AUF DIESER SEITE
eBPF Kernel Data Plane (Tech Preview)
ZUSAMMENFASSUNG Juniper Cloud-Native Contrail Networking (CN2) Version 23.3 unterstützt eine erweiterte Berkeley Packet Filter (eBPF) Data Plane für den Linux-Kernel. Eine eBPF-basierte Data Plane ermöglicht das Laden von Programmen in den Kernel für Hochleistungsanwendungen.
Linux-Kernel – Übersicht
Der Linux-Kernel-Speicher ist grob in die folgenden zwei Bereiche unterteilt:
-
Kernel-Space: Der Kern des Betriebssystems arbeitet im Kernel-Space. Das Betriebssystem hat uneingeschränkten Zugriff auf alle Hostressourcen, einschließlich: Arbeitsspeicher, Speicher und CPU. Der Kernel-Speicherplatz ist ausschließlich für die Ausführung eines privilegierten Betriebssystem-Kernels, Kernel-Erweiterungen und der meisten Gerätetreiber des Hosts reserviert. Der Kernelbereich ist geschützt und führt nur vertrauenswürdigen Code aus.
-
Userspace-Bibliothek: Nicht-Kernel-Prozesse, wie z.B. reguläre Anwendungen, arbeiten innerhalb des Userspace. Der Code, der im Userspace ausgeführt wird, hat nur begrenzten Zugriff auf Hardwareressourcen und ist in der Regel auf Kernelspace angewiesen, um privilegierte Operationen wie Festplatten- oder Netzwerk-E/A auszuführen. Userspace-Anwendungen fordern einen Service vom Kernel über APIs oder Systemaufrufe an. Systemaufrufe stellen eine Schnittstelle zwischen einem Prozess und dem Betriebssystem bereit, damit Userspace-Prozesse Dienste des Betriebssystems anfordern können.
In einigen Fällen benötigt ein Entwickler möglicherweise mehr Kernelleistung, als über die Systemaufrufschnittstelle zugewiesen wird. Benutzerdefinierte Systemaufrufe, Unterstützung für neue Hardware und neue Dateisysteme erfordern möglicherweise zusätzliche Kernel-Flexibilität. Fälle wie dieser erfordern Verbesserungen am Kernel, ohne den Quellcode zu ergänzen. Ein Linux Kernel Module (LKM) erweitert den Basiskernel, ohne den Quellcode hinzuzufügen oder zu verändern. LKMs werden, im Gegensatz zu Systemaufrufen, zur Laufzeit direkt in den Kernel geladen. Das bedeutet, dass der Kernel nicht jedes Mal neu kompiliert und neu gestartet werden muss, wenn ein neues LKM benötigt wird. Obwohl LKMs den Kernel erweitern, sind LKMs bei Anwendungsfällen wie der Hochleistungspaketverarbeitung immer noch durch den Overhead und die Netzwerkbeschränkungen des Kernels selbst eingeschränkt. Darüber hinaus haben LKMs oft Kompatibilitätsprobleme mit Kernel-Versionen, die behoben werden müssen, und nicht upstreamte LKMs können Vertrauensprobleme haben.
Weitere Informationen finden Sie unter Juniper CN2 Technology Previews (Tech Previews) oder wenden Sie sich an den Juniper Support.
eBPF-Übersicht
Der Berkeley Packet Filter (BPF) bietet eine Möglichkeit, Pakete effizient zu filtern und nutzlose Paketkopien vom Kernel in den Benutzerbereich zu vermeiden. eBPF ist ein Mechanismus zum Schreiben von Code, der im Kernelraum ausgeführt wird. Entwickler schreiben eBPF-Programme in einer eingeschränkten C-Sprache. Dieser Code, der als Bytecode bezeichnet wird, wird von Compiler-Toolchains wie Clang/LLVM kompiliert und erzeugt.
Ein Sicherheitsvorteil von BPF ist die Anforderung, dass BPF-Programme verifiziert werden müssen, bevor sie im Kernel aktiv werden. BPF-Programme werden in einer virtuellen Maschine (VM) im Kernel ausgeführt. Der Überprüfungsprozess stellt sicher, dass BPF-Programme innerhalb der VM ohne Schleife vollständig ausgeführt werden. Der Verifizierungsprozess umfasst auch Prüfungen auf gültigen Registerstatus, die Größe des Programms und Sprünge außerhalb des zulässigen Bereichs. Nach dem Verifizierungsprozess wird das Programm im Kernel aktiv.
