CRPD ベースのルートサーバーを使用する
この章では、cRPD インスタンスまたはインスタンスをルートサーバーとして使用する際の特別な構成に関するいくつかの考慮事項について説明します。
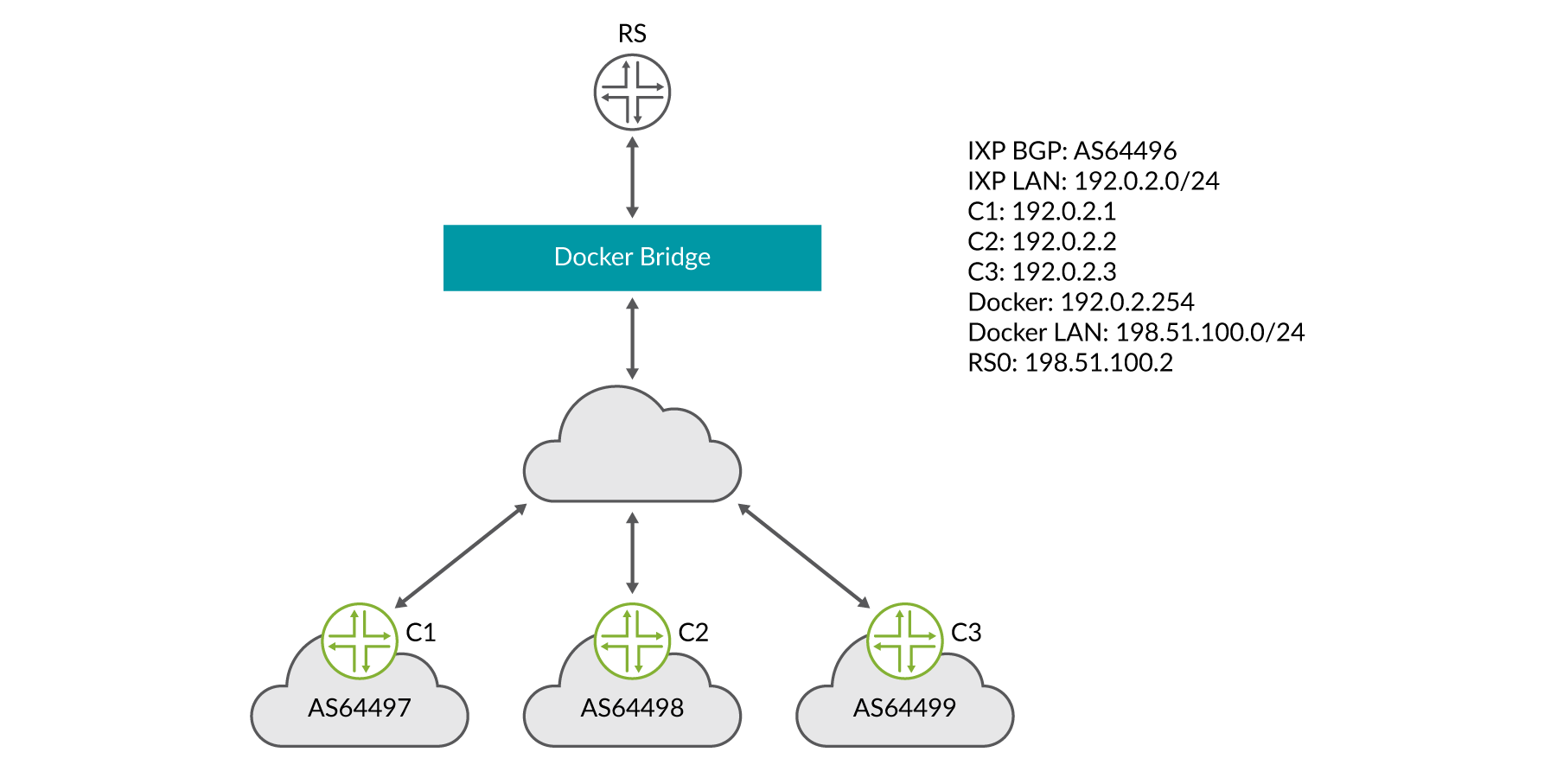
次の例では、以下の属性を使用します。
Docker ブリッジ IP サブネットは 198.51.100.0/24
IXP LAN サブネットは 192.0.2.0/24
ルーターサーバーには、IXP LAN 上の192.0.2.254 の IP アドレスが割り当てられています。
IXP BGP is 100
この導入事例に関する特別な考慮事項は次のとおりです。
EBGP クライアントは、IXP LAN とは異なる IP サブネット上にあるため、EBGP セッションはマルチホップでなければなりません。これは、コンテナーが Docker ブリッジサブネット上で実行されていることが原因です。
’Crpd を使用している場合、インターフェイスを構成する必要はありません。インターフェイスアドレスは Docker コンテナから読み取られます。
ルートサーバーのローカルアドレスの例:
root@rs0> show interfaces routing
Interface State Addresses
eth0.0 Up MPLS enabled
ISO enabled
INET 198.51.100.2
lo.0 Up MPLS enabled
ISO enabled
INET 127.0.0.1
CRPD ルート-サーバー構成の例:
IXP クライアントルーターの構成:
この例’では、実際のネットワークで運用ルートサーバーを使用して、クライアントルーターのピアリングに設定するすべてを網羅しているわけではないことに注意してください。IXP 運用に含まれる Junos OS を実行しているクライアントデバイスで構成する必要があるものの好例を以下に示します。https://www.ams-ix.net/ams/documentation/config-guide.
データと制御プレーンの同期
IXP Lan の問題としては、ルートサーバーが IXP メンバークライアント間のデータプレーンでアクティブになってい’ないことが挙げられます。そのため、ルートサーバーとの ebgp セッションが終了している間、クライアント間でデータプレーンを停止させることができます。ご想像のとおり、これによって blackhole –のレイヤー3が作成され、宛先が到達可能であることがわかっ“た”ため、クライアントがトラフィックを送信している間、レイヤー2回線がダウンしていることになります。
BFD (https://datatracker.ietf.org/doc/draft-ietf-idr-rs-bfd/) に関するこの問題を解決するために、IETF で作業が行われています。
前述のドラフト状態の概要は以下のとおりです。
BGP ルートサーバーを使用している場合、データプレーンは制御プレーンと合致していません。したがって、インターネット交換では、制御プレーンが認識されずにデータ接続が失われる可能性があり、パケットが失われることがあります。このドキュメントでは、新たに定義された BGP 後続のアドレスファミリ識別子 (SAFI) を使用して、ルートサーバーが BFD を使用してデータプレーンの接続’をピアアドレスに追跡し、クライアントがその接続状態をルートサーバーに通知するように要求することができます。
