Exemple : configuration de la surveillance multicast
Comprendre la surveillance multicast
Les équipements réseau tels que les routeurs fonctionnent principalement au niveau des paquets ou de la couche 3. D’autres équipements réseau, tels que les ponts ou les commutateurs LAN, fonctionnent principalement au niveau de la trame ou de la couche 2. Le multicast fonctionne principalement au niveau des paquets, la couche 3, mais il existe un moyen de mapper des adresses de groupe IP multicast de couche 3 aux adresses de groupe MAC multicast de couche 2 au niveau de la trame.
Les routeurs peuvent gérer à la fois les informations d’adressage de couche 2 et de couche 3, car la trame et ses adresses doivent être traitées pour accéder au paquet encapsulé à l’intérieur. Les routeurs peuvent exécuter des protocoles multicast de couche 3 tels que PIM ou IGMP et déterminer où transférer du contenu multicast ou quand un hôte sur une interface rejoint ou quitte un groupe. Toutefois, les ponts et les commutateurs LAN, en tant qu’équipements de couche 2, ne sont pas censés avoir accès aux informations multicast dans les paquets que leurs trames transportent.
Comment les ponts et autres équipements de couche 2 peuvent-ils alors déterminer quand un équipement sur une interface rejoint ou quitte un arbre de multicast, ou si un hôte sur un LAN connecté souhaite recevoir le contenu d’un groupe multicast particulier ?
La réponse est que l’équipement de couche 2 implémente la surveillance multicast. La surveillance multicast est un terme général qui s’applique au processus de surveillance d’un équipement de couche 2 au niveau du contenu du paquet de couche 3 afin de déterminer les actions à entreprendre pour traiter ou transférer une trame. Il existe des formes plus spécifiques de surveillance, telles que la surveillance IGMP ou la surveillance PIM. Dans tous les cas, la surveillance implique qu’un équipement configuré pour fonctionner au niveau de la couche 2 a accès à des informations de couche 3 (paquets) normalement « interdites ». La surveillance rend le multicast plus efficace dans ces équipements.
Voir aussi
Comprendre la surveillance multicast et la protection racine VPLS
La surveillance se produit lorsqu’un protocole de couche 2 tel qu’un protocole Spanning-Tree connaît les détails opérationnels d’un protocole de couche 3 tel que le protocole IGMP (Internet Group Management Protocol) ou un autre protocole multicast. La surveillance est nécessaire lorsque les équipements de couche 2 tels que les commutateurs VLAN doivent connaître les informations de couche 3 telles que les adresses MAC (Media Access Control) des membres d’un groupe multicast.
La protection racine VPLS est un processus de protocole Spanning-Tree dans lequel une seule interface dans un environnement multihébergement transfère activement les trames de protocole Spanning-Tree. Cela protège la racine du Spanning Tree contre les boucles de pontage, mais empêche également les deux équipements de la topologie multihébergement d’informations fouinées, telles que les rapports d’appartenance IGMP.
Prenons l’exemple d’un ensemble d’hôtes multicast connectés à deux routeurs de périphérie client (CE1 et CE2) connectés les uns aux autres (une liaison CE1-CE2 est configurée) et multi-hébergement à deux routeurs de périphérie de fournisseur (PE1 et PE2, respectivement). Le PE actif reçoit uniquement les informations de protocole Spanning-Tree transférés sur la liaison PE-CE active, en raison de l’opération de protection racine. Tant que la liaison CE1-CE2 est opérationnelle, ce n’est pas un problème. Toutefois, si la liaison entre CE1 et CE2 échoue et que l’autre PE devient la liaison active du protocole Spanning-Tree, aucune information de surveillance multicast n’est disponible sur le nouveau PE actif. Le nouveau PE actif ne transfère pas le trafic multicast vers le CE et les hôtes gérés par ce routeur CE.
La panne de service est corrigée une fois que les hôtes ont envoyé de nouveaux rapports IGMP d’appartenance aux groupes aux routeurs CE. Toutefois, la panne de service peut être évitée si des informations de surveillance multicast sont disponibles pour les deux PE en dépit du fonctionnement normal de la protection racine du protocole Spanning-Tree.
