Uso de un servidor de enrutamiento basado en cRPD
Este capítulo trata algunas consideraciones de configuración especiales para usar una instancia cRPD o instancias como servidor de enrutamiento.
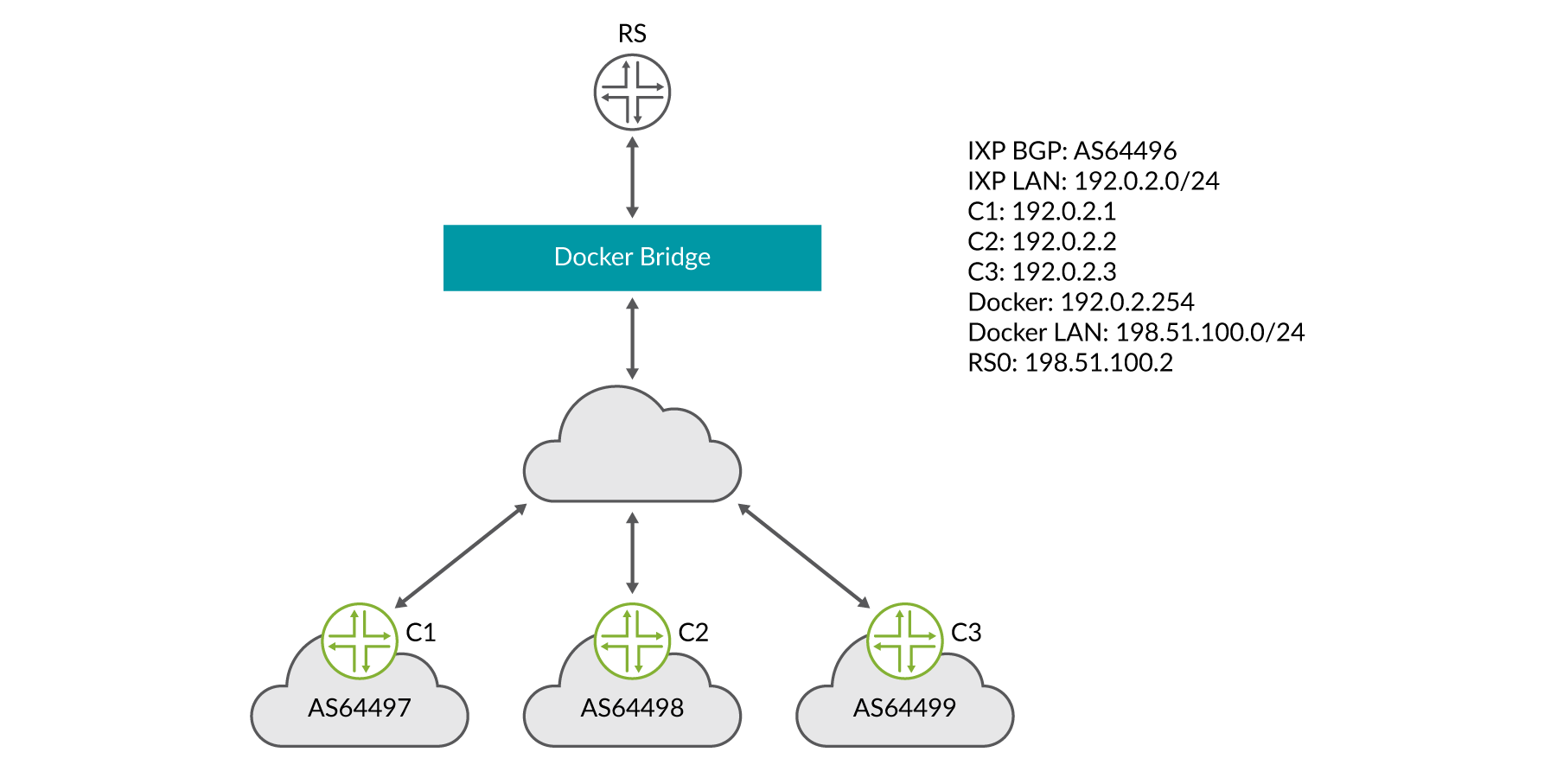
Para el ejemplo siguiente, usaremos los siguientes atributos:
La subred IP de puente de Docker es de 198.51.100.0/24
La subred LAN IXP es 192.0.2.0/24
Se ha asignado la dirección IP de 192.0.2.254 al servidor enrutador en la LAN IXP
IXP BGP tal y como 100
Consideraciones especiales para este ejemplo de implementación:
Dado que los clientes EBGP se encuentran en una subred IP diferente a la de la LAN IXP, las sesiones EBGP deben ser de salto múltiple. Esto se debe al hecho de que el contenedor se ejecuta en la subred del puente del Docker.
