ディザスタリカバリの概要
Junos Spaceクラスタにより、ネットワーク管理ソリューションの高可用性と拡張性を維持できます。ただし、クラスタ内のすべてのノードは同じサブネット内に存在する必要があるため、通常は同じデータセンターまたは同じキャンパス内に導入されます。しかし、クラスタ上の元のJunos Spaceインストールを、地理的に異なる場所にある別のクラスタにミラーリングすることで、ある場所の災害からクラスタを簡単に回復できます。そのため、地震などの災害によりメインのJunos Spaceサイトに障害が発生した場合、他のサイトが引き継ぐことができます。したがって、ディザスタリカバリセットアップの物理的なインストールは、通常、地理的に離れた2つのクラスタのセット、アクティブまたはメインサイト(つまり、ローカルサイト)とスタンバイサイトまたはバックアップサイト(つまり、リモートサイト)です。
基本的な接続要件と前提条件が満たされている場合(「 障害回復を設定するための前提条件 」および「 障害回復を設定するための接続要件 」を参照)、アクティブ サイトのクラスタのデータがスタンバイ サイトのクラスタにほぼリアルタイムで複製されます。
MySQLおよびPgSQLデータベースのデータは、SSL 接続を介してアクティブサイトからスタンバイサイトに非同期的にレプリケートされます。ディザスタリカバリサイト間のMySQLおよびPgSQLデータは、ディザスタリカバリが初期化されたときに生成される自己署名SSL証明書を使用して暗号化されます。CA ルート証明書、CRL、ユーザー証明書、スクリプト、デバイス イメージ、アーカイブされた監査ログ、およびスケジュールされたジョブに関する情報は、スタンバイ サイトへのリアルタイム データ レプリケーション中にスタンバイ サイトにレプリケートされます。設定ファイルとラウンドロビンデータベース(RRD)ファイルは、アクティブサイトからスタンバイサイトにセキュアコピープロトコル(SCP)を使用して定期的に同期されます。
Junos Space の組み込みメカニズムである障害復旧ウォッチドッグは、サイト間でのデータベース レプリケーションの整合性を監視します。他のすべてのサービス (JBoss、OpenNMS、Apache など) は、アクティブサイトがスタンバイサイトにフェイルオーバーするまで、スタンバイサイトでは実行されません。スタンバイ サイトへのフェールオーバーは、アクティブ サイトがダウンすると自動的に開始されます。デバイス調停アルゴリズムを使用して、両方のサイトがアクティブになろうとするスプリットブレインシナリオを防ぐために、どちらのサイトをアクティブサイトにするかを決定します。デバイス調停アルゴリズムの詳細については、「 デバイス調停アルゴリズムを使用したエラー検出」を参照してください。
次のセクションでは、障害回復プロセスの接続要件、障害検出メカニズム、および障害回復コマンドについて説明します。
災害復旧ソリューション
アクティブ・サイトとスタンバイ・サイト間のディザスタ・リカバリ・プロセスを構成して開始すると、サイト間のMySQLおよびPgSQLデータベースの非同期レプリケーションが開始されます。設定ファイルとRRDファイルは、定義された時間間隔でSCPを介してスタンバイサイトにバックアップされます。
ディザスタリカバリプロセスでは、スタンバイサイトへのCassandraデータベースのリアルタイムレプリケーションは実行されず、Junos Spaceノードで実行されているCassandraサービスも監視されません。
ディザスタリカバリソリューションの通常の動作中、GUIとAPIのユーザと管理対象デバイスは、すべてのネットワーク管理サービスのアクティブサイトに接続されます。スタンバイサイトと管理対象デバイス間の接続は、アクティブサイトが機能している限り無効になります。災害によりアクティブ・サイトが使用できなくなると、スタンバイ・サイトが稼働します。この時点で、スタンバイサイト上のすべてのサービスが開始され、スタンバイサイトと管理対象デバイス間の接続が確立されます。
図 1 は、災害復旧ソリューションを示しています。
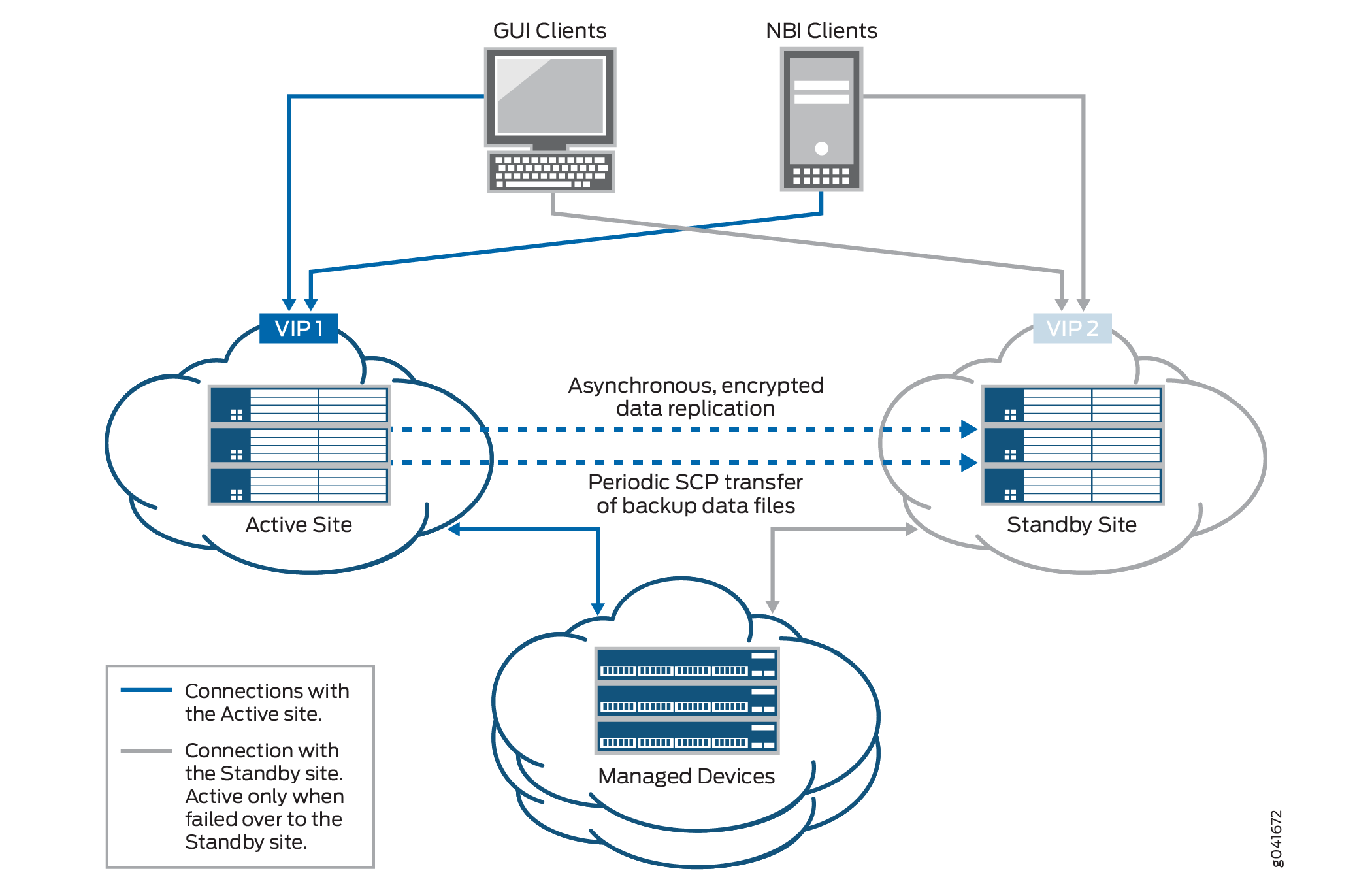
ディザスタリカバリウォッチドッグプロセスは、アクティブサイトとスタンバイサイトの両方のVIPノードで開始され、レプリケーションプロセスの正常性を監視し、リモートサイトがダウンしたときを検出します。ローカル・サイトの災害復旧ウォッチドッグは、両方のサイト間に接続の問題があるかどうか(リモート・サイトのノードにpingを実行することによって)と、サイトが監視デバイスに接続されているかどうか(デバイス・アービトレーション・アルゴリズムを使用している場合)をチェックします。
サイトの災害復旧ウォッチドッグは、以下のタスクを実行して、リモートサイトおよび監視デバイスとの接続を確認します。
-
設定可能な一定の間隔でリモートサイトのVIPアドレスにpingを実行します。間隔のデフォルト値は30秒です。
各pingについて、設定可能なタイムアウト間隔内に応答を期待します。タイムアウト間隔のデフォルト値は 5 秒です。
-
