Présentation de l’architecture JDM
Compréhension de la désagrégation des Junos OS
De nombreux fournisseurs d’équipements réseau ont traditionnellement lié leurs logiciels à du matériel dédié et ont vendu à leurs clients l’offre logicielle/matérielle groupée et regroupée. Cependant, avec l’architecture Junos OS désagrégée, les équipements réseau Juniper sont désormais alignés sur les réseaux orientés cloud, ouverts et s’appuyant sur des scénarios d’implémentation plus flexibles.
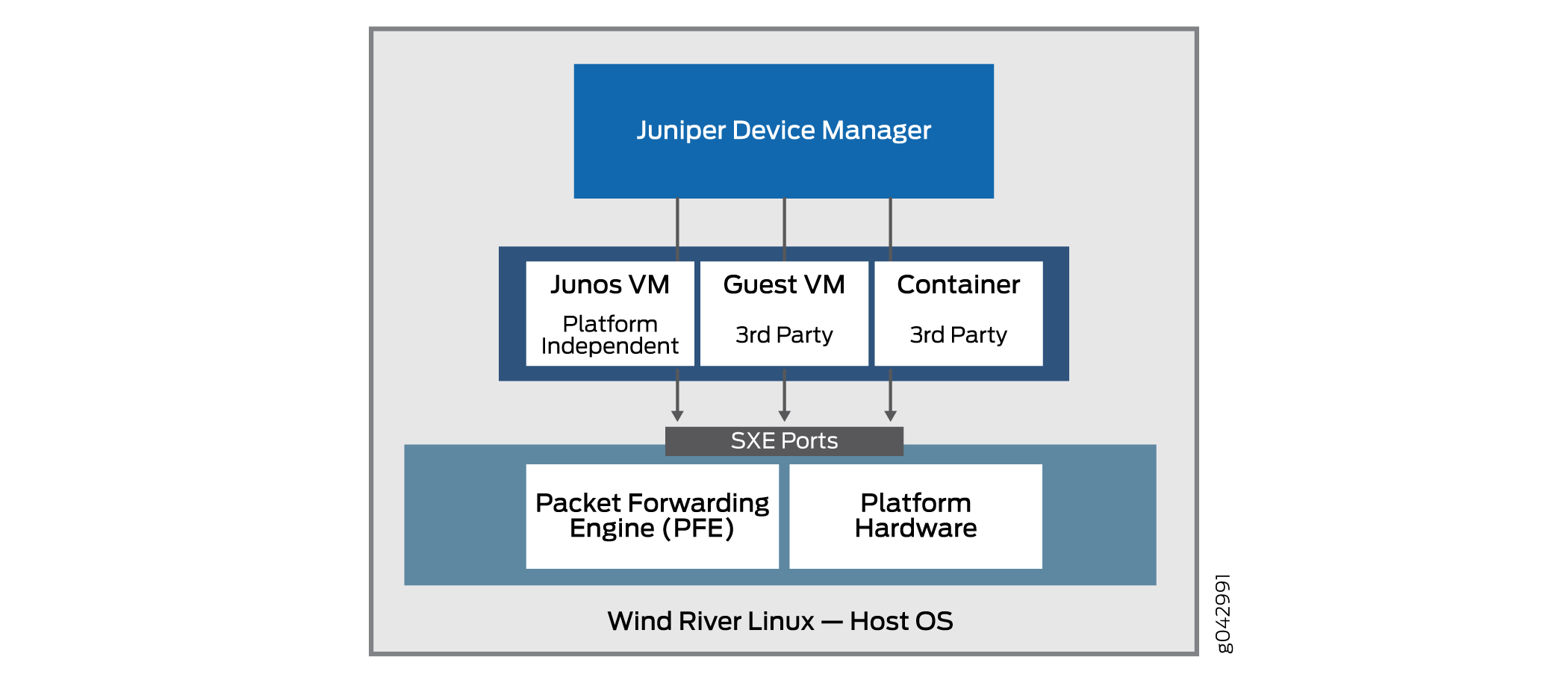
Le principe de base de l’architecture Junos OS désagrégée est ladésagrégationdu logiciel Junos OS étroitement lié et du matériel propriétaire en composants virtualisés qui peuvent s’exécuter non seulement sur le matériel Juniper Networks, mais aussi sur des boîtes blanches ou des serveurs bare metal. Dans cette nouvelle architecture, le Juniper Device Manager (JDM) est un conteneur racine virtualisé qui gère les composants logiciels.
Le JDM est le seul conteneur racine dans l’architecture Junos OS désagrégée (d’autres modèles de l’industrie permettent plusieurs conteneurs racines, mais l’architecture Junos OS désagrégée n’en fait pas partie). Le modèle d’Junos OS désagrégé est un modèle à racine unique. L’une des principales fonctions de JDM est d’empêcher les modifications et les activités sur la plate-forme d’avoir un impact sur l’OS hôte sous-jacent (généralement Linux). En tant qu’entité racine, le JDM est parfaitement adapté à cette tâche. L’autre fonction majeure du JDM consiste à faire en sorte que le matériel de l’équipement ressemble autant que possible au système physique traditionnel basé Junos OS’équipement. Cela nécessite également une certaine forme de fonctionnalités racine.
La Figure 1 illustre la position importante que JDM occupe dans l’architecture globale.
Une VNF est une offre consolidée qui contient tous les composants nécessaires à la prise en charge d’un environnement réseau entièrement virtualisé. Une VNF se concentre sur l’optimisation du réseau.
JDM permet de:
Gestion des fonctions réseau virtualisées (VNF) des invités pendant leur cycle de vie.
Installation de modules tiers.
Formation de chaînes de services VNF.
Gestion des images VNF invités (leurs fichiers binaires).
Contrôle de l’inventaire système et de l’utilisation des ressources.
Notez que certaines implémentations de l’architecture de base incluent un moteur de transfert de paquets ainsi que les ports matériels habituels de la plate-forme Linux. Cela permet une meilleure intégration du Juniper Networks de données avec le matériel bare metal d’une plate-forme générique.
