Sur cette page
Exemple : Configuration des routes BGP IPv6 sur le transport IPv4
Présentation des sessions IPv6 sur BGP et des routes IPv4 publicitaires
Comprendre la redistribution des routes IPv4 avec IPv6 Next Hop into BGP
Configuration de BGP pour redistribuer les routes IPv4 avec les adresses IPv6 Next-Hop
Comprendre les itinéraires de flux BGP pour le filtrage du trafic
Exemple : Activation de BGP pour transporter des routes de spécification de flux
Exemple : Configuration de BGP pour transporter les routes de spécification de flux IPv6
Configuration de l’action de spécification de flux BGP Rediriger vers IP pour filtrer le trafic DDoS
Transfert de trafic à l’aide de l’action DSCP de spécification de flux BGP
BGP multi-protocole
Comprendre le BGP multiprotocole
Le BGP multiprotocole (MP-BGP) est une extension du BGP qui permet au BGP de transporter des informations de routage pour plusieurs couches réseau et familles d’adresses. MP-BGP peut transporter les routes unicast utilisées pour le routage multicast séparément des routes utilisées pour le transfert IP unicast.
Pour activer MP-BGP, vous configurez BGP afin qu’il transporte les informations d’accessibilité de la couche réseau (NLRI) pour les familles d’adresses autres que l’IPv4 unicast en incluant l’instruction family inet suivante :
family inet { (any | flow | labeled-unicast | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; topology name { community { target identifier; } } } }
Pour permettre à MP-BGP de transporter NLRI pour la famille d’adresses IPv6, incluez l’instruction family inet6 suivante :
family inet6 { (any | labeled-unicast | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; } }
Sur les routeurs uniquement, pour permettre à MP-BGP de transporter le NLRI de réseau privé virtuel (VPN) de couche 3 pour la famille d’adresses IPv4, incluez l’instruction family inet-vpn suivante :
family inet-vpn { (any | flow | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } rib-group group-name; } }
Sur les routeurs uniquement, pour permettre à MP-BGP de transporter le NLRI VPN de couche 3 pour la famille d’adresses IPv6, incluez l’instruction family inet6-vpn suivante :
family inet6-vpn { (any | multicast | unicast) { accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;} } <loops number>; prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;}} rib-group group-name; } }
Sur les routeurs uniquement, pour permettre à MP-BGP de transporter le NLRI VPN multicast pour la famille d’adresses IPv4 et d’activer la signalisation VPN, incluez l’instruction family inet-mvpn suivante :
family inet-mvpn {
signaling {
accepted-prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
<loops number>;
prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
}
}
Pour permettre à MP-BGP de transporter des NLRI VPN multicast pour la famille d’adresses IPv6 et d’activer la signalisation VPN, incluez l’instruction suivante family inet6-mvpn :
family inet6-mvpn {
signaling {
accepted-prefix-limit {
maximum number;
teardown <percentage> <idle-timeout (forever | minutes)>;
drop-excess <percentage>;
hide-excess <percentage>;}}
<loops number>;
prefix-limit {
maximum number;
teardown <percentage> <idle-timeout <forever | minutes>;
drop-excess <percentage>;
hide-excess <percentage>;}}
}
}
Pour plus d’informations sur les VPN multicast basés sur BGP, consultez le Guide de l’utilisateur des protocoles multicast Junos OS.
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure ces instructions, reportez-vous aux sections de résumé des instructions pour ces instructions.
Si vous modifiez la famille d’adresses spécifiée dans le niveau hiérarchique, toutes les sessions BGP en cours sur le [edit protocols bgp family] périphérique de routage sont abandonnées, puis rétablies.
Dans Junos OS version 9.6 et ultérieure, vous pouvez spécifier une valeur de boucle pour une famille d’adresses BGP spécifique.
Par défaut, les homologues BGP transportent uniquement les routes unicast utilisées à des fins de transfert unicast. Pour configurer les homologues BGP afin qu’ils transportent uniquement des routes de multidiffusion, spécifiez l’option multicast . Pour configurer les homologues BGP afin qu’ils transportent à la fois des routes unicast et multicast, spécifiez l’option any .
Lorsque MP-BGP est configuré, BGP installe les routes MP-BGP dans différentes tables de routage. Chaque table de routage est identifiée par la famille de protocoles ou l’indicateur de famille d’adresses (AFI) et un identifiant de famille d’adresses ultérieur (SAFI).
La liste suivante présente toutes les combinaisons possibles d’AFI et de SAFI :
AFI=1, SAFI=1, IPv4 unicast
AFI=1, SAFI=2, multicast IPv4
AFI=1, SAFI=128, L3VPN IPv4 unicast
AFI=1, SAFI=129, multicast IPv4 L3VPN
AFI=2, SAFI=1, unicast IPv6
AFI=2, SAFI=2, multicast IPv6
AFI = 25, SAFI = 65, BGP-VPLS/BGP-L2VPN
AFI=2, SAFI=128, L3VPN IPv6 unicast
AFI=2, SAFI=129, multicast IPv6 L3VPN
AFI = 1, SAFI = 132, contrainte RT
AFI=1, SAFI=133, Spécification de flux
AFI=1, SAFI=134, Spécification de flux
AFI=3, SAFI=128, CLNS VPN
AFI=1, SAFI=5, NG-MVPN IPv4
AFI=2, SAFI=5, NG-MVPN IPv6
AFI=1, SAFI=66, MDT-SAFI
AFI=1, SAFI=4, étiquetés IPv4
AFI=2, SAFI=4, étiquetés IPv6 (6PE)
Les routes installées dans la table de routage inet.2 peuvent uniquement être exportées vers des homologues MP-BGP car elles utilisent le SAFI, en les identifiant comme des routes vers des sources multicast. Les routes installées dans la table de routage inet.0 peuvent uniquement être exportées vers des homologues BGP standard.
La table de routage inet.2 doit être un sous-ensemble des routes que vous avez dans inet.0, car il est peu probable que vous ayez une route vers une source multicast à laquelle vous ne pourriez pas envoyer de trafic unicast. La table de routage inet.2 stocke les routes unicast utilisées pour les vérifications de transfert de chemin inverse multicast et les informations d’accessibilité supplémentaires apprises par MP-BGP à partir des mises à jour multicast NLRI. Une table de routage inet.2 est automatiquement créée lorsque vous configurez MP-BGP (en définissant NLRI sur any).
Lorsque vous activez MP-BGP, vous pouvez effectuer les opérations suivantes :
- Limitation du nombre de préfixes reçus sur une session homologue BGP
- Limitation du nombre de préfixes acceptés sur une session homologue BGP
- Configuration des groupes de tables de routage BGP
- résolution des routes vers les périphériques de routage PE situés dans d’autres OS
- Autoriser les routes étiquetées et non étiquetées
Limitation du nombre de préfixes reçus sur une session homologue BGP
Vous pouvez limiter le nombre de préfixes reçus sur une session pair BGP et consigner des messages à débit limité lorsque le nombre de préfixes injectés dépasse une limite définie. Vous pouvez également supprimer l’appairage lorsque le nombre de préfixes dépasse la limite.
Pour configurer une limite au nombre de préfixes pouvant être reçus sur une session BGP, incluez l’instruction prefix-limit suivante :
prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>; }
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Pour maximum number, spécifiez une valeur comprise entre 1 et 4 294 967 295. Lorsque le nombre maximal de préfixes spécifié est dépassé, un message de journal système est envoyé.
Si vous incluez l’instruction teardown , la session est supprimée lorsque le nombre maximal de préfixes est dépassé. Si vous spécifiez un pourcentage, les messages sont consignés lorsque le nombre de préfixes dépasse ce pourcentage de la limite maximale spécifiée. Une fois la session détruite, elle est rétablie en peu de temps (à moins que vous n’incluiez la idle-timeout déclaration). Si vous incluez l’instruction idle-timeout , la session peut être interrompue pendant une durée spécifiée ou pour toujours. Si vous spécifiez forever, la session n’est rétablie qu’après l’exécution d’une clear bgp neighbor commande. Si vous incluez l’option drop-excess <percentage> , les routes excédentaires sont supprimées lorsque le nombre maximal de préfixes est atteint. Si vous spécifiez un pourcentage, les routes sont consignées lorsque le nombre de préfixes dépasse cette valeur de pourcentage du nombre maximal. Si vous incluez l’option hide-excess <percentage> , les routes excédentaires sont masquées lorsque le nombre maximal de préfixes est atteint. Si vous spécifiez un pourcentage, les routes sont consignées lorsque le nombre de préfixes dépasse cette valeur de pourcentage du nombre maximal. Si le pourcentage est modifié, les itinéraires sont réévalués automatiquement. Si les routes actives tombent en dessous du pourcentage spécifié, elles sont conservées comme masquées.
Dans Junos OS version 9.2 et ultérieure, vous pouvez également configurer une limite au nombre de préfixes pouvant être acceptés sur une session pair BGP. Pour plus d’informations, reportez-vous à la section Limitation du nombre de préfixes acceptés sur une session homologue BGP.
Limitation du nombre de préfixes acceptés sur une session homologue BGP
Dans Junos OS version 9.2 et ultérieure, vous pouvez limiter le nombre de préfixes pouvant être acceptés sur une session pair BGP. Lorsque cette limite spécifiée est dépassée, un message de journal système est envoyé. Vous pouvez également spécifier de réinitialiser la session BGP si la limite du nombre de préfixes spécifiés est dépassée.
Pour configurer une limite au nombre de préfixes pouvant être acceptés sur une session pair BGP, incluez l’instruction accepted-prefix-limit suivante :
accepted-prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop <percentage>; hide <percentage>; }
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Pour maximum number, spécifiez une valeur comprise entre 1 et 4 294 967 295.
Incluez l’instruction teardown permettant de réinitialiser la session pair BGP lorsque le nombre de préfixes acceptés dépasse la limite configurée. Vous pouvez également inclure une valeur de pourcentage comprise entre 1 et 100 pour qu’un message du journal système soit envoyé lorsque le nombre de préfixes acceptés dépasse ce pourcentage de la limite maximale. Par défaut, une session BGP réinitialisée est rétablie dans un court laps de temps. Incluez l’instruction idle-timeout pour empêcher le rétablissement de la session BGP pendant une période de temps spécifiée. Vous pouvez configurer une valeur de délai d’expiration comprise entre 1 et 2400 minutes. Incluez l’option forever permettant d’empêcher le rétablissement de la session BGP jusqu’à ce que vous émettiez la clear bgp neighbor commande. Si vous incluez l’instruction drop-excess <percentage> et spécifiez un pourcentage, les routes excédentaires sont supprimées lorsque le nombre de préfixes dépasse le pourcentage. Si vous incluez l’instruction hide-excess <percentage> et spécifiez un pourcentage, les routes excédentaires sont masquées lorsque le nombre de préfixes dépasse le pourcentage. Si le pourcentage est modifié, les itinéraires sont réévalués automatiquement.
Lorsque le routage actif continu (NSR) est activé et qu’un basculement vers un moteur de routage de secours se produit, les homologues BGP inactifs sont automatiquement redémarrés. Les homologues sont redémarrés même si l’instruction idle-timeout forever est configurée.
Vous pouvez également configurer une limite au nombre de préfixes pouvant être reçus (par opposition à acceptés) sur une session pair BGP. Pour plus d’informations, reportez-vous à la section Limitation du nombre de préfixes reçus sur une session homologue BGP.
Configuration des groupes de tables de routage BGP
Lorsqu’une session BGP reçoit un NLRI unicast ou multicast, elle installe la route dans la table appropriée (inet.0 ou inet6.0 pour unicast, et inet.2 ou inet6.2 pour multicast). Pour ajouter des préfixes unicast aux tables unicast et multicast, vous pouvez configurer des groupes de tables de routage BGP. Ceci est utile si vous ne pouvez pas effectuer de négociation NLRI multicast.
Pour configurer les groupes de tables de routage BGP, incluez l’instruction rib-group suivante :
rib-group group-name;
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
résolution des routes vers les périphériques de routage PE situés dans d’autres OS
Vous pouvez autoriser le placement d’itinéraires étiquetés dans la table de routage pour la inet.3 résolution des itinéraires. Ces routes sont ensuite résolues pour les connexions d’appareil de routage de périphérie (PE) du fournisseur lorsque le PE distant est situé sur un autre système autonome (AS). Pour qu’un périphérique de routage PE installe une route dans l’instance de routage VRF (VPN routing and forwarding), le tronçon suivant doit être résolu en une route stockée dans la inet.3 table.
Pour résoudre les routes dans la inet.3 table de routage, incluez l’instruction resolve-vpn suivante :
resolve-vpn group-name;
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Autoriser les routes étiquetées et non étiquetées
Vous pouvez autoriser l’échange d’itinéraires étiquetés et non étiquetés au cours d’une seule session. Les routes étiquetées sont placées dans la table de routage inet.3 ou inet6.3, et les routes unicast étiquetées et non étiquetées peuvent être envoyées ou reçues par le périphérique de routage.
Pour permettre l’échange de routes étiquetées et non étiquetées, incluez l’instruction rib suivante :
rib (inet.3 | inet6.3);
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Exemple : Configuration des routes BGP IPv6 sur le transport IPv4
Cet exemple montre comment exporter des préfixes IPv6 et IPv4 sur une connexion IPv4 où les deux côtés sont configurés avec une interface IPv4.
Conditions préalables
Aucune configuration spéciale au-delà de l’initialisation de l’appareil n’est requise avant de configurer cet exemple.
Présentation
Gardez les points suivants à l’esprit lors de l’exportation de préfixes BGP IPv6 :
BGP dérive les préfixes next-hop à l’aide du préfixe IPv6 mappé IPv4. Par exemple, le préfixe de saut suivant IPv4 se traduit par le préfixe
10.19.1.1de saut suivant IPv6 ::ffff :10.19.1.1.REMARQUE :Il doit exister une route active vers le saut suivant IPv6 mappé IPv4 pour exporter les préfixes BGP IPv6.
Une connexion IPv6 doit être configurée sur la liaison. Il doit s’agir d’un tunnel IPv6 ou d’une configuration à double pile. L’empilage double est utilisé dans cet exemple.
Lors de la configuration des préfixes IPv6 mappés IPv4, utilisez un masque dont la longueur est supérieure à 96 bits.
Configurez une route statique si vous souhaitez utiliser des préfixes IPv6 normaux. Cet exemple utilise des routes statiques.
Figure 1 montre l’exemple de topologie.