ローカル サイトがタイムアウト間隔内に応答を受信しなかった場合、ディザスタ リカバリ ウォッチドッグは設定可能な回数だけ ping を再試行します。デフォルトでは、再試行回数は 4 回です。
-
すべての再試行に失敗した場合、ローカル サイトのディザスタ リカバリ ウォッチドッグは、リモート サイトの VIP アドレスに到達できないと結論付けます。
ただし、ディザスタリカバリウォッチドッグは、ローカルスイッチオーバーによりリモートサイトがVIPアドレスをスタンバイノードにスイッチオーバーしている可能性があるため、リモートサイトがダウンしているとは結論付けません。
-
VIP アドレスの切り替えの可能性を検討するために、ディザスター リカバリー ウォッチドッグは、リモート サイトにある他のロード バランサー ノードの IP アドレスに ping を実行します。いずれかのノードへのpingが応答を受信すると、ディザスタリカバリウォッチドッグはリモートサイトがまだ稼働していると結論付けます。
ノードへの ping が失敗した場合、災害復旧ウォッチドッグはリモート サイトがダウンしているとは結論付けません。代わりに、ディザスタリカバリウォッチドッグは、サイト間の接続問題の可能性を考慮します。どちらのサイトもアクティブになろうとします。
-
両方のサイトがアクティブにならないようにするために、ディザスター リカバリー ウォッチドッグはデバイス アービトレーション アルゴリズムを開始し、フェールオーバーが必要かどうかを判断します。
フェイルオーバーは、アクティブ・サイトで管理される監視デバイスの割合がフェイルオーバーしきい値を下回った場合にのみ開始されます。その後、アクティブ・サイトがスタンバイ・サイトになり、スタンバイ・サイトがアクティブ・サイトになります。
監視デバイスの割合がフェイルオーバーしきい値を上回っている場合、スタンバイサイトはスタンバイのままで、アクティブサイトはアクティブなままになります。アクティブ・サイトで管理される監視デバイスの割合は設定可能で、デフォルト値は50%です。
フェールオーバーは、次の条件が満たされた場合に開始されます。
-
スタンバイ・サイトは、アクティブ・サイトのVIPアドレス、またはアクティブ・サイトの他のロード・バランサー・ノードのノードIPアドレスに到達できません。
-
アクティブ・サイトによって管理される監視デバイスの割合がフェイルオーバーしきい値を下回っている。
デバイス調停アルゴリズムの詳細については、「 デバイス調停アルゴリズムを使用したエラー検出」を参照してください。
ディザスタリカバリを設定するための前提条件
災害復旧を設定する前に、Junos Spaceのインストールが次の前提条件を満たしていることを確認する必要があります。
-
プライマリまたはアクティブサイトのJunos Spaceクラスタ(単一ノードまたは複数ノード)とリモートサイトまたはスタンバイサイトのクラスタ(単一ノードまたは複数ノード)は、まったく同じ方法で、すべて同じアプリケーション、デバイスアダプタ、同じIPファミリー設定で設定する必要があります。 などなど。
-
どちらのクラスタも、Junos SpaceユーザーインターフェイスからのSMTPサーバー情報を使用して設定する必要があります。詳細については、「 SMTP サーバーの管理」を参照してください。この構成により、レプリケーションが失敗した場合に、アクティブ サイトとスタンバイ サイトの両方のクラスタが管理者に電子メールで通知できます。
アクティブサイトとスタンバイサイトのノード数は同じである必要があります。
ディザスタリカバリを設定するための接続要件
ディザスタリカバリを設定する前に、ディザスタリカバリソリューションが次の接続要件を満たしていることを確認する必要があります。
-
アクティブ サイトとスタンバイ サイトの Junos Space クラスタ間のレイヤー 3 接続。これはですね:
-
クラスタ内のすべてのノードは、他のクラスタのVIPアドレスに正常にpingを実行できます
-
クラスタ内のすべてのノードは、SCPを使用してアクティブサイトとスタンバイサイト間でファイルを転送できます
-
2 つのクラスター間のデータベース レプリケーションは、TCP ポート 3306 (MySQL データベース レプリケーション) と 5432 (PostgreSQL データベース レプリケーション) を介して可能です
-
2 つのクラスター間の接続の帯域幅と待機時間は、リアルタイム データベース レプリケーションが成功するようなものです。必要な帯域幅は転送されるデータの量によって異なりますが、最低でも 100 Mbps の帯域幅で、150 ミリ秒未満の遅延で接続することをお勧めします。
-
-
各クラスタと管理対象デバイス間の独立したレイヤー3接続
-
各クラスタとGUIまたはNBIクライアント間の独立したレイヤー3接続
ディザスタリカバリプロセスを設定するには、 アクティブサイトとスタンバイサイト間のディザスタリカバリプロセスの設定を参照してください。
災害復旧ウォッチドッグ
