複数の地理的冗長性を備えたJuniper BNG CUPSを使用する
細分化されたBNGモデルでは、コントロールプレーンは、多くのユーザープレーンとそれに関連付けられた加入者にサービスを提供します。細分化されたモデルにおけるコントロールプレーンの役割は、新しいユースケース、サービス、ネットワーク冗長性レベルを可能にします。このようなユースケースでは、コントロールプレーンに新たなレベルの冗長性が必要です。コントロールプレーンをKubernetesクラスターに支えられたクラウドに移動することで、こうした冗長性が可能になります。
Kubernetesは、ソリューションに拡張性、運用効率、信頼性をもたらします。Kubernetesクラウドのモジュール性により、クラスターアーキテクチャに比類のない冗長性を持たせることができます。しかし、どんなに冗長性の高いクラスターアーキテクチャであっても、特定の場所や地域を標的とした自然災害やサイバー攻撃の影響を受けやすくなります。複数の地域、複数のクラスターを設定することで、これらの影響を受けやすくなります。
図 1 は、複数の地域、複数のクラスターのセットアップの例を示しています。
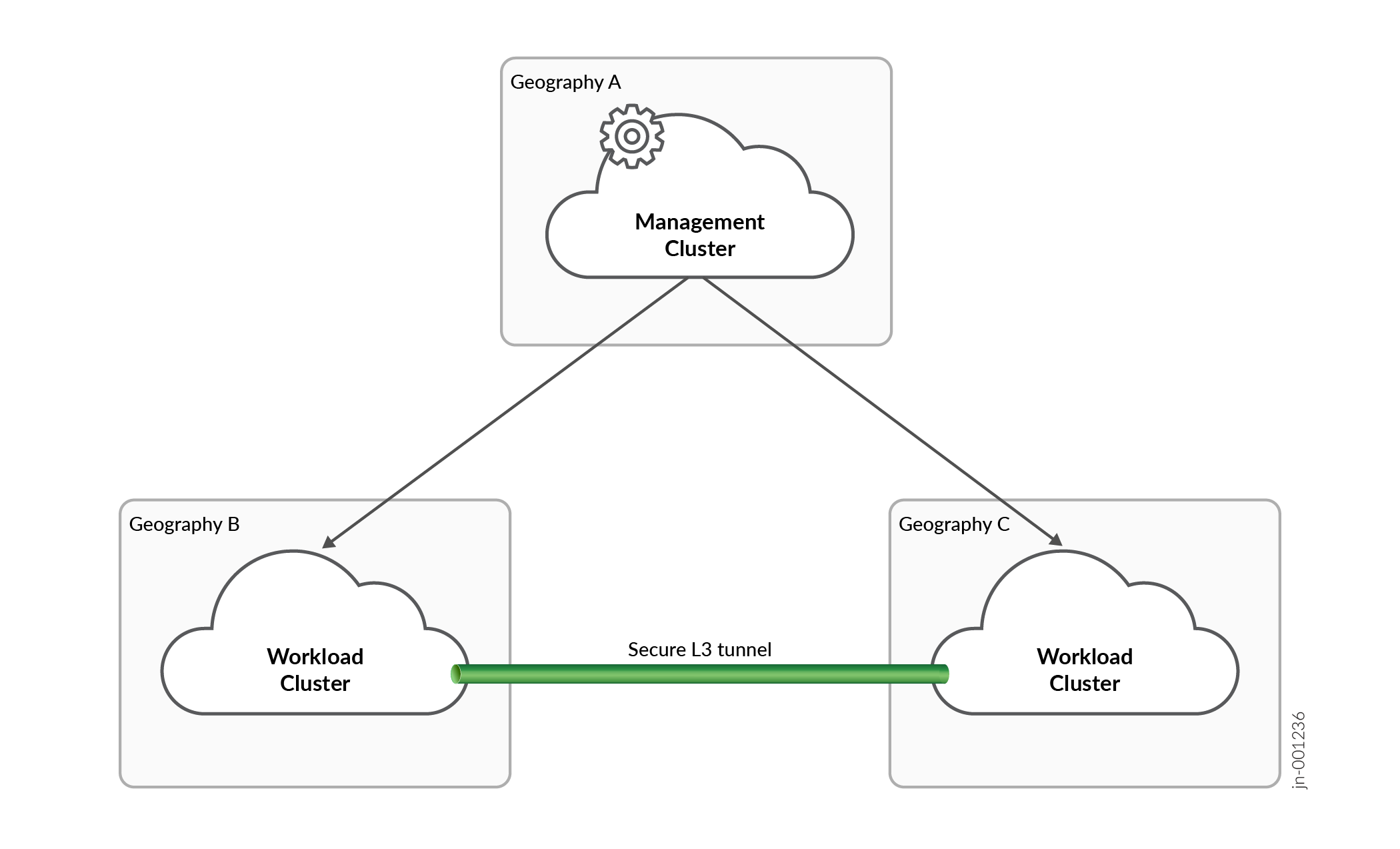
複数の地理的および複数のクラスターのセットアップでは、管理クラスターは、複数のクラスターのスケジューリングおよび監視機能を実行するための個別のコンテキストを保持し、両方のワークロードクラスターに接続されます。複数クラスターのコンテキストは、ワークロードクラスター間でアプリケーションを分散する方法をスケジューラに通知するポリシーエンジンによって駆動されます。複数の地理的冗長性のために複数クラスター設定を使用するアプリケーションには、状態レプリケーションに関連するアプリケーション マイクロサービスを両方のワークロード クラスターに分散するポリシー ルールがあります。その他のアプリケーション マイクロサービスは、プライマリ ワークロード クラスターとして選択された 1 つのワークロード クラスターに分散されます。
ワークロード クラスターは、Kubernetes REST API を介して管理クラスターからの作業を受け入れます。ワークロード クラスターは、標準の Kubernetes クラスターです。ワークロード クラスター間でセキュリティで保護された L3 トンネルが維持されます。トンネルにより、2 つのワークロード クラスター間でのアプリケーション状態の交換と一般的な通信が容易になります。標準の Kubernetes クラスターとして、ワークロード クラスターはポッドとデプロイを監視し、クラスター内のワーカー ノードのスケジューリング タスクを実行して、デプロイされたアプリケーション コンポーネントを維持します。ワークロード・クラスターは、アプリケーション・ワークロードを維持するために管理クラスターの存在を必要としません。アプリケーションがデプロイされると、アプリケーションのデプロイを維持するのはワークロード クラスターの責任です。
