Überwachen der Netzwerkdienstqualität mithilfe von RMON
RMON zur Überwachung der Servicequalität
Die Zustands- und Leistungsüberwachung kann von der Fernüberwachung von SNMP-Variablen durch die lokalen SNMP-Agenten profitieren, die auf jedem Router ausgeführt werden. Die SNMP-Agenten vergleichen MIB-Werte mit vordefinierten Schwellenwerten und erzeugen Ausnahmealarme, ohne dass eine Abfrage durch eine zentrale SNMP-Managementplattform erforderlich ist. Dies ist ein wirksamer Mechanismus für ein proaktives Management, solange für die Schwellenwerte Ausgangswerte festgelegt und korrekt festgelegt wurden. Weitere Informationen finden Sie unter RFC 2819, Remote Network Monitoring MIB.
Dieses Thema umfasst die folgenden Abschnitte:
- Festlegen von Schwellenwerten
- RMON-Befehlszeilenschnittstelle
- RMON-Ereignistabelle
- RMON-Alarmtabelle
- RMON-Fehlerbehebung
Festlegen von Schwellenwerten
Durch das Festlegen eines steigenden und eines fallenden Schwellenwerts für eine überwachte Variable können Sie benachrichtigt werden, wenn der Wert der Variablen außerhalb des zulässigen Betriebsbereichs liegt. (Siehe Abbildung 1.)

Ereignisse werden nur generiert, wenn der Schwellenwert zum ersten Mal in eine Richtung überschritten wird, und nicht erst nach jedem Abtastzeitraum. Wenn z. B. ein Ereignis mit steigendem Schwellenwert ausgelöst wird, treten bis zu einem entsprechenden fallenden Ereignis keine Schwellenwertüberschreitungsereignisse mehr auf. Dadurch wird die Anzahl der vom System erzeugten Alarme erheblich reduziert und das Einsatzpersonal kann leichter reagieren, wenn Alarme auftreten.
Um die Remoteüberwachung zu konfigurieren, geben Sie die folgenden Informationen an:
Die zu überwachende Variable (anhand ihrer SNMP-Objektkennung)
Die Zeitspanne zwischen den einzelnen Inspektionen
Eine steigende Schwelle
Eine fallende Schwelle
Ein aufstrebendes Ereignis
Ein fallendes Ereignis
Bevor Sie die Remoteüberwachung erfolgreich konfigurieren können, sollten Sie ermitteln, welche Variablen überwacht werden müssen und welchen Betriebsbereich zulässig ist. Dies erfordert eine gewisse Baselining-Zeit, um die zulässigen Betriebsbereiche zu bestimmen. Ein anfänglicher Baseline-Zeitraum von mindestens drei Monaten ist nicht ungewöhnlich, wenn die operativen Bereiche identifiziert und Schwellenwerte definiert werden, aber die Baseline-Überwachung sollte über die Lebensdauer jeder überwachten Variablen fortgesetzt werden.
RMON-Befehlszeilenschnittstelle
Junos OS bietet zwei Mechanismen, mit denen Sie den Remote Monitoring-Agent auf dem Router steuern können: Befehlszeilenschnittstelle (CLI) und SNMP. Um einen RMON-Eintrag mithilfe der CLI zu konfigurieren, fügen Sie die folgenden Anweisungen auf Hierarchieebene [edit snmp] ein:
rmon {
alarm index {
description;
falling-event-index;
falling-threshold;
intervals;
rising-event-index;
rising-threshold;
sample-type (absolute-value | delta-value);
startup-alarm (falling | rising | rising-or-falling);
variable;
}
event index {
community;
description;
type (log | trap | log-and-trap | none);
}
}
Wenn Sie keinen CLI-Zugriff haben, können Sie die Fernüberwachung mit dem SNMP-Manager oder der Verwaltungsanwendung konfigurieren, vorausgesetzt, der SNMP-Zugriff wurde gewährt. (Siehe Tabelle 1.) Um RMON mit SNMP zu konfigurieren, führen Sie SNMP-Anforderungen Set an die RMON-Ereignis- und Alarmtabellen aus.
RMON-Ereignistabelle
Richten Sie für jeden Typ, den Sie generieren möchten, ein Ereignis ein. Sie können z. B. zwei generische Ereignisse haben, steigend und fallend, oder viele verschiedene Ereignisse für jede Variable, die überwacht wird (z. B. Temperaturanstiegsereignis , Temperaturabfallereignis , Firewall-Trefferereignis , Schnittstellenauslastungsereignis usw.). Sobald die Ereignisse konfiguriert wurden, müssen Sie sie nicht mehr aktualisieren.
Feld |
Beschreibung |
|---|---|
|
Textbeschreibung dieser Veranstaltung |
|
Art des Ereignisses (z. B. |
|
Trap-Gruppe, an die dieses Ereignis gesendet werden soll (wie in der Junos OS-Konfiguration definiert, die nicht mit der Community identisch ist) |
|
Entität (z. B. |
|
Status dieser Zeile (z.B. |
RMON-Alarmtabelle
In der RMON-Alarmtabelle werden die SNMP-Objektbezeichner (einschließlich ihrer Instanzen) der überwachten Variablen zusammen mit allen steigenden und fallenden Schwellenwerten und den entsprechenden Ereignisindizes gespeichert. Um eine RMON-Anforderung zu erstellen, geben Sie die Felder an, die in angezeigt werden Tabelle 2.
