Kubernetes の実践
この章では、Kubernetes の基本的なオブジェクトと機能について説明します。
特定の仕様でマシンにホストする必要があるポッドがあると仮定します (SSD の HD、物理的な場所、処理能力など)。または、ポッドを検索またはグループ化して管理を容易にすることができます。お仕事は何をなさっていますか。ラベルを使うことができます。Kubernetes では、ラベルはオブジェクトに関連付けられています。
ラベル’を使用して、特定のマシンで pod を起動してみましょう。
ラベル
Kubernetes では、ラベルを使用して任意のオブジェクトを識別できます。
1つのオブジェクトに複数のラベルを割り当てることはできますが、使用するラベル数が多すぎるとは限らないので注意してください。非常に多くの場合、混乱’を得られるため、グループ化、選択、検索の実際のメリットが得られます。
最適な方法は、以下のようにラベルを割り当てることです。
この pod を使用したアプリケーション/プログラム ID
所有者 (この pod/アプリケーションを管理する人)
ステージ (開発/テスト/実務バージョンでのポッド/アプリケーション)
リソース要件 (SSD、CPU、ストレージ)
場所 (この pod/application を実行する推奨位置/ゾーン/データセンター)
では、’ラベルを割り当ててみましょう (stage: testingやり直しzone: production) を2つのノードにそれぞれ実行し、そのラベルがあるノードで pod を起動します (stage: testing):
$kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS cent222 Ready <none> 2h v1.9.2 <none> cent111 NotReady <none> 2h v1.9.2 <none> cent333 Ready <none> 2h v1.9.2 <none> $kubectl label nodes cent333 stage=testing $kubectl label nodes cent222 stage=production $kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS cent222 Ready <none> 2h v1.9.2 stage=production cent111 NotReady <none> 2h v1.9.2 <none> cent333 Ready <none> 2h v1.9.2 stage=testing
では’、基本的な Nginx ポッドを起動してみましょう。 stage: testingを確認し、ノードに着陸するかどうかを選択します。 stage: testing。Kube は、pod YAML の nodeSelector セクションで記述されたラベルを使用して、pod を起動するノードを選択します。
Kube は、個々のリソース要件、ハードウェア、ソフトウェア、ポリシーの制約、アフィニティとアンチアフィニティの仕様、データの局所性、ワークロード間の干渉、納期など、さまざまな要因に基づいてノードを選択します。
#pod-webserver-do-label.yaml apiVersion: v1 kind: Pod metadata: name: contrail-webserver labels: app: webserver spec: containers: - name: contrail-webserver image: contrailk8sdayone/contrail-webserver nodeSelector: stage: testing $ $ kubectl create -f pod-webserver-do-label.yaml pod "contrail-webserver" created $ kubectl get pods --output=wide NAME READY STATUS RESTARTS AGE IP NODE contrail-webserver 1/1 Running 0 48s 10.47.255.238 cent333
引数を追加して、ラベルなしで特定のノードに pod を割り当てることができます。 nodeName: nodeX、YAML ファイルの仕様で nodeXノードの名前です。
名前空間
他の多くのプラットフォームと同様に、通常、Kubernetes クラスター上で複数のユーザー (チーム) が稼働しています。Webserver1という名前の pod が devops 部門によって構築されているとしても、営業部門が同じ名前の pod を起動しようとした場合、このシステムではエラーが発生します。
Error from server (AlreadyExists): error when creating
"webserver1.yaml": pods "webserver1" already exists
’Kubernetes は、同じスコープ内で Kubernetes リソースと同一のオブジェクト名を複数回出現させることを可能にしています。
名前空間は、OpenStack での project/テナントのような Kubernetes リソースのスコープを提供します。リソース名は、名前空間内では一意である必要はありませんが、名前空間間では重複してはなりません。これ’は、複数のユーザー間でクラスターリソースを分割するための自然な方法です。
Kubernetes は、最初の3つの名前空間から始まります。
デフォルト:その他の名前空間を持たないオブジェクトのデフォルトの名前空間。
kube-システム:Kubernetes システムによって作成されたオブジェクトの名前空間。
kube-パブリック:Kubeadm ツールによって初めてクラスターを導入したときに作成されます。慣例では、この名前空間の目的は、認証なしですべてのユーザーがいくつかのリソースを読み取れるようにすることです。ほとんどの場合、kubeadm ツールのみを使用して Kubernetes のクラスターブート stapped として存在します。
名前空間を作成
名前空間の作成は非常にシンプルです。Kubectl コマンドはマジックを実行します。’Yaml ファイルが必要になるわけではありません。
新しい名前空間devが作成されました。
現在、 dev名前空間’の webserver1 pod は、 sales名前空間の webserver1 ポッドと競合しています。
$ kubectl get pod --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE dev webserver1 1/1 Running 4 2d4h 10.47.255.249 cent222 <none> sales webserver1 1/1 Running 4 2d4h 10.47.255.244 cent222 <none>
限度
OpenStack テナントと同様に、名前空間あたりのリソース消費を制限する制約を適用できるようになりました。たとえば、名前空間に作成できるオブジェクトの数、リソースによって消費される可能性があるコンピューティングリソースの総量などを制限できます。K8s の制約はquotaと呼ばれています。ここ’で例を示します。
ここでは、quota quota-onepod を作成しただけで、与えられた–制約はポッド = 1 であるため、この名前空間では1つの pod のみを作成することができます。
その内部に pod を作成しましょう。
うまく機能するようになりまし’た。そのため、次のように2つ目のポッドを作成してみましょう。
すぐにエラーを超えたクォータを実行しています。クォータ’クォータ-onepod を削除してみましょう。この新しい pod は、クォータの削除後に作成されます。
レプリケーションコントローラ
ここでは、第2章の YAML ファイルからコンテナーを表す pod を起動する方法を学びました。コンテナで1つの質問が生じます。完全に同じである3つのポッドが必要な場合は (それぞれが Apache コンテナーを実行します)、web サービスがより堅牢になっていることを確認します。YAML ファイルの名前を変更してから、同じコマンドを繰り返し、必要なポッドを作成しますか? あるいは、シェルスクリプトがあるでしょうか。Kubernetes には、この需要に対応するオブジェクトが RC で既に存在しています- ReplicationController、または RS– ReplicaSet。
Replicationcontroller (rc) は、指定された数のポッドレプリカが一度に実行されることを保証します。言い換えると、複製コントローラは、pod または同種のポッドセットが常に稼働していることを確認します。
Rc の作成
Rc’を例とともに作成してみましょう。まず、次に、web サーバの rc オブジェクトの YAML ファイルを作成します。
この YAML ファイルが定義するオブジェクトタイプを示す kind は、pod ではなく rc であることを覚えておいてください。メタデータには、rc’s name が web サーバとして表示されています。この仕様は、この rc オブジェクトの詳細な仕様であり、レプリカは以下のとおりです。3は、rc で作成されたポッドの総数が常に3つであることを確認するために、同じ pod を複製することを示します。最後に、このテンプレートは、pod で実行されるコンテナに関する情報を提供します。これは、pod YAML ファイルで見たものと同じです。ここで、この YAML ファイルを使用して rc オブジェクトを作成します。
十分に簡単な場合は、新しいポッドが作成されているときに、中間状態をキャプチャできます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5ggv6 1/1 Running 0 9s webserver-lbj89 0/1 ContainerCreating 0 9s webserver-m6nrx 0/1 ContainerCreating 0 9s
最終的に、3個のポッドが起動します。
$ kubectl get rc NAME DESIRED CURRENT READY AGE webserver 3 3 3 3m29s $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5ggv6 1/1 Running 0 21m webserver-lbj89 1/1 Running 0 21m webserver-m6nrx 1/1 Running 0 21m
Rc は pod と直接連携しています。Figure 1は、ワークフローを示しています。
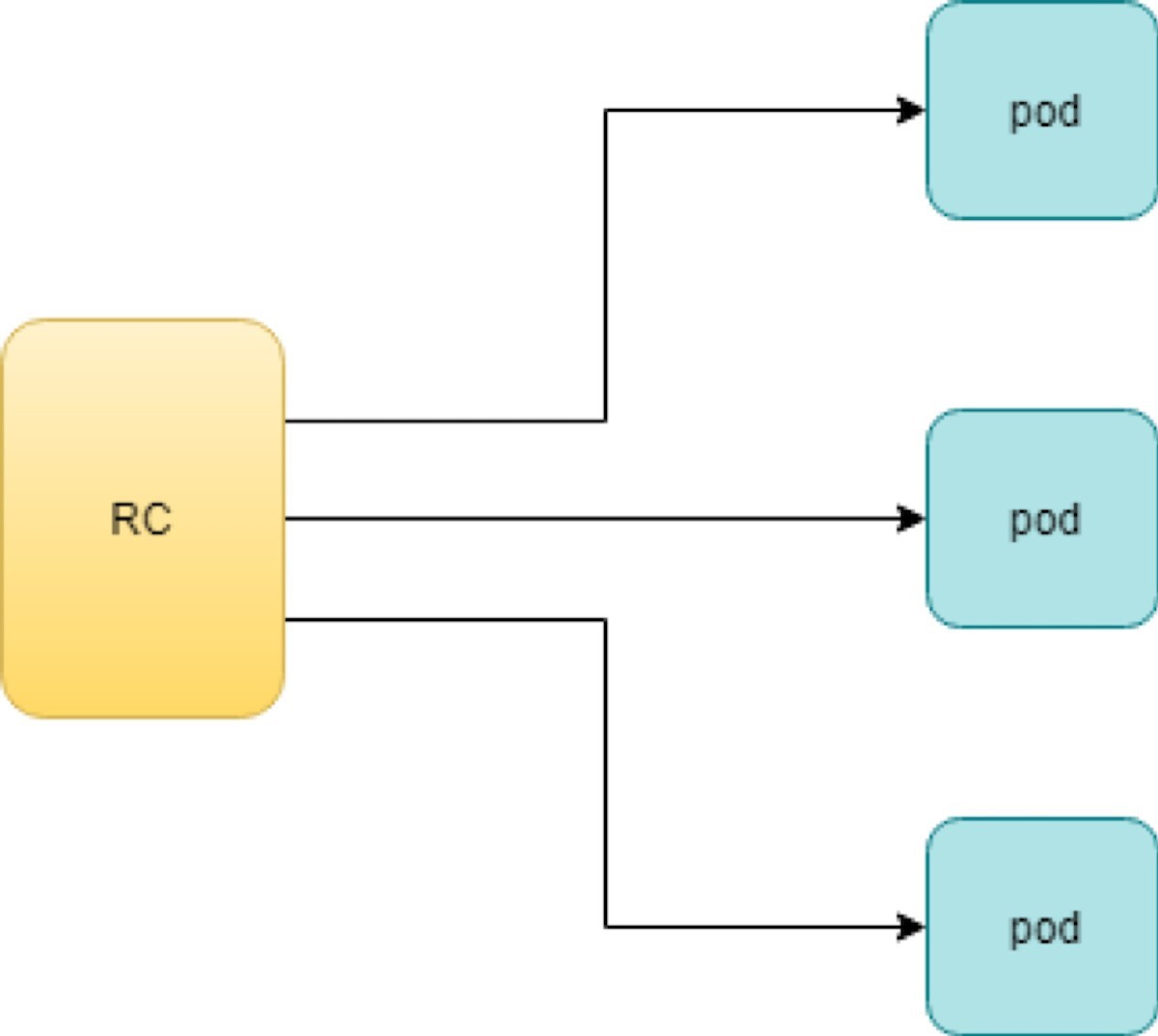
Rc object YAML ファイルに指定されているレプリカパラメーターを使用すると、Kubernetes レプリケーションコントローラは、マスターノードで kube のコントローラマネージャープロセスの一部として動作して、rc によって起動されたポッドの数を監視し、そのうちのいずれかが失敗した場合でも新しいものを自動的に起動します。学習すべき重要なことは、個々のポッドがいつでも停止するかもしれませんが、プール全体を常に稼働させ、堅牢なサービスを実現することです。Kubernetes サービスについて学習すると、これを理解することができます。
テスト Rc
ポッドの1つを’削除することで、rc s への影響をテストすることができます。Kubectl を使用してリソースを削除するには、kubectl delete サブコマンドを使用します。
$ kubectl delete pod webserver-5ggv6 pod "webserver-5ggv6" deleted $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5ggv6 0/1 Terminating 0 22m #<--- webserver-5v9w6 1/1 Running 0 2s #<--- webserver-lbj89 1/1 Running 0 22m webserver-m6nrx 1/1 Running 0 22m $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5v9w6 1/1 Running 0 5s webserver-lbj89 1/1 Running 0 22m webserver-m6nrx 1/1 Running 0 22m
ご覧のように、1つのポッドが終了すると、新しい pod がすぐに生成されます。最終的には古いポッドが消え、新しい pod が稼働します。動作しているポッドの総数は変わりません。
Rc でレプリカを拡張または縮小することもできます。たとえば、3 ~ 5 の数値にスケールアップするには、以下のようにします。
$ kubectl scale rc webserver --replica=5 replicationcontroller/webserver scaled $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5v9w6 1/1 Running 0 8s webserver-lbj89 1/1 Running 0 22m webserver-m6nrx 1/1 Running 0 22m webserver-hnnlj 0/1 ContainerCreating 0 2s webserver-kbgwm 1/1 ContainerCreating 0 2s $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-5v9w6 1/1 Running 0 10s webserver-lbj89 1/1 Running 0 22m webserver-m6nrx 1/1 Running 0 22m webserver-hnnlj 1/1 Running 0 5s webserver-kbgwm 1/1 Running 0 5s
