9513 lsp_id=1 report_type=STATE_CHANGE Apr 25 10:06:45.208039 ns-PCS PCServer JTAC@10.0.0.102, lsp add/update event lsp_state=ACTIVE admin_state=UP, delegated=true Apr 25 10:06:45.208042 ns-PCS PCServer from=10.0.0.102 to=10.0.0.104 Apr 25 10:06:45.208046 ns-PCS PCServer primary path Apr 25 10:06:45.208049 ns-PCS PCServer association.group_id=128 association_type=1 Apr 25 10:06:45.208052 ns-PCS PCServer priority=7/7 bw=100000 metric=30 Apr 25 10:06:45.208056 ns-PCS PCServer admin group bits exclude=0 include_any=0 include_all=0 Apr 25 10:06:45.208059 ns-PCS PCServer PCE initiated Apr 25 10:06:45.208062 ns-PCS PCServer ERO=0110.0000.0102--10.102.105.2--10.105.107.2--10.114.117.1 Apr 25 10:06:45.208065 ns-PCS PCServer RRO=0110.0000.0102--10.102.105.2--10.105.107.2--10.114.117.1 Apr 25 10:06:45.208068 ns-PCS PCServer samepath, state changed
2つの利用率が互いに十分に異なっているため、パスの計算やシグナリングの成功に干渉する可能性があります。例えば、計画された使用率がライブ使用率よりも高い場合、PCSがパスの余地がないと考えてパスを計算できないという、パス計算の問題が発生する可能性があります。しかし、計画された利用率は実際の実際の利用率よりも高いため、余地がある可能性が非常に高いです。
また、計画使用率が実際の使用率よりも低くなる可能性もあります。その場合、PCCはパスのための余地がないと考え、パスをシグナリングしません。
Web UIトポロジーマップで使用率を表示するには、トポロジービューの左側のペインにあるオプションに移動します。RSVPライブ使用率を選択した場合、トポロジーマップにはルーターからのライブ使用率が反映されます。RSVP使用率を選択した場合、トポロジーマップには計画された使用率が反映され、NorthStar Controllerは計画されたプロパティに基づいて計算します。
Web UIのより優れたトラブルシューティングツールは、ダッシュボードビューのネットワークモデル監査ウィジェットです。リンクRSVP使用率ラインアイテムには、ライブ使用率と計画使用率の間に不一致があるかどうかが反映されます。ある場合は、Web UI から [ Administration > System Settings] に移動し、表示されるウィンドウの右上隅にある [ Advanced Settings ] をクリックして、ネットワーク モデルの同期を実行することができます。
右上隅のボタンは、 General Settings と Advanced Settingsを切り替えます。
PCS が Toposerver と同期していません
PCSがToposerverと同期しなくなり、LSPの状態に同意しない場合、同期を復元するためにPCEPプロトコルを非アクティブ化し、再アクティブ化する必要があります。NorthStarサーバーで以下の手順を実行します。
次の手順に従うことに注意してください。
-
問題のあるPCCだけでなく、すべてのPCCのPCEPセッションを強制終了します。
-
その結果、すべてのユーザーデータが失われ、再入力する必要があります。
-
再同期により、実稼働システムに影響を与えます。
-
PCEサーバーを停止し、PCCが残っているすべてのLSPを削除するまで10秒待ちます。
supervisorctl stop northstar:pceserver -
PCEサーバーを再起動します。
supervisorctl start northstar:pceserver -
Toposerver を再起動します。
supervisorctl restart northstar:toposerver注:Toposerver を再起動する別の方法は、NorthStar Controller Web UI (Administration > System Settings、Advanced) からネットワーク モデルのリセットを実行することです。 Sync Network Model および Reset Network Model 操作の詳細については、「消失する変更」セクションを参照してください。
