Présentation des interfaces Ethernet agrégées
En savoir plus sur les interfaces Ethernet agrégées, LACP et LAG.
Aperçu
L’agrégation de liens IEEE 802.3ad vous permet de regrouper des interfaces Ethernet pour former une seule interface de couche de liaison, également connue sous le nom de groupe d’agrégation de liens (LAG) ou bundle.
L’agrégation de plusieurs liens entre des interfaces physiques crée une liaison trunk point à point logique unique, ou LAG. Le LAG équilibre le trafic sur les liaisons membres au sein d’un bundle Ethernet agrégé et augmente efficacement la bande passante de liaison montante. L’agrégation de liens a un autre avantage : leur disponibilité accrue, car le LAG est composé de plusieurs liens membres. Si une liaison membre tombe en panne, le LAG continue d’acheminer le trafic sur les liaisons restantes.
Vous pouvez configurer un débit mixte de vitesses de liaison pour l’offre Ethernet agrégée. Des vitesses de liaison de 10 GbE, 40 GbE et 100 GbE sont prises en charge. L’équilibrage de charge ne fonctionne pas si vous configurez des vitesses de liaison qui ne sont pas prises en charge.
Utilisez l’interface Ethernet agrégée pour confirmer la prise en charge de la plate-forme et de la version pour des fonctionnalités spécifiques.
Vous pouvez configurer un canal de port à l’aide de modèles SFP différents entre deux points de terminaison tout en conservant la même bande passante.
Par exemple:
switch 1 gig0/1 (SFP-10G-SR-S) --------- MX 1 gig0/1 (SFP-10G-SR-S)
switch 1 gig0/2 (SFP-10G-LR-S) --------- MX 1 gig0/2 (SFP-10G-LR-S)
Le protocole LACP (Link Aggregation Control Protocol) est un sous-composant de la norme IEEE 802.3ad et est utilisé comme protocole de découverte.
Pour assurer l’équilibrage de charge entre les interfaces Ethernet agrégées (AE) sur un groupe de nœuds de serveur redondant, les membres de l’AE doivent être répartis de manière égale sur le groupe de nœuds de serveur redondant.
Lors du basculement d’un groupe de nœuds réseau, le trafic peut être interrompu pendant quelques secondes.
LAG (Link Aggregation Group)
Vous configurez un LAG en spécifiant le numéro de liaison en tant que périphérique physique, puis en associant un ensemble d’interfaces (ports) à la liaison. Toutes les interfaces doivent avoir la même vitesse et être en mode full-duplex. Le système d’exploitation Junos (Junos OS) de Juniper Networks pour les commutateurs Ethernet EX Series attribue un ID unique et une priorité de port à chaque interface. L’ID et la priorité ne sont pas configurables.
Le nombre d’interfaces pouvant être regroupées dans un LAG et le nombre total de LAG pris en charge sur un commutateur varient selon le modèle de commutateur. Informations supplémentaires sur la plate-forme répertorie les commutateurs EX Series ainsi que le nombre maximal d’interfaces par LAG et le nombre maximal de LAG qu’ils prennent en charge.
Les LAG avec des liaisons de membres de différents types d’interfaces (par exemple, GE et MGE) ne sont pas pris en charge sur les commutateurs multidébits.
Pour Junos OS Evolved, le logiciel n’impose pas de limite au nombre maximal d’AEX dans un bundle Ethernet agrégé à débit mixte. Toutes les interfaces logiques enfants appartiennent à la même interface physique Ethernet agrégée et partagent le même sélecteur. Ainsi, beaucoup moins de mémoire d’équilibrage de charge et de configurations AEX à débit mixte devraient être utilisées, même si le nombre dépasse 64 interfaces logiques.
Sur les commutateurs QFX Series, si vous essayez de valider une configuration contenant plus de 64 interfaces Ethernet dans un LAG, vous recevez un message d’erreur. Le message d’erreur indique que la limite de groupe de 64 a été dépassée et que l’extraction de la configuration a échoué.
Pour créer un LAG :
-
Créez une interface Ethernet logique agrégée.
-
Définissez les paramètres associés à l’interface Ethernet agrégée logique, tels qu’une unité logique, les propriétés de l’interface et le protocole LACP (Link Aggregation Control Protocol).
-
Définissez les liens de membre à contenir dans l’interface Ethernet agrégée (par exemple, deux interfaces Ethernet 10 Gigabit).
-
Configurez LACP pour la détection des liens.
Gardez à l’esprit les consignes matérielles et logicielles suivantes :
-
Pour Junos OS Evolved, lorsqu’une nouvelle interface est ajoutée en tant que membre de l’offre Ethernet agrégée, un événement d’instabilité de liaison est généré. Lorsque vous ajoutez une interface au bundle, l’interface physique est supprimée en tant qu’interface standard, puis rajoutée en tant que membre. Pendant ce temps, les détails de l’interface physique sont perdus.