Feld |
Beschreibung |
|---|---|
|
Status dieser Zeile (z.B. |
|
Abtastdauer (in Sekunden) der überwachten Größe |
|
OID (und Instanz) der zu überwachenden Variablen |
|
Tatsächlicher Wert der Stichprobenvariablen |
|
Stichprobentyp ( |
|
Initialer Alarm ( |
|
Steigender Schwellenwert, mit dem der Wert verglichen werden soll |
|
Fallender Schwellenwert, mit dem der Wert verglichen werden soll |
|
Index (Zeile) des steigenden Ereignisses in der Ereignistabelle |
|
Index (Zeile) des fallenden Ereignisses in der Ereignistabelle |
Sowohl die alarmStatus Felder als eventStatus auch sind entryStatus Primitive, wie in RFC 2579, Textual Conventions for SMIv2, definiert.
RMON-Fehlerbehebung
Sie beheben Probleme mit dem RMON-Agenten, der auf dem Router ausgeführt wird, rmopdindem Sie den Inhalt der Unternehmens-RMON-MIB von Juniper Networks überprüfen, jnxRmondie die in Tabelle 3 RFC 2819 alarmTableaufgeführten Erweiterungen bereitstellt.
Feld |
Beschreibung |
|---|---|
|
Häufigkeit, mit der die interne |
|
Wert, |
|
Grund, warum die |
|
Wert, |
|
Status dieses Alarmeintrags |
Die Überwachung der Erweiterungen in dieser Tabelle gibt Hinweise darauf, warum sich Remotealarme möglicherweise nicht wie erwartet verhalten.
Verstehen von Messpunkten, Leistungskennzahlen und Basiswerten
Dieses Kapitel enthält Richtlinien für die Überwachung der Dienstqualität eines IP-Netzwerks. Darin wird beschrieben, wie Service Provider und Netzwerkadministratoren die von den Routern von Juniper Networks bereitgestellten Informationen nutzen können, um die Netzwerkleistung und -kapazität zu überwachen. Sie sollten über ein gründliches Verständnis von SNMP und der zugehörigen MIB verfügen, die von Junos OS unterstützt werden.
Eine gute Einführung in den Prozess der Überwachung eines IP-Netzwerks finden Sie unter RFC 2330, Framework for IP Performance Metrics.
Dieses Thema enthält die folgenden Abschnitte:
Messstellen
Die Definition der Messpunkte, an denen Metriken gemessen werden, ist genauso wichtig wie die Definition der Metriken selbst. Dieser Abschnitt beschreibt Messpunkte im Kontext dieses Kapitels und hilft zu identifizieren, wo Messungen von einem Service Provider-Netzwerk aus durchgeführt werden können. Es ist wichtig, genau zu verstehen, wo sich ein Messpunkt befindet. Messpunkte sind von entscheidender Bedeutung, um die Bedeutung der eigentlichen Messung zu verstehen.
Ein IP-Netzwerk besteht aus einer Sammlung von Routern, die über physische Verbindungen verbunden sind und alle das Internetprotokoll ausführen. Sie können sich das Netzwerk als eine Sammlung von Routern mit einem Eingangspunkt (Einstiegspunkt) und einem Ausgangspunkt (Ausgangspunkt) vorstellen. Siehe Abbildung 2.
Netzwerkzentrierte Messungen werden an Messpunkten durchgeführt, die den Eingangs- und Ausgangspunkten des Netzwerks selbst am nächsten kommen. Um beispielsweise die Verzögerung im gesamten Anbieternetzwerk von Standort A zu Standort B zu messen, sollten die Messpunkte der Eingangspunkt zum Anbieternetzwerk an Standort A und der Ausgangspunkt an Standort B sein.
Routerzentrierte Messungen werden direkt von den Routern selbst durchgeführt, aber stellen Sie sicher, dass die richtigen Router-Unterkomponenten im Voraus identifiziert wurden.

Abbildung 2 zeigt die Clientnetzwerke am Standort des Kunden nicht an, sie befinden sich jedoch auf beiden Seiten der Eingangs- und Ausgangspunkte. Obwohl in diesem Kapitel nicht erläutert wird, wie Netzwerkdienste gemessen werden, wie sie von diesen Client-Netzwerken wahrgenommen werden, können Sie für das Service Provider-Netzwerk durchgeführte Messungen als Eingabe für solche Berechnungen verwenden.
Grundlegende Leistungskennzahlen
Sie können beispielsweise ein Service Provider-Netzwerk auf drei grundlegende Key Performance Indicators (KPIs) überwachen:
misst die "Erreichbarkeit" eines Messpunktes von einem anderen Messpunkt auf der Netzwerkschicht (z. B. mit ICMP-Ping). Die zugrunde liegende Routing- und Transportinfrastruktur des Anbieternetzwerks unterstützt die Verfügbarkeitsmessungen, wobei Fehler als Nichtverfügbarkeit hervorgehoben werden.
Misst die Anzahl und Art der Fehler, die im Netzwerk des Anbieters auftreten, und kann sowohl aus router- als auch aus netzwerkzentrierten Messungen bestehen, z. B. Hardwareausfälle oder Paketverluste.
des Provider-Netzwerks misst, wie gut es IP-Dienste unterstützen kann (z. B. in Bezug auf Verzögerung oder Auslastung).