L’architecture de Junos OS désagrégée permet à JDM de gérer des fonctions réseau virtualisées telles qu’un pare-feu ou des fonctions de traduction des adresses réseau (NAT). Les autres VFF et conteneurs intégrés à JDM peuvent être utilisés Juniper Networks produits tiers ou des produits tiers en tant qu’applications Linux natives. L’architecture de base du système désagrégé Junos OS schématiser en figure 2.
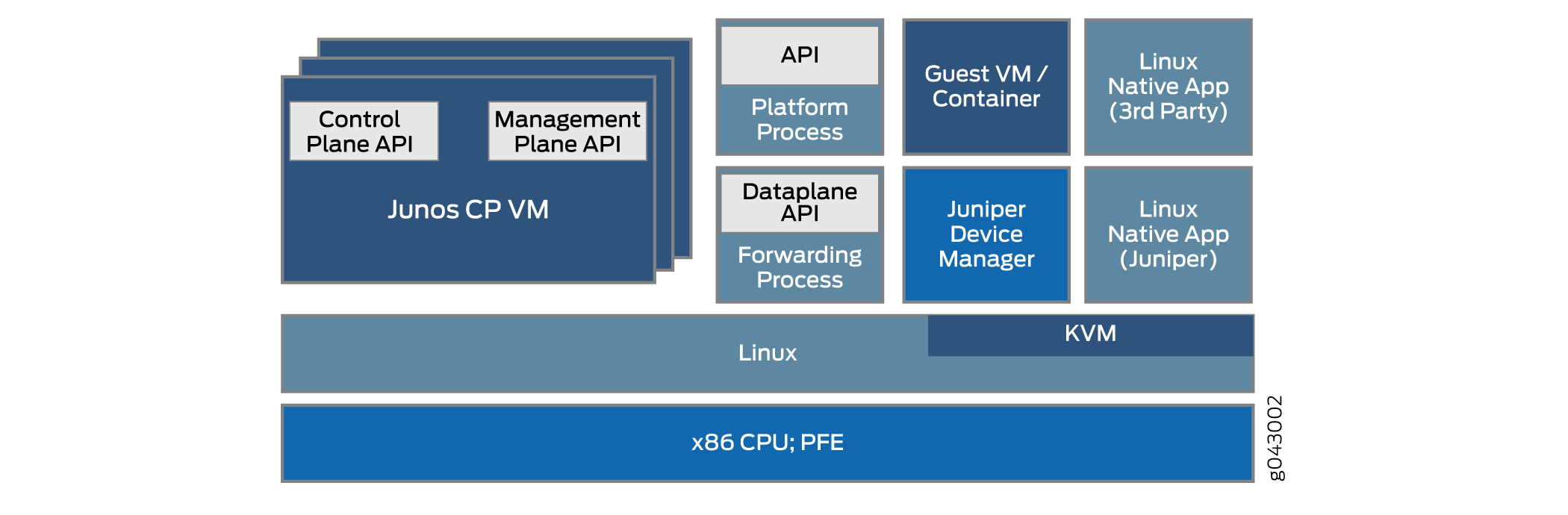
Il existe de nombreuses façons d’implémenter l’architecture de base désagrégée Junos OS sur diverses plates-formes. Les détails peuvent varier considérablement. Ce sujet décrit l’architecture globale.
La virtualisation du processus logiciel simple qui s’exécute sur du matériel fixe pose plusieurs défis en matière de communication interprocess. Comment, par exemple, une VNF avec fonction NAT fonctionne-t-elle avec un pare-feu qui s’exécute comme conteneur sur le même équipement? Après tout, il n’y a peut-être qu’un ou deux ports Ethernet externes sur l’ensemble de l’équipement et les processus sont toujours internes à l’équipement. Un des avantages est que les interfaces entre ces processus virtualisés sont souvent virtualisées elles-mêmes, peut-être en tant que ports SXE; ce qui signifie que vous pouvez configurer un type de pont de couche MAC entre les processus directement, ou entre un processus et le système d’exploitation hôte, puis entre le système d’exploitation hôte et un autre processus. Cette gestion prend en charge le chaînage des services à mesure que le trafic pénètre et sort de l’équipement.
JDM fournit aux utilisateurs une Junos OS CLI et gère toutes les interactions avec le noyau Linux sous-jacent pour maintenir le « look and feel » d’un Juniper Networks réseau.
Les avantages de la désagrégation des Junos OS:
Tout le système peut être géré comme une plate-forme de serveur.
Les clients peuvent installer des applications, des outils et des services tiers, tels que Chef, Leurreshark ou Quagga, sur une machine virtuelle ou un conteneur.
Ces applications et outils peuvent être mis à niveau à l’aide de référentiels Linux classiques et ne sont pas disponibles Junos OS version.
La modularité augmente la fiabilité car les pannes sont contenues dans le module.
Les plans de contrôle et de données peuvent être programmés directement via des API.
Comprendre les composants physiques et virtuels
Dans l’environnement Junos OS virtualisation des fonctions réseau (NFV), les composants des équipements peuvent être physiques ou virtuels. Une même distinction entre physique et virtuel peut être appliquée aux interfaces (ports), aux chemins que les paquets ou les trames prennent par l’équipement, ainsi qu’à d’autres aspects tels que les cœurs de processeur ou l’espace disque.
La spécification d’architecture Junos OS désagrégée inclut un modèle architectural. Le modèle architectural d’une maison peut avoir des itinéraires pour y inclure une cuisine, une salle à manger et une salle à manger, et peut représenter différents types de logement ; d’un faitasse ou d’un retial à une plus grande resserrité. Toutes ces chambres ont l’air très différentes, mais respectent toujours un modèle architectural de base et partagent de nombreuses caractéristiques.
De même, dans les modèles architecturaux Junos OS désagrégés, les modèles couvrent de nombreux types de plates-formes, qu’il s’agit d’équipements CPE (Customer Premises Equipment) simples ou d’équipements de commutation complexes installés dans un grand centre de données, mais leurs caractéristiques de base partagent certaines caractéristiques de base.
