Fehlerbehebung bei Sicherheitsgeräten
Fehlerbehebung bei der DNS-Namensauflösung in Sicherheitsrichtlinien für logische Systeme (nur für primäre Administratoren)
Problem
Beschreibung
Die Adresse eines Hostnamens in einem Adressbucheintrag, der in einer Sicherheitsrichtlinie verwendet wird, kann möglicherweise nicht ordnungsgemäß aufgelöst werden.
Verursachen
Normalerweise werden Adressbucheinträge, die dynamische Hostnamen enthalten, für Firewalls der SRX-Serie automatisch aktualisiert. Das TTL-Feld, das einem DNS-Eintrag zugeordnet ist, gibt die Zeit an, nach der der Eintrag im Richtliniencache aktualisiert werden soll. Sobald der TTL-Wert abläuft, aktualisiert die Firewall der SRX-Serie automatisch den DNS-Eintrag für einen Adressbucheintrag.
Wenn die Firewall der SRX-Serie jedoch keine Antwort vom DNS-Server erhalten kann (z. B. weil die DNS-Anforderung oder das DNS-Antwortpaket im Netzwerk verloren geht oder der DNS-Server keine Antwort senden kann), kann die Adresse eines Hostnamens in einem Adressbucheintrag möglicherweise nicht korrekt aufgelöst werden. Dies kann dazu führen, dass der Datenverkehr zurückgeht, da keine Übereinstimmung mit der Sicherheitsrichtlinie oder -sitzung gefunden wird.
Lösung
Der primäre Administrator kann den show security dns-cache Befehl verwenden, um DNS-Cache-Informationen auf der Firewall der SRX-Serie anzuzeigen. Wenn die DNS-Cache-Informationen aktualisiert werden müssen, kann der primäre Administrator den clear security dns-cache Befehl verwenden.
Diese Befehle stehen nur dem primären Administrator auf Geräten zur Verfügung, die für logische Systeme konfiguriert sind. Dieser Befehl ist in logischen Benutzersystemen oder auf Geräten, die nicht für logische Systeme konfiguriert sind, nicht verfügbar.
Siehe auch
Fehlerbehebung bei der Link Services-Schnittstelle
So lösen Sie Konfigurationsprobleme auf einer Link Services-Schnittstelle:
- Bestimmen Sie, welche CoS-Komponenten auf die konstituierenden Links angewendet werden
- Ermitteln der Ursachen von Jitter und Latenz beim Multilink-Bundle
- Bestimmen Sie, ob LFI und Load Balancing ordnungsgemäß funktionieren
- Ermitteln, warum Pakete auf einem PVC zwischen einem Gerät von Juniper Networks und einem Gerät eines Drittanbieters verworfen werden
Bestimmen Sie, welche CoS-Komponenten auf die konstituierenden Links angewendet werden
Problem
Beschreibung
Sie konfigurieren ein Multilink-Bundle, haben aber auch Datenverkehr ohne MLPPP-Kapselung, der über die einzelnen Links des Multilink-Bundles geleitet wird. Wenden Sie alle CoS-Komponenten auf die konstituierenden Links an, oder reicht es aus, sie auf das Multilink-Bündel anzuwenden?
Lösung
Sie können eine Scheduler-Zuordnung auf das Multilink-Bundle und seine zugehörigen Links anwenden. Sie können zwar mehrere CoS-Komponenten mit der Scheduler-Zuordnung anwenden, konfigurieren Sie jedoch nur die erforderlichen. Es wird empfohlen, die Konfiguration der einzelnen Links einfach zu halten, um unnötige Verzögerungen bei der Übertragung zu vermeiden.
Tabelle 1 zeigt die CoS-Komponenten, die auf ein Multilink-Bündel angewendet werden sollen, und die darin enthaltenen Links.