Festlegen von Baselines
Wie gut funktioniert das Anbieternetzwerk? Wir empfehlen eine anfängliche dreimonatige Überwachung, um die normalen Betriebsparameter eines Netzwerks zu ermitteln. Mit diesen Informationen können Sie Ausnahmen erkennen und abnormales Verhalten erkennen. Sie sollten die Basisüberwachung für die gesamte Lebensdauer jeder gemessenen Metrik fortsetzen. Im Laufe der Zeit müssen Sie in der Lage sein, Leistungstrends und Wachstumsmuster zu erkennen.
Im Rahmen dieses Kapitels ist vielen der identifizierten Metriken kein zulässiger Betriebsbereich zugeordnet. In den meisten Fällen können Sie den zulässigen Betriebsbereich erst ermitteln, wenn Sie einen Basiswert für die tatsächliche Variable in einem bestimmten Netzwerk festgelegt haben.
Definition und Messung der Netzwerkverfügbarkeit
Dieses Thema umfasst die folgenden Abschnitte:
Definieren der Netzwerkverfügbarkeit
Die Verfügbarkeit des IP-Netzwerks eines Service Providers kann als die Erreichbarkeit zwischen den regionalen Points of Presence (POP) betrachtet werden, wie in Abbildung 3dargestellt.

Wenn Sie im obigen Beispiel ein vollständiges Netz von Messpunkten verwenden, bei dem jeder POP die Verfügbarkeit für jeden anderen POP misst, können Sie die Gesamtverfügbarkeit des Netzwerks des Service Providers berechnen. Dieser KPI kann auch zur Überwachung des Servicelevels des Netzwerks verwendet werden und kann vom Service Provider und seinen Kunden verwendet werden, um festzustellen, ob sie innerhalb der Bedingungen ihres Service Level Agreements (SLA) arbeiten.
Wenn ein POP aus mehreren Routern bestehen kann, nehmen Sie Messungen an jedem Router vor, wie in Abbildung 4gezeigt.

Zu den Messungen gehören:
Pfadverfügbarkeit: Verfügbarkeit einer Ausgangsschnittstelle B1 aus Sicht einer Eingangsschnittstelle A1.
Routerverfügbarkeit: Prozentsatz der Pfadverfügbarkeit aller gemessenen Pfade, die auf dem Router enden.
POP-Verfügbarkeit: Prozentsatz der Routerverfügbarkeit zwischen zwei beliebigen regionalen POPs, A und B.
Netzwerkverfügbarkeit: Prozentsatz der POP-Verfügbarkeit für alle regionalen POPs im Netzwerk des Service Providers.
Um die POP-Verfügbarkeit von POP A zu POP B in Abbildung 4zu messen, müssen Sie die folgenden vier Pfade messen:
Path A1 => B1 Path A1 => B2 Path A2 => B1 Path A2 => B2
Die Messung der Verfügbarkeit von POP B zu POP A würde vier weitere Messungen erfordern und so weiter.
Ein vollständiges Netz von Verfügbarkeitsmessungen kann erheblichen Verwaltungsdatenverkehr erzeugen. Aus dem obigen Beispieldiagramm:
Jeder POP verfügt über zwei Co-Location-Provider-Edge-Router (PE) mit jeweils 2 xSTM1-Schnittstellen, sodass insgesamt 18 PE-Router und 36 x STM1-Schnittstellen vorhanden sind.
Es gibt sechs Core-Provider-Router (P), vier mit jeweils 2xSTM4- und 3xSTM1-Schnittstellen und zwei mit jeweils 3xSTM4- und 3xSTM1-Schnittstellen.
Das macht insgesamt 68 Schnittstellen. Ein vollständiges Netz von Pfaden zwischen jeder Schnittstelle ist:
[n x (n–l)] / 2 ergibt [68 x (68–1)] / 2=2278 Pfade
Um den Verwaltungsdatenverkehr im Netzwerk des Service Providers zu reduzieren, können Sie von der Loopback-Adresse jedes Routers aus messen, anstatt ein vollständiges Netz von Schnittstellenverfügbarkeitstests zu generieren (z. B. von jeder Schnittstelle zu jeder anderen Schnittstelle). Dadurch reduziert sich die Anzahl der erforderlichen Verfügbarkeitsmessungen auf insgesamt eine für jeden Router, oder:
n [ x (n–1)] / 2 ergibt [24 x (24–1)] / 2=276 Maße
Dadurch wird die Verfügbarkeit von jedem Router zu jedem anderen Router gemessen.
Überwachung des SLA und der erforderlichen Bandbreite
Ein typisches SLA zwischen einem Service Provider und einem Kunden könnte lauten:
A Point of Presence is the connection of two back-to-back provider edge routers to separate core provider routers using different links for resilience. The system is considered to be unavailable when either an entire POP becomes unavailable or for the duration of a Priority 1 fault.
