本页内容
网络连接:参考示例
如需了解更多详情,本节将深入了解每个交换矩阵的设置以及参考示例的预期值。
本节介绍了集群 1、条带 1 中的常见前端和存储后端交换矩阵以及 GPU 后端交换矩阵之间的 IP 连接。群集 1、条带 2 和群集 2 的 GPU 后端交换矩阵遵循相同的模型。
无论使用 Apstra 是否 支持 Apstra Terraform 自动化,IP 寻址池、ASN 池和接口地址基本上都是自动分配和配置,除非需要,管理员几乎无需进行交互。
请注意,本部分中显示的所有地址均代表瞻博网络实验室用于验证设计的 IP 寻址模式。
前端网络连接
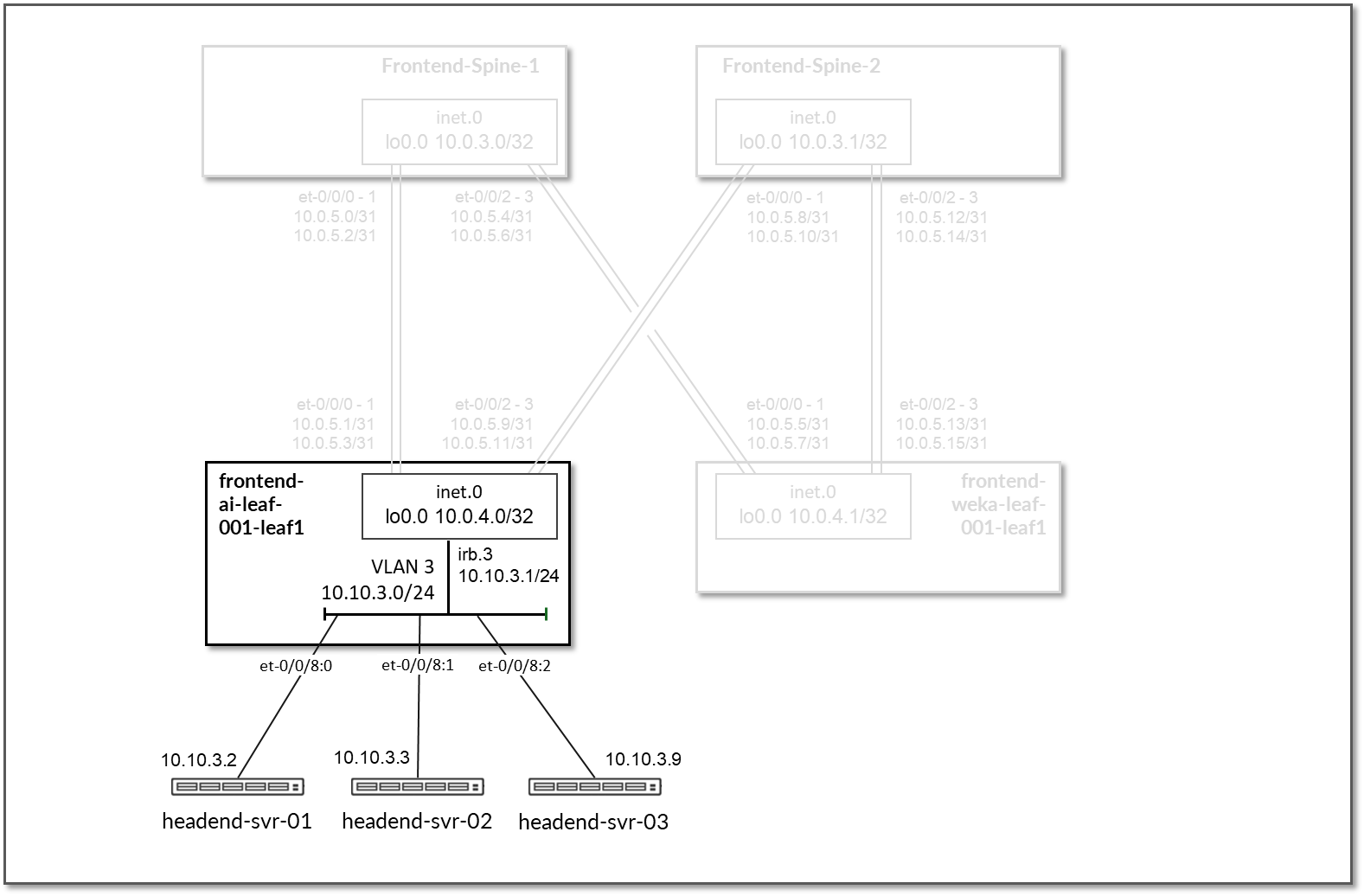
前端交换矩阵设计为第 3 层 IP 交换矩阵,其中叶节点和主干节点之间的链路配置了 /31 IP 地址,如表 26 所示。交换矩阵由 2 个主干节点和 2 个叶节点组成,其中 1 个叶节点用于连接到存储服务器(命名为 frontend-weka-leaf 1), 1 个用于连接到 GPU 服务器(命名为 frontend-ai-leaf1)。 此外,执行 AI 训练和推理模型的工作负载管理器 (Slurm) 的前端服务器也驻留在此交换矩阵中。
每个 frontend-weka-leaf 1 节点和主干节点之间有两个 400GE 链路,每个 frontend-ai-leaf1 节点和主干节点之间有两个 400GE 链路,如图 71 所示。
图 71:前端主干到叶节点的连接 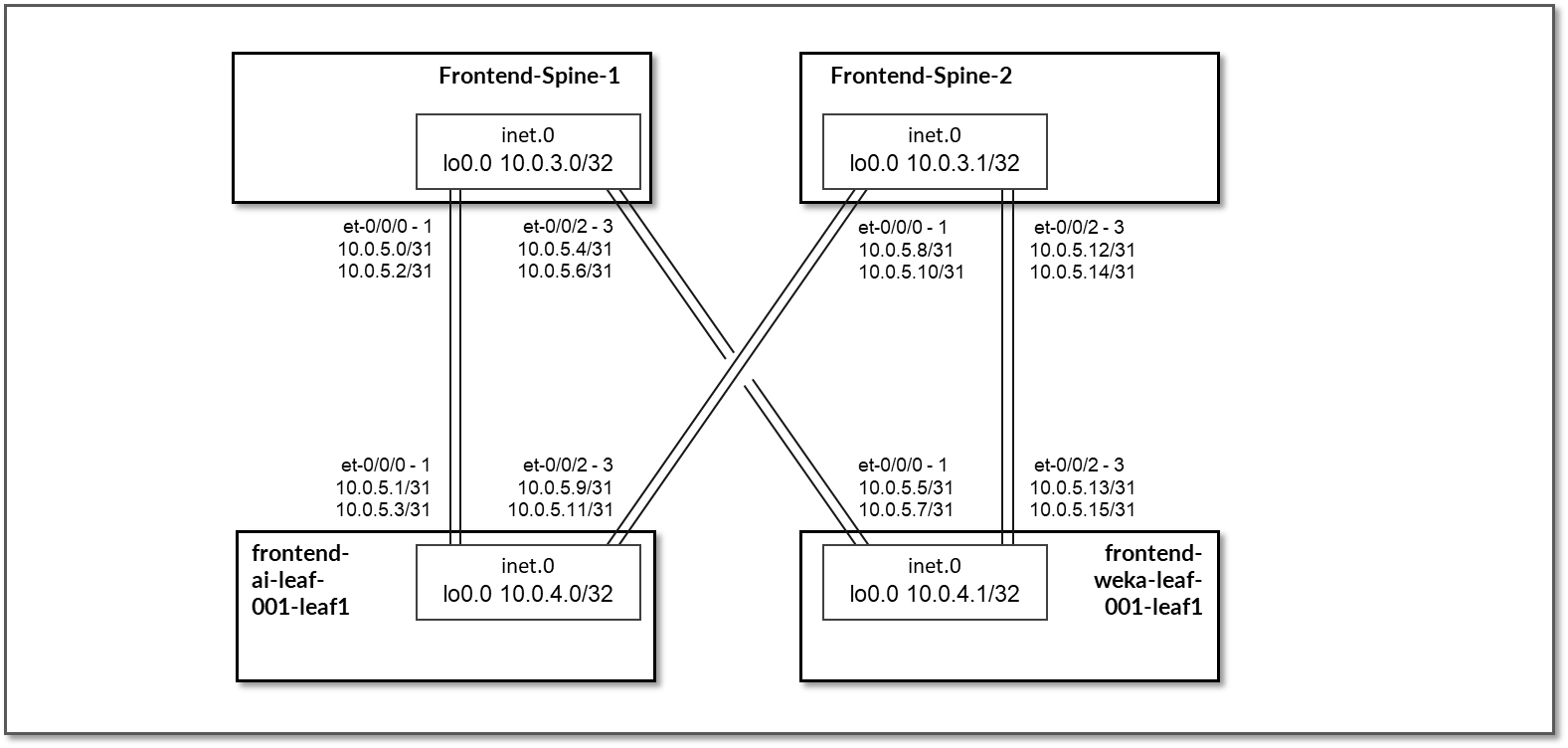
表 26:前端接口地址
| 主干节点 | 叶节点 | 主干 IP 地址 | 分叶 IP 地址 |
|---|---|---|---|
| 前端-主干1 | 前端-ai-leaf1 | 10.0.5.0/31 10.0.5.2/31 |
10.0.5.1/31 10.0.5.3/31 |
| 前端-主干1 | 前端-weka-leaf1 | 10.0.5.4/31 10.0.5.6/31 |
10.0.5.5/31 10.0.5.7/31 |
| 前端-主干2 | 前端-ai-leaf1 | 10.0.5.8/31 10.0.5.10/31 |
10.0.5.9/31 10.0.5.11/31 |
| 前端-主干2 | 前端-weka-leaf1 | 10.0.5.12/31 10.0.5.14/31 |
10.0.5.13/31 10.0.5.15/31 |
环路接口还具有 Apstra 从预定义池中自动分配的地址。
表 27:前端环路地址
| 设备 | 环路接口地址 |
|---|---|
| 前端-主干1 | 10.0.3.0/32 |
| 前端-主干2 | 10.0.3.1/32 |
| 前端-ai-leaf1 | 10.0.1.0/32 |
| 前端-weka-leaf1 | 10.0.1.1/32 |
H100 GPU 服务器和 A100 GPU 服务器都连接到前端 ai-leaf1 节点。
GPU 服务器和叶节点叶 1 之间的链路被分配了 10.0.5.0/24 中的 /31 个子网,如图 72 和表 28 所示。
图 72:前端叶节点到 GPU 服务器的连接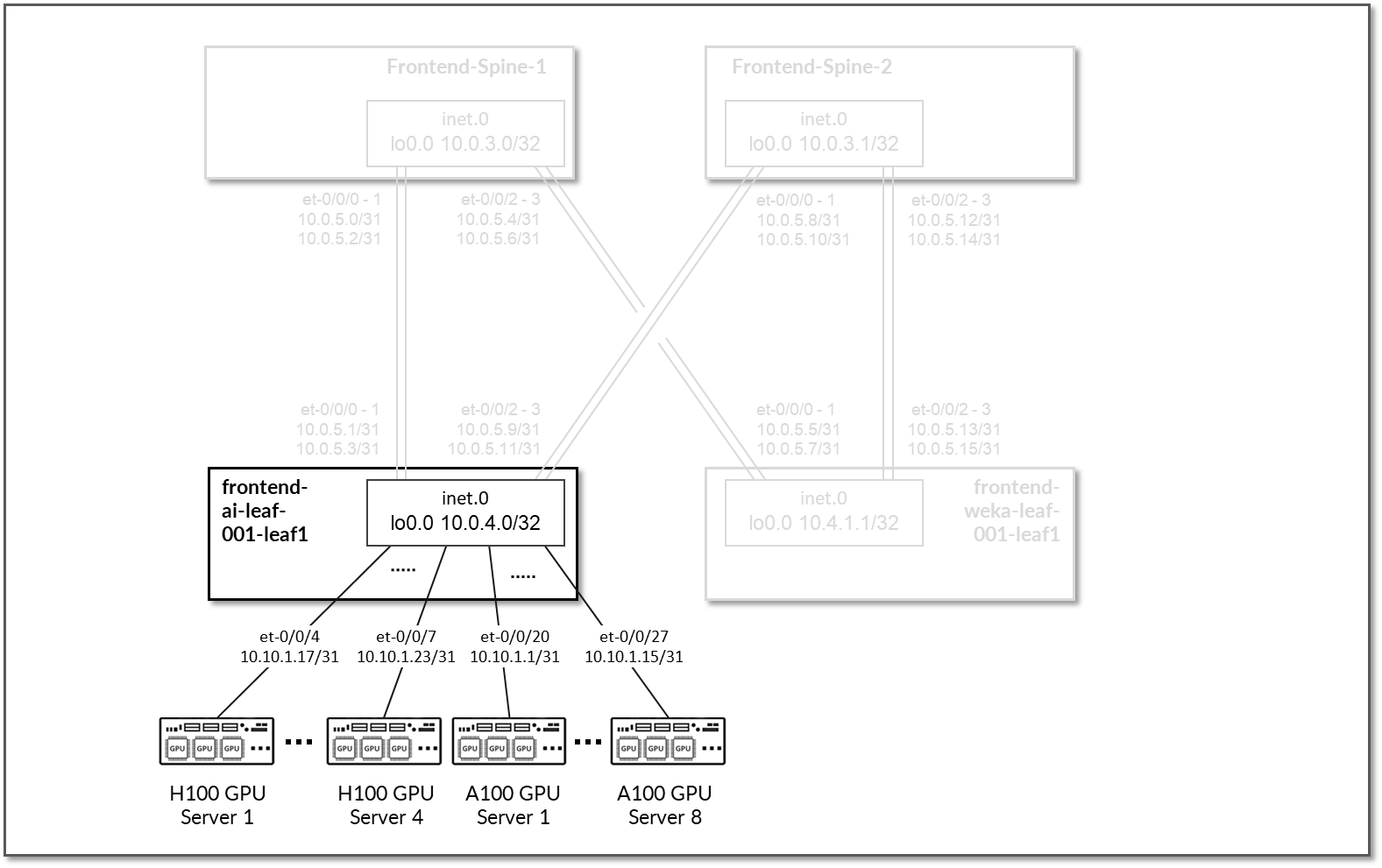
表 28:前端叶节点到 GPU 服务器接口地址
| GPU 服务器 | 叶节点 | GPU 服务器 IP 地址 | 叶 IP 地址 |
|---|---|---|---|
| H100 GPU 服务器 1 | 前端-ai-leaf1 | 10.10.1.17/31 | 10.100.1.9/31 |
| H100 GPU 服务器 2 | 10.10.1.19/31 | 10.100.1.11/31 | |
| H100 GPU 服务器 3 | 10.10.1.21/31 | 10.100.1.1/31 | |
| H100 GPU 服务器 4 | 10.10.1.23/31 | 10.100.1.3/31 | |
| A100 GPU 服务器 1 | 10.10.1.1/31 | 10.100.1.5/31 | |
| A100 GPU 服务器 2 | 10.10.1.3/31 | 10.100.1.7/31 | |
| A100 GPU 服务器 3 | 10.10.1.5/31 | 10.100.2.9/31 | |
| A100 GPU 服务器 4 | 10.10.1.7/31 | 10.100.2.11/31 | |
| A100 GPU 服务器 5 | 10.10.1.9/31 | 10.100.2.1/31 | |
| A100 GPU 服务器 6 | 10.10.1.11/31 | 10.100.2.3/31 | |
| A100 GPU 服务器 7 | 10.10.1.13/31 | 10.100.2.5/31 | |
| A100 GPU 服务器 8 | 10.10.1.15/31 | 10.100.2.7/31 |
WEKA 存储服务器都连接到 frontend-weka-leaf 1 节点。
指向这些服务器的链路没有在叶节点上分配 IP 地址。通过地址不在子网 10.10.2.1/24 的 IRB 接口提供第 3 层连接。WEKA 服务器的地址来自 10.10.2.0/24,如图 73 和 表 29 所示。
图 73:前端叶节点到 WEKA 存储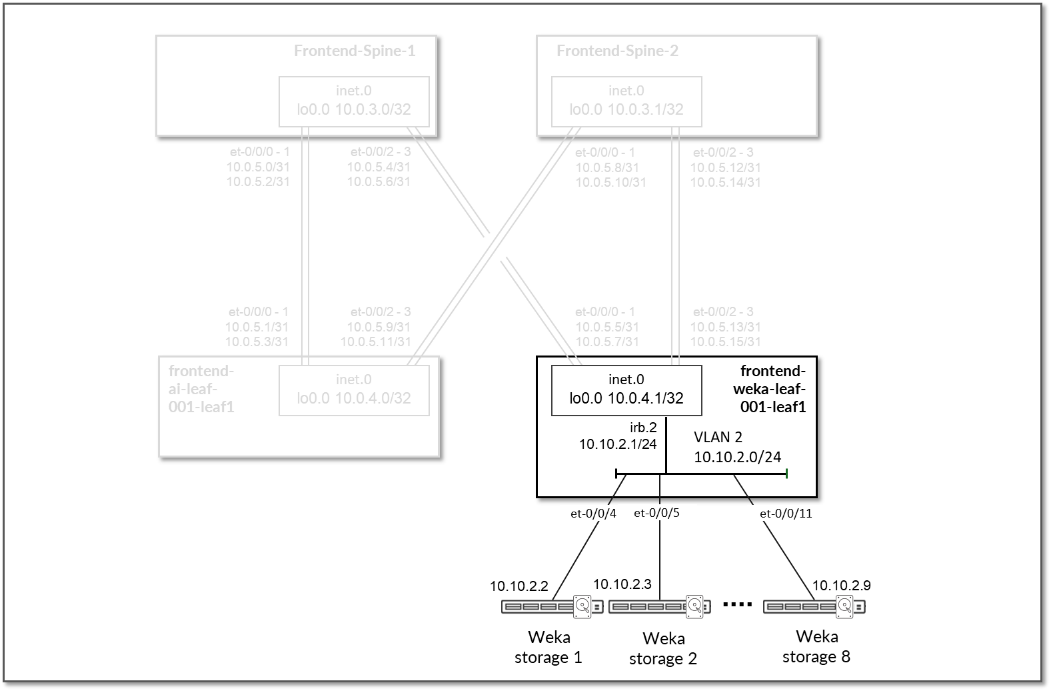 连接
连接
表 29:前端叶节点到 WEKA 存储接口地址
| GPU 服务器 | 叶节点 | WEKA 服务器 IP 地址 | 叶 IP 地址 |
