本页内容
通过 API 使用 Mist SLE 和洞察
使用 RESTful API 获取有关网络性能的洞察。
当您使用瞻博网络 Mist 门户监控网络运维时,您可以在问题变成问题之前洞悉当前的情况。您可以从多个角度查看网络:无线、有线、WAN 等等。此外,您还可以使用瞻博网络 Mist™ 提供的工具来排除故障并纠正潜在问题。
监控>服务级别的主要Mist仪表板以服务级别预期 (SLE) 指标的形式显示预测分析和关联引擎 (PACE) 的结果。SLE 在瞻博网络 Mist 云中利用机器学习和 Mist PACE。利用这些资源,SLE 可将来自接入点 (AP) 的流式遥测结果转化为近乎实时的最终用户网络体验可视化物。有关 SLE 的更多信息,请参阅瞻博网络 Mist AI 原生运维指南。
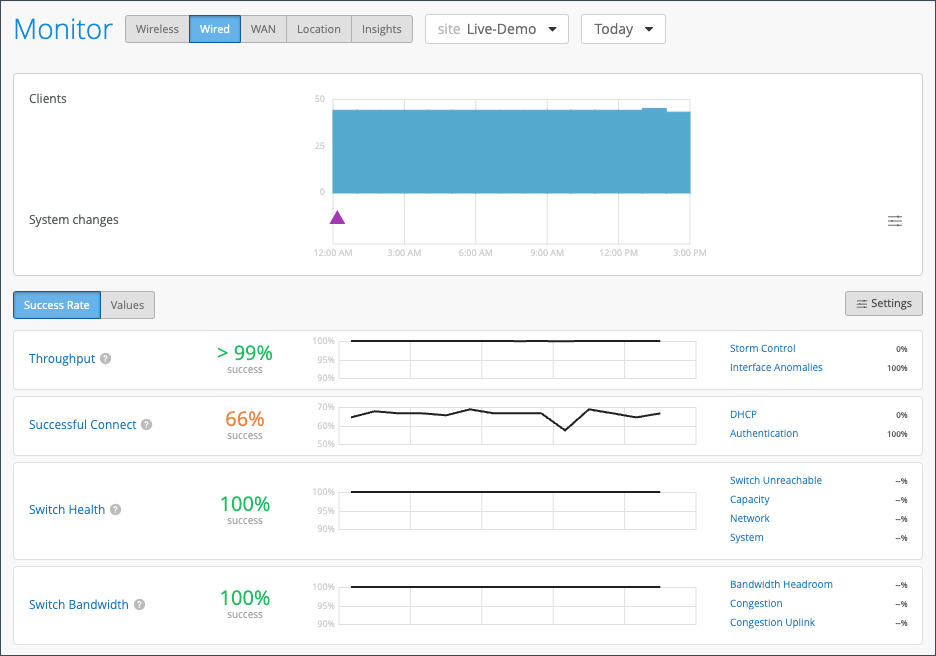
与 Mist GUI 中显示的所有内容一样,SLE 和洞察信息也可从 API 获得。
SLE
收集有关特定 SLE 的信息以用于历史报告或触发其他自动化可能会对您有所帮助。与其他 API 调用一样,首先要确定要从哪个端点收集数据。以下是对端点的 getOrgsSitesSle API GET 请求的示例:
GET
/api/v1/orgs/{org_id}/insights/sites-sle
有关更多信息,请参阅 SLE 概述。
洞察
洞察可以概括分析整个站点、接入点或无线客户端的网络体验。这是在网站上检查时的一个很好的起点。
可以通过向以下 Insights 端点之一发出 GET 请求来查找 Insight 信息:
- GetSiteInsightMetrics
- GetSiteInsightMetricsForDevice
- GetSiteInsightMetricsForClient
有关详细信息,请参阅 见解概述。
指标和分类符
瞻博网络 Mist SLE 和洞察端点支持指标和分类符。指标跟踪服务级别是否满足配置的阈值。如果指标未达到阈值,则此故障可能归因于其中一个分类器,以进一步了解故障发生的位置。
SLE 和 Insights 终结点通常需要参数 metric 。这是因为,除了原始统计数据或配置之外,Mist 还会公开内部数据分析所得的计算值。Mist 不会在每次添加新的数据分析功能时都创建唯一的 API 函数,而是只公开少数函数,而是使用 metric 参数来指定要检索哪些派生数据值。
以下 API 端点将在即将发布的 2026 年版本中弃用:
-
:site_id/sle/:scope/:scope_id/metric/:metric/summary
-
:site_id/sle/:scope/:scope_id/metric/:metric/classifier/:classifier/summary
这些端点将替换为以下新端点:
-
:site_id/sle/:scope/:scope_id/metric/:metric/summary-trend
-
:site_id/sle/:scope/:scope_id/metric/:metric/classifier/:classifier/summary-trend
若要获取见解指标列表,可以发出以下 GET 调用:
GET
/api/v1/sites/{site_id}/insights/{metric}
响应将如下所示:
{
"bytes": {
"description": "aggregated bytes over time",
"example": [
185,
197,
250
],
"intervals": {
"10m": {
"interval": 600,
"max_age": 86400
},
"1h": {
"interval": 3600,
"max_age": 1209600
}
},
"report_durations": {
"1d": {
"duration": 86400,
"interval": 3600
},
"1w": {
"duration": 604800,
"interval": 3600
}
},
"report_scopes": [
"site",
"org"
],
"scopes": [
"site",
"ap",
"client"
],
"type": "timeseries",
"unit": "byte"
},
"num_clients": {
"description": "number of client over time",
"example": [
18,
null,
15
],
"intervals": {
"10m": {
"interval": 600,
"max_age": 86400
},
"1h": {
"interval": 3600,
"max_age": 1209600
}
},
"report_durations": {
"1d": {
"duration": 86400,
"interval": 3600
},
"1w": {
"duration": 604800,
"interval": 3600
}
},
"report_scopes": [
"site",
"org"
],
"scopes": [
"site",
"ap",
"device"
],
"type": "timeseries",
"unit": ""
}
}
查看可用 Insight 指标示例的另一种方法是登录 Mist 门户,然后从同一浏览器在新选项卡中打开此链接:
https://{api/api/v1/const/insight_metrics
使用前面的 GET 调用示例 GET /api/v1/const/insight_metrics,您可以在调用结束时添加所需的指标。有关当前支持的一些指标及其分类器,请参阅下面的示例 GET 调用。
接入点正常运行时间: 接入点可用性
获取电话:GET /api/v1/sites/{site_id}/insights/ap-availability