ワークロード クラスターに障害が発生したこと、またはアプリケーションのマイクロサービスをワークロード クラスターで適切にスケジュールできないことを管理クラスターが検出した場合、管理クラスターはスイッチオーバー イベントを駆動します。スイッチオーバー・アクションは、アプリケーションに定義されているポリシーによって制御されます。切り替えイベントでは、障害が発生したワークロード クラスターにのみ存在するアプリケーションのマイクロサービスは、他のワークロード クラスターに再デプロイされます。
BNG CUPS コントローラは、複数の地域、複数のクラスタ環境に導入できます。BNG コントローラーの Helm チャートには、管理クラスターの複数のクラスター コンテキストに、状態キャッシュ マイクロサービスのインスタンスを両方のワークロード クラスターにデプロイするように指示する伝達ポリシー ルールが含まれています。2 つの状態キャッシュインスタンスは、安全なトンネルを介して通信し、2 つの地域間の加入者の状態をミラーリングします。コントロール プレーン インスタンスは、1 つのワークロード クラスターにのみデプロイされます。コントロール プレーン インスタンスは、その状態をローカル状態キャッシュ インスタンスにミラーリングし、そのインスタンスは他のワークロード クラスター内の状態キャッシュ ピアにレプリケートされます。
図2 複数の地域、複数のクラスタ設定での BNG CUPS コントローラを示しています。
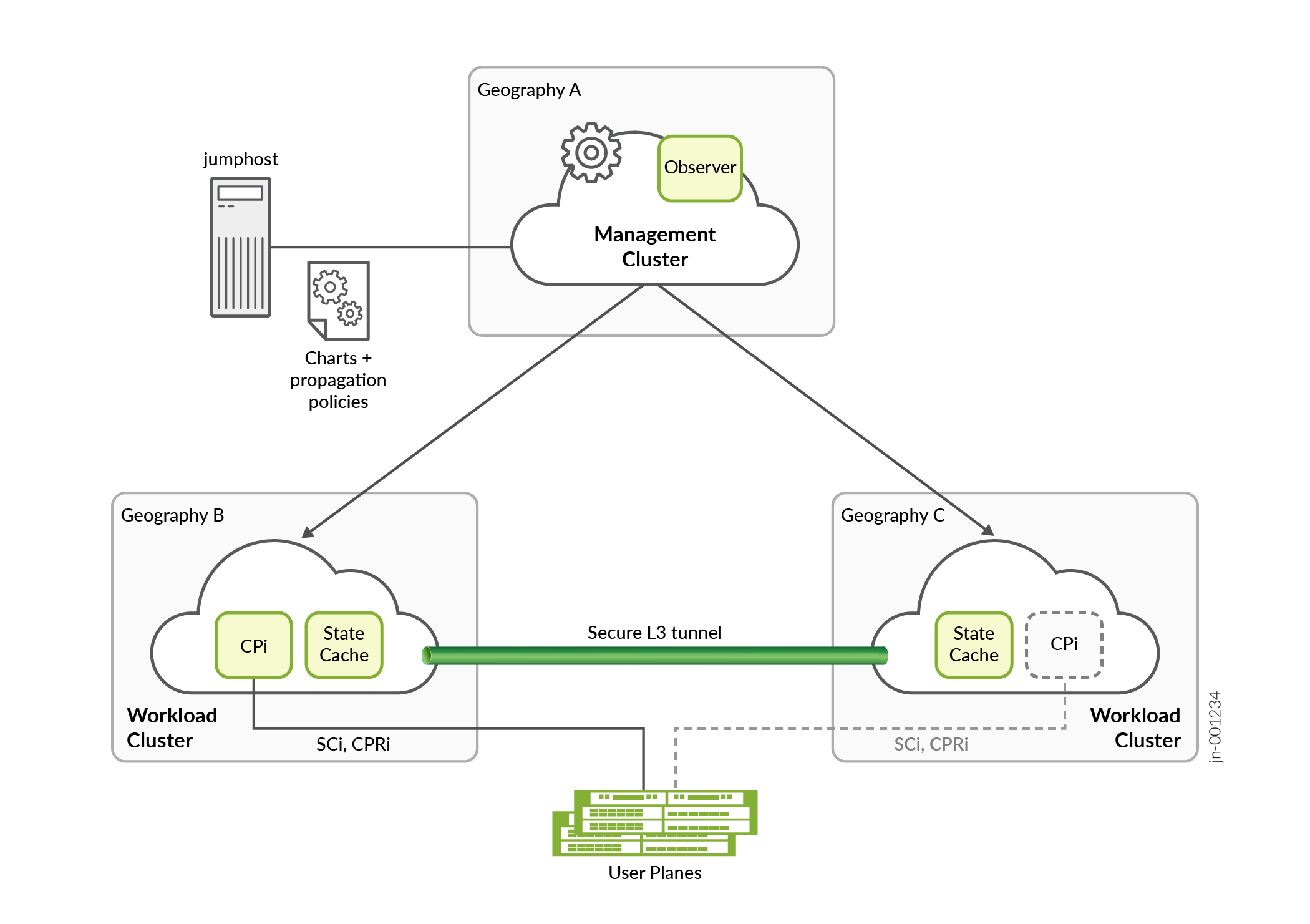 における BNG CUPS コントローラ
における BNG CUPS コントローラ
コントロール プレーン インスタンスがデプロイされているワークロード クラスターに障害が発生した場合、管理クラスターは他のワークロード クラスターでコントロール プレーン インスタンスを再スケジュールします。コントロール プレーン インスタンスが 2 番目のワークロード クラスターで初期化されると、レプリケートされた構成キャッシュ (図示せず) から構成が回復されます。また、コントロールプレーンインスタンスは、マイクロサービスの再起動時と同様に、ローカル状態キャッシュインスタンスからサブスクライバーの状態を回復します。ローカル状態キャッシュは、前のワークロード クラスターからレプリケーション状態情報を受け取ったため、すべての安定した状態が回復されます。状態が回復すると、コントロール プレーン インスタンスは BNG ユーザー プレーンとの関連付けを確立します。BNG ユーザ プレーン アソシエーション ロジックは、新しいアソシエーションが同じ BNG CUPS コントローラ(ただし、異なる地域)から発信されていることを検出します。
