后端 GPU 轨道优化的 Stripe 架构
如前所述, 轨道优化条带架构 可在 GPU 之间提供高效的数据传输,尤其是在计算密集型任务(例如 AI 大型语言模型 (LLM) 训练工作负载)期间,在这些任务中,需要无缝数据传输才能在合理的时间范围内完成任务。轨道优化拓扑旨在通过提供最小的带宽争用、最小的延迟和最小的网络干扰来最大限度地提高性能,从而确保数据可以在网络中高效且可靠地传输。
在轨道优化的条带架构中,有两个重要概念: 轨道 和 条带。
服务器上的 GPU 编号为 1-8,其中数字代表 GPU 在服务器中的位置,如图 6 所示。此数字有时称为 “排名 ”,或者更具体地说,与 GPU 所在的服务器中的 GPU 相关的“本地排名”,或者与分配给单个作业的所有 GPU(在多个服务器中)相关的“全局排名”。
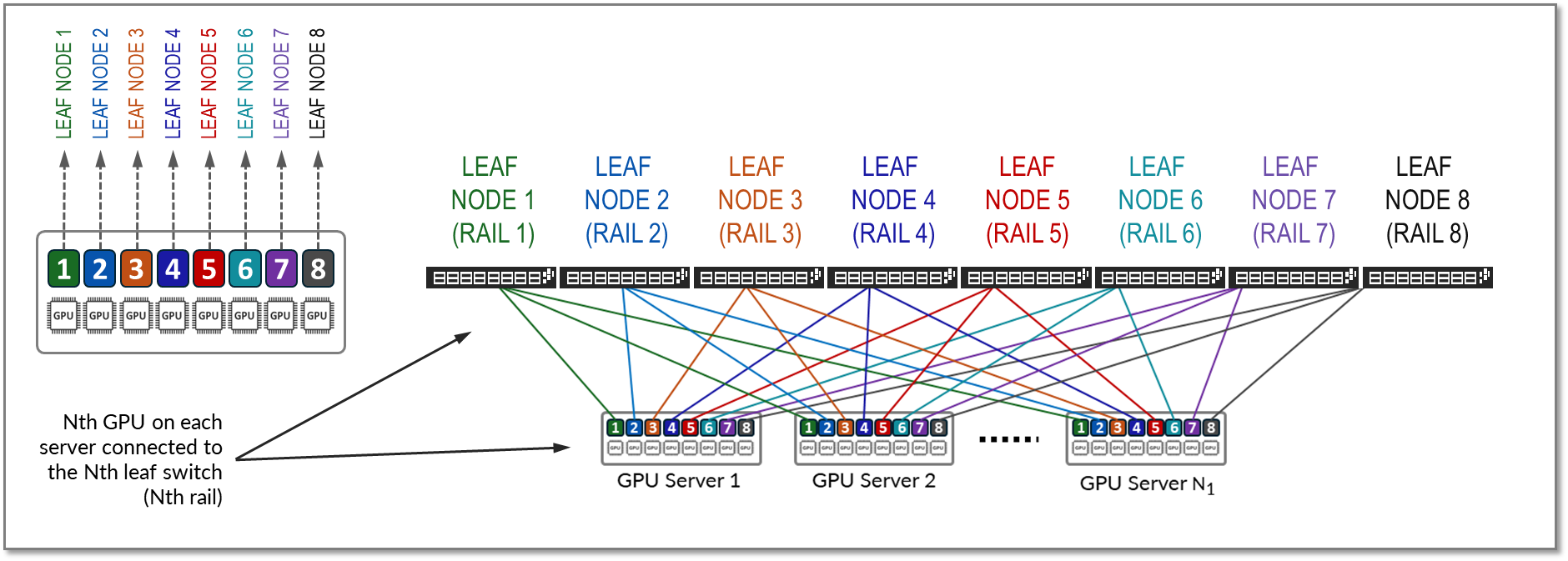
轨道跨交换矩阵中的一个叶节点连接相同顺序的 GPU;也就是说,轨道 Nth 将所有服务器上位置 N 位的所有 GPU 连接到叶节点 Nth,如图 9 所示。