災害復旧ウォッチドッグは、DRウォッチドッグとも呼ばれ、サイト間のデータレプリケーション(MySQLデータベース、PgSQLデータベース、構成ファイル、RRDファイル)の整合性を監視する組み込みのJunos Spaceメカニズムです。また、ディザスタリカバリウォッチドッグは、ディザスタリカバリ設定の全体的な状態を監視し、アクティブサイトに障害が発生したときにアクティブサイトからスタンバイサイトへのフェイルオーバーを開始し、スタンバイサイトが最小限のサービス中断でネットワーク管理サービスを再開できるようにします。ディザスター リカバリー ウォッチドッグのインスタンスは、ディザスター リカバリー プロセスを開始すると、両方のサイトの VIP ノードで開始されます。
ディザスタリカバリウォッチドッグは、次のサービスを提供します。
心音
アクティブ・サイトとスタンバイ・サイト間のハートビート・サービスでは、pingを使用してサイト間の接続を確認します。両方のサイトが相互にハートビート メッセージを送信します。ハートビート・サービスは、以下のタスクを実行します。
-
一定の間隔でリモートサイトにpingを実行して、リモートサイトの障害を検出します。
-
リモート・サイトが応答しない場合は、リモート・サイトでのローカル・フェイルオーバーによる一時的な問題の可能性を除外します。
-
ディザスタリカバリの構成設定に応じて、自動フェイルオーバーを有効または無効にします。
-
スプリットブレインのシナリオを回避するには、デバイスアービトレーションアルゴリズム(デフォルト)またはカスタムスクリプトで構成されたロジックを実行します。
-
サイトの再起動後にディザスター リカバリー構成を確認します。
mysqlモニター
mysqlMonitor サービスは、次のタスクを実行します。
-
サイト内およびアクティブサイトとスタンバイサイト間のMySQLデータベースレプリケーションの正常性を監視します。
-
MySQLデータベースのレプリケーションエラーを修正しました。
-
MySQLデータベースレプリケーションエラーを自動的に修正できない場合は、電子メールで管理者に通知します。
pgsqlモニター
pgsqlMonitor サービスは、次のタスクを実行します。
-
サイト内およびアクティブ サイトとスタンバイ サイト間の PgSQL データベース レプリケーションの正常性を監視します。
-
PgSQLデータベースのレプリケーションエラーを修正しました。
-
PgSQLデータベースのレプリケーションエラーを自動的に修正できない場合は、電子メールで管理者に通知します。
ファイルモニター
fileMonitor サービスは、次のタスクを実行します。
-
サイト内、およびアクティブ・サイトとスタンバイ・サイト間で複製された構成ファイルおよび RRD ファイルの正常性をモニターします。
-
構成ファイルおよび RRD ファイルの複製中に検出されたエラーを修正しました。
-
レプリケーション エラーを自動的に修正できない場合は、電子メールで管理者に通知します。また、cron ジョブの出力でレプリケーション エラーを表示することもできます。
アービターモニター
arbiterMonitor サービスは、ローカル サイトがすべての監視デバイスに ping できるかどうかを定期的にチェックします。到達可能な監視デバイスの割合が、設定された警告しきい値(デフォルトでは 70%)を下回ると、管理者に電子メール通知が送信されます。
コンフィグモニター
configMonitor サービスは、次のタスクを実行します。
-
両方のサイトのすべてのノードでディザスタリカバリ設定ファイルを監視します。
-
ファイルが同期していない場合は、サイト内のノード間で構成ファイルを転送します。
サービスモニター
serviceMonitor サービスは、以下のタスクを実行します。
-
特定のサイト内の選択したサービス(jboss、jboss-dc、httpd、dr-watchdog など)のステータスを監視します。
-
選択したサービスが正しく表示されない場合は、開始または停止します。
通知
通知サービスは、障害復旧ウォッチドッグによって検出されたエラー状態、警告、または障害回復状態の変化について、電子メールで管理者に通知します。通知メールは、次の場合に送信されます。
-
サイトと監視デバイス間の接続の問題により、自動フェイルオーバーは無効になっています。
-
到達可能な監視デバイスの割合が警告しきい値より低い。
-
サイトがスタンバイまたはアクティブになります。
-
スタンバイ・サイトは、SCPを介してアクティブ・サイトからファイルをバックアップできません。
-
サイトがリモートサイトへのSSH接続を確立できません。
-
ローカルサイトは、MySQLプライマリノードのホスト名を取得できません。
-
サイトでは、MySQLおよびPgSQLデータベースのレプリケーションエラーを修正できません。
通知サービスは、構成可能な期間内(デフォルトでは 3600 秒)内に同じエラーを報告する電子メールを送信しません。
デバイスアービトレーションアルゴリズムを使用した障害検出
デバイスアービトレーションアルゴリズムは、サイトの障害を検出するために使用されます。Junos OSを実行し、Junos Spaceプラットフォームによって管理される到達性の高いデバイスのリストが、監視デバイスとして選択されます。監視デバイスは、以下の基準に基づいて選択することを推奨します。