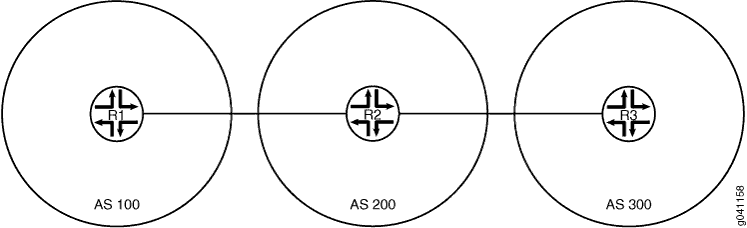
Configuration
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
Appareil R1
set interfaces fe-1/2/0 unit 1 family inet address 192.168.10.1/24 set interfaces fe-1/2/0 unit 1 family inet6 address ::ffff:192.168.10.1/120 set interfaces lo0 unit 1 family inet address 10.10.10.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext peer-as 200 set protocols bgp group ext neighbor 192.168.10.10 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options rib inet6.0 static route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10 set routing-options static route 192.168.20.0/24 next-hop 192.168.10.10 set routing-options autonomous-system 100
Appareil R2
set interfaces fe-1/2/0 unit 2 family inet address 192.168.10.10/24 set interfaces fe-1/2/0 unit 2 family inet6 address ::ffff:192.168.10.10/120 set interfaces fe-1/2/1 unit 3 family inet address 192.168.20.21/24 set interfaces fe-1/2/1 unit 3 family inet6 address ::ffff:192.168.20.21/120 set interfaces lo0 unit 2 family inet address 10.10.0.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext neighbor 192.168.10.1 peer-as 100 set protocols bgp group ext neighbor 192.168.20.1 peer-as 300 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options autonomous-system 200
Appareil R3
set interfaces fe-1/2/0 unit 4 family inet address 192.168.20.1/24 set interfaces fe-1/2/0 unit 4 family inet6 address ::ffff:192.168.20.1/120 set interfaces lo0 unit 3 family inet address 10.10.20.1/32 set protocols bgp group ext type external set protocols bgp group ext family inet unicast set protocols bgp group ext family inet6 unicast set protocols bgp group ext export send-direct set protocols bgp group ext export send-static set protocols bgp group ext peer-as 200 set protocols bgp group ext neighbor 192.168.20.21 set policy-options policy-statement send-direct term 1 from protocol direct set policy-options policy-statement send-direct term 1 then accept set policy-options policy-statement send-static term 1 from protocol static set policy-options policy-statement send-static term 1 then accept set routing-options rib inet6.0 static route ::ffff:192.168.10.0/120 next-hop ::ffff:192.168.20.21 set routing-options static route 192.168.10.0/24 next-hop 192.168.20.21 set routing-options autonomous-system 300
Configuration de l’appareil R1
Procédure étape par étape
L’exemple suivant vous oblige à naviguer à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
Pour configurer l’appareil R1 :
Configurez les interfaces, y compris une adresse IPv4 et une adresse IPv6.
[edit interfaces] user@R1# set fe-1/2/0 unit 1 family inet address 192.168.10.1/24 user@R1# set fe-1/2/0 unit 1 family inet6 address ::ffff:192.168.10.1/120 user@R1# set lo0 unit 1 family inet address 10.10.10.1/32
Configurez EBGP.
[edit protocols bgp group ext] user@R1# set type external user@R1# set export send-direct user@R1# set export send-static user@R1# set peer-as 200 user@R1# set neighbor 192.168.10.10
-
Activez BGP pour transporter les routes unicast IPv4 et unicast IPv6.
[edit protocols bgp group ext] user@R1# set family inet unicast user@R1# set family inet6 unicast
Les routes unicast IPv4 sont activées par défaut. Toutefois, lorsque vous configurez d’autres familles d’adresses NLRI, la monodiffusion IPv4 doit être configurée explicitement.
-
Configurez la stratégie de routage.
[edit policy-options] user@R1# set policy-statement send-direct term 1 from protocol direct user@R1# set policy-statement send-direct term 1 then accept user@R1# set policy-statement send-static term 1 from protocol static user@R1# set policy-statement send-static term 1 then accept
Configurez des routes statiques.
[edit routing-options] user@R1# set rib inet6.0 static route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10 user@R1# set static route 192.168.20.0/24 next-hop 192.168.10.10
Configurez le numéro du système autonome (AS).
[edit routing-options] user@R1# set autonomous-system 100
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show interfaces, show policy-options, show protocolset show routing-options. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@R1# show interfaces
fe-1/2/0 {
unit 1 {
family inet {
address 192.168.10.1/24;
}
family inet6 {
address ::ffff:192.168.10.1/120;
}
}
}
lo0 {
unit 1 {
family inet {
address 10.10.10.1/32;
}
}
}
user@R1# show policy-options
policy-statement send-direct {
term 1 {
from protocol direct;
then accept;
}
}
policy-statement send-static {
term 1 {
from protocol static;
then accept;
}
}
user@R1# show protocols
bgp {
group ext {
type external;
family inet {
unicast;
}
family inet6 {
unicast;
}
export [ send-direct send-static ];
peer-as 200;
neighbor 192.168.10.10;
}
}
user@R1# show routing-options
rib inet6.0 {
static {
route ::ffff:192.168.20.0/120 next-hop ::ffff:192.168.10.10;
}
}
static {
route 192.168.20.0/24 next-hop 192.168.10.10;
}
autonomous-system 100;
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration. Répétez la configuration sur les équipements R2 et R3, en modifiant les noms d’interface et les adresses IP si nécessaire.
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de l’état du voisinage
But
Assurez-vous que BGP est activé pour transporter les routes unicast IPv6.
Action
À partir du mode opérationnel, entrez la show bgp neighbor commande.
user@R2> show bgp neighbor
Peer: 192.168.10.1+179 AS 100 Local: 192.168.10.10+54226 AS 200
Type: External State: Established Flags: <Sync>
Last State: OpenConfirm Last Event: RecvKeepAlive
Last Error: None
Export: [ send-direct send-static ]
Options: <Preference AddressFamily PeerAS Refresh>
Address families configured: inet-unicast inet6-unicast
Holdtime: 90 Preference: 170
Number of flaps: 0
Peer ID: 10.10.10.1 Local ID: 10.10.0.1 Active Holdtime: 90
Keepalive Interval: 30 Peer index: 0
BFD: disabled, down
Local Interface: fe-1/2/0.2
NLRI for restart configured on peer: inet-unicast inet6-unicast
NLRI advertised by peer: inet-unicast inet6-unicast
NLRI for this session: inet-unicast inet6-unicast
Peer supports Refresh capability (2)
Stale routes from peer are kept for: 300
Peer does not support Restarter functionality
NLRI that restart is negotiated for: inet-unicast inet6-unicast
NLRI of received end-of-rib markers: inet-unicast inet6-unicast
NLRI of all end-of-rib markers sent: inet-unicast inet6-unicast
Peer supports 4 byte AS extension (peer-as 100)
Peer does not support Addpath
Table inet.0 Bit: 10000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 1
Received prefixes: 3
Accepted prefixes: 2
Suppressed due to damping: 0
Advertised prefixes: 4
Table inet6.0 Bit: 20000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 0
Received prefixes: 1
Accepted prefixes: 1
Suppressed due to damping: 0
Advertised prefixes: 2
Last traffic (seconds): Received 24 Sent 12 Checked 60
Input messages: Total 132 Updates 6 Refreshes 0 Octets 2700
Output messages: Total 133 Updates 3 Refreshes 0 Octets 2772
Output Queue[0]: 0
Output Queue[1]: 0
Peer: 192.168.20.1+179 AS 300 Local: 192.168.20.21+54706 AS 200
Type: External State: Established Flags: <Sync>
Last State: OpenConfirm Last Event: RecvKeepAlive
Last Error: None
Export: [ send-direct send-static ]
Options: <Preference AddressFamily PeerAS Refresh>
Address families configured: inet-unicast inet6-unicast
Holdtime: 90 Preference: 170
Number of flaps: 0
Peer ID: 10.10.20.1 Local ID: 10.10.0.1 Active Holdtime: 90
Keepalive Interval: 30 Peer index: 1
BFD: disabled, down
Local Interface: fe-1/2/1.3
NLRI for restart configured on peer: inet-unicast inet6-unicast
NLRI advertised by peer: inet-unicast inet6-unicast
NLRI for this session: inet-unicast inet6-unicast
Peer supports Refresh capability (2)
Stale routes from peer are kept for: 300
Peer does not support Restarter functionality
NLRI that restart is negotiated for: inet-unicast inet6-unicast
NLRI of received end-of-rib markers: inet-unicast inet6-unicast
NLRI of all end-of-rib markers sent: inet-unicast inet6-unicast
Peer supports 4 byte AS extension (peer-as 300)
Peer does not support Addpath
Table inet.0 Bit: 10000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 1
Received prefixes: 3
Accepted prefixes: 2
Suppressed due to damping: 0
Advertised prefixes: 4
Table inet6.0 Bit: 20000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 0
Received prefixes: 1
Accepted prefixes: 1
Suppressed due to damping: 0
Advertised prefixes: 2
Last traffic (seconds): Received 1 Sent 15 Checked 75
Input messages: Total 133 Updates 6 Refreshes 0 Octets 2719
Output messages: Total 131 Updates 3 Refreshes 0 Octets 2734
Output Queue[0]: 0
Output Queue[1]: 0Sens
Les différentes occurrences de inet6-unicast dans la sortie montrent que BGP est activé pour transporter des routes unicast IPv6.
Vérification de la table de routage
But
Assurez-vous que le périphérique R2 a des routes BGP dans sa table de routage inet6.0.
Action
À partir du mode opérationnel, entrez la show route protocol bgp inet6.0 commande.
user@R2> show route protocol bgp table inet6.0
inet6.0: 7 destinations, 10 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
::ffff:192.168.10.0/120 [BGP/170] 01:03:49, localpref 100, from 192.168.20.1
AS path: 300 I
> to ::ffff:192.168.20.21 via fe-1/2/1.3
::ffff:192.168.20.0/120 [BGP/170] 01:03:53, localpref 100, from 192.168.10.1
AS path: 100 I
> to ::ffff:192.168.10.10 via fe-1/2/0.2Présentation des sessions IPv6 sur BGP et des routes IPv4 publicitaires
Dans un réseau IPv6, BGP publie généralement des informations sur l’accessibilité de la couche réseau IPv6 sur une session IPv6 entre homologues BGP. Dans les versions antérieures, Junos OS prenait en charge l’échange de familles d’adresses unicast inet6, inet6 multicast ou inet6 labeled-unicast uniquement. Cette fonctionnalité permet l’échange de toutes les familles d’adresses BGP. Dans un environnement à double pile centré sur IPv6. cette fonctionnalité permet au BGP d’annoncer l’accessibilité de la monodiffusion IPv4 avec IPv4 next hop sur une session BGP IPv6.
Cette fonctionnalité s’applique uniquement aux sessions BGP IPv6, où IPv4 est configuré sur les deux points de terminaison. Il local-ipv4-address peut s’agir d’une adresse de bouclage ou de n’importe quelle adresse ipv4 pour une session IBGP ou EBGP à sauts multiples. Pour les haut-parleurs BGP externes à saut unique qui ne font pas partie des confédérations BGP, si l’adresse IPv4 locale configurée n’est pas directement connectée, la session BGP est fermée et reste inactive et une erreur est générée, qui s’affiche dans la sortie de la show bgp neighbor commande.
Pour activer l’annonce de routage IPv4 sur une session IPv6, configurez local-ipv4-address comme suit :
[edit protocols bgp family inet unicast] local-ipv4-address local ipv4 address;
Vous ne pouvez pas configurer cette fonctionnalité pour les familles d’adresses unicast inet6, inet6 multicast ou inet6 labeled-unicast, car BGP a déjà la capacité de publier ces familles d’adresses sur une session BGP IPv6.
Le configured local-ipv4-address est utilisé uniquement lorsque BGP annonce des routes avec self-next hop. Lorsqu’IBGP publie des routes apprises auprès d’homologues EBGP ou que le réflecteur de route annonce des routes BGP à ses clients, BGP ne modifie pas le tronçon suivant de route, ignore le tronçon suivant configuré et utilise le tronçon suivant local-ipv4-address IPv4 d’origine.
Voir également
Exemple : Annonce de routes IPv4 sur des sessions BGP IPv6
Cet exemple montre comment annoncer des routes IPv4 sur une session BGP IPv6. Dans un environnement à double pile basé sur IPv6, il est nécessaire d’atteindre des hôtes IPv4 distants. Par conséquent, BGP annonce les routes IPv4 avec des sauts IPv4 suivants vers les homologues BGP sur des sessions BGP utilisant les adresses source et de destination IPv6. Cette fonctionnalité permet à BGP d’annoncer l’accessibilité de la monodiffusion IPv4 avec les sessions BGP IPv6 next hop over IPv6.
Conditions préalables
Cet exemple utilise les composants matériels et logiciels suivants :
Trois routeurs avec une capacité d’empilage double
Junos OS version 16.1 ou ultérieure s’exécutant sur tous les périphériques
Avant d’activer les annonces IPv4 sur des sessions BGP IPv6, veillez à :
Configurez les interfaces de l’appareil.
Configurez le double empilage sur tous les appareils.
Présentation
À partir de la version 16.1, Junos OS permet à BGP d’annoncer l’accessibilité unicast IPv4 avec IPv4 next hop sur une session BGP IPv6. Dans les versions antérieures de Junos OS, BGP pouvait uniquement annoncer les familles d’adresses unicast inet6, inet6 multicast et inet6 étiquetées unicast sur des sessions BGP IPv6. Cette fonctionnalité permet à BGP d’échanger toutes les familles d’adresses BGP au cours d’une session IPv6. Vous pouvez activer BGP pour annoncer des routes IPv4 avec des sauts alternatifs IPv4 vers des homologues BGP sur une session IPv6. Le configured local-ipv4-address est utilisé uniquement lorsque BGP annonce des routes avec self-next hop.
Vous ne pouvez pas configurer cette fonctionnalité pour les familles d’adresses unicast inet6, inet6 multicast ou inet6 labeled-unicast, car BGP a déjà la capacité de publier ces familles d’adresses sur une session BGP IPv6.
Topologie
En Figure 2, une session BGP externe IPv6 est en cours d’exécution entre les routeurs R1 et R2. Une session IBGP IPv6 est établie entre le routeur R2 et le routeur R3. Les routes statiques IPv4 sont redistribuées vers le BGP sur R1. Pour redistribuer les routes IPv4 sur la session BGP IPv6, la nouvelle fonctionnalité doit être activée sur tous les routeurs au niveau de la [edit protocols bgp address family] hiérarchie.
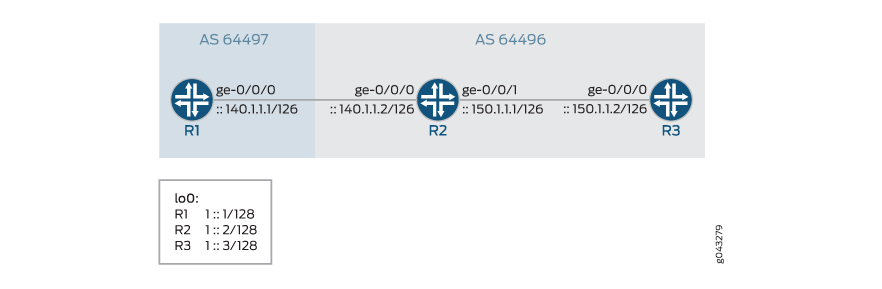
Configuration
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à la configuration de votre réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie, puis passez commit en mode de configuration.