|---|---|---|---|
| WEKA 存储服务器 1 | 前端-weka-leaf1 | 10.10.2.2/24 | 10.10.2.1/24 (IRB.2) |
| WEKA 存储服务器 2 | 10.10.2.3/24 | ||
| WEKA 存储服务器 3 | 10.10.2.4/24 | ||
| WEKA 存储服务器 4 | 10.10.2.5/24 | ||
| WEKA 存储服务器 5 | 10.10.2.6/24 | ||
| WEKA 存储服务器 6 | 10.10.2.7/24 | ||
| WEKA 存储服务器 7 | 10.10.2.8/24 | ||
| WEKA 存储服务器 8 | 10.10.2.9/24 |
执行工作负载管理器的前端服务器都连接到 frontend-ai-leaf1 节点。
指向这些服务器的链路没有在叶节点上分配 IP 地址。通过地址为 10.10.3.1/24 的 IRB 接口提供第 3 层连接。前端服务器分配的地址超出了 10.10.3.0/24,如下表所示。
图 74:前端叶节点到前端服务器的连接
EBGP 配置在分配给主干叶节点链路的 IP 地址之间。 frontend-ai-leaf# 节点和每个主干节点之间将有 2 个 EBGP 会话,每个 frontend-weka-leaf # 节点和每个主干节点之间将有 2 个 EBGP 会话,如图 75 所示。
图 75:前端 EBGP
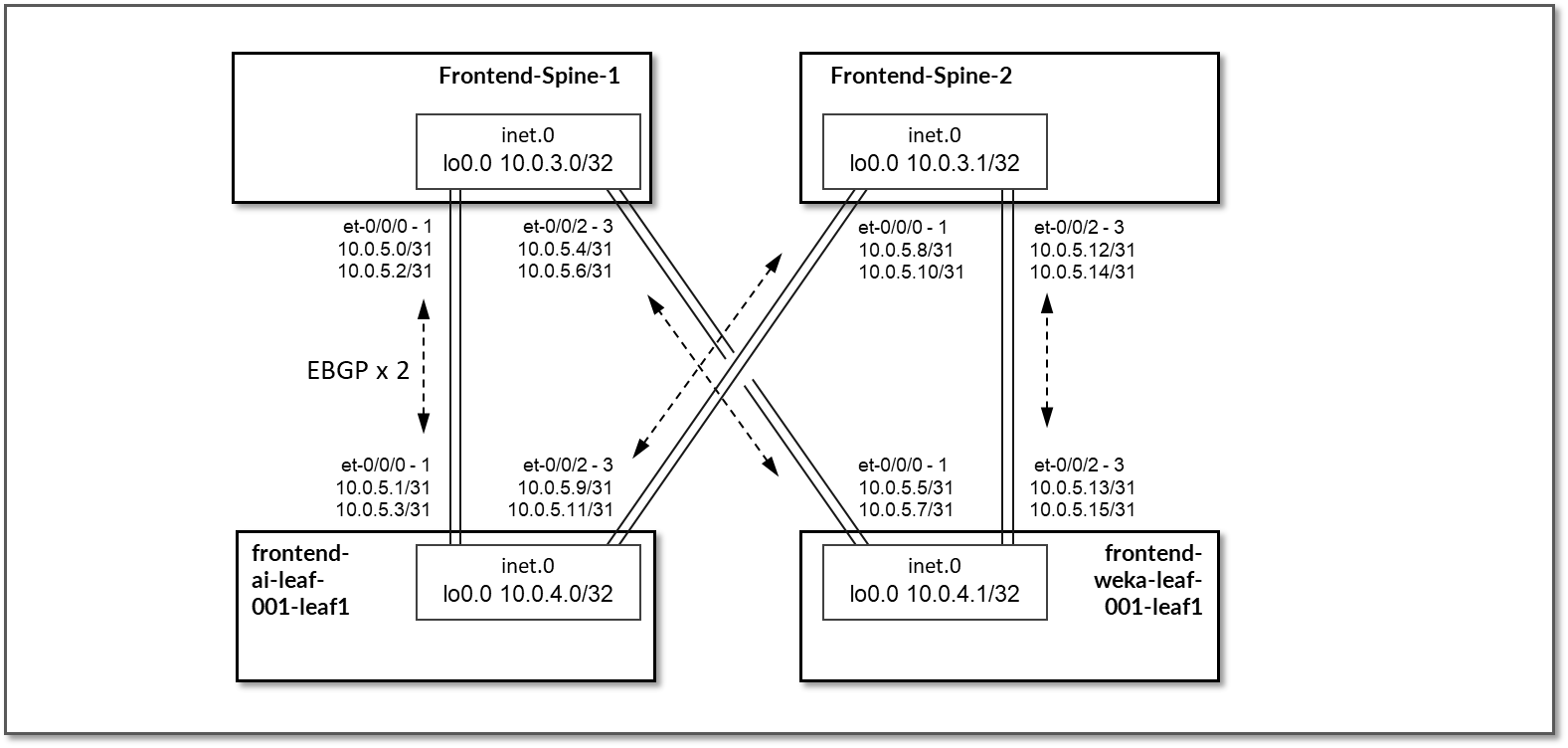
表 30:前端会话
| 主干节点 | 叶节点 | 主干 | 分叶 ASN | 主干 IP 地址 | 叶 IP 地址 |
|---|---|---|---|---|---|
| 前端-主干1 | 前端-ai-leaf1 | 4201032300 | 4201032400 | 10.0.5.0/31 10.0.5.2/31 |
10.0.5.1/31 10.0.5.3/31 |
| 前端-主干1 | 前端 weka-leaf 1 | 4201032401 | 10.0.5.4/31 10.0.5.6/31 |
10.0.5.4/31 10.0.5.7/31 |
|
| 前端-主干2 | 前端-ai-leaf1 | 4201032301 | 4201032400 | 10.0.5.8/31 10.0.5.10/31 |
10.0.5.9/31 10.0.5.11/31 |
| 前端-主干2 | 前端 weka-leaf 1 | 4201032401 | 10.0.5.12/31 10.0.5.14/31 |
10.0.5.13/31 10.0.5.15/31 |
在 frontend-ai-leaf1 节点上,Apstra 配置了 BGP 策略,以向主干节点播发以下路由:
- frontend-ai-leaf1 节点自己的环路接口地址,
- frontend-ai-leaf1 节点到主干接口、子网和
- GPU 服务器到 frontend-ai-leaf1 节点链接子网。
- WEKA 服务器的管理子网
图 76:前端叶到 GPU 服务器 BGP
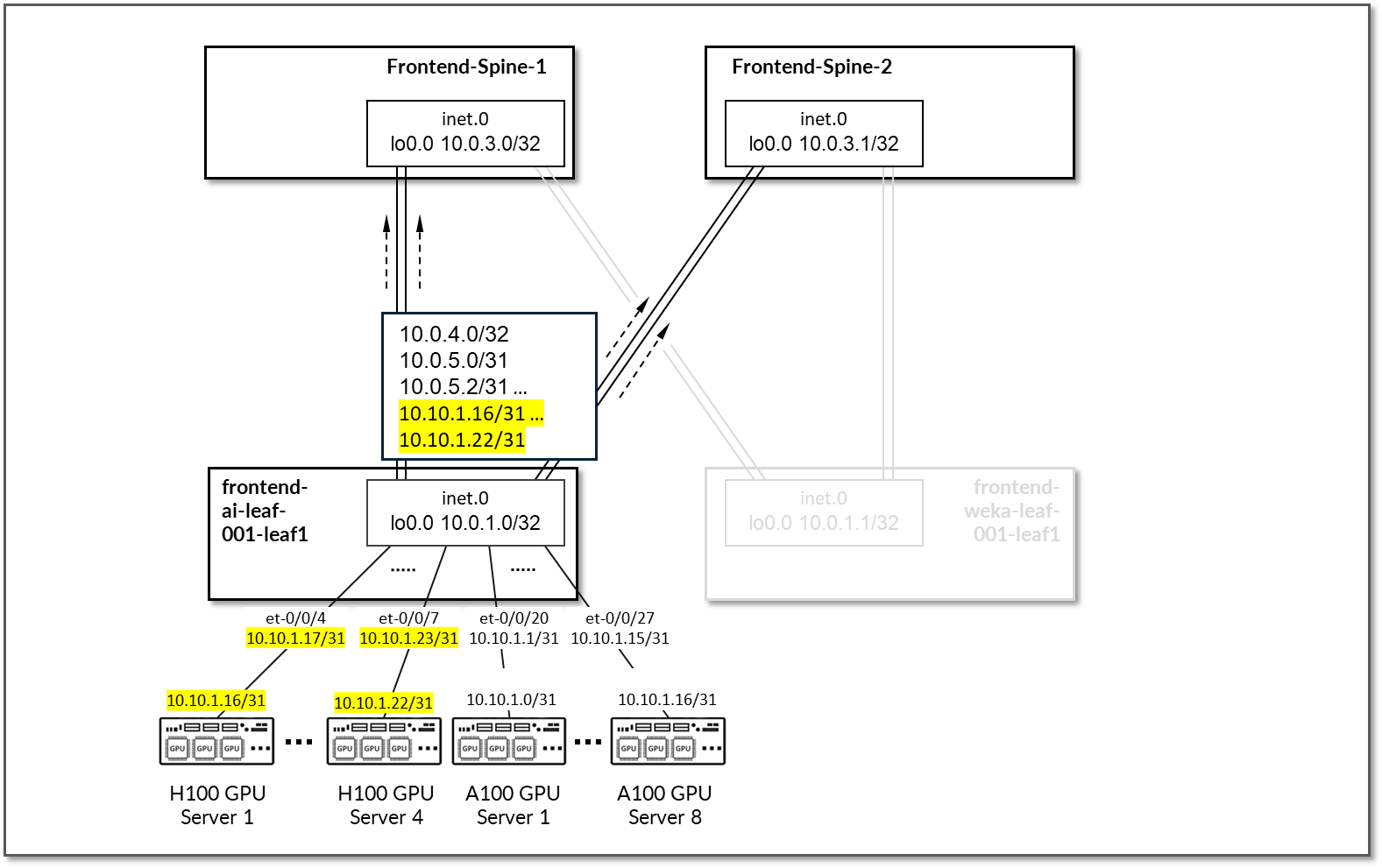
图 77:前端叶到前端服务器 BGP
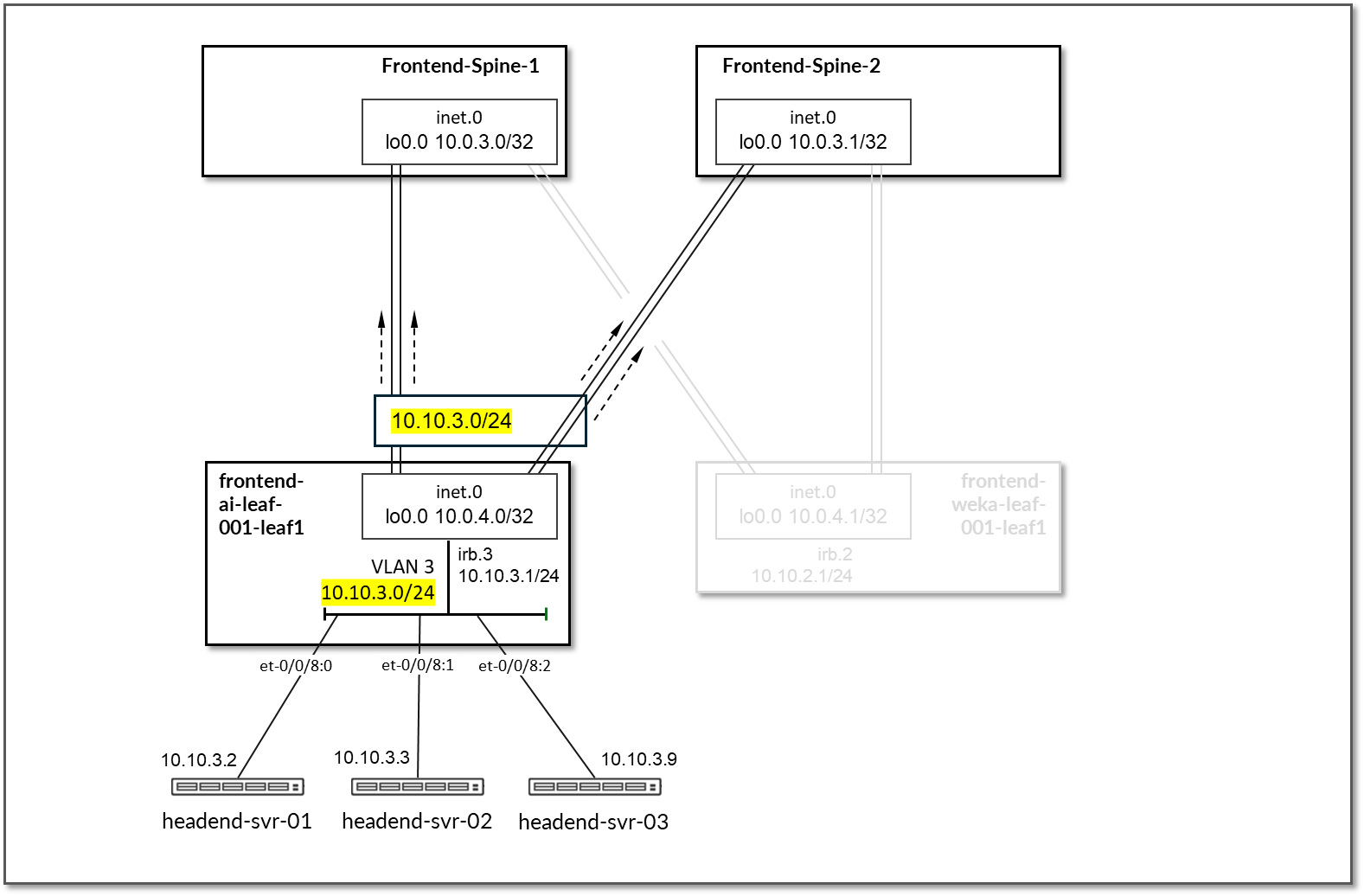
表 31:前端叶到 GPU/头端服务器通告的路由
| 叶节点 | 对等方 | 通告路由 | BGP 社区 | |
|---|---|---|---|---|
| 前端-ai-leaf1 | frontend-spine1 和前端-spine2 | 环路: 10.0.4.0/32 叶脊式链路: 10.0.5.0/31 10.0.5.2/31 10.0.5.8/31 10.0.5.10/31 |
GPU 服务器 <=> 前端主干链路: 10.10.1.16/31 10.10.1.18/31 10.10.1.20/31 10.10.1.22/31 10.10.1.0/31 10.10.1.2/31 10.10.1.4/31 10.10.1.6/31 10.10.1.8/31 10.10.1.10/31 10.10.1.12/31 10.10.1.14/31 WEKA 管理服务器的子网: 10.10.3.0/24 |
3:20007 21001:26000 |
在前端 weka-leaf 1 节点上,Apstra 配置了 BGP 策略,以向主干节点通告以下路由:
- frontend-weka-leaf 1 个节点自己的环路接口地址,
- frontend-weka-leaf 1 个节点到主干接口、子网和
- WEKA 存储服务器的子网
图 78:前端叶式到 WEKA 存储 BGP
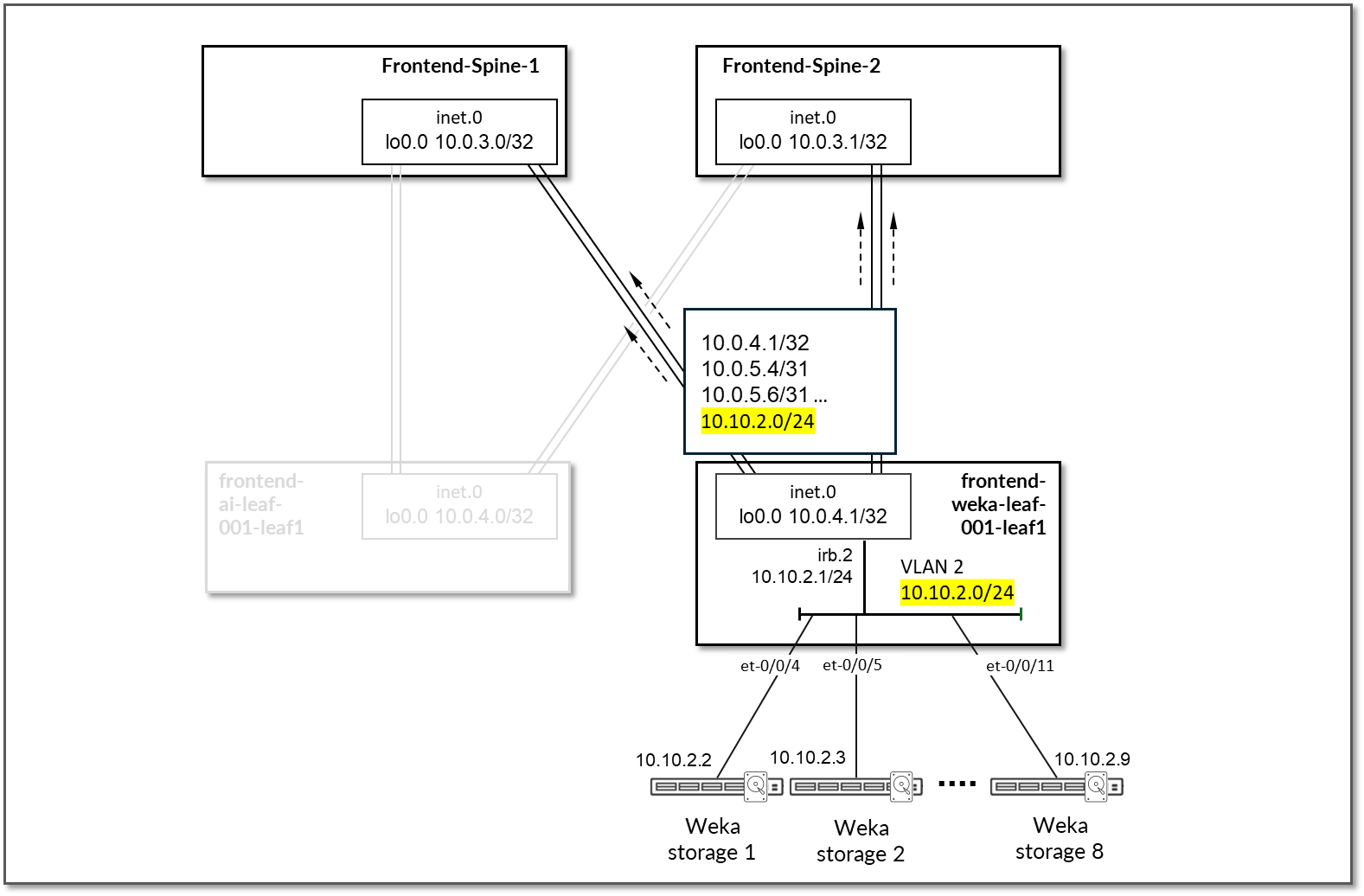
表 32:前端叶式到 Weka 存储的通告路由
| 叶节点 | 对等方 | 通告路由 | BGP 社区 | |
|---|---|---|---|---|
| 前端 weka-leaf 1 | frontend-spine1 和 前端-主干2 |
环路: 10.0.4.1/32 叶脊式链路: 10.0.5.4/31 10.0.5.6/31 10.0.5.12/31 10.0.5.14/31 |
GPU 服务器 <=> 前端主干链路: 10.10.2.0/24 |
4:20007 21001:26000 |
在主干节点上,Apstra 配置了 BGP 策略,以将以下路由播发到前端人工智能叶节点:
- 前端-主干节点自己的环路接口地址
