AI 用例和参考设计
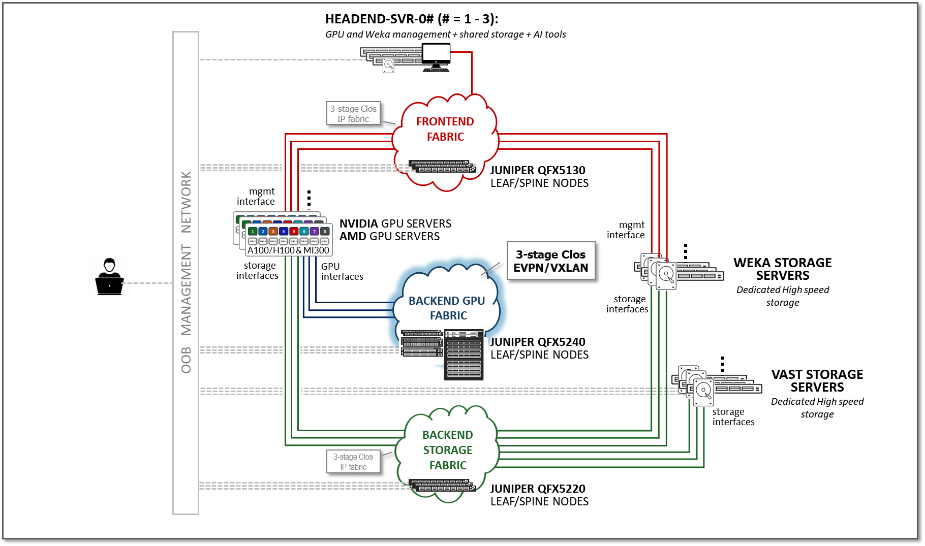
AI JVD 参考设计涵盖一个完整的基于以太网的端到端 AI 基础架构,包括前端交换矩阵、GPU 后端交换矩阵和存储后端交换矩阵。这三种交换矩阵具有共生关系,并且每种交换矩阵都提供独特的功能来支持 AI 训练和推理任务。通过在 AI 交换矩阵中使用以太网网络,我们的客户能够构建易于运维的大容量网络交换矩阵,最大限度地缩短工作完成时间,提高 GPU 利用率,并充分利用有限的 IT 资源。
图 1 所示的 AI JVD 参考设计包括:
- 前端交换矩阵:此交换矩阵是从驻留在前端服务器中的 AI 工具到 GPU 节点和存储节点的网关网络。前端 GPU 交换矩阵允许用户与 GPU 和存储节点进行交互,以启动训练或推理工作负载,并可视化其进度和结果,并提供 NVIDIA Collective Communications Library (NCCL) 和 RCCL (ROCm Communication Collectives Library) 的带外路径。
- GPU 后端交换矩阵:此交换矩阵连接 GPU 节点(执行 AI 工作流的计算任务)。GPU 后端交换矩阵在训练作业期间在 GPU 之间以无损方式高速传输信息。GPU 生成的流量使用 RoCEv2(以太网 RDMA v2)进行传输。
- 存储后端交换矩阵:此交换矩阵连接高可用性存储系统(保存大型模型训练数据)和 GPU(在训练或推理作业期间使用这些数据)。存储后端交换矩阵以无缝且可靠的方式传输大量数据。
图 1:AI JVD 参考设计
前端概述
AI 前端包括使用户能够与 AI 系统交互的界面、工具和方法,以及允许这些交互的基础架构。前端使用户能够启动训练或推理任务,并可视化结果,同时隐藏底层技术复杂性。
前端系统的关键组件包括:
- 模型调度:用于管理脚本化 AI 模型作业的工具和方法,通常基于 SLURM(用于资源管理的简单 Linux 实用程序)工作负载管理器。这些工具使用户能够通过 shell CLI 或基于 Web 的图形界面发送指令、命令和查询,以编排在 GPU 上运行的学习和推理作业。用户可以配置模型参数、输入数据和解释结果,并以交互方式启动或终止作业。在 AI JVD 中,这些工具托管在连接到 AI 前端交换矩阵的前端服务器上。
- 人工智能系统管理:用于管理(配置、监控和执行维护任务)人工智能存储和处理组件的工具。这些工具有助于有效地构建、运行、训练和利用 AI 模型。示例包括 SLURM、TensorFlow、PyTorch 和 Scikit-learn。
- 交换矩阵组件管理:旨在帮助用户根据其要求和目标轻松部署和管理交换矩阵设备的机制和工作流。它包括设备上线、配置管理和交换矩阵部署编排等任务。
- 性能监控和错误分析:遥测系统跟踪与 AI 模型相关的关键性能指标,例如准确度、精确度、召回率和计算资源利用率(例如 CPU、GPU 使用率),这对于在训练和推理作业期间评估模型有效性至关重要。这些系统还可以深入了解训练和推理作期间的错误率和故障模式,并帮助识别模型漂移、数据质量问题或算法错误等可能影响 AI 性能的问题。