Routeur R1
set interfaces ge-0/0/0 unit 0 description R1->R2 set interfaces ge-0/0/0 unit 0 family inet address 140.1.1.1/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::140.1.1.1/126 set interfaces lo0 unit 0 family inet6 address 1::1/128 set routing-options static route 11.1.1.1/32 discard set routing-options static route 11.1.1.2/32 discard set routing-options autonomous-system 64497 set protocols bgp group ebgp-v6 type external set protocols bgp group ebgp-v6 export p1 set protocols bgp group ebgp-v6 peer-as 64496 set protocols bgp group ebgp-v6 neighbor ::140.1.1.2 description R2 set protocols bgp group ebgp-v6 neighbor ::140.1.1.2 family inet unicast local-ipv4-address 140.1.1.1 set policy-options policy-statement p1 from protocol static set policy-options policy-statement p1 then accept
Routeur R2
set interfaces ge-0/0/0 unit 0 description R2->R1 set interfaces ge-0/0/0 unit 0 family inet address 140.1.1.2/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::140.1.1.2/126 set interfaces ge-0/0/1 unit 0 description R2->R3 set interfaces ge-0/0/1 unit 0 family inet address 150.1.1.1/24 set interfaces ge-0/0/1 unit 0 family inet6 address ::150.1.1.1/126 set interfaces lo0 unit 0 family inet6 address 1::2/128 set routing-options autonomous-system 64496 set protocols bgp group ibgp-v6 type internal set protocols bgp group ibgp-v6 export change-nh set protocols bgp group ibgp-v6 neighbor ::150.1.1.2 description R3 set protocols bgp group ibgp-v6 neighbor ::150.1.1.2 family inet unicast local-ipv4-address 150.1.1.1 set protocols bgp group ebgp-v6 type external set protocols bgp group ebgp-v6 peer-as 64497 set protocols bgp group ebgp-v6 neighbor ::140.1.1.1 description R1 set protocols bgp group ebgp-v6 neighbor ::140.1.1.1 family inet unicast local-ipv4-address 140.1.1.2 set policy-options policy-statement change-nh from protocol bgp set policy-options policy-statement change-nh then next-hop self set policy-options policy-statement change-nh then accept
Routeur R3
set interfaces ge-0/0/0 unit 0 description R3->R2 set interfaces ge-0/0/0 unit 0 family inet address 150.1.1.2/24 set interfaces ge-0/0/0 unit 0 family inet6 address ::150.1.1.2/126 set interfaces lo0 unit 0 family inet6 address 1::3/128 set routing-options autonomous-system 64496 set protocols bgp group ibgp-v6 type internal set protocols bgp group ibgp-v6 neighbor ::150.1.1.1 description R2 set protocols bgp group ibgp-v6 neighbor ::150.1.1.1 family inet unicast local-ipv4-address 150.1.1.2
Configuration du routeur R1
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode de configuration dans le Guide de l’utilisateur de l’interface de ligne de commande.
Pour configurer le routeur R1 :
Répétez cette procédure pour les autres routeurs après avoir modifié les noms d’interface, les adresses et les autres paramètres appropriés.
Configurez les interfaces avec les adresses IPv4 et IPv6.
[edit interfaces] user@R1# set ge-0/0/0 unit 0 description R1->R2 user@R1# set ge-0/0/0 unit 0 family inet address 140.1.1.1/24 user@R1# set ge-0/0/0 unit 0 family inet6 address ::140.1.1.1/126
Configurez l’adresse de bouclage.
[edit interfaces] user@R1# set lo0 unit 0 family inet6 address 1::1/128
Configurez une route statique IPv4 qui doit être annoncée.
[edit routing-options] user@R1# set static route 11.1.1.1/32 discard user@R1# set static route 11.1.1.2/32 discard
Configurez le système autonome pour les hôtes BGP.
[edit routing-options] user@R1# set autonomous-system 64497
Configurez EBGP sur les routeurs de périphérie externes.
[edit protocols] user@R1# set bgp group ebgp-v6 type external user@R1# set bgp group ebgp-v6 peer-as 64496 user@R1# set bgp group ebgp-v6 neighbor ::140.1.1.2 description R2
Activez la fonctionnalité pour annoncer IPv4 adddress 140.1.1.1 sur des sessions IPv6 BGP.
[edit protocols] user@R1# set bgp group ebgp-v6 neighbor ::140.1.1.2 family inet unicast local-ipv4-address 140.1.1.1
Définir une stratégie p1 pour accepter toutes les routes statiques.
[edit policy-options] user@R1# set policy-statement p1 from protocol static user@R1# set policy-statement p1 then accept
Appliquez la stratégie p1 sur le groupe EBGP ebgp-v6.
[edit protocols] user@R1# set bgp group ebgp-v6 export p1
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show interfaces, show protocols, show routing-optionset show policy-options. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@R1# show interfaces
ge-0/0/0 {
unit 0 {
description R1->R2;
family inet {
address 140.1.1.1/24;
}
family inet6 {
address ::140.1.1.1/126;
}
}
lo0 {
unit 0 {
family inet {
address 1::1/128;
}
}
}
}
[edit]
user@R1# show protocols
bgp {
group ebgp-v6 {
type external;
export p1;
peer-as 64496;
neighbor ::140.1.1.2 {
description R2;
family inet {
unicast {
local-ipv4-address 140.1.1.1;
}
}
}
}
}
[edit]
user@R1# show routing-options
static {
route 11.1.1.1/32 discard;
route 11.1.1.2/32 discard;
}
autonomous-system 64497;
[edit]
user@R1# show policy-options
policy-statement p1 {
from {
protocol static;
}
then accept;
}
Si vous avez terminé de configurer l’appareil, validez la configuration.
user@R1# commit
Vérification
Vérifiez que la configuration fonctionne correctement.
- Vérification du fonctionnement de la session BGP
- Vérification de l’annonce de l’adresse IPv4
- Vérification que le routeur BGP voisin R2 reçoit l’adresse IPv4 annoncée
Vérification du fonctionnement de la session BGP
But
Vérifiez que BGP est en cours d’exécution sur les interfaces configurées et que la session BGP est active pour chaque adresse voisine.
Action
À partir du mode opérationnel, exécutez la commande sur le show bgp summary routeur R1.
user@R1> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
::140.1.1.2 64496 4140 4158 0 0 1d 7:10:36 0/0/0/0 0/0/0/0
Sens
La session BGP est opérationnelle et l’appairage BGP est établi.
Vérification de l’annonce de l’adresse IPv4
But
Vérifiez que l’adresse IPv4 configurée est annoncée par le routeur R1 aux voisins BGP configurés.
Action
À partir du mode opérationnel, exécutez la commande sur le show route advertising-protocol bgp ::150.1.1.2 routeur R1.
user@R1> show route advertising-protocol bgp ::150.1.1.2 inet.0: 48 destinations, 48 routes (48 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 11.1.1.1/32 Self 64497 64497 I * 11.1.1.2/32 Self 64497 64497 I
Sens
La route statique IPv4 est annoncée sur le routeur BGP voisin R2.
Vérification que le routeur BGP voisin R2 reçoit l’adresse IPv4 annoncée
But
Vérifiez que le routeur R2 reçoit l’adresse IPv4 que le routeur R1 annonce au voisin BGP via IPv6.
Action
user@R2> show route receive-protocol bgp ::140.1.1.1 inet.0: 48 destinations, 48 routes (48 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 11.1.1.1/32 140.1.1.1 64497 I * 11.1.1.2/32 140.1.1.1 64497 I iso.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden) inet6.0: 9 destinations, 10 routes (9 active, 0 holddown, 0 hidden)
Sens
La présence de la route IPv4 statique dans la table de routage du routeur R2 indique qu’il reçoit les routes IPv4 annoncées du routeur R1.
Comprendre la redistribution des routes IPv4 avec IPv6 Next Hop into BGP
Dans un réseau qui transporte principalement du trafic IPv6, il est nécessaire d’acheminer des routes IPv4 si nécessaire. Par exemple, un fournisseur de services Internet qui dispose d’un réseau IPv6 uniquement, mais dont les clients acheminent toujours le trafic IPv4. Dans ce cas, il est nécessaire de répondre aux besoins de ces clients et de transférer le trafic IPv4 sur un réseau IPv6. Comme décrit dans le RFC 5549, Publicité des informations d’accessibilité de la couche réseau IPv4 avec un saut IPv6 Next Hop Le trafic IPv4 est tunnelisé depuis les équipements CPE (CustomerPremises Equipment) vers les passerelles IPv4 sur IPv6. Ces passerelles sont annoncées aux appareils CPE par le biais d’adresses anycast. Les périphériques de passerelle créent ensuite des tunnels IPv4 sur IPv6 dynamiques vers les équipements CPE distants et annoncent les routes d’agrégation IPv4 pour orienter le trafic.
La fonctionnalité de tunnel dynamique IPv4 sur IPv6 ne prend pas en charge ISSU unifié dans Junos OS version 17.3R1.
Les réflecteurs de route (RR) dotés d’une interface programmable sont connectés via IBGP aux routeurs de passerelle et aux routes hôtes avec l’adresse IPv6 comme prochain saut. Ces RR annoncent les adresses IPv4/32 pour injecter les informations du tunnel dans le réseau. Les routeurs de passerelle créent des tunnels dynamiques IPv4 sur IPv6 jusqu’à la périphérie du fournisseur client. Le routeur de passerelle annonce également les routes d’agrégation IPv4 pour diriger le trafic. Le RR annonce ensuite les routes sources de tunnel au FAI. Lorsque le RR supprime l’itinéraire du tunnel, BGP retire également l’itinéraire, ce qui entraîne la destruction du tunnel et l’inaccessibilité du CPE. Le routeur de passerelle retire également les routes d’agrégation IPv4 et les routes source de tunnel IPv6 lorsque toutes les routes d’agrégation et les routes contributrices sont supprimées. Le routeur de passerelle envoie un retrait de route lorsque la carte de ligne du moteur de transfert de paquets d’ancrage tombe en panne, de sorte qu’il redirige le trafic vers d’autres routeurs de passerelle.
Les extensions suivantes ont été introduites pour prendre en charge les routes IPv4 avec un saut suivant IPv6 :
- Encodage BGP Next Hop
- Localisation des tunnels
- Gestion des tunnels
- Gestion des défaillances de l’équilibrage de charge de tunnel et du moteur de transfert de paquets Anchor
- Statistiques de flux de bouclage de tunnel
Encodage BGP Next Hop
BGP est étendu avec la fonctionnalité d’encodage next hop qui est utilisée pour envoyer des routes IPv4 avec des next hops IPv6. Si cette fonctionnalité n’est pas disponible sur l’homologue distant, BGP regroupe les homologues en fonction de cette fonctionnalité d’encodage et supprime la famille BGP sans fonctionnalité d’encodage de la liste des informations d’accessibilité de la couche réseau (NLRI) négociées. Junos OS n’autorise qu’une seule table de résolution telle que inet.0. Pour autoriser les routes BGP IPv4 avec les sauts suivants IPv6, BGP crée une nouvelle arborescence de résolution. Cette fonctionnalité permet à un Junos OS table de routage d’avoir plusieurs arbres de résolution.
Outre la RFC 5549, Publier des informations sur l’accessibilité de la couche réseau IPv4 avec un saut suivant IPv6 une nouvelle communauté d’encapsulation spécifiée dans la RFC 5512, l’identificateur de famille d’adresses ultérieures d’encapsulation BGP (SAFI) et l’attribut d’encapsulation de tunnel BGP sont introduits pour déterminer la famille d’adresses de l’adresse de saut suivant. La communauté d’encapsulation indique le type de tunnels que le nœud entrant doit créer. Lorsque BGP reçoit des routes IPv4 avec l’adresse IPv6 next hop et la communauté d’encapsulation V4oV6, il crée des tunnels dynamiques IPv4 sur IPv6. Lorsque BGP reçoit des routes sans la communauté d’encapsulation, les routes BGP sont résolues sans créer le tunnel V4oV6.
Une nouvelle action dynamic-tunnel-attributes dyan-attribute de stratégie est disponible au niveau de la hiérarchie pour prendre en charge la [edit policy-statement policy name term then] nouvelle encapsulation étendue.
Localisation des tunnels
L’infrastructure dynamique des tunnels est améliorée avec la localisation des tunnels afin de prendre en charge un plus grand nombre de tunnels. La localisation des tunnels est nécessaire afin d’assurer la résilience nécessaire pour gérer le trafic en cas de défaillance de l’ancrage. Un ou plusieurs châssis se sauvegardent les uns les autres et laissez le processus de protocole de routage (rpd) diriger le trafic du point de défaillance vers le châssis de secours. Le châssis annonce uniquement ces préfixes d’agrégation au lieu des adresses de bouclage individuelles dans le réseau.
Gestion des tunnels
Les tunnels IPv4 sur IPv6 utilisent l’infrastructure de tunnels dynamique ainsi que l’ancrage de tunnel pour prendre en charge les châssis à grande échelle requis. L’état du tunnel est localisé sur un moteur de transfert de paquets et les autres moteurs de transfert de paquets dirigent le trafic vers l’ancre de tunnel.
Entrée de tunnel
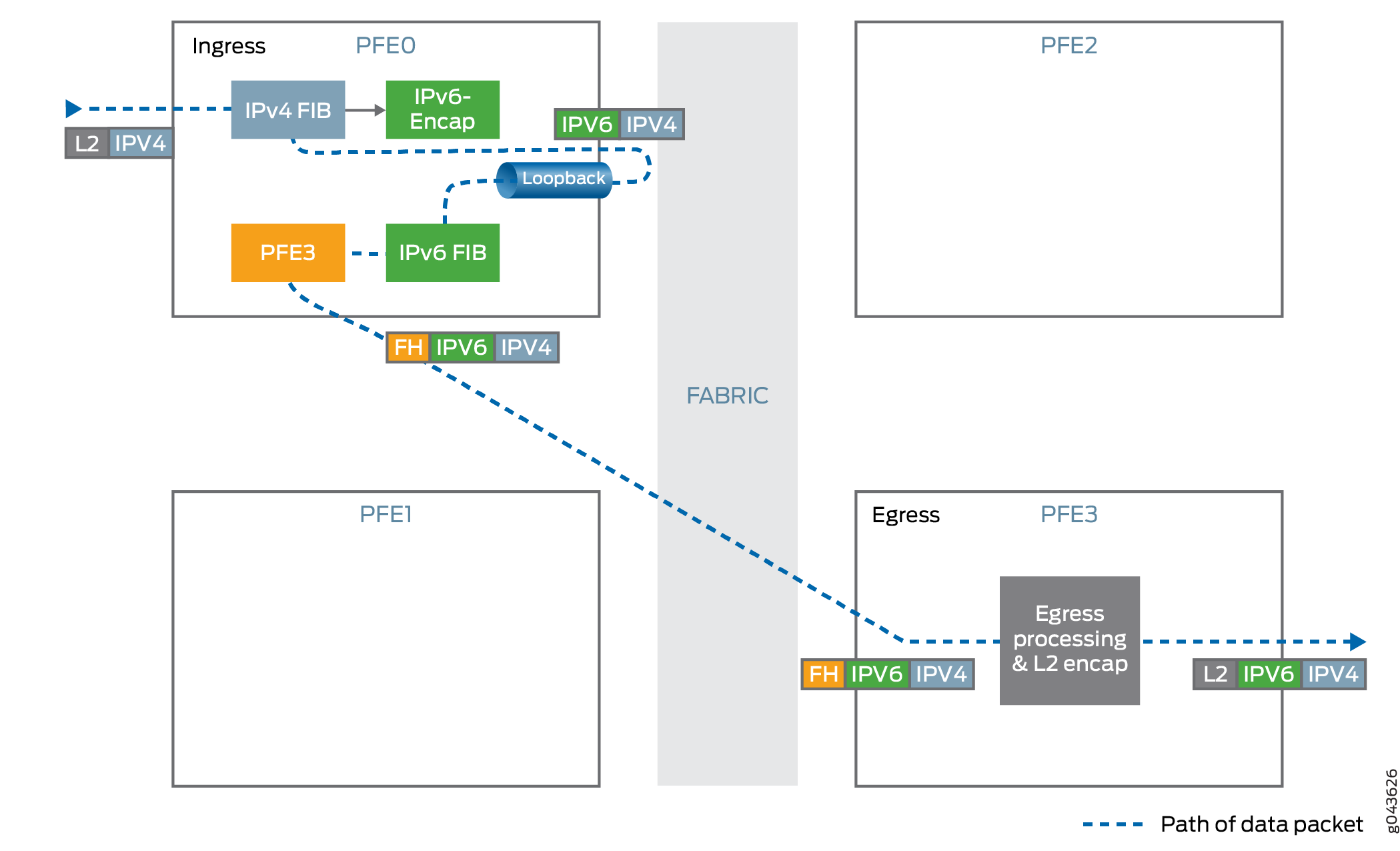
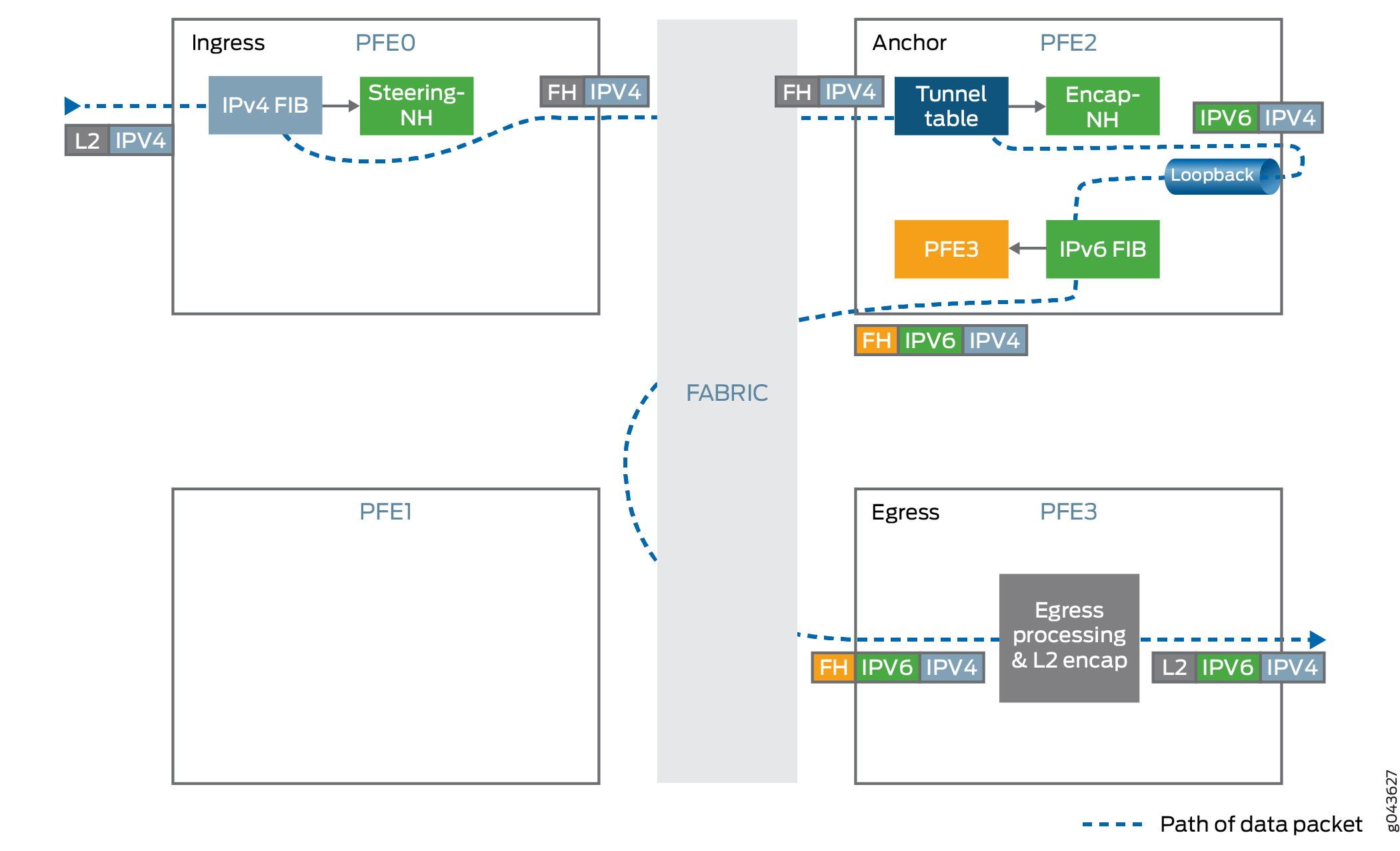
Encapsule le trafic IPv4 à l’intérieur de l’en-tête IPv6.