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/ap-availability/summary?start&end&duration
{
"start": 1727696747,
"end": 1727783147,
"sle": {
"name": "ap-availability",
"x_label": "seconds",
"y_label": "seconds",
"interval": 3600,
"samples": {
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"value": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
]
}
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
},
"classifiers": [
{
"name": "ap-disconnected-ap-unreachable",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "ethernet-ethernet-errors",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "ethernet-speed-mismatch",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "low-power",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "ap-disconnected-switch-down",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "ap-disconnected-site-down",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
},
{
"name": "ap-disconnected-ap-reboot",
"x_label": "seconds",
"y_label": "minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null,
null
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": null,
"num_aps": 0,
"total_users": 0,
"total_aps": 0
}
}
],
"events": []
}
- 接入点重新启动: ap-reboot
- 接入点无法访问: 接入点无法访问
- 站点关闭: 站点关闭
容量: 容量
获取电话:GET /api/v1/sites/{site_id}/insights/capacity
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/capacity/summary?start&end&duration
{
"start": 1727696707,
"end": 1727783107,
"sle": {
"name": "capacity",
"x_label": "seconds",
"y_label": "%",
"interval": 3600,
"samples": {
"total": [
1204.1,
1243.9333,
1184.7667,
1136.9667,
1133.6666,
1152.7167,
1137.8334,
1131.2167,
1119.2167,
1136.1,
1143.9667,
1167.2667,
1133.8667,
1182.5,
1274.6333,
1281.5333,
1232.7333,
1260.9833,
1258.3167,
1250.7167,
1215.25,
1236.0834,
1247.9667,
828.05
],
"degraded": [
228.71666,
301.41666,
110.13333,
88.183334,
82.416664,
128.93333,
139.23334,
295.08334,
170.0,
201.7,
151.41667,
145.06667,
153.91667,
181.76666,
256.45,
239.83333,
214.08333,
215.9,
147.68333,
163.25,
120.36667,
120.2,
135.0,
184.68333
],
"value": [
0.58172977,
0.5803318,
0.5925928,
0.6017501,
0.61211795,
0.611349,
0.6141628,
0.59855264,
0.6093941,
0.60869706,
0.60907525,
0.60685295,
0.60197794,
0.5995983,
0.6004573,
0.6096473,
0.61228454,
0.6112147,
0.60956645,
0.6057745,
0.6139534,
0.6133245,
0.5969889,
0.5707334
]
}
},
"impact": {
"num_users": 26,
"num_aps": 4,
"total_users": 30,
"total_aps": 4
},
"classifiers": [
{
"name": "client-count",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1204.1,
1243.9333,
1184.7667,
1136.9667,
1133.6666,
1152.7167,
1137.8334,
1131.2167,
