GPU 后端交换矩阵
GPU 后端交换矩阵使用 RDMA over Converged Ethernet (RoCEv2) 为 GPU 提供基础架构,以便在群集内相互通信。ROCEv2 使 GPU 能够像使用 InfiniBand 协议一样进行通信,从而提高数据中心效率,降低整体复杂性,并提高数据传输性能。
丢包会影响工作完成时间,应避免丢包。因此,在设计网络基础设施以支持 AI 群集的 RoCEv2 时,关键目标之一是提供无损交换矩阵,同时还要为 AI 流量实现最大吞吐量、最小延迟和最小网络干扰。ROCEv2 在无损网络上效率更高,从而尽可能缩短工作完成时间。
此 JVD 中的 GPU 后端交换矩阵在设计时充分考虑到了这些目标,并遵循 3 级 IP clos 架构与 NVIDIA 的轨道优化条带架构 相结合(下一节将讨论),如图 5 所示。
图 5:GPU 后端交换矩阵架构
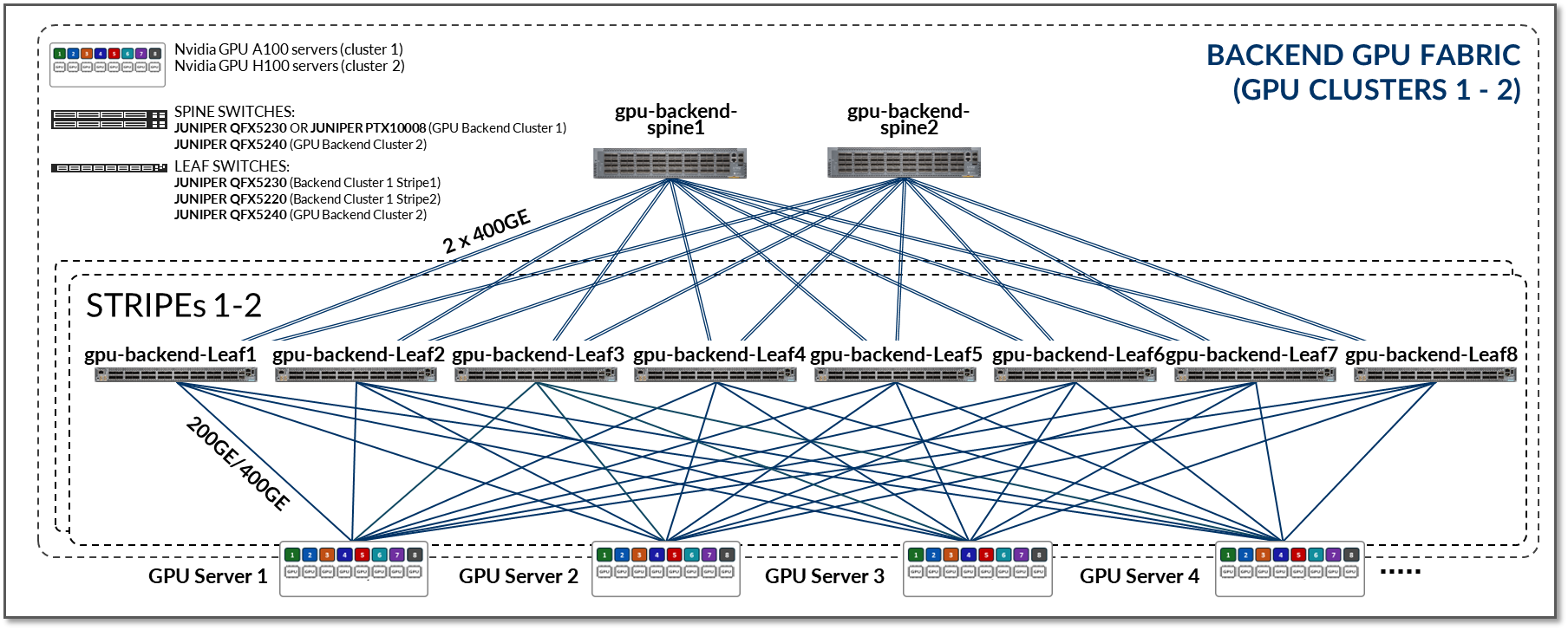
下表总结了此交换矩阵中包含的 GPU 后端 设备以及它们之间的连接:
表 3:每个群集和条带的 GPU 后端设备数
| 群集 | 条纹 | Nvidia DGX GPU 服务器 | GPU 后端叶节点交换机型号 (GPU-后端-叶式#) |
GPU 后端主干节点交换机型号 (GPU-后端-主干#) |
| 1 | 1 | A100-01 至 A100-04 | QFX5230-64CD x 8 | QFX5230-64CD x 2 或 PTX10008 带 JNP10K-LC1201 |
| 1 | 2 | A100-05 至 A100-08 | QFX5220-32CD x 8 | |
| 2 | 1 | H100-01 至 H100-02 | QFX5240-64OD x 8 | QFX5230-64OD x 4 |
| 2 | 2 | H100-03 至 H100-04 | QFX5240-64OD x 8 |