L’application de l’unité de transmission maximale (MTU) est effectuée avant l’encapsulation. Si la taille du paquet encapsulé dépasse la MTU du tunnel et que celle du paquet IPv4
DF-bitn’est pas définie, le paquet est fragmenté et ces fragments sont encapsulés .Utilise l’équilibrage de charge du trafic basé sur le hachage sur les en-têtes de paquets internes.
Transfère le trafic vers l’adresse IPv6 de destination. L’adresse IPv6 est extraite de l’en-tête IPv6.
Sortie de tunnel
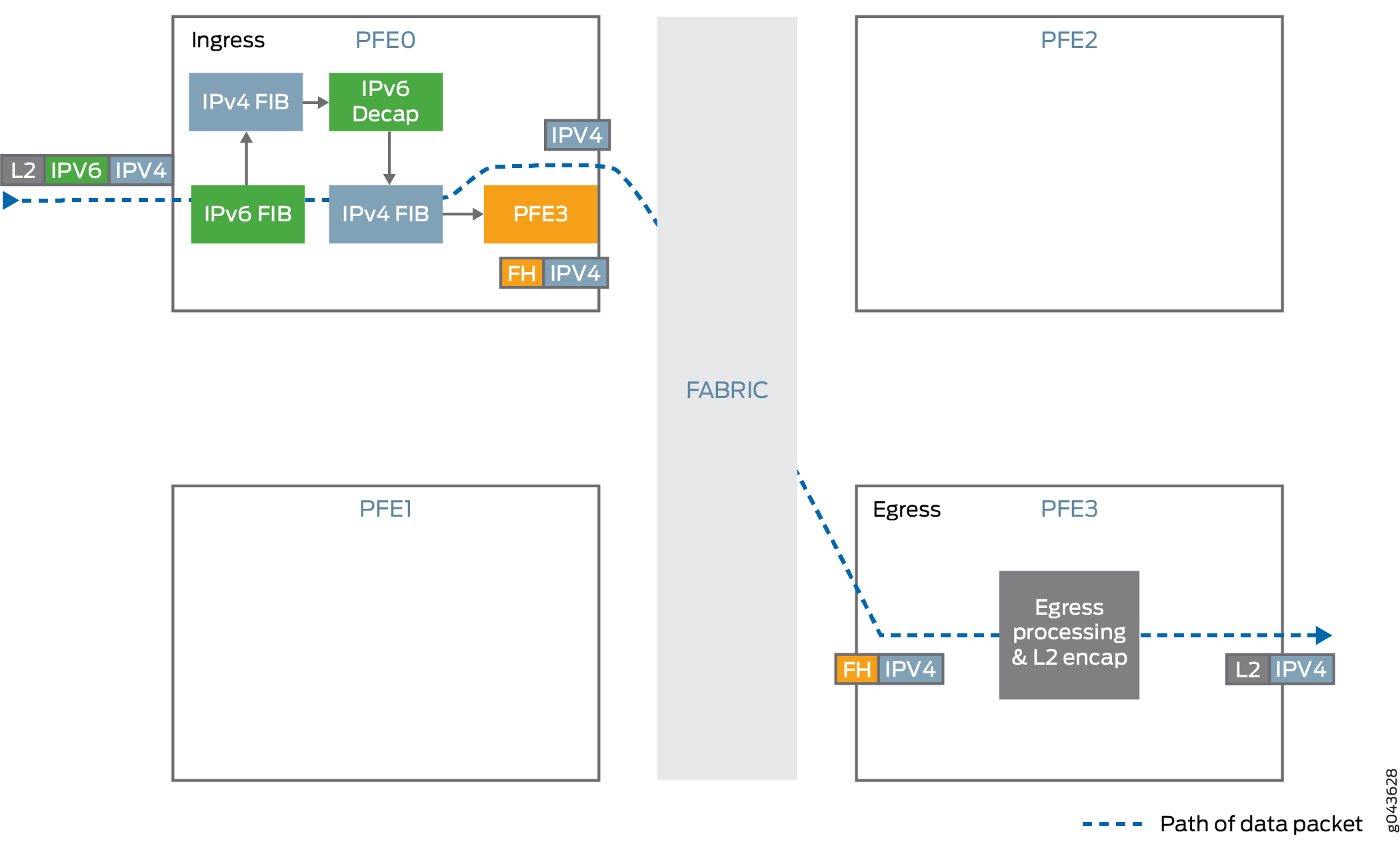
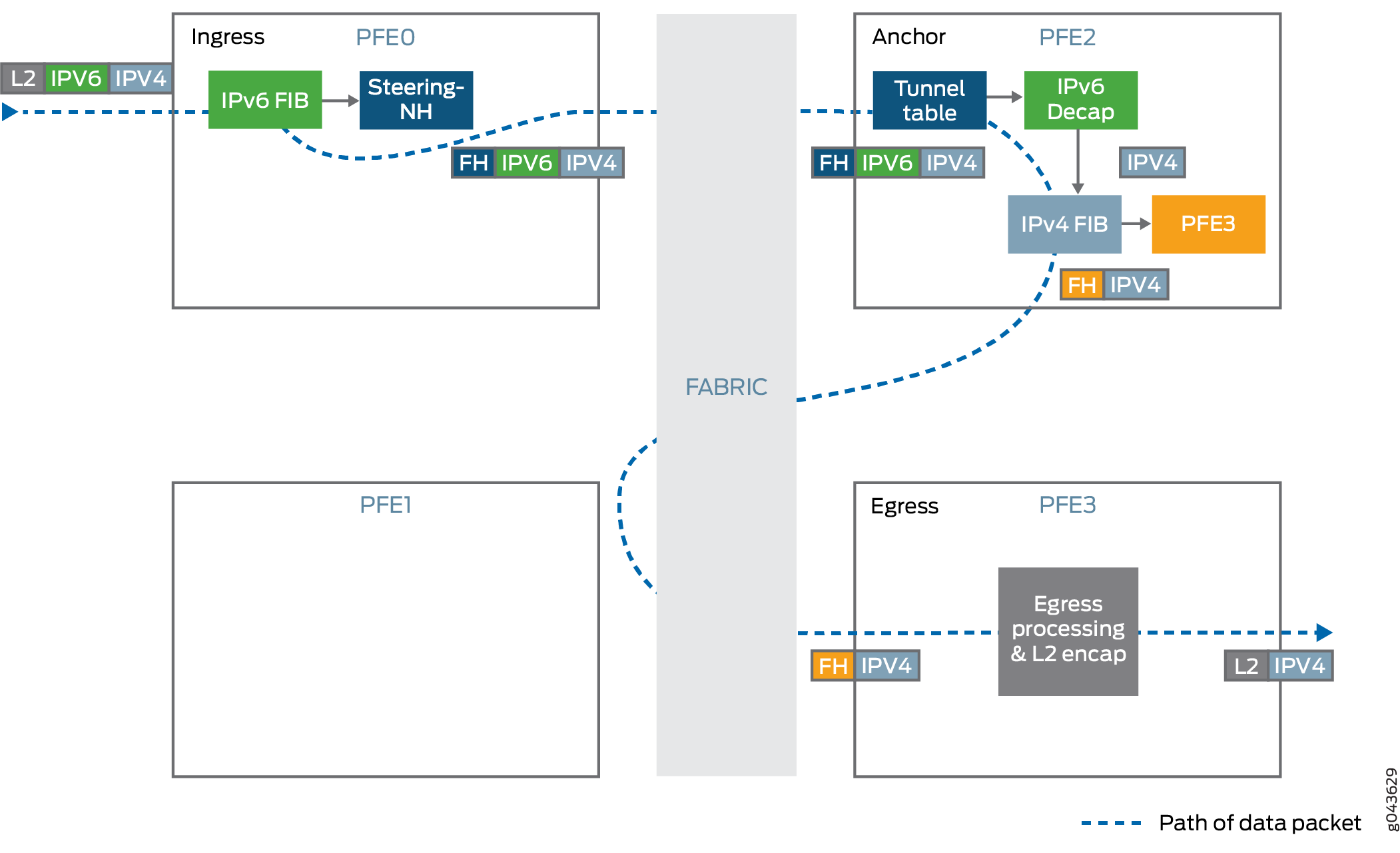
Décapsule le paquet IPv4 présent à l’intérieur du paquet IPv6.
Effectue une vérification anti-usurpation d’identité pour s’assurer que la paire IPv6/IPv4 correspond aux informations qui ont été utilisées pour configurer le tunnel.
Recherche l’adresse de destination IPv4 à partir de l’en-tête IPv4 du paquet décapsulé et transfère le paquet à l’adresse IPv4 spécifiée.
Gestion des défaillances de l’équilibrage de charge de tunnel et du moteur de transfert de paquets Anchor
La défaillance du moteur de transfert de paquets doit être traitée rapidement pour éviter le filtrage à routage nul du trafic de tunnel ancré sur le moteur de transfert de paquets. La localisation des tunnels implique l’utilisation de publications BGP pour réparer la défaillance globalement. Le trafic du tunnel est redirigé du point de défaillance vers un autre châssis de secours contenant le même état de tunnel. Pour l’équilibrage de charge du trafic, le châssis est configuré pour annoncer différentes valeurs MED (multiple exit discriminator) pour chacun des jeux de préfixes, de sorte que seul le trafic d’un quart des tunnels passe par chaque châssis. Le trafic CPE est également traité de la même manière en configurant le même ensemble d’adresses anycast sur chaque châssis et en ne dirigeant qu’un quart du trafic vers chaque châssis.
Le moteur de transfert de paquets Anchor est l’entité unique qui effectue tous les traitements pour un tunnel. La sélection du moteur de transfert de paquets d’ancrage s’effectue via le provisionnement statique et est liée aux interfaces physiques du moteur de transfert de paquets. Lorsqu’un des moteurs de transfert de paquets tombe en panne, le démon marque tous les moteurs de transfert de paquets sur la carte de ligne et communique cette information au processus du protocole de routage, au processus du protocole de routage et aux autres démons. Le processus de protocole de routage envoie des retraits BGP pour les préfixes ancrés sur le moteur de transfert de paquets défaillant et les adresses IPv6 affectées au moteur de transfert de paquets qui est indisponible. Ces annonces redirigent le trafic vers d’autres châssis de sauvegarde. Lorsque le moteur de transfert de paquets défaillant est à nouveau opérationnel, le châssis marque le moteur de transfert de paquets comme up et met à jour le processus du protocole de routage. Le processus de protocole de routage déclenche des mises à jour BGP vers ses homologues indiquant que les tunnels ancrés au moteur de transfert de paquets spécifique sont désormais disponibles pour le trafic de routage. Ce processus peut prendre quelques minutes pour la configuration d’un tunnel à grande échelle. Par conséquent, le mécanisme est intégré au système pour minimiser les pertes de trafic lors de la rebasculement du trafic vers le Ack châssis d’origine.
Statistiques de flux de bouclage de tunnel
L’infrastructure de tunnel dynamique utilise des flux de bouclage dans le moteur de transfert de paquets pour boucler le paquet après l’encapsulation. Étant donné que la bande passante de ce flux de bouclage est limitée, il est nécessaire de surveiller les performances des flux de bouclage de tunnel.
Pour surveiller les statistiques du flux de bouclage, utilisez la commande show pfe statistics traffic detail opérationnelle qui affiche les statistiques agrégées du flux de bouclage, y compris le taux de transfert, le taux d’abandon de paquets et le débit d’octets.
Voir également
Configuration de BGP pour redistribuer les routes IPv4 avec les adresses IPv6 Next-Hop
À partir de la version 17.3R1, les équipements Junos OS peuvent transférer du trafic IPv4 sur un réseau IPv6 uniquement, qui ne peut généralement pas transférer le trafic IPv4. Comme décrit dans la RFC 5549, le trafic IPv4 est tunnelisé depuis les équipements CPE vers les passerelles IPv4 sur IPv6. Ces passerelles sont annoncées aux appareils CPE par le biais d’adresses anycast. Les passerelles créent ensuite des tunnels dynamiques IPv4 sur IPv6 vers les équipements distants sur site client et annoncent des routes d’agrégation IPv4 pour orienter le trafic. Des réflecteurs de route avec des interfaces programmables injectent les informations du tunnel dans le réseau. Les réflecteurs de route sont connectés via IBGP aux routeurs de passerelle, qui annoncent les adresses IPv4 des routes hôtes avec des adresses IPv6 comme prochain saut.