’No configurará interfaces cuando utilice cRPD. La dirección de interfaz se lee desde el contenedor del acoplador.
Ejemplo de dirección local de servidor de enrutamiento:
root@rs0> show interfaces routing
Interface State Addresses
eth0.0 Up MPLS enabled
ISO enabled
INET 198.51.100.2
lo.0 Up MPLS enabled
ISO enabled
INET 127.0.0.1
Ejemplo de configuración de servidor de enrutamiento cRPD:
Configuración de enrutadores de cliente IXP:
Se debe tener en cuenta que este ejemplo no’cubre todo lo que debe configurarse en un enrutador de cliente de emparejamiento con un servidor de enrutamiento operativo en una red activa. Aquí se puede encontrar un buen ejemplo de lo que se debe configurar en un dispositivo cliente que ejecuta Junos OS que participan en las operaciones de IXP: https://www.ams-ix.net/ams/documentation/config-guide.
Sincronización del plano de datos y de control
Un difícil problema con las LAN IXP son que los servidores de enrutamiento no están activos en el plano de datos entre clientes miembros IXP’, de modo que es posible que el plano de datos entre los clientes esté fuera de funcionamiento mientras las sesiones de EBGP con el servidor de enrutamiento se conserven. Como puede imaginar, esto crearía una capa negra – 3 cree que el destino es alcanzable y, por lo tanto, el cliente está enviando tráfico “mientras” el circuito de capa 2 está inactivo.
Se está realizando el trabajo en IETF para resolver este problema con BFD (https://datatracker.ietf.org/doc/draft-ietf-IDR-RS-BFD/).
El extracto de los anteriores Estados de borrador:
Cuando se utilizan BGP servidores de enrutamiento, el plano de datos no es congruente con el plano de control. Por lo tanto, los elementos del mismo nivel en un intercambio de Internet pueden perder la conectividad de datos sin que el plano de control sea consciente de ello, y los paquetes se pierden. Este documento propone el uso de un BGP identificador subsiguiente de familia de direcciones (SAFI) recién definido para permitir que el servidor de enrutamiento solicite a sus clientes que usen BFD para hacer un seguimiento de la’ Conectividad del plano de datos a sus direcciones de equipos del mismo nivel, y para que los clientes señalen ese estado de conectividad al servidor de enrutamiento.
En el desarrollo de este libro no existen implementaciones de este borrador que se encuentren disponibles de forma general. Una aplicación externa, como HealthBot, puede detectar y mitigar este problema como alternativa a las extensiones nativas de BGP propuestas en el borrador de IETF.
La solución HealthBot
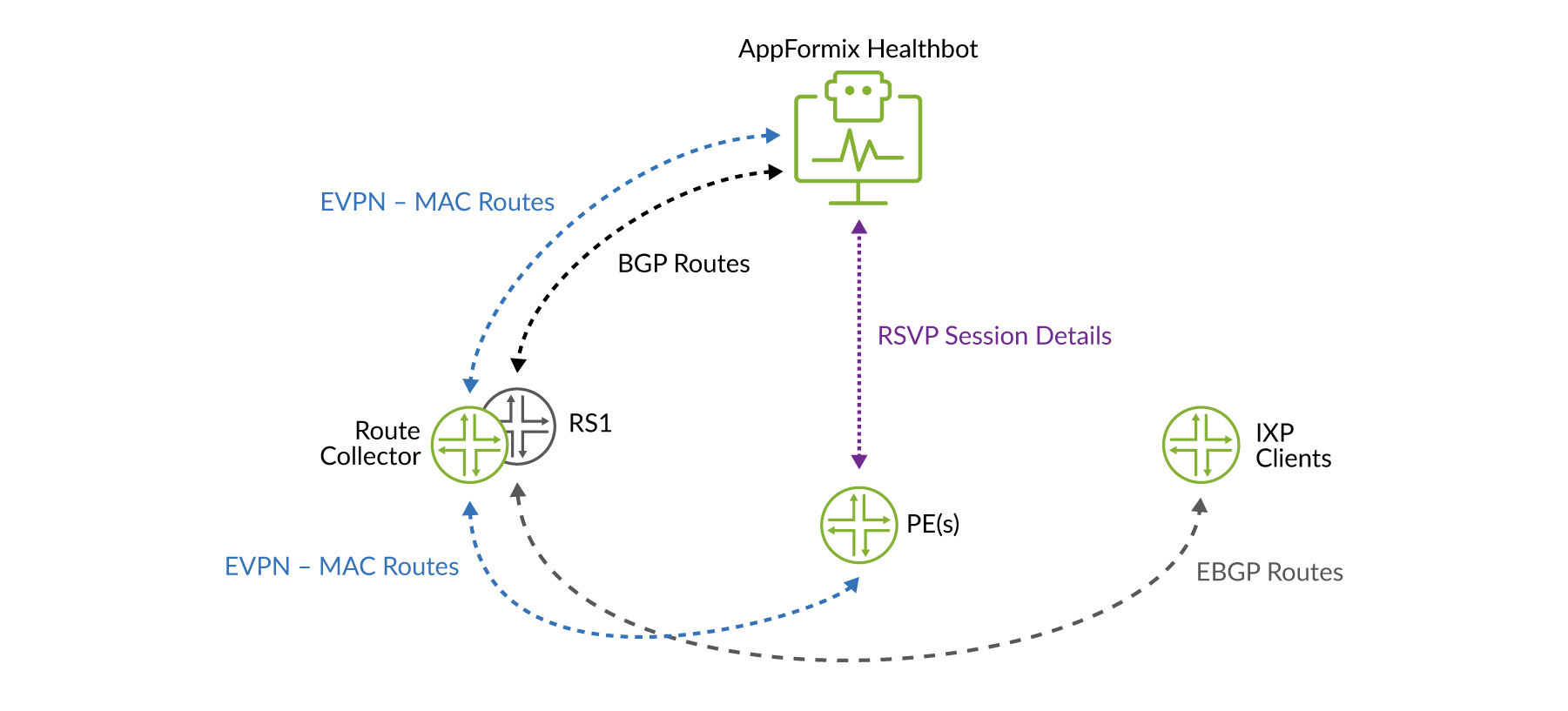
La solución HealthBot funciona primero mediante la correlación de varios segmentos de datos para detectar la condición. HealthBot recopila y/o recibe los siguientes datos:
EBGP siguientes saltos desde el servidor de enrutamiento
EVPN rutas MAC desde un selector de ruta
MANTENIMIENTO seguros de plano de datos estadísticas entre los enrutadores de PE
Para corregir el evento, que no es directo, HealthBot realiza lo siguiente, tal y Figure 2como se muestra en:
Restringe la distribución de rutas únicamente entre clientes de servidores de rutas que se vean afectados por la modificación de las políticas de importación de instancias en consecuencia.
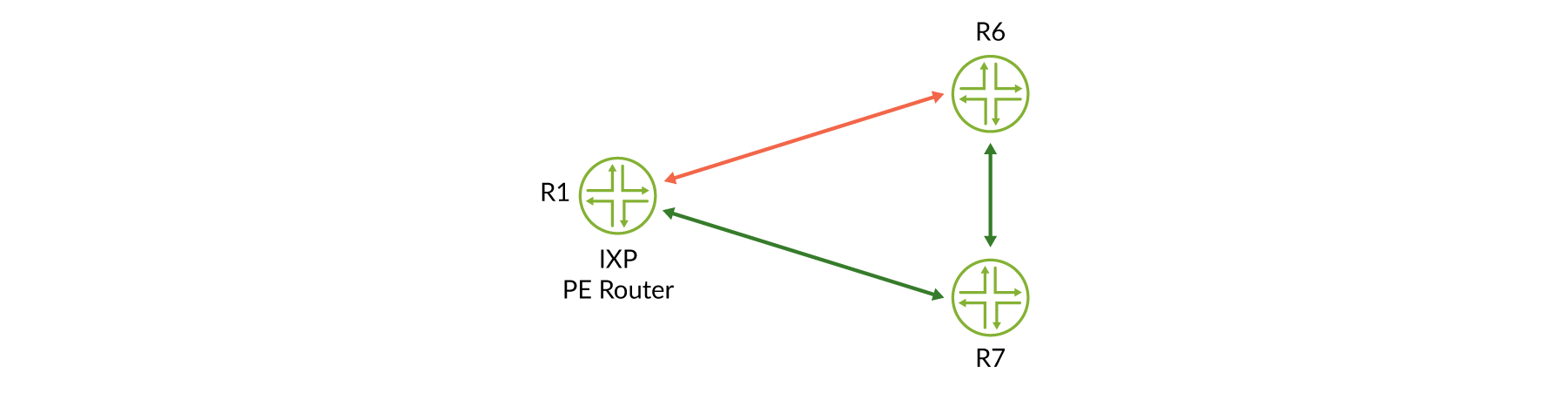
Ahora vamos’a analizar un ejemplo funcional; considere la topología de ejemplo en Figure 3.