Eine SLA-Verfügbarkeit von 99,999 Prozent für das Netzwerk eines Anbieters würde einer Ausfallzeit von etwa 5 Minuten pro Jahr entsprechen. Um dies proaktiv zu messen, müssten Sie daher Verfügbarkeitsmessungen mit einer Granularität von weniger als einer alle fünf Minuten durchführen. Bei einer Standardgröße von 64 Byte pro ICMP-Ping-Anforderung würde ein Ping-Test pro Minute 7680 Byte Datenverkehr pro Stunde und Ziel generieren, einschließlich Ping-Antworten. Ein vollständiges Netz von Ping-Tests für 276 Ziele würde 2.119.680 Byte pro Stunde generieren, was Folgendes entspricht:
Bei einer OC3/STM1-Verbindung von 155,52 Mbit/s ergibt sich eine Auslastung von 1,362 Prozent
Bei einer OC12/STM4-Verbindung von 622,08 Mbit/s ergibt sich eine Auslastung von 0,340 Prozent
Bei einer Größe von 1500 Byte pro ICMP-Ping-Anfrage würde ein Ping-Test pro Minute 180.000 Byte pro Stunde und Ziel erzeugen, einschließlich Ping-Antworten. Ein vollständiges Netz von Ping-Tests für 276 Ziele würde 49.680.000 Byte pro Stunde generieren, was Folgendes entspricht:
Bei einer OC3/STM1-Verbindung 31,94 Prozent Auslastung
Bei einer OC12/STM4-Verbindung 7,986 Prozent Auslastung
Jeder Router kann die Ergebnisse für jedes getestete Ziel aufzeichnen. Mit einem Test pro Minute zu jedem Ziel würden insgesamt 1 x 60 x 24 x 276 = 397.440 Tests pro Tag von jedem Router durchgeführt und aufgezeichnet werden. Alle Ping-Ergebnisse werden in der pingProbeHistoryTable (siehe RFC 2925) gespeichert und können von einer SNMP-Performance-Reporting-Anwendung (z. B. Service-Performance-Management-Software von InfoVista, Inc. oder Concord Communications, Inc.) zur Nachbearbeitung abgerufen werden. Diese Tabelle hat eine maximale Größe von 4.294.967.295 Zeilen, was mehr als ausreichend ist.
Verfügbarkeit messen
Es gibt zwei Methoden, mit denen Sie die Verfügbarkeit messen können:
Proaktiv: Die Verfügbarkeit wird automatisch so oft wie möglich von einem operativen Supportsystem gemessen.
Reaktiv: Die Verfügbarkeit wird von einem Helpdesk aufgezeichnet, wenn ein Fehler zum ersten Mal von einem Benutzer oder einem Fehlerüberwachungssystem gemeldet wird.
In diesem Abschnitt wird die Leistungsüberwachung in Echtzeit als proaktive Überwachungslösung erläutert.
Leistungsüberwachung in Echtzeit
Juniper Networks stellt einen Echtzeit-Performance-Monitoring-Service (RPM) zur Überwachung der Netzwerkleistung in Echtzeit bereit. Verwenden Sie die J-Web-Schnellkonfigurationsfunktion, um Parameter für die Echtzeit-Leistungsüberwachung zu konfigurieren, die in Echtzeit-Leistungsüberwachungstests verwendet werden. (J-Web Quick Configuration ist eine browserbasierte Benutzeroberfläche, die auf Routern von Juniper Networks ausgeführt wird. Weitere Informationen finden Sie im J-Web Interface-Benutzerhandbuch.)
Konfigurieren der Echtzeit-Leistungsüberwachung
Einige der gebräuchlichsten Optionen, die Sie für Echtzeit-Leistungsüberwachungstests konfigurieren können, werden in Tabelle 4gezeigt.
Feld |
Beschreibung |
|---|---|
| Informationen anfordern | |
|
Art der Sonde, die als Teil des Tests gesendet werden soll. Sondentypen können sein:
|
|
Wartezeit (in Sekunden) zwischen den einzelnen Sondenübertragungen. Der Bereich liegt zwischen 1 und 255 Sekunden. |
|
Wartezeit (in Sekunden) zwischen den Tests. Der Bereich liegt zwischen 0 und 86400 Sekunden. |
|
Gesamtzahl der Sonden, die für jeden Test gesendet wurden. Der Bereich liegt zwischen 1 und 15 Sonden. |
|
TCP- oder UDP-Port, an den Sondierungen gesendet werden. Verwenden Sie die Nummer 7 – eine standardmäßige TCP- oder UDP-Portnummer – oder wählen Sie eine Portnummer zwischen 49152 und 65535 aus. |
|
DSCP-Bits (Differentiated Services Code Point). Bei diesem Wert muss es sich um ein gültiges 6-Bit-Muster handeln. Der Standardwert ist 000000. |
|
Größe (in Byte) des Datenteils der ICMP-Sonden. Der Bereich liegt zwischen 0 und 65507 Byte. |
|
Inhalt des Datenteils der ICMP-Sonden. Der Inhalt muss ein Hexadezimalwert sein. Der Bereich liegt zwischen 1 und 800 Stunden. |
| Maximale Sondenschwellenwerte | |
|
Gesamtzahl der Sonden, die nacheinander verloren gehen müssen, um einen Testfehler auszulösen und eine Systemprotokollmeldung zu generieren. Der Bereich liegt zwischen 0 und 15 Sonden. |
|
Gesamtzahl der Tests, die verloren gehen müssen, um einen Testfehler auszulösen und eine Systemprotokollmeldung zu generieren. Der Bereich liegt zwischen 0 und 15 Sonden. |
|