La fonctionnalité de tunnel dynamique IPv4 sur IPv6 ne prend pas en charge ISSU unifié dans Junos OS version 17.3R1.
Avant de commencer à configurer BGP pour distribuer des routes IPv4 avec des adresses IPv6 next-hop, procédez comme suit :
Configurez les interfaces de l’appareil.
Configurez OSPF ou tout autre protocole IGP.
Configurez MPLS et LDP.
Configurez BGP.
Pour configurer BGP afin de distribuer des routes IPv4 avec des adresses de saut alternatif IPv6 :
Voir également
Activation des signaux VPN et VPLS de couche 2
Vous pouvez activer BGP pour transporter les messages NLRI VPN et VPLS de couche 2.
Pour activer la signalisation VPN et VPLS, incluez l’instruction family suivante :
family { l2vpn { signaling { prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>; } } } }
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Pour configurer un nombre maximal de préfixes, incluez l’instruction prefix-limit suivante :
prefix-limit { maximum number; teardown <percentage> <idle-timeout (forever | minutes)>; drop-excess <percentage>; hide-excess <percentage>;}
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
Lorsque vous définissez le nombre maximal de préfixes, un message est enregistré lorsque ce nombre est atteint. Si vous incluez l’instruction teardown , la session est supprimée lorsque le nombre maximal de préfixes est atteint. Si vous spécifiez un pourcentage, les messages sont consignés lorsque le nombre de préfixes atteint ce pourcentage. Une fois la session démontée, elle est rétablie en peu de temps. Incluez l’instruction idle-timeout pour maintenir la session inactive pendant une durée spécifiée, ou pour toujours. Si vous spécifiez forever, la session n’est rétablie qu’après l’utilisation de la clear bgp neighbor commande. Si vous incluez l’instruction drop-excess <percentage> et spécifiez un pourcentage, les routes excédentaires sont supprimées lorsque le nombre de préfixes dépasse le pourcentage. Si vous incluez l’instruction hide-excess <percentage> et spécifiez un pourcentage, les routes excédentaires sont masquées lorsque le nombre de préfixes dépasse le pourcentage. Si le pourcentage est modifié, les itinéraires sont réévalués automatiquement.
Voir également
Comprendre les itinéraires de flux BGP pour le filtrage du trafic
Une route de flux est une agrégation de conditions de correspondance pour les paquets IP. Les routes de flux sont installées en tant que filtres de table de transfert en entrée (implicites) et sont propagées dans le réseau à l’aide de messages NLRI (network-layer accessability information) de spécification de flux et installées dans la table de routage de instance-name.inetflow.0flux. Les paquets ne peuvent transiter par des itinéraires de flux que si des conditions de correspondance spécifiques sont remplies.
Les routes de flux et les filtres de pare-feu sont similaires en ce sens qu’ils filtrent les paquets en fonction de leurs composants et effectuent une action sur les paquets correspondants. Les routes de flux offrent des fonctionnalités de filtrage du trafic et de limitation du débit, tout comme les filtres de pare-feu. En outre, vous pouvez propager des itinéraires de flux entre différents systèmes autonomes.
Les routes de flux sont propagées par BGP par le biais de messages NLRI de spécification de flux. Vous devez activer BGP pour propager ces NLRI.
À partir de la version 15.1 de Junos OS, des modifications sont implémentées pour étendre la prise en charge du routage actif non-stop (NSR) aux familles inet-flow et inetvpn-flow existantes et pour étendre la validation de route pour BGP flowspec par draft-ietf-idr-bgp-flowspec-oid-01. Deux nouveaux énoncés sont introduits dans le cadre de cette amélioration. Voir enforce-first-as et no-install.
À partir de Junos OS version 16.1, la prise en charge d’IPv6 est étendue à la spécification de flux BGP qui permet la propagation des règles de spécification de flux de trafic pour les paquets IPv6 et VPN-IPv6. La spécification de flux BGP automatise la coordination des règles de filtrage du trafic afin d’atténuer les attaques par déni de service distribué lors du routage actif ininterrompu (NSR).
À partir de Junos OS version 16.1R1, la spécification de flux BGP prend en charge l’action de filtrage du marquage extended-community du trafic. Pour le trafic IPv4, Junos OS modifie les bits DSCP (DiffServ code point) d’un paquet IPv4 en transit avec la valeur correspondante de la communauté étendue. Pour les paquets IPv6, Junos OS modifie les six premiers bits du champ du traffic class paquet IPv6 émetteur en la valeur correspondante de la communauté étendue.
À partir de Junos OS version 17.1R1, BGP peut transporter des messages d’informations d’accessibilité de la couche réseau (NLRI) de spécification de flux sur des routeurs PTX Series sur lesquels sont installés des FPC de troisième génération (FPC3-PTX-U2 et FPC3-PTX-U3 sur PTX5000 et FPC3-SFF-PTX-U0 et FPC3-SFF-PTX-U1 sur PTX3000). La propagation des informations de filtre de pare-feu dans le cadre de BGP vous permet de propager dynamiquement les filtres de pare-feu contre les attaques par déni de service (DOS) sur des systèmes autonomes.
À partir de Junos OS version 17.2R1, BGP peut transporter des messages d’informations d’accessibilité de la couche réseau (NLRI) de spécification de flux sur les routeurs PTX1000 sur lesquels des FPC de troisième génération sont installés. La propagation des informations de filtre de pare-feu dans le cadre de BGP vous permet de propager dynamiquement les filtres de pare-feu contre les attaques par déni de service (DOS) sur des systèmes autonomes.
À compter de la version 20.3R1 de cRPD, les routes de flux et les règles de contrôle propagées via la spécification de flux BGP NLRI sont téléchargées sur le noyau Linux via l’infrastructure Linux Netfilter sur les environnements cRPD.
- Conditions de correspondance pour les itinéraires de flux
- Actions pour les itinéraires de flux
- Validation des itinéraires de flux
- Prise en charge de l’algorithme de spécification de flux BGP version 7 et ultérieures
Conditions de correspondance pour les itinéraires de flux
Vous spécifiez les conditions auxquelles le paquet doit correspondre avant que l’action de l’instruction then ne soit effectuée pour un itinéraire de flux. Toutes les conditions de l’instruction doivent correspondre pour l’action from à entreprendre. L’ordre dans lequel vous spécifiez les conditions de correspondance n’a pas d’importance, car un paquet doit répondre à toutes les conditions d’un terme pour qu’une correspondance se produise.
Pour configurer une condition de correspondance, incluez l’instruction match au niveau de la [edit routing-options flow] hiérarchie.
Tableau 1 Décrit les conditions de correspondance de l’itinéraire de flux.
|
Condition de correspondance |
Description |
|---|---|
|
|
Champ d’adresse IP de destination. Vous pouvez utiliser le champ facultatif |
|
|
Champ de port de destination TCP ou UDP (User Datagram Protocol). Vous ne pouvez pas spécifier à la fois les conditions de correspondance À la place de la valeur numérique, vous pouvez spécifier l’un des synonymes de texte suivants (les numéros de port sont également répertoriés) : |
|
|
DSCP (Differentiated Services Code Point). Le protocole DiffServ utilise l’octet de type de service (ToS) dans l’en-tête IP. Les six bits les plus significatifs de cet octet forment le DSCP. Vous pouvez spécifier DSCP sous forme hexadécimale ou décimale. |
|
|
Faites correspondre la valeur de l’étiquette de flux. La valeur de ce champ est comprise entre 0 et 1048575. Cette condition de correspondance n’est prise en charge que sur les équipements Junos avec des MPC améliorés configurés pour |
|
|
Champ Type de fragment. Les mots-clés sont regroupés selon le type de fragment auquel ils sont associés :
Cette condition de correspondance est prise en charge uniquement sur les périphériques Junos OS avec des MPC améliorés configurés pour |
|
|
Champ de code ICMP. Cette valeur ou mot-clé fournit des informations plus spécifiques que À la place de la valeur numérique, vous pouvez spécifier l’un des synonymes textuels suivants (les valeurs de champ sont également répertoriées). Les mots-clés sont regroupés selon le type ICMP auquel ils sont associés :
|
|
|
Champ de type de paquet ICMP. Normalement, vous spécifiez cette correspondance en conjonction avec l’instruction À la place de la valeur numérique, vous pouvez spécifier l’un des synonymes de texte suivants (les valeurs de champ sont également répertoriées) : |
|
|
Longueur totale du paquet IP. |
|
|
Champ de port source ou de destination TCP ou UDP. Vous ne pouvez pas spécifier à la fois la correspondance et la À la place de la valeur numérique, vous pouvez spécifier l’un des synonymes de texte répertoriés sous |
|
|
Champ de protocole IP. À la place de la valeur numérique, vous pouvez spécifier l’un des synonymes de texte suivants (les valeurs de champ sont également répertoriées) : Cette condition de correspondance est prise en charge pour IPv6 uniquement sur les équipements Junos avec des MPC améliorés configurés pour |
|
|
Champ d’adresse IP source. Vous pouvez utiliser le champ facultatif |
|
|
Champ de port source TCP ou UDP. Vous ne pouvez pas spécifier les À la place du champ numérique, vous pouvez spécifier l’un des synonymes de texte répertoriés sous |
|
|
Format d’en-tête TCP. |
Actions pour les itinéraires de flux
Vous pouvez spécifier l’action à effectuer si le paquet correspond aux conditions que vous avez configurées dans l’itinéraire de flux. Pour configurer une action, incluez l’instruction then au niveau de la [edit routing-options flow] hiérarchie.
Tableau 2 Décrit les actions de routage de flux.
|
Action ou modificateur d’action |
Description |
|---|---|
| Actions | |
|
|
Accepter un paquet. Il s’agit de l’option par défaut. |
|
|
Rejeter un paquet en mode silencieux, sans envoyer de message ICMP (Internet Control Message Protocol). |
|
|
Remplacez toutes les communautés de l’itinéraire par les communautés spécifiées. |
|
Marque value |
Définissez une valeur DSCP pour le trafic qui correspond à ce flux. Spécifiez une valeur comprise entre 0 et 63. Cette action n’est prise en charge que sur les équipements Junos avec des MPC améliorés configurés pour |
|
|
Passez à la condition de correspondance suivante pour l’évaluation. |
|
|
Spécifiez une instance de routage vers laquelle les paquets sont transférés. |
|
|
Limitez la bande passante sur l’itinéraire de flux. Exprimez la limite en bits par seconde (bps). À partir de Junos OS version 16.1R4, la plage de limites de débit est [0 à 100000000000]. |
|
|
Echantillonnez le trafic sur l’itinéraire de flux. |
Validation des itinéraires de flux
Junos OS installe les routes de flux dans la table de routage de flux uniquement si elles ont été validées à l’aide de la procédure de validation. Le moteur de routage effectue la validation avant l’installation des routes dans la table de routage de flux.
Les itinéraires de flux reçus à l’aide des messages d’informations d’accessibilité de la couche réseau (NLRI) BGP sont validés avant d’être installés dans la table de routage de l’instance principale du instance.inetflow.0 flux. La procédure de validation est décrite dans le draft-ietf-idr-flow-spec-09.txt, Diffusion des règles de spécification de flux. Vous pouvez contourner le processus de validation des routes de flux à l’aide de messages BGP NLRI et utiliser votre propre stratégie d’importation.
Pour tracer les opérations de validation, incluez l’instruction validation au niveau de la [edit routing-options flow] hiérarchie.
Prise en charge de l’algorithme de spécification de flux BGP version 7 et ultérieures
Par défaut, Junos OS utilise l’algorithme d’ordre des termes défini dans la version 6 du projet de spécification de flux BGP. Dans Junos OS version 10.0 et ultérieure, vous pouvez configurer le routeur pour qu’il se conforme à l’algorithme d’ordre des termes défini pour la première fois dans la version 7 de la spécification de flux BGP et pris en charge par le RFC 5575, Dissemination of Flow Specification Routes.
Nous vous recommandons de configurer Junos OS pour utiliser l’algorithme d’ordre des termes défini pour la première fois dans la version 7 du projet de spécification de flux BGP. Nous vous recommandons également de configurer Junos OS pour qu’il utilise le même algorithme de classement des termes sur toutes les instances de routage configurées sur un routeur.
Pour configurer BGP afin d’utiliser l’algorithme de spécification de flux défini pour la première fois dans la version 7 du brouillon Internet, incluez l’instruction standard au niveau de la [edit routing-options flow term-order] hiérarchie.
Pour revenir à l’utilisation de l’algorithme d’ordre des termes défini dans la version 6, incluez l’instruction legacy au niveau de la [edit routing-options flow term-order] hiérarchie.
L’ordre des termes configuré n’a qu’une signification locale. En d’autres termes, l’ordre des termes ne se propage pas avec les routes de flux envoyées aux homologues BGP distants, dont l’ordre des termes est entièrement déterminé par leur propre configuration d’ordre des termes. Par conséquent, vous devez être prudent lors de la configuration de l’action next term dépendante de l’ordre lorsque vous n’êtes pas au courant de la configuration de l’ordre à terme des homologues distants. Le local next term peut différer de celui next term configuré sur l’homologue distant.
Sur Junos OS Evolved, next term ne peut pas apparaître comme le dernier terme de l’action. Un terme de filtre où next term est spécifié en tant qu’action mais sans aucune condition de correspondance configurée n’est pas pris en charge.
À partir de Junos OS version 16.1, vous avez la possibilité de ne pas appliquer le flowspec filtre au trafic reçu sur des interfaces spécifiques. Un nouveau terme est ajouté au début du flowspec filtre qui accepte tout paquet reçu sur ces interfaces spécifiques. Le nouveau terme est une variable qui crée une liste d’exclusion de termes attachés au filtre de la table de transfert dans le cadre du filtre de spécification de flux.
Pour empêcher le flowspec filtre d’être appliqué au trafic reçu sur des interfaces spécifiques, vous devez d’abord configurer un group-id sur ces interfaces en incluant l’instruction family inet filter group group-id au niveau de la [edit interfaces] hiérarchie, puis attacher le flowspec filtre au groupe d’interfaces en incluant l’instruction flow interface-group group-id exclude au niveau de la [edit routing-options] hiérarchie. Vous ne pouvez en configurer qu’une group-id seule par instance de routage avec l’instruction set routing-options flow interface-group group-id .
Voir également
Exemple : Activation de BGP pour transporter des routes de spécification de flux
Cet exemple montre comment autoriser BGP à transporter des messages NLRI (Network Layer Accessibility Information) de spécification de flux.
Conditions préalables
Avant de commencer :
Configurez les interfaces de l’appareil.
Configurez un protocole IGP (Interior Gateway Protocol).
Configurez BGP.
Configurez une stratégie de routage qui exporte les routes (telles que les routes directes ou les routes IGP) de la table de routage vers BGP.
Présentation
La propagation des informations de filtre de pare-feu dans le cadre de BGP vous permet de propager dynamiquement les filtres de pare-feu contre les attaques par déni de service (DOS) sur des systèmes autonomes. Les routes de flux sont encapsulées dans le NLRI de spécification de flux et propagées par le biais d’un réseau ou de réseaux privés virtuels (VPN), partageant ainsi des informations de type filtre. Les routes de flux sont une agrégation de conditions de correspondance et d’actions résultantes pour les paquets. Ils vous offrent des fonctionnalités de filtrage du trafic et de limitation du débit, tout comme les filtres de pare-feu. Les routes de flux unicast sont prises en charge pour l’instance par défaut, les instances VRF (VPN routing and forwarding) et les instances de routeur virtuel.
