轨道优化交换矩阵
每个服务器上的 GPU 编号为 1-8,其中数字代表 GPU 在服务器中的位置,如图 11 所示。
图 11:GPU 和叶节点之间的轨道优化连接
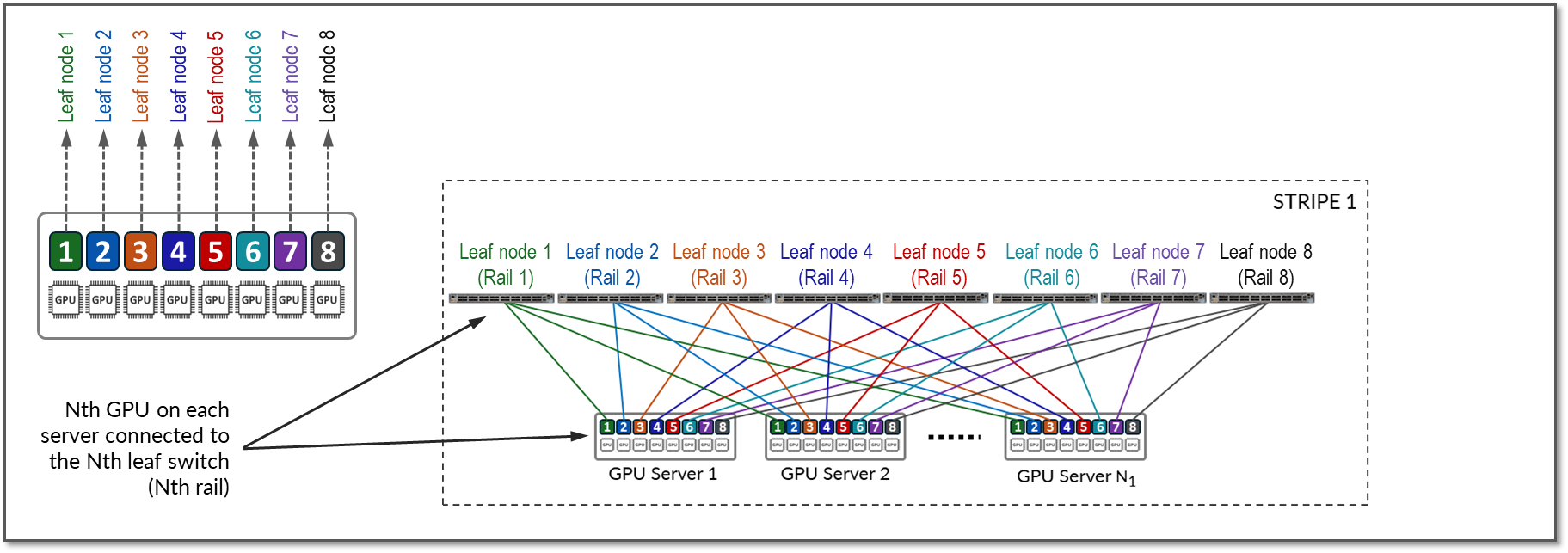
同一服务器中的 GPU 之间的通信通过连接到内部 NV 交换机的高吞吐量 NV-Link(Nvidia 链接)通道在内部进行,而不同服务器中的 GPU 之间的通信通过提供 400Gbps GPU 到 GPU 带宽的 QFX 交换矩阵进行。跨交换矩阵的通信发生在同一轨道上的 GPU 之间,这是轨道优化架构的基础: 轨道 跨其中一个叶节点连接相同顺序的 GPU;也就是说,轨道 N 通过叶交换机 N 连接位于所有服务器中位置 N 位置的 GPU。