Rc を使用した他のメリットもあります。実際、この抽象化は非常に人気が高く、頻繁に使用されているため、非常に類似–した2つのオブジェクト、Rs-Replicaset、導入導入が、より強力な機能で開発されています。一般に、次世代の rc を呼び出すことができます。ここでは、’rc 機能の詳細をご紹介し、これらの2つの新しいオブジェクトにフォーカスを移動してみましょう。
次のオブジェクトに移る前に、rc を削除できます。
$ kubectl delete rc webserver replicationcontroller/webserver deleted
レプリケーション Aset
ReplicaSet、または rs object は rc オブジェクトとほぼ同じですが、1つの主な例外–として、セレクターの外観が異なります。
#rs-webserver-do.yaml
apiVersion: apps/v1
kind: ReplicaSet metadata:
name: webserver
labels:
app: webserver
spec:
replicas: 3
selector:
matchLabels: #<---
app: webserver #<---
matchExpressions: #<---
- {key: app, operator: In, values: [webserver]} #<---
template:
metadata:
name: webserver
labels:
spec:
containers:
- name: webserver
image: contrailk8sdayone/contrail-webserver
securityContext:
privileged: true
ports:
- containerPort: 80webservercontrailK8sdayone
Rc は同等のセレクターのみを使用しています。 rs は、追加のセレクターフォーマットであるセットベースをサポートしています。機能の2つの形式のセレクターでは– 、同じ—ジョブを実行し、次のように一致するラベルを持つ pod を選択します。
#RS selector
matchLabels:
app: webserver
webserver
matchExpressions:
- {key: app, operator: In, values: [webserver]}
#RC selector
app: webserver
webserver
$ kubectl create -f rs-webserver.yaml
replicaset.extensions/webserver created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
webserver-lkwvt 1/1 Running 0 8s
Rs が作成され、rc と同様の方法で pod が起動します。Kubectl を比較した場合 describe次の2つのオブジェクトがあります。
$ kubectl describe rs webserver ...... Selector: app=webserver,app in (webserver) #<--- ...... Type Reason Age From Message ...... ...... .... .... ...... Normal SuccessfulCreate 15s replicaset-controller Created pod: webserver-lkwvt $ kubectl describe rc webserver ...... Selector: app=webserver #<--- ...... Type Reason Age From Message ...... ...... .. . .... ...... Normal SuccessfulCreate 19s replication-controller Created pod: webserver-lkwvt
お分かりのように、ほとんどの場合、出力は同じになり、セレクターのフォーマットが唯一の例外になります。また、rc と同じ方法で、rs を拡張することもできます。
$ kubectl scale rs webserver --replicas=5 replicaset.extensions/webserver scaled $ kubectl get pod NAME READY STATUS RESTARTS AGE webserver-4jvvx 1/1 Running 0 3m30s webserver-722pf 1/1 Running 0 3m30s webserver-8z8f8 1/1 Running 0 3m30s webserver-lkwvt 1/1 Running 0 4m28s webserver-ww9tn 1/1 Running 0 3m30s
次のオブジェクトに移行する前に、rs を削除します。
$ kubectl delete rs webserver replicaset.extensions/webserver deleted
導入
Kubernetes が、ほぼ同じ作業を実行するために異なるオブジェクトを持っている理由を不思議に思うかもしれません。すでに述べたように、rc の機能は rs and deployment によって拡張されています。’Rs 社では、同じ作業を実行しています。 rc とは異なるセレクター形式を使用した場合のみです。’ここでは、その他の新しいオブジェクトをチェックアウト–し、導入を展開し、そこからの機能について解説します。
導入の作成
Kind 属性を ReplicaSet から配備’に変更するだけでは、配備オブジェクトの yaml ファイルが得られます。
#deploy-webserver-do.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webserver
labels:
app: webserver
spec:
replicas: 1
selector:
matchLabels:
app: webserver
matchExpressions:
- {key: app, operator: In, values: [webserver]}
template:
metadata:
name: webserver
labels:
app: webserver
spec:
containers:
- name: webserver
image: contrailk8sdayone/contrail-webserver
securityContext:
privileged: true
ports:
- containerPort: 80
を使用して導入を作成する kubectlコマンド
..... $ kubectl create -f deploy-webserver-do.yaml deployment.extensions/webserver created $ kubectl get deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/webserver 1 1 1 1 21s .....
実際の導入では、rc と rs よりも比較的高いレベルの抽象化が行われます。導入によって pod が直接作成されるわけではなく、[説明] コマンドは次のようになります。
$ kubectl describe deployments
Name: webserver
Namespace: default
CreationTimestamp: Sat, 14 Sep 2019 23:17:17 -0400
Labels: app=webserver
Annotations: deployment.kubernetes.io/revision: 5
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},
"labels":{"app":"webserver"},
"name":"webserver","namespace":"defa...
Selector: app=webserver,app in (webserver)
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=webserver
Containers:
webserver:
Image: contrailk8sdayone/contrail-webserver
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
.... ..... ......
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: webserver-7c7c458cc5 (1/1 replicas created) #<---
Events: <none>
導入ワークフロー
配置を作成すると、レプリカセットが自動的に作成されます。導入オブジェクトに定義されているポッドは、導入’のレプリケーションによって作成および監視されます。
Figure 2は、ワークフローを示しています。
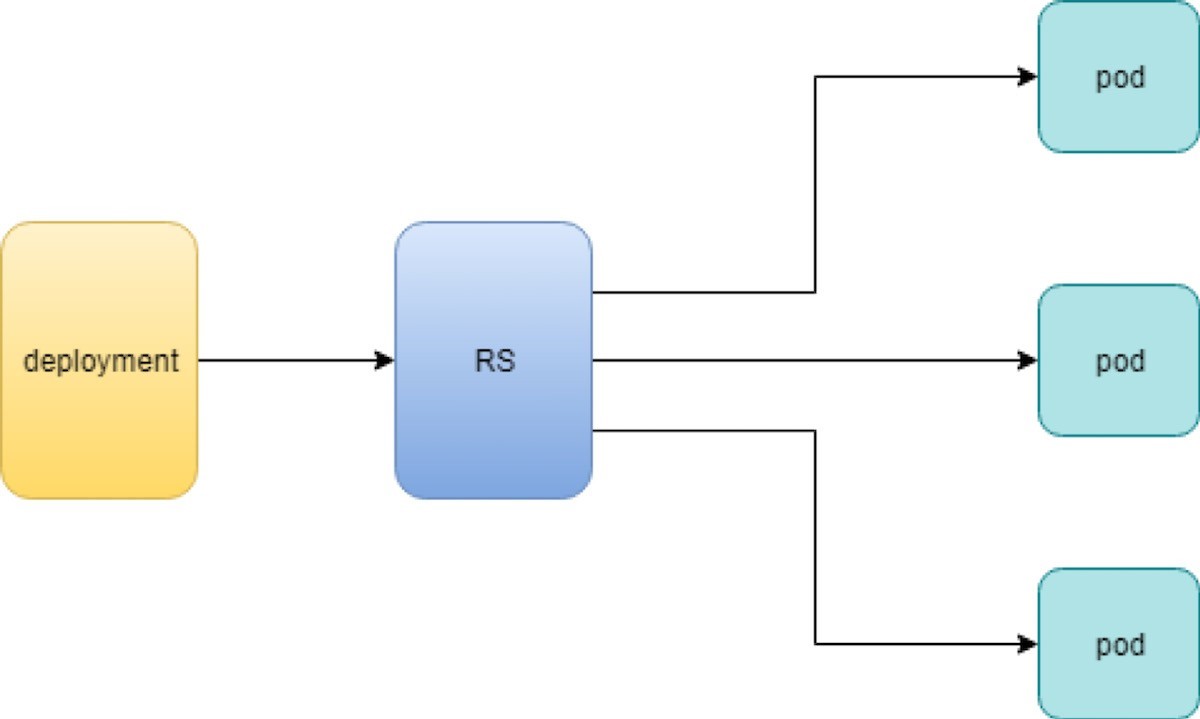
場合によっては、導入とポッドの間に1つ以上のレイヤーを配置し’、その後に回答することで、rs が必要になる理由が気になるかもしれません。
ローリング更新
ローリング更新機能は、導入オブジェクトに付属する強力な機能の1つです。’この機能について、テストケースでどのように動作するかを示します。
実際には、以前の rc オブジェクトに対しても同様のローリング更新機能が存在します。この実装には、導入によってサポートされる新しいバージョンと比べてかなり不利な点があります。このガイドでは、導入に伴う新しい実装について説明します。
テストケース: ローリング更新
たとえば、 nginx-deployment、レプリカ = 3、pod image 1.7.9 が使用されています。当社では、イメージをバージョン1.7.9 から新しいイメージバージョン1.9.1 にアップグレードしたいと考えています。Kuberctl では、[イメージの設定] オプションを使用して新しいバージョン番号を指定し、更新をトリガーすることができます。
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 deployment.extensions/nginx-deployment image updated
次に、導入情報をもう一度確認してみましょう。
$ kubectl describe deployment/nginx-deployment Name: nginx-deployment Namespace: default CreationTimestamp: Tue, 11 Sep 2018 20:49:45 -0400 Labels: app=nginx Annotations: deployment.Kubernetes.io/revision=2 Selector: app=nginx Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.9.1 #<------ Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason .... ..... ..... Available True MinimumReplicasAvailable Progressing True ReplicaSetUpdated OldReplicaSets: nginx-deployment-67594d6bf6 (3/3 replicas created) NewReplicaSet: nginx-deployment-6fdbb596db (1/1 replicas created) Events: Type Reason Age From Message .... ...... ... .... ...... Normal ScalingReplicaSet 4m deployment-controller Scaled up replica set nginx-deployment-67594d6bf6 to 3 #<--- Normal ScalingReplicaSet 7s deployment-controller Scaled up replica set nginx-deployment-6fdbb596db to 1 #<---
ここでは、以下の2つの変更を行うことができます。
配置のイメージバージョンが更新されます。
新しい rs nginx-deployment-6fdbb596db が作成され、レプリカは1にセット
また、レプリカを1とした新しい rs では、新しい pod (4 つ目) が生成されました。
$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-67594d6bf6-88wqk 1/1 Running 0 4m nginx-deployment-67594d6bf6-m4fbj 1/1 Running 0 4m nginx-deployment-67594d6bf6-td2xn 1/1 Running 0 4m nginx-deployment-6fdbb596db-4b8z7 0/1 ContainerCreating 0 17s #<------
新しい pod は新しい画像で使用されています。
$ kubectl describe pod/nginx-deployment-6fdbb596db-4b8z7 | grep Image: ...(snipped)... Image: nginx:1.9.1 #<--- ...(snipped)...
古い pod は依然として古い画像を使用しています。
$ kubectl describe pod/nginx-deployment-67594d6bf6-td2xn | grep Image: ...(snipped)... Image: nginx:1.7.9 #<------ ...(snipped)...
