EVPN/VXLAN GPU 后端交换矩阵 – GPU 多租户
GPU 多租户(GPU 即服务 – GPUaaS)
GPU 即服务 (GPUaaS) 是一种按需向用户或应用提供 GPU 计算资源的模型,类似于其他实用程序类型的计算服务。GPUaaS 不是将整个服务器或集群专用于单个团队或目的,而是允许根据当前的工作负载要求动态分配资源。租户可以请求特定数量的 GPU(通常跨多个服务器),并将其用于 AI 训练、数据分析或可视化等任务。该服务抽象化底层基础架构,为用户提供无缝、可扩展的体验,同时保持安全高效的资源隔离。通过将灵活性与集中管理相结合,GPUaaS 可以提高资源利用率,并简化多团队或项目共享同一数据中心环境中的运维。
GPU 多租户是一种资源管理方法,允许多个租户在共享基础架构中独立使用 GPU 资源。GPU 多租户不是将服务器中的所有 GPU 分配给单个租户,而是实现更灵活的分配,其中服务器上的一个或多个 GPU 可以为不同的租户保留。此模型允许组织将 GPU 资源与每个工作负载的特定需求相匹配,而不是过度配置整个服务器,从而提高效率。每个租户都在逻辑隔离的环境中运作,计算资源、网络路径和相关配置明确分离。这种隔离可确保租户可以不受干扰地运行其应用,同时管理员可以集中控制 GPU 分发和访问。
GPU 多租户和 GPU 即服务 (GPUaaS) 是密切相关的概念,当它们结合起来时,可以在多租户环境中高效、可扩展地使用 GPU 基础架构。GPU 多租户允许将 GPU 资源灵活地精细分配给不同的租户,无论是一个 GPU、多个 GPU,还是跨不同服务器的特定 GPU,都奠定了基础。这种方法可确保每个租户在逻辑隔离的环境中运行,即使在共享物理基础架构时也能保持安全性和性能一致性。
在此基础上,GPUaaS 将这些功能抽象成按需服务模型。GPUaaS 不需要用户管理物理服务器或硬件配置,而是根据需要动态提供 GPU 资源。它利用底层多租户框架,根据用户请求分配 GPU,实施隔离,并跨不同的工作负载优化使用。这使得数据中心能够同时支持各种团队或应用,而无需为每个团队或应用分配整个服务器。
GPU 多租户和 GPUaaS 一起可实现高效率、更好的资源利用率和更简单的运维。虽然多租户处理安全、灵活的 GPU 资源切片,但 GPUaaS 将这些切片作为消耗服务提供,根据需要扩大或缩减计算容量,并使 GPU 驱动的计算更易于访问且更具成本效益,从而适应各种用例。
GPU 多租户的类型
服务器隔离:
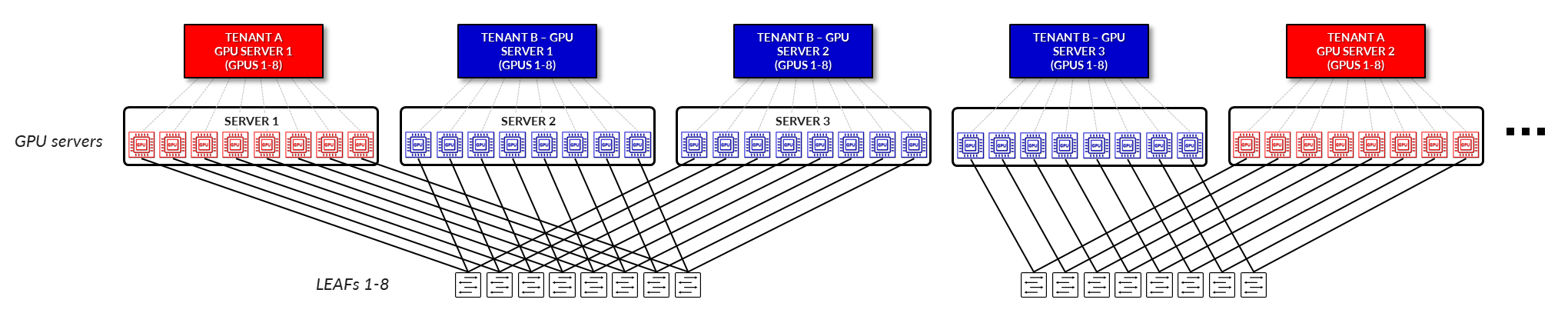
在服务器隔离模型中,系统会为每个租户分配一个或多个完整的服务器。这些服务器中的所有 GPU 都专用于单个租户,确保与其他租户在物理和逻辑上完全分离。该模型简化了资源分配,并将跨租户干扰的风险降至最低,非常适合需要可预测性能和严格隔离的工作负载。(图 4)。
图 4:GPU 即服务 - 服务器隔离
GPU 隔离:
在 GPU 隔离模型中,服务器中的各个 GPU 会分配给不同的租户。这允许多个租户安全地共享同一台物理服务器,每个租户仅访问分配给他们的 GPU。底层交换矩阵提供逻辑隔离,并保证 GPU 级别的隔离,在不影响安全性或性能的情况下实现更大的灵活性和更高的资源利用率。(图 5)。
图 5:GPU 即服务 – GPU 隔离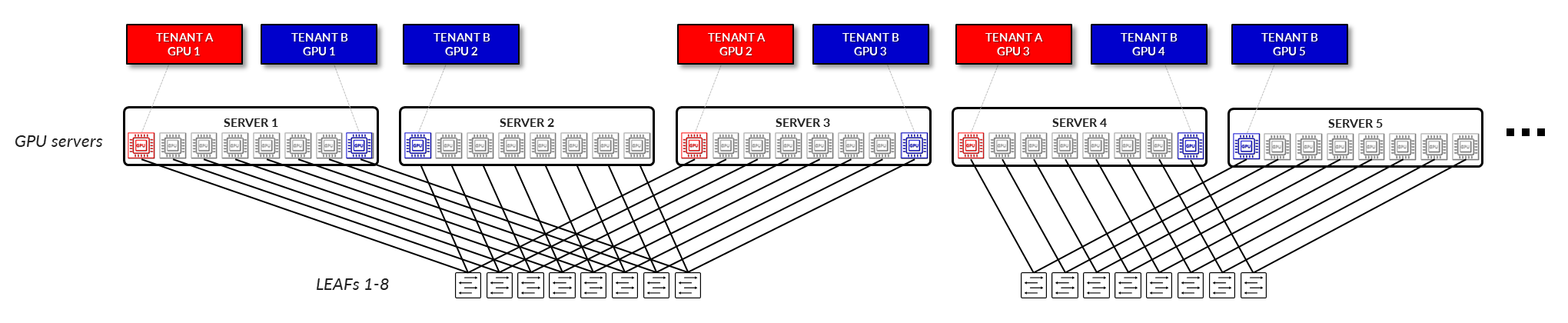
适用于多租户架构的 GPU 后端交换矩阵
适用于多租户的 GPU 后端交换矩阵的设计遵循使用 EVPN/VXLAN 的三级 Clos 轨道优化条带架构。此方法可在分配给同一租户的 GPU 之间实现高性能通信,同时确保租户之间的流量隔离,从而实现服务器隔离和 GPU 隔离。有关服务器隔离和 GPU 隔离的详细信息,请参阅 使用 GPU 多租户的轨道对齐和局部优化注意事项。
图 6:GPU 后端交换矩阵架构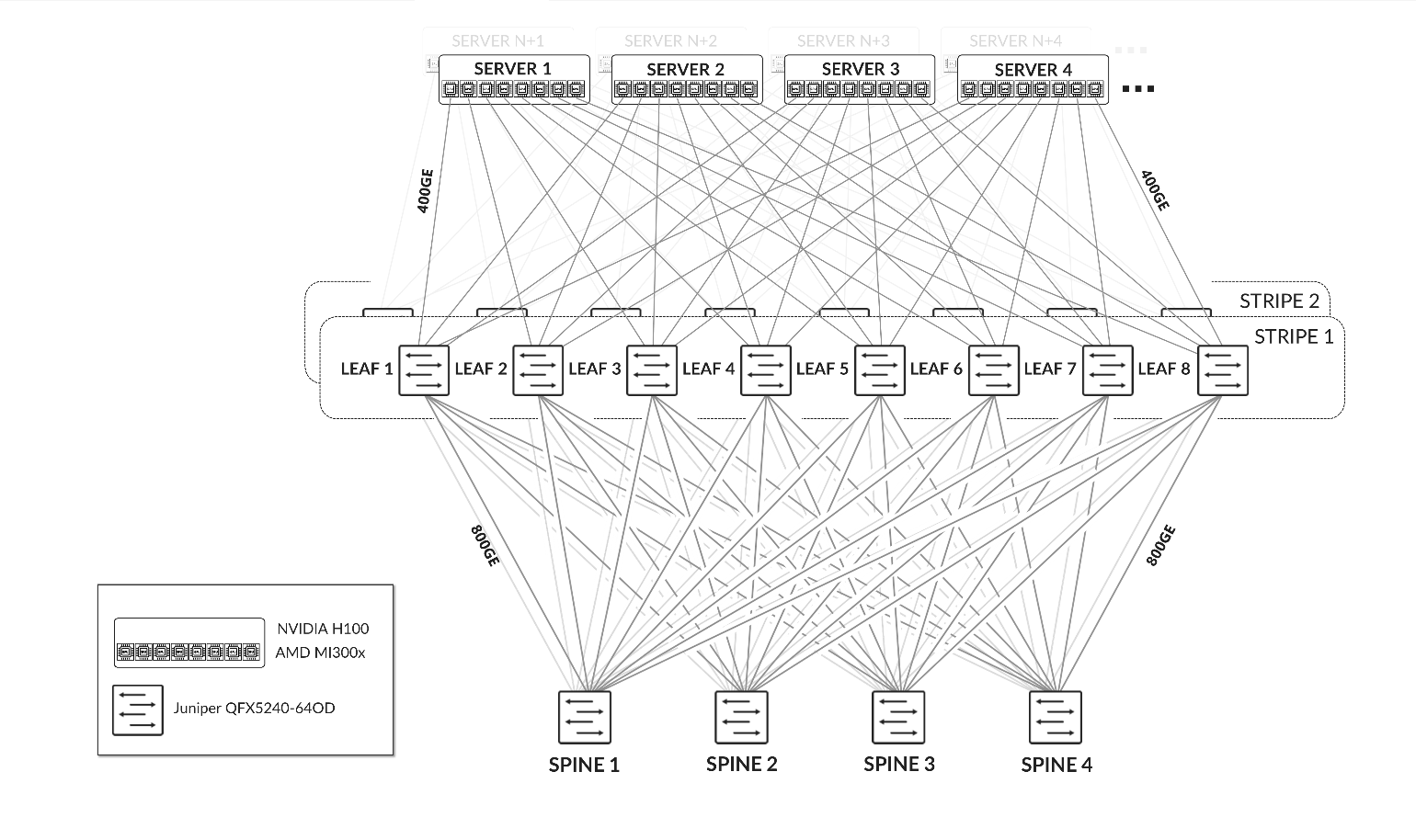
图 7:GPU 后端交换矩阵 EVPN/VXLAN 连接 – 服务器隔离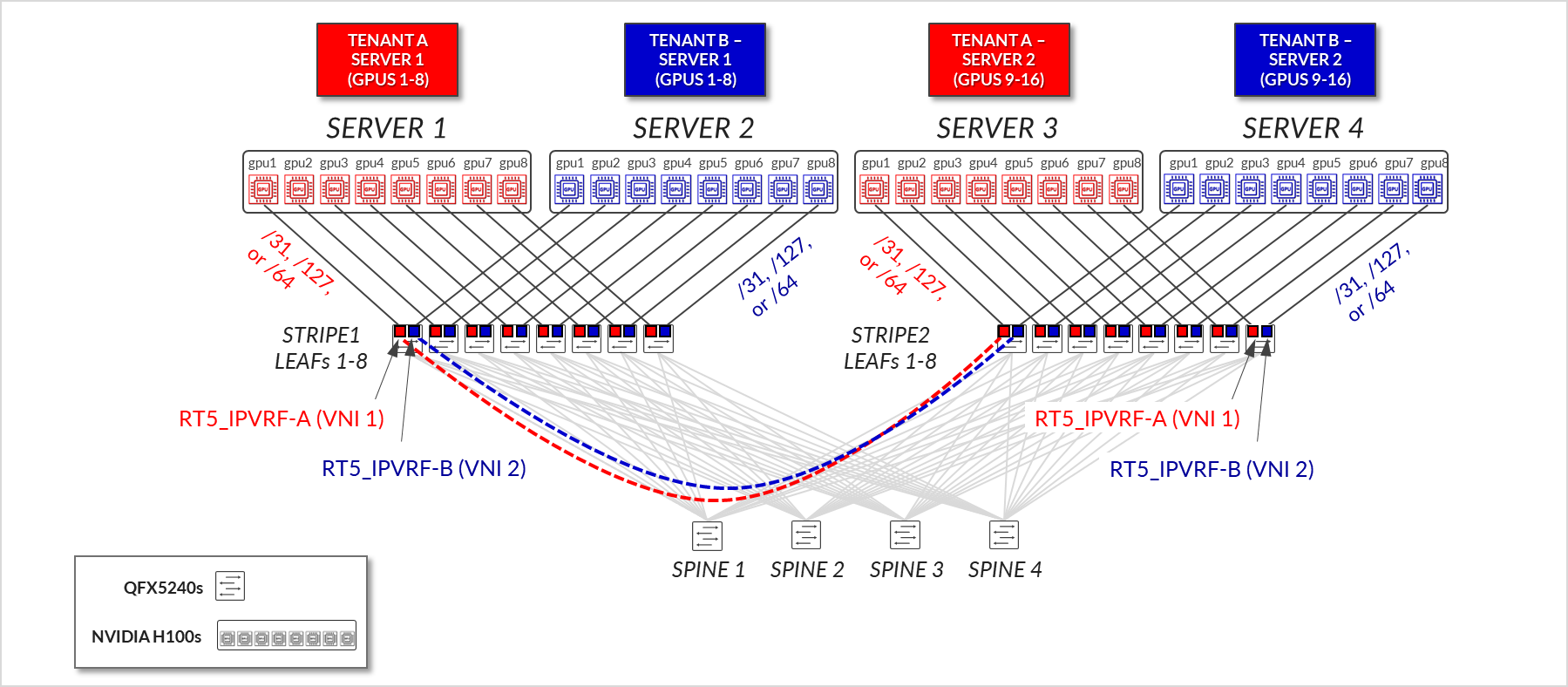
图 8:GPU 后端交换矩阵 EVPN/VXLAN 连接 - GPU 隔离
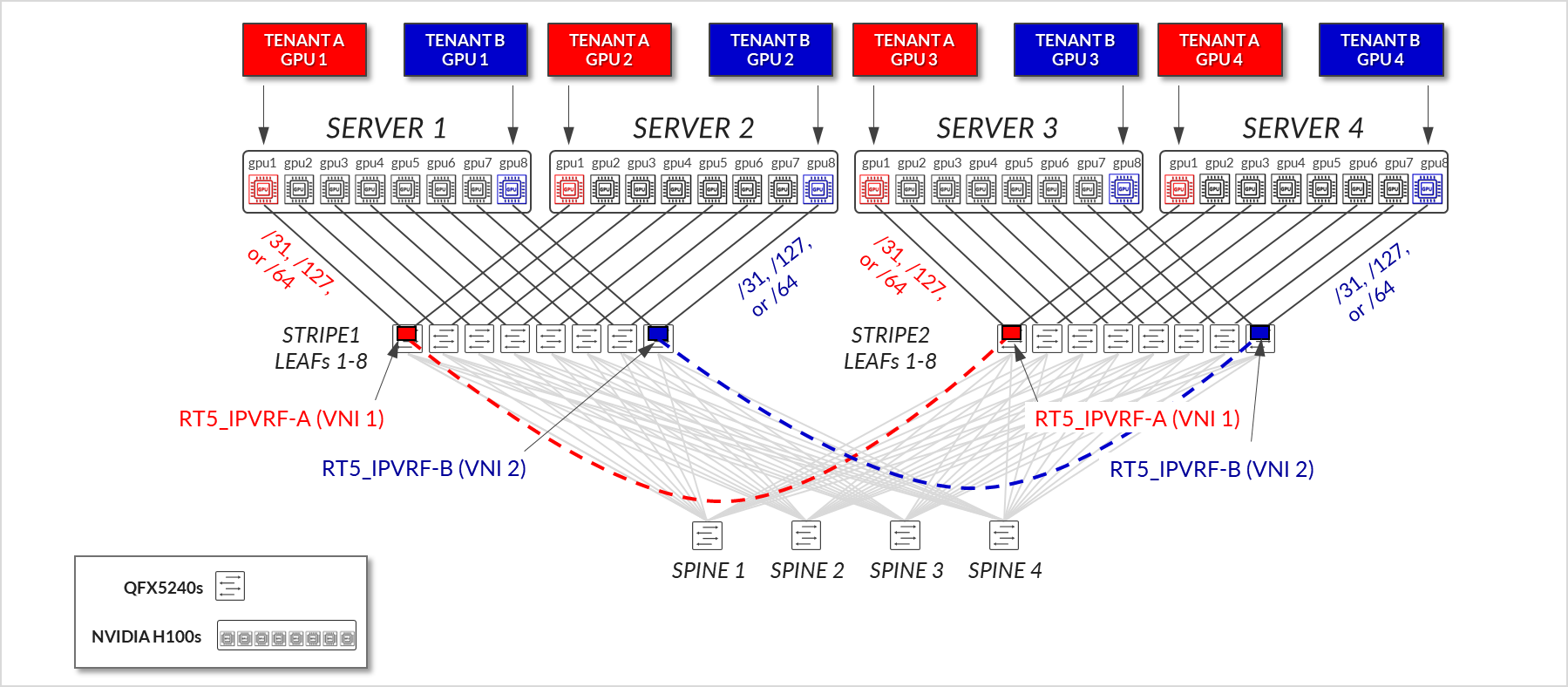
表 1 和表 2 总结了属于 AI 实验室中 GPU 后端交换矩阵的设备以及它们之间的连接:
表 1:每个 Stripe 的 GPU 后端设备数