また、BNG CUPS コントローラは、オブザーバーと呼ばれるマイクロサービスを管理クラスタに展開します。オブザーバーは、管理クラスターの通常のコンテキストで実行され、複数のクラスター コンテキスト (管理クラスターに関連付けられている) でコントロール プレーン インスタンスのスケジューリング イベントを監視します。コントロール プレーン インスタンスが両方のワークロード クラスタに一時的に存在する可能性があるスイッチオーバーの状況では、オブザーバーは BNG CUPS コントローラで、どのコントロール プレーン インスタンスを実行する必要があるかのあいまいさを解決できます。
例えば、管理クラスターがワークロード・クラスターに到達またはモニターできなくなった場合、管理クラスターはワークロード・クラスターに障害が発生したと宣言します。管理クラスターは、障害が発生したワークロード・クラスターから他のワークロード・クラスターへのワークロードの切り替えを開始します。
障害が発生したワークロード クラスターが動作しているが、管理クラスターから到達できないシナリオでは、あいまいなデプロイが作成されます。アプリケーション ワークロードの複数のインスタンスが、両方のワークロード クラスターに存在します。管理クラスターは、複数クラスター展開でワークロードが実行される場所の最終的なアービターであるため、スイッチオーバーされたワークロードに従って、非アクティブまたは休止状態に移行できなかったと認識されたワークロードクラスター上の重複するワークロードを強制するメカニズムが必要です。
前述したように、オブザーバー マイクロサービスは管理クラスターで実行されます。オブザーバーは、アプリケーション ワークロードのスケジューリング イベントを監視します。ワークロード クラスターでアプリケーション ワークロードがスケジュールされるたびに、オブザーバーはそのワークロードに一意の世代番号を割り当てます。同じワークロードを他のワークロード クラスターに切り替えると、世代番号がインクリメントされます。アプリケーション ワークロードが初期化されると、オブザーバーに世代番号が要求されます。世代番号は、ワークロード・クラスター間で渡されます。障害が発生したワークロード・クラスター上のアプリケーション・ワークロードは、同じワークロードが他方のワークロード・クラスターでより高い世代番号を持つことに注意し、アプリケーションを休止状態に移行します (すべての接続がドロップされ、状態は生成または消費されません)。
世代番号は、管理クラスターが障害が発生したワークロード クラスターの実際の状態を表示できないことによって引き起こされるあいまいなデプロイを修正するのに役立ちます。障害が発生したワークロード クラスターに到達可能性が復元されると、管理クラスターは休止状態のアプリケーション ワークロードを削除します。