消え去る変更
Web UIでは、トポロジーをライブネットワークと同期させるための2つのオプションを利用できます。これらのオプションはシステム管理者のみが使用でき、最初に Administration > System Settings に移動し、結果のウィンドウの右上隅にある Advanced Settings をクリックすることでアクセスできます。
右上隅のボタンは、 General Settings と Advanced Settingsを切り替えます。
図 6 は、表示される 2 つのオプションを示しています。
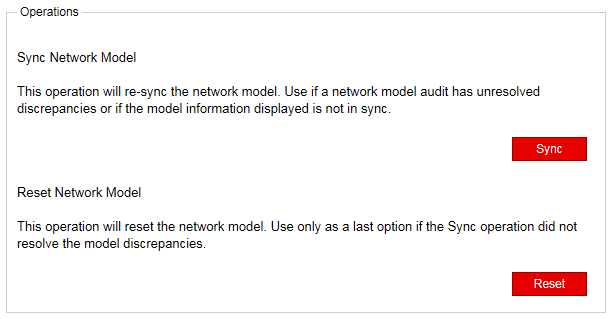
Web UIでネットワークモデルのリセットを実行すると、データベースに加えた変更が失われることに注意することが重要です。マルチユーザー環境では、1 人のユーザーが他のユーザーの知らないうちにネットワーク モデルをリセットする可能性があります。リセットが要求されると、要求はPCSサーバーからトポサーバーに送信され、PCSログには以下が反映されます。
Apr 25 10:54:50.385008 user-PCS PCServer [->TopoServer] Request topology reset
トポサーバーログには、データベース要素が削除されていることが反映されます。
Apr 25 10:54:50.386912 user-PCS TopoServer Truncating pcs.links... Apr 25 10:54:50.469722 user-PCS TopoServer Truncating pcs.nodes... Apr 25 10:54:50.517501 user-PCS TopoServer Truncating pcs.lsps... Apr 25 10:54:50.753705 user-PCS TopoServer Truncating pcs.interfaces... Apr 25 10:54:50.806737 user-PCS TopoServer Truncating pcs.facilities...
次に、トポサーバーは、トポロジーノードとリンクを取得するためにJunos VMと、LSPを取得するためにPCEPサーバーの両方との同期を要求します。このようにして、トポサーバーはトポロジーを再学習しますが、ユーザーの更新は欠落しています。 図7 は、トポロジーリセットリクエストからJunos VMおよびPCEPサーバーとの同期リクエストまでのフローを示しています。
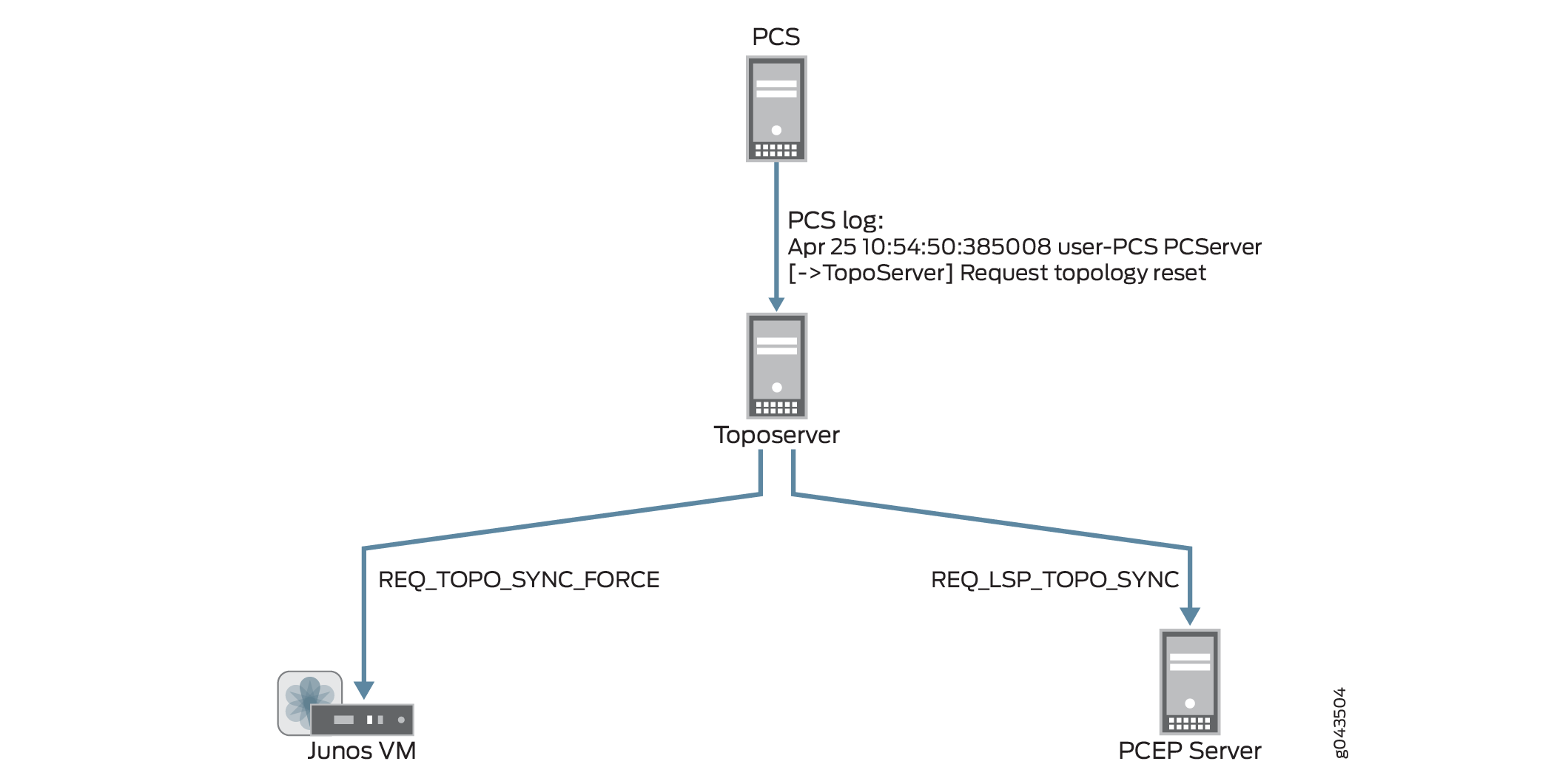 をリセットする
をリセットする
同期リクエストを受信すると、Junos VMとPCEPサーバーは、現在のライブネットワークを反映したトポロジー更新を返します。PCSログには、次の情報がデータベースに追加されていることが示されています。
Apr 25 10:54:52.237882 user-PCS PCServer [<-TopoServer] Update Topology Apr 25 10:54:52.237894 user-PCS PCServer [<-TopoServer] Update Topology Persisted Nodes (0) Apr 25 10:54:52.238957 user-PCS PCServer [<-TopoServer] Update Topology Live Nodes (7) Apr 25 10:54:52.242336 user-PCS PCServer [<-TopoServer] Update Topology Persisted Links (0) Apr 25 10:54:52.242372 user-PCS PCServer [<-TopoServer] Update Topology live Links (10) Apr 25 10:54:52.242556 user-PCS PCServer [<-TopoServer] Update Topology Persisted Facilities (1) Apr 25 10:54:52.242674 user-PCS PCServer [<-TopoServer] Update Topology Persisted LSPs (0) Apr 25 10:54:52.279716 user-PCS PCServer [<-TopoServer] Update Topology Live LSPs (47) Apr 25 10:54:52.279765 user-PCS PCServer [<-TopoServer] Update Topology Finished
図8は、Junos VMとPCEPサーバーからトポサーバーとPCSへのトポロジー更新の復帰を示しています。
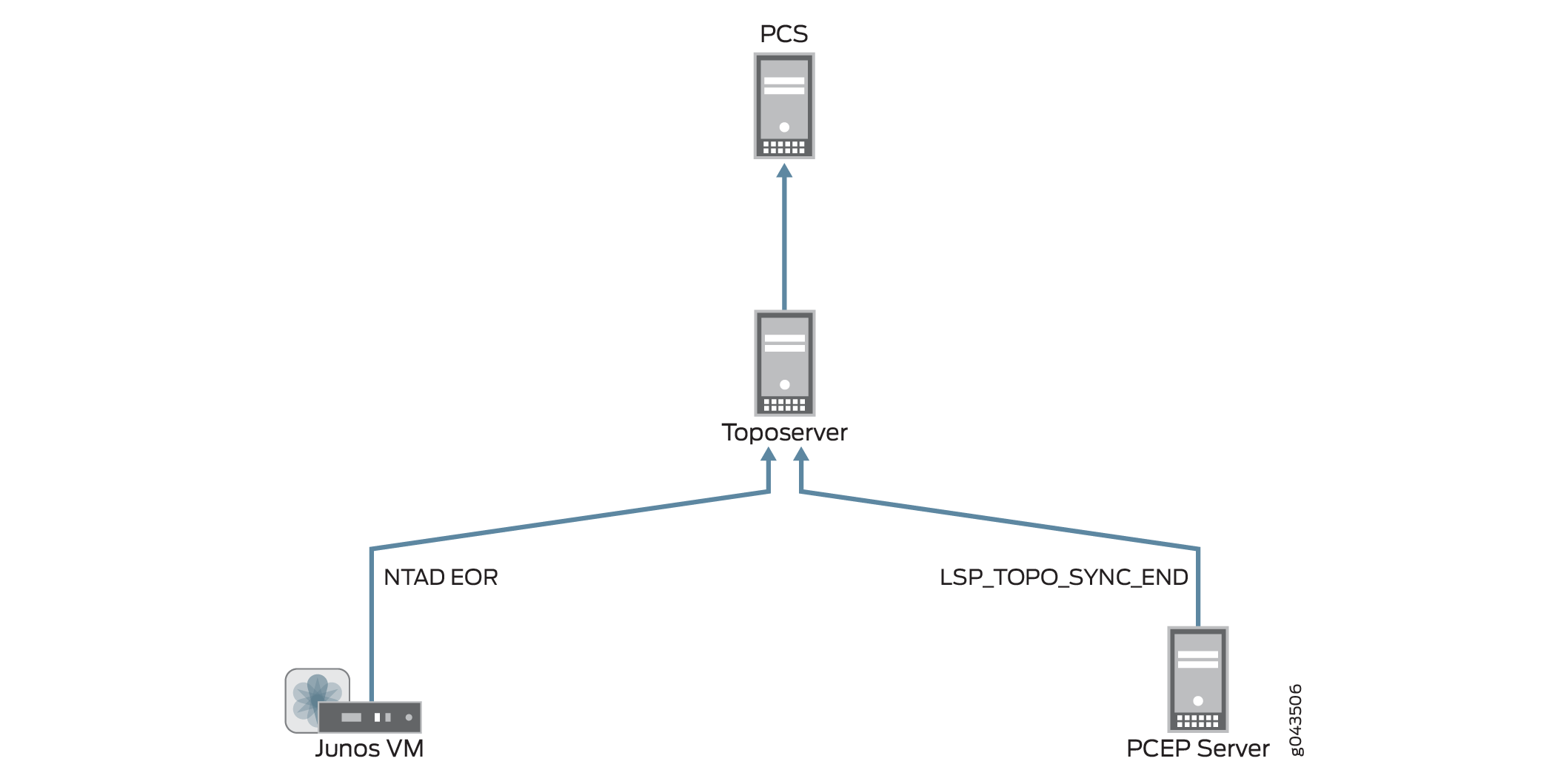 リセットを使用したモデル更新
リセットを使用したモデル更新