Cos-Komponente |
Multilink-Bundle |
Konstituierende Links |
Erklärung |
|---|---|---|---|
Klassifikator |
Ja |
Nein |
Die CoS-Klassifizierung erfolgt auf der eingehenden Seite der Schnittstelle, nicht auf der sendenden Seite, sodass keine Klassifikatoren für die konstituierenden Links erforderlich sind. |
Weiterleitungsklasse |
Ja |
Nein |
Die Weiterleitungsklasse ist einer Warteschlange zugeordnet, und die Warteschlange wird durch eine Scheduler-Zuordnung auf die Schnittstelle angewendet. Die Warteschlangenzuweisung ist für die konstituierenden Links vorgegeben. Alle Pakete aus Q2 des Multilink-Bundles werden Q2 der konstituierenden Verbindung zugewiesen, und Pakete aus allen anderen Warteschlangen werden Q0 der konstituierenden Verbindung in die Warteschlange eingereiht. |
Scheduler-Karte |
Ja |
Ja |
Wenden Sie Scheduler-Maps wie folgt auf das Multilink-Bundle und den zugehörigen Link an:
|
Shaping-Rate für einen Scheduler pro Einheit oder einen Scheduler auf Schnittstellenebene |
Nein |
Ja |
Da die Planung pro Einheit nur am Endpunkt angewendet wird, wenden Sie diese Shaping-Rate nur auf die konstituierenden Links an. Jede zuvor angewendete Konfiguration wird durch die konstituierende Linkkonfiguration überschrieben. |
Exaktes Shaping mit Übertragungsrate oder auf Warteschlangenebene |
Ja |
Nein |
Die Formgebung auf Schnittstellenebene, die auf die konstituierenden Verknüpfungen angewendet wird, überschreibt jede Formgebung in der Warteschlange. Wenden Sie daher die exakte Formgebung der Übertragungsrate nur auf das Multilink-Bündel an. |
Rewrite-Regeln |
Ja |
Nein |
Rewrite-Bits werden während der Fragmentierung automatisch aus dem Paket in die Fragmente kopiert. Daher wird das, was Sie auf dem Multilink-Bundle konfigurieren, über die Fragmente zu den konstituierenden Links übertragen. |
Virtuelle Channelgruppe |
Ja |
Nein |
Virtuelle Kanalgruppen werden durch Firewall-Filterregeln identifiziert, die nur auf Pakete vor dem Multilink-Bundle angewendet werden. Daher müssen Sie die Konfiguration der virtuellen Kanalgruppe nicht auf die zugehörigen Links anwenden. |
Siehe auch
Ermitteln der Ursachen von Jitter und Latenz beim Multilink-Bundle
Problem
Beschreibung
Um Jitter und Latenz zu testen, senden Sie drei Streams von IP-Paketen. Alle Pakete haben die gleichen Einstellungen für die IP-Rangfolge. Nach der Konfiguration von LFI und CRTP erhöhte sich die Latenz sogar über eine nicht überlastete Verbindung. Wie können Sie Jitter und Latenz reduzieren?
Lösung
Gehen Sie wie folgt vor, um Jitter und Latenz zu reduzieren:
Stellen Sie sicher, dass Sie für jede konstituierende Verknüpfung eine Shaping-Rate konfiguriert haben.
Stellen Sie sicher, dass Sie auf der Link-Services-Schnittstelle keine Shaping-Rate konfiguriert haben.
Stellen Sie sicher, dass der konfigurierte Wert für die Shaping-Rate mit der Bandbreite der physischen Schnittstelle übereinstimmt.
Wenn die Shaping-Raten korrekt konfiguriert sind und der Jitter weiterhin besteht, wenden Sie sich an das Juniper Networks Technical Assistance Center (JTAC).
Bestimmen Sie, ob LFI und Load Balancing ordnungsgemäß funktionieren
Problem
Beschreibung
In diesem Fall verfügen Sie über ein einziges Netzwerk, das mehrere Dienste unterstützt. Das Netzwerk überträgt daten- und verzögerungsempfindlichen Sprachverkehr. Stellen Sie nach der Konfiguration von MLPPP und LFI sicher, dass Sprachpakete mit sehr geringer Verzögerung und geringem Jitter über das Netzwerk übertragen werden. Wie können Sie herausfinden, ob Sprachpakete als LFI-Pakete behandelt werden und der Lastenausgleich korrekt durchgeführt wird?
Lösung
Wenn LFI aktiviert ist, werden Datenpakete (Nicht-LFI-Pakete) mit einem MLPPP-Header gekapselt und in Pakete einer bestimmten Größe fragmentiert. Die verzögerungssensitiven Sprachpakete (LFI) sind PPP-gekapselt und zwischen Datenpaketfragmenten verschachtelt. Warteschlangen und Lastenausgleich werden für LFI- und Nicht-LFI-Pakete unterschiedlich ausgeführt.