表 4:GPU 后端中每个群集和条带的服务器、叶节点和主干节点之间的连接
| 群集 | 条纹 | GPU 服务器 <=> GPU 后端叶节点 |
GPU 后端主干节点 <=> GPU 后端叶节点 |
| 1 | 1 | 1 个 200GE 链路 在每台 A100 服务器和每个叶节点之间(每台服务器 200GE x 8 个链路) |
2 个 400GE 链路 在每个叶节点和每个主干节点之间(每个叶节点 2 个 400GE x 2 个链路) |
| 1 | 2 | 1 个 200GE 链路 在每台 A100 服务器和每个叶节点之间(每台服务器 200GE x 8 个链路) |
2 个 400GE 链路 在每个叶节点和每个主干节点之间(每个叶节点 2 个 400GE x 2 个链路) |
| 2 | 1 | 1 个 400GE 链路 在每台 H100 服务器和每个叶节点之间(每台服务器 400GE x 8 个链路) |
2 个 400GE 链路 在每个叶节点和每个主干节点之间(每个叶节点 2 个 400GE x 4 个链路) |
| 2 | 2 | 1 个 400GE 链路 在每台 H100 服务器和每个叶节点之间(每台服务器 400GE x 8 个链路) |
2 个 400GE 链路 在每个叶节点和每个主干节点之间(每个叶节点 2 个 400GE x 4 个链路) |
- 实验室中的所有 Nvidia A100 服务器使用 200GE 接口连接到 群集 1 中的 QFX5220 和 QFX5230 个叶节点,而 H100 服务器则使用 400GE 接口连接到 群集 2 中的QFX5240叶节点。
- 此交换矩阵是纯 L3 IP 交换矩阵(IPv4 或 IPV6),使用 EBGP 进行路由播发(在“网络”部分中介绍)。
- 服务器和叶节点之间的连接基于 L2 VLAN,叶节点上的 IRB 充当服务器的默认网关(在网络部分中介绍)。