- frontend-weka-leaf 1 环路接口地址
- frontend-主干到frontend-weka-leaf 1节点接口子网
- WEKA 存储服务器的子网(从 frontend-weka-leaf 1 中学习)
图 79:GPU/头服务器 BGP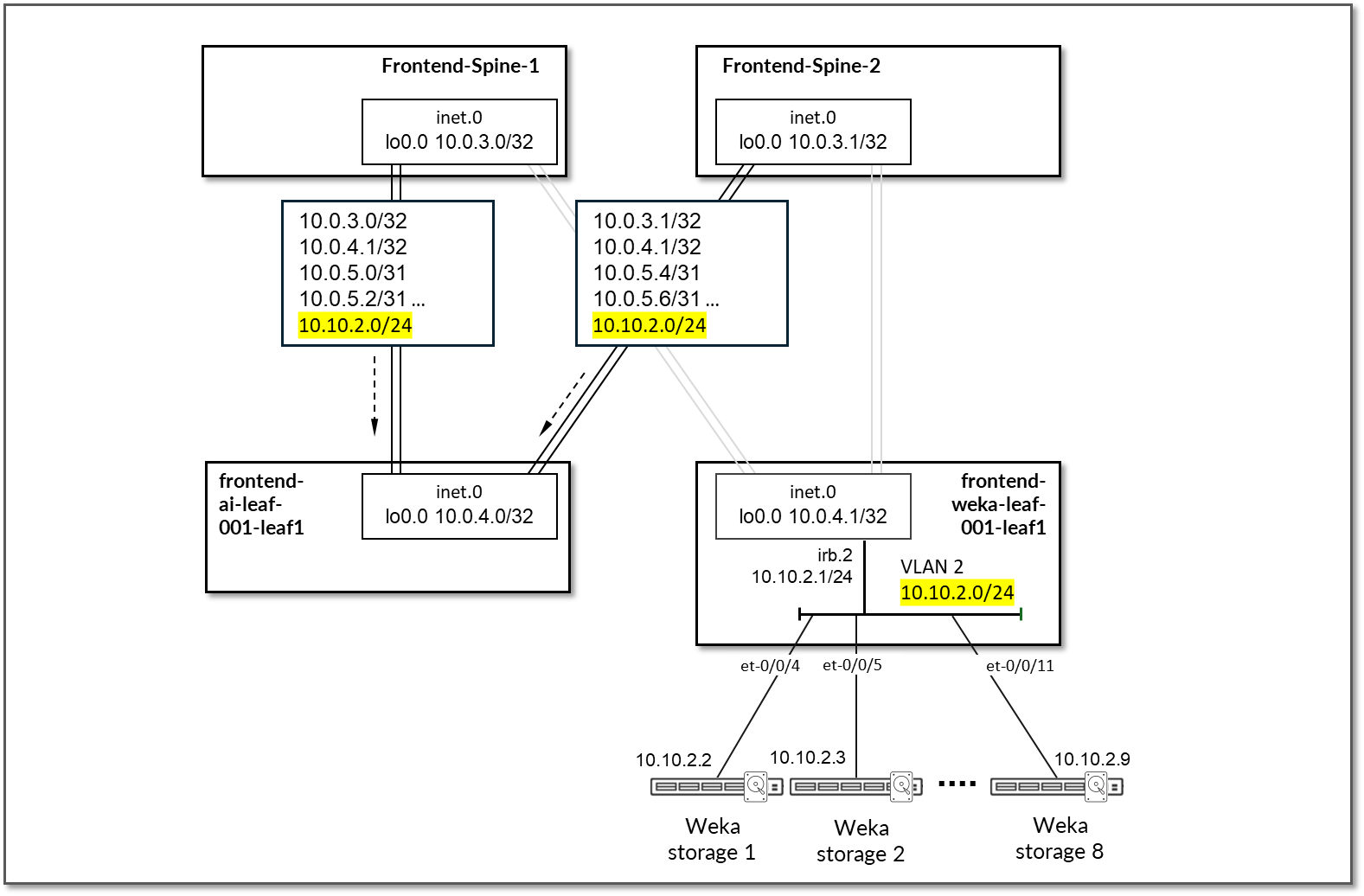 的前端主干到前端叶
的前端主干到前端叶
表 33:GPU/头服务器的前端主干到前端叶 通告路由
| 叶节点 | 对等方 | 通告路由 | BGP 社区 | |
|---|---|---|---|---|
| 前端-主干1 | 前端人工智能叶 | 环路: 10.0.3.0/32 10.0.4.0/32 叶脊式链路: 10.0.5.0/31 10.0.5.2/31 10.0.5.4/31 10.0.5.6/31 10.0.5.12/31 10.0.5.14/31 |
WEKA 服务器子网: 10.10.2.0/24 |
0:15 1:20007 21001:26000 10.0.4.0/32 除外 (0:15 3:20007 21001:26000) |
| 前端-主干2 | 前端人工智能叶 | 环路: 10.0.3.1/32 10.0.4.0/32 叶脊式链路: 10.0.5.4/31 10.0.5.6/31 10.0.5.8/31 10.0.5.10/31 10.0.5.12/31 10.0.5.14/31 |
WEKA 服务器子网: 10.10.2.0/24 |
0:15 2:20007 21001:26000 10.0.4.0/32 除外 (0:15 3:20007 21001:26000) |
在主干节点上,Apstra 配置了 BGP 策略,以将以下路由播发至前端 weka-leaf 1 叶节点:
- 主干节点自己的环路接口地址
- frontend-ai-leaf1 环路接口地址
- 主干到前端 AI-Leaf1 节点、接口、子网
- GPU 服务器到 frontend-ai-leaf1 节点链路子网
图 80:WEKA 存储前端服务器 BGP 的前端主干到前端叶
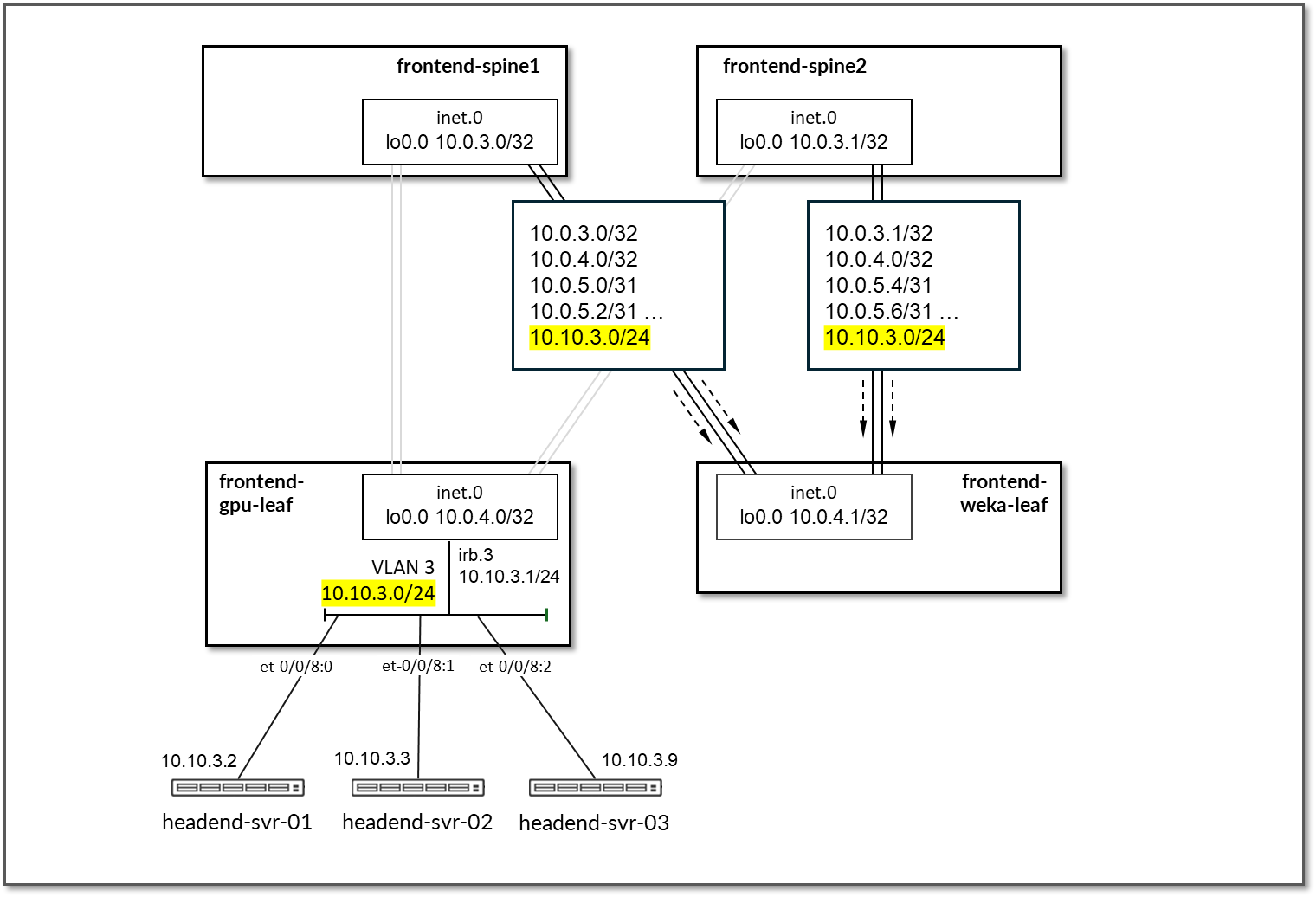
图 81:WEKA 存储 GPU 服务器 BGP 的前端主干到前端叶
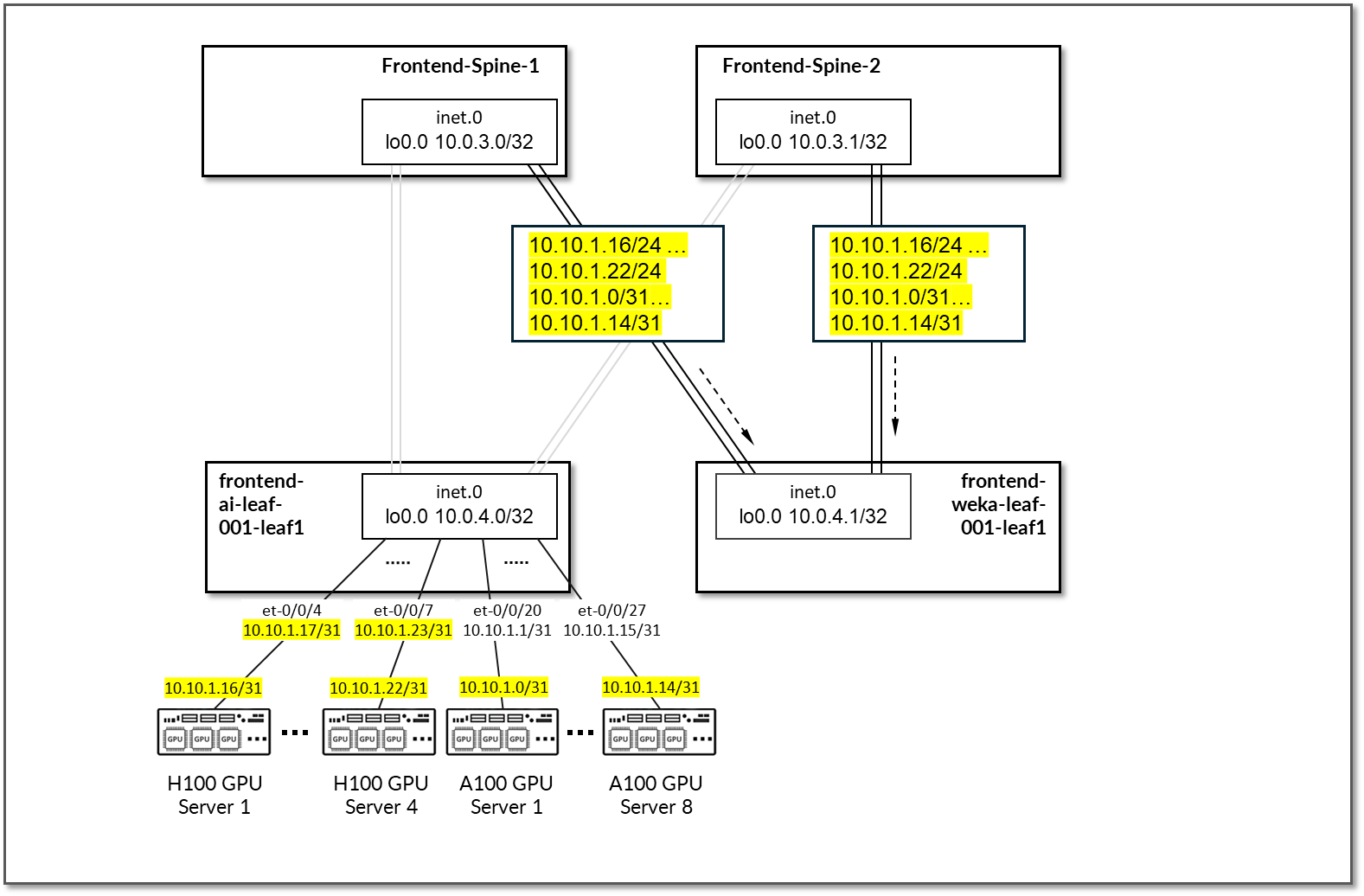
表 34 WEKA 存储的前端主干到前端叶 通告路由
| 叶节点 | 对等方 | 通告路由 | BGP 社区 | |
|---|---|---|---|---|
| 前端-主干1 | 前端人工智能叶 | 环路: 10.0.3.0/32 10.0.4.1/32 叶脊式链路: 10.0.5.0/31 10.0.5.2/31 10.0.5.4/31 10.0.5.6/31 10.0.5.8/31 10.0.5.10/31 |
GPU 服务器 <=> 前端主干链路: 10.10.1.16/31 10.10.1.18/31 10.10.1.20/31 10.10.1.22/31 10.10.1.0/31 10.10.1.2/31 10.10.1.4/31 10.10.1.6/31 10.10.1.8/31 10.10.1.10/31 10.10.1.12/31 10.10.1.14/31 WEKA 服务器的管理子网: 10.10.3.0/24 |
0:15 1:20007 21001:26000 10.0.4.1/32 除外 (0:15 4:20007 21001:26000) |
| 前端-主干2 | 前端人工智能叶 | 环路: 10.0.3.1/32 10.0.4.1/32 叶脊式链路: 10.0.5.0/31 10.0.5.2/31 10.0.5.8/31 10.0.5.10/31 10.0.5.12/31 10.0.5.14/31 |
GPU 服务器 <=> 前端主干链路: 10.10.1.16/31 10.10.1.18/31 10.10.1.20/31 10.10.1.22/31 10.10.1.0/31 10.10.1.2/31 10.10.1.4/31 10.10.1.6/31 10.10.1.8/31 10.10.1.10/31 10.10.1.12/31 10.10.1.14/31 WEKA 管理服务器的子网: 10.10.3.0/24 |
0:15 2:20007 21001:26000 10.0.4.1/32 除外 (0:15 4:20007 21001:26000) |
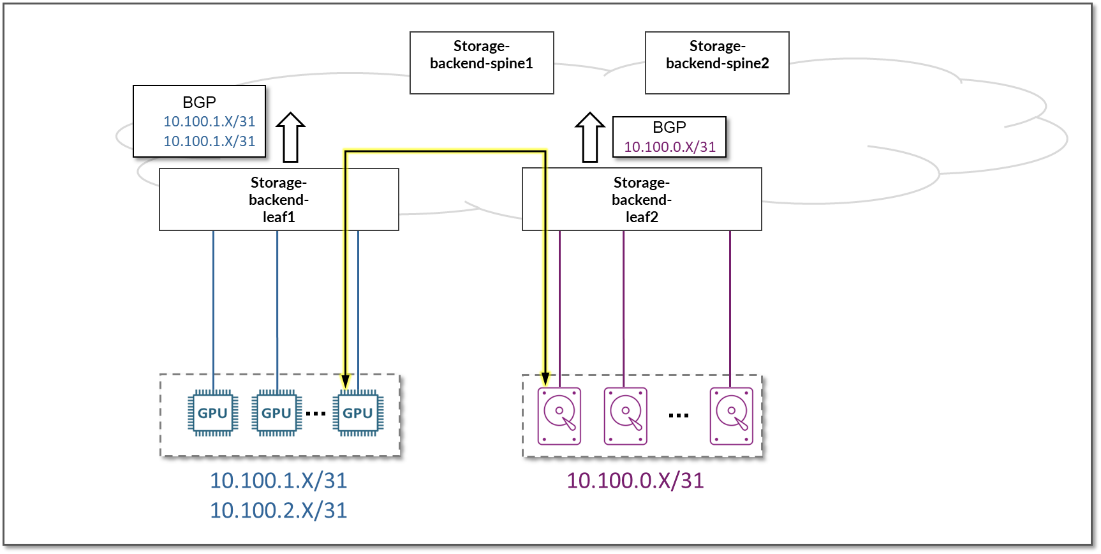
通过播发分配给叶节点与 GPU/存储服务器之间链路的子网,GPU 与 WEKA 存储和 WEKA 管理服务器之间的通信可以在整个交换矩阵中实现。
图 82:GPU 服务器到 WEKA 存储和 WEKA 管理服务器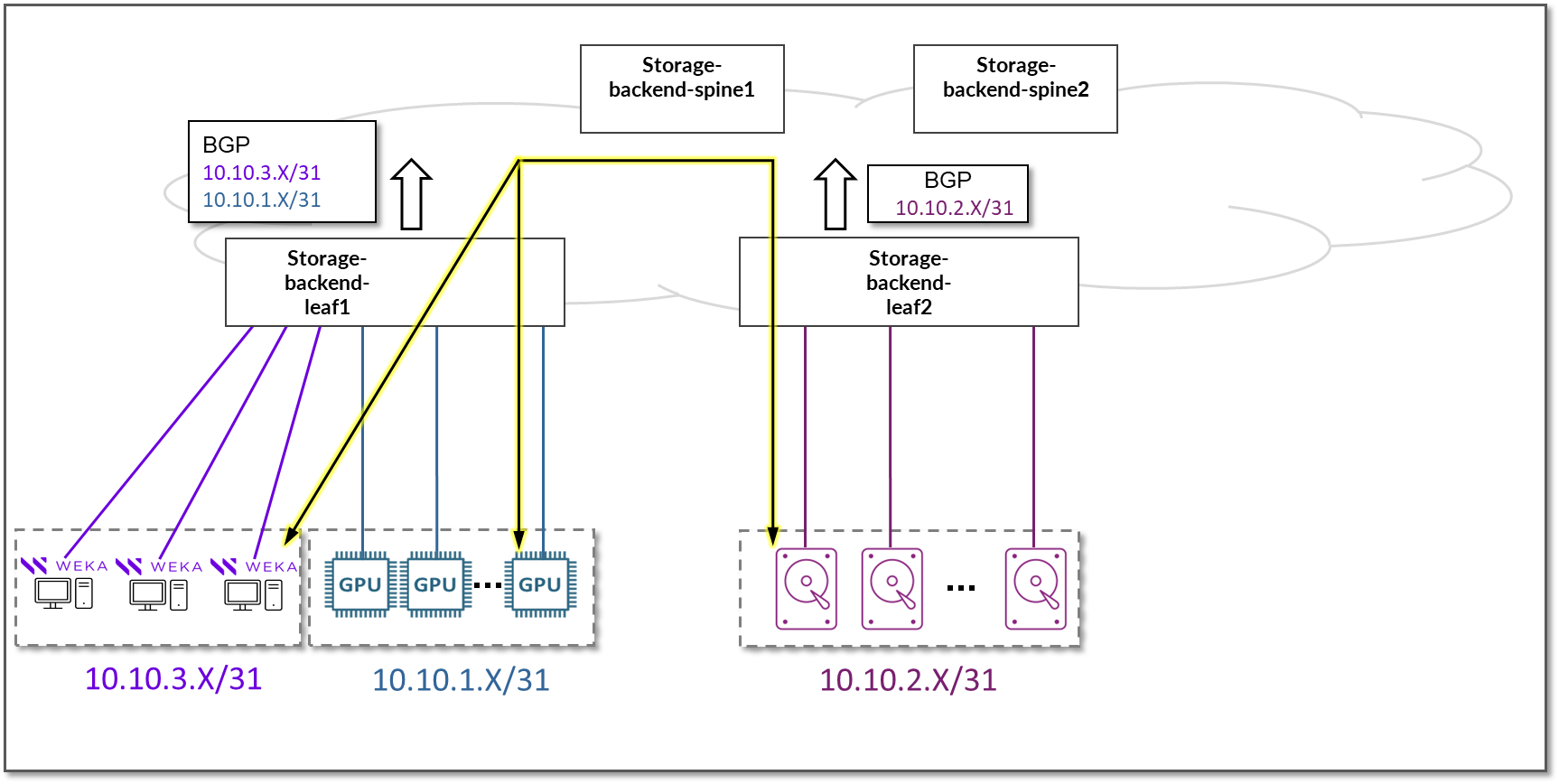
GPU 后端网络连接
GPU 后端交换矩阵设计为第 3 层 IP 交换矩阵,其中叶节点和主干节点之间的链路配置了 /31 IP 地址并运行 EBGP。交换矩阵由 2 个主干节点和 8 个主干节点(每个条带)组成。
每个叶节点和主干节点之间都有一个 400GE 链路。
图 83:GPU 后端主干到 GPU 后端叶节点的连接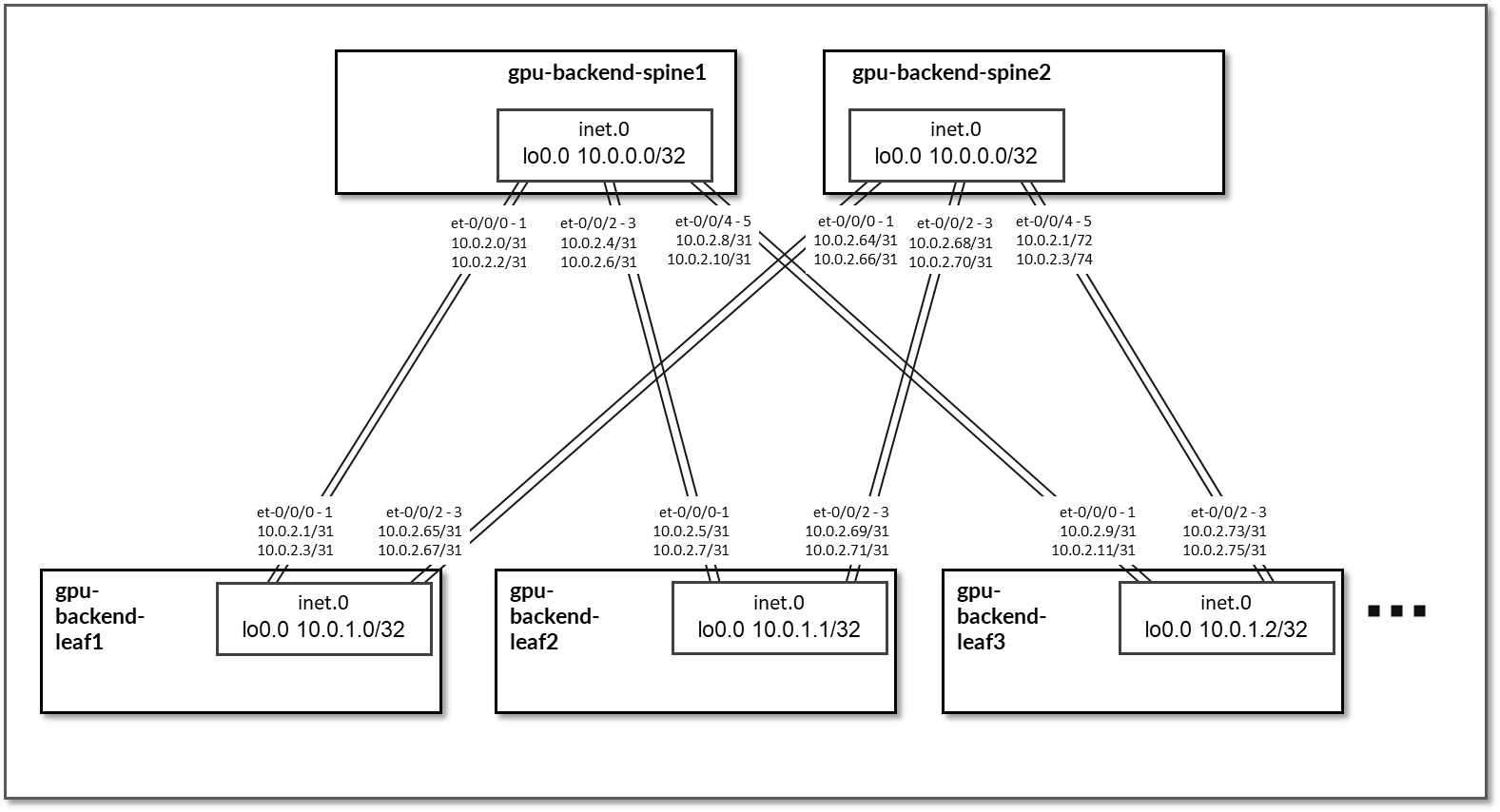
表 35:GPU 后端接口地址
| 条带 # | 主干节点 | 叶节点 | 主干 IP 地址 | 叶 IP 地址 |
|---|---|---|---|---|