Um zu überprüfen, ob LFI korrekt ausgeführt wird, stellen Sie fest, dass die Pakete fragmentiert und wie konfiguriert gekapselt sind. Nachdem Sie wissen, ob ein Paket als LFI-Paket oder als Nicht-LFI-Paket behandelt wird, können Sie überprüfen, ob der Lastenausgleich ordnungsgemäß durchgeführt wird.
Solution Scenario– Angenommen, zwei Juniper Networks-Geräte, R0 und R1, sind durch ein Multilink-Bündel lsq-0/0/0.0 verbunden, das zwei serielle Verbindungen aggregiert, se-1/0/0 und se-1/0/1. Auf R0 und R1 sind MLPPP und LFI auf der Link Services-Schnittstelle aktiviert, und der Fragmentierungsschwellenwert ist auf 128 Byte festgelegt.
In diesem Beispiel haben wir einen Paketgenerator verwendet, um Sprach- und Datenströme zu generieren. Sie können die Paketerfassungsfunktion verwenden, um die Pakete auf der eingehenden Schnittstelle zu erfassen und zu analysieren.
Die folgenden zwei Datenströme wurden über das Multilink-Bundle gesendet:
100 Datenpakete à 200 Byte (größer als die Fragmentierungsschwelle)
500 Datenpakete à 60 Byte (kleiner als die Fragmentierungsschwelle)
Die folgenden zwei Sprachstreams wurden über das Multilink-Bundle gesendet:
100 Sprachpakete à 200 Byte von Quellport 100
300 Sprachpakete à 200 Byte von Quellport 200
So überprüfen Sie, ob LFI und Load Balancing korrekt durchgeführt werden:
In diesem Beispiel werden nur die wesentlichen Teile der Befehlsausgabe angezeigt und beschrieben.
Überprüfen Sie die Paketfragmentierung. Geben Sie im Betriebsmodus den
show interfaces lsq-0/0/0Befehl ein, um zu überprüfen, ob große Pakete korrekt fragmentiert sind.user@R0#> show interfaces lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Link-level type: LinkService, MTU: 1504 Device flags : Present Running Interface flags: Point-To-Point SNMP-Traps Last flapped : 2006-08-01 10:45:13 PDT (2w0d 06:06 ago) Input rate : 0 bps (0 pps) Output rate : 0 bps (0 pps) Logical interface lsq-0/0/0.0 (Index 69) (SNMP ifIndex 42) Flags: Point-To-Point SNMP-Traps 0x4000 Encapsulation: Multilink-PPP Bandwidth: 16mbps Statistics Frames fps Bytes bps Bundle: Fragments: Input : 0 0 0 0 Output: 1100 0 118800 0 Packets: Input : 0 0 0 0 Output: 1000 0 112000 0 ... Protocol inet, MTU: 1500 Flags: None Addresses, Flags: Is-Preferred Is-Primary Destination: 9.9.9/24, Local: 9.9.9.10Meaning—Die Ausgabe zeigt eine Zusammenfassung der Pakete, die das Gerät im Multilink-Bundle durchlaufen. Überprüfen Sie die folgenden Informationen auf dem Multilink-Bundle:Die Gesamtzahl der Transitpakete = 1000
Die Gesamtzahl der transitierenden Fragmente = 1100
Die Anzahl der Datenpakete, die fragmentiert wurden =100
Die Gesamtzahl der im Multilink-Bundle gesendeten Pakete (600 + 400) stimmt mit der Anzahl der Transitpakete (1000) überein, was darauf hinweist, dass keine Pakete verworfen wurden.
Die Anzahl der transitierenden Fragmente übersteigt die Anzahl der transitierenden Pakete um 100, was darauf hinweist, dass 100 große Datenpakete korrekt fragmentiert wurden.
