存储后端交换矩阵
存储后端交换矩阵为可从 GPU 服务器访问的存储设备提供连接基础架构。
存储基础架构的性能显着影响 AI 工作流程的效率。提供快速访问数据的存储系统可以显着减少训练 AI 模型的时间。同样,支持高效数据查询和索引的存储系统可以最大限度地缩短 AI 工作流程中预处理和特征提取的完成时间。
JVD 中的 存储后端交换矩阵 设计也遵循 3 级 IP clos 架构,如图 16 所示。存储群集中没有轨道优化的概念。每个 GPU 服务器与叶节点都有一个连接,而不是 8 个。
图 16:存储后端交换矩阵架构
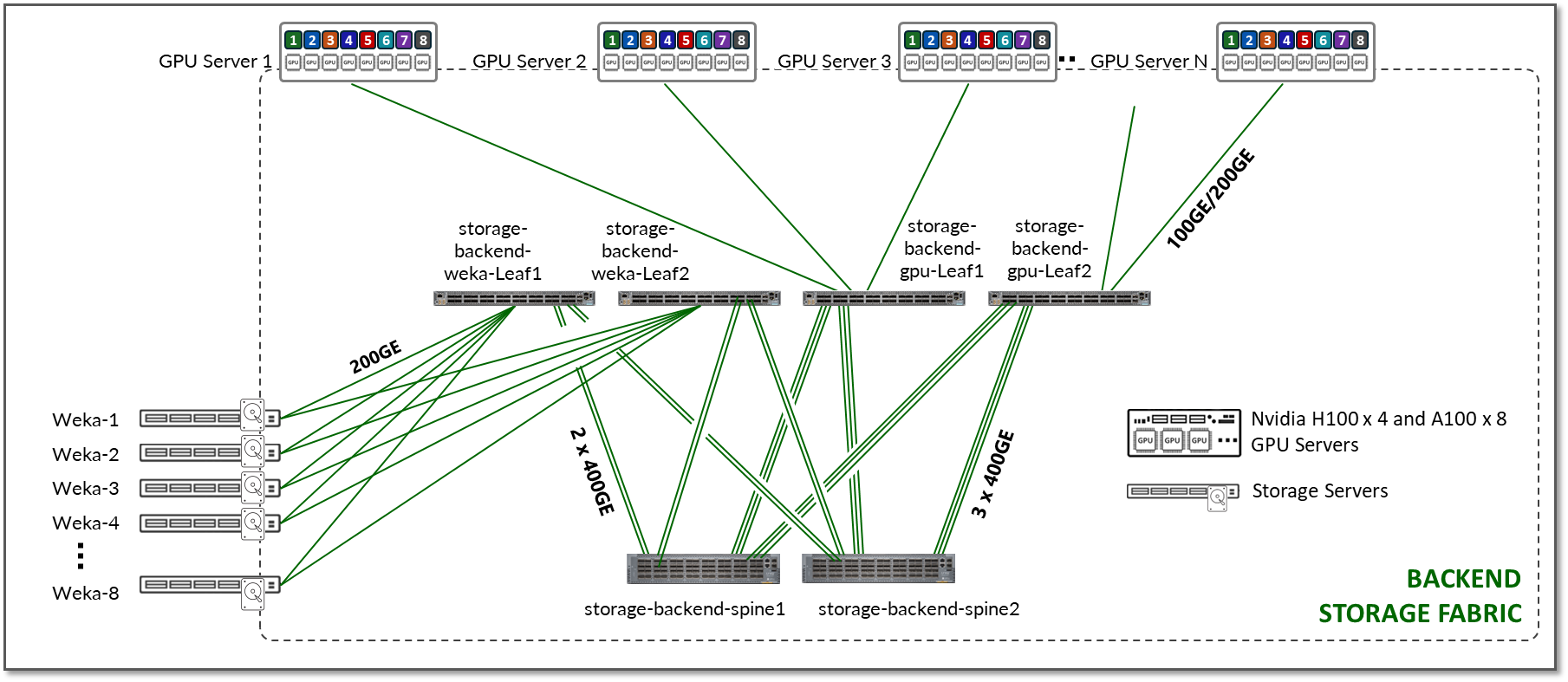
下表汇总了此交换矩阵中包含的存储后端设备以及它们之间的连接:
表 16:存储后端设备
| Nvidia DGX GPU 服务器 | WEKA 存储服务器 | 存储后端叶节点交换机型号 (存储-后端-gpu-leaf 和存储-后端-weka-leaf) |
存储后端主干节点交换机型号 (存储-后端-主干#) |
| A100 x 8 H100 x 4 |
Weka 存储服务器 x 8 | QFX5130-32CD x 4 (2 个存储后端 GPU-叶节点,以及 2 个存储后端 weka-leaf 节点) |
QFX5130-32CD x 2 |
QFX5230 和 QFX5240 还针对存储后端叶和主干角色进行了验证。
表 17:存储后端中服务器、叶节点和主干节点之间的连接
| GPU 服务器 <=> 存储后端 GPU 叶节点 |
WEKA 存储服务器 <=> 存储后端 WEKA 叶节点 |
存储后端主干节点 <=> 存储后端叶节点 |
| 1 个 100GE 链路 在每台 H100 服务器和存储后端 GPU 叶交换机之间 1 个 200GE 链路 在每台 A100 服务器和存储-后端-gpu-叶交换机之间 |