Quelles sont les caractéristiques communes de ces plates-formes? Toutes les plates-formes de Junos OS désagrégées sont construites sur trois couches. Ces couches et certains contenus possibles sont illustrés à la Figure 3.
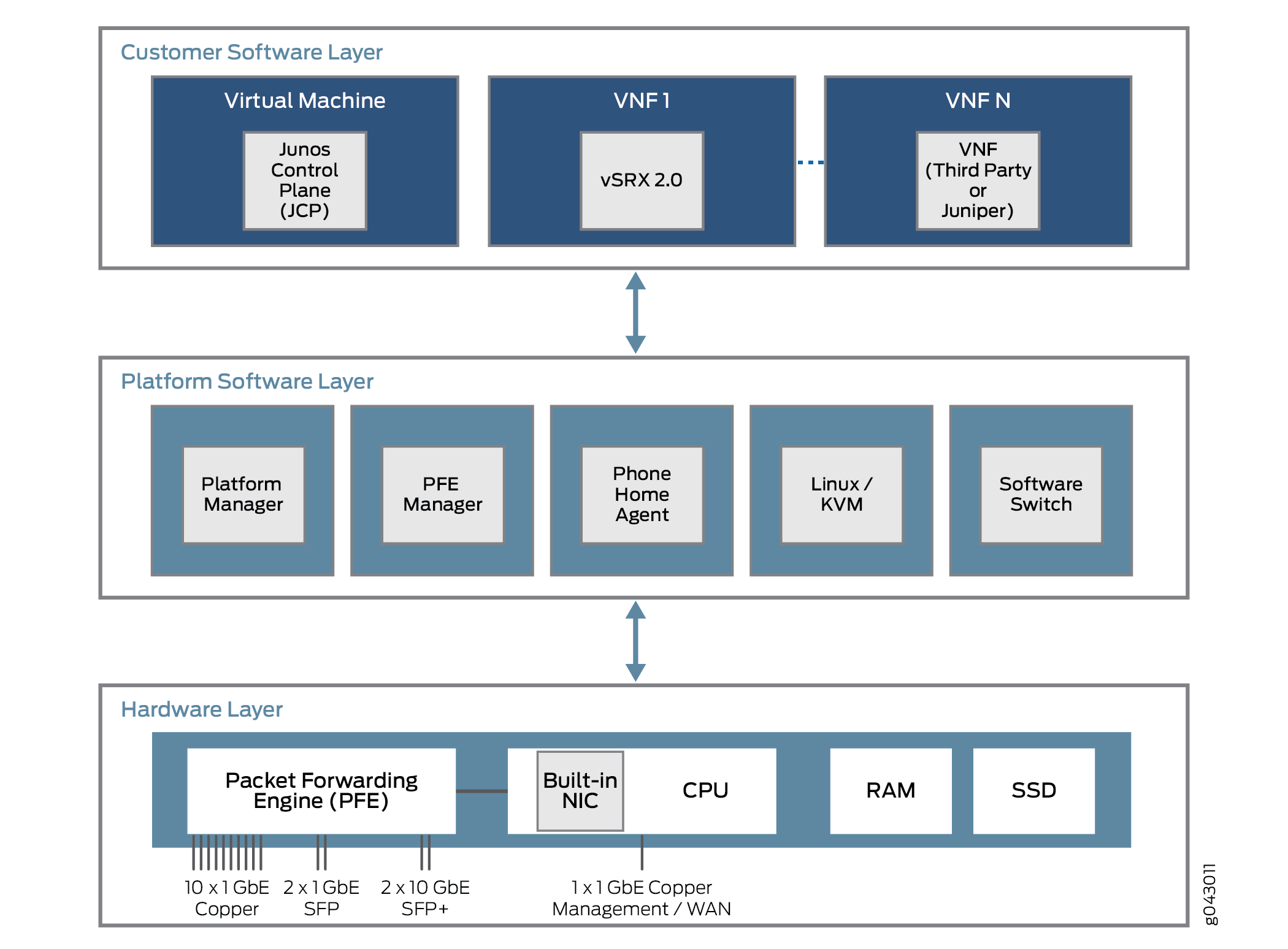
La couche la plus basse est la couche matérielle. En plus de la mémoire (RAM) et de l’espace disque (SSD), le matériel de la plate-forme dispose d’un processeur multi-cœur avec un port de gestion NIC externe. Dans certains cas, un seul port NIC sera utilisé pour le plan de contrôle et de données, mais il pourra également être utilisé pour communiquer avec une moteur de transfert de paquets pour les flux de trafic utilisateur.
La couche logicielle de la plate-forme s’installe au-dessus de la couche matérielle. Toutes les fonctions dépendent de la plate-forme ici. Ces fonctions peuvent inclure une fonction de commutation logicielle pour divers composants virtuels afin d’ponter le trafic entre eux. Une machine virtuelle Linux ou KVM basée sur le noyau exécute la plate-forme et, dans certains modèles, un agent d’appel contacte un fournisseur ou un équipement de fournisseur de services pour réaliser des tâches de configuration automatique. L’agent d’accueil de téléphone est particulièrement préféré pour les plates-formes CPE plus petites.
Au-dessus de la couche logicielle de la plate-forme se trouve la couche logicielle du client, qui perfomait diverses fonctions indépendantes de la plate-forme. Certains des composants peuvent être Juniper Networks des machines virtuelles, comme un équipement SRX virtuel (vSRX) ou le plan de contrôle Junos (JCP). La JCP fonctionne avec le JDM pour que l’équipement ressemble à une plate-Juniper Networks dédiée, mais avec beaucoup plus de flexibilité. Cette flexibilité provient en grande partie de la capacité de prendre en charge une ou plusieurs VNF qui implémentent une fonction réseau virtualisée (VNF). Ces VNF se composent de nombreux types de tâches, telles que les traduction des adresses réseau (NAT), les recherches de serveurs DNS (Domain Name System) spécialisées, etc.
En règle générale, le nombre de cœurs de processeur est fixe et l’espace disque est limité. Mais dans un environnement virtuel, l’allocation et l’utilisation des ressources sont plus complexes. Les ressources virtuelles telles que les interfaces, l’espace disque, la mémoire ou les cœurs sont sorties de l’image VNF au sein des VNF qui s’exécutent à l’époque.