本書の執筆時点では、このドラフトの実装や相互運用は一般的ではありません。HealthBot などの外部アプリケーションは、IETF ドラフトで提案されているネイティブ BGP 拡張機能の代わりとして、この問題を発見して緩和できます。
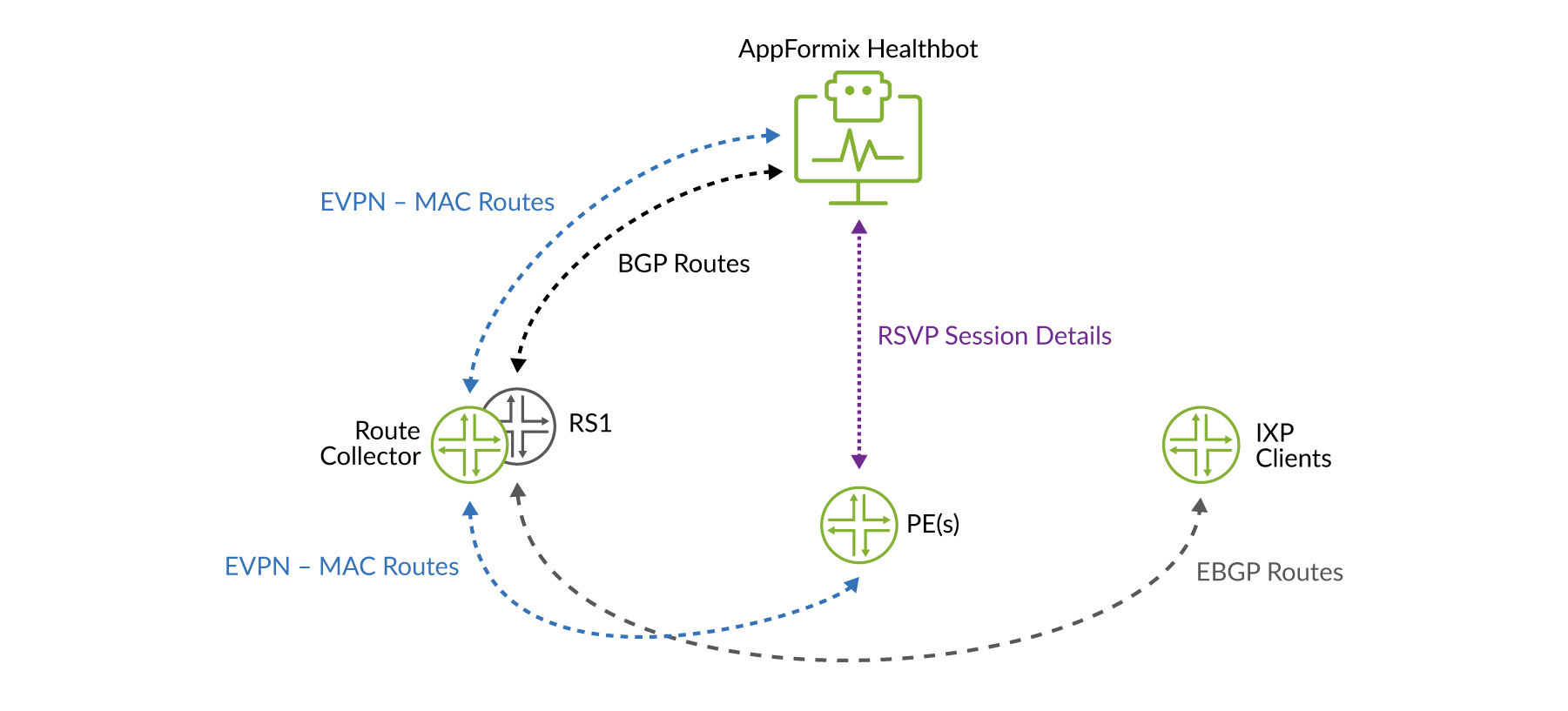
HealthBot のソリューション
HealthBot ソリューションは、データの複数の部分を関連付け、条件を検知することで最初に機能します。HealthBot は、以下のデータを収集および受信します。
ルートサーバーからの EBGP 次ホップ
ルートコレクターからの EVPN MAC ルート
PE ルーター間のデータプレーン OAM 統計
イベントを修正するには、HealthBot は簡単ではありませんが、 Figure 2以下のとおりです。
それに応じてインスタンスインポートポリシーを変更することで影響を受けるルートサーバークライアント間でのみルートの配信を制限します。
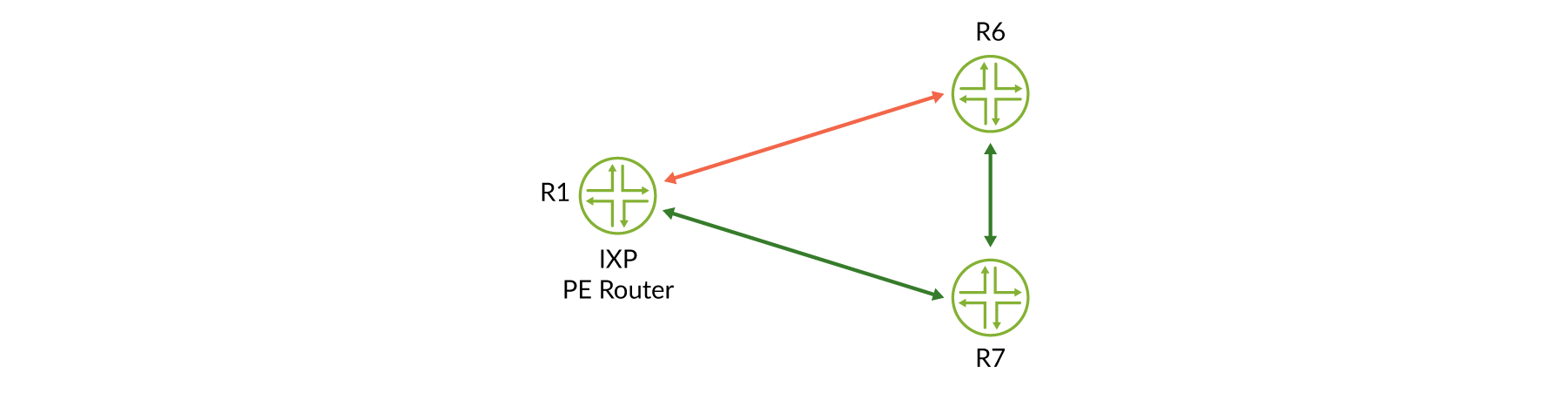
では’、実際の例を見てみましょう。のFigure 3サンプルトポロジについて考えてみましょう。
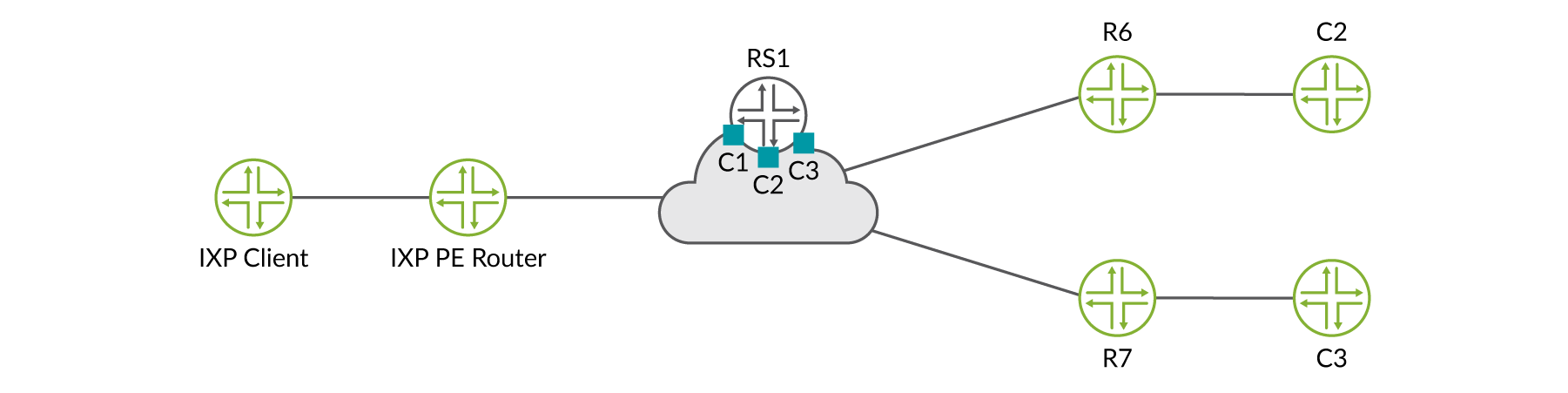
最初の HealthBot は、BGP テレメトリセンサーに加入し、ルートサーバー (vRR) とルートコレクターからデータを収集します。この例では、ルートサーバーはルートコレクターとしても機能しています。さらに、HealthBot は、iAgent R1、R6、および R7 のラベルスイッチパス (LSP) 統計を収集して、MPLS i エージェントセンサーにサブスクライブします。