Vous pouvez configurer la surveillance multicast pour ignorer les messages concernant les changements de topologie Spanning Tree sur les domaines de pont sur les commutateurs virtuels et les commutateurs de routage par défaut des domaines de pont. Vous pouvez utiliser la commande pour ignorer les ignore-stp-topology-change messages concernant les modifications de topologie Spanning Tree
Voir aussi
Configuration de la surveillance multicast
Pour configurer les paramètres généraux de surveillance multicast pour les routeurs MX Series, incluez la multicast-snooping-options déclaration :
multicast-snooping-options { flood-groups [ ip-addresses ]; forwarding-cache { threshold suppress value <reuse value>; } graceful-restart <restart-duration seconds>; ignore-stp-topology-change; multichassis-lag-replicate-state; nexthop-hold-time milliseconds; traceoptions { file filename <files number> <size size> <world-readable | no-world-readable>; flag flag <flag-modifier> <disable>; } }
Vous pouvez inclure cette déclaration aux niveaux hiérarchiques suivants :
[edit routing-instances routing-instance-name][edit logical-systems logical-system-name routing-instances routing-instance-name]
Par défaut, la surveillance multicast est désactivée. Vous pouvez activer la surveillance multicast dans les types d’instances VPLS ou de commutateurs virtuels dans la hiérarchie d’instances.
Si plusieurs domaines de pont sont configurés sous un VPLS ou une instance de commutateur virtuel, les options de surveillance multicast configurées au niveau de l’instance s’appliquent à tous les domaines de pont.
L’instruction ignore-stp-topology-change est prise en charge uniquement pour le type d’instance de routage de commutateurs virtuels et n’est pas prise en charge sous la [edit logical-systems] hiérarchie.
L’instruction nexthop-hold-time n’est prise en charge que dans la [edit routing-instances routing-instance-name] hiérarchie, et uniquement pour un type d’instance de commutateur virtuel ou vpls.
Voir aussi
Exemple : configuration de la surveillance multicast
Cet exemple montre comment configurer la surveillance multicast dans un scénario d’instance de routage VPLS ou de pont.
Exigences
Cet exemple utilise les composants matériels suivants :
Un routeur MX Series
Un équipement de couche 3 fonctionnant comme un routeur multicast
Avant de commencer :
Configurez les interfaces.
Configurez un protocole de passerelle intérieure. Consultez la bibliothèque de protocoles de routage Junos OS pour les équipements de routage.
Configurez un protocole multicast. Cette fonctionnalité fonctionne avec les protocoles multicast suivants :
DVMRP
PIM-DM
PIM-SM
PIM-SSM
Présentation et topologie
La surveillance IGMP empêche les équipements de couche 2 d’inonder indifféremment le trafic multicast de toutes les interfaces. Les paramètres que vous configurez pour la surveillance multicast aident à gérer le comportement de la surveillance IGMP.
Vous pouvez configurer des options de surveillance multicast sur l’instance maître par défaut et sur les instances de pont ou VPLS individuelles. La configuration d’instance maître par défaut est globale et s’applique à toutes les instances de pont ou VPLS individuelles du routeur logique. La configuration des instances individuelles remplace la configuration globale.
Cet exemple comprend les déclarations suivantes :
flood-groups : vous permet de lister les adresses de groupes multicast pour lesquelles le trafic doit être inondé. Ce paramètre s’il est utile pour s’assurer que la surveillance IGMP n’empêche pas les inondations multicast nécessaires. Le bloc d’adresses multicast de 224.0.0.1 à 224.0.0.255 est réservé à une utilisation filaire locale. Les groupes de cette plage sont assignés à diverses utilisations, y compris les protocoles de routage et les mécanismes de découverte locaux. Par exemple, OSPF utilise 224.0.0.5 pour tous les routeurs OSPF.
transfert-cache : spécifie comment les entrées de transfert sont vieillies et comment le nombre d’entrées est contrôlé.
Vous pouvez configurer des valeurs de seuil sur le cache de transfert pour supprimer (suspendre) la surveillance lorsque les entrées de cache atteignent un certain maximum et réutiliser le cache lorsque le nombre tombe à une autre valeur de seuil. Par défaut, aucune valeur seuil n’est activée sur le routeur.
Le seuil de suppression supprime les nouvelles entrées de cache de transfert multicast. Un seuil de réutilisation facultatif spécifie le point à partir duquel le routeur commence à créer de nouvelles entrées de cache de transfert multicast. Les deux seuils sont de 1 à 200 000. En cas de configuration, la valeur de réutilisation doit être inférieure à la valeur de suppression. La valeur de suppression est obligatoire. Si vous ne spécifiez pas la valeur de réutilisation facultative, le nombre d’entrées de cache de transfert multicast est limité à la valeur de suppression. Une nouvelle entrée est créée dès que le nombre d’entrées de cache de transfert multicast tombe en dessous de la valeur de suppression.
graceful-restart : configure le temps après lequel les routes apprises avant un redémarrage sont remplacées par des routes réapprendes. Si le redémarrage progressif pour la surveillance multicast est désactivé, les informations de surveillance sont perdues après le redémarrage d’un moteur de routage.