-
両方のサイトからJunos Spaceが開始するSSH接続を介して監視デバイスに到達できる必要があります。Junos Spaceプラットフォームへのデバイス起動接続を使用するデバイスは選択しないでください。
-
両方の障害復旧サイトから監視サーバデバイスに ping を実行できる必要があります。
-
デバイスアービトレーションアルゴリズムの結果に影響を与える可能性があるため、Junos Spaceプラットフォームに接続された状態を維持するか、再起動またはシャットダウンの頻度が低い監視デバイスを選択する必要があります。特定の監視デバイスが寿命のどこかでオフラインになることが予想される場合は、それらのデバイスを選択しないでください。
-
地理的に異なる場所にある監視デバイスを選択して、ある場所の管理ネットワークで問題が発生しても、すべての監視デバイスがサイトから到達できなくなることがないようにする必要があります。
-
NATおよびWW Junos OSデバイスを監視デバイスとして選択することはできません。
アクティブ・サイトのデバイス・アービトレーション・アルゴリズムは、ping を使用してアクティブ・サイトから監視デバイスに接続します。スタンバイ・サイトのデバイス・アービトレーション・アルゴリズムは、Junos Spaceプラットフォーム・データベースからのログイン資格情報を使用して、SSH接続を介して監視デバイスにログインします。以下は、アクティブサイトとスタンバイサイトでのデバイスアービトレーションアルゴリズムのワークフローです。
アクティブなサイトでは、次のようになります。
-
選択した監視デバイスすべてに ping を実行します。
-
pingできる監視デバイスの割合を計算する。
-
ping できる監視デバイスの割合が、フェイルオーバーしきい値の設定値と同じか、同じかどうかを確認します。
-
接続されている監視デバイスの割合がフェイルオーバーしきい値の構成値(ディザスタリカバリ API のウォッチドッグセクションの failureDetection.threshold.failover パラメータ)の設定値以上または同じ場合、アクティブサイトが監視デバイスの大部分を管理しているため、フェイルオーバーは開始されません。
-
監視デバイスの割合がフェイルオーバーしきい値の設定値を下回ると、フェイルオーバーが開始され(自動フェイルオーバーが有効な場合)、アクティブ・サイトはスタンバイ状態になります。自動フェイルオーバーが無効になっている場合、アクティブ・サイトはアクティブなままになります。
-
スタンバイ・サイトで、次の操作を行います。
-
SSH接続を介して監視デバイスにログインします。
-
各監視デバイス上で コマンドを実行して、アクティブサイトの任意のノード(ノードによって管理される)への SSH 接続のリストを取得します。
-
アクティブサイトで管理されている監視デバイスの割合を計算します。
-
SSH接続でアクセスできない監視デバイスの割合を計算します。
-
アクティブ・サイトによって管理される監視デバイスの割合がフェイルオーバーしきい値の設定値以上または同じ場合、アクティブ・サイトは依然として監視デバイスの大部分を管理しているため、フェイルオーバーは必要ありません。
-
アクティブ・サイトによって管理される監視デバイスの割合がフェイルオーバーしきい値の構成値を下回っている場合、障害回復ウォッチドッグはフェイルオーバーが必要であると結論付けます。
-
-
ただし、スタンバイ・サイトからアクセスできないデバイスは、アクティブ・サイトによって接続および管理される可能性があるため、スタンバイ・サイトは、到達できないすべての監視デバイスがアクティブ・サイトによって管理されていると仮定し、アクティブ・サイトで管理されるデバイスの新しい割合を計算します。
-
アクティブ・サイトによって管理されるデバイスの割合が、管理対象デバイスを調整するしきい値の割合 (ディザスター・リカバリー API のウォッチドッグ・セクションの failureDetection.threshold.adjustManaged パラメーター、デフォルト値は 50%) を下回っている場合、スタンバイ・サイトはスタンバイのままになります。既定では、管理対象デバイスを調整するしきい値の割合は、フェールオーバーのしきい値を下回る必要があります。
-
アクティブサイトによって管理されているデバイスと監視デバイスのうち、到達できないものを追加して計算された新しい割合がフェイルオーバーしきい値を下回っている場合、障害復旧ウォッチドッグはフェイルオーバーを開始する必要があると結論付けます。
自動フェイルオーバーが有効な場合、スタンバイ・サイトはアクティブになるプロセスを開始します。自動フェールオーバーが無効になっている場合、フェールオーバーは行われません。
-
自動フェールオーバーを無効にした場合、または接続の問題が原因で機能が無効になった場合は、スタンバイ サイトで jmp-dr manualFailover を実行して、スタンバイ サイトからネットワーク管理サービスを再開する必要があります。