’S を待機し、ポッドのステータス…を常にチェックして、すべての古いポッドが終了し、3個の新しいポッドが pod 名を実行–していることを確認します。これは新しいもので、
$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-6fdbb596db-4b8z7 1/1 Running 0 1m nginx-deployment-6fdbb596db-bsw25 1/1 Running 0 18s nginx-deployment-6fdbb596db-n9tpg 1/1 Running 0 21s
そのため、更新が行われ、すべてのポッドが新しいバージョンの画像で実行されるようになりました。
仕組み
Kubernetes は新しいイメージで3個の新しいポッドを使用して古いポッドを置き換えるので、このようなことは、これを「置換」と呼んでいます。正確に言えば、これは真実です。しかし、これが機能しています。Kubernetes’の原理は、ポッドが安価であることを理解–しているため、各ポッドにログインし、古い画像をアンインストールし、環境をクリーンアップして、新しい画像をインストールすることが簡単であると考えられます。この’プロセスの詳細を確認して、ローリング更新と呼ばれる理由を理解してみましょう。
ポッドを新しいソフトウェアで更新すると、配備オブジェクトは、pod 更新プロセスを開始する新しい rs を導入します。ここでの考え方は、既存の pod にログインしてイメージを更新することではありません。新しい rs は、新しいソフトウェアリリースを備えた新しいポッドを作成するだけです。この新しい (そして追加の) ポッドが起動して実行されると、元の rs は1つずつスケールダウンされるため、動作しているポッドの合計数は変化しません。新しい rs は1つの拡張を続け、元の rs は1つずつ拡張されます。このプロセスは、新しい rs によって作成されたポッド数が、導入時に定義された元のレプリカ番号に到達するまで繰り返されます。これは、元のすべての rs ポッドが終了したときです。Figure 3は、このプロセスを示しています。
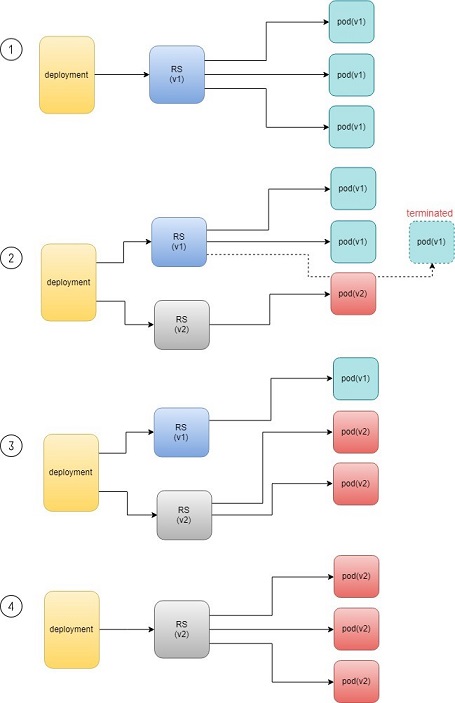
ご覧のように、新しい rs を作成するプロセス全体、新しい rs をスケールアップする、同時に古いものを拡張することは、完全に自動化され、導入オブジェクトによって実現します。この導入は、ReplicaSet オブジェクトを導入して推進しているので、このような意味ではバックエンドとしてのみ機能しています。
その理由は、導入が Kubernetes の上位レイヤーオブジェクトと見なされる理由と、導入なしでは ReplicaSet のみを使用しないことが正式に推奨されているためです。
録画
また、導入によってロール更新のプロセス全体を記録することもできるため、必要に応じて、更新ジョブの完了後に更新プログラムの履歴を確認できます。
$ kubectl describe deployment/nginx-deployment Name: nginx-deployment ...(snipped)... NewReplicaSet: nginx-deployment-6fdbb596db (3/3 replicas created) Events: Type Reason Age From Message Normal ScalingReplicaSet 28m deployment-controller Scaled up replica set nginx-deployment-67594d6bf6 to 3 Normal ScalingReplicaSet 24m deployment-controller Scaled up replica set nginx-deployment-6fdbb596db to 1 Normal ScalingReplicaSet 23m deployment-controller Scaled down replica set nginx-deployment-67594d6bf6 to 2 Normal ScalingReplicaSet 23m deployment-controller Scaled up replica set nginx-deployment-6fdbb596db to 2 Normal ScalingReplicaSet 23m deployment-controller Scaled down replica set nginx-deployment-67594d6bf6 to 1 Normal ScalingReplicaSet 23m deployment-controller Scaled up replica set nginx-deployment-6fdbb596db to 3 Normal ScalingReplicaSet 23m deployment-controller Scaled down replica set nginx-deployment-67594d6bf6 to 0
一時停止/再開/元に戻す
さらに、更新プロセスを一時停止/再開して、変更内容を確認してから続行することもできます。
$ kubectl rollout pause deployment/nginx-deployment $ kubectl rollout resume deployment/nginx-deployment
メンテナンス期間中に問題が発生した場合、更新を取り消すこともできます。
$ kubectl rollout undo deployment/nginx-deployment $ kubectl describe deployment/nginx-deployment Name: nginx-deployment ...(snipped)... NewReplicaSet: nginx-deployment-6fdbb596db (3/3 replicas created) NewReplicaSet: nginx-deployment-67594d6bf6 (3/3 replicas created) Events: Type Reason Age From Message Normal DeploymentRollback 8m deployment-controller Rolled back deployment "nginx-deployment" to revision 1 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled up replica set nginx-deployment-67594d6bf6 to 1 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled down replica set nginx-deployment-6fdbb596db to 2 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled up replica set nginx-deployment-67594d6bf6 to 2 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled up replica set nginx-deployment-67594d6bf6 to 3 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled down replica set nginx-deployment-6fdbb596db to 1 #<------ Normal ScalingReplicaSet 8m deployment-controller Scaled down replica set nginx-deployment-6fdbb596db to 0 #<------
これは通常、導入環境で問題が発生した場合に行います。従来の期間のメンテナンス期間中にソフトウェアアップグレードを準備するのにかかる時間と比較すると、これはソフトウェアアップグレードを行ったすべての人にとって驚くべき機能と言えます。
これは、Junos ロールバックマジックコマンドと非常に似ています。ルーターに加えた変更をすばやく元に戻す必要がある場合に、毎日使用することをお勧めします。
機密性
現在のすべてのネットワークシステムでは、プラットフォームのユーザー名、パスワード、SSH キーなどの機密情報を処理する必要があります。Kubernetes 環境のポッドにも同じことが当てはまります。しかし、この情報を pod 仕様でクリアテキストとして公開すると、セキュリティーの問題が発生する可能性があり–ます。この問題を解決するには、少なくともクリアテキストの資格情報をできるだけ回避するツールまたは方法が必要です。
Kubernetes の機密オブジェクトはこの目的–に合わせて設計されており、すべての機密データをエンコードし、制御された方法でポッドに公開します。
Kubernetes シークレットの公式の定義は以下のとおりです。
「機密とは、パスワード、トークン、鍵などの少量の機密データを含むオブジェクトのことです。このような情報は、Pod 仕様または画像内に配置される場合があります。これを秘匿オブジェクトに配置することで、it がどのように使用されるかをより細かく制御し、偶発的な危険を軽減することができます」
ユーザーはシークレットを作成できます。また、システムでもシークレットが作成されます。シークレットを使用するには、pod がシークレットを参照する必要があります。
さまざまなタイプのシークレットがあり、それぞれが特定のユースケースに対応しています。また、さまざまな方法でシークレットを作成する方法も数多くあります。このガイドでは、シークレットの詳細については記載されていません。そのすべてをご確認いただくとともに、最新の変更をすべて記録するには、公式マニュアルを参照してください。
ここでは’、一般的に使用される機密タイプについてご紹介します。また、機密情報を作成する方法と、ポッドでシークレットを参照する方法についても学習します。セクションの最後に達すると、Kubernetes の機密オブジェクトの主なメリットと、それを活用してシステムのセキュリティを強化する方法を理解しておく必要があります。
まず’、次のような秘密の用語を見てみましょう。
不透明: このタイプのシークレットは、任意のキーと値のペアを含むことができるため、Kubernetes’の観点からは非構造化データとして扱われます。その他すべてのタイプの機密情報は、常に一貫しています。
Kubernetes.io/Dockerconfigjson: このタイプの機密情報は、プライベートコンテナレジストリ (Juniper サーバーなど) との認証に使用され、独自のプライベートイメージを取得します。
TLS: TLS シークレットには、TLS 秘密鍵と証明書が含まれています。受信のセキュリティーを強化するために使用されます。第4章では、TLS シークレットの受信の例を示しています。
Kubernetes.io/service-account-token: Pod のコンテナで実行されているプロセスが API サーバーにアクセスする場合、特定のアカウントとして認証される必要があります (デフォルトでは、アカウントデフォルト)。Pod に関連付けられたアカウントは、サービスアカウントと呼ばれます。Kubernetes.io/service-account-token タイプのシークレットには、Kubernetes サービスアカウントに関する情報が記載されています。’本書では、この種の秘密とサービスアカウントについて詳しくは触れません。
非透過シークレット: タイプ固定型のシークレットは、任意のユーザー所有–のデータを表すので、通常、ユーザー名、パスワード、セキュリティ pin など、機密性の高い機密データを保存したいと考えています。そのため、機密性が確保されていることに気がついていることを知りたいと思います。
非透過シークレットの定義
まず、機密データの機密性を低くするには、’次のように base64 ツールを使用してエンコードしてみましょう。
$ echo -n 'username1' | base64 dXNlcm5hbWUx $ echo -n 'password1' | base64 cGFzc3dvcmQx
次に、エンコードされたデータを機密の定義 YAML ファイルに挿入します。
apiVersion: v1 kind: Secret metadata: name: secret-opaque type: Opaque data: username: dXNlcm5hbWUx password: cGFzc3dvcmQx
また、-literal オプションを使用して、kubectl CLI との間で同じシークレットを直接定義することもできます。
kubectl create secret generic secret-opaque \ --from-literal=username='username1' \ --from-literal=password='password1'
いずれにしても、シークレットが生成されます。
$ kubectl get secrets
NAME TYPE DATA AGE
secret-opaque Opaque 2 8s
$ kubectl get secrets secret-opaque -o yaml
apiVersion: v1
data:
password: cGFzc3dvcmQx
username: dXNlcm5hbWUx
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"password":"cGFzc3dvcmQx","username":"dXNlcm5hbWUx"},"kind":"Secret","metadata":{"annotations":{},"name"
:"secret-opaque","namespace":"ns-user-1"},"type":"Opaque"}
creationTimestamp: 2019-08-22T22:51:18Z
name: secret-opaque
namespace: ns-user-1
resourceVersion: "885702"
selfLink: /api/v1/namespaces/ns-user-1/secrets/secret-opaque
uid: 5a78d9d4-c52f-11e9-90a3-0050569e6cfc
type: Opaque
透過シークレットを参照
次に、pod でシークレットを使用する必要があり、シークレットに含まれるユーザー情報が pod に送られます。前述したように、pod 内の不透明なシークレットを参照するにはさまざまな方法がありますが、その結果は異なっています。
通常、シークレットから実行されるユーザー情報は、次のいずれかの形式のコンテナに表示できます。
Files
環境変数
’ここでは、シークレットを使用して、コンテナに環境変数を生成する例を示します。
#pod-webserver-do-secret.yaml apiVersion: v1 kind: Pod metadata: name: contrail-webserver-secret labels: app: webserver spec: containers: - name: contrail-webserver-secret image: contrailk8sdayone/contrail-webserver #envFrom: #- secretRef: # name: test-secret env: - name: SECRET_USERNAME valueFrom: secretKeyRef: name: secret-opaque key: username - name: SECRET_PASSWORD valueFrom: secretKeyRef: name: secret-opaque key: password
次の YAML ファイルから pod とコンテナを生成します。
$ kubectl apply -f pod/pod-webserver-do-secret.yaml pod/contrail-webserver-secret created
コンテナにログインし、生成された環境変数を確認します。
$ kubectl exec -it contrail-webserver-secret -- printenv | grep SECRET SECRET_USERNAME=username1 SECRET_PASSWORD=password1
Base64 でエンコードされた元の機密データが、コンテナに存在するようになりました。
Dockerconfigjson Secret
Dockerconfigjson secret は、名前が示すように、通常は docker/config ファイルに保存されている Docker アカウントの認証情報を保持しています。Kubernetes ポッド内の画像は、プライベートコンテナレジストリを指している場合があります。その場合、Kubernetes はそのレジストリを使用してイメージを取得する必要があります。Dockerconfigjson タイプの secret は、この非常に目的に合わせて設計されています。
Docker 資格データ
Kubernetes.io/dockerconfigjson タイプのシークレットを作成する最も簡単な方法は、ログイン情報を kubectl コマンドで直接提供し、それによってシークレットを生成させることです。
$ kubectl create secret docker-registry secret-jnpr1 \ --docker-server=hub.juniper.net \ --docker-username=JNPR-FieldUser213 \ --docker-password=CLJd2kpMsVc9zrAuTFPn secret/secret-jnpr created
シークレットの作成を確認します。
$ kubectl get secrets NAME TYPE DATA AGE secret-jnpr kubernetes.io/dockerconfigjson 1 6s #<--- default-token-hkkzr kubernetes.io/service-account-token 3 62d
作成したシークレットだけが、出力の最初の行だけになります。2行目は kubernetes.io/service-account-token タイプのシークレットで、contrail のセットアップが起動して実行されているときに、Kubernetes システムが自動的に作成します。
ここで、シークレットの詳細を確認します。
$ kubectl get secrets secret-jnpr -o yaml apiVersion: v1 data: .dockerconfigjson: eyJhdXRocyI6eyJodWIuanVuaXBlci5uZXQvc2...<snipped>... kind: Secret metadata: creationTimestamp: 2019-08-14T05:58:48Z name: secret-jnpr namespace: ns-user-1 resourceVersion: "870370" selfLink: /api/v1/namespaces/ns-user-1/secrets/secret-jnpr uid: 9561cdc3-be58-11e9-9367-0050569e6cfc type: kubernetes.io/dockerconfigjson
当然のこと’ですが、クリアテキスト形式の機密情報は一切表示されません。この出力には、key の値として非常に長いストリングがあることを示すデータ部分があります。dockerconfigjson. その外観は元のデータから変換されているように見えますが、少なくとも–機密性の高い情報を含んでいないため、シークレットを使用する1つの目的がシステムセキュリティの向上になります。
ただし、変換は暗号化ではなく、エンコードによって実行されるため、元の機密情報を手動で取得する方法はあります。dockerconfigjson を base64 ツールにパイプするだけで、元のユーザー名とパスワード情報が再び表示されます。
$ echo "eyJhdXRocyI6eyJodWIuanVua..." | base64 -d | python -mjson.tool
{
"auths": {
"hub.juniper.net": {
"auth": "Sj5QUi1GaWVsZFVzZXIyMTM6Q0xKZDJqcE1zVmM5enJBdVRGUG4=",
"password": "CLJd2kpMsVc9zrAuTFPn", "username": "JNPR-FieldUser213"
}
}
}
この出力では、以下の点についてハイライトしています。
Python-mjson. ツールは、デコードされた json データをフォーマットしてから端末に表示するために使用します。
認証キーと値のペアがあります。与えられた認証情報 (ユーザー名とパスワード) に基づいて生成されるトークンです。
その後、このシークレットが装備されている場合、pod はこのトークンを使用して、ユーザー名とパスワードの代わりに、hub.juniper.net の Docker レジストリに基づいてそれ自体を認証し、Docker 画像を取得します。
ここ’では、データをシークレットオブジェクトから直接デコードする方法をもう1つ紹介しています。
$ kubectl get secret secret-jnpr1 \
--output="jsonpath={.data.\.dockerconfigjson}" \
| base64 --decode | python -mjson.tool
{
"auths": {
"hub.juniper.net/security": {
"auth": "Sj5QUi1GaWVsZFVzZXIyMTM6Q0xKZDJqcE1zVmM5enJBdVRGUG4=",
"password": "CLJd2kpMsVc9zrAuTFPn", "username": "JNPR-FieldUser213"
}
}
}
こちらの --output=xxxxオプションは、kubectl get の出力をフィルタリングして、データにある dockerconfigjson の値のみが表示されるようにします。その後、この値は、デコードするオプション (-d のエイリアス) によって base64 にパイプされます。
このように手動で作成された docker レジストリシークレットは、1つのプライベートレジストリでのみ機能します。複数のプライベートコンテナレジストリをサポートするために、Docker credential ファイルからシークレットを作成できます。
Docker 資格ファイル (~/.Docker/config. json)
キーの名前として dockerconfigjson を作成すると、Docker 設定ファイルと同様の役割を果たします。docker/config. 実際には、このシークレットを Docker 構成ファイルから直接生成することができます。
Docker 認定資格情報を生成するには、まず、Docker 設定ファイルを確認します。
$ cat .docker/config.json
{
......