Les VNF, que ce soit des machines virtuelles (VM) ou des conteneurs, qui partagent l’équipement physique, sont souvent nécessaires pour communiquer entre elles. Les paquets ou trames pénètrent un équipement par le biais d’une interface physique (un port) et sont distribués vers quelques VNF initiaux. Après un certain traitement du flux de trafic, le VNF transmet le trafic à un autre VNF si c’est configuré pour cela, puis à un autre, avant que le trafic ne quitte l’équipement physique. Ces VNF forment une chaîne de services de plan de données qui est traversée à l’intérieur de l’équipement.
Comment les VNF, qui sont des VM ou des conteneurs isolés, peuvent-elles transmettre du trafic de l’un à l’autre? La chaîne de services est configurée pour transmettre le trafic d’une interface physique à une ou plusieurs interfaces virtuelles internes. Par conséquent, il existe des SPC virtuels associés à chaque VM ou conteneur, tous connectés par un commutateur virtuel ou une fonction de pontage à l’intérieur de l’équipement. Cette relation générique, qui permet la communication entre interfaces physiques et virtuelles, est présentée en figure 4.
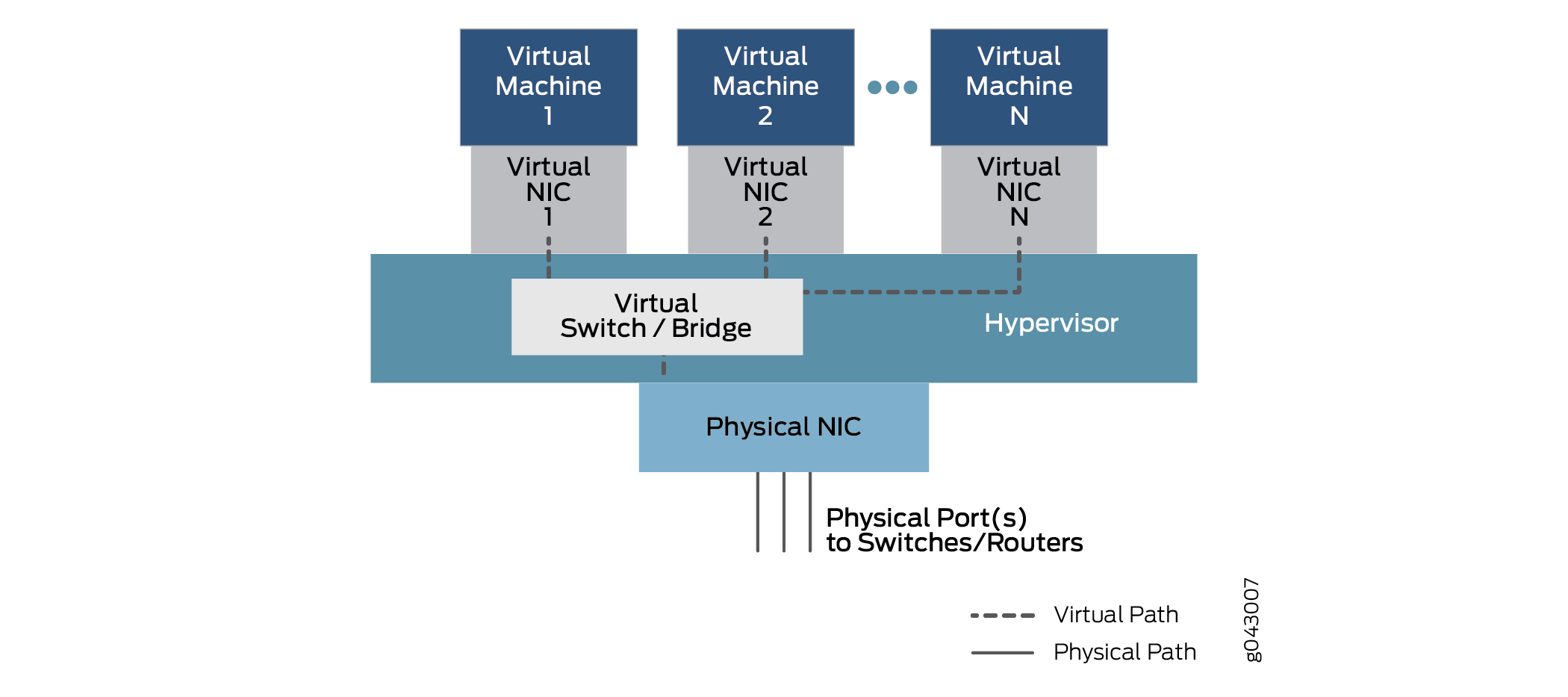
Dans ce modèle général, qui peut varier selon les plates-formes, les données pénètrent par un port du NIC physique et sont pontés par la fonction de commutateur virtuel vers la machine virtuelle 1 à Virtual NIC 1, en fonction de l’adresse MAC de destination. Le trafic peut également être ponté via une autre interface virtuelle configurée pour une machine virtuelle2 ou plus, jusqu’à ce qu’il soit transmis à un port physique et qu’il sorte de l’équipement.
À des fins de configuration, ces interfaces peuvent avoir des désignations connues, telles que ge-0/0/0 ou fxp0, ou de nouvelles désignations telles que sxe0 ou hsxe0. Certains peuvent êtreréels, mais les ports internes (comme le sxe0) et d’autres peuvent être des constructions virtuelles (telles que hsxe0) nécessaires pour rendre l’équipement opérationnel.
VM désagrégrées Junos OS VM
Le cloud computing permet d’exécuter les applications dans un environnement virtualisé, à la fois pour les fonctions de serveur de l’utilisateur final et pour les fonctions réseau nécessaires pour connecter des points de terminaison dispersés sur un grand centre de données, voire entre plusieurs centres de données. Les applications et les fonctions réseau peuvent être implémentées par des fonctions réseau virtualisées (VNF). Quelles sont les différences entre ces deux types de packages et pourquoi une personne utiliserait-elle un type ou un autre?