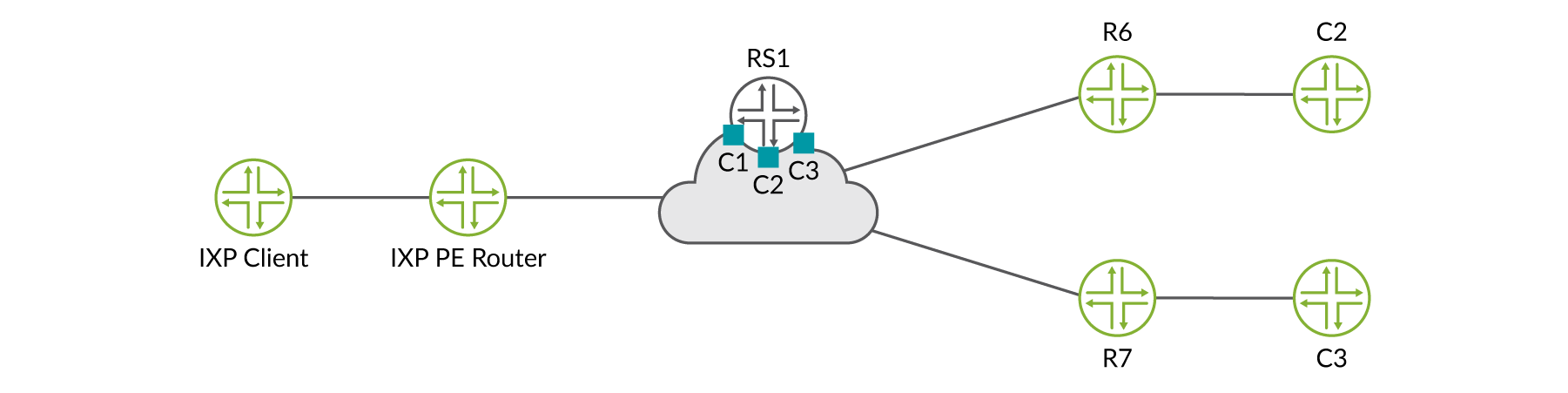
En primer lugar HealthBot se suscribe al sensor de telemetría BGP y recopila los datos del servidor de enrutamiento (vRR) y el selector Route. En este ejemplo, el servidor de ruta actúa también como el selector Route. Además, HealthBot se suscribe al sensor de iAgent MPLS y recopila estadísticas de la ruta conmutada por etiqueta (LSP) de los enrutadores de PE R1, R6 y R7.