"auths": {},
......
}
実際’には何もありません。設定の使用状況によっては、異なる出力が表示される場合がありますが、ここでは、新しいレジストリに docker ログインするたびに、この Docker 構成ファイルが自動的に更新されることを示します。
$ cat mydockerpass.txt | \ docker login hub.juniper.net \ --username JNPR-FieldUser213 \ --password-stdin Login Succeeded
ファイル mydockerpass .txt は、ユーザー名 JNPR-FieldUser213 のログインパスワードです。パスワードをファイルに保存し、それを docker login コマンドに渡すと、--password-stdin オプションには、シェル履歴でパスワードクリアテキストが公開されないというメリットがあります。
パスワードを直接書き込むことができれば、これは安全ではないというわかりやすい警告が表示されます。
$ docker login hub.juniper.net --username XXXXXXXXXXXXXXX --password XXXXXXXXXXXXXX WARNING! Using --password via the CLI is insecure. Use --password-stdin. Login Succeeded
これで、Docker の認証情報が更新された config.json拡張子
$ cat .docker/config.json
{
......
"auths": { #<---
"hub.juniper.net": {
"auth": "Sj5QUi1GaWVsZFVzZXIyMTM6Q0xKZDJqcE1zVmM5enJBdVRGUG4="
}
},
......
}
ログインプロセスによって、 config.json認証トークンを保持するファイル。S’を使用して、 .docker/config.json拡張子
$ kubectl create secret generic secret-jnpr2 \
--from-file=.dockerconfigjson=/root/.docker/config.json \
--type=kubernetes.io/dockerconfigjson
secret/secret-jnpr2 created
$ kubectl get secrets
NAME TYPE DATA AGE
secret-jnpr2 kubernetes.io/dockerconfigjson 1 8s #<--- default-token-
hkkzr kubernetes.io/service-account-token 3 63d secret-jnpr
kubernetes.io/dockerconfigjson 1 26m
$ kubectl get secrets secret-jnpr2 -o yaml
apiVersion: v1
data:
.dockerconfigjson: ewoJImF1dGhzIjoIlNrNVFVaTFHYVdWc1pGVnpaWEl5TVRNNlEweEtaREpxY0UxelZtTTVlbkpCZ
FZSR1VHND0iCgkJfQoJfSwKCSJIdHRwSGVhZGVycyI6IHsKCQkiVXNlci1BZ2VudCI6ICJEb2NrZXItQ2xpZW50LzE4LjAzLjE
tY2UgKGxpbnV4KSIKCX0sCgkiZGV0YWNoS2V5cyI6ICJjdHJsLUAiCn0=
kind: Secret
metadata:
creationTimestamp: 2019-08-15T07:35:25Z
name: csrx-secret-dr2
namespace: ns-user-1
resourceVersion: "878490"
selfLink: /api/v1/namespaces/ns-user-1/secrets/secret-jnpr2
uid: 3efc3bd8-bf2f-11e9-bb2a-0050569e6cfc
type: kubernetes.io/dockerconfigjson
$ kubectl get secret secret-jnpr2 --output="jsonpath={.data.\.dockerconfigjson}" | base64 --decode
{
......
"auths": { "hub.juniper.net": {
"auth": "Sj5QUi1GaWVsZFVzZXIyMTM6Q0xKZDJqcE1zVmM5enJBdVRGUG4="
}
},
......
}
YAML ファイル
また、サービスや受信などの他のオブジェクトを作成する場合と同じ方法で、YAML ファイルから直接シークレットを作成することもできます。
のコンテンツを手動でエンコードするには .docker/config.json拡張子
$ cat .docker/config.json | base64 ewoJImF1dGhzIjogewoJCSJodWIuanVuaXBlci5uZXQiOiB7CgkJCSJhdXRoIjogIlNrNVFVaTFH YVdWc1pGVnpaWEl5TVRNNlEweEtaREpxY0UxelZtTTVlbkpCZFZSR1VHND0iCgkJfQoJfSwKCSJI dHRwSGVhZGVycyI6IHsKCQkiVXNlci1BZ2VudCI6ICJEb2NrZXItQ2xpZW50LzE4LjAzLjEtY2Ug KGxpbnV4KSIKCX0sCgkiZGV0YWNoS2V5cyI6ICJjdUAiCn0=
その後で、base 64 エンコード値 .docker/config.jsonファイルは YAML ファイルの下のデータとして、以下のようになります。
#secret-jnpr.yaml apiVersion: v1 kind: Secret type: kubernetes.io/dockerconfigjson metadata: name: secret-jnpr3 namespace: ns-user-1 data: .dockerconfigjson: ewoJImF1dGhzIjogewoJCSJodW...... $ kubectl apply -f secret-jnpr.yaml secret/secret-jnpr3 created $ kubectl get secrets NAME TYPE DATA AGE default-token-hkkzr kubernetes.io/service-account-token 3 64d secret-jnpr1 kubernetes.io/dockerconfigjson 1 9s secret-jnpr2 kubernetes.io/dockerconfigjson 1 6m12s secret-jnpr3 kubernetes.io/dockerconfigjson 1 78s
Base64 は暗号化–ではなくエンコードに関するものであることに注意してください。これはプレーンテキストと同じであると見なされます。そのため、このファイルを共有することで、シークレットが危険にさらされます。
ポッドのシークレットを参照
作成されたシークレットは、プライベートレジストリからイメージを取得するために pod/rc またはデプロイメントによって参照できます。シークレットを参照するには、さまざまな方法があります。このセクションでは、pod spec で imagePullSecrets を使用してシークレットを参照する方法をご確認ください。
ImagePullSecret は、Docker (またはその他の) イメージレジストリパスワードを含むシークレットを kubelet に渡す方法で、pod の代わりにプライベートイメージを取得できます。
プライベートリポジトリから Juniper cSRX コンテナをプルするポッドを作成します。
apiVersion: v1
kind: Pod
metadata:
name: csrx-jnpr
labels:
app: csrx
annotations:
k8s.v1.cni.cncf.io/networks: '[
{ "name": "vn-left-1" },
{ "name": "vn-right-1" }
]'
spec:
containers:
#- name: csrx
# image: csrx
- name: csrx
image: hub.juniper.net/security/csrx:18.1R1.9
ports:
- containerPort: 22
#imagePullPolicy: Never
imagePullPolicy: IfNotPresent
stdin: true
tty: true
securityContext:
privileged: true
imagePullSecrets:
- name: secret-jnpr
ここで、pod を生成します。
$ kubectl apply -f csrx/csrx-with-secret.yaml pod/csrx-jnpr created
CSRX は動作しています。
$ kubectl get pod NAME READY STATUS RESTARTS AGE csrx-jnpr 1/1 Running 0 20h
そして背後では、pod はプライベートレジストリに対して自己認証を行い、画像を取得して、cSRX コンテナを起動します。
$ kubectl describe pod csrx ...... Events: 19h Normal Scheduled Pod Successfully assigned ns-user-1/csrx to cent333 19h Normal Pulling Pod pulling image "hub.juniper.net/security/csrx:18.1R1.9" 19h Normal Pulled Pod Successfully pulled image "hub.juniper.net/security/csrx:18.1R1.9" 19h Normal Created Pod Created container 19h Normal Started Pod Started container
このテストで見たように、共有オブジェクトはポッドとは別に作成されます。また、オブジェクト仕様を確認しても、機密性の高い情報が画面上に直接提供されるわけではありません。
機密情報がディスクに書き込まれることはありませんが、その代わりに、必要なノード上でのみ、tmpfs ファイルシステムに保存されます。また、シークレットは、依存している pod が削除されたときにも削除されます。
ほとんどのネイティブ Kubernetes ディストリビューションでは、ユーザーと API サーバー間の通信は SSL/TLS によって保護されています。そのため、これらのチャネル経由で送信される機密情報は、適切に保護することができます。
任意のポッドは、別のポッドによって使用されるシークレットにアクセスできません。これにより、異なるポッド間の機密データのカプセル化が容易になります。ポッド内の各コンテナは、そのボリュームがコンテナ内に表示されるように、ボリュームの機密を要求する必要があります。この機能を使用して、ポッドレベルでセキュリティーパーティションを構築できます。
サービス
Pod がインスタンス化されて終了し、1つのノードから別の node に移動したのに対して、その IP アドレスを変更するには、ポッドから中断のない機能を入手するにはどうすればよいでしょうか。ポッド’が移動しない場合でも、トラフィックはどのようにして1つのエンティティでどのようにポッドのグループに到達するか?
両方の質問に答えることは、Kubernetes のサービスです。
サービスは、ポッドの論理セットとポリシーを定義した抽象化であり、これらにアクセスすることができます。サービスを大きなレストラン–での作業と考えます。このよう’な待機’は、キッチンでのすべての happing の抽象化であり、この1回の処理のみに対処する必要があります。
サービスはレイヤー4ロードバランサーであり、特定の IP およびポートを介して pod 機能を公開します。サービスとポッドは rs のようなラベルを介してリンクされています。さらに’、次の3つのタイプのサービスがあります。
ClusterIP
NodePort
ロード
ClusterIP サービス
ClusterIP サービスは最もシンプルなサービスであり、ServiceType が指定されていない場合の既定のモードです。Figure 4は、clusterip サービスがどのように機能するかを示しています。
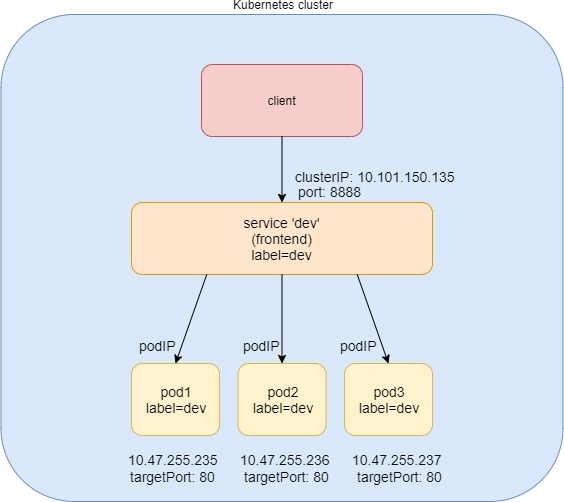
Clusterip サービスが clusterIP および Service port 上で公開されていることがわかります。クライアントがサービスにアクセスする必要がある場合は、この clusterIP および service port に対して要求を送信します。このモデルは、すべての要求が同じクラスター内から送信された場合に最適です。ClusterIP の性質により、サービスの範囲はクラスター内のみに限定されます。概して、デフォルトでは、clusterIP は外部から到達できません。
ClusterIP サービスの作成
#service-web-clusterip.yaml apiVersion: v1 kind: Service metadata: name: service-web-clusterip spec: ports: - port: 8888 targetPort: 80 selector: app: webserver
YAML ファイルは、非常にシンプルでわかりやすいものに見えます。を定義しています service/service-web-clusteripサービスポート8888では、targetPort にマッピングします。これは、一部のポッドのコンテナポート80を意味します。このセレクターは、どの pod がラベルとアプリケーションを使用しているかを示しています。web サーバーは、バックエンドポッドの応答するサービス要求になります。
それでは、次のようにサービスを生成します。
$ kubectl apply -f service-web-clusterip.yaml service/service-web-clusterip created
使用 kubectlサービスおよびバックエンドポッドオブジェクトを迅速に検証するためのコマンド:
$ kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service-web-clusterip ClusterIP 10.101.150.135 <none> 8888/TCP 9m10s app=webserver $ kubectl get pod -o wide -l 'app=webserver' No resources found.