eBPF Kernel Data Plane
Die eBPF-Kernel-Datenebene ermöglicht es Ihnen, das Verhalten des Kernels sicherer und effizienter zu erweitern und anzupassen, als dies mit herkömmlichen LKMs möglich ist. Wie bei LKMs wird der Kernel nicht neu geladen und der Code des Kernels wird nicht verändert. eBPF in der Datenebene des Kernels bedeutet, dass Anwendungen im Userspace Daten verarbeiten können, während sie durch den Kernel fließen. Mit anderen Worten, Anwendungen, die die Vorteile von eBPF nutzen, werden innerhalb des Kernels geschrieben und verarbeitet, wodurch der Overhead der Netzwerkschicht typischer Kernel-Prozesse drastisch reduziert wird. Aufgaben wie leistungsstarke Paketverarbeitung, Paketfilterung, Tracing und Sicherheitsüberwachung profitieren alle von der zusätzlichen Kernel-Leistung, die eBPF bietet.
Grundlegendes zu eBPF-Programmen
Events und Hooking
eBPF-Programme werden in einer ereignisgesteuerten Umgebung ausgeführt. Ereignisse sind bestimmte Situationen oder Bedingungen, die überwacht, verfolgt oder analysiert werden. Beispielsweise ist das Eintreffen von Netzwerkpaketen an einer Schnittstelle ein Ereignis. Ein eBPF-Programm ist an dieses Ereignis angehängt und kann eingehende Netzwerkpakete analysieren oder den Pfad eines Pakets verfolgen.
Hooking bezieht sich auf den Prozess des Anhängens eines eBPF-Programms an bestimmte Ausführungspunkte innerhalb des Kernel-Flows. Wenn ein Hook ausgelöst wird, wird das eBPF-Programm ausgeführt. Das eBPF-Programm kann das Verhalten von Ereignissen ändern oder Daten aufzeichnen, die sich auf das Ereignis beziehen. Beispielsweise kann ein Systemaufruf als Hook fungieren. Wenn der Systemaufruf initiiert wird, wird ein Hook ausgelöst, der es dem eBPF-Programm ermöglicht, Systemprozesse zu überwachen.
Weitere Beispiele für Hooks sind:
-
Funktionsein- und -ausstieg: Das eBPF-Programm fängt Aufrufe bereits vorhandener Funktionen ab.
-
Netzwerkereignisse: Das Programm wird ausgeführt, wenn Pakete auf einer angegebenen Schnittstelle empfangen werden.
-
Kprobes und Uprobes: Das Programm hängt an Sonden für Kernel- oder Userspace-Funktionen an.
Hilfsfunktionen
eBPF-Programme rufen Hilfsfunktionen auf, wodurch eBPF-Programme effektiv funktionsreich werden. Hilfsfunktionen führen Folgendes aus:
- Suchen, Aktualisieren und Löschen von Schlüssel-Wert-Paaren
- Generieren einer Pseudozufallszahl
- Abrufen und Festlegen von Tunnelmetadaten
- Verkettung von eBPF-Programmen (Tail Calls)
- Ausführen von Aufgaben mit Sockets wie Bindung, Abrufen von Cookies und Umleiten von Paketen
Der Kernel definiert Hilfsfunktionen, was bedeutet, dass der Kernel den Bereich der Aufrufe, die eBPF-Programme machen, auf die Whitelist setzt.
eBPF-Karten
Karten sind die wichtigsten Datenstrukturen, die von eBPF-Programmen verwendet werden. Maps ermöglichen die Kommunikation von Daten zwischen dem Kernel und dem Benutzerbereich. Eine Zuordnung ist ein Schlüssel-Wert-Speicher, in dem Werte als binäre Blobs beliebiger Daten behandelt werden. Wenn die Zuordnung nicht mehr benötigt wird, wird sie entfernt, indem der zugehörige Dateideskriptor geschlossen wird.
Jede Zuordnung hat die folgenden vier Attribute: ihren Typ, die maximale Anzahl von Elementen, die sie enthalten kann, die Größe ihrer Werte in Byte und die Größe ihrer Schlüssel in Bytes. Es stehen verschiedene Kartentypen zur Verfügung, die jeweils unterschiedliche Verhaltensweisen und Kompromisse bieten. Alle Karten können sowohl von eBPF-Programmen als auch von Userspace-Programmen aus durch die Verwendung von bpf_map_lookup_elem() und bpf_map_update_elem() Funktionen aufgerufen und manipuliert werden.
Ausführen eines eBPF-Programms
Der Kernel erwartet, dass alle eBPF-Programme als Bytecode geladen werden. Dies hat zur Folge, dass eBPF-Programme mit Hilfe von Toolchains in Bytecode kompiliert werden müssen. Nach der Kompilierung werden eBPF-Programme innerhalb des Kernels verifiziert, bevor sie am vorgesehenen Hook-Punkt bereitgestellt werden. eBPF unterstützt moderne Architektur, d. h. es wird auf eine 64-Bit-Kodierung mit insgesamt 11 Registern aktualisiert. Dadurch wird eBPF eng auf Hardware für unter anderem x86_64-, ARM- und arm64-Architektur abgebildet.