カスタム障害検出スクリプトを使用した障害検出
デバイス調停アルゴリズムの使用に加えて、カスタムの障害検出スクリプト (sh、bash、Perl、または Python) を作成して、スタンバイ サイトにフェールオーバーするタイミング、またはフェールオーバーするかどうかを決定できます。カスタム障害スクリプトは、 jmp-dr api v1 config ––include コマンドを呼び出し、障害復旧の構成と障害復旧ウォッチドッグサービスのステータスを取得します。サイトのディザスタリカバリ構成とディザスタリカバリウォッチドッグサービスのステータスは、さまざまなセクションとして整理されています。 表 1 に、これらのセクションを示します。
-- include <section-name> オプションを使用してセクションの詳細を表示するか、カスタム障害検出スクリプトでセクションの詳細を使用します。
| 節 |
形容 |
セクションに含まれる詳細 |
サンプル出力 |
|---|---|---|---|
| 役割 |
現在のサイトの災害復旧の役割 |
ロールは、アクティブ、スタンバイ、またはスタンドアロンです。 |
– |
| フェイルオーバー |
最後に発生したフェールオーバーの種類 |
値は、active_to_standby、standby_to_active、またはフェールオーバーがまだ発生していない場合は空にすることができます。 |
– |
| コア |
リモートサイトノードの詳細を含むコアディザスタリカバリ構成 |
peerVip - リモートサイトのロードバランサーの VIP adminPass:リモートサイトの暗号化された管理者パスワード。複数のエントリはコンマで区切られます。 scpTimeout:サイト間の SCP 転送障害を検出するために使用されるタイムアウト値 peerLoadBalancerNodes - リモートサイトのロードバランサーノードのノード IP アドレス。複数のエントリはコンマで区切られます。 peerBusinessLogicNodes - リモートサイトの JBoss ノードのノード IP アドレス。複数のエントリはコンマで区切られます。 peerDeviceMgtIps:リモートサイトのデバイス管理 IP アドレス。複数のエントリはコンマで区切られます。 |
{
"core": {
"peerVip": "10.155.90.210",
"adminPass": "ABCDE12345",
"scpTimeout": 120,
"peerLoadBalancerNodes": "10.155.90.211",
"peerBusinessLogicNodes": "10.155.90.211",
"peerDeviceMgtIps": "10.155.90.211"}
}
|
| MySQLの |
リモート・サイトのMySQLデータベースに関連する災害復旧構成 |
hasDedicatedDb - リモートサイトに専用データベースノードが含まれているかどうか peerVip - リモートサイトの MySQL ノードの VIP(通常ノードまたは専用データベースノード) peerNodes - リモートサイトの MySQL ノードのノード IP アドレス(通常のノードまたは専用 DB ノード)。複数のエントリはコンマで区切られます。 |
{ "mysql": {
"hasDedicatedDb": false,
"peerVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
| pgsqlの |
リモート サイトの PgSQL データベースに関連するディザスタ リカバリ構成 |
hasFmpm:リモート サイトに特殊な FMPM ノードが含まれているかどうか peerFmpmVip - リモート サイトの PostgreSQL ノード(通常のノードまたは FM/PM 専用ノード)の VIP peerNodes - リモート サイトの PostgreSQL ノード(通常のノードまたは FM/PM 専用ノード)のノード IP アドレス。複数のエントリはコンマで区切られます。 |
{ "psql": {
"hasFmpm": false,
"peerFmpmVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
| ファイル |
リモート・サイトでの構成およびRRDファイル関連の災害復旧構成 |
backup.maxCount:保持するバックアップファイルの最大数 backup.hoursOfDay:ファイルをバックアップする時刻 backup.daysOfWeek - ファイルをバックアップする曜日 restore.hoursOfDay:アクティブサイトからファイルをポーリングする時刻 restore.daysOfWeek - アクティブサイトからファイルをポーリングする曜日 |
{ "file": {
"backup": {
"maxCount": 3,
"hoursOfDay": "*",
"daysOfWeek": "*" },
"restore": {
"hoursOfDay": "*",
"daysOfWeek": "*" }