Búsqueda de nombres de instancias de enrutamiento para cada cliente de servidor de enrutamiento ejemplo de CLI:
regress@RS1> show route instance summary | match C
Instance Type
Primary RIB Active/holddown/hidden
C1 non-forwarding
C1.inet.0 93/0/0
C2 non-forwarding
C2.inet.0 62/0/0
C3 non-forwarding
C3.inet.0 62/0/0
Búsqueda de los enrutadores de cliente IXP direcciones IP (el BGP próximos saltos) ejemplo:
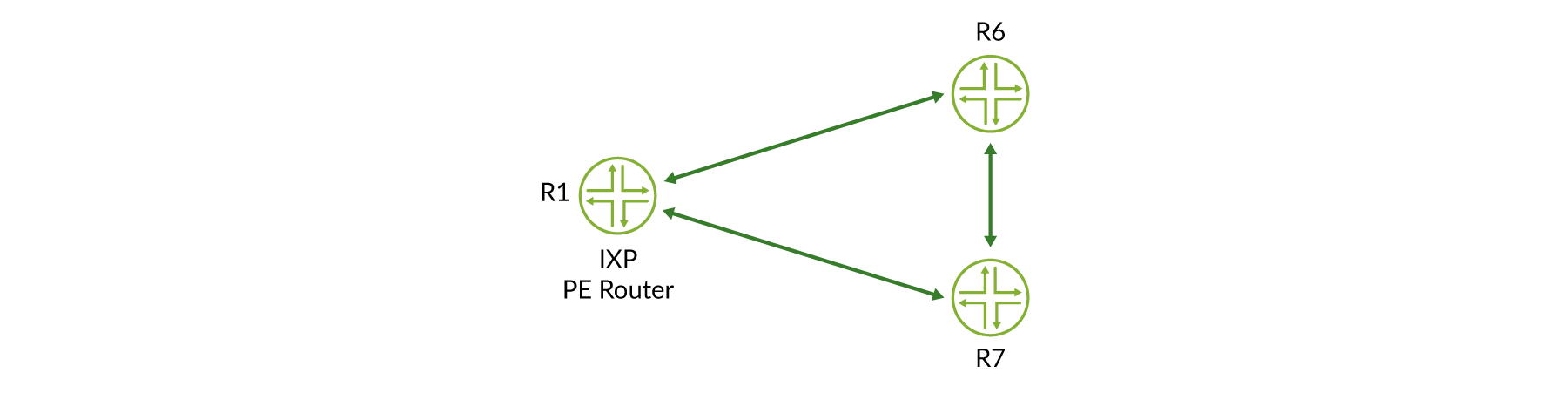
Figure 4 En referencia a para garantizar que el plano de datos está intacto entre enrutadores PE, HealthBot supervisa el estado de RSVP-te LSP entre todos los enrutadores de PE IXP:
regress@R6> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.1 192.0.2.6 Up 0 * to-r1 192.0.2.2 192.0.2.6 Up 0 * to-r2 regress@R7> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.1 192.0.2.7 Up 0 * to-r1 192.0.2.6 192.0.2.7 Up 0 * to-r6 regress@R1> show mpls lsp | match Up Ingress LSP: 2 sessions To From State RtP ActivePath LSPname 192.0.2.6 192.0.2.1 Up 0 * to-r6 192.0.2.7 192.0.2.1 Up 0 * to-r7
Durante el funcionamiento normal, las rutas se intercambian entre los miembros de IXP de acuerdo con las políticas de salida basadas en la comunidad. Aquí podemos ver que C1 recibe rutas de C2 (198.51.100.0/24) y C3 (203.0.113.0/24), respectivamente:
regress@C1> show route protocol bgp 198.51.100.1
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 2d 23:20:23, localpref100, from 192.0.2.254
AS path: 2 I, validation-state: unverified
> to 192.0.2.2 via ge-0/0/1.0
regress@C1> show route protocol bgp 203.0.113.0
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 00:46:29, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0
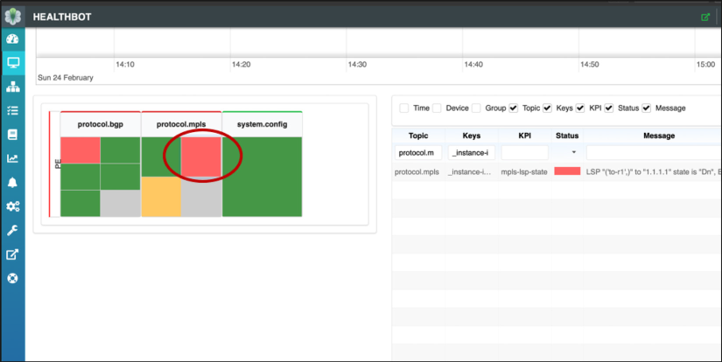
Sin embargo, ¿qué sucede si uno de los LSP de RSVP-TE deja de funcionar, por alguna razón, lo que da como resultado un desglose de datos entre R1 y R6, pero el servidor de enrutamiento sigue recibiendo rutas de miembros IXP adjuntos a esos enrutadores de PE?
