计算轨道优化架构中的叶节点和主干节点、服务器和 GPU 的数量
在轨道优化架构中,单个条带中的 叶节点数 由每台服务器的 GPU 数(轨道数)定义。每台 NVIDIA DGX H100 GPU 服务器包括 8 个 NVIDIA H100 Tensor 核心 GPU。因此,单个条带包括 8 个叶节点(8 条轨道)。
叶节点数 = 每台服务器的 GPU 数 = 8
单个条带 (N1) 中支持的最大 服务器数 由叶节点上的 可用端口数 定义,具体取决于交换机型号。
GPU 服务器和叶节点之间的总带宽必须与叶节点和主干节点之间的总带宽相匹配,以保持 1:1 的订阅比。
假设叶节点上的所有接口都以相同的速度运行,则一半接口将用于连接到 GPU 服务器,另一半将用于连接到主干。因此,条带中的 最大服务器数 计算为每个叶节点上 可用端口数的 一半。表 14 包括一些示例。
图 14.1:1 订阅系数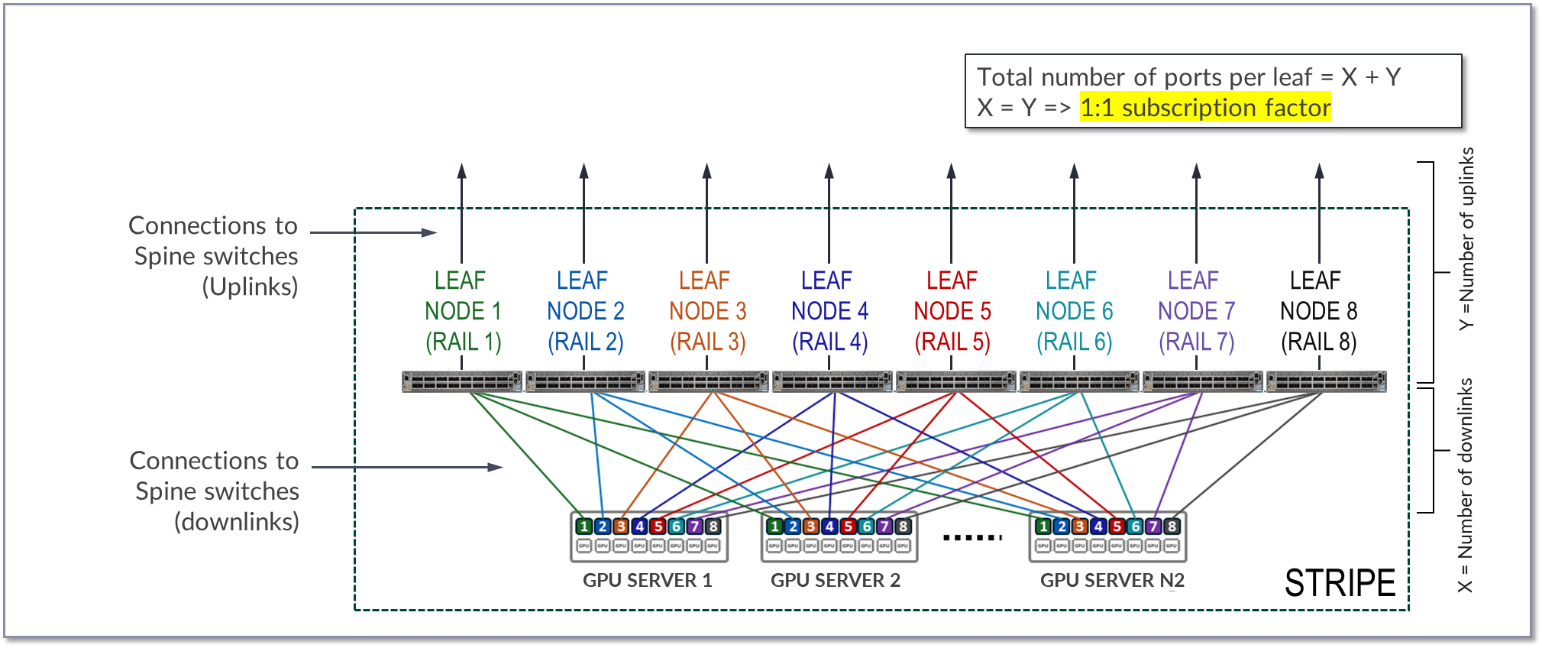 的上行链路和下行链路数量
的上行链路和下行链路数量
I 图 X 表示下行链路(叶节点和 GPU 服务器之间的链路)的数量,而 Y 表示上行链路(叶节点和主干节点之间的链路)的数量。要允许 1:1 订阅系数,X 必须等于 Y。
每个叶节点上的 可用端口数 等于 X + Y 或 2 * X。
由于条带中的所有服务器都有一个端口连接到条带中的每个叶,因此条带中的最大服务器数 (N1) 等于 X。
N1(每个条带的最大服务器数)= 可用端口数 ÷ 2
条带中的 最大 GPU 数 是通过简单地乘以每台服务器的 GPU 数来计算的。
N2(最大 GPU 数)= N1(每个条带的最大服务器数)* 8
可用端口的总数取决于用于叶节点的交换机型号。表 9 显示了一些示例。
表 9:每个条带支持的最大 GPU 数
| 叶节点 QFX 交换机型号 |
每台交换机可用的 400 GE 端口总数 | 1:1 订阅中每个条带支持的最大服务器数 (N1) |
每台服务器的 GPU 数 | 每个条带支持的最大 GPU 数 (第2 页) |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 16 台服务器 x 8 个 GPU/服务器 = 128 个 GPU |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 32 台服务器 x 8 个 GPU/服务器 = 256 个 GPU |
| QFX5240-64OD | 128 | 128 ÷ 2 = 64 | 8 | 64 台服务器 x 8 个 GPU/服务器 = 512 个 GPU |
- QFX5220-32CD 交换机提供 32 个 400 GE 端口(16 个用于连接到服务器,16 个用于连接到主干节点)