Am wichtigsten ist, dass eBPF den Zugriff auf Ereignisse auf Kernel-Ebene freischaltet und die typischen Einschränkungen vermeidet, die mit der direkten Änderung von Kernel-Code verbunden sind. Zusammenfassend lässt sich sagen, dass eBPF wie folgt funktioniert:
-
eBPF-Programme in Bytecode kompilieren
-
Überprüfen, ob Programme in einer VM sicher ausgeführt werden und am Hook-Punkt geladen werden
-
Anhängen von Programmen an Hook-Punkte innerhalb des Kernels, die durch bestimmte Ereignisse ausgelöst werden
-
Kompilieren in nativen Bytecode zur Laufzeit für bessere Portabilität
-
Aufrufen von Hilfsfunktionen zum Bearbeiten von Daten, wenn ein Programm ausgeführt wird
-
Verwenden von Maps (Schlüssel-Wert-Paaren) zum Teilen von Daten zwischen dem Benutzerbereich und dem Kernelbereich und zum Beibehalten des Zustands
Abbildung 1: Ausführung des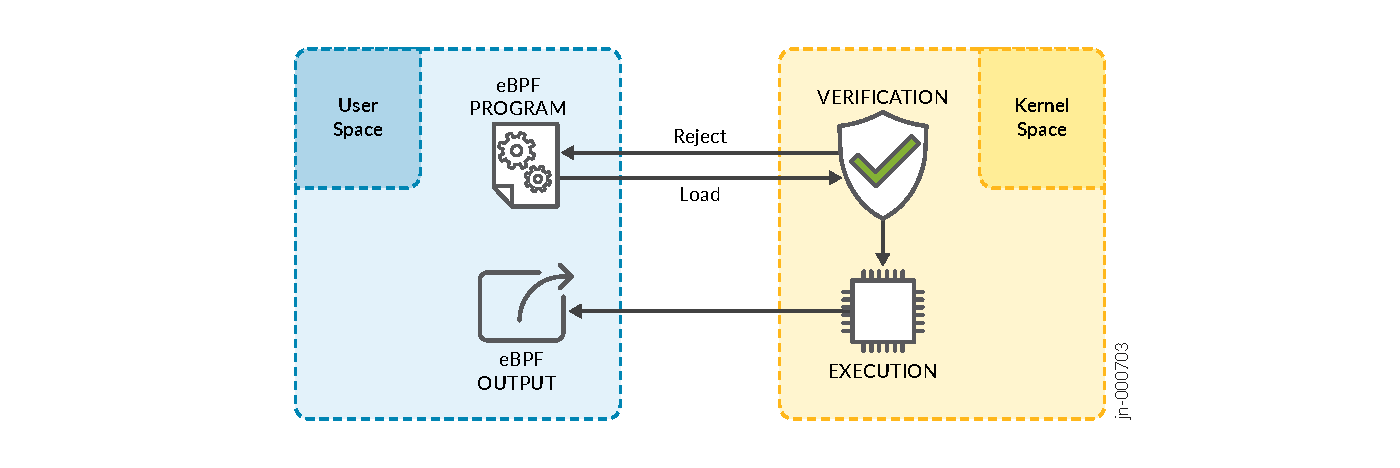 eBPF-Programms
eBPF-Programms
XDP – Übersicht
eXpress Data Path (XDP) ist eine neuere programmierbare Schicht im Kernel-Netzwerk-Stack. XDP ist einer der neueren Hook-Punkte, an die eBPF-Bytecode angehängt und von dort aus ausgeführt wird. XDP-Objektdateien werden auf mehrere Kernel und Architekturen geladen, ohne dass eine Neukompilierung erforderlich ist, die für herkömmliche eBPF-Programme erforderlich ist. Obwohl XDP-Programme die Leistungslücke im Vergleich zu Kernel-Bypass-Lösungen verringern, umgehen die Programme den Kernel nicht. Im Folgenden sind einige wichtige Merkmale aufgeführt, die XDP definieren:
-
Nicht als Kernel-Bypass gedacht
-
Arbeitet direkt mit Paketpuffern
-
Verringert die Anzahl der pro Paket ausgeführten Anweisungen
Der Kernel-Netzwerk-Stack ist für Anwendungsfälle mit Socket-Bereitstellung konzipiert. Daher werden immer alle eingehenden Pakete in Socketpuffer (SKBs) konvertiert. XDP ermöglicht die Verarbeitung von Paketen, bevor sie in SKBs konvertiert werden. XDP arbeitet in Verbindung mit dem bestehenden Kernel-Stack, ohne dass Kernel-Modifikationen erforderlich sind. Dies macht XDP zu einer In-Kernel-Alternative, die mehr Flexibilität bietet.