Les stratégies d’importation et d’exportation peuvent être appliquées à la famille inet flow ou à la famille inet-vpn flow NLRI, ce qui affecte les routes de flux acceptées ou annoncées, de la même manière que les stratégies d’importation et d’exportation sont appliquées à d’autres familles BGP. La seule différence est que la configuration de la stratégie de flux doit inclure l’instruction from rib inetflow.0 . Cette instruction entraîne l’application de la stratégie aux itinéraires de flux. Une exception à cette règle se produit si la stratégie ne contient que l’instruction then reject ou et then accept aucune from instruction. Ensuite, la stratégie affecte toutes les routes, y compris la unidiffusion IP et le flux IP.
Les filtres de route de flux sont d’abord configurés sur un routeur de manière statique, avec un ensemble de critères de correspondance suivis des actions à entreprendre. Ensuite, en plus de family inet unicast, family inet flow (ou family inet-vpn flow) est configuré entre ce périphérique compatible BGP et ses homologues.
Par défaut, les routes de flux configurées statiquement (filtres de pare-feu) sont annoncées aux autres périphériques compatibles BGP qui prennent en charge le family inet flow ou family inet-vpn flow NLRI.
Le périphérique BGP récepteur exécute un processus de validation avant d’installer le filtre de pare-feu dans la table de routage de instance-name.inetflow.0 flux . La procédure de validation est décrite dans la RFC 5575, Dissemination of Flow Specification Rules.
L’appareil BGP de réception accepte une route de flux si elle répond aux critères suivants :
L’émetteur d’une route de flux correspond à l’émetteur de la route unicast la mieux adaptée pour l’adresse de destination incorporée dans la route.
Il n’y a plus de routes unicast spécifiques, par rapport à l’adresse de destination de la route de flux, pour laquelle la route active a été reçue d’un système autonome next-hop différent.
Le premier critère permet de s’assurer que le filtre est annoncé par le next-hop utilisé par le transfert unicast pour l’adresse de destination incorporée dans l’itinéraire de flux. Par exemple, si une route de flux est donnée sous la forme 10.1.1.1, proto=6, port=80, le périphérique BGP de réception sélectionne la route unicast la plus spécifique dans la table de routage unicast qui correspond au préfixe de destination 10.1.1.1/32. Sur une table de routage unicast contenant 10.1/16 et 10.1.1/24, cette dernière est choisie comme route unicast à comparer. Seule l’entrée de route unicast active est prise en compte. Cela suit le concept selon lequel une route de flux est valide si elle est annoncée par l’auteur de la meilleure route unicast.
Le deuxième critère concerne les situations dans lesquelles un bloc d’adresses donné est attribué à différentes entités. Les flux qui se résolvent en une route unicast de meilleure correspondance, c’est-à-dire une route agrégée, ne sont acceptés que s’ils ne couvrent pas des routes plus spécifiques qui sont acheminées vers différents systèmes autonomes next-hop.
Vous pouvez contourner le processus de validation des routes de flux à l’aide de messages BGP NLRI et utiliser votre propre stratégie d’importation. Lorsque BGP transporte des messages NLRI de spécification de flux, l’instruction no-validate au niveau de la hiérarchie omet la [edit protocols bgp group group-name family inet flow] procédure de validation de l’itinéraire de flux une fois que les paquets sont acceptés par une stratégie. Vous pouvez configurer la stratégie d’importation pour qu’elle corresponde à l’adresse de destination et aux attributs de chemin tels que la communauté, le tronçon suivant et le chemin AS. Vous pouvez spécifier l’action à effectuer si le paquet correspond aux conditions que vous avez configurées dans l’itinéraire de flux. Pour configurer une action, incluez l’instruction au niveau de la [edit routing-options flow] hiérarchie. Le type NLRI de spécification de flux comprend des composants tels que le préfixe de destination, le préfixe source, le protocole et les ports, tels que définis dans la RFC 5575. La stratégie d’importation peut filtrer un itinéraire entrant à l’aide des attributs de chemin et de l’adresse de destination dans la spécification de flux NLRI. La stratégie d’importation ne peut pas filtrer les autres composants de la RFC 5575.
La spécification de flux définit les extensions de protocole requises pour traiter les applications les plus courantes du filtrage unicast IPv4 et VPN unicast. Le même mécanisme peut être réutilisé et de nouveaux critères de correspondance peuvent être ajoutés pour adresser un filtrage similaire pour d’autres familles d’adresses BGP (par exemple, unicast IPv6).
Une fois qu’une route de flux est installée dans la table, elle est également ajoutée à la inetflow.0 liste des filtres de pare-feu dans le noyau.
Sur les routeurs uniquement, les messages NLRI de spécification de flux sont pris en charge dans les VPN. Le VPN compare la communauté étendue de la cible de route dans le NLRI à la stratégie d’importation. S’il y a une correspondance, le VPN peut commencer à utiliser les routes de flux pour filtrer et limiter le trafic de paquets. Les routes de flux reçues sont installées dans la table de routage de instance-name.inetflow.0flux . Les routes de flux peuvent également être propagées sur un réseau VPN et partagées entre les VPN. Pour permettre au BGP multiprotocole (MP-BGP) de transporter le NLRI de spécification de flux pour la inet-vpn famille d’adresses, incluez flow l’instruction au niveau de la [edit protocols bgp group group-name family inet-vpn] hiérarchie. Les routes de flux VPN ne sont prises en charge que pour l’instance par défaut. Les routes de flux configurées pour les VPN avec famille inet-vpn ne sont pas automatiquement validées, de sorte que l’instruction n’est no-validate pas prise en charge au niveau de la [edit protocols bgp group group-name family inet-vpn] hiérarchie. Aucune validation n’est nécessaire si les routes de flux sont configurées localement entre les équipements d’un seul AS.
Des stratégies d’importation et d’exportation peuvent être appliquées au family inet flow ou family inet-vpn flow NLRI, ce qui affecte les routes de flux acceptées ou annoncées, de la même manière que les stratégies d’importation et d’exportation sont appliquées à d’autres familles BGP. La seule différence est que la configuration de la stratégie de flux doit inclure l’instruction from rib inetflow.0 . Cette instruction entraîne l’application de la stratégie aux itinéraires de flux. Une exception à cette règle se produit si la stratégie ne contient que l’instruction then reject ou et then accept aucune from instruction. Ensuite, la stratégie affecte toutes les routes, y compris la unidiffusion IP et le flux IP.
Cet exemple montre comment configurer les stratégies d’exportation suivantes :
Stratégie qui autorise la publication des routes de flux spécifiées par un filtre de route. Seules les routes de flux couvertes par le bloc 10.13/16 sont annoncées. Cette stratégie n’affecte pas les routes unicast.
Stratégie qui autorise tous les itinéraires unicast et de flux à être annoncés au voisin.
Une stratégie qui interdit à tous les itinéraires (unicast ou de flux) d’être annoncés au voisin.
Topologie
Configuration
- Configuration d’une route de flux statique
- Itinéraires de flux publicitaires spécifiés par un filtre de route
- Publicité de toutes les routes Unicast et Flow
- Publicité Pas d’unicast ou de routes de flux
- Limitation du nombre de routes de flux installées dans une table de routage
- Limitation du nombre de préfixes reçus sur une session d’appairage BGP
Configuration d’une route de flux statique
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set routing-options flow route block-10.131.1.1 match destination 10.131.1.1/32 set routing-options flow route block-10.131.1.1 match protocol icmp set routing-options flow route block-10.131.1.1 match icmp-type echo-request set routing-options flow route block-10.131.1.1 then discard set routing-options flow term-order standard
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
Pour configurer les sessions pair BGP :
Configurez les conditions de correspondance.
[edit routing-options flow route block-10.131.1.1] user@host# set match destination 10.131.1.1/32 user@host# set match protocol icmp user@host# set match icmp-type echo-request
Configurez l’action.
[edit routing-options flow route block-10.131.1.1] user@host# set then discard
(Recommandé) Pour l’algorithme de spécification de flux, configurez l’ordre des termes basé sur la norme.
[edit routing-options flow] user@host# set term-order standard
Dans l’algorithme de tri des termes par défaut, tel que spécifié dans la version 6 de la RFC Flowspec, un terme avec des conditions d’appariement moins spécifiques est toujours évalué avant un terme avec des conditions d’appariement plus spécifiques. Par conséquent, le terme avec des conditions d’appariement plus spécifiques n’est jamais évalué. La version 7 de la RFC 5575 a apporté une révision à l’algorithme afin que les conditions d’appariement les plus spécifiques soient évaluées avant les conditions d’appariement moins spécifiques. Pour des raisons de rétrocompatibilité, le comportement par défaut n’est pas modifié dans Junos OS, même si le nouvel algorithme a plus de sens. Pour utiliser le nouvel algorithme, incluez l’instruction
term-order standarddans la configuration. Cette instruction est prise en charge dans Junos OS version 10.0 et ultérieure.
Résultats
À partir du mode configuration, confirmez votre configuration en entrant la show routing-options commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show routing-options
flow {
term-order standard;
route block-10.131.1.1 {
match {
destination 10.131.1.1/32;
protocol icmp;
icmp-type echo-request;
}
then discard;
}
}
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Itinéraires de flux publicitaires spécifiés par un filtre de route
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a from rib inetflow.0 set policy-options policy-statement p1 term a from route-filter 10.13.0.0/16 orlonger set policy-options policy-statement p1 term a then accept set policy-options policy-statement p1 term b then reject set routing-options autonomous-system 65001
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
Pour configurer les sessions pair BGP :
Configurez le groupe BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configurez la stratégie de flux.
[edit policy-options policy-statement p1] user@host# set term a from rib inetflow.0 user@host# set term a from route-filter 10.13.0.0/16 orlonger user@host# set term a then accept user@host# set term b then reject
Configurez le numéro du système autonome local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show protocols, show policy-optionset show routing-options . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
from {
rib inetflow.0;
route-filter 10.13.0.0/16 orlonger;
}
then accept;
}
term b {
then reject;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Publicité de toutes les routes Unicast et Flow
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a then accept set routing-options autonomous-system 65001
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
Pour configurer les sessions pair BGP :
Configurez le groupe BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configurez la stratégie de flux.
[edit policy-options policy-statement p1] user@host# set term a then accept
Configurez le numéro du système autonome local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show protocols, show policy-optionset show routing-options . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
prefix-list inetflow;
}
then accept;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Publicité Pas d’unicast ou de routes de flux
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set protocols bgp group core family inet unicast set protocols bgp group core family inet flow set protocols bgp group core export p1 set protocols bgp group core peer-as 65000 set protocols bgp group core neighbor 10.12.99.5 set policy-options policy-statement p1 term a then reject set routing-options autonomous-system 65001
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
Pour configurer les sessions pair BGP :
Configurez le groupe BGP.
[edit protocols bgp group core] user@host# set family inet unicast user@host# set family inet flow user@host# set export p1 user@host# set peer-as 65000 user@host# set neighbor 10.12.99.5
Configurez la stratégie de flux.
[edit policy-options policy-statement p1] user@host# set term a then reject
Configurez le numéro du système autonome local (AS).
[edit routing-options] user@host# set autonomous-system 65001
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show protocols, show policy-optionset show routing-options . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show protocols
bgp {
group core {
family inet {
unicast;
flow;
}
export p1;
peer-as 65000;
neighbor 10.12.99.5;
}
}
[edit]
user@host# show policy-options
policy-statement p1 {
term a {
then reject;
}
}
[edit] user@host# show routing-options autonomous-system 65001;
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Limitation du nombre de routes de flux installées dans une table de routage
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set routing-options rib inetflow.0 maximum-prefixes 1000 set routing-options rib inetflow.0 maximum-prefixes threshold 50
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
L’application d’une limite de route peut entraîner un comportement imprévisible du protocole de route dynamique. Par exemple, une fois que la limite est atteinte et que les routes sont rejetées, BGP ne tente pas nécessairement de réinstaller les routes rejetées une fois que le nombre de routes est passé en dessous de la limite. Pour résoudre ce problème, il peut être nécessaire d’effacer les sessions BGP.
Pour limiter les itinéraires de flux :
Définissez une limite supérieure pour le nombre de préfixes installés dans
inetflow.0la table.[edit routing-options rib inetflow.0] user@host# set maximum-prefixes 1000
Définissez une valeur seuil de 50 %, où lorsque 500 routes sont installées, un avertissement est consigné dans le journal système.
[edit routing-options rib inetflow.0] user@host# set maximum-prefixes threshold 50
Résultats
À partir du mode configuration, confirmez votre configuration en entrant la show routing-options commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show routing-options
rib inetflow.0 {
maximum-prefixes 1000 threshold 50;
}
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Limitation du nombre de préfixes reçus sur une session d’appairage BGP
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie.
set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit maximum 1000 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit teardown 50 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit drop-excess 50 set protocols bgp group x1 neighbor 10.12.99.2 family inet flow prefix-limit hide-excess 50
Vous pouvez inclure l’option d’instruction teardown <percentage>, drop-excess <percentage>ou hide-excess<percentage> une à la fois.
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode configuration du Guide de l’utilisateur de l’interface de ligne de commande Junos OS.
La configuration d’une limite de préfixes pour un voisin spécifique offre un contrôle plus prévisible sur l’homologue qui peut annoncer le nombre de routes de flux.
Pour limiter le nombre de préfixes :
Définissez une limite de 1000 routes BGP à partir du voisin 10.12.99.2.
[edit protocols bgp group x1] user@host# set neighbor 10.12.99.2 family inet flow prefix-limit maximum 1000
-
Configurez la session voisine ou les préfixes pour qu’ils exécutent l’option d’instruction
teardown <percentage>,drop-excess <percentage>ouhide-excess<percentage>lorsque la session ou les préfixes atteignent leur limite.[edit routing-options rib inetflow.0] user@host# set neighbor 10.12.99.2 family inet flow prefix-limit teardown 50 set neighbor 10.12.99.2 family inet flow prefix-limit drop-excess 50 set neighbor 10.12.99.2 family inet flow prefix-limit hide-excess 50
Si vous spécifiez l’instruction
teardown <percentage>et spécifiez un pourcentage, les messages sont consignés lorsque le nombre de préfixes atteint ce pourcentage. Une fois la session arrêtée, elle est rétablie peu de temps après, sauf si vous incluez l’instructionidle-timeout.Si vous spécifiez l’instruction
drop-excess <percentage>et spécifiez un pourcentage, les routes excédentaires sont supprimées lorsque le nombre de préfixes dépasse ce pourcentageSi vous spécifiez l’instruction
hide-excess <percentage>et spécifiez un pourcentage, les routes excédentaires sont masquées lorsque le nombre de préfixes dépasse ce pourcentage.
Résultats
À partir du mode configuration, confirmez votre configuration en entrant la show protocols commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@host# show protocols
bgp {
group x1 {
neighbor 10.12.99.2 {
flow {
prefix-limit {
maximum 1000;
teardown 50;
drop-excess <percentage>;
hide-excess <percentage>;
}
}
}
}
}
}
Si vous avez terminé de configurer l’appareil, passez commit en mode de configuration.
Vérification
Vérifiez que la configuration fonctionne correctement.
- Vérification du NLRI
- Vérification des itinéraires
- Vérification de la validation du flux
- Vérification des filtres de pare-feu
- Vérification de la journalisation système en cas de dépassement du nombre de routes de flux autorisées
- Vérification de la journalisation système en cas de dépassement du nombre de préfixes reçus lors d’une session d’appairage BGP
Vérification du NLRI
But
Regardez le NLRI activé pour le voisin.