| Stripe | GPU 服务器 | GPU 后端叶设备 节点交换机型号 |
GPU 后端主干节点 交换机型号 |
|---|---|---|---|
| 1 | MI300X x 2 (MI300X-01 和 MI300X-02) 高 100 x 2 (H100-01 & H100-02) |
QFX5240-64 外径 x 8 (gpu-backend-001_leaf#; #=1-8) |
QFX5240-64 外径 x 4 (gpu-backend-spine#; #=1-4) |
| 2 | MI300X x 2 (MI300X-03 和 MI300X-04) 高 100 x 2 (H100-01 & H100-02) |
QFX5240-64 外径 x 8 (gpu-backend-002_leaf#; #=1-8) |
所有 Nvidia H100 和 AMD MI300X GPU 服务器都使用 400GE 接口连接到 GPU 后端交换矩阵。
表 2:服务器、叶节点和主干节点之间的 GPU 后端连接。
| 条纹 | GPU 服务器 <=> GPU 后端叶节点 |
GPU 后端叶节点 <=> GPU 后端主干节点 |
|---|---|---|
| 1 | 400GE 链路总数 服务器和叶节点之间 = 8(每台服务器的 GPU 数)x 1(400GE 服务器到叶链路的数量)x 4(服务器数量)= 32 |
400GE 链路总数 GPU 后端叶节点和主干节点之间 = 8(叶节点数)x 2(每个枝叶到主干连接的 400GE 链路数)x 4(主干节点数)= 64 |
| 2 | 400GE 链路总数 服务器和叶节点之间 = 8(每台服务器的 GPU 数)x 1(400GE 服务器到叶链路的数量)x 4(服务器数量)= 32 |
400GE 链路总数 GPU 后端叶节点和主干节点之间 = 8(叶节点数)x 2(每个枝叶到主干连接的 400GE 链路数)x 4(主干节点数)= 64 |
GPU 服务器和叶节点之间以及叶节点和主干节点之间的速度和链路数量决定了超额订阅因素。例如,考虑实验室中可用的 GPU 服务器数量,以及它们连接到 GPU 后端交换矩阵的方式,如上所述。
服务器和叶节点之间的带宽为 25.6 Tbps(表 3),而叶节点和主干节点之间的可用带宽也为 51.2 Tbps(表 4)。这意味着交换矩阵有足够的容量来处理 GPU 之间的所有流量,即使这些流量是 100% 的条纹间流量,并且具有额外的容量来容纳另外 4 台服务器。如果增加 4 台服务器,订阅系数将为 1:1(无超额订阅)。
表 3:每条带服务器到叶带宽
| 每个条带的服务器到叶带宽 | ||||
|---|---|---|---|---|
| 条纹 | 服务器数量 每个 Stripe |
400 GE 数量 服务器 Ó 叶链路 每台服务器 (与叶节点数量 & 相同 每台服务器的 GPU 数量) |
服务器 <=>叶 链路带宽 [Gbps] |
服务器总数 <=> 叶链路 每个条带的带宽 [Tbps] |
| 1 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
| 2 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
| 总 服务器 <=>叶带宽 |
25.6 Tbps | |||
表 4:每条带叶到主干带宽
| 叶节点到主干节点每个条带的带宽 | |||||
|---|---|---|---|---|---|
| 条纹 | 数量 叶节点 |
主干节点数 | 800 GE 数量 叶式 Ó 主干链路 每叶节点 |
服务器 <=>叶 链路带宽 [Gbps] |
带宽叶<=>主干 每条带 [Tbps] |
| 1 | 8 | 4 | 1 | 800 Gbps | 8 x 4 x 1 x 800 Gbps = 25.6 Tbps |
| 2 | 8 | 4 | 1 | 800 Gbps | 8 个 4 个 1 个 400 Gbps = 25.6 Tbps |
| 总 叶<=>主干带宽 |
51.2 Tbps | ||||
GPU 到叶节点的连接遵循 Rail 优化架构,如 后端 GPU Rail 优化条带架构中所述。
后端 GPU 轨道优化条带架构
Rail 优化的条带架构可在 GPU 之间提供高效的数据传输,尤其是在计算密集型任务(如 AI 大型语言模型 (LLM) 训练工作负载)期间,在这些任务中,为了在合理的时间范围内完成任务,需要无缝的数据传输。轨道优化拓扑旨在通过提供最小的带宽争用、最小的延迟和最小的网络干扰来最大限度地提高性能,从而实现这种高效的数据传输。
