グラフ
グラフの概要
Apstraは、グラフモデルを使用して、インフラストラクチャ、ポリシー、制約などに関する信頼できる単一の情報源を表します。このグラフモデルは絶えず変更される可能性があり、さまざまな理由でクエリを実行できます。グラフで表されます。ネットワークに関するすべての情報は、ノードおよびノード間の関係としてモデル化されます。
グラフ内のすべてのオブジェクトには一意の ID があります。ノードには、型 (文字列) と、特定の型に基づく一連の追加プロパティがあります。たとえば、システム内のすべてのスイッチは、システムタイプのノードで表され、ネットワーク内で割り当てられている役割(スパイン/リーフ/サーバー)を決定するプロパティロールを持つことができます。物理および論理スイッチポートは、if_typeと呼ばれるプロパティを持つインターフェイスノードによって表されます。
異なるノード間の関係は、関係と呼ばれるグラフエッジとして表されます。リレーションシップは有向型であり、各リレーションシップにはソース ノードとターゲット ノードがあります。リレーションシップには、特定のリレーションシップが持つことができる追加のプロパティを決定する型もあります。たとえば、システムノードには、インターフェイスノードに対してhosted_interfacesタイプの関係があります。
使用可能なノードと関係の種類のセットは、グラフ スキーマによって決定されます。スキーマは、特定の型のノードとリレーションシップが持つことができるプロパティと、それらのプロパティの型 (文字列/整数/ブール値など) と制約を定義します。私たちは、値型の柔軟なカスタマイズを可能にするオープンソースのスキーマライブラリLollipopを使用および維持しています。
信頼できる唯一の情報源を表すグラフに戻ると、最も困難な側面の1つは、オペレーターと管理対象システムの両方から生じる変更が存在する場合に、それについてどのように推論するかということでした。これをサポートするために、3つの重要なコンポーネントを持つライブクエリメカニズムと呼ばれるものを開発しました。
- クエリ仕様
- 変更通知
- 通知処理
ドメインモデルをグラフとしてモデル化すると、グラフクエリで指定されたグラフで検索を実行して、グラフ内の特定のパターン(サブグラフ)を見つけることができます。クエリを表現する言語は、概念的には、オープンソースのグラフ探索言語である Gremlin に基づいています。また、別の言語で表現されたクエリ用のパーサーもあります-一般的なグラフデータベースneo4jで使用されるクエリ言語であるCypher。
クエリ仕様
node()から始めて、一致する関係とノードを交互に繰り返しながらメソッド呼び出しを連鎖し続けます。
node('system', name='system').out().node('interface', name='interface').out().node('link', name='link')
上記の英語に翻訳されたクエリは、システム型のノードから開始して、インターフェイス型のノードに到達する発信関係をトラバースし、そのノードから型 'linkのノードにつながるすべての発信関係をトラバースします。
任意の時点で、制約を追加できます。
node('system', role='spine', name='system').out().node('interface', if_type='ip', name='interface')
role='spine' 引数に注目すると、role プロパティが spine に設定されているシステムノードのみが選択されます。
インタフェースノードのif_typeプロパティと同じです。
node('system', role=is_in(['spine', 'leaf']), name='system')
.out()
.node('interface', if_type=ne('ip'), name='interface')
このクエリは、スパインまたはリーフのいずれかの役割を持つすべてのシステムノードと、ip以外のif_typeを持つインターフェイスノードを選択します(neは等しくないことを意味します)。
任意のPython関数であるクロスオブジェクト条件を追加することもできます。
node('system', name='system')
.out().node('interface', name='if1')
.out().node('link')
.in_().node('interface', name='if2')
.in_().node('system', name='remote_system')
.where(lambda if1, if2: if1.if_type != if2.if_type)