Action
À partir du mode opérationnel, exécutez la show bgp neighbor 10.12.99.5 commande. inet-flow Recherchez dans la sortie.
user@host> show bgp neighbor 10.12.99.5 Peer: 10.12.99.5+3792 AS 65000 Local: 10.12.99.6+179 AS 65002 Type: External State: Established Flags: <Sync> Last State: OpenConfirm Last Event: RecvKeepAlive Last Error: None Export: [ direct ] Options: <Preference HoldTime AddressFamily PeerAS Refresh> Address families configured: inet-unicast inet-multicast inet-flow Holdtime: 90 Preference: 170 Number of flaps: 1 Error: 'Cease' Sent: 0 Recv: 1 Peer ID: 10.255.71.161 Local ID: 10.255.124.107 Active Holdtime: 90 Keepalive Interval: 30 Peer index: 0 Local Interface: e1-3/0/0.0 NLRI advertised by peer: inet-unicast inet-multicast inet-flow NLRI for this session: inet-unicast inet-multicast inet-flow Peer supports Refresh capability (2) Table inet.0 Bit: 10000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 2 Received prefixes: 2 Suppressed due to damping: 0 Advertised prefixes: 3 Table inet.2 Bit: 20000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 0 Received prefixes: 0 Suppressed due to damping: 0 Advertised prefixes: 0 Table inetflow.0 Bit: 30000 RIB State: BGP restart is complete Send state: in sync Active prefixes: 0 Received prefixes: 0 Suppressed due to damping: 0 Advertised prefixes: 0 Last traffic (seconds): Received 29 Sent 15 Checked 15 Input messages: Total 5549 Updates 2618 Refreshes 0 Octets 416486 Output messages: Total 2943 Updates 1 Refreshes 0 Octets 55995 Output Queue[0]: 0 Output Queue[1]: 0 Output Queue[2]: 0
Vérification des itinéraires
But
Regardez les voies d’écoulement. L’exemple de sortie montre un itinéraire de flux appris à partir de BGP et un itinéraire de flux configuré de manière statique.
Pour les routes de flux configurées localement (configurées au niveau de la hiérarchie), les routes sont installées par le protocole de [edit routing-options flow] flux. Par conséquent, vous pouvez afficher les routes de flux en spécifiant la table, comme dans show route table inetflow.0 ou show route table instance-name.inetflow.0 où instance-name est le nom de l’instance de routage. Vous pouvez également afficher tous les itinéraires de flux configurés localement sur plusieurs instances de routage en exécutant la show route protocol flow commande.
Si une route de flux n’est pas configurée localement, mais reçue du pair BGP du routeur, cette route de flux est installée dans le table de routage par BGP. Vous pouvez afficher les routes de flux en spécifiant la table ou en exécutant show route protocol bgp, qui affiche toutes les routes BGP (de flux et de non-flux).
Action
À partir du mode opérationnel, exécutez la show route table inetflow.0 commande.
user@host> show route table inetflow.0
inetflow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
100.100.100.100,*,proto=1,icmp-type=8/term:1
*[BGP/170] 00:00:18, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
200.200.200.200,*,proto=6,port=80/term:2
*[BGP/170] 00:00:18, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
user@host> show route table inetflow.0 extensive
inetflow.0: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden)
7.7.7.7,8.8.8.8/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
*Flow Preference: 5
Next hop type: Fictitious
Address: 0x8d383a4
Next-hop reference count: 3
State: <Active>
Local AS: 65000
Age: 9:50
Task: RT Flow
Announcement bits (1): 0-Flow
AS path: I
user@host> show route hidden
inetflow.0: 2 destinations, 2 routes (0 active, 0 holddown, 2 hidden)
+ = Active Route, - = Last Active, * = Both
100.100.100.100,*,proto=1,icmp-type=8/term:N/A
[BGP ] 00:00:17, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
200.200.200.200,*,proto=6,port=80/term:N/A
[BGP ] 00:00:17, localpref 100, from 100.0.12.2
AS path: 2000 I, validation-state: unverified
Fictitious
Sens
Une route de flux représente le terme d’un filtre de pare-feu. Lorsque vous configurez un itinéraire de flux, vous spécifiez les conditions de correspondance et les actions. Dans les attributs de correspondance, vous pouvez faire correspondre une adresse source, une adresse de destination et d’autres qualificatifs tels que le port et le protocole. Pour un itinéraire de flux unique qui contient plusieurs conditions de correspondance, toutes les conditions de correspondance sont encapsulées dans le champ de préfixe de l’itinéraire. Lorsque vous émettez la show route commande sur un itinéraire de flux, le champ de préfixe de l’itinéraire s’affiche avec toutes les conditions de correspondance. 10.12.44.1,* signifie que la condition correspondante est match destination 10.12.44.1/32. Si le préfixe dans la sortie était , cela signifierait que la condition de correspondance était *,10.12.44.1match source 10.12.44.1/32. Si les conditions de correspondance contiennent à la fois une source et une destination, l’astérisque est remplacé par l’adresse.
Les numéros d’ordre des termes indiquent la séquence des termes (voies de flux) en cours d’évaluation dans le filtre du pare-feu. La show route extensive commande affiche les actions pour chaque terme (tournée).
Vérification de la validation du flux
But
Affichez les informations sur l’itinéraire de flux.
Action
À partir du mode opérationnel, exécutez la show route flow validation detail commande.
user@host> show route flow validation detail
inet.0:
0.0.0.0/0
Internal node: best match, inconsistent
10.0.0.0/8
Internal node: no match, inconsistent
10.12.42.0/24
Internal node: no match, consistent, next-as: 65003
Active unicast route
Dependent flow destinations: 1
Origin: 10.255.124.106, Neighbor AS: 65003
10.12.42.1/32
Flow destination (1 entries, 1 match origin)
Unicast best match: 10.12.42.0/24
Flags: Consistent
10.131.0.0/16
Internal node: no match, consistent, next-as: 65001
Active unicast route
Dependent flow destinations: 5000
Origin: 10.12.99.2, Neighbor AS: 65001
10.131.0.0/19
Internal node: best match
10.131.0.0/20
Internal node: best match
10.131.0.0/21
Vérification des filtres de pare-feu
But
Affichez les filtres de pare-feu installés dans le noyau.
Action
À partir du mode opérationnel, exécutez la show firewall commande.
user@host> show firewall Filter: __default_bpdu_filter__ Filter: __flowspec_default_inet__ Counters: Name Bytes Packets 10.12.42.1,* 0 0 196.1.28/23,* 0 0 196.1.30/24,* 0 0 196.1.31/24,* 0 0 196.1.32/24,* 0 0 196.1.56/21,* 0 0 196.1.68/24,* 0 0 196.1.69/24,* 0 0 196.1.70/24,* 0 0 196.1.75/24,* 0 0 196.1.76/24,* 0 0
Vérification de la journalisation système en cas de dépassement du nombre de routes de flux autorisées
But
Si vous configurez une limite sur le nombre de routes de flux installées, comme décrit à Limitation du nombre de routes de flux installées dans une table de routagela section , affichez le message du journal système lorsque le seuil est atteint.
Action
À partir du mode opérationnel, exécutez la show log <message> commande.
user@host> show log message Jul 12 08:19:01 host rpd[2748]: RPD_RT_MAXROUTES_WARN: Number of routes (1000) in table inetflow.0 exceeded warning threshold (50 percent of configured maximum 1000)
Vérification de la journalisation système en cas de dépassement du nombre de préfixes reçus lors d’une session d’appairage BGP
But
Si vous configurez une limite sur le nombre de routes de flux installées, comme décrit à Limitation du nombre de préfixes reçus sur une session d’appairage BGPla section , affichez le message du journal système lorsque le seuil est atteint.
Action
À partir du mode opérationnel, exécutez la show log message commande.
Si vous spécifiez l’option d’instruction teradown <percentage> :
user@host> show log message Jul 12 08:44:47 host rpd[2748]: 10.12.99.2 (External AS 65001): Shutting down peer due to exceeding configured maximum prefix-limit(1000) for inet-flow nlri: 1001
Si vous spécifiez l’option d’instruction drop-excess <percentage> :
user@host> show log message Jul 27 15:26:57 R1_re rpd[32443]: BGP_DROP_PREFIX_LIMIT_EXCEEDED: 1.1.1.2 (Internal AS 1): Exceeded drop-excess maximum prefix-limit(4) for inet-unicast nlri: 5 (instance master)
Si vous spécifiez l’option d’instruction hide-excess <percentage> :
user@host> show log message Jul 27 15:26:57 R1_re rpd[32443]: BGP_HIDE_PREFIX_LIMIT_EXCEEDED: 1.1.1.2 (Internal AS 1): Exceeded hide-excess maximum prefix-limit(4) for inet-unicast nlri: 5 (instance master)
Exemple : Configuration de BGP pour transporter les routes de spécification de flux IPv6
Cet exemple montre comment configurer la spécification de flux IPv6 pour le filtrage du trafic. La spécification de flux BGP peut être utilisée pour automatiser la coordination interdomaine et intradomaine des règles de filtrage du trafic afin d’atténuer les attaques par déni de service.
Conditions préalables
Cet exemple utilise les composants matériels et logiciels suivants :
Deux routeurs MX Series
Junos OS version 16.1 ou ultérieure
Avant d’activer BGP pour transporter les routes de spécification de flux IPv6 :
Configurez les adresses IP sur les interfaces des appareils.
Configurez BGP.
Configurez une stratégie de routage qui exporte les routes (telles que les routes statiques, les routes directes ou les routes IGP) de la table de routage vers BGP.
Présentation
La spécification de flux fournit une protection contre les attaques par déni de service et limite le trafic malveillant qui consomme la bande passante et l’arrête près de la source. Dans les versions antérieures de Junos OS, les règles de spécification de flux étaient propagées pour IPv4 sur BGP en tant qu’informations d’accessibilité de la couche réseau. À partir de Junos OS version 16.1, la fonctionnalité de spécification de flux est prise en charge sur la famille IPv6 et permet la propagation des règles de spécification de flux de trafic pour les VPN IPv6 et IPv6.
Topologie
Figure 7 montre l’exemple de topologie. Le routeur R1 et le routeur R2 appartiennent à des systèmes autonomes différents. La spécification de flux IPv6 est configurée sur le routeur R2. L’ensemble du trafic entrant est filtré en fonction des conditions de spécification du flux, et le trafic est traité différemment en fonction de l’action spécifiée. Dans cet exemple, tout le trafic qui se dirige vers abcd ::11 :11 :11 :10/128 et qui correspond aux conditions de spécification de flux est ignoré ; En revanche, le trafic destiné à ABCD ::11 :11 :11 :30/128 et correspondant aux conditions de spécification de flux est accepté.
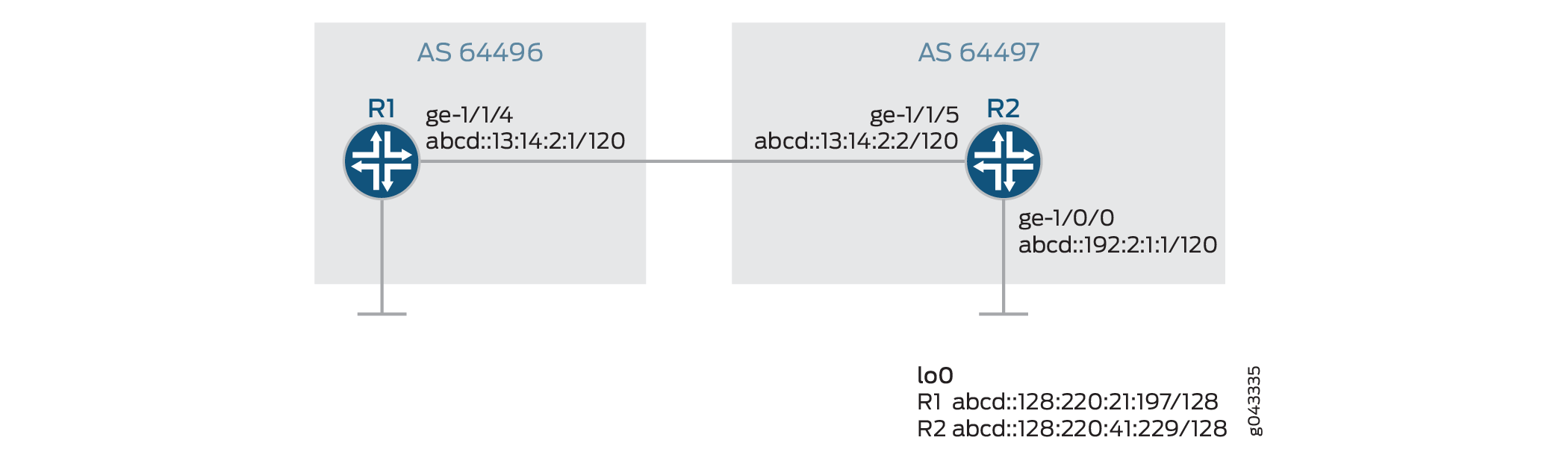
Configuration
Configuration rapide de l’interface de ligne de commande
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à la configuration de votre réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la [edit] hiérarchie, puis passez commit en mode de configuration.
Routeur R1
set interfaces ge-1/1/4 unit 0 family inet6 address abcd::13:14:2:1/120 set interfaces lo0 unit 0 family inet6 address abcd::128:220:21:197/128 set routing-options router-id 128.220.21.197 set routing-options autonomous-system 64496 set protocols bgp group ebgp type external set protocols bgp group ebgp family inet6 unicast set protocols bgp group ebgp family inet6 flow set protocols bgp group ebgp peer-as 64497 set protocols bgp group ebgp neighbor abcd::13:14:2:2
Routeur R2
set interfaces ge-1/0/0 unit 0 family inet6 address abcd::192:2:1:1/120 set interfaces ge-1/1/5 unit 0 family inet6 address abcd::13:14:2:2/120 set interfaces lo0 unit 0 family inet6 address abcd::128:220:41:229/128 set routing-options rib inet6.0 static route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2 set routing-options rib inet6.0 flow route route-1 match destination abcd::11:11:11:10/128 set routing-options rib inet6.0 flow route route-1 match protocol tcp set routing-options rib inet6.0 flow route route-1 match destination-port http set routing-options rib inet6.0 flow route route-1 match source-port 65535 set routing-options rib inet6.0 flow route route-1 then discard set routing-options rib inet6.0 flow route route-2 match destination abcd::11:11:11:30/128 set routing-options rib inet6.0 flow route route-2 match icmp6-type echo-request set routing-options rib inet6.0 flow route route-2 match packet-length 100 set routing-options rib inet6.0 flow route route-2 match dscp 10 set routing-options rib inet6.0 flow route route-2 then accept set routing-options router-id 128.220.41.229 set routing-options autonomous-system 64497 set protocols bgp group ebgp type external set protocols bgp group ebgp family inet6 unicast set protocols bgp group ebgp family inet6 flow set protocols bgp group ebgp export redis set protocols bgp group ebgp peer-as 64496 set protocols bgp group ebgp neighbor abcd::13:14:2:1 set policy-options policy-statement redis from protocol static set policy-options policy-statement redis then accept
Configuration du routeur R2
Procédure étape par étape
L’exemple suivant nécessite que vous naviguiez à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans l’interface de ligne de commande, reportez-vous à la section Utilisation de l’éditeur CLI en mode de configuration dans le Guide de l’utilisateur de l’interface de ligne de commande.
Pour configurer le routeur R2 :
Répétez cette procédure pour le routeur R1 après avoir modifié les noms d’interface, les adresses et les autres paramètres appropriés.
Configurez les interfaces avec des adresses IPv6.
