Flujo de trabajo Kubernetes
Hasta ahora,’ha leído información acerca del maestro y el nodo, y los principales procesos que se ejecutan en cada uno de ellos. Ahora es’hora de ver cómo funcionan los elementos juntos, como se muestra en la Figure 1.
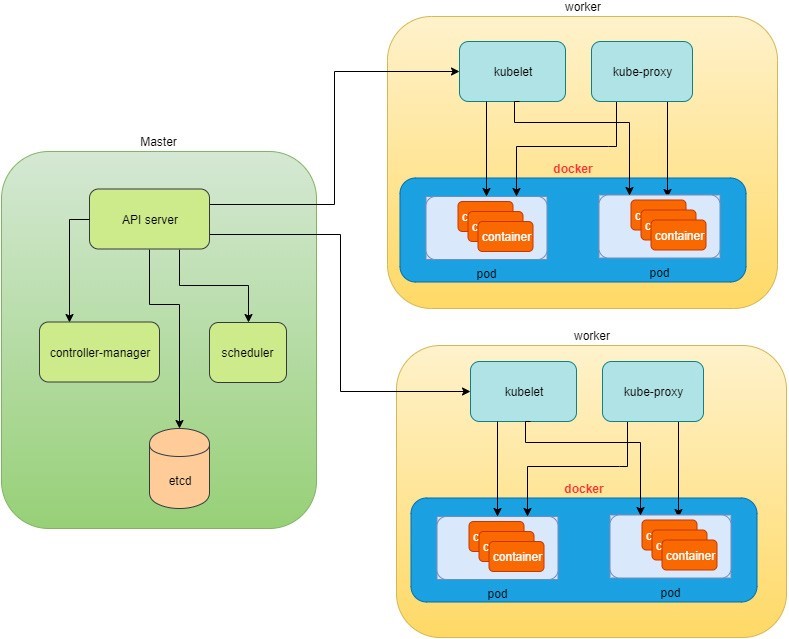
En la parte superior de la Figure 1, a través de kubectl comandos, se comunica con el maestro Kubernetes, que administra los dos cuadros de nodo a la derecha. Kubectl interactúa con el proceso principal Kube-apiserver a través de la API de REST que está expuesta al usuario y otros procesos del sistema.
Deje’que s envíe algunos comandos – kubectl algo parecido kubectl create x, para generar un nuevo contenedor. Puede proporcionar detalles sobre el contenedor que se va a generar junto con sus comportamientos de ejecución, y estas especificaciones pueden proporcionarse como kubectl parámetros de línea de comandos, u opciones y valores definidos en un archivo de configuración (en breve, aparece un ejemplo). El flujo de trabajo sería:
El cliente kubectlprimero traducirá su comando de CLI a una o más llamadas Rest API y lo enviará a Kube-apiserver.
Después de validar estas llamadas a API REST, Kube-apiserver entiende la tarea y llama al proceso Kube-programador para seleccionar un nodo de entre los disponibles para ejecutar el trabajo. Este es el procedimiento de programación.
Una vez que Kube-Scheduler devuelva el nodo de destino, Kube-apiserver lo enviará con todos los detalles que describen la tarea.
El proceso kubelet del nodo de destino recibe la tarea y se comunica con el motor de contenedor, por ejemplo, el motor de acoplamiento de la Figure 1, para generar un contenedor con todos los parámetros proporcionados.
Este trabajo y sus especificaciones se grabarán en una base de datos centralizada etcd. Su trabajo consiste en conservar y proporcionar acceso a todos los datos del clúster.
En realidad, un Master también puede ser un nodo de alta funcionalidad y transportar a los trabajadores de los pods igual que un nodo. Por lo tanto, los componentes proxy de kubelet y Kube existentes en node también pueden existir en el Master. En la Figure 1,’no incluimos estos componentes en el patrón para proporcionar una separación conceptual simplificada del maestro y del nodo. En su instalación puede utilizar el comando kubectl get pods --all-namespaces
-o wide para enumerar todos los pods con su ubicación. Los pods generados en el Master se ejecutan normalmente como parte del propio – sistema Kubernetes, normalmente dentro de un espacio de nombres del sistema Kube. El espacio de nombres Kubernetes se explica en el capítulo 3.
Evidentemente, esto es un flujo de trabajo simplificado, pero debe obtener la idea básica. De hecho, con la potencia de Kubernetes, rara vez es necesario trabajar directamente con contenedores. Trabaja con objetos de mayor nivel que tienden a ocultar la mayoría de los detalles de las operaciones de bajo nivel.
Por ejemplo, en la Figure 1 , cuando se da la tarea de generar contenedores, en vez de decir lo siguiente: cree dos contenedores y asegúrese de generar otros nuevos si falla alguno, en la práctica, debe decir: Cree un objeto RC (controlador de replicación) con la réplica dos.
Una vez que los dos contenedores de acoplamiento estén funcionando, kubeapiserver interactuará con Kube-Controller-Manager para seguir supervisando el estado del trabajo y tomar todas las medidas necesarias para asegurarse de que el estado de ejecución sea como se definió. Por ejemplo, si alguno de los contenedores del acoplador funciona, se generará automáticamente un nuevo contenedor y se quitará el dañado.
El RC de este ejemplo es uno de los objetos que proporciona el proceso de Kubernetes Kube-Controller-Manager. Los objetos Kubernetes proporcionan una capa de abstracción adicional que recibe el mismo trabajo (y normalmente más) bajo el capó, de una manera más sencilla y limpia. Y dado que trabaja en un nivel superior y se mantiene lejos de los detalles de bajo nivel, los objetos de Kubernetes reducen claramente su tiempo de implementación general, el esfuerzo de los cerebros y la solución de problemas. Let’-s examine.