オブジェクトに名前を付けて参照し、それらの名前を制約関数の引数名として使用します(もちろん、それをオーバーライドすることもできますが、便利なデフォルトの動作になります)。したがって、上記の例では、if1とif2という名前の2つのインターフェイスノードを取り、それらを指定されたwhere関数に渡し、それらのパスを除外し、関数がFalseを返します。制約を配置する場所を気にしないでください:制約によって参照されるすべてのオブジェクトが使用可能になるとすぐに検索中に適用されます。
これで、パスが 1 つになり、それを使用して検索を実行できます。ただし、単一のパスよりも複雑なクエリが必要な場合があります。これをサポートするために、クエリ DSL では、同じクエリ内で複数のパスをコンマで区切って定義できます。
match(
node('a').out().node('b', name='b').out().node('c'),
node(name='b').out().node('d'),
)
この match() 関数は、パスのグループを作成します。異なるパスで同じ名前を共有するすべてのオブジェクトは、実際には同じオブジェクトを参照します。また、 match() を使用してオブジェクト where()にさらに制約を追加できます。特定のオブジェクトに対して個別の検索を行うことができ、値の各組み合わせが結果に一度だけ表示されるようになります。
match(
node('a', name='a').out().node('b').out().node('c', name='c')
).distinct(['a', 'c'])
これは、a -> b -> c ノードのチェーンと一致します。2 つのノード a と c がタイプ b の複数のノードを介して接続されている場合、結果には 1 つの (a, c) ペアのみが含まれます。
クエリを記述するときに使用する別の便利なパターンがあります: 構造を条件から分離します。
match(
node('a', name='a').out().node('b').out().node('c', name='c'),
node('a', foo='bar'),
node('c', bar=123),
)
クエリ エンジンは、そのクエリを次のように最適化します。
match(
node('a', name='a', foo='bar')
.out().node('b')
.out().node('c', name='c', bar=123)
)
デカルト積も不要なステップもありません。
変更通知
これでグラフクエリが定義されました。通知結果はどのように表示されますか?各結果は、クエリ オブジェクトに対して定義した名前を見つかったオブジェクトにマッピングするディクショナリになります。例:次のクエリの場合
node('a', name='a').out().node('b').out().node('c', name='c')
結果は次のようになります {'a': <node type='a'>, 'c': <node type='c'>}。名前付きオブジェクトのみが存在することに注意してください( <node type='b'> 名前がないため、そのノードはクエリに存在しますが、結果にはありません)。
監視するクエリと、何かが変更される場合に実行するコールバックを登録します。後で誰かが監視対象のグラフを変更すると、新しいグラフの更新によって新しいクエリ結果が表示されたり、古い結果が消えたり更新されたりしたことが検出されます。応答は、クエリに関連付けられているコールバックを実行します。コールバックは、クエリからパス全体を応答として受け取り、実行する特定のアクション (追加/更新/削除) を受け取ります。
通知処理
結果が処理 (コールバック) 関数に渡されると、そこから推論ロジックを指定することができます。これは、ログやエラーの生成から、構成のレンダリング、セマンティック検証の実行まで、実際には何でもかまいません。グラフAPIを使用してグラフ自体を変更することもでき、他のロジックが行った変更に反応する場合があります。このようにして、グラフを信頼できる唯一の情報源として強制すると同時に、アプリケーションロジックの部分間の論理的な通信チャネルとしても機能させることができます。グラフ API は、次の 3 つの部分で構成されます。
グラフ管理 - グラフ内のものを追加/更新/削除するメソッド。add_node()、 、 、 、 、 、 set_relationship()del_relationship()、 、 get_node()get_relationship()commit() del_node()add_relationship()set_node()クエリget_nodes()get_relationships()監視可能なインターフェイスadd_observer(),remove_observer()