Les VNF et les conteneurs permettent le multiplexage du matériel avec des dizaines, voire des centaines de VFV partageant un serveur physique. Cela permet non seulement le déploiement rapide de nouveaux services, mais aussi l’extension et la migration des charges de travail en cas d’utilisation importante (lorsque des extensions peuvent être utilisées) ou de maintenance physique (lorsque la migration peut être utilisée).
Dans un environnement de cloud computing, il est courant d’utiliser des VNF pour faire le travail lourd sur les batteries de serveurs massives qui caractérisent le Big Data dans les réseaux modernes. La virtualisation de serveur permet aux applications écrites pour différents environnements de développement, plates-formes matérielles ou systèmes d’exploitation de s’exécuter sur du matériel générique qui exécute une suite logicielle appropriée.
Les VFV s’appuient sur un hyperviseur pour gérer l’environnement physique et allouer des ressources aux VFV s’exécutant à un moment particulier. Les hyperviseurs les plus populaires incluent Xen, KVM et VMWare ESXi, mais il en existe beaucoup d’autres. Les VNF s’exécutent dans l’espace utilisateur au-dessus de l’hyperviseur et comprennent une implémentation complète du système d’exploitation de l’application de VM. Par exemple, une application écrite dans le langage C++ et conforme et exécuté sur le système d’exploitation Microsoft Windows peut être exécuté sur un système d’exploitation Linux à l’aide de l’hyperviseur. Ici, Windows est un système d’exploitation invité.
L’hyperviseur fournit au système d’exploitation invité une vue émule du matériel des NFV. L’hyperviseur offre, entre autres, une vue virtualisée de la carte d’interface réseau (NIC) lorsque les points de terminaison de différentes VM résident sur différents serveurs ou hôtes (une situation courante). L’hyperviseur gère les CCI physiques et n’expose que les interfaces virtualisées aux VNF.
L’hyperviseur exécute également un environnement de commutation virtuel, qui permet aux VLAN au niveau de la couche de trames du VLAN d’échanger des paquets à l’intérieur de la même boîte, ou sur un réseau (virtuel).
Le principal avantage des VNF est que la plupart des applications peuvent être facilement portées vers l’environnement d’hyperviseur et s’exécuter sans modification.
Le principal inconvénient est que, bien souvent, le système d’exploitation invité doit offrir une version complète du système d’exploitation même si son rôle consiste à fournir un service simple, tel qu’un système de noms de domaine (DNS).
Contrairement aux VNF, les conteneurs sont conçus pour être exécutés en tant que tâches indépendantes dans un environnement virtuel. Les conteneurs ne regroupent pas l’ensemble d’un système d’exploitation à l’intérieur comme le font les VFV. Les conteneurs peuvent être codés et groupés de différentes façons, mais il existe également des moyens de créer des conteneurs standard faciles à entretenir et à étendre. Les conteneurs standard sont beaucoup plus ouverts que les conteneurs créés de façon haphaphasé.
Les conteneurs Linux standard définissent une unité de distribution logicielle appelée conteneur standard. Au lieu d’encapsuler l’ensemble du système d’exploitation invité, le conteneur standard n’encapsule que l’application et les dépendances requises pour exécuter la tâche programmée de l’application. Il est possible de modifier cet élément d’runtime unique, puis de re-refaire le conteneur pour y inclure toutes les dépendances supplémentaires nécessaires à la fonction étendue. L’architecture globale des conteneurs sur la figure 5.
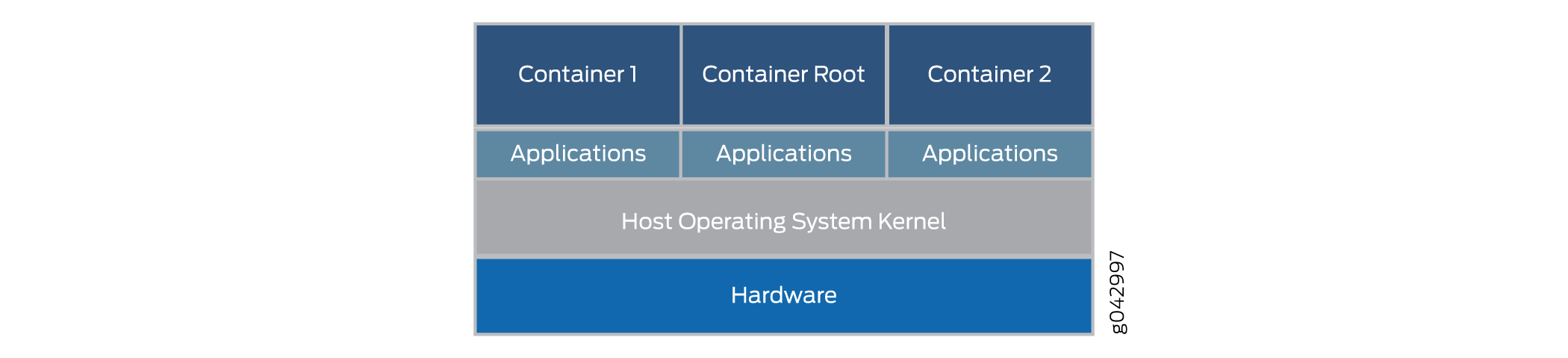 conteneurs
conteneurs
Les conteneurs s’exécutent sur le noyau de l’OS hôte et non sur l’hyperviseur. L’architecture de conteneur utilise un moteur de conteneur pour gérer la plate-forme sous-jacente. Si vous souhaitez toujours exécuter des VNF, le conteneur peut également mettre en place un hyperviseur complet et un environnement DES invité.
Les conteneurs standard incluent:
Un fichier de configuration.
Ensemble d’opérations standard.
Un environnement d’exécution.
Le nom de conteneur est emprunté aux conteneurs utilisés pour transporter des biens dans le monde entier. Les conteneurs d’expédition sont des unités de livraison standard qui peuvent être chargées, étiquetées, empilées, soulever et déchargées par des équipements conçus spécifiquement pour gérer les conteneurs. Quel que soit l’espace à l’intérieur, le conteneur peut être traité de façon standard, chaque conteneur possède son propre espace utilisateur, qui ne peut pas être utilisé par les autres conteneurs. Bien que Docker soit un système de gestion des conteneurs populaire pour exécuter des conteneurs sur un serveur physique, il existe des alternatives telles que Drawbridge ou Rocket à prendre en compte.