XDP- und Traffic Control Hooks
Das Laden, Erstellen, Aktualisieren und Lesen von eBPF-Bytecode wird über den BPF-Systemaufruf verarbeitet. Es ist wichtig zu beachten, dass die XDP-Treiber-Hooks nur am Eingang verfügbar sind. Wenn Ausgangspakete verarbeitet werden müssen, muss möglicherweise ein alternativer Hook, z. B. TC (Traffic Control), verwendet werden. Auf einer breiteren Ebene gibt es mehrere Unterschiede zwischen XDP-BPF-Programmen und TC-BPF-Programmen:
-
XDP-Hooks treten früher auf, was zu einer schnelleren Leistung führt.
-
TC-Hooks treten später auf. Daher haben sie Zugriff auf die Struktur und die Felder des Socketpuffers (
sk_buff). Dies trägt wesentlich zum Leistungsunterschied zwischen den XDP- und TC-Hooks bei, da diesk_buffDatenstruktur Metadaten und Informationen enthält, die es dem Netzwerk-Stack des Kernels ermöglichen, Pakete effizient zu verarbeiten und weiterzuleiten. Der Zugriff auf diesk_buffStruktur und ihre Attribute ist mit einem gewissen Overhead verbunden, da der Kernel-Stack das Paket zuweisen, Metadaten extrahieren und verwalten muss, bis es den TC-Hook erreicht.
-
-
TC-Hooks ermöglichen eine bessere Paketverstümmelung.
-
XDP eignet sich besser für vollständige Paketumschreibungen.
-
Der
sk_buffAnwendungsfall enthält umfangreiche protokollspezifische Details, wie z.B. Zustandsinformationen zu GSO (Generic Segmentation Offload). Dies macht es schwierig, Protokolle allein durch Umschreiben der Paketdaten zu wechseln. Daher ist eine weitere Konvertierung erforderlich, die durch BPF-Hilfsfunktionen erreicht wird. Diese Hilfsfunktionen stellen sicher, dass die internen Komponenten dessk_buffordnungsgemäß konvertiert werden.Im Gegensatz dazu treten diese
xdp_buffProbleme im Anwendungsfall nicht auf. Es arbeitet in einem frühen Stadium der Paketverarbeitung, noch bevor der Kernel einesk_buff. Daher ist es in diesem Szenario einfach, jede Art von Paketumschreibung durchzuführen.
-
-
TC, eBPF und XDP als komplementäre Programme.
-
In Fällen, in denen der Anwendungsfall sowohl das Umschreiben von Paketen als auch das komplizierte Verstümmeln von Daten erfordert, können die Einschränkungen jedes Programmtyps durch den Betrieb komplementärer Programme beider Typen überwunden werden. Beispielsweise kann ein XDP-Programm am Eingangspunkt ein vollständiges Umschreiben von Paketen durchführen und benutzerdefinierte Metadaten von XDP BPF an TC BPF übertragen. Das TC BPF-Programm kann dann die XDP-Metadaten und -
sk_buffFelder nutzen, um eine komplexe Paketverarbeitung durchzuführen.
-
-
TC BPF erfordert keine Änderungen des Hardwaretreibers. XDP verwendet den nativen Treibermodus für beste Leistung.