在轨道优化的条带架构中,有两个重要概念:轨道和条纹。
服务器上的 GPU 编号为 1-8,其中数字表示 GPU 在服务器中的位置,如图 9 所示。
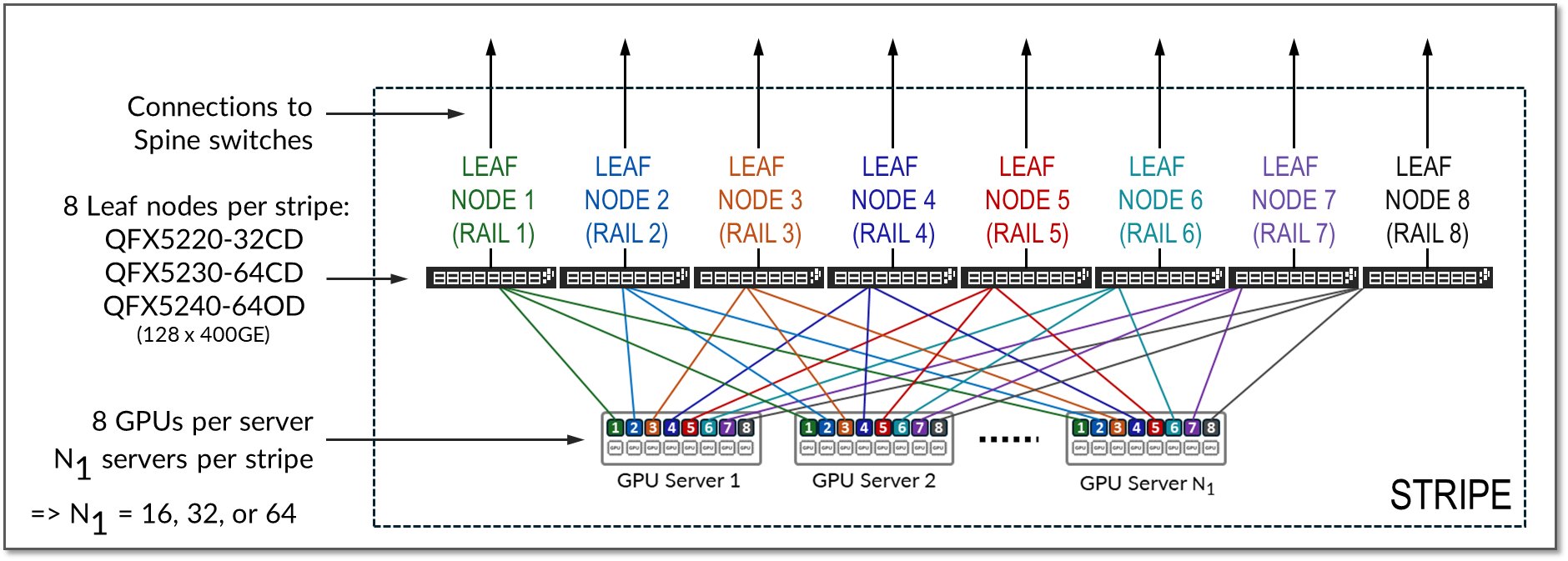
导轨将相同顺序的 GPU 连接到交换矩阵中的一个叶节点上;也就是说,轨道 N 将所有服务器中位置 N 中的 GPU 连接到叶节点 N。
图 9:轨道优化架构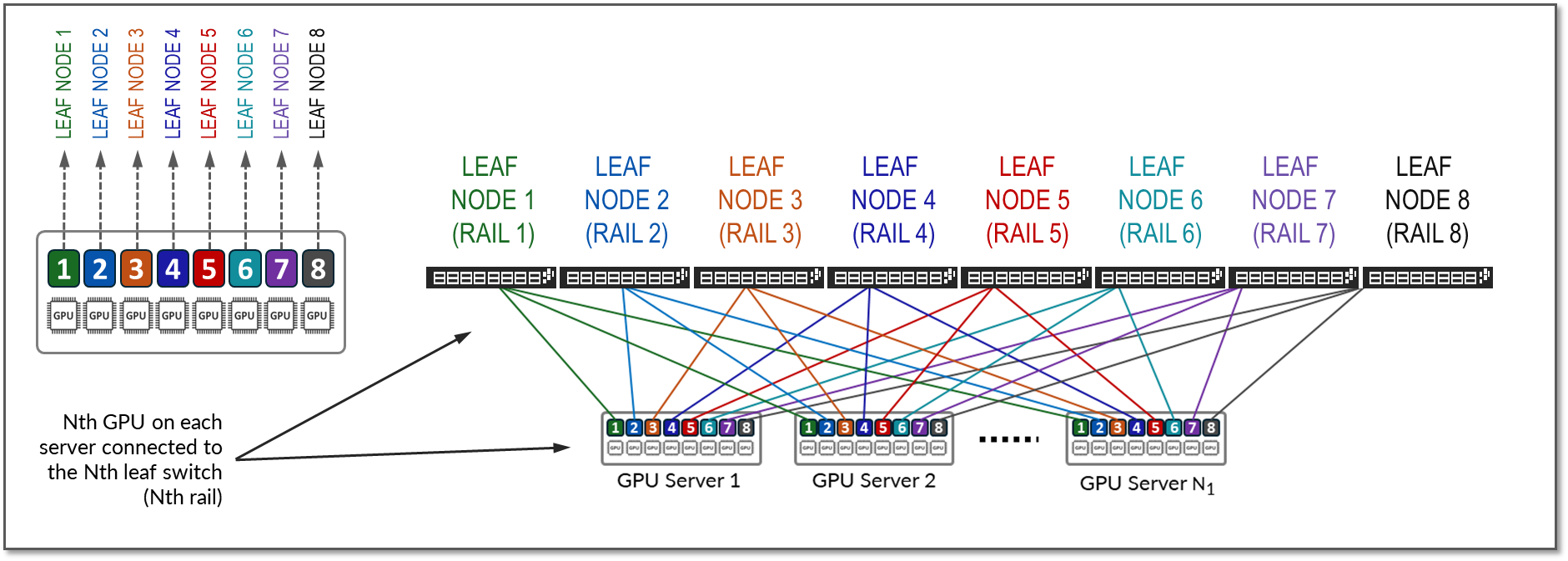 中的轨道
中的轨道
条带是指由一组叶节点和 GPU 服务器组成的设计模块或构建块,如图 10 所示。可以复制此模块以纵向扩展 AI 群集。
图 10:轨道优化架构中的条纹
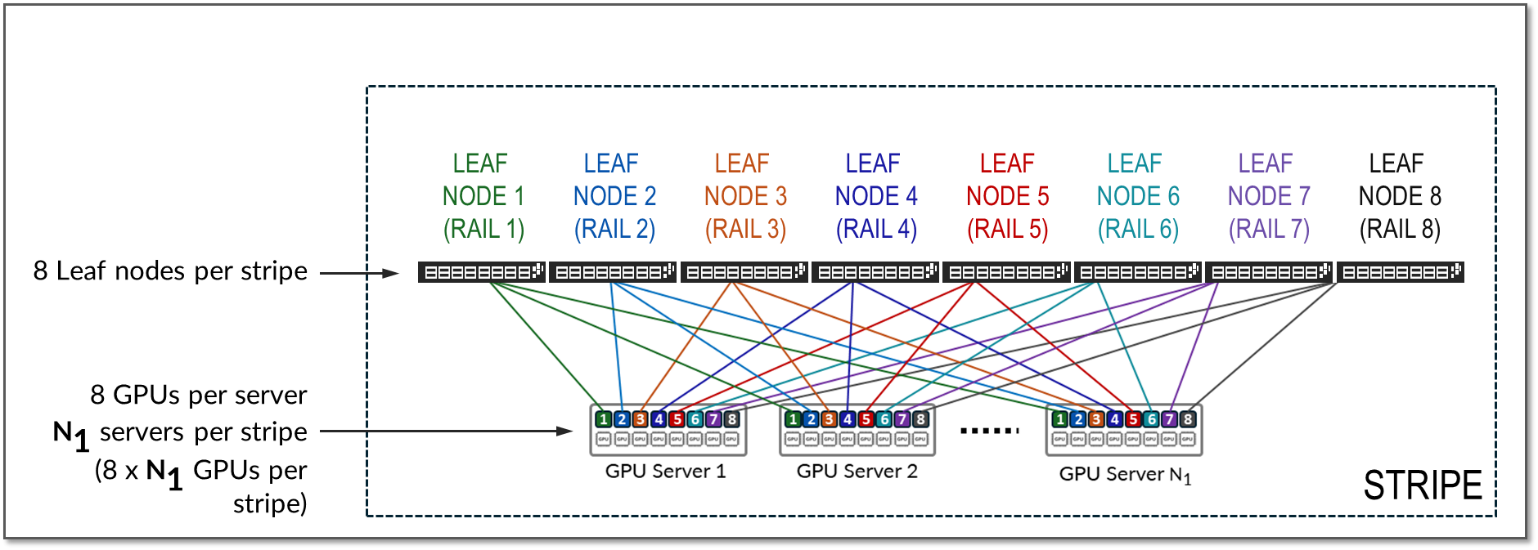
单个条带中的叶节点数,以及单个条带中的轨道数,始终由每个服务器的 GPU 数量定义。每个 GPU 服务器通常包含 8 个 GPU。因此,单个条带通常包括 8 个叶节点(8 个导轨)。
在轨道优化架构中,单条带(图 7 中的 N1)支持的最大服务器数量受叶节点交换机模型支持的接口数量和速度的限制。这是因为 GPU 服务器和叶节点之间的总带宽必须与叶节点和主干节点之间的总带宽相匹配,以保持 1:1 的订阅比例,这是理想的。
假设叶节点上的所有接口都以相同的速度运行,则一半的接口将用于连接到 GPU 服务器,另一半用于连接到主干。因此,条带中的最大服务器数计算为每个叶节点上接口总数的一半。表 5 中列出了一些示例。
表 5:每个条带支持的最大 GPU 数
| 叶节点 QFX 交换机型号 |
最大 400 GE 接口数 每台交换机 |
每个条带支持的最大服务器数(1:1 订阅) | 每个服务器的 GPU | 数 每个条带支持的最大 GPU 数 |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 16 个服务器 x 8 个 GPU/服务器 = 128 个 GPU |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 32 个服务器 x 8 个 GPU/服务器 = 256 个 GPU |
| QFX5240-64OD | 128 | 128 ÷ 2 = 64 | 8 | 64 个服务器 x 8 个 GPU/服务器 = 512 个 GPU |
- QFX5220-32CD 交换机提供 32 个 400 GE 端口(16 个用于连接服务器,16 个用于连接主干节点)
- QFX5230-64CD 交换机提供多达 64 个 400 GE 端口(32 个用于连接到服务器,32 个用于连接到主干节点)。
- QFX5240-64OD 交换机提供多达 128 个 400 GE 端口(其中 64 个用于连接服务器,64 个用于连接主干节点)。请参阅图 11。
QFX5240-64OD 交换机配有 64 个 800GE 端口,可分成 2 个 400GE 端口,最多可容纳 128 个 400GE 接口,如表 5 所示。
图 11:轨道优化架构中每条带的最大服务器数。
举例来说,为了说明如何计算支持的服务器数量,为了强化轨道和条带的概念,假设交换机只有 8 个相同速度的端口,而每个 GPU 服务器有 8 个 GPU,如图 12 所示。
图 12.8 端换机支持的服务器数作为叶节点示例。 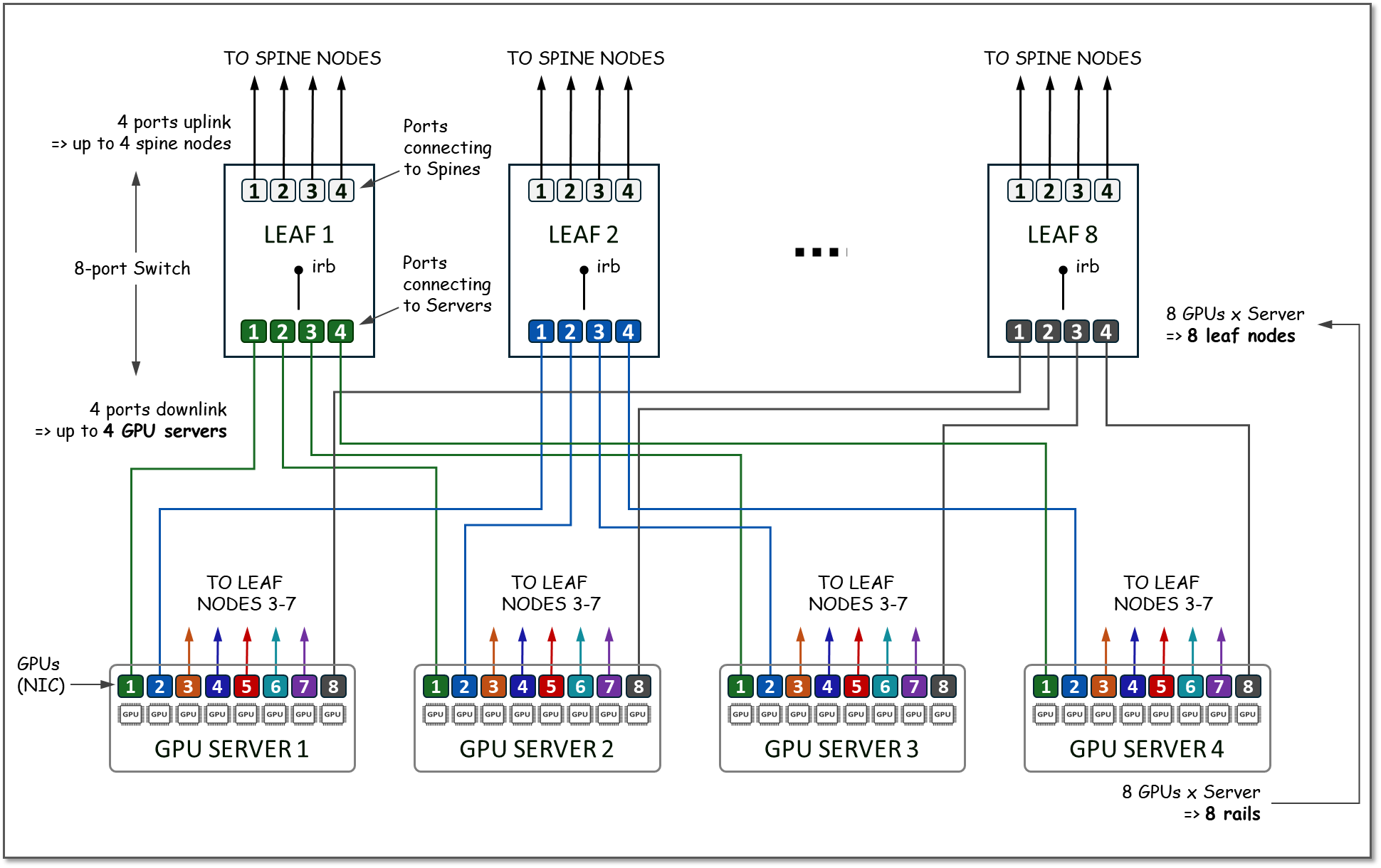
由于 GPU 服务器有 8 个 GPU,因此叶节点的数量将为 8。在每个叶节点上,将使用 4 个端口连接到主干节点(用于下一节所述的扩展目的),4 个端口将用于连接到 GPU 服务器。所有编号为 1 的 GPU 将连接到叶节点 1,所有编号为 2 的 GPU 将连接到叶节点 2,依此类推,每个组代表一个 RAIL(总共 8 个 RAILS),所有 4 台服务器和 8 台交换机的组共同代表一个 STRIPE(总共 32 个 GPU), 如图 13 所示。
图 13.带 8 叶(8 端换机)节点的条带和 Rails 示例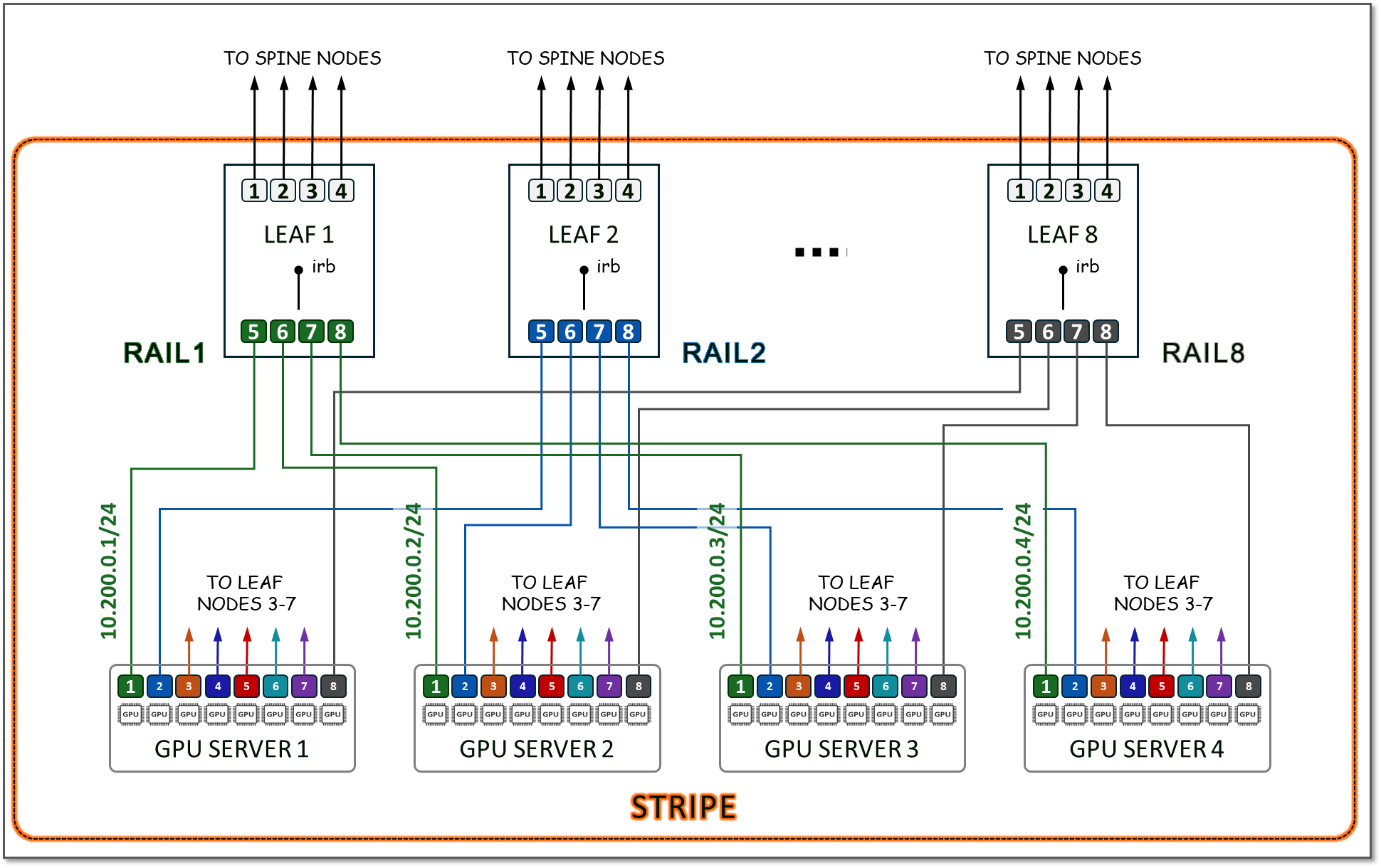
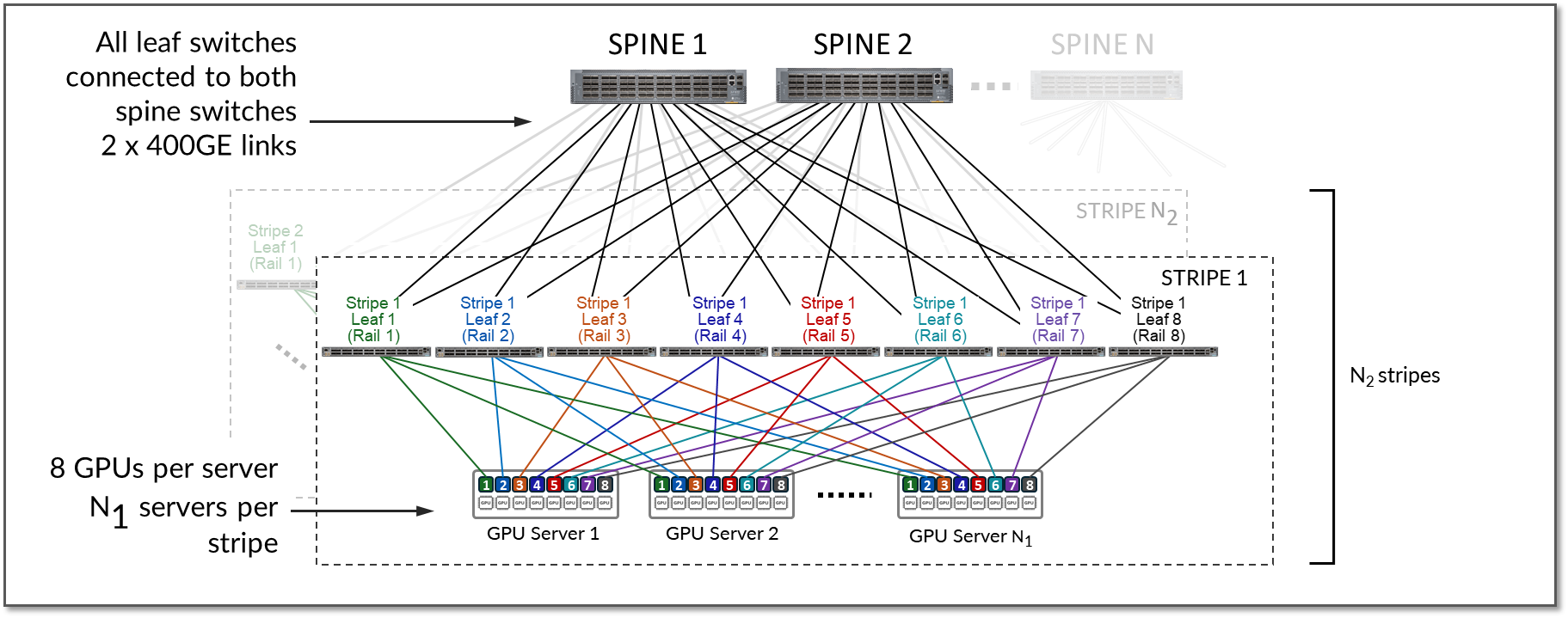
为了实现更大的规模,可以实现多个条带。条带使用主干开关连接,主干开关提供条带间连接,如图 14 所示。