サービスは正常に作成されましたが、サービスのポッドがありません。これは、サービスのセレクターに一致するラベルを持つ pod が存在しないためです。そのため、適切なラベルを持つ pod を作成するだけで済みます。
ここでは、rc を直接定義することもできますが、前述したように rc と導入のメリットが得られます。 (’すぐにわかるでしょう)。
例として、’次のようにして、ウェブサーバという名前の配備オブジェクトを定義してみましょう。
#deploy-webserver-do.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webserver
labels:
app: webserver
spec:
replicas: 1
selector:
matchLabels:
app: webserver
matchExpressions:
- {key: app, operator: In, values: [webserver]} template:
metadata:
name: webserver
labels:
app: webserver
spec:
containers:
- name: webserver
image: contrailk8sdayone/contrail-webserver
securityContext:
privileged: true
ports:
- containerPort: 80
配備されたウェブサーバにはラベルアプリケーションがあります。web サーバを selectorサービスで定義されています。こちらの replicas: 1の時点で1つのポッドを開始するようにコントローラに指示します。見’てみましょう。
$ kubectl apply -f deployment-webserver-do.yaml deployment.extensions/webserver created $ kubectl get pod -o wide -l 'app=webserver' NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE webserver-7c7c458cc5-vl6zs 1/1 Running 0 24s 10.47.255.238 cent333 <none>
そしてすぐに、pod がバックエンドとして選択されます。
前述のその他の概要 kubectl
get svcコマンドの出力は以下のとおりです。
このサービスは、サービス IP プールから割り当てられた10.101.150.135 の clusterIP またはサービス IP を取得しました。
YAML で定義されているのは、サービスポートの8888です。
デフォルトでは、YAML ファイルで宣言されていなければ、プロトコルタイプは TCP です。次のプロトコルを使用できます。Udp サービスを宣言します。
バックエンドポッドはラベルセレクターを使用して見つけることができます。
ここで示す例では、バックエンドポッドを探すために、等式ベースのセレクター (-l) を使用していますが、セットベースの構文を使用して同じ結果をアーカイブすることもできます。たとえば、以下のように記述します。 kubectl get
pod -o wide -l 'app in (webserver)'。
ClusterIP サービスを検証します。
サービスが実際に機能するかどうか’を確認するために、クライアントとして別のポッドを起動して、サービスへの HTTP 要求を開始してみましょう。このテストでは、’クライアントポッドを起動してログインし、curl コマンドを使用して HTTP 要求をサービスに送信します。’このガイド全体で同じ pod をクライアントとして使用して、要求を送信しています。
#pod-client-do.yaml apiVersion: v1 kind: Pod metadata: name: client labels: app: client spec: containers: - name: contrail-webserver image: contrailk8sdayone/contrail-webserver
クライアントポッドを作成します。
$ kubectl apply -f pod-client-do.yaml pod/client created
クライアントポッドは、web サーバ導入とポッドに関係なく、まったく同じ画像を基にした別の pod です。これは、物理サーバーと Vm の場合と同じです。サーバーがクライアント’のジョブの実行を停止することはありません。
$ kubectl exec -it client -- curl 10.101.150.135:8888
<html>
<style>
h1 {color:green}
h2 {color:red}
</style>
<div align="center">
<head>
<title>Contrail Pod</title>
</head>
<body>
<h1>Hello</h1><br><h2>This page is served by a <b>Contrail</b>
pod</h2><br><h3>IP address = 10.47.255.238<br>Hostname =
webserver-7c7c458cc5-vl6zs</h3>
<img src="/static/giphy.gif">
</body>
</div>
</html>
サービスに向かう HTTP 要求が、web サーバーアプリケーションを実行しているバックエンドポッドに達し、HTML ページとして応答します。
どの pod がサービスを提供しているかを’わかりやすくするために、シンプルな web サーバーを実行するカスタマイズされた pod イメージを設定しましょう。Web サーバーは、要求を受信すると、ローカルポッド IP およびホスト名が埋め込まれたシンプルな HTML ページを返すように設定されています。このようにすることで、curl はテストにおいてより意味のあるものを返します。
返された HTML は比較的読みやすいと思われていますが、次のような方法でも簡単に見ることができます。
$ kubectl exec -it client -- curl 10.101.150.135:8888 | w3m -T text/html | head Hello This page is served by a Contrail pod IP address = 10.47.255.238 Hostname = webserver-7c7c458cc5-vl6zs
W3m ツールは、ホストにインストールされた軽量のコンソールベースの web ブラウザーです。W3m で HTML web ページをテキストに表示することができます。これは、HTML よりも読みやすくなっています。
サービスの検証が完了したので、サービスへの要求は、pod IP 10.47.255.238 と、7c7c458cc5-vl6zs のポッド名を使用して、正しいバックエンドポッドにリダイレクトされました。
ClusterIP を指定してください
特定の clusterIP を使用する場合は、スペックに言及できます。IP アドレスは、サービス IP プールに含まれている必要があります。
以下’のサンプル yaml と特定の clusterIP:
#service-web-clusterip-static.yaml apiVersion: v1 kind: Service metadata: name: service-web-clusterip-static spec: clusterIP: 10.101.150.150 #<--- ports: - port: 8888 targetPort: 80 selector: app: webserver
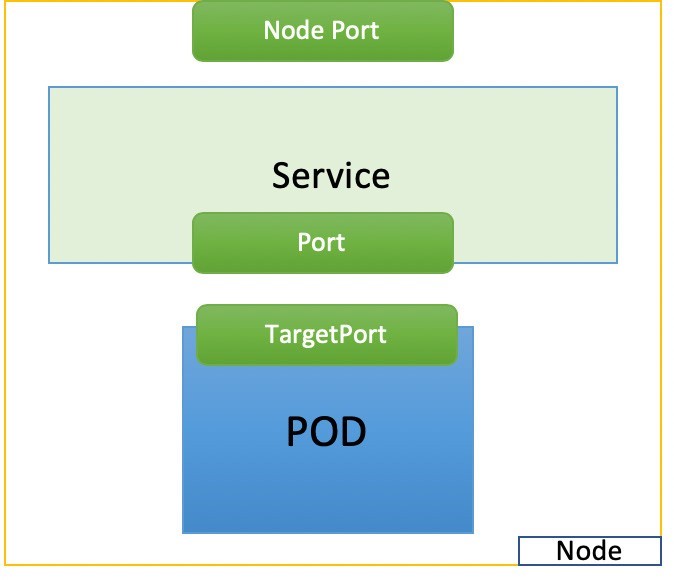
NodePort Service
2つ目の一般的なサービスタイプである NodePort は、静的’なポートの各ノードの IP でサービスを公開します。Figure 5に示すように、各ノードの静的なポートをポッド上のアプリケーションのポートにマッピングします。
#service-web-nodeport apiVersion: v1 kind: Service metadata: name: service-web-nodeport spec: selector: app: webserver type: NodePort ports: - targetPort: 80 port: 80 nodePort: 32001 #<--- (optional)
ここでは、このサービス YAML ファイルのいくつかの特徴を示します。
selector: このサービスの対象となるポッドのセットを決定するラベルセレクター。ここでは、ラベルアプリケーションを使用した任意の pod を示しています。web サーバーは、バックエンドとしてこのサービスによって選択されます。Port: これは、サービスポートです。TargetPort: コンテナー内のアプリケーションによって使用される実際のポート。ここでは’、web サーバーの稼働を計画しているので、it のポート80をご紹介します。NodePort: クラスター内の各ノードのホスト上のポート。
サービス’を作成しましょう。
$ kubectl create -f service-web-nodeport.yaml service "service-web-nodeport" created $ kubectl describe service web-app Name: service-web-nodeport Namespace: default Labels: <none> Annotations: <none> Selector: app=webserver Type: NodePort IP: 10.98.108.168 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 32001/TCP Endpoints: 10.47.255.228:80 Session Affinity: None External Traffic Policy: Cluster Events: <none>
種デフォルトのサービスタイプは
ClusterIP。この例では、型をNodePort。NodePort: デフォルトでは、Kubernetes はノードポートが仕様に記載されていない場合は、30000-32767 の範囲内で割り当てます。これはフラグを使用して変更できます。--service-node-port-range。こちらのNodePort値を設定することもできますが、’構成された範囲内にあることを確認してください。Endpoints: PodIP と公開コンテナポートがあります。サービス IP およびサービスポートへの要求はここで指示されますが、10.47.255.252:80 は、サービスに一致するラベルを持つ pod を作成していることを示しています。この IP はバックエンドの1つとして選択されます。
このテストには、少なくとも1つの pod がラベルに含まれていることを確認してください。 app:webserver,. 以前のセクションのポッドはすべてこのラベルで作成されます。クライアントポッドを再作成する’ことにより、既に削除してしまった場合には十分です。
ここでは、curl コマンドを使用して、ノードの IP アドレスへの HTTP リクエストをトリガーすることで、これをテストできます。
$kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE client 1/1 Running 0 20m 10.47.255.252 cent222 <none>
NodePort サービスの機能により、pod で実行されている web サーバーに nodePort 32001 を介して任意のノードからアクセスできます。
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP ... KERNEL-VERSION CONTAINER-RUNTIME
cent111 NotReady master 100d v1.12.3 10.85.188.19 ... 3.10.0-957.10.1.el7.x86_64 docker://18.3.1 cent222
Ready <none> 100d v1.12.3 10.85.188.20 ... 3.10.0-957.10.1.el7.x86_64 docker://18.3.1 cent333 Ready
<none> 100d v1.12.3 10.85.188.21 ... 3.10.0-957.10.1.el7.x86_64 docker://18.3.1
$ curl 10.85.188.20:32001
<html>
<style>
h1 {color:green}
h2 {color:red}
</style>
<div align="center">
<head>
<title>Contrail Pod</title>
</head>
<body>
<h1>Hello</h1><br><h2>This page is served by a <b>Contrail</b>
pod</h2><br><h3>IP address = 10.47.255.228<br>Hostname
= client</h3>
<img src="/static/giphy.gif">
</body>
</div>
</html>
ロードバランサーサービス
ロードバランサーサービスの3つ目のサービスでは、クラウドプロバイダ’のロードバランサーを使用してサービスを外部から公開することで、nodeport サービスを超えて1ステップ進んでいます。その性質によって、ロードバランサーサービスには、NodePort と ClusterIP サービスのすべての機能が自動的に組み込まれます。
クラウドプロバイダ上で実行されている Kubernetes クラスターは、ロードバランサーの自動プロビジョニングをサポートしています。3つのサービスの違いは、type 値のみです。同じ NodePort service YAML ファイルを再利用し、ロードバランサーサービスを作成するには、タイプを LoadBalancer に設定するだけです。
#service-web-lb.yaml apiVersion: v1 kind: Service metadata: name: service-web-lb spec: ports: - port: 8888 targetPort: 80 selector: app: webserver type: LoadBalancer #<---
クラウドはこのキーワードを認識し、ロードバランサーが作成されます。一方で、外部のパブリック負荷 balancerIP はフロントエンドの仮想 IP として機能するように割り当てられています。この loadbalancerIP に着信するトラフィックは、サービスバックエンドのポッドにリダイレクトされます。このリダイレクトプロセスは単なるトランスポートレイヤー操作であることに注意してください。LoadbalancerIP とポートは、プライベートバックエンドの clusterIP およびその’ターゲットポートに変換されます。アプリケーションレイヤーのアクティビティは含まれていません。HTTP プロキシプロセスの場合と同様に、URL、プロキシ HTTP リクエストなどを解析することは何もありません。LoadbalancerIP が公開されているため、it (およびサービスポート) にアクセス可能な任意のインターネットホストが、Kubernetes クラスターによって提供されるサービスにアクセスできるようになっています。
インターネットのホスト’s の視点から見ると、サービスを要求したときに、このパブリック外部 loadbalancerIP とサービスポートが参照され、要求はバックエンドポッドに到達します。LoadbalancerIP は、クラスター内および外部のサービス間のゲートウェイとして機能しています。
一部のクラウドプロバイダでは、 loadBalancerIP。そのような場合は、ユーザーが指定した loadBalancerIP を使用してロードバランサーが作成されます。LoadBalancerIP フィールドが指定されていない場合、ロードバランサーは一時的な IP アドレスを使用して設定されます。LoadBalancerIP を指定しても、クラウドプロバイダがこの機能をサポートしていない場合、設定した loadbalancerIP フィールドは無視されます。
ロードバランサーサービスに実装されている負荷分散機器は、ベンダーによって異なります。GCE ロードバランサーは、AWS ロードバランサーとまったく異なる方法で動作することがあります。第4章の Contrail Kubernetes 環境でロードバランサーサービスがどのように機能するかについて詳しく説明します。
外部 IPs
また、クラスター外のサービスを公開するには、 externalIPsボタン. ここ’で例を示します。
#service-web-externalips.yaml apiVersion: v1 kind: Service metadata: name: service-web-externalips spec: ports: - port: 8888 targetPort: 80 selector: app: webserver externalIPs: #<--- - 101.101.101.1 #<---
の Serviceスペシフィケーションでは、externalIPs を任意のサービスタイプとともに指定できます。外部 IPs は Kubernetes によって管理されておらず、クラスター管理者が責任を持っています。
外部 IPs は loadbalancerIP とは異なり、クラスター管理者によって IP アドレスが割り当てられているのに対し、外部 ip はそれをサポートするクラスターによって作成されたロードバランサーを備えています。
サービスの実装: Kube
デフォルトでは、Kubernetes はサービスに対して kube プロキシーモジュールを使用しますが、CNI のプロバイダはサービスに独自の実装を持つことができます。