1119.2167,
1136.1,
1143.9667,
1167.2667,
1133.8667,
1182.5,
1274.6333,
1281.5333,
1232.7333,
1260.9833,
1258.3167,
1250.7167,
1215.25,
1236.0834,
1247.9667,
828.05
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 30,
"total_aps": 4
}
},
{
"name": "wifi-interference",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
202.51666,
226.98334,
84.25,
82.63333,
79.28333,
106.566666,
105.23333,
295.08334,
162.65,
190.48334,
129.05,
140.58333,
146.63333,
163.33333,
245.2,
237.3,
214.08333,
213.75,
139.35,
160.76666,
115.45,
115.0,
115.2,
165.38333
],
"total": [
1204.1,
1243.9333,
1184.7667,
1136.9667,
1133.6666,
1152.7167,
1137.8334,
1131.2167,
1119.2167,
1136.1,
1143.9667,
1167.2667,
1133.8667,
1182.5,
1274.6333,
1281.5333,
1232.7333,
1260.9833,
1258.3167,
1250.7167,
1215.25,
1236.0834,
1247.9667,
828.05
],
"degraded": [
202.51666,
226.98334,
84.25,
82.63333,
79.28333,
106.566666,
105.23333,
295.08334,
162.65,
190.48334,
129.05,
140.58333,
146.63333,
163.33333,
245.2,
237.3,
214.08333,
213.75,
139.35,
160.76666,
115.45,
115.0,
115.2,
165.38333
]
},
"impact": {
"num_users": 26,
"num_aps": 4,
"total_users": 30,
"total_aps": 4
}
},
{
"name": "client-usage",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
26.2,
74.433334,
20.983334,
5.55,
3.1333334,
0,
27.2,
0,
7.35,
1.7333333,
4.616667,
4.483333,
7.2833333,
8.3,
11.25,
2.5333333,
0,
2.15,
8.333333,
2.4833333,
4.9166665,
5.2,
2.6666667,
17.183332
],
"total": [
1204.1,
1243.9333,
1184.7667,
1136.9667,
1133.6666,
1152.7167,
1137.8334,
1131.2167,
1119.2167,
1136.1,
1143.9667,
1167.2667,
1133.8667,
1182.5,
1274.6333,
1281.5333,
1232.7333,
1260.9833,
1258.3167,
1250.7167,
1215.25,
1236.0834,
1247.9667,
828.05
],
"degraded": [
26.2,
74.433334,
20.983334,
5.55,
3.1333334,
0,
27.2,
0,
7.35,
1.7333333,
4.616667,
4.483333,
7.2833333,
8.3,
11.25,
2.5333333,
0,
2.15,
8.333333,
2.4833333,
4.9166665,
5.2,
2.6666667,
17.183332
]
},
"impact": {
"num_users": 16,
"num_aps": 2,
"total_users": 30,
"total_aps": 4
}
},
{
"name": "non-wifi-interference",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
4.9,
0,
0,
22.366667,
6.8,
0,
0,
9.483334,
17.75,
0,
0,
10.133333,
0,
0,
0,
0,
0,
0,
0,
0,
17.133333,
22.966667
],
"total": [
1204.1,
1243.9333,
1184.7667,
1136.9667,
1133.6666,
1152.7167,
1137.8334,
1131.2167,
1119.2167,
1136.1,
1143.9667,
1167.2667,
1133.8667,
1182.5,
1274.6333,
1281.5333,
1232.7333,
1260.9833,
1258.3167,
1250.7167,
1215.25,
1236.0834,
1247.9667,
828.05
],
"degraded": [
0,
0,
4.9,
0,
0,
22.366667,
6.8,
0,
0,
9.483334,
17.75,
0,
0,
10.133333,
0,
0,
0,
0,
0,
0,
0,
0,
17.133333,
22.966667
]
},
"impact": {