トポロジーを最初からやり直す場合は [ネットワーク モデルのリセット] を使用しますが、ライブ ネットワークとの同期時にユーザー計画データを失いたくない場合は、代わりに [ネットワーク モデルの同期] 操作を実行します。この操作では、PCS はトポロジー同期を要求しますが、トポサーバーは既存の要素を削除しません。 図9 は、PCSからJunos VMおよびPCEPサーバーへのフローと、Toposerverに戻ってくるアップデートを示しています。
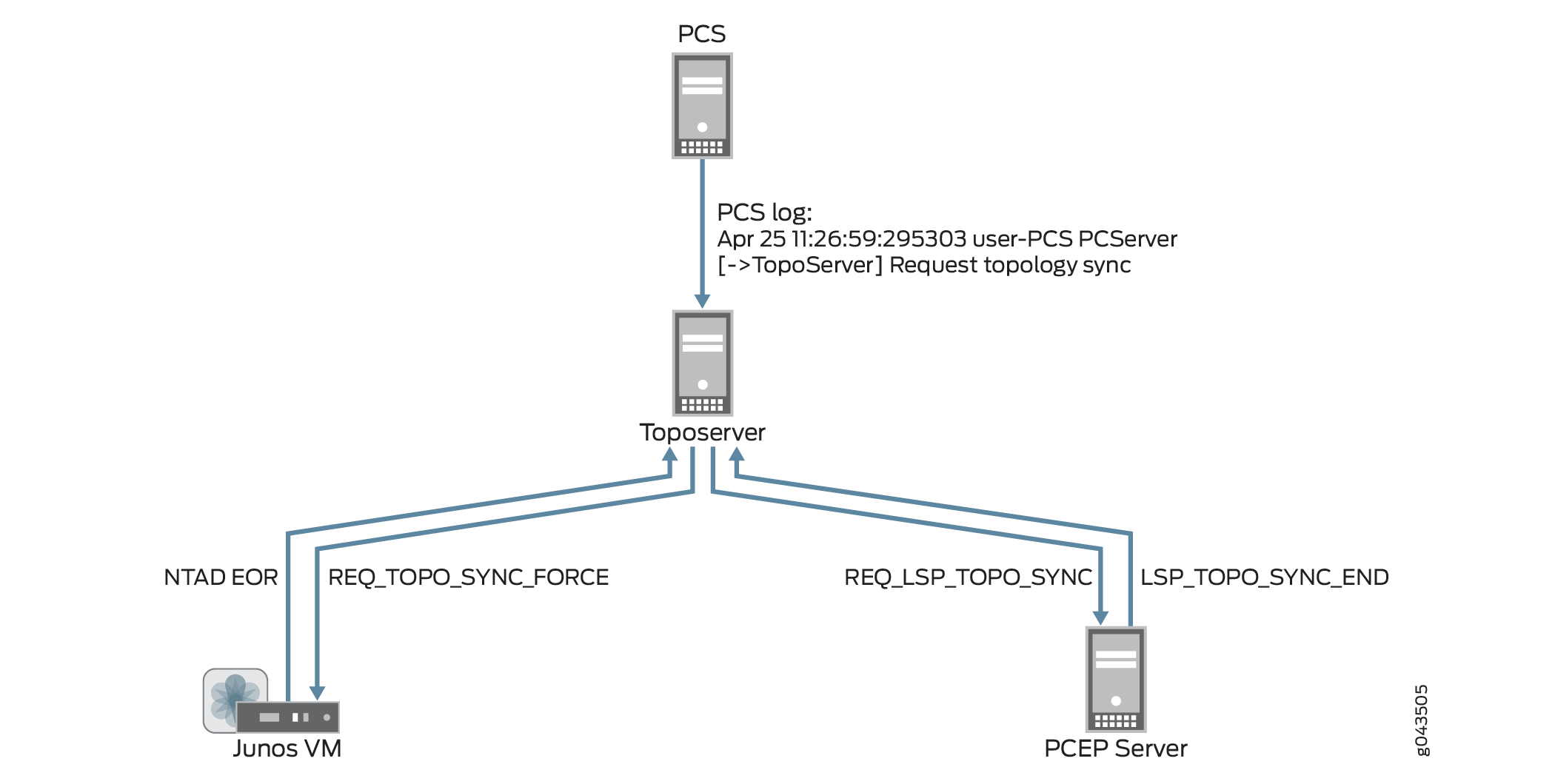 を使用した同期要求とモデル更新
を使用した同期要求とモデル更新
クライアント側の問題の調査
問題の原因を探していて、システムのサーバー側で問題が見つからない場合は、クライアント側で問題を見つけるのに役立つデバッグフラグがあります。このフラグにより、サーバーとクライアント間で交換された内容に関する詳細なメッセージをWebブラウザコンソールで表示できます。例えば、更新がWeb UIに反映されていないことに気付くかもしれません。これらの詳細なメッセージを使用すると、たとえばサーバーが実際に更新を送信しないなど、サーバーとクライアント間の通信ミスの可能性を特定できます。
このデバッグフラグを有効にするには、Web UIの起動に使用するURLを次のように変更します。
https://server_address:8443/client/app.html?debug=true
帯域幅サイジングスケジュールされたタスクの結果が不完全
帯域幅サイジングスケジュールタスクを実行しても、帯域幅サイジングが有効になっているすべてのLSPの統計が公開されない場合は、スケジュールされた期間にわたって、帯域幅サイジングが有効になっているすべてのLSPのトラフィック統計が収集されているかどうかを確認します。トラフィック統計が利用できない場合、これらのLSPの帯域幅統計はサイズ変更できません。
NorthStar Collector Web UIを使用して、トラフィック統計が収集されているかどうかを確認できます。
-
ネットワーク情報テーブルでトンネルタブを開きます。
-
サイズ変更されていないLSPを選択します。
-
右クリックして [ View LSP Traffic] を選択します。
-
左上隅にある[ custom ]をクリックし、スケジュールの期間を入力して、[ Submit]をクリックします。
NorthStarとHealthBotとの統合のトラブルシューティング
NorthStarでデバイスのHealthBotへの更新が失敗する場合は、まずNorthStar Webアプリケーションサーバーのログにエラーがないか確認します。
[root@ns1-site1 ~]# tail -f /opt/northstar/logs/web_app.msg
2019 Oct 15 02:46:49.824 - info: Request: User:admin (full):http:GET:127.0.0.1:/NorthStar/API/v1/tenant/1/RouterProfiles/vendorList
2019 Oct 15 02:46:52.165 - info: Request: User:admin (full):http:GET:127.0.0.1:/NorthStar/API/v1/tenant/1/RouterProfiles/liveNetwork
2019 Oct 15 02:47:10.466 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/updateDevices
req: {}
2019 Oct 15 02:47:17.084 - debug: Devices updated, Healthbot response body = ""
2019 Oct 15 02:47:17.512 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/updateDeviceGroup
req: {"devices":["vmx104","vmx101","vmx107","vmx103","vmx106","vmx105","vmx102"]}
2019 Oct 15 02:47:18.453 - debug: Device Group updated, Healthbot response body = ""
2019 Oct 15 02:47:18.860 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/commitConfigs
2019 Oct 15 02:47:18.935 - debug: Commit completed, Healthbot response body = "{\n \"detail\": \"Committing the configuration.\",\n \"status\": 202,\n \"url\": \"/api/v1/configuration/jobs/?job_id=c6be7387-bfbf-45e4-97c8-993f27bcbe09\"\n}\n"