| 1 | GPU 后端主干 1 | GPU-后端-叶 1 | 10.0.2.0/31 10.0.2.2/31 |
10.0.2.1/31 10.0.2.3/31 |
| 1 | GPU 后端主干 1 | GPU-后端-叶式 2 | 10.0.2.4/31 10.0.2.6/31 |
10.0.2.5/31 10.0.2.7/31 |
| 1 | GPU 后端主干 1 | GPU-后端-叶式 3 | 10.0.2.8/31 10.0.2.10/31 |
10.0.2.9/31 10.0.2.11/31 |
| . . . |
||||
| 1 | GPU-后端-主干 2 | GPU-后端-叶 1 | 10.0.2.64/31 10.0.2.66/31 |
10.0.2.65/31 10.0.2.67/31 |
| 1 | GPU-后端-主干 2 | GPU-后端-叶式 2 | 10.0.2.68/31 10.0.2.70/31 |
10.0.2.69/31 10.0.2.71/31 |
| 1 | GPU-后端-主干 2 | GPU-后端-叶式 3 | 10.0.2.72/31 10.0.2.74/31 |
10.0.2.73/31 10.0.2.75/31 |
环路接口还具有 Apstra 从预定义池中自动分配的地址。
表 36:GPU 后端环路地址
| 条带 # | 设备 | 环路接口地址 |
|---|---|---|
| 1 | GPU-后端-主干1 | 10.0.0.0/32 |
| 1 | GPU-后端-主干 2 | 10.0.0.1/32 |
| 1 | GPU-后端-叶 1 | 10.0.1.0/32 |
| 1 | GPU-后端-叶式 2 | 10.0.1.1/32 |
| 1 | GPU-后端-叶式 3 | 10.0.1.2/32 |
系统会为每个叶节点分配一个 /24 子网(满分 10.200/16)和一个唯一的 VLAN ID,以提供与 GPU 服务器的连接。第 3 层连接通过具有特定 IP 子网之外地址的 IRB 接口提供,如下表所示。
由于每个叶节点代表一个轨道,所有具有给定编号的 GPU 都在其中连接,因此群集中的每个轨道都映射到不同的 /24 IP 子网。
图 84:GPU 后端服务器到叶节点的连接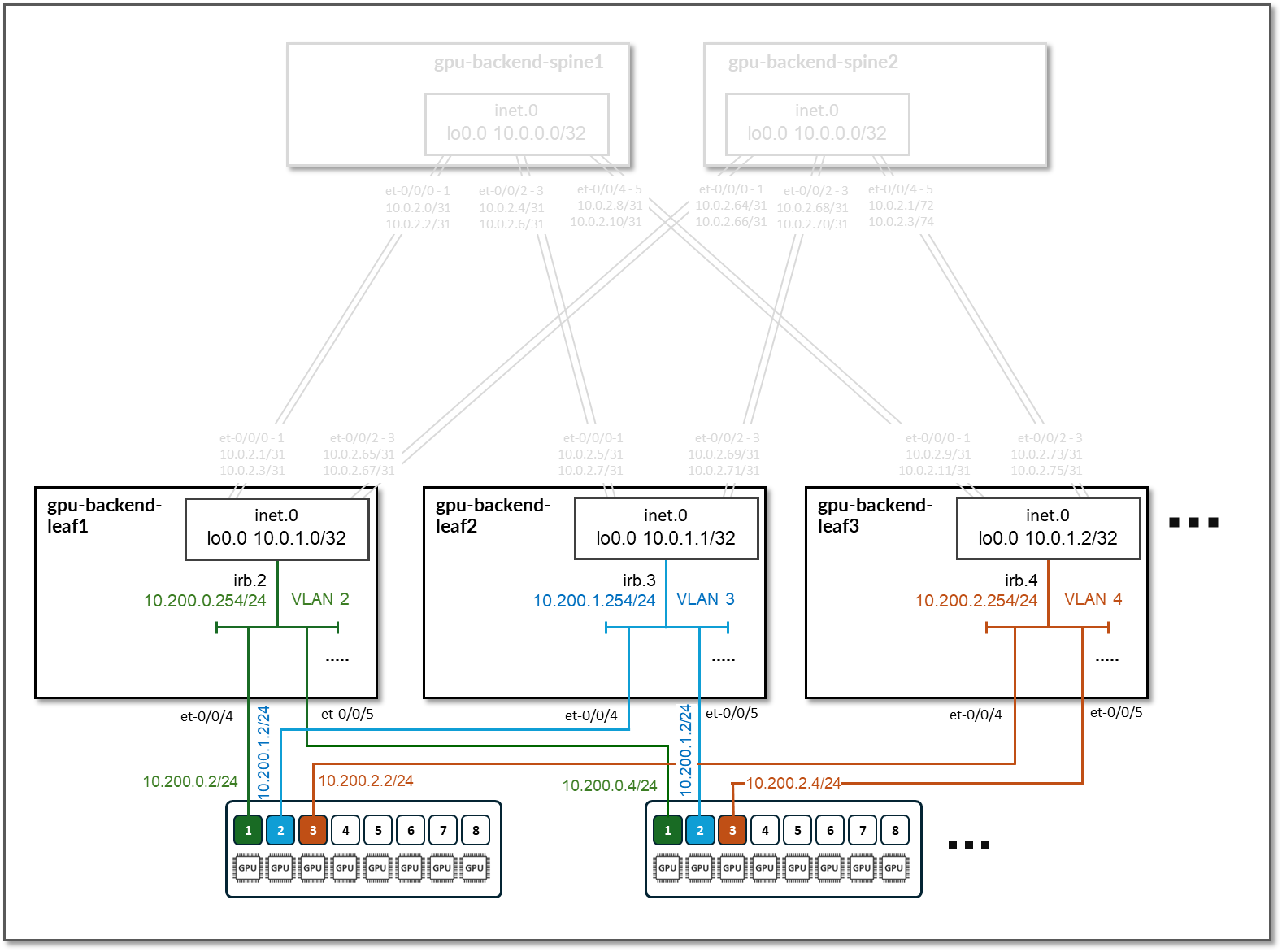
表 37:GPU 后端服务器到叶节点的连接
| 条带 # | 设备 | 轨道 # | VLAN # | 叶连接设备上 | 的子网 | IRB |
|---|---|---|---|---|---|---|
| 1 | GPU-后端-叶 1 | 1 | 2 | 10.200.0.0/24 | 10.200.0.254 | GPU 1 来自所有 8 台 GPU 服务器 |
| 1 | GPU-后端-叶 2 | 2 | 3 | 10.200.1.0/24 | 10.200.1.254 | GPU 2 个,来自 8 台 GPU 服务器 |
| 1 | GPU-后端-叶式 3 | 3 | 4 | 10.200.2.0/24 | 10.200.2.254 | GPU 3 个,来自 8 个 GPU 服务器 |
| . . . |
||||||
EBGP 配置在分配给主干叶节点链路的 IP 地址之间,如图 81 所示。每个 gpu-backend-leaf # 节点和每个 gpu-backend-主干 # 之间将有 2 个 EBGP 会话。
图 85:GPU 后端 BGP 会话
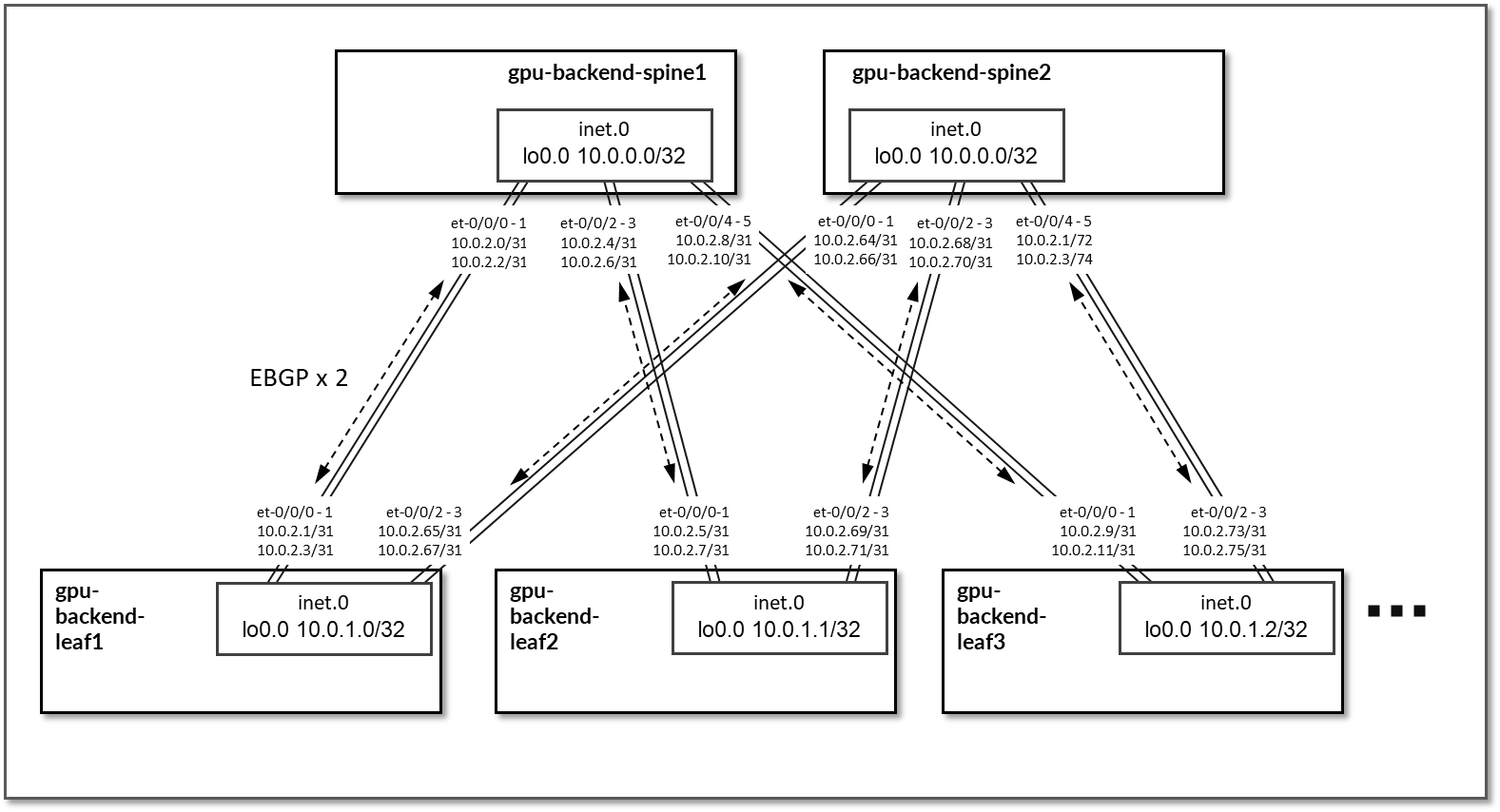
表 38:GPU 后端会话
| 条带 # | 主干节点 | 叶节点 | 主干 ASN | 叶 ASN 主 | 干 IP 地址 | 叶 IP 地址 |
|---|---|---|---|---|---|---|
| 1 | GPU-后端-主干1 | GPU-后端-叶 1 | 4201032100 | 4201032200 | 10.0.2.0/31 10.0.2.2/31 |
10.0.2.1/31 10.0.2.3/31 |
| 1 | GPU-后端-主干1 | GPU-后端-叶式 2 | 4201032201 | 10.0.2.4/31 10.0.2.6/31 |
10.0.2.5/31 10.0.2.7/31 |
|
| 1 | GPU-后端-主干1 | GPU-后端-叶式 3 | 4201032202 | 10.0.2.8/31 10.0.2.10/31 |
10.0.2.9/31 10.0.2.11/31 |
|
| 。 . . . |
||||||
| 1 | GPU-后端-主干 2 | GPU-后端-叶 1 | 4201032101 | 4201032200 | 10.0.2.64/31 10.0.2.66/31 |
10.0.2.65/31 10.0.2.67/31 |
| 1 | GPU-后端-主干 2 | GPU-后端-叶式 2 | 4201032201 | 10.0.2.68/31 10.0.2.70/31 |
10.0.2.69/31 10.0.2.71/31 |
|
| 1 | GPU-后端-主干 2 | GPU-后端-叶式 3 | 4201032202 | 10.0.2.72/31 10.0.2.74/31 |
10.0.2.73/31 10.0.2.75/31 |
|
| . . . . |
在叶节点上,Apstra 配置了 BGP 策略,以向主干节点播发以下路由:
- 叶节点自己的环路接口地址
- 叶到主干接口、子网和
- IRB 接口子网
图 86:GPU 后端叶节点 BGP
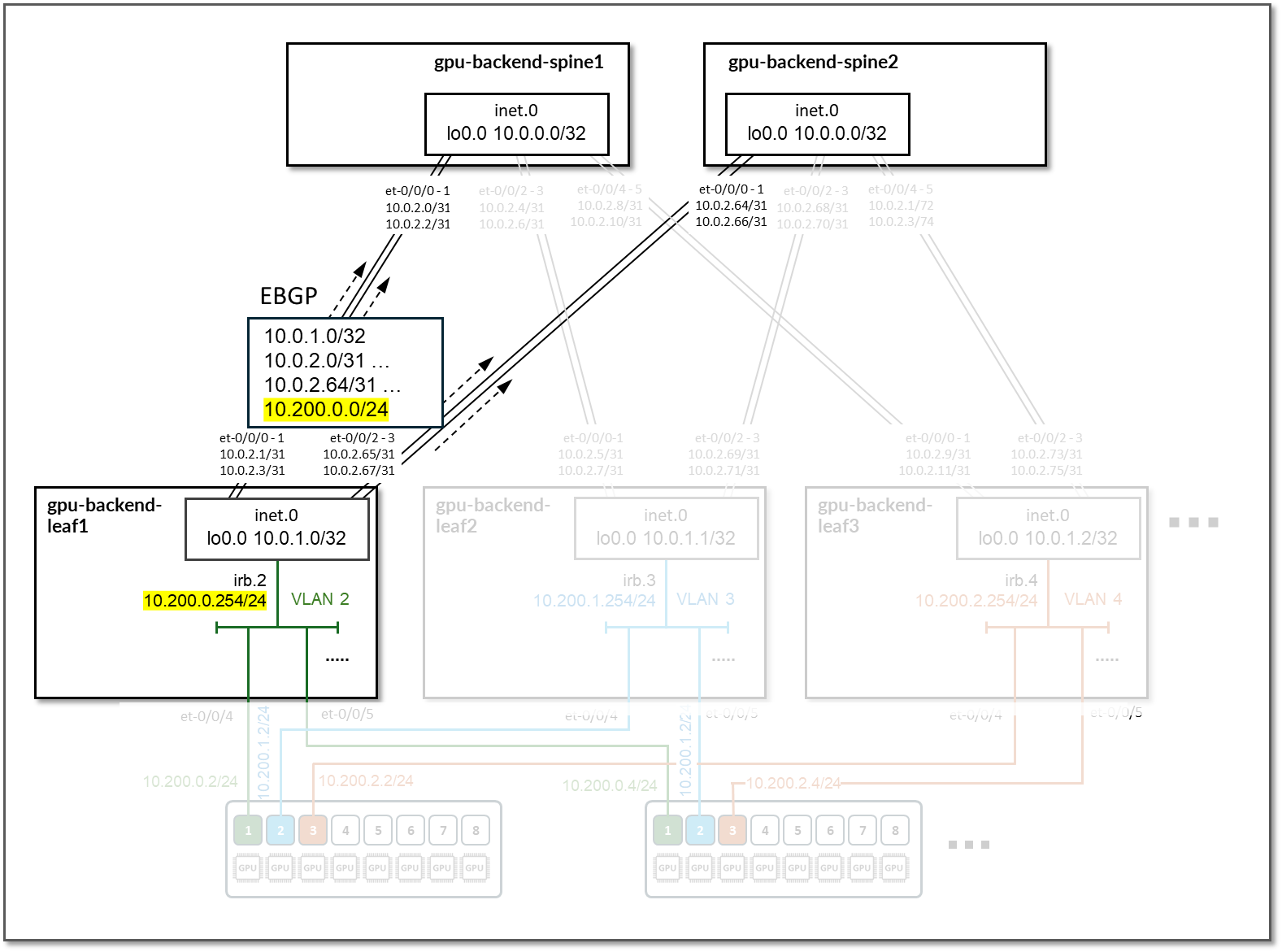