各ルーティングサーバーのルーティングインスタンス名の検索クライアント CLI の例:
regress@RS1> show route instance summary | match C
Instance Type
Primary RIB Active/holddown/hidden
C1 non-forwarding
C1.inet.0 93/0/0
C2 non-forwarding
C2.inet.0 62/0/0
C3 non-forwarding
C3.inet.0 62/0/0
IXP クライアントルーターの IP アドレス (BGP ネクストホップ) の確認例は次のとおりです。
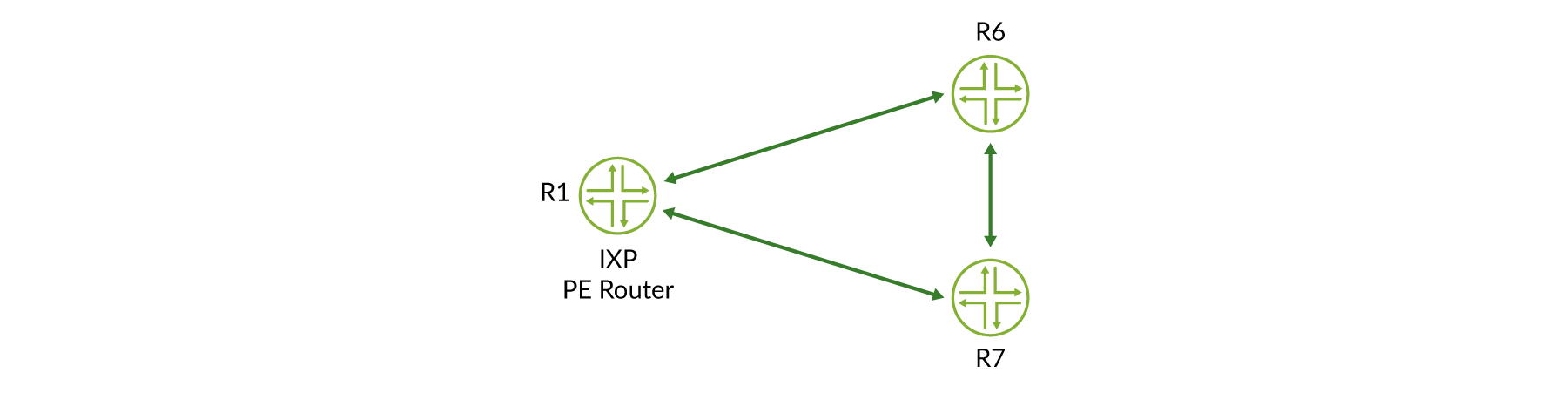
HealthBot はFigure 4 、pe ルーター間でデータプレーンが損傷していることを保証するために、すべての IXP PE ルーター間での RSVP TE lsp のステータスを監視しています。
regress@R6> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.1 192.0.2.6 Up 0 * to-r1 192.0.2.2 192.0.2.6 Up 0 * to-r2 regress@R7> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.1 192.0.2.7 Up 0 * to-r1 192.0.2.6 192.0.2.7 Up 0 * to-r6 regress@R1> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.6 192.0.2.1 Up 0 * to-r6 192.0.2.7 192.0.2.1 Up 0 * to-r7