-
Jusqu’à 32 interfaces Ethernet peuvent être regroupées pour former un LAG sur un groupe de nœuds de serveur redondant, un groupe de nœuds de serveur et un groupe de nœuds de réseau sur un système QFabric. Jusqu’à 48 LAG sont pris en charge sur les groupes de nœuds de serveur redondants et les groupes de nœuds de serveur sur un système QFabric, et jusqu’à 128 LAG sont pris en charge sur les groupes de nœuds réseau sur un système QFabric. Vous pouvez configurer des LAG sur des périphériques de nœud dans des groupes de nœuds, des groupes de nœuds de serveur et des groupes de nœuds réseau redondants.
Sur un système Qfabric, si vous essayez de valider une configuration contenant plus de 32 interfaces Ethernet dans un LAG, vous recevrez un message d’erreur indiquant que la limite de groupe de 32 a été dépassée et que l’extraction de la configuration a échoué.
-
Le LAG doit être configuré des deux côtés de la liaison.
-
Les interfaces situées de part et d’autre de la liaison doivent être réglées sur la même vitesse et être en mode full-duplex.
Junos OS attribue un ID unique et une priorité de port à chaque port. L’ID et la priorité ne sont pas configurables.
-
Les systèmes QFabric prennent en charge un LAG spécial appelé FCoE LAG, qui vous permet de transporter du trafic FCoE et du trafic Ethernet normal (trafic qui n’est pas du trafic FCoE) sur le même bundle d’agrégation de liens. Les LAG standard utilisent un algorithme de hachage pour déterminer le lien physique utilisé pour la transmission. Ainsi, la communication entre deux appareils peut utiliser des liaisons physiques différentes dans le LAG pour différentes transmissions. Un LAG FCoE garantit que le trafic FCoE utilise le même lien physique dans le LAG pour les requêtes et les réponses. Cela préserve la liaison virtuelle point à point entre l’appareil FCoE, la carte réseau convergente (CNA) et le commutateur SAN FC sur un appareil QFabric System Node. Un LAG FCoE n’assure pas d’équilibrage de charge ni de redondance de liaison pour le trafic FCoE. Cependant, le trafic Ethernet classique utilise l’algorithme de hachage standard et bénéficie des avantages LAG habituels de l’équilibrage de charge et de la redondance des liaisons dans un LAG FCoE. Consultez Comprendre les LAG FCoE pour plus d’informations.
Configurer des interfaces Ethernet agrégées
Découvrez comment configurer des interfaces Ethernet agrégées. Comprend également un exemple de configuration.
Pour configurer un aex :
Vérifiez les instructions suivantes lors de la configuration des interfaces Ethernet agrégées :
En général, les offres Ethernet agrégées prennent en charge les fonctionnalités disponibles sur toutes les interfaces prises en charge qui peuvent devenir un lien membre dans l’offre groupée. À titre exceptionnel, les fonctionnalités GbE IQ et certaines fonctionnalités GbE plus récentes ne sont pas prises en charge dans les offres Ethernet agrégées.
Les interfaces GbE IQ et SFP peuvent être des liaisons membres, mais les fonctionnalités spécifiques à IQ et SFP ne sont pas prises en charge sur le bundle Ethernet agrégé, même si toutes les liaisons membres prennent individuellement en charge ces fonctionnalités.
Avant de valider une configuration Ethernet agrégée, assurez-vous que le mode liaison n’est configuré sur aucune interface membre de l’offre groupée Ethernet agrégée ; sinon, la vérification de la validation de la configuration échoue.
Exemple de configuration d’interfaces Ethernet agrégées
Les interfaces Ethernet agrégées peuvent utiliser des interfaces de différents FPC, DPC ou PIC. La configuration suivante est suffisante pour mettre en place une interface Gigabit Ethernet agrégée.