Une interface virtuelle est attribuée à chaque conteneur. Les systèmes de gestion de conteneurs tels que Docker comprennent un pont Ethernet virtuel qui connecte plusieurs interfaces virtuelles et le réseau physique NIC. Les variables de configuration et d’environnement dans le conteneur déterminent les conteneurs qui peuvent communiquer entre eux, qui peuvent utiliser le réseau externe, etc. La mise en réseau externe est généralement mise en NAT même s’il existe d’autres méthodes, car les conteneurs utilisent souvent le même espace d’adresse réseau.
Le principal avantage des conteneurs est qu’ils peuvent être chargés sur un équipement et exécutés beaucoup plus rapidement que les VNF. Les conteneurs utilisent également les ressources beaucoup plus économes: vous pouvez exécuter beaucoup plus de conteneurs que de VFV sur le même matériel. Cela est dû au fait que les conteneurs ne nécessitent pas de système d’exploitation ou de temps d’amorçage complets. Les conteneurs peuvent être chargés et exécutés en millisecondes, et non en dizaines de secondes. Cependant, le plus gros inconvénient des conteneurs est qu’ils doivent être écrits spécifiquement pour se conformer à des implémentations standard ou courantes, alors que les VFV peuvent être exécutés dans leur état natif.
Utilisation de Virtio et SR-IOV
Vous pouvez activer la communication entre un équipement virtualisé Linux et un module de virtualisation des fonctions réseau (NFV) en utilisant virtio ou en utilisant du matériel adapté et la virtualisation E/S racine unique (SR-IOV). Chaque méthode présente des caractéristiques distinctes.
- Compréhension de l’utilisation de Virtio
- Compréhension de l’utilisation de SR-IOV
- Comparaison de Virtio et SR-IOV
Compréhension de l’utilisation de Virtio
Lorsqu’un équipement physique est virtualisé, les interfaces de NIC interfaces physiques et les commutateurs physiques externes, ainsi que les interfaces NIC virtuelles et les commutateurs virtuels internes coexistent. Ainsi, lorsque les VNF isolés de l’équipement, chacun 1 avec sa propre mémoire, son espace disque et ses cycles de processeur, tentent de communiquer entre eux, les ports, les adresses MAC et les adresses IP utilisés posent un défi. Avec la bibliothèque Virtio, le flux de trafic entre les fonctions virtuelles isolées devient de plus en plus simple.
Virtio fait partie de la bibliothèque Linux libvirt standard de fonctions de virtualisation utiles et est normalement inclus dans la plupart des versions de Linux. Virtio est une approche logicielle uniquement pour la communication entre VNF. Virtio permet de connecter des processus virtuels individuels. La nature groupée de Virtio permet à n’importe quel équipement linux d’utiliser virtio.
Virtio permet aux VNF et conteneurs d’utiliser de simples ponts internes pour envoyer et recevoir du trafic. Le trafic peut encore arriver et quitter par un pont externe. Un pont externe utilise une interface de NIC interne virtualisée à une extrémité du pont et une interface NIC externe physique à l’autre extrémité du pont pour envoyer et recevoir des paquets et des trames. Un pont interne, dont plusieurs types, relie deux interfaces NIC internes virtualisées en les reliant via une fonction de commutation interne virtualisée dans le système d’exploitation hôte. L’architecture globale de virtio est représentée sur la Figure 6.
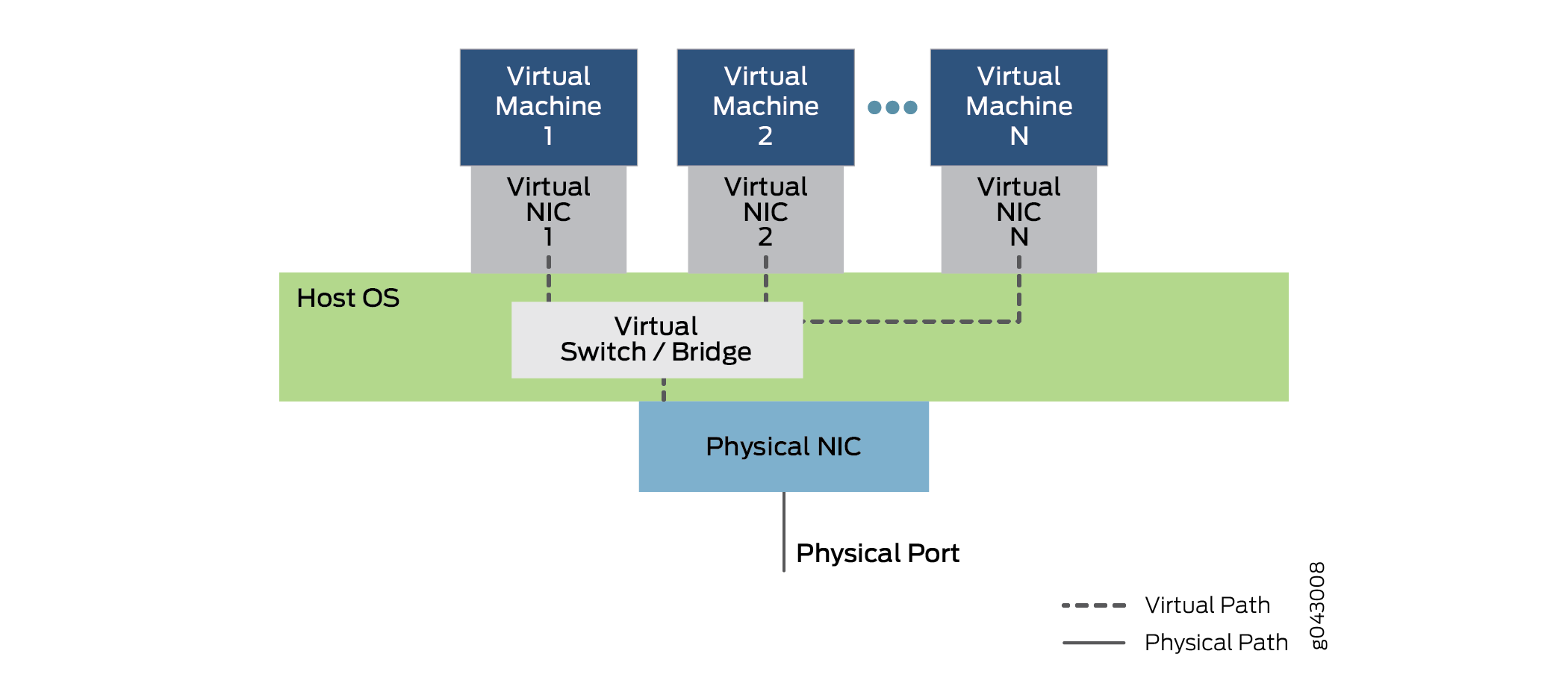
La figure 6 montre la structure interne d’un équipement de serveur avec une seule carte de NIC physique exécutant un système d’exploitation hôte (le couvercle extérieur de l’équipement n’est pas affiché). Le système d’exploitation hôte contient le commutateur virtuel ou le pont mis en œuvre avec virtio. Au-dessus du système d’exploitation, plusieurs machines virtuelles emploient des C NI virtuels qui communiquent par virtio. Plusieurs machines virtuelles sont en cours d’exécution et sont numéroées de 1 à N sur la figure. La notation standard « dot dot dot » indique les machines virtuelles et les SPC non affichées sur le chiffre. Les lignes en pointillé indiquent des chemins de données possibles à l’aide de la virtio. Notez que le trafic entrant ou quittant l’équipement le fait par le biais du NIC et du port.