Abbildung 2: XDP- und TC-Hooks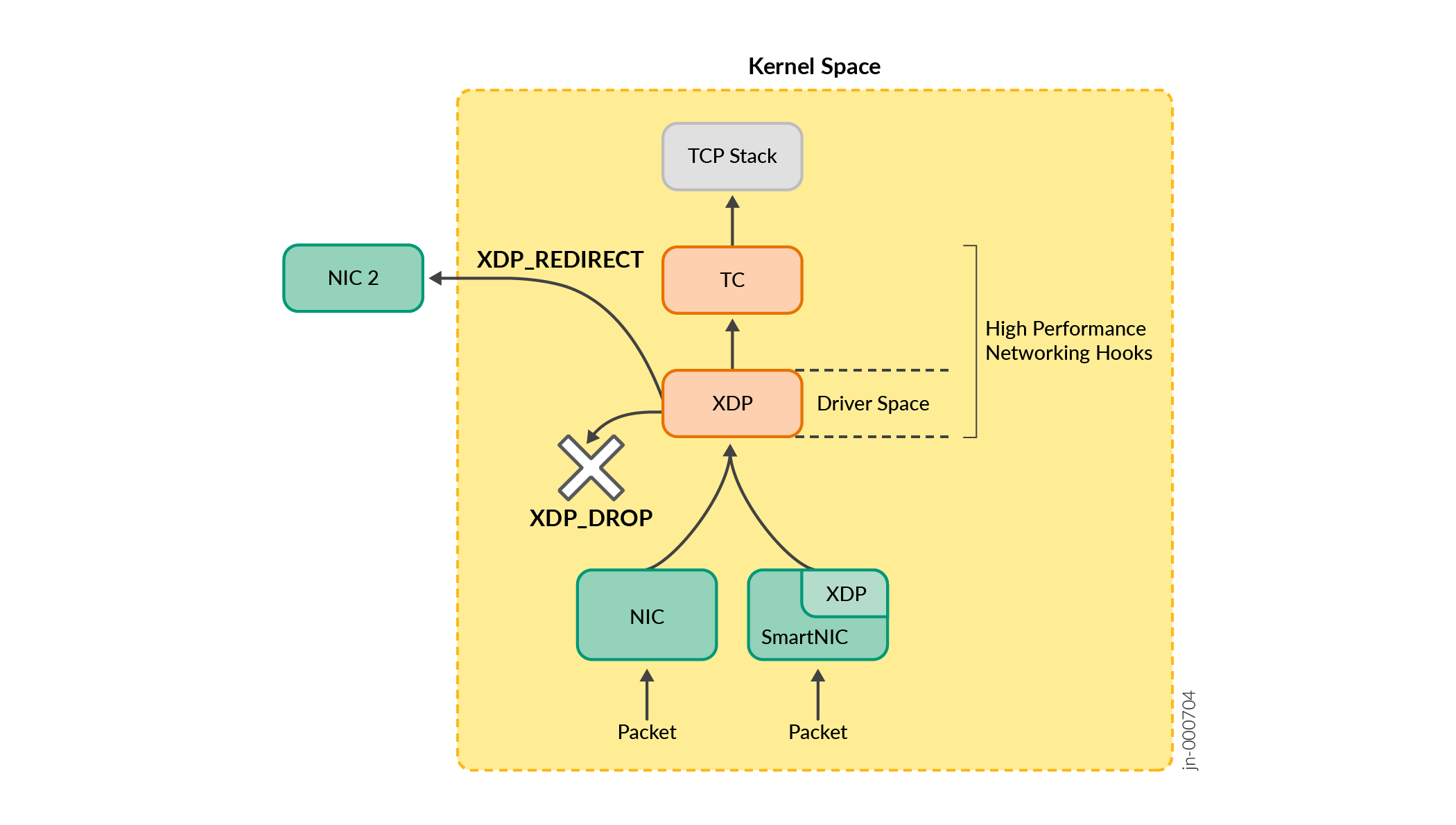
XDP-Steuerungs- und Datenebene
Bei XDP befindet sich die Datenebene innerhalb des Kernels und unterteilt ihn in zwei Komponenten: den Kernel-Kern und das In-Kernel-eBPF-Programm. Die Steuerungsebene befindet sich im Benutzerbereich und arbeitet in Verbindung mit dem Kernelbereich, um wichtige Aufgaben auszuführen, wie z. B. das Laden von BPF-Programmen in den Kernel und das Verwalten des Programmverhaltens durch die Verwendung von Maps.
XDP-Aktion und -Verhalten
Ein eBPF-Programm, das an einem XDP-Hook-Punkt ausgeführt wird, gibt die folgenden Aktionen zurück, je nachdem, wie das Programm das Paket verarbeitet:
- Leitet eingehende Pakete an andere Schnittstellen oder in den Benutzerbereich um.
-
Sendet das empfangene Paket über dieselbe Schnittstelle zurück, auf der es angekommen ist.
-
Sendet das Paket zur Verarbeitung an den Kernel-Stack.
-
Verwirft das Paket.
XDP und eBPF
XDP dient als Software-Offload-Schicht für den Netzwerk-Stack des Kernels. Ein idealer Anwendungsfall ist die Verbindung mit dem Netzwerk-Stack des Linux-Kernels, um die Leistung zu verbessern. In einem IP-Routing-Anwendungsfall übernimmt der Kernel beispielsweise die Verwaltung von Routing-Tabellen und Nachbar-Lookups, während XDP die Paketverarbeitung beschleunigt, indem es effizient auf diese Routing-Tabellen mit Hilfsfunktionen zugreift. Nachdem die Suche abgeschlossen und der nächste Hop identifiziert wurde, werden die Paketheader entsprechend geändert. Wenn keine Änderung erforderlich ist, wird das Paket unverändert an den Kernel weitergeleitet.