图 14:通过主干节点连接的多个条带
例如,假设所需的 GPU 数量为 16,000,并且交换矩阵使用 QFX5230-64CD 或 QFX5240-64OD 作为叶节点:
- QFX5240-64OD 叶节点支持多达 128 个 400Gbps 端口
- 每条带的最大服务器数 (N1) 通过除以叶节点支持的端口数计算得出。
N1 = 128 ÷ 2 = 64
- 每个条带支持的最大 GPU 数是通过将每个条带的最大服务器数 (N1) 乘以每个服务器上的 GPU 数计算得出的:
N1 x 8 = 64 x 8 = 512
- 所需条带数 (N2) 的计算方法是将所需的 GPU 数除以每个条带支持的最大 GPU 数:
N2 = 16000/512 ≈ 31.25 条条纹(四舍五入为 32)
当 N2 = 64 条带和 N1 服务器 = 32 时,集群可以提供 16,384 个 GPU。如果 N2 增加到 72 个 &N 1 服务器 = 32,集群可以提供 18432 个 GPU。
AI JVD 设置中的 条带 由枯萎的 8 台瞻博网络 QFX5220-32CD、QFX5230-64CD 或 QFX5240-64OD 交换机组成,具体取决于集群和条带,如表 6 所示。
表 6.JVD 实验室中每个群集中支持的最大 GPU 数
| 群集 | 条纹 | 叶节点 QFX 模型 | 每个条纹支持的最大 GPU 数 |
|---|---|---|---|
| 1 | 1 | QFX5230-64CD | 32 个服务器 x 8 个 GPU/服务器 = 256 个 GPU |
| 1 | 2 | QFX5220-32CD | 16 个服务器 x 8 个 GPU/服务器 = 128 个 GPU |
| 群集支持的 GPU 总数 = 384 个 GPU | |||
| 2 | 1 | QFX5240-64OD | 64 个服务器 x 8 个 GPU/服务器 = 512 个 GPU |
| 2 | 2 | QFX5240-64OD | 64 个服务器 x 8 个 GPU/服务器 = 512 个 GPU |
| 群集支持的 GPU 总数 = 1024 个 GPU | |||
本地优化
轨道优化拓扑中的优化是指如何管理 GPU 通信,以最大限度地减少拥塞和延迟,同时最大限度地提高吞吐量。这种优化策略的一个关键部分是尽可能将流量保持在本地。通过确保 GPU 通信保持在同一轨道或条带内,甚至在可能的情况下保持在同一服务器内,从而减少了遍历主干或外部链接的需求。这样可以降低延迟,最大限度减少拥塞,并提高整体效率。
虽然本地化流量是优先事项,但在较大的 GPU 群集中,条纹间通信将是必要的。通过适当的路由和可用链路上的平衡技术,优化了条纹间通信,以避免瓶颈和数据包丢失。优化的本质在于利用拓扑将流量引导至最短、拥塞最少的路径,即使在网络扩展时也能确保性能稳定。
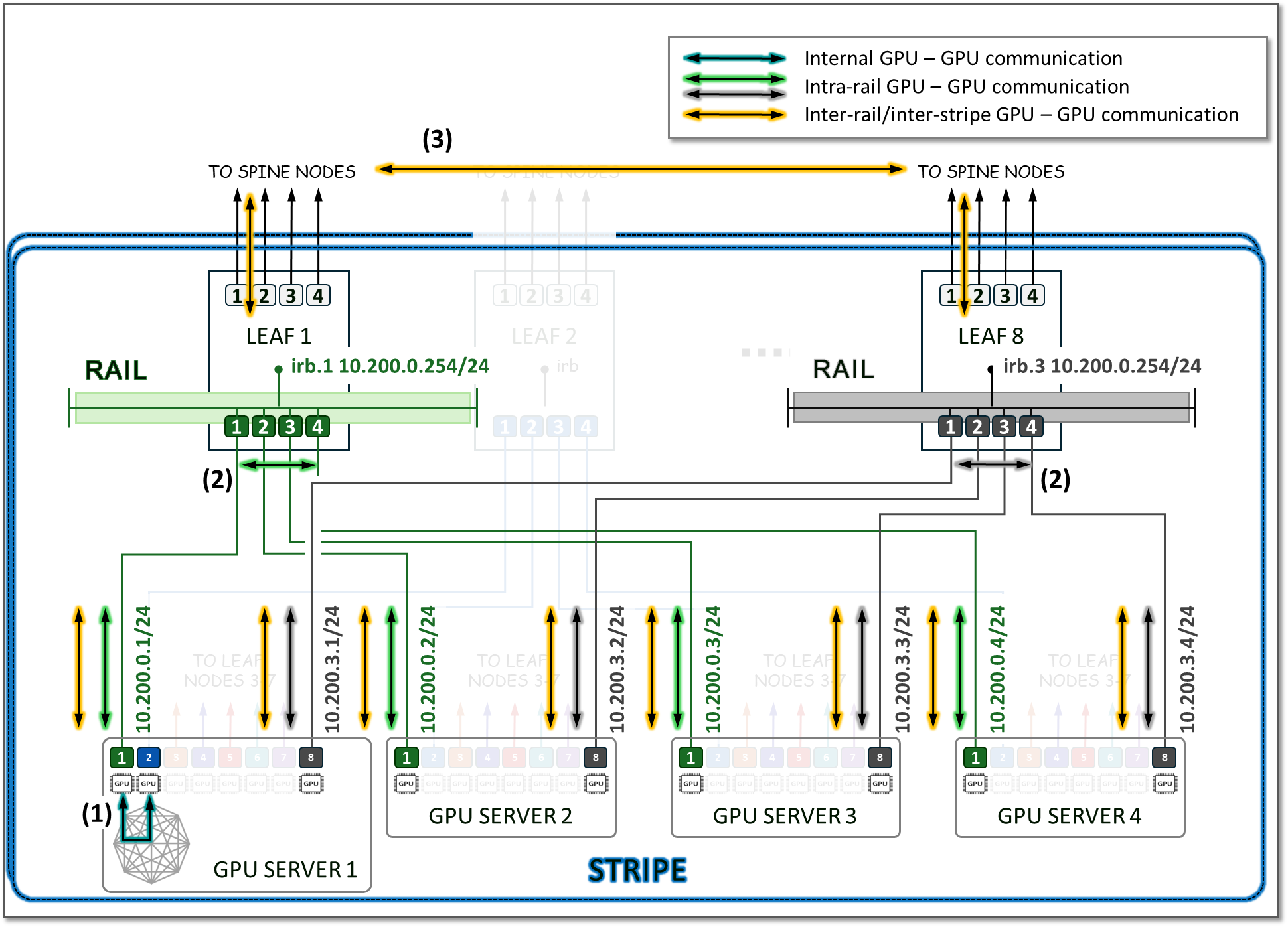
同一服务器上 GPU 之间的流量可以通过内部服务器结构本地转发(取决于服务器架构)。不同服务器中 GPU 之间的流量发生在 GPU 后端基础设施中,要么在同一轨道内(轨道内),要么在不同轨道内(轨道间/条纹间)。
轨道内流量在本地叶节点进行处理。按照这种设计,不同服务器上的 GPU 之间的数据(但在同一条带中)始终在同一轨道上并通过单个交换机移动,而不同轨道上的 GPU 之间的数据需要跨主干转发。
使用上一节中提供的用于计算每个条带的服务器数量的示例,我们可以看到如何:
- 服务器 1 中的 GPU 1 和 GPU 2 之间的通信发生在服务器的内部交换矩阵 (1) 上,
- 服务器 1-4 中的 GPU 1 和服务器 1-4 中的 GPU 8 之间的通信分别发生在枝叶 1 和枝叶 8 (2) 之间,并且
- GPU 1 和 GPU 8(在服务器 1-4 中)之间的通信发生在叶 1、主干节点和叶 8 (3) 上
如图 15 所示。
图 15:轨际 GPU-GPU 通信与轨内 GPU-GPU 通信
大多数供应商会实施 本地优化 ,以最大程度地减少 GPU 到 GPU 流量的延迟。相同数量的 GPU 之间的流量仍保留在轨道内。图 16 显示了服务器 1 中的 GPU1 与服务器 2 中的 GPU1 通信的示例。流量由叶节点 1 转发,并保留在轨道 1 内。