"num_users": 11,
"num_aps": 2,
"total_users": 30,
"total_aps": 4
}
}
],
"events": []
}
- 接入点负载: 接入点负载
- 非 WiFi 干扰: 非 wifi 干扰
- wifi干扰: wifi干扰
覆盖范围: 覆盖范围
获取电话:GET /api/v1/sites/{site_id}/insights/coverage
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/coverage/summary?start&end&duration
{
"start": 1727696673,
"end": 1727783073,
"sle": {
"name": "coverage",
"x_label": "seconds",
"y_label": "dBm",
"interval": 3600,
"samples": {
"total": [
1166.2,
1229.7,
1180.7,
1127.1833,
1132.2,
1133.5834,
1129.7167,
1128.1333,
1113.1,
1122.7667,
1119.1333,
1155.6333,
1127.75,
1147.85,
1251.3833,
1279.7833,
1232.7333,
1263.7333,
1253.3,
1249.0333,
1215.25,
1235.1,
1242.0,
948.4667
],
"degraded": [
14.05,
10.433333,
9.583333,
4.516667,
0.0,
10.383333,
0.0,
0.0,
2.3166666,
4.1,
6.5333333,
6.3,
5.15,
10.15,
41.35,
76.03333,
32.666668,
42.25,
11.35,
3.2666667,
1.05,
2.0333333,
15.433333,
12.183333
],
"value": [
-57.629894,
-57.33048,
-57.447754,
-57.30583,
-56.43402,
-56.627388,
-55.95337,
-54.501797,
-54.907463,
-54.84789,
-55.376183,
-56.49305,
-56.228077,
-56.321236,
-57.631668,
-57.97819,
-57.058994,
-56.97246,
-56.41033,
-56.125,
-56.128677,
-56.17078,
-55.696415,
-55.79176
]
}
},
"impact": {
"num_users": 8,
"num_aps": 3,
"total_users": 28,
"total_aps": 4
},
"classifiers": [
{
"name": "asymmetry-uplink",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
9.433333,
7.55,
3.3,
2.8666666,
0,
0,
0,
0,
0,
0,
0,
0.8833333,
0,
1.9166666,
23.383333,
31.1,
1.25,
0,
8.433333,
1.2166667,
0,
0,
13.25,
2.15
],
"total": [
1166.2,
1229.7,
1180.7,
1127.1833,
1132.2,
1133.5834,
1129.7167,
1128.1333,
1113.1,
1122.7667,
1119.1333,
1155.6333,
1127.75,
1147.85,
1251.3833,
1279.7833,
1232.7333,
1263.7333,
1253.3,
1249.0333,
1215.25,
1235.1,
1242.0,
948.4667
],
"degraded": [
9.433333,
7.55,
3.3,
2.8666666,
0,
0,
0,
0,
0,
0,
0,
0.8833333,
0,
1.9166666,
23.383333,
31.1,
1.25,
0,
8.433333,
1.2166667,
0,
0,
13.25,
2.15
]
},
"impact": {
"num_users": 5,
"num_aps": 3,
"total_users": 28,
"total_aps": 4
}
},
{
"name": "asymmetry-downlink",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1166.2,
1229.7,
1180.7,
1127.1833,
1132.2,
1133.5834,
1129.7167,
1128.1333,
1113.1,
1122.7667,
1119.1333,
1155.6333,
1127.75,
1147.85,
1251.3833,
1279.7833,
1232.7333,
1263.7333,
1253.3,
1249.0333,
1215.25,
1235.1,
1242.0,
948.4667
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 28,
"total_aps": 4
}
},
{
"name": "weak-signal",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
4.616667,
2.8833334,
6.2833333,
1.65,
0,
10.383333,
0,
0,
2.3166666,
4.1,
6.5333333,
5.4166665,
5.15,
8.233334,
17.966667,