Gesamtumlaufzeit (in Mikrosekunden) vom Services Router zum Remote-Server, die bei Überschreitung einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Gesamtjitter (in Mikrosekunden) für einen Test, der, wenn er überschritten wird, einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Maximal zulässige Standardabweichung (in Mikrosekunden) für einen Test, die bei Überschreitung einen Sondenausfall auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Einweg-Gesamtzeit (in Mikrosekunden) vom Router zum Remote-Server, die bei Überschreitung einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Einweg-Gesamtzeit (in Mikrosekunden) vom Remote-Server zum Router, die bei Überschreitung einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Gesamter Jitter der ausgehenden Zeit (in Mikrosekunden) für einen Test, der bei Überschreitung einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Gesamter eingehender Jitter (in Mikrosekunden) für einen Test, der bei Überschreitung einen Testfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Maximal zulässige Standardabweichung der ausgehenden Zeiten (in Mikrosekunden) für einen Test, die bei Überschreitung einen Sondenfehler auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
|
Maximal zulässige Standardabweichung der eingehenden Zeiten (in Mikrosekunden) für einen Test, die bei Überschreitung einen Sondenausfall auslöst und eine Systemprotokollmeldung generiert. Der Bereich liegt zwischen 0 und 60.000.000 Mikrosekunden. |
Anzeigen von Informationen zur Leistungsüberwachung in Echtzeit
Für jeden auf dem Router konfigurierten Echtzeit-Leistungsüberwachungstest umfassen die Überwachungsinformationen die Umlaufzeit, den Jitter und die Standardabweichung. Um diese Informationen anzuzeigen, wählen Sie in der J-Web-Schnittstelle aus, oder geben Sie Monitor > RPM den show services rpm Befehl Befehlszeilenschnittstelle (CLI) ein.
Geben Sie den show services rpm probe-results CLI-Befehl ein, um die Ergebnisse der neuesten Echtzeit-Leistungsüberwachungstests anzuzeigen:
user@host> show services rpm probe-results
Owner: p1, Test: t1
Target address: 10.8.4.1, Source address: 10.8.4.2, Probe type: icmp-ping
Destination interface name: lt-0/0/0.0
Test size: 10 probes
Probe results:
Response received, Sun Jul 10 19:07:34 2005
Rtt: 50302 usec
Results over current test:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Results over all tests:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Messen des Zustands
Sie können Zustandsmetriken reaktiv überwachen, indem Sie Fehlerverwaltungssoftware wie SMARTS InCharge, Micromuse Netcool Omnibus oder Concord Live Exceptions verwenden. Es wird empfohlen, die in Tabelle 5.
Metrik |
Beschreibung |
Parameter |
|
|---|---|---|---|
Name |
Wert |
||
Fehler in |
Anzahl der eingehenden Pakete, die Fehler enthielten und deren Zustellung verhinderten |
MIB-Name | IF-MIB (RFC 2233) |
| Variablenname | ifInErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.14 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Logische Schnittstellen |
||
Fehler werden behoben |
Anzahl der ausgehenden Pakete, die Fehler enthielten und deren Übertragung verhinderten |
MIB-Name | IF-MIB (RFC 2233) |
| Variablenname | ifOutErrors |
||
| Variable OID | .1.3.6.1.31.2.2.1.20 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Logische Schnittstellen |
||
Verwirft in |
Anzahl der verworfenen eingehenden Pakete, obwohl keine Fehler erkannt wurden |
MIB-Name | IF-MIB (RFC 2233) |
| Variablenname | ifInDiscards |
||
| Variable OID | .1.3.6.1.31.2.2.1.13 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Logische Schnittstellen |
||
Unbekannte Protokolle |
Anzahl der eingehenden Pakete, die verworfen wurden, weil sie einem unbekannten Protokoll angehörten |
MIB-Name | IF-MIB (RFC 2233) |
| Variablenname | ifInUnknownProtos |
||
| Variable OID | .1.3.6.1.31.2.2.1.15 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Logische Schnittstellen |
||
Betriebsstatus der Schnittstelle |
Betriebszustand einer Schnittstelle |
MIB-Name | IF-MIB (RFC 2233) |
| Variablenname | ifOperStatus |
||
| Variable OID | .1.3.6.1.31.2.2.1.8 |
||
| Frequenz (Minuten) | 15 |
||
| Zulässiger Bereich | 1 (nach oben) |
||
| Verwaltete Objekte | Logische Schnittstellen |
||
Status von Label Switched Path (LSP) |
Betriebszustand eines MPLS-Label-Switched-Pfads |
MIB-Name | MPLS-MIB |
| Variablenname | mplsLspState |
||
| Variable OID | mplsLspEntry.2 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | 2 (nach oben) |
||
| Verwaltete Objekte | Alle Label-Switched-Pfade im Netzwerk |
||
Betriebszustand der Komponente |
Betriebsstatus einer Router-Hardwarekomponente |
MIB-Name | JUNIPER-MIB |