HealthBot APIサーバーログは、デバイスのHealthBotへの更新が失敗した場合に役立つ情報を提供する場合もあります。
root@healthbot-vm1:~# healthbot logs --device-group healthbot -s api_server docker logs 1557243a5b 2>&1 | vi - Vim: Reading from stdin...
RPM プローブ・データおよび LDP 需要統計収集が機能しているかどうかを確認するには、IAgent コンテナー・ログにアクセスします。IAgent は、RPM データ(リンク 遅延)と LDP 需要の統計収集に使用されます。
root@healthbot-vm1:~# docker ps | grep iagent | grep northstar 3492c1f3774f healthbot_iagent:2.1.0-beta-custom "/entrypoint.sh salt…" 23 hours ago Up 23 hours device-group-northstar_device-group-northstar-iagent_1 root@healthbot-vm1:~# docker exec -it 7382325c375f bash root@3492c1f3774f:/# tail -f /tmp/inter-packet-export.log 2019-10-15 07:19:15,329 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx106 2019-10-15 07:19:24,546 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx102 2019-10-15 07:19:27,522 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx101 2019-10-15 07:19:33,788 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx105 2019-10-15 07:19:38,110 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx104 2019-10-15 07:19:39,251 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx103 2019-10-15 07:20:04,654 inter-packet.ns_link_latency Aggregates sent for 2 objects for node=vmx104 2019-10-15 07:20:05,878 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx105 2019-10-15 07:20:06,535 inter-packet.ns_link_latency Aggregates sent for 1 objects for node=vmx103 2019-10-15 07:20:07,537 inter-packet.ns_link_latency Aggregates sent for 3 objects for node=vmx101 2019-10-15 07:20:09,479 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx102 2019-10-15 07:20:15,332 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx106 2019-10-15 07:21:04,657 inter-packet.ns_link_latency Aggregates sent for 2 objects for node=vmx104 2019-10-15 07:21:05,881 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx105 2019-10-15 07:21:06,538 inter-packet.ns_link_latency Aggregates sent for 1 objects for node=vmx103 2019-10-15 07:21:07,540 inter-packet.ns_link_latency Aggregates sent for 3 objects for node=vmx101 2019-10-15 07:21:09,484 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vm