44.933334,
31.416666,
42.25,
2.9166667,
2.05,
1.05,
2.0333333,
2.1833334,
5.0333333
],
"total": [
1166.2,
1229.7,
1180.7,
1127.1833,
1132.2,
1133.5834,
1129.7167,
1128.1333,
1113.1,
1122.7667,
1119.1333,
1155.6333,
1127.75,
1147.85,
1251.3833,
1279.7833,
1232.7333,
1263.7333,
1253.3,
1249.0333,
1215.25,
1235.1,
1242.0,
948.4667
],
"degraded": [
4.616667,
2.8833334,
6.2833333,
1.65,
0,
10.383333,
0,
0,
2.3166666,
4.1,
6.5333333,
5.4166665,
5.15,
8.233334,
17.966667,
44.933334,
31.416666,
42.25,
2.9166667,
2.05,
1.05,
2.0333333,
2.1833334,
5.0333333
]
},
"impact": {
"num_users": 6,
"num_aps": 3,
"total_users": 28,
"total_aps": 4
}
}
],
"events": []
}
- 非对称下行链路: asymmetry-downlink
- 非对称上行链路: asymmetry-uplink
- 弱信号: weak-signal
漫游: 漫游
获取电话:GET /api/v1/sites/{site_id}/insights/roaming
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/roaming/summary?start&end&duration
{
"start": 1727696635,
"end": 1727783035,
"sle": {
"name": "roaming",
"x_label": "seconds",
"y_label": "roaming-score",
"interval": 3600,
"samples": {
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
1.0,
1.0,
0.0,
0.0,
0.0,
1.0,
0.0,
0.0,
2.0,
0.0,
0.0,
1.0,
1.0,
0.0,
4.0,
0.0,
null,
null,
0.0,
null,
null,
null,
1.0,
1.0
],
"value": [
1.0666667,
1.1333333,
1.0,
1.0,
1.0,
1.173913,
1.0,
1.0,
1.4615384,
1.0,
1.0,
1.2307693,
1.1034483,
1.0,
1.4324324,
1.0,
null,
null,
1.0,
null,
null,
null,
1.5,
1.1515151
]
}
},
"impact": {
"num_users": 3,
"num_aps": 3,
"total_users": 9,
"total_aps": 4
},
"classifiers": [
{
"name": "latency-slow-okc-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "latency-slow-11r-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "stability-failed-to-fast-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "signal-quality-interband-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
0,
0,
0,
1.0,
0,
3.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
0,
0,
0,
1.0,
0,
3.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0
]
},
"impact": {
"num_users": 2,
"num_aps": 3,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "signal-quality-suboptimal-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
1.0,
1.0,
0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
0,
0,
0,
0,
0,
1.0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
1.0,
1.0,
0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
1.0,
0,
0,
0,
0,
0,
0,
0,
1.0,
0
]
},
"impact": {
"num_users": 3,
"num_aps": 2,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "latency-slow-standard-roam",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 9,
"total_aps": 4
}
},
{