Inactivo LSP...
regress@R6# run show mpls lsp Ingress LSP: 3 sessions To From State RtP ActivePath LSPname 192.0.2.1 0.0.0.0 Dn 0 - to-r1 192.0.2.7 192.0.2.6 Up 0 * to-r7 Total 3 displayed, Up 1, Down 2
Pero...
regress@C1> show route protocol bgp 198.51.100.1
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
198.51.100.0/24 *[BGP/170] 2d 23:20:23, localpref100, from 192.0.2.254
AS path: 2 I, validation-state: unverified
> to 192.0.2.2 via ge-0/0/1.0
regress@C1> show route protocol bgp 203.0.113.0
inet.0: 96 destinations, 96 routes (95 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 00:46:29, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0
HealthBot detectará la situación, mostrará una alarma de panel y modificará la configuración de la Directiva de servidor de enrutamiento para limitar la distribución de rutas entre los enrutadores de miembro IXP afectados.
Configuración modificada del servidor de rutas:
Comprobación en enrutador de miembro IXP C1. Como puede ver, las rutas ya no se reciben del miembro C2:
regress@C1> show route protocol bgp 198.51.100.1
egress@C1> show route protocol bgp 203.0.113.0
iet.0: 68 destinations, 68 routes (67 active, 0 holddown, 1 hidden)
+ = Active Route, - = Last Active, * = Both
203.0.113.0/24 *[BGP/170] 3d 01:10:07, localpref100, from 192.0.2.254
AS path: 3 I, validation-state: unverified
> to 192.0.2.3 via ge-0/0/1.0Una vez que se haya restaurado el plano de datos, HealthBot borrará la alarma y volverá a la configuración de la política.
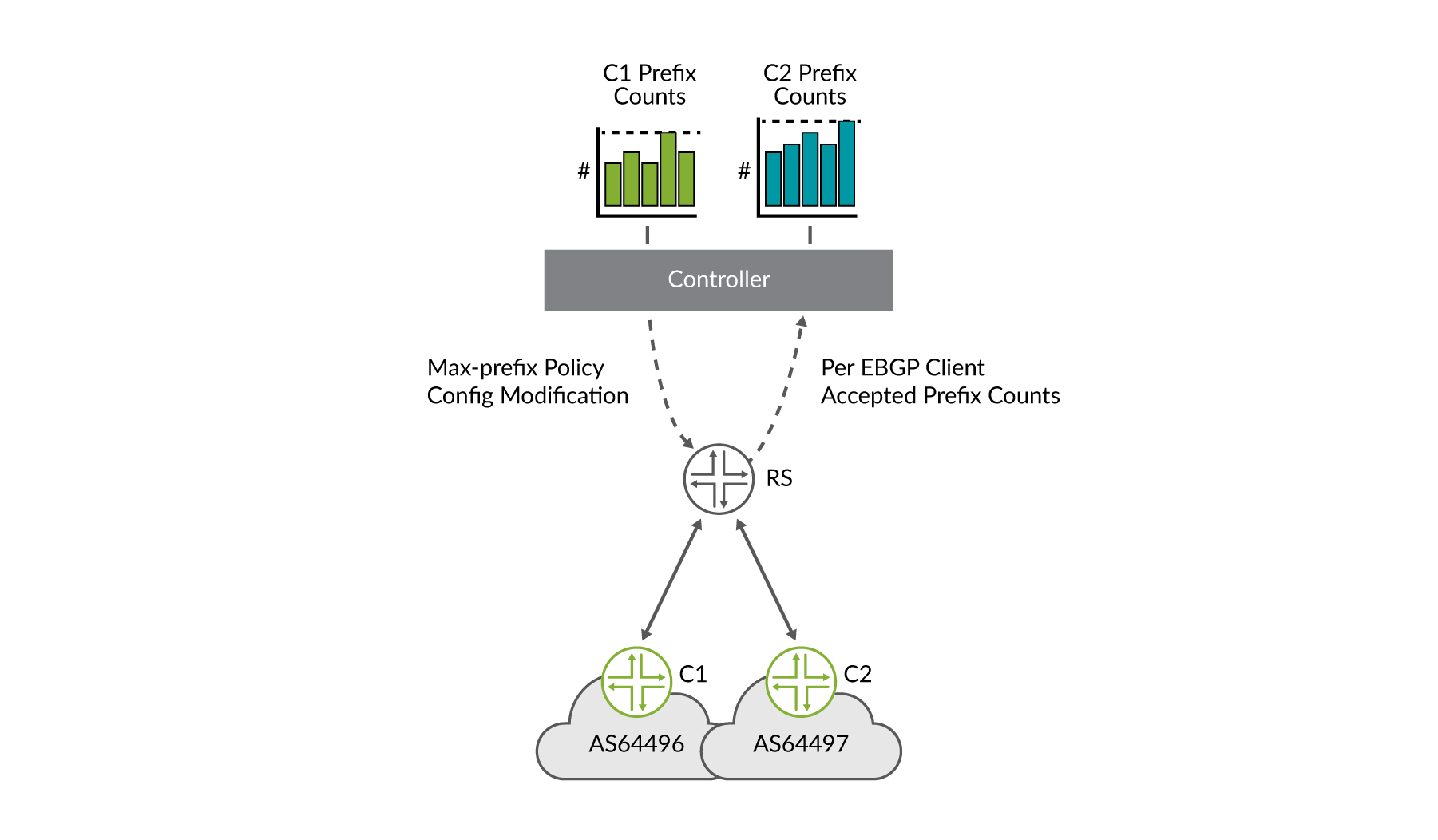
Una solución de prefijo máximo aceptado dinámica y automatizada
Como se analizó anteriormente en la sección consideraciones de seguridad del capítulo Internet Exchange Point Overview , determinar, supervisar y mantener prefijos máximos por servidor de ruta puede’ser algo difícil para una implementación de servidor de enrutamiento IXP s. Se presentaron varias