}
}
|
| 番犬 |
現在のサイトの災害復旧ウォッチドッグに関連する災害復旧構成 |
heartbeat.retries:ハートビートメッセージを再試行する回数 heartbeat.timeout:各ハートビートメッセージのタイムアウト(秒単位) heartbeat.interval - サイト間のハートビートメッセージの間隔(秒単位) notification.email – サービスの問題を報告するための連絡先メールアドレス notification.interval:影響を受けるサービスに関する電子メールの受信間隔を減衰させます。 failureDetection.isCustom:リモート サイトがカスタム障害検出を使用するかどうか failureDetection.script:障害検出スクリプトのパス failureDetection.threshold.failover–フェイルオーバーをトリガーするしきい値の割合 failureDetection.threshold.adjustManaged–管理対象デバイスの割合を調整するしきい値の割合 failureDetection.threshold.warning–ディザスタリカバリサイトがより多くの監視デバイスに到達できるように警告を送信し、デバイスアービトレーションアルゴリズムの精度を向上させるしきい値の割合 failureDetection.waitDuration- 両方のサイトがスタンバイ状態になったときに、元のアクティブサイトが再びアクティブになるための猶予期間 failureDetection.arbiters:監視デバイスのリスト |
{ "watchdog": {
"heartbeat": {
"retries": 4,
"timeout": 5,
"interval": 30 },
"notification": {
"email": "abc@example.com",
"interval": 3600 },
"failureDetection": {
"isCustom": false,
"script": "/var/cache/jmp-geo/watchdog/bin/arbitration",
"threshold": {
"failover": 0.5,
"adjustManaged": 0.5,
"warning": 0.7 },
"waitDuration": "8h",
"arbiters": [{
"username": "user1",
"password": "xxx",
"host": "10.155.69.114",
"port": 22,
"privateKey": ""
}]
}
}
}
|
| デバイス管理 |
リモート サイトのデバイス管理 IP アドレス |
peerNodes:リモートサイトのデバイス管理 IP アドレス。複数のエントリはコンマで区切られます。 ノード - 現在のサイトのデバイス管理 IP アドレス。複数のエントリはコンマで区切られます。 ip:このノード( |
{ "deviceManagement": {
"peerNodes": "10.155.90.211",
"nodes": "10.155.90.222",
”ip”: “10.155.90.228,eth0”
}
}
|
| 列国 |
現在のサイトでのディザスタリカバリウォッチドッグサービスのランタイム情報。ディザスタリカバリウォッチドッグがこのサイトで実行されていない場合、このセクションは使用できません。ディザスタリカバリウォッチドッグが停止した場合、このセクションの情報は古くなっています。 |
– |
{ "states": {
"arbiterMonitor": {
"progress": "idle",
"msg": {
"service": "arbiterMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:55+00:00"
},
"service": {}
}, |
"configMonitor": {
"progress": "idle",
"msg": {
"service": "configMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:15+00:00"
},"service": {}
},
|
|||
"fileMonitor": {
"progress": "idle",
"msg": {
"service": "fileMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:59+00:00"
},
"service": {}
},
|
|||
"heartbeat": {
"progress": "unknown",
"msg": {
"service": "heartbeat",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"localFailover": false
},
"time": "2015-07-18T22:17:49+00:00"
},
"service": {