グラフ管理 API は一目瞭然です。 add_node() 新しいノードの作成、既存のノードのプロパティの更新、 set_node() および del_node() ノードの削除を行います。
commit() は、グラフに対するすべての更新が完了し、すべてのリスナーに伝達できることを通知するために使用されます。
リレーションシップにも同様の API があります。
監視可能インターフェイスを使用すると、オブザーバー (コールバック インターフェイスの通知を実装するオブジェクト) を追加/削除できます。通知コールバックは、次の 3 つのメソッドで構成されます。
on_node()- ノード/リレーションシップが追加、削除、または更新されたときに呼び出されますon_relationship()- ノード/リレーションシップが追加、削除、または更新されたときに呼び出されますon_graph()- グラフがコミットされたときに呼び出されます
クエリ API はグラフ API の中心であり、すべての検索を強化するものです。両方 get_nodes() および get_relationships() グラフ内の対応するオブジェクトを検索できます。これらの関数の引数は、検索されたオブジェクトに対する制約です。
たとえば get_nodes() 、グラフ内のすべてのノードを返し、すべてのシステムノードを返し、 get_nodes(type='system') get_nodes(type='system', role='spine') 返されたノードを特定のプロパティ値を持つノードに制限できます。各引数の値は、プレーン値または特別なプロパティ matcher オブジェクトのいずれかです。値がプレーン値の場合、対応する結果オブジェクトのプロパティは、指定されたプレーン値と等しくなければなりません。プロパティマッチャーを使用すると、より複雑な基準、たとえば、等しくない、より小さい、指定された値の1つなどを表すことができます。
以下の例は、Graph Python を直接使用するためのものです。デモンストレーションの目的で、graph.get_nodes を Graph エクスプローラーのノードに置き換えることができます。この特定の例は、Apstra GUIでは機能しません。
graph.get_nodes(
type='system',
role=is_in(['spine', 'leaf']),
system_id=not_none(),
)
グラフスキーマでは、特定のノード/関係タイプとメソッド get_nodes() のカスタムインデックスを定義し、 get_relationships() 渡された制約の特定の組み合わせごとに最適なインデックスを選択して、検索時間を最小限に抑えることができます。
/get_relationships() の結果get_nodes()は特別なイテレータオブジェクトです。それらを反復処理すると、見つかったすべてのグラフオブジェクトが生成されます。これらの反復子が提供する API を使用して、これらの結果セットをナビゲートすることもできます。たとえばget_nodes()、メソッドout()とin_().これらを使用して、元の結果セットの各ノードからすべての発信または受信リレーションシップの反復子を取得できます。次に、それらを使用して、それらのリレーションシップのもう一方の端にあるノードを取得し、そこから続行できます。これらのメソッドにプロパティ制約を渡す方法は、 や get_nodes() get_relationships()に対して行うのと同じ方法で行うことができます。
graph.get_nodes('system', role='spine') \
.out('interface').node('interface', if_type='loopback')
上記の例のコードでは、system 型とロール spine を持つすべてのノードを検索し、それらのループバック インターフェイスをすべて検索します。
すべてをまとめる
以下のクエリーは、Apstraがテレメトリの期待値(リンクやインターフェイスのステータスなど)を導き出すために使用できる内部ルールの例です。@ruleはprocess_spine_leaf_linkへのコールバックを挿入し、その場合はテレメトリの期待値に書き込みます。
@rule(match(
node('system', name='spine_device', role='spine')
.out('hosted_interfaces')
.node('interface', name='spine_if')
.out('link')
.node('link', name='link')
.in_('link')