Es ist wichtig zu beachten, dass XDP dem RX-Speichermodell die folgenden Einschränkungen auferlegt:
- Unterstützt derzeit nicht Jumbo-Frames für alle gängigen Treiber, obwohl i40e, Veth und virtio Jumbo-Frames unterstützen.
-
Multicast-Unterstützung im Kernel-Bereich vorhanden
Die Verwendung eines eBPF XDP-Treibermodus-basierten Ansatzes bietet Vorteile gegenüber einem proprietären Kernel-Modul wie dem vRouter-Kernel-Modul. Zu den Vorteilen gehören ein verbessertes Lebenszyklusmanagement (LCM), Sicherheit und Leistung. Im Vergleich zu einem Kernel-Modul, das in den Linux-Upstream-Baum integriert ist, ist die Pflege eines alternativen eBPF-XDP-Kernelprogramms über Kernel-Versionen hinweg effizienter. Dies liegt daran, dass Kernel-Abhängigkeiten auf eine kleine Anzahl von eBPF-Hilfsfunktionen beschränkt sind.
Es ist wichtig zu beachten, dass im Falle eines Controller-/Bibliotheksabsturzes das XDP- oder TC-Programm immer noch den Datenverkehr weiterleitet. Das erneute Anhängen oder Ersetzen eines XDP- oder TC-Programms unterbricht den Netzwerkverkehr nicht.
Kommunikation zwischen Kernel und Userspace
AF_XDP Sockets werden verwendet, um die Kommunikation zwischen dem Kernel-Space-Programm, das am XDP-Hook arbeitet, und der Userspace-Bibliothek zu erleichtern. AF_XDP wurde in Linux 4.1.8 eingeführt. AF_XDP ist ein neuer Socket-Typ für die schnelle Zustellung von Rohpaketen an Anwendungen im Userspace. AF_XDP nutzt Linux-Kerneltreiber für hohe Leistung und Skalierbarkeit. Insbesondere bietet es auch Funktionen wie Unterstützung für Zero-Copy-Datenübertragung, minimale Abhängigkeit von Interrupts und Optimierung für Netzwerktreiber, ähnlich wie das Data Plane Development Kit (DPDK) und Vector Packet Processing (VPP).
Der Pfad eines Pakets, das durch einen AF_XDP Socket fließt, lautet wie folgt:
Der NIC-spezifische Treiber greift auf eingehende Pakete an der NIC zu. Der Treiber fängt sie ab und verarbeitet sie durch das eBPF-Programm, das am XDP-Hook ausgeführt wird, der an die entsprechende Schnittstelle gebunden ist. Das XDP-Programm verarbeitet jedes Paket einzeln und generiert nach Abschluss eine Aktion, wie im Abschnitt XDP-Aktion und -Zusammenarbeit beschrieben. Durch die Verwendung von XDP_REDIRECT wird das Paket über einen AF_XDP-Socket, der dieser Schnittstelle zugeordnet ist, in den Benutzerbereich geleitet. Dadurch ist es möglich, Rohpakete direkt von der Netzwerkkarte zu empfangen. Durch die Umgehung des Kernel-Speicherplatzes wird Kernel-Overhead vermieden und das Paket greift direkt auf die Benutzerbereichsbibliotheken zu.
Unterstützte eBPF-Funktionen
Unterstützte Funktionen in CN2 Version 23.2
-
Standard-Pod-Netzwerk
-
Pod-zu-Pod-Konnektivität
- ClusterIP-Dienst
-
Unterstützte Funktionen in CN2 Version 23.3
eBPF Data Plane aktivieren
Sie können die eBPF-Datenebenenfunktion aktivieren, indem Sie dies in der Spezifikation des vRouters angeben agentModeType: xdp . Da derzeit nicht alle XDP-Treiber Jumbo-Frames unterstützen, legt der CN2-Deployer die MTU-Werte (Maximum Transmission Unit) der Fabric-, Loopback- und Veth-Schnittstellen fest.