"booting": false,
"bootEndTime": null,
"waitTime": null,
"automaticFailover": false,
"automaticFailoverEndTime": "2015-07-18T07:41:41+00:00"
}
},
|
|||
"mysqlMonitor": {
"progress": "idle",
"msg": {
"service": "mysqlMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:09+00:00"
},
"service": {}
},
|
|||
"pgsqlMonitor": {
"progress": "unknown",
"msg": {
"service": "pgsqlMonitor",
"description": "Master node pgsql in active or standby site maybe CRASHED. Pgsql replication is in bad status. Please manually check Postgresql-9.4 status.",
"state": false,
"force": false,
"progress": "unknown",
"payload": {
"code": 1098
},
"time": "2015-07-18T22:18:27+00:00"
},"service": {}
},
|
|||
"serviceMonitor": {
"progress": "running",
"msg": {
"service": "serviceMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:30+00:00"
},
"service": {}
}
}
} |
カスタム スクリプトからの出力は、スタンバイ サイトへのフェールオーバーが必要かどうかをディザスタ リカバリ ウォッチドッグに通知します。ディザスタリカバリウォッチドッグは、スクリプトからの出力をJSON形式で解釈します。次に例を示します。
{
"state": "active",
"action": "nothing",
"description": "",
"payload": {
"waitTime": "",
"details": {
"percentages": {
"connected": 1,
"arbiters": {
"10.155.69.114": "reachable"
}
}
}
}
}
表 2 は、スクリプト出力の詳細を示しています。
| 財産 |
形容 |
データ型 |
値または形式 |
その他の詳細 |
|---|---|---|---|---|
| 状態 |
このサイトの現在の災害復旧の役割 |
糸 |
能動 スタンバイ |
必須 空の文字列は許可されません。 |
| アクション |
災害復旧ウォッチドッグが実行する必要があるアクション |
糸 |
beActive - ロールを active に変更します。 beStandby - ロールをスタンバイに変更します。 nothing:ロールを変更しません。 wait - payload.waitTime プロパティで指定された時間だけ、現在のロールで待機します。 |
必須 空の文字列は許可されません。 |
| 形容 |
アクションフィールドの説明と、電子メール通知で送信されるメッセージ |
糸 |
– |
必須 空の文字列を使用できます。 |
| ペイロード.waitTime |
両方のサイトがスタンバイ状態になった猶予期間の終了時刻 |
文字列 (日付) |
YYYY-MM-DD、HTC 時刻 (HH:MM+00:00 形式) |
必須 空の文字列を使用できます。 このプロパティは、action の値を wait に指定した場合に使用されます。 |
| ペイロード.詳細 |
スクリプトのデバッグに使用できる、ユーザーがカスタマイズした情報 |
– |
JSON オブジェクト |
随意 空の文字列は許可されません。 |
ディザスタリカバリを設定する手順
アクティブ・サイトとスタンバイ・サイト間のディザスタ・リカバリを設定するには、次の手順に従います。
-
Junos Spaceネットワーク管理プラットフォーム リリース 15.2R1 にアップグレードする前に、以前のリリースで設定されたディザスタ リカバリ プロセスを停止してください。アップグレードプロセスの詳細については、 Junos Spaceネットワーク管理プラットフォームリリースノート15.2R1の「アップグレード手順」セクションを参照してください。
以前のリリースで設定された災害復旧プロセスの停止については、 Junos Spaceネットワーク管理プラットフォームリリース14.1R3以前での障害回復プロセスの停止を参照してください。
Junos Spaceネットワーク管理プラットフォーム リリース 15.2R1 のクリーン インストールでは、この手順を実行する必要はありません。
-