.node('interface', name='leaf_if')
.in_('hosted_interfaces')
.node('system', name='leaf_device', role='leaf')
))
def process_spine_leaf_link(self, path, action):
"""
Process link between spine and leaf
"""
spine = path['spine_device']
leaf = path['leaf_device']
if action in ['added', 'updated']:
# do something with added/updated link
pass
else:
# do something about removed link
pass
便利な機能
グラフクエリの作成時に複雑な where() 句を作成しないようにするには、Apstra GUIから利用できる便利な関数を使用します。
-
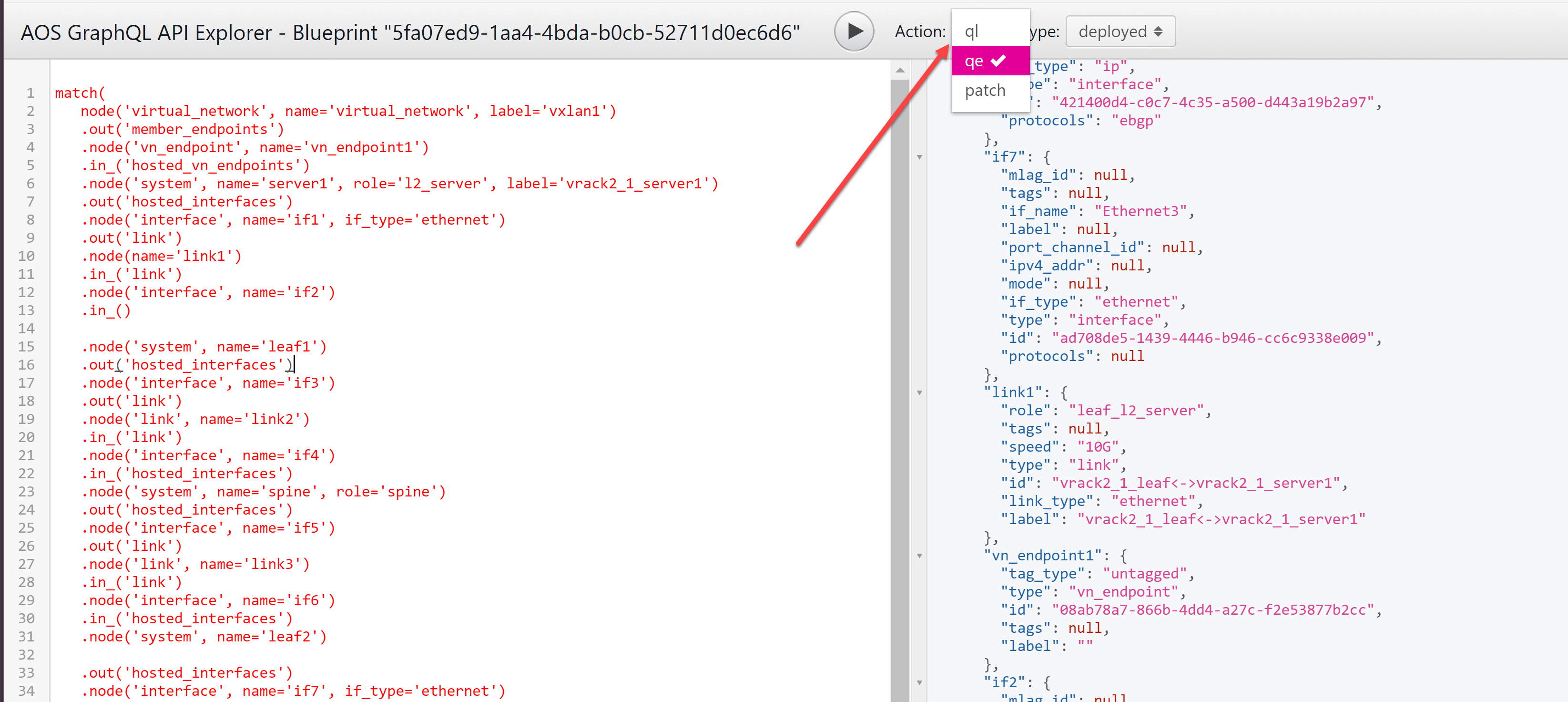
ブループリントから [ステージング] ビューまたは [アクティブ] ビューに移動し、[GraphQL API エクスプローラー] ボタン (右上の >_) をクリックします。グラフエクスプローラが新しいタブで開きます。
-
左側にグラフクエリを入力します。以下の関数の説明を参照してください。
-
アクション ドロップダウン リストから、qe を選択します。
-
[ クエリの実行 ] ボタン (再生ボタンのように見えます) をクリックして、結果を表示します。
関数
クエリ エンジンには、いくつかの便利な関数が記述されています。
一致(*path_queries)
この関数は、 QueryBuilder 一致したクエリの各結果を含むオブジェクトを返します。これは通常、複数の一致クエリをグループ化するための便利なショートカットです。
これらの2つのクエリは、一緒に「パス」ではありません(意図された関係はありません)。引数を区切るコンマに注目してください。このクエリは、すべてのリーフ デバイスとスパイン デバイスをまとめて返します。
match(
node('system', name='leaf', role='leaf'),
node('system', name='spine', role='spine'),
)
node(self, type=None, name=None, id=None, **properties)
- パラメーター
- タイプ (str またはなし) - 検索するノードのタイプ
- name (str または None) - 結果のプロパティ マッチャーの名前を設定します。
- id (str またはなし) - グラフ内のノード ID で特定のノードを照合します。
- properties (dict または None) - 使用する追加のキーワード引数または追加のプロパティマッチャーコンビニエンス関数
- 戻り値 - クエリをチェーンするためのクエリビルダーオブジェクト
- 戻り値の型 - クエリ ビルダー
どちらも関数ですが、これは PathQueryBuilder ノードのエイリアスです -- 以下を参照してください。
反復()
- 戻り値 - ジェネレータ
- 戻り値の型: 発電機
Iterateは、個々のパスクエリをリストであるかのように反復するために使用できるジェネレーター関数を提供します。例えば:
def find_router_facing_systems_and_intfs(graph):
return q.iterate(graph, q.match(
q.node('link', role='to_external_router')
.in_('link')
.node('interface', name='interface')
.in_('hosted_interfaces')
.node('system', name='system')
))
パスクエリビルダーノード
node(self, type=None, name=None, id=None, **properties)
この関数は特定のグラフ ノードを記述しますが、特定のノードからパス クエリを開始するためのショートカットでもあります。呼び出しの結果 `node() は、パス クエリ オブジェクトを返します。パスを照会するときは、通常、ノード 'type'を指定します:たとえば node('system') 、システムノードを返します。
- パラメーター
- タイプ (str またはなし) - 検索するノードのタイプ
- name (str または None) - 結果のプロパティ マッチャーの名前を設定します。
- id (str またはなし) - グラフ内のノード ID で特定のノードを照合します。