通常の運用では、コミュニティベースの出力ポリシーに従って、IXP メンバー間でルートが交換されます。ここでは、C1 が C2 (198.51.100.0/24) と C3 (203.0.113.0/24) の両方のルートを受信していることがわかります。
regress@C1> show route protocol bgp 198.51.100.1
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 2d 23:20:23, localpref100, from 192.0.2.254
AS path: 2 I, validation-state: unverified
> to 192.0.2.2 via ge-0/0/1.0
regress@C1> show route protocol bgp 203.0.113.0
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 00:46:29, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0
しかし、何らかの理由で RSVP TE Lsp がダウンすると、R1 と R6 の間でデータプレーンの損失が発生することになりますが、ルートサーバーは、これらの PE ルーターに接続された IXP メンバーからルートを受信していますか?
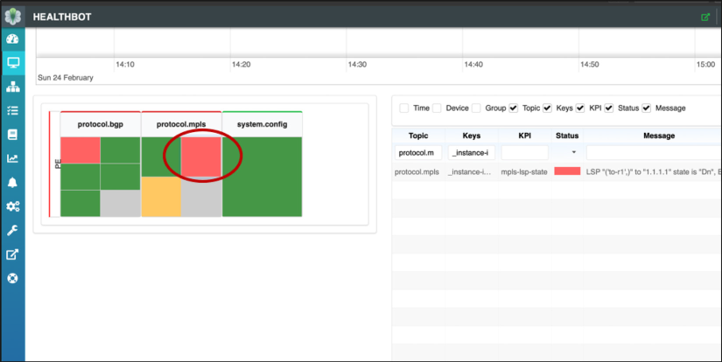
LSP がダウンしています...