soluciones, incluidos varios factores de multiplicación para determinar el valor. HealthBot ofrece otra solución que implica la recopilación de telemetría de transmisión por secuencias en tiempo real del servidor de enrutamiento, el mantenimiento de los recuentos aceptados por el cliente de servidores de ruta y la modificación dinámica de la Directiva de servidor de enrutamiento cuando vales cambia. Este flujo de trabajo para dos clientes del servidor de enrutamiento se Figure 7muestra en la.
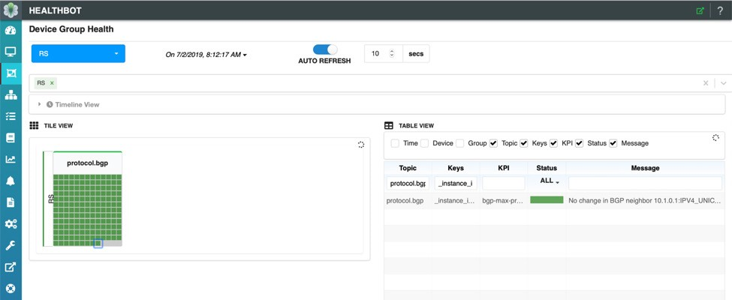
Echemos’un vistazo a un ejemplo real. En la salida de la CLI siguiente, puede ver el cliente de servidor de enrutamiento C1. El servidor de enrutamiento está recibiendo y aceptando 10 prefijos del cliente C1. También puede ver que el servidor de enrutamiento está configurado con una directiva para aceptar un máximo de 15 prefijos del cliente C1:
root@rs> show bgp summary | match “Peer |C1.inet.0” Peer AS InPkt OutPkt OutQ Flaps Last Up/DwState|#Active/ Received/Accepted/Damped... C1.inet.0: 10/10/10/0
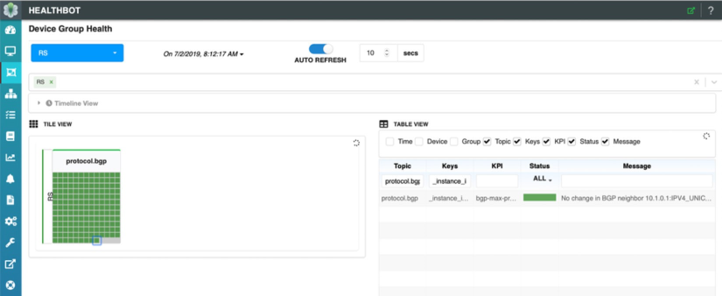
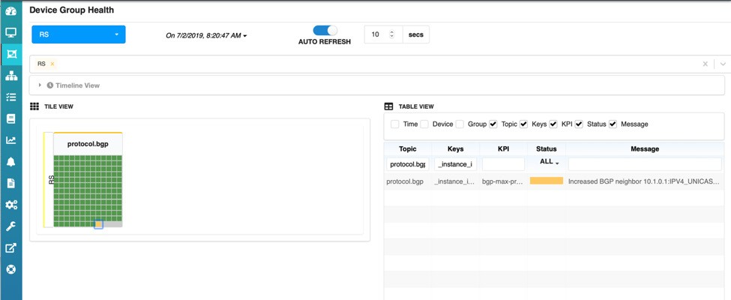
Observe también el panel HealthBot; el cliente C1 se selecciona Figure 8 a continuación y podemos ver que durante el último intervalo de estadísticas, no se han producido cambios en la Directiva de prefijo máximo determinada por HealthBot. Esto se indica con el ‘estado verde’ y el mensaje en la tabla de ese cliente. ¿Qué es un intervalo estadístico, puede que se le pregunte? En esta solución de HealthBot, aplicamos un intervalo muy simple y definido por el usuario en el que se recopilará el número de prefijos aceptados por cliente de servidor de ruta. Después de cada intervalo de estadísticas, HealthBot toma el valor actual de los prefijos aceptados, los multiplica por 1,5, el usuario puede configurar también y actualiza la Directiva de cliente de servidor de enrutamiento con el nuevo valor.