此外,可以启用称为 PXN 的 NCCL 功能,以利用服务器内 GPU 之间的内部交换矩阵连接,其中数据首先移动到与目标位于同一轨道上的 GPU,然后将其发送到目的地,而无需交叉轨道。例如,如果服务器 1 中的 GPU4 想要与服务器 2 中的 GPU5 通信,而服务器 1 中的 GPU5 可以通过内部交换矩阵使用,则流量自然会优先选择此路径,以优化性能并保持 GPU 到 GPU 之间的通信。
图 16:使用 PXN 的两台服务器之间的 GPU 到 GPU 轨间通信。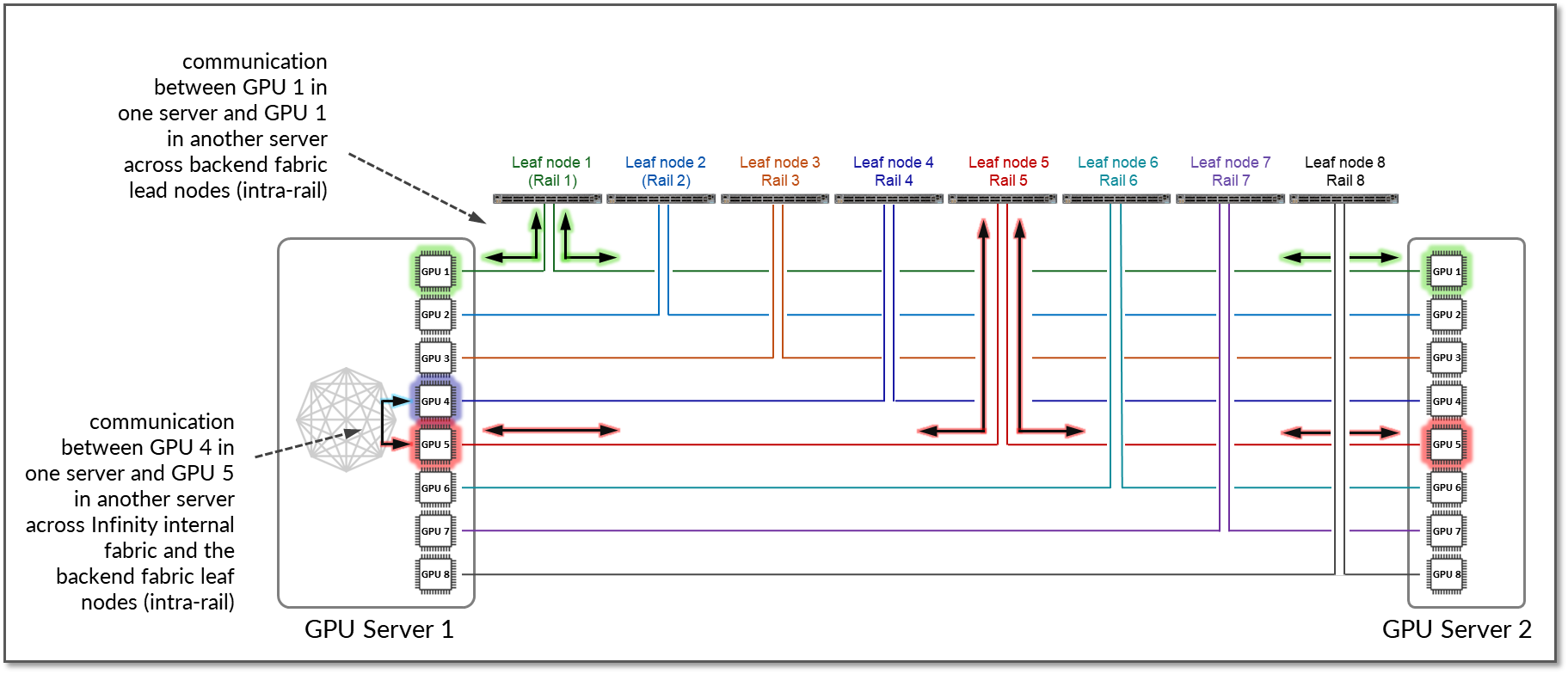
如果此 路径 由于工作负载或服务限制而不可行,或者因为 PXN 被禁用,则流量将使用 RDMA(基于 NIC 的离节点通信)。在这种情况下,服务器 1 中的 GPU4 与服务器 2 中的 GPU5 通信,方法是使用 RDMA 直接通过 NIC 发送数据,然后通过交换矩阵转发数据,如图 17 所示。
图 17:没有 PXN 的两台服务器之间的 GPU 到 GPU 轨间通信。 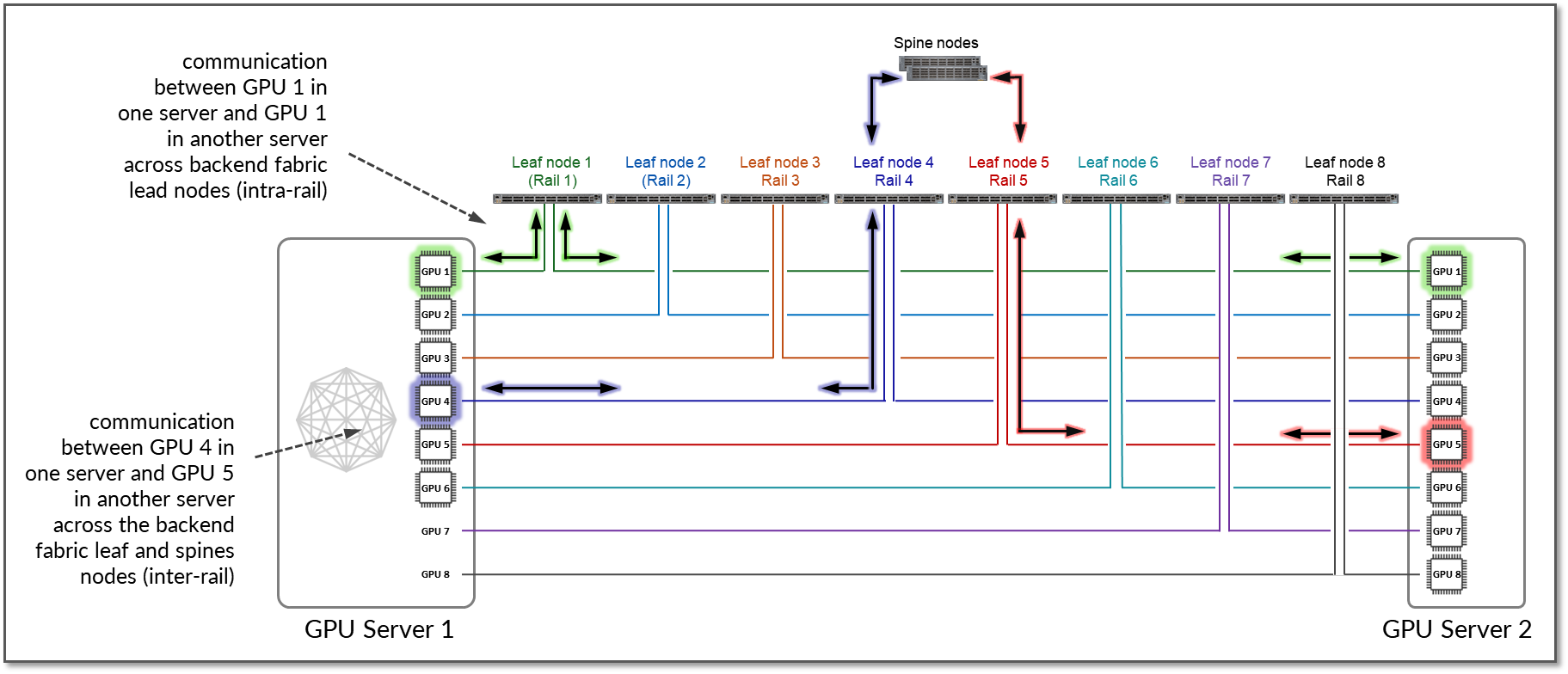
虽然 PXN 是 NCCL(NVIDIA Collective Communication Library),但它也受到 AMD ROCm Communication Collectives Library 的支持。要启用或禁用 PXN,请使用变量 NCCL_PXN_DISABLE
GPU 多租户的轨道对齐和局部优化注意事项
在 GPU 交换矩阵中实施多租户时,还需要考虑 GPU 的分配方式和处理 GPU 之间的通信方式。
服务器隔离模型
在服务器隔离模型中,服务器中的所有 GPU 都专用于单个租户。在这种模式下,同一服务器内的 GPU 之间的直接通信既合适又可取。将连接分配给不同租户的服务器的网络接口放置到叶节点上的不同 VRF 中足以使租户在网络中保持独立,但还需要考虑 GPU 到 GPU 的通信。局部优化确保 GPU 之间的通信遵循最佳内部路径:
-
- 同一服务器内的 GPU 使用服务器的内部机制进行通信。
- 位于不同服务器但连接到同一条带的 GPU 可以跨叶节点进行通信。
- 位于连接到不同条带的服务器中的 GPU 通过主干层进行通信,其中流量封装在 VXLAN 中并通过 EVPN/VXLAN 交换矩阵路由。
本节中的示例显示了 GPU 之间数据的可能路径。实际路径取决于所选的集合体(All-Gather、All-Reduce、All-To-All 等)和拓扑算法(环、树等)。此外,当作业运行时,可能会同时存在多个拓扑结构(例如多个环),它们遵循不同的路径,旨在提高效率。实际路径可以在 slurm 日志中找到,如示例所示:
-
jnpr@headend-svr-1:/mnt/nfsshare/logs/nccl/H100-RAILS-ALL/06102025_19_35_46$ cat slurm-25432.out | egrep Channel H100-01:3179628:3180857 [0] NCCL INFO Channel 00/16 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 H100-01:3179628:3180857 [0] NCCL INFO Channel 01/16 : 0 3 2 9 15 14 13 12 8 11 10 1 7 6 5 4 H100-01:3179628:3180857 [0] NCCL INFO Channel 02/16 : 0 3 10 15 14 13 12 9 8 11 2 7 6 5 4 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 03/16 : 0 11 15 14 13 12 10 9 8 3 7 6 5 4 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 04/16 : 0 7 6 5 12 11 10 9 8 15 14 13 4 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 05/16 : 0 4 7 6 13 11 10 9 8 12 15 14 5 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 06/16 : 0 5 4 7 14 11 10 9 8 13 12 15 6 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 07/16 : 0 6 5 4 15 11 10 9 8 14 