"name": "signal-quality-sticky-client",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
45.0,
30.0,
3.0,
12.0,
1.0,
23.0,
2.0,
3.0,
13.0,
10.0,
46.0,
13.0,
29.0,
59.0,
37.0,
4.0,
null,
null,
1.0,
null,
null,
null,
6.0,
33.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 9,
"total_aps": 4
}
}
],
"events": []
}
- 快速漫游失败: 无快速漫游
- 慢速 11r 漫游:次优-11r-漫游
- 俄克拉荷马城漫游速度缓慢: 次优-okc-漫游
- 慢速标准漫游:慢漫游
成功连接: successful-connect
获取电话:GET /api/v1/sites/{site_id}/insights/successful-connect
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/time-to-connect/summary?start&end&duration
{
"start": 1727696454,
"end": 1727782854,
"sle": {
"name": "time-to-connect",
"x_label": "seconds",
"y_label": "seconds",
"interval": 3600,
"samples": {
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
4.0,
1.0,
2.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
1.0,
1.0,
0.0,
0.0,
0.0,
0.0,
0.0,
null,
0.0,
0.0,
0.0,
null,
null,
0.0,
0.0
],
"value": [
1.0913653,
0.5267187,
6.8511662,
0.20886666,
1.885,
0.038458332,
0.059428573,
0.039666668,
0.044153847,
0.27992308,
0.09634693,
0.0908,
0.021689653,
0.047080643,
0.037736844,
0.0205,
null,
0.223,
0.027,
0.344,
null,
null,
0.15811113,
0.04767742
]
}
},
"impact": {
"num_users": 4,
"num_aps": 4,
"total_users": 26,
"total_aps": 4
},
"classifiers": [
{
"name": "IP-Services",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "authorization",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "dhcp-nack",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "association",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
3.0,
1.0,
2.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
3.0,
1.0,
2.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 1,
"num_aps": 3,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "dhcp-stuck",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "dhcp-unresponsive",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
31.0
],
"degraded": [
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 3,
"num_aps": 3,
"total_users": 26,
"total_aps": 4
}
}
],
"events": []
}
- 协会: 协会
- 授权: 授权
- DHCP: DHCP
吞吐量: 吞吐量
获取电话:GET /api/v1/sites/{site_id}/insights/throughput
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/throughput/summary?start&end&duration
{
"start": 1727696554,
"end": 1727782954,
"sle": {
"name": "throughput",
"x_label": "seconds",
"y_label": "Mbps",
"interval": 3600,
"samples": {
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0
],
"value": [
4416.122,
4364.1084,
4225.373,
4254.209,
4319.275,
4330.7563,
4346.148,
4395.728,
4414.8213,
4376.623,
4303.742,
4317.217,
4516.579,
4510.3657,
4462.7544,
4514.023,