1 个 100GE 链路 在每个存储服务器(WEKA-1 到 WEKA-8)和存储后端 WEKA 叶交换机之间 |
2 个 400GE 链路 在每个叶和主干节点与 storage-backend-weka-leaf 交换机之间 3 个 400GE 链路 在每个叶节点和主干节点与存储后端 GPU 叶交换机之间 |
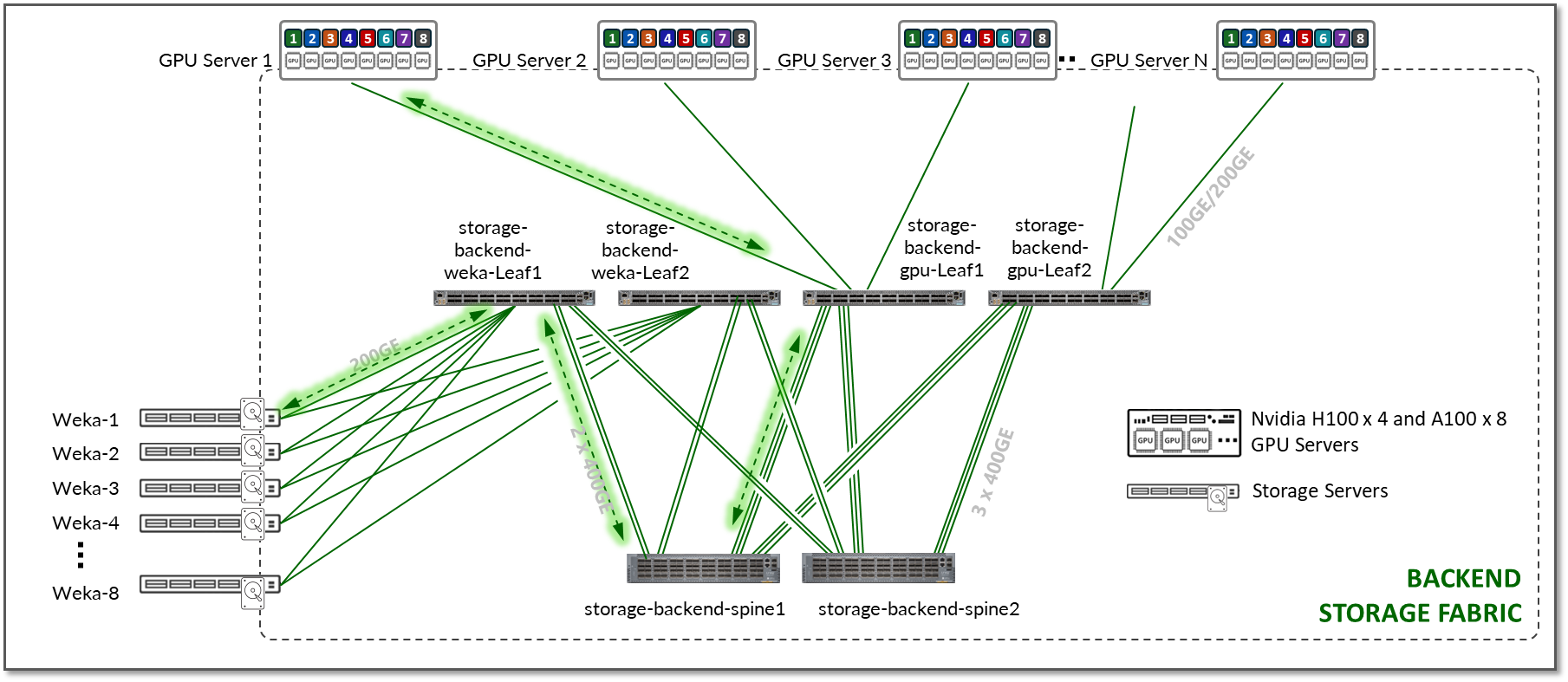
托管 GPU 的 NVIDIA 服务器具有专用存储网络适配器 (NVIDIA ConnectX),支持以太网和 InfiniBand 协议并提供与外部存储阵列的连接。
GPU 和存储设备之间的通信利用 WEKA 分布式 POSIX 客户端,该客户端支持将存储的数据从 WEKA 节点传输到 GPU 客户端服务器的多条数据路径。WEKA 客户端利用数据平面开发工具包 (DPDK) 从作系统内核卸载 TCP 数据包处理,以实现更高的吞吐量。
此通信由上一节中描述的存储后端结构支持,并在图 17 中进行了示例。
图 17:GPU 后端到存储后端的通信
WEKA 存储解决方案
在小型群集中,使用每个 GPU 服务器上的本地存储,或者使用开源或商业软件将此存储聚合在一起可能就足够了。在工作负载较重的大型集群中,需要外部专用存储系统来提供数据集暂存以进行摄取,并在训练期间进行群集检查点。此 JVD 描述了使用 WEKA 存储的专用存储的基础架构。
WEKA 是一个分布式数据平台,允许高性能和并发访问,并允许群集中的所有 GPU 服务器有效地利用共享存储资源。凭借极致的 I/O 功能,WEKA 系统可以满足所有服务器的需求,并可扩展以支持数百甚至数千个 GPU。
在本文档的末尾,您可以找到有关 WEKA 存储系统的更多详细信息,包括配置设置、驱动程序详细信息等。