Kube は、次の3つのモードのいずれかで導入できます。
ユーザー空間プロキシモード
iptables プロキシモード
ipvs プロキシモード
ノードが通過すると、トラフィック’は、導入された kube の転送プレーンを経由して、バックエンドポッドの1つに転送されるようになります。この3つのモードの詳細な説明と比較は、本書では説明されていませんが、Kubernetes の公式 web サイトで詳細情報を確認できます。第4章では、コンテナネットワークインターフェイス (CNI) プロバイダとして Contrail を Juniper して、サービスを実装する方法を示します。
エンドポイント
これまでに紹介’したオブジェクトが1つあります。EP、またはエンドポイントです。ここ’では、ラベルセレクターを使用してバックエンドとして特定の pod またはポッドが選択されていることがわかりました。そのため、サービスリクエストトラフィックはそのグループにリダイレクトされます。一致するポッドの IP およびポート情報は、エンドポイントオブジェクトに保持されます。ポッドが消滅して、いつでも生成されることがあります。そのため、pod の mortal の性質により、新しいポッドが新たな IP アドレスで追加される可能性があります。この動的なプロセスでは、エンドポイントは常に更新され、現在のバックエンドポッド IPs が反映されるため、サービストラフィックのリダイレクトが適切に動作するようになります。(CNI プロバイダが独自のサービス実装を保有している場合は、エンドポイントオブジェクトに基づいてサービスのバックエンドを更新します)。
ここでは、サービス、対応するエンドポイント、および pod とラベルが一致することを検証するためのクイックステップをいくつか示します。
サービスを作成するには、次のようにします。
#service-web-clusterip.yaml apiVersion: v1 kind: Service metadata: name: service-web-clusterip spec: ports: - port: 8888 targetPort: 80 selector: app: webserver $kubectl apply -f service-web-clusterip.yaml service/service-web-clusterip created
エンドポイントのリストを表示するには
サービスのセレクターによって使用されるラベルを持つ pod を探すには、以下のようにします。
最後に、バックエンドポッドを拡張します。
ここで、エンドポイントを再びチェックして、それに応じて更新されたことを確認します。
セレクターなしのサービス
上記の例では、サービスが作成されるたびに Kubernetes システムによって自動的にエンドポイントオブジェクトが生成され、同じラベルが付いた pod が少なくとも1つ存在します。ただし、別のエンドポイントの使用事例としては、ラベルセレクターが定義されておらず、エンドポイントオブジェクトを手動で追加’することにより、サービスをネットワークアドレスとポートに手動で割り当てることができるサービスがあります。その後、エンドポイントをサービスに接続できます。これは、たとえば、物理サーバー上で実行されているバックエンド web サーバーが存在する設定など、状況によっては、Kubernetes サービスに統合する必要がある場合などに、非常に便利です。そのような場合は、通常どおりにサービスを作成してから、web サーバーを指すアドレスとポートを持つエンドポイントを作成するだけです。それ’だけではないでしょうか。このサービスはバックエンドタイプを気にすることなく、すべてのバックエンドが pod であるかのように、サービスリクエストトラフィックを正確にリダイレクトするだけです。
入口
ここまでは’、クラスター外のクライアントにサービスを公開する方法について見てきましたが、別の方法も入口になっています。サービスセクションでは、サービスはトランスポート層で機能します。実際には、Url を使用してすべてのサービスにアクセスします。
Kubernetes のコアの概念としては、サービスに存在しない HTTP/HTTPS ルーティングを可能にするものがあります。受信は、サービスの上に構築されています。入口では、URL ベースルールを定義して、複数の異なるバックエンドサービスに HTTP/HTTPS ルートを分散させることができます。そのため、受信は HTTP/HTTPS ルート経由でサービスを公開します。その後、リクエストは各サービス’に対応するバックエンドポッドに転送されます。
入口とサービス
ロードバランサーサービスと受信の間には共通点があります。どちらもクラスター外のサービスを公開できますが、いくつかの大きな違いがあります。
運用レイヤー
受信は OSI ネットワークモデルのアプリケーションレイヤーで動作しますが、サービスはトランスポートレイヤーでのみ動作します。受信した HTTP/HTTPS プロトコルは、IP とポートに基づいた enacts フォワーディングを理解しているため、アプリケーションレイヤープロトコル (HTTP/HTTPS) の詳細については関知しません。受信はトランスポートレイヤーで動作しますが、サービスは同じことを’行いますが、そのための特別な理由がなければ、それを受信しても意味がありません。
転送モード
受信するアプリケーションレイヤープロキシは、従来の web ロードバランサーとほぼ同じように機能します。マシン A (クライアント) と B (サーバー) の間に置かれた典型的な web ロードバランサープロキシは、アプリケーションレイヤーで動作します。アプリケーションレイヤープロトコル (HTTP/HTTPS) を認識しているため、クライアントとサーバー間の相互作用はロードバランサーに対して透過的に見えません。基本的には、送信元、(A)、宛先 (B)、機械の2つの接続が作成されます。機械 A はマシン B の存在についても認識していません。機械 A では、プロキシが話しているだけで、プロキシがどこでデータを取得しているのかについては関知しません。
パブリック Ip の数です。
受信する各サービスは、クラスターの外部に直接公開されている場合、パブリック IP を必要とします。これらのサービスのフロントエンドで入口が出てくると、1つのパブリック IP だけで十分です。クラウド管理者にとっては簡単です。
受信オブジェクト
入口オブジェクトについて詳しく説明する前に、YAML 定義を確認しておくことをお勧めします。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-sf spec: rules: - host: www.juniper.net http: paths: - path: /dev backend: serviceName: webservice-1 servicePort: 8888 - path: /qa backend: serviceName: webservice-2 servicePort: 8888
これは非常にシンプルであることがわかります。この仕様では、ルール–である1つの項目だけが定義されています。このルールは、ホスト (ここでは Juniper URL) が URL 文字列で2つのパスを持つ場合があるということを示しています。このパスは、URL 内のホストの後に続くもので、この場合は/dev と/qa. が該当します。その後、各パスは別のサービスに関連付けられます。受信した HTTP 要求が到着すると、そのバックエンドサービスに関連付けられた各 URL パスにトラフィックがプロキシされます。このサービスセクションで学習’したように、各サービスは、対応するバックエンドパスに要求を配信します。’そうですね実際、これは、Kubernetes が今日–のシンプルなファンアウト受信をサポートする、3種類の受信タイプの1つです。その他の2種類の入口については、この章の後半で説明します。
URL、ホスト、パスについて
ホストとパスという用語は、Kubernetes 入口のマニュアルで頻繁に使用されています。このホストは、サーバーの完全修飾ドメイン名です。パス、または url パスは、URL 内のホストの後の残りの文字列部分です。サポートされている場合、URL にポートがある場合は、ポートの後の文字列になります。
次の URL をご覧ください。
http://www.juniper.net:1234/my/resource host port path http://www.juniper.net/my/resource host path
この例では、www.juniper.net は、ポート1234をパス、my/resource という名前で示しています。URL にポートがない場合は、host の次の文字列がパスになります。詳細については、RFC 1738 を参照してください。ただし、このガイドの目的は、ここで何が導入されているかを理解することで十分です。
Kubernetes の入口がいくつかのルールを定義していることを考えると、このルールは、Url に基づいて別のサービスに着信要求を送信するようシステムに指示するだけではありません。Figure 6は、3つの Kubernetes オブジェクト間の interdependency を示しています。入口、サービス、ポッド
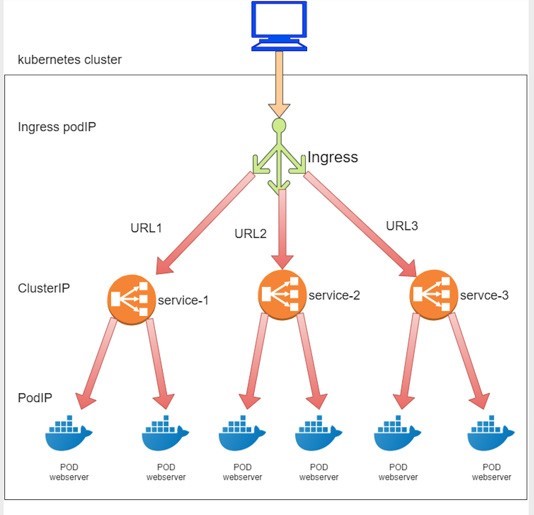
実際には、受信ルールを処理するために、その他に理解しておく必要があることがあります。この場合、受信コントローラーと呼ばれる少なくとも1つのコンポーネントが必要になります。
受信コントローラ
受信したコントローラーは、受信ルールを読み取ってから、ルールをプロキシにプログラミングします。これに–より、ホスト/URL に基づいてトラフィックのリアルタイムのディスパッチが行われます。
受信コントローラは、通常、サードパーティーベンダーによって実装されています。クラスターのニーズに応じて、さまざまな Kubernetes 環境で受信コントローラが異なります。受信する各コントローラは、入口ルールをプログラミングする独自の実装を備えています。結論として、クラスター内では入口のコントローラが必要です。
入口コントローラプロバイダには以下のものがあります。
nginx
gce
haproxy
パソコン
f5
i・ o
表面
1つのクラスター内に任意の数の受信コントローラを導入できます。受信用の作成時には、各受信に注釈を付けて、使用する受信コントローラを指定する必要があります (クラスター内に複数存在する場合)。
入口オブジェクトで使用されるアノテーションについては、「アノテーション」セクションを参照してください。
入口の例
Ingresses には次の3種類があります。
単一のサービスの入口
シンプルな Fanout の入口
名前ベースのバーチャルホスティングの入口
’Fanout のシンプルな入口について見てきまし’た。そのため、他の2種類の受信のための yaml ファイルの例を見てみましょう。
単一のサービスの入口
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-single-service spec: backend: serviceName: webservice servicePort: 80
これは入口の最もシンプルな形態です。受信には外部 IP が設定されるため、サービスをパブリックに公開できます。ただし、ルールが定義されていないため、Url 内のホストやパスを解析することはありません。すべての要求は同じサービスに送られます。
シンプルな Fanout の入口
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-sf spec: rules: - host: www.juniper.net http: paths: - path: /dev backend: serviceName: webservice-1 servicePort: 8888 - path: /qa backend: serviceName: webservice-2 servicePort: 8888
このセクションの冒頭で、このことをご確認しました。単一のサービスの入口と比較して、シンプルな fanout の入口がより実用的です。’パブリック IP 経由でサービスを公開するだけでなく、パスに基づいて URL のルーティングやファンアウトを実行することもできます。これは、ドメイン名の後に URL のサフィックスを基にして、各部門’の専用サーバーにトラフィックを送信するという、非常に一般的な使用事例です。
バーチャルホストの入口
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-virutal-host spec: rules: - host: www.juniperhr.com http: paths: - backend: serviceName: webservice-1 servicePort: 80 - host: www.junipersales.com http: paths: - backend: serviceName: webservice-2 servicePort: 80
名前ベースの仮想ホストは、ルールベースの URL ルーティングを実行できるという点で、シンプルな fanout 入口に似ています。このタイプの受信は、同じ IP アドレスで複数のホスト名への HTTP トラフィックのルーティングをサポートしているという、ユニークな受信能力です。この例は実用的ではないかもしれません (2 つのドメインが統合されている場合を除く)。そのアイデアをお勧めします。Yaml ファイルでは、2つのホストが定義されています。 “juniperhr”と“junipersales” URL がそれぞれ設定されています。URL 内のホストに基づいて1つのパブリック IP のみで受信が割り当てられる場合でも、同じパブリック IP への要求は、別のバックエンドサービスにルーティングされます。その理由は、仮想ホスティングの入口と呼ばれて’おり、第4章では詳細な導入事例をご紹介します。’
また、シンプルな fanout 入口とバーチャルホストを1つに結合することもできますが、ここでは詳細は説明していません。
複数の入口コントローラ
1つのクラスターに複数の受信コントローラを持たせることができますが、クラスターはどちらを選択すべきかを把握している必要があります。たとえば第 4’章では、Contrail’の内蔵型受信コントローラについて説明します。この場合、nginx の入口コントローラーのようなサードパーティー製の受信コントローラをインストールしてしまうことはありません。その代わりに、同じクラスター内に次の名前を持つ2つの受信コントローラを用意します。
opencontrail (デフォルト)
nginx
Contrail’の実装がデフォルトであるため’、特に選択する必要はありません。Nginx を受信コントローラとして選択するには、この注釈を使用します。Kubernetes.io/ingress.class:
metadata: name: foo annotations: Kubernetes.io/ingress.class: "nginx"
これにより Contrail’の入口コントローラ opencontrail は、入口設定を無視するように指示されます。
Kubernetes ネットワークポリシー
Kubernetes のネットワークモデルでは、デフォルトですべてのポッドが他のすべてのポッドにアクセスできることが求められています。これは「フラットネットワーク」と呼ばれるのは、どのモデルでも続いているからです。Kubernetes ネットワークの設計と実装が大幅に簡素化され、拡張性が大幅に高まります。
第4章では、Kubernetes がネットワーク実装に適用する要件について説明します。
セキュリティは重要な問題です。実際には、特定のレベルのネットワークセグメンテーション方式で、一部のポッドのみが相互に通信できるようにし、Kubernetes のネットワークポリシーが画像に含まれていることを確認する必要があります。Kubernetes のネットワークポリシーは、VM インスタンスへのアクセスを制御するためにクラウドのセキュリティグループを使用する場合と同じ方法で、ポッドのグループに対してアクセス許可を定義します。
Kubernetes は、Kubernetes のリソースである NetworkPolicy オブジェクトを介してネットワークポリシーをサポートしています。これは、ポッド’、サービス、入口など、この章で先に学習した多くの他の人と同様です。ネットワークポリシーオブジェクトの役割は、ポッドのグループ間の通信をどのように許可するかを定義することです。
Kubernetes’ネットワークポリシーの仕組みをご確認ください。
1 Kubernetes クラスター内では、すべてのポッドがデフォルトで非分離され、すべての pod が任意のモデルで動作するようになっています。そのため、任意のポッドで他の pod と通信できます。
2. ここで、policy1 という名前のネットワークポリシーをポッド A に適用します。ポリシー policy1 では、pod A が pod B との通信を明示的に許可するルールを定義します。この場合、発信’側ポッドは、ネットワークポリシーの適用対象となるポッドであるため、ポッドによって pod として使用されます。
3. この瞬間には、以下のようなことが起こります。
ターゲットポッド A は pod B と通信できます。また、B がポリシーで許可されている唯一の pod であるため、ポッド b にのみ接続できます。ポリシールールの性質により、このルールをホワイトリストと呼ぶことができます。
ターゲットポッド A のみの場合、このネットワークポリシー policy1 のホワイトリストで明示的に許可されていない接続は拒否されます。’Policy1 は、Kubernetes のネットワークポリシーの性質によって適用されるため、明示的に定義する必要はありません。ここ’では、この暗黙のポリシーを「すべて拒否」ポリシーを呼び出してみましょう。