13 12 7 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 08/16 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 H100-01:3179628:3180857 [0] NCCL INFO Channel 09/16 : 0 3 2 9 15 14 13 12 8 11 10 1 7 6 5 4 H100-01:3179628:3180857 [0] NCCL INFO Channel 10/16 : 0 3 10 15 14 13 12 9 8 11 2 7 6 5 4 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 11/16 : 0 11 15 14 13 12 10 9 8 3 7 6 5 4 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 12/16 : 0 7 6 5 12 11 10 9 8 15 14 13 4 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 13/16 : 0 4 7 6 13 11 10 9 8 12 15 14 5 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 14/16 : 0 5 4 7 14 11 10 9 8 13 12 15 6 3 2 1 H100-01:3179628:3180857 [0] NCCL INFO Channel 15/16 : 0 6 5 4 15 11 10 9 8 14 13 12 7 3 2 1 H100-02:2723777:2725118 [2] NCCL INFO Channel 00/0 : 10[2] -> 11[3] via P2P/IPC H100-02:2723779:2725122 [4] NCCL INFO Channel 00/0 : 12[4] -> 13[5] via P2P/IPC H100-02:2723778:2725124 [3] NCCL INFO Channel 00/0 : 11[3] -> 12[4] via P2P/IPC H100-02:2723780:2725121 [5] NCCL INFO Channel 00/0 : 13[5] -> 14[6] via P2P/IPC H100-02:2723781:2725125 [6] NCCL INFO Channel 00/0 : 14[6] -> 15[7] via P2P/IPC H100-02:2723776:2725123 [1] NCCL INFO Channel 00/0 : 9[1] -> 10[2] via P2P/IPC H100-02:2723777:2725118 [2] NCCL INFO Channel 08/0 : 10[2] -> 11[3] via P2P/IPC H100-02:2723775:2725119 [0] NCCL INFO Channel 00/0 : 7[7] -> 8[0] [receive] via NET/IBext/0/GDRDMA H100-02:2723779:2725122 [4] NCCL INFO Channel 08/0 : 12[4] -> 13[5] via P2P/IPC H100-02:2723780:2725121 [5] NCCL INFO Channel 08/0 : 13[5] -> 14[6] via P2P/IPC H100-02:2723782:2725120 [7] NCCL INFO Channel 00/0 : 15[7] -> 0[0] [send] via NET/IBext/0(8)/GDRDMA H100-02:2723775:2725119 [0] NCCL INFO Channel 08/0 : 7[7] -> 8[0] [receive] via NET/IBext/0/GDRDMA H100-02:2723775:2725119 [0] NCCL INFO Channel 00/0 : 8[0] -> 9[1] via P2P/IPC --more---
哪里:
X[Y] -> A[B]:
- X 源 GPU 全局索引。
- Y 本地 GPU 索引(在节点内)。
- 目标 GPU 全局索引。