Ahora, dejar’que el cliente C1 anuncie algunas rutas más al servidor de enrutamiento y agregue dos rutas más estáticas a C1’s BGP Directiva de exportación:
Podemos ver que el servidor de enrutamiento recibe y acepta los prefijos adicionales en el resultado siguiente:
root@rs> show bgp summary | match “Peer |C1.inet.0” Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/ Received/Accepted/Damped... r1001.inet.0: 12/12/12/0
Pero ahora miremos el panel de HealthBot. El icono del cliente C1 se ha convertido en rojo. Esto se debe a que el número de prefijos aceptados supera el umbral del 90%, que también puede ser configurable por el usuario.
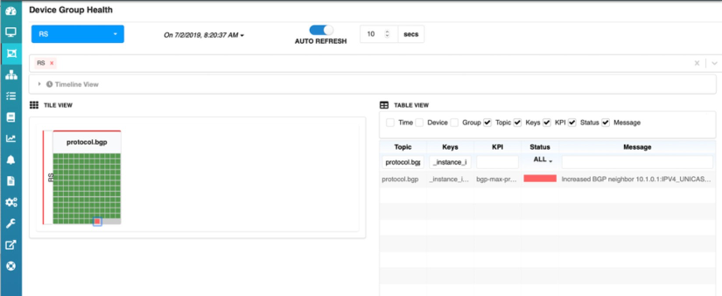
Al final del intervalo de recopilación de estadísticas, también se puede ver que el’icono de C1 s se ha convertido en amarillo, lo que significa que HealthBot está cambiando la Directiva de prefijo máximo del cliente C1 en el servidor de enrutamiento. Y el panel de HealthBot volverá a mostrar’el icono de C1 en verde ya que se encuentra dentro de la política y no supera los umbrales
Como puede ver, la configuración del servidor de ruta se ha actualizado con el nuevo valor (12 prefijo * 1,5) de 18:
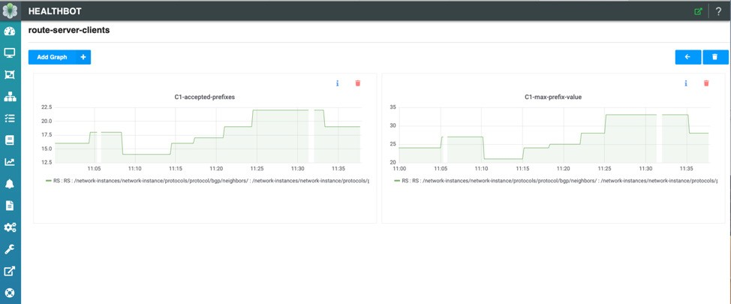
Por último, cada cliente’de enrutadores de enrutamiento acepta prefijos y el valor de prefijo máximo correspondiente puede ser supervisado individualmente. En Figure 12, puede ver el número de prefijos aceptados para el cliente C1 junto con el valor Max-prefix Policy configurado durante el intervalo de estadísticas.
Resumen
Los autores esperan que la información proporcionada en este libro le ayude a comenzar a diseñar, probar e implementar servidores de enrutamiento basados en Junos OS. Las consideraciones acerca de la configuración y el diseño que se tratan en este libro son simplemente para empezar. En extremo, cada IXP es único y tendrá sus propias consideraciones para la implementación de políticas.