[edit chassis]
aggregated-devices {
ethernet {
device-count 15;
}
}
[edit interfaces]
ge-1/3/0 {
gigether-options {
802.3ad ae0;
}
}
ge-2/0/1 {
gigether-options {
802.3ad ae0;
}
}
ae0 {
aggregated-ether-options {
link-speed 1g;
minimum-links 1;
}
}
vlan-tagging;
unit 0 {
vlan-id 1;
family inet {
address 10.0.0.1/24;
}
}
unit 1 {
vlan-id 1024;
family inet {
address 10.0.0.2/24;
}
}
unit 2 {
vlan-id 1025;
family inet {
address 10.0.0.3/24;
}
}
unit 3 {
vlan-id 4094;
family inet {
address 10.0.0.4/24;
}
}
}
Exemple : Configuration de l’agrégation de liens entre un commutateur QFX Series et un commutateur d’agrégation
Un produit QFX Series vous permet de combiner plusieurs liaisons Ethernet dans une seule interface logique pour plus de bande passante et de redondance. Les ports combinés de cette manière sont appelés groupe d’agrégation de liens (LAG) ou bundle. Le nombre de liaisons Ethernet que vous pouvez combiner dans un LAG dépend du modèle de votre produit QFX Series. Vous pouvez configurer les LAG pour connecter un produit QFX Series ou un commutateur EX4600 à d’autres commutateurs, tels que des commutateurs d’agrégation, des serveurs ou des routeurs. Cet exemple décrit comment configurer des LAG pour connecter un commutateur QFX3500, QFX3600, EX4600, QFX5100 et QFX10002 à un commutateur d’agrégation.
Exigences
Cet exemple utilise les composants logiciels et matériels suivants :
Junos OS version 11.1 ou ultérieure pour les commutateurs QFX3500 et QFX3600, Junos OS 13.2 ou version ultérieure pour les commutateurs QFX5100 et EX4600, et Junos OS version 15.1X53-D10 ou ultérieure pour les commutateurs QFX10002.
Un commutateur QFX3500, QFX3600, EX4600, QFX5100 ou QFX10002.
Vue d’ensemble et topologie
Dans cet exemple, le commutateur dispose d’un LAG comprenant deux interfaces Ethernet 10 Gigabit. Ce LAG est configuré en liaison en mode port (ou liaison en mode interface) afin que le commutateur et le VLAN auquel il a été affecté puissent envoyer et recevoir du trafic.
La configuration des interfaces Ethernet en tant que LAG présente les avantages suivants :
Si un port physique est perdu pour une raison quelconque (un câble est débranché ou un port de commutation tombe en panne), le port logique continue de fonctionner de manière transparente sur le port physique restant.
Le protocole LACP (Link Aggregation Control Protocol) peut être configuré en option pour surveiller les liens et ajouter et supprimer automatiquement des liens individuels sans intervention de l’utilisateur.
Si l’extrémité distante de la liaison LAG est un équipement de sécurité, LACP peut ne pas être pris en charge, car les équipements de sécurité nécessitent une configuration déterministe. Dans ce cas, ne configurez pas LACP. Toutes les liaisons du LAG sont opérationnelles en permanence, sauf si le commutateur détecte une défaillance de liaison dans la couche physique Ethernet ou les couches de liaison de données.
La topologie utilisée dans cet exemple se compose d’un commutateur avec un LAG configuré entre deux de ses interfaces Ethernet 10 Gigabit. Le commutateur est connecté à un commutateur d’agrégation.
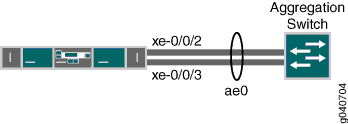
Le Tableau 1 détaille la topologie utilisée dans cet exemple de configuration.
| Nom d’hôte | Port trunk matériel de base | |
|---|---|---|
interrupteur |
Commutateur QFX3500, QFX3600, EX4600, QFX5100 ou QFX10002 |
|
Configuration
Pour configurer un LAG entre deux interfaces Ethernet 10 Gigabit.
Procédure
Configuration rapide de la CLI
Pour configurer rapidement un LAG entre deux interfaces Ethernet 10 Gigabit sur un commutateur, copiez les commandes suivantes et collez-les dans la fenêtre du terminal du commutateur :
Pour configurer un LAG à l’aide de Logiciels de couche 2 améliorés (par exemple, sur les commutateurs EX4600, QFX5100 ou QFX10002), utilisez l’instruction à la interface-mode place de l’instruction port-mode . Pour plus de détails sur ELS, reportez-vous à la section Utilisation du CLI de Logiciels de couche 2 amélioré.