- B 本地 GPU 索引。
[send] / [receive]:从写入日志的进程角度来看的方向。
NET/IBext/N 或 NET/IBext/N(P):
- N=InfiniBand 接口索引 (N)
- P(括号内)= NIC 端口或对等方排名。
GDRDMA:GPUDirect RDMA,这意味着数据通过支持 RDMA 的 NIC 直接在 GPU 的内存之间传输,而无需 CPU 参与。这对于延迟和带宽来说是最佳的。使用 PCI Express 的标准功能,实现 GPU 与第三方对等设备之间的直接数据交换。它基于一个名为 nv_peer_mem 的内核模块,该模块允许 Mellanox 和其他支持 RDMA 的 NIC 使用 NIC RDMA 路径直接读取和写入 CUDA 内存。NCCL 通过 PCIe、NVLink 和 NVIDIA Mellanox 网络提供针对高带宽和低延迟进行优化的例程。
P2P/IPC:NVIDIA Collective Communications Library (NCCL) 中的点对点 (P2P) 传输。它使 GPU 能够直接相互通信,而无需通过主机、CPU 或网络。NCCL 提供具有拓扑感知能力的 GPU 间通信原语,可轻松集成到应用中。
示例 1
考虑图 18 中描述的示例,其中租户 A 被分配了同一条带中的服务器 4 和服务器 5,租户 B 被分配了服务器 1、服务器 2 和服务器 3,也在同一条带中。
图 18:服务器隔离模型 GPU 到 GPU 通信示例 1
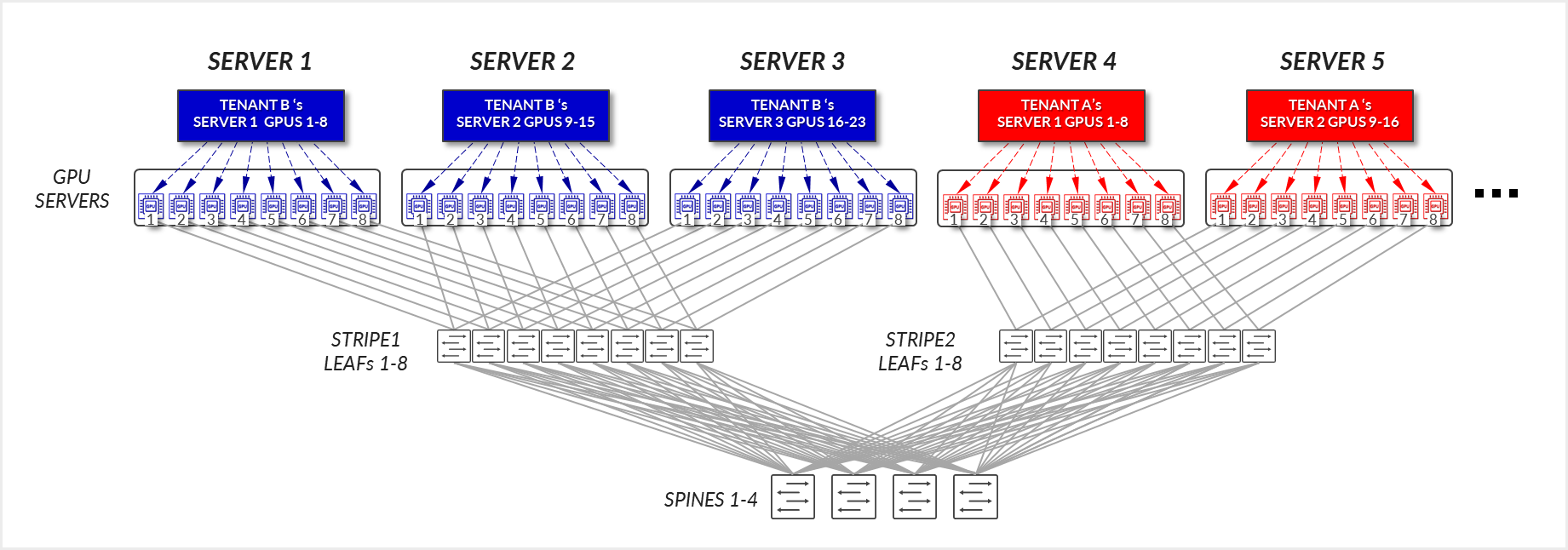
对于租户 A:
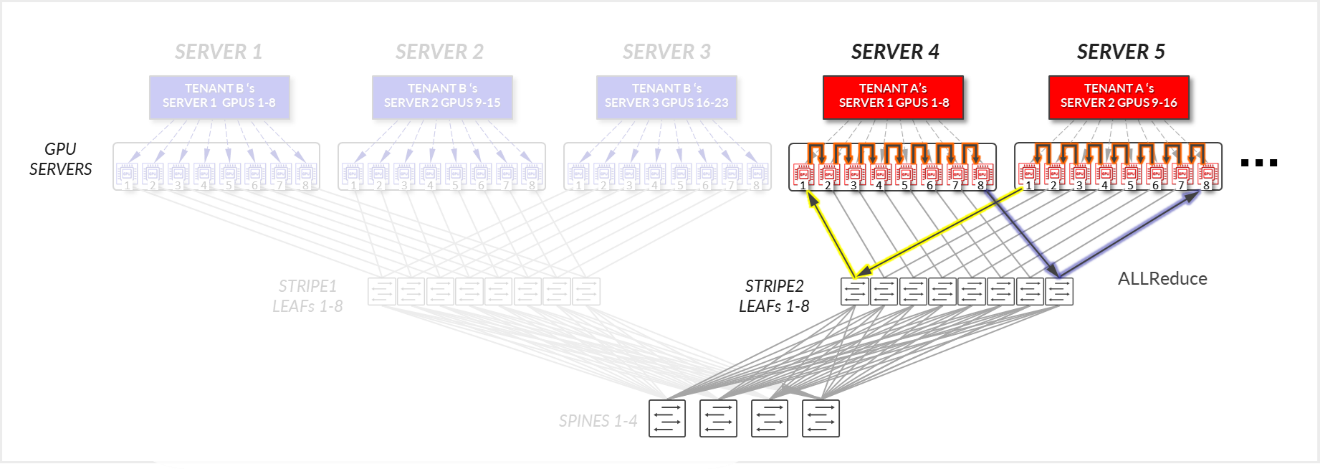
- 服务器 4 中的 GPU 1-8 和服务器 5 中的 GPU 1-8 在各自的服务器内进行内部通信,如 局部优化部分所述。
- 服务器 4 中的 GPU 1 和 8 与服务器 5 中的 GPU 1 和 8 通过叶节点和主干节点进行通信 - 轨内(流量停留在叶节点级别)。
图 19:服务器隔离模型 GPU 到 GPU 通信 示例 1 – 租户 A
-
- 您可以看到如何建立环形逻辑拓扑,将分配给租户 A 的 16 个 GPU 互连起来,而没有任何流量穿过主干节点。
图 20:服务器隔离模型 GPU 到 GPU 通信 示例 1 – 租户 A 环拓扑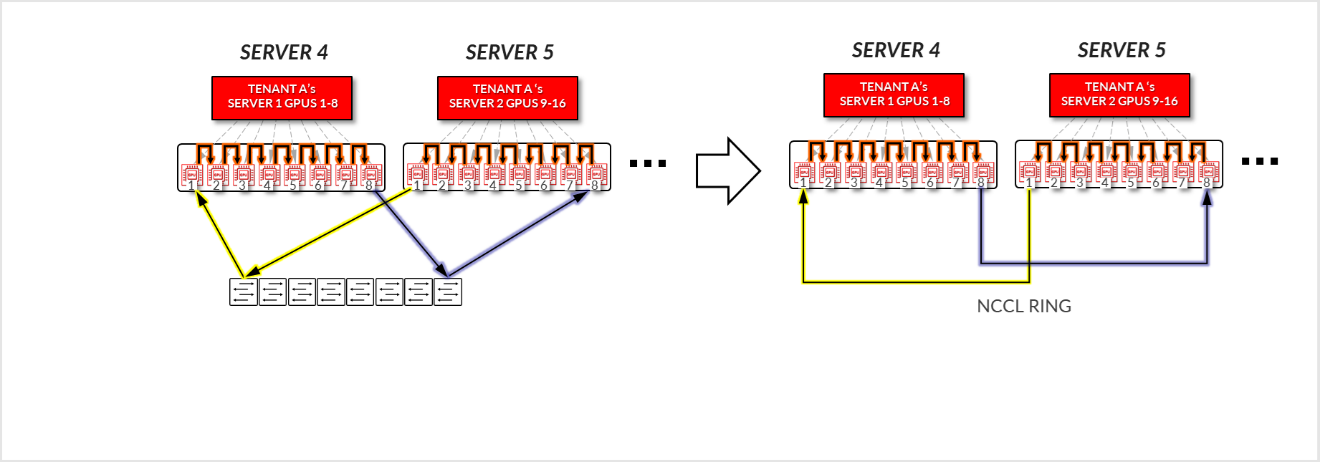
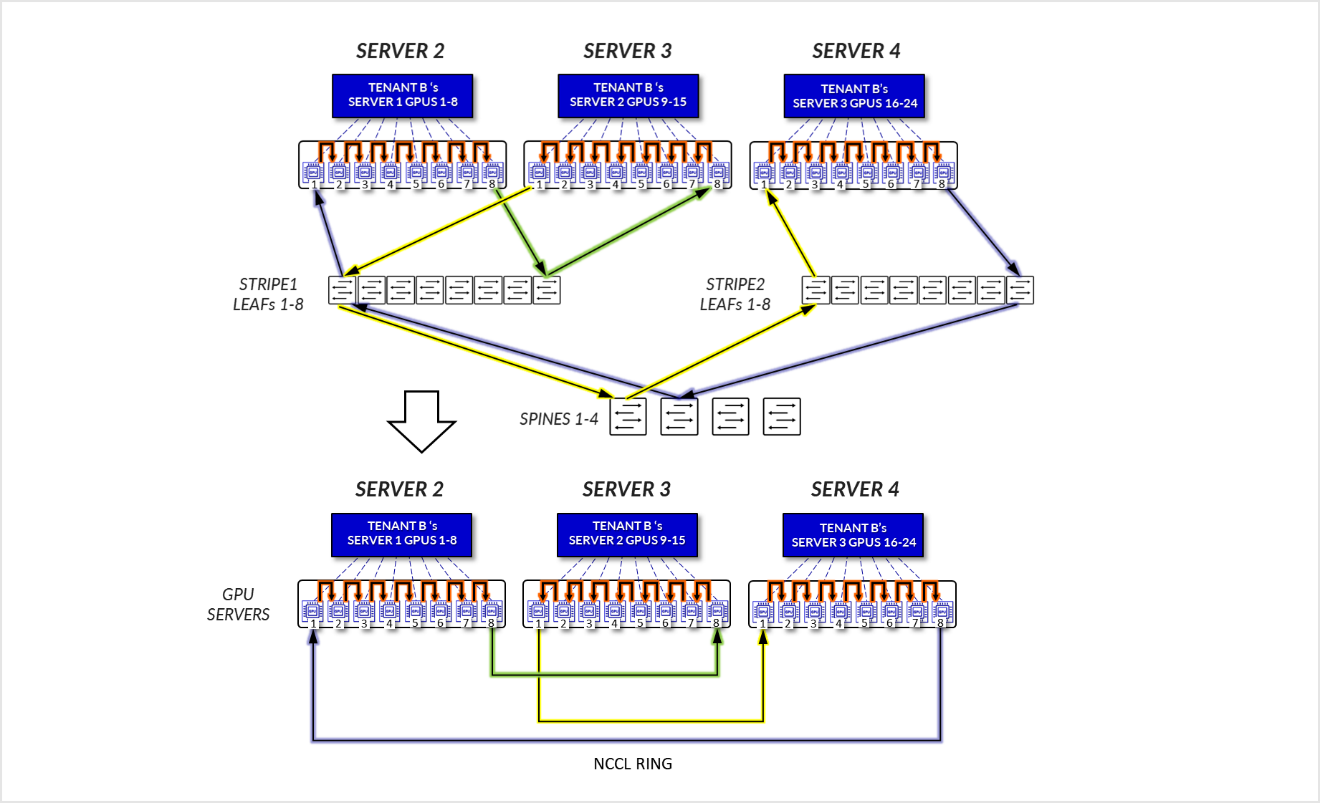
对于租户 B:
- GPU 1-8、服务器 1、GPU 1-8 和 SERVER3 中的 GPU 1-8 在各自的服务器内进行内部通信,如 局部优化部分所述。
- 服务器 1 中的 GPU 1 进行通信 服务器 3 中的 GPU 1 跨叶节点相互通信 - 轨内(流量停留在叶节点级别)。
- 服务器 1 中的 GPU 8 进行通信 服务器 3 中的 GPU 8 跨叶节点相互通信 - 轨内(流量停留在叶节点级别)。
- 服务器 1 中的 GPU 8 和服务器 2 中的 GPU 1 跨叶节点和主干节点进行通信 - 轨间。这是完成环所必需的。
图 21:服务器隔离模型 GPU 到 GPU 通信 示例 1 – 租户 B
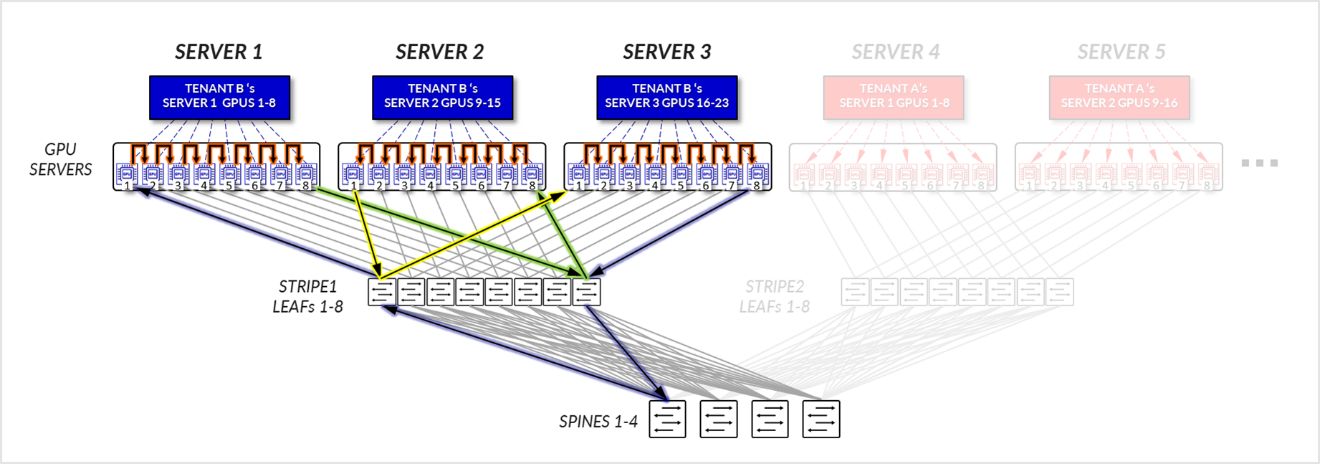
图 22:服务器隔离模型 GPU 到 GPU 通信 示例 1 – 租户 B 环拓扑
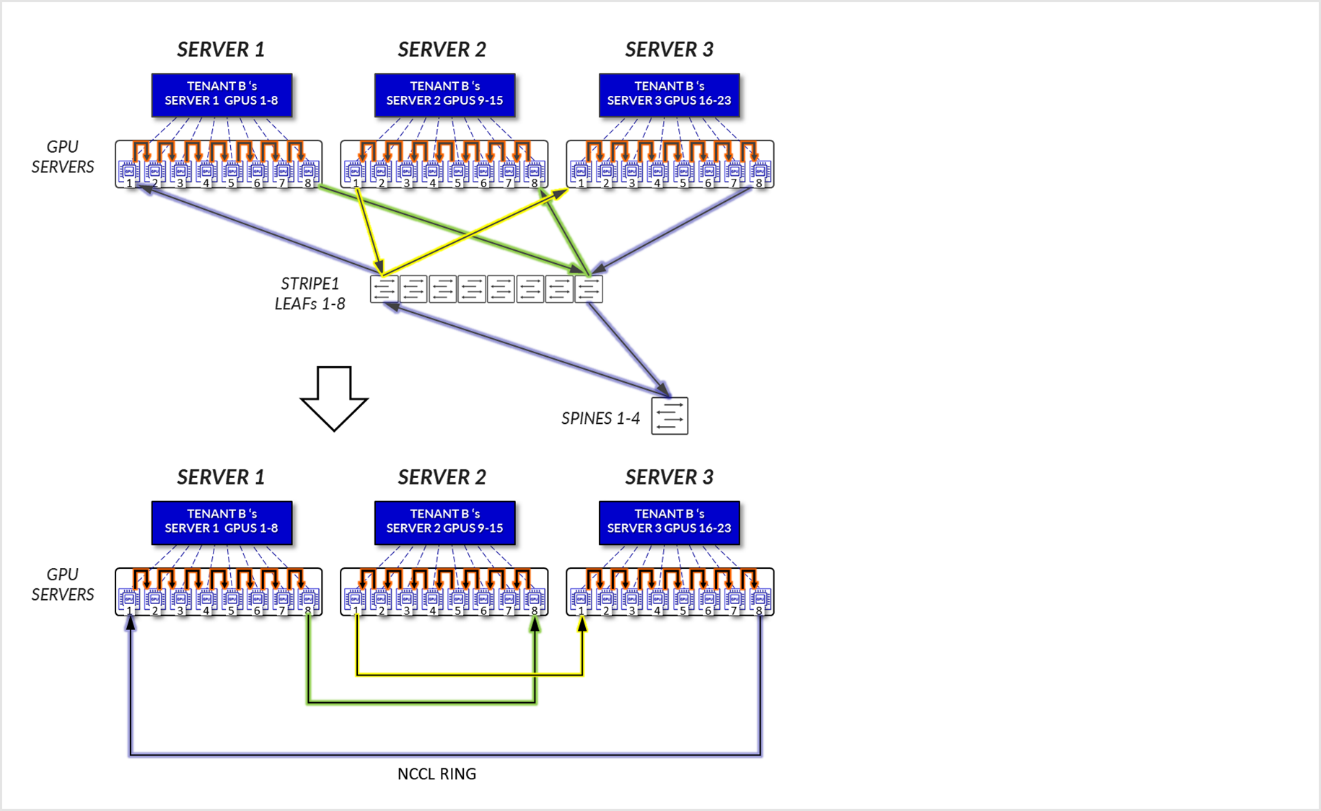
示例 2
现在考虑图 23 中描述的示例,其中租户 A 被分配了两个不同条带的服务器 1 和服务器 5,租户 B 被分配了同一条带中的服务器 2 和服务器 3,以及服务器 4 的不同条带。
图 23:服务器隔离模型 GPU 到 GPU 通信示例 2
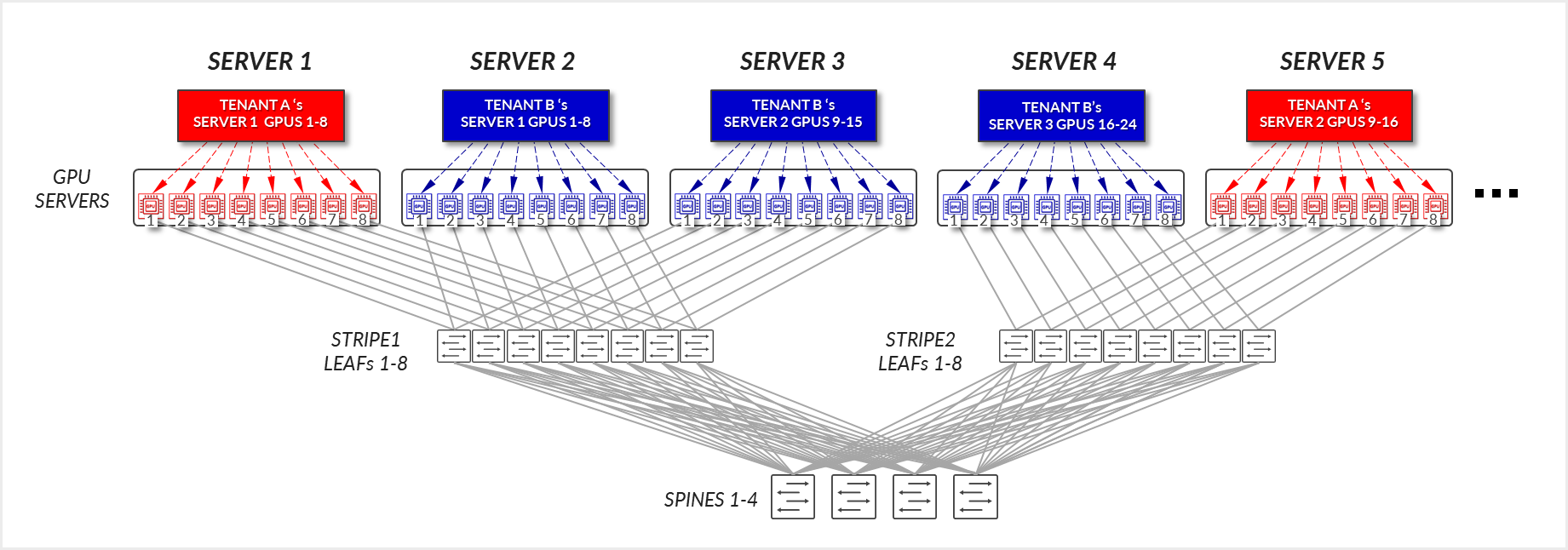
对于租户 A:
- 服务器 1 中的 GPU 1-8 和服务器 5 中的 GPU 1-8 在各自的服务器内进行内部通信。
- 服务器 1 中的 GPU 1 和服务器 5 中的 GPU 1 跨叶节点和主干节点进行通信 - 条纹间流量。
- 服务器 1 中的 GPU 8 和服务器 5 中的 GPU 8 跨叶节点和主干节点进行通信 - 条纹间流量。这是完成环所必需的。
图 24:服务器隔离模型 GPU 到 GPU 通信 示例 2 – 租户 A