JTI LSPとインターフェイス統計データの収集が機能しているかどうかを確認するには、fluentdコンテナログにアクセスします。ネイティブGBPは、JTIデータ収集に使用されます。
root@healthbot-vm1:~# docker ps | grep fluentd | grep northstar 5fa268d0410b healthbot_fluentd:2.1.0-beta-custom "/fluentd/etc/startu…" 20 hours ago Up 20 hours 5140/tcp, 0.0.0.0:4000->4000/tcp, 0.0.0.0:4000->4000/udp, 24224/tcp device-group-northstar_device-group-northstar-fluentd_1 root@healthbot-vm1:~# docker exec -it 5fa268d0410b bash root@5fa268d0410b:/# tail -f /tmp/inter-packet-export.log 2019-10-15 06:00:01,241 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:01:01,245 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:02:01,248 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:03:01,255 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:04:01,259 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:05:01,265 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:06:01,269 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:07:01,274 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:08:01,279 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:09:01,285 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105
統計データが HealthBot サーバーから PCS に通知されているかどうかを確認するには、PCS ログにアクセスして、ライブ統計通知情報を確認します。
[root@ns1-site1-q-pod21 ~]# tail -f /opt/northstar/logs/pcs.log
2019 Oct 15 00:09:19.221768 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.3@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221783 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/1.0@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221798 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.200@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221812 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.301@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.880395 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_tunnel_traffic
2019 Oct 15 00:09:19.880456 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 test1_102_105-1@vmx102 3836219
2019 Oct 15 00:09:19.880463 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 rsvp-102-105@vmx102 0
2019 Oct 15 00:09:19.880469 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-101@vmx102 1041649
2019 Oct 15 00:09:19.880479 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-104@vmx102 3390530