[edit interfaces] user@R2# set ge-1/0/0 unit 0 family inet6 address abcd::192:2:1:1/120 user@R2# set ge-1/1/5 unit 0 family inet6 address abcd::13:14:2:2/120
Configurez l’adresse de bouclage IPv6.
[edit interfaces] user@R2# set lo0 unit 0 family inet6 address abcd::128:220:41:229/128
Configurez l’ID du routeur et le numéro du système autonome (AS).
[edit routing-options] user@R2# set router-id 128.220.41.229 user@R2# set autonomous-system 64497
Configurez une session d’appairage EBGP entre le routeur R1 et le routeur R2.
[edit protocols] user@R2# set bgp group ebgp type external user@R2# set bgp group ebgp family inet6 unicast user@R2# set bgp group ebgp family inet6 flow user@R2# set bgp group ebgp export redis user@R2# set bgp group ebgp peer-as 64496 user@R2# set bgp group ebgp neighbor abcd::13:14:2:1
Configurez une route statique et un saut suivant. Ainsi, une route est ajoutée à la table de routage pour vérifier la fonctionnalité dans cet exemple.
[edit routing-options] user@R2# set rib inet6.0 static route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2
Spécifiez les conditions de spécification de flux.
[edit routing-options] user@R2# set rib inet6.0 flow route route-1 match destination abcd::11:11:11:10/128 user@R2# set rib inet6.0 flow route route-1 match protocol tcp user@R2# set rib inet6.0 flow route route-1 match destination-port http user@R2# set rib inet6.0 flow route route-1 match source-port 65535
Configurez une discard action pour rejeter les paquets qui correspondent aux conditions de correspondance spécifiées.
[edit routing-options] user@R2# set rib inet6.0 flow route route-1 then discard
Spécifiez les conditions de spécification de flux.
[edit routing-options] user@R2# set rib inet6.0 flow route route-2 match destination abcd::11:11:11:30/128 user@R2# set rib inet6.0 flow route route-2 match icmp6-type echo-request user@R2# set rib inet6.0 flow route route-2 match packet-length 100 user@R2# set rib inet6.0 flow route route-2 match dscp 10
Configurer une accept action pour accepter les paquets qui correspondent aux conditions de correspondance spécifiées
[edit routing-options] user@R2# set rib inet6.0 flow route route-2 then accept
Définissez une stratégie qui autorise BGP à accepter les routes statiques.
[edit policy-options] user@R2# set policy-statement redis from protocol static user@R2# set policy-statement redis then accept
Résultats
À partir du mode de configuration, confirmez votre configuration en saisissant les commandes show interfaces, show protocols, show routing-optionset show policy-options. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
[edit]
user@R2# show interfaces
ge-1/0/0 {
unit 0 {
family inet6 {
address abcd::192:2:1:1/120;
}
}
}
ge-1/1/5 {
unit 0 {
family inet6 {
address abcd::13:14:2:2/120;
}
}
}
lo0 {
unit 0 {
family inet6 {
address abcd::128:220:41:229/128;
}
}
}
[edit]
user@R2# show protocols
bgp {
group ebgp {
type external;
family inet6 {
unicast;
flow;
}
export redis;
peer-as 64496;
neighbor abcd::13:14:2:1;
}
}
[edit]
user@R2# show routing-options
rib inet6.0 {
static {
route abcd::11:11:11:0/120 next-hop abcd::192:2:1:2;
}
flow {
route route-1 {
match {
destination abcd::11:11:11:10/128;
protocol tcp;
destination-port http;
source-port 65535;
}
then discard;
}
route route-2 {
match {
destination abcd::11:11:11:30/128;
icmp6-type echo-request;
packet-length 100;
dscp 10;
}
then accept;
}
}
}
router-id 128.220.41.229;
autonomous-system 64497;
[edit]
user@R2# show policy-options
policy-statement redis {
from protocol static;
then accept;
}
Vérification
Vérifiez que la configuration fonctionne correctement.
- Vérification de la présence de routes de spécification de flux IPv6 dans la table inet6flow
- Vérification des informations récapitulatives BGP
- Vérification de la validation du flux
- Vérification de la spécification de flux des routes IPv6
Vérification de la présence de routes de spécification de flux IPv6 dans la table inet6flow
But
Affichez les routes dans le tableau dans les routeurs R1 et R2 et vérifiez que BGP a appris les inet6flow routes de flux.
Action
À partir du mode opérationnel, exécutez la commande sur le show route table inet6flow.0 extensive routeur R1.
user@R1> show route table inet6flow.0 extensive
inet6flow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): discard,count
*BGP Preference: 170/-101
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 2
State:<Active Ext>
Local AS: 64496 Peer AS: 64497
Age: 20:55
Validation State: unverified
Task: BGP_64497.abcd::13:14:2:2
Announcement bits (1): 0-Flow
AS path: 64497 I
Communities: traffic-rate:64497:0
Accepted
Validation state: Accept, Originator: abcd::13:14:2:2, Nbr AS: 64497
Via: abcd::11:11:11:0/120, Active
Localpref: 100
Router ID: 128.220.41.229
abcd::11:11:11:30/128,*,icmp6-type=128,len=100,dscp=10/term:2 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
*BGP Preference: 170/-101
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 2
State: <Active Ext>
Local AS: 64496 Peer AS: 64497
Age: 12:51
Validation State: unverified
Task: BGP_64497.abcd::13:14:2:2
Announcement bits (1): 0-Flow
AS path: 64497 I
Accepted
Validation state: Accept, Originator: abcd::13:14:2:2, Nbr AS: 64497
Via: abcd::11:11:11:0/120, Active
Localpref: 100
Router ID: 128.220.41.229En mode opérationnel, exécutez la commande sur le show route table inet6flow.0 extensive routeur R2.
user@R2> show route table inet6flow.0 extensive
inet6flow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535/term:1 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): discard,count
Page 0 idx 0, (group pe-v6 type External) Type 1 val 0xaec8850 (adv_entry)
Advertised metrics:
Nexthop: Self
AS path: [64497]
Communities: traffic-rate:64497:0
Path abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535 Vector len 4. Val: 0
*Flow Preference: 5
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 3
State: <Active>
Local AS: 64497
Age: 14:21
Validation State: unverified
Task: RT Flow
Announcement bits (2): 0-Flow 1-BGP_RT_Background
AS path: I
Communities: traffic-rate:64497:0
abcd::11:11:11:30/128,*,proto=17,port=65535/term:2 (1 entry, 1 announced)
TSI:
KRT in dfwd;
Action(s): accept,count
Page 0 idx 0, (group pe-v6 type External) Type 1 val 0xaec8930 (adv_entry)
Advertised metrics:
Nexthop: Self
AS path: [64497]
Communities:
Path abcd::11:11:11:30/128,*,proto=17,port=65535 Vector len 4. Val: 0
*Flow Preference: 5
Next hop type: Fictitious, Next hop index: 0
Address: 0x9b24064
Next-hop reference count: 3
State: <Active>
Local AS: 64497
Age: 14:21
Validation State: unverified
Task: RT Flow
Announcement bits (2): 0-Flow 1-BGP_RT_Background
AS path: I Sens
La présence des routes abcd ::11 :11 :11 :10/128 et abcd ::11 :11 :11 :30/128 dans la inet6flow table confirme que BGP a appris les routes de flux.
Vérification des informations récapitulatives BGP
But
Vérifiez que la configuration BGP est correcte.
Action
À partir du mode opérationnel, exécutez la commande sur les show bgp summary routeurs R1 et R2.
user@R1> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet6.0
1 1 0 0 0 0
inet6flow.0
2 2 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
abcd::13:14:2:2 2000 58 58 0 2 19:48 Establ
inet6.0: 1/1/1/0
inet6flow.0: 2/2/2/0
user@R2> show bgp summary
Groups: 1 Peers: 1 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet6.0
0 0 0 0 0 0
inet6flow.0
0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
abcd::13:14:2:1 64496 51 52 0 0 23:03 Establ
inet6.0: 0/0/0/0
inet6flow.0: 0/0/0/0Sens
Vérifiez que la inet6.0 table contient l’adresse voisine BGP et qu’une session d’appairage a été établie avec son voisin BGP.
Vérification de la validation du flux
But
Affichez les informations sur l’itinéraire de flux.
Action
À partir du mode opérationnel, exécutez la commande sur le show route flow validation routeur R1.
user@R1> show route flow validation
inet6.0:
abcd::11:11:11:0/120
Active unicast route
Dependent flow destinations: 2
Origin: abcd::13:14:2:2, Neighbor AS: 64497
abcd::11:11:11:10/128
Flow destination (1 entries, 1 match origin, next-as)
Unicast best match: abcd::11:11:11:0/120
Flags: Consistent
abcd::11:11:11:30/128
Flow destination (1 entries, 1 match origin, next-as)
Unicast best match: abcd::11:11:11:0/120
Flags: ConsistentSens
La sortie affiche les itinéraires de flux dans le inet6.0 tableau.
Vérification de la spécification de flux des routes IPv6
But
Affichez le nombre de paquets qui sont rejetés et acceptés en fonction des routes de spécification de flux spécifiées.
Action
En mode opérationnel, exécutez la commande sur le show firewall filter_flowspec_default_inet6_ routeur R2.
user@R2> show firewall filter __flowspec_default_inet6__ Filter: __flowspec_default_inet6__ Counters: Name Bytes Packets abcd::11:11:11:10/128,*,proto=6,dstport=80,srcport=65535 0 0 abcd::11:11:11:30/128,*,proto=17,port=65535 6395472 88826
Sens
La sortie indique que les paquets destinés à abcd ::11 :11 :11 :10/128 sont ignorés et que 88826 paquets ont été acceptés pour la route abcd ::11 :11 :11 :11 :30/128.
Configuration de l’action de spécification de flux BGP Rediriger vers IP pour filtrer le trafic DDoS
À partir de Junos OS version 18.4R1, la spécification de flux BGP telle que décrite dans le draft-ietf-idr-flowspec-redirect-ip-02.txt préliminaire Internet BGP Flow-Spec, la redirection vers Action IP est prise en charge. Rediriger vers IP action uses extended BGP community to provide traffic filtering options for DDoS mitigation in services provider networks (Rediriger vers IP action uses extended BGP community to provide traffic filtering options for DDoS mitigation in Service provider networks). La redirection vers IP utilise l’attribut BGP nexthop. Par défaut, Junos OS annonce la redirection vers l’action de spécification de flux IP à l’aide de la communauté étendue. Cette fonctionnalité est nécessaire pour prendre en charge le chaînage de services dans la passerelle de contrôle de service virtuel (vSCG). La redirection vers l’action IP permet de rediriger le trafic de spécification de flux correspondant vers une adresse accessible globalement qui pourrait être connectée à un équipement de filtrage capable de filtrer le trafic DDoS et d’envoyer le trafic propre vers l’équipement de sortie.
Avant de commencer à rediriger le trafic vers IP pour les routes de spécification de flux BGP, procédez comme suit :
Configurez les interfaces de l’appareil.
Configurez OSPF ou tout autre protocole IGP.
Configurez MPLS et LDP.
Configurez BGP.
Configurez la fonctionnalité de redirection vers IP à l’aide de la communauté étendue BGP.
Configurez la fonctionnalité de redirection de la spécification de flux héritée vers IP à l’aide de l’attribut nexthop.
Vous ne pouvez pas configurer de stratégies pour rediriger le trafic vers une adresse IP à l’aide de BGP Extended Community et de l’ancienne redirection vers l’adresse IP du tronçon suivant.
Configurez la redirection de spécification de flux héritée vers l’adresse IP spécifiée dans le brouillon Internet draft-ietf-idr-flowspec-redirect-ip-00.txt , la communauté étendue BGP Flow-Spec pour la redirection du trafic vers l’adresse IP Next Hop inclure au niveau de la hiérarchie.
[edit group bgp-group neighbor bgp neighbor family inet flow] user@host# set legacy-redirect-ip-action
Définissez une stratégie pour correspondre à l’attribut de tronçon suivant.
[edit policy options] user@host#policy statement policy_name user@host#from community community-name user@host#from next-hop ip-address
Par exemple, définissez une stratégie p1 pour rediriger le trafic vers l’adresse IP du saut suivant 10.1.1.1.
[edit policy options] user@host#policy statement p1 user@host#from community redirnh user@host#from next-hop 10.1.1.1
Définissez une stratégie pour définir, ajouter ou supprimer la communauté BGP à l’aide de la redirection de l’attribut next hop de spécification de flux héritée vers l’action IP.
[edit policy-options] user@host# policy-statement policy_name user@host# then community set community-name user@host# then community add community-name user@host# then community delete community-name user@host# then next-hop next-hop-address
Par exemple, définissez une stratégie p1 et définissez, ajoutez ou supprimez un redirnh de communauté BGP pour rediriger le trafic DDoS vers l’adresse IP du saut suivant 10.1.1.1.
[edit policy-options policy-statement p1] user@host# then community set redirnh user@host# then community add redirnh user@host# then community delete redirnh user@host# then next-hop 10.1.1.1
Voir également
Transfert de trafic à l’aide de l’action DSCP de spécification de flux BGP
Configurez l’action DSCP BGP Flow Specification (FlowSpec) pour transférer efficacement les paquets à l’aide de la classe de transfert et des informations de priorité de perte sur le réseau.
Avantages de l’action BGP FlowSpec DSCP pour transférer des paquets
-
Transfère le trafic vers les files d’attente COS prévues, où les stratégies COS sont correctement appliquées au trafic.
-
Influence le comportement du transfert local (par exemple, la sélection du tunnel) en fonction de la valeur DSCP provisionnée.
-
Aide à gérer efficacement le trafic sur votre réseau.
Lorsqu’un paquet entre dans un routeur, il passe par les fonctionnalités (pare-feu, COS, etc.) appliquées à l’interface entrante. Lorsque vous configurez le filtre BGP FlowSpec sur l’interface d’entrée, le filtre est appliqué aux paquets par instance de routage en fonction de l’action DSCP. L’action DSCP classe et réécrit les paquets, ainsi que la modification du code DSCP via le filtre BGP FlowSpec. En fonction de la classe de transfert et des informations de priorité de perte, les paquets sont placés dans la file d’attente de transfert appropriée. Les paquets transitent par des routes de flux uniquement si des conditions de correspondance spécifiques sont remplies. Les conditions de correspondance peuvent être l’adresse IP source et de destination, le port source et de destination, le DSCP, le numéro de protocole, etc. Les informations sur la classe de transfert et la priorité des pertes sont mises à jour via la table de mappage inverse.
Voici une topologie d’une session BGP établie entre les réseaux du fournisseur de services et de l’entreprise cliente.
Dans cette topologie, une session BGP est configurée entre le fournisseur de services et le réseau du client d’entreprise pour BGP FlowSpec. Le filtre BGP FlowSpec est appliqué aux routeurs PE1 et PE2. Les paquets entrant dans ces routeurs sont réécrits en fonction du filtre BGP FlowSpec et de l’action DSCP.
Pour activer le filtre BGP FlowSpec sur un périphérique, vous devez ajouter l’instruction de configuration dscp-mapping-classifier au niveau de la hiérarchie [edit forwarding-options family (inet | inet6)] :
forwarding-options {
family inet {
dscp-mapping-classifier ipv4-classifer;
}
family inet6 {
dscp-mapping-classifier ipv6-classifer;
}
}
L’exemple suivant de configuration de classe de service mappe le code DSCP à la classe de transfert et à la priorité de perte :
class-of-service {
classifiers {
dscp dscp1 {
forwarding-class best-effort {
loss-priority low code-points 000000;
}
}
}
}
Tableau de l'historique des modifications
La prise en charge des fonctionnalités est déterminée par la plateforme et la version que vous utilisez. Utilisez l' Feature Explorer pour déterminer si une fonctionnalité est prise en charge sur votre plateforme.
extended-community du trafic.