regress@R6# run show mpls lsp Ingress LSP: 3 sessions To From State RtP ActivePath LSPname 192.0.2.1 0.0.0.0 Dn 0 - to-r1 192.0.2.7 192.0.2.6 Up 0 * to-r7 Total 3 displayed, Up 1, Down 2
だがしかし。。。
regress@C1> show route protocol bgp 198.51.100.1
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 2d 23:20:23, localpref100, from 192.0.2.254
AS path: 2 I, validation-state: unverified
> to 192.0.2.2 via ge-0/0/1.0
regress@C1> show route protocol bgp 203.0.113.0
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 00:46:29, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0
HealthBot は、状況を発見し、ダッシュボードアラームを表示し、ルートサーバーのポリシー設定を変更して、影響を受けている IXP メンバールーター間のルート配信を制限します。
変更されたルートサーバー構成:
IXP のメンバールーター C1 で検証しています。ご覧のように、ルートはメンバー C2 から受信していません。
regress@C1> show route protocol bgp 198.51.100.1
egress@C1> show route protocol bgp 203.0.113.0
iet.0: 68 destinations, 68 routes (67 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 01:10:07, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0データプレーンが復元されると、HealthBot はアラームをクリアし、ポリシーの設定を元に戻します。
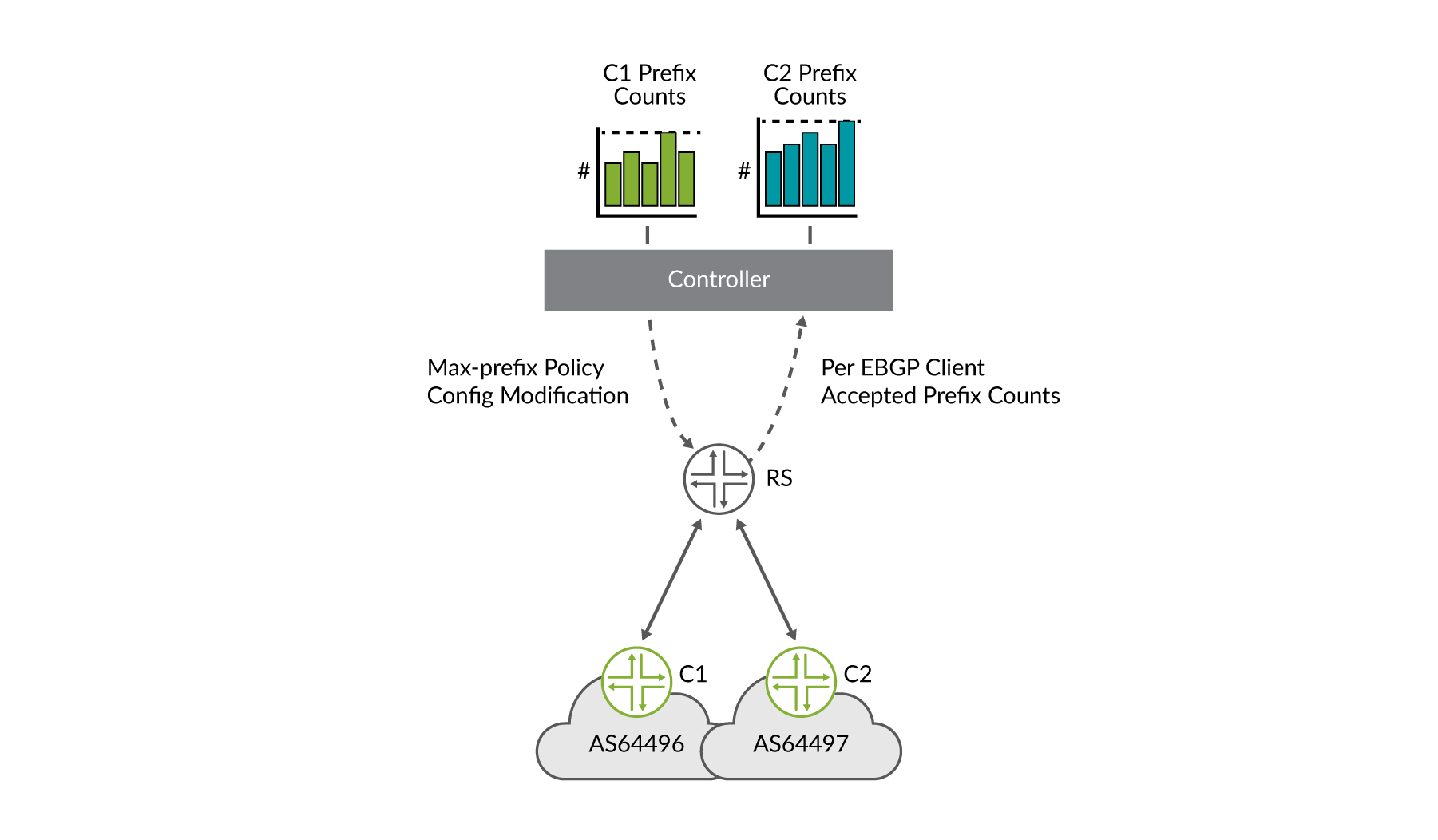