| Variablenname | jnxOperatingState |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.6 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | 2 (läuft) oder 3 (bereit) |
||
| Verwaltete Objekte | Alle Komponenten in jedem Router von Juniper Networks |
||
Betriebstemperatur der Komponente |
Betriebstemperatur einer Hardwarekomponente in Celsius |
MIB-Name | JUNIPER-MIB |
| Variablenname | jnxOperatingTemp |
||
| Variable OID | .1.3.6.1.4.1.2636.1.13.1.7 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Alle Komponenten in einem Chassis |
||
Betriebszeit des Systems |
Zeit in Millisekunden, bis das System betriebsbereit war. |
MIB-Name | MIB-2 (RFC 1213) |
| Variablenname | sysUpTime |
||
| Variable OID | .1.3.6.1.1.3 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Nur Erhöhen (Dekrementierung zeigt einen Neustart an) |
||
| Verwaltete Objekte | Alle Router |
||
Keine IP-Routenfehler |
Anzahl der Pakete, die nicht zugestellt werden konnten, weil es keine IP-Route zu ihrem Ziel gab. |
MIB-Name | MIB-2 (RFC 1213) |
| Variablenname | ipOutNoRoutes |
||
| Variable OID | IP.12 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Jeder Router |
||
Falsche SNMP-Community-Namen |
Anzahl der falsch empfangenen SNMP-Community-Namen |
MIB-Name | MIB-2 (RFC 1213) |
| Variablenname | snmpInBadCommunityNames |
||
| Variable OID | SNMP.4 |
||
| Frequenz (Minuten) | 24 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Jeder Router |
||
Verstöße gegen die SNMP-Community |
Anzahl der gültigen SNMP-Communities, die für ungültige Vorgänge verwendet werden (z. B. der Versuch, SNMP-Set-Anforderungen auszuführen) |
MIB-Name | MIB-2 (RFC 1213) |
| Variablenname | snmpInBadCommunityUses |
||
| Variable OID | SNMP.5 |
||
| Frequenz (Minuten) | 24 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Jeder Router |
||
Redundanzumschaltung |
Gesamtzahl der von diesem Unternehmen gemeldeten Redundanzumstellungen |
MIB-Name | JUNIPER-MIB |
| Variablenname | jnxRedundancySwitchoverCount |
||
| Variable OID | jnxRedundancyEntry.8 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Alle Router von Juniper Networks mit redundanten Routing-Engines |
||
FRU-Status |
Betriebsstatus jeder vor Ort austauschbaren Einheit (FRU) |
MIB-Name | JUNIPER-MIB |
| Variablenname | jnxFruState |
||
| Variable OID | jnxFruEntry.8 |
||
| Frequenz (Minuten) | 15 |
||
| Zulässiger Bereich | 2 bis 6 für Bereitschafts-/Online-Zustände. Weitere Hinweise finden Sie unter jnxFruOfflineReason im Falle eines FRU-Fehlers. |
||
| Verwaltete Objekte | Alle FRUs in allen Routern von Juniper Networks. |
||
Rate der Tail-Drop-Pakete |
Rate der Tail-Drop-Pakete pro Ausgabewarteschlange, pro Weiterleitungsklasse, pro Schnittstelle. |
MIB-Name | JUNIPER-COS-MIB |
| Variablenname | jnxCosIfqTailDropPktRate |
||
| Variable OID | jnxCosIfqStatsEntry.12 |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Für jede Weiterleitungsklasse pro Schnittstelle im Provider-Netzwerk, wenn CoS aktiviert ist. |
||
Schnittstellennutzung: Empfangene Oktette |
Gesamtzahl der Oktette, die auf der Benutzeroberfläche empfangen wurden, einschließlich der Rahmenzeichen. |
MIB-Name | IF-MIB |
| Variablenname | ifInOctets |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.10.x |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Alle Betriebsschnittstellen im Netzwerk |
||
Schnittstellennutzung: Übertragene Oktette |
Gesamtzahl der Oktette, die aus der Benutzeroberfläche übertragen wurden, einschließlich der Rahmenzeichen. |
MIB-Name | IF-MIB |
| Variablenname | ifOutOktette |
||
| Variable OID | .1.3.6.1.2.1.2.2.1.16.x |
||
| Frequenz (Minuten) | 60 |
||
| Zulässiger Bereich | Zur Baseline |
||
| Verwaltete Objekte | Alle Betriebsschnittstellen im Netzwerk |
||
Die Byteanzahl variiert je nach Schnittstellentyp, verwendeter Kapselung und unterstütztem PIC. Bei der VLAN-CCC-Kapselung auf einem 4xFE-, GE- oder GE 1Q-PIC umfasst die Byteanzahl beispielsweise das Framing und den Steuerwort-Overhead. (Siehe Tabelle 6.)
PIC-Typ |
Verkapselung |
Eingabe (Einheitsebene) |
Ausgang (Einheitsebene) |
SNMP |
|---|---|---|---|---|
4xFE |
VLAN-CCC |
Frame (keine Frame-Check-Sequenz [FCS]) |
Rahmen (inkl. FCS und Steuerwort) |
ifInOctets, ifOutOctets |
GE |
VLAN-CCC |
Rahmen (kein FCS) |
Rahmen (inkl. FCS und Steuerwort) |
ifInOctets, ifOutOctets |
GE IQ |
VLAN-CCC |
Rahmen (kein FCS) |
Rahmen (inkl. FCS und Steuerwort) |
ifInOctets, ifOutOctets |
SNMP-Traps sind auch ein guter Mechanismus für die Systemverwaltung. Weitere Informationen finden Sie unter "SNMP-Traps, die von Junos OS unterstützt werden" und "Unternehmensspezifische SNMP-Traps, die von Junos OS unterstütztwerden".