通知を受信するには、Junos Space のユーザー インターフェイスから両方のサイトで SMTP サーバーを設定します。詳細については、Junos Spaceネットワーク管理プラットフォームワークスペースユーザーガイドの SMTP サーバーの管理を参照してください。
-
監視デバイスのリスト(デバイスアービトレーションアルゴリズムを使用している場合)またはカスタム障害検出スクリプトを含むファイルを、アクティブサイトの適切な場所にコピーします。すべての監視デバイスがアクティブ・サイトで検出されていることを確認します。詳細については、Junos Spaceネットワーク管理プラットフォーム Workspaces ユーザー ガイドの「デバイス検出プロファイルの概要」を参照してください。
-
アクティブ・サイトで災害復旧構成ファイルを構成します。災害復旧の構成には、構成と RRD ファイルを同期するための SCP 設定、ハートビート設定、通知設定、および障害検出メカニズムが含まれます。
-
スタンバイ・サイトで災害復旧構成ファイルを構成します。ディザスタリカバリ設定には、設定とRRDファイルを同期するためのSCP設定、ハートビート設定、および通知設定が含まれています。
-
アクティブ・サイトから災害復旧プロセスを開始します。
詳細については、「 アクティブ サイトとスタンバイ サイト間のディザスタ リカバリ プロセスの設定」を参照してください。
災害復旧コマンド
表 3 に示す災害復旧コマンドを使用して、災害復旧サイトを構成および管理します。これらのコマンドは、サイトの VIP ノードで実行する必要があります。これらのコマンドで --help オプションを使用すると、詳細情報を表示できます。
| 命令 |
形容 |
オプション |
|---|---|---|
|
|
両方のサイトで災害復旧構成ファイルを初期化します。 コマンドでプロンプトされるパラメータの値を入力する必要があります。 データをレプリケートし、ディザスタリカバリサイト間でレプリケーションを監視するために必要なMySQLおよびPgSQLユーザーとパスワードを作成します。次のユーザーが作成されます。
|
|
|
|
||
|
|
両方のサイトでディザスタリカバリプロセスを開始します。 このコマンドは、アクティブ サイトの VIP ノードで実行する必要があります。アクティブサイトは、スタンバイサイトへのSSH接続を確立し、スタンバイサイトで このコマンドを実行すると、MySQL データベースと PgSQL データベースのレプリケーションと構成、およびスタンバイ サイトへの RRD ファイルのバックアップが開始されます。 次のコマンドを実行します。
|
|
|
|
||
|
|
コマンドをオプションなしで実行すると、コマンドは次のようになります。
以下の順番でコマンドを実行する必要があります。
このコマンドをローカル サイトの VIP ノードで実行して設定を変更し、リモート サイトの VIP ノードで実行して変更した設定を受け入れる必要があります。 |
これらのオプションを使用して、サイトのディザスタリカバリ設定を変更し、ピアサイトで変更を更新します。 |
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
ディザスタリカバリプロセスのステータスを確認します。 このコマンドは、MySQLおよびPgSQLデータベースがレプリケートされているかどうか、および構成ファイルとRRDファイルがバックアップされているかどうかをチェックし、災害復旧ウォッチドッグのステータスを検証してエラーを報告します。 |
– |
|
|
サイト間のディザスタリカバリプロセスを停止します。 このコマンドを実行すると、サイト間の MySQL および PgSQL データベースのレプリケーションと構成、および RRD ファイルのバックアップが停止されます。ディザスタリカバリデータファイルは削除されません。JBoss、OpenNMS、Apacheなどのサービスのステータスは変更されません。 |
– |
|
|
ディザスタリカバリプロセスを停止し、サイトからディザスタリカバリデータファイルを削除します。サイトは、スタンドアロン クラスタとしてサービスを開始します。 両方のサイトのVIPノードでこのコマンドを実行して、ディザスタリカバリプロセスを完全に停止し、両方のサイトからディザスタリカバリデータファイルを削除する必要があります。 |
– |
|
|
スタンバイ サイトに手動でフェールオーバーします。 このコマンドを実行すると、スタンバイサイトが新しいアクティブサイトになり、アクティブサイトが新しいスタンバイサイトになります。 |
|
|
|
||
|
|
指定した期間、スタンバイ・サイトへの自動フェイルオーバーを有効にするか、スタンバイ・サイトへの自動フェイルオーバーを無効にします。
手記:
このコマンドは、サイトで災害復旧ウォッチドッグがアクティブになっている場合にのみ実行できます。 |
|
|
|
||
|
|
ディザスタリカバリの設定とランタイム情報をJSON形式で表示します。 |
|
|
このコマンドをカスタム障害検出スクリプトに含めると、コマンドは障害回復ウォッチドッグサービスの障害復旧構成とステータスを取得し、スクリプト内のロジックを実行します。 |