Das folgende Beispiel zeigt eine vRouter-Ressource mit aktiviertem XDP-eBPF.
apiVersion: dataplane.juniper.net/v1
kind: Vrouter
metadata:
name: contrail-vrouter-masters
namespace: contrail
spec:
agent:
default:
collectors:
- localhost:6700
xmppAuthEnable: true
sandesh:
introspectSslEnable: true
sandeshSslEnable: true
agentModeType: xdp
common:
containers:
- name: contrail-vrouter-agent
image: contrail-vrouter-agent
- name: contrail-watcher
image: contrail-init
- name: contrail-vrouter-telemetry-exporter
image: contrail-vrouter-telemetry-exporter
initContainers:
- name: contrail-init
image: contrail-init
- name: contrail-cni-init
image: contrail-cni-init
Notieren Sie sich das name: contrail-vrouter-masters Feld. Da dieser vRouter als Master-Knoten festgelegt ist, werden alle verfügbaren Master-Knoten auf den Zeitpunkt gesetzt, an agentModeType: xdp dem der Deployer angewendet wird. Diese Logik gilt auch für Workerknoten. Wenn Sie "xdp" für die Worker-Knotenressource im Deployer angeben, werden alle Worker-Knoten für XDP-eBPF konfiguriert.
Von XDP unterstützte Treiber
In der folgenden Tabelle sind die CN2-validierten XDP-Treiber mit dem eBPF-XDP-Datenpfad aufgeführt.
| Name des Treibers | Zugrunde liegende Plattform |
|---|---|
| ENA | AWS |
| Veth | Pod-Konnektivität |
| Virtio | CN2-auf-CN2 |
| i40e | Nacktes Metall |
Wenn Ihr Cluster AWS ENA-Treiber für NIC-Schnittstellen verwendet, legt der Bereitsteller die Warteschlangenkonfiguration von 4 empfangenden (RX) und 4 übertragenen (TX) physischen Schnittstellen fest. Diese Änderung tritt auf, weil die standardmäßige Anzahl von RX- und TX-Warteschlangen von ENA-Treibern für XDP nicht unterstützt wird.
eBPF Data Plane Design und CN2 Implementierung
Die eBPF-Kernel-Datenebene besteht aus zwei Kernkomponenten: dem In-Kernel-XDP-Programm und einer komplementären Userspace-Bibliothek. Diese eBPF-basierte Data Plane ist neben dem auf dem Kernelmodul basierenden vRouter und DPDK die dritte Data Plane-Option für vRouter. In den folgenden Abschnitten werden die Entwurfs- und Implementierungsbesonderheiten der verschiedenen Funktionen der Datenebene erläutert, die von dieser Technologie bereitgestellt werden.
eBPF Data Plane-Komponenten
Wie bereits erwähnt, basiert die eBPF-Datenebene auf XDP. Für Funktionen, für die Pakete aus dem Standardnamespace stammen müssen, ist möglicherweise auch ein ausgehender TC-Hook erforderlich. Dies liegt am Fehlen des XDP-Hooks auf dem Ausgangspfad. Das TC-Programm führt auch neue Parsing-Funktionen ein, da TC-Hooks mit SKBs arbeiten.