Par défaut, la durée de redémarrage est de 180 secondes (3 minutes). Vous pouvez définir cette valeur entre 0 et 300 secondes. Si vous définissez la durée sur 0, le redémarrage progressif est effectivement désactivé. Définissez cette valeur légèrement supérieure à l’intervalle de réponse aux requêtes IGMP.
ignore-stp-topology-change : configure le routeur MX Series pour ignorer les messages concernant le changement d’état de topologie Spanning-Tree.
Par défaut, le processus de surveillance IGMP sur un routeur MX Series détecte les modifications d’état d’interface apportées par n’importe quel protocole Spanning Tree (STP).
Dans un environnement de multihébergement VPLS où deux routeurs PE sont connectés à deux routeurs CE interconnectés et où la protection racine STP est activée sur les routeurs PE, l’une des interfaces de routeur PE est en état de transfert et l’autre est en état de blocage.
Si la liaison qui interconnecte les deux routeurs CE échoue, l’interface du routeur PE bloque les transitions d’état vers l’état de transfert.
L’interface du routeur PE n’attend pas pour recevoir les rapports d’appartenance en réponse à la prochaine requête générale ou spécifique au groupe. Au lieu de cela, le processus de surveillance IGMP envoie un message de requête général au routeur CE. Les hôtes connectés au routeur CE répondent avec des rapports pour tous les groupes qui les intéressent.
Lorsque la liaison interconnectant les deux routeurs CE est restaurée, l’état d’origine spanning-tree des deux routeurs PE est rétabli. Le PE de transfert reçoit un message de modification de topologie Spanning-Tree et envoie un message de requête général au routeur CE pour reconstruire immédiatement l’état d’appartenance au groupe.
Note:L’instruction
ignore-stp-topology-changeest prise en charge uniquement pour le type d’instance de routage de commutateur virtuel .
Topologie
La figure 1 montre une topologie de multihébergement VPLS dans laquelle un réseau client dispose de deux équipements CE avec une liaison entre eux. Chaque CE est connecté à un PE.
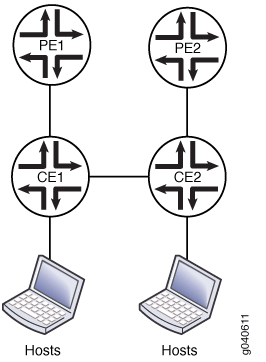 multihébergement VPLS
multihébergement VPLS
Configuration
Procédure
Configuration rapide cli
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez les détails nécessaires pour correspondre à la configuration de votre réseau, copiez et collez les commandes dans la CLI au niveau de la [edit] hiérarchie, puis entrez commit à partir du mode de configuration.
set bridge-domains domain1 multicast-snooping-options forwarding-cache threshold suppress 100 set bridge-domains domain1 multicast-snooping-options forwarding-cache threshold reuse 50 set bridge-domains domain1 multicast-snooping-options graceful-restart restart-duration 120 set routing-instances ce1 instance-type virtual-switch set routing-instances ce1 bridge-domains domain1 domain-type bridge set routing-instances ce1 bridge-domains domain1 vlan-id 100 set routing-instances ce1 bridge-domains domain1 interface ge-0/3/9.0 set routing-instances ce1 bridge-domains domain1 interface ge-0/0/6.0 set routing-instances ce1 bridge-domains domain1 multicast-snooping-options flood-groups 224.0.0.5 set routing-instances ce1 bridge-domains domain1 multicast-snooping-options ignore-stp-topology-change
Procédure étape par étape
Dans l’exemple suivant, vous devez parcourir différents niveaux de la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface cli, consultez le Guide de l’utilisateur de Junos OS CLI.
Pour configurer la surveillance IGMP :
Configurez les paramètres de surveillance multicast dans l’instance de routage maître.
[edit bridge-domains domain1] user@host# set multicast-snooping-options forwarding-cache threshold suppress 100 reuse 50 user@host# set multicast-snooping-options graceful-restart 120
Configurez l’instance de routage.
[edit routing-instances ce1] user@host# set instance-type virtual-switch
Configurez le domaine de pont dans l’instance de routage.
[edit routing-instances ce1 bridge-domains domain1] user@host# set domain-type bridge user@host# set interface ge-0/0/6.0 user@host# set interface ge-0/3/9.0 user@host# set vlan-id 100
Configurez les groupes d’inondation.
[edit routing-instances ce1 bridge-domains domain1] user@host# set multicast-snooping-options flood-groups 224.0.0.5
Configurez le routeur pour ignorer les messages concernant les changements d’état de topologie Spanning Tree.