4607.6772,
4556.474,
4582.5347,
4593.3706,
4579.6895,
4564.7954,
4442.6,
4417.6904
]
}
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
},
"classifiers": [
{
"name": "capacity-excessive-client-load",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "device-capability",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "network-issues",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "coverage",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "capacity-high-bandwidth-utilization",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "capacity-wifi-interference",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
},
{
"name": "capacity-non-wifi-interference",
"x_label": "seconds",
"y_label": "user-minutes",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
1167.6,
1229.75,
1180.7333,
1123.25,
1135.45,
1134.7333,
1125.95,
1132.2833,
1109.35,
1128.3334,
1114.8167,
1162.75,
1122.4333,
1149.5,
1249.2667,
1276.7833,
1238.9667,
1254.6333,
1257.2,
1244.3833,
1217.2667,
1237.2333,
1239.7833,
758.88336
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 29,
"total_aps": 4
}
}
],
"events": []
}
- 容量: 容量
- 覆盖范围: 覆盖范围
- 设备功能: device-capability
- 网络问题: network-issues
连接时间: 连接时间
获取电话::GET /api/v1/sites/{site_id}/insights/time-to-connect
https://api.gc2.mist.com/api/v1/sites/aee83225-1773-4e55-af64-c8b5a86b1fa6/sle/site/aee83225-1773-4e55-af64-c8b5a86b1fa6/metric/time-to-connect/summary?start&end&duration
{
"start": 1727696603,
"end": 1727783003,
"sle": {
"name": "time-to-connect",
"x_label": "seconds",
"y_label": "seconds",
"interval": 3600,
"samples": {
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
4.0,
1.0,
2.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
1.0,
1.0,
0.0,
0.0,
0.0,
0.0,
0.0,
null,
0.0,
0.0,
0.0,
null,
null,
0.0,
0.0
],
"value": [
1.0913653,
0.5267187,
6.8511662,
0.20886666,
1.885,
0.038458332,
0.059428573,
0.039666668,
0.044153847,
0.27992308,
0.09634693,
0.0908,
0.021689653,
0.047080643,
0.037736844,
0.0205,
null,
0.223,
0.027,
0.344,
null,
null,
0.15811113,
0.07152778
]
}
},
"impact": {
"num_users": 4,
"num_aps": 4,
"total_users": 26,
"total_aps": 4
},
"classifiers": [
{
"name": "dhcp-unresponsive",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
1.0,
1.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 3,
"num_aps": 3,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "dhcp-stuck",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "dhcp-nack",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "association",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
3.0,
1.0,