Corrective Action—Wenn die Pakete nicht korrekt fragmentiert sind, überprüfen Sie die Konfiguration des Fragmentierungsschwellenwerts. Pakete, die kleiner als der angegebene Fragmentierungsschwellenwert sind, werden nicht fragmentiert.Überprüfen Sie die Paketkapselung. Um herauszufinden, ob ein Paket als LFI- oder Nicht-LFI-Paket behandelt wird, bestimmen Sie seinen Kapselungstyp. LFI-Pakete sind PPP-gekapselt, Nicht-LFI-Pakete werden sowohl mit PPP als auch mit MLPPP gekapselt. PPP- und MLPPP-Kapselungen haben unterschiedliche Overheads, was zu unterschiedlich großen Paketen führt. Sie können Paketgrößen vergleichen, um den Verkapselungstyp zu bestimmen.
Ein kleines, unfragmentiertes Datenpaket enthält einen PPP-Header und einen einzelnen MLPPP-Header. In einem großen fragmentierten Datenpaket enthält das erste Fragment einen PPP-Header und einen MLPPP-Header, die nachfolgenden Fragmente jedoch nur einen MLPPP-Header.
PPP- und MLPPP-Kapselungen fügen einem Paket die folgende Anzahl von Bytes hinzu:
Die PPP-Kapselung fügt 7 Bytes hinzu:
4 Byte Header + 2 Byte Frame-Check-Sequenz (FCS) + 1 Byte, das sich im Leerlauf befindet oder ein Flag enthält
Die MLPPP-Kapselung fügt zwischen 6 und 8 Byte hinzu:
4 Byte PPP-Header + 2 bis 4 Byte Multilink-Header
Abbildung 1 zeigt den Overhead an, der den PPP- und MLPPP-Headern hinzugefügt wurde.
Abbildung 1: PPP- und MLPPP-Header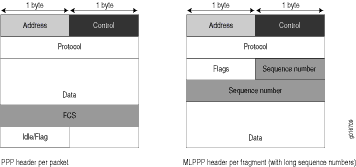
Bei CRTP-Paketen sind der Kapselungsaufwand und die Paketgröße sogar kleiner als bei einem LFI-Paket. Weitere Informationen finden Sie unter Beispiel: Konfigurieren des komprimierten Echtzeit-Transportprotokolls.
Tabelle 2 Zeigt den Kapselungsaufwand für ein Datenpaket und ein Sprachpaket von jeweils 70 Byte. Nach der Kapselung ist die Größe des Datenpakets größer als die Größe des Sprachpakets.
Tabelle 2: PPP- und MLPPP-Kapselungs-Overhead Pakettyp
Verkapselung
Anfängliche Paketgröße
Kapselungs-Overhead
Paketgröße nach der Kapselung
Sprachpaket (LFI)
KAUFKRAFTPARITÄT
70 Bytes
4 + 2 + 1 = 7 Bytes
77 Bytes
Datenfragment (non-LFI) mit kurzer Sequenz
MLPPP
70 Bytes
4 + 2 + 1 + 4 + 2 = 13 Byte
83 Bytes
Datenfragment (Nicht-LFI) mit langer Sequenz
MLPPP
70 Bytes
4 + 2 + 1 + 4 + 4 = 15 Bytes
85 Bytes
Geben Sie im Betriebsmodus den
show interfaces queueBefehl ein, um die Größe des übertragenen Pakets in jeder Warteschlange anzuzeigen. Teilen Sie die Anzahl der übertragenen Bytes durch die Anzahl der Pakete, um die Größe der Pakete zu erhalten und den Kapselungstyp zu bestimmen.Überprüfen Sie den Lastenausgleich. Geben Sie im Betriebsmodus den
show interfaces queueBefehl für das Multilink-Bundle und seine zugehörigen Links ein, um zu bestätigen, ob der Lastenausgleich für die Pakete entsprechend durchgeführt wird.user@R0> show interfaces queue lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 600 0 pps Bytes : 44800 0 bps Transmitted: Packets : 600 0 pps Bytes : 44800 0 bps Tail-dropped packets : 0 0 pps RED-dropped packets : 0 0 pps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 400 0 pps Bytes : 61344 0 bps Transmitted: Packets : 400 0 pps Bytes : 61344 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 0 0 pps Bytes : 0 0 bps …user@R0> show interfaces queue se-1/0/0 Physical interface: se-1/0/0, Enabled, Physical link is Up Interface index: 141, SNMP ifIndex: 35 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps ... Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 100 0 pps Bytes : 15272 0 bps Transmitted: Packets : 100 0 pps Bytes : 15272 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 19 0 pps Bytes : 247 0 bps Transmitted: Packets : 19 0 pps Bytes : 247 0 bps …user@R0> show interfaces queue se-1/0/1 Physical interface: se-1/0/1, Enabled, Physical link is Up Interface index: 142, SNMP ifIndex: 38 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 300 0 pps Bytes : 45672 0 bps Transmitted: Packets : 300 0 pps Bytes : 45672 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 18 0 pps Bytes : 234 0 bps Transmitted: Packets : 18 0 pps Bytes : 234 0 bpsMeaning—Die Ausgabe dieser Befehle zeigt die Pakete, die in jeder Warteschlange der Link-Services-Schnittstelle und der zugehörigen Links übertragen und in die Warteschlange eingereiht wurden. Tabelle 3 Zeigt eine Zusammenfassung dieser Werte an. (Da die Anzahl der übertragenen Pakete der Anzahl der Pakete in der Warteschlange auf allen Verbindungen entsprach, werden in dieser Tabelle nur die Pakete in der Warteschlange angezeigt.)Tabelle 3: Anzahl der Pakete, die in einer Warteschlange übertragen wurden Pakete in der Warteschlange
Paket lsq-0/0/0.0
Konstituierender Link se-1/0/0
Konstituierender Link se-1/0/1
Erklärung
Pakete auf Q0
600
350
350
Die Gesamtzahl der Pakete, die die konstituierenden Verbindungen durchliefen (350+350 = 700), überstieg die Anzahl der Pakete (600) in der Warteschlange des Multilink-Pakets.
Pakete im 2. Quartal
400
100
300
Die Gesamtzahl der Pakete, die die konstituierenden Links durchliefen, entsprach der Anzahl der Pakete auf dem Paket.
Pakete im 3. Quartal
0
19
18
Die Pakete, die Q3 der konstituierenden Links durchqueren, sind für Keepalive-Nachrichten, die zwischen konstituierenden Verbindungen ausgetauscht werden. Somit wurden in Q3 des Bundles keine Pakete gezählt.
Überprüfen Sie im Multilink-Bundle Folgendes:
Die Anzahl der Pakete, die sich in der Warteschlange befinden, stimmt mit der Anzahl der übertragenen Pakete überein. Wenn die Nummern übereinstimmen, wurden keine Pakete verworfen. Wenn mehr Pakete in die Warteschlange eingereiht als übertragen wurden, wurden Pakete verworfen, weil der Puffer zu klein war. Die Puffergröße auf den konstituierenden Links steuert die Überlastung in der Ausgangsstufe. Um dieses Problem zu beheben, erhöhen Sie die Puffergröße für die konstituierenden Links.
Die Anzahl der Pakete, die Q0 (600) durchqueren, stimmt mit der Anzahl der großen und kleinen Datenpakete überein, die auf dem Multilink-Bundle empfangen wurden (100+500). Stimmen die Nummern überein, haben alle Datenpakete Q0 korrekt durchquert.
Die Anzahl der Pakete, die Q2 auf dem Multilink-Bundle (400) durchqueren, stimmt mit der Anzahl der Sprachpakete überein, die auf dem Multilink-Bundle empfangen wurden. Wenn die Nummern übereinstimmen, haben alle Sprach-LFI-Pakete Q2 korrekt übertragen.
Überprüfen Sie bei den konstituierenden Links Folgendes:
Die Gesamtzahl der Pakete, die Q0 durchqueren (350+350), stimmt mit der Anzahl der Datenpakete und Datenfragmente (500+200) überein. Wenn die Zahlen übereinstimmen, haben alle Datenpakete nach der Fragmentierung Q0 der konstituierenden Links korrekt durchlaufen.
Pakete durchliefen beide konstituierenden Links, was darauf hindeutet, dass der Lastenausgleich bei Nicht-LFI-Paketen korrekt durchgeführt wurde.
Die Gesamtzahl der Pakete, die Q2 (300+100) auf konstituierenden Verbindungen durchlaufen, stimmt mit der Anzahl der empfangenen Sprachpakete (400) auf dem Multilink-Bundle überein. Wenn die Nummern übereinstimmen, haben alle Sprach-LFI-Pakete Q2 korrekt übertragen.