動的で自動化された最大受け入れ可能なプレフィックスソリューション
前述したように、Internet Exchange Point Overviewのセキュリティに関する考慮事項について説明しました。この章では、ルートサーバー単位での特定、監視、’保守を行うことは、ixp のルートサーバーの導入において多少難しいものです。価値を判断するためのさまざまな乗算要素など、複数のソリューションが提供されました。HealthBot は、ルートサーバーからの ingesting リアルタイムストリーミングテレメトリを必要とする別のソリューションを提供し、ルートサーバーのクライアントごとに許可されたプレフィックス数を維持し、vales が変化したときにルートサーバーのポリシーを動的に変更しています。2つのルートサーバークライアント用のこのワークフローはFigure 7、に示されています。
実際’の例を見てみましょう。下記の CLI 出力では、route server client C1 をご覧いただけます。ルートサーバーは、クライアント C1 から10個のプレフィックスを受信し、受け入れています。また、ルートサーバーが、クライアント C1 から最大15個のプレフィックスを受け付けるポリシーで構成されていることを確認することもできます。
root@rs> show bgp summary | match “Peer |C1.inet.0” Peer AS InPkt OutPkt OutQ Flaps Last Up/DwState|#Active/ Received/Accepted/Damped... C1.inet.0: 10/10/10/0
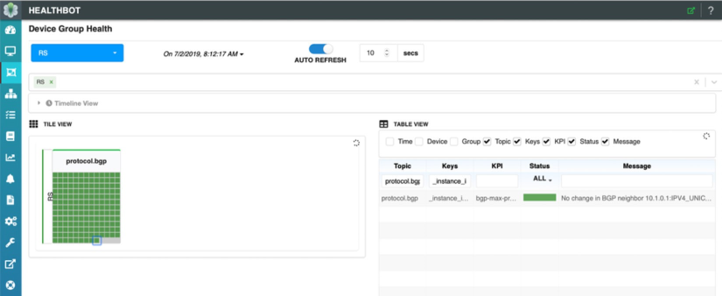
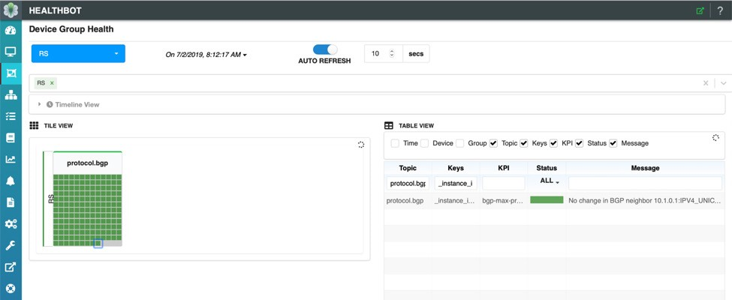
HealthBot のダッシュボードにも注目してください。クライアント C1 が以下でFigure 8選択されています。ここでは、最終統計区間において、HealthBot によって決定される最大プレフィックスポリシーへの変更はありません。これは‘緑色’のステータスと、そのクライアントの表にあるメッセージの両方によって示されます。統計の間隔とは、どのようなものでしょうか。この HealthBot ソリューションでは、非常にシンプルでユーザー定義の間隔を適用して、ルートサーバークライアントごとに受け付けるプレフィックス数を収集します。統計の間隔ごとに、HealthBot は受け入れられたプレフィックスの現在の値を取得し、1.5 によってユーザーの構成可能な状態にして、ルートサーバークライアントポリシーを新しい値で更新します。