Leistung messen
Die Leistung des Netzwerks eines Service Providers wird in der Regel als die Qualität definiert, mit der Services unterstützt werden können, und wird anhand von Metriken wie Verzögerung und Auslastung gemessen. Wir empfehlen Ihnen, die folgenden Leistungsmetriken mit Anwendungen wie InfoVista Service Performance Management oder Concord Network Health zu überwachen (siehe Tabelle 7).
| Metrik: | Durchschnittliche Verzögerung |
Beschreibung |
Durchschnittliche Umlaufzeit (in Millisekunden) zwischen zwei Messpunkten. |
MIB-Name |
DISMAN-PING-MIB (RFC 2925) |
Variablenname |
|
Variable OID |
pingResultsEntry.6 |
Frequenz (Minuten) |
15 (oder abhängig von der Häufigkeit des Ping-Tests) |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Jeder gemessene Pfad im Netzwerk |
| Metrik: | Schnittstellenauslastung |
Beschreibung |
Prozentsatz der Auslastung einer logischen Verbindung. |
MIB-Name |
IF-MIB |
Variablenname |
|
Variable OID |
ifTable-Einträge |
Frequenz (Minuten) |
60 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Alle Betriebsschnittstellen im Netzwerk |
| Metrik: | Festplattenauslastung |
Beschreibung |
Nutzung des Speicherplatzes im Router von Juniper Networks |
MIB-Name |
HOST-RESOURCES-MIB (RFC 2790) |
Variablenname |
hrStorageSize – hrStorageUsed |
Variable OID |
hrStorageEntry.5 – hrStorageEntry.6 |
Frequenz (Minuten) |
1440 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Alle Routing-Engine-Festplatten |
| Metrik: | Speicherauslastung |
Beschreibung |
Auslastung des Arbeitsspeichers auf der Routing-Engine und der FPC. |
MIB-Name |
JUNIPER-MIB (Juniper Networks enterprise Chassis MIB) |
Variablenname |
jnxOperatingHeap |
Variable OID |
Tabelle für jede Komponente |
Frequenz (Minuten) |
60 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Alle Router von Juniper Networks |
| Metrik: | CPU-Auslastung |
Beschreibung |
Durchschnittliche Auslastung einer CPU in der letzten Minute. |
MIB-Name |
JUNIPER-MIB (Juniper Networks enterprise Chassis MIB) |
Variablenname |
jnxOperatingCPU |
Variable OID |
Tabelle für jede Komponente |
Frequenz (Minuten) |
60 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Alle Router von Juniper Networks |
| Metrik: | LSP-Auslastung |
Beschreibung |
Verwendung des MPLS-Label-Switched-Pfads. |
MIB-Name |
MPLS-MIB |
Variablenname |
mplsPathBandwidth / (mplsLspOctets * 8) |
Variable OID |
mplsLspEntry.21 und mplsLspEntry.3 |
Frequenz (Minuten) |
60 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Alle Label-Switched-Pfade im Netzwerk |
| Metrik: | Größe der Ausgabewarteschlange |
Beschreibung |
Größe (in Paketen) jeder Ausgabewarteschlange pro Weiterleitungsklasse und Schnittstelle. |
MIB-Name |
JUNIPER-COS-MIB |
Variablenname |
jnxCosIfqQedPkts |
Variable OID |
jnxCosIfqStatsEntry.3 |
Frequenz (Minuten) |
60 |
Zulässiger Bereich |
Zur Baseline |
Verwaltete Objekte |
Für jede Weiterleitungsklasse pro Schnittstelle im Netzwerk, sobald CoS aktiviert ist. |
Dieser Abschnitt enthält die folgenden Themen:
- Messen der Serviceklasse
- Filterzähler für eingehende Firewalls pro Klasse
- Überwachen der Ausgabebytes pro Warteschlange
- Berechnen des verworfenen Datenverkehrs
Messen der Serviceklasse
Sie können Class-of-Service (CoS)-Mechanismen verwenden, um zu regeln, wie bestimmte Paketklassen in Ihrem Netzwerk in Zeiten maximaler Überlastung behandelt werden. In der Regel müssen Sie bei der Implementierung eines CoS-Mechanismus die folgenden Schritte ausführen:
Identifizieren Sie den Pakettyp, der auf diese Klasse angewendet wird. Schließen Sie beispielsweise den gesamten Kundendatenverkehr von einer bestimmten Eingangs-Edge-Schnittstelle innerhalb einer Klasse oder alle Pakete eines bestimmten Protokolls wie Voice over IP (VoIP) ein.
Identifizieren Sie das erforderliche deterministische Verhalten für jede Klasse. Wenn VoIP beispielsweise wichtig ist, sollten Sie dem VoIP-Datenverkehr in Zeiten von Netzwerküberlastung die höchste Priorität einräumen. Umgekehrt können Sie die Bedeutung des Webdatenverkehrs bei Überlastung herabstufen, da er sich möglicherweise nicht allzu stark auf die Kunden auswirkt.
Mit diesen Informationen können Sie Mechanismen am Netzwerkeingang konfigurieren, um Datenverkehrsklassen zu überwachen, zu markieren und zu überwachen. Markierter Datenverkehr kann dann an Ausgangsschnittstellen deterministischer behandelt werden, indem in der Regel unterschiedliche Warteschlangenmechanismen für jede Klasse in Zeiten von Netzwerküberlastung angewendet werden. Sie können Informationen aus dem Netzwerk sammeln, um Kunden Berichte zur Verfügung zu stellen, die zeigen, wie sich das Netzwerk in Zeiten von Überlastung verhält. (Siehe Abbildung 5.)