表 39:GPU 后端叶节点通告的路由
| Stripe # | 设备 | 通告路由 | BGP 社区 |
|---|---|---|---|
| 1 | GPU-后端-叶 1 | 10.0.1.0/32 10.0.2.0/31 10.0.2.64/31 10.200.0.0/24 |
3:20007 21001:26000 |
| 1 | GPU-后端-叶 2 | 10.0.1.1/32 10.0.2.4/31 10.0.2.68/31 10.200.1.0/24 |
4:20007 21001:26000 |
| 1 | GPU-后端-叶式 3 | 10.0.1.2/32 10.0.2.8/31 10.0.2.72/31 10.200.2.0/24 |
5:20007 21001:26000 |
在主干节点上,Apstra 配置了 BGP 策略,以向叶节点播发以下路由:
- 主干节点自己的环路接口地址
- 叶节点的环路接口地址
- 主干到叶接口子网
- IRB 接口子网中,如下所示:
图 87:GPU 后端主干节点 BGP
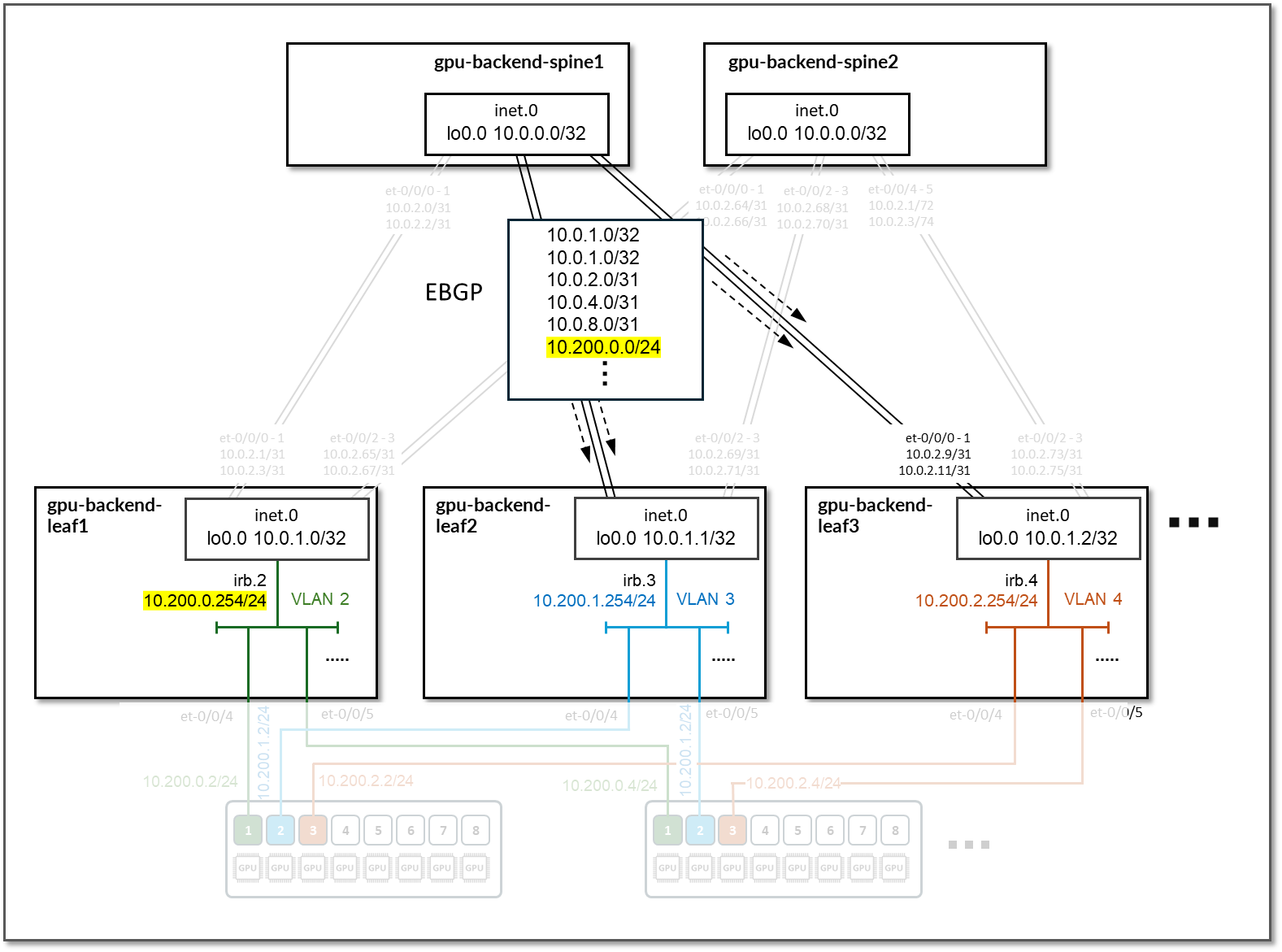
表 40:GPU 后端主干节点通告的路由
| Stripe # | 主干节点 | 通告路由 | BGP 社区 |
|---|---|---|---|
| 1 | GPU 后端主干 1 | 10.0.0.0/32 10.0.2.0/31 10.0.2.4/31 … 10.200.1.0/24 … |
0:15 X:20007 21001:26000 |
| 1 | GPU-后端-主干 2 | 10.0.0.1/32 10.0.2.64/31 10.0.2.68/31 … 10.200.1.0/24 … |
0:15 X:20007 21001:26000 |
通过播发 IRB 接口子网,不同轨道中的 GPU 之间可以跨交换矩阵进行通信。
图 88:跨轨道通信
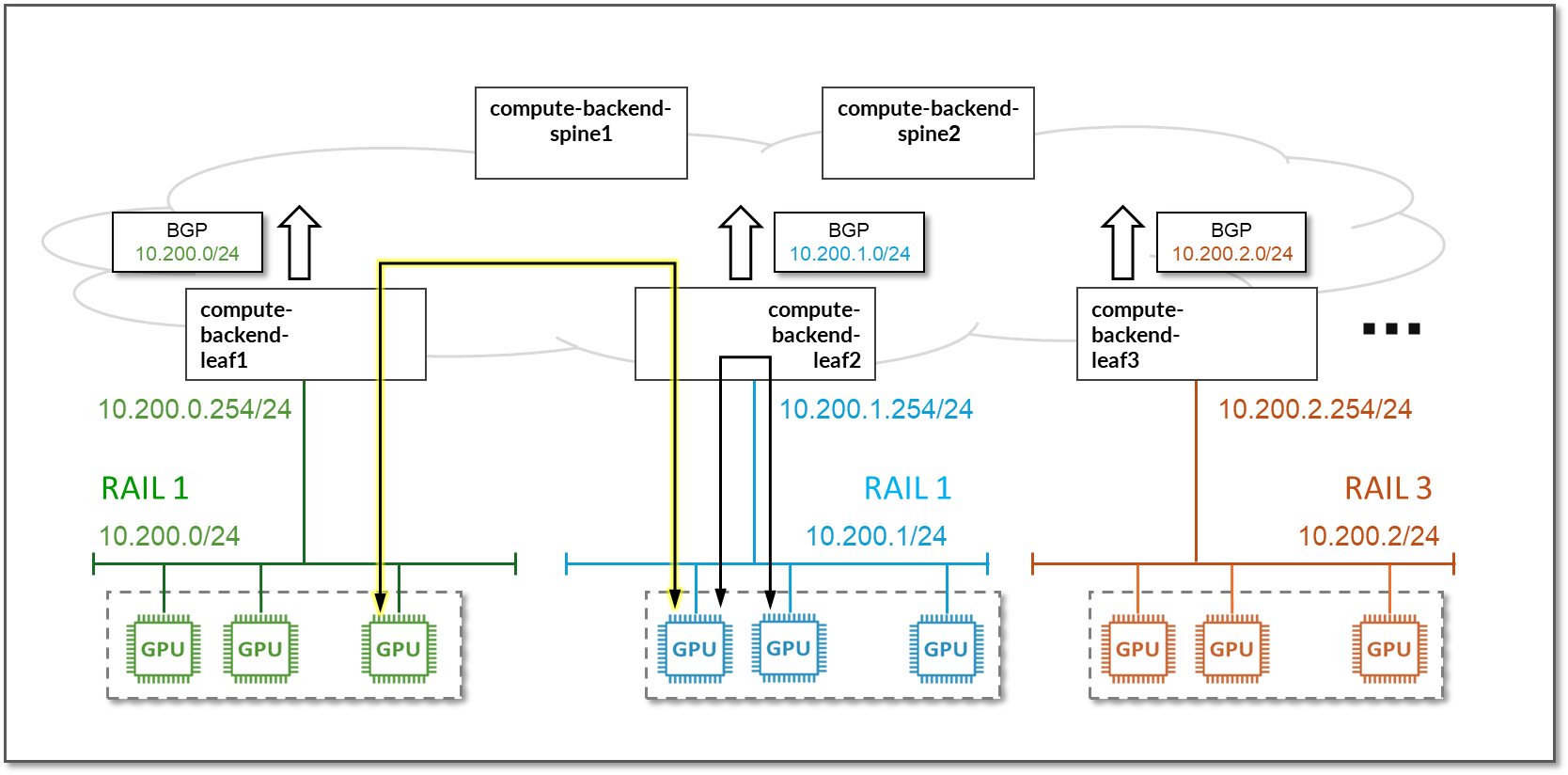
存储后端网络连接
存储后端交换矩阵设计为第 3 层 IP 交换矩阵,其中叶节点和主干节点之间的链路配置为 /31 IP 地址,如下表所示。交换矩阵由 2 个主干节点和 4 个叶节点组成,其中 2 个叶节点用于连接存储服务器(名为 storage-backend-weka-leaf #), 2 个用于连接 GPU 服务器(名为 storage-backend-gpu-leaf #)。
每个存储后端 weka-leaf # 节点和主干节点之间有三个 400GE 链路,每个存储后端 gpu-leaf # 节点和主干节点之间有两个 400GE 链路,如图 89 所示。
图 89 :存储后端主干到存储后端 GPU 叶节点的连接
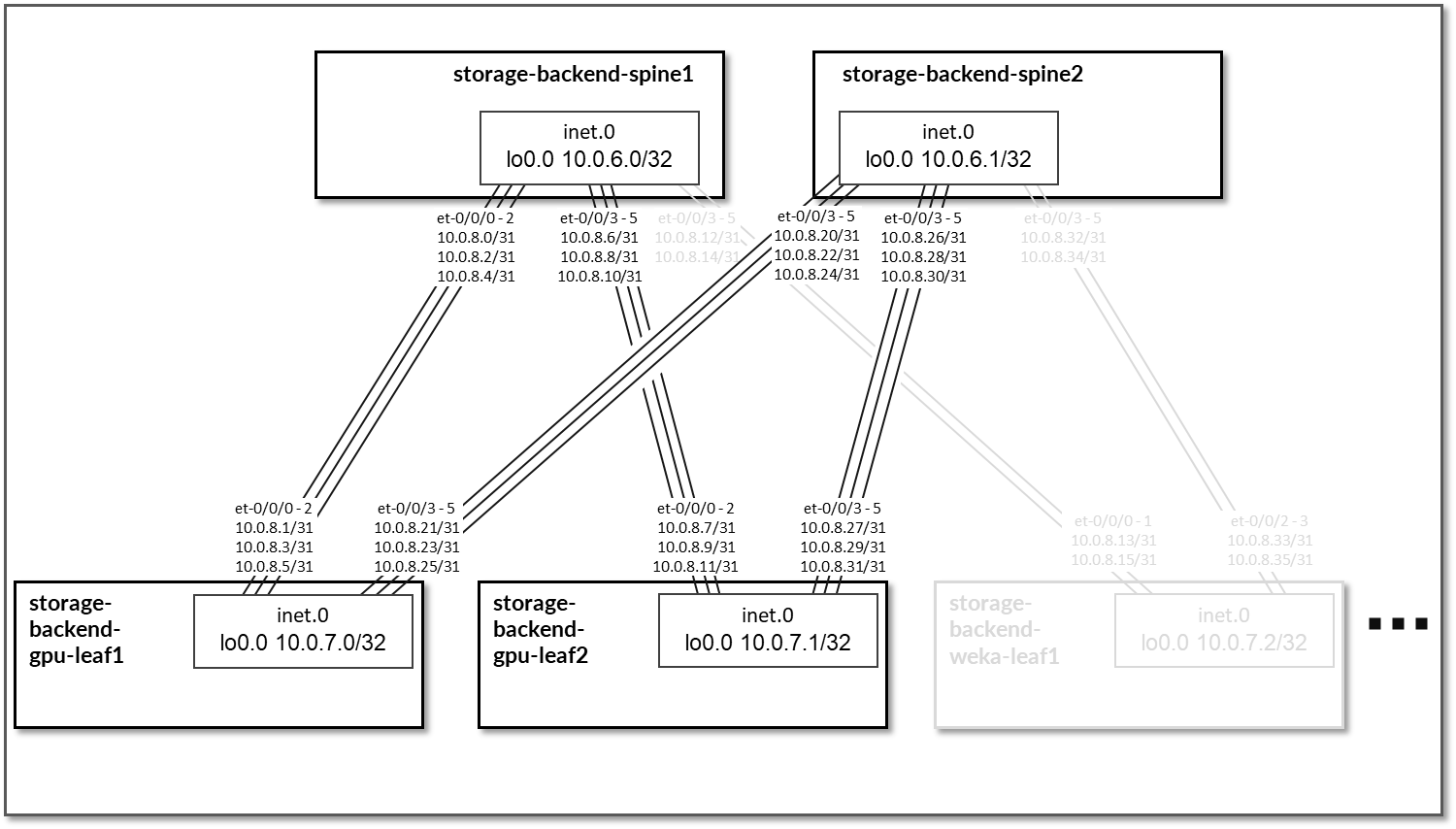
图 90:存储后端主干到存储后端 WEKA 存储叶节点连接
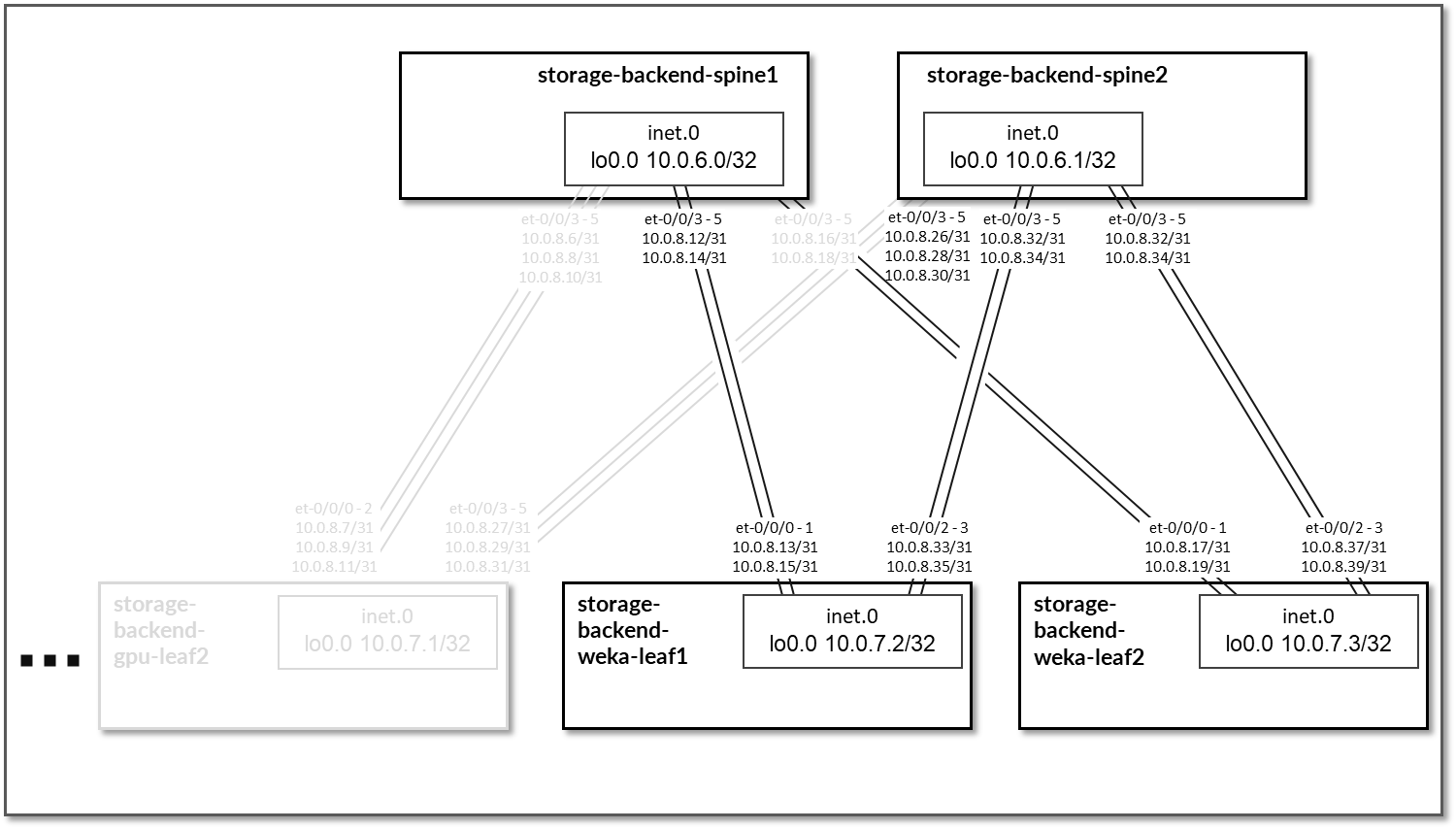
表 41:存储后端接口地址
| 主干节点 | 叶节点 | 主干 IP 地址 | 叶 IP 地址 |
|---|---|---|---|
| 存储后端主干 1 | 存储-后端-gpu-叶 1 | 10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 |
10.0.8.1/31 10.0.8.3/31 10.0.8.5/31 |
| 存储-后端-主干1 | 存储-后端-gpu-leaf2 | 10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 |
10.0.8.7/31 10.0.8.9/31 10.0.8.11/31 |
| 存储-后端-主干1 | 存储-后端-weka-leaf1 | 10.0.8.12/31 10.0.8.14/31 |
10.0.8.13/31 10.0.8.15/31 |
| 存储-后端-主干1 | 存储后端-weka-leaf2 | 10.0.8.16/31 10.0.8.18/31 |
10.0.8.17/31 10.0.8.19/31 |
| 存储-后端-主干2 | 存储-后端-gpu-leaf1 | 10.0.8.20/31 10.0.8.22/31 10.0.8.24/31 |
10.0.8.21/31 10.0.8.23/31 10.0.8.25/31 |
| 存储-后端-主干2 | 存储-后端-gpu-leaf2 | 10.0.8.26/31 10.0.8.28/31 10.0.8.30/31 |
10.0.8.27/31 10.0.8.29/31 10.0.8.31/31 |
| 存储-后端-主干2 | 存储-后端-weka-leaf1 | 10.0.8.32/31 10.0.8.34/31 |
10.0.8.33/31 10.0.8.35/31 |
| 存储-后端-主干2 | 存储后端-weka-leaf2 | 10.0.8.36/31 10.0.8.38/31 |
10.0.8.37/31 10.0.8.39/31 |
环路接口还具有 Apstra 从预定义池中自动分配的地址。
表 42:存储后端环路接口
| 设备 | 环路接口地址 |
|---|---|
| 存储-后端-主干1 | 10.0.6.0/32 |
| 存储-后端-主干2 | 10.0.6.1/32 |
| 存储-后端-gpu-leaf1 | 10.0.7.0/32 |
| 存储-后端-gpu-leaf2 | 10.0.7.1/32 |
| 存储-后端-weka-leaf1 | 10.0.7.2/32 |