2019 Oct 15 00:09:19.880483 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-103@vmx102 4261408
2019 Oct 15 00:09:26.795447 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_link_latency
2019 Oct 15 00:09:26.795453 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/8.0@vmx103 20.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795462 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/0/6.0@vmx101 4.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795471 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/0/5.0@vmx101 3.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795473 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/1.0@vmx101 19.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795476 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/9.0@vmx104 10.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795479 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/7.0@vmx104 0.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:27.710072 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_demand
2019 Oct 15 00:09:27.710264 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.101/32 bit_rate:0 demand_name=vmx102_10.0.0.101/32 to=10.0.0.101/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.710599 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.710667 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.710697 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.101/32@10.0.0.102 pathname=10.0.0.101 to=10.0.0.101 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.101) path= op_state=ACTIVE ns_lsp_id =42 demand=true prefix=10.0.0.101/32
2019 Oct 15 00:09:27.710724 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 42 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.711440 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.711450 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.105/32 bit_rate:0 demand_name=vmx102_10.0.0.105/32 to=10.0.0.105/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.711454 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.711457 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.711461 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.105/32@10.0.0.102 pathname=10.0.0.105 to=10.0.0.105 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.105) path= op_state=ACTIVE ns_lsp_id =44 demand=true prefix=10.0.0.105/32