- properties (dict または None) - 使用する追加のキーワード引数または追加のプロパティマッチャーコンビニエンス関数
- 戻り値 - クエリをチェーンするためのクエリビルダーオブジェクト
- 戻り値の型 - クエリ ビルダー
クエリ結果でノードを使用する場合は、--node('system', name='device') という名前を付ける必要があります。さらに、特定のkwargプロパティを一致させる場合は、一致要件を直接指定できます。
node('system', name='device', role='leaf')
node('system', name='device', role='leaf')
out(type=None、id=None、name=None、**properties)
グラフスキーマに従って「外」方向に関係をトラバースします。使用できるパラメーターは、リレーションシップの種類 (インターフェイスなど)、リレーションシップの特定名、リレーションシップの ID、またはキーワード引数として指定されたものと完全に一致する必要があるその他のプロパティの一致です。
- パラメーター
- type (str またはなし) - 検索するノード関係のタイプ
- id (str またはなし) - グラフ内の関係 ID によって特定の関係を照合します。
- name (str または None) - 名前付きリレーションシップによって特定のリレーションシップを照合します。
例えば:
node('system', name='system') \
.out('hosted_interfaces')
in_(型 = なし、ID = なし、名前 = なし、**プロパティ)
リレーションシップを 'in' 方向にトラバースします。現在のノードをリレーションシップのソース ノードに設定します。使用できるパラメーターは、リレーションシップの種類 (インターフェイスなど)、リレーションシップの特定名、リレーションシップの ID、またはキーワード引数として指定されたものと完全に一致する必要があるその他のプロパティの一致です。
- パラメーター
- type (str またはなし) - 検索するノード関係のタイプ
- id (str またはなし) - グラフ内の関係 ID によって特定の関係を照合します。
- name (str または None) - 名前付きリレーションシップによって特定のリレーションシップを照合します。
- プロパティ (dict またはなし) - 任意の kwargs または関数によってリレーションシップを照合します。
node('interface', name='interface') \
.in_('hosted_interfaces')
ここで(述語、名前=なし)
グラフ結果に対するコールバック関数をフィルターまたは制約として指定できます。述語は、クエリ結果全体に対して実行されるコールバック (通常はラムダ関数) です。 where() は、パス クエリ結果で直接使用できます。
- パラメーター
- 述語 (コールバック) - グラフ内のすべてのノードに対して実行するコールバック関数
- names (str または None) - 名前が指定されている場合、それらは一致のためにコールバック関数に渡されます
node('system', name='system') \
.where(lambda system: system.role in ('leaf', 'spine'))
enure_different(*名前)
グラフ内の 2 つの異なる名前付きノードが同じでないことをユーザーが確認できるようにします。これは、双方向である可能性があり、独自のソースノードで一致する可能性のある関係に役立ちます。次のクエリについて考えてみます。
- パラメーター
- names (タプルまたはリスト) - グラフから異なるノードまたはリレーションシップを返すための名前のリスト
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.ensure_different('interface', 'remote_interface')
最後の行は、ラムダコールバック関数を持つ関数と where() 機能的に同等にすることができます
match(node('system', name='system', role='leaf') \
.out('hosted_interfaces') \
.node('interface', name='interface', ipv4_addr=not_none()) \
.out('link') \
.node('link', name='link') \
.in_('link') \