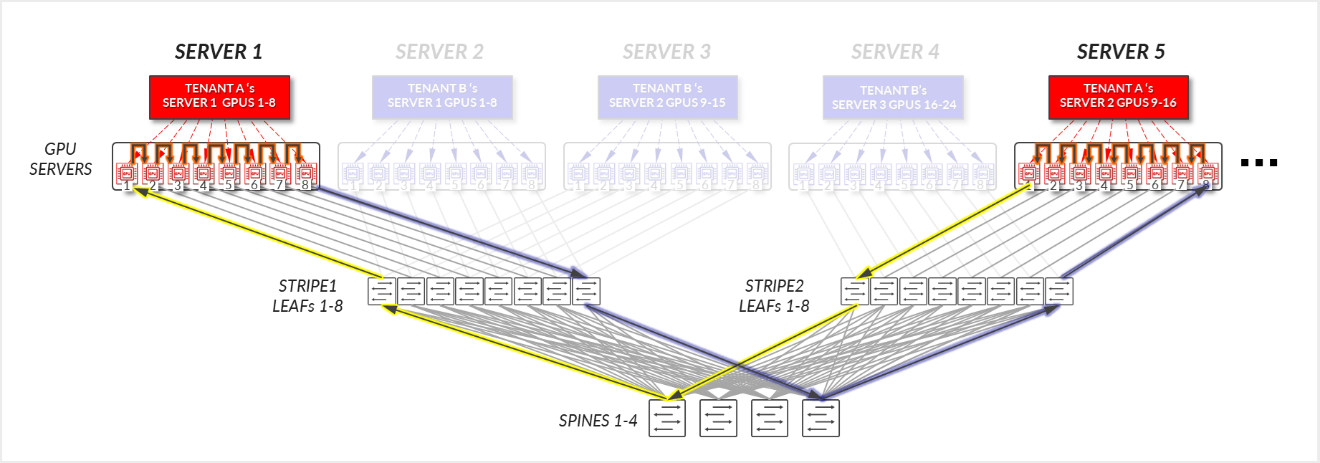
图 25:服务器隔离模型 GPU 到 GPU 通信 示例 2 – 租户 A 环拓扑
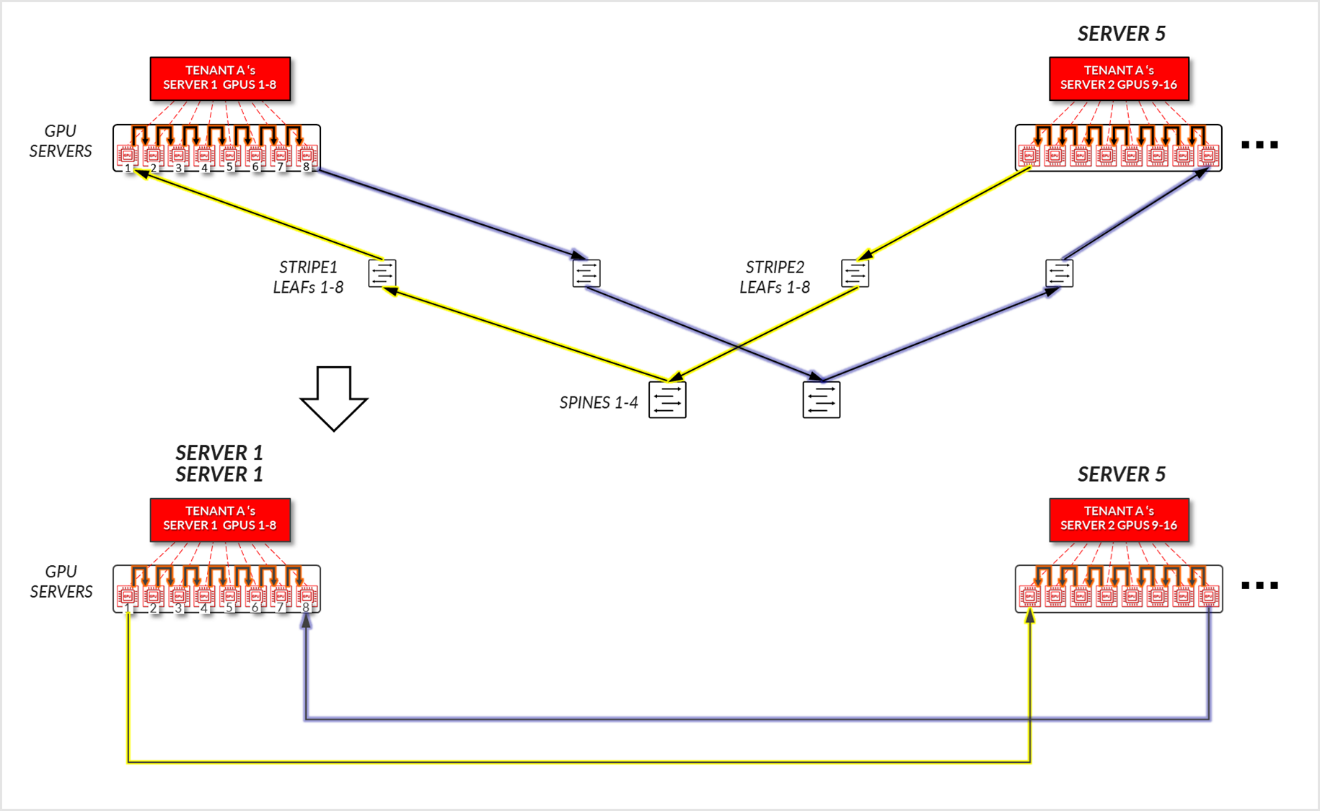
对于租户 B:
- GPU 1-8 服务器 2、GPU 1-8 在服务器 3 和 GPU 1-8 在 SERVER4 中,在各自的服务器内进行内部通信。
- 服务器 2 中的 GPU 1 和服务器 4 中的 GPU 1 跨叶节点和主干节点进行通信 - 条纹间流量。
- 服务器 4 中的 GPU 8 和服务器 3 中的 GPU 8 跨叶节点和主干节点进行通信 - 条纹间流量。
- 服务器 3 中的 GPU 1 和服务器 2 中的 GPU 8 跨叶节点和主干节点 – Inter-rail 进行通信。这是完成环所必需的。
图 26:服务器隔离模型 GPU 到 GPU 通信示例 2 – 租户 B
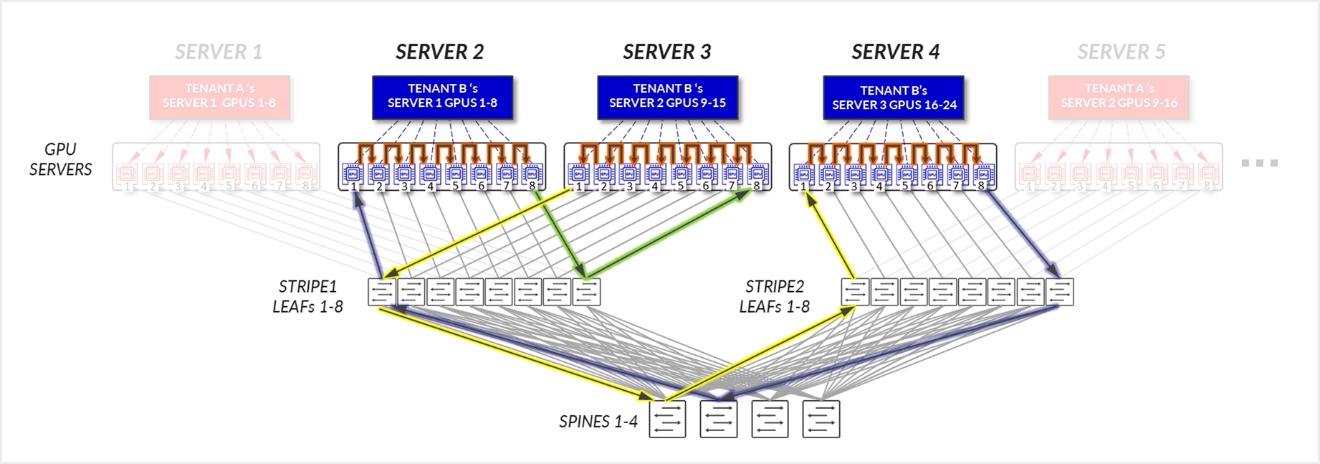
图 27:服务器隔离模型 GPU 到 GPU 通信 示例 2 – 租户 B 环拓扑
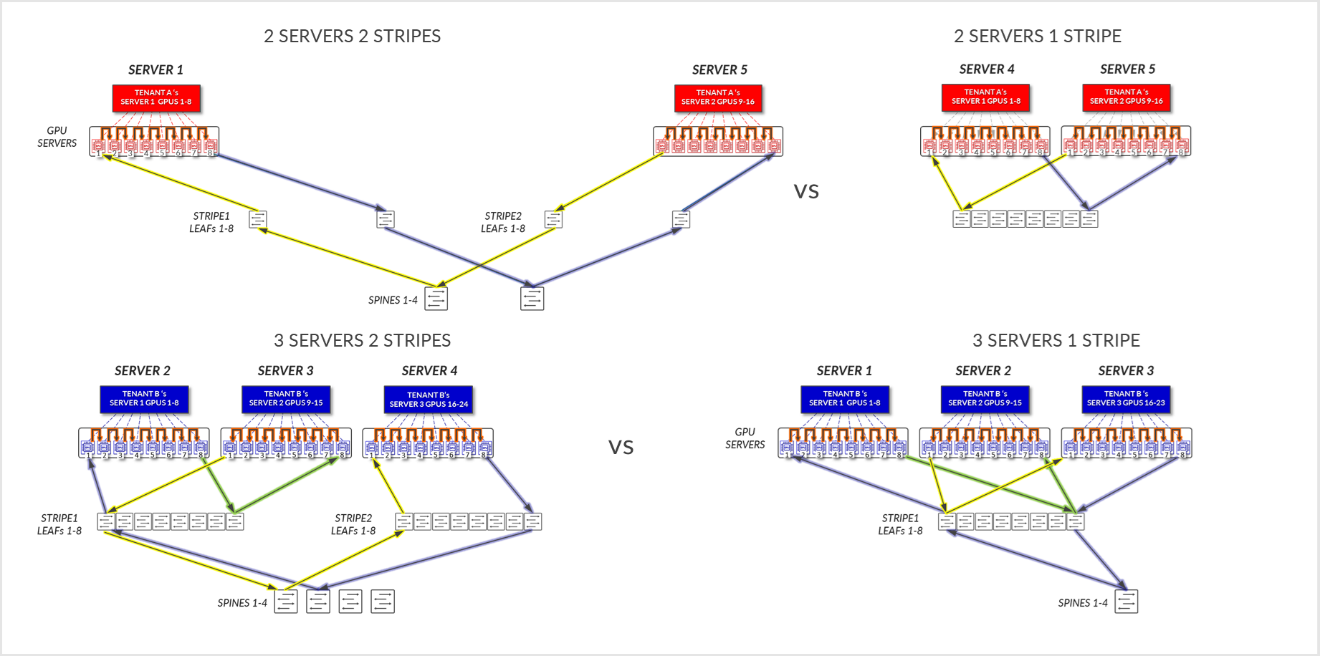
比较示例 1 和示例 2 中的数据流,显示了将服务器分配给租户如何影响作业的性能。
图 28:相同条带服务器与不同条带服务器的服务器隔离
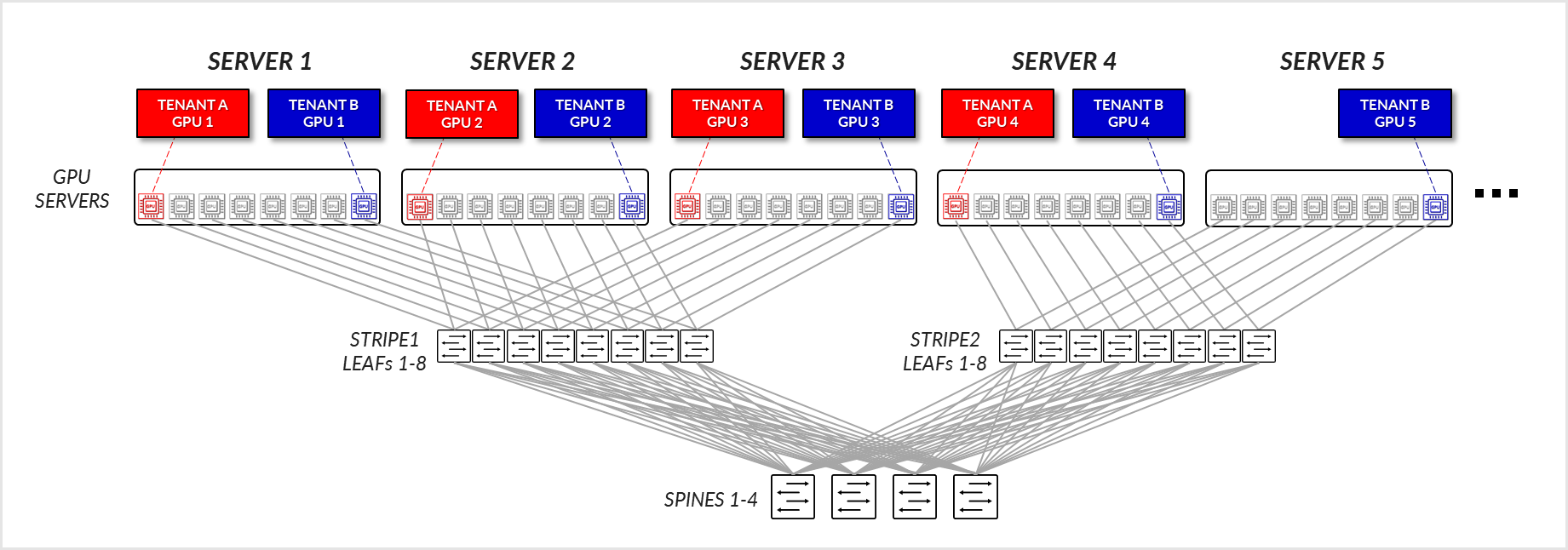
GPU 隔离模型
在 GPU 隔离模型中, 可以将同一服务器中的不同 GPU 分配给不同的租户。此外,可能会在多个条带的多个服务器中为租户分配 GPU。至于服务器隔离模型,分配的 GPU 所在的位置会影响路径,并可能影响性能。
示例 1
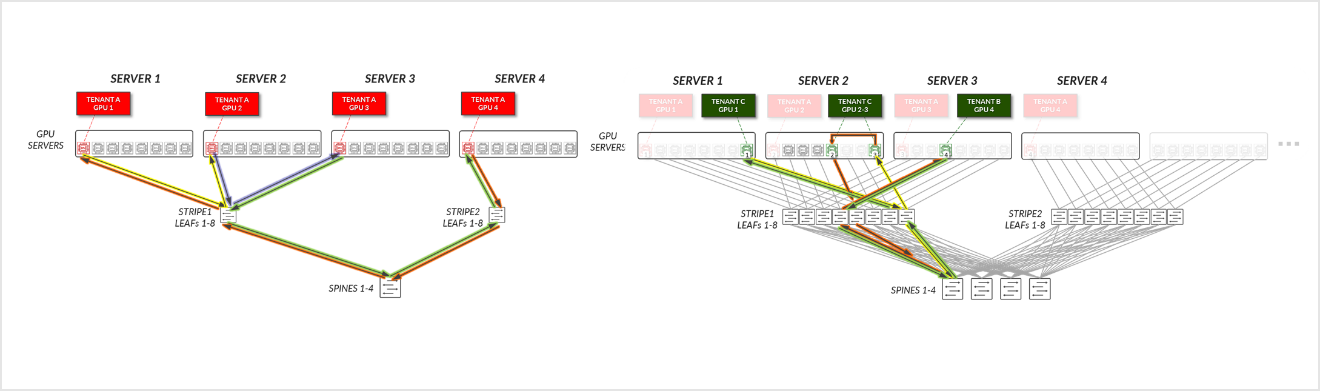
考虑图 29 中描述的示例,其中在服务器 1-4 上为租户 A 分配了 GPU1,在服务器 1-5 上为租户 B 分配了 GPU8。
图 29:GPU 隔离模型 GPU 到 GPU 通信示例 1
对于租户 A:
- 租户 A 的 GPU 1、GPU 2 和 GPU 3 通过它们连接的叶节点相互通信。(铁路内)
- 租户 A 的 GPU 1、2 和 3 与 GPU 4 通过叶节点和主干节点进行通信。
图 30:GPU 隔离模型 GPU 到 GPU 通信 示例 1 – 租户 A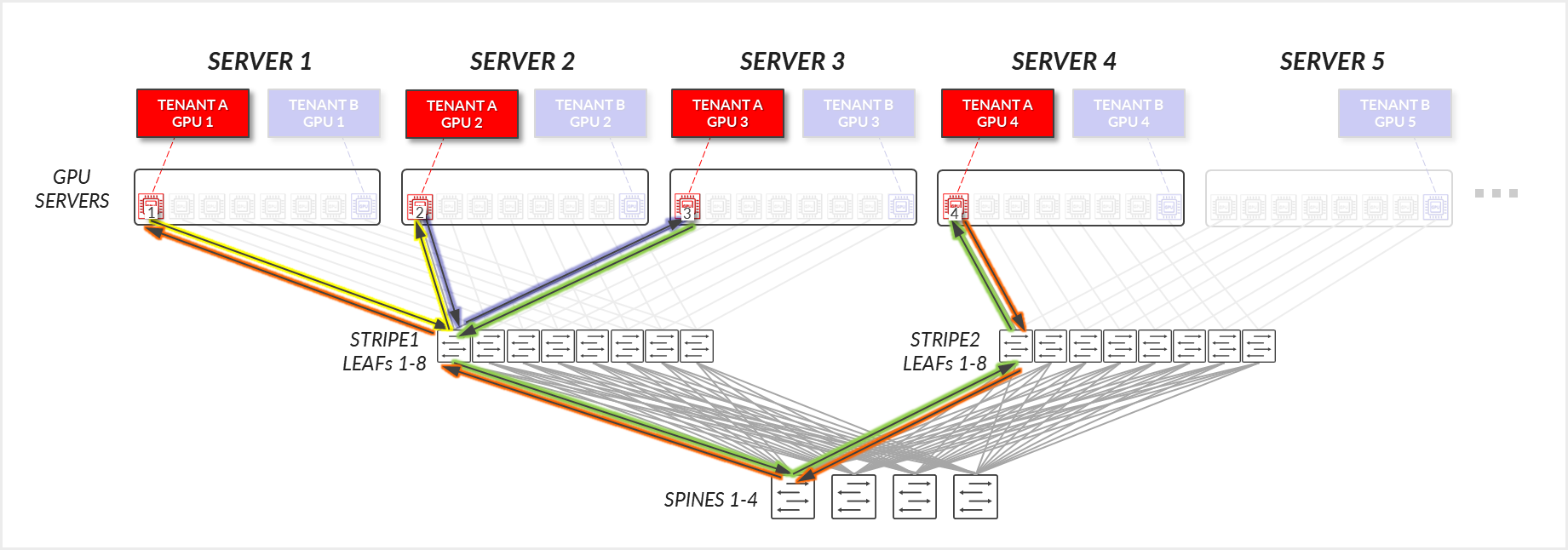
图 31:GPU 隔离模型 GPU 到 GPU 通信 示例 1 – 租户 A 环形拓扑
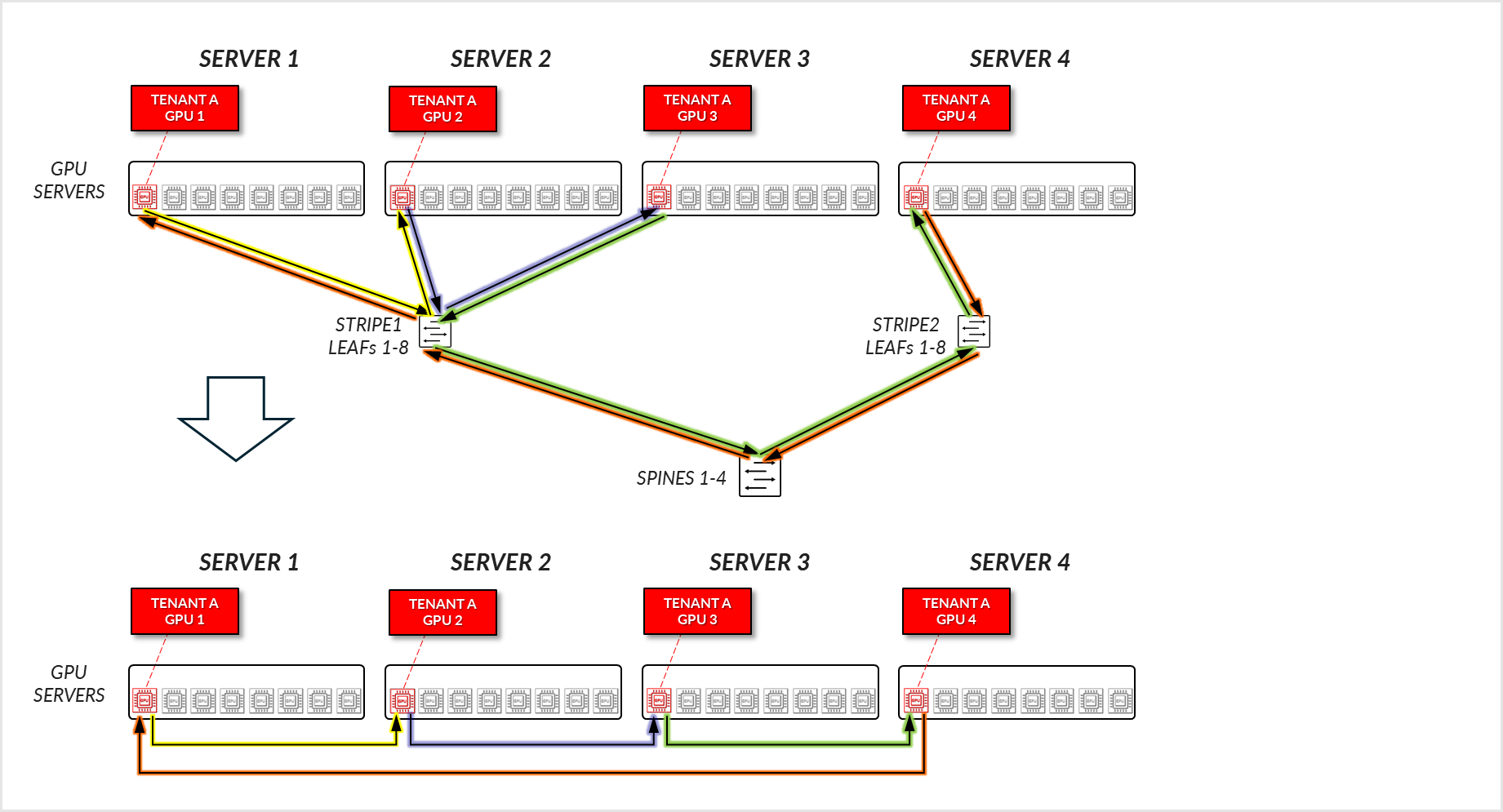
对于租户 B,将建立类似的通信路径。
示例 2
现在考虑图 32 中描述的示例,其中租户 C 在服务器 1 上分配了 GPU 8,在服务器 2 上分配了 GPU 5 和 8,在服务器 3 上分配了 GPU 4(对应于图中租户 C 的 GPU 1-4)。
图 32:GPU 隔离模型 GPU 到 GPU 通信示例 2
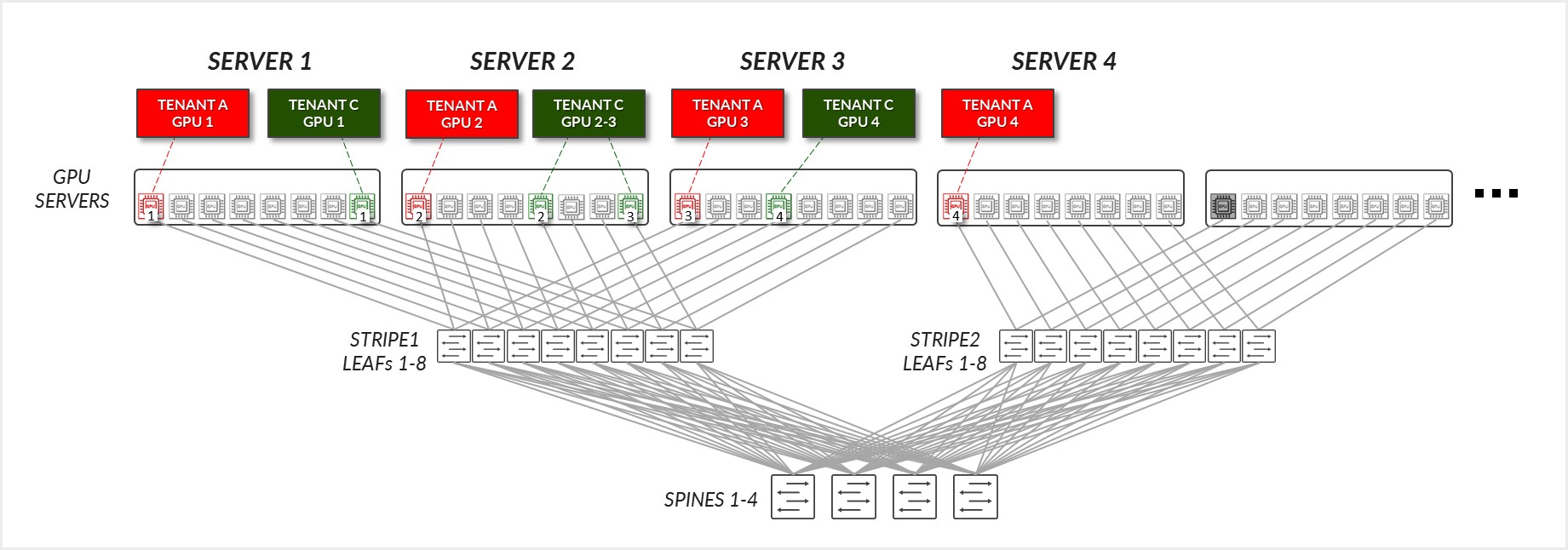
对于租户 C:
- 租户 C 的 GPU 2 和 3(在同一台服务器上)在其服务器内部进行通信。
- 租户 C 的 GPU 3(服务器 2)和 GPU 4(服务器 3)跨叶节点和主干节点进行通信。
- 租户 C 的 GPU 4(服务器 3)和 GPU 1(服务器 1)跨叶节点和主干节点进行通信。
- 租户 C 的 GPU 1(服务器 1)和 GPU 2(服务器 2)跨叶节点和主干节点进行通信。
图 33:GPU 隔离模型 GPU 到 GPU 通信 示例 2 – 租户 C
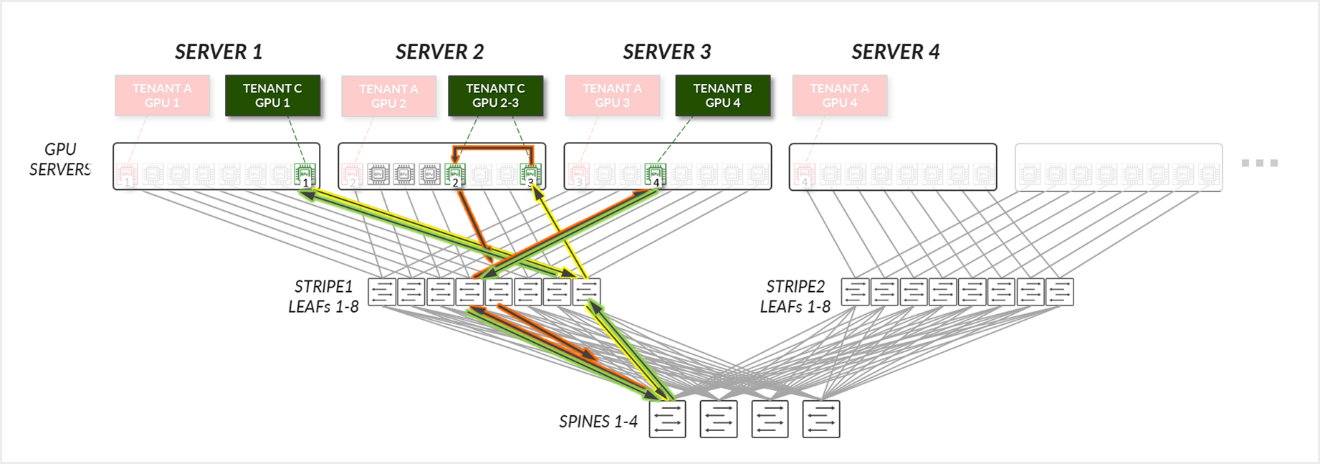
通过比较示例 1 和示例 2,可以清楚地看出,轨道对齐和正确的服务器或 GPU 分配策略对于实现大规模上的最佳 GPU 到 GPU 通信效率至关重要。
示例 1 中的租户 A 在服务器 1-4 上分配了 GPU0,因此通信主要停留在叶级别。示例 2 中的租户 C 在服务器 1 上分配了 GPU 8,在服务器 2 上分配了 GPU 5 和 8,在服务器 3 上分配了 GPU 4,因此通信必须跨主干进行,这会带来额外的延迟和潜在的拥塞 租户 A 和租户 C 都被分配了相同数量的 GPU,但其 GPU 之间的通信遵循不同的路径 这可能会导致不同的性能水平
图 34:相同条带服务器与不同条带服务器的 GPU 隔离