图 9:轨道优化架构中的轨道
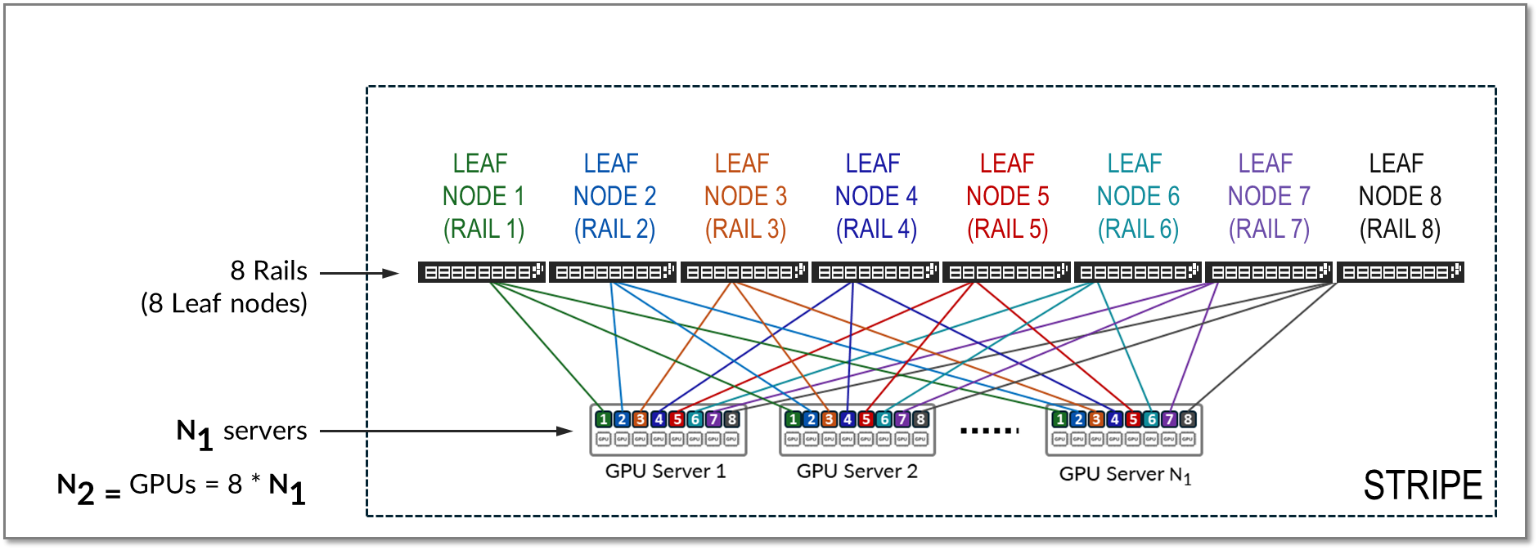
条带是指由多个轨道组成的设计模块或构建块,其中包括许多叶节点和 GPU 服务器。
图 10:轨道优化架构中的条带
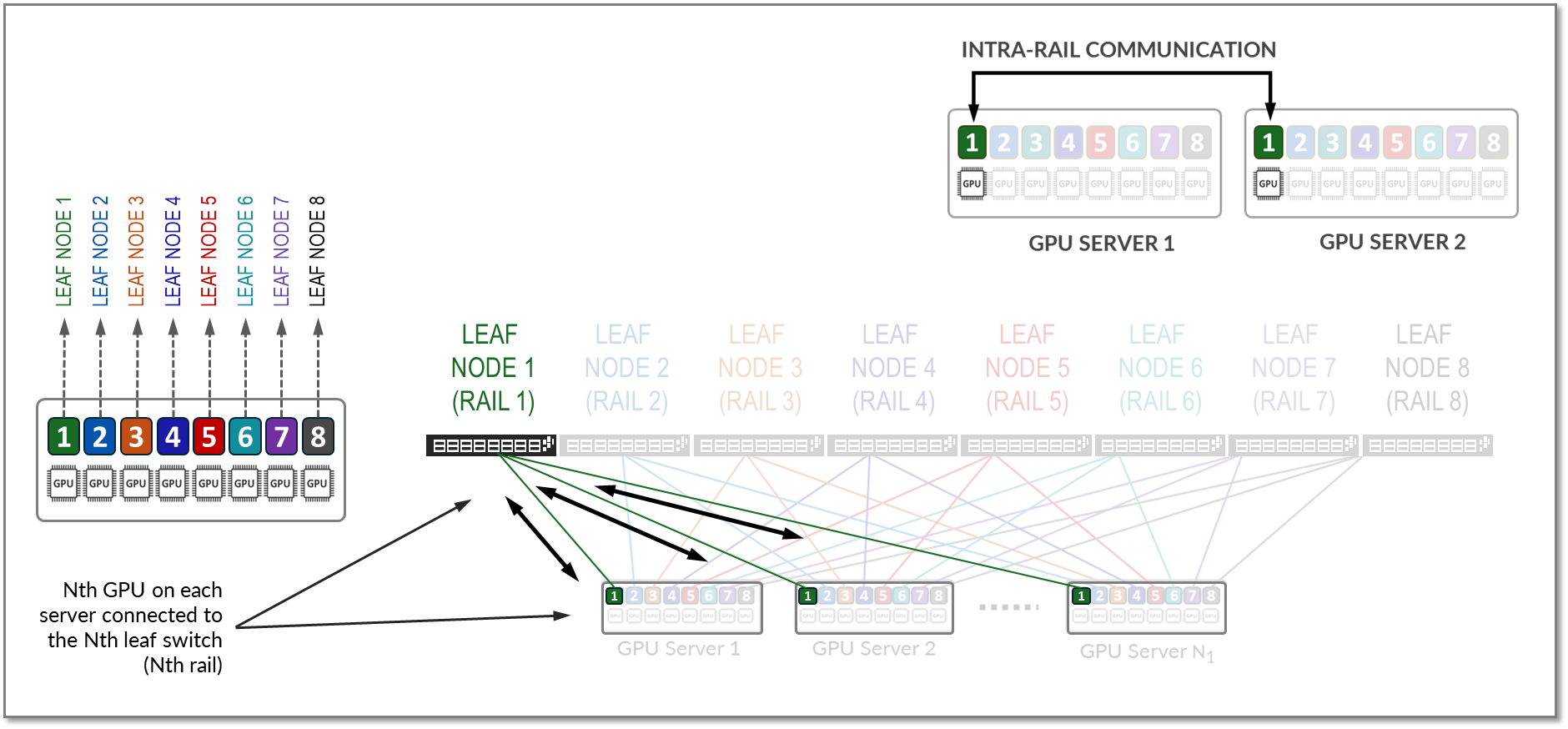
相同等级的 GPU 之间的所有流量(轨内流量)都在叶节点级别转发,如图 11 所示。
图 11:轨内 GPU 到 GPU 流量示例。