图 12 表示了一个拓扑结构,其中一条 条带 和 8 条轨道 分别跨叶交换机 1-8 连接 GPU 1-8。
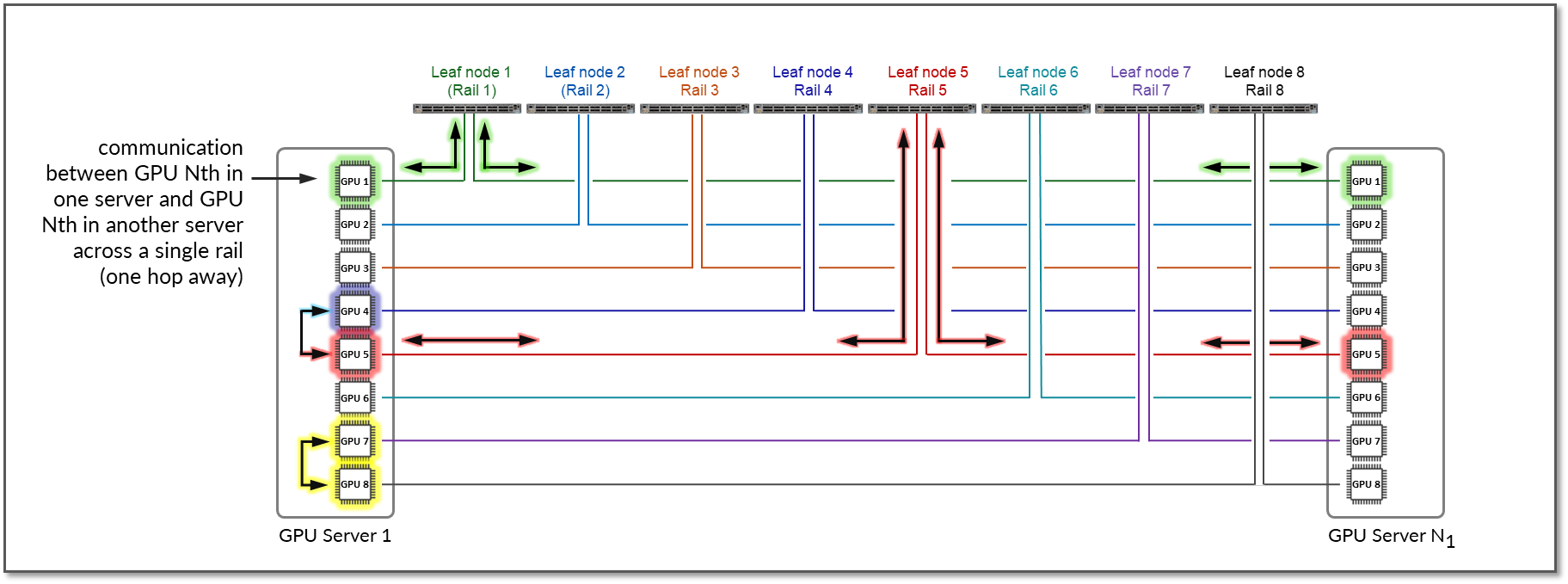
该示例显示,服务器 1 中的 GPU 7 和 GPU 8 之间的通信在内部通过 Nvidia 的 NVlinks/NV 交换机(未显示)进行,而服务器 1 中的 GPU 1 和服务器 N1 中的 GPU 1 之间的通信通过叶交换机 1(在同一轨道内)进行。
请注意,如果需要不同条带中的 GPU 和不同服务器之间进行任何通信(例如,服务器 1 中的 GPU 4 与服务器 N1 中的 GPU 5 进行通信),则首先将数据移动到与目标 GPU 位于同一轨道中的 GPU 接口,从而将数据发送到目标 GPU,而无需跨越轨道。