表 5:每个群集、每个条带服务器到叶的带宽
| 每个条带的服务器到叶带宽(每个群集) | |||||
| 群集 | AI 系统(服务器类型) | 每条带的服务器数 | 服务器 <=每台服务器 > 个叶链路数 | 服务器带宽 <=> 个叶链路 [Gbps] | 总带宽 服务器 <=每条带 > 分叶数 [Tbps} |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6.4 |
| 2 | H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6.4 |
表 6:每个群集、每个条带的叶脊带宽
| 每个条带的叶到主干带宽 | |||
| 叶 <=每个主干节点和每个条带的主干链路数> | 速度 叶式 <=> 主干链路 [Gbps] |
主干节点数量 | 总带宽 分叶 <=每条带 > 个主干 [Tbps] |
| 8 | 2 个 400 | 2 | 12.8 |
(超额)认购率是通过比较上两个表格中的数字来简单计算的:
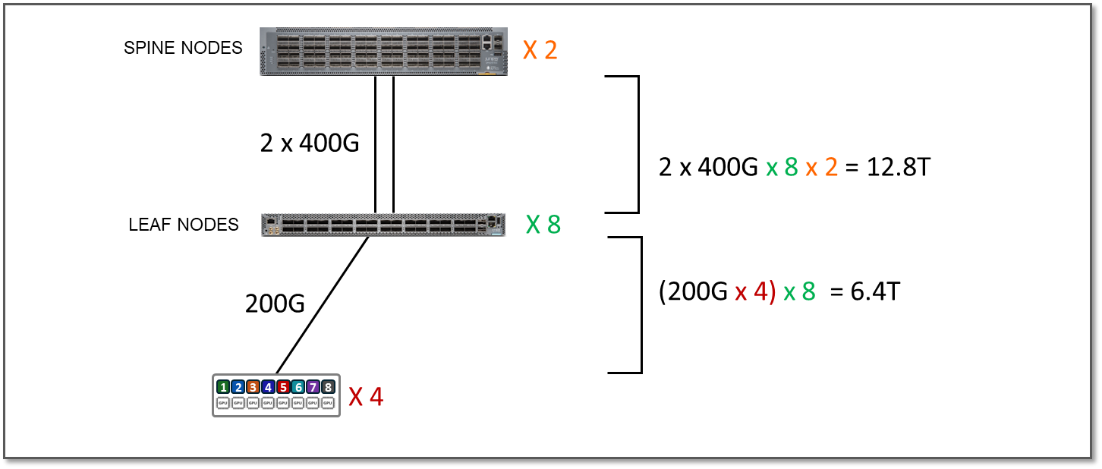
在群集 1 中,服务器和叶节点之间的带宽为每个条带 6.4 Tbps,而叶节点和主干节点之间的可用带宽为每个条带 12.8 Tbps。这意味着即使该流量是 100% 条带间流量,交换矩阵也有足够的容量来处理 GPU 之间的所有流量,同时仍有额外的容量来容纳其他服务器,而不会出现超额订阅。
图 6:额外容量示例
我们还测试了将 A100 服务器上的 H100 GPU 服务器连接到集群 1 中的条带,如下所示:
图 7: 1:1 订阅示例
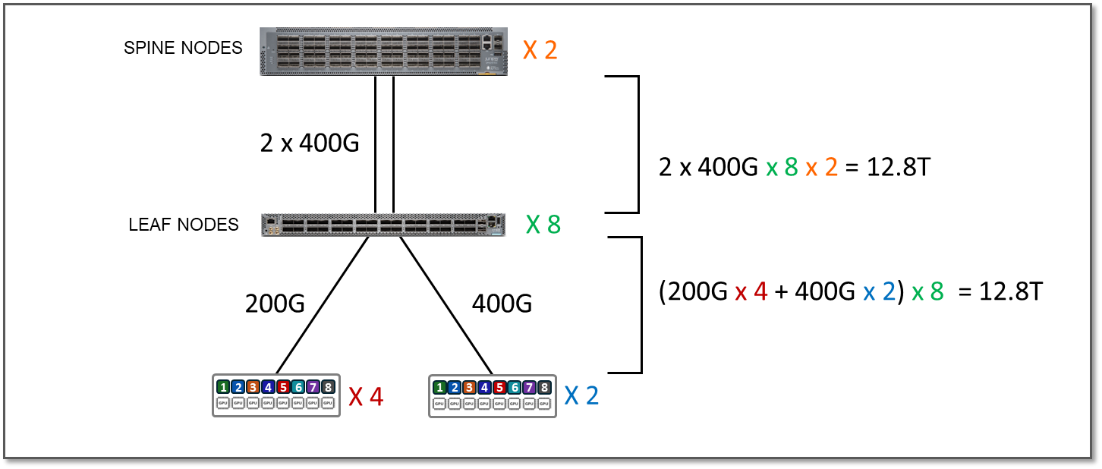
表 7:每个群集、每个条带的服务器到叶带宽,所有服务器连接到同一群集
| 每个条带的服务器到叶带宽 | |||||
| 群集 | Al Systems | 每条带的服务器数 | 服务器 <=每台服务器 > 个叶链路数 | 服务器 <=> 叶链路带宽 [Gbps] |
服务器总数 <=> 个叶链路 每条带的带宽 [Tbps] |
| 1 | A100 | 4 | 8 | 200 | 4 x 8 x 200/1000 = 6.4 |
| H100 | 2 | 8 | 400 | 2 x 8 x 400/1000 = 6.4 | |
| 服务器 < 的总带宽 = > 个叶链路 | 12.8 | ||||
服务器和叶节点之间的带宽现在为每个条带 12.8 Tbps,而叶节点和主干节点之间的可用带宽也是每个条带 12.8 Tbps(如上表所示)。这意味着即使该流量是 100% 条间流量,交换矩阵也有足够的容量来处理 GPU 之间的所有流量,但现在没有额外的容量来容纳额外的服务器。本例中的订阅系数为 1:1(无订阅)。
为了运行超额订阅测试,我们禁用了叶和主干之间的某些接口以减少可用带宽,如图 8 中的示例所示:
图 8:2:1 超额订阅示例
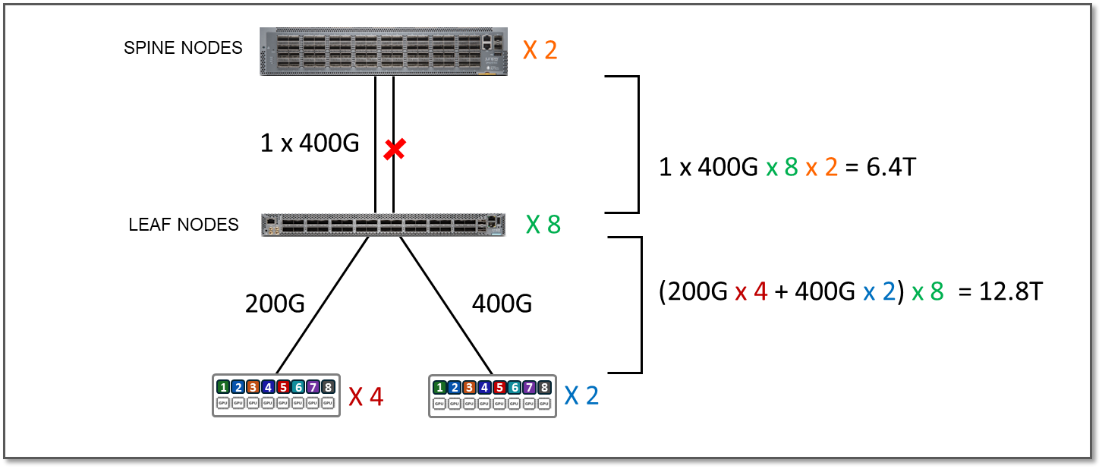
每个条带的服务器到叶链路总带宽没有更改。它仍然是 12.8 Tbps,如上一个方案中的表 3 所示。
但是,叶节点和主干节点之间的可用带宽现在每个条带仅为 6.4 Tbps。
表 8:每条带叶脊的带宽
| 每个条带的叶到主干带宽 | |||
| 叶 <=每个主干节点和每个条带的主干链路数> | 速度 叶式 <=> 主干链路 [Gbps] |
主干节点数量 | 总带宽 分叶 <=每条带 > 个主干 [Tbps] |
| 8 | 1 x 400 | 2 | 6.4 |
这意味着交换矩阵不再有足够的容量来处理 GPU 之间的所有流量,即使这些流量 100% 是条带间流量,也可能导致拥塞和流量丢失。本例中的超额预订系数为 2:1。