| 存储后端-weka-leaf2 | 10.0.7.3/32 |
H100 GPU 服务器和 A100 GPU 服务器连接到存储后端叶交换机,如下表所示。
表 43:存储 GPU 后端服务器到叶节点的连接
| GPU 服务器 | 叶节点 |
|---|---|
| H100-1 | 存储-后端-gpu-leaf1 |
| H100-2 | |
| A100-1 | |
| A100-2 | |
| A100-3 | |
| A100-4 | |
| H100-3 | 存储-后端-gpu-leaf2 |
| H100-4 | |
| A100-5 | |
| A100-6 | |
| A100-7 | |
| A100-8 |
GPU 服务器和 storage-backend-gpu-leaf 1 之间的链接被分配了 10.100.1/24 中的 /31 个子网,而 GPU 服务器和 storage-backend-gpu-leaf 2 之间的链接被分配了 10.100.2/24 中的 /31 个子网,如图 91 所示。
图 91:GPU 服务器到存储后端 GPU 叶节点的连接
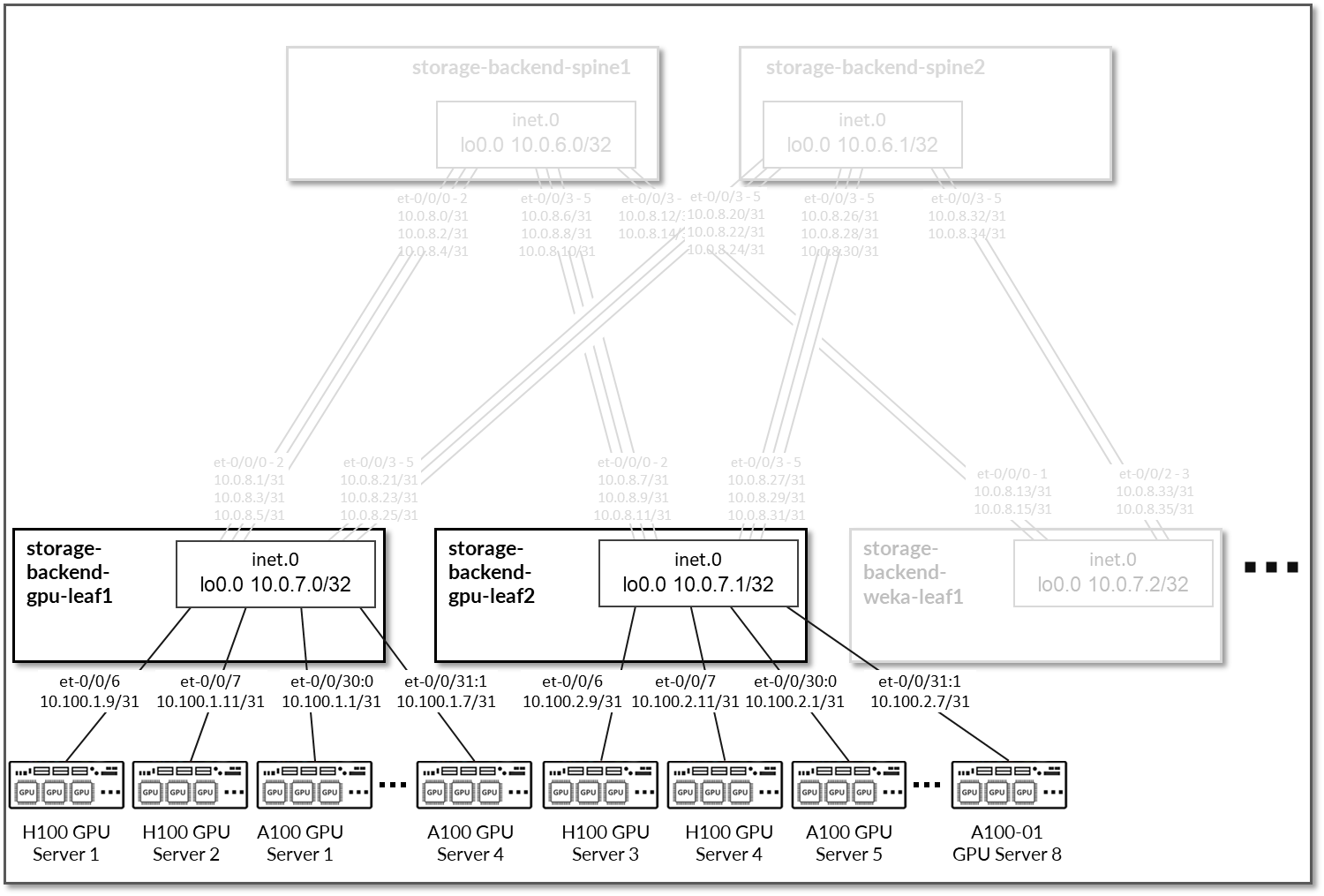
表 44:GPU 服务器到存储 GPU 后端接口地址
| GPU 服务器 | 叶节点 | GPU 服务器 IP 地址 | 叶 IP 地址 |
|---|---|---|---|
| H100 GPU 服务器 1 | 存储-后端-gpu-叶 1 | 10.100.1.8/31 | 10.100.1.9/31 |
| H100 GPU 服务器 2 | 存储-后端-gpu-叶 1 | 10.100.1.10/31 | 10.100.1.11/31 |
| A100 GPU 服务器 1 | 存储-后端-gpu-叶 1 | 10.100.1.0/31 | 10.100.1.1/31 |
| A100 GPU 服务器 2 | 存储-后端-gpu-叶 1 | 10.100.1.2/31 | 10.100.1.3/31 |
| A100 GPU 服务器 3 | 存储-后端-gpu-叶 1 | 10.100.1.4/31 | 10.100.1.5/31 |
| A100 GPU 服务器 4 | 存储-后端-gpu-叶 1 | 10.100.1.6/31 | 10.100.1.7/31 |
| H100 GPU 服务器 3 | 存储-后端-gpu-叶 2 | 10.100.2.8/31 | 10.100.2.9/31 |
| H100 GPU 服务器 4 | 存储-后端-gpu-叶 2 | 10.100.2.10/31 | 10.100.2.11/31 |
| A100 GPU 服务器 5 | 存储-后端-gpu-叶 2 | 10.100.2.0/31 | 10.100.2.1/31 |
| A100 GPU 服务器 6 | 存储-后端-gpu-叶 2 | 10.100.2.2/31 | 10.100.2.3/31 |
| A100 GPU 服务器 7 | 存储-后端-gpu-叶 2 | 10.100.2.4/31 | 10.100.2.5/31 |
| A100 GPU 服务器 8 | 存储-后端-gpu-叶 2 | 10.100.2.6/31 | 10.100.2.7/31 |
与 GPU 服务器一样,WEKA 存储服务器连接到两个存储后端 weka-leaf # 节点,如图 92 所示。
图 92:WEKA 存储服务器到叶节点的连接
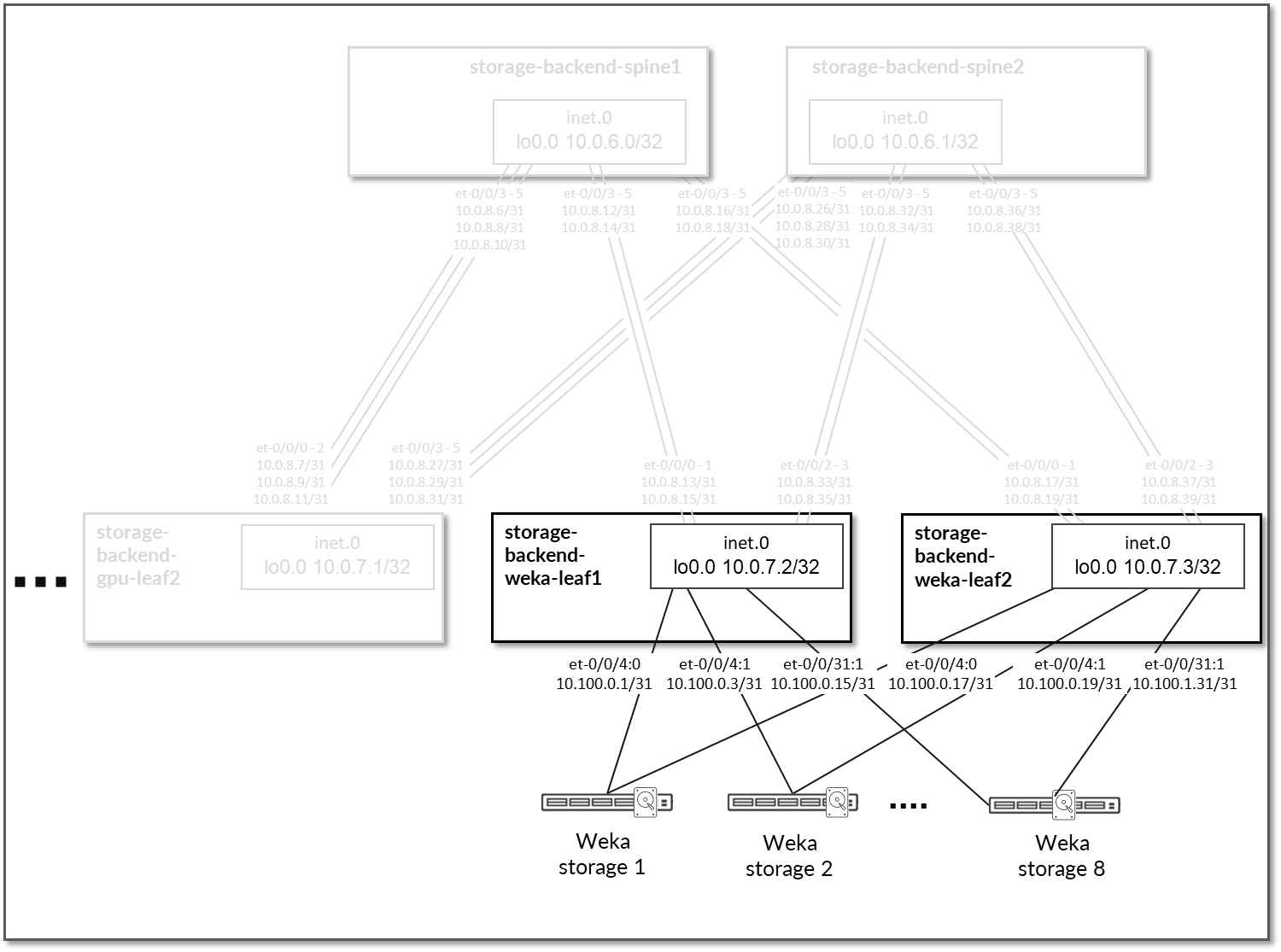
每个 GPU 服务器到叶节点的连接都分配了一个 10.100.0.0/24 中的 /31 子网,如下表所示。
表 45:WEKA 存储服务器到叶节点接口地址
| WEKA 服务器 | 叶节点 | WEKA 服务器 IP 地址 | 叶 IP 地址 |
|---|---|---|---|
| WEKA 存储服务器 1 | 存储后端 weka-leaf 1 | 10.100.0.0/31 | 10.100.0.1/31 |
| WEKA 存储服务器 2 | 存储后端 weka-leaf 1 | 10.100.0.2/31 | 10.100.0.3/31 |
| WEKA 存储服务器 3 | 存储后端 weka-leaf 1 | 10.100.0.4/31 | 10.100.0.5/31 |
| WEKA 存储服务器 4 | 存储后端 weka-leaf 1 | 10.100.0.5/31 | 10.100.0.7/31 |
| WEKA 存储服务器 5 | 存储后端 weka-leaf 1 | 10.100.0.8/31 | 10.100.0.9/31 |
| WEKA 存储服务器 6 | 存储后端 weka-leaf 1 | 10.100.0.10/31 | 10.100.0.11/31 |
| WEKA 存储服务器 7 | 存储后端 weka-leaf 1 | 10.100.0.12/31 | 10.100.0.13/31 |
| WEKA 存储服务器 8 | 存储后端 weka-leaf 1 | 10.100.0.14/31 | 10.100.0.15/31 |
| WEKA 存储服务器 1 | 存储后端 weka-leaf 1 | 10.100.0.16/31 | 10.100.0.17/31 |
| WEKA 存储服务器 2 | 存储后端 weka-leaf 1 | 10.100.0.18/31 | 10.100.0.19/31 |
| WEKA 存储服务器 3 | 存储后端 weka-leaf 1 | 10.100.0.20/31 | 10.100.0.21/31 |