按照这种设计,不同服务器上的 GPU 之间(但采用相同条带)的数据始终在同一轨道上通过单个交换机移动,这可以保证 GPU 彼此之间相距 1 跳,并创建单独的独立高带宽通道,从而最大限度地减少争用并最大限度地提高性能。
请注意,此示例假定已启用 Nvidia 的 PXN 功能。在启动训练或推理作业之前,可以轻松启用/禁用 PXN。
图 12:启用了 PXN 的两台服务器之间的 GPU 到 GPU 通信
为了参考,图 13 显示了禁用 PXN 的示例。
图 13:未启用 PXN 的两台服务器之间的 GPU 到 GPU 通信
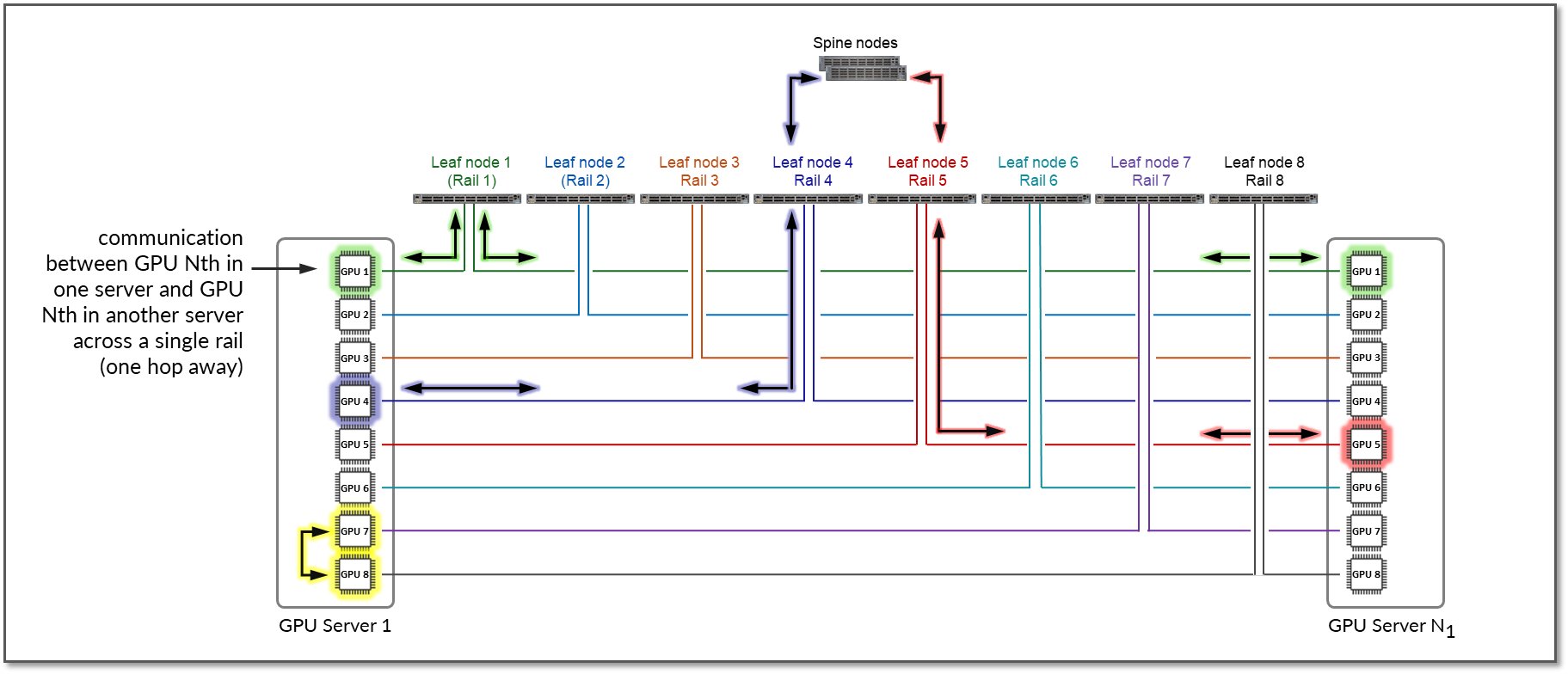
该示例显示,服务器 1 中的 GPU 4 和服务器 N1 中的 GPU 5 之间的通信跨叶交换机 1、主干节点和叶交换机 5(在两个不同的轨道之间)进行。