2.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
3.0,
1.0,
2.0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 1,
"num_aps": 3,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "authorization",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
},
{
"name": "IP-Services",
"x_label": "seconds",
"y_label": "attempts",
"interval": 3600,
"samples": {
"duration": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"total": [
52.0,
32.0,
6.0,
15.0,
2.0,
24.0,
7.0,
3.0,
13.0,
13.0,
49.0,
15.0,
29.0,
62.0,
38.0,
4.0,
null,
1.0,
1.0,
2.0,
null,
null,
9.0,
36.0
],
"degraded": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
]
},
"impact": {
"num_users": 0,
"num_aps": 0,
"total_users": 26,
"total_aps": 4
}
}
],
"events": []
}
- 协会: 协会
- 授权: 授权
- DHCP: DHCP
- 互联网服务: IP 服务\u000C
计算 SLE 百分比
SLE 指标成功率计算为所选时间范围内达到阈值频率的百分比。分类器也按百分比计算,但这些值表示它们对父故障的影响。
例如,下面的屏幕截图显示 Time to Connect 在 96% 的时间内成功;所有在下午 3:00-4:00 成功连接的客户端在 4 秒阈值内完成了连接过程。
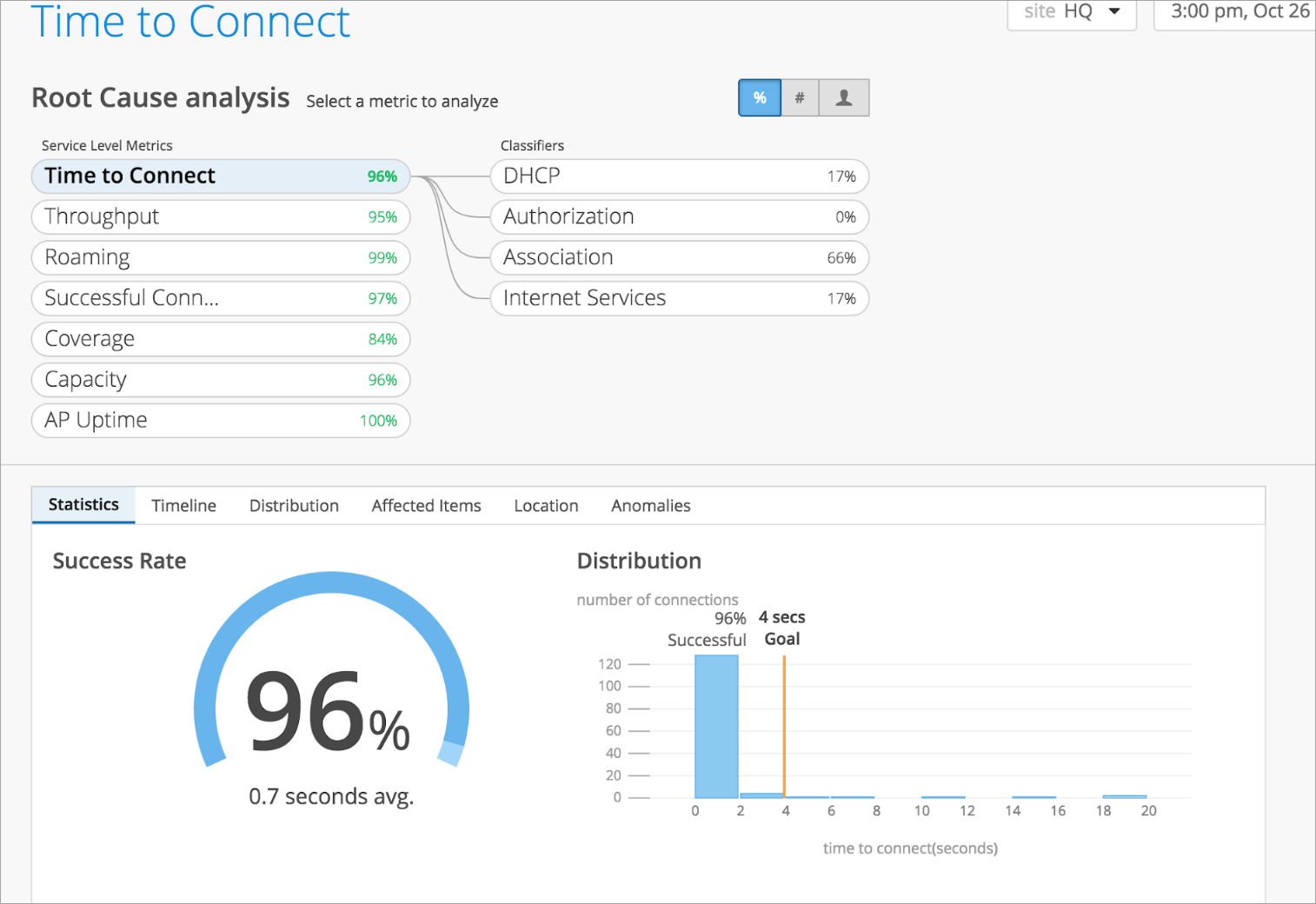
此指标的成功率 (%) 源自“指标摘要”API 端点。
/api/v1/sites/:site_id/sle/site/:site_id/metric/time-to-connect/summary?start=1540591200&end=1540594800
{
“start”: 1540591200,
“end”: 1540594800,
“sle”: {
“x_label”: “seconds”,
“y_label”: “seconds”,
“interval”: 600,
“name”: “time-to-connect”,
“samples”: {
“degraded”: [
0.0,
0.0,
3.0,
0.0,
3.0,
0.0
],
“total”: [
19.0,
14.0,
34.0,
8.0,
20.0,
43.0
]
}
}
}
度量失败率的计算方法是将故障数 (sle.samples.degraded) 除以总数 (sle.samples.total)。然后将其转换为成功率百分比。使用上述 API 响应有效负载,计算如下所示:
ceil(1-[(0.0+0.0+3.0+0.0+3.0+0.0)/(19.0+14.0+34.0+8.0+20.0+43.0)])*100= ceil(1-[6/138])*100= ceil(1-0.04347826086)*100= ceil(0.95652173914)*100= 0.96*100= =96%
此屏幕截图显示了导致指标故障的分类器(DHCP、授权、关联和 Internet 服务):
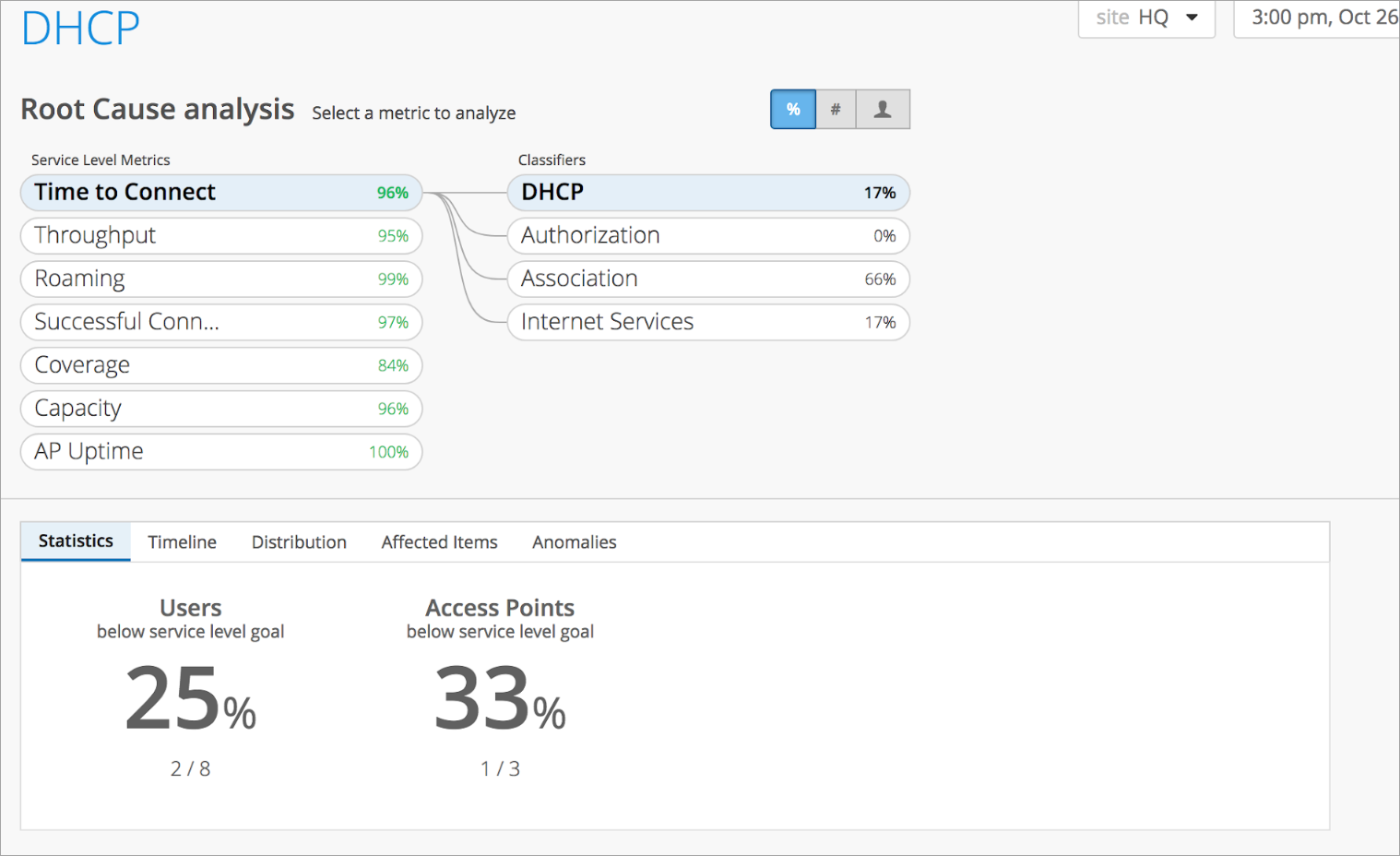
分类器的影响 (%) 源自同一个“指标摘要”API 端点。
/api/v1/sites/:site_id/sle/site/:site_id/metric/time-to-connect/summary?start=1540591200&end=1540594800
{
“start”: 1540591200,
“end”: 1540594800,
“classifiers”: [
{
“name”: “DHCP”,
“samples”: {
“degraded”: [
0,
0,
0,
0,
1.0,
0
]
}
},
{
“name”: “authorization”,
“samples”: {
“degraded”: [
0,
0,
0,
0,
0,
0
]
}
},
{
“name”: “association”,
“samples”: {
“degraded”: [
0,
0,
3.0,
0,
1.0,
0
]
}
},
{
“name”: “IP-Services”,
“samples”: {
“degraded”: [
0,
0,
0,
0,
1.0,
0
]
}
}
]
}
分类器影响的计算方法是将分类器的故障 (classifiers[n].samples.degraded) 除以所有故障的总和 (classifiers[].samples.degraded)。然后将其转换为百分比。使用上述 API 响应有效负载,DHCP 的计算如下所示:
ceil([0+0+0+0+1.0+0]/[(0+0+0+0+1.0+0)+(0+0+0+0+0+0)+(0+0+3.0+0+1.0+0)+(0+0+0+0+1.0+0)])*100= ceil(1/[1.0+0+4.0+1.0])*100= ceil(1/6)*100= ceil(0.16666666666)*100= 0.17*100= =17%
监控 SLE
SLE 数据每 10 分钟更新一次。但是,在此粒度下进行监控时,SLE 容易出现波动。因此,建议使用显式开始和结束时间查询 1 小时间隔,并且每小时仅轮询一次。