ここで、’クライアント C1 がルートサーバーへのルートをさらにいくつかルーティングし、c1’s への静的ルートを2つ追加しているとしましょう。 BGP エクスポートポリシー:
以下の出力に、ルートサーバーによって追加のプレフィックスが受信され、受け付けられることがわかります。
root@rs> show bgp summary | match “Peer |C1.inet.0” Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/ Received/Accepted/Damped... r1001.inet.0: 12/12/12/0
では、HealthBot ダッシュボードをご覧ください。クライアント C1 のアイコンが赤くなっています。これは、受け入れられるプレフィックス数がしきい値の90% を超えているため、ユーザーによる構成も可能です。
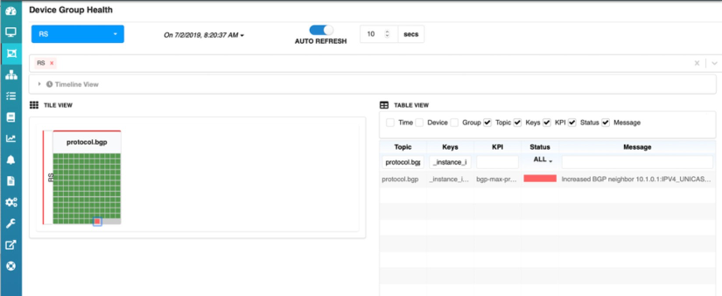
統計収集間隔の最後に、C1’s アイコンが黄色に変わり、HealthBot がルートサーバー上のクライアント C1 の最大プレフィックスポリシーを変更していることを示していることもわかります。HealthBot のダッシュボードはポリシーに含まれ’、しきい値を超えないため、ここでも C1 s アイコンが緑として表示されます。
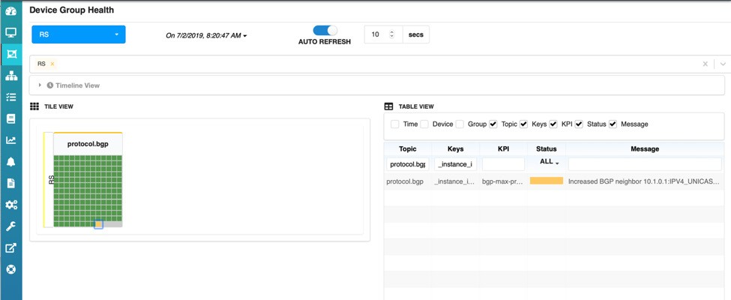
ご覧のように、ルートサーバーの設定は新しい値で更新されています (12 のプレフィックス * 1.5) 18:
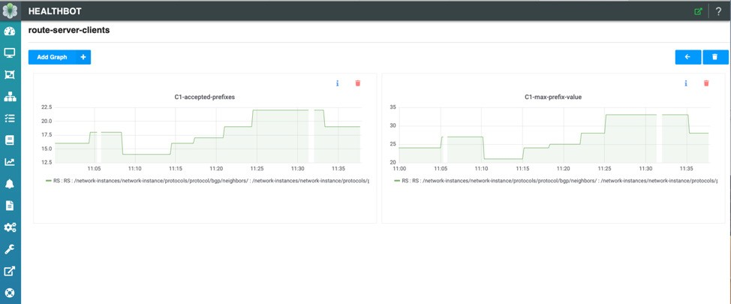
最後に、ルートサーバークライアント’と受信した接頭辞および対応する最大プリフィックス値を個別に監視できます。でFigure 12は、クライアント C1 用に受け入れられたプレフィックスの数と、統計の間隔中に設定される最大プレフィックスのポリシー値を確認できます。
サマリー
このガイドに記載されている情報を参考にして、Junos OS ベースのルートサーバーの設計、テスト、導入を支援していることを願っています。このガイドに記載されている構成と設計の考慮事項は、単に開始することを目的としています。最終的には、すべての IXP が独自性があり、ポリシーの実装に関する独自の検討事項が記載されています。