La figure 6 montre également que le trafic pénètre et quitte l’appareil via le pont interne. La machine virtuelle 1 relie son interface NIC interne virtualisée à l’interface physique NIC externe. Les systèmes Virtual Machine 2 et Virtual Machine N relient les NI virtuels internes via le pont interne du système d’exploitation hôte. Notez que ces interfaces peuvent être associées à des labels VLAN ou des noms d’interface internes. Les trames envoyées sur ce pont interne entre les VNF ne quittent jamais l’équipement. Notez la position du pont (et de la fonction de commutation virtualisée) dans le système d’exploitation hôte. Notez l’utilisation d’un pontage simple dans l’équipement. Ces ponts peuvent être configurés soit à l’aide des commandes Linux régulières, soit avec l’utilisation CLI des instructions de configuration. Il est possible d’utiliser des scripts pour automatiser le processus.
Virtio est une norme de virtualisation pour les conducteurs de disques et d’équipements réseau. Seul le pilote de l’équipement invité (le facteur d’équipement des fonctions virtualisées) doit savoir qu’il est en cours d’exécution dans un environnement virtuel. Ces facteurs de collaboration avec l’hyperviseur et les fonctions virtuelles obtiennent des avantages en terme de performances en échange de la complication supplémentaire. L’architecture de Virtio est similaire à celle des pilotes d’équipements paravirtualisés Xen (pilotes ajoutés à un invité pour les rendre plus rapides lorsqu’ils s’exécutent sur Xen). Les outils invités de VMWare sont également similaires à virtio.
Notez qu’une grande partie du trafic est concentré sur le processeur du système d’exploitation hôte, plus clairement sur les ponts internes virtualisés. C’est pourquoi le processeur hôte doit être capable de s’exécuter correctement à mesure que l’équipement est capable d’être capable de s’exécuter à mesure que l’équipement s’exécute.
Compréhension de l’utilisation de SR-IOV
Lorsqu’un équipement physique est virtualisé, coexistent les interfaces de carte d’interface réseau physique (NIC) et les commutateurs physiques externes, ainsi que les interfaces NIC virtuelles et les commutateurs virtuels internes. Ainsi, lorsque les machines virtuelles (VM) ou les conteneurs isolés de l’équipement, chacun 1 000 avec son propre mémoire, son espace disque et ses cycles de processeur, tentent de communiquer entre eux, les ports, les adresses MAC et les adresses IP utilisés posent un défi.
SR-IOV étend le concept de fonctions virtualisées jusqu’aux environnements NIC . La carte physique unique est divisée en jusqu’à 16 partitions par port de NIC qui correspondent aux fonctions virtuelles qui s’exécutent au niveau des couches supérieures. Les communications entre ces fonctions virtuelles sont gérées de la même manière que les communications entre équipements avec des NIC individuelles: avec un pont. SR-IOV comprend un ensemble de méthodes standard pour la création, la suppression, l’ingérisation et l’interrogation du commutateur NIC SR-IOV, ainsi que les paramètres standard qui peuvent être fixés.
La partie racine unique du SR-IOV fait référence au fait qu’il n’existe en réalité qu’un seul élément principal du système NIC contrôle de toutes les opérations. Un port DSR-IOV NIC est un port Ethernet standard offrant la même fonction physique bit par bit que toute carte réseau.
Toutefois, le SR-IOV offre également plusieurs fonctions virtuelles, qui sont réalisées par de simples files d’attente pour gérer les tâches d’entrée et de sortie. Chaque VNF s’exécutant sur l’équipement est mapé sur l’une NIC partitions de sorte que les VNF disposent eux-mêmes d’un accès direct NIC ressources matérielles. La NIC dispose également d’une fonction de tri de couche 2 simple, qui classifie les trames dans les files d’attente de trafic. Les paquets sont transférés directement vers et depuis la fonction virtuelle du réseau vers la mémoire de la VM à l’aide d’un accès à mémoire directe (DMA), dérivation complète de l’hyperviseur. Le rôle des NIC dans l’opération SR-IOV est illustré en figure 7.