LFI-Pakete vom Quellport
100übertragense-1/0/0und LFI-Pakete vom Quellport200übertragen.se-1/0/1Daher wurden alle LFI (Q2)-Pakete basierend auf dem Quellport gehasht und führten beide konstituierenden Links korrekt durch.
Corrective Action—Wenn die Pakete nur eine Verbindung übertragen haben, führen Sie die folgenden Schritte aus, um das Problem zu beheben:Bestimmen Sie, ob die physische Verbindung (betriebsbereit) oder
down(nicht verfügbar) istup. Eine nicht verfügbare Verbindung weist auf ein Problem mit dem PIM, dem Schnittstellenport oder der physischen Verbindung hin (Fehler auf der Verbindungsebene). Wenn die Verbindung betriebsbereit ist, fahren Sie mit dem nächsten Schritt fort.Stellen Sie sicher, dass die Klassifizierer für Nicht-LFI-Pakete korrekt definiert sind. Stellen Sie sicher, dass Nicht-LFI-Pakete nicht so konfiguriert sind, dass sie in Q2 in die Warteschlange gestellt werden. Alle Pakete, die sich in Q2 in der Warteschlange befinden, werden als LFI-Pakete behandelt.
Stellen Sie sicher, dass mindestens einer der folgenden Werte in den LFI-Paketen unterschiedlich ist: Quelladresse, Zieladresse, IP-Protokoll, Quellport oder Zielport. Wenn für alle LFI-Pakete die gleichen Werte konfiguriert sind, werden die Pakete alle mit demselben Datenstrom gehasht und durchlaufen dieselbe Verbindung.
Verwenden Sie die Ergebnisse, um den Lastenausgleich zu überprüfen.
Ermitteln, warum Pakete auf einem PVC zwischen einem Gerät von Juniper Networks und einem Gerät eines Drittanbieters verworfen werden
Problem
Beschreibung
Sie konfigurieren eine permanente virtuelle Verbindung (PVC) zwischen T1-, E1-, T3- oder E3-Schnittstellen auf einem Gerät von Juniper Networks und einem Gerät eines Drittanbieters, und Pakete werden verworfen und der Ping schlägt fehl.
Lösung
Wenn das Gerät eines Drittanbieters nicht über die gleiche FRF.12-Unterstützung wie das Gerät von Juniper Networks verfügt oder FRF.12 auf andere Weise unterstützt, verwirft die Geräteschnittstelle von Juniper Networks auf dem PVC möglicherweise ein fragmentiertes Paket, das FRF.12-Header enthält, und zählt es als "polizeilich verworfen".
Um dieses Problem zu umgehen, konfigurieren Sie Multilink-Bundles auf beiden Peers und Fragmentierungsschwellenwerte für die Multilink-Bundles.
Fehlerbehebung bei Sicherheitsrichtlinien
- Synchronisieren von Richtlinien zwischen Routing-Engine und Packet Forwarding Engine
- Überprüfen eines Commit-Fehlers für eine Sicherheitsrichtlinie
- Überprüfen eines Sicherheitsrichtlinien-Commits
- Debuggen-Richtliniensuche
Synchronisieren von Richtlinien zwischen Routing-Engine und Packet Forwarding Engine
Problem
Beschreibung
Sicherheitsrichtlinien werden in der Routing-Engine und der Paketweiterleitungs-Engine gespeichert. Sicherheitsrichtlinien werden von der Routing-Engine an die Paketweiterleitungs-Engine übertragen, wenn Sie Konfigurationen bestätigen. Wenn die Sicherheitsrichtlinien der Routing-Engine nicht mit der Paketweiterleitungs-Engine synchronisiert sind, schlägt der Commit einer Konfiguration fehl. Core-Dump-Dateien können generiert werden, wenn der Commit wiederholt versucht wird. Die Störung der Synchronisierung kann folgende Ursachen haben:
Eine Richtliniennachricht von der Routing-Engine an die Paketweiterleitungs-Engine geht während der Übertragung verloren.
Ein Fehler mit der Routing-Engine, z. B. eine wiederverwendete Richtlinien-UID.