.node('interface', name='remote_interface', ipv4_addr=not_none())) \
.where(lambda interface, remote_interface: interface != remote_interface)
プロパティマッチャー
プロパティの一致は、グラフクエリオブジェクトで直接実行できます - 通常は関数内で node() 使用されます。プロパティの一致により、いくつかの関数を使用できます。
等価(値)
ノードのプロパティ値が関数の結果 eq(value) と正確に一致するようにします。
- パラメーター
- value - 等価性のために照合するプロパティ
node('system', name='system', role=eq('leaf'))
これは、単にノードオブジェクトのkwargとして値を設定するのと似ています。
node('system', name='system', role='leaf')
node('system', name='system').where(lambda system: system.role == 'leaf')
返します:
{
"count": 4,
"items": [
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf1",
"label": "l2_virtual_mlag_2_leaf1",
"system_id": "000C29EE8EBE",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "391598de-c2c7-4cd7-acdd-7611cb097b5e"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-2-leaf2",
"label": "l2_virtual_mlag_2_leaf2",
"system_id": "000C29D62A69",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "7f286634-fbd1-43b3-9aed-159f1e0e6abb"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf2",
"label": "l2_virtual_mlag_1_leaf2",
"system_id": "000C29CFDEAF",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "b9ad6921-6ce3-4d05-a5c7-c31d96785045"
}
},
{
"system": {
"tags": null,
"hostname": "l2-virtual-mlag-1-leaf1",
"label": "l2_virtual_mlag_1_leaf1",
"system_id": "000C297823FD",
"system_type": "switch",
"deploy_mode": "deploy",
"position": null,
"role": "leaf",
"type": "system",
"id": "71bbd11c-ed0f-4a38-842f-341781c01c24"
}
}
]
}
ne(値)
等しくない。ノードのプロパティ値が関数の結果 ne(value) と一致しないことを確認します。
- パラメーター
- value - 不等式条件に対して保証する値
node('system', name='system', role=ne('spine'))
に似ている:
node('system', name='system').where(lambda system: system != 'spine')
gt(値)
より大きい。ノードのプロパティが関数の結果 gt(value) よりも大きいことを確認します。
- パラメーター
- value - プロパティ関数がこの値より大きいことを確認します
node('vn_instance', name='vlan', vlan_id=gt(200))
ge(値)
より大きいか等しい。ノードのプロパティが の結果 ge()以上であることを確認します。
- パラメーター: value - プロパティ関数がこの値以上であることを確認します
node('vn_instance', name='vlan', vlan_id=ge(200))
lt(値)
未満。ノードのプロパティが の結果 lt(value)より小さいことを確認します。
- パラメーター
- value - プロパティ関数がこの値より小さいことを確認します