2019 Oct 15 00:09:27.711464 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 44 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.712010 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.712033 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.103/32 bit_rate:0 demand_name=vmx102_10.0.0.103/32 to=10.0.0.103/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.712039 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.712042 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.712048 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.103/32@10.0.0.102 pathname=10.0.0.103 to=10.0.0.103 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.103) path= op_state=ACTIVE ns_lsp_id =48 demand=true prefix=10.0.0.103/32
2019 Oct 15 00:09:27.712808 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 48 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.713209 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.713219 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.104/32 bit_rate:0 demand_name=vmx102_10.0.0.104/32 to=10.0.0.104/32 SNMP_ifIndex:0 next_hope=
NorthStar Controllerデバッグファイルの収集
NorthStar Controllerの問題を解決できない場合は、NorthStar Controllerデバッグユーティリティで生成されたデバッグファイルをJTACに転送して評価を受けることをお勧めします。現在、すべてのデバッグファイルは、 u/wandl/tmp ディレクトリの下のサブディレクトリにあります。
デバッグファイルを収集するには、NorthStar Controller CLIにログインし、 コマンド u/wandl/bin/system-diagnostic.sh filename を実行します。
出力が生成され、filename.tbz2デバッグファイルの/tmpディレクトリから利用できます。
リモートSyslog
ほとんどの NorthStar プロセスは、 /etc/rsyslog.conf で定義されている rsyslog を使用します。rsyslogの使用に関する詳細については、Linuxシステムで実行されている特定のrsyslogバージョンの http://www.rsyslog.com/doc を参照してください。
SNMP収集の規模の拡大
-
5分のポーリング間隔でSNMP収集の規模を増やすには、以下のタスクを実行します。
-
viなどのテキスト編集ツールを使用して、
supervisord_snmp_slave.confファイルを開いて編集します。設定ファイルが開きます。
vi opt/northstar/data/supervisord/supervisord_snmp_slave.conf
-
次のコマンドを追加して、スレッドの数を 100 から 200 に増やします。
/opt/northstar/thirdparty/python3/bin/celery -A collector.celery -Q netsnmp -n worker2@%%n worker -P threads -c 200--loglevel=info
-
前のワーカーを複製して、ワーカー (例: worker3) を追加します。