| WEKA 存储服务器 4 | 存储后端 weka-leaf 1 | 10.100.0.22/31 | 10.100.0.23/31 |
| WEKA 存储服务器 5 | 存储后端 weka-leaf 1 | 10.100.0.24/31 | 10.100.0.25/31 |
| WEKA 存储服务器 6 | 存储后端 weka-leaf 1 | 10.100.0.26/31 | 10.100.0.27/31 |
| WEKA 存储服务器 7 | 存储后端 weka-leaf 1 | 10.100.0.28/31 | 10.100.0.29/31 |
| WEKA 存储服务器 8 | 存储后端 weka-leaf 1 | 10.100.0.30/31 | 10.100.0.31/31 |
请注意,在这种情况下,叶节点使用物理接口连接到存储服务器。因此,此连接不会使用 IRB 接口或 VLAN ID。
EBGP 配置在分配给主干节点和叶节点之间链路的 IP 地址之间,如图 93 所示。
每个 storage-backend-weka-leaf # 节点和主干节点之间将有 3 个 EBGP 会话。同样,每个 storage-backend-gpu-leaf # 节点之间将有 2 个 EBGP 会话。
图 93:存储后端主干到存储后端为 GPU 服务器 EBGP
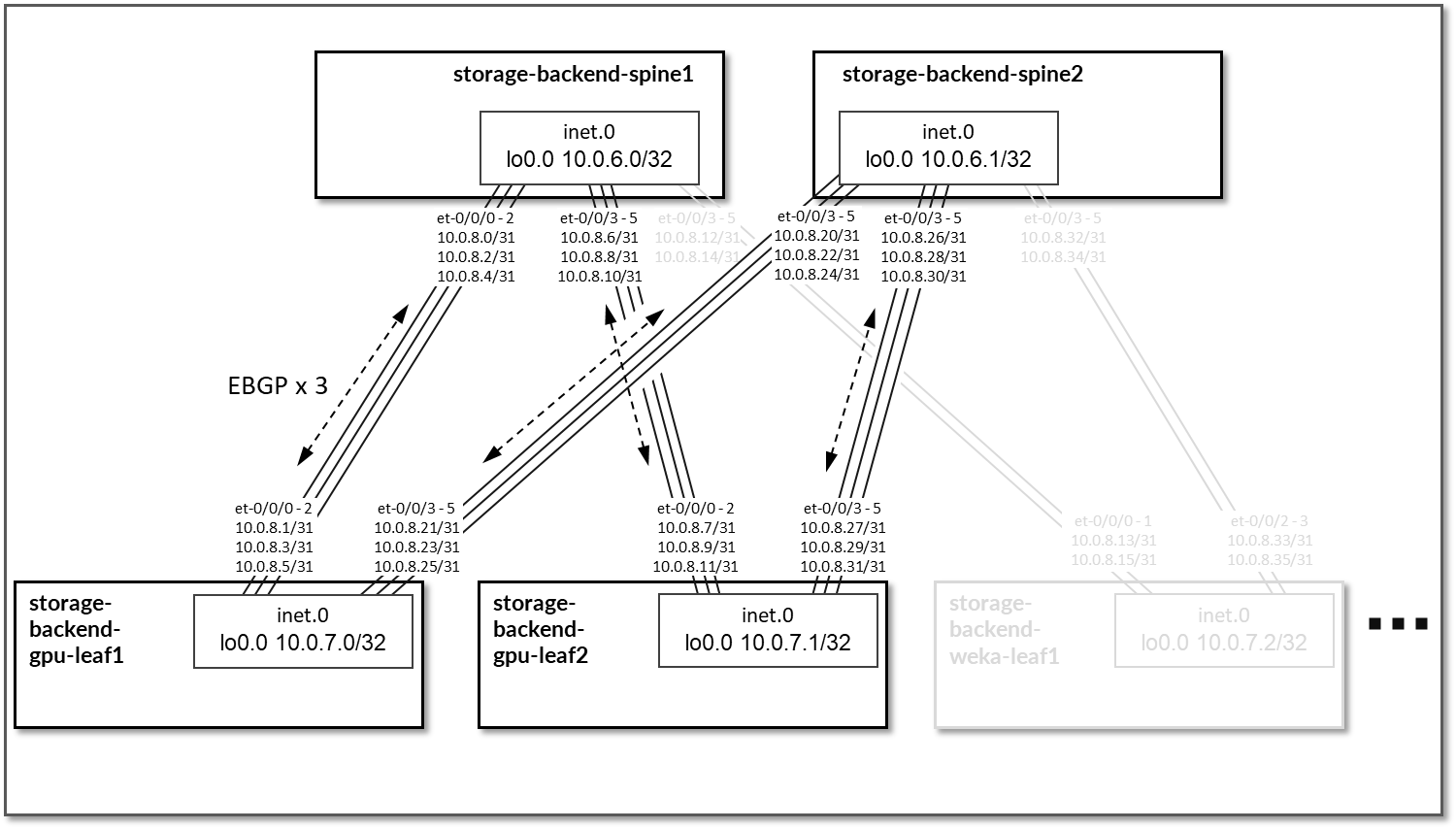
图 94:存储后端主干到存储后端离开 WEKA 服务器 EBGP 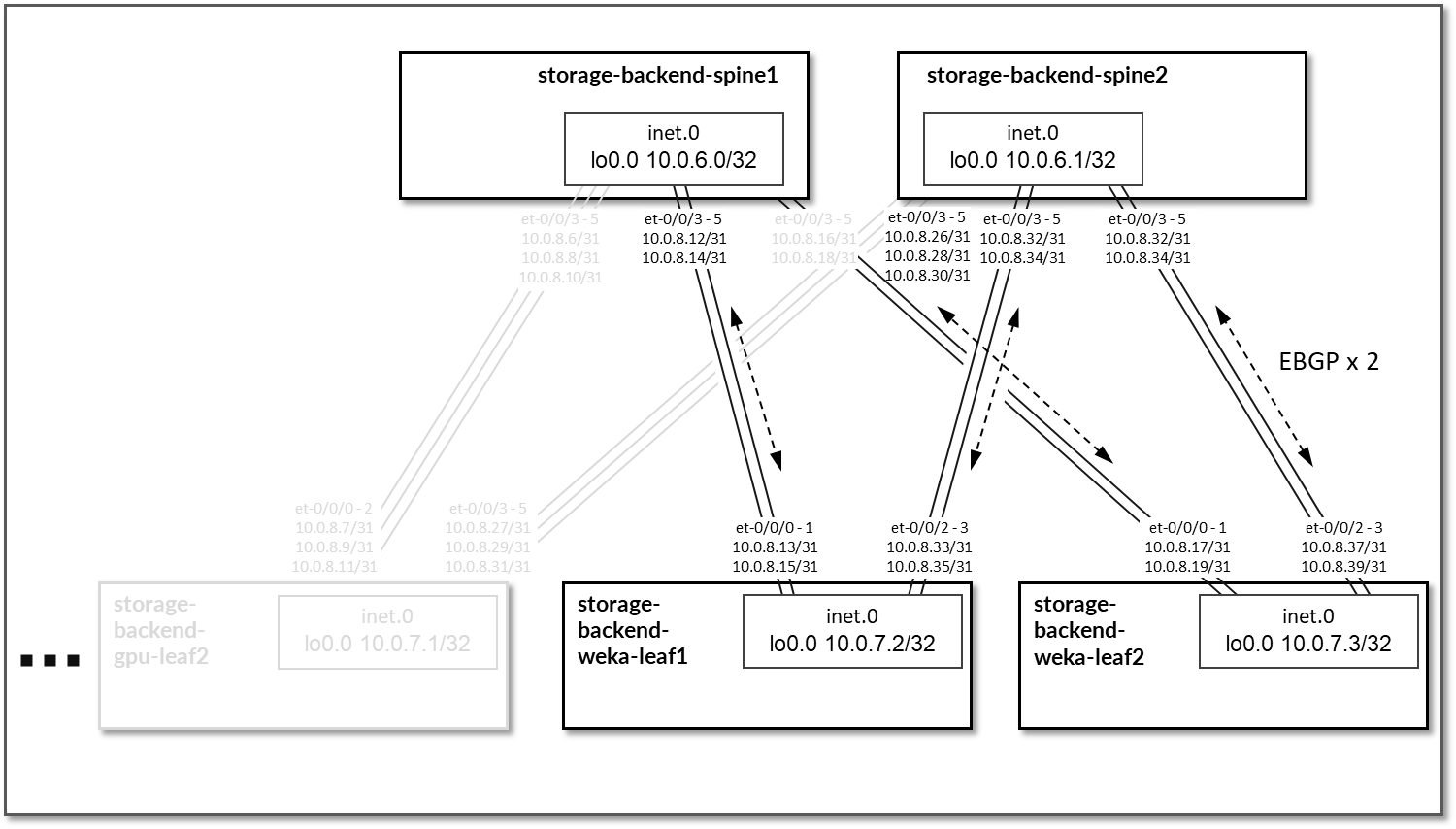
表 46:存储后端会话
| 主干节点 | 叶节点 | 主干 ASN | 叶 ASN | 主干 IP 地址 | 叶 IP 地址 |
|---|---|---|---|---|---|
| 存储-后端-主干1 | 存储-后端-gpu-leaf1 | 4201032500 | 4201032600 | 10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 |
10.0.8.1/31 10.0.8.3/31 10.0.8.5/31 |
| 存储-后端-主干1 | 存储-后端-gpu-leaf2 | 4201032601 | 10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 |
10.0.8.7/31 10.0.8.9/31 10.0.8.11/31 |
|
| 存储-后端-主干1 | 存储-后端-weka-leaf1 | 4201032602 | 10.0.8.12/31 10.0.8.14/31 |
10.0.8.13/31 10.0.8.15/31 |
|
| 存储-后端-主干1 | 存储后端-weka-leaf2 | 4201032603 | 10.0.8.16/31 10.0.8.18/31 |
10.0.8.17/31 10.0.8.19/31 |
|
| 存储-后端-主干2 | 存储-后端-gpu-leaf1 | 4201032501 | 4201032600 | 10.0.8.20/31 10.0.8.22/31 10.0.8.24/31 |
10.0.8.21/31 10.0.8.23/31 10.0.8.25/31 |
| 存储-后端-主干2 | 存储-后端-gpu-leaf2 | 4201032601 | 10.0.8.26/31 10.0.8.28/31 10.0.8.30/31 |
10.0.8.27/31 10.0.8.29/31 10.0.8.31/31 |
|
| 存储-后端-主干2 | 存储-后端-weka-leaf1 | 4201032602 | 10.0.8.32/31 10.0.8.34/31 |
10.0.8.33/31 10.0.8.35/31 |
|
| 存储-后端-主干2 | 存储后端-weka-leaf2 | 4201032603 | 10.0.8.36/31 10.0.8.38/31 |
10.0.8.37/31 10.0.8.39/31 |
在叶节点上,Apstra 配置了 BGP 策略,以向主干节点通告以下路由:
- 叶节点自己的环路接口地址,
- 叶到主干接口、子网和
- GPU/WEKA 存储服务器到叶节点链路子网。
图 95:存储后端叶 BGP
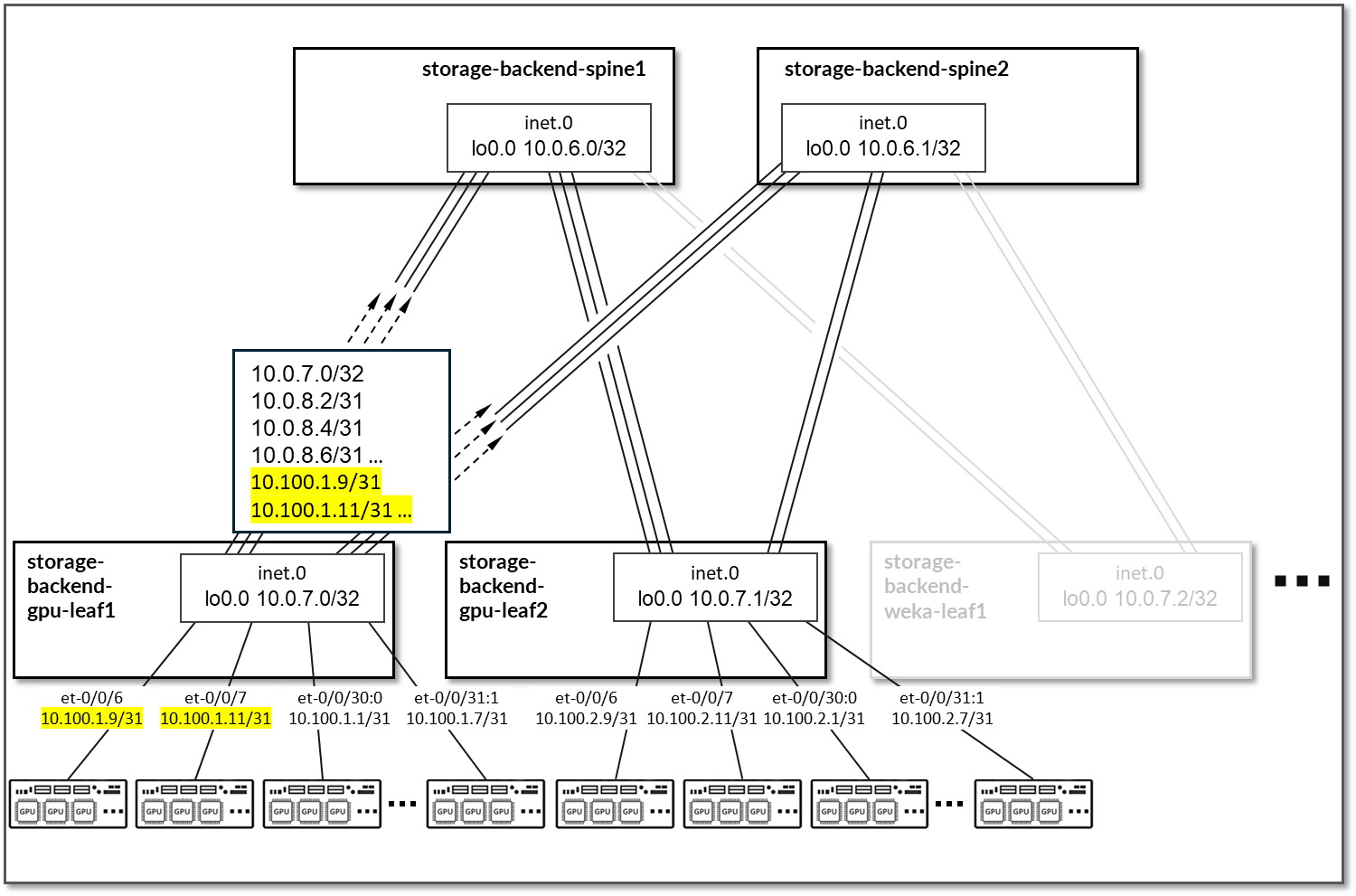
表 47:存储后端叶节点通告的路由
| 节点 | 对等体 | 播发路由 | BGP 社区 | |
|---|---|---|---|---|
| 存储-后端-gpu-leaf1 | storage-backend-spine1 和 存储-后端-主干2 |
10.0.7.0/32 10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 10.0.8.20/31 … |
10.100.1.0/31 10.100.1.2/31 … |
3:20007 21001:26000 |
| 存储-后端-gpu-leaf2 | storage-backend-spine1 和 存储-后端-主干2 |
10.0.7.1/32 10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 10.0.8.26/31 … |
10.100.2.0/31 10.100.2.2/31 … |
4:20007 21001:26000 |