たとえば、policy1 やその他のネットワークポリシーには適用されない pod B や pod C などのターゲット化していないポッドの場合も、any モデルに従って処理が継続されます。そのため、影響を受けずに、クラスター内の他のすべてのポッドとの通信を続けることができます。これはもう1つの暗黙のポリシーであり、すべてのポリシーが許可されています。
Pod A が pod C と通信できるようにする場合は、ネットワークポリシー policy1 とルールを更新して、明示的に許可する必要があります。言い換えると、ホワイトリストを更新して、トラフィックのタイプ数を増やすことができるようにしておく必要があります。
ご覧のように、ポリシーを定義すると、少なくとも3つのポリシーがクラスターに適用されます。
明示的 policy1: これは、定義したネットワークポリシーです。ホワイトリストルールを使用して、選択した (ターゲット) ポッドに特定タイプのトラフィックを許可します。
暗黙的拒否すべてのネットワークポリシー: これにより、ターゲットポッドのホワイトリストに含まれていないその他すべてのトラフィックが拒否されます。
暗黙的に許可されるすべてのネットワークポリシー: これにより、policy1 によって選択されていないその他のターゲットではないポッドに対して、その他すべてのトラフィックを許可します。’「すべて拒否」と「すべてのポリシーをもう一度許可する」については、「第8章」をご覧ください。
ここでは、Kubernetes ネットワークポリシーの概要を示します。
Pod 固有: ネットワークポリシーの仕様は、rc や導入 do と同様に、ラベルに基づいて1つのポッドまたはポッドのグループに適用されます。
ホワイトリストベースのルール: ホワイトリストを構成する明示的なルール。各ルールには、許可する特定タイプのトラフィックが記述されています。このホワイトリストのルールに記載されていないその他のトラフィックはすべて、ターゲットポッド用に削除されることになります。
暗黙的に許可: ポッドは、ターゲットとしてネットワークポリシーによって選択された場合にのみ影響を受け、選択したネットワークポリシーによってのみ影響を受けます。Pod にネットワークポリシーが適用されていない場合は、この pod にすべてのポリシーを許可することが暗示的に示されています。つまり、非ターゲットポッドが任意のネットワークモデルを継続する場合は、
入口と出口の分離: ポリシールールは特定の方向に定義されている必要があります。方向には、入口、出口、なし、またはその両方を指定できます。
フローベース (パケットベースの比較): 開始パケットが許可されると、同じフローのリターンパケットも許可されます。たとえば、ポッド A に適用された受信ポリシーが受信 HTTP 要求を許可したとすると、HTTP 相互作用全体が pod A に許可されます。これには、双方向 TCP 接続の確立とすべてのデータおよび肯定応答が、どちらの方向にも含まれています。
ネットワークポリシーはネットワークコンポーネントによって実装されるため、ネットワークポリシーをサポートするネットワークソリューションを使用する必要があります。これを実装するためのコントローラがない状態でネットワークポリシーリソースを作成しただけでは、効果はありません。このガイドでは、Contrail はネットワークポリシーが実装されたネットワークコンポーネントを使用しています。第8章では’、これらのネットワークポリシーが Contrail でどのように機能するかをご紹介します。
ネットワークポリシーの定義
Kubernetes のその他すべてのオブジェクトと同様に、ネットワークポリシーは YAML ファイルで定義できます。例’を見てみましょう (第8章では同じ例を使用しています)。
#policy1-do.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy1 namespace: dev spec: podSelector: matchLabels: app: webserver-dev policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 10.169.25.20/32 - namespaceSelector: matchLabels: project: jtac - podSelector: matchLabels: app: client1-dev ports: - protocol: TCP port: 80 egress: - to: - podSelector: matchLabels: app: dbserver-dev ports: - protocol: TCP port: 80
他’のセクションが自明であるため、この yaml ファイルのスペック部分を見てみましょう。この仕様は次のような構造になっています。
spec: podSelector: ...... policyTypes: - Ingress - Egress ingress: - from: ...... egress: - to: ......
ここでは、ネットワークポリシー定義 YAML ファイルを論理的に4つのセクションに分けることができることをご確認いただけます。
podSelector: ここで選択したポッドが定義されます。現在のネットワークポリシーが適用されるポッドを識別します。
policyTypes: ポリシールールのタイプを指定します。入口、出口、またはその両方。
入口ターゲットポッドの入口ポリシールールを定義します。
エグレスターゲットポッドの送信ポリシールールを定義します。
次に’、各セクションについて詳しく見ていきましょう。
ターゲットポッドの選択
ネットワークポリシーを定義する場合、Kubernetes はこのポリシーの適用対象となるポッドを知る必要があります。サービスがバックエンドポッドを選択する方法と同様に、ネットワークポリシーはラベルに基づいて、適用されるポッドを選択します。
podSelector: matchLabels: app: webserver-dev
ここでは、ラベルが付いたすべてのポッド app: webserver-devは、ネットワークポリシーによってターゲットポッドとして選択されています。以下の仕様の内容はすべて、ターゲットポッドのみに適用されます。
ポリシータイプ
2つ目のセクションでは、 policyTypesターゲットポッドの場合:
policyTypes: - Ingress - Egress
PolicyTypes は、入口、出口、または両方のいずれかです。さらに、次に説明するように、どちらのタイプも、1つ以上のルールの形式で特定のトラフィックタイプを定義します。
ポリシールール
入口と出口のセクションは、選択されたターゲットポッド’の視点から、トラフィックの方向を定義します。たとえば、次のような簡素化された例を考えてみましょう。
ingress: - from: - podSelector: matchLabels: app: client1-dev ports: - protocol: TCP port: 80 egress: - to: - podSelector: matchLabels: app: client1-dev ports: - protocol: TCP port: 8080
ターゲットポッドが webserver-dev pod で、クラスター内に pod client1-dev が1つしかない場合は、次のような2点が発生します。
入口の方向: pod webserver は、pod client1 から開始した宛先ポート80との間で TCP セッションを受け入れることができます。これは、パケットベースではなく Kubernetes のネットワークポリシーがフローベースであると回答した理由を示しています。TCP 接続を確立できませんでした。このポリシーがパケットベースで設計されている場合、受信 tcp 同期を受信するときに、送信 TCP 同期-ack を返すことが拒否されます。対応する発信ポリシーはありません。
出口方向: pod webserver は、宛先ポート8080を使用して TCP セッションを開始できます。
送信接続を通過するために、もう1つの終端は受信接続を許可する入口ポリシーを定義する必要があります。
ネットワークポリシールール
From または to ステートメントごとに、ネットワークポリシーのルールを定義します。
From 文は、入口ポリシールールを定義します。
A to 文は、送信ポリシールールを定義します。
どちらのルールでも、オプションでポート文を指定できます。これについては後ほど説明します。
そのため、複数のルールを定義して、それぞれの方向に複雑なトラフィックモードを許可することができます。
ingress: INGRESS RULE1 INGRESS RULE2 egress: EGRESS RULE1 EGRESS RULE2
各ルールは、ターゲットポッドが通信できるネットワークエンドポイントを識別します。ネットワークエンドポイントは、さまざまな方法で特定できます。
ipBlock: IP アドレスブロックに基づいてポッドを選択します。
namespaceSelector: 名前空間のラベルに基づいてポッドを選択します。
podSelector: ポッドのラベルに基づいてポッドを選択します。
PodSelector は、YAML ファイルの異なる場所で使用されたときに、異なる項目を選択します。以前 (仕様下)、ネットワークポリシーが適用されるポッドを選択しまし’た。これはターゲットポッドと呼ばれていました。ここでは、ルール (from または to の下) で、ターゲットポッドが通信するポッドを選択します。このような podピアリングポッドを呼び出すこともあります。
このため、ルールの YAML 構造は次のようになります。
ingress: - from: - ipBlock: ..... - namespaceSelector: ..... - podSelector: ..... ports: ......
たとえば、以下のように記述します。
ingress: - from: - ipBlock: cidr: 10.169.25.20/32 - namespaceSelector: matchLabels: project: jtac - podSelector: matchLabels: app: client1-dev ports: - protocol: TCP port: 80 egress: - to: - podSelector: matchLabels: app: dbserver-dev ports: - protocol: TCP port: 80
ここでは、入口ネットワークエンドポイントはサブネット 10.169.25.20/32 です。または、次のラベルプロジェクトを持つ名前空間のすべてのポッド: jtacまたは、ラベルアプリケーションを持つポッド: client1-現在の名前空間 (ターゲットポッドの名前空間) 内の dev、送信ネットワークポイントは pod dbserver-dev です。’すぐにポートの部分に到達します。
または
’また、すべてのポッドと通信するのではなく、名前空間の一部のポッドだけを指定することもできます。この例では、podSelector はすべて使用され、ターゲットポッドと同じ名前空間を前提としています。もう1つの方法は、namespaceSelector と共に podSelector を使用することです。この場合、ポッドが属する名前空間は、ターゲット pod’s の名前空間とは異なり、namespaceSelector と一致するラベルを持つものです。
たとえば、ターゲットポッドが webserver で、名前空間が dev であると仮定すると、ネームスペース qa のみが namespaceSelector というラベルを持つことになります。
ingress: - from: - namespaceSelector: matchLabels: project: qa podSelector: matchLabels: app: client1-qa
ここでは、ターゲットポッドは、名前空間の qa にあるポッド (またはラベルではない) とのみ通信できます。 app:
client1-qa。
ここでは、以下の定義とはまったく異なるので注意してください。ターゲットポッドは、以下のようなポッドと通信できます。名前空間で qaまたは (not AND) ラベル付き app: client1-qaターゲットポッド’s の名前空間 dev:
ingress: - from: - namespaceSelector: matchLabels: project: qa - podSelector: matchLabels: app: client1-qa
プロトコルとポート
入口と出口のルールのポートを指定することもできます。プロトコルタイプとプロトコルポートを同時に指定することもできます。たとえば、以下のように記述します。
egress: - to: - podSelector: matchLabels: app: dbserver-dev ports: - protocol: TCP port: 80
受信したポートは、ターゲットポッドが、指定されたポートとプロトコルの着信トラフィックを許可できることを伝えます。送信のポートは、ターゲットポッドが特定のポートとプロトコルへのトラフィックを開始できることを述べています。ポートが記載されていない場合は、すべてのポートとプロトコルが許可されます。
ラインバイラインの説明
次’の例をもう一度詳しく見てみましょう。
podSelector: matchLabels: app: webserver-dev policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 10.169.25.20/32 - namespaceSelector: matchLabels: project: jtac - podSelector: matchLabels: app: client1-dev ports: - protocol: TCP port: 80 egress: - to: - podSelector: matchLabels: app: dbserver-dev ports: - protocol: TCP port: 80
ネットワークポリシーが適用しようとしていることを正確に把握する必要があります。
ライン 1-3: pod webserver-dev はポリシーによって選択されるため、ターゲットポッドとなります。以下のポリシールールがすべて適用されます。
ライン 4-6: このポリシーでは、受信/送信トラフィックの両方のルールが定義されます。
ライン 7-19: 入口セクションでは、受信ポリシーを定義しています。
ライン 8: 差出人:とライン 17: この2つのセクションでは、入口ポリシーにおける1つのポリシールールを定義しています。
ライン 9-16: 以下の8行が from: セクションでは、入口のホワイトリストを作成します。
ライン 9-10: 送信元 IP が 10.169.25.20/32 であるすべての受信データは、ターゲット pod webserver-dev にアクセスできます。
ライン 11-13: 名前空間 jtac 下の任意のポッドから、ターゲットポッド webserver-dev にアクセスできます。
ライン 14-16: ラベル client1 で使用される任意のポッドは、ターゲット pod web サーバ-dev にアクセスできます。
ライン 17-19: ports セクションは、同じポリシールールの2つ目 (オプション) の一部になっています。ターゲットポッド webserver では、TCP ポート 80 (web サービス) のみが公開され、アクセスできます。その他すべてのポートへのアクセスは拒否されます。
ライン 20-26: エグレスセクションでは、送信ポリシーを定義しています。
21行: 目的:とライン 24: これらの2つのセクションでは、送信ポリシーにおける1つのポリシールールを定義しています。
ライン 21-24: 以下の4行を対象としています。セクションでは、出力ホワイトリストを作成します。ここで、ターゲットポッドは、出力トラフィックを pod dbserver に送信できます。
ライン 25: ports セクションは、同じポリシールールの2番目の部分です。ターゲットポッドの pod は、宛先ポートが80の TCP セッションのみを、他のポッドに対してのみ起動できます。
’それだけではありません。この章の冒頭で覚えていると思いますが、Kubernetes デフォルトのネットワークモデルと暗黙で拒否するすべてのポリシーについて説明したところで、これまでに it の明示的な部分であることを理解しています (『 the network policy イントロダクション』セクションを参照してください)。その後、さらに暗黙のポリシーが2つあります。
すべてのネットワークポリシーを拒否します。ターゲット pod webserver 開発において、上記のホワイトリストで明示的に許可されている以外のすべてのトラフィックを拒否します。これには、少なくとも2つのルールが必要です。
入口入口ホワイトウェブに記載されている受信トラフィックをすべて拒否します。このようなものは、入り口で定義されるものとは異なります。
エグレス出力ホワイトリストで定義されているものを除く、対象の pod ウェブサーバから送出するすべての送信トラフィックを拒否します。
[すべてのネットワークポリシーを許可] では、このネットワークポリシーのターゲットではないその他のポッドのすべてのトラフィックが、入口と出口の両方で許可されます。
第8章で’は、これらの暗黙のネットワークポリシーと、Contrail 実装におけるそれらのルールについて詳しく見ていきましょう。
ネットワークポリシーの作成
他の Kubernetes オブジェクトを作成するのと同じ方法で、ネットワークポリシーを作成して検証することができます。