[program:worker3] /opt/northstar/thirdparty/python3/bin/celery -A collector.celery -Q netsnmp -n worker3@%%n worker -P threads -c 200--loglevel=info process_name=%(program_name)s numprocs=1 ;directory=/tmp ;umask=022 priority=999 autostart=true autorestart=true startsecs=10 startretries=3 exitcodes=0,2 stopsignal=TERM stopwaitsecs=10 user=pcs stopasgroup=true killasgroup=true redirect_stderr=true stopasgroup=true stdout_logfile=/opt/northstar/logs/celery_worker3.msg stdout_logfile_maxbytes=10MB stdout_logfile_backups=10 stdout_capture_maxbytes=10MB stderr_logfile=/opt/northstar/logs/celery_worker3.err stderr_logfile_maxbytes=10MB stderr_logfile_backups=10 stderr_capture_maxbytes=10MB environment=PYTHONPATH="/opt/northstar/snmp-collector",LD_LIBRARY_PATH="/opt/northstar/lib" ;environment=A="1",B="2" ;serverurl=AUTO
-
group ステートメントにワーカーを追加します。
ベストプラクティス:追加できるワーカーの数は、CPUのコア数以下である必要があります。
[group:collector] programs=worker1,worker2,worker3
-
スーパーバイザーの
collector:* groupを再起動します。supervisorctl reread supervisorctl update
-
worker1、worker2、および worker3 の supervisorctl ステータスを表示して、それらが稼働していることを確認します。
supervisorctl status
-
出力にいくつかの worker1 プロセスが表示されるが、worker2 と worker3 にはそれぞれ 1 つの親プロセスしか表示されていないことを確認します。
ps -ef | grep celery
-
-
スレッド数を増やしてスケーラビリティを高めるには、以下のタスクを実行します。
-
viなどのテキスト編集ツールを使用して、
data_gateway.pyファイルを開いて編集します。設定ファイルが開きます。
vi /opt/northstar/snmp-collector/collector/data_gateway.py
-
プール内のスレッドの数を 10 から 20 に増やします。
pool_size = 20
-
collector_main:data_gatewayプロセスを停止し、プロセスを再起動します。supervisorctl stop collector_main:data_gateway supervisorctl restart collector_main:data_gateway
-
-
スケーラビリティを向上させるためにスループットを増やすには、以下のタスクを実行します。
-
viなどのテキスト編集ツールを使用して、
es_publisher.cfgファイルを開いて編集します。設定ファイルが開きます。
vi /opt/northstar/data/es_publisher/es_publisher.cfg
-
以下のパラメーターを設定します。
polling_interval=5 batch_size=5000 pool_size=20
注:1回の操作でElasticSearchデータベース(batch_size)に送信されるレコードの最大数は5000ですが、SNMP統計(pool_size)を収集するために実行できるスレッドの最大数(スレッドプール内)は20です。
-
-
ポーリングごとにより多くのルーターインターフェイスからデータを収集するには、以下のタスクを実行します。
-
NorthStar Controller GUIでデバイスプロファイル(管理>デバイスプロファイル)ページに移動します。
-
デバイスリストでルーターを選択し、 変更をクリックします。
デバイスの変更ページが表示されます。
-
ユーザー定義のプロパティタブの名前列で、プロパティの名前を bulk_sizeとして指定します。値列で、バルクサイズを 100に設定します。
バルクサイズは、ネットワークがポーリングされるたびに収集されるインターフェイスの数を示します。
-
変更をクリックします。
デバイスプロファイルページにリダイレクトされ、変更が保存されたことを示す確認メッセージが表示されます。
-