| 存储-后端-weka-leaf1 | storage-backend-spine1 和 存储-后端-主干2 |
10.0.7.2/32 10.0.8.12/31 10.0.8.14/31 10.0.8.32/31 … |
10.100.0.16/31 10.100.0.18/31 … |
5:20007 21001:26000 |
| 存储后端-weka-leaf2 | storage-backend-spine1 和 存储-后端-主干2 |
10.0.7.3/32 10.0.8.16/31 10.0.8.17/31 10.0.8.36/31 … |
10.100.0.16/31 10.100.0.18/31 … |
6:20007 21001:26000 |
在主干节点上,Apstra 配置了 BGP 策略,以向叶节点播发以下路由:
- 主干节点自己的环路接口地址
- 叶节点的环路接口地址
- 主干到叶接口子网
- GPU/WEKA 存储服务器到叶节点链路子网。
图 96:存储后端主干 BGP
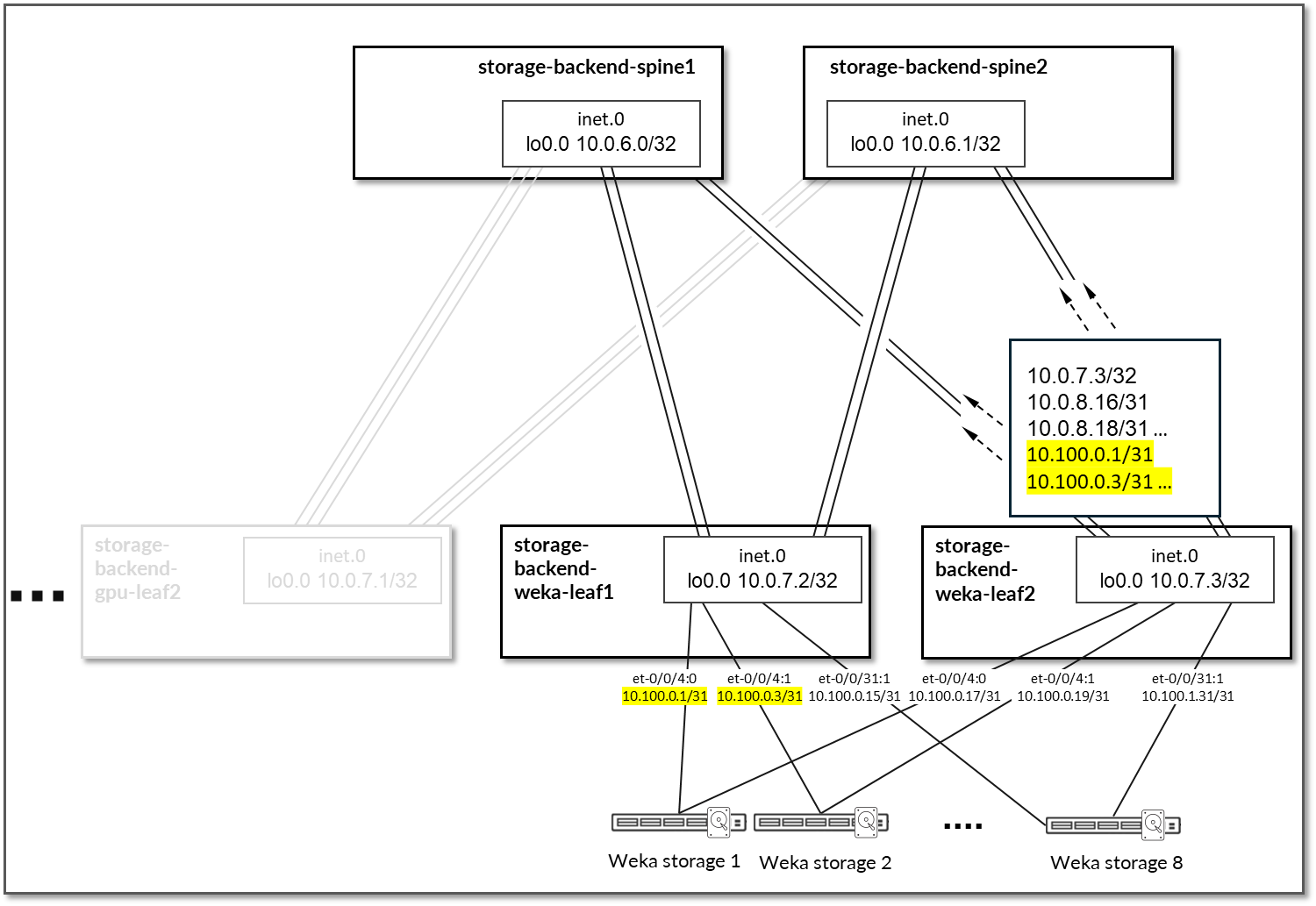
表 48:存储后端主干节点通告的路由
| 主干节点 | 对等体 | 播发路由 | BGP 社区 | ||
|---|---|---|---|---|---|
| 存储-后端-主干1 | 存储-后端-gpu-leaf1 | 10.0.6.0/32 10.0.7.1/32 10.0.7.2/32 10.0.7.3/32 |
10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 10.0.8.12/31 10.0.8.14/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
3:20007 21001:26000 |
| 存储-后端-gpu-leaf2 | 10.0.6.0/32 10.0.7.0/32 10.0.7.2/32 10.0.7.3/32 |
10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 10.0.8.12/31 10.0.8.14/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.1.0/31 10.100.1.2/31 … |
||
| 存储后端 weka-leaf 1 | 10.0.6.0/32 10.0.7.0/32 10.0.7.1/32 10.0.7.3/32 |
10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.1.0/31 10.100.1.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
||
| 存储后端 weka-leaf 2 | 10.0.6.0/32 10.0.7.0/32 10.0.7.1/32 10.0.7.2/32 |
10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 10.0.8.20/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.1.0/31 10.100.1.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
||
| 存储-后端-主干2 | 存储-后端-gpu-leaf1 | 10.0.6.1/32 10.0.7.1/32 10.0.7.2/32 10.0.7.3/32 |
10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 10.0.8.12/31 10.0.8.14/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
4:20007 21001:26000 |
| 存储-后端-gpu-leaf2 | 10.0.6.1/32 10.0.7.0/32 10.0.7.2/32 10.0.7.3/32 |
10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 10.0.8.12/31 10.0.8.14/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
||
| 存储后端 weka-leaf 1 | 10.0.6.1/32 10.0.7.0/32 10.0.7.1/32 10.0.7.3/32 |
10.0.8.0/31 10.0.8.2/31 10.0.8.4/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.1.0/31 10.100.1.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
||
| 存储后端 weka-leaf 2 | 10.0.6.0/32 10.0.7.1/32 10.0.7.2/32 10.0.7.3/32 |
10.0.8.6/31 10.0.8.8/31 10.0.8.10/31 10.0.8.12/31 10.0.8.14/31 … |
10.100.0.0/31 10.100.0.2/31 … 10.100.2.0/31 10.100.2.2/31 … |
||
通过播发分配给叶节点与 GPU/存储服务器之间链路的子网,GPU 与存储服务器之间的通信可以在整个交换矩阵中实现。
图 97:存储子网通告