$ kubectl apply -f policy1-do.yaml networkpolicy.networking.k8s.io/policy1-do created $ kubectl get netpol -n dev NAME POD-SELECTOR AGE policy1 app=webserver-dev 6s $ kubectl describe netpol policy -n dev Name: policy1 Namespace: dev Created on: 2019-10-01 11:18:19 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: app=webserver-dev Allowing ingress traffic: To Port: 80/TCP From: IPBlock: CIDR: 10.169.25.20/32 Except: From: NamespaceSelector: project=jtac From: PodSelector: app=client1-dev Allowing egress traffic: To Port: 80/TCP To: PodSelector: app=dbserver-dev Policy Types: Ingress, Egress
第 8’章では、このネットワークポリシーの効果をより詳しく検証するためのテスト環境を設定します。
活性プローブ
Pod 内のアプリケーションが動作している場合にはどう’なりますか? それとも、何らかの理由で主要な目的を果たすことができますか? また、長時間実行されるアプリケーションは壊れた状態に移行することがありますが、これが最後に必要な場合は、pod を再起動して簡単に解決できるアプリケーションの問題を報告することをお勧めします。活性プローブは、この種の状況に特化した Kubernetes の機能です。事前定義された要求を定期的に pod に送信し、その要求が失敗した場合には pod を再起動します。最も一般的に使用されている活性プローブは HTTP GET 要求ですが、TCP ソケットを開くことも、コマンドを発行できます。
次は HTTP GET request probe の例であり、 initialDelaySecondsは、ポート80への最初の HTTP GET 要求を試みる前の待機時間であり、その後、プローブは20秒ごとに実行されます。 periodSeconds。これが失敗した場合、ポッドが自動的に再起動します。ここでは、パスを指定するためのオプションとして、メイン web サイトのみを示しています。また、カスタマイズされたヘッダーを使用してプローブを送信することもできます。簡単に見てみましょう。
apiVersion: v1 kind: Pod metadata: name: liveness-pod labels: app: tcpsocket-test spec: containers: - name: liveness-pod image: contrailk8sdayone/ubuntu ports: - containerPort: 80 securityContext: privileged: true capabilities: add: - NET_ADMIN livenessProbe: httpGet: path: / port: 80 httpHeaders: - name: some-header value: Running initialDelaySeconds: 15 periodSeconds: 20
ここで’、この pod を起動し、次にログインして HTTP GET 要求を処理するプロセスを終了させます。
[root@cent11 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE liveness-pod 1/1 Running 0 114s [root@cent11 ~]# kubectl exec -it liveness-pod bash root@liveness-pod:/# sudo netstat -tulpn Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 111/apache2 tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 45/sshd tcp6 0 0 :::22 :::* LISTEN 45/sshd root@liveness-pod:/# service apache2 stop * Stopping web server apache2 * root@liveness-pod:/# sudo netstat -tulpn Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 45/sshd tcp6 0 0 :::22 :::* LISTEN 45/sshd [root@cent11 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE liveness-pod 1/1 Running 1 5m33s
Pod が自動的に再起動されたことを確認できます。また、再起動の理由をイベントで確認することもできます。
Killing container with id docker://liveness-pod:Container failed liveness probe. Container will be killed and recreated.
[root@cent11 ~]# kubectl describe pod liveness-pod
Name: liveness-pod
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: cent22/10.85.188.17
Start Time: Fri, 05 Jul 2019 16:39:12 -0400
Labels: app=tcpsocket-test
Annotations: k8s.v1.cni.cncf.io/network-status:
[
{
"ips": "10.47.255.249",
"mac": "02:c2:59:4a:82:9f",
"name": "cluster-wide-default"
}
]
Status: Running
IP: 10.47.255.249
Containers:
liveness-pod:
Container ID: docker://01969f51d32f38a15baab18487b85c54cee4125f55c8c7667236722084e4df06
Image: virtualhops/ato-ubuntu:latest
Image ID: docker-pullable://virtualhops/ato-ubuntu@sha256:fa2930cb8f4b766e5b335dfa42de510ecd30af6433ceada14cdaae8de9065d2a
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Fri, 05 Jul 2019 16:41:35 -0400
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Fri, 05 Jul 2019 16:39:20 -0400
Finished: Fri, 05 Jul 2019 16:41:34 -0400
Ready: True
Restart Count: 1
Liveness: http-get http://:80/ delay=15s timeout=1s period=20s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-m75c5 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-m75c5:
Type : Secret (a volume populated by a Secret)
SecretName: default-token-m75c5
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
Normal Scheduled 7m19s default-scheduler Successfully assigned default/liveness-pod to cent22
Warning Unhealthy 4m6s (x3 over 4m46s) kubelet, cent22 Liveness probe failed: Get http://10.47.255.249:80/: dial tcp 10.47.255.249:80: connect:
connection refused
Normal Pulling 3m36s (x2 over 5m53s) kubelet, cent22 pulling image "virtualhops/ato-ubuntu:latest"
Normal Killing 3m36s kubelet, cent22 Killing container with id docker://liveness-pod:Container failed liveness probe.. Container will be
killed and recreated.
Normal Pulled 3m35s (x2 over 5m50s) kubelet, cent22 Successfully pulled image "virtualhops/ato-ubuntu:latest"
Normal Created 3m35s (x2 over 5m50s) kubelet, cent22 Created container
Normal Started 3m35s (x2 over 5m50s) kubelet, cent22 Started container
これは、TCP ソケットプローブの例です。TCP ソケットプローブは、HTTP GET request プローブと似ていますが、TCP ソケットが開きます。
apiVersion: v1 kind: Pod metadata: name: liveness-pod labels: app: tcpsocket-test spec: containers: - name: liveness-pod image: contrailk8sdayone/ubuntu ports: - containerPort: 80 securityContext: privileged: true capabilities: add: - NET_ADMIN livenessProbe: tcpSocket: port: 80 initialDelaySeconds: 15 periodSeconds: 20
このコマンドは、HTTP GET と TCP ソケットプローブに似ています。しかし、プローブは、次のようにコンテナーでコマンドを実行します。
apiVersion: v1 kind: Pod metadata: name: liveness-pod labels: app: command-test spec: containers: - name: liveness-pod image: k8s.gcr.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; while true; do sleep 600;done; livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5
準備信号
活性プローブは、pod が良好な状態にあることを確認しますが、十分’ではない一部のアプリケーションについては使用しています。アプリケーションによっては、開始前に大きなファイルを読み込む必要があります。上位に設定した方がよいかもしれません initialDelaySeconds価値この問題は解決されていますが、これは効率的な解決策ではありません。対応プローブは、Kubernetes サービスの場合に特に役立ちます。 pod は、トラフィックが準備が整うまで受信することはありません。準備信号が失敗するたびに、pod のエンドポイントはサービスから削除され、対応可能なプローブが成功した時点で再び追加されるようになります。準備済みプローブは、活性プローブと同じ方法で構成されています。
apiVersion: v1 kind: Pod metadata: name: liveness-readiness labels: app: tcpsocket-test spec: containers: - name: liveness-readiness-pod image: virtualhops/ato-ubuntu:latest ports: - containerPort: 80 securityContext: privileged: true capabilities: add: - NET_ADMIN livenessProbe: httpGet: path: / port: 80 httpHeaders: - name: some-header value: Running initialDelaySeconds: 15 periodSeconds: 20 readinessProbe: tcpSocket: port: 80 initialDelaySeconds: 5 periodSeconds: 10
’準備されたプローブと活性プローブの両方を使用して、活性プローブが失敗した場合に pod を再起動し、トラフィックを取得する前に対応プローブがポッドの準備が整っていることを確認することを推奨します。
プローブパラメーター
調査には多数のパラメーターがあり、これを使用して、活性およびレディネスのチェックの動作をより正確に制御できます。
初期遅延秒: ライブまたは準備中の調査が開始されるまでにコンテナが開始してから経過した秒数。
periodSeconds: プローブを実行する頻度 (秒単位) です。デフォルトは10秒です。最小値は1です。
timeoutSeconds: プローブがタイムアウトになるまでの秒数。デフォルトは1秒です。最小値は1です。
successThreshold: 障害が発生した後、そのプローブの最小連続成功が成功したと見なされるようになります。デフォルトは1です。活性の場合は1でなければなりません。最小値は1です。
failureThreshold: ポッドが起動してプローブが失敗した場合、Kubernetes は、その後にしきい値の時間を試します。「活性プローブ」の場合は、ポッドを再起動することを意味します。準備が整ったプローブの場合、ポッドは未準備としてマークされます。デフォルトは3です。最小値は1です。
HTTP プローブには、オンに設定可能なその他のパラメーターがあります。 httpGet:
host: 接続先のホスト名。デフォルトでは pod IP が使用されます。ホスト“”を設定する必要があるかもしれませんhttpHeadersその代わりに。scheme: ホストへの接続に使用するスキーム (HTTP または HTTPS)。デフォルトは HTTP です。path: HTTP サーバー上でアクセスするためのパスです。httpHeaders: リクエストに設定するカスタムヘッダー。HTTP では、ヘッダーを繰り返し使用できます。port: コンテナでアクセスするポートの名前または番号。番号は 1 ~ 65535 の範囲内である必要があります。
アノテーションセット
Kubernetes のラベルがオブジェクトの識別、選択、整理にどのように使用されているかについては、すでにご確認済みです。ただし、ラベルは、メタデータを Kubernetes オブジェクトに添付する1つの方法に過ぎません。
もう1つの方法は、識別できないメタデータをオブジェクトに付加するキー/値マップである注釈です。コメントには、以下のように、添付などの多くの使用事例があります。
ロギングと分析のためのポインター
電話番号、ディレクトリエントリ、web サイト
タイムスタンプ、画像ハッシュ、レジストリアドレス
ネットワーク、名前空間
そして、受信コントローラのタイプ
以下’に、注釈の例を示します。
apiVersion: v1 kind: Pod metadata: name: annotations-demo annotations: #<--- imageregistry: https://hub.docker.com spec: containers: name: annotation-pod image: contrailk8sdayone/ubuntu ports: containerPort: 80
注釈を使用してネットワーク情報をポッドに割り当てることができますが、’第9章では、Kubernetes の注釈で Juniper Contrail に対して、特定のネットワークにインターフェイスをアタッチする方法について説明します。実に魅力的です。
コメントが表示される前に’、このネットワークカスタムリソース定義の事実上の Kubernetes に基づいて、最小構成でネットワークを構築してみましょう。 NetworkAttachmentDefinitionここでは、CNI と、インターフェイスポッドに接続するネットワークのパラメーターを示しています。
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: net-a
spec:
config: '{
"cniVersion": "0.3.0",
"type": "awesome-plugin"
}'
こちらの type, awesome-pluginは、Flannel、Calico、Contrail-CNI などの CNI の名前であることを示しています。
ポッドを作成し、注釈を使用して、インターフェイスを net a というネットワークに接続します。
公式の Kubernetes network custom のカスタムリソース定義によれば、注釈 k8s.v1.cni.cncf.io/networks を使用して NetworkAttachmentDefinition2つの形式があります。
既存の Kubernetes 導入との互換性を維持するには、すべてのポッドを cluster-wideデフォルトのネットワークでは、1つの pod インターフェイスを特定のネットワークに接続した場合でも、このポッドには次の2つのインターフェイスがあります。1つは添付されています cluster-wideデフォルトのネットワークと、annotation 引数で指定されたネットワークに接続されているもう1つの network (net-aこのケースで)。