- QFX5230-64CD 交换机提供多达 64 个 400 GE 端口(32 个用于连接到服务器,32 个用于连接到主干节点)。
- QFX5240-64OD 交换机提供多达 128 个 400 GE 端口(64 个用于连接到服务器,64 个用于连接到主干节点)。
- 为了实现更大的规模,可以使用一组主干节点 (N4) 连接多个条带 (N3),如图 10 所示。
图 10:跨主干节点连接的多个条带。
.png)
所需的条带数量是根据所需的 GPU 数量以及每个条带支持的 GPU 数量计算得出的。
例如,假设所需的 GPU (GPU) 数量为 16,000,并且交换矩阵使用 QFX5240-64OD 作为叶节点。
可用 400G 端口数为 128,这意味着:
- 每个条带的最大服务器数 (N1) = 64
- 每个条带的最大 GPU 数 (N2) = 512
所需的 条带数 (N3) 是通过潜水所需的 GPU 数量和每个条带的 GPU 数量计算得出的,如下所示:
N 3(条带数)= GPU/ N 2(每个条带的最大 GPU 数)= 16000/256 ≈ 64 条带
- 每个条带有 64 个条带和 256 个服务器,该群集可以提供 16,384 个 GPU。
- 当 N2 = 72 和 N1 服务器 = 32 时,该群集可以提供 18432 个 GPU。
- 每个条带有 64 个条带和 256 个服务器,该群集可以提供 16,384 个 GPU。
知道 所需的条带数 (N 3) 和 每个叶节点的上行链路端口数 (Y),您可以计算出需要多少个主干节点。
记住 X = Y = N1
首先,叶 节点总数 可以通过将 所需的条带数 乘以 8(每个条带的叶节点数)来计算。
叶节点总数 = N3 x 8 = 64 x 8 = 512
然后可以得到上 行链路总数 乘以 每个叶节点的上行链路数 (N1) 和 叶节点总数。
上行链路总数 = N1 x N3 = 64 x 512 = 32768
然后,可以通过将上行链路总数除以每个主干节点上的可用端口数来确定所需的主干数量(N4),就叶节点而言,这取决于用于主干角色的交换机型号。
所需主干数 (N4) = 32768 / 每个主干节点上的可用端口数
例如,如果主干节点为QFX5240,则 每个主干节点上的可用端口数 为 128。
表 8:两个条带的主干节点数。
| 主干节点 QFX 交换机型号 |
每台交换机的最大 400 GE 接口数 | 所需主干数 (N4),带 64 条条带 |
|---|---|---|
| QFX5240-64OD | 128 | 32768 ÷ 128 = 256 |
| PTX10008 | 288 | 32768 ÷ 288 ~ 128 |