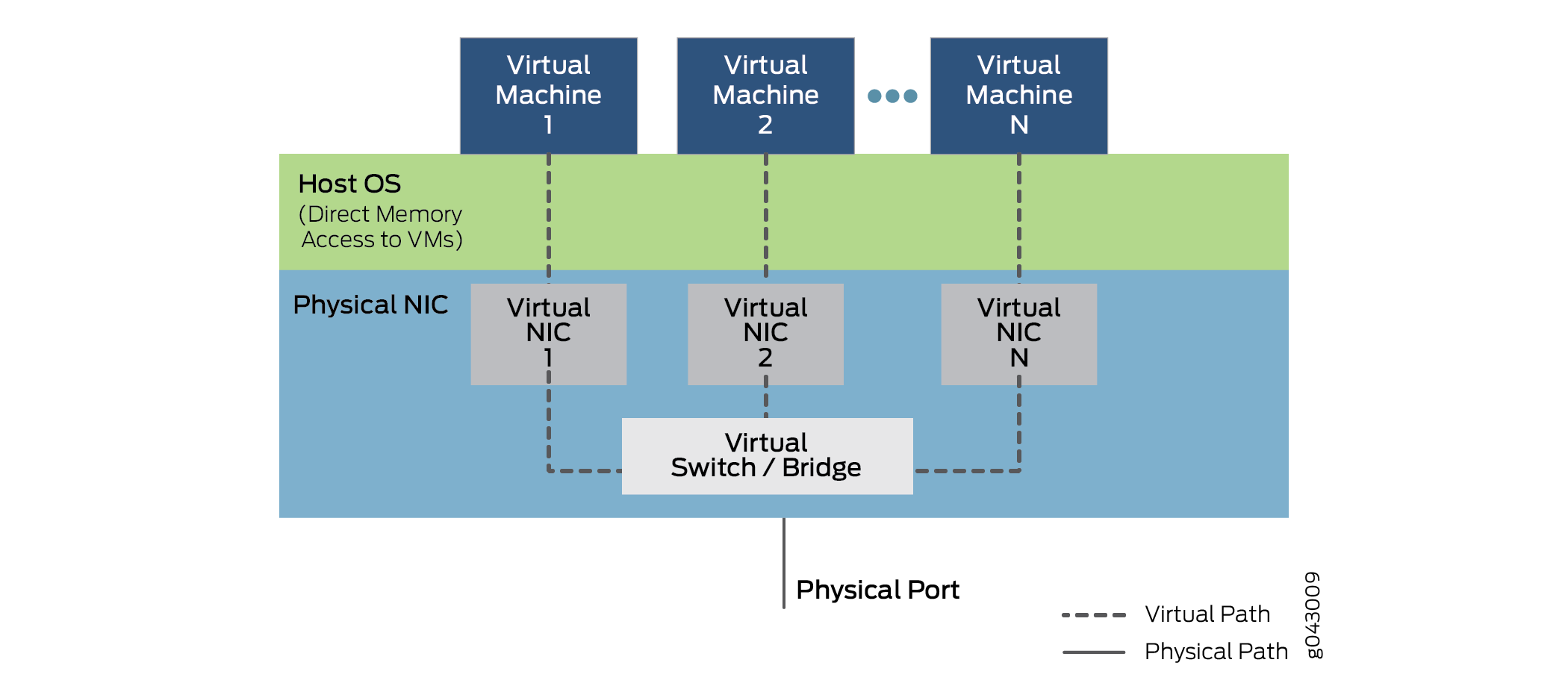
L’hyperviseur est toujours impliqué dans l’attribution des fonctions réseau virtuelles aux fonctions du réseau virtuel, et dans la gestion de la carte physique, mais pas dans le transfert des données à l’intérieur des paquets. Notez que la communication VNF vers VNF est effectuée par Virtual NIC 1, Virtual NIC 2 et Virtual NIC N. Une partie des NIC (non affichées) permet également de suivre toutes les fonctions virtuelles et le tri pour faire une navette entre les VNF et les ports des équipements externes.
Notez que la prise en charge de SR-IOV dépend du matériel de la plate-forme, en particulier du matériel NIC, et du logiciel des NFV ou des conteneurs pour utiliser la DMA pour le transfert de données. Les SNCI partitionnables et le pontage interne requis sont généralement plus coûteux. De ce fait, leur utilisation peut augmenter le coût sur les équipements de petite taille d’une valeur sensible. La réécriture des VNF et des conteneurs n’est pas une mince affaire non plus.
Comparaison de Virtio et SR-IOV
Virtio fait partie de la bibliothèque libvirt standard de fonctions de virtualisation utiles et est normalement incluse dans la plupart des versions de Linux. Virtio adopte une approche logicielle uniquement. SR-IOV nécessite des logiciels écrits d’une certaine façon et du matériel spécialisé, ce qui se traduit par une augmentation des coûts, même avec un équipement simple.
L’utilisation de virtio est généralement rapide et facile. Libvirt fait partie de chaque distribution Linux et les commandes à établir sont bien comprises. Cependant, Virtio alla la charge de performance sur le système d’exploitation hôte, qui relie normalement l’ensemble du trafic entre les NFV, en entrée et en sortie de l’équipement.
En général, le SR-IOV peut offrir une latence moindre et une utilisation moindre du processeur, en bref, des performances presque natives et non virtuelles des équipements. Cependant, la migration de la VNF d’un équipement vers un autre est complexe, car cette VNF dépend de NIC ressources sur une machine. L’état de transfert du VNF réside également dans le commutateur de couche 2 intégré à la NIC SR-IOV. C’est pour cette raison que le forwarding n’est plus aussi flexible, car les règles de la forwarding sont codées dans le matériel et ne peuvent pas être modifiées fréquemment.
Bien que la prise en charge de virtio soit quasi universelle, la prise en charge de SR-IOV varie en fonction NIC matériel et de plate-forme. La Juniper Networks NFX250 Plate-forme de services réseau prend en charge les capacités de SR-IOV et permet de 16 partitions sur chaque port de NIC physique.
Notez qu’un VNF donné peut utiliser soit virtio, soit SR-IOV, ou même les deux méthodes simultanément, si elle est prise en charge.
Virtio est la méthode recommandée pour établir une connexion entre un équipement virtualisé et un module NFV.