node('vn_instance', name='vlan', vlan_id=lt(200))
に似ている:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id <= 200)
le(値)
より小さいか等しい。プロパティが関数の結果 le(value) 以下であることを確認します。
- パラメーター
- value - 指定された値がプロパティ関数以下であることを保証します。
node('vn_instance', name='vlan', vlan_id=le(200))
に似ている:
node('vn_instance', name='vlan').where(lambda vlan: vlan.vlan_id < 200)
is_in(値)
(リスト)にあります。プロパティがアイテム is_in(value)を含む特定のリストまたはセットにあるかどうかを確認します。
- パラメーター
- 値 (リスト) - 指定されたプロパティがこのリストにあることを確認します
node('system', name='system', role=is_in(['leaf', 'spine']))
に似ている:
node('system', name='system').where(lambda system: system.role in ['leaf', 'spine'])
not_in(値)
(リスト)にありません。プロパティがアイテム not_in(value)を含む特定のリストまたはセットに含まれていないかどうかを確認します。
- パラメーター
- 値 (リスト) - プロパティ マッチャーが入っていないことを確認するためのリスト値
node('system', name='system', role=not_in(['leaf', 'spine']))
に似ている:
node('system', name='system').where(lambda system: system.role not in ['leaf', 'spine'])
is_none()
この特定の属性が具体的に Noneであることを予期するクエリis_none であることを期待するクエリ。
node('interface', name='interface', ipv4_addr=is_none()
に似ている:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is None)
not_none()
この属性に値があることを想定するマッチャー。
node('interface', name='interface', ipv4_addr=not_none()
に似ている:
node('interface', name='interface').where(lambda interface: interface.ipv4_addr is not None)
Apstraグラフデータストア
Apstraグラフデータストアは、インメモリグラフデータベースです。ログ ファイルのサイズは、ブループリントの変更がコミットされたときに定期的にチェックされます。グラフ データストアが 100 MB 以上に達すると、新しいグラフ データストア チェックポイント ファイルが生成されます。データベース自体は、グラフデータストアの永続性ログやチェックポイントファイルを削除しません。Apstraは、メインのグラフデータストア用のクリーンアップツールを提供します。
有効なグラフデータストア永続性ファイルグループには、 、 、 log-validcheckpointの checkpoint-valid4 つのファイルlogが含まれます。有効なファイルは、ログ ファイルとチェックポイント ファイルの有効なインジケーターです。各永続ファイルの名前には、ベース名、ID、および拡張子の 3 つの部分があります。
# regex for sysdb persistence files. # e.g. # _Main-0000000059ba612e-00017938-checkpoint-valid # \--/ \-----------------------/ \--------------/ # basename id extension
- BaseName - メイン グラフ データストアのパーティション名から派生します。
- id - getTimeofday から取得した UNIX タイムスタンプ。タイムスタンプの秒とマイクロ秒は「-」で区切られます。永続化ファイル グループは id で識別できます。タイムスタンプは、永続化ファイル・グループの生成された時間シーケンスを判別するのにも役立ちます。
- 拡張子 -
log、 、 、log-validcheckpointまたはcheckpoint-valid.