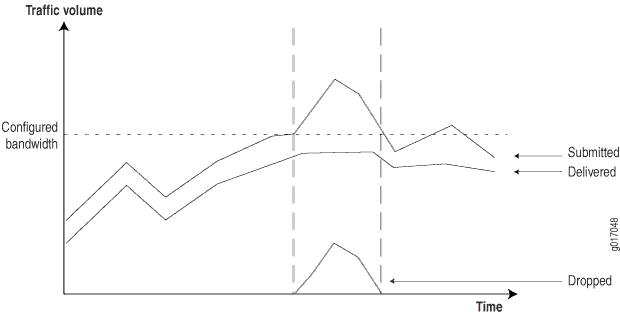
Um diese Berichte zu generieren, müssen Router die folgenden Informationen bereitstellen:
Gesendeter Traffic: Menge des pro Klasse empfangenen Traffics.
Delivered traffic: Menge des pro Klasse übertragenen Datenverkehrs.
Verlorener Datenverkehr: Menge des Datenverkehrs, der aufgrund von CoS-Limits zurückgegangen ist.
Im folgenden Abschnitt wird beschrieben, wie diese Informationen von Routern von Juniper Networks bereitgestellt werden.
Filterzähler für eingehende Firewalls pro Klasse
Firewall-Filterzähler sind ein sehr flexibler Mechanismus, mit dem Sie eingehenden Datenverkehr pro Klasse und Schnittstelle abgleichen und zählen können. Zum Beispiel:
firewall {
filter f1 {
term t1 {
from {
dscp af11;
}
then {
# Assured forwarding class 1 drop profile 1 count inbound-af11;
accept;
}
}
}
}
Zeigt z. B. zusätzliche Filter an, Tabelle 8 die verwendet werden, um den anderen Klassen zu entsprechen.
DSCP-Wert |
Firewall-Übereinstimmungsbedingung |
Beschreibung |
|---|---|---|
10 |
af11 |
Gesicherte Weiterleitung Klasse 1 Fallprofil 1 |
12 |
af12 |
Gesicherte Weiterleitung Klasse 1 Fallprofil 2 |
18 |
af21 |
Best-Effort-Klasse 2 Drop-Profil 1 |
20 |
af22 |
Best-Effort-Klasse 2 Drop-Profil 2 |
26 |
af31 |
Best-Effort-Klasse 3 Fallprofil 1 |
Jedes Paket mit einem CoS DiffServ Code Point (DSCP), der RFC 2474 entspricht, kann auf diese Weise gezählt werden. Die unternehmensspezifische Firewall-Filter-MIB von Juniper Networks zeigt die Zählerinformationen in den Variablen Tabelle 9an.
Name des Indikators |
Eingehende Zähler |
|---|---|
MIB |
|
Tisch |
|
Index |
|
Variablen |
|
Beschreibung |
Anzahl der Bytes, die in Bezug auf den angegebenen Firewallfilterzähler gezählt werden |
SNMP-Version |
SNMPv2 |
Diese Informationen können von jeder SNMP-Verwaltungsanwendung erfasst werden, die SNMPv2 unterstützt. Produkte von Anbietern wie Concord Communications, Inc. und InfoVista, Inc. unterstützen die Juniper Networks Firewall MIB mit ihren nativen Juniper Networks-Gerätetreibern.
Überwachen der Ausgabebytes pro Warteschlange
Sie können die Juniper Networks Enterprise ATM CoS MIB verwenden, um den ausgehenden Datenverkehr pro Virtual Circuit-Weiterleitungsklasse und pro Schnittstelle zu überwachen. (Siehe Tabelle 10.)
Name des Indikators |
Ausgehende Zähler |
|---|---|
MIB |
|
Variable |
|
Index |
|
Beschreibung |
Anzahl der Bytes der angegebenen Weiterleitungsklasse, die über die angegebene virtuelle Verbindung übertragen wurden. |
SNMP-Version |
SNMPv2 |
Zähler für Nicht-ATM-Schnittstellen werden von der unternehmensspezifischen CoS MIB von Juniper Networks bereitgestellt, die die in Tabelle 11.
Name des Indikators |
Ausgehende Zähler |
|---|---|
MIB |
|
Tisch |
|
Index |
|
Variablen |
|
Beschreibung |
Anzahl der übertragenen Bytes oder Pakete pro Schnittstelle pro Weiterleitungsklasse |
SNMP-Version |
SNMPv2 |
Berechnen des verworfenen Datenverkehrs
Sie können die Menge des verworfenen Datenverkehrs berechnen, indem Sie den ausgehenden Datenverkehr vom eingehenden Datenverkehr subtrahieren:
Dropped = Inbound Counter – Outbound Counter
Sie können auch Zähler aus der CoS MIB auswählen, wie in Tabelle 12gezeigt.
Name des Indikators |
Unterbrochener Datenverkehr |
|---|---|
MIB |
|
Tisch |
|
Index |
|
Variablen |
|
Beschreibung |
Die Anzahl der Tail-Drop- oder RED-Drop-Pakete pro Schnittstelle und Weiterleitungsklasse |
SNMP-Version |
SNMPv2 |