Infrastruktur
Die Richtlinien in der Routing-Engine und der Paketweiterleitungs-Engine müssen synchron sein, damit die Konfiguration festgeschrieben werden kann. Unter bestimmten Umständen können die Richtlinien in der Routing-Engine und der Paketweiterleitungs-Engine jedoch nicht synchron sein, was dazu führt, dass der Commit fehlschlägt.
Symptome
Wenn die Richtlinienkonfigurationen geändert werden und die Richtlinien nicht synchron sind, wird die folgende Fehlermeldung angezeigt: error: Warning: policy might be out of sync between RE and PFE <SPU-name(s)> Please request security policies check/resync.
Lösung
Verwenden Sie den show security policies checksum Befehl, um den Prüfsummenwert der Sicherheitsrichtlinie anzuzeigen, und verwenden Sie den request security policies resync Befehl, um die Konfiguration der Sicherheitsrichtlinien in der Routing-Engine und der Paketweiterleitungs-Engine zu synchronisieren, wenn die Sicherheitsrichtlinien nicht synchron sind.
Überprüfen eines Commit-Fehlers für eine Sicherheitsrichtlinie
Problem
Beschreibung
Die meisten Richtlinienkonfigurationsfehler treten während eines Commits oder zur Laufzeit auf.
Commit-Fehler werden direkt in der CLI gemeldet, wenn Sie den CLI-Befehl commit-check im Konfigurationsmodus ausführen. Bei diesen Fehlern handelt es sich um Konfigurationsfehler, und Sie können die Konfiguration nicht bestätigen, ohne diese Fehler zu beheben.
Lösung
Gehen Sie wie folgt vor, um diese Fehler zu beheben:
Überprüfen Sie Ihre Konfigurationsdaten.
Öffnen Sie die Datei /var/log/nsd_chk_only. Diese Datei wird jedes Mal überschrieben, wenn Sie eine Commit-Prüfung durchführen, und enthält detaillierte Fehlerinformationen.
Überprüfen eines Sicherheitsrichtlinien-Commits
Problem
Beschreibung
Wenn Sie nach dem Ausführen eines Commits für die Richtlinienkonfiguration feststellen, dass das Systemverhalten nicht korrekt ist, führen Sie die folgenden Schritte aus, um dieses Problem zu beheben:
Lösung
Betriebsbefehle show : Führen Sie die Betriebsbefehle für Sicherheitsrichtlinien aus und überprüfen Sie, ob die in der Ausgabe angezeigten Informationen mit Ihren Erwartungen übereinstimmen. Ist dies nicht der Fall, muss die Konfiguration entsprechend geändert werden.
Traceoptions: Legen Sie den
traceoptionsBefehl in Ihrer Richtlinienkonfiguration fest. Die Flags unter dieser Hierarchie können gemäß der Benutzeranalyse dershowBefehlsausgabe ausgewählt werden. Wenn Sie nicht bestimmen können, welches Flag verwendet werden soll, kann die Optionallflag verwendet werden, um alle Ablaufverfolgungsprotokolle zu erfassen.user@host#
set security policies traceoptions <flag all>
Sie können auch einen optionalen Dateinamen konfigurieren, um die Protokolle zu erfassen.
user@host# set security policies traceoptions <filename>
Wenn Sie in den Trace-Optionen einen Dateinamen angegeben haben, können Sie in /var/log/<filename> nach der Protokolldatei suchen, um festzustellen, ob Fehler in der Datei gemeldet wurden. (Wenn Sie keinen Dateinamen angegeben haben, lautet der Standarddateiname eventd.) Die Fehlermeldungen geben den Ort des Fehlers und die entsprechende Ursache an.
Nachdem Sie die Ablaufverfolgungsoptionen konfiguriert haben, müssen Sie die Konfigurationsänderung, die das falsche Systemverhalten verursacht hat, erneut bestätigen.
Debuggen-Richtliniensuche
Problem
Beschreibung
Wenn Sie über die richtige Konfiguration verfügen, aber ein Teil des Datenverkehrs fälschlicherweise verworfen oder zugelassen wurde, können Sie das Flag lookup in den Trace-Optionen für Sicherheitsrichtlinien aktivieren. Das lookup Flag protokolliert die ablaufverfolgungsbezogenen Ablaufverfolgungen in der Ablaufverfolgungsdatei.
Lösung
user@host# set security policies traceoptions <flag lookup>