[edit] set chassis aggregated-devices ethernet device-count 1 set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options link-speed 10g set interfaces ae0 unit 0 family ethernet-switching vlan members green set interfaces xe-0/0/2 ether-options 802.3ad ae0 set interfaces xe-0/0/3 ether-options 802.3ad ae0 set interfaces ae0 unit 0 family ethernet-switching port-mode trunk set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 aggregated-ether-options lacp periodic fast
Procédure étape par étape
Pour configurer un LAG entre un commutateur QFX Series et un commutateur d’agrégation :
Spécifiez le nombre de LAG à créer sur le commutateur :
[edit chassis] user@switch# set aggregated-devices ethernet device-count 1
Spécifiez le nombre de liens qui doivent être présents pour que l’interface
ae0LAG soitup:[edit interfaces] user@switch# set ae0 aggregated-ether-options minimum-links 1
Spécifiez la vitesse de support
ae0du lien :[edit interfaces] user@switch# set ae0 aggregated-ether-options link-speed 10g
Spécifiez les membres à inclure dans le bundle Ethernet agrégé :
[edit interfaces] user@switch# set interfaces xe-0/0/2 ether-options 802.3ad ae0 [edit interfaces] user@switch# set interfaces xe-0/0/3 ether-options 802.3ad ae0
Attribuez un mode de port trunk à la
ae0liaison :Note:Pour configurer un LAG à l’aide de Logiciels de couche 2 améliorés (par exemple, sur les commutateurs EX4600, QFX5100 ou QFX10002), utilisez l’instruction à la
interface-modeplace de l’instructionport-mode. Pour plus de détails sur ELS, reportez-vous à la section Utilisation du CLI de Logiciels de couche 2 amélioré.[edit interfaces] user@switch# set ae0 unit 0 family ethernet-switching port-mode trunk
ou
[edit interfaces] user@switch# set ae0 unit 0 family ethernet-switching interface-mode trunk
Attribuer le LAG à un VLAN :
[edit interfaces] user@switch# set ae0 unit 0 family ethernet-switching vlan members green vlan-id 200
(Facultatif) : Désignez un côté du LAG comme actif pour LACP :
[edit interfaces] user@switch# set ae0 aggregated-ether-options lacp active
(Facultatif) : Désigner l’intervalle et la vitesse auxquels les interfaces envoient des paquets LACP :
[edit interfaces] user@switch# set ae0 aggregated-ether-options lacp periodic fast
Résultats
Affichez les résultats de la configuration sur un commutateur QFX3500 ou QFX3600 :
[edit]
chassis {
aggregated-devices {
ethernet {
device-count 1;
}
}
}
green {
vlan-id 200;
}
}
interfaces {
ae0 {
aggregated-ether-options {
link-speed 10g;
minimum-links 1;
}
unit 0 {
family ethernet-switching {
port-mode trunk;
vlan {
members green;
}
}
}
xe-0/0/2 {
ether-options {
802.3ad ae0;
}
}
xe-0/0/3 {
ether-options {
802.3ad ae0;
}
}
}
Vérification
Pour vérifier que la commutation est opérationnelle et qu’un LAG a été créé, effectuez les tâches suivantes :
Vérifiez que LAG ae0.0 a été créé
But
Vérifiez qu’un LAG ae0.0 a été créé sur le commutateur.
Action
show interfaces ae0 terse
Interface Admin Link Proto Local Remote ae0 up up ae0.0 up up eth-switch
Signification
La sortie confirme que la ae0.0 liaison est active et affiche l’adresse family IP attribuée à cette liaison.
Vérifiez que LAG ae0 a été créé
But
Vérifiez qu’un LAG ae0 a été créé sur le commutateur
Action
show interfaces ae0 terse
Interface Admin Link Proto Local Remote ae0 up down ae0.0 up down eth-switch
Signification
La sortie indique que la ae0.0 liaison est inopérante.
Dépannage
Dépannage d’un LAG en panne
Problème
La show interfaces terse commande indique que le LAG est down.
Solution
Vérifiez les points suivants :
Vérifiez qu’il n’y a pas d’incompatibilité de configuration.
Vérifiez que tous les ports membres sont opérationnels.
Vérifiez qu’un LAG fait partie de la famille de commutateurs Ethernet (LAG de couche 2) ou de la famille d’inets (LAG de couche 3).
Vérifiez que le membre du LAG est connecté au bon LAG à l’autre extrémité.
Informations supplémentaires sur la plate-forme
Utilisez le groupe d’agrégation de liens pour confirmer la prise en charge de la plate-forme et de la version pour des fonctionnalités spécifiques. D’autres plates-formes peuvent être prises en charge.
| Informations LAG | EX4100-F Virtual Chassis EX4200 | et EX4200 Virtual Chassis | EX4300 et EX4300 Virtual Chassis | EX4600 | EX4650 Virtual Chassis | EX9200 |
|---|---|---|---|---|---|---|
| EX6200 | et EX4400 | |||||
| Nombre maximal d’interfaces par LAG | 8 | 8 | 16 | 32 | 64 | 64 |
| Nombre maximal de LAG par commutateur | 128 | 111 | 128 | 128 | 72 | 150 |
| Informations LAG | QFX5100 | QFX5120 | QFX5130 | QFX5700 | QFX10002 | QFX10008 | |
|---|---|---|---|---|---|---|---|
| QFX5110 | et QFX5200 | ||||||
| Nombre maximal d’interfaces par LAG | 64 | 64 | 64 | 128 | 64 | 64 | 64 |
| Nombre maximal de LAG par commutateur | 96 | 72 | 128 | 144 | 150 | 1000 | 1000 |