[edit routing-instances ce1 bridge-domains domain1] user@host# set multicast-snooping-options ignore-stp-topology-change
Si vous avez fini de configurer l’équipement, validez la configuration.
user@host# commit
Résultats
Confirmez votre configuration en entrant les show bridge-domains commandes et show routing-instances .
user@host# show bridge-domains
domain1 {
multicast-snooping-options {
forwarding-cache {
threshold {
suppress 100;
reuse 50;
}
}
}
}
user@host# show routing-instances
ce1 {
instance-type virtual-switch;
bridge-domains {
domain1 {
domain-type bridge;
vlan-id 100;
interface ge-0/3/9.0; ## 'ge-0/3/9.0' is not defined
interface ge-0/0/6.0; ## 'ge-0/0/6.0' is not defined
multicast-snooping-options {
flood-groups 224.0.0.5;
ignore-stp-topology-change;
}
}
}
}
Vérification
Pour vérifier la configuration, exécutez les commandes suivantes :
afficher l’interface de surveillance igmp
afficher l’appartenance igmp à la surveillance
afficher les statistiques de surveillance igmp
afficher une route de surveillance multicast
afficher la table de routage
Activation des mises à jour en masse pour la surveillance multicast
Chaque fois qu’une interface individuelle rejoint ou quitte un groupe multicast, une nouvelle entrée de saut suivant est installée dans la table de routage et la table de transfert. Vous pouvez utiliser l’instruction nexthop-hold-time pour spécifier un temps, de 1 à 1 000 millisecondes (ms), pendant lequel les modifications d’interface sortantes sont accumulées, puis mises à jour en masse vers la table de routage et la table de transfert. Les mises à jour en bloc réduisent le temps de traitement et les frais de mémoire requis pour traiter la jointure et la sortie des messages. Cela est utile pour des applications telles que Internet Potocol Television (IPTV), dans lesquelles les utilisateurs changeant de canal peuvent créer des milliers d’interfaces qui rejoignent ou quittent un groupe dans un court laps de temps. Dans les scénarios IPTV, il y a généralement un nombre relativement faible et contrôlé de flux et un nombre élevé d’interfaces sortantes. L’utilisation de mises à jour en masse peut réduire le délai de participation.
Dans cet exemple, vous configurez un temps d’attente de 20 millisecondes pour un commutateur virtuel de type instance, à l’aide de l’instruction nexthop-hold-time :
Vous pouvez inclure l’instruction uniquement pour les nexthop-hold-time types d’instances de routage de commutateurs virtuels ou vpls au niveau hiérarchique suivant.
[edit routing-instances routing-instance-name multicast-snooping-options]
Si l’instruction nexthop-hold-time est supprimée de la configuration du routeur, les mises à jour en bloc sont désactivées.
Voir aussi
Activation de la surveillance multicast pour les interfaces de groupe d’agrégation de liaisons multichâssis
Incluez l’instruction multichassis-lag-replicate-state au niveau de la hiérarchie pour permettre la [edit multicast-snooping-options] surveillance IGMP et la réplication d’état pour les interfaces MC-LAG (Link Aggregation Group) multichâssis.
[edit]
multicast-snooping-options {
multichassis-lag-replicate-state;
}
La réplication des messages de connexion et de sortie entre les liaisons d’une interface MC-LAG à double liaison permet de récupérer plus rapidement les informations d’appartenance aux interfaces MC-LAG qui subissent une interruption de service.
Sans réplication d’état, si une interface MC-LAG à double liaison subit une interruption de service (par exemple, si une liaison active est mise en veille), les informations d’appartenance de l’interface sont récupérées en générant une requête IGMP vers le réseau. L’application de cette méthode peut prendre de 1 à 10 secondes, ce qui peut être trop long pour certaines applications.
Lorsque la réplication d’état est fournie pour les interfaces MC-LAG, les messages IGMP de joint ou de sortie reçus sur un équipement MC-LAG sont répliqués à partir de la liaison MC-LAG active vers la liaison de réserve via une connexion ICCP (Interchassis Communication Protocol). La liaison de réserve traite les messages comme s’ils étaient reçus de la liaison MC-LAG active correspondante, sauf qu’elle ne s’ajoute pas elle-même en tant que saut suivant et qu’elle n’inonde pas le message vers le réseau. Après un basculement, le statut d’appartenance multicast de la liaison peut être récupéré en quelques secondes ou moins en récupérant les messages répliqués.
Cet exemple permet la réplication d’état pour les interfaces MC-LAG :