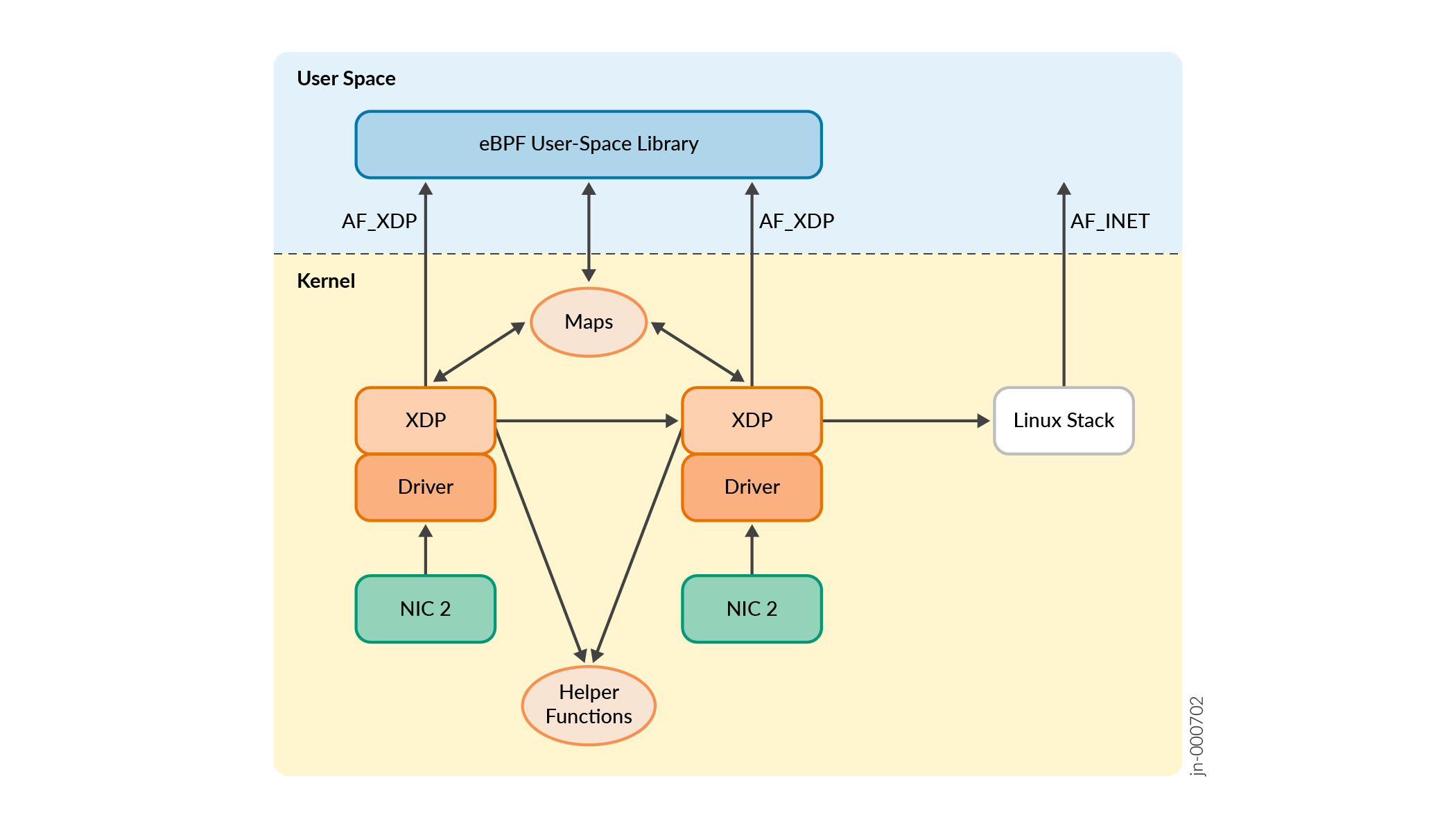
Die eBPF-Datenebene ist nicht als separater Daemon vorgesehen. Stattdessen wird es als Bibliothek in den Controller integriert (vRouter-Agent im Fall von CN2). Diese Implementierung ist in zwei Komponenten unterteilt:
-
Userspace-Bibliothek: Die Userspace-Bibliothek fungiert als Schnittstelle zwischen dem eBPF-Kernelprogramm und einem Controller, der im Userspace ausgeführt wird (vRouter-Agent). Es stellt APIs zur Verfügung, die der vRouter-Agent zum Programmieren des Datenpfads verwendet. Diese Komponente führt die folgenden Funktionen aus:
-
Lädt und entlädt das eBPF-Programm in den Kernel
-
Bindet eBPF-Programme an Schnittstellen
-
Konfiguriert und liest Karteneinträge
-
Weiterleiten, Ändern und Filtern von Paketen innerhalb des Datenpfads im Benutzerbereich
-
-
Kernel-Space-Programm: Diese eBPF-Programme bilden den Hauptdatenpfad, der im Kernel-Kern ausgeführt wird. Dieses Programm wird auf den XDP-Hook von Schnittstellen geladen und verarbeitet alle eingehenden Pakete für diese Schnittstellen. TC wird auch für den Ausgang der Loopback-Schnittstelle verwendet. Wie bereits erwähnt, ist die eBPF-Bibliothek im Benutzerbereich für das Laden des eBPF-Programms in den Kernel-Kern verantwortlich. Das Kernel-Space-Programm macht Folgendes:
-
Weiterleiten, Ändern und Filtern von Paketen im Kernel
-
Verwendet Hilfsfunktionen, um mit dem Rest des Kernels zu interagieren
-
Erstellt, aktualisiert und liest Maps (Maps sind Datenstrukturen, die von der Userspace-Bibliothek und dem Kernelspace-Programm gemeinsam genutzt werden)
-
Der vRouter-Agent interagiert auf verschiedene Weise mit der eBPF-Datenebene über die Userspace-Bibliothek:
-
Der Controller (vRouter-Agent) ruft APIs auf, die von der eBPF-Bibliothek des Benutzerbereichs direkt verfügbar gemacht werden.
-
Die öffentlichen APIs, die von der Bibliothek verfügbar gemacht werden, ersetzen die Funktionalität, die von der ksync/Sandesh-Schicht bereitgestellt wird, die für andere Datenpfade verwendet wird
-
Der Agent registriert Rückrufe bei der Benutzerbereichsbibliothek für Datenflussfehler und für den Empfang relevanter Pakete
-
- Die Bibliothek lauscht auch auf Netlink-Socket-Ereignisse. Die User-Space-Bibliothek kann Routen sowie ARP- und Adressaktualisierungen vom Kernel überwachen
- Die Bibliothek fragt den Kernel auch nach anderen Informationen ab