クラスタのスイッチオーバーが発生すると、BNG CUPS コントローラへの接続に使用される外部 IP アドレスのセットが、新しいワークロード クラスタで使用されるアドレス空間に変更されます。一部のバックオフィスアプリケーションは、IPアドレスの変更に敏感です。たとえば、RADIUSでは、NAS-IP-Addressの値がクラスタのスイッチオーバー間で一定に保たれることを望んでいます。
BNG CUPS コントローラは、MIRP(Multi-geo IP Route Prioritization Operator)と呼ばれるマイクロサービスを通じて、NAS-IP-Address の一貫した値をサポートします。Multi-geo IP Route Prioritization Operator は、各ワークロード クラスターにデプロイされるマイクロサービスです。
CPi が追加された場合、cpi add コマンドに ip-aaa external-radius-address オプションを追加することにより、CPi の RADIUS リスナー・アドレスに使用する永続的な外部アドレスを提供することができます。
CPi マイクロサービスがデプロイされると、構成された外部アドレスを含む MetalLB IP アドレスプールのカスタムリソースが作成されます。IP アドレス プールを参照するための MetalLB アノテーションを持つ RADIUS リスナー ポート用に、別のロード バランサー サービスが作成されます。これにより、一覧表示された外部アドレスがサービスに割り当てられます。
CPi の RADIUS ロード バランサー サービスが作成されるワークロード クラスターの Multi-geo IP Route Prioritization Operator は、BGP アドバタイズメント カスタム リソースを生成します。このリソースには、オブザーバーによって取得された CPi の世代番号から派生した LOCAL_PREF 値が含まれています (クラスター切り替えイベントが観察されると、世代番号はオブザーバーによってインクリメントされます)。BGP広告は、ネットワーク・ロード・バランサのIBGPピアと交換されます。バックオフィスシステム(この場合はRADIUS)は、IBGPピアの背後にあります。CPi が他のワークロード・クラスターに切り替わると、その世代番号が増加します。Multi-Geo IP Route Prioritization Operator-generated BGP advertisement の関連する LOCAL_PREF 値もインクリメントされます。サービスの外部IPアドレスに向かうトラフィックは、CPi のアクティブなワークロード・クラスターでもある、 LOCAL_PREF 値が高いクラスターにルーティングされます。