- 数据可视化:允许用户直观地理解 AI 模型和工作负载生成的见解的应用和工具。它们提供有效的可视化,可增强基于人工智能输出的理解和决策。用于监控和测量系统和网络级别性能的遥测系统通常也提供这种可视化效果。
- 用户接口:路由和交换基础架构,允许用户界面、应用和工具与执行任务的人工智能系统(包括 GPU 和存储设备)之间进行通信。此基础架构可确保用户与有效利用人工智能功能所需的计算资源之间实现无缝交互。
- GPU 到 GPU 控制:通信建立、信息交换,包括 QP GID(全局 ID)、本地和远程缓冲区地址以及 RDMA 密钥(用于内存访问权限的 RKEY)。
GPU 后端概述
AI GPU 后端包括执行学习和推理作业或计算任务的设备,即进行数据处理的 GPU 服务器,以及允许 GPU 相互通信以完成作业的基础架构。
GPU 后端系统的关键组件包括:
- 人工智能系统:专用硬件,例如 GPU(图形处理单元)和 TPU(张量处理单元),可以同时执行大量计算。GPU 特别擅长处理 AI 工作负载,包括完成学习和推理任务所需的复杂矩阵乘法和卷积。GPU 系统的选择和数量会显著影响这些任务的速度和效率。
- 人工智能软件:开发和执行 AI 模型所必需的作系统、库和框架。这些工具为有效编码、训练和部署人工智能算法提供了必要的环境。这些工具的功能包括:
- 数据管理:对训练和执行 AI 模型所用数据进行预处理和转换。这包括清理、规范化和特征提取等任务。鉴于 AI 数据集的数量和复杂性,并行处理和分布式计算等高效的数据管理策略至关重要。
- 模型管理:与 AI 模型本身相关的任务,包括评估(例如,交叉验证)、选择(根据性能指标选择最佳模型)和部署(使模型可用于实际应用)。
- GPU 后端交换矩阵:路由和交换基础架构,允许 GPU 到 GPU 通信,用于工作负载分配、内存共享、模型参数同步、结果交换等。这种交换矩阵的设计会显著影响 AI/ML 模型训练和推理作业的速度和效率,并且在大多数情况下应为 GPU 到 GPU 的流量提供无损连接。
存储后端概述
AI 存储后端包括用于存储、检索和管理 AI 工作负载中涉及的大量数据的硬件和软件组件,以及允许 GPU 与这些存储组件通信的基础架构。
存储后端的关键方面包括:
- 高性能存储设备:针对高 I/O 吞吐量进行了优化,这对于处理深度学习等 AI 任务的高强度数据处理要求至关重要。这包括高性能存储设备,旨在促进在模型训练期间快速访问数据并满足大型数据集的存储需求。这些存储设备必须提供:
- 数据管理功能:支持高效的数据查询、索引和检索,这对于最大限度减少 AI 工作流程中的预处理和特征提取时间,以及在推理过程中促进快速数据访问至关重要。
- 可扩展性:适应不断增长的数据量,并随着时间的推移有效地管理和存储大量数据,以支持通常涉及大规模数据集的 AI 工作负载。
- 存储后端交换矩阵:在 GPU 和存储设备之间提供连接的路由和交换基础架构。这种集成可确保数据能够在存储和计算资源之间高效传输,从而优化整体 AI 工作流程性能。存储后端的性能会显著影响 AI/ML 工作流程的效率和 JCT。提供快速数据访问的存储后端可以显著减少训练 AI/ML 模型的时间。