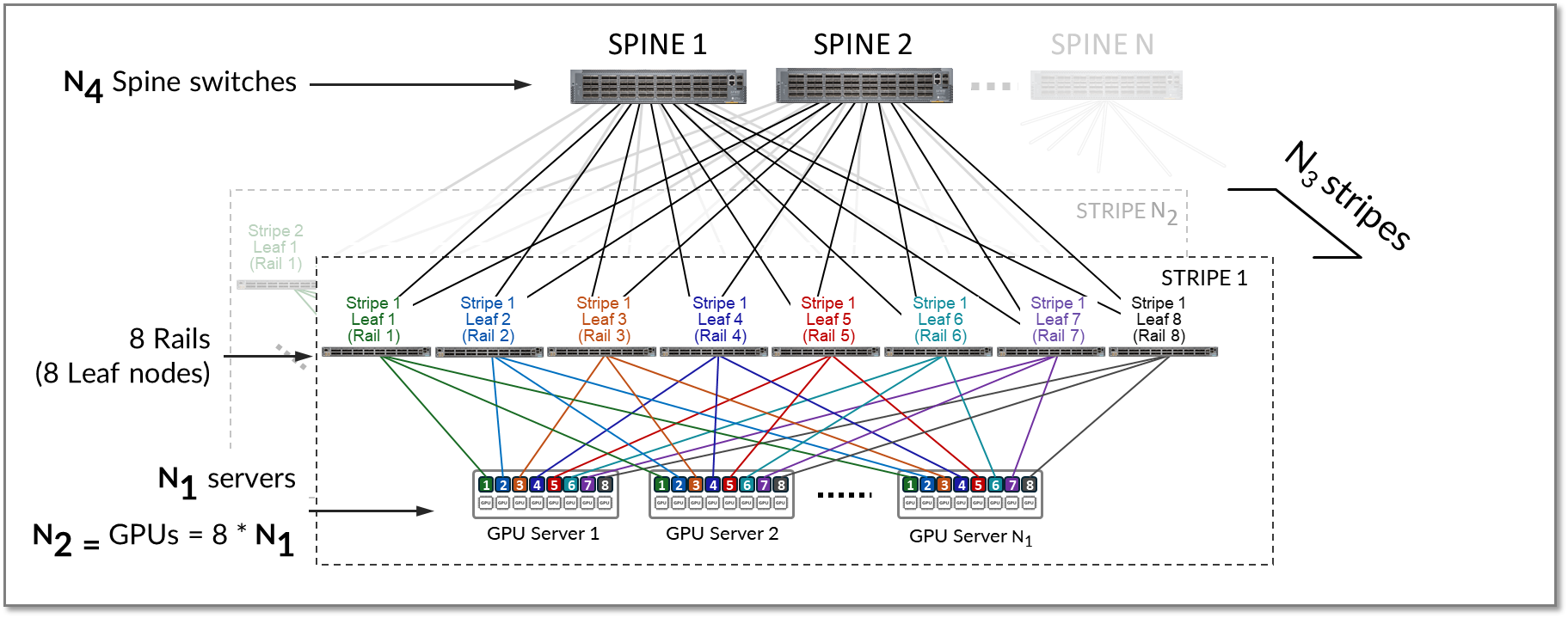
可以复制条带以纵向扩展 AI 群集中的服务器 (N1) 和 GPU (N2) 的数量。然后在主干交换机上连接多个条带 (N3),如图 12 所示。
图 12:通过主干节点连接的多个条带
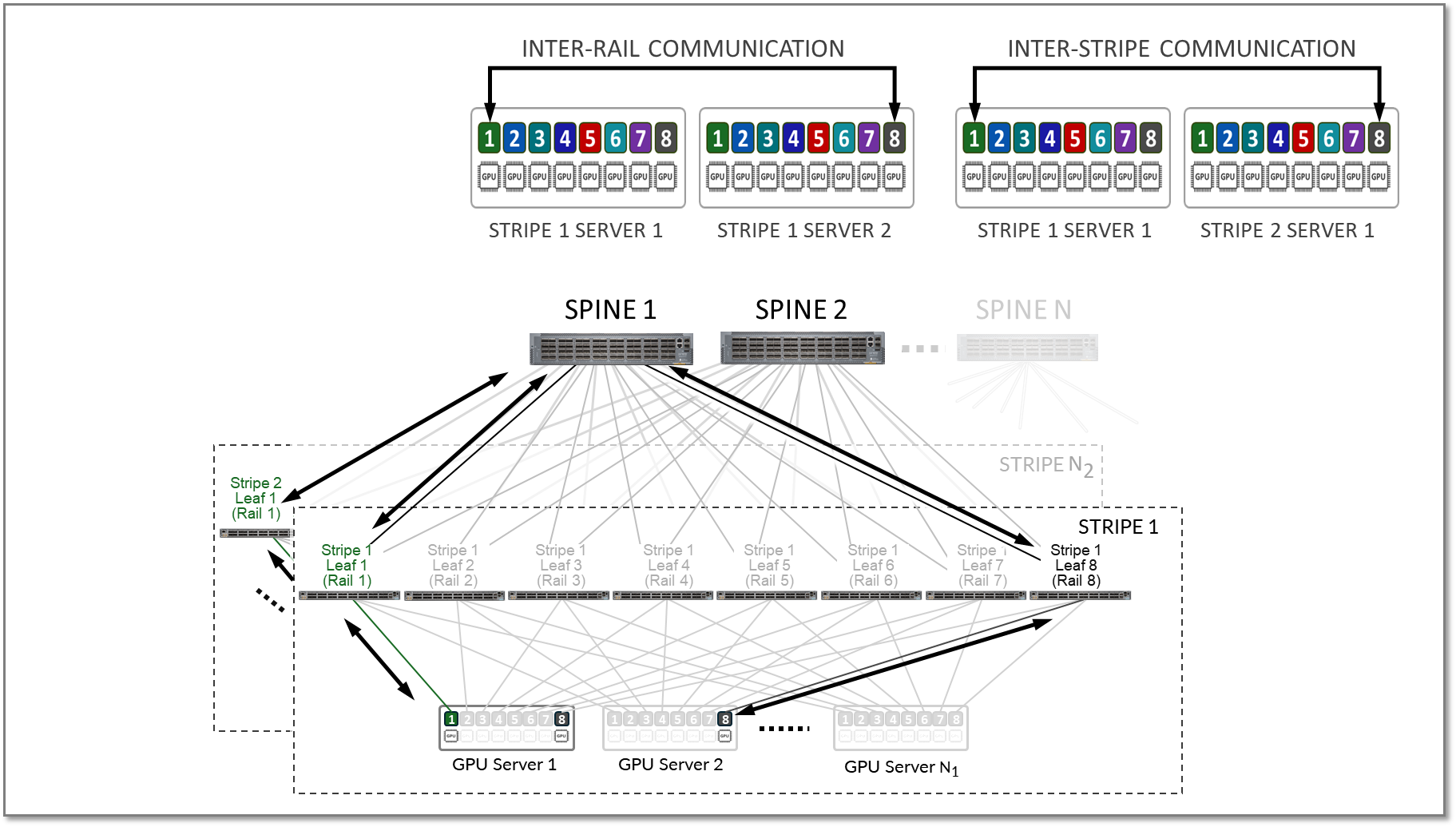
 轨间和条间流量都将跨主干节点转发,如图 13 所示。
轨间和条间流量都将跨主干节点转发,如图 13 所示。
图 13